ES(elasticsearch) - 三种姿势进行分页查询
1. from + size 浅分页
"浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。
GET test_dev/_search
{"query": {"bool": {"filter": [{"term": {"age": 28}}]}},"size": 10,"from": 20,"sort": [{"timestamp": {"order": "desc"},"_id": {"order": "desc"}}]
}
![]()
其中,from定义了目标数据的偏移值,size定义当前返回的数目。默认from为0,size为10,即所有的查询默认仅仅返回前10条数据。
在这里有必要了解一下from/size的原理:因为es是基于分片的,假设有5个分片,from=100,size=10。则会根据排序规则从5个分片中各取回100条数据数据,然后汇总成500条数据后选择最后面的10条数据。
做过测试,越往后的分页,执行的效率越低。总体上会随着from的增加,消耗时间也会增加。而且数据量越大,就越明显!
2. scroll 深分页
from+size查询在10000-50000条数据(1000到5000页)以内的时候还是可以的,但是如果数据过多的话,就会出现深分页问题。
为了解决上面的问题,elasticsearch提出了一个scroll滚动的方式。
scroll 类似于sql中的cursor,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景。
GET test_dev/_search?scroll=5m
{"query": {"bool": {"filter": [{"term": {"age": 28}}]}},"size": 10,"from": 0,"sort": [{"timestamp": {"order": "desc"},"_id": {"order": "desc"}}]
}
- scroll=5m表示设置scroll_id保留5分钟可用。
- 使用scroll必须要将from设置为0。
- size决定后面每次调用_search搜索返回的数量
然后我们可以通过数据返回的_scroll_id读取下一页内容,每次请求将会读取下10条数据,直到数据读取完毕或者scroll_id保留时间截止:
GET _search/scroll
{"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAJZ9Fnk1d......","scroll": "5m"
}
注意:请求的接口不再使用索引名了,而是 _search/scroll,其中GET和POST方法都可以使用。
scroll删除
根据官方文档的说法,scroll的搜索上下文会在scroll的保留时间截止后自动清除,但是我们知道scroll是非常消耗资源的,所以一个建议就是当不需要了scroll数据的时候,尽可能快的把scroll_id显式删除掉。
清除指定的scroll_id:
DELETE _search/scroll/DnF1ZXJ5VGhlbkZldGNo.....
- 1
清除所有的scroll:
DELETE _search/scroll/_all
- 1
3. search_after 深分页
scroll 的方式,官方的建议不用于实时的请求(一般用于数据导出),因为每一个 scroll_id 不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。但是需要注意,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
GET test_dev/_search
{"query": {"bool": {"filter": [{"term": {"age": 28}}]}},"size": 20,"from": 0,"sort": [{"timestamp": {"order": "desc"},"_id": {"order": "desc"}}]
}
- 使用search_after必须要设置from=0。
- 这里我使用timestamp和_id作为唯一值排序。
- 我们在返回的最后一条数据里拿到sort属性的值传入到search_after。
使用sort返回的值搜索下一页:
GET test_dev/_search
{"query": {"bool": {"filter": [{"term": {"age": 28}}]}},"size": 10,"from": 0,"search_after": [1541495312521,"d0xH6GYBBtbwbQSP0j1A"],"sort": [{"timestamp": {"order": "desc"},"_id": {"order": "desc"}}]
}
4. 比较图
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本)维护成本高,需要维护一个 scroll_id | 海量数据的导出需要查询海量结果集的数据 |
| search_after | 高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
相关文章:

ES(elasticsearch) - 三种姿势进行分页查询
1. from size 浅分页 "浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。 GET test_dev/_search {"query": {"bool&…...
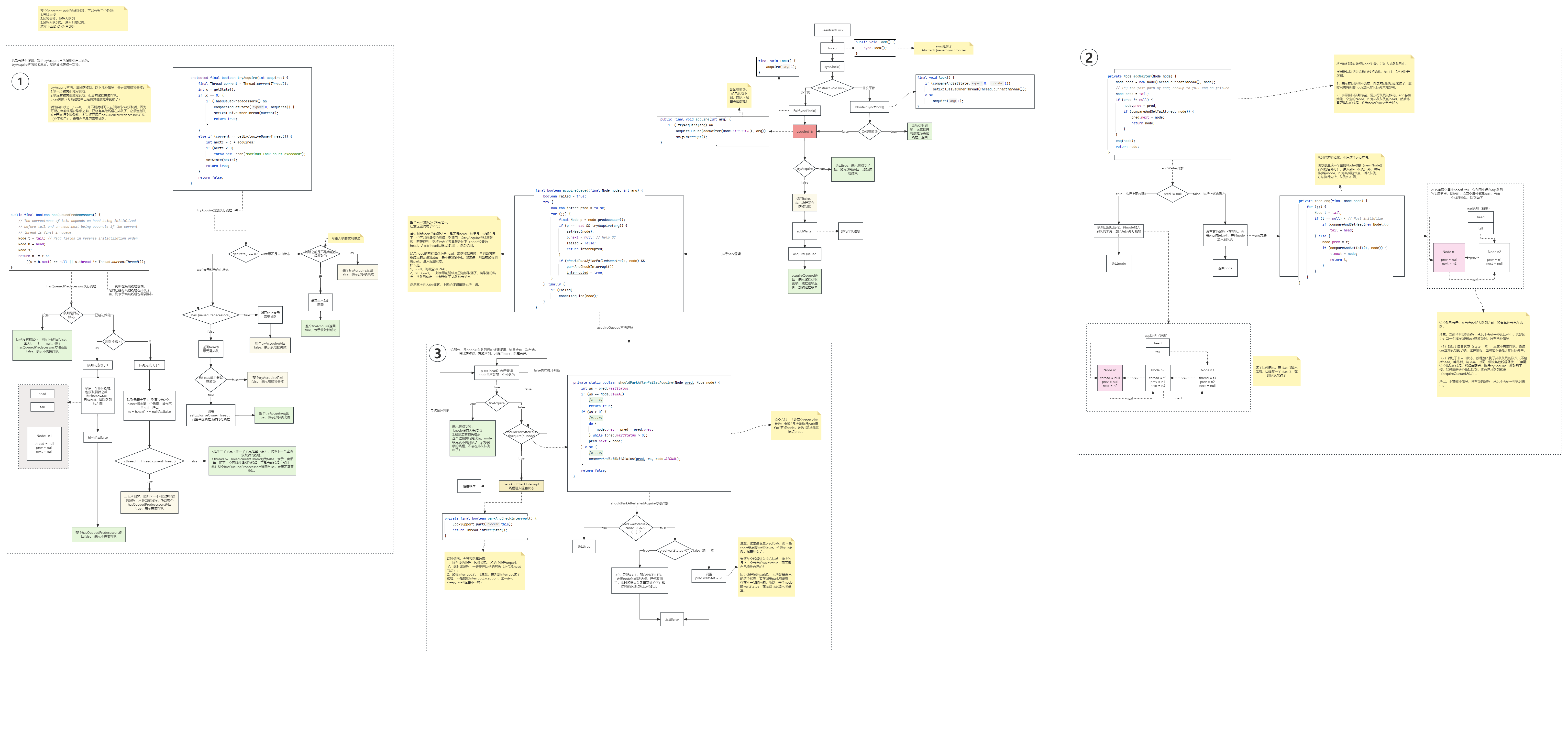
AQS是什么?AbstractQueuedSynchronizer之AQS原理及源码深度分析
文章目录 一、AQS概述1、什么是AQS2、技术解释3、基本原理4、AQS为什么这么重要 二、AQS数据结构1、AQS的结构2、ReentrantLock与AbstractQueuedSynchronizer3、AQS的state变量4、AQS的队列5、AQS的Node(1)Node的waitStatus(2)属性…...
)
【数据库】函数处理(文本处理函数、日期和时间处理函数、数值处理函数)
函数处理数据 算术运算函数文本处理函数日期和时间处理函数数值处理函数 算术运算 操作符说明加-减*乘/除 e . g . e.g. e.g. 列出 Orders 表中所有每项物品的 id,数量 quantity,单价 item_price,总价 expanded_price(数量 * 单价…...

GEE案例——一个完整的火灾监测案例dNBR差异化归一化烧毁指数
差异化归一化烧毁指数 dNBR是"差异化归一化烧毁指数"的缩写。它是一种用于评估卫星图像中烧毁区域严重程度的遥感指数。dNBR值通过将火灾前的归一化烧毁指数(NBR)减去火灾后的NBR来计算得出。该指数常用于野火监测和评估。 dNBR(差异化归一化烧毁指数)是一种用…...

计算机算法分析与设计(20)---回溯法(0-1背包问题)
文章目录 1. 题目描述2. 算法思路3. 例题分析4. 代码编写 1. 题目描述 对于给定的 n n n 个物品,第 i i i 个物品的重量为 W i W_i Wi,价值为 V i V_i Vi,对于一个最多能装重量 c c c 的背包,应该如何选择放入包中的物品…...

什么是IO多路复用?Redis中对于IO多路复用的应用?
IO多路复用是一种高效的IO处理方式,它允许一个进程同时监控多个文件描述符(包括套接字、管道等),并在有数据可读或可写时进行相应的处理。这种机制可以大大提高系统的并发处理能力,减少资源的占用和浪费。 在Redis中&…...

NanoPC-T4 RK3399:DTS之io-domain,FAN
前言: 之后所有改动均是基于rk3399-evb.dts修改以满足NanoPC-T4功能正常。 NanoPC-T4开发板上有一片散热风扇,本章将讲述使风扇正常工作起来的多种方法。 一:硬件分析 GPIO4_C6/PWM1:实际控制风扇引脚,GPIO与PWM复用 输入高电平1:FAN2pin电路导通,风扇转动 输入低电…...

vue3+vite+ts项目使用jQuery
1、安装jQuery npm install --save jquery 2、安装声明文件 npm install --save types/jquery 3、在需要的文件中引入 import $ from jquery...
一起学数据结构(10)——排序
从本文开始,通过若干篇文章展开对于数据结构中——排序的介绍。 1. 排序的概念: 将一堆杂乱无章的数据,通过一定的规律顺序排列起来。即将一个无序序列排列成一个有序序(由小到大或者由大到小)的运算。 在数据的排序中…...
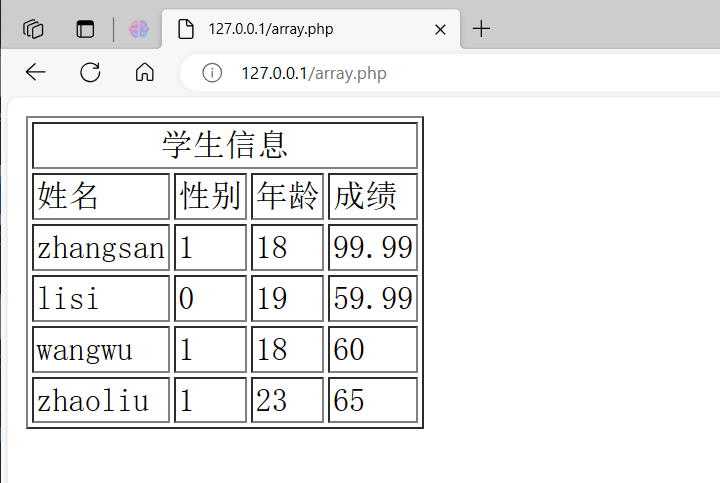
php 数组基础/练习
数组 练习在最后 数组概述 概述与定义 数组中存储键值对 数组实际上是一个有序映射 key-value,可将其当成真正的数组、列表(向量)、散列表、字典、集合、栈、队列等 数组中的元素可以是任意类型的数据对象(可以嵌套数组&#…...
Redbook Chapter 7: Query Optimization翻译批注
首先说明一下redbook上的几篇文章是做什么的。这几篇文章是通过几位作者对不同方面的论文进行阅读和筛选后,挑出其中具备代表性或者权威的论文来做分析,为读者提供阅读指导和建议,同时,也是对某个方面的论文进行高度的总结&#x…...
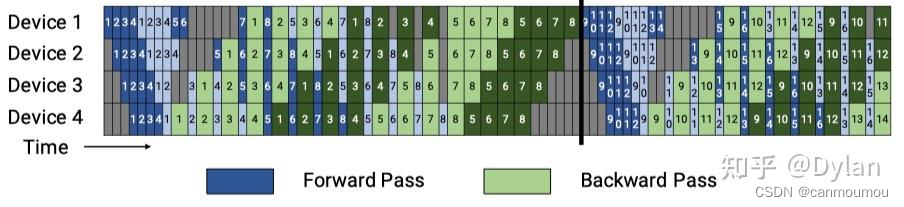
【分布式】大模型分布式训练入门与实践 - 04
大模型分布式训练 数据并行-Distributed Data Parallel1.1 背景1.2 PyTorch DDP1) DDP训练流程2)DistributedSampler3)DataLoader: Parallelizing data loading4)Data-parallel(DP)5)DDP原理解析…...

欧拉图相关的生成与计数问题探究
最近学了一波国家集训队2018论文的最后一个专题。顺便带上了一些我的注解。 先放一波这个论文 1.基本概念 欧拉图问题是图论中的一类特殊的问题。在本文的介绍过程中,我们将会使用一些图 论术语。为了使本文叙述准确,本节将给出一些术语的定义。 定义…...
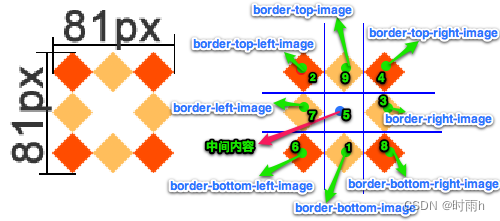
CSS3属性详解(一)文本 盒模型中的 box-ssize 属性 处理兼容性问题:私有前缀 边框 背景属性 渐变 前端开发入门笔记(七)
CSS3是用于为HTML文档添加样式和布局的最新版本的层叠样式表(Cascading Style Sheets)。下面是一些常用的CSS3属性及其详细解释: border-radius:设置元素的边框圆角的半径。可以使用四个值设置四个不同的圆角半径,也可…...

小程序:如何合理规划分包使主包不超过2M
背景 做过小程序项目的同学应该都有这样的经历,项目做着做着,突然发现代码包的大小超过了 2M,小程序无法提审,然后痛苦的删文件改代码来减少包大小。 虽然我们也知道小程序给我们提供了分包的功能可以减少主包的大小,…...

迭代器的封装与反向迭代器
一、反向迭代器 在list模拟实现的过程中,第一次接触了迭代器的封装,将list的指针封装成了一个新的类型,并且以迭代器的基本功能对其进行了运算符重载 反向迭代器是对正向迭代器的封装,并且体现了泛型编程的思想,任意…...

PHP项目学习笔记-萤火商城https://www.yiovo.com/doc
萤火商城学习笔记 注意事项关于建表增加页面流程前台页面的数据列表数据下拉列表的数据 关于时间的处理前台界面数据处理 多年没有碰过php代码了,这个项目不错,想好好学习下,持续更新 注意事项 打开APP_DEBUG有些时候改了前台页面后&#x…...

我国有多少个港口?
港口是什么? 港口是海洋运输中不可或缺的重要设施之一,是连接陆路和水路运输的重要节点。港口通常是指位于沿海地区的水陆交通枢纽,是船舶停靠、装卸货物、储存物资和维修船只的场所。港口一般由码头、泊位、仓库、货场、客运站等设施组成&a…...
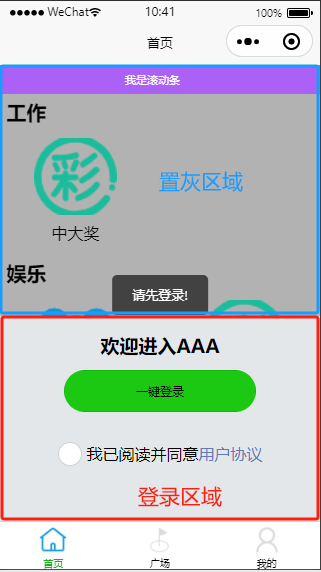
uniapp实现登录组件之外区域置灰并引导登录
实现需求 每个页面需要根据用户是否登录决定是否显示登陆组件,登录组件半屏底部显示,登录组件之外区域置灰,功能按钮点击之后引导提示登录.页面效果如下: 实现思路说明 设置登录组件背景颜色为灰色,将页面分成登录区域(底部)和非登陆区域(上面灰色显示部分), 置灰区域添加…...
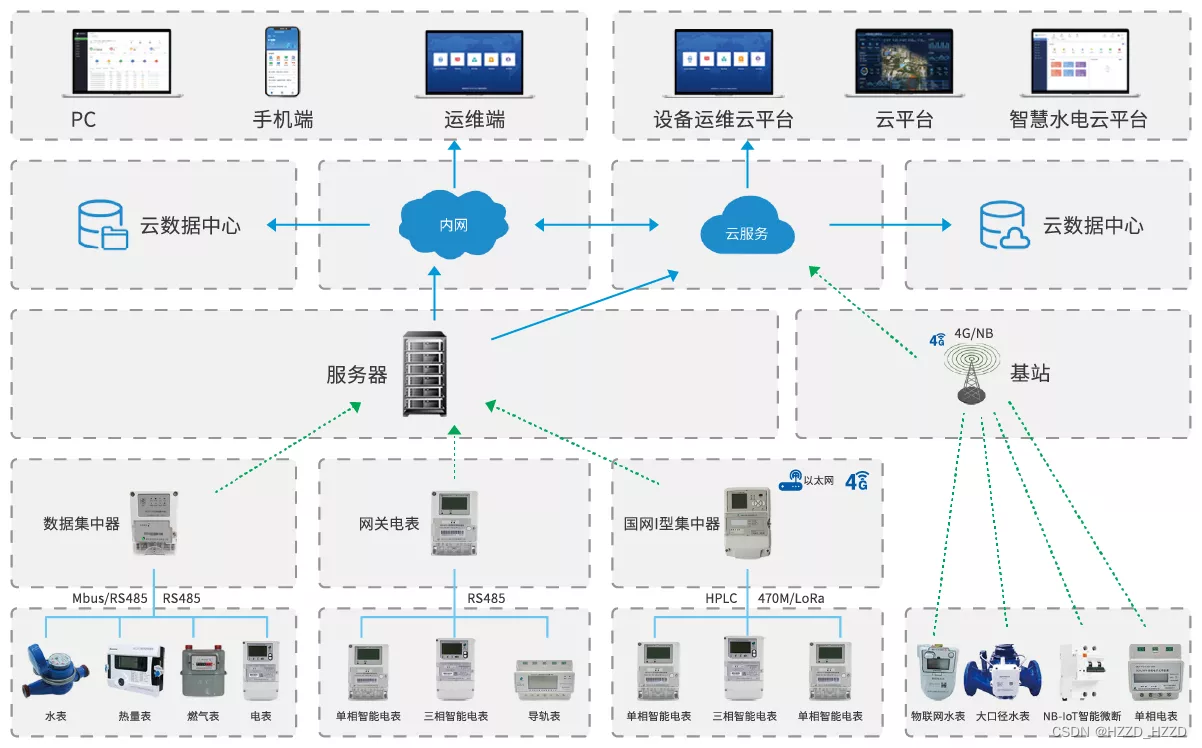
抄表系统是如何抄到电表水表的数据的?
抄表系统是一种利用无线通信技术,实现远程读取电表水表数据的系统。抄表系统主要由三部分组成:电表水表、集中器和后台管理平台。接下来,小编来为大家详细的介绍下抄表系统是如何抄到电表水表的数据的,一起来看下吧! 电表水表是抄…...

惠普OMEN游戏本终极性能优化:OmenSuperHub开源工具完全指南
惠普OMEN游戏本终极性能优化:OmenSuperHub开源工具完全指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件的臃…...
)
Aspose全家桶实战:从零构建一个.NET 6的文档转换微服务(含Docker部署)
Aspose全家桶实战:从零构建.NET 6文档转换微服务 在数字化转型浪潮中,企业文档处理需求正经历从碎片化到集中化的转变。传统单体应用中分散的Word转PDF、Excel报表生成等功能,不仅难以维护,更无法适应云原生时代对弹性伸缩和高可用…...

TalkingHeads开源项目:基于扩散模型的AI人脸说话视频生成技术详解
1. 项目概述:当AI学会“眉目传情” 最近在折腾一个挺有意思的开源项目,叫TalkingHeads。简单来说,它能让一张静态的人脸照片“活”过来,不仅能根据你输入的音频或文本生成口型同步的说话视频,还能让视频里的人做出各种…...

共享茶室智能系统与运营全解析:从空间设计到自动化管理
1. 项目概述:为什么“共享茶室”正在重塑传统茶饮消费如果你最近留意过城市里的新业态,可能会发现一种名为“共享茶室”的空间正在悄然兴起。它不像传统的茶馆那样需要高昂的消费和复杂的社交礼仪,也不像奶茶店那样主打快节奏的“即买即走”。…...

gomicro如何安装部暑
根据最新官方文档,以下是 go-micro(v5 最新版) 的完整安装与部署指南。目前最新稳定版本为 v5.16.0,推荐使用特定版本号安装以避免模块路径冲突。---一、环境准备 要求 说明 Go Go 1.21(建议最新版) …...

终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁
终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS激活锁绕过是许多iPhone用户在设备所有权验证遇到困难时的迫切需求。AppleRa1n…...

Hackintool:黑苹果配置不再复杂,这款工具让你轻松搞定所有难题
Hackintool:黑苹果配置不再复杂,这款工具让你轻松搞定所有难题 【免费下载链接】Hackintool The Swiss army knife of vanilla Hackintoshing 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintool 还在为黑苹果的配置问题头疼吗?…...

Canvas游戏开发实战:从零实现鼠标交互与碰撞检测的趣味拉面游戏
1. 项目概述:一个用光标“吃”拉面的趣味小游戏最近在GitHub上看到一个挺有意思的开源小项目,叫fishyramen/cursorball。光看名字,可能有点摸不着头脑——“鱼味拉面/光标球”?其实,这是一个用你电脑上的鼠标光标来玩的…...

误删/lib64/libc.so.6软连接:从系统“脑死亡”到紧急救援
1. 当系统突然"脑死亡":一场由软连接引发的灾难 那天下午我正在服务器上调试一个依赖glibc 2.18版本的程序,突然看到熟悉的报错:"/lib64/libc.so.6: version GLIBC_2.18 not found"。当时脑子一热,直接执行了…...

TegraRcmGUI:Switch RCM注入工具新手完全指南
TegraRcmGUI:Switch RCM注入工具新手完全指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Nintendo Switch设计的图形化…...