Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第二章 线程同步精要
并发编程有两种基本模型,一种是message passing,另一种是shared memory。在分布式系统中,运行在多台机器上的多个进程的并行编程只有一种实用模型:message passing。在单机上,我们也可以照搬message passing作为多个进程的并发模型。这样整个分布式系统的架构的一致性很强,扩容(scale out)起来也较容易。在多线程编程中,message passing更容易保证程序的正确性,有的语音只提供这一种模型。
线程同步的四项原则,按重要性排列:
1.首要原则是尽量最低限度地共享对象,减少需要同步的场合。一个对象能不暴露给别的线程就不要暴露,如果要暴露,优先考虑immutable对象,实在不行才暴露可修改的对象,并用同步措施来充分保护它。
2.其次是使用高级的并发编程构件,如TaskQueue、Producer-Consumer Queue、CountDownLatch(计数器闭锁,它是一种计数器,初始时设置一个计数值,并在多个线程完成各自任务后递减这个计数值,当计数值达到零时,允许某个等待的线程继续执行)等。
3.最后不得已必须使用底层同步原语(primitives)时,只用非递归的互斥器和条件变量,慎用读写锁(它们适用于读操作频繁而写操作较少的情况,使用不当可能会导致性能问题,需要仔细评估使用场景),不要用信号量。
4.除了使用atomic整数外,不自己编写lock-free代码(编写无锁(lock-free)代码是一项极具挑战性的任务,需要深入了解硬件和多线程编程的细节),也不要用内核级同步原语(如memory barrier)。不凭空猜测哪种做法性能会更好,如spin lock vs. mutex。
互斥器(mutex)可能是使用得最多的同步原语,它保护了临界区,任何时刻最多只能有一个线程在此mutex划出的临界区内活动。单独使用mutex时,主要为了保护共享数据。作者的原则是:
1.用RAII手法封装mutex的创建、销毁、加锁、解锁四个操作。用RAII封装这几个操作是通行的做法,几乎是C++的标准实践。Java里的synchronized语句和C#的using语句也有类似效果,即保证锁额生效期间等于一个作用域(scope),不会因异常而忘记解锁。
2.只用非递归的mutex(即不可重入的mutex)。
3.不手工调用lock()和unlock()函数,一切交给栈上的Guard对象的构造和析构函数负责。Guard对象的生命期正好等于临界区,这样我们保证始终在同一个函数同一个scope里对某个mutex加锁和解锁。避免在foo()里加锁,然后跑到bar()里解锁;也避免在不同的语句分支中分别加锁、解锁。这种做法称为Scoped Locking。
4.在每次构造Guard对象时,思考一路上(调用栈上)已经持有的锁,防止因加锁顺序不同而导致死锁。由于Guard对象时栈上对象,看函数调用栈就能分析用锁情况,非常便利。
次要原则有:
1.不使用跨进程的mutex,进程间通信只用TCP sockets。
2.加锁、解锁在同一个线程,线程a不能去unlock线程b已经锁住的mutex(RAII自动保证)。
3.别忘了解锁(RAII自动保证)。
4.不重复解锁(RAII自动保证)。
5.必要的时候考虑用PTHREAD_MUTEX_ERRORCHECK来排错。这种类型的互斥锁在锁定和解锁操作时会执行额外的错误检查,如果违反了互斥锁的使用规则,例如线程尝试解锁未锁定的互斥锁,或者尝试嵌套锁定同一个互斥锁,互斥锁会返回错误代码而不是阻塞或成功。它的性能更慢,通常用于调试和测试阶段。
mutex恐怕是最简单的同步原语,按照上面的规则,几乎不可能用错。
mutex分为递归(recursive)和非递归(non-recursive)两种,这是POSIX叫法,另外的名字是可重入(reentrant)与非可重入。这两种mutex作为线程间(inter-thread)的同步工具时没有区别,唯一的区别在于,同一个线程可以重复对recursive mutex加锁,但不能重复对non-recursive mutex加锁。
首选非递归mutex不是为了性能,而是为了体现设计意图。non-recursive和recursive的性能差别其实不大,因为少用一个计数器,前者略快一点点而已。在同一个线程里多次对non-recursive mutex加锁会立刻导致死锁,这是它的有点,能帮我们思考代码对锁的需求,且及早(在编码阶段)发现问题。
毫无疑问recursive mutex使用起来方便一些,因为不用考虑一个线程自己把自己锁死,作者猜测这也是Java和Windows默认提供revursive mutex的原因。Java自带的intrinsic lock是可重入的,它的util.concurrent库里提供ReentrantLock,Windows的CRITICAL_SECTION也是可重入的,似乎它们都不提供轻量级的non-recursive mutex。
正因为recursive mutex方便,它可能会隐藏代码里的一些问题。典型情况是你以为拿到一个锁就能修改对象了,没想到外层代码已经拿到了锁,正在修改(或读取)同一个对象,下面是一个具体的例子:
MutexLock mutex;
std::vector<Foo> foos;void post(const Foo &f)
{MutexLockGuard lock(mutex);foos.push_back(f);
}void traverse()
{MutexLockGuard lock(mutex);for (std::vector<Foo>::const_iterator it = foos.begin(); it != foos.end(); ++it){it->doit();}
}
post()加锁,然后修改foos对象;traverse()加锁,然后遍历foos向量。这些都正确。
将来有一天,Foo::doit()间接调用了post(),可能出现以下结果:
1.mutex是非递归的,于是死锁了。
2.mutex是递归的,由于push_back()可能(不总是)导致vector迭代器失效,程序偶尔会crash。
这是就能体现出non-recursive的优越性:把程序的逻辑错误暴露出来。死锁比较容易debug,把各个线程的调用栈打出来(通过gdb的命令thread apply all bt,其中thread apply all告诉调试器要对所有线程执行操作,bt告诉调试器执行bt操作),只要每个函数不是特别长,很容易看出是怎么死锁的。或者用PTHREAD_MUTEX_ERRORCHECK一下就能找到错误(前提是自定义MutexLock类中带debug选项)。程序反正要死,不如死得有意义一点,留个全尸,让验尸(post-mortem)更容易些。
如果确实需要在遍历时修改vector,有两种做法,一是把修改推后,记住循环中试图添加或删除哪些元素,等循环结束了再依记录修改foos;二是用copy-on-write,下面会介绍。
如果一个函数既可能在已加锁的情况下调用,又可能在未加锁的情况下调用,那就拆成两个函数:
1.跟原来的函数同名,函数加锁,转而调用第2个函数。
2.给函数名加上后缀WithLockHold,不加锁,把原来的函数体搬过来。
考虑一个情景,成员函数A需要递归调用,在A中会访问共享数据,因此需要加锁,此时可以加递归锁,但最好不用递归锁,而是将A函数写两个版本,一个是加锁版本,一个是不加锁版本,递归时调用不加锁版本即可。如果成员函数A和B都访问同一共享数据(两者都需要加锁),而A也要调用B时,类似地,也调用B的不加锁版本。
就像这样:
void post(const Foo &f)
{MutexLockGuard lock(mutex);// 不用担心开销,编译器会自动内联的postWithLockHold(f);
}// 引入这个函数是为了体现代码作者的意图,此处的push_back通常可以手动内联(即不用函数postWithLockHold)
void postWithLockHold(const Foo &f)
{foos.push_back(f);
}
这有可能出现两个问题:
1.误用了加锁版本,死锁了。
2.误用了不加锁版本,数据损坏了。
对于1,后面讲到的方法能比较容易地排错。对于2,如果Pthread提供isLockedByThisThread()就好办了,可以写成:
void postWithLockHold(const Foo &f)
{// muduo::MutexLock提供了这个成员函数assert(mutex.isLockedByThisThread();
}
另外,WithLockHold这个显眼的后缀也让程序中的误用容易暴露出来。
C++没有annotation(注解),不能像Java那样给method或field标上@GuardedBy注解。在Java中,@GuardedBy可以标明字段或方法被哪个锁所保护,从而可以用辅助工具(而非编译器)生成警告或建议,这些工具可以检查你的代码以确保锁的正确使用。
对于需要使用recursive mutex的情况,可以借助wrapper(封装,可能指的是将一段代码封装一个加锁版本,这段代码本身是一个函数,其中没有加锁,这样就有加锁版本和非加锁版本了)改用non-recursive mutex,代码只会更清晰。
Pthreads的权威专家,《Programming with POSIX Threads》的作者David Butenhof也排斥使用recursive mutex,他说:

Linux的Pthreads mutex采用futex实现(futex是fast user-space mutex的缩写,是一种优化了的用户空间互斥锁机制),不必每次加锁、解锁都陷入系统调用,效率不错。Windows的CRITICAL_SECTION也类似,不过它可以嵌入一小段spin lock,在多CPU系统上,如果不能立刻拿到锁,它会先spin一小段时间,如果还不能拿到锁,才挂起当前线程。
如果坚持只使用Scoped Locking,那么在出现死锁时很容易定位,考虑下面这个线程自己与自己死锁的例子:
class Request
{
public:// __attribute__((noinline))void process(){muduo::MutexLockGuard lock(mutex_);// ...// 原本没有print函数,某人为了调试程序不小心添加了print();}// __attribute__((noinline))void print() const {muduo::MutexLockGuard lock(mutex_);// ...}private:mutable muduo::MutexLock mutex_;
};int main()
{Request req;req.process();
}
上例中,process()里加上print()后会出现死锁,要调试定位这种死锁很容易,只要把函数调用栈打印出来,结合源码一看,立刻就会发现第六帧Request::process()和第五帧Request::print()先后对同一个mutex上锁,引发了死锁。必要的时候可以在函数前加上__attribute__(GCC的扩展)来防止函数inline展开,因为被内联的函数不会打印在调用栈中。
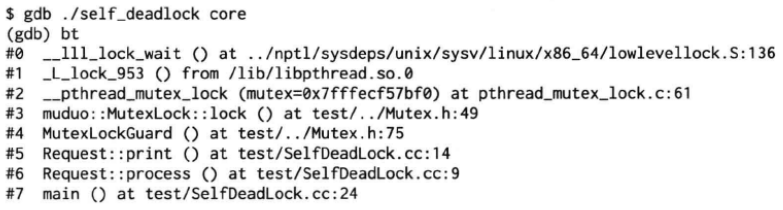
上图中,命令的含义是分析self_deadlock程序的核心转储文件core的内容,此时,不需要对self_deadlock程序加任何参数。
要修复以上错误也很容易,按前面的办法,从Request::print()抽取出Request::printWithLockHold(),并让Request::print()和Request::process()都调用它即可。
再看一个更真实的两个线程死锁的例子。有一个Inventory(清单)class,记录当前的Request对象:
class Inventory
{
public:void add(Request *req){muduo::MutexLockGuard lock(mutex_);requests_.insert(req);}// __attribute__((noinline))void remove(Request *req) {moduo::MutexLockGuard lock(mutex_);requests_.erase(req);}void printAll() const;private:mutable muduo::MutexLock mutex_;std::set<Request *> requests_;
};// 简单起见,这里使用了全局对象
Inventory g_inventory;
可见以上Inventory class的add()和remove()成员函数都是线程安全的,它使用了mutex来保护共享数据requests_。
Request class与Inventory class的交互逻辑很简单,在处理(process)请求的时候,往g_inventory中添加自己,在析构的时候,从g_inventory中移除自己,目前来看,整个程序还是线程安全的。
class Request
{
public:// __attribute__((noinline))void process(){muduo::MutexLockGuard lock(mutex_);g_inventory.add(this);// ...}~Request() __attribute__((noinline)) {muduo::MutexLockGuard lock(mutex_);// 为了复现死锁,这里用了延时sleep(1);g_inventory.remove(this);}void print() const __attribute__((noinline)){muduo::MutexLockGuard lock(mutex_);// ...}private:mutable muduo::MutexLock mutex_;
};
Inventory class还有一个功能是打印全部已知的Request对象。Inventory::printfAll()里的逻辑单独看是没问题的,但它可能引发死锁:
void Inventory::printAll() const
{muduo::MutexLockGuard lock(mutex_);// 为了容易复现死锁,这里用了延时sleep(1);for (std::set<Request *>::const_iterator it = requests_.begin(); it != requests_.end(); ++it){(*it)->print();}printf("Inventory::printAll() unlocked\n");
}
下面这个程序运行起来会发生死锁:
void threadFunc()
{Request *req = new Request;req->process();delete req;
}int main()
{muduo::Thread thread(threadFunc);thread.start();// 为了让另一个线程等待在Request::~Request()的sleep上usleep(500 * 1000);g_inventory.printAll();thread.join();
}
通过gdb查看两个线程的函数调用栈,我们发现两个线程都等在mutex上(__lll_lock_wait),估计是发生了死锁,因为一个程序中的线程一般只会等在condition variable或epoll_wait上:
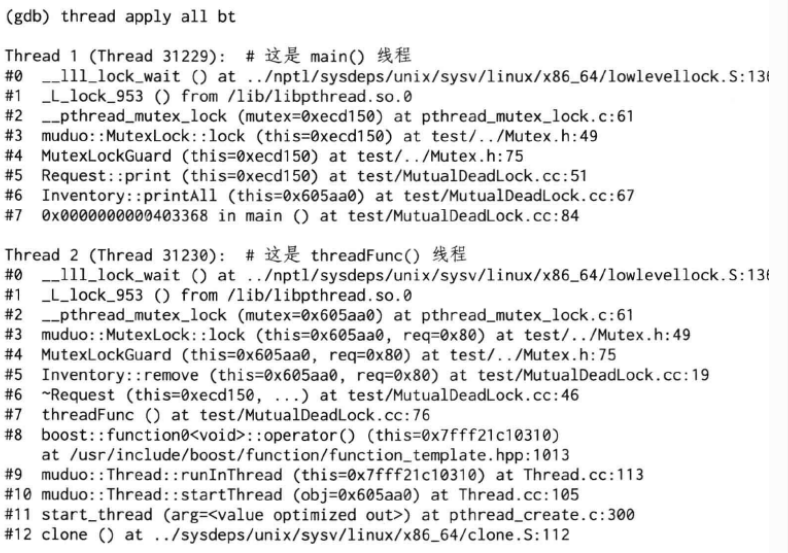
注意到main()线程是先调用Inventory::printAll(#6)再调用Request::print(#5),而threadFunc()线程是先调用Request::~Request(#6)再调用Inventory::remove(#5)。这两个调用序列对两个mutex的加锁顺序正好相反,于是造成了经典的死锁。如下图:
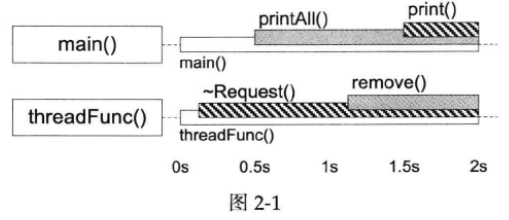
Inventory class的mutex的临界区由灰底表示,Request class的mutex的临界区由斜纹表示,一旦main()线程中的printAll()在另一个线程的~Request()和remove()之间开始执行,死锁就不可避免。
如果printAll()晚于remove()执行,此时threadFunc()已经获取到了两个锁,就不会再出现死锁了。
让~Request()在PrintAll()和print()之间执行,也会出现死锁。
这里也出现了第一章中的race condition,即一个线程正在析构对象,另一个线程却在调用它的成员函数。
为了解决死锁,要么把print()移除pringAll()的临界区,这可以用下面介绍的方法;要么把remove()移出~Request()的临界区,如交换Request的析构函数中加锁和调用remove的顺序。但这没有解决对象析构的race condition。
Inventory::printAll->Request::print不会与Request::process->Inventory::add发生死锁,因为如果Inventory::printAll先获得了Inventory的锁,则Request::process在将自身放入Inventory前,获取不到Inventory的锁,此时Inventory::printAll不会打印出当前正在竞争的Request;如果Request::process先获得了Inventory的锁,则Inventory::printAll需要等待将Request加入requests_后才能继续打印,而Inventory::printAll获得Inventory的锁时,Request已加入Inventory完毕,正在或已经解锁了两个锁。
死锁会让程序行为失常,而其他锁使用不当会影响性能。编写高性能多线程程序还需了解false sharing和CPU cache效应:
1.false sharing:这是一种性能问题,它发生在多线程程序中的不同线程同时访问共享内存中不同变量或数据结构的不同部分,而这些变量或数据结构被映射到相同的缓存行(cache line)。因为现代CPU通常以缓存行为单位来加载和存储数据,当不同线程访问同一缓存行时,会导致缓存一致性开销,可能会使程序的性能大幅下降。False sharing会引发不必要的缓存失效,因为一个线程的写操作会导致其他线程的缓存无效,尽管它们实际上并没有修改相同的数据。
解决False Sharing的方法通常包括使用线程本地存储(Thread-Local Storage)或者对共享数据进行对齐,以确保不同线程访问的数据不会映射到相同的缓存行。
缓存行(cache line)用于缓存数据以提高内存访问性能。缓存行是缓存的最小单位,通常由一组相邻的字节或字组成。当处理器从主内存中加载数据时,它会将一整个缓存行的数据复制到高速缓存中。这个缓存行中的数据可以是指令或数据,具体取决于缓存的类型(指令缓存或数据缓存)。
2.CPU Cache效应:指利用CPU的缓存来提高程序性能的现象。CPU缓存是一种用于存储频繁访问的数据的高速存储器,以减少对主内存的访问延迟。当多线程程序访问相同的数据时,合理地利用缓存可以显著提高性能。但同时,不恰当的缓存使用也可能导致性能下降。
CPU Cache效应包括缓存命中(数据在缓存中)和缓存未命中(数据不在缓存中)。为了获得最佳性能,我们需要考虑数据的局部性,以减少缓存未命中,并避免False Sharing。
互斥器是加锁原语,用来排他性地访问共享数据,它不是等待原语。在使用mutex时,我们一般都会期望加锁不要阻塞,总是能立刻拿到锁,然后尽快访问数据,用完后尽快解锁,这样才能不影响并发性和性能。
如果需要等待某个条件成立,我们应使用条件变量(condition variable)。条件变量顾名思义是一个或多个线程等待某个布尔表达式为真,即等待别的线程唤醒它。条件变量的学名叫管程(monitor)。Java Object内置的wait()、notify()、notifyAll是条件变量。
条件变量只有一种正确使用方式,对于wait端:
1.必须与mutex一起使用,该布尔表达式的读写需要受到此mutex的保护。
2.在mutex已上锁的时候才能调用wait()。
3.把判断布尔条件和wait()放到while循环中。
写成代码是:
muduo::MutexLock mutex;
muduo::Condition cond(mutex);
std::deque<int> queue;int dequeue()
{MutexLockGuard lock(mutex);// 必须用循环,必须在判断后再waitwhile (queue.empty()){// 这一步会原子地unlock mutex并进入等待,不会与enqueue死锁cond.wait();// wait()执行完毕会自动重新加锁}assert(!queue.empty());int top = queue.front();queue.pop_front();return top;
}
上面的代码必须用while循环来等待条件变量,而不能用if语句,原因是spurious wakeup。Spurious wakeup是多线程编程中一个可能会发生的现象,特别是在使用条件变量等线程同步机制时。当一个线程在等待某个条件满足时,它可能在没有明确信号的情况下被唤醒。这种唤醒是“虚假的”或“伪唤醒”,因为它没有基于条件的实际变化来触发。
Spurious wakeup通常是由操作系统或编程语言库的内部实现引起的。虽然spurious wakeup在理论上是可能的,但在实践中发生的频率相对较低,通常情况下不会引起严重问题。
对于signal/boradcast端:
1.不一定要在mutex已上锁的情况下调用signal(理论上)。
2.在signal前一般要修改布尔表达式。
3.修改布尔表达式通常要用mutex保护(至少用作full memory barrier)。内存屏障是一种同步机制,用于确保线程之间的内存访问顺序和可见性。Full memory barrier提供了以下保证:
(1)保证顺序性:Full memory barrier确保在内存屏障之前的所有读写操作都在内存屏障之前执行,而在内存屏障之后的所有读写操作都在内存屏障之后执行。这防止了指令重排序,确保了操作的顺序性。指令重排序是一种CPU优化技术,用于提高指令执行效率,在处理器内部,有多个执行单元,它们可以同时执行不依赖于彼此结果的指令,以充分利用硬件资源。指令重排序允许处理器在不违反程序语义的前提下,重新排列指令的执行顺序,以加速执行。多线程程序的正确性通常依赖于特定指令的执行顺序,如果处理器进行了不合理的重排序,可能导致数据竞争、不一致的状态和程序错误。Full memory barrier阻止处理器在内存屏障之前的写入操作与内存屏障之后的读取操作之间发生重排序,这确保了写入操作在读取操作之前完成,防止了数据不一致性。Full memory barrier也禁止了读取操作之间的重排序,以及读取操作和写入操作之间的重排序,这有助于确保操作之间的顺序性。
(2)保证可见性:Full memory barrier确保在内存屏障之前的写操作对于其他线程可见。这意味着在内存屏障之前的写入将被刷新到主内存,并在内存屏障之后的读操作将从主内存中获取最新的值。这有助于确保线程之间对共享数据的正确访问。
4.注意区分signal和broadcast:broadcast通常用于表明状态变化,signal通常用于表示资源可用。
写成代码是:
void enqueue(int x)
{MutexLockGuard lock(mutex);queue.push_back(x);// notify可以移出临界区之外cond.notify();
}
上面的dequeue()/enqueue()实际上实现了一个简单的容量无限的(unbounded)BlockingQueue(阻塞队列)。
如果以上代码中,enqueue()每次添加元素都会调用Condition::notify(),如果改成只在queue.size()从0变1的时候才调用Condition::notify(),会造成只有一个线程工作的情形,例如当前dequeue中有10个元素,且由于只有从0变1时才调用过一次Condition::notify(),因此当前只会有一个线程被唤醒,取出一个元素,然后处理,在处理这个元素的过程中,如果又有5个元素加入dequeue,则加入过程不会唤醒其他线程,从而只有一个线程处理完所有元素。
条件变量是非常底层的同步原语,很少直接使用,一般都是用它来实现高层的同步措施,如BlockingQueue<T>或CountDownLatch。
倒计时(CountDownLatch)是一种常用且易用的同步手段,它的用途有:
1.主线程发起多个子线程,等这些子线程各自都完成一定的任务后,主线程才继续执行。通常用于主线程等待多个子线程完成初始化。
2.主线程发起多个子线程,子线程都等待主线程,主线程完成一些任务后通知所有子线程开始执行。通常用于多个子线程等待主线程发出起跑命令。
当然我们可以直接用条件变量来实现以上两种同步,但如果用CountDownLatch,程序的逻辑更清晰。CountDownLatch的接口很简单:
class CountDownLatch : boost::noncopyable
{
public:// 倒数几次explicit CountDownLatch(int count);// 等待计数值变为0void wait();// 计数减一void countDown();private:mutable MutexLock mutex_;Condition condition_;int count_;
};
CountDownLatch的实现也很简单,几乎是条件变量的教科书式应用:
void CountDownLatch::wait()
{MutexLockGuard lock(mutex_);while (count_ > 0){condition_.wait();}
}void CountDownLatch::countDown()
{MutexLockGuard lock(mutex_);--count_;if (count_ == 0) {condition_.notifyAll();}
}
注意到CountDownLatch::countDown()使用的是Condition::notifyAll(),而前面的enqueue()使用的是Condition::notify(),这是因为CountDownLatch::countDown()将计数减少到0时,需要通知所有阻塞线程运行,而enqueue()只添加了一个元素,只需通知一个线程运行即可。
互斥器和条件变量构成了多线程编程的全部必备原语,用它们即可完成任何多线程同步任务,二者不能相互替代。
读写锁(Readers-Writer lock,简写为rwlock)看上去是个很美的抽象,它明确区分了read和write两种行为。
初学者常干的一件事是,一见到某个共享数据结构频繁读而很少写,就把mutex替换为rwlock,甚至首选rwlock来保护共享状态,这不见得是正确的。
1.从正确性方面说,一种典型的易犯错误是在持有read lock时修改了共享数据。这通常发生在程序的维护阶段,为了新增功能,程序员不小心在原来read lock保护的函数中调用了会修改状态的函数。这种错误的后果跟无保护并发读写共享数据是一样的。
2.从性能方面说,读写锁不见得比mutex更高效,无论如何reader lock加锁的开销不会比mutex lock小,因为它要更新当前reader的数目。如果临界区很小,锁竞争不激烈,那么mutex往往更快。
3.reader lock可能允许提升(upgrade)为writer lock(指的是已经获取读锁的情况下,尝试再加写锁),也可能不允许提升(Pthread rwlock不允许提升)。考虑到上面的post()和traverse()示例,如果用读写锁来保护foos对象,那么post()应该持有写锁,而traverse()应该持有读锁。如果允许把读锁提升为写锁,后果跟使用recursive mutex一样,会造成迭代器失效(例如,获得写锁后,如果删除或添加了某个位置的元素,会导致这个位置后面的所有迭代器失效),程序崩溃。如果不允许提升,后果跟使用non-recursive mutex一样,会造成死锁(先加读锁,同一线程再加写锁,从而导致死锁)。最好程序死锁,留个全尸好查验。
4.通常reader lock是可重入的,writer lock是不可重入的。但为了防止writer饥饿,writer lock通常会阻塞后来的reader lock,因此reader lock在重入的时候可能死锁(线程A先加了读锁,然后线程B加写锁,然后线程A再加读锁,此时B会等待A释放第一个读锁,而A会等待B获得写锁然后解锁写锁),另外,在追求低延迟读取的场合也不适用读写锁。
muduo线程库有意不提供读写锁的封装,因为作者还未在工作中遇到过用rwlock替换普通mutex会显著提高性能的例子,相反,作者建议首选mutex。
遇到并发读写,如果条件合适,作者通常用shared_ptr实现copy-on-write(见下文),而不用读写锁,同时避免reader比writer阻塞。如果确实对并发读写有极高的性能要求,可以考虑read-copy-update(RCU的基本思想是在写操作时,不会立即修改共享数据,而是创建一个副本(copy)并在副本上进行修改。同时,读操作会继续访问原始数据,而写操作则继续在副本上进行修改。一旦写操作完成,它会更新共享数据的引用,以便读操作可以开始访问新的数据)。
作者没有遇到过需要使用信号量的情况,且认为信号量不是必备的同步原语,因为条件变量配合互斥器完全可以替代其功能,且更不容易用错。信号量的一个问题在于它有自己的计数值,而通常我们自己的数据结构也有长度值,这就造成了同样的信息存了两份,需要时刻保持一致,这增加了程序员的负担和出错的可能。
作者认为,如果程序里需要解决哲学家就餐之类的复杂IPC问题,应首先检讨这个设计,为什么线程之间会有如此复杂的资源争抢(一个线程要同时抢到两个资源,一个资源可以被两个线程争夺)。如果在工作中遇到,作者会把想吃饭这个事情专门交给一个为各位哲学家分派餐具的线程来做,然后每个哲学家等在一个简单的condition variable上,到时间了有人通知他去吃饭。从哲学上说,教科书上的解决方案是平权,每个哲学家有自己的线程,自己去拿筷子,作者宁愿用集权方式,用一个线程专门管餐具的分配,让其他哲学家线程拿个号等在食堂门口好了,这样不损失多少效率,却让程序简单很多。虽然Windows的WaitForMultipleObjects(它允许程序等待多个对象中的一个或多个对象达到可等待状态,这个函数通常用于多线程编程和进程间通信,以协调多个操作的执行顺序)让这个问题trivial化,但在Linux下正确模拟WaitForMultipleObjects不是普通程序员该干的。
Pthreads还提供了barrier这个同步原语,但不如CountDownLatch实用。
MutexLock、MutexLockGuard、Condition等class都不允许拷贝构造和赋值。
MutexLock和MutexLockGuard这两个class应该能在纸上默写出来,没有太多需要解释的。MutexLock的附加值在于提供了isLockedByThisThread()函数,用于程序断言,它用到的CurrentThread::tid()在第四章介绍。
以下是MutexLock类:
class MutexLock : boost::noncopyable
{
public:MutexLock() : holder_(0){pthread_mutex_init(&mutex_, NULL);}~MutexLock(){assert(holder_ == 0);pthread_mutex_destory(&mutex_);}bool isLockedByThisThread(){return holder_ == CurrentThread::tid();}void assertLocked(){assert(isLockedByThisThread();}// 仅供MutexLockGuard调用,严禁用户代码调用void lock(){// 这两行顺序不能反pthread_mutex_lock(&mutex_);holder_ = CurrentThread::tid();}// 仅供MutexLockGuard调用,严禁用户代码调用void unlock(){// 这两行顺序不能反holder_ = 0;pthread_mutex_unlock(&mutex_);}// 仅供Condition调用,严禁用户代码调用pthread_mutex_t *getPthreadMutex(){return &mutex_;}private:pthread_mutex_t mutex_;pid_t holder_;
};class MutexLockGuard : boost::noncopyable
{
public:explicit MutexLockGuard(MutexLock &mutex) : mutex_(mutex){mutex_.lock();}~MutexLockGuard(){mutex_.unlock();}private:MutexLock &mutex_;
};#define MutexLockGuard(x) static_assert(false, "missing mutex guard var name");
以上代码最后定义了一个宏,作用是防止程序里出现以下错误:
void doit()
{// 遗漏变量名,产生一个临时对象又马上销毁了MutexLockGuard(mutex);// 没有锁住临界区// 正确写法是MutexLockGuard lock(mutex);// 临界区
}
有人把MutexLockGuard写成template,以上没有这么做是因为它的模板类型参数只有MutexLock一种可能,没有必要随意增加灵活性,于是就手工把模板具现化(instantiate)了。此外一种更激进的写法是,把lock/unlock放到private区,然后把MutexLockGuard设为MutexLock的friend。以上MutexLock类中给lock()和unlock()加上注释即可,在check-in(将代码或更改提交到版本控制系统)前的code review也很容易发现误用情况(grep getPthreadMutex)。
以上代码没有达到工业强度:
1.mutex创建为PTHREAD_MUTEX_DEFAULT类型,而不是我们预想的PTHREAD_MUTEX_NORMAL类型(实际上这两者很可能是等同的),严格的做法是用mutexattr来显示指定mutex的类型。
2.没有检查锁相关系统调用的返回值。这里不能用assert()检查返回值,因为assert()在release build里(加上#define NDEBUG宏)是空语句。检查返回值的意义在于防止ENOMEM之类的资源不足情况,这一般只可能在负载很重的产品程序中出现,一旦出现这种情况,程序必须立刻清理现场并主动退出,否则会莫名其妙地崩溃,给事后调查造成困难。这里我们需要non-debug的assert,或许google-glog的CHECK()宏是个不错的思路。CHECK宏类似CHECK(x > 0) "x is not greater than 0!";,根据返回值(即x)的值进行某个行为,可以将宏的行为修改。
muduo库的一个特点是只提供最常用、最基本的功能,特别有意避免提供多种功能近似的选择,删繁就简,举重若轻,减少选择余地。
MutexLock没有提供tryLock(),因为作者没有在代码中用过它,不知道什么时候程序需要试着去锁一锁。truyock()可用于观察lock contention。
Pthreads condition variable允许在wait()的时候指定一个mutex,但想不出有什么理由一个condition variable会和不同的mutex配合使用(两个线程使用同一个条件变量的wait()时,可传不同的mutex参数给条件变量的wait())。Java的intrinsic condition和Condition class都不支持这么做,因此可以放弃这一灵活性,老老实实地一对一。
相反,boost::thread的condition_variable是在wait()时指定mutex的。以下是boost的同步原语的庞杂设计:
1.Concept有:Lockable、TimedLockable、SharedLockable、UpgradeLockable。
2.Lock有:lock_guard、unique_lock、shared_lock、upgrade_lock、upgrade_to_unique_lock、scoped_try_lock。
3.Mutex有:mutex、try_mutex、timed_mutex、recursive_mutex、recursive_try_mutex、recursive_timed_mutex、shared_mutex。
见到boost::thread这样如Rube Goldberg Machine(鲁布·戈尔德伯格机是一种机械装置或装置链,旨在以非常复杂和不必要的方式执行相对简单的任务)一样让人眼花缭乱的库,只得绕道而行。C++11的线程库也采纳了这套方案,这些class名字也很无厘头,不老老实实用readers_writer_lock这样通俗名字,非得增加精神负担,自己发明新名字。作者不愿为这样的灵活性付出代价,宁愿自己做几个简单的一看就明白的class来用,这种简单的几行代码的轮子造造也无妨。
以下muduo::Condition class简单地封装了Pthreads condition variable,用起来也容易,这里用notify/notifyAll作为函数名,因为signal有别的含义,C++里的signal/slot、C里的signal handler等,就不overload这个术语了。
class Condition : boost::noncopyable
{
public:explicit Condition(MutexLock &mutex) : mutex_(mutex){pthread_cond_init(&pcond_, NULL);}~Condition(){pthread_cond_destory(&pcond_);}void wait(){pthread_cond_wait(&pcond_, mutex_.getPthreadMutex());}void notify(){pthread_cond_signal(&pcond_);}void notifyAll(){pthread_cond_broadcast(&pcond_);}private:MutexLock &mutex_;pthread_cond_t pcond_;
};
如果一个class要包含MutexLock和Condition,要注意它们的生命顺序和初始化顺序,mutex_应先于condition_构造,并作为后者的构造参数:
class CountDownLatch
{
public:// 初始化列表中初始化的顺序与成员声明的顺序一致CountDownLatch(int count) : mutex_(), condition_(mutex_), count_(count) { }private:// 顺序很重要,先mutex后conditionmutable MutexLock mutex_;Condition condition_;int count_;
};
虽然本章花了大量篇幅介绍如何正确使用mutex和condition variable,但不代表鼓励到处使用它们,这两者都是非常底层的同步原语,主要用来实现更高级的并发编程工具。一个多线程程序里如果大量使用mutex和condition variable来同步,基本跟用铅笔刀锯大树一样。
在程序里使用Pthreads库有一个额外好处:分析工具认得它们,懂得其语意。线程分析工具如Intel Thread Checker和Valgrind-Helgrind能识别Pthreads调用,并依据happens-before关系分析程序有无data race。
研究Singleton的线程安全实现的历史会发现很多有意思的事,人们一度认为double checked locking(DCL)是王道,兼顾了效率和正确性。后来有“神牛”指出由于乱序执行的影响,DCL是靠不住的。Java开发者还算幸运,可以借助内部静态类的装载来实现。C++就比较惨,要么次次锁,要么eager initialize(Eager initialization,急切初始化,是一种初始化数据结构或对象的方法,它在程序启动或对象创建时立即进行初始化,这意味着在数据结构或对象第一次使用之前,它已经包含了所需的初始化值,相对应的是lazy initialization,懒惰初始化,它是一种延迟初始化的方式,仅在首次访问时才进行初始化),或动用memory barrier这样的“大杀器”。接下来Java 5修订了内存模型,并给volatile赋予了acquire/release语义,这下DCL(with volatile)又是安全的了。但C++的内存模型还在修订中,C++的volatile目前还不能(将来也难说)保证DCL的正确性。
注:"acquire"和"release"是一种内存操作语义,用于确保对共享数据的读取和写入操作在多线程环境下的正确同步:
1.Acquire (获取):当一个线程执行"acquire"操作时,它确保之前的所有读取和写入操作都已经完成。这意味着在"acquire"操作之前的所有写入都将在该操作之前对其他线程可见。"Acquire"语义通常与读取操作相关联,以确保在读取之前所有必要的写入都已完成。
2.Release (释放):当一个线程执行"release"操作时,它确保之后的所有读取和写入操作都不会提前执行。这意味着在"release"操作之后的所有写入都将在该操作之后对其他线程可见。"Release"语义通常与写入操作相关联,以确保在写入之后所有必要的读取都不会提前执行。
其实实践中直接用pthread_once就行:
template <typename T>
class Singleton : boost::noncopyable
{
public:static T& instance(){pthread_once(&ponce_, &Singleton::init);return *value_;}private:Singleton();~Singleton();static void init(){value_ = new T();}private:static pthread_once_t ponce_;static T* value_;
};// 必须在头文件中定义static变量
template<typename T>
pthread_once_t Singleton<T>::ponce_ = PTHREAD_ONCE_INIT;template<typename T>
T* Singleton<T>::value_ = NULL;
上面这个Singleton没有任何花哨的地方,它用pthread_once_t来保证lazy-initialization的线程安全。线程安全性由Pthreads库保证,如果系统的Pthreads库有bug,那就认命吧。
使用方法也很简单:
Foo &foo = Singleton<Foo>::instance();
这个Singleton没有考虑对象的销毁。在长时间运行的服务器程序里,这不是一个问题,反正进程也不打算正常退出。在短期运行的程序中,程序退出的时候自然就释放所有资源了(前提是程序里不使用不能由操作系统自动关闭的资源,如跨进程的mutex)。在实际的muduo::Singleton class中,通过atexit函数提供了销毁功能,聊胜于无罢了。
另外,以上Singleton只能调用默认构造函数。如果用户想要指定T的构造方式,可以用模板特化(template specialization)技术来提供一个定制点),这需要引入另一层间接(another level of indirection)。类似这样:
template <typename T>
class Singleton : boost::noncopyable
{
public:// 模板特化,定制构造函数template <typename... Args>static void initWithArgs(Args... args) {value_ = new T(args...);}/* ... */
};// 模板特化版本的Singleton类,允许定制构造方式
// 特例化一个函数模板时,必须为原模板中每个模板参数都提供实参,为指出我们在实例化一个模板
// 应使用template后跟一个空尖括号对<>,空尖括号对指出我们将为原模板的所有模板参数提供实参
template <>
template <typename... Args>
void Singleton<YourCustomType>::initWithArgs(Args... args) {value_ = new YourCustomType(args...);
}
作者认为sleep()/usleep()/nanosleep()只能出现在测试代码中,如写单元测试时;或用于有意延长临界区,加速复现死锁的情况。sleep不具备memory barrier语义,不能保证内存的可见性。
生产代码中线程的等待可分为两种:一种是等待资源可用(要么等在select/poll/epoll_wait上,要么等在条件变量上);一种是等着进入临界区(等在mutex上)以便读写共享数据。后一种等待通常极短,否则程序性能和伸缩性(指程序能够有效地应对不同规模的工作负载和数据集,而不需要重大的修改或性能下降。)就会有问题。
在程序的正常执行中,如果需要等待一段已知的时间,应该往event loop里注册一个timer,然后在timer的回调函数里接着干活,因为县城是个珍贵的共享资源,不能轻易浪费(阻塞也是浪费)。如果等待某个事件发生,那么应该采用条件变量或IO事件回调,不能用sleep来轮询。不要使用以下这种业余做法:
while (true)
{if (!dataAvailable){sleep(some_time);} else{consumeData();}
}
如果多线程的安全性和效率要靠代码主动调用sleep来保证,这显然是设计出了问题。等待某个事件发生,正确的做法是使用select()等价物或Condition,抑或(更理想地)高层同步工具;在用户态做轮询是低效的。
用好以上介绍的内容,基本上就能应付多线程服务端开发的各种场合,可能有人觉得性能没有发挥到极致,但应该先把程序写正确(并尽量保持清晰和简单),然后再考虑性能优化,如果确实还有必要优化的话。让一个正确的程序变快,远比让一个快的程序变正确要容易。
在现代的多核计算背景下,多线程是不可避免的。尽管在一定程度上可通过framework(框架)来屏蔽,让你感觉像是在写单线程程序,如Java Servlet。了解under the hood(“在引擎盖下面”,通常用来描述某事物的内部工作或机制)发生了什么对于编写这种程序也会有帮助。
通篇来看,效率不是作者的主要考虑点,作者提倡正确加锁而不是自己编写lock-free算法(使用原子整数除外),更不要想当然地自己发明同步设施。在没有实测数据支持的情况下,妄谈哪种做法效率更高是靠不住的,不能听信传言或凭感觉优化。很多人误认为用锁会让程序变慢,其实真正影响性能的不是锁,而是锁争用(lock contention)。在程序的复杂度和性能之间取得平衡,并考虑未来两三年扩容的可能(无论是CPU变快、核数变多、机器数量增加、网络升级)。在分布式系统中,多机伸缩性(scale out)比单机的性能优化更值得投入精力。
借shared_ptr实现copy-on-write,可以解决本章中的几个未决问题:
1.post()和traverse()死锁。
2.把Request::print()移出Inventory::printAll()临界区。
3.解决Request对象析构的race condition。
之后再示范用普通mutex替换读写锁。解决办法都基于同一个思路,就是用shared_ptr来管理共享数据,原理如下:
1.shared_ptr是引用计数型智能指针,如果当前只有一个观察者,那么引用计数的值为1。
2.对于write端,如果发现引用计数为1,这是可以安全地修改共享对象,不必担心有人正在读它。
3.对于read端,在读之前把引用计数加1,读完之后减1,这样保证在读的期间其引用计数大于1,可以阻止并发写。
4.比较难的是,对于write端,如果发现引用计数大于1,该如何处理?sleep()一小段时间肯定是错的。
先看一个简单的例子,解决post()和traverse()死锁。数据结构改成:
typedef std::vector<Foo> FooList;
typedef boost::shared_ptr<FooList> FooListPtr;
MutexLock mutex;
FooListPtr g_foos;
在read端,用一个栈上局部FooListPtr变量当作观察者,它使得g_foos的引用计数增加:
void traverse()
{FooListPtr foos;// 以下块作用域是traverse函数的临界区,临界区里只读了一次共享变量g_foos// 这里多线程并发读写shared_ptr g_foos,因此必须用mutex保护{MutexLockGuard lock(mutex);// 由于我们要进行读操作,读之前把引用计数加1,这样可以保证在读期间其引用计数大于1,以阻止并发写foos = g_foos;// shared_ptr的unique()成员函数用来判断自己是否是资源的唯一所有者// 此处至少有g_foos和foos在引用该资源,一定不是唯一所有者assert(!g_foos.unique());}// assert(!foos.unique()); 这个断言不成立for (std::vector<Foo>::const_iterator it = foos->begin(); it != foos->end(); ++it){it->doit();}
}
关键是write端的post()如何写,按前面的描述,如果g_foos.unique()为true,我们可以放心地在原地(in-place)修改FooList。如果g_foos.unique()为false,说明这时别的线程正在读取FooList,我们不能原地修改,而是复制一份,在副本上修改,这样就避免了死锁:
void post(const Foo &f)
{printf("post\n");MutexLockGuardLock(mutex);if (!g_foos.unique()){g_foos.reset(new FooList(*g_foos));printf("copy the whole list\n");}assert(g_foos.unique());g_foos->push_back(f);
}
以上post函数的临界区是整个函数,其他写法都是错的。找出以下几种写法的错误:
// 直接修改g_foos所指的FooList
void post(const Foo& f)
{MutexLockGuard lock(mutex);// 此处的push_back和traverse中的遍历过程是并发的,可能导致迭代器失效g_foos->push_back(f);
}// 试图缩小临界区,把copying移出临界区,这样每次都复制整个FooList,有性能问题
// 还有逻辑错误,如果有两个线程同时写,那么两个写线程中第二个写的会把第一个写的覆盖
void post(const Foo& f)
{FooListPtr newFoos(new FooList(*g_foos));newFoos->push_back(f);MutexLockGuard lock(mutex);g_foos = newFoos; // 或g_foos.swap(newFoos);
}// 把临界区拆成两个小的,把copying放到临界区外
void post(const Foo& f)
{FooListPtr oldFoos;{MutexLockGuard lock(mutex);oldFoos = g_foos;}// 第一次解锁后,第二次加锁前,可能其他线程改变了oldFoos,会覆盖其他线程的修改FooListPtr newFoos(new FooList(*oldFoos));newFoos->push_back(f);MutexLockGuard lock(mutex);g_foos = newFoos; // 或g_foos.swap(newFoos);
}
解决把Request::print()移出Inventory::printAll()临界区有两个做法,其一很简单,把requests_复制一份,在临界区外遍历这个副本:
void Inventory::printAll() const
{std::set<Request*> requests;{muduo::MutexLockGuard lock(mutex_);requests = requests_;}// 遍历局部变量requests,调用Request::print()
}
这样做有一个明显的缺点,它复制了整个std::set中的每个元素,开销可能会比较大。如果遍历期间没有其他人修改requests_,那么我们可以减小开销,这就引入了第二种做法。
第二种做法的要点是用shared_ptr管理std::set,在遍历时先增加引用计数,阻止并发修改。当然Inventory::add()和Inventory::remove()也要相应修改,采用前面post()和traverse()的方案。
用普通mutex替换读写锁的一个例子:有以下场景,一个多线程C++程序,24h x 5.5d运行。有几个工作线程Thread Worker{0,1,2,3},处理客户发过来的交易请求;另外有一个背景线程ThreadBackground,不定期更新程序内部的参考数据。这些线程都跟一个hash表打交道,工作线程只读,背景线程读写,必然要用到一些同步机制,防止数据损坏。以下示例代码用std::map代替hash表,意思是一样的:
using namespace std;
typedef map<string, vector<pair<string, int>>> Map;
Map的key是用户名,value是一个vector,里边存的是不同stock的最小交易间隔,vector已经排好序,可以用二分查找。
我们的系统要求工作线程的延迟尽可能小,可以容忍背景线程的延迟略大。一天之内,背景线程对数据更新的次数屈指可数,最多一小时一次,更新的数据来自于网络,所以对更新的及时性不敏感。Map的数据量也不大,大约一千多条数据。
最简单的同步办法是用读写锁:工作线程加读锁,背景线程加写锁。但是读写锁的开销比普通mutex要大,而且是写锁有限,会阻塞后面的读锁。如果工作线程能用最普通的非重入mutex实现同步,就不必用读写锁,这能减轻工作线程延迟。我们借助shared_ptr做到了这一点:
class CustomerData : boost::noncopyable
{
public:CustomerData() : data_(new Map) { }int query(const string& customer, const string& stock) const;private:typedef std::pair<string, int> Entry;typedef std::vector<Entry> EntryList;typedef std::map<string, EntryList> Map;typedef boost::shared_ptr<Map> MapPtr;void update(const string& customer, const EntryList& entries);// 用lower_bound函数在entries里找stock,entries是有序的,否则不能用lower_bound函数static int findEntry(const EntryList& entries, const string& stock);MapPtr getData() const{MutexLockGuard lock(mutex_);return data_;}mutable MutexLock mutex_;MapPtr data_;
}
CustomerData::query()就用前面说的引用计数加1的办法,用局部MapPtr data变量来持有Map,防止并发修改:
int CustomerData::query(const string& customer, const string& stock) const
{MapPtr data = getData();// data一旦拿到,就不再需要锁了// 取数据的时候只有getData()内部有锁,多线程并发读的性能很好// 查找特定键是否存在于map中Map::const_iterator entries = data->find(customer);if (entries != data->end()){return findEntry(entries->second, stock);}else{return -1;}
}
关键看CustomerData::update()怎么写。既然要更新数据,那肯定得加锁,如果此时其他线程正在读,那么不能再原来的数据上修改,得创建一个副本,在副本上修改,修改完了再替换。如果没有用户在读,那么就能直接修改,节约一次Map拷贝:
// 每次收到一个customer的数据更新
void CustomerData::update(const string& customer, const EntryList& entries)
{// update必须全程持锁MutexLockGuard lock(mutex_);if (!data_.unique()){MapPtr newData(new Map(*data_));// 在这里打印日志,然后统计日志来判断worst case发生的次数data_.swap(newData);}assert(data_.unique());(*data_)[customer] = entries;
}
CustomerData::update()中使用了shared_ptr::unique()来判断是不是有人在读,如果有人在读,那么我们不能直接修改,因为query()并没有全程加锁,只在getData()内部有锁。shared_ptr::swap()把data_替换为新副本,而且我们还在锁里,不会有别的线程来读,可以放心地更新。如果别的reader线程已经刚刚通过getData()拿到了MapPtr,它会读到稍旧的数据,这不是问题,因为数据更新来自网络,如果网络稍有延迟,反而正reader线程也会读到旧数据。
如果每次都更新全部数据,且始终是在同一个线程更新数据,临界区还可以进一步缩小:
// 解析收到的消息,返回新的MapPtr
MapPtr parseData(const string& message);// 函数原型有变,此时网络上传来的是完整的Map数据
void CustomerData::update(const string& message)
{// 解析新数据,在临界区之外MapPtr newData = parseData(message);if (newData){MutexLockGuard lock(mutex_);// 不要用data_ = newData;,它会导致没有读者时在临界区内析构旧数据data_.swap(newData); }// 旧数据的析构也在临界区外,进一步缩短了临界区
}
根据作者线上环境测试,大多情况下更新都是在原来数据上进行的,拷贝的比例不到1%,很高效。准确地说,这不是copy-on-write,而是copy-on-other-reading。
将来作者可能会采用无锁数据结构,但目前这个实现已经非常好,可以满足作者的要求。
相关文章:
Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第二章 线程同步精要
并发编程有两种基本模型,一种是message passing,另一种是shared memory。在分布式系统中,运行在多台机器上的多个进程的并行编程只有一种实用模型:message passing。在单机上,我们也可以照搬message passing作为多个进…...
中间件安全-CVE复现WeblogicJenkinsGlassFish漏洞复现
目录 服务攻防-中间件安全&CVE复现&Weblogic&Jenkins&GlassFish漏洞复现中间件-Weblogic安全问题漏洞复现CVE_2017_3506漏洞复现 中间件-JBoos安全问题漏洞复现CVE-2017-12149漏洞复现CVE-2017-7504漏洞复现 中间件-Jenkins安全问题漏洞复现CVE-2017-1000353漏…...

辅助驾驶功能开发-功能规范篇(16)-2-领航辅助系统NAP-HMI人机交互
书接上回 2.3.7HMI人机交互 2.3.7.1显示 (1)图标 序号 图标状态 (图形、颜色供参考) 含义说明 备注 1 辅助驾驶功能READY (允许激活) 2 辅助驾驶功能激活 3 辅助驾驶系统故障 4...
[计算机入门] 应用软件介绍(娱乐类)
3.21 应用软件介绍(娱乐类) 3.21.1 音乐:酷狗 音乐软件是一类可以帮助人们播放、管理和发现音乐的应用程序。它们提供了丰富的音乐内容,用户可以通过搜索、分类浏览或个性化推荐等方式找到自己喜欢的歌曲、专辑或艺术家。音乐软件还通常支持创建和管理…...
SL8541 android系统环境+编译
1.Ubuntu系统的安装 最好使用ubuntu18.0.4 2.工具环境包的安装 // 安装Android8.1源码编译环境 sudo apt-get install openjdk-8-jdk --------------ok sudo apt-get install libx11-dev:i386 libreadline6-dev:i386 libgl1-mesa-dev g-multilib --------------ok sudo…...

【苍穹外卖 | 项目日记】第八天
前言: 昨天晚上跑完步回来宿舍都快停电了,就没写项目日记,今天补上 目录 前言: 今日完结任务: 今日收获: 引入百度地图接口: 引入spring task ,定时处理异常订单: …...
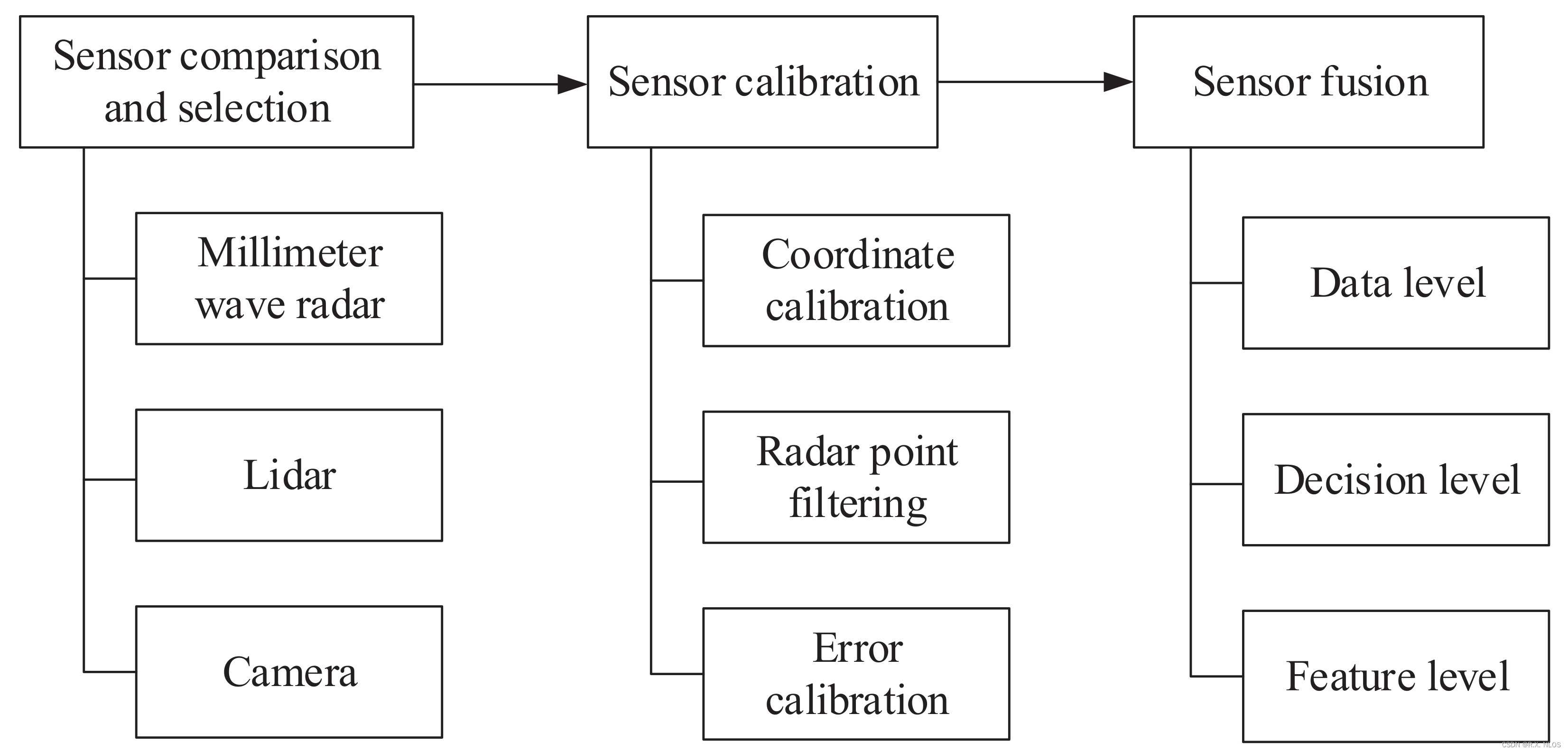
概念解析 | 毫米波雷达与计算机视觉的融合
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:毫米波雷达与计算机视觉的融合。 毫米波雷达与计算机视觉的融合 Sensors | Free Full-Text | MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A …...
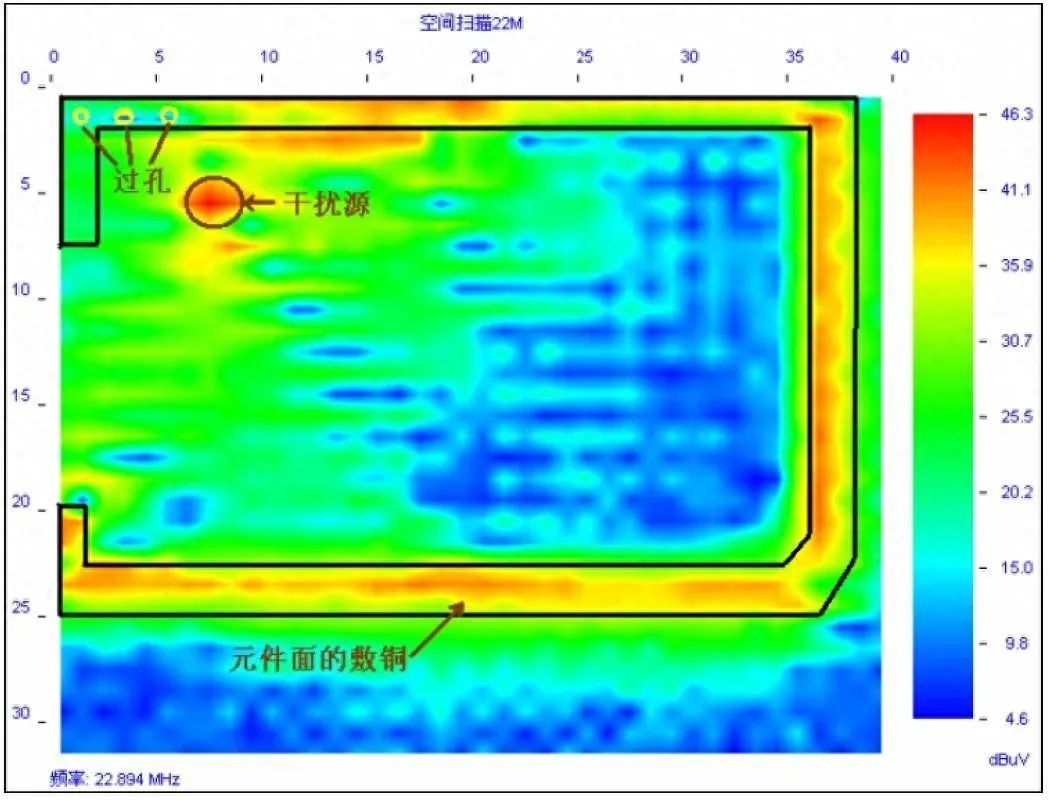
嵌入式硬件中常见的100种硬件选型方式
1请列举您知道的电阻、电容、电感品牌(最好包括国内、国外品牌)。 电阻: 美国:AVX、VISHAY 威世 日本:KOA 兴亚、Kyocera 京瓷、muRata 村田、Panasonic 松下、ROHM 罗姆、susumu、TDK 台湾:LIZ 丽智、PHY…...
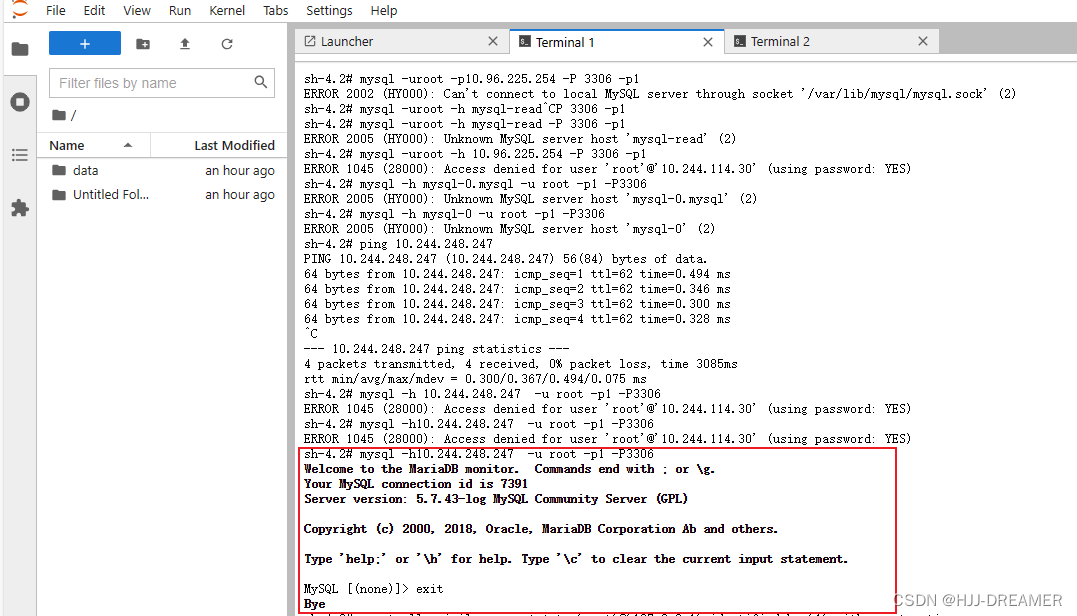
Kubernetes 通过 Deployment 部署Jupyterlab
概要 在Kubernetes上部署jupyterlab服务,链接Kubernetes集群内的MySQL,实现简单的数据开发功能。 前置条件 镜像准备:自定义Docker镜像--Jupyterlab-CSDN博客 MySQL-Statefulset准备:StatefulSet 简单实践 Kubernetes-CSDN博客…...

【Linux常用命令15】shell脚本
shell概述:shell是一个命令行解释器,它接收应用程序或用户的命令,然后调用操作系统内核 Linux Shell 种类非常多, 常见的有: Bourne Shell (/usr/bin/sh 或/bin/sh)、 Bourne Again Shell (/bin/bash)、 C Shell (/us…...

LTE系统TDD无线帧结构特点
LTE系统TDD无线帧结构的特点主要表现在以下几个方面: 无线帧结构时间描述的最小单位是采样周期Ts。在LTE中,每个子载波为2048阶IFFT采样,△f15kHz,因此采样周期Ts1/(204815000)0.033us。 TDD的帧结构包括两个5ms的半帧࿰…...

微信小程序OA会议系统数据交互
前言 经过我们所写的上一文章:微信小程序会议OA系统其他页面-CSDN博客 在我们的是基础面板上面,可以看到出来我们的数据是死数据,今天我们就完善我们的是数据 后台 在我们去完成项目之前我们要把我们的项目后台准备好资源我放在我资源中&…...

TypeScript环境安装
一、windows环境 安装node,附带自动安装npm工具 安装tsc npm install -g typescript 对于不支持 Nuget 的项目类型,你可以使用 TypeScript Visual Studio 扩展。 你可以使用 Visual Studio 中的 Extensions > Manage Extensions 安装扩展。 安装下…...

连接Mumu模拟器使用ADB
要连接Mumu模拟器使用ADB,您可以按照以下详细步骤进行操作: 安装ADB驱动程序:在您的计算机上安装ADB驱动程序。ADB是Android Debug Bridge的缩写,它允许您与Android设备进行通信。您可以从Android开发者网站(https://d…...

springboot缓存篇之mybatis一级缓存和二级缓存
前言 相信很多人都用过mybatis,这篇文章主要是介绍mybatis的缓存,了解一下mybatis缓存是如何实现,以及它在实际中的应用 一级缓存 什么是mybatis一级缓存?我们先看一个例子: GetMapping("/list") public…...

云计算认证有哪些?认证考了有什么用?
云计算作为一项快速发展的技术,对人才的需求持续增长。无论是男生还是女生,只要具备相关的技能和知识,都可以在云计算领域找到就业机会。 目前入行云计算最好最便捷的方式就是考证,拿到一个云计算相关的证书,就能开启…...

[ 云计算 | AWS 实践 ] Java 如何重命名 Amazon S3 中的文件和文件夹
本文收录于【#云计算入门与实践 - AWS】专栏中,收录 AWS 入门与实践相关博文。 本文同步于个人公众号:【云计算洞察】 更多关于云计算技术内容敬请关注:CSDN【#云计算入门与实践 - AWS】专栏。 本系列已更新博文: [ 云计算 | …...
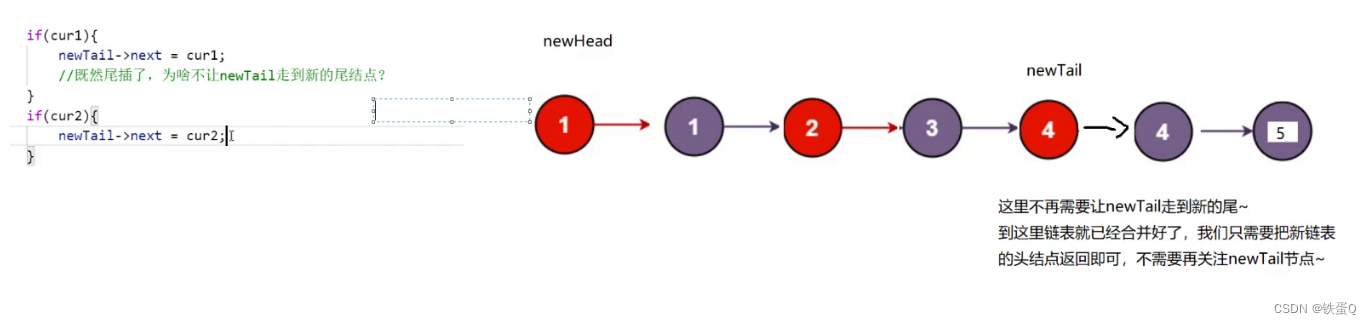
c语言练习91:合并两个有序链表
合并两个有序链表 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 代码1: /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode; struct Li…...
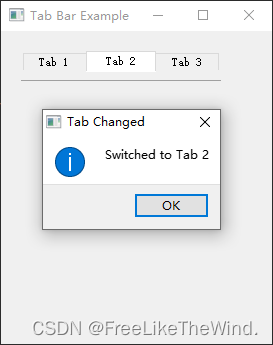
【Qt控件之QTabBar】介绍及使用
概述 QTabBar类提供了一个选项卡栏,例如用于选项卡对话框。 QTabBar非常简单易用,它使用预定义的形状绘制选项卡,并在选择选项卡时发出信号。它可以被子类化以调整外观和感觉。Qt还提供了一个实现好的QTabWidget。 每个选项卡具有一个tabT…...
最新Tuxera NTFS2023最新版Mac读写NTFS磁盘工具 更新详情介绍
Tuxera NTFS for Mac是一款Mac系统NTFS磁盘读写软件。在系统默认状态下,MacOSX只能实现对NTFS的读取功能,Tuxera NTFS可以帮助MacOS 系统的电脑顺利实现对NTFS分区的读/写功能。Tuxera NTFS 2023完美兼容最新版本的MacOS 11 Big Sur,在M1芯片…...

HCPL-2502-500E,单通道高速光耦合器
简介今天我要向大家介绍的是 Broadcom 的光耦合器——HCPL-2502-500E。它是一款单通道、兼容 TTL/LSTTL 的高速光耦器件。该器件内部采用绝缘层隔离 LED 与集成光探测器,通过为光电二极管偏置和输出晶体管集电极提供独立连接,有效减小了基极-集电极电容&…...

cv_unet_image-colorization生产环境部署:支持批量处理+日志记录+错误重试机制
cv_unet_image-colorization生产环境部署:支持批量处理日志记录错误重试机制 你是不是遇到过这样的场景?手里有一堆珍贵的黑白老照片,想给它们上色,但一张张手动处理太费时,用在线工具又担心隐私泄露,而且…...
)
Zotero 7搭配Attanger插件:打造比官方同步更稳的OneDrive文献工作流(含手机端适配技巧)
Zotero 7与Attanger插件深度整合:构建基于OneDrive的全平台文献管理生态 作为一名长期被文献管理工具同步问题困扰的研究者,我至今记得那个截稿日前夜的噩梦:WebDAV同步卡在97%整整两小时,而云端存储的附件在手机端始终显示"…...

WiFiAnalyzer深度解析:Android上不可或缺的Wi-Fi网络优化利器
1. WiFiAnalyzer:你的无线网络诊断专家 每次刷视频卡顿、游戏延迟飙升时,你是不是也对着路由器咬牙切齿?作为一款专为Android设计的开源工具,WiFiAnalyzer就像给手机装上了X光机,能透视周围所有Wi-Fi信号的"身体状…...

免费跨平台开源音乐播放器:LX Music桌面版完全指南
免费跨平台开源音乐播放器:LX Music桌面版完全指南 【免费下载链接】lx-music-desktop 一个基于 Electron 的音乐软件 项目地址: https://gitcode.com/GitHub_Trending/lx/lx-music-desktop 你是否正在寻找一款真正免费、功能强大且支持多平台的音乐播放软件…...

org.openpnp.vision.pipeline.stages.DetectLinesHough
文章目录org.openpnp.vision.pipeline.stages.DetectLinesHough功能参数例子测试图像generate_line_test_image.pycv-pipeline效果ENDorg.openpnp.vision.pipeline.stages.DetectLinesHough 功能 在图像中检测直线段 在DetectLinesHough之前,需要执行DetectEdgesC…...

Three.js进阶技巧:如何让GLTF模型在Vue中实现交互式旋转与缩放
Three.js与Vue深度整合:打造专业级3D模型交互方案 在数字展示领域,3D模型交互已成为提升用户体验的关键要素。想象一下,当用户能够自由旋转、缩放产品模型,从各个角度观察细节时,转化率将获得怎样的提升?这…...

Chart.js项目实战:物流运输跟踪系统的终极可视化指南
Chart.js项目实战:物流运输跟踪系统的终极可视化指南 【免费下载链接】awesome A curated list of awesome Chart.js resources and libraries 项目地址: https://gitcode.com/GitHub_Trending/awesome/awesome 在当今快节奏的物流行业中,实时数据…...

小公司要不要逼供应商把系统接入IDaaS?这篇ROI算账指南帮你做决定!
小公司要不要逼供应商把系统接入IDaaS?这篇ROI算账指南帮你做决定! 摘要:很多中小企业的CTO/CIO都有个误区——“我们才几十号人,用不上高大上的IDaaS吧?”其实不然。本文将用真实数据和落地经验告诉你:小公…...

TortoiseSVN与BeyondCompare高效协作:从配置到实战的完整指南
1. 为什么需要TortoiseSVN与BeyondCompare集成 如果你经常使用TortoiseSVN进行版本控制,肯定遇到过内置差异查看器不够直观的问题。默认的diff工具只能显示简单的文本对比,对于代码变更的识别效率很低。而BeyondCompare作为专业的文件对比工具࿰…...