机器学习-K-近邻(KNN)算法
目录
一 . K-近邻算法(KNN)概述
二、KNN算法实现
三、 MATLAB实现
四、 实战

一 . K-近邻算法(KNN)概述
K-近邻算法(KNN)是一种基本的分类算法,它通过计算数据点之间的距离来进行分类。在KNN算法中,当我们需要对一个未知数据点进行分类时,它会与训练集中的各个数据点进行特征比较,并找到与之最相似的前K个数据点。然后根据这K个数据点的类别来确定未知数据点所属的类别。
KNN算法的步骤非常简单: 1)计算未知数据点与训练集中各个数据点之间的距离。常用的距离度量包括欧氏距离和曼哈顿距离。 2)按照距离递增的顺序对数据点进行排序。 3)选择距离最小的K个数据点。 4)根据这K个数据点的类别来确定未知数据点的类别。通常采用多数表决的方式,即统计K个数据点中各个类别出现的次数,将出现次数最多的类别作为未知数据点的预测类别。
KNN算法的特点是简单易懂,容易实现。它没有显式的训练过程,仅依赖于已有的训练数据。然而,KNN算法的计算复杂度较高,尤其是当训练集很大时。此外,KNN算法还对训练样本的质量和数量敏感,需要合理地选择K值和距离度量方法。

在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
首先需要收集足够的带有标签的训练数据,这些数据包含了输入特征和相应的输出标签。
对于输入的测试数据,需要计算它与每个训练数据之间的距离(如欧氏距离、曼哈顿距离等)。
选取距离测试数据最近的K个训练数据,并统计它们中出现最多的标签类别。
将测试数据归类为出现次数最多的标签类别。
二、KNN算法实现
KNN算法的实现通常可以使用Python等编程语言进行实现
import numpy as npclass KNN():def __init__(self, k=3, distance='euclidean'):self.k = kself.distance = distancedef fit(self, X, y):self.X_train = Xself.y_train = ydef predict(self, X):y_pred = []for x in X:distances = []for i, x_train in enumerate(self.X_train):if self.distance == 'euclidean':dist = np.linalg.norm(x - x_train)elif self.distance == 'manhattan':dist = np.sum(np.abs(x - x_train))distances.append((dist, self.y_train[i]))distances.sort()neighbors = distances[:self.k]classes = {}for neighbor in neighbors:if neighbor[1] in classes:classes[neighbor[1]] += 1else:classes[neighbor[1]] = 1max_class = max(classes, key=classes.get)y_pred.append(max_class)return y_pred
这段代码实现了基本的KNN分类算法,包括fit函数进行训练集拟合,predict函数进行预测。其中k参数表示要选择的最近邻居数,distance参数为距离度量方法。在上述示例代码中,欧氏距离和曼哈顿距离两种距离度量方法均已实现。
通过选择不同的数据集和参数,可以验证KNN算法的分类性能。在实现KNN算法时,还可以采用更加高效的数据结构(如kd树、球树)和距离度量方法等技巧,来对算法进行优化和改进。
三、 MATLAB实现
使用pdist2函数计算欧氏距离,而不是手动计算,可以极大地提高计算速度。
在计算距离之后,直接利用sort函数进行排序,并选择前k个最近邻。这样可以简化代码,并且使用向量化计算,计算速度更快。
使用mode函数求取邻居中出现次数最多的类别作为预测结果,并且使用2维输入方式保证正确性。
function y_pred = knn(X_train, y_train, X_test, k)n_train = size(X_train, 1);n_test = size(X_test, 1);y_pred = zeros(n_test, 1);% 计算欧氏距离distances = pdist2(X_train, X_test);% 选择前k个最近邻[~, indices] = sort(distances);neighbors = y_train(indices(1:k,:));% 使用投票法预测标签y_pred = mode(neighbors, 1)';
end
四、 实战
在这里根据一个人收集的约会数据,根据主要的样本特征以及得到的分类,对一些未知类别的数据进行分类,大致就是这样。
我使用的是python 3.4.3,首先建立一个文件,例如date.py,具体的代码如下:
#coding:utf-8from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt###导入特征数据
def file2matrix(filename):fr = open(filename)contain = fr.readlines()###读取文件的所有内容count = len(contain)returnMat = zeros((count,3))classLabelVector = []index = 0for line in contain:line = line.strip() ###截取所有的回车字符listFromLine = line.split('\t')returnMat[index,:] = listFromLine[0:3]###选取前三个元素,存储在特征矩阵中classLabelVector.append(listFromLine[-1])###将列表的最后一列存储到向量classLabelVector中index += 1##将列表的最后一列由字符串转化为数字,便于以后的计算dictClassLabel = Counter(classLabelVector)classLabel = []kind = list(dictClassLabel)for item in classLabelVector:if item == kind[0]:item = 1elif item == kind[1]:item = 2else:item = 3classLabel.append(item)return returnMat,classLabel#####将文本中的数据导入到列表##绘图(可以直观的表示出各特征对分类结果的影响程度)
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()## 归一化数据,保证特征等权重
def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = zeros(shape(dataSet))##建立与dataSet结构一样的矩阵m = dataSet.shape[0]for i in range(1,m):normDataSet[i,:] = (dataSet[i,:] - minVals) / rangesreturn normDataSet,ranges,minVals##KNN算法
def classify(input,dataSet,label,k):dataSize = dataSet.shape[0]####计算欧式距离diff = tile(input,(dataSize,1)) - dataSetsqdiff = diff ** 2squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量dist = squareDist ** 0.5##对距离进行排序sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标classCount={}for i in range(k):voteLabel = label[sortedDistIndex[i]]###对选取的K个样本所属的类别个数进行统计classCount[voteLabel] = classCount.get(voteLabel,0) + 1###选取出现的类别次数最多的类别maxCount = 0for key,value in classCount.items():if value > maxCount:maxCount = valueclasses = keyreturn classes##测试(选取10%测试)
def datingTest():rate = 0.10datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet.txt')normMat,ranges,minVals = autoNorm(datingDataMat)m = normMat.shape[0]testNum = int(m * rate)errorCount = 0.0for i in range(1,testNum):classifyResult = classify(normMat[i,:],normMat[testNum:m,:],datingLabels[testNum:m],3)print("分类后的结果为:,", classifyResult)print("原结果为:",datingLabels[i])if(classifyResult != datingLabels[i]):errorCount += 1.0print("误分率为:",(errorCount/float(testNum)))###预测函数
def classifyPerson():resultList = ['一点也不喜欢','有一丢丢喜欢','灰常喜欢']percentTats = float(input("玩视频所占的时间比?"))miles = float(input("每年获得的飞行常客里程数?"))iceCream = float(input("每周所消费的冰淇淋公升数?"))datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet2.txt')normMat,ranges,minVals = autoNorm(datingDataMat)inArr = array([miles,percentTats,iceCream])classifierResult = classify((inArr-minVals)/ranges,normMat,datingLabels,3)print("你对这个人的喜欢程度:",resultList[classifierResult - 1])新建test.py文件了解程序的运行结果,代码:
#coding:utf-8from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as pltimport sys
sys.path.append("D:\python\Mechine learing in Action\KNN")
import date
date.classifyPerson()相关文章:
机器学习-K-近邻(KNN)算法
目录 一 . K-近邻算法(KNN)概述 二、KNN算法实现 三、 MATLAB实现 四、 实战 一 . K-近邻算法(KNN)概述 K-近邻算法(KNN)是一种基本的分类算法,它通过计算数据点之间的距离来进行分类。在…...

shell_38.Linux读取脚本名
读取脚本名 (1)示例 $ cat positional0.sh #!/bin/bash # Handling the $0 command-line parameter # echo This script name is $0. exit $ $ bash positional0.sh This script name is positional0.sh. $ (2)如果使用另一个命令来运行 shell 脚本,则命令…...
:如何使用RTK进行状态管理)
面试题-React(十七):如何使用RTK进行状态管理
Redux Toolkit(RTK) 是一个强大的工具集,旨在简化和改进Redux的使用。它提供了一组工具和约定,使Redux的配置和编写更加直观和高效。 一、Redux Toolkit简介 Redux Toolkit是一个由Redux官方团队开发和维护的库,旨在…...

网络安全—自学笔记
目录 一、自学网络安全学习的误区和陷阱 二、学习网络安全的一些前期准备 三、网络安全学习路线 四、学习资料的推荐 想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客! 网络安全可以基于攻击和防御视角来分类…...
-- 对象转换工具类)
Java后端开发(五)-- 对象转换工具类
为避免返回给前端的字段信息太多,在缓解前、后端通信的带宽压力的前提下,对不必要的字段的信息进行不返回时,entity层对象需要向vo层对象进行转换,同事尽量减少geetter与setter方法的编码。 1. ConvertUtils工具类 import org.slf4j.Logger; import org.slf4j.LoggerFacto…...
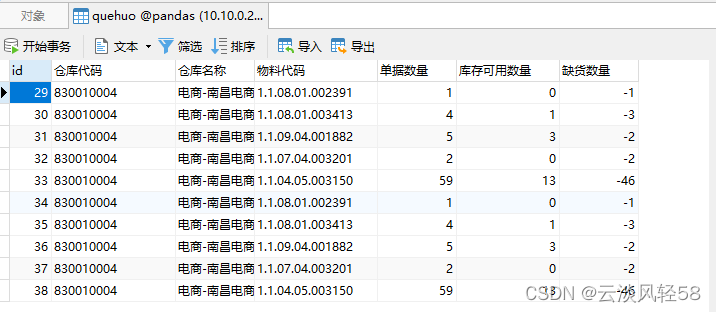
pandas写入MySQL
安装好pandas、mysql pip install pandas pip install pymysql 导入pandas、mysql import pymysql as mysql import pandas as pd 建立连接 conmysql.connect(host10.10.0.221,userroot,passwordroot,databasepandas,port3306,charsetutf8) 创建游标 curcon.cursor() 读…...

TCP实战:即时通信-端口转发
1、即时通信是什么含义,要实现怎么样的设计? 即时通信,是指一个客户端的消息发出去,其他客户端可以接收到即时通信需要进行端口转发的设计思想服务端需要把在线的Socket管道存储起来一旦收到一个消息要推送给其他管道 服务端 pac…...

CMakeLists.txt详解
CMakeLists.txt详解 CMakeLists.txt是一个用于构建C/C项目的CMake配置文件。它定义了项目的编译选项,包括编译器类型、依赖库、预处理宏和子目录等。让我们逐步解析这个文件。 编译器检测 CMAKE_CXX_COMPILER_ID 变量用于检测编译器类型。在这个示例中࿰…...

记一个JSON返回数据的bug
记一个JSON返回数据的bug:‘Object of type int64 is not JSON serializable’ 我在打包数组进行json数据返回时,有一个参数是numpy数组里计算出来的,类型为int64,直接进行json打包会报错 提示(‘Object of type int64 is not JSON serializa…...

毫米波雷达模块技术革新:在自动驾驶汽车中的前沿应用
随着自动驾驶技术的快速发展,毫米波雷达模块的技术革新成为推动这一领域的关键因素之一。本文将深入研究毫米波雷达模块技术的最新进展,并探讨其在自动驾驶汽车中的前沿应用。 毫米波雷达模块的基本原理 解释毫米波雷达模块的基本工作原理,强…...
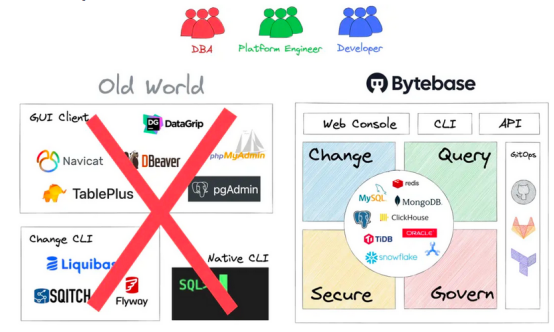
优秀数据库模式迁移工具的发展历程
数据库模式迁移可能是应用程序开发中风险最大的领域——因为这是一个困难的、有风险的和痛苦的过程。数据库模式迁移工具的存在是为了减轻这种痛苦,并且已经取得了长足的进步:从基本的CLI工具到GUI工具,从简单的SQL GUI客户端到一体化协作数据…...
【深度学习】数据集最常见的问题及其解决方案
简介 如果您还没有听过,请告诉您一个事实,作为一名数据科学家,您应该始终站在一个角落跟你说:“你的结果与你的数据一样好。” 尝试通过提高模型能力来弥补糟糕的数据是许多人会犯的错误。这相当于你因为原来的汽车使用了劣质汽…...
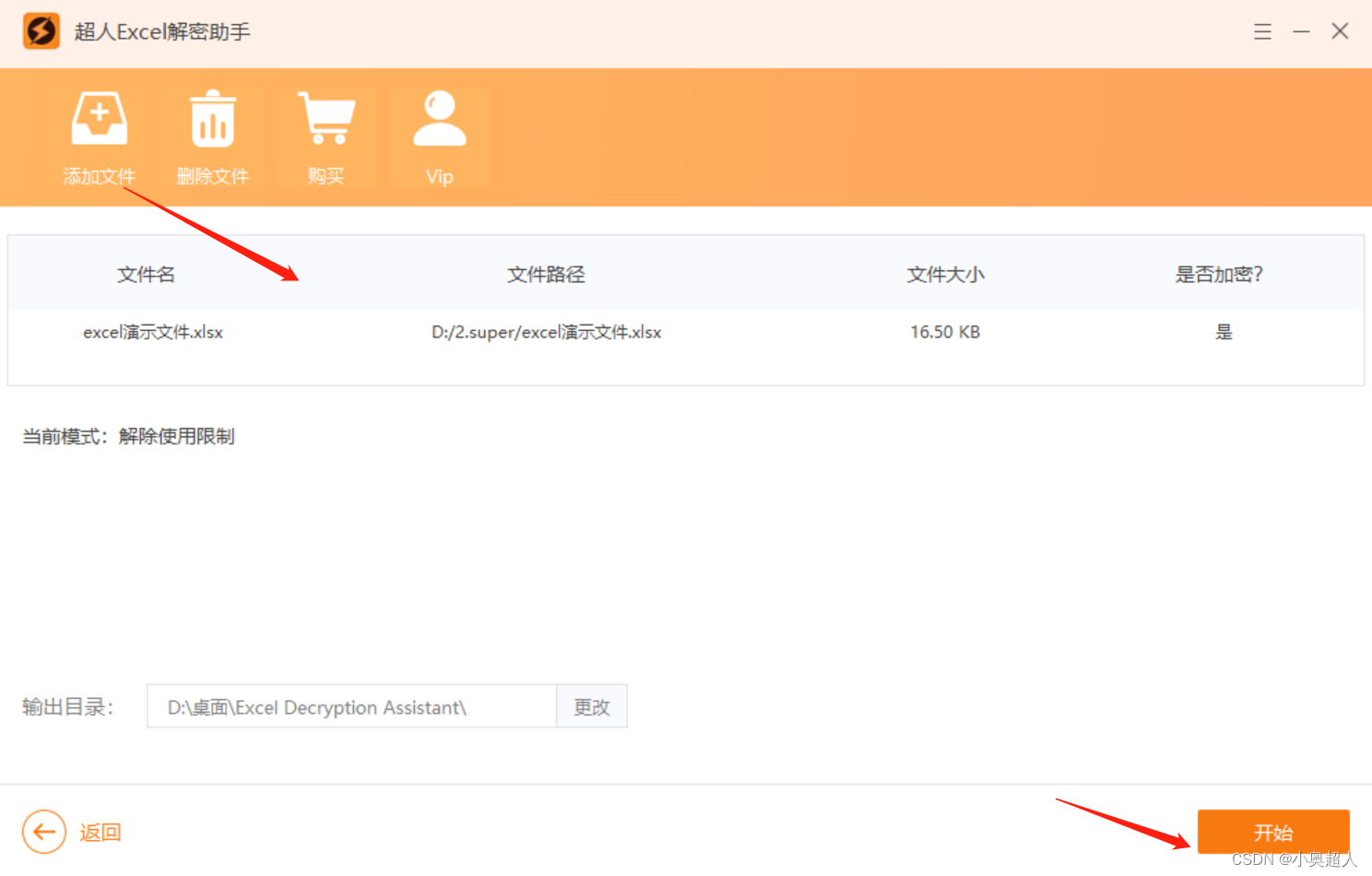
Excel文件带有密码的只读模式,如何设置?
Excel带有密码的除了打开密码和工作表保护以外,其实还有一种可以设置密码的方法,今天给大家分享如何设置带有密码的只读模式。 打开excel文件,将文件进行【另存为】设置,然后停留在保存路径的界面中,我们点击下面的工…...

【Qt之json文件】json文件介绍及相关读写类介绍、示例
JSON介绍 JSON(JavaScript Object Notation)是一种源自Javascript的编码对象数据的轻量级的数据交换格式,易于理解和编写,JSON但现在已广泛用作互联网上的数据交换格式。 Qt提供了处理JSON数据的支持。Qt中的JSON支持提供了一个易…...

arp 隔离
目录 问题查找解决方式参考 问题 linux 在使用双网卡系统时,当这两个不同网段的网口接到同一个交换机上,会出现 eth0 的 arp 请求,会在 eth1 上收到并回复,相当于自己检测到了自己的 ip。 查找 linux 的底层,默认情…...
)
数据结构与算法(文章链接汇总)
数据结构与算法(一):概述与复杂度分析 数据结构与算法(二):数组与链表 数据结构与算法(三):栈与队列 数据结构与算法(四):哈希表 数据…...
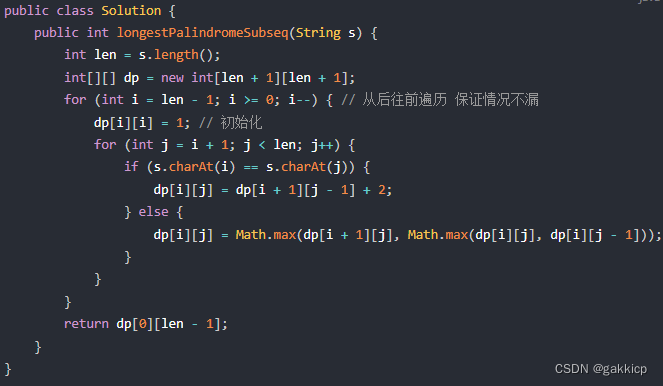
代码随想录算法训练营第五十九天 | 647. 回文子串、516.最长回文子序列
647. 回文子串 链接: 代码随想录 (1)代码 516.最长回文子序列 链接: 代码随想录 (1)代码...
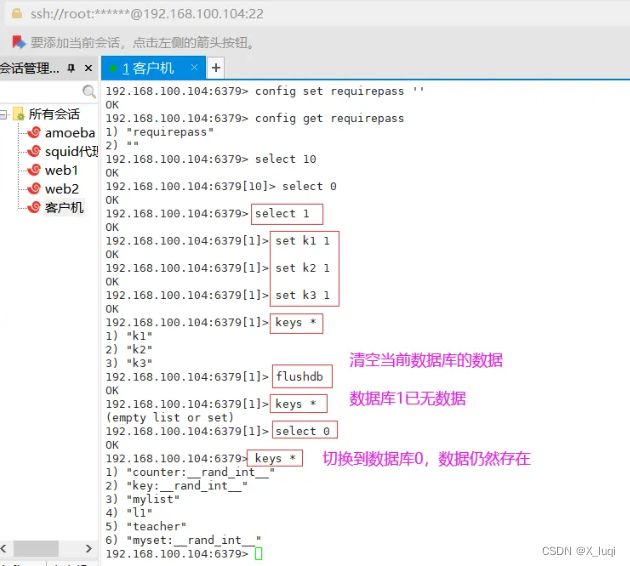
非关系型数据库-Redis
一、缓存概念 缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存…...

HTML基本讲解与使用
目录 html的由来: 什么是HTML: HTML的主要特点: HTML文档结构: HTML元素: HTML元素属性: 文本和格式化: 链接和图像: 列表: 表格: 表单: 嵌套和结构: HTML注释: 样式…...

linux uname详解 -s -r -a 查看内核版本
简介 uname命令用于显示操作系统信息,例如内核版本、主机名、处理器类型等 uname常用的有-a,-r,-rs 参数 --help 显示帮助。-a 或--all 显示全部信息,包括内核名、主机名、内核版本、处理器类型和硬件架构等…...

C++ STL string模拟实现全解析
C STL string 模拟实现(下)1. 迭代器实现class MyString {// ... 成员变量声明 public:using iterator char*;using const_iterator const char*;iterator begin() noexcept { return _str; }iterator end() noexcept { return _str _size; }const_it…...
)
别再让用户轻易划走了!微信小程序用page-container实现复杂拦截(附完整代码)
微信小程序用户留存实战:用page-container打造无死角拦截系统 每次看到用户在小程序关键页面划走时,就像眼睁睁看着煮熟的鸭子飞了——特别是那些已经加购商品或填写了一半表单的用户。电商平台拼多多给我们上了生动一课:当用户试图退出时&am…...
)
【仅内部团队流通】VSCode容器调试安全加固配置包:禁用root、启用seccomp、自动注入tracee-agent(含CI/CD集成checklist)
更多请点击: https://intelliparadigm.com 第一章:【仅内部团队流通】VSCode容器调试安全加固配置包:禁用root、启用seccomp、自动注入tracee-agent(含CI/CD集成checklist) 在生产级容器化开发环境中,VSCo…...

AngularJS Material-Start完全指南:从零开始构建现代化Web应用
AngularJS Material-Start完全指南:从零开始构建现代化Web应用 【免费下载链接】material-start Starter Repository for AngularJS Material 项目地址: https://gitcode.com/gh_mirrors/ma/material-start AngularJS Material-Start是一个基于AngularJS Mat…...

应对设计高峰期的Allegro的license峰值管理技巧
待激活的“隐形财富”:破解Allegro license高峰瓶颈的实战经验你是并非也常常听到工程师在项目关键时刻喊:“又抢不到许可证了!”项目急着出图,偏偏授权全被占用,这事儿干过,也见过太多。你有还没有想过你买…...

不会 PS、AI 也能画顶刊插图
做科研的朋友大概都遇见过这种尴尬:实验做了大半年,数据整理得清晰合理,论文逻辑也打磨通顺,偏偏就卡在一张论文插图上。零设计基础不会用专业绘图软件,PS的图层逻辑理不清,通用AI绘图生成的图到处都是专业…...

抖音批量下载器:三步搞定无水印视频批量下载
抖音批量下载器:三步搞定无水印视频批量下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批…...

3步可视化清理:用WinDirStat彻底告别Windows磁盘空间焦虑
3步可视化清理:用WinDirStat彻底告别Windows磁盘空间焦虑 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat 还在为电脑C盘飘红而…...

告别在线焦虑:B站视频下载器如何帮你永久收藏4K超清内容
告别在线焦虑:B站视频下载器如何帮你永久收藏4K超清内容 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 你是否曾遇到过这…...
)
别再用官方教程了!用Awesome-Backbones库5分钟搞定EfficientNetV2图像分类(附花卉数据集实战)
5分钟极速实战:用Awesome-Backbones解锁EfficientNetV2图像分类新姿势 当你第一次接触图像分类任务时,是否曾被PyTorch官方教程中复杂的代码结构和繁琐的配置步骤劝退?现在,一个名为Awesome-Backbones的开源库正在改变这一现状。这…...