Flink之Window窗口机制
窗口Window机制
- 窗口概述
- 窗口的分类
- 是否按键分区
- 按键分区窗口
- 非按键分区
- 按照驱动类型
- 按具体分配规则
- 滚动窗口Tumbling Windows
- 滑动窗口 Sliding Windows
- 会话窗口 Session Windows
- 全局窗口 Global Windows
- 时间语义
- 窗口分配器 Window Assigners
- 时间窗口
- 计数窗口
- 例子
- 窗口函数 Window Functions
- 增量聚合函数
- ReduceFunction
- AggregateFunction
- 全窗/全量口函数
- WindowFunction
- ProcessWindowFunction
- 增量聚合和全窗口函数的结合
- 其他
- 触发器 Trigger
- 移除器 Evictor
窗口概述
在大多数场景下,需要统计的数据流都是无界的,因此无法等待整个数据流终止后才进行统计。通常情况下,只需要对某个时间范围或者数量范围内的数据进行统计分析
例如:
每隔10分钟统计一次过去30分钟内某个对象的点击量每发生100次点击后,就去统计一下每个对象点击率的占比
因此,在Apache Flink中,窗口是对无界数据流进行有界处理的机制。窗口可以将无限的数据流划分为有限的、可处理的块,使得可以基于这些有限的数据块执行聚合、计算和分析操作。
窗口的分类
是否按键分区
在定义窗口操作之前,首先需要确定,到底是基于按键分区的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。
两者区别:
1.keyed streams要调用keyBy(...)后再调用window(...) , 而non-keyed streams只用直接调用windowAll(...)2.对于keyed stream,其中数据的任何属性都可以作为key。 允许窗口计算由多个task并行,因为每个逻辑上的 keyed stream都可以被单独处理。 属于同一个key的元素会被发送到同一个 task。3.对于non-keyed stream,原始的stream不会被分割为多个逻辑上的stream, 所有的窗口计算会被同一个 task完成,也就是parallelism为1
按键分区窗口
经过按键分区keyBy操作后,数据流会按照key被分为多条逻辑流,这就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的处理。所以可以认为,每个key上都定义了一组窗口,各自独立地进行统计计算。
按键分区窗口写法:
stream.keyBy(...) <- 仅 keyed 窗口需要.window(...) <- 必填项:"assigner"[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output).reduce/aggregate/apply() <- 必填项:"function"[.getSideOutput(...)] <- 可选项:"output tag"
代码示例:
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为(key, value)元组DataStream<Tuple2<String, Integer>> dataStream = source.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2 map(String s) throws Exception {int number = Integer.parseInt(s);String key = number % 2 == 0 ? "key1" : "key2";Tuple2 tuple2 = new Tuple2(key, number);return tuple2;}}).returns(Types.TUPLE(Types.STRING, Types.INT));// keyBy操作KeyedStream<Tuple2<String, Integer>, String> keyBy = dataStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}});// 每10秒统计一次数量和SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = keyBy.window(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(1);streamOperator.print();env.execute();}
发送测试数据
[root@administrator ~]# nc -lk 8086
1
2
3
4
等待10秒后,控制台打印如下
(key2,4)
(key1,6)
非按键分区
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务task上执行,就相当于并行度变成了1。
非按键分区窗口写法:
stream.windowAll(...) <- 必填项:"assigner"[.trigger(...)] <- 可选项:"trigger" (else default trigger)[.evictor(...)] <- 可选项:"evictor" (else no evictor)[.allowedLateness(...)] <- 可选项:"lateness" (else zero)[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data).reduce/aggregate/apply() <- 必填项:"function"[.getSideOutput(...)] <- 可选项:"output tag"
代码示例:
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为IntegerDataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));// 每10秒统计一次数量和SingleOutputStreamOperator<Integer> streamOperator = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(0);streamOperator.print();env.execute();}
按照驱动类型
窗口按照驱动类型可以分成时间窗口和计数窗口,这两种窗口类型根据其触发机制和边界规则的不同,适用于不同的应用场景。
时间窗口 Time Windows:
时间窗口根据事件时间Event Time或处理时间Processing Time来划分时间窗口根据时间的进展划分数据流,当一个窗口的时间到达或窗口中的元素数量达到阈值时,触发窗口计算
计数窗口 Count Windows:
计数窗口根据元素的数量或元素的增量来划分计数窗口在数据流中累积固定数量的元素后,触发窗口计算窗口的大小可以是固定的,也可以是动态变化的,取决于所设置的阈值和策略
按具体分配规则
窗口按照具体的分配规则,又有滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
滚动窗口Tumbling Windows
滚动窗口将数据流划分为固定大小的、不重叠的窗口。
例如:将数据流按照5秒的滚动窗口大小进行划分,每个窗口包含5秒的数据。那么每5秒就会有一个窗口被计算,且一个新的窗口被创建
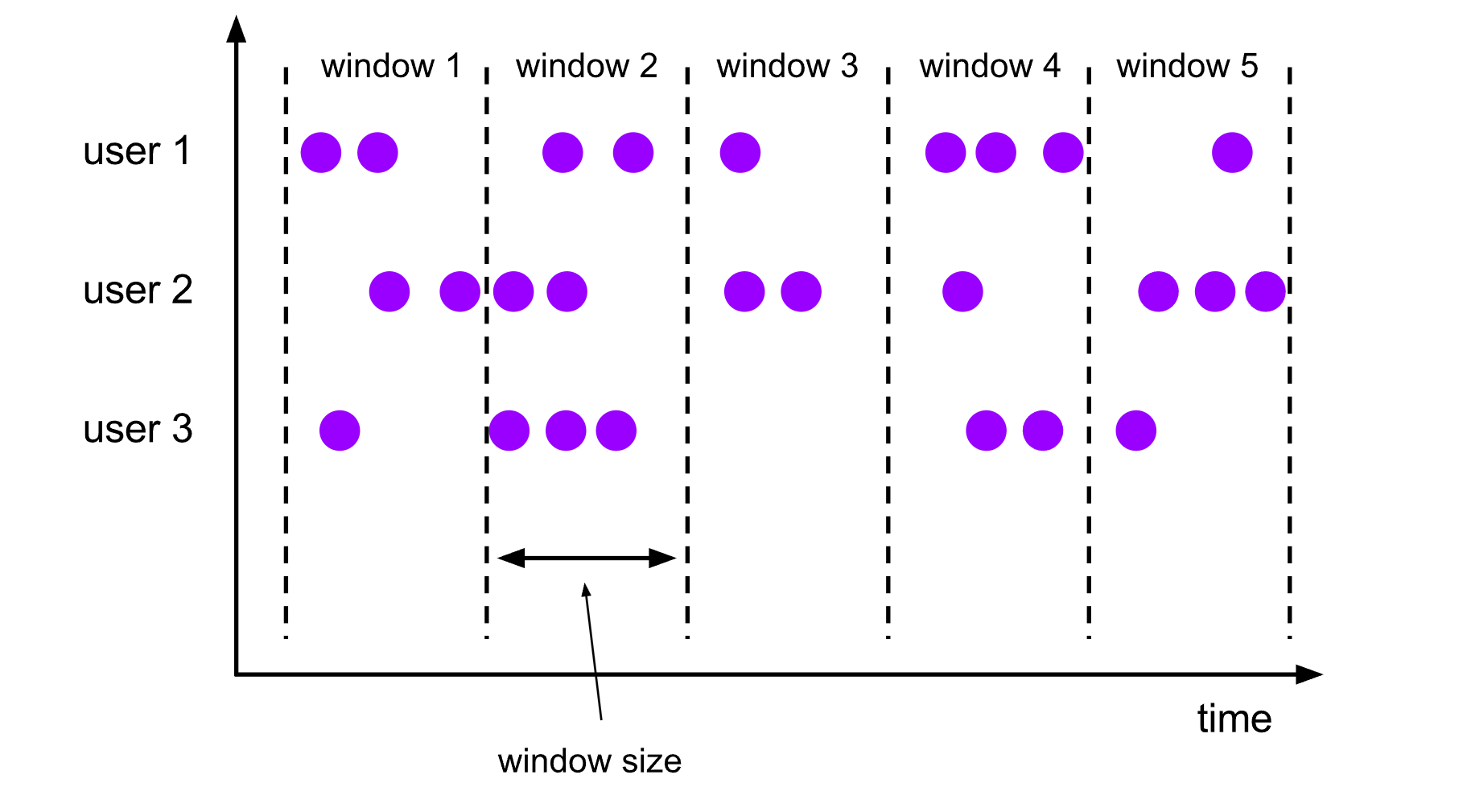
代码示例:
DataStream<T> input = ...;// 滚动 event-time 窗口
input.keyBy(<key selector>)// 间间隔可以用 Time.milliseconds(x)、Time.seconds(x)、Time.minutes(x) 等来指定.window(TumblingEventTimeWindows.of(Time.seconds(5))).<windowed transformation>(<window function>);// 滚动 processing-time 窗口
input.keyBy(<key selector>).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).<windowed transformation>(<window function>);// 长度为一天的滚动 event-time 窗口, 偏移量为 -8 小时。
input.keyBy(<key selector>).window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8))).<windowed transformation>(<window function>);
滑动窗口 Sliding Windows
滑动窗口将数据流划分为固定大小的窗口,窗口大小通过window size参数设置,需要一个额外的滑动距离window slide参数来控制生成新窗口的频率。
如果slide小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
例如:将数据流按照5秒的滑动窗口大小和3秒的滑动步长进行划分,窗口之间有2秒的重叠。
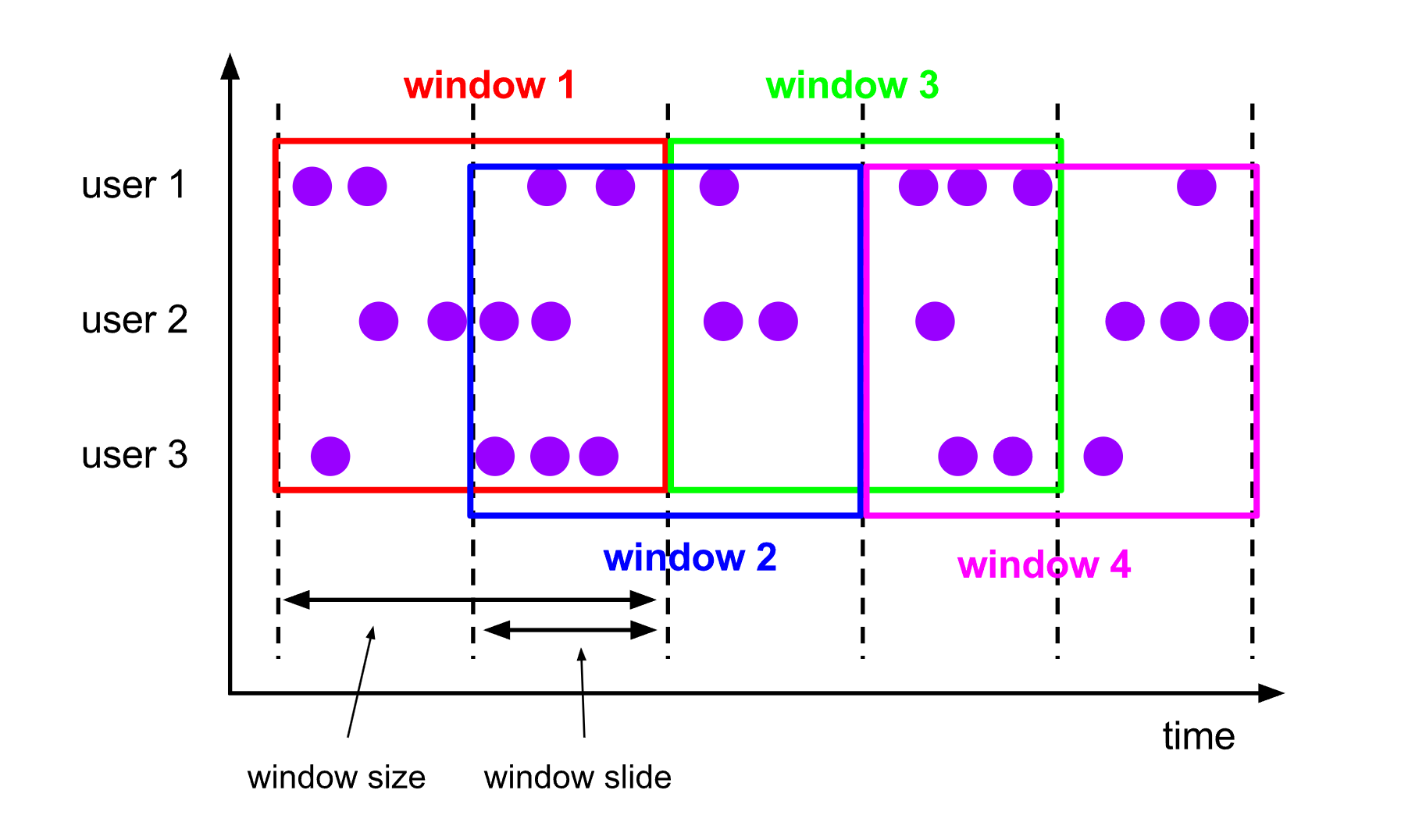
DataStream<T> input = ...;// 滑动 event-time 窗口
input.keyBy(<key selector>).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))).<windowed transformation>(<window function>);// 滑动 processing-time 窗口
input.keyBy(<key selector>).window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).<windowed transformation>(<window function>);// 滑动 processing-time 窗口,偏移量为 -8 小时
input.keyBy(<key selector>).window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8))).<windowed transformation>(<window function>);
会话窗口 Session Windows
与滚动窗口和滑动窗口不同,会话窗口不会相互重叠,且没有固定的开始或结束时间。 会话窗口在一段时间没有收到数据之后会关闭,即在一段不活跃的间隔之后。
如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的时间就是会话窗口的gap(间隔)
可以配置静态的gap, 也可以通过一个gap extractor函数来定义gap的长度
当时间超过了这个gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话窗口
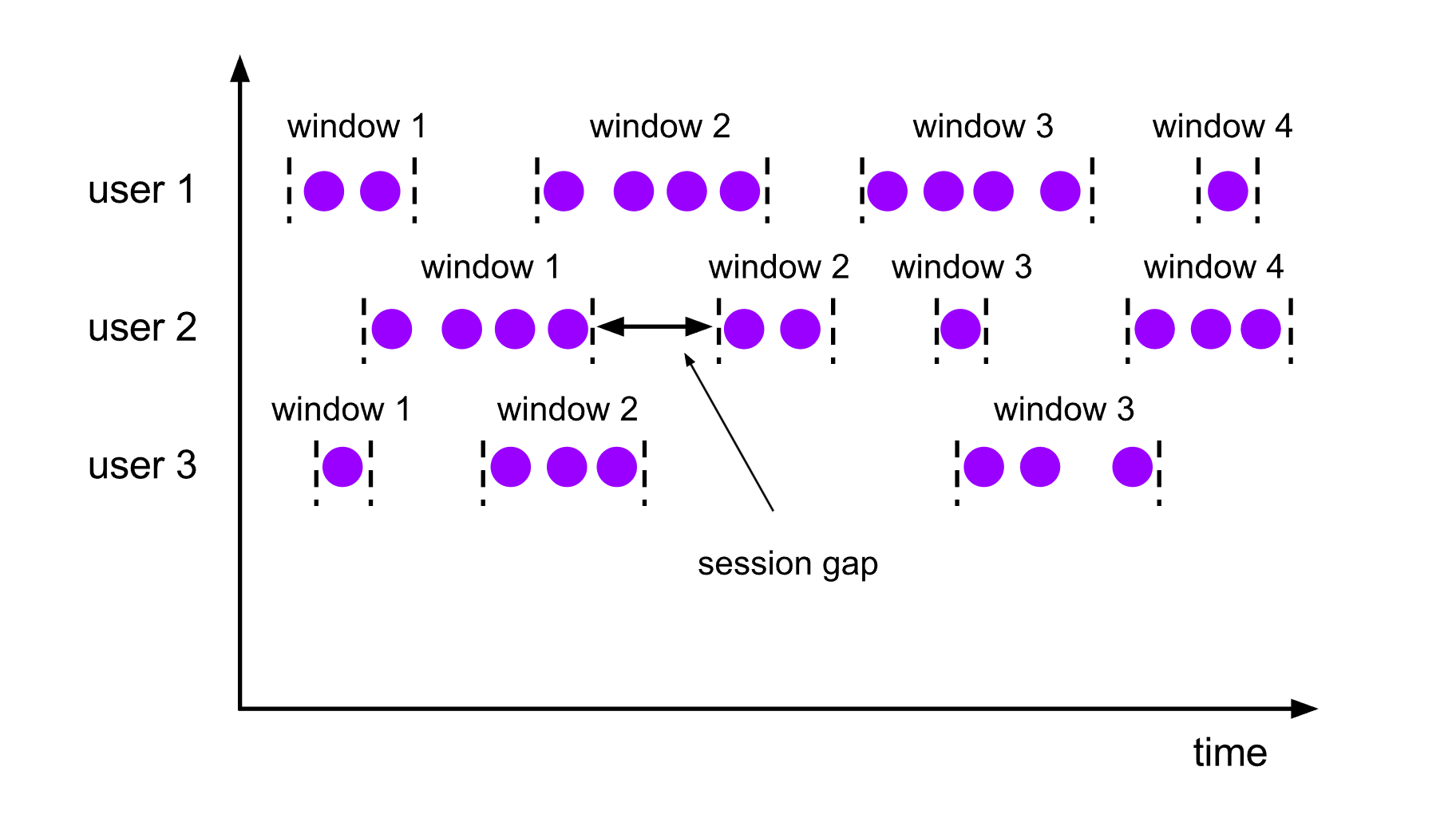
DataStream<T> input = ...;// 设置了固定间隔的 event-time 会话窗口
input.keyBy(<key selector>).window(EventTimeSessionWindows.withGap(Time.minutes(10))).<windowed transformation>(<window function>);// 设置了动态间隔的 event-time 会话窗口
input.keyBy(<key selector>).window(EventTimeSessionWindows.withDynamicGap((element) -> {// 决定并返回会话间隔})).<windowed transformation>(<window function>);// 设置了固定间隔的 processing-time session 窗口
input.keyBy(<key selector>).window(ProcessingTimeSessionWindows.withGap(Time.minutes(10))).<windowed transformation>(<window function>);// 设置了动态间隔的 processing-time 会话窗口
input.keyBy(<key selector>).window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {// 决定并返回会话间隔})).<windowed transformation>(<window function>);
全局窗口 Global Windows
全局窗口将整个数据流作为一个窗口进行处理,不进行分割。全局窗口适用于需要在整个数据流上执行聚合操作的场景。

DataStream<T> input = ...;input.keyBy(<key selector>).window(GlobalWindows.create()).<windowed transformation>(<window function>);
时间语义
在Flink的流式操作中, 会涉及不同的时间概念,即时间语义,它是指在数据处理中确定事件的时间基准的机制。
在实时数据流处理中,常见的时间语义有以下三种:
1.处理时间(Processing Time):
处理时间是指数据处理引擎的本地时钟时间,也称为机器时间或系统时间使用处理时间时,事件的时间顺序是根据数据到达处理引擎的顺序来确定的处理时间是一种简单和实时性较高的时间语义,但不考虑数据可能存在的延迟或乱序
2.事件时间(Event Time):
事件时间是数据流中记录的实际时间,通常是数据本身携带的时间戳使用事件时间时,数据记录的时间戳决定事件在时间轴上的顺序,而不受数据到达引擎的顺序影响事件时间是一种准确和可重现的时间语义,能够处理延迟和乱序数据,但可能需要关注水印的处理
3.摄取时间(Ingestion Time):
注意:较新版本的Flink已经弃用,推荐使用事件时间
摄取时间是数据进入数据处理引擎的时间使用摄取时间时,数据到达引擎的顺序决定事件的时间顺序摄取时间是介于处理时间和事件时间之间的折中方案。它可以处理一定程度的延迟和乱序数据,但不会像事件时间那样需要处理水印。
区别:
处理时间适用于实时性要求较高、不关心事件的顺序和时间戳的场景事件时间适用于需要准确处理事件顺序和考虑延迟、乱序数据的场景摄取时间提供了某种程度上的准确性和实时性折中
窗口分配器 Window Assigners
在Apache Flink中,窗口分配器(Window Assigner)用于定义如何将数据流中的元素分配到窗口。窗口分配器确定了窗口的边界以及如何对元素进行分组和分配
窗口分配器最通用的定义方式:
如果是按键分区窗口, 直接调用.keyBy().window()方法,传入一个WindowAssigner作为参数,返回WindowedStream。如果是非按键分区窗口,直接调用.windowAll()方法,传入一个WindowAssigner,返回的是AllWindowedStream。
时间窗口
时间窗口是最常用的窗口类型,可以大致细分为滚动、滑动和会话三种。
1.滚动处理时间窗口
窗口分配器由类TumblingProcessingTimeWindows提供,需要调用它的静态方法.of(),需要传入一个Time类型的参数size,表示滚动窗口的大小
// 非按键分区 滚动事件时间窗口,窗口长度10s。每10秒操作一次
dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 按键分区
dataStream.keyBy().window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
2.滚动事件时间窗口
窗口分配器由类TumblingEventTimeWindows提供,用法与滚动处理事件窗口完全一致。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
3.滑动处理时间窗口
窗口分配器由类SlidingProcessingTimeWindows提供,同样需要调用它的静态方法.of(),需要传入两个Time类型的参数:size和slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长
// 窗口长度10s,滑动步长2s。 每2秒滑动一次,窗口大小为10秒的滑动时间窗口,并对窗口中的元素进行操作。
dataStream.windowAll(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(2)));
4.滑动事件时间窗口
窗口分配器由类SlidingEventTimeWindows提供,用法与滑动处理事件窗口完全一致
dataStream.windowAll(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)));
5.处理时间会话窗口
窗口分配器由类ProcessingTimeSessionWindows提供,需要调用它的静态方法withGap()或者withDynamicGap()。需要传入一个Time类型的参数size,表示会话的超时时间
// 会话窗口,超时间隔5s
dataStream.windowAll(ProcessingTimeSessionWindows.withGap(Time.seconds(5)));
6.事件时间会话窗口
窗口分配器由类EventTimeSessionWindows提供,用法与处理事件会话窗口完全一致。
dataStream.windowAll(EventTimeSessionWindows.withGap(Time.seconds(10)));
计数窗口
1.滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数size,表示窗口的大小。
当窗口中元素数量达到size时,就会触发计算执行并关闭窗口。
// 滚动窗口,窗口长度2个元素
dataStream.countWindowAll(2);
2.滑动计数窗口
在countWindow()调用时传入两个参数:size和slide,前者表示窗口大小,后者表示滑动步长。
每个窗口统计size个数据,每隔slide个数据就统计输出一次结果。
// 滑动窗口,窗口长度2个元素,滑动步长2个元素
dataStream.countWindowAll(5,2);
3.全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由GlobalWindows类提供。
// 全局窗口,需要自定义的时候才会用
dataStream.windowAll(GlobalWindows.create());dataStream.keyBy().window(GlobalWindows.create());
注意:使用全局窗口必须自行定义触发器才能实现窗口计算,否则不起作用。
例子
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为IntegerDataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));// 时间窗口示例:滚动处理时间窗口,窗口长度10s。 每10秒统计一次数量和SingleOutputStreamOperator<Integer> streamOperator = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(0);streamOperator.print();env.execute();}
发送测试数据
[root@administrator ~]# nc -lk 8086
1
2
3
4
等待10秒后,控制台打印如下
10
窗口函数 Window Functions
定义了window assigner之后,需要指定当窗口触发之后,如何计算每个窗口中的数据, 这就是window function的职责
窗口函数是在窗口操作中应用于窗口中元素的函数。Flink提供了丰富的窗口函数,用于对窗口中的元素进行各种操作和计算。
根据处理的方式可以分为两类:增量聚合函数和全窗/全量口函数,它们是Flink中用于窗口计算的两种不同的函数。
增量聚合函数
增量聚合函数是指对窗口中的数据进行累积计算的函数。它会在每个元素到达窗口时进行计算,并且仅保留窗口计算所需的中间状态。这种方式可以显著提高计算性能,尤其适用于大规模数据和长窗口的情况。
对于增量聚合函数,Flink 提供了一系列内置的聚合函数,例如 sum、min、max、avg等,它们的底层,其实都是通过AggregateFunction来实现的。还可以通过实现 AggregateFunction接口来定义自定义的增量聚合函数。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction。
ReduceFunction
ReduceFunction指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为IntegerDataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));// 指定窗口分配器AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 指定窗口函数,使用 增量聚合ReduceSingleOutputStreamOperator<Integer> reduce = allWindowedStream.reduce(new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2) throws Exception {System.out.println("前一个值: " + value1 + " ,后一个值:" + value2);return value1 + value2;}});// 在窗口触发的时候,才会输出窗口的最终计算结果reduce.print();env.execute();}
发送测试数据:
[root@administrator ~]# nc -lk 8086
1
2
3
4
5
控制台输出:
前一个值: 1 ,后一个值:2
前一个值: 3 ,后一个值:3
前一个值: 6 ,后一个值:4
前一个值: 10 ,后一个值:5
15
AggregateFunction
ReduceFunction接口存在一个限制:聚合状态的类型、输出结果的类型都必须和输入数据类型一样。聚合函数则突破了这个限制,可以定义更加灵活的窗口聚合操作。
AggregateFunction函数接口方法参数有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
输入类型IN就是输入流中元素的数据类型累加器类型ACC则是我们进行聚合的中间状态类型而输出类型当然就是最终计算结果的类型
接口中有四个方法:
createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次add():将输入的元素添加到累加器中getResult():从累加器中提取聚合的输出结果merge():合并两个累加器,并将合并后的状态作为一个累加器返回
与ReduceFunction相同,AggregateFunction也是增量式的聚合,而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为IntegerDataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));// 指定窗口分配器AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 窗口函数 增量聚合 AggregateSingleOutputStreamOperator<String> aggregate = allWindowedStream.aggregate(new MyAggregateFunction());aggregate.print();env.execute();}/*** 第一个类型: 输入数据的类型* 第二个类型: 累加器的类型,存储的中间计算结果的类型* 第三个类型: 输出的类型*/public static class MyAggregateFunction implements AggregateFunction<Integer, Integer, String> {/*** 创建累加器,初始化累加器** @return*/@Overridepublic Integer createAccumulator() {System.out.println("createAccumulator方法执行");return 0;}/*** 聚合逻辑* 来一条计算一条,调用一次add方法** @param value 当前值* @param accumulator 累加器的值* @return*/@Overridepublic Integer add(Integer value, Integer accumulator) {System.out.println("add方法执行,当前值 :" + value + "累加器值 :" + accumulator);return value + accumulator;}/*** 获取最终结果,窗口触发时输出** @param accumulator* @return*/@Overridepublic String getResult(Integer accumulator) {System.out.println("getResult方法执行");return "最终计算值:" + accumulator;}@Overridepublic Integer merge(Integer a, Integer b) {// 只有会话窗口才会用到System.out.println("merge方法执行");return null;}}
发送测试数据:
[root@administrator ~]# nc -lk 8086
1
2
3
4
5
控制台输出:
createAccumulator方法执行
add方法执行,当前值 :1累加器值 :0
add方法执行,当前值 :2累加器值 :1
add方法执行,当前值 :3累加器值 :3
add方法执行,当前值 :4累加器值 :6
add方法执行,当前值 :5累加器值 :10
getResult方法执行
最终计算值:15
全窗/全量口函数
全窗口函数是对窗口中的所有元素进行计算的函数。它会在窗口触发时对窗口中的所有元素进行处理,并输出一个或多个结果。全窗口函数可以访问窗口的所有元素,并且可以使用窗口中的状态信息。
对于全窗口函数,Flink提供了 ProcessWindowFunction 和 WindowFunction 两个接口供用户使用。
ProcessWindowFunction: 可以处理每个元素,并输出零个、一个或多个结果WindowFunction: 是一个转换函数,对窗口的所有元素进行转换,并输出一个或多个结果。
与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
WindowFunction
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为(key, value)元组DataStream<Tuple2<String, Integer>> dataStream = source.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2 map(String s) throws Exception {int number = Integer.parseInt(s);String key = number % 2 == 0 ? "key1" : "key2";Tuple2 tuple2 = new Tuple2(key, number);return tuple2;}}).returns(Types.TUPLE(Types.STRING, Types.INT));// keyBy操作KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}});// 指定窗口分配器 非键分区窗口
// AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 键分区窗口WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 使用WindowFunction窗口函数SingleOutputStreamOperator<String> apply = windowedStream.apply(new MyWindowFunction());apply.print();env.execute();}/*** 窗口函数* <p>* 窗口触发时才会调用一次,统一计算窗口的所有数据*/public static class MyWindowFunction implements WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow> {/*** @param s 分组的key,非键分区窗口则无该参数* @param window 窗口对象* @param input 存的数据* @param out 采集器*/@Overridepublic void apply(String s, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {// 上下文拿到window对象,获取相关信息long start = window.getStart();long end = window.getEnd();String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss");String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss");long count = input.spliterator().estimateSize();out.collect("分组 " + s + " 的窗口,在时间区间: " + windowStart + "-" + windowEnd + " 产生" + count + "条数据,具体数据:" + input.toString());}}
]# nc -lk 8086
1
2
3
4
5
分组 key2 的窗口,在时间区间: 2023-06-27 16:50:10-2023-06-27 16:50:20 产生3条数据,具体数据:[(key2,1), (key2,3), (key2,5)]
分组 key1 的窗口,在时间区间: 2023-06-27 16:50:10-2023-06-27 16:50:20 产生2条数据,具体数据:[(key1,2), (key1,4)]
ProcessWindowFunction
// 使用ProcessWindowFunction处理窗口函数SingleOutputStreamOperator<String> process = windowedStream.process(new MyProcessWindowFunction()); /*** 处理窗口函数* <p>* 窗口触发时才会调用一次,统一计算窗口的所有数据*/public static class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow> {/*** @param s 分组的key,非键分区窗口则无该参数* @param context 上下文* @param input 存的数据* @param out 采集器* @throws Exception*/@Overridepublic void process(String s, Context context, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {// 上下文拿到window对象,获取相关信息long start = context.window().getStart();long end = context.window().getEnd();String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss");String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss");long count = input.spliterator().estimateSize();out.collect("分组 " + s + " 的窗口,在时间区间: " + windowStart + "-" + windowEnd + " 产生" + count + "条数据,具体数据:" + input.toString());}}
增量聚合和全窗口函数的结合
在调用窗口的增量聚合函数方法时,第一个参数直接传入一个ReduceFunction或AggregateFunction进行增量聚合,第二个参数传入一个全窗口函数WindowFunction或者ProcessWindowFunction。
基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果注意这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了Iterable类型的输入
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从socket接收数据流SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);// 将输入数据转换为IntegerDataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));// 指定窗口分配器 非键分区窗口AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 使用ProcessWindowFunction处理窗口函数SingleOutputStreamOperator<String> process = allWindowedStream.aggregate(new MyAggregateFunction(), new MyProcessWindowFunction());process.print();env.execute();}/*** 第一个类型: 输入数据的类型* 第二个类型: 累加器的类型,存储的中间计算结果的类型* 第三个类型: 输出的类型*/public static class MyAggregateFunction implements AggregateFunction<Integer, Integer, String> {/*** 创建累加器,初始化累加器** @return*/@Overridepublic Integer createAccumulator() {System.out.println("createAccumulator方法执行");return 0;}/*** 聚合逻辑* 来一条计算一条,调用一次add方法** @param value 当前值* @param accumulator 累加器的值* @return*/@Overridepublic Integer add(Integer value, Integer accumulator) {System.out.println("add方法执行,当前值 :" + value + " 累加器值 :" + accumulator);return value + accumulator;}/*** 获取最终结果,窗口触发时输出** @param accumulator* @return*/@Overridepublic String getResult(Integer accumulator) {System.out.println("getResult方法执行");return "最终计算值:" + accumulator;}@Overridepublic Integer merge(Integer a, Integer b) {// 只有会话窗口才会用到System.out.println("merge方法执行");return null;}}/*** 处理窗口函数* <p>* 窗口触发时才会调用一次,统一计算窗口的所有数据* <p>* 注意:增量聚合函数的输出类型 是 全窗口函数的输入类型*/public static class MyProcessWindowFunction extends ProcessAllWindowFunction<String, String, TimeWindow> {/*** @param context 上下文* @param input 存的数据* @param out 采集器* @throws Exception*/@Overridepublic void process(Context context, Iterable<String> input, Collector<String> out) throws Exception {// 上下文拿到window对象,获取相关信息long start = context.window().getStart();long end = context.window().getEnd();String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss");String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss");long count = input.spliterator().estimateSize();out.collect("窗口在时间区间: " + windowStart + "-" + windowEnd + " 产生" + count + "条数据,具体数据:" + input.toString());}}
createAccumulator方法执行
add方法执行,当前值 :1 累加器值 :0
add方法执行,当前值 :2 累加器值 :1
add方法执行,当前值 :3 累加器值 :3
add方法执行,当前值 :4 累加器值 :6
add方法执行,当前值 :5 累加器值 :10
getResult方法执行
窗口在时间区间: 2023-06-27 17:07:50-2023-06-27 17:08:00 产生1条数据,具体数据:[最终计算值:15]
其他
触发器 Trigger
Trigger决定了一个窗口(由windowassigner定义)何时可以被windowfunction处理。每个WindowAssigner都有一个默认的Trigger。如果默认trigger无法满足需要,可以在trigger(…)调用中指定自定义的trigger。
Trigger接口提供了五个方法来响应不同的事件:
onElement()方法在每个元素被加入窗口时调用onEventTime()方法在注册的event-timetimer触发时调用onProcessingTime()方法在注册的processing-timetimer触发时调用onMerge()方法与有状态的trigger相关。该方法会在两个窗口合并时,将窗口对应trigger的状态进行合并,比如使用会话窗口时clear()方法处理在对应窗口被移除时所需的逻辑
注意:
前三个方法通过返回TriggerResult来决定trigger如何应对到达窗口的事件。
应对方案:
CONTINUE: 什么也不做FIRE: 触发计算PURGE: 清空窗口内的元素FIRE_AND_PURGE: 触发计算,计算结束后清空窗口内的元素
内置触发器
EventTimeTrigger:基于事件时间和watermark机制来对窗口进行触发计算ProcessingTimeTrigger: 基于处理时间触发CountTrigger:窗口元素数超过预先给定的限制值的话会触发计算PurgingTrigger:作为其它trigger的参数,将其转化为一个purging触发器
基于WindowedStream调用.trigger()方法,就可以传入一个自定义的窗口触发器
stream.keyBy(...).window(...).trigger(new MyTrigger())
移除器 Evictor
Evictor可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素。Evictor是一个接口,不同的窗口类型都有各自预实现的移除器。
内置evictor:
默认情况下,所有内置的 evictor 逻辑都在调用窗口函数前执行。
CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除DeltaEvictor: 接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值, 并移除差值大于或等于 threshold 的元素。TimeEvictor: 接收 interval 参数,以毫秒表示。 它会找到窗口中元素的最大 timestamp max_ts 并移除比 max_ts - interval 小的所有元素
基于WindowedStream调用.evictor()方法,就可以传入一个自定义的移除器
stream.keyBy(...).window(...).evictor(new MyEvictor())
相关文章:
Flink之Window窗口机制
窗口Window机制 窗口概述窗口的分类是否按键分区按键分区窗口非按键分区 按照驱动类型按具体分配规则滚动窗口Tumbling Windows滑动窗口 Sliding Windows会话窗口 Session Windows全局窗口 Global Windows 时间语义窗口分配器 Window Assigners时间窗口计数窗口例子 窗口函数 W…...
【C++】继承 ⑧ ( 继承 + 组合 模式的类对象 构造函数 和 析构函数 调用规则 )
文章目录 一、继承 组合 模式的类对象 构造函数和析构函数调用规则1、场景说明2、调用规则 二、完整代码示例分析1、代码分析2、代码示例 一、继承 组合 模式的类对象 构造函数和析构函数调用规则 1、场景说明 如果一个类 既 继承了 基类 ,又 在类中 维护了一个 其它类型 的…...
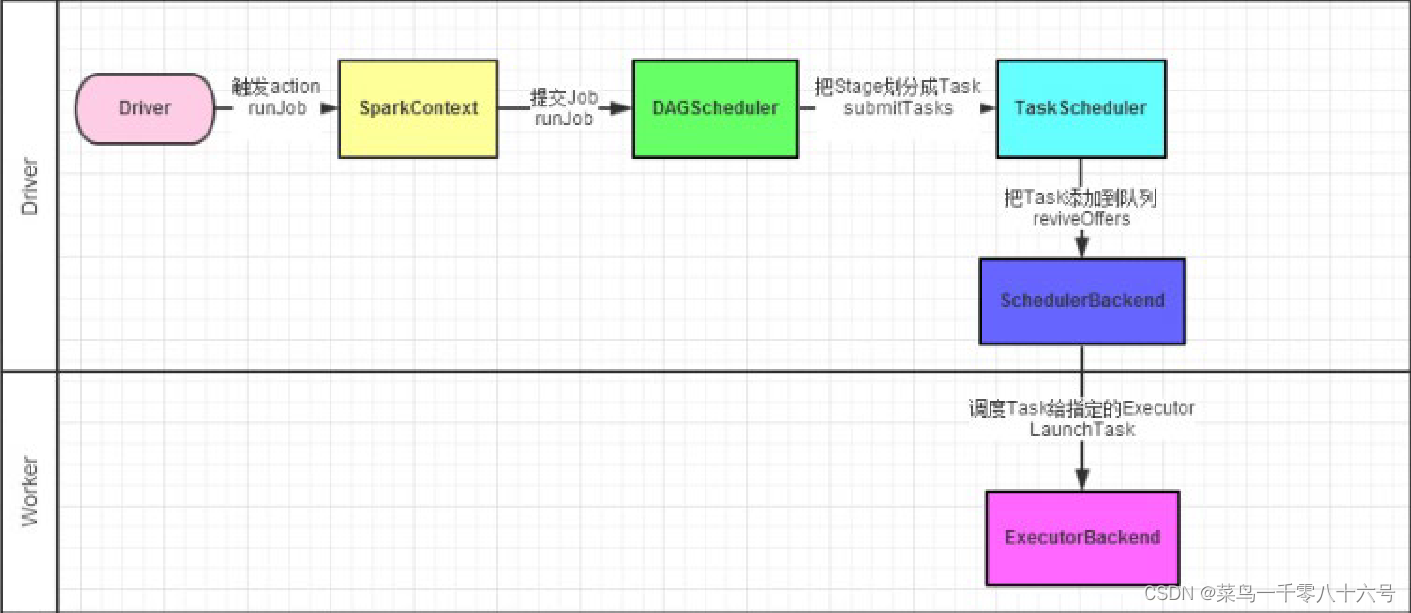
Spark内核调度
目录 一、DAG (1)概念 (2)Job和Action关系 (3)DAG的宽窄依赖关系和阶段划分 二、Spark内存迭代计算 三、spark的并行度 (1)并行度设置 (2)集群中如何规划并…...
STM32串口
前言 提示:这里可以添加本文要记录的大概内容: 目前已经学习了GPIO的输入输出,但是没有完整的显示信息,最便宜的显示就是串口。 000 -111 AVR单片机 已经学会过了, 提示:以下是本篇文章正文内容&#x…...

解决使用WebTestClient访问接口报[185c31bb] 500 Server Error for HTTP GET “/**“
解决使用WebTestClient访问接口报[185c31bb] 500 Server Error for HTTP GET "/**" 问题发现问题解决 问题发现 WebTestClient 是 Spring WebFlux 框架中提供的用于测试 Web 请求的客户端工具。它可以不用启动服务器,模拟发送 HTTP 请求并验证服务器的响…...

Windows安装virtualenv虚拟环境
需要先安装好python环境 1 创建虚拟环境目录 还是在D:\Program\ 的文件夹新建 .env 目录(你也可以不叫这个名字,一般命名为 .env 或者 .virtualenv ,你也可以在其他目录中创建) 2 配置虚拟环境目录的环境变量 3 安装虚拟环境 进…...

掌握Go类型内嵌:设计模式与架构的新视角
一、引言 在软件开发中,编程语言的类型系统扮演着至关重要的角色。它不仅决定了代码的结构和组织方式,还影响着软件的可维护性、可读性和可扩展性。Go语言,在被广泛应用于云原生、微服务和并发高性能系统的同时,也因其简单但强大…...
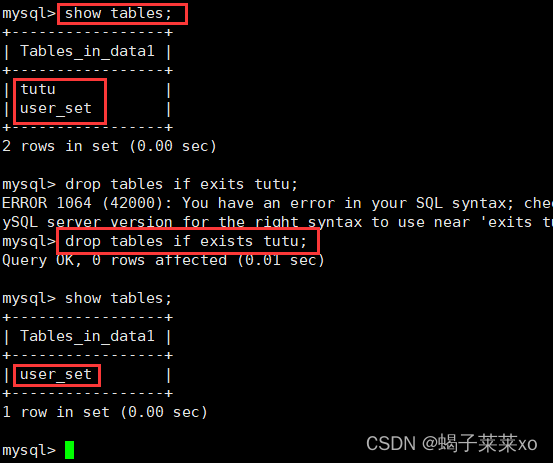
MySQL -- 库和表的操作
MySQL – 库和表的操作 文章目录 MySQL -- 库和表的操作一、库的操作1.创建数据库2.查看数据库3.删除数据库4.字符集和校验规则5.校验规则对数据库的影响6.修改数据库7.备份和恢复8.查看连接情况 二、表的操作1.创建表2.查看表结构3.修改表4.删除表 一、库的操作 注意…...
JAVAEE初阶相关内容第十五弹--网络編程
写在前 简单描述一下关于路由器的三层转发和交换机的二层转发。 路由器是三层转发-->在网络层转发。【需要解析出IP协议中的源IP、目的IP来规划路径】 交换机是二层转发-->在数据链路层转发。【只需要关注下一步发展到哪个相邻的设备上,不需要IP地址&#…...

ChatGPT/GPT4科研技术与AI绘图及论文高效写作
2023年我们进入了AI2.0时代。微软创始人比尔盖茨称ChatGPT的出现有着重大历史意义,不亚于互联网和个人电脑的问世。360创始人周鸿祎认为未来各行各业如果不能搭上这班车,就有可能被淘汰在这个数字化时代,如何能高效地处理文本、文献查阅、PPT…...

机器学习笔记 - 特斯拉的占用网络简述
一、简述 2022 年,特斯拉宣布即将在其车辆中发布全新算法。该算法被称为occupancy networks,它应该是对Tesla 的HydraNet 的改进。 自动驾驶汽车行业在技术上分为两类:基于视觉的系统和基于激光雷达的系统。后者使用激光传感器来确定物体的存在和距离,而视觉系统…...

Elesticsearch使用总结
写在前面 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于[云计…...
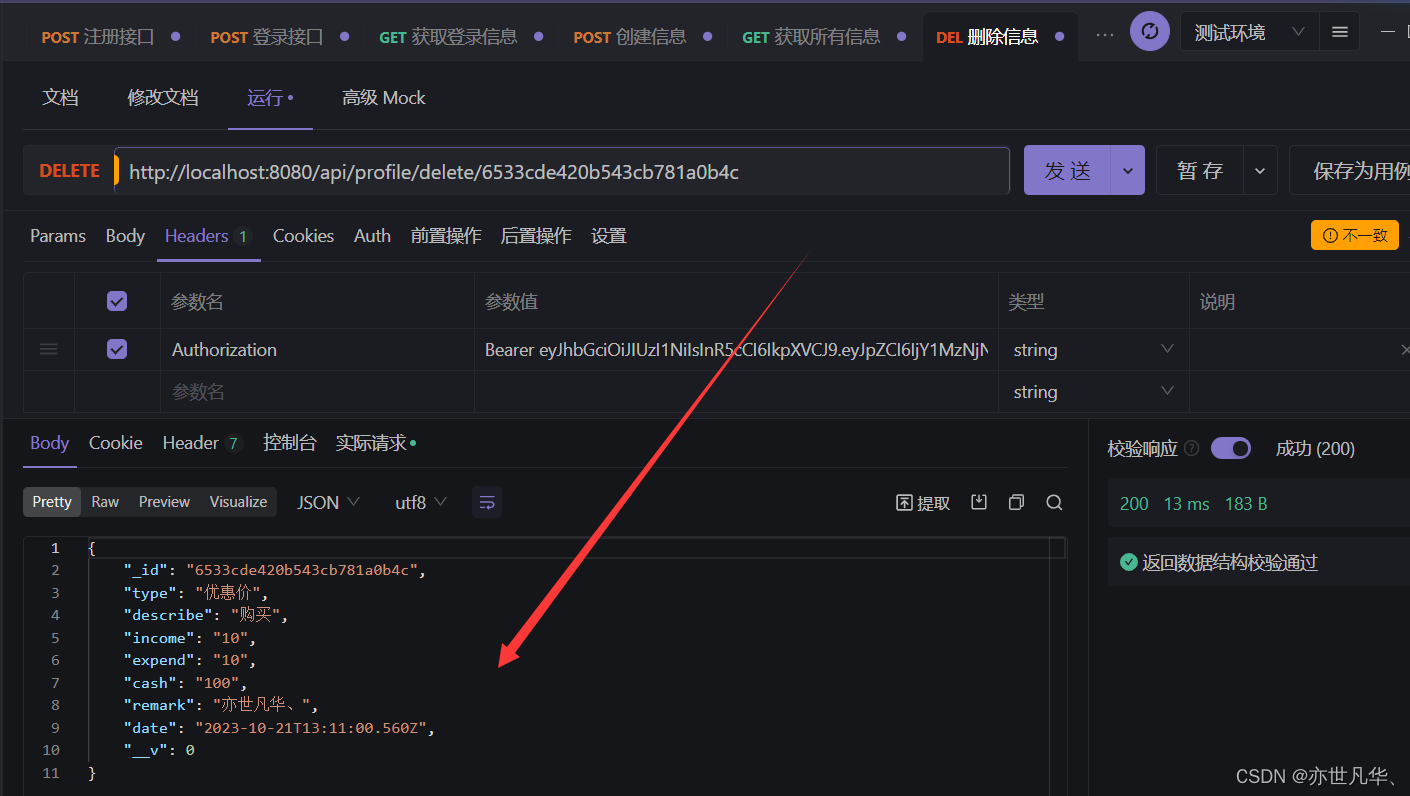
Node.js--》简易资金管理系统后台项目实战(后端)
今天开始使用 node vue3 ts搭建一个简易资金管理系统的前后端分离项目,因为前后端分离所以会分两个专栏分别讲解前端与后端的实现,后端项目文章讲解可参考:前端链接,我会在前后端的两类专栏的最后一篇文章中会将项目代码开源到我…...

执行autoreconf -fi的过程报错
https://xie.infoq.cn/article/6bba9dd34fb49b7adacb4aacd https://github.com/curl/curl/blob/master/docs/HTTP3.md#quiche-version curl配置quiche的过程中报错, configure:7902: error: possibly undefined macro: AC_LIBTOOL_WIN32_DLLIf this token and ot…...
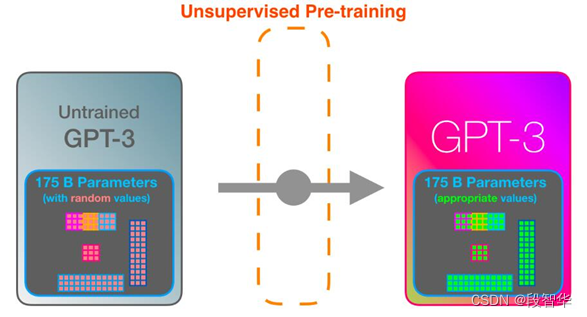
GPT-3 内幕机制可视化解析
GPT-3 内幕机制可视化解析 GPT-3是一个基于Transformer的语言模型,通过不同的层次提取语言不同层面的特性,构建整个语言的语义信息,它学习的过程跟人类正常学习的过程是类似的,开始的时候是一个无监督预训练,如图5-5所示,GPT-3模型可以将网络上的所有文档下载下来,包含 …...

Linux命令行安装图形化界面
Linux命令行安装图形化界面 安装CentOS默认安装没有配置图形化界面,如何在命令行进行安装图形化界面? 首先要以root用户登录,输入用户名和密码。 切换root用户命令: su root 查看ip地址和网卡编号。 ip addr show 知道网卡编号…...

Rust逆向学习 (2)
文章目录 Guess a number0x01. Guess a number .part 1line 1loopline 3~7match 0x02. Reverse for enum0x03. Reverse for Tuple0x04. Guess a number .part 20x05. 总结 在上一篇文章中,我们比较完美地完成了第一次Rust ELF的逆向工作,但第一次编写的R…...
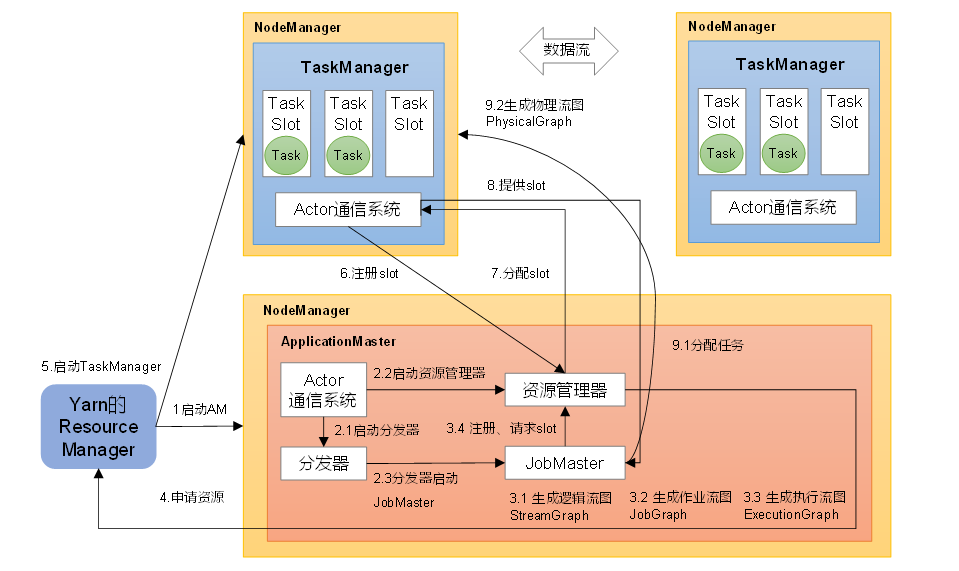
Flink部署模式及核心概念
一.部署模式 1.1会话模式(Session Mode) 需要先启动一个 Flink 集群,保持一个会话,所有提交的作业都会运行在此集群上,且启动时所需的资源以确定,无法更改,所以所有已提交的作业都会竞争集群中…...
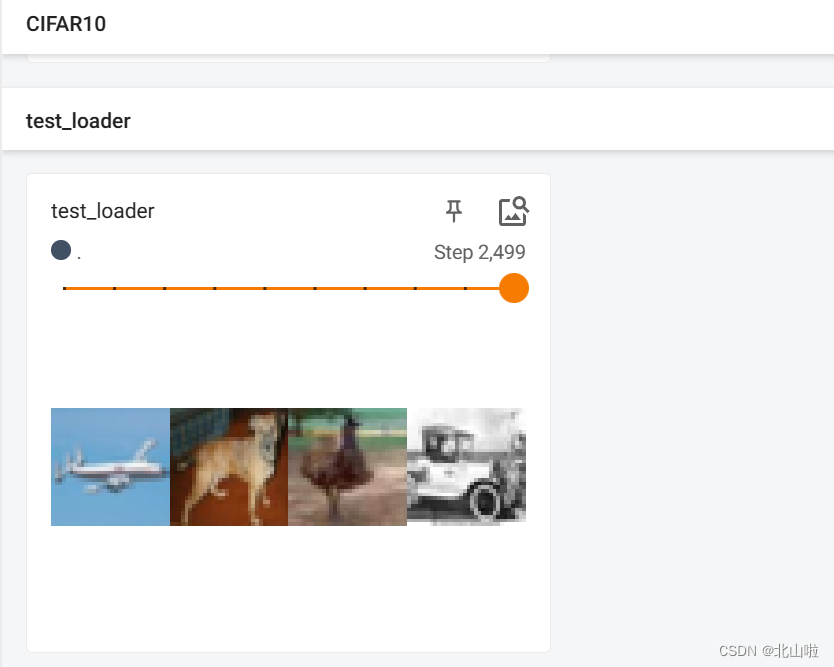
Pytorch公共数据集、tensorboard、DataLoader使用
本文将主要介绍torchvision.datasets的使用,并以CIFAR-10为例进行介绍,对可视化工具tensorboard进行介绍,包括安装,使用,可视化过程等,最后介绍DataLoader的使用。希望对你有帮助 Pytorch公共数据集 torc…...
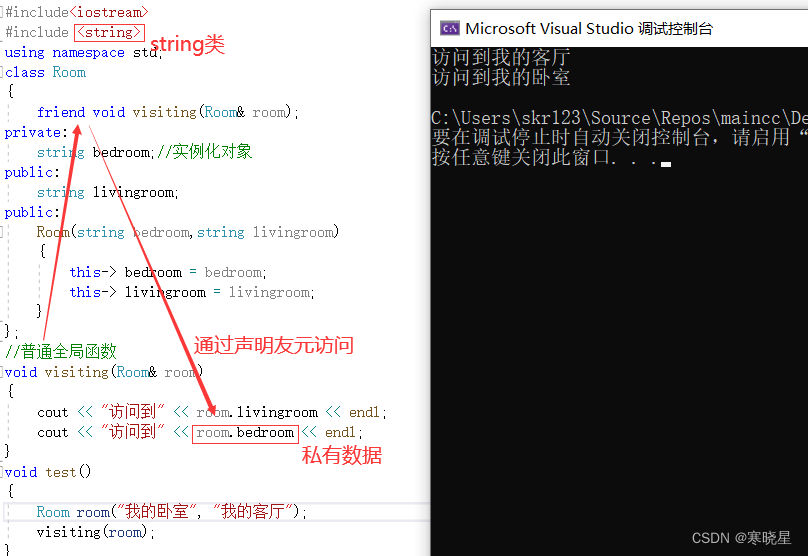
【第三天】C++类和对象进阶指南:从堆区空间操作到友元的深度掌握
一、new和delete 堆区空间操作 1、new和delete操作基本类型的空间 new与C语言中malloc、delete和C语言中free 作用基本相同 区别: new 不用强制类型转换 new在申请空间的时候可以 初始化空间内容 2、 new申请基本类型的数组 3、new和delete操作类的空间 4、new申请…...

3分钟掌握AltDrag:Windows窗口拖拽的革命性操作体验
3分钟掌握AltDrag:Windows窗口拖拽的革命性操作体验 【免费下载链接】altdrag :file_folder: Easily drag windows when pressing the alt key. (Windows) 项目地址: https://gitcode.com/gh_mirrors/al/altdrag 你是否厌倦了每次都要精准点击标题栏才能移动…...

大厂 HR 直言:IT 简历里最加分的 3 个项目类型,别乱写
每年金三银四、秋招旺季,我作为大厂HR,每天要刷几百份IT简历,平均每份停留不超过10秒。很多程序员明明技术不错,却因为项目写得乱七八糟,直接被ATS系统筛掉,连面试机会都没有。重点说一句:IT简历…...

SOONet在工业质检中的应用:自然语言‘conveyor belt stops unexpectedly’定位异常停机片段
SOONet在工业质检中的应用:自然语言conveyor belt stops unexpectedly定位异常停机片段 1. 项目概述 在工业生产线中,传送带异常停机是常见但影响严重的问题。传统的人工监控方式效率低下,往往需要操作人员反复观看数小时的监控录像才能找到…...

Python双目三维重建系统项目:双目标定、立体校正与双目测距全流程解析
python双目三维重建系统项目 双目标定,立体校正,双目测距,三维重建 该项目旨在带你了解三维重建流程:包括相机标定,立体匹配,深度计算等等 代码包含: 支持双USB连接线的双目摄像头 支持单USB连接线的双目摄…...

如何快速彻底清理显卡驱动:Display Driver Uninstaller终极使用指南
如何快速彻底清理显卡驱动:Display Driver Uninstaller终极使用指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...
✅)
计算机毕业设计:Python空气污染数据分析可视化系统 Django框架 可视化 数据分析 Prophet时间序列 大数据 大模型 深度学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...
)
基于HTTP协议的PLC数据交互实战(涵盖欧姆龙、三菱、西门子等主流品牌)
1. 为什么需要HTTP协议与PLC交互? 在工业自动化领域,PLC(可编程逻辑控制器)就像工厂的"大脑",负责控制各种设备的运行。但传统PLC数据交互方式存在明显痛点:比如欧姆龙用FINS协议、三菱用MC协议、…...
 终极避坑与实战指南》俏)
《OpenClaw (Docker手工部署版) 终极避坑与实战指南》俏
MySQL 中的 count 三兄弟:效率大比拼! 一、快速结论(先看结论再看分析) 方式 作用 效率 一句话总结 count(*) 统计所有行数 最高 我是专业的!我为统计而生 count(1) 统计所有行数 同样高效 我是 count(*) 的马甲兄弟…...

混合型MMC多电平整流侧仿真研究:电压电流双闭环控制与环流抑制策略的实现
混合型MMC多电平,整流侧仿真,加入了电压电流双闭环,环流抑制,子模块电容电压均压控制,采用载波移相调制 PS:仿真搭建不易,仅一个仿真最近在实验室熬了几个通宵,终于搞定了混合型MMC多…...
从零搞懂Transformer,从位置编码到自注意力,大模型的核心逻辑全拆解
平时我们用ChatGPT聊天、用翻译软件做中英互译、用AI写文案,甚至让AI帮忙编代码,背后最核心的“功臣”,都是2017年Google团队提出的Transformer模型。这个看起来复杂的模型,其实打破了传统AI的局限,靠着高效的计算能力…...