【深度学习】数据集最常见的问题及其解决方案
简介
如果您还没有听过,请告诉您一个事实,作为一名数据科学家,您应该始终站在一个角落跟你说:“你的结果与你的数据一样好。”
尝试通过提高模型能力来弥补糟糕的数据是许多人会犯的错误。这相当于你因为原来的汽车使用了劣质汽油导致汽车表现不佳,而更换了一辆超级跑车。这种情况下应该做的是提炼汽油,而不是升级的车。在这篇文章中。我将向您解释如何通过提高数据集质量的方法来轻松获取更好的结果。
注意:我将以图像分类的任务为例,但这些技巧可以应用于各种数据集。
问题1:数据量不够。
如果你的数据集过小,你的模型将没有足够多的样本,概括找到其中的特征,在此基础上拟合的数据,会导致虽然训练结果没太出错但是测试错误会很高。
解决方案1:收集更多数据。
您可以尝试找到更多的相同源做为您的原始数据集,或者从另一个相似度很高的源,再或者如果你绝对要来概括。
注意事项:这通常不是一件容易的事,需要投入时间和金钱。此外,你可能想要做一个分析,以确定你需要有多少额外的数据。将结果与不同的数据集大小进行比较,并尝试进行推断。
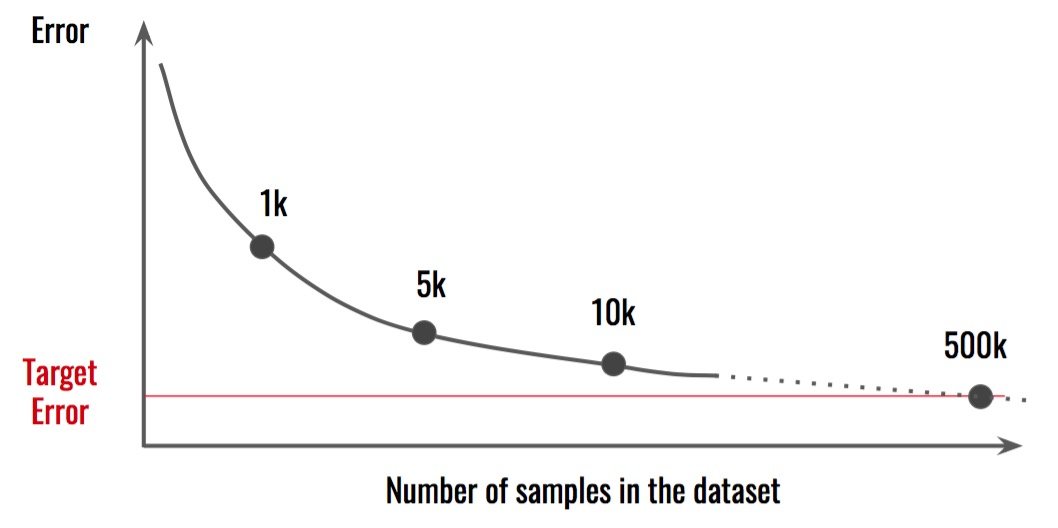
在这种情况下,似乎我们需要500k样本才能达到目标 误差。这意味着我们现在收集的数据量是目前的50倍。处理数据的其他方面或 模型可能更有效。
解决方案2:通过创建具有轻微变化的同一图像的多个副本来增强数据。
这种技术可以创造奇迹,并以极低的成本生成大量额外的图像。您可以尝试裁剪,旋转,平移或缩放图像。您可以添加 噪点,模糊,改变颜色或阻挡部分噪音。在所有情况下,您需要确保数据仍然代表同一个类。

所有这些图像仍然代表“猫”类别
这可能非常强大,因为堆叠这些效果会为您的数据集提供指数级的样本。请注意,这通常不如收集更多 原始 数据。

组合数据增强技术。班级仍然是“猫”,应该被认可。
注意事项:所有增强技术可能无法用于您的问题。例如,如果要归类柠檬和酸橙,不与色相玩,因为这将是有意义颜色是对分类重要。

这种类型的数据增加将使模型更难找到区别特征。
问题2:低质量的分类
这很简单,但如果可能的话,花些时间浏览一下您的数据集,并验证每个样本的标签。这可能需要一段时间,但在数据集中使用反例会对 学习过程产生不利影响。
此外,为您的类选择正确的粒度级别。根据问题,您可能需要更多或更少的类。例如,您可以使用全局分类器对小猫的图像进行分类,以确定它是动物,然后通过动物分类器运行它以确定它是小猫。一个巨大的模型可以做到这两点,但它会更难。
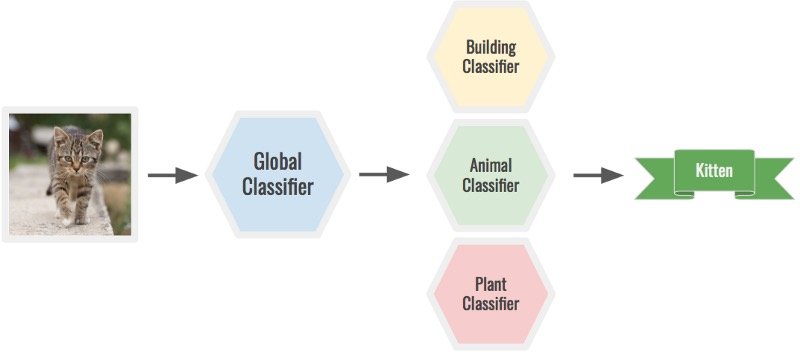
具有专门分类器的两阶段预测。
问题3:低质量的数据
如引言中所述,低质量数据只会导致低质量的结果。
数据集中的数据集中的样本可能与您要使用的数据集相差太远。这些可能会更混乱的模式不是很有帮助。
解决方案:删除最糟糕的图像。
这是一个漫长的过程,但会改善您的结果。

当然,这三个图像代表猫,但模型可能无法使用它。
另一个常见问题是当您的数据集由与真实世界应用程序不 匹配的数据组成时。例如,如果图像来自完全不同的来源。
解决方案:考虑技术的长期应用,以及将用于获取生产数据的方法。
如果可能,尝试使用相同的工具查找/构建数据集。
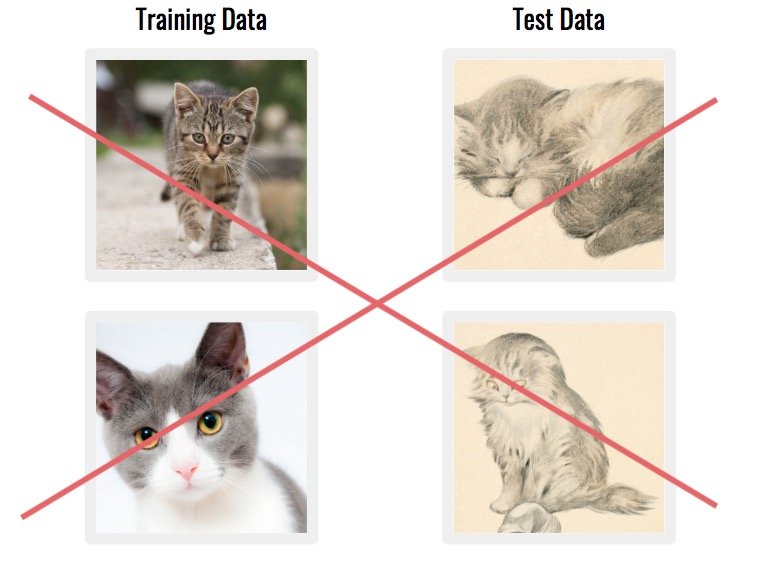
使用不代表您的真实世界应用程序的数据通常是一个坏主意。您的模型可能会提取在现实世界中无法使用的功能。
问题4:不平衡的分类
如果数每类样本的不是大致的相同的所有类,模型可能有利于统治阶级的倾向,因为它会导致一个较低的 错误。我们说该模型存在偏差,因为类分布是偏态的。这是一个严重的问题,也是您需要查看精度,召回或混淆矩阵的原因。
解决方案1:收集代表性不足的分类的更多样本。
然而,这在时间和金钱上通常 是昂贵的,或者根本不可行。
解决方案2:对数据进行过度/不足的采样。
这意味着您从过度表示的类中删除一些样本,或从代表不足的类中复制样本。比重复更好,使用数据增加,如前所述。

补充猫类图片,减少青柠的图片可以让数据集不同的分类更平衡
问题5:数据不平衡
如果您的数据没有特定 格式,或者值不在特定 范围内,则您的模型可能无法处理它。你将有形象,有更好的结果横宽比和像素值。
解决方案1:裁剪或拉伸数据,使其具有与其他样本相同的方面或格式。

两种可能性来改善格两种可能性来改善格式错误的图像式错误的图像。
解决方案2:规范化数据,使每个样本的数据都在相同的值范围内。

将值范围标准化为在整个数据集中保持一致。
问题6:没有验证集和测试集
清理,扩充和正确标记数据集后,需要将其拆分。许多人通过以下方式将其拆分:80%用于训练,20%用于测试,这 使您可以轻松发现过度装配。但是,如果您在同一测试集上尝试多个模型,则会发生其他情况。通过选择具有最佳测试精度的模型,您实际上过度拟合了测试集。发生这种情况是因为您手动选择的模型不是其内在模型 值,但其性能上的特定数据集。
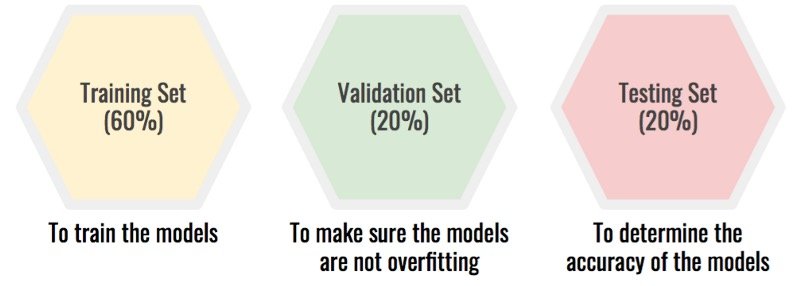
解决方案:将数据集拆分为三个:训练集、验证集、测试集。
该屏蔽你的测试被设置过度拟合由模型的选择。选择过程变为:
- 在训练集上训练你的模型。
- 在验证集上测试它们以确保没有过拟合。
- 选择最有希望的模型。在测试集上测试它,这将为您提供模型的真实准确性。
注意:一旦您选择了生产模型,请不要忘记在整个 数据集上进行训练!数据越多越好!
结论
我希望到现在你确信在考虑你的模型之前你必须注意你的数据集。您现在知道处理数据的最大错误,如何避免陷阱,以及如何构建杀手数据集的提示和技巧!如有疑问,请记住:“获胜者是不是一个最好的模式,这是一个最好的数据。”。
原文:Stop Feeding Garbage To Your Model! — The 6 biggest mistakes with datasets and how to avoid them.
相关文章:
【深度学习】数据集最常见的问题及其解决方案
简介 如果您还没有听过,请告诉您一个事实,作为一名数据科学家,您应该始终站在一个角落跟你说:“你的结果与你的数据一样好。” 尝试通过提高模型能力来弥补糟糕的数据是许多人会犯的错误。这相当于你因为原来的汽车使用了劣质汽…...
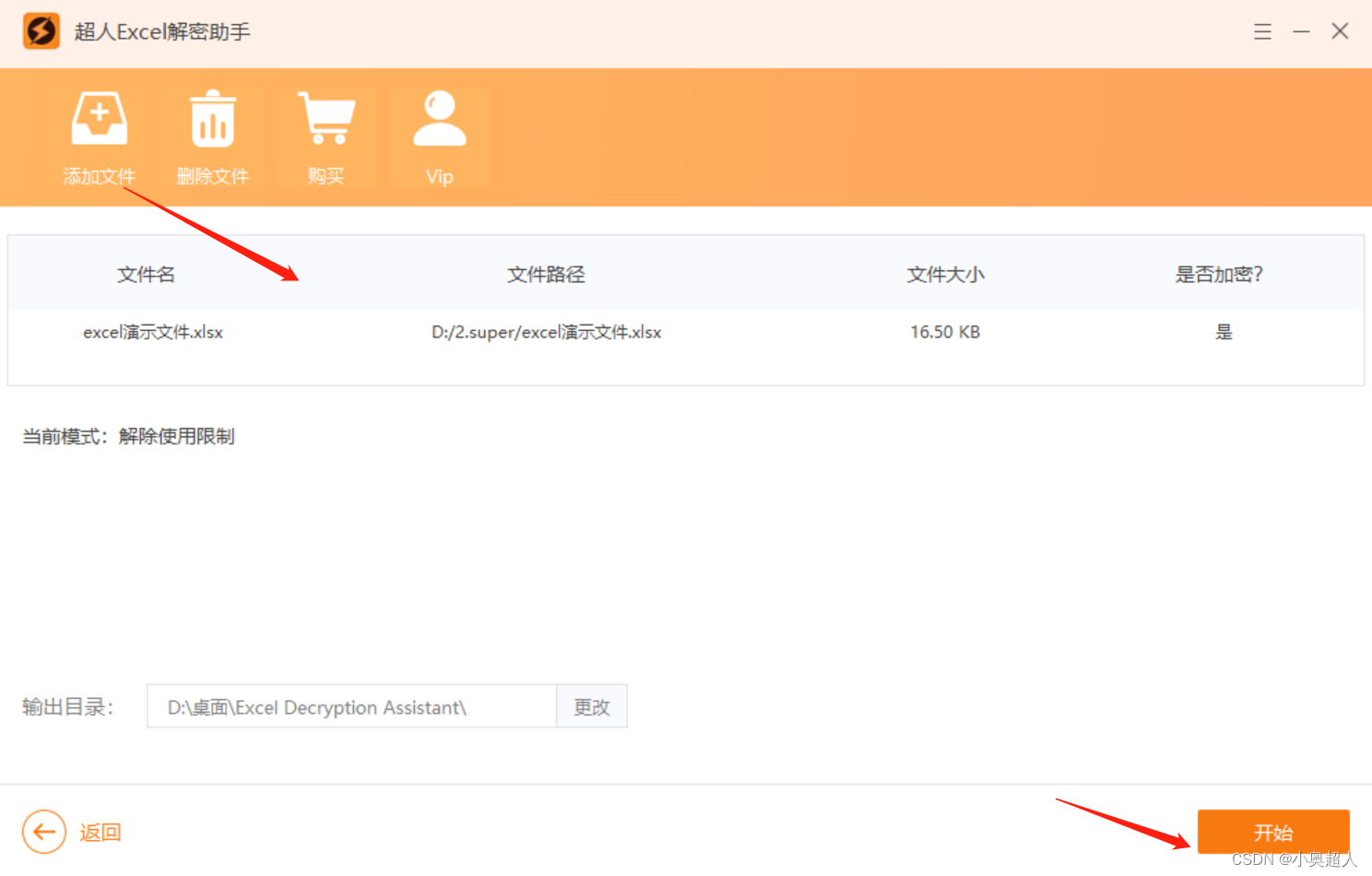
Excel文件带有密码的只读模式,如何设置?
Excel带有密码的除了打开密码和工作表保护以外,其实还有一种可以设置密码的方法,今天给大家分享如何设置带有密码的只读模式。 打开excel文件,将文件进行【另存为】设置,然后停留在保存路径的界面中,我们点击下面的工…...

【Qt之json文件】json文件介绍及相关读写类介绍、示例
JSON介绍 JSON(JavaScript Object Notation)是一种源自Javascript的编码对象数据的轻量级的数据交换格式,易于理解和编写,JSON但现在已广泛用作互联网上的数据交换格式。 Qt提供了处理JSON数据的支持。Qt中的JSON支持提供了一个易…...

arp 隔离
目录 问题查找解决方式参考 问题 linux 在使用双网卡系统时,当这两个不同网段的网口接到同一个交换机上,会出现 eth0 的 arp 请求,会在 eth1 上收到并回复,相当于自己检测到了自己的 ip。 查找 linux 的底层,默认情…...
)
数据结构与算法(文章链接汇总)
数据结构与算法(一):概述与复杂度分析 数据结构与算法(二):数组与链表 数据结构与算法(三):栈与队列 数据结构与算法(四):哈希表 数据…...
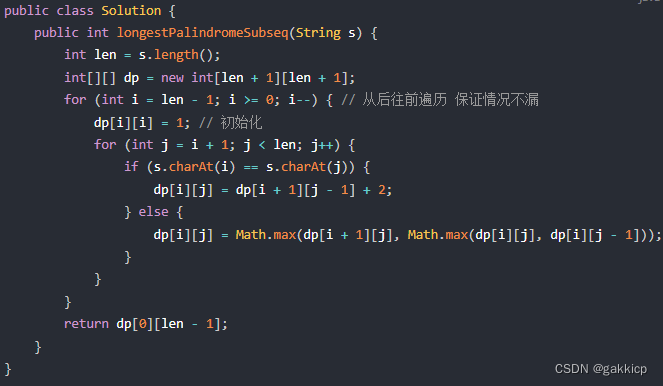
代码随想录算法训练营第五十九天 | 647. 回文子串、516.最长回文子序列
647. 回文子串 链接: 代码随想录 (1)代码 516.最长回文子序列 链接: 代码随想录 (1)代码...
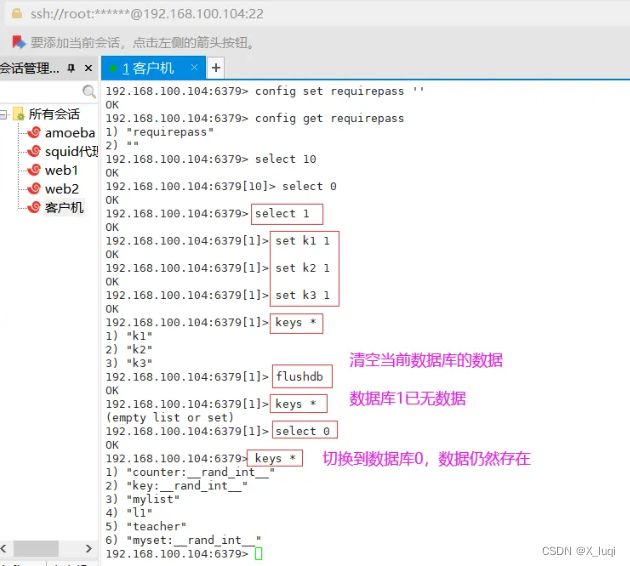
非关系型数据库-Redis
一、缓存概念 缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存…...

HTML基本讲解与使用
目录 html的由来: 什么是HTML: HTML的主要特点: HTML文档结构: HTML元素: HTML元素属性: 文本和格式化: 链接和图像: 列表: 表格: 表单: 嵌套和结构: HTML注释: 样式…...

linux uname详解 -s -r -a 查看内核版本
简介 uname命令用于显示操作系统信息,例如内核版本、主机名、处理器类型等 uname常用的有-a,-r,-rs 参数 --help 显示帮助。-a 或--all 显示全部信息,包括内核名、主机名、内核版本、处理器类型和硬件架构等…...

Linux常用命令——cmp命令
在线Linux命令查询工具 cmp 比较两个文件是否有差异 补充说明 cmp命令用来比较两个文件是否有差异。当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有差异,预设会标示出第一个不通之处的字符和列数编号。若不指定任何文件名称或是…...
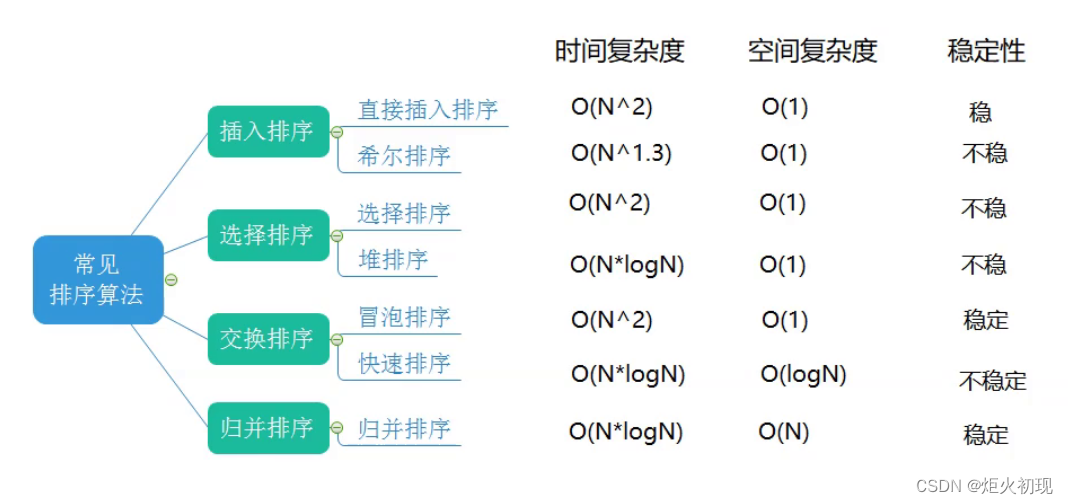
C语言之排序
1.冒泡排序 冒泡排序就不多说了,只需要两层循环嵌套,两两比较确定相对正确的顺序即可。 2.插入排序 插入排序的思想就是每一次向后寻找一个再将其与前面有序的部分进行对比,寻找合适位置插入。 这里关键要避免让前移超出目前读取的数字&…...
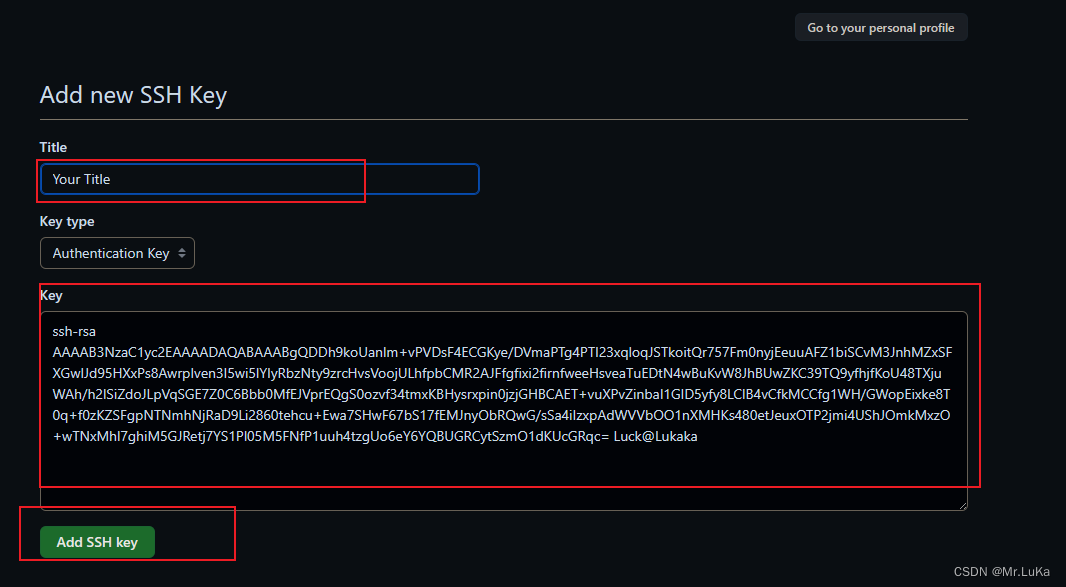
GitHub-使用 Git工具 创建密钥id_rsa.pub
快速导航 步骤1 打开Git Bash步骤2 输入指令【ssh-keygen】步骤3 打开创建的公钥文件步骤4 复制其中所有内容步骤5 打开GitHub中的Setting界面步骤6 添加SSH keys 步骤1 打开Git Bash 打开Git Bash 工具 步骤2 输入指令【ssh-keygen】 输入指令【ssh-keygen】,并…...

C++多重、多层、分层继承
在本文中,您将学习C 编程中的不同继承模型:带有示例的多继承,多层和分层继承。 继承是面向对象编程语言的核心功能之一。它允许软件开发人员从现有的类派生一个新的类。派生类继承基类(现有类)的功能。C 编程中有多种…...

ThingsBoard的数据分析-自定义节点来订阅kafka stream的消息
1、概述 在ThingsBoard官方文档中有说明:ThingsBoard 规则引擎支持对传入遥测数据的基本分析,例如阈值交叉。规则引擎背后的想法是提供基于设备属性或数据本身将数据从物联网设备路由到不同插件的功能。 然而,大多数现实生活中的用例也需要高级分析的支持:机器学习、预测分…...

Python WSGI HTTP Server - Gunicorn
基本概念 Gunicorn,也称为“Green Unicorn”,是一个Python WSGI HTTP Server,用于运行Python Web应用程序。WSGI(Web Server Gateway Interface)是Python应用程序和Web服务器之间的一个接口,允许应用程序和…...

[论文笔记]GPT-2
引言 今天继续GPT系列论文, 这次是Language Models are Unsupervised Multitask Learners,即GPT-2,中文题目的意思是 语言模型是无监督多任务学习器。 自然语言任务,比如问答、机器翻译、阅读理解和摘要,是在任务相关数据集上利用监督学习的典型方法。作者展示了语言模型…...

第十三届蓝桥杯模拟赛第三期
A.填空题 问题描述 请问十六进制数 2021ABCD 对应的十进制是多少? 参考答案 539077581 import java.math.*; public class Main {public static void main(String[] args) {String strnew BigInteger("2021ABCD",16).toString(10);System.out.printl…...
)
代碼隨想錄算法訓練營|第四十四天|01背包问题 二维、01背包问题 一维、416. 分割等和子集。刷题心得(c++)
目录 01背包問題 - DP二維數組 01 背包問題描述 暴力解 動態規劃 確認DP數組以及下標的含意 確定遞推公式 01背包问题 一维 一维DP 数組(滾動数組) 動態規劃五部曲 定義DP数組以及其下標含意 遞推公式 初始化 遍歷順序 讀題 416. 分割等和子集 自己看到题目的第…...
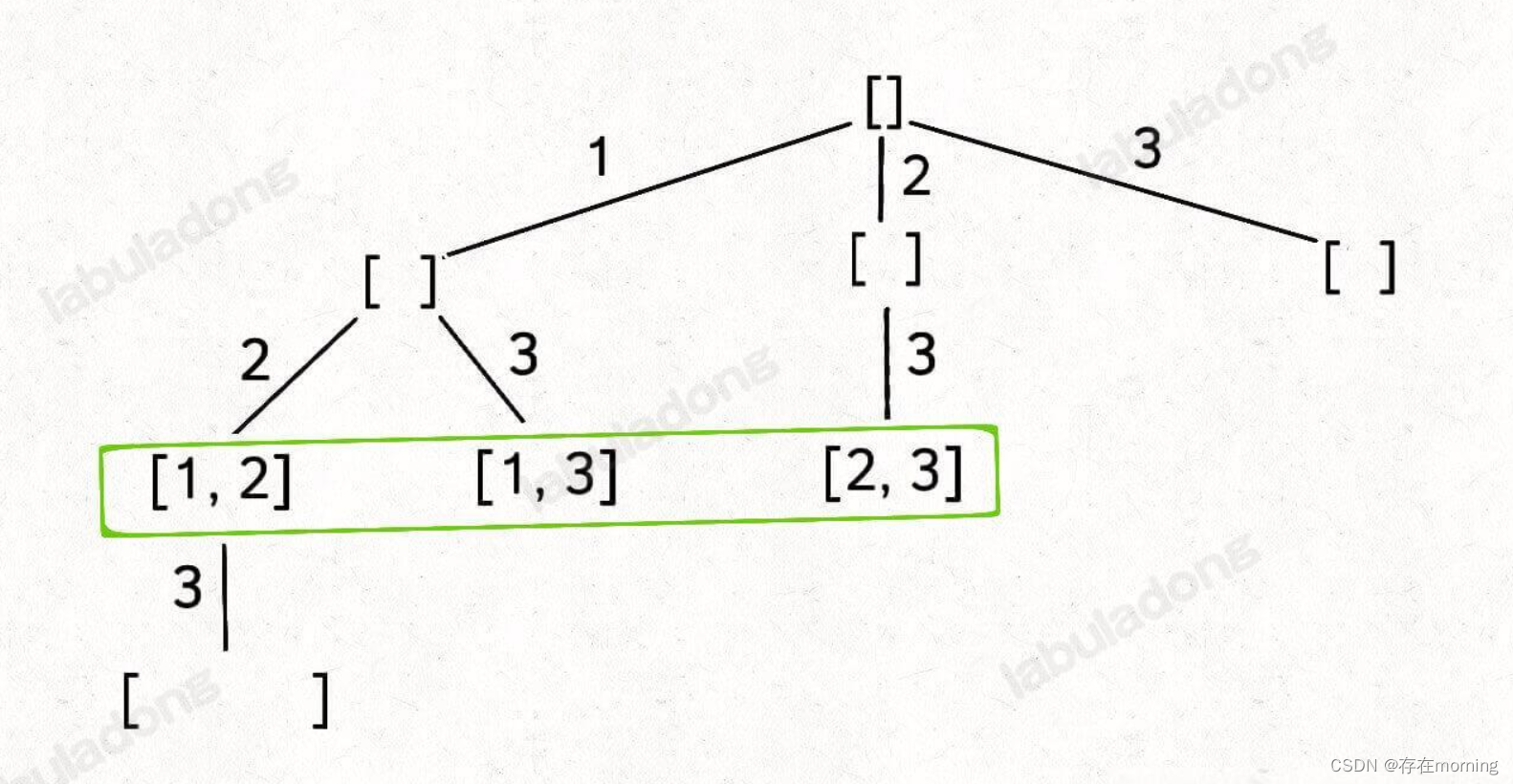
【算法训练-回溯算法 零】回溯算法解题框架
抽象地说,解决一个回溯问题,实际上就是遍历一棵决策树的过程,树的每个叶子节点存放着一个合法答案。你把整棵树遍历一遍,把叶子节点上的答案都收集起来,就能得到所有的合法答案。站在回溯树的一个节点上,你…...

GAN.py
原代码地址:github.com/zqhang/MTGFLOW 目录 def ConvEncoder() def ConvDecoder() class CNNAE(torch.nn.Module): class R_Net(torch.nn.Module): class D_Net(torch.nn.Module): def R_Loss() def D_Loss()…...
下海面回波信号的差异与选择)
避开海面遥感坑:实测讲解SAR不同入射角(20°-70°)下海面回波信号的差异与选择
避开海面遥感坑:实测讲解SAR不同入射角(20-70)下海面回波信号的差异与选择 海洋监测的精度往往藏在雷达参数的细节里。去年参与南海风场反演项目时,团队因入射角选择不当导致数据信噪比骤降30%,不得不返工重飞。这个教…...

Claude AI技术解析:从对话模型到企业级应用开发
1. Claude AI 初探:新一代对话式AI的独特魅力第一次接触Claude AI时,我立刻被它流畅自然的对话能力所吸引。与市面上大多数AI助手不同,Claude展现出惊人的上下文理解能力和逻辑推理水平。记得有一次我让它帮忙分析一段复杂的技术文档…...

新手避坑指南:是德N5171B信号源从开机到输出第一个信号的完整流程
新手避坑指南:是德N5171B信号源从开机到输出第一个信号的完整流程 第一次接触是德科技N5171B信号源时,面对密密麻麻的按键和复杂的菜单系统,即使是经验丰富的工程师也可能感到无从下手。这台价值数十万元的射频仪器,功能强大但操作…...

STM32CubeMX配置SPI驱动AD7124-8:从时序图到代码实现的避坑全记录
STM32CubeMX配置SPI驱动AD7124-8:从时序图到代码实现的避坑全记录 在嵌入式开发中,高精度ADC的应用往往伴随着复杂的驱动实现。AD7124-8作为ADI公司推出的24位Σ-Δ型ADC,凭借其低噪声、多通道特性,成为工业测量领域的常客。本文将…...

AI断点失效、变量预测错乱、上下文丢失全解析,深度拆解VSCode 1.89+ AI调试协议栈
更多请点击: https://intelliparadigm.com 第一章:AI断点失效、变量预测错乱、上下文丢失全解析,深度拆解VSCode 1.89 AI调试协议栈 VSCode 1.89 版本起引入的 AI Debug Protocol(AIDP)v2 协议栈,在集成 C…...

终极指南:如何快速掌握 Iris Web Framework 完整示例项目
终极指南:如何快速掌握 Iris Web Framework 完整示例项目 【免费下载链接】examples This repository contains small and practical examples for the Iris Web Framework. 项目地址: https://gitcode.com/gh_mirrors/examples22/examples Iris Web Framewo…...

从零构建本地优先知识库:Vue 3 + Node.js + FlexSearch实战指南
1. 项目概述与核心价值最近在折腾一个本地文档管理工具,起因很简单:手头的笔记、代码片段、项目文档散落在十几个不同的地方,有在线的Notion,有本地的Obsidian,还有一堆Markdown文件扔在Dropbox里。每次想找点东西&…...

工业现场通信避坑指南:Modbus RTU over RS485的CRC校验与异常处理实战
工业现场通信避坑指南:Modbus RTU over RS485的CRC校验与异常处理实战 在工业自动化领域,稳定可靠的通信是系统正常运行的基石。RS485总线因其抗干扰能力强、传输距离远等优势,成为工业现场最常见的物理层通信标准之一。而Modbus RTU协议则因…...

【告别for循环】Java Stream 流式编程精通:从入门到源码级的性能优化
告别冗长的 for 循环,拥抱函数式编程的优雅与高效 前言 自 Java 8 问世以来,Stream API 便成为了 Java 开发者手中一把锋利的利器。它让我们能够以声明式的方式处理集合数据,写出更加简洁、可读、可维护的代码。然而,在实际项目中…...

AI 在软件开发中的角色:工具、场景、效率与未来趋势深度研究报告
核心摘要与关键发现截至 2026 年 4 月,人工智能(AI)已从软件开发的 “辅助工具” 演进为 “核心协同引擎”—— 这一转变并非线性的功能增强,而是软件工程范式的根本性重构:AI 不再是简单的代码补全工具,而…...