Netty——序列化的作用及自定义协议
序列化的作用及自定义协议
- 序列化的重要性
- 大小对比
- 效率对比
- 自定义协议
- 序列化
- 数据结构
- 自定义编码器
- 自定义解码器
- 安全性
- 验证
- NettyClient
- NettyServer
- NettyClientTestHandler
- NettyServerTestHandler
- 结果
上一章已经说了怎么解决沾包和拆包的问题,但是这样离一个成熟的通信还是有一点距离,我们还需要让服务端和客户端使用同一个"语言"来沟通,要不然一个讲英文一个讲中文,两个都听不懂岂不是很尴尬?这种语言就叫协议。
Netty自身就支持很多种协议比如Http、Websocket等等,但如果用来作为自己的RPC框架通常会自定义协议,所以这也是本文的重点!
序列化的重要性
在说协议之前,我们需要先知道什么是序列化,序列化是干嘛的?
我们要知道数据在传输的过程中是以0和1的形式传输的,而把对象转化成二进制的过程就叫序列化,将二进制转化为对象的过程就叫反序列化。
为什么要说这个很重要呢?因为序列化和反序列化是需要耗时的,而序列化后的字节大小也会影响到传输的效率,所以选对一种高效的序列化方式是非常之重要的,下面我们以JDK自带的序列化和我们常用的JSON序列化来做一个对比,序列化后大小的对比、序列化效率的对比
大小对比
我们先准备一个实体类SerializeTestVO实现Serializable 接口
public class SerializeTestVO implements Serializable {private Integer id;private String name;private Integer age;private Integer sex;private Integer bodyWeight;private Integer height;private String school;//Set、get方法省略
}
测试方法:
public static void main(String[] args) throws IOException {// 普普通通的实体类SerializeTestVO serializeTestVO = new SerializeTestVO();serializeTestVO.setAge(18);serializeTestVO.setBodyWeight(120);serializeTestVO.setHeight(180);serializeTestVO.setId(10000);serializeTestVO.setName("张三");serializeTestVO.setSchool("XXXXXXXXXXXX");// JDK序列化ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);objectOutputStream.writeObject(serializeTestVO);objectOutputStream.flush();objectOutputStream.close();System.out.println("JDK 序列化大小: "+(byteArrayOutputStream.toByteArray().length));byteArrayOutputStream.close();//JSON序列化System.out.println("JSON 序列化大小: " + JSON.toJSONString(serializeTestVO).getBytes().length);
}
结果:
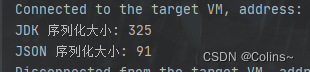
可以看到序列化后大小相差了好几倍,这也意味着传输效率的几倍
效率对比
实体类保持不变,我们序列化300W次,看看结果
public static void main(String[] args) throws IOException {SerializeTestVO serializeTestVO = new SerializeTestVO();serializeTestVO.setAge(18);serializeTestVO.setBodyWeight(120);serializeTestVO.setHeight(180);serializeTestVO.setId(10000);serializeTestVO.setName("张三");serializeTestVO.setSchool("XXXXXXXXXXXX");long start = System.currentTimeMillis();for (int i = 0; i < 3000000; i++) {ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);objectOutputStream.writeObject(serializeTestVO);objectOutputStream.flush();objectOutputStream.close();byte[] bytes = byteArrayOutputStream.toByteArray();byteArrayOutputStream.close();}System.out.println("JDK 序列化耗时: " + (System.currentTimeMillis() - start));long start1 = System.currentTimeMillis();for (int i = 0; i < 3000000; i++) {byte[] bytes = JSON.toJSONString(serializeTestVO).getBytes();}System.out.println("JSON 序列化耗时: " + (System.currentTimeMillis() - start1));}
结果:
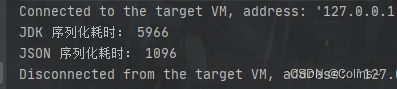
几乎6倍的差距,结合序列化后的大小综合来看,选择一种好的序列化方式是多么的重要
自定义协议
其实到现在我们已经掌握了自定义协议里面最关键的几个点了,序列化、数据结构、编解码器,我们一个一个来
序列化
直接采用我们常用且熟悉的JSON序列化
数据结构
我们设置为消息头和消息体,结构如下:
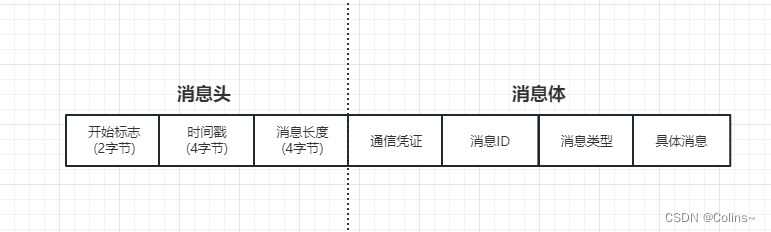
消息头包含:开始标志、时间戳、消息体长度
消息体包含:通信凭证、消息ID、消息类型、消息
实体类如下:
@Data
public class NettyMsg {private NettyMsgHead msgHead=new NettyMsgHead();private NettyBody nettyBody;public NettyMsg(ServiceCodeEnum codeEnum, Object msg){this.nettyBody=new NettyBody(codeEnum, msg);}
}@Data
public class NettyMsgHead {// 开始标识private short startSign = (short) 0xFFFF;// 时间戳private final int timeStamp;public NettyMsgHead(){this.timeStamp=(int)(DateUtil.current() / 1000);}
}@Data
public class NettyBody {// 通信凭证private String token;// 消息IDprivate String msgId;// 消息类型private short msgType;// 消息 这里序列化采用JSON序列化// 所以这个msg可以是实体类的msg 两端通过消息类型来判断实体类类型private String msg;public NettyBody(){}public NettyBody(ServiceCodeEnum codeEnum,Object msg){this.token=""; // 鉴权使用this.msgId=""; // 拓展使用this.msgType=codeEnum.getCode();this.msg= JSON.toJSONString(msg);}
}消息类型枚举
@JsonFormat(shape = JsonFormat.Shape.OBJECT)
public enum ServiceCodeEnum {TEST_TYPE((short) 0xFFF1, "测试");private final short code;private final String desc;ServiceCodeEnum(short code, String desc) {this.code = code;this.desc = desc;}public short getCode() {return code;}}
自定义编码器
编码器的作用就是固定好我们的数据格式,无需在每次发送数据的时候还需要去对数据进行格式编码
public class MyNettyEncoder extends MessageToByteEncoder<NettyMsg> {@Overrideprotected void encode(ChannelHandlerContext channelHandlerContext, NettyMsg msg, ByteBuf out) throws Exception {// 写入开头的标志out.writeShort(msg.getMsgHead().getStartSign());// 写入秒时间戳out.writeInt(msg.getMsgHead().getTimeStamp());byte[] bytes = JSON.toJSON(msg.getNettyBody()).toString().getBytes();// 写入消息长度out.writeInt(bytes.length);// 写入消息主体out.writeBytes(bytes);}
}
自定义解码器
解码器的第一个作用就是解决沾包和拆包的问题,第二个作用就是对数据有效性的校验,比如数据协议是否匹配、数据是否被篡改、数据加解密等等
所以我们直接继承LengthFieldBasedFrameDecoder类,重写decode方法,利用父类来解决沾包和拆包问题,自定义来解决数据有效性问题
public class MyNettyDecoder extends LengthFieldBasedFrameDecoder {// 开始标记private final short HEAD_START = (short) 0xFFFF;public MyNettyDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength) {super(maxFrameLength, lengthFieldOffset, lengthFieldLength);}public MyNettyDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip) {super(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip);}public MyNettyDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) {super(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, failFast);}public MyNettyDecoder(ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) {super(byteOrder, maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, failFast);}@Overrideprotected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {// 经过父解码器的处理 我们就不需要在考虑沾包和半包了// 当然,想要自己处理沾包和半包问题也不是不可以ByteBuf decode = (ByteBuf) super.decode(ctx, in);if (decode == null) {return null;}// 开始标志校验 开始标志不匹配直接 过滤此条消息short startIndex = decode.readShort();if (startIndex != HEAD_START) {return null;}// 时间戳int timeIndex = decode.readInt();// 消息体长度int lenOfBody = decode.readInt();// 读取消息byte[] msgByte = new byte[lenOfBody];decode.readBytes(msgByte);String msgContent = new String(msgByte);// 将消息转成实体类 传递给下面的数据处理器return JSON.parseObject(msgContent, NettyBody.class);}
}
安全性
上述的协议里面,我只预留了三种简单的校验,一个是开始标识,二是消息凭证,三是时间戳,实时上这太简单了,下面我说几种可以加上去拓展的:
消息整体加密:消息头添加一个加密类型,客户端和服务端都内置几种加解密手段,在发送消息的时候随机一种加密方式对加密类型、消息长度以外的其他内容加密,接收的时候再解密,但是要注意加密后不能影响沾包和拆包的处理
消息体加密:添加结束标识放入消息体,和上述方式类似,但是是对消息体中的内容再次加密,可和上述方式结合,形成二次加密
时间戳:可以对长时间才接收到的消息拒收,或者要求重发根据消息ID
加签和验签:对具体的消息加签和验签,防止篡改
凭证:这个很熟悉了,就比如登录凭证
复杂格式:上述的数据格式还是过于简单,实际可以整了更加复杂
验证
主体代码呢还是之前的,我们改动几个地方
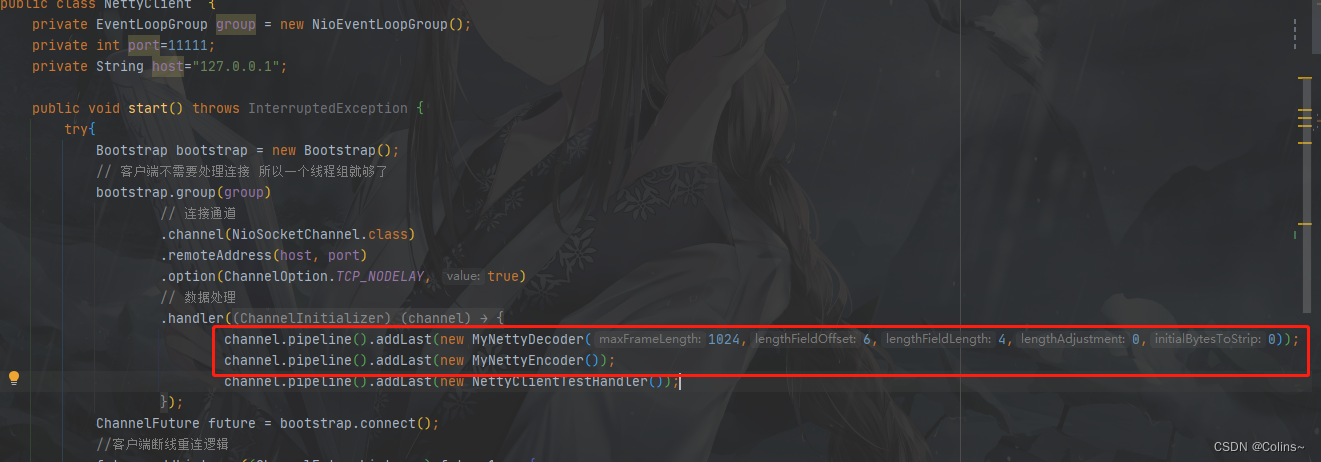
NettyClient
解码器是继承的LengthFieldBasedFrameDecoder,所以参数也一样,不懂的看一下上一篇
NettyServer
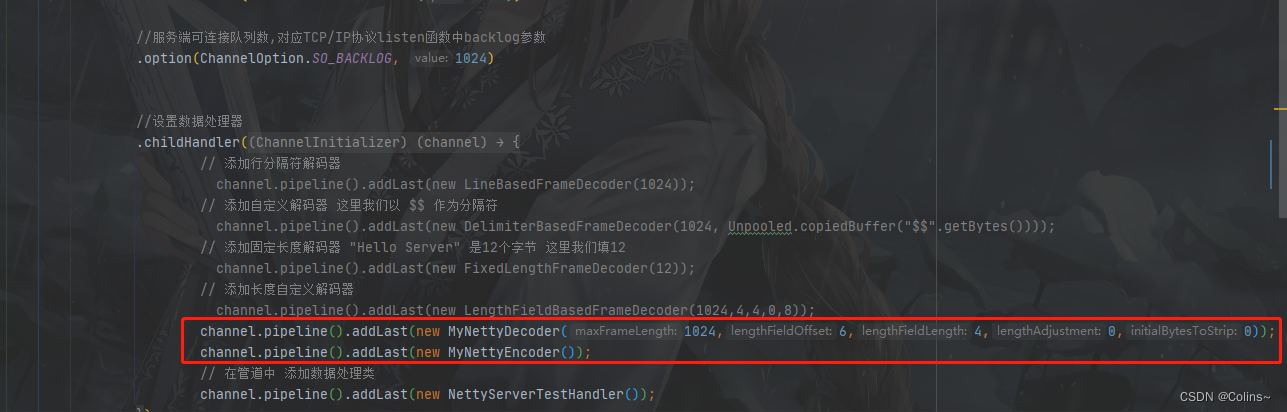
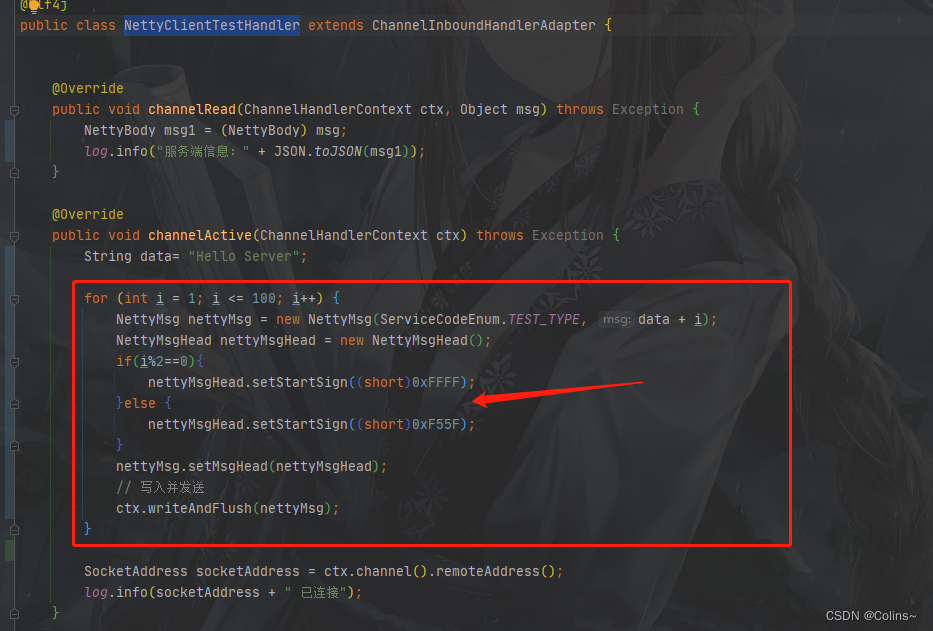
NettyClientTestHandler
发送100次是为了验证沾包和拆包,发送不同的开始标志,是为了验证接收的时候是否有过滤无效数据
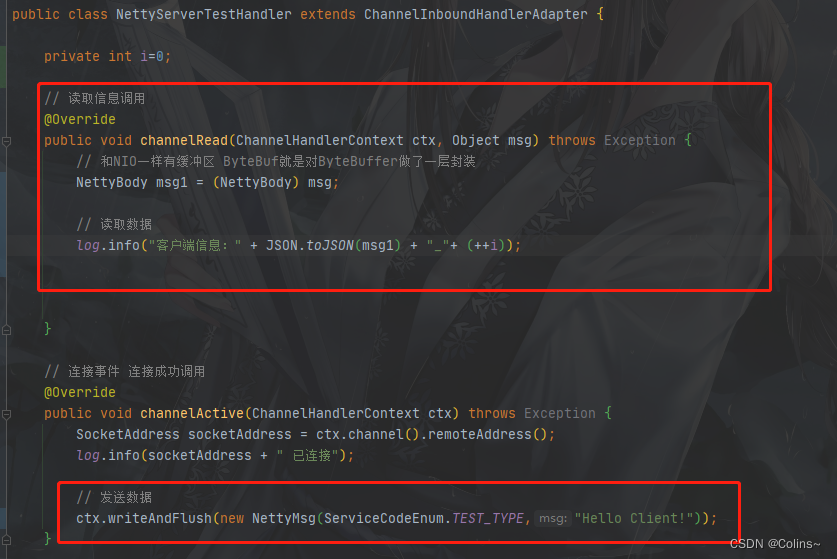
NettyServerTestHandler
有了编码器,发送可以直接发送实体类,有了解码器我们可以直接用实体类接收数据,因为解码器里面往下传递的是过滤了消息头的实体类
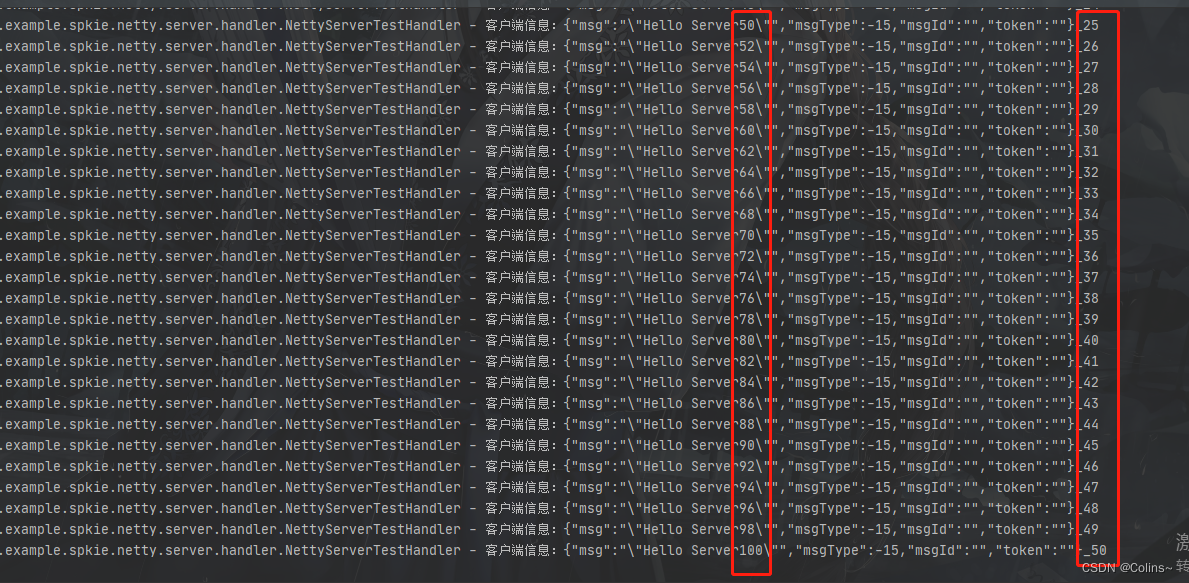
结果
一共接收到了50条消息,而且都是偶数消息,说明无效消息被过滤了,也没有沾包和拆包
相关文章:
Netty——序列化的作用及自定义协议
序列化的作用及自定义协议序列化的重要性大小对比效率对比自定义协议序列化数据结构自定义编码器自定义解码器安全性验证NettyClientNettyServerNettyClientTestHandlerNettyServerTestHandler结果上一章已经说了怎么解决沾包和拆包的问题,但是这样离一个成熟的通信…...
)
一起Talk Android吧(第五百零五回:如何调整组件在约束布局中的大小)
文章目录 背景介绍调整方法各位看官们大家好,上一回中咱们说的例子是"如何调整组件在约束布局中的位置",这一回中咱们说的例子是" 如何调整组件在约束布局中的大小"。闲话休提,言归正转, 让我们一起Talk Android吧! 背景介绍 在使用约束(constraintl…...

【数据库】数据库的完整性
第五章 数据库完整性 数据库完整性 数据库的完整性是指数据的正确性和相容性 数据的正确性是指数据是符合现实世界语义,反映当前实际状况的数据的相容性是指数据库的同一对象在不同的关系中的数据是符合逻辑的 关系模型中有三类完整性约束:实体完整性…...

基因净化车间装修设计方案SICOLAB
基因净化车间的设计方案应该根据实际需求进行定制,以下是一些规划建设要点和洁净设计要注意的事项:一、净化车间规划建设要点:(1)基因车间的面积应该根据实验项目的规模进行规划,包括充足的操作区域和足够的…...
java 内部类的四种“写法”
基本介绍语法格式分类成员内部类静态内部类局部内部类匿名内部类(🐂🖊)一、基本介绍 : 1.概述当一个类的内部又完整地嵌套了另一个类时,被嵌套于内部的“内核”我们称之为“内部类”(inner class);而包含该…...

【python】main方法教程
嗨害大家好鸭! 我是小熊猫~ 首先 if name "main": 可以看成是python程序的入口, 就像java中的main()方法, 但不完全正确。 事实上python程序是从上而下逐行运行的, 在.py文件中, 除…...

公司对不同职级能力抽象要求的具体化
要先把当前级别要求的能力提升到精通,然后尝试做下一级别的事情。 但可能不确定高一级的能力要求究竟怎样,不同Title,如“工程师”“高级工程师”和“资深工程师”等。但这样 Title 对我们理解不同级别的能力要求,完全无用。“高…...

Java之MinIO存储桶和对象API使用
环境搭建 创建一个 maven项目,引入依赖: <!-- minio依赖--><dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.3.3</version></dependency><!-- 官方 minio…...

如何用java实现同时进行多个请求,可以将它们并行执行,从而减少总共的请求时间。
1.使用线程池 通过使用Java提供的线程池,可以将多个请求分配到不同的线程中并行执行。可以通过创建固定数量的线程池,然后将请求分配给线程池来实现。线程池会自动管理线程的数量和复用,从而减少了线程创建和销毁的开销,提高了程序…...
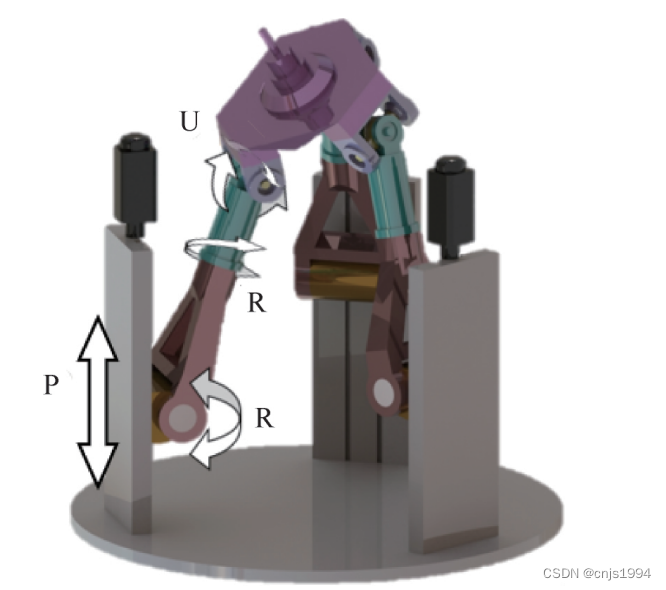
高端装备的AC主轴头结构
加工机器人的AC主轴头和位置相关动力学特性1. 位置依赖动态特性及其复杂性2. AC主轴头2.1 常见主轴头摆角结构2.2 摆动机构3. 加装AC主轴头的作用和局限性4. 切削机器人的减速器类型5. 其他并联结构形式参考文献资料1. 位置依赖动态特性及其复杂性 However, FRF measurements …...
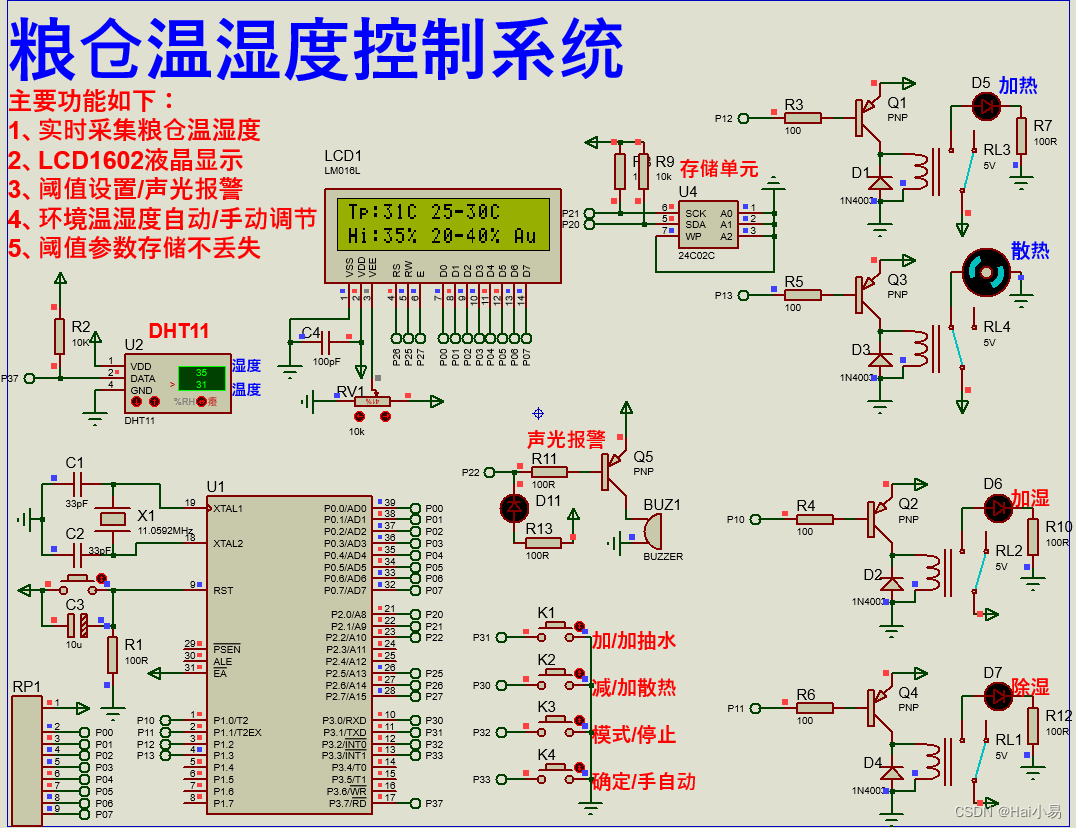
【Proteus仿真】【51单片机】粮仓温湿度控制系统设计
文章目录一、功能简介二、软件设计三、实验现象联系作者一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用声光报警模块、LCD1602显示模块、DHT11温湿度模块、继电器模块、加热加湿除湿风扇等。 主要功能: 系统运行后,LCD1602显示传…...
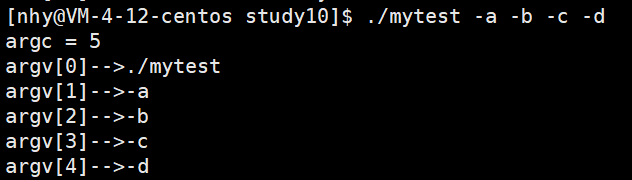
【LINUX】环境变量以及main函数的参数
文章目录前言环境变量常见环境变量:设置环境变量:和环境变量相关的命令:环境变量的组织方式:获取环境变量环境变量可以被子进程继承环境变量总结main函数的参数前言 大家好久不见,今天分享的内容是环境变量和main函数…...

使用Pyparsing为嵌入式开发定义自己的脚本语言
Python在嵌入式开发中也很流行生成实用脚本。Pyparsing还允许你轻松地定义在Python上下文中运行的定制脚本语言。Python实现的系统旨在能够独立执行用户传递的一系列命令。你希望系统以脚本的形式接收命令。用户应该能够定义条件。这种对通信中逻辑元素的最初简单的声音要求&am…...
)
C win32基础学习(二)
上一篇我们已经介绍了关于窗口程序的一些基本知识。从本篇开始我们将正式进入C win32的学习中去。 正文 窗口创建过程 定义WinMain函数 定义窗口处理函数(自定义,处理消息) 注册窗口类(向操作系统写入一些数据) 创建窗口(内存…...

理论五:控制反转、依赖反转、依赖注入,这三者有何区别和联系?
关于SOLID原则,我们已经学过单一职责、开闭、里式替换、接口隔离这四个原则。今天,我们再来学习最后一个原则:依赖反转原则。在前面几节课中,我们讲到,单一职责原则和开闭原则的原理比较简单,但是,想要在实践中用好却比较难。而今天我们要讲到的依赖反转原则正好相反。这个原则…...
读书笔记//《数据分析之道》
出版时间:2022年 作者曾在互联网大厂做数据分析。从举例可以洞见作者的工作经历。 点评:作者在数据分析领域非常资深,尝试在书中提供一个数据分析工作框架参考。书本内容有点感觉是ppt的集合,辅以案例说明。不过,干货还…...
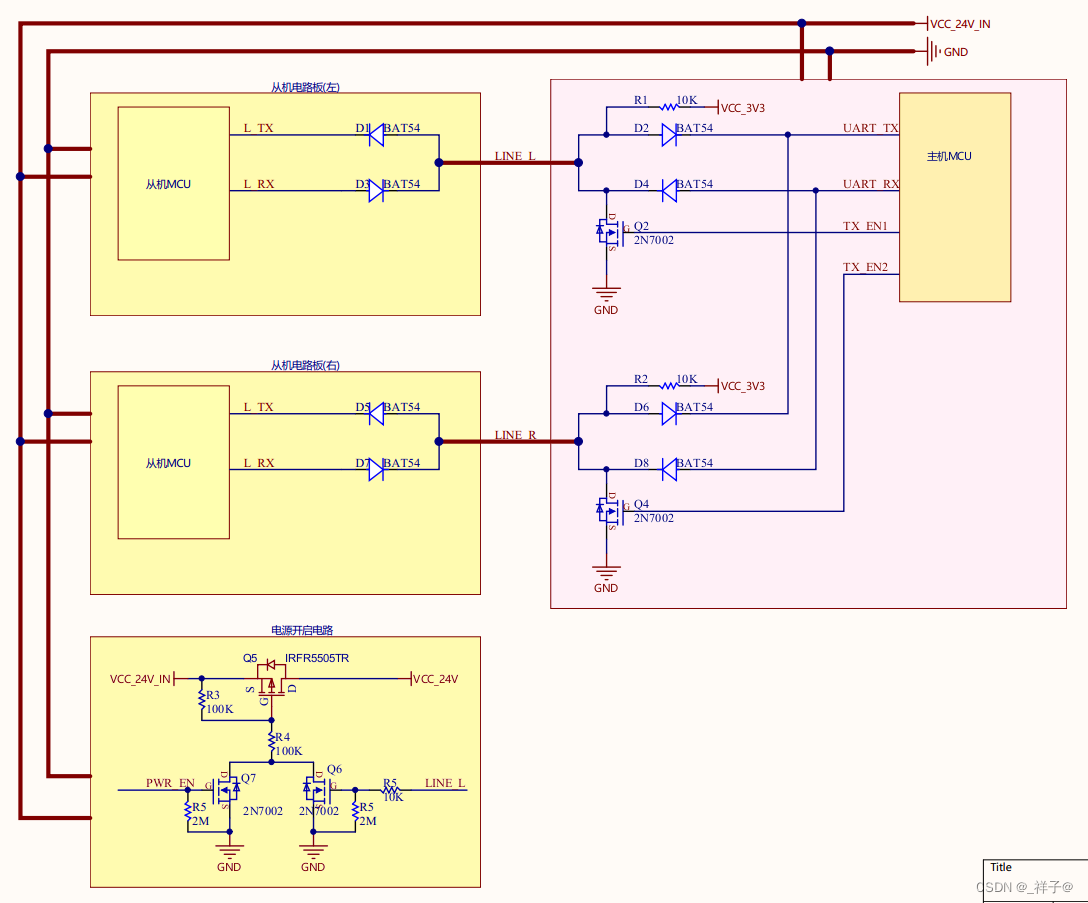
1个串口用1根线实现多机半双工通信+开机控制电路
功能需求: 主机使用一个串口,与两个从机进行双向通信,主机向从机发送数据,从机能够返回数据,由于结构限制,主机与从机之间只有3根线(电源、地、数据线),并且从机上没有设…...
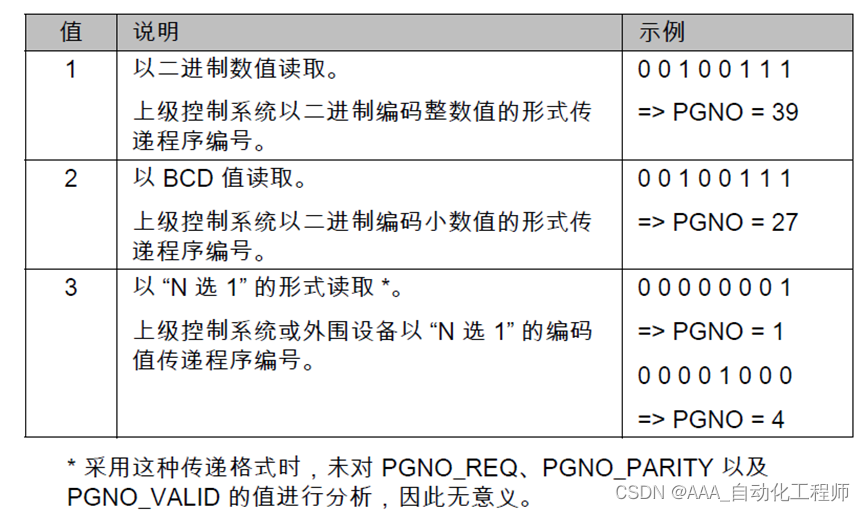
KUKA机器人外部自动运行模式的相关信号配置
KUKA机器人外部自动运行模式的相关信号配置 通过例如PLC这样的控制器来进行外部自动运行控制时,运行接口向机器人控制系统发出机器人进程的相关信号(例如运行许可、故障确认、程序启动等),机器人向上级控制系统发送有关运行状态和故障状态的信息。 必需的配置: 配置CEL…...
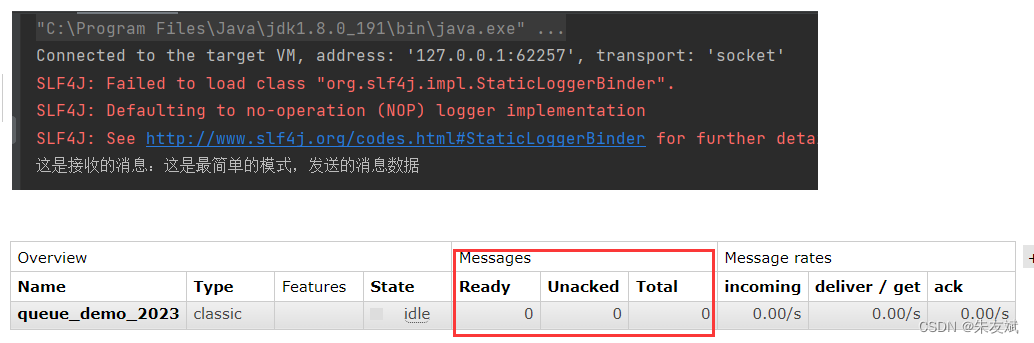
【RabbitMQ笔记02】消息队列RabbitMQ七种模式之最简单的模式
这篇文章,主要介绍RabbitMQ消息队列中七种模式里面最简单的使用模式。 目录 一、消息队列的使用 1.1、消息队列七种模式 1.2、最简单的模式使用 (1)引入依赖 (2)编写生产者 (3)编写消费者…...
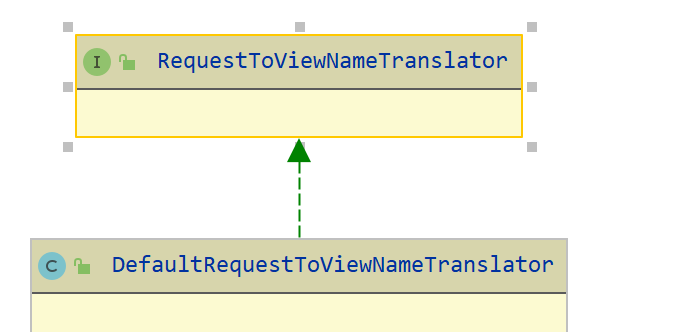
Spring MVC 源码- RequestToViewNameTranslator 组件
RequestToViewNameTranslator 组件RequestToViewNameTranslator 组件,视图名称转换器,用于解析出请求的默认视图名。就是说当 ModelAndView 对象不为 null,但是它的 View 对象为 null,则需要通过 RequestToViewNameTranslator 组件…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

Fiddler手机断网真相:TLS握手与证书固定的协议级拦截
1. 为什么Fiddler一开,手机就断网?这不是配置问题,是协议层的“信任危机”Fiddler抓包手机流量,本该是移动开发、测试、安全分析中最基础的操作之一。但几乎每个刚上手的人,都会在第二天早上发现:手机Wi-Fi…...