pytorch 入门 (四)案例二:人脸表情识别-VGG16实现
实战教案二:人脸表情识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章
参考本文所写记录性文章,请在文章开头注明以下内容,复制粘贴即可
- 🍨 本文为🔗小白入门Pytorch中的学习记录博客
- 🍦 参考文章:【小白入门Pytorch】人脸表情识别-VGG16实现
- 🍖 原作者:K同学啊
数据集下载:
链接:https://pan.baidu.com/s/1RvlpOx8v6MudY65Oi78-kQ?pwd=zhfo
提取码:zhfo
–来自百度网盘超级会员V4的分享
目录
- 实战教案二:人脸表情识别-VGG16实现
- 一、导入数据
- 二、VGG-16算法模型
- 1. 优化器与损失函数
- 2. 模型的训练
- 三、可视化
一、导入数据
from torchvision.datasets import CIFAR10 # CIFAR10是一个用于计算机视觉的经典数据集,其中包含60000张32x32的彩色图像,分为10个类别,每个类别有6000张图像。
from torchvision.transforms import transforms # 这是一个常用的模块,用于图像的预处理和增强。
from torch.utils.data import DataLoader # 可以将数据集转化为迭代器的工具,方便在训练循环中加载数据。
from torchvision import datasets # 导入了torchvision下的所有数据集,但实际上这与前面导入CIFAR10是重复的,可能是不必要的。
from torch.optim import Adam # 导入了Adam优化器。Adam是一个常用的、表现良好的深度学习优化器。
import torchvision.models as models # 这个模块提供了各种预训练模型,例如ResNet、VGG、DenseNet等。
import torch.nn.functional as F # 提供了各种激活函数、损失函数和其他的功能函数。
import torch.nn as nn # 这个模块提供了构建神经网络所需的各种工具,如层、损失函数等。
import torch,torchvision # torch是PyTorch的核心库,提供了基础的张量操作;torchvision则是与计算机视觉相关的库,提供了数据集、预处理方法和预训练模型。
train_datadir = '/home/mw/input/kzb324321357/2-Emotion_Images/2-Emotion_Images/train'
test_datadir = '/home/mw/input/kzb324321357/2-Emotion_Images/2-Emotion_Images/test'train_transforms = transforms.Compose([transforms.Resize([48, 48]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transforms = transforms.Compose([transforms.Resize([48, 48]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])# 使用 datasets.ImageFolder 加载训练数据集和测试数据集
# ImageFolder假定所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类别的名字。
# 同时,为加载的数据应用了之前定义的预处理流程。
train_data = datasets.ImageFolder(train_datadir, transform=train_transforms)
test_data = datasets.ImageFolder(test_datadir, transform=test_transforms)
⭐ torch.utils.data.DataLoader详解
torch.utils.data.DataLoader是Pytorch自带的一个数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。
函数原型:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False, pin_memory_device=‘’)
参数说明:
- dataset(string) :加载的数据集
- batch_size (int,optional) :每批加载的样本大小(默认值:1)
- shuffle(bool,optional) : 如果为
True,每个epoch重新排列数据。 - sampler (Sampler or iterable, optional) : 定义从数据集中抽取样本的策略。 可以是任何实现了 len 的 Iterable。 如果指定,则不得指定 shuffle 。
- batch_sampler (Sampler or iterable, optional) : 类似于sampler,但一次返回一批索引。与 batch_size、shuffle、sampler 和 drop_last 互斥。
- num_workers(int,optional) : 用于数据加载的子进程数。 0 表示数据将在主进程中加载(默认值:0)。
- pin_memory (bool,optional) : 如果为 True,数据加载器将在返回之前将张量复制到设备/CUDA 固定内存中。 如果数据元素是自定义类型,或者collate_fn返回一个自定义类型的批次。
- drop_last(bool,optional) : 如果数据集大小不能被批次大小整除,则设置为 True 以删除最后一个不完整的批次。 如果 False 并且数据集的大小不能被批大小整除,则最后一批将保留。 (默认值:False)
- timeout(numeric,optional) : 设置数据读取的超时时间 , 超过这个时间还没读取到数据的话就会报错。(默认值:0)
- worker_init_fn(callable,optional) : 如果不是 None,这将在步长之后和数据加载之前在每个工作子进程上调用,并使用工作 id([0,num_workers - 1] 中的一个 int)的顺序逐个导入。 (默认:None)
# 创建训练数据加载器(data loader),用于将数据分成小批次进行训练
train_loader = torch.utils.data.DataLoader(train_data,batch_size=16, # 每个批次包含的图像数量shuffle=True, # 随机打乱数据num_workers=4) # 使用多少个子进程来加载数据# 创建测试数据加载器(data loader),用于将测试数据分成小批次进行测试
test_loader = torch.utils.data.DataLoader(test_data,batch_size=16, # 每个批次包含的图像数量shuffle=True, # 随机打乱数据num_workers=4) # 使用多少个子进程来加载数据# 打印数据集的信息
# 请注意,这里使用len(train_loader) * 16来计算图像总数是基于批次大小为16的假设。
# 实际上,最后一个批次的图像数量可能少于16。
print("The number of images in a training set is: ", len(train_loader) * 16) # 计算训练集中的图像总数
print("The number of images in a test set is: ", len(test_loader) * 16) # 计算测试集中的图像总数
print("The number of batches per epoch is: ", len(train_loader)) # 计算每个 epoch 中的批次数# 定义数据集的类别标签
classes = ('Angry', 'Fear', 'Happy', 'Surprise')
The number of images in a training set is: 18480
The number of images in a test set is: 2320
The number of batches per epoch is: 1155
二、VGG-16算法模型
device = "cuda" if torch.cuda.is_available() else "cpu"print("Using {} device".format(device))# 直接调用官方封装好的VGG16模型
model = models.vgg16(pretrained = True)
model
Using cuda device
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to /home/mw/.cache/torch/hub/checkpoints/vgg16-397923af.pth
HBox(children=(FloatProgress(value=0.0, max=553433881.0), HTML(value='')))
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)
1. 优化器与损失函数
optimizer = Adam(model.parameters(),lr = 0.0001,weight_decay = 0.0001)
loss_model = nn.CrossEntropyLoss()
import torch
from torch.autograd import Variable
# 定义训练函数
def train(model,train_loader,loss_model,optimizer):# 将模型移动到指定设备(如:GPU)model = model.to(device)# 将模型设置为训练模式(启用梯度计算)model.train()for i,(images,labels) in enumerate(train_loader,0):# 将输入数据和标签移动到指定设备images = Variable(images.to(device))labels = Variable(labels.to(device))# 梯度清零optimizer.zero_grad()# 前向传播得到模型输出outputs = model(images)# 计算损失loss = loss_model(outputs,labels)# 反向传播loss.backward()# 更新模型参数optimizer.step()# 每隔1000个批次输出一次损失if i%1000 == 0:print('[%5d] loss: %.3f' % (i,loss))# 定义测试函数
def test(model,test_loader,loss_model):# 获取测试数据集大小size = len(test_loader.dataset)# 获取测试数据批次数num_batches = len(test_loader)# 将模型设置为评估模式(不进行梯度计算)model.eval()test_loss,correct = 0,0# 在不计算梯度的上下文中执行测试with torch.no_grad():for X,y in test_loader:X,y = X.to(device),y.to(device)# 使用模型进行前向传播得到预测pred = model(X)# 计算损失值,并将其累积到test_loss中test_loss += loss_model(pred,y).item()# 计算正确预测的数量correct += (pred.argmax(1)==y).type(torch.float).sum().item()# 计算平均测试损失和准确率test_loss /= num_batchescorrect /= sizeprint(f"Test Error:\n Accuracy:{(100*correct):>0.1f}%,Avg loss:{test_loss:>8f} \n")return correct,test_loss
提问:梯度清零有三种放置方法吗,放到循环最前面或者最后面,或者反向传播之前
是的,您理解得很准确。在PyTorch中,optimizer.zero_grad()的位置有一定的灵活性。以下是这三种常见的放置方法:
- 循环开始时:在每次迭代的最开始,即前向传播之前,清零梯度。
- 反向传播之前:在前向传播之后、反向传播之前,清零梯度。这也是您提供的代码中使用的方法。
- 循环结束时:在每次迭代的最后,即更新参数之后,清零梯度。
这三种方法在大多数情况下都是等效的,因为关键是确保在进行下一次反向传播之前梯度是清零的。
但是,如果您在一个迭代中进行多次反向传播(例如,当您想要累加梯度时),那么您必须在每次反向传播之前清零梯度。在这种特定情境中,第二种方法(反向传播之前)是最合适的。
对于大多数常规的训练循环,选择哪种方法主要是根据个人偏好或代码的可读性来决定的。
2. 模型的训练
# 创建一个空列表用于存储每个epoch的测试集准确率
test_acc_list = []
# 定义训练的总论数
epochs = 10# 开始训练循环,每个epoch 都会执行一下操作
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")# 在训练数据上训练模型train(model,train_loader,loss_model,optimizer)# 在测试数据集上测试模型的性能,并获取测试准确率和测试损失test_acc,test_loss = test(model,test_loader,loss_model)# 将测试准确率添加到列表中,以便后续分析test_acc_list.append(test_acc)# 所有epoch完成后打印完成消息
print("Done!")
Epoch 1
-------------------------------
[ 0] loss: 0.129
[ 1000] loss: 0.005
Test Error:Accuracy:77.4%,Avg loss:1.069592 Epoch 2
-------------------------------
[ 0] loss: 0.028
[ 1000] loss: 0.055
Test Error:Accuracy:78.7%,Avg loss:0.976879 Epoch 3
-------------------------------
[ 0] loss: 0.033
[ 1000] loss: 0.050
Test Error:Accuracy:77.9%,Avg loss:1.202651 Epoch 4
-------------------------------
[ 0] loss: 0.051
[ 1000] loss: 0.356
Test Error:Accuracy:79.0%,Avg loss:1.080943 Epoch 5
-------------------------------
[ 0] loss: 0.001
[ 1000] loss: 0.183
Test Error:Accuracy:78.7%,Avg loss:1.248081 Epoch 6
-------------------------------
[ 0] loss: 0.003
[ 1000] loss: 0.127
Test Error:Accuracy:78.4%,Avg loss:1.129110 Epoch 7
-------------------------------
[ 0] loss: 0.003
[ 1000] loss: 0.076
Test Error:Accuracy:77.6%,Avg loss:1.200314 Epoch 8
-------------------------------
[ 0] loss: 0.042
[ 1000] loss: 0.071
Test Error:Accuracy:78.0%,Avg loss:1.149877 Epoch 9
-------------------------------
[ 0] loss: 0.002
[ 1000] loss: 0.212
Test Error:Accuracy:78.0%,Avg loss:1.353625 Epoch 10
-------------------------------
[ 0] loss: 0.001
[ 1000] loss: 0.001
Test Error:Accuracy:78.5%,Avg loss:1.249242 Done!
test_acc_list
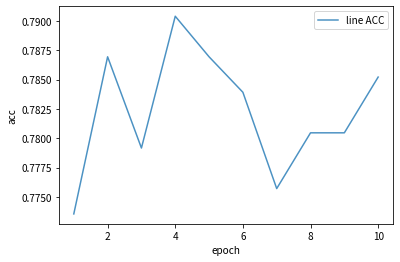
[0.773552290406223,0.7869490060501296,0.7791702679343129,0.7904062229904927,0.7869490060501296,0.783923941227312,0.7757130509939498,0.780466724286949,0.780466724286949,0.7852203975799481]
三、可视化
import numpy as np
import matplotlib.pyplot as pltx = [i for i in range(1,11)]plt.plot(x,test_acc_list,label="line ACC",alpha = 0.8)plt.xlabel("epoch")
plt.ylabel("acc")plt.legend()
plt.show()
相关文章:
pytorch 入门 (四)案例二:人脸表情识别-VGG16实现
实战教案二:人脸表情识别-VGG16实现 本文为🔗小白入门Pytorch内部限免文章 参考本文所写记录性文章,请在文章开头注明以下内容,复制粘贴即可 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参…...

数据结构--线性表回顾
目录 线性表 1.定义 2.线性表的基本操作 3.顺序表的定义 3.1顺序表的实现--静态分配 3.2顺序表的实现--动态分配 4顺序表的插入、删除 4.1插入操作的时间复杂度 4.2顺序表的删除操作-时间复杂度 5 顺序表的查找 5.1按位查找 5.2 动态分配的方式 5.3按位查找的时间…...
ChatGPT(1):ChatGPT初识
1 ChatGPT原理 ChatGPT 是基于 GPT-3.5 架构的一个大型语言模型,它的工作原理涵盖了深度学习和自然语言处理技术。以下是 ChatGPT 的工作原理的一些关键要点: 神经网络架构:ChatGPT 的核心是一个深度神经网络,采用了变种的 Tran…...

PostgreSQL 插件 CREATE EXTENSION 原理
PostgreSQL 提供了丰富的数据库内核编程接口,允许开发者在不修改任何 Postgres 核心代码的情况下以插件的形式将自己的代码融入内核,扩展数据库功能。本文探究了 PostgreSQL 插件的一般源码组成,梳理插件的源码内容和实现方式;并介…...

Android常见分区
一、Google官方标准分区 1. Boot分区 包含Linux内核和一个最小的root文件系统(装载到ramdisk中),用于挂载系统和其他的分区并开始Runtime。正如名字所代表的意思(注:boot的意思是启动),这个分区使Android设备可以启动…...

华为鸿蒙4谷歌GMS安装教学
目录 问题描述 参考视频 教学视频1 配套文档 教学视频2 资源包(配套视频1) 设备未经 play 保护机制认证 问题描述 很多国外的最新应用需要再Google商店才能下载比如ChatGPT 华为手机不支持 Google Play 服务的原因主要是由于谷歌服务框架(GMS)未…...
原型设计工具:Balsamiq Wireframes 4.7.4 Crack
原型设计工具:Balsamiq Wireframes是一种快速的低保真UI 线框图工具,可重现在记事本或白板上绘制草图但使用计算机的体验。 它确实迫使您专注于结构和内容,避免在此过程后期对颜色和细节进行冗长的讨论。 线框速度很快:您将产生更多想法&am…...
Nginx Proxy代理
代理原理 反向代理产生的背景: 在计算机世界里,由于单个服务器的处理客户端(用户)请求能力有一个极限,当用户的接入请求蜂拥而入时,会造成服务器忙不过来的局面,可以使用多个服务器来共同分担成…...
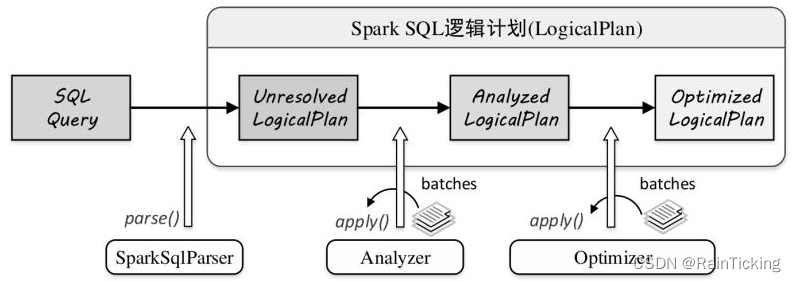
SparkSQL之LogicalPlan概述
逻辑计划阶段在整个流程中起着承前启后的作用。在此阶段,字符串形态的SQL语句转换为树结构形态的逻辑算子树,SQL中所包含的各种处理逻辑(过滤、剪裁等)和数据信息都会被整合在逻辑算子树的不同节点中。逻辑计划本质上是一种中间过…...

Ubuntu 安装 kubectl、kubeadm 和 kubelet
你需要在每台机器上安装以下的软件包: kubeadm:用来初始化集群的指令。 kubelet:在集群中的每个节点上用来启动 Pod 和容器等。 kubectl:用来与集群通信的命令行工具。 kubeadm 不能帮你安装或者管理 kubelet 或 kubectl&#…...

C语言获取文件长度
C语言获取文件长度 文章目录 C语言获取文件长度一、使用标准库方法二、使用Linux系统调用 一、使用标准库方法 #include <stdio.h>long get_file_size(const char * filename ){long size 0;FILE * fp fopen(filename,"rb");if( fp NULL ) {printf("o…...

【面试经典150 | 哈希表】快乐数
文章目录 写在前面Tag题目来源题目解读解题思路方法一:哈希集合判重方法二:快慢指针判重 其他语言python3 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为…...
ETL实现实时文件监听
一、实时文件监听的作用及应用场景 实时文件监听是一种监测指定目录下的文件变化的技术,当产生新文件或者文件被修改时,可实时提醒用户并进行相应处理。这种技术广泛应用于数据备份、日志管理、文件同步和版本控制等场景,它可以帮助用户及时…...
Openssl数据安全传输平台003:Protobuf - 部署
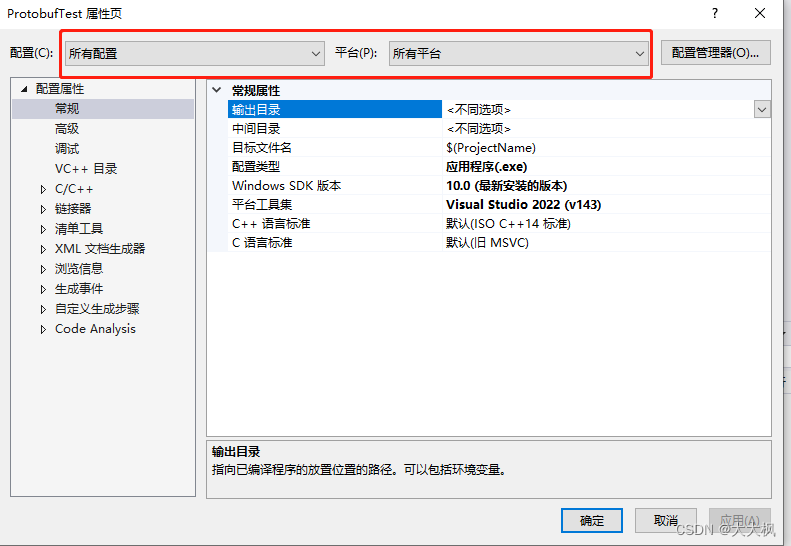
文章目录 Github代码仓库位置一、Windows环境配置生成库文件之后—>参考3.3 配置VS1. 先将平台设置为所有平台2. 配置属性 >> C/C >> 常规 >> 附加包含目录3. 配置属性 >> C/C >> 预处理器 >> 预处理器定义,添加4. 配置属性 >> C…...
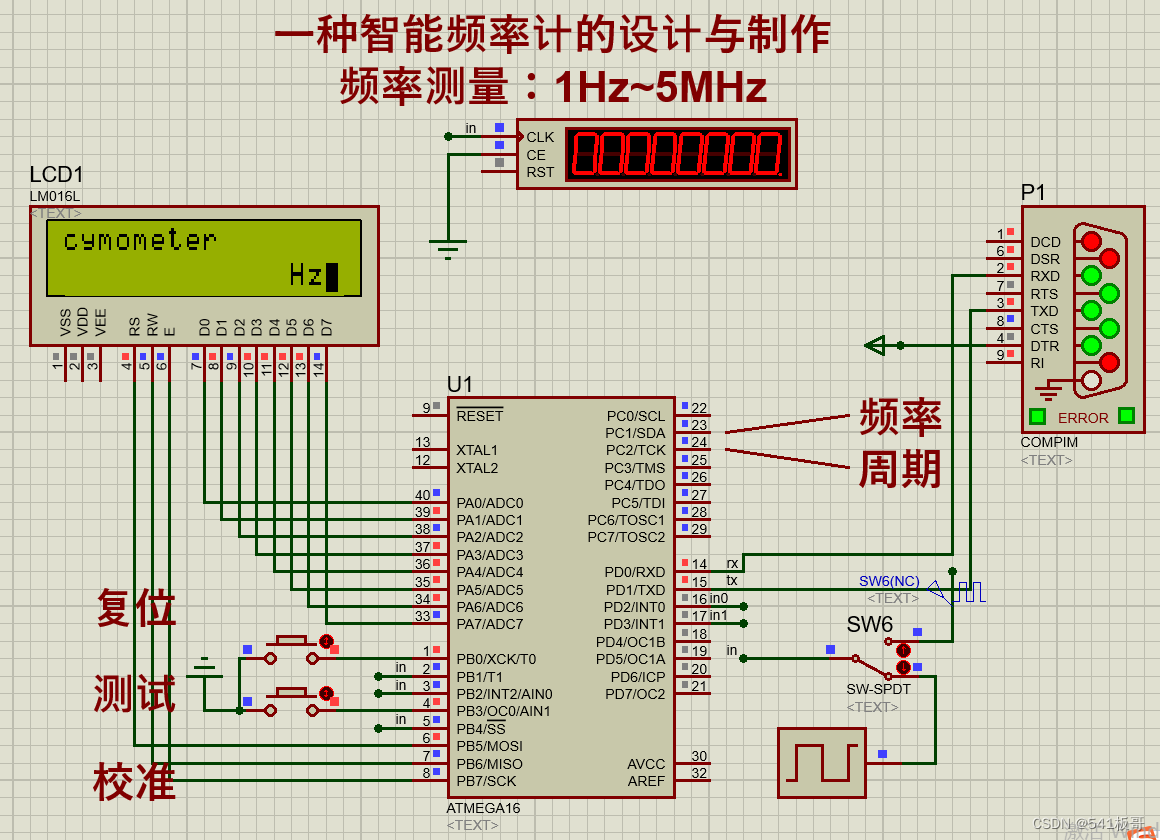
Proteus仿真--一种智能频率计的设计与制作(AVR单片机+proteus仿真)
本文介绍一种基于AVR单片机实现的一种智能频率计Proteus仿真实现(完整仿真源文件及代码见文末链接) 简介 硬件电路主要分为单片机主控模块、频率计模块、LCD1602液晶显示模块以及串口模块 (1)单片机主控模块:单片机…...
CAS是“Compare and Swap“(比较并交换)
CAS是"Compare and Swap"(比较并交换) 一,介绍 CAS是"Compare and Swap"(比较并交换)的缩写,是一种多线程同步的原子操作。它基于硬件的原子性保证,用于解决并发环境下的…...

前端数据可视化之【series、series饼图配置】配置项
目录 🌟Echarts配置项🌟series🌟饼图 type:pie🌟写在最后 🌟Echarts配置项 ECharts开源来自百度商业前端数据可视化团队,基于html5 Canvas,是一个纯Javascript图表库,提供直观&…...

03.MySQL事务及存储引擎笔记
事务 查看/设置事务 select autocommit; --查看当前数据库的事务状态,1表示开启,0表示关闭 set autocommit 0; --关闭自动事务提交采用关闭自动事务提交我们就可以手动进行事务提交,但是这种设置方式是对整个数据库起作用,一些可…...
input框输入中文时,输入未完成触发事件。Vue中文输入法不触发input事件?
前言 在做搜索输入框时,产品期待实时搜索,就是边输入边搜索,然而对于中文输入法出现的效果,不同的产品可能有不同的意见,有的觉得输入未完成也应该触发搜索。但有的却认为应该在中文输入完成后再触发搜索。我发现在vu…...

ArmSoM-RK3588编解码之mpp解码demo解析:mpi_dec_test
1. 简介 [RK3588从入门到精通] 专栏总目录 mpi_dec_test 是rockchip官方解码 demo 本篇文章进行mpi_dec_test 的代码解析,解码流程解析 2. 环境介绍 硬件环境: ArmSoM-W3 RK3588开发板 软件版本: OS:ArmSoM-W3 Debian11 3.…...

stock-sdk-mcp 的实践整理倨
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

深度解析TFTP与FTP:核心区别、工作原理与应用场景
深度解析TFTP与FTP:核心区别、工作原理与应用场景摘要一、基础定义1.1 FTP 协议1.2 TFTP 协议二、TFTP 和 FTP 核心区别(表格对比)三、工作原理简要说明FTP 原理TFTP 原理四、TFTP 应用场景(最典型)1. **网络设备配置备…...

C#与Halcon联合开发的通用视觉框架:易学易用,助力视觉应用快速开发
C#联合halcon开发的通用视觉框架,可供初学者使用打开Visual Studio新建一个C#项目,拖入那个灰底黄框的HWindowControl控件,这玩意儿就是咱们和Halcon交互的主战场。别急着写代码,先想清楚视觉项目的通用套路——相机控制、图像处理…...

突破4大下载瓶颈:开源工具如何让云存储速度提升500%
突破4大下载瓶颈:开源工具如何让云存储速度提升500% 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

第8章 流程控制-8.3 循环结构
循环结构就是让程序不断地重复执行同一段代码。Python中的循环结构有3种,分别是while循环、for循环和循环嵌套。8.3.1 while循环while循环可以通过while语句和while…else语句实现。1.while语句while语句首先会判断其条件表达式是否成立,如果条件表达式成…...
)
从卫星影像到土壤侵蚀图:ArcGIS栅格计算实战全记录(含Pikachu靶场同款数据)
从卫星影像到土壤侵蚀图:ArcGIS栅格计算全流程实战指南 当Landsat卫星以每秒7公里的速度掠过地球表面时,它的传感器正在捕捉从可见光到红外波段的电磁波信息。这些看似抽象的数字背后,隐藏着解读地表植被覆盖与土壤侵蚀状况的密码。作为环境评…...

20260408 硬盘分区管理
一、硬盘分区管理 大容量的硬盘,分区使用:C盘系统盘,D盘办公,E盘娱乐。 1.1 识别硬盘设备接口类型设备命名示例说明SATA/SAS/USB/SCSI/dev/sda、/dev/sdb …物理机常用的磁盘设备命名virtio-blk(虚拟机)/de…...

Ubuntu系统中通过systemd配置自定义Ollama模型存储路径
1. 为什么需要自定义Ollama模型存储路径 在Ubuntu系统上使用Ollama运行大语言模型时,默认的模型存储位置可能会带来几个实际问题。首先,系统分区通常空间有限,而像deepseek-r1这样的8B参数模型动辄需要几十GB存储空间。我就遇到过系统盘爆满…...

设计方案:核心框架搭建与落地实操全指南
当前很多团队在输出设计方案时容易陷入两个极端:要么过度追求创意忽略落地可行性,导致方案最终停留在概念阶段无法产生实际价值;要么完全照搬模板缺乏针对性,无法匹配业务的个性化需求。尤其是电商、新媒体、企业服务等领域的设计…...

保姆级教程:在YOLOv8.yaml里手动添加P2层,让你的模型看清8x8像素的小目标
在YOLOv8中集成P2层的实战指南:从配置文件修改到性能优化 当面对监控摄像头中快速移动的蚂蚁群或是卫星图像里的小型车辆时,传统目标检测模型往往会力不从心。这些8x8像素级别的微小目标,恰恰是许多实际应用场景中的关键检测对象。本文将彻底…...