基于卷积神经网络的乳腺癌分类 深度学习 医学图像 计算机竞赛
文章目录
- 1 前言
- 2 前言
- 3 数据集
- 3.1 良性样本
- 3.2 病变样本
- 4 开发环境
- 5 代码实现
- 5.1 实现流程
- 5.2 部分代码实现
- 5.2.1 导入库
- 5.2.2 图像加载
- 5.2.3 标记
- 5.2.4 分组
- 5.2.5 构建模型训练
- 6 分析指标
- 6.1 精度,召回率和F1度量
- 6.2 混淆矩阵
- 7 结果和结论
- 8 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于卷积神经网络的乳腺癌分类
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 前言
乳腺癌是全球第二常见的女性癌症。2012年,它占所有新癌症病例的12%,占所有女性癌症病例的25%。
当乳腺细胞生长失控时,乳腺癌就开始了。这些细胞通常形成一个肿瘤,通常可以在x光片上直接看到或感觉到有一个肿块。如果癌细胞能生长到周围组织或扩散到身体的其他地方,那么这个肿瘤就是恶性的。
以下是报告:
- 大约八分之一的美国女性(约12%)将在其一生中患上浸润性乳腺癌。
- 2019年,美国预计将有268,600例新的侵袭性乳腺癌病例,以及62,930例新的非侵袭性乳腺癌。
- 大约85%的乳腺癌发生在没有乳腺癌家族史的女性身上。这些发生是由于基因突变,而不是遗传突变
- 如果一名女性的一级亲属(母亲、姐妹、女儿)被诊断出患有乳腺癌,那么她患乳腺癌的风险几乎会增加一倍。在患乳腺癌的女性中,只有不到15%的人的家人被诊断出患有乳腺癌。
3 数据集
该数据集为学长实验室数据集。
搜先这是图像二分类问题。我把数据拆分如图所示
dataset trainbenignb1.jpgb2.jpg//malignantm1.jpgm2.jpg// validationbenignb1.jpgb2.jpg//malignantm1.jpgm2.jpg//...
训练文件夹在每个类别中有1000个图像,而验证文件夹在每个类别中有250个图像。
3.1 良性样本


3.2 病变样本


4 开发环境
- scikit-learn
- keras
- numpy
- pandas
- matplotlib
- tensorflow
5 代码实现
5.1 实现流程
完整的图像分类流程可以形式化如下:
我们的输入是一个由N个图像组成的训练数据集,每个图像都有相应的标签。
然后,我们使用这个训练集来训练分类器,来学习每个类。
最后,我们通过让分类器预测一组从未见过的新图像的标签来评估分类器的质量。然后我们将这些图像的真实标签与分类器预测的标签进行比较。
5.2 部分代码实现
5.2.1 导入库
import jsonimport mathimport osimport cv2from PIL import Imageimport numpy as npfrom keras import layersfrom keras.applications import DenseNet201from keras.callbacks import Callback, ModelCheckpoint, ReduceLROnPlateau, TensorBoardfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.utils.np_utils import to_categoricalfrom keras.models import Sequentialfrom keras.optimizers import Adamimport matplotlib.pyplot as pltimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import cohen_kappa_score, accuracy_scoreimport scipyfrom tqdm import tqdmimport tensorflow as tffrom keras import backend as Kimport gcfrom functools import partialfrom sklearn import metricsfrom collections import Counterimport jsonimport itertools
5.2.2 图像加载
接下来,我将图像加载到相应的文件夹中。
def Dataset_loader(DIR, RESIZE, sigmaX=10):IMG = []read = lambda imname: np.asarray(Image.open(imname).convert("RGB"))for IMAGE_NAME in tqdm(os.listdir(DIR)):PATH = os.path.join(DIR,IMAGE_NAME)_, ftype = os.path.splitext(PATH)if ftype == ".png":img = read(PATH)img = cv2.resize(img, (RESIZE,RESIZE))IMG.append(np.array(img))return IMGbenign_train = np.array(Dataset_loader('data/train/benign',224))malign_train = np.array(Dataset_loader('data/train/malignant',224))benign_test = np.array(Dataset_loader('data/validation/benign',224))malign_test = np.array(Dataset_loader('data/validation/malignant',224))5.2.3 标记
之后,我创建了一个全0的numpy数组,用于标记良性图像,以及全1的numpy数组,用于标记恶性图像。我还重新整理了数据集,并将标签转换为分类格式。
benign_train_label = np.zeros(len(benign_train))malign_train_label = np.ones(len(malign_train))benign_test_label = np.zeros(len(benign_test))malign_test_label = np.ones(len(malign_test))X_train = np.concatenate((benign_train, malign_train), axis = 0)Y_train = np.concatenate((benign_train_label, malign_train_label), axis = 0)X_test = np.concatenate((benign_test, malign_test), axis = 0)Y_test = np.concatenate((benign_test_label, malign_test_label), axis = 0)s = np.arange(X_train.shape[0])np.random.shuffle(s)X_train = X_train[s]Y_train = Y_train[s]s = np.arange(X_test.shape[0])np.random.shuffle(s)X_test = X_test[s]Y_test = Y_test[s]Y_train = to_categorical(Y_train, num_classes= 2)Y_test = to_categorical(Y_test, num_classes= 2)5.2.4 分组
然后我将数据集分成两组,分别具有80%和20%图像的训练集和测试集。让我们看一些样本良性和恶性图像
x_train, x_val, y_train, y_val = train_test_split(X_train, Y_train, test_size=0.2, random_state=11)w=60h=40fig=plt.figure(figsize=(15, 15))columns = 4rows = 3for i in range(1, columns*rows +1):ax = fig.add_subplot(rows, columns, i)if np.argmax(Y_train[i]) == 0:ax.title.set_text('Benign')else:ax.title.set_text('Malignant')plt.imshow(x_train[i], interpolation='nearest')plt.show()
5.2.5 构建模型训练
我使用的batch值为16。batch是深度学习中最重要的超参数之一。我更喜欢使用更大的batch来训练我的模型,因为它允许从gpu的并行性中提高计算速度。但是,众所周知,batch太大会导致泛化效果不好。在一个极端下,使用一个等于整个数据集的batch将保证收敛到目标函数的全局最优。但是这是以收敛到最优值较慢为代价的。另一方面,使用更小的batch已被证明能够更快的收敛到好的结果。这可以直观地解释为,较小的batch允许模型在必须查看所有数据之前就开始学习。使用较小的batch的缺点是不能保证模型收敛到全局最优。因此,通常建议从小batch开始,通过训练慢慢增加batch大小来加快收敛速度。
我还做了一些数据扩充。数据扩充的实践是增加训练集规模的一种有效方式。训练实例的扩充使网络在训练过程中可以看到更加多样化,仍然具有代表性的数据点。
然后,我创建了一个数据生成器,自动从文件夹中获取数据。Keras为此提供了方便的python生成器函数。
BATCH_SIZE = 16train_generator = ImageDataGenerator(zoom_range=2, # 设置范围为随机缩放rotation_range = 90,horizontal_flip=True, # 随机翻转图片vertical_flip=True, # 随机翻转图片)下一步是构建模型。这可以通过以下3个步骤来描述:
-
我使用DenseNet201作为训练前的权重,它已经在Imagenet比赛中训练过了。设置学习率为0.0001。
-
在此基础上,我使用了globalaveragepooling层和50%的dropout来减少过拟合。
-
我使用batch标准化和一个以softmax为激活函数的含有2个神经元的全连接层,用于2个输出类的良恶性。
-
我使用Adam作为优化器,使用二元交叉熵作为损失函数。
def build_model(backbone, lr=1e-4):model = Sequential()model.add(backbone)model.add(layers.GlobalAveragePooling2D())model.add(layers.Dropout(0.5))model.add(layers.BatchNormalization())model.add(layers.Dense(2, activation='softmax'))model.compile(loss='binary_crossentropy',optimizer=Adam(lr=lr),metrics=['accuracy'])return modelresnet = DenseNet201(weights='imagenet',include_top=False,input_shape=(224,224,3) )model = build_model(resnet ,lr = 1e-4) model.summary()
让我们看看每个层中的输出形状和参数。

在训练模型之前,定义一个或多个回调函数很有用。非常方便的是:ModelCheckpoint和ReduceLROnPlateau。
-
ModelCheckpoint:当训练通常需要多次迭代并且需要大量的时间来达到一个好的结果时,在这种情况下,ModelCheckpoint保存训练过程中的最佳模型。
-
ReduceLROnPlateau:当度量停止改进时,降低学习率。一旦学习停滞不前,模型通常会从将学习率降低2-10倍。这个回调函数会进行监视,如果在’patience’(耐心)次数下,模型没有任何优化的话,学习率就会降低。

该模型我训练了60个epoch。
learn_control = ReduceLROnPlateau(monitor='val_acc', patience=5,verbose=1,factor=0.2, min_lr=1e-7)filepath="weights.best.hdf5"checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')history = model.fit_generator(train_generator.flow(x_train, y_train, batch_size=BATCH_SIZE),steps_per_epoch=x_train.shape[0] / BATCH_SIZE,epochs=20,validation_data=(x_val, y_val),callbacks=[learn_control, checkpoint])6 分析指标
评价模型性能最常用的指标是精度。然而,当您的数据集中只有2%属于一个类(恶性),98%属于其他类(良性)时,错误分类的分数就没有意义了。你可以有98%的准确率,但仍然没有发现恶性病例,即预测的时候全部打上良性的标签,这是一个不好的分类器。
history_df = pd.DataFrame(history.history)history_df[['loss', 'val_loss']].plot()history_df = pd.DataFrame(history.history)history_df[['acc', 'val_acc']].plot()
6.1 精度,召回率和F1度量
为了更好地理解错误分类,我们经常使用以下度量来更好地理解真正例(TP)、真负例(TN)、假正例(FP)和假负例(FN)。
精度反映了被分类器判定的正例中真正的正例样本的比重。
召回率反映了所有真正为正例的样本中被分类器判定出来为正例的比例。
F1度量是准确率和召回率的调和平均值。
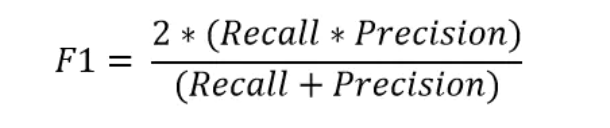
6.2 混淆矩阵
混淆矩阵是分析误分类的一个重要指标。矩阵的每一行表示预测类中的实例,而每一列表示实际类中的实例。对角线表示已正确分类的类。这很有帮助,因为我们不仅知道哪些类被错误分类,还知道它们为什么被错误分类。
from sklearn.metrics import classification_reportclassification_report( np.argmax(Y_test, axis=1), np.argmax(Y_pred_tta, axis=1))from sklearn.metrics import confusion_matrixdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=55)plt.yticks(tick_marks, classes)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label')plt.xlabel('Predicted label')plt.tight_layout()cm = confusion_matrix(np.argmax(Y_test, axis=1), np.argmax(Y_pred, axis=1))cm_plot_label =['benign', 'malignant']plot_confusion_matrix(cm, cm_plot_label, title ='Confusion Metrix for Skin Cancer')
7 结果和结论

在这个博客中,学长我演示了如何使用卷积神经网络和迁移学习从一组显微图像中对良性和恶性乳腺癌进行分类,希望对大家有所帮助。
8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
基于卷积神经网络的乳腺癌分类 深度学习 医学图像 计算机竞赛
文章目录 1 前言2 前言3 数据集3.1 良性样本3.2 病变样本 4 开发环境5 代码实现5.1 实现流程5.2 部分代码实现5.2.1 导入库5.2.2 图像加载5.2.3 标记5.2.4 分组5.2.5 构建模型训练 6 分析指标6.1 精度,召回率和F1度量6.2 混淆矩阵 7 结果和结论8 最后 1 前言 &…...
模式识别——高斯分类器
模式识别——高斯分类器 需知定义特殊情况(方差一致)Sigmoid 需知 所有问题定义在分类问题下,基于贝叶斯决策 定义 条件概率为多元高斯分布,此时观测为向量 X X 1 , X 2 , . . . , X n X{X_1,X_2,...,X_n} XX1,X2,...,Xn…...

LeetCode 15. 三数之和
三数之和 题目链接 15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 **注意:**答案…...
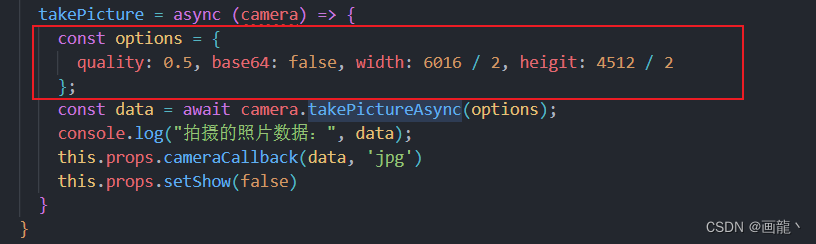
React-native-camera 在小米手机上拍照查看闪退
场景:为实现可拍照和录像的相机用react-native-camera这个库手写一个相机,发现了拍出来的图片在小米10上查看闪退 根据手机后台捕获的错误信息是什么玩意太大了(之前还以为是图片显示组件的问题) 改进:相机吊起的时候…...
nodejs+vue大学生社团管理系统
通过软件的需求分析已经获得了系统的基本功能需求,根据需求,将大学生社团管理系统平台功能模块主要分为管理员模块。管理员添加社团成员管理、社团信息管理,社长管理、用户注册管理等操作。 目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1…...
异步编程详解(.NET)
在之前写的一篇关于async和await的前世今生的文章之后,大家似乎在async和await提高网站处理能力方面还有一些疑问,很多网站本身也做了不少的尝试。今天我们再来回答一下这个问题,同时我会做一个async和await在WinForm中的尝试,并且…...

excel怎么固定前几行前几列不滚动?
在Excel中,如果你想固定前几行或前几列不滚动,可以通过以下几种方法来实现。详细的介绍如下: **固定前几行不滚动:** 1. 选择需要固定的行数。例如,如果你想要固定前3行,应该选中第4行的单元格。 2. 在E…...

elasticsearch完整学习
文章目录 elasticsearch一、概念二、ELK集群部署三、图形化界面 elasticsearch 一、概念 1、ELKStack简介(都是java架构,需要jdk底层) 什么是ELK?通俗来讲,ELK是由Elasticsearch、Logstash、Kibana 三个开源软件组成的…...
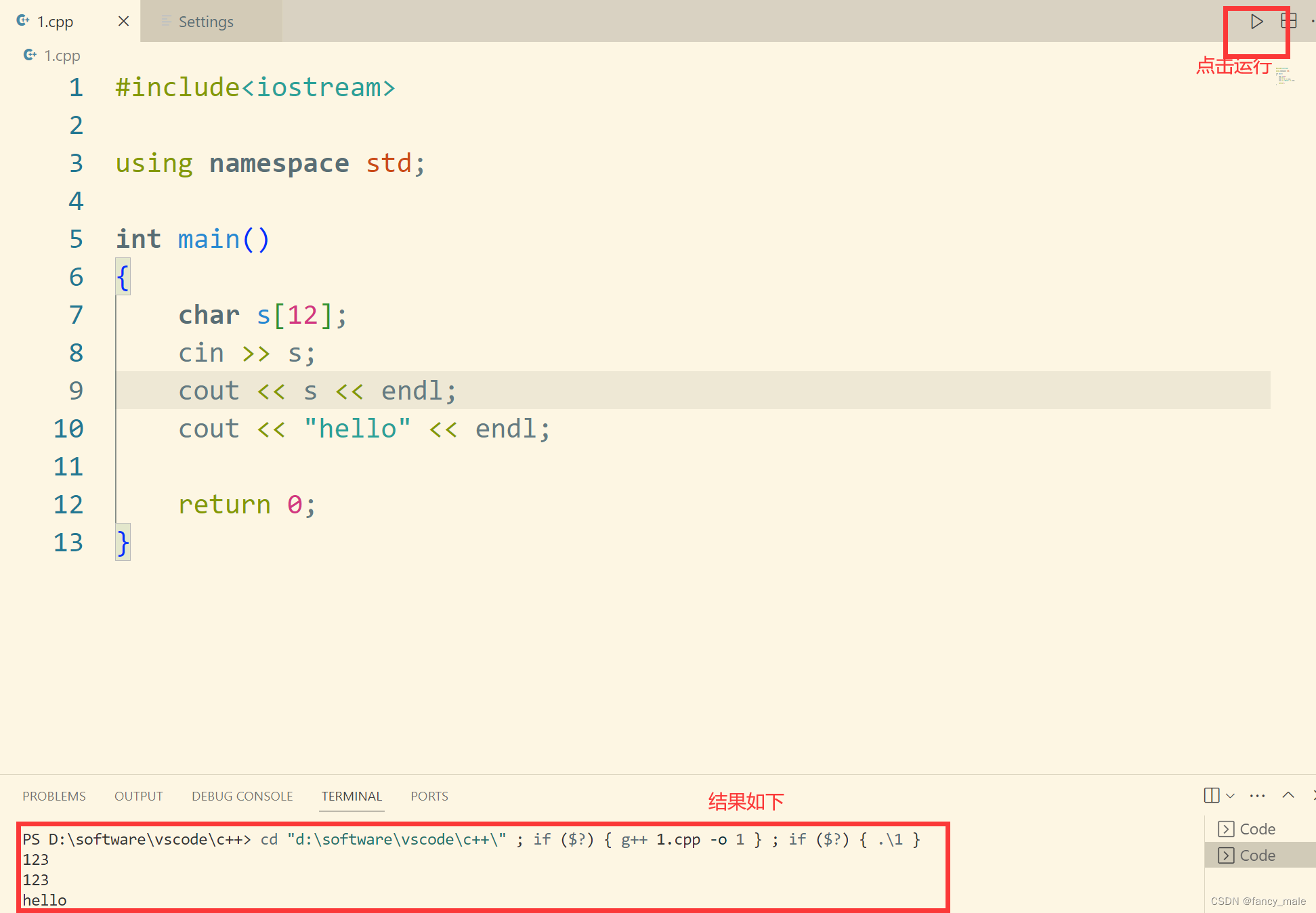
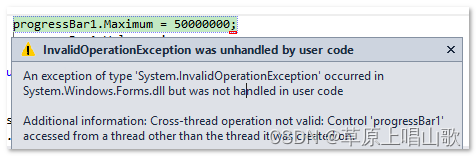
vscode Coder Runner 运行C++
1. 设置Code Runner 2. 防止输入读不到,把在终端运行勾上。 3. 设置minw/bin的环境变量 安装mingw教程:https://blog.csdn.net/fancy_male/article/details/133992000 4. 见图...

牛客网刷题-(2)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

FreeRTOS基础(如何学好FreeRTOS?)
目录 基础知识 进阶内容 后期“摆烂” 基础知识 实时操作系统 (RTOS):FreeRTOS是一个实时操作系统,它提供了任务管理、调度和同步等功能,在嵌入式系统中有效地管理多个任务。 任务(Task):任务是在RTOS…...
、条款44(概念明确)、条款45-50(杂项))
读书笔记:Effective C++ 2.0 版,条款43(多继承)、条款44(概念明确)、条款45-50(杂项)
条款43: 明智地使用多继承 并没有禁止,从概念上讲,多继承可能更符合真实世界。 条款44: 说你想说的;理解你所说的 概念明确 条款45: 弄清C在幕后为你所写、所调用的函数 隐性成本,看下编译后的c、asm源码。 条款46: 宁可编译和…...
最新Jn建站系统2.0 已集成各类源码 【附视频安装教程】
附视频安装教程|已集成各类源码 目前已集成的网站: 1.发卡网(最新) 2.代刷网(无需授权) 3. 博客网(自带模板) 4.易支付(稳定版) 5.个人导航网(简洁) 6.代理查询网 7.留言网 8.匿名网 9.表白墙(最新) 10.抽奖网 11.源码站 12.z-blog博客程序 13.织梦CM…...
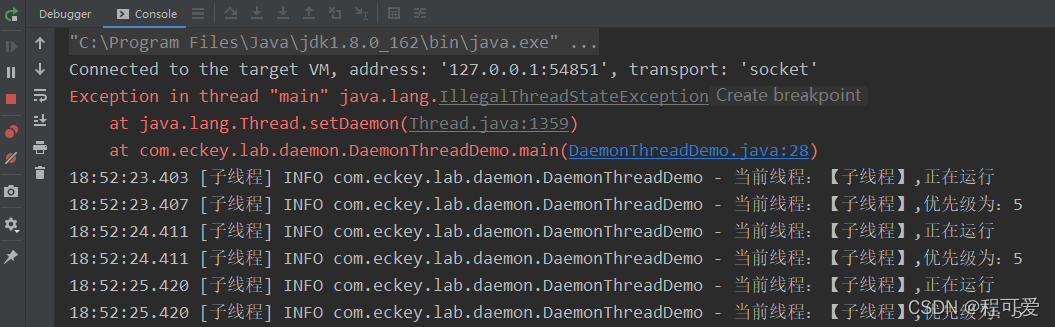
JAVA多线程基础篇--守护线程(Daemon Thread)
1.概述 JAVA中的线程主要分为两类:用户线程(User Thread)和守护线程(Daemon Thread)。JAVA语言中无论是线程还是线程池,默认都是用户线程,因此用户线程也被称为普通线程。守护线程也被称之为后台线程、服务线程或精灵…...

对知识蒸馏的一些理解
知识蒸馏是一种模型压缩技术,它通过从一个大模型(教师模型)中传输知识到一个小模型(学生模型)中来提高学生模型的性能,知识蒸馏也要用到真实的数据集标签。 软损失soft loss就是拿教师模型在蒸馏温度为T的…...
概率论_概率公式中的分号(;)、逗号(,)、竖线(|) 及其优先级
目录 1.概率公式中的分号(;)、逗号(,)、竖线(|) 2.各种概率相关的基本概念 2.1 联合概率 2.2 条件概率(定义) 2.3 全概率(乘法公式的加强版) 2.4 贝叶斯公式 贝叶斯定理的公式推导 1.概率公式中的分号(;)、逗号(,)、竖线(|) ; 分号代表前后是两类…...
【C++】二叉树进阶 -- 详解
一、二叉搜索树概念 二叉搜索树 又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 若它的右子树不为空,则右子树上所有节点的值都大于根节点…...

K8S集群中Node节点资源不足导致Pod无法运行的故障排查思路
K8S集群中Node节点资源不足导致Pod无法运行的故障排查思路 Node节点资源不足可能会产生的故障 故障一:Pod数量太多超出物理节点的限制每一台Node节点中默认限制最多运行110个Pod资源,当一个应用程序有成百上千的Pod资源时,如果不扩容Node节…...
Node.js与npm版本比对
Node.js与npm版本比对 Node.js与npm版本比对版本对比表Node版本对比 Node.js与npm版本比对 我们在项目开发过程中,经常会遇到公司一些老的前端工程项目,而我们当前的node及npm版本都是相对比较新的了。 在运行以前工程时,会遇到相关环境不匹…...

智加科技与东风柳汽达成深度合作 自动驾驶重卡计划2024年初量产交付
(2023年10月19日,苏州)全球领先的重卡自动驾驶技术公司智加科技与东风柳汽宣布,双方共同开发的自动驾驶重卡H7计划2024年初实现量产交付。未来,双方将携手推出安全可靠、高性价比、性能卓越的自动驾驶重卡产品…...

Spyglass CDC实战:从约束到验证的完整流程解析
1. Spyglass CDC验证入门:为什么需要它? 第一次接触多时钟域设计时,我完全低估了CDC问题的复杂性。直到仿真阶段出现数据丢失,才意识到异步时钟域交互就像两个语言不通的人交流——如果没有合适的翻译机制(同步器&…...

LFM2.5-1.2B-Thinking参数详解:temperature和top_k调优指南
LFM2.5-1.2B-Thinking参数详解:temperature和top_k调优指南 你是不是也遇到过这种情况:同一个问题问AI模型,有时候回答得特别精准,有时候却感觉它“脑子有点乱”,要么重复啰嗦,要么答非所问? …...

猫抓浏览器扩展:网页媒体资源嗅探与下载解决方案指南
猫抓浏览器扩展:网页媒体资源嗅探与下载解决方案指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在当今多媒体内容丰富的互联网环境…...
滓)
再次革新 .NET 的构建和发布方式(一)滓
本文能帮你解决什么? 1. 搞懂FastAPI异步(async/await)到底在什么场景下能真正提升性能。 2. 掌握在FastAPI中正确使用多线程处理CPU密集型任务的方法。 3. 避开常见的坑(比如阻塞操作、数据库连接池耗尽、GIL限制)。 …...

Graphormer分子预测模型5分钟快速部署:零基础搭建药物发现AI工具
Graphormer分子预测模型5分钟快速部署:零基础搭建药物发现AI工具 1. 项目概述 Graphormer是微软研究院开发的基于Transformer架构的分子属性预测模型,专门用于处理分子图结构数据。与传统的图神经网络(GNN)相比,Graphormer通过创新的结构编…...

忍者像素绘卷多模态延伸:文字描述→像素绘卷→微信小程序动效导出
忍者像素绘卷多模态延伸:文字描述→像素绘卷→微信小程序动效导出 1. 创作工具介绍 忍者像素绘卷是一款革命性的图像生成工具,专为复古游戏风格内容创作而设计。基于Z-Image-Turbo深度优化引擎,它将传统像素艺术与现代AI技术完美结合&#…...

OpenClaw学术研究流:Phi-3-mini-128k-instruct自动生成论文综述
OpenClaw学术研究流:Phi-3-mini-128k-instruct自动生成论文综述 1. 为什么需要自动化文献综述 每次开始新的研究课题时,最让我头疼的就是文献综述环节。作为独立研究者,我常常需要花费数周时间阅读上百篇论文,手动整理关键观点和…...

创建私有云主机
1. 环境准备与规划在搭建IaaS平台之前,合理的硬件与网络规划是成功的关键。本环境基于VMware Workstation搭建,采用双节点架构。1.1 硬件资源配置请严格按照以下标准配置虚拟机,资源不足会导致安装失败或运行卡顿。表格组件内存处理器硬盘网卡…...

Windows下OpenClaw全攻略:千问3.5-35B-A3B-FP8接入与飞书联动
Windows下OpenClaw全攻略:千问3.5-35B-A3B-FP8接入与飞书联动 1. 为什么选择OpenClaw作为Windows自动化助手 去年我接手了一个跨部门协作项目,每天需要在飞书、Excel和多个网页工具间反复切换操作。当我在凌晨三点第七次手动整理数据时,突然…...

FreakStudio泄
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try:ks Ks(KS_ARCH_X86, KS_MODE_64)encoding, count ks.asm(CODE)…...