Java虚拟机内存区域、异常、垃圾收集器
java虚拟机
java内存区域
jvm的主要组成部分及作用
主要包含两个子系统和两个组件
子系统
类加载器(Class loader):根据给定的类路径来装载class文件到运行时数据区
执行引擎(Execution engine):执行class中的指令
组件
运行时数据区(runtime data area):jvm内存
本地接口(native interface) 与本地接口库进行交互,与其他语言交互的接口
作用:通过编译器把java代码转换成字节码,类加载器再把字节码加载到内存中,将其放在运行时数据区的方法区中,而字节码文件只是jvm的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器执行引擎,将字节码翻译成底层系统指令,在交由cpu执行,而这个过程中需要调用其他语言的本地接口来实现整个程序的功能
java程序运行机制步骤
首先编写java源码,源文件.java
在利用编译器将源码编译成字节码文件。.class
运行字节码文件是通过解释器(java命令)来完成
jvm运行时数据区
程序计算器(program counter register):当前程序所执行的字节码的行号指示器。字节码解析器的工作是通过改变这个计数器的值,来选取下一次需要执行的字节码指令
栈(java virtual Machine stacks):用于存储局部变量表,操作数栈,动态链接,方法出口等信息
本地方法栈(native method stack):为虚拟机调用本地方法服务的
堆(java heap):虚拟机内存最大的一块,是被所有线程共享的,几乎所有的对象实例都在这里分配内存
方法区(method area):用户存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据
深拷贝和浅拷贝
浅拷贝
只是增加了一个指针指向已存在的内存地址
深拷贝
增加了一个指针并且申请了一块新内存,使新增的指针指向新内存
浅复制
指向被复制的内存地址,如果原地址发生改变,那么复制出来的对象也会相应改变
深复制
开辟一块新的内存地址存放被复制的对象
堆栈的区别
物理地址
堆的物理地址分配对对象是不联系的。因此性能慢些,在gc的时候也要考虑到不连续的分配,所以由各种算法。比如:标记清楚、复制、标记压缩、分代(新生代用复制,老年代用压缩)
栈使用的是数据结构的中的栈,先进后出的原则,物理地址分配的是连续的,所以性能快
内存分别
堆因为是不连续的,所以分配内存是在运行时确认的,因此大小不固定,一般堆大小远远大于栈
栈是连续的,所以分配的大小要在编译期就确定,大小是固定的
存放的内容
堆存放的是对象的实例和数组
栈存放局部变量,操作数栈,返回结果
程序的可见性
堆对于整个应用程序都是可见、共享的
栈只对于线程是可见的,所以线程也是私有的,他的生命周期和线程相同
队列和栈是什么?有什么区别
队列和栈都是用来存储数据的
区别
操作名称不同
队列的插入称为入队,删除称为出队,栈的插入称为入栈,删除称为出栈
可操作的方式不同
队列是在尾部入队,头部出队,两边都可操作。栈的出栈、出栈都是在栈顶进行的
操作的方法不同
队列是FIFO(先进先出),栈是LIFO(后进先出)
hotspot虚拟机对象
对象的创建
创建对象的几种方式
使用new关键字
调用构造函数
使用Class的newInstance方法
调用构造函数
使用Constructor类的newInstance方法
调用构造函数
使用clone方法
没有调用构造函数
使用反序列化
没有调用构造函数
创建对象的流程
类加载检查
虚拟机收到一个new的指令(new 关键字、clone、对象序列化)时,首先去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否被加载、解析、初始化过,如果没有就需要执行相应的类加载过程
分配内存
类加载检查通过后,虚拟机会为新生对象分配内存,对象所需内存的大小在类加载完成后便可完全确定,为对象分配的空间任务等同于把一块确定大小的内存从java堆中划分出来
划分内存的方法
指针碰撞(Bump the pointer)默认使用
如果堆中的内存是规整的,所有用过的内存都放在一边,空闲的放一边,中间放着一个指针作为分界点的指示器,分配空间就是把那个指针网·向空闲空间那边挪动一段与对象大小相等的距离
空闲列表(free list)
如果堆中的内存不是规整的,已使用的内存和空闲内存相互交错,那就没办法简单的指针碰撞,虚拟机必须维护一个列表,记录哪些内存块是可用的,再分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录
解决并发问题
cas
采用cas配上失败重试的方式保证更新操作的原子性,来分配内存空间的动作进行同步出咯
本地线程分配缓冲(TLAB)
把内存分配的动作按照线程划分在不同的空间之中进行
初始化零值
内存分配完后,虚拟机要将分配到的内存空间都初始化为0值(不包括对象头),这一步保证了对象的实例字段在java代码中可不赋初始值就可以直接使用
设置对象头
初始化零值后,虚拟机要对对象进行必要的设置,如:对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象gc的分代年龄等信息,这个信息存放在对象头中
在Hotspot虚拟机中,对象在内存中存储的布局可以分为三个区域:对象头、实例数据、对齐填充
对象头包括两部分信息,第一部分用于存储对象自身运行时数据,如:哈希码、gc分代年龄、锁标志、线程持有的锁、偏向线程id、偏向时间戳等。另一部分是他的类元数据指针,即对象指向它的类元数据指针,虚拟机通过这个指针来确定这个对象是哪个类的实例
执行init方法
对象按照程序猿的意愿进行初始化,就是为属性赋值和执行构造方法。
对象的访问定位
java程序需要通过jvm栈上的引用访问堆中的具体对象。目前主流的访问方式有句柄和指针
句柄访问【堆中分出一块内存作为句柄池,引用中存储对象的句柄地址,而句柄中包含了对象实例数据与对象类型数据各自的具体地址信息】
优势:引用存储的是稳定的句柄地址,在对象被移动时智慧改变句柄中的实例数据指针,而引用本身不需要修改
指针访问【引用中存储的直接就是对象地址】
优势:速度更快,节省了一次指针定位的时间开销,hotspot使用的就是这种
内存溢出异常
java会存在内存泄漏吗,请简单描述
存在
长生命周期的对象持有短声音周期对象的引用就可能导致内存泄漏
垃圾收集器
简述java垃圾回收机制
在java中,程序员是不需要主动的去释放一个对象的内存。而是由虚拟机自行执行,在jvm中,有一个垃圾回收线程,他是低优先级的,在正常情况下是不会执行的,只有在虚拟机空闲或者当前堆内存不足时,才会触发执行,扫描哪些没有被任何引用的对象,并将它们添加到要回收的集合中,进行回收
GC是什么?为什么需要GC
gc是垃圾收集
为什么需要GC:保证程序能够正常运行的条件,随着程序的运行可用的内存就会越来越少,GC不可避免同时还要对内存碎片进行管理
垃圾回收的优点和原理?并考虑两种回收机制
编程时程序员可以不用考虑内存的问题,可以有效的放置内存泄漏,有效的使用可使用的内存
垃圾回收机制:分代复制垃圾回收、标量垃圾回收、增量垃圾回收
垃圾回收的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
当程序员擦行间对象时,gc就开始监控这个对象的地址、大小不急使用情况
通常GC采用有向图的方式记录和管理堆中的所有对象,通过这种方式确定哪些对象是“可达的”哪些对象是“不可达”;当gc确定一些对象为不可达时,gc就有责任回收这些内存
可以手动调用system.gc(),通知gc回收,但是java语言规范并不保证gc一定会执行
Java中有哪些引用类型
强引用:发生gc时不会回收
软引用:有用但不是必须的对象,在发生内存溢出之前会被回收
弱引用:有用但不是必须的对象,在 下次GC时会被回收
虚引用:用途是在gc时,返回一个通知
怎么判断对象是否可以被回收?
引用计数法
为每个对象创建一个计数器,被引用+1,释放引用-1,当计数器为0时就会被回收,他有一个缺点不能解决循环引用的问题
可达性分析
从GC Root(线程栈的本地变量、静态变量、本地方法栈等)开始向下搜索引用的对象,找到的对象被标记为非垃圾对象,其余未被标记的都视为垃圾对象。
在java中,对象什么时候可以被垃圾回收
设置为null
没有被其他线程,对象引用
JVm中永久代中会发生垃圾回收吗?
gc。这时候永久代是会被回收的,这也就是为什么正确的永久代大小对避免full gc是非常重要的原因
说一下JVM有哪些垃圾回收算法?
标记清除
标记无用对象,然后进行回收。缺点:效率不高,无法清除垃圾碎片
复制算法
按照容量划分2个大小一样的内存区域,当一块用完的时候,将存货的对象复制到另一块内存中,然后把已使用的内存一次清理掉。缺点:内存使用率不高,只有原来的一半
标记整理
标记无用对象,将存活的对象向一端移动,然后直接清除端边界以外的内存
分代算法
将对象存货周期的不同将内存划分几块,一般是新生代(复制算法)、老年代(标记整理算法)和永久代
说一下JVM有哪些垃圾回收器?
如果说垃圾回收算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
用户回收新生代的回收器有:Serial、PraNew、Parallel Scavenge,回收老年代的回收器有:Serial Old、Parallel Old、CMS,还有用于回收整个Java堆的G1回收器。不同的回收器之间可以搭配使用
serial(复制算法):新生代单线程收集器,标记和清理都是单线程,有点是简单高效
PraNew(复制算法):新生代并行收集器,实际上是serial的多线程版本,在多核cpu环境下有着比serial更好的表现
Parallel Scavenge(复制算法):新生代并行收集器和parNew差不多,区别主要在于parNew可以喝CMS配合使用
serial old (标记整理算法)老年代单线程收集器,serial的老年代版本
parallel old(标记整理算法)老年代并行收集器,吞吐量优先,parallel scavenge的老年代版本
CMS(Concurrent Mark Sweep)标记清楚算法:老年代并行收集器,以获取最短回收停顿为目标的收集器,具有高并发,低停顿的特点,追求最短的gc回收停顿时间
G1(Garbage First)收集器(标记整理算法):Java堆并行收集器,【g1的回收范围是整个堆(包括新生代和老年代)而上面六个回收的范围仅限于老年代或者新生代
详细介绍一下CMS垃圾回收器
CMS(Concurrent Mark sweep)是以牺牲吞吐量为代价来获得最短的回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
在JVM参数上加上:-XX:+UseConcMarkSweepGC指定使用
CMS使用的是标记清除算法,所以在gc的时候会产生大量的内存碎片,当剩余内存不足以满足程序运行要求是,系统会出现“Concurrent mode Failure”,此时进入stop the world,用serial old垃圾回收器进行回收
新生代垃圾回收器和老年代回收器都有哪些?有什么区别
新生代
serial、parNew、Parallel scavenge
老年代
serial old、parallel old 、CMS
整堆回收
G1
新生代采用的复制算法,优点是效率高,缺点是内存利用率低
老年代一般用的都是标记整理算法
简述一下分代垃圾回收器是怎么工作的
分代回收器有两个分区:老年代和新生代,新生代默认的空间占总空间的1/3,老年代是2/3
新生代使用的是复制算法,有三个分区,eden、to Survivor、from Survivor,他们的默认占比是8:1:1.执行流程如下
把eden+from survivor存活的对象放入 to survivor区
清空 eden和from survivor分区
from survivor和to survivor分区相互交换
每次from survivor到to survivor移动时都存活的对象,年龄就+1,当年龄到达15(默认配置15)时就升级到老年代,大对象也会进入老年代
老年代当空间占用到达某个值后就会触发全局垃圾回收,一般使用标记整理的执行算法。以上这些循环往复就构成了整个分代垃圾回收的整体流程
内存分配策略
简述java内存分配与回收策略以及minor gc和major gc
对象内存的分配通常是在堆上分配(随着虚拟机的优化技术诞生,某些场景下也会在栈上分配),对象主要分配在新生代的eden区,如果启用了本地线程缓冲(TLAB),将按照线程优先在TLAB上分配,少数情况下也会直接在老年代上分配,总的来说分配规则不是百分百固定的,其细节处决于哪一种垃圾收集器组合以及虚拟机相关参数
对象优先在eden区分配
多数情况下,对象都在新生代eden区进行分配。当eden区分配没有足够的空间时,虚拟机将会发起一次minor gc,如果本次gc后还是内存还是不够,将启用老年代空间分配担保机制在老年代中分配。
mainor gc:是指发生在新生代的gc,因为java对象大多数是朝生夕死,所以mainor gc非常频繁,一般回收速度也很快
major gc/Full gc:是指发生在老年代的gc,出现major gc通常会伴随着一次minor gc。major gc的速度通常会比minor gc慢10倍以上
大对象直接进入老年代
所谓的大对象是指需要大量连续内存空间地址的对象,频繁出现大对象是致命的,会导致内存中还有不少空间的情况下提前触发GC以获取足够的连续空间来安置新对象
因为新生代是使用复制算法来处理回收,如果大对象直接在新生代分配就会导致eden区和两个survivor区之间发生大量的复制。因此大对象都会在老年代进行分配
长期存活对象将进入老年代
虚拟机给每个对象定义了一个年龄计数器,如果对象在eden区中出生,并且能够被survivor容纳,将被移动到survivor空间中,这是设置对象的年龄为1,对象在survivor区中每minorgc一次年龄就+1.当达到一定值后(默认15)就会被晋升为老年代
类加载机制
简述java类加载机制
虚拟机把描述类的数据从Clas文件中加载到内存,并对数据进行校验,解析和初始化,最终形成可以被虚拟机直接使用的java类(对象)
描述一下JVM加载Class文件的原理机制
java中的所有类都需要类加载器装载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把Class文件从硬盘读取到内存中。在写程序的时候我们继续不需要关心累的加载,因为这些都是隐式装载的,除非我们有特殊的用法,像是反射我们就需要显式的加载所需的类
类装载的方式两种
隐式装载
在程序运行过程中通过new等方式生成对象时,隐式调用类装载器架子啊对应的类到JVM中
显式装载
通过class.forNamed()等方法,显式加载需要的类
什么是类加载器,类加载器有哪些
通过类的权限定义名获取该类的二进制字节流的代码叫做类加载器
四类加载器
启动类加载器
负责加载支撑jvm运行的位于jre的lib目录下的核心类库,如:rt.jar
扩展类加载器
负责加载支持jvm运行的位于jre的lib目录下的ext扩展目录中的jar类包
应用程序加载类(系统加载类)
负责加载classPath路径下的类包,主要就是加载自己写的类
自定义加载器
负责加载用户自定义路径下的类包
说一下类加载器的执行过程
类加载分为5个步骤
加载:在硬盘上查找并通过io读入字节码文件(使用到的类才会加载)
验证:校验字节码文件的正确性
准备:给类的静态变量分配内存、并赋予默认值
解析:将符号引用替换为直接引用。该阶段会把一些静态方法(符号引用)替换为指向数据所在内存的指针或者句柄(直接引用),这就是所谓的静态链接,动态链接是指在程序运行期间完成的符号引用替换直接引用
初始化:对类的静态变量初始化为指定的值,执行静态代码块
什么是双亲委派模型
加载某个类时会先委托父加载器寻找目标类,找不到再委托上层父加载器加载,如果所有的父加载器都找不到,则在自己的类加载路径中查找并载入类
简单说就是:先找父亲加载,是在不行再有儿子加载。
为什么要设计双亲委派机制?
沙箱安全机制
自己写的String类不会被加载,这样可以防止核心api被随意篡改
避免类的重复加载
当父类已经加载了该类,就没有必要子加载器在加载一次,保证被加载类的唯一性
java类加载是动态的,它并不会一次性将所有的类全部加载后运行,而是加载能保证程序运行的基础类,至于其他类,则是在需要的时候才加载,为了节省内存开销
JVM调优
调优工具
阿里的Arthas
Jdk自带的jconsole和jvisualVm
JVM调优参数都有哪些?
• -Xms2g:初始化推大小为 2g;
• -Xmx2g:堆最大内存为 2g;
• -XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
• -XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2;
• –XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
• -XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
• -XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
• -XX:+PrintGC:开启打印 gc 信息;
• -XX:+PrintGCDetails:打印 gc 详细信息。
相关文章:

Java虚拟机内存区域、异常、垃圾收集器
java虚拟机 java内存区域 jvm的主要组成部分及作用 主要包含两个子系统和两个组件 子系统 类加载器(Class loader):根据给定的类路径来装载class文件到运行时数据区 …...

深入理解JVM虚拟机第十三篇:详解JVM中的程序计数器
文章目录 一:程序计数器 1:概念 2:官方说法 3:图解 4:特点...
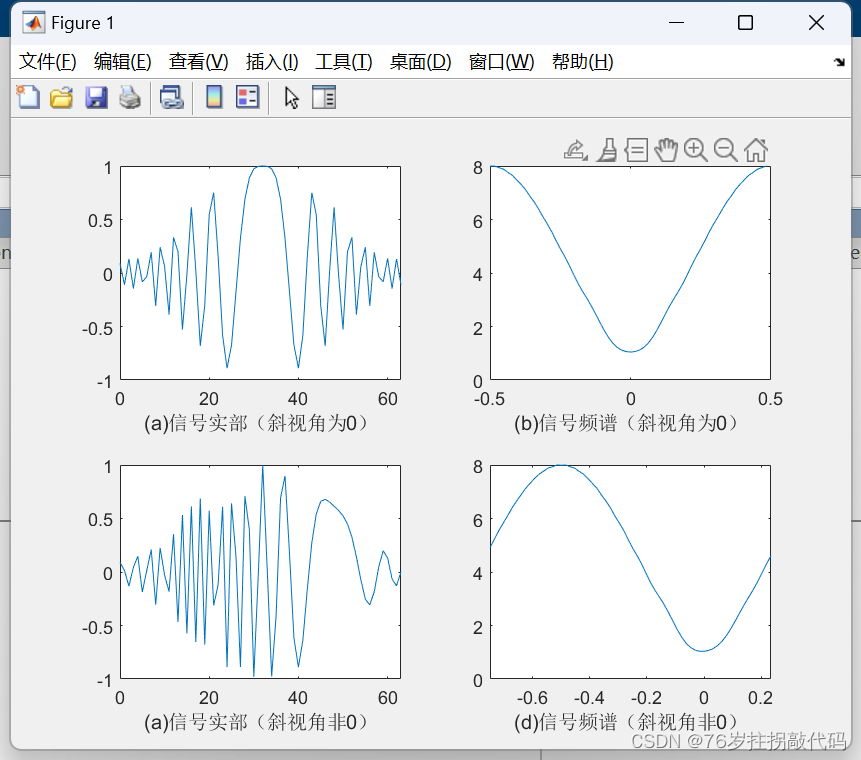
《合成孔径雷达成像算法与实现》Figure5.5
clc clear close all%% 参数设置 Ta 64; % 脉冲持续时间 Ka -1.56e-2; % 方位向调频率 Delta_f_dop abs(Ta*Ka); …...

leetcode经典面试150题---2.移除元素
题目描述 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新…...

【尘缘赠书活动:01期】Python数据挖掘——入门进阶与实用案例分析
引言 本案例将根据已收集到的电力数据,深度挖掘各电力设备的电流、电压和功率等情况,分析各电力设备的实际用电量,进而为电力公司制定电能能源策略提供一定的参考依据。更多详细内容请参考**《Python数据挖掘:入门进阶与实用案例…...

计算机网络(谢希仁)第八版课后题答案(第二章)
1.物理层要解决哪些问题?物理层的主要特点是什么? (1)物理层要尽可能地屏蔽掉物理设备和传输媒体,通信手段的不同,使数据链路层感觉不到这些差异,只考虑完成本层的协议和服务。 (2)给其服务用户(数据链路…...

搭建nuxt3项目(框架构建)
需求 目标:我想搭建一个nuxt3的框架,实现一些基本的组件和路由、页面,方便后续遇到相关ssr项目直接复用。 同时:记录关于nuxt3的使用介绍关于Nuxt(详解以及周边) Nuxt 框架 1、一种基于 Node.js 的服务端…...

系统架构设计之微内核架构(Microkernel Architecture)
微内核架构(Microkernel Architecture) 一. 什么是微内核架构二. 微内核架构风格-拓扑结构三. 微内核的核心系统设计的三个关键点3.1 插件管理3.2 插件连接3.3 插件通信 四. 微内核架构的优缺点 一. 什么是微内核架构 微内核架构是一种面向功能进行拆分的…...

51单片机实现换能器超声波测水深
一,超声波换能器定义: 定义1:可把电能、机械能或声能从一种形式转换为另一种形式的能的装置。 所属学科:测绘学下的测绘仪器。 定义2:能量转换的器件。在水声领域中常把声呐换能器、水声换能器、电声换能器统称换能器。…...
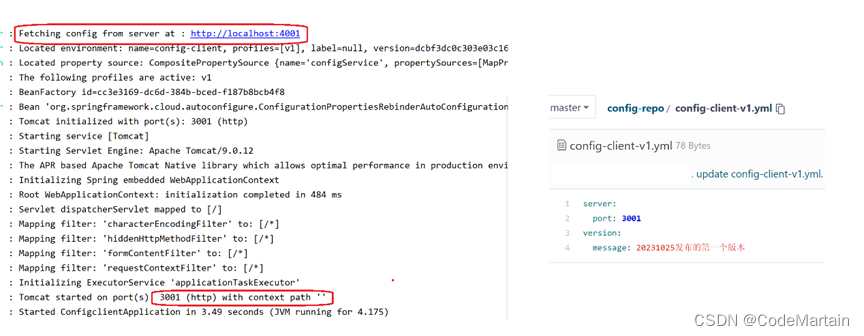
Spring Cloud Config
Spring Cloud Config 服务端:一个集中化配置中心,可以是一个独立的服务,也可以注册到服务治理中心,它可以集中管理各个 微服务的配置; 作用原理是从某个地方读取(本地/云端)提供给其客户端作为配置; 客户端:作为一个服务端,通过读取Config的服务端来获取自己的配置文件; 服务…...
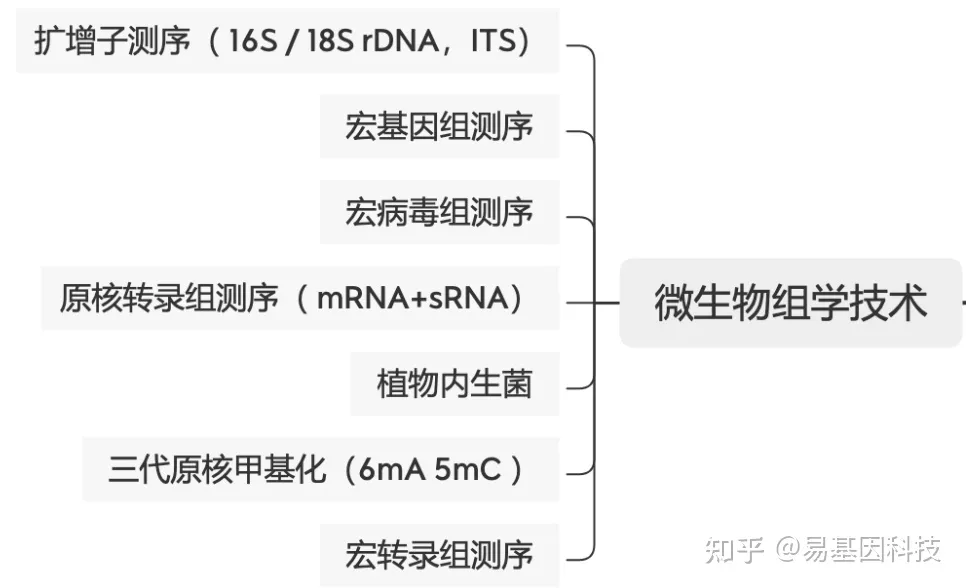
易基因: Nature Biotech:番茄细菌性青枯病的噬菌体联合治疗|国人佳作
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 生物防治是利用细菌接种剂来改变植物根际微生物群落的组成,但在以往研究中存在有接种的细菌在根际建立不良,与本地微生物组争夺资源,干扰本地微生物的…...

震坤行亮相2023工博会,并荣获第23届中国工博会“CIIF信息技术奖”
震坤行亮相2023工博会,并荣获第23届中国工博会“CIIF信息技术奖” 2023年9月19日,2023年第23届中国国际工业博览会CIIF(以下简称“工博会”)在上海国家会展中心盛大开幕。震坤行紧跟智能制造产业发展步伐,携数字化解决…...

灯带代码实现
#include "FastLED.h" // FastLED库#define NUM_LEDS 60 // LED灯珠数量 #define DATA_PIN 3 // Arduino输出控制信号引脚 #define LED_TYPE WS2812 // LED灯带型号 #define COLOR_ORDER GRB // RGB灯珠中红色、…...

Monocular arbitrary moving object discovery and segmentation 论文阅读
基本信息 题目:Monocular Arbitrary Moving Object Discovery and Segmentation 作者: 来源:BMVC 时间:2021 代码地址:https://github.com/michalneoral/Raptor Abstract 我们提出了一种发现和分割场景中独立移动的…...

ROS | 命名空间
文章目录 概述一、定义介绍二、原理解读1.命名空间2.调用规则概述 本节详细介绍了ROS中的命名空间机制原理和使用。 一、定义介绍 在ROS(Robot Operating System)中,命名空间是一种用于组织和区分节点、话题、服务和参数等资源的层次结构。命名空间使用斜线(/)作为分隔符…...

【中国数据】中国基础矢量数据(shp格式)
数据目录 数据举例 数据获取 专栏分享常用的地理空间数据,包括矢量数据、栅格数据、统计数据等,订阅专栏后,从私信查收专栏完整数据包,持续同步更新。...

Docker:创建主从复制的Redis集群
一、Redis集群 在实际项目里,一般不会简单地只在一台服务器上部署Redis服务器,因为单台Redis服务器不能满足高并发的压力,另外如果该服务器或Redis服务器失效,整个系统就可能崩溃。项目里一般会用主从复制的模式来提升性能&#x…...

c++ 智能指针
1. 起源 c++ 把内存的控制权对开发人员开放,让程序显式的控制内存,这样能够快速的定位到占用的内存,完成释放的工作。但是这样也会引发一些问题,也就是普通指针的隐患: 1.1 野指针 出现野指针的有几个地方 : 指针声明而未初始化,此时指针的将会随机指向内存已经被释放…...

【vue3】依赖注 provide、inject(父组件与儿子、孙子、曾孙子组件之间的传值)
一、基本用法: //父组件 import { ref, provide } from vue const radio ref<string>(red) provide(myColor,radio) //注入依赖//儿子组件、孙子组件、曾孙子组件 import { inject } from vue import type { Ref } from vue; const myColor inject<Ref&l…...

docker 部署tig监控服务
前言 tig对应的服务是influxdb grafana telegraf 此架构比传统的promethus架构更为简洁,虽然influxdb开源方案没有集群部署,但是对于中小型服务监控需求该方案简单高效 本文以docker-compose来演示这套监控体系的快速搭建和效果。 部署 docker-compos…...

如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案
如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否为WeMod免费版的诸多限制感到…...

环境科学论文降AI工具免费推荐:2026年环境科学研究生毕业论文降AI知网维普99.26%4.8元完整指南
环境科学论文降AI工具免费推荐:2026年环境科学研究生毕业论文降AI知网维普99.26%4.8元完整指南 整理了一份环境科学论文降AI的完整选购指南,按性价比排序。 首推嘎嘎降AI(www.aigcleaner.com),4.8元,99.2…...

英雄联盟R3nzSkin换肤工具:3分钟实现安全免费的全皮肤体验
英雄联盟R3nzSkin换肤工具:3分钟实现安全免费的全皮肤体验 【免费下载链接】R3nzSkin Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3n/R3nzSkin R3nzSkin是一款专为英雄联盟玩家设计的开源内存换肤工具,…...

Gita异步执行机制详解:高效管理大型项目的核心技术
Gita异步执行机制详解:高效管理大型项目的核心技术 【免费下载链接】gita Manage many git repos with sanity 从容管理多个git库 项目地址: https://gitcode.com/gh_mirrors/gi/gita 在现代软件开发中,开发者经常需要同时管理多个Git仓库。随着项…...

Google:让鼠标学会「看见」这件事意味着什么#Magic Pointer
Google DeepMind发布的Magic Pointer(AI Pointer)让鼠标指针获得了视觉理解和语义推理能力。用户只需要指向画面中的某个对象并说出简短指令,AI就能理解意图并执行复杂操作:订餐、查路线、比价。这个看似简单的能力跃迁࿰…...

SFT与RL:AI训练的黄金搭档,何时介入才能事半功倍?
本文探讨了SFT(监督微调)和RL(强化学习)在AI训练中的协同作用。SFT负责建立模型的基础能力,确保其遵循格式和指令;RL在此基础上优化输出质量,使其更符合人类使用习惯。文章详细分析了何时进行RL…...

多智能体协同控制未来的前景和方向如何?
在AI技术快速演进的今天,单一智能体已难以满足企业复杂业务场景的需求,多智能体协同正成为行业关注的焦点,它通过多个智能体分工协作、动态交互,形成更强大、更灵活的数字员工团队,有望重塑企业运营模式,推…...

开发者必备:极简CLI工具高效管理个人代码片段库
1. 项目概述:一个面向开发者的代码片段管理工具最近在整理自己的开发环境,发现一个挺普遍的问题:那些临时写出来、解决了某个具体问题、但又不够格放进正式项目库的代码片段,到底该放哪儿?它们就像散落在硬盘各处的“知…...

使用Nodejs快速将Taotoken大模型API集成到你的Web应用中
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js快速将Taotoken大模型API集成到你的Web应用中 基础教程类,面向全栈或前端开发者,讲解如何在Nod…...

企业级应用如何通过Taotoken实现API调用的审计与安全管控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken实现API调用的审计与安全管控 将大模型能力集成到企业内部系统,为业务流程带来智能化的同时…...