Flink之输出算子Redis Sink
Redis Sink
- Redis Sink
- jedis实现
- 添加依赖
- 自定义Redis Sink
- 使用Sink
- 验证
- 开源 Redis Connector
- 添加依赖
- 自定义Redis Sink
- RedisCommand
- String数据类型示例
- Hash数据类型示例
- 使用Sink
- RedisStringSink
- RedisHashSink
- 验证
Redis Sink
在新版Flink的文档中,并没有发现Redis Sink的具体使用,但可通过 Apache Bahir了解到其具体使用
Redis具有其极高的写入读取性能,因此也是经常使用的Sink之一。可以使用Java Redis客户端Jedis手动实现,也可以使用Flink和Bahir提供的实现来实现。
开源实现的Redis Connector使用非常方便,但是无法使用一些Jedis中的高级功能,如设置过期时间等
jedis实现
添加依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>5.0.0</version>
</dependency>
自定义Redis Sink
自定义一个 RedisSink 函数,继承 RichSinkFunction,重写其中的open、invoke和close方法
open:用于新建Redis客户端invoke:将数据存储到Redis中,这里将数据以字符串的形式存储到Redis中close:使用完毕后关闭Redis客户端
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import redis.clients.jedis.Jedis;public class RedisSink extends RichSinkFunction {private transient Jedis jedis;@Overridepublic void open(Configuration config) {jedis = new Jedis("localhost", 6379);}@Overridepublic void invoke(Object value, Context context) throws Exception {Tuple2<String, String> val = (Tuple2<String, String>) value;if (!jedis.isConnected()) {jedis.connect();}jedis.set(val.f0, val.f1);}@Overridepublic void close() throws Exception {jedis.close();}
}
使用Sink
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建data sourceDataStreamSource<String> dataStreamSource = env.fromElements("Flink", "Spark", "Storm");// 应用转换算子SingleOutputStreamOperator<Tuple2<String, String>> streamOperator = dataStreamSource.map(new MapFunction<String, Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> map(String s) throws Exception {return new Tuple2<>(s, s);}});// 关联sink:将给定接收器添加到此数据流streamOperator.addSink(new RedisSink());// 执行env.execute("redis sink");}
验证
在Redis的控制台中查询数据
本地:0>keys *
1) "Flink"
2) "Storm"
3) "Spark"
开源 Redis Connector
可以使用Flink和Bahir提供的实现,其内部都是使用Java Redis客户端Jedis实现Redis Sink。
Flink:https://mvnrepository.com/artifact/org.apache.bahir/flink-connector-redis
Bahir:https://bahir.apache.org/#home
添加依赖
Flink与Bahir的使用方法类似,这里以使用Flink提供的依赖Jar使用为例,引入flink-connector-redis。
Flink提供的依赖包
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.12</artifactId><version>1.1.0</version>
</dependency>
Bahir提供的依赖包
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version>
</dependency>
自定义Redis Sink
可以通过实现 RedisMapper 来自定义Redis Sink
自定义的MyRedisSink实现了RedisMapper并覆写了其中的getCommandDescription、getKeyFromData、getValueFromData。
getCommandDescription:定义存储到Redis中的数据格式,这里定义RedisCommand为SET,将数据以字符串的形式存储getKeyFromData:定义SET的KeygetValueFromData:定义SET的值
RedisCommand
Redis的所有可用命令,每个命令属于RedisDataType。
public enum RedisCommand {/*** 将指定值插入到存储在键上的列表的头部。* 如果键不存在,则在执行推送操作之前将其创建为空列表。*/LPUSH(RedisDataType.LIST),/*** 将指定值插入到存储在键上的列表的尾部。* 如果键不存在,则在执行推送操作之前将其创建为空列表。*/RPUSH(RedisDataType.LIST),/*** 将指定成员添加到存储在键上的集合中。* 忽略已经是该集合成员的指定成员。*/SADD(RedisDataType.SET),/*** 设置键的字符串值。如果键已经持有一个值,* 则无论其类型如何,都会被覆盖。*/SET(RedisDataType.STRING),/*** 设置键的字符串值,并设置生存时间(TTL)。* 如果键已经持有一个值,则无论其类型如何,都会被覆盖。*/SETEX(RedisDataType.STRING),/*** 将元素添加到以第一个参数指定的变量名存储的HyperLogLog数据结构中。*/PFADD(RedisDataType.HYPER_LOG_LOG),/*** 将消息发布到给定的频道。*/PUBLISH(RedisDataType.PUBSUB),/*** 将具有指定分数的指定成员添加到存储在键上的有序集合中。*/ZADD(RedisDataType.SORTED_SET),ZINCRBY(RedisDataType.SORTED_SET),/*** 从存储在键上的有序集合中删除指定的成员。*/ZREM(RedisDataType.SORTED_SET),/*** 在键上的哈希中设置字段的值。如果键不存在,* 则创建一个持有哈希的新键。如果字段已经存在于哈希中,则会覆盖它。*/HSET(RedisDataType.HASH),HINCRBY(RedisDataType.HINCRBY),/*** 为指定的键进行加法操作。*/INCRBY(RedisDataType.STRING),/*** 为指定的键进行加法操作,并在固定时间后过期。*/INCRBY_EX(RedisDataType.STRING),/*** 为指定的键进行减法操作。*/DECRBY(RedisDataType.STRING),/*** 为指定的键进行减法操作,并在固定时间后过期。*/DESCRBY_EX(RedisDataType.STRING);/*** 此命令所属的{@link RedisDataType}。*/private RedisDataType redisDataType;RedisCommand(RedisDataType redisDataType) {this.redisDataType = redisDataType;}/*** 获取此命令所属的{@link RedisDataType}。** @return {@link RedisDataType}*/public RedisDataType getRedisDataType() {return redisDataType;}
}
String数据类型示例
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;public class RedisStringSink implements RedisMapper<Tuple2<String, String>> {/*** 设置redis数据类型*/@Overridepublic RedisCommandDescription getCommandDescription() {return new RedisCommandDescription(RedisCommand.SET);}/*** 设置Key*/@Overridepublic String getKeyFromData(Tuple2<String, String> data) {return data.f0;}/*** 设置value*/@Overridepublic String getValueFromData(Tuple2<String, String> data) {return data.f1;}
}
Hash数据类型示例
创建一个Order对象
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.math.BigDecimal;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order {private Integer id;private String name;private BigDecimal price;
}
编码示例:
import com.alibaba.fastjson.JSON;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;public class RedisHashSink implements RedisMapper<Order> {/*** 设置redis数据类型*/@Overridepublic RedisCommandDescription getCommandDescription() {/*** 第二个参数是Hash数据类型, 第二个参数是外面的key** @redisCommand: Hash数据类型* @additionalKey: 哈希和排序集数据类型时使用(RedisDataType.HASH组或RedisDataType.SORTED_SET), 其他类型忽略additionalKey*/return new RedisCommandDescription(RedisCommand.HSET, "redis");}/*** 设置Key*/@Overridepublic String getKeyFromData(Order oder) {return oder.getId() + "";}/*** 设置value*/@Overridepublic String getValueFromData(Order oder) {// 从数据中获取Value: Hash的valuereturn JSON.toJSONString(oder);}
}
使用Sink
RedisStringSink
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建data sourceDataStreamSource<String> dataStreamSource = env.fromElements("Flink", "Spark", "Storm");// 应用转换算子SingleOutputStreamOperator<Tuple2<String, String>> streamOperator = dataStreamSource.map(new MapFunction<String, Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> map(String s) throws Exception {return new Tuple2<>(s, s);}});// Jedis池配置FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build();// 关联sink:将给定接收器添加到此数据流streamOperator.addSink(new RedisSink<>(conf, new RedisStringSink()));// 执行env.execute("redis sink");}
RedisHashSink
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建data sourceDataStreamSource<Order> dataStreamSource = env.fromElements(new Order(1,"Flink", BigDecimal.valueOf(100)),new Order(2,"Spark", BigDecimal.valueOf(200)),new Order(3,"Storm", BigDecimal.valueOf(300)));// Jedis池配置FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379)// 池可分配的最大对象数,默认值为8.setMaxTotal(100)// 设置超时,默认值为2000.setTimeout(1000 * 10).build();// 关联sink:将给定接收器添加到此数据流dataStreamSource.addSink(new RedisSink<>(conf, new RedisHashSink()));// 执行env.execute("redis sink");}
验证
在Redis的控制台中查询数据
查看String数据类型
本地:0>get Flink
"Flink"
本地:0>get Spark
"Spark"
查看Hash数据类型
Redis:0>keys *
1) "redis"
Redis:0>HGETALL redis
1) "3"
2) "{"id":3,"name":"Storm","price":300}"
3) "2"
4) "{"id":2,"name":"Spark","price":200}"
5) "1"
6) "{"id":1,"name":"Flink","price":100}"
相关文章:

Flink之输出算子Redis Sink
Redis Sink Redis Sinkjedis实现添加依赖自定义Redis Sink使用Sink验证 开源 Redis Connector添加依赖自定义Redis SinkRedisCommandString数据类型示例Hash数据类型示例 使用SinkRedisStringSinkRedisHashSink 验证 Redis Sink 在新版Flink的文档中,并没有发现Redi…...

【数据结构】顺序表实现通讯录
前言 在上一节中我们实现了顺序表,现在我们将使用顺序表完成通讯录的实现。(注:本人水平有限,“小屎山”有些许bug,代码冗余且语无伦次,望谅解!😅) 文章目录 一、数据结构…...
JMeter 随机数生成器简介:使用 Random 和 UUID 算法
在压力测试中,经常需要生成随机值来模拟用户行为。JMeter 提供了多种方式来生成随机值,本文来具体介绍一下。 随机数函数 JMeter 提供了多个用于生成随机数的函数,其中最常用的是 __Random 函数。该函数可以生成一个指定范围内的随机整数或…...

vue3 更换 elemnt-ui / element-plus 版本npm命令
1. 安装 / 更换 element-ui 版本 [ 在 后面指定想要安装的版本 ] //卸载当前版本 npm uninstall element-ui //安装指定版本 npm i element-ui2.4.8 -S --legacy-peer-deps 2. 安装 / 更换 element-plus 版本 [ 在 后面指定想要安装的版本 ] npm install element-plus2.3…...

react.js 手写响应式 reactive
Redux 太繁琐,Mbox 很酷但我们可能没必要引入新的包,那就让我们亲自在 react.js 中通过代理实现一套钩子来达到类似 vue 的响应式状态: 实现 reactive hooks 代理类声明 代理状态的类应当提供可访问的状态,和订阅变化的接口。 …...

代码随想录打卡第四十六天|完全背包 ● 518. 零钱兑换 II ● 377. 组合总和 Ⅳ
完全背包理论 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 完全背包和01背包问题唯一…...
【BP-Adaboost预测】基于BP神经网络的Adaboost的单维时间序列预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Origami Studio for Mac:塑造未来,掌握原型设计之巅
在当今高度竞争的设计领域,原型设计的重要性不言而喻。它不仅是沟通想法,也是测试和改进设计的关键环节。而现在,一款强大的原型设计工具——Origami Studio for Mac,正在席卷设计界,以其独特的功能和卓越的性能&#…...
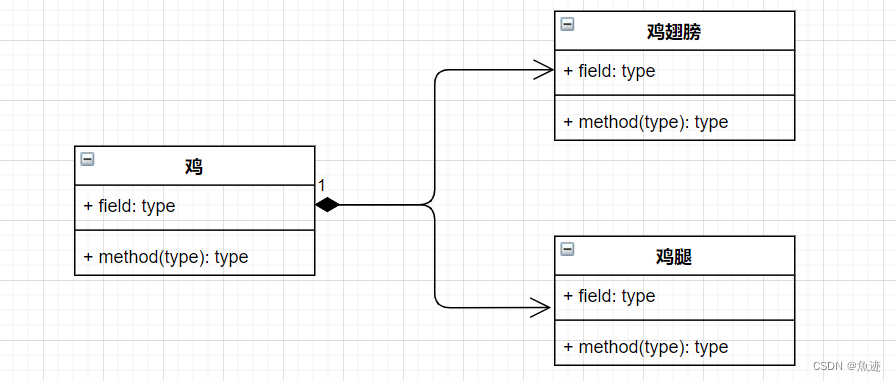
UML类图中各箭头表示总结
UML类图中各箭头表示总结 1、泛化2、实现3、依赖4、关联5、聚合6、组合 在UML类图中,箭头关系是用来表示类之间的关系的。箭头关系的种类有以下几种: 1、泛化 泛化:表示类之间的继承关系。箭头从子类指向父类。箭头:实线空心三角…...
神经网络量化----为了部署而特别设计
引言:一般神经网络量化有两个目的: 为了加速,在某些平台上浮点数计算比较耗费时间,替换为整形可以加快运算为了部署,某些平台上只支持整形运算,比如在芯片中如果是第1个目的,则使用常规的量化手段就可以满足,将浮点数运算变成整形运算+较少的浮点运算 但是如果是第2个目…...

代码随想录算法训练营Day60|单调栈01
代码随想录算法训练营Day60|单调栈01 文章目录 代码随想录算法训练营Day60|单调栈01一、739. 每日温度二、496.下一个更大元素 I 一、739. 每日温度 class Solution {public int[] dailyTemperatures(int[] temperatures) {//单调栈int lenstemperatures.length;int result[]n…...

openMP学习笔记 -编程模型
OpenMP模型 gcc编译openmp指令:gcc test.cpp -o test -fopenmp 定积分计算 函数面积 给定一个定积分,计算其面积: ∫ 0 1 4.0 ( 1 x 2 ) d x \int^{1}_{0}{\frac{4.0}{(1x^2)}dx} ∫01(1x2)4.0dx omp 概念 并行区域 并行区域用于…...

【Hive SQL 每日一题】环比增长率、环比增长率、复合增长率
文章目录 环比增长率同比增长率复合增长率测试数据需求说明需求实现 环比增长率 环比增长率是指两个相邻时段之间某种指标的增长率。通常来说,环比增长率是比较两个连续时间段内某项数据的增长量大小的百分比。 环比增长率反映了两个相邻时间段内某种经济指标的变…...
)
Java设计模式之外观模式(Facade Pattern)
外观模式(Facade Pattern)是一种结构型设计模式,它提供了一个统一的接口,用于访问子系统中的一组接口。外观模式通过隐藏子系统的复杂性,简化了客户端与子系统之间的交互,提供了一个更简单、更直观的接口。…...

【大疆智图】大疆智图(DJI Terra 3.0.0)安装及使用教程
大疆智图是一款以二维正射影像与三维模型重建为主的软件,同时提供二维多光谱重建、激光雷达点云处理、精细化巡检等功能。它能够将无人机采集的数据可视化,实时生成高精度、高质量三维模型,满足事故现场、工程监测、电力巡线等场景的展示与精确测量需求。 文章目录 1. 安装D…...
腾讯地图基本使用(撒点位,点位点击,弹框等...功能) 搭配Vue3
腾讯地图的基础注册账号 展示地图等基础功能在专栏的上一篇内容 大家有兴趣可以去看一看 今天说的是腾讯地图的在稍微一点的基础操作 话不多说 直接上代码 var marker ref(null) var map var center ref(null) // 地图初始化 const initMap () > {//定义地图中心点坐标…...
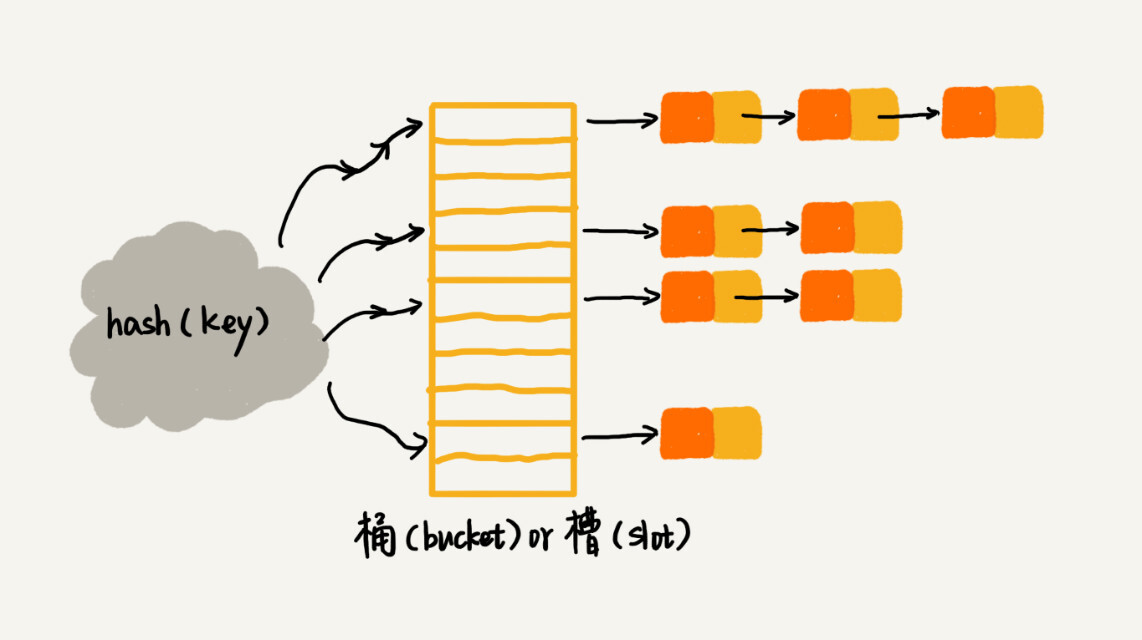
散列表:Word文档中的单词拼写检查功能是如何实现的?
文章来源于极客时间前google工程师−王争专栏。 一旦我们在Word里输入一个错误的英文单词,它就会用标红的方式提示“编写错误”。Word的这个单词拼写检查功能,虽然很小但却非常实用。这个功能是如何实现的? 散列别(Hash Table&am…...

智慧公厕蜕变多功能城市智慧驿站公厕的创新
随着城市发展的不断推进,对公共设施的便利性和智能化要求也日益提高。为满足市民对高品质、便捷、舒适的公共厕所的需求,智慧公厕行业的领航厂家广州中期科技有限公司,全新推出了一体化智慧公厕驿站。凭借着“高科技碳中和物联网创意设计新经…...

R语言清洗与处理数据常用代码段
去掉数据框df的某一列: # 删除不必要的变量 data$unnecessary_var <- NULL 选择需要的列进行读入数据框: # 选择需要的列 selected_cols <- c("col1", "col2", "col3") data <- fread("data.csv", s…...

centos 7.9 安装python 3.10的tls问题,
本地开发升级成了py3.10.6,服务器测试时安装py3.10.4 发现无法正常使用pip3 pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available. 印象中py3的高版本依赖高版本的openssl,centos 7下默认的openssl为1.0.x, 问题很简…...

10分钟搞定《Degrees of Lewdity》中文本地化:从零开始到完整汉化体验
10分钟搞定《Degrees of Lewdity》中文本地化:从零开始到完整汉化体验 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chinese-Lo…...

Z-Image Turbo免配置环境实战:快速搭建个人绘画平台
Z-Image Turbo免配置环境实战:快速搭建个人绘画平台 1. 项目概述 Z-Image Turbo是一个基于Gradio和Diffusers构建的高性能AI绘图Web界面,专门为Z-Image-Turbo模型优化设计。这个平台最大的特点就是开箱即用,无需复杂的环境配置,…...

别再信网上乱排的降AI率工具榜单了,真实排名看这里
标题党的降AI率榜单我见太多了。 “震惊!2026年降AI率工具第一名竟然是它!” “重磅发布!降AI率工具权威排名TOP10!” “2026最新!学生党必看的降AI率榜单!” 点进去看内容,不是文字游戏就是软文广告。真正靠谱的、基于实测数据的榜单,少之又少。 今天我就不搞那些虚头巴脑的…...
)
第29篇:AI项目实战复盘:我们如何用AI工具月增10万粉丝?(踩坑总结)
文章目录问题现象:从“技术自嗨”到“增长停滞”排查过程:从数据、用户反馈到流程拆解根本原因:错把“工具展示”当成了“价值交付”解决方案:转向“以用户价值为核心”的AI内容引擎1. 选题革命:从“技术驱动”到“场景…...

Phi-3-vision-128k-instruct多场景落地案例集:从教育到工业的AI赋能
Phi-3-vision-128k-instruct多场景落地案例集:从教育到工业的AI赋能 1. 开篇:一款改变行业工作方式的视觉大模型 最近试用了一款名为Phi-3-vision-128k-instruct的视觉大模型,它的表现确实让人眼前一亮。不同于常见的单一功能AI工具&#x…...

Python篇---# -*- coding: utf-8 -*- 声明
简单来说,# -*- coding: utf-8 -*- 这行声明的作用,就是告诉Python解释器:“这个.py文件是用UTF-8编码保存的,请按这个规则来读取它。”关于Windows和Linux下的差异,最核心的原因在于Python 2与Python 3的默认编码不同…...

SQL插入数据时忽略错误行_使用错误日志表暂存失败条目
INSERT IGNORE 无法记录错误详情,因其静默忽略所有错误(包括主键冲突、字段超长、类型不匹配等),不触发错误日志、不返回具体错误码和消息,导致无法审计、重试或告警。MySQL INSERT IGNORE 为什么不能记录错误详情INSE…...

用STM32玩转PS2无线手柄:从时序图到按键读取的保姆级代码解析
STM32与PS2无线手柄深度实战:时序解析与按键捕获全流程 第一次拿到PS2手柄想接入STM32时,我盯着那四根线发愣——CLK、CMD、DAT、CS,看似简单的接口背后藏着怎样的通信奥秘?作为嵌入式开发者,理解并实现这种专有协议是…...
3分钟快速上手Translumo:Windows平台终极实时屏幕翻译神器
3分钟快速上手Translumo:Windows平台终极实时屏幕翻译神器 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 想要…...

从“按键精灵”到“内存修改器”:聊聊我这些年见过的游戏外挂技术演变史
游戏外挂技术二十年:从脚本小子到内存猎手的进化之路 2003年夏天,我在网吧第一次见识到《传奇》的"自动打怪"外挂——那个简陋的窗口上只有五个按钮,却让周围所有玩家趋之若鹜。二十年后的今天,当我在《Apex英雄》中遇到…...