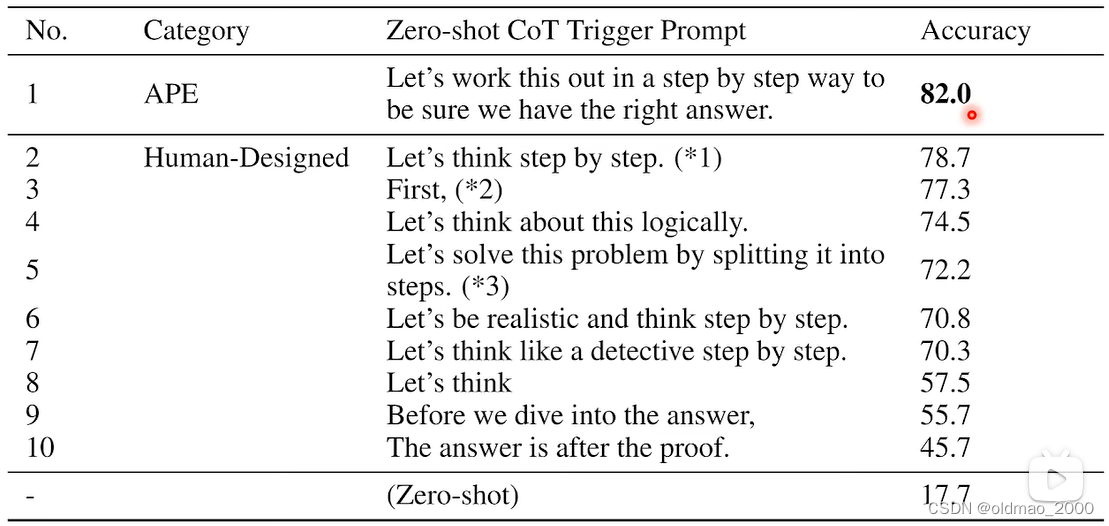
04.Finetune vs. Prompt
目录
- 语言模型回顾
- 大模型的两种路线
- 专才
- 通才
- 二者的比较
- 专才养成记
- 通才养成记
- Instruction Learning
- In-context Learning
- 自动Prompt
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索
语言模型回顾
GPT:文字接龙
How are __.
Bert:文字填空
How __ you.
使用大型语言模型就好比下图:

小老鼠就能驾驭大象。
大模型的两种路线
专才
主要利用模型解决某一个特定的任务,例如翻译

或者是文本摘要:

通才
主要利用模型解决解决各种不同的任务,对不同Prompt有不同的响应。

例如上图中的红色字体就是Prompt。
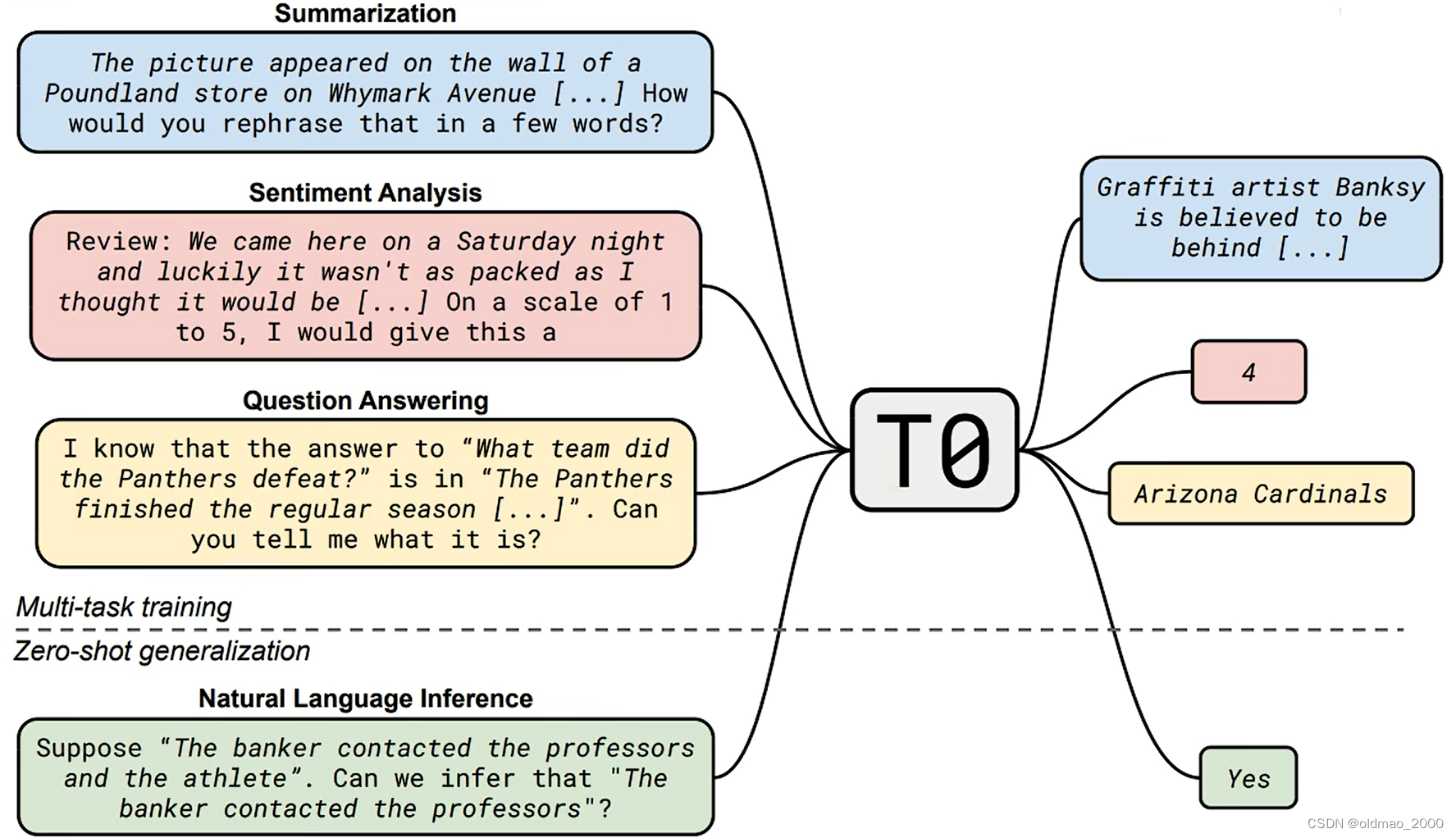
早在18年就有The Natural Language Decathlon: Multitask Learning as Question Answering,让语言模型完成各种不同的任务,文章的思想就是将所有的不同的任务都看做是问答,例如:

上面的提问分别对应了多种不同的任务:阅读理解,摘要,情感分析等。
这些提问用在现在的GPT上就是Prompt
二者的比较
专才的优点:在专才的单一任务上比通才性能要强。
Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine
这个文章给出分析九印证了这一点,先自问自答找出GPT翻译的Prompt:
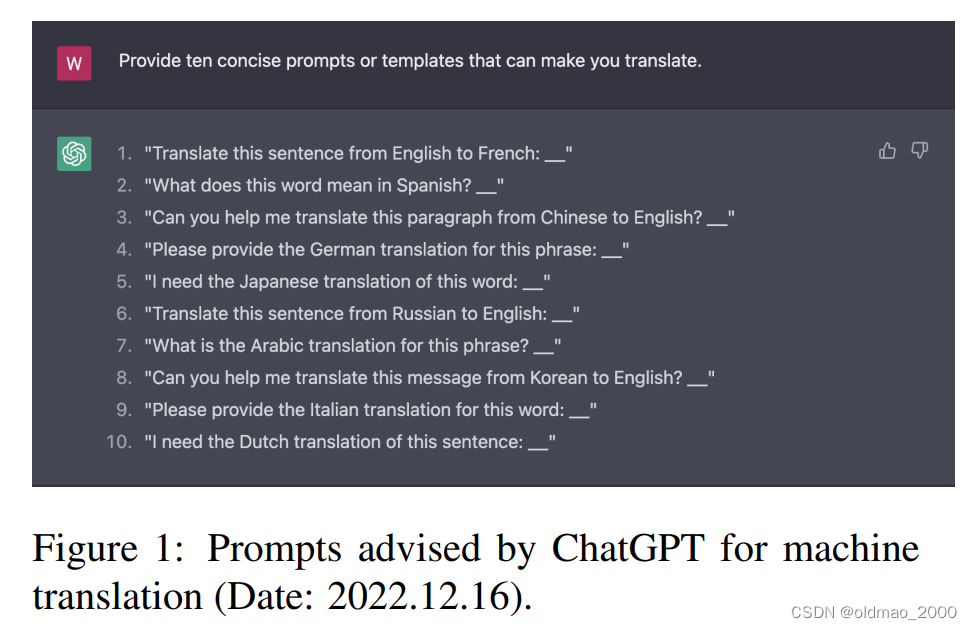
然后给出12种翻译结果(两两互翻译),从结果中可以看到ChatGPT比单一任务模型的BLEU分数要低一些
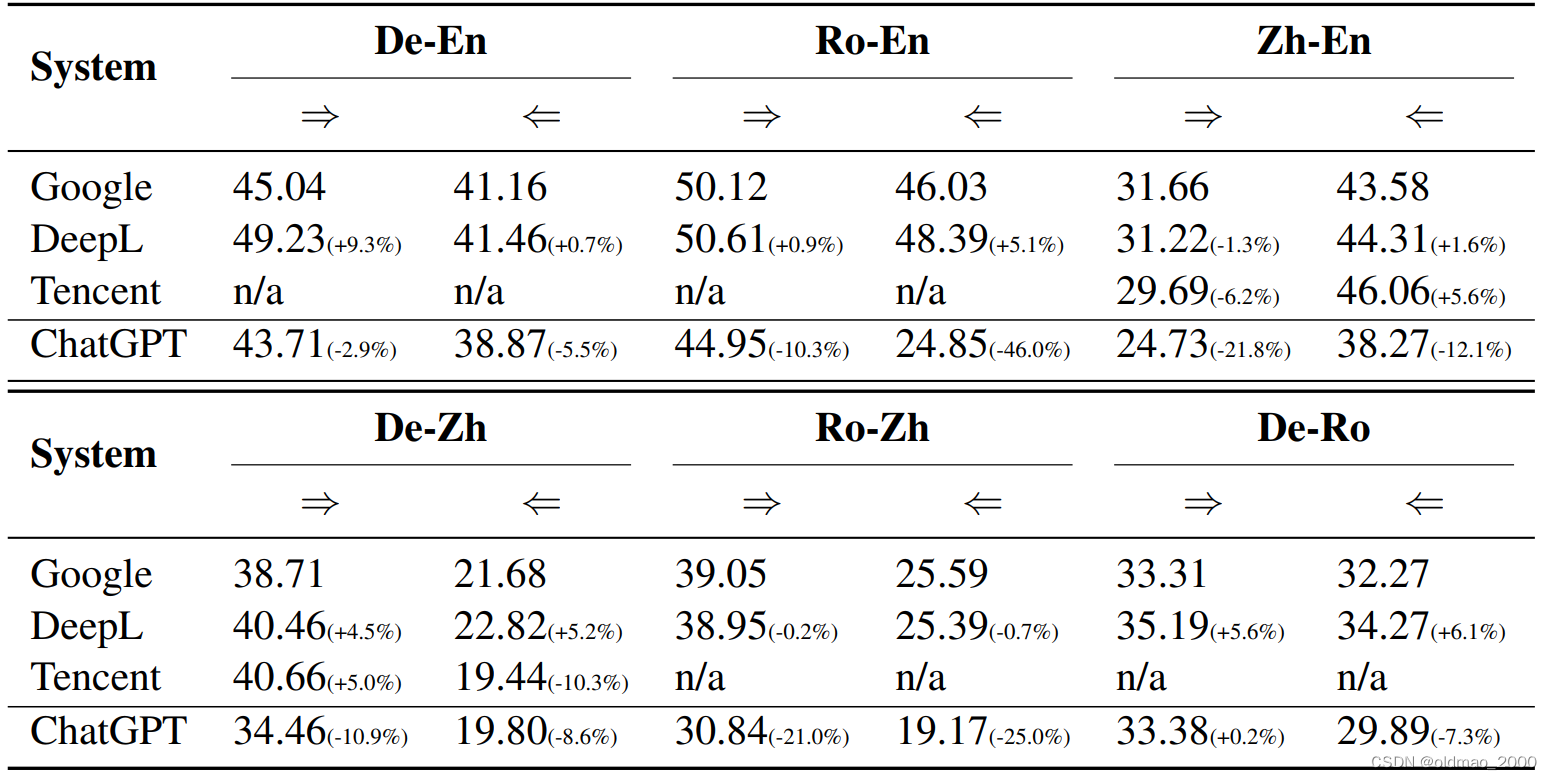
这个文章是腾讯在ChatGPT刚出来的时候,还未发布API的时候测的(文章在23年3月有更新),且只做了10个句子。
微软在23年2月发表了How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation,ChatGPT与在WMT上取得最好成绩的模型进行比较,还是比不过。
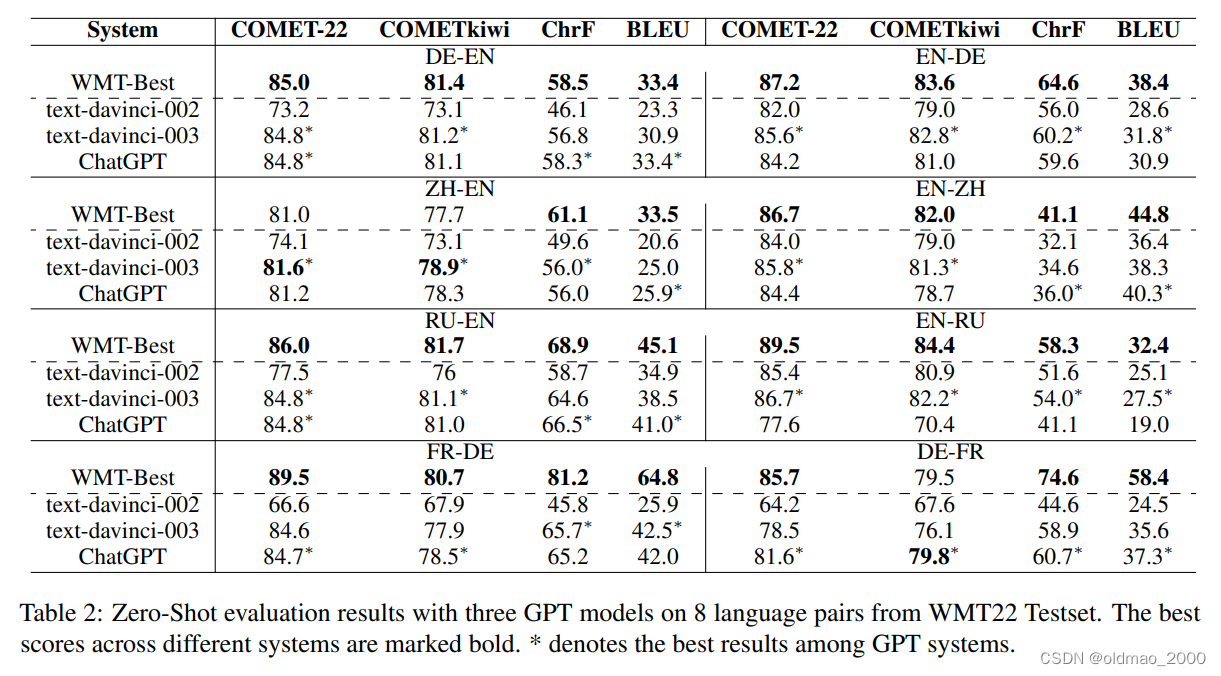
通才的优点:只需要重新设计Prompt就可以开发新功能,不需要修改代码。
专才养成记
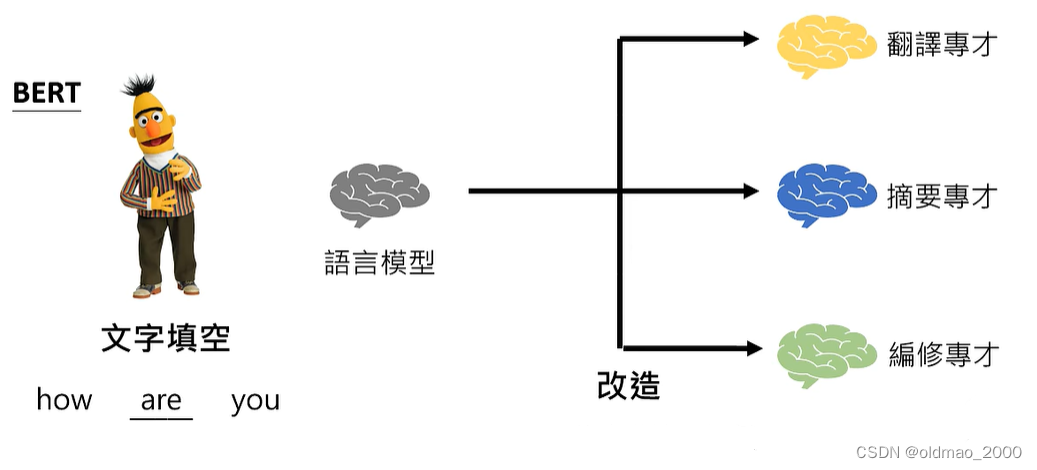
改造方式有两种:加外挂和微调
所谓加外挂就是基于BERT有四种用法,具体可以看这里。
微调:以翻译任务为例就是收集成对的语料,可以不用很大量,然后在训练好的语言模型(预训练好的)基础上进行GD。
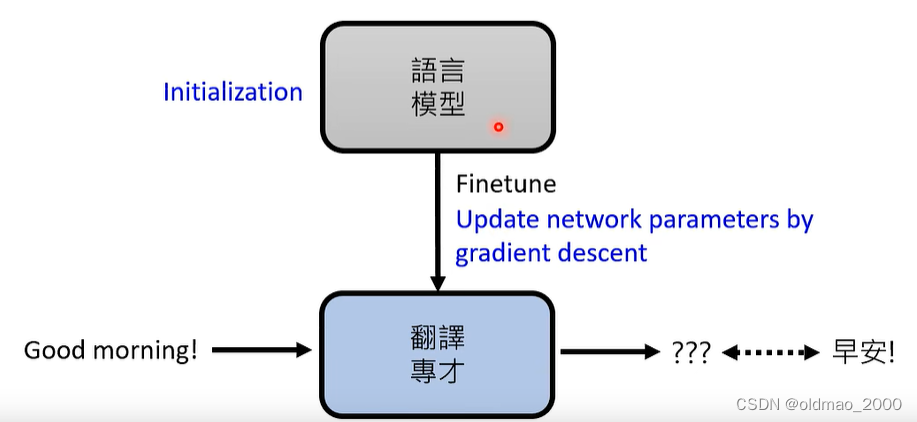
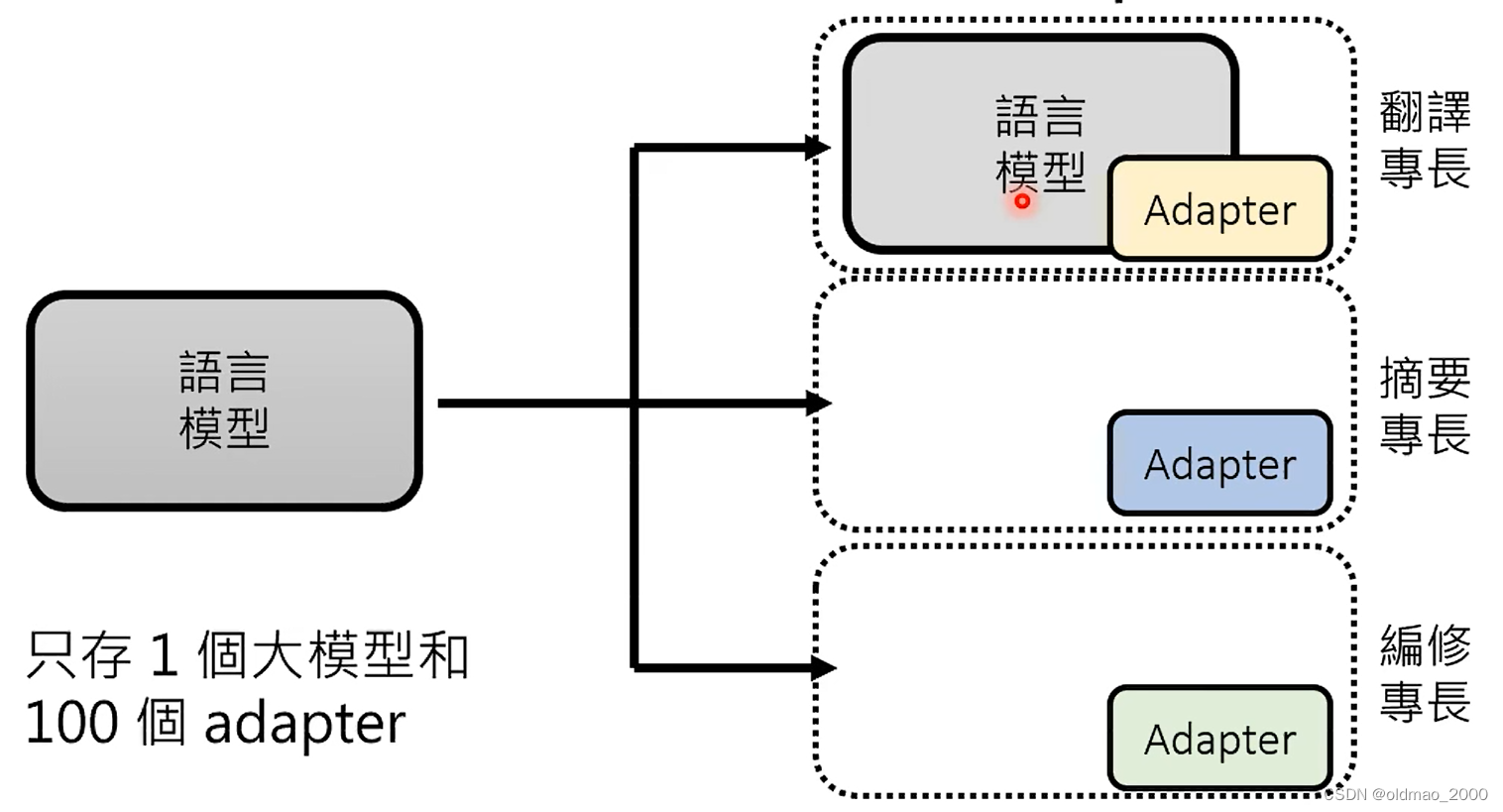
Adapter:在语言模型中加入额外的layer,在训练过程中保存语言模型的参数不变,只更新Adapter中的参数。
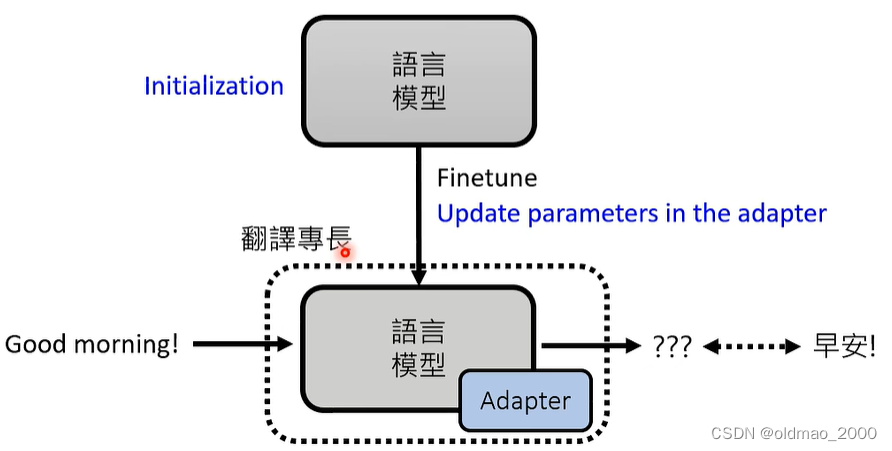
Adapter有很多种,可以看这里。
魔鬼筋肉人版BERT。。。
EXPLORING EFFICIENT-TUNING METHODS IN SELF-SUPERVISED SPEECH MODELS,这篇李宏毅团队发表的文章中介绍了如何在BERT里面加Adapter
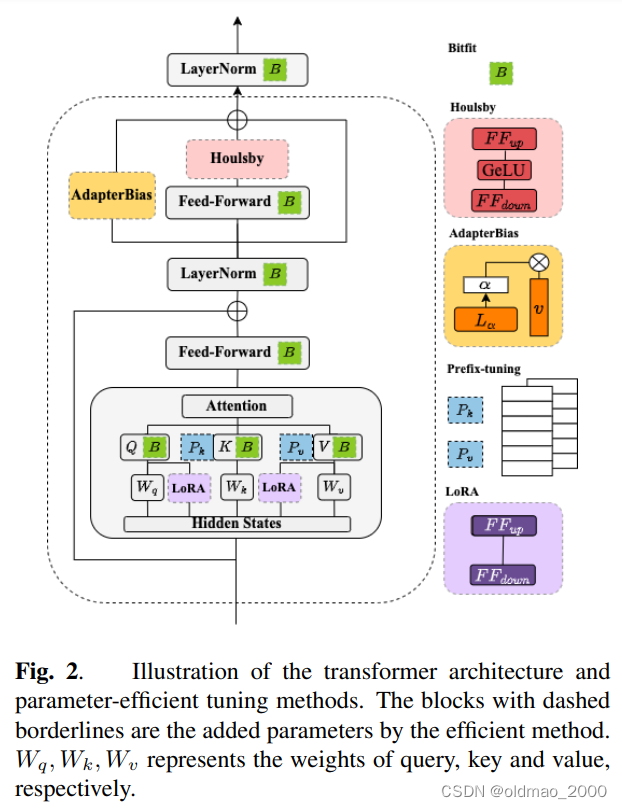
Bitfit:把Bias作为额外插件,在微调时只更新神经元的Bias;
Houlsby:在最后的Feed-Forward后面的Houlsby再加入一层Feed-Forward结构,并只更新该结构的参数;
AdapterBias:是对后面Houlsby是结果加的Bias,主要是对结果进行平移;
Prefix-tuning:修改Attention部分;
LoRA:修改Attention部分。
这里给出了多个Adapter专才的解决方法
通才养成记
有两种做题方式:
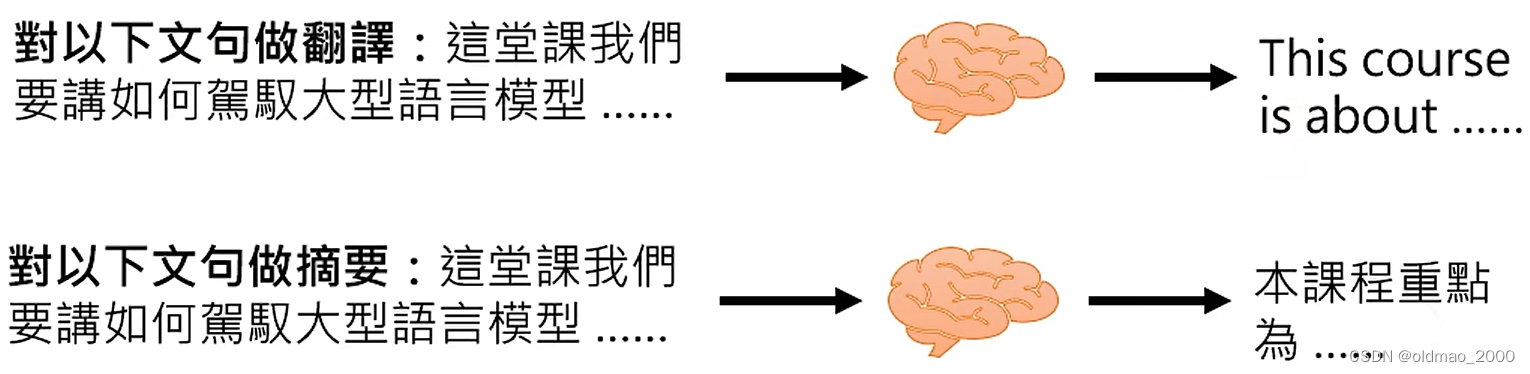
Instruction Learning
根据题目叙述来回答问题

只做文字接龙的模型是看不同题目的,无法明白题目的含义,因此,需要对模型进行Instruction-tuning,就是对模型进行如下训练
21年的文章Multitask Prompted Training Enables Zero-Shot Task Generalization中就提出了类似的思想:
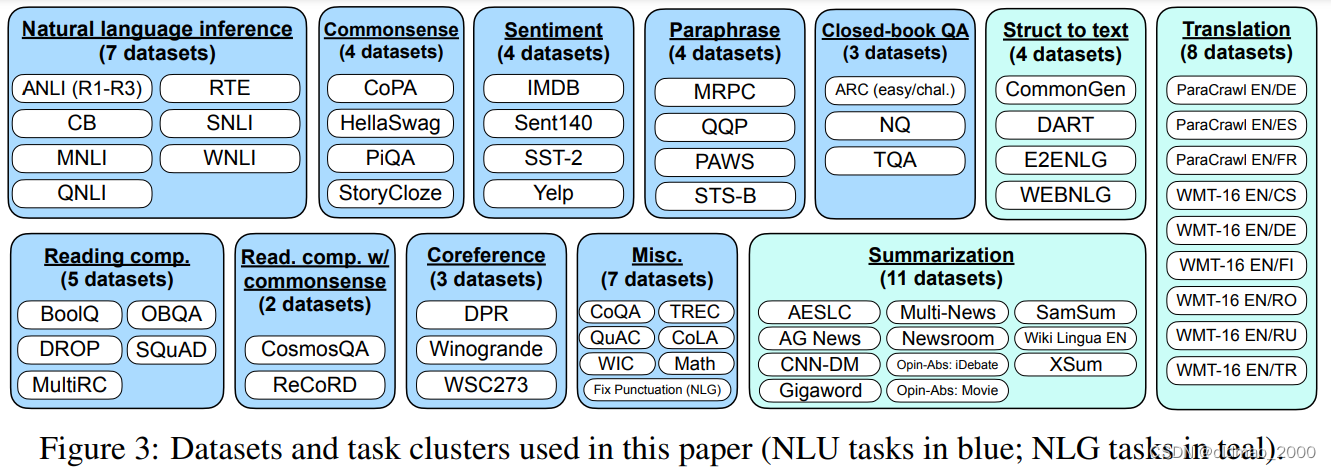
文章Finetuned Language Models Are Zero-Shot Learners提出FLAN(Finetuned Language Net),收集了大量不同领域NLP相关的数据集:
然后将这些任务转化为相应的模板,例如下面NLI的任务,原文就给出10个模板。
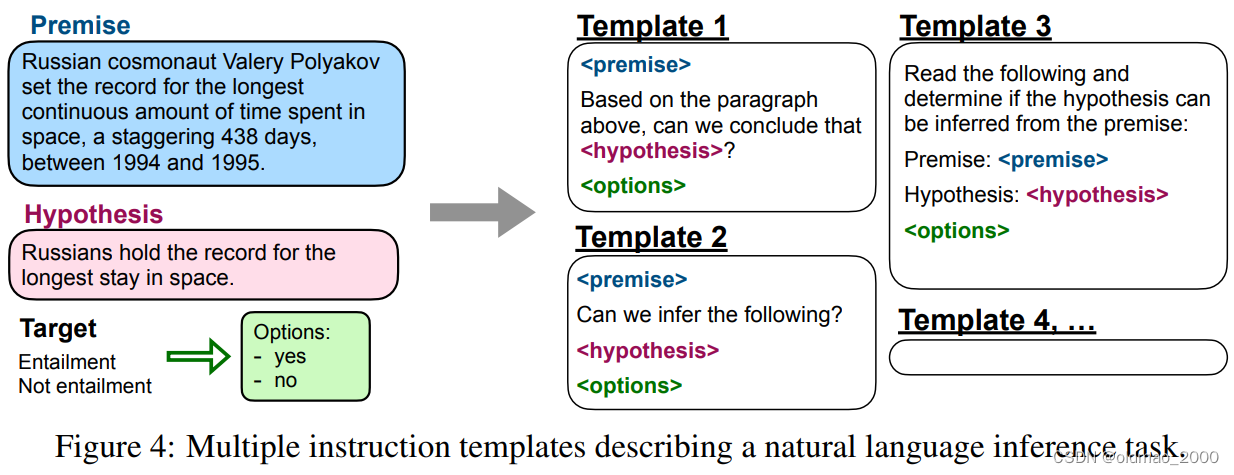
最后结果如下,需要注意的是,在做各个任务evaluation的时候,训练过程是不带evaluation任务的数据的,只是训练模型看各种模板。

文章Chain-of-Thought Prompting Elicits Reasoning in Large Language Models提供了另外一种让模型学会看懂不同Prompt的思路。
模型在逻辑推理方面效果不好,例如下面例子中虽然给出了例子,但是模型回答应用题就不对:

具体改进就是在Prompt中加入亿点点解题思路和推论过程:

最后模型在应用题上的结果还不错:
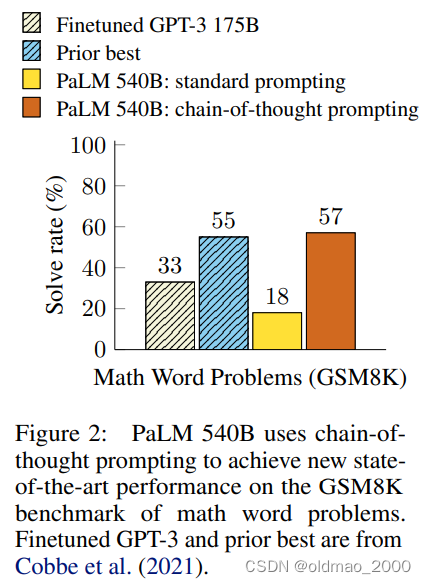
当然这个好麻烦,我都会解题步骤还需要模型干嘛,然后就出现了下面的Prompt,结果居然起飞。

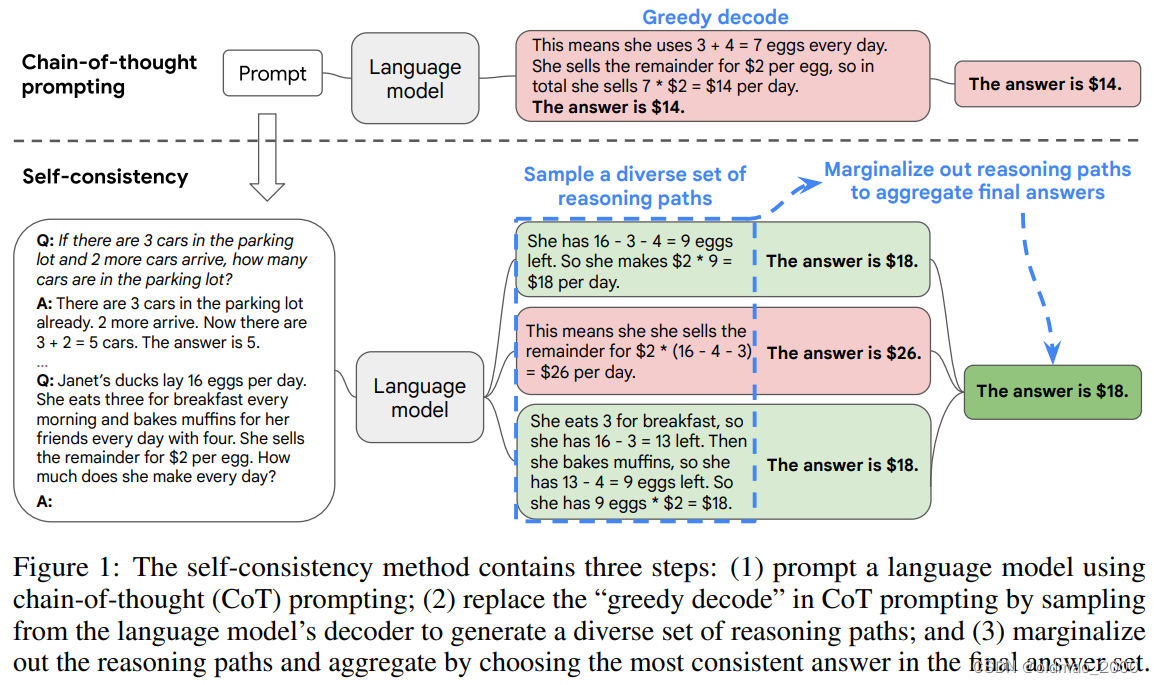
然后进一步的在Self-Consistency Improves Chain of Thought Reasoning in Language Models里面借鉴了少数服从多数的理念,对CoT进行了改进:
由于模型在生成答案是有随机性的,因此考虑如果模型生成的答案中通过不同的计算方式得到相同的答案,那么这个答案大概率就是正确答案。
CoT的另外一个做法在文章Least-to-Most Prompting Enables Complex Reasoning in Large Language Models中提到,就是Least-to-Most Prompting。思想就是将复杂的数学问题进行分解(Problem Reduction)
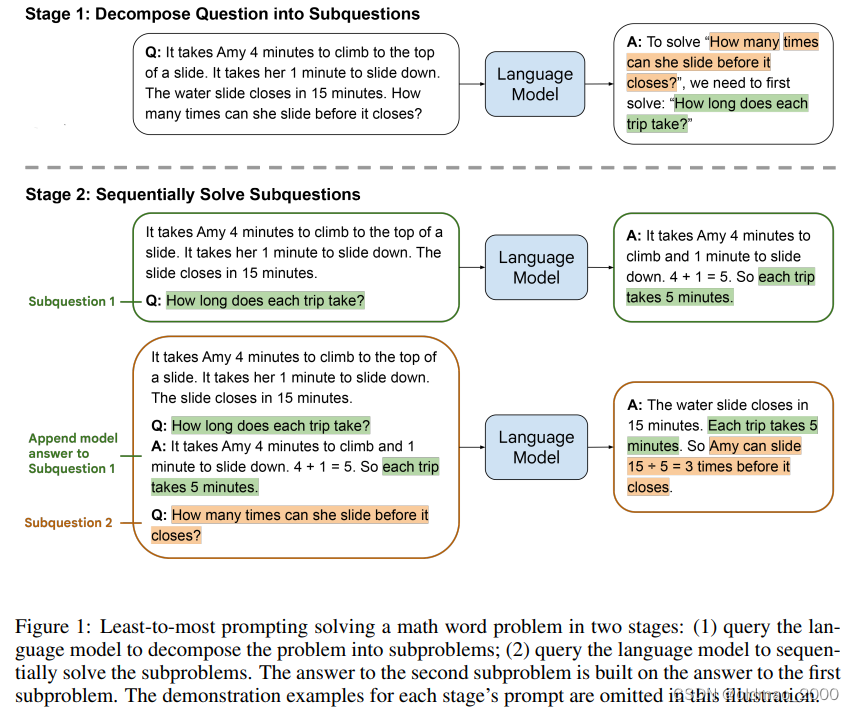
这里的数学问题是小女孩要玩滑梯,爬上去要4分钟,滑下来要1分钟,如果还有15游乐园关门,小女孩能玩几次?
这里的第一次分解是依靠模型完成的,得到结果是先要求小女孩玩一次滑梯要多少时间?然后将分解的问题在丢进模型得到结果是5分钟,然后在将中间过程和最后的问题放入模型得到答案:3次。
In-context Learning
根据范例来回答问题

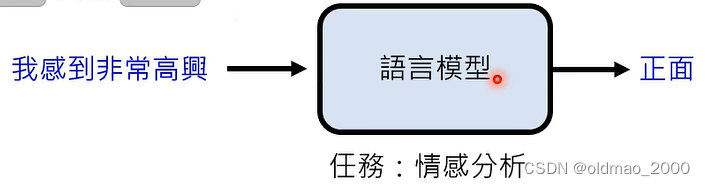
例如要做SA任务,先要给一些例子

然后模型可以完成相关任务,这个过程不涉及到GD:
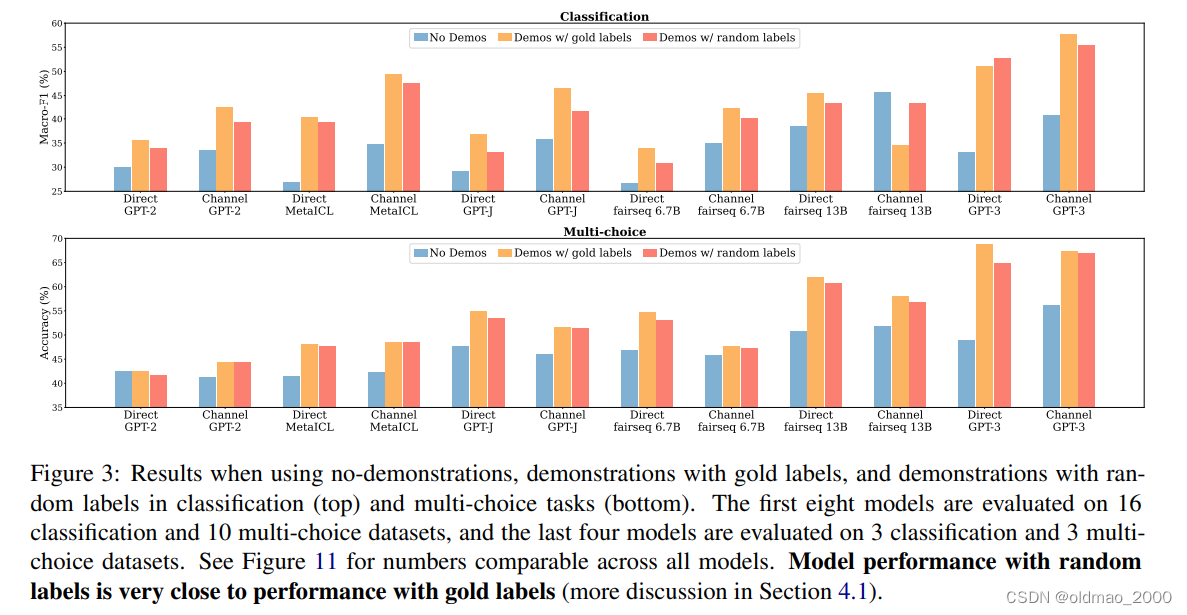
由于不涉及到GD,模型是没有对所给的范例进行学习的,例如论文:Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?中做了相关实验,故意给出标注错误/随机的范例,发现模型性能并未下降很多,说明模型并未受到范例的影响。
下图蓝色是未给范例的结果,橙色正确范例的结果,而最后深橙色是随机范例结果:
文章还做了另外一个实验,用随机sample来的语料进行情感分析

下图中紫色部分就是给错误语料示范的结果,发现性能下降比较厉害,也就意味在跨Domain上进行Evaluation效果较差。

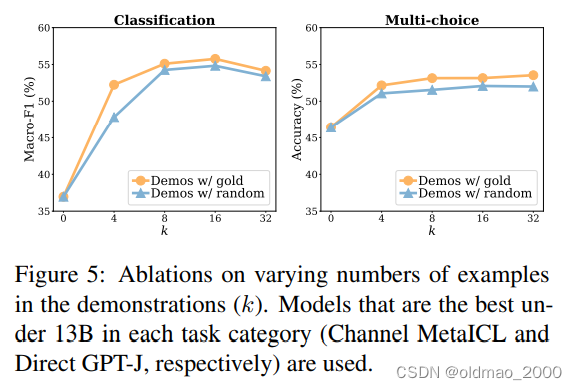
最后文章分析:模型本来就知道如何做情感分析,只不过需要范例来提示它,指出需要做情感任务。范例的样本数量多少其实并不太重要。文中也给出了相应的实验结果,横轴为范例个数:
也有部分论文提出其他观点:模型可以从范例中学习到相关知识,具体没有展开。
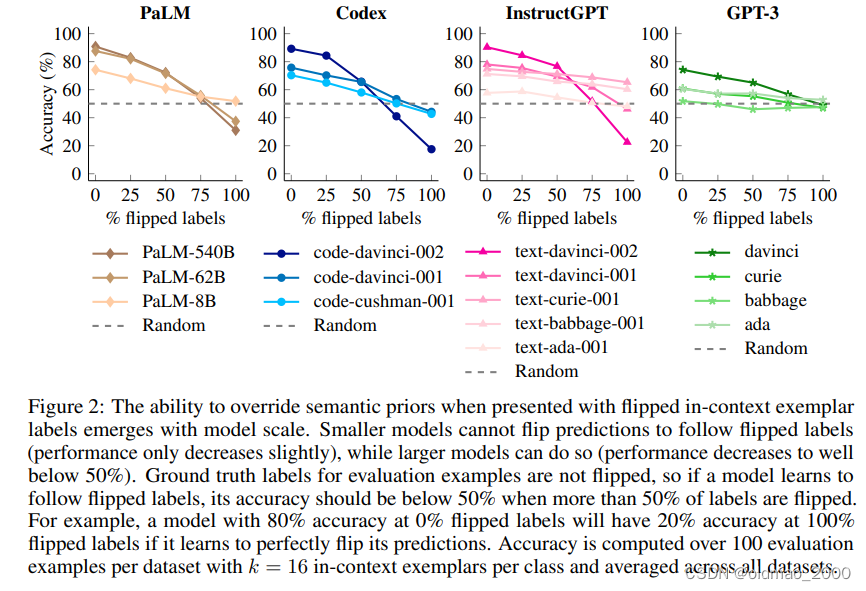
当下谷歌最新文章Larger language models do in-context learning differently做了以下实验,颜色越深模型越大,横轴表示模型吃进去的标签错误百分比。图中显示模型越大越容易受到标签的影响。
附录中还给出了一个离谱的用大模型做线性分类的实验,实验数据如下:
Input: 648, 626, 543, 103, 865, 910, 239, 665, 132, 40, 348, 479, 640, 913, 885, 456
Output: Bar
Input: 720, 813, 995, 103, 24, 94, 85, 349, 48, 113, 482, 208, 940, 644, 859, 494
Output: Foo
Input: 981, 847, 924, 687, 925, 244, 89, 861, 341, 986, 689, 936, 576, 377, 982, 258
Output: Bar
Input: 191, 85, 928, 807, 348, 738, 482, 564, 532, 550, 37, 380, 149, 138, 425, 155
Output: Foo
Input: 284, 361, 948, 307, 196, 979, 212, 981, 903, 193, 151, 154, 368, 527, 677, 32
Output: Bar
Input: 240, 910, 355, 37, 102, 623, 818, 476, 234, 538, 733, 713, 186, 1, 481, 504
Output: Foo
Input: 917, 948, 483, 44, 1, 72, 354, 962, 972, 693, 381, 511, 199, 980, 723, 412
Output: Bar
Input: 729, 960, 127, 474, 392, 384, 689, 266, 91, 420, 315, 958, 949, 643, 707, 407
Output: Bar
Input: 441, 987, 604, 248, 392, 164, 230, 791, 803, 978, 63, 700, 294, 576, 914, 393
Output: Bar
…
期待模型根据:
Input: 101, 969, 495, 149, 394, 964, 428, 946, 542, 814, 240, 467, 435, 987, 297, 466
Output:
得到:
Answer:
Bar
结果如下,横轴是给出的输入的维度:
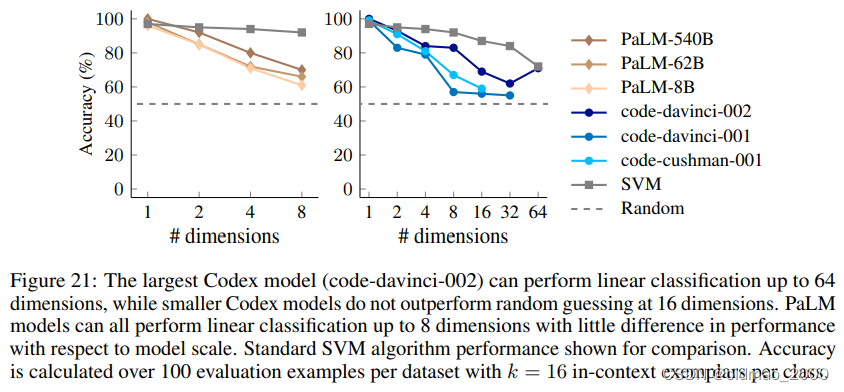
上面的模型都是只学习文字接龙,就来做其他任务,文章MetaICL: Learning to Learn In Context中提出让模型学习如何进行In-context Learning,就是要更好的驯化模型以达到更好的结果。
自动Prompt
现在大多数都是人直接下指令,属于:
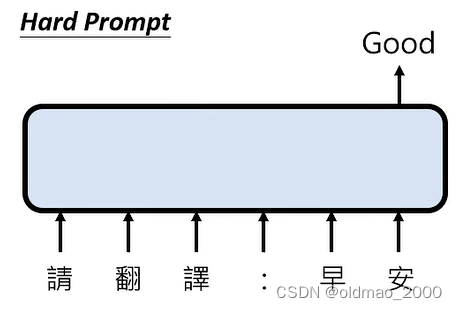
如果不给指令:
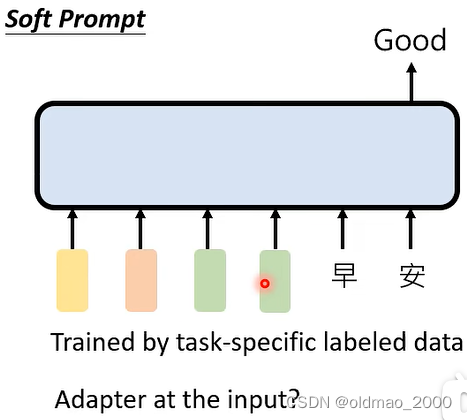
这种其实与专才中的Adapter流派类似。
还有使用RL的方法来找Prompt:Learning to Generate Prompts for Dialogue Generation through Reinforcement Learning
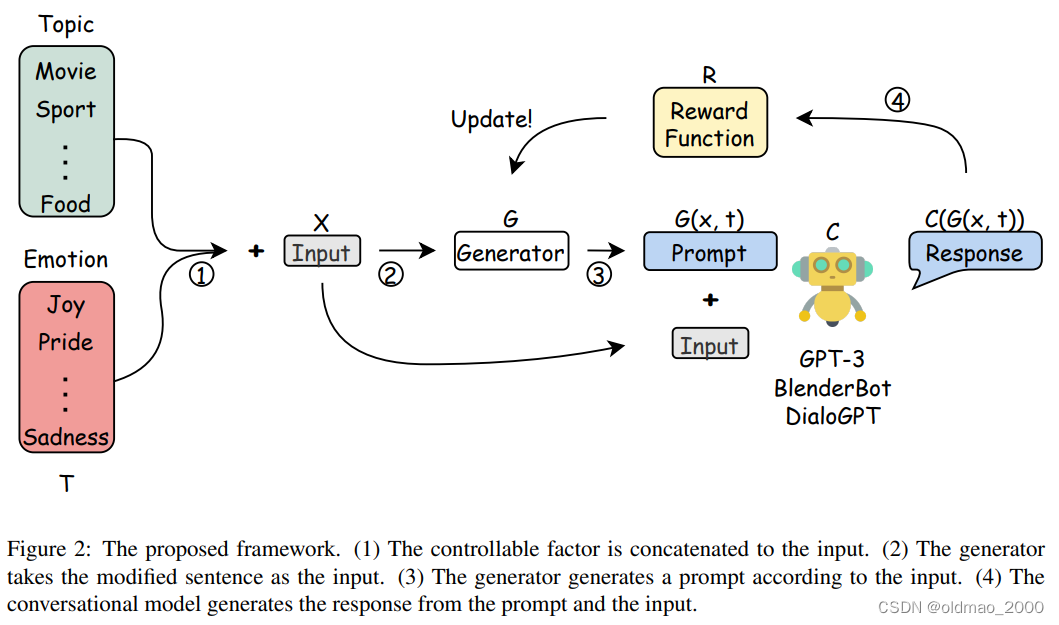
还有使用LM自己找出Prompt:Large Language Models Are Human-Level Prompt Engineers
先来一个模板:
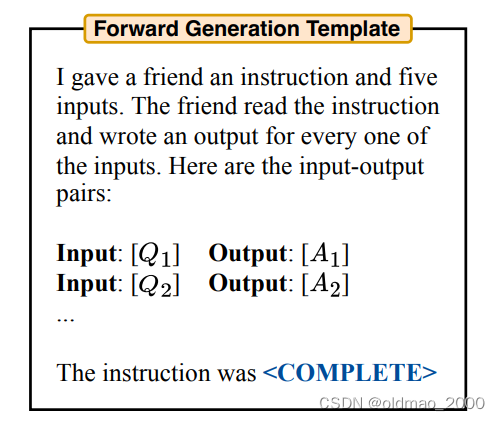
然后为这个模板提供类似以下数据:
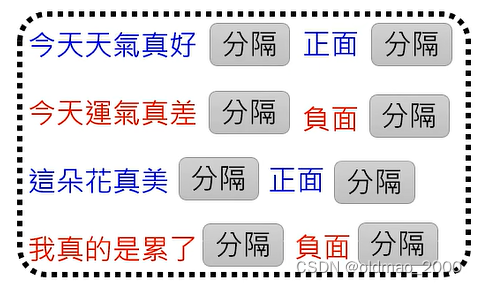
希望模型能够给出情感分类的Prompt。
具体流程如下图:
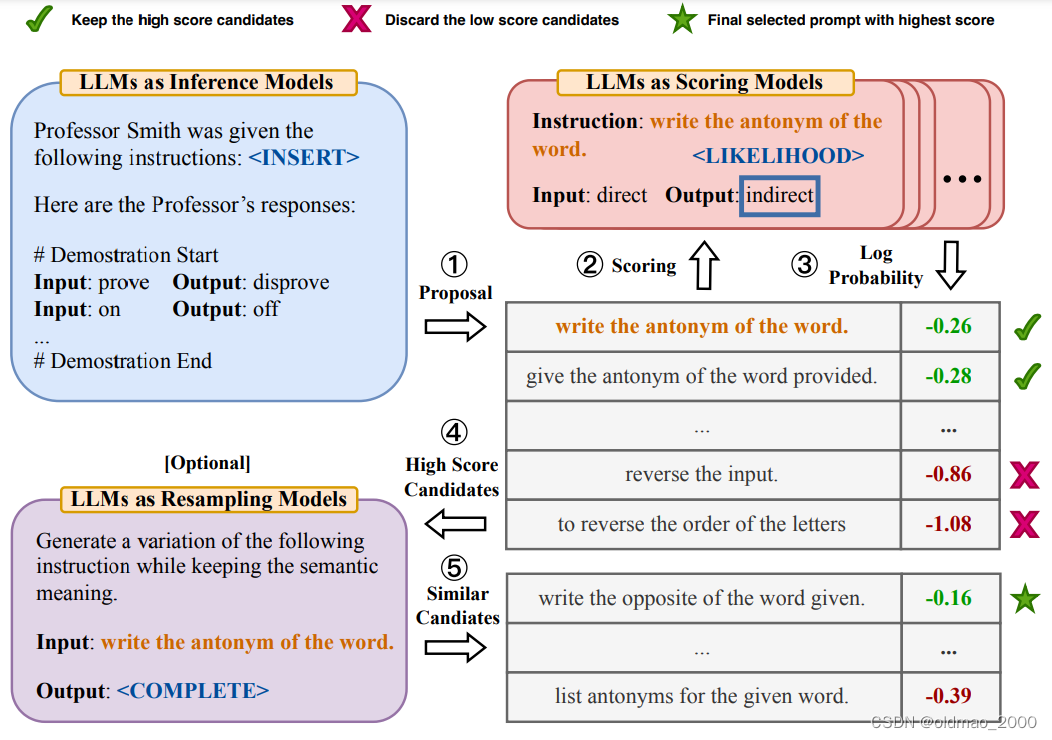
1.先是给模板然后模型根据模板生成若干个Prompt;
2.将Prompt结果分别丢进模型进行生成;
3.对生成对结果排序;
4.选出较好的结果;
5.让模型再次生成与这些结果相近的Prompt。
最后两步效果提升不明显,到第3步就好了。
划重点:注意看第一句最强催眠Prompt
相关文章:
04.Finetune vs. Prompt
目录 语言模型回顾大模型的两种路线专才通才二者的比较 专才养成记通才养成记Instruction LearningIn-context Learning 自动Prompt 部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索 语言模型回顾 GPT:文字接龙 How are __. Bert&a…...
-采用NXOpen完成对象的合并操作)
UG NX二次开发(C#)-采用NXOpen完成对象的合并操作
文章目录 1、前言2、Ufun实现布尔和操作的函数2.1 函数说明2.2 源代码3、采用NXOpen实现布尔和操作的函数3.1 函数说明3.2 源代码4、测试结果4.1 采用UFun 与NXOpen的结果4.2采用UFun 与NXOpen的对比说明1、前言 在UG NX中开发过程中,创建特征对象的时候往往会用到布尔操作,…...

测开不得不会的python之re模块正则表达式匹配
学习目录 正则表达式介绍 正则表达式的常用符号 python的re模块 findall()函数 finditer()函数 match()函数 search()函数 split()函数 正则表达式的介绍 Python 通过标准库中的 re 模块来支持正则表达式。 正则表达式作为高级的文本模式匹配、抽取、和搜索。简单地说…...

selenium4 元素定位
selenium4 9种元素定位 ID driver.find_element(By.ID,"kw")NAME driver.find_element(By.NAME,"tj_settingicon")CLASS_NAME driver.find_element(By.CLASS_NAME,"ipt_rec")TAG_NAME driver.find_element(By.TAG_NAME,"area")LINK_T…...

sql高级教程-索引
文章目录 架构简介1.连接层2.服务层3.引擎层4.存储层 索引优化背景目的劣势分类基本语法索引结构和适用场景 性能分析MySq| Query Optimizerexplain 索引优化单表优化两表优化三表优化 索引失效原因 架构简介 1.连接层 最上层是一些客户端和连接服务,包含本地sock通…...
拼团小程序制作技巧大揭秘:零基础也能轻松掌握
随着拼团模式的日益流行,越来越多的商家和消费者开始关注拼团小程序的制作。对于没有技术背景的普通人来说,制作一个拼团小程序似乎是一项艰巨的任务。但实际上,选择一个简单易用的第三方平台或工具,可以轻松完成拼团小程序的制作…...

报错:The supplied javaHome seems to be invalid. I cannot find the java executable
AS 升级遇到的问题 问题 升级 Android Studio,碰到无法检测到 java The supplied javaHome seems to be invalid. I cannot find the java executable. Tried location: D:\Program Files\Android\Android Studio\jre\bin\java.exe 然后去网上找解决思路。 终于…...
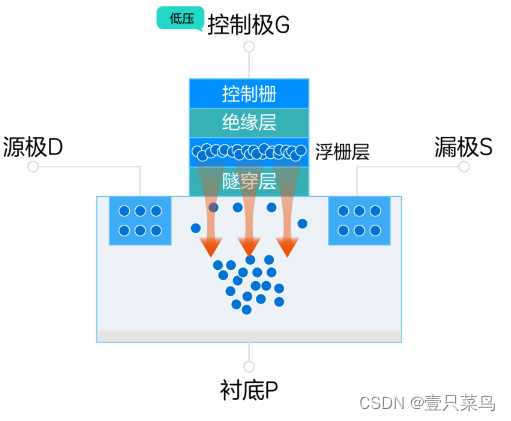
关于 硬盘
关于 硬盘 1. 机械硬盘1.1 基本概念1.2 工作原理1.3 寻址方式1.4 磁盘磁记录方式 2. 固态硬盘2.1 基本概念2.2 工作原理 1. 机械硬盘 1.1 基本概念 机械硬盘即是传统普通硬盘,硬盘的物理结构一般由磁头与盘片、电动机、主控芯片与排线等部件组成。 所有的数据都是…...
Java反射实体组装SQL
之前在LIS.Core定义了实体特性,在LIS.Model给实体类加了表特性,属性特性,外键特性等。ORM要实现增删改查和查带外键的父表信息就需要解析Model的特性和实体信息组装SQL来供数据库驱动实现增删改查功能。 实现实体得到SQL的工具类,…...

tensorrt安装使用教程
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深…...
-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销)
Java后端开发(十)-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销
目录 1.多次 修改Test01类后,提交到本地仓库 。 2.多次重复 1 的步骤,多次commit成功后,在Git =》Log中会显示,commit记录...
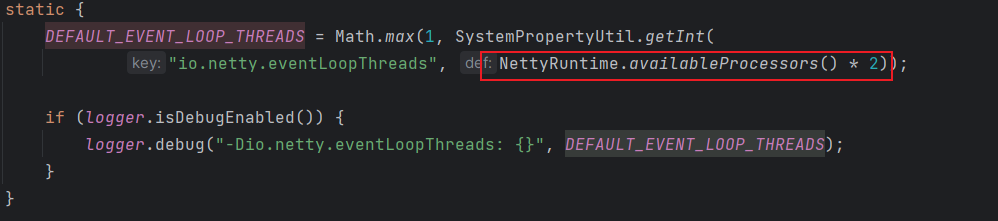
常见面试题-Netty专栏(一)
typora-copy-images-to: imgs Netty 是什么呢?Netty 用于做什么呢? 答: Netty 是一个 NIO 客户服务端框架,可以快速开发网络应用程序,如协议服务端和客户端,极大简化了网络编程,如 TCP 和 UDP …...

【iOS】JSONModel的基本使用
文章目录 前言一、导入JSONModel二、JSONModel的基本使用1.基本用法2.模型集合3.模型导出为NSDictionary或JSON4.设置所有属性可选(所有属性值可以为空)5.下划线(蛇式)转驼峰命名法 前言 JSONModel 是一个用于 Objective-C 的开源库,它用于简…...
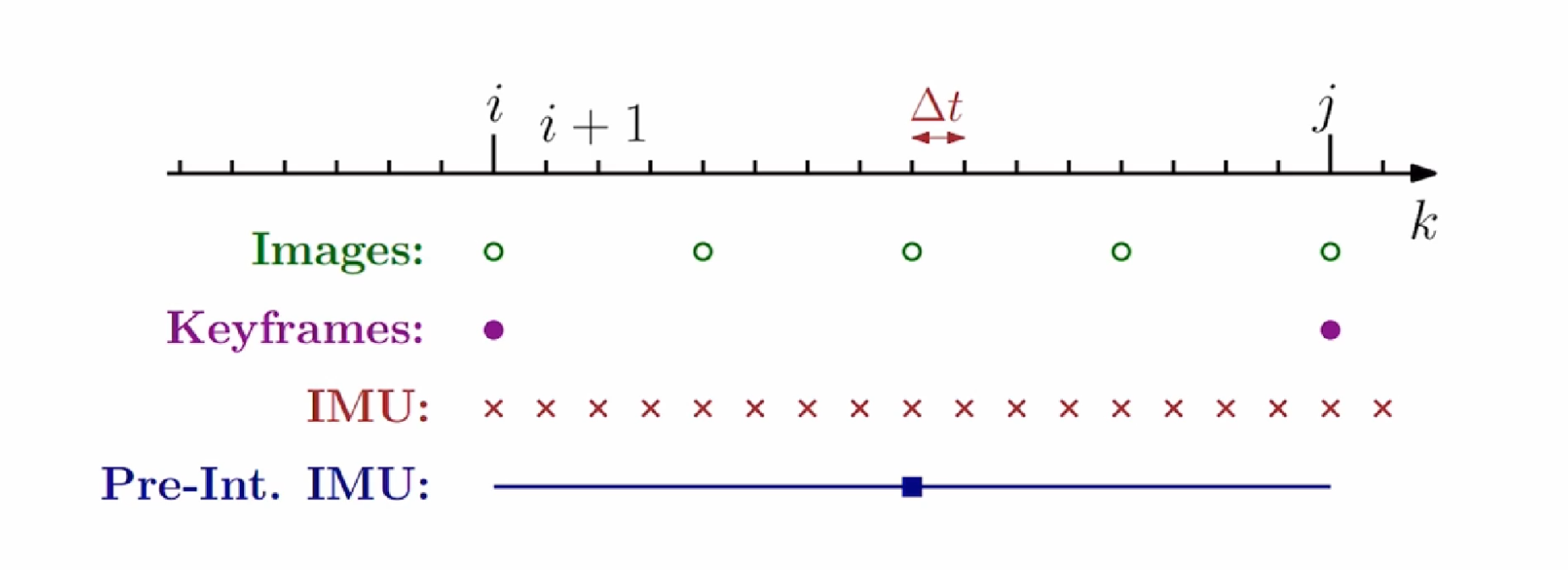
imu预积分学习(更新中)
imu预积分学习(更新中) IMU预积分可以做什么? 以上面那个经典图片为例子,IMU可以通过六轴数据,拿到第i帧和第j帧之间的相对位姿,这样不就可以去用来添加约束了吗 但是有一个比较大的问题是: I…...
算法刷题-链表
算法刷题-链表 203. 移除链表元素 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head [1,2,6,3,4,5,6], val 6 输出:[1,2,3,4,5]…...
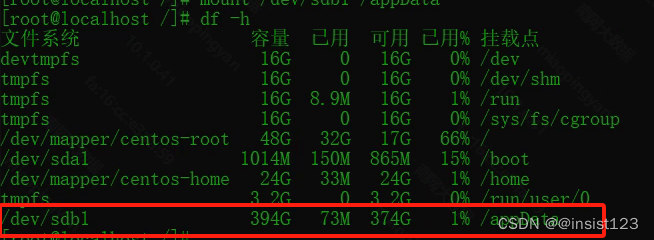
Linux 挂载磁盘到指定目录
问题:公司分配了数据磁盘,但是分区也没有挂载到目录 首先 df -h 查看一下挂载点的情况 查看服务器上未挂载的磁盘 fdisk -l 注:图中sda、sdb (a、b指的是硬盘的序号) 分区操作 我们可以看到b硬盘有536G未分区&…...

ZYNQ linux调试LCD7789
一,硬件管脚 1,参数解释和实物 LVGL是一个开源的图形库,主要用于MCU上屏幕UI的部署,功能完善,封装合理,可裁切性强,也可以实现Linux上fbx的部署。LVGL官网LVGL - Light and Versatile Embedded Graphics Library 每根线的作用...
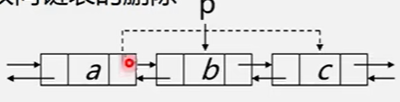
【双向链表的插入和删除】
文章目录 双向链表双向链表的插入双向链表的删除操作 双向链表 双向链表的结构定义如下: //双向链表的结构定义 typedef struct DuLNode {ElemType data;struct DuLNode* prior, * next; }DuLNode,*DuLinkList;双向链表的结点有两个指针域:prior&#…...
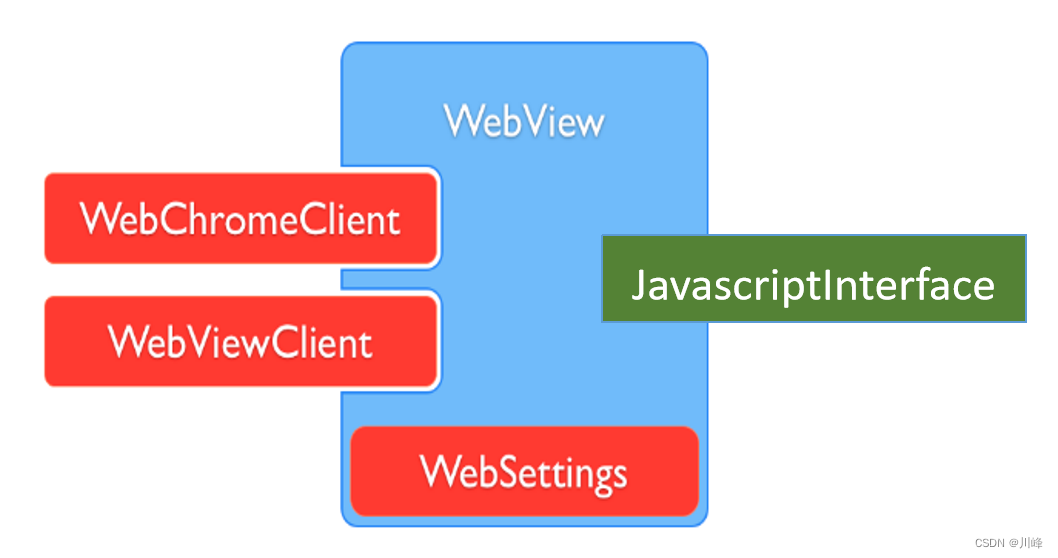
【Android知识笔记】Webview专题
WebView 核心组件 类名作用常用方法WebView创建对象加载URL生命周期管理状态管理loadUrl():加载网页 goBack():后退WebSettings配置&管理 WebView缓存:setCacheMode() 与JS交互:setJavaScriptEnabled()WebViewClient处理各种通知&请求事件should...

Leetcode第 368 场周赛
元素和最小的山形三元组 II 预处理前缀和后缀最小值,记为pre[i]和sa[i] 对于当前编号i,如果前面的最小值和后面的最大值都小于nums[i],则记录ans[i] nums[i]pre[i-1]sa[i1] 结果输出最小的ans[i]即可。 合法分组的最少组数 统计每一个数字出现的次数。将每一个数…...

SDC实战解析 —— 复杂时钟树约束中的互斥与条件分析
1. 复杂时钟树约束的核心挑战 在芯片设计中,时钟树就像人体血液循环系统一样重要。想象一下,如果心脏跳动节奏紊乱,全身器官都会出问题。同样,当时钟信号不能准确同步到达各个寄存器时,整个芯片就会"心律不齐&quo…...

【大模型工程化生死线】:版本失控=线上崩盘?3步构建军工级回滚机制
第一章:大模型工程化版本管理与回滚机制 2026奇点智能技术大会(https://ml-summit.org) 大模型工程化中的版本管理远超传统软件的 Git commit 粒度,需同时追踪模型权重、Tokenizer 配置、训练超参、推理服务镜像及依赖环境快照。单一 SHA 哈希已无法承载…...
)
SITS2026独家解密:LLM边缘部署的7层压缩栈(含实测吞吐提升217%的INT4量化方案)
第一章:SITS2026独家解密:LLM边缘部署的7层压缩栈(含实测吞吐提升217%的INT4量化方案) 2026奇点智能技术大会(https://ml-summit.org) SITS2026首次公开完整披露面向端侧LLM推理的七层协同压缩架构,该栈在树莓派5RP2…...

cereal与Boost序列化对比:终极迁移指南和性能基准测试
cereal与Boost序列化对比:终极迁移指南和性能基准测试 【免费下载链接】cereal A C11 library for serialization 项目地址: https://gitcode.com/gh_mirrors/ce/cereal 在C开发中,序列化是数据持久化和跨系统通信的关键技术。cereal作为一款轻量…...

SensitivityMatcher:终极免费鼠标灵敏度跨游戏转换工具
SensitivityMatcher:终极免费鼠标灵敏度跨游戏转换工具 【免费下载链接】SensitivityMatcher Script that can be used to convert your mouse sensitivity between different 3D games. 项目地址: https://gitcode.com/gh_mirrors/se/SensitivityMatcher 还…...

OBS背景移除插件:零绿幕实现专业级直播虚化的终极指南
OBS背景移除插件:零绿幕实现专业级直播虚化的终极指南 【免费下载链接】obs-backgroundremoval An OBS plugin for removing background in portrait images (video), making it easy to replace the background when recording or streaming. 项目地址: https://…...

如何用这个开源工具让英雄联盟游戏体验提升3倍?
如何用这个开源工具让英雄联盟游戏体验提升3倍? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为错过对局接受而懊恼…...

3个革命性功能:让2D照片秒变3D场景的相机匹配神器
3个革命性功能:让2D照片秒变3D场景的相机匹配神器 【免费下载链接】fSpy A cross platform app for quick and easy still image camera matching 项目地址: https://gitcode.com/gh_mirrors/fs/fSpy 想象一下,你手头有一张建筑照片,想…...

抖音弹幕监听完整实战指南:基于系统代理的高效抓包技术解析
抖音弹幕监听完整实战指南:基于系统代理的高效抓包技术解析 【免费下载链接】DouyinBarrageGrab 基于系统代理的抖音弹幕wss抓取程序,能够获取所有数据来源,包括chrome,抖音直播伴侣等,可进行进程过滤 项目地址: htt…...

如何用Zotero Style插件高效管理文献:从阅读追踪到智能标签的完整攻略
如何用Zotero Style插件高效管理文献:从阅读追踪到智能标签的完整攻略 【免费下载链接】zotero-style Ethereal Style for Zotero 项目地址: https://gitcode.com/GitHub_Trending/zo/zotero-style Zotero Style插件是一款能够彻底改变你文献管理体验的Zoter…...