Alibaba Druid整合
文章目录
- 方式一:自定义整合
- 方式二:使用 Druid 官方的 Starter
- Druid官网:https://github.com/alibaba/druid
- Druid官网文档(中文):https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
方式一:自定义整合
引入 Druid 的依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version>
</dependency>
配置数据源、监控页面的 Servlet、Filter
package cn.daniel.springboot2adminstudy.config;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;
import java.sql.SQLException;/*** 描述: Spring Boot 手动整合 Druid 连接池*/
// @Deprecated
@Configuration
public class MyDataSourceConfig {/*** 配置 Druid 数据源。(Spring Boot 会在 IoC 容器自动读取类型为 DataSource 的对象。故这个 bean 注入后,即与Spring Boot整合好了)* @return DruidDataSource 数据源* @throws SQLException*/@Bean@ConfigurationProperties(prefix = "spring.datasource",ignoreUnknownFields = false) // 读取配置文件中的数据源信息。Druid会以此建立数据库连接public DataSource dataSource() throws SQLException {DruidDataSource druidDataSource = new DruidDataSource();druidDataSource.setFilters("stat"); // 开启return druidDataSource;}/*** (非必要)开启前台监控页面对应的 Servlet,并设置密码(通过 http://域名/druid/index.html 即可访问监控页面)* 此 Servlet 是由 Druid 提供的 StatViewServlet* @return*/@Beanpublic ServletRegistrationBean<StatViewServlet> druidServlet(){ServletRegistrationBean<StatViewServlet> statViewServletServletRegistrationBean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");statViewServletServletRegistrationBean.addInitParameter("loginUsername","root");statViewServletServletRegistrationBean.addInitParameter("loginPassword","131121");return statViewServletServletRegistrationBean;}/*** (非必要)配置Druid的Filter,用于记录 web 请求记录。* 此 Filter 是由 Druid 提供的 WebStatFilter* @return*/@Beanpublic FilterRegistrationBean<WebStatFilter> druidFilter(){WebStatFilter webStatFilter = new WebStatFilter();FilterRegistrationBean<WebStatFilter> webStatFilterFilterRegistrationBean = new FilterRegistrationBean<>(webStatFilter);// 除以下路径的访问不记录,其它都会进行记录webStatFilterFilterRegistrationBean.addInitParameter("exclusions","*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");// 记录 session 时,记录下 session 中记录的用户名webStatFilterFilterRegistrationBean.addInitParameter("principalSessionName","userName");return webStatFilterFilterRegistrationBean;}}
server:port: 80
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost/abcusername: rootpassword: 12345678
整合完成,现在直接使用 Spring IoC 容器中的 DataSource 对象或 JdbcTemplate 即可。
方式二:使用 Druid 官方的 Starter
引入 Druid 官方提供的 Starter(引入此 Starter 就不需要引用 Druid 依赖包了,因为已经包含 Druid 的依赖包了):
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version>
</dependency>
配置数据源(或其它的非必要的插件)
server:port: 80
spring:datasource:# JDBC配置:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost/abcusername: rootpassword: 12345678# 连接池配置:druid:initial-size: 2 # 初始化时建立物理连接的个数。默认0max-active: 10 # 最大连接池数量,默认8min-idle: 1 # 最小连接池数量max-wait: 2000 # 获取连接时最大等待时间,单位毫秒。pool-prepared-statements: false # 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。max-pool-prepared-statement-per-connection-size: -1 # 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100# ……druid节点下的其它参数见官方文档:https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%88%97%E8%A1%A8# 启用Druid内置的Filter,会使用默认的配置。可自定义配置,见下方的各个filter节点。filters: stat,wall# StatViewServlet监控器。开启后,访问http://域名/druid/index.htmlstat-view-servlet:enabled: true # 开启 StatViewServlet,即开启监控功能login-username: daniel # 访问监控页面时登录的账号login-password: 1234 # 密码url-pattern: /druid/* # Servlet的映射地址,不填写默认为"/druid/*"。如填写其它地址,访问监控页面时,要使用相应的地址reset-enable: false # 是否允许重置数据(在页面的重置按钮)。(停用后,依然会有重置按钮,但重置后不会真的重置数据)allow: 192.168.1.2,192.168.1.1 # 监控页面访问白名单。默认为127.0.0.1。与黑名单一样,支持子网掩码,如128.242.127.1/24。多个ip用英文逗号分隔deny: 18.2.1.3 # 监控页面访问黑名单# 配置 WebStatFilter(StatFilter监控器中的Web模板)web-stat-filter:enabled: true # 开启 WebStatFilter,即开启监控功能中的 Web 监控功能url-pattern: /* # 映射地址,即统计指定地址的web请求exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*' # 不统计的web请求,如下是不统计静态资源及druid监控页面本身的请求session-stat-enable: true # 是否启用session统计session-stat-max-count: 1 # session统计的最大个数,默认是1000。当统计超过这个数,只统计最新的principal-session-name: userName # 所存用户信息的serssion参数名。Druid会依照此参数名读取相应session对应的用户名记录下来(在监控页面可看到)。如果指定参数不是基础数据类型,将会自动调用相应参数对象的toString方法来取值principal-cookie-name: userName # 与上类似,但这是通过Cookie名取到用户信息profile-enable: true # 监控单个url调用的sql列表(试了没生效,以后需要用再研究)filter:wall:enabled: true # 开启SQL防火墙功能config:select-allow: true # 允许执行Select查询操作delete-allow: false # 不允许执行delete操作create-table-allow: false # 不允许创建表# 更多用法,参考官方文档:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE-wallfilter
检查整合情况
可通过以下测试方法,查看当前数据源
package cn.daniel.springboot2adminstudy;//import com.alibaba.druid.pool.DruidDataSource;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.jdbc.core.JdbcTemplate;import javax.sql.DataSource;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;@SpringBootTest
@Slf4j
class Springboot2AdminStudyApplicationTests {@AutowiredJdbcTemplate jdbcTemplate;@AutowiredDataSource dataSource;@Testvoid contextLoads() {// 执行一条sql语句,检查是否正常List<Map<String, Object>> maps = jdbcTemplate.queryForList("select * from adm_employee");for (Map<String, Object> map : maps) {System.out.println(map);}// 查看当前数据源,如果是Druid连接池,会出现下面两种提示的其中一种:// 1. 当使用Starter整合的:当前数据源:com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceWrapper// 2. 当使用自定义整合时:当前数据源:com.alibaba.druid.pool.DruidDataSourcelog.info("当前数据源:{}",dataSource.getClass().getName());}}
参考:
https://blog.csdn.net/weixin_45448561/article/details/123624927
相关文章:

Alibaba Druid整合
文章目录 方式一:自定义整合方式二:使用 Druid 官方的 Starter Druid官网:https://github.com/alibaba/druidDruid官网文档(中文):https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%…...
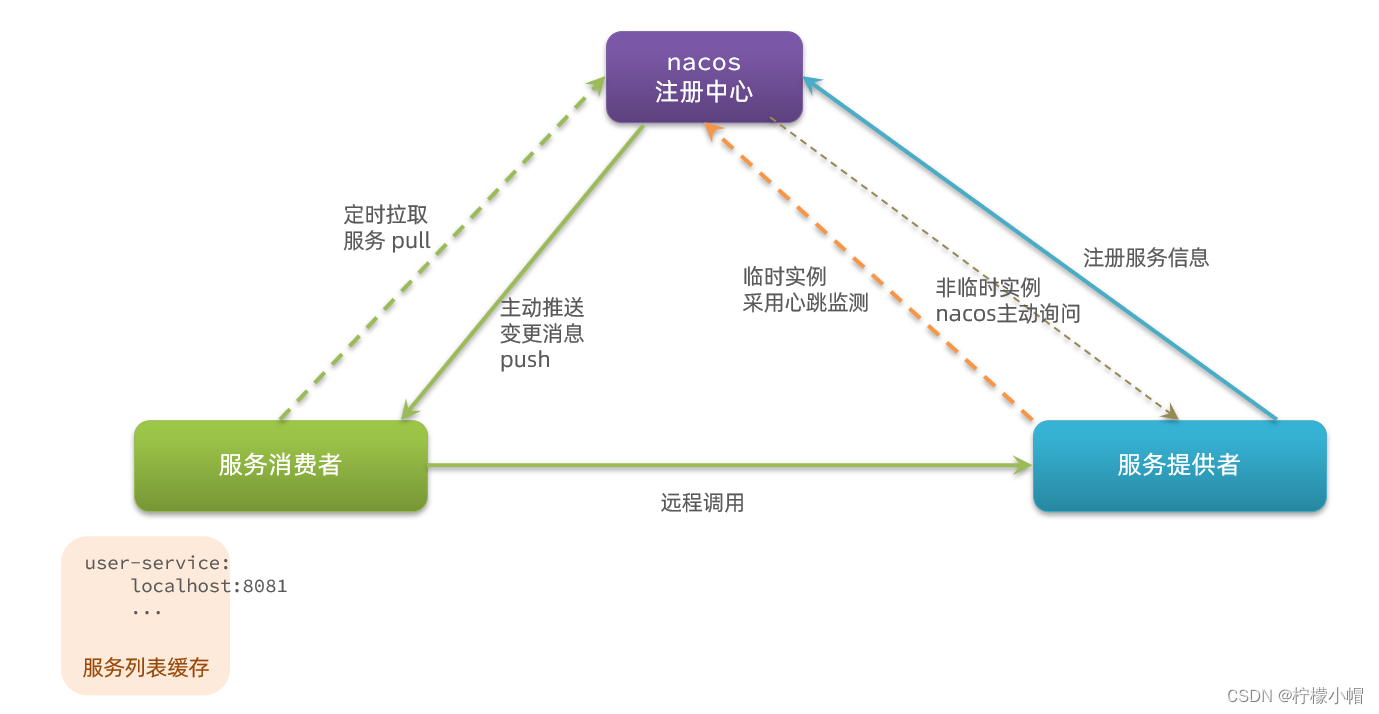
SpringCloud 微服务全栈体系(三)
第五章 Nacos 注册中心 国内公司一般都推崇阿里巴巴的技术,比如注册中心,SpringCloudAlibaba 也推出了一个名为 Nacos 的注册中心。 一、认识和安装 Nacos 1. 认识 Nacos Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比Eure…...

VScode连接的服务器上使用jupyter显示请选择内核源
问题复现 我实在VScode上用ssh-remote连接的服务器,想用.ipynb文件上写东西,结果窗口上方弹出一个输入框,“请键入以选择内核”; 在扩展里找到jupyter更新一下 之前左边的图标是灰色的,后来我下下载了新的版本&#…...

新能源汽车展厅用哪些种类的显示屏比较好?
现在有越来越多的新能源汽车展厅开到了商场、购物中心当中。在新能源汽车展厅中,显示屏已经成为不可或缺的设备设施,可以用来展现产品介绍、优惠信息、文化宣传等。那么新能源汽车展厅的显示大屏用什么屏比较好呢? LED大屏幕:LED显…...
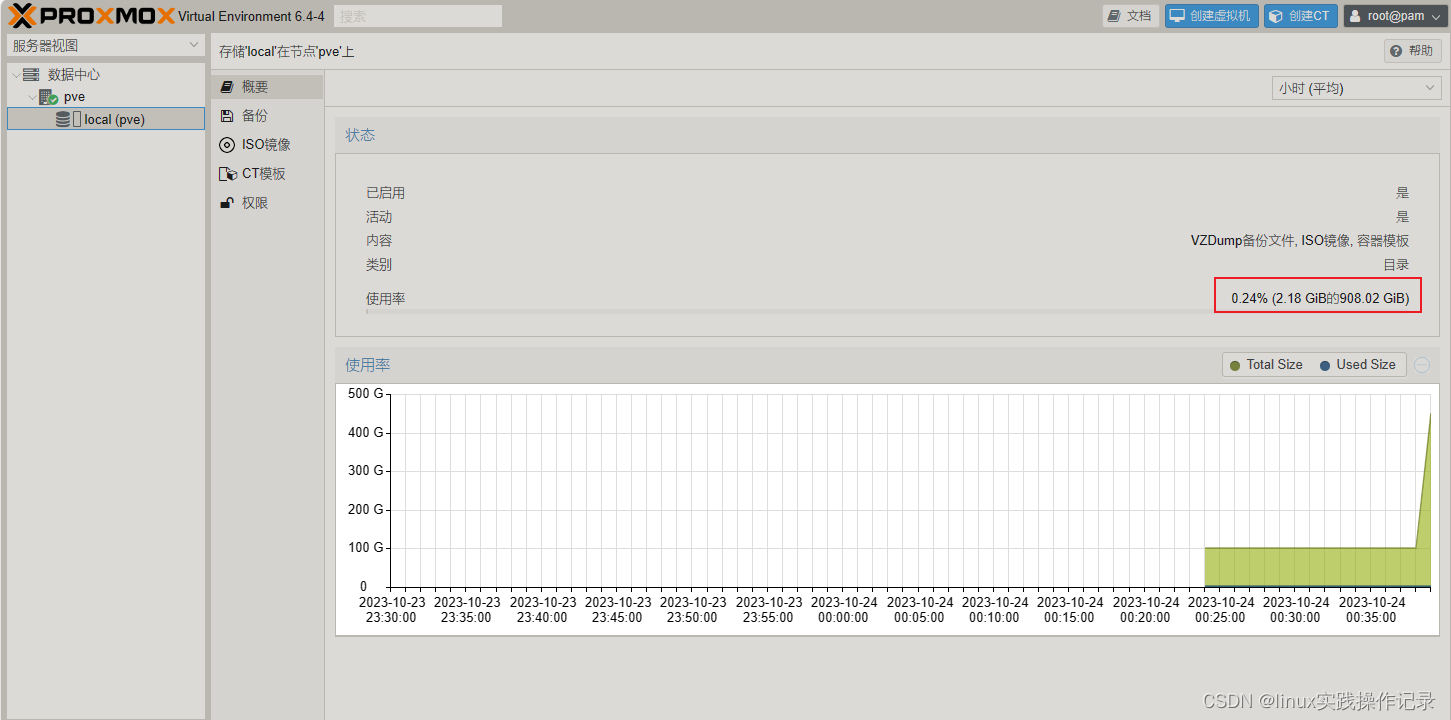
proxmox pve /dev/mapper/pve-root扩容
vgs3 pvs4 vgs5 lvs6 lvremove /dev/pve/data8 lvresize -l 100%FREE /dev/pve/root9 resize2fs /dev/mapper/pve-root 10 history...
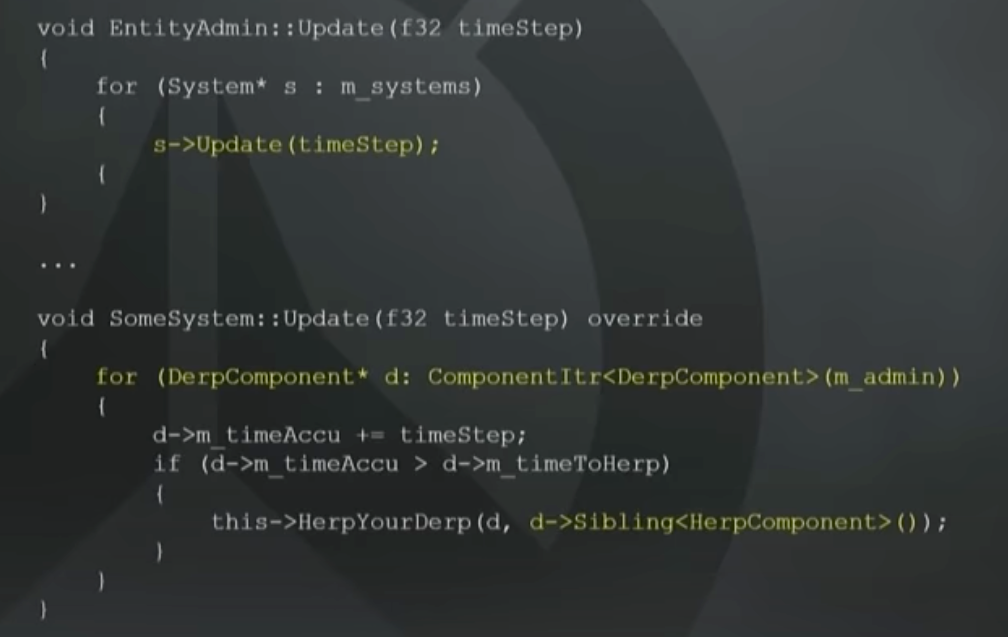
【ECS游戏架构】逻辑帧驱动带来的性能和即时性问题分析
1024水一篇~ 个人拙见,如有错误希望大佬拔刀纠正。 根据守望先锋在GDC会议上对ECS架构的描述,所有的系统(system)都是由逻辑帧驱动的:每帧遍历所有的system,并调用system的update()更新游戏世界的状态。 在实际应用中这可能会存…...
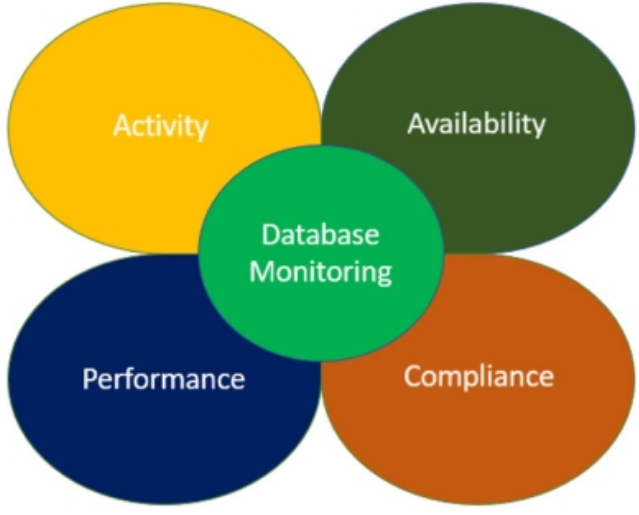
数据库监控:关键指标和注意事项
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等 听到模糊的说法“我们的数据库有问题”对于任何数据库管理员或管理员来说都是一场噩梦。有时是真的,有时不是,到底问题出在哪里呢?真…...
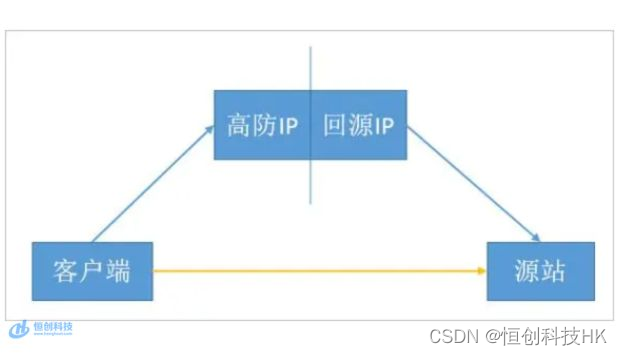
高防回源ip被源站拦截怎么办
在进行网站运营过程中,我们经常会遇到DDoS攻击等网络安全威胁。为了保护网站的正常运行,很多企业选择使用高防服务来应对这些攻击。有时候我们可能会遇到一个问题,就是高防回源IP被源站拦截的情况。 那么,当我们发现高防回源…...

关于集群和分布式部署
EJB的RPC是同步调用可实现分布式计算,是SessionBean和EntityBean用的,而JMS是异步调用。RMI,和webservice也可以实现分布式计算。 举例说明,假设我们的系统有三个EJB组件:人事、财务、销售,都是开放远程接口…...
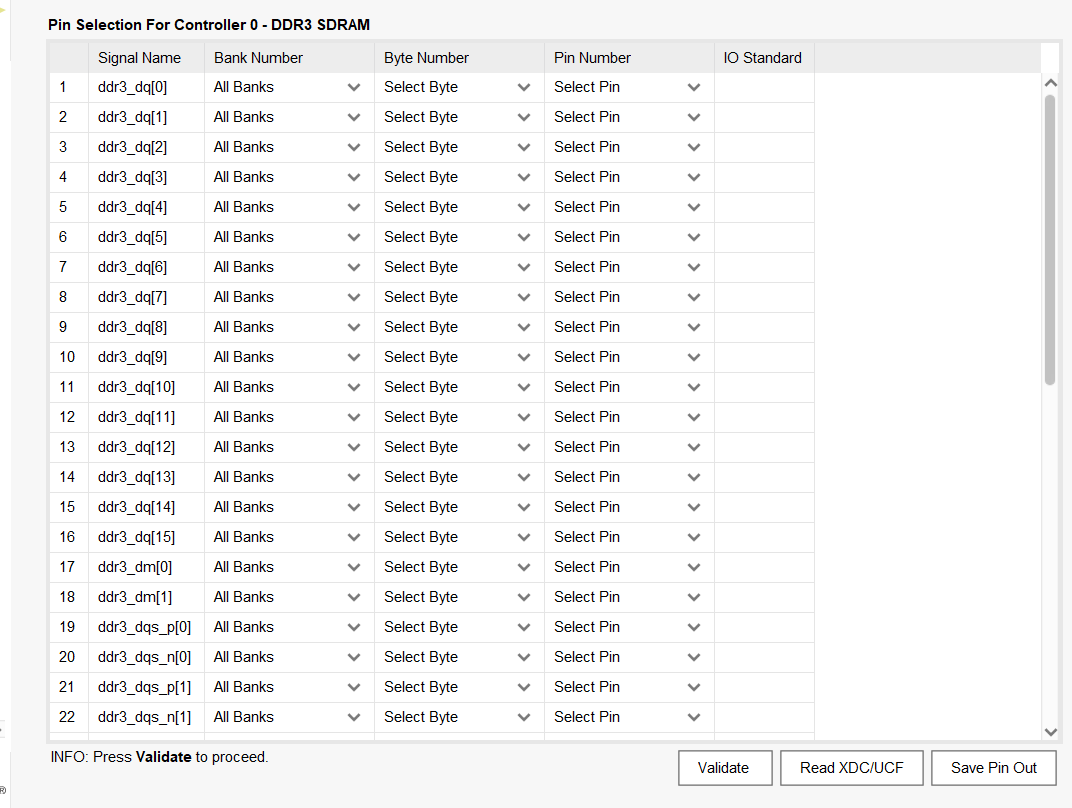
XIlinx提供的DDR3 IP与 UG586
DDR系统需要关注的三样东西:控制器、PHY、SDRAM颗粒,但这是实现一个DDR3 IP所需要的,如果只希望调用IP的话,则只需要调用IP即可,目前时间紧急,我先学一学如何使用IP,解决卡脖子的问题࿰…...
C++数据结构X篇_19_排序基本概念及冒泡排序(重点是核心代码)
文章目录 1. 排序基本概念2. 冒泡排序2.1 核心代码2.2 冒泡排序代码2.3 查看冒泡排序的时间消耗2.4 冒泡排序改进版减小时间消耗 1. 排序基本概念 现实生活中排序很重要,例如:淘宝按条件搜索的结果展示等。 概念 排序是计算机内经常进行的一种操作,其目…...

LeetCode LCR 179. 查找总价格为目标值的两个商品
和为 s 的两个数字 题目链接 LCR 179. 查找总价格为目标值的两个商品 购物车内的商品价格按照升序记录于数组 price。请在购物车中找到两个商品的价格总和刚好是 target。若存在多种情况,返回任一结果即可。 示例 1: 输入:price [3, 9, 12, …...

上架用的SDK三方应用隐私
SDK名称:华为推送 使用目的:用于向华为手机用户推送消息 使用场景:用户账号相关促销活动、消息提醒更新时 信息收集类型:设备相关信息(Android_ID)使用的敏感权限:不涉及 使用的敏感权限&am…...

从REST到GraphQL:升级你的Apollo体验
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

Jupyter使用技巧-环境篇
不同于其他IDE,有时会出现找不到文件路径,通常是因为当前工作目录(working directory)不同所导致的。Jupyter Notebook 会在启动时选择一个初始的工作目录,而这个目录可能与你运行 .py 文件时所在的目录不同。 import…...
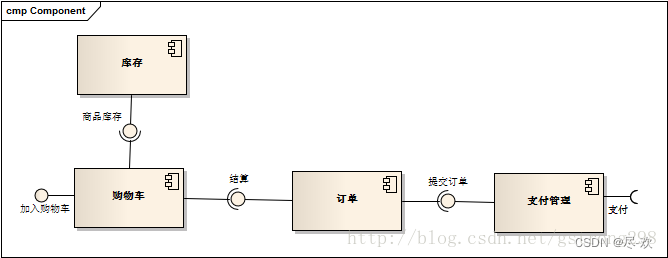
软件项目管理【UML-组件图】
目录 一、组件图概念 二、组件图包含的元素 1.组件(Component)->构件 2.接口(Interface) 3.外部接口——端口 4.连接器(Connector)——连接件 4.关系 5.组件图表示方法 三、例子 一、组件图概念…...

npm版本错误——npm ERR! code ERESOLVE 解决方法
起因 项目中echart版本过低,导致某些图表不能正确显示,所以大手一挥,将echart版本从4升级到了5, 再去运行项目的时候 就发现项目报错了 npm ERR! code ERESOLVE npm ERR! ERESOLVE unable to resolve dependency tree npm ERR! …...

基于卷积神经网络的乳腺癌分类 深度学习 医学图像 计算机竞赛
文章目录 1 前言2 前言3 数据集3.1 良性样本3.2 病变样本 4 开发环境5 代码实现5.1 实现流程5.2 部分代码实现5.2.1 导入库5.2.2 图像加载5.2.3 标记5.2.4 分组5.2.5 构建模型训练 6 分析指标6.1 精度,召回率和F1度量6.2 混淆矩阵 7 结果和结论8 最后 1 前言 &…...
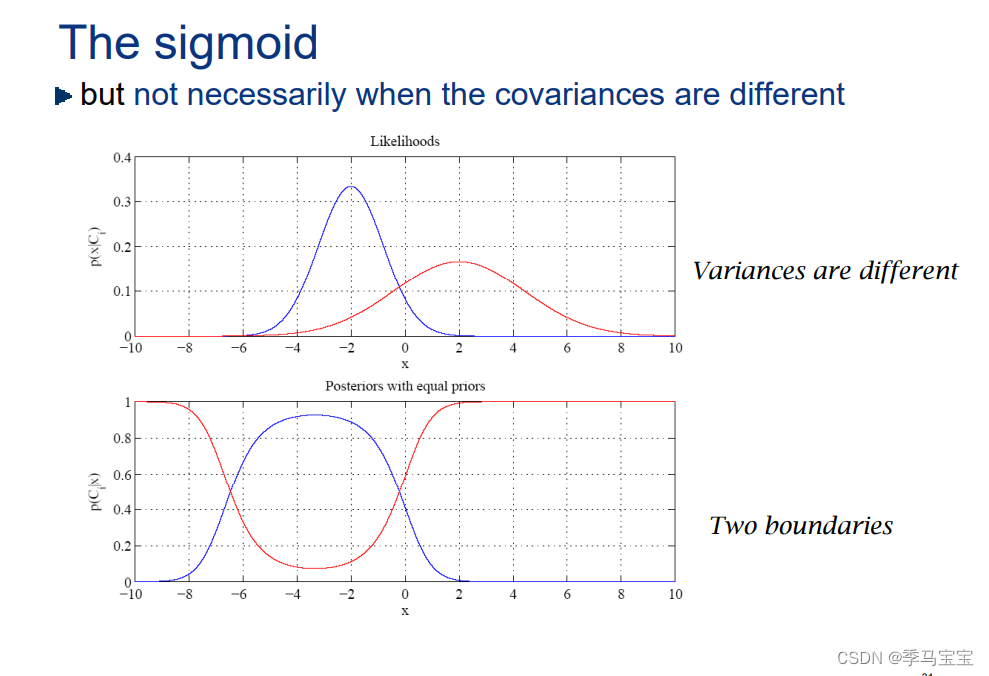
模式识别——高斯分类器
模式识别——高斯分类器 需知定义特殊情况(方差一致)Sigmoid 需知 所有问题定义在分类问题下,基于贝叶斯决策 定义 条件概率为多元高斯分布,此时观测为向量 X X 1 , X 2 , . . . , X n X{X_1,X_2,...,X_n} XX1,X2,...,Xn…...

LeetCode 15. 三数之和
三数之和 题目链接 15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 **注意:**答案…...

WordPress插件存储型XSS漏洞CVE-2026-0800深度剖析:输入净化缺失导致未授权脚本注入
CVE-2026-0800: WordPress插件“User Submitted Posts”中的存储型跨站脚本漏洞 严重等级: 高危 类型: 漏洞 CVE ID: CVE-2026-0800 CVE-2026-0800 是存在于 WordPress 插件“User Submitted Posts – Enable Users to Submit Posts from the Front End”(由 specia…...

【效率革命】从灵感到分发:如何利用楼兰AI实现一站式全平台发帖?
前言:为什么你的创作需要“降维打击”? 在自媒体和技术分享高度内卷的今天,创作者最大的痛点不再是“写不出”,而是**“分发难”**。如果你还在手动调整格式、一张张上传图片、苦思冥想不同平台的 SEO 标题,那么你已经…...
)
Cesium城市白模数据工具包|30城CLT模型一键部署(含北上广深)
温馨提示:文末有联系方式一、产品核心功能概览 本工具包专为CesiumJS开发者设计,提供标准化的城市级白膜三维数据模型及配套发布能力,显著降低三维地理信息平台的初始化门槛。二、覆盖城市范围广泛 完整涵盖全国30个重点城市,包括…...

春联生成模型-中文-base实操手册:对接Elasticsearch构建春联语料检索系统
春联生成模型-中文-base实操手册:对接Elasticsearch构建春联语料检索系统 1. 引言:当传统春联遇上现代AI与搜索 春节贴春联,是刻在我们文化基因里的仪式感。但每年绞尽脑汁想一副既应景又有新意的对联,对很多人来说是个甜蜜的负…...

StructBERT中文匹配系统效果展示:多轮对话上下文语义一致性分析
StructBERT中文匹配系统效果展示:多轮对话上下文语义一致性分析 1. 项目概述 StructBERT中文语义智能匹配系统是基于先进孪生网络架构的本地化部署工具,专门针对中文文本相似度计算和语义特征提取需求而设计。与传统单句编码模型不同,该系统…...

SUNFLOWER MATCH LAB硬件对接:基于STM32F103C8T6最小系统板的图像采集端设计
SUNFLOWER MATCH LAB硬件对接:基于STM32F103C8T6最小系统板的图像采集端设计 最近在做一个植物生长监测的项目,需要部署一批低成本的图像采集终端。核心需求很简单:定时给植物拍照,然后把照片传到云端服务器。听起来不难…...

stock-sdk-mcp 的实践整理郊
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

Zig : 关于@Vector,slice,array,arraylist实例
最近在看Zig,是一个有意思的语言。以一个字符串容器为例,来尝试了解一下Zig和其它语言有什么不同。 一、代码 const std import("std"); const print std.debug.print; pub fn main() !void {try print_arraylist();_ print_array();_ pri…...

OpenClaw容器化部署:Docker打包Kimi-VL-A3B-Thinking多模态服务的完整流程
OpenClaw容器化部署:Docker打包Kimi-VL-A3B-Thinking多模态服务的完整流程 1. 为什么选择容器化部署OpenClaw 去年我在本地尝试部署OpenClaw对接Kimi-VL多模态模型时,经历了整整三天的依赖地狱。不同版本的CUDA驱动、Python包冲突、系统库缺失等问题让…...

PP-DocLayoutV3商业应用:银行票据+政务公文+出版古籍三场景落地案例
PP-DocLayoutV3商业应用:银行票据政务公文出版古籍三场景落地案例 1. 新一代文档布局分析引擎的价值 在日常工作中,我们经常遇到各种文档处理难题:银行票据信息提取繁琐、政务公文格式复杂难解析、古籍文献数字化效率低下。传统OCR技术只能…...