Spark SQL概述与基本操作
目录
一、Spark SQL概述
(1)概念
(2)特点
(3)Spark SQL与Hive异同
(4)Spark的数据抽象
二、Spark Session对象执行环境构建
(1)Spark Session对象
(2)代码演示
三、DataFrame创建
(1)DataFrame组成
(2)DataFrame创建方式(转换)
(3)DataFrame创建方式(标准API读取)
四、DataFrame编程
(1)DSL语法风格
(2)SQL语法风格
五、Spark SQL——wordcount代码示例
(1)pyspark.sql.functions包
(2)代码示例
一、Spark SQL概述
(1)概念
Spark SQL是Apache Spark的一个模块,它用于处理结构化和半结构化的数据。Spark SQL允许用户使用SQL查询和操作数据,这种操作可以直接在Spark的DataFrame/Dataset API中进行。此外,Spark SQL还支持多种语言,包括Scala、Java、Python和R。
(2)特点
①融合性:SQL可以无缝集成在代码中,随时用SQL处理数据。
②统一数据访问:一套标准API可读写不同的数据源。
③Hive兼容:可以使用Spark SQL直接计算生成Hive数据表。
④标准化连接:支持标准化JDBC \ ODBC连接,方便和各种数据库进行数据交互。
(3)Spark SQL与Hive异同
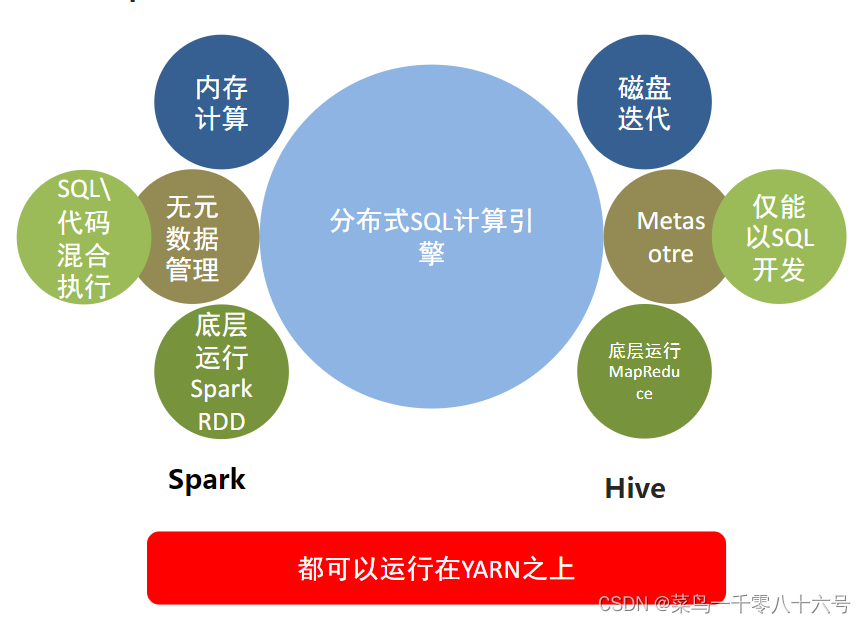
共同点:Hive和Spark均是:“分布式SQL计算引擎”,均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。
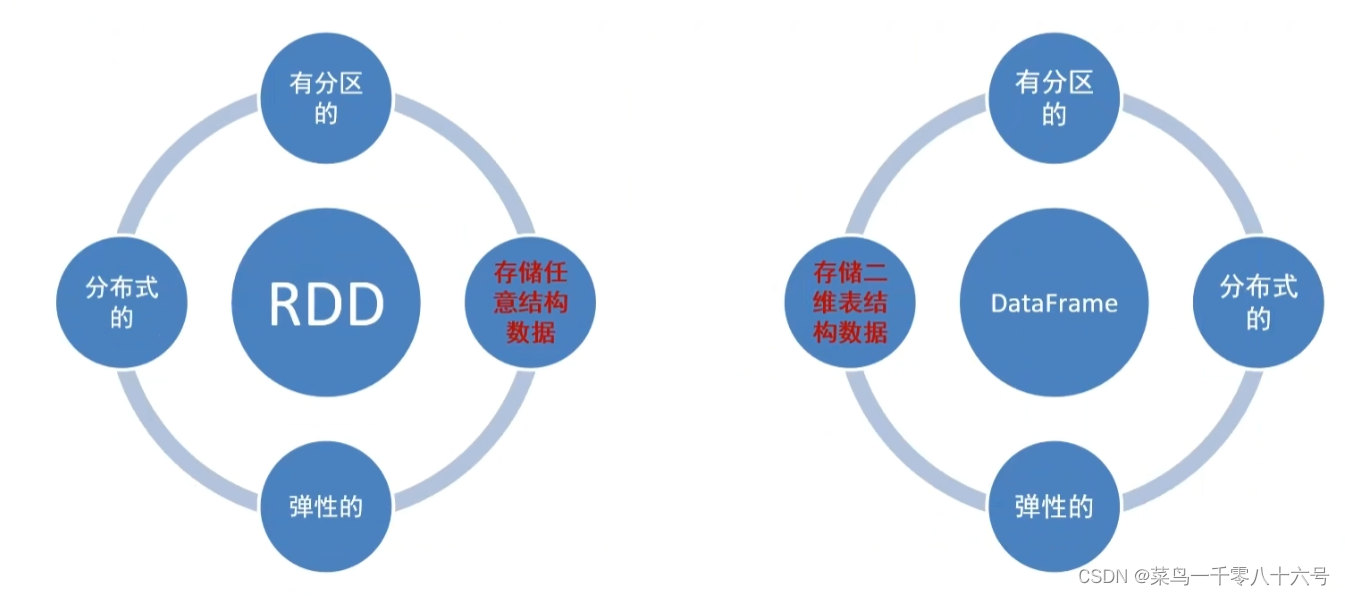
(4)Spark的数据抽象

Spark SQL的数据抽象:

Data Frame与RDD:
二、Spark Session对象执行环境构建
(1)Spark Session对象
在RDD阶段,程序的执行入口对象是:SparkContext。在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
Spark Session对象作用:
①用于SparkSQL编程作为入口对象。
②用于SparkCore编程,可以通过Spark Session对象中获取到Spark Context。
(2)代码演示
# cording:utf8# Spark Session对象的导包,对象是来自于pyspark.sql包中
from pyspark.sql import SparkSession
if __name__ == '__main__':# 构建Spark Session执行环境入口对象spark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()# 通过Spark Session对象 获取SparkContext对象sc = spark.sparkContext# SparkSQL测试df = spark.read.csv('../input/stu_score.txt', sep=',', header=False)df2 = df.toDF('id', 'name', 'score')# 打印表结构# df2.printSchema()# 打印数据内容# df2.show()df2.createTempView('score')# SQL风格spark.sql("""SELECT * FROM score WHERE name='语文' LIMIT 5""").show()# DSL 风格df2.where("name='语文'").limit(5).show()
三、DataFrame创建
(1)DataFrame组成
DataFrame是一个二维表结构,表格结构的组成:
①行
②列
③表结构描述
比如,在MySQL中的一个表:
①有许多列组成
②数据也被分为多个列
③表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提下,DataFrame的组成如下:
在结构层面:
①StructType对象描述整个DataFrame的表结构
②StructField对象描述一个列的信息
在数据层面:
①Row对象记录一行数据
②Column对象记录一列数据并包含列的信息

(2)DataFrame创建方式(转换)
①基于RDD方式
# cording:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 构建执行环境对象Spark Sessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()# 构建SparkContextsc = spark.sparkContext# 基于RDD转换为DataFramerdd = sc.textFile('../input/people.txt').\map(lambda x: x.split(',')).\map(lambda x: (x[0], int(x[1])))# 构建DataFrame对象# 参数1,被转换的RDD# 参数2,指定列名,通过list的形式指定,按照顺序依次提供字符串名称即可df = spark.createDataFrame(rdd,schema=['name', 'age'])# 打印Data Frame的表结构df.printSchema()# 打印df中的数据# 参数1,表示 展示出多少条数据,默认不传的话是20# 参数2,表示是否对列进行截断,如果列的数据长度超过20个字符串长度,厚旬欸日不显示,以....代替# 如果给False 表示不截断全部显示,默认是Truedf.show(20,False)# 将DF对象转换成临时视图表,可供sql语句查询df.createOrReplaceTempView('people')spark.sql('SELECT * FROM people WHERE age < 30').show()
②通过StructType对象来定义DataFrame的 ‘ 表结构 ’ 转换RDD
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
if __name__ == '__main__':# 构建执行环境对象Spark Sessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()# 构建SparkContextsc = spark.sparkContext# 基于RDD转换为DataFramerdd = sc.textFile('../input/people.txt').\map(lambda x: x.split(',')).\map(lambda x: (x[0], int(x[1])))# 构建表结构的描述对象:StructType 对象# 参数1,列名# 参数2,列数据类型# 参数3,是否允许为空schema = StructType().add('name', StringType(), nullable=True).\add('age', IntegerType(), nullable=False)# 构建DataFrame对象# 参数1,被转换的RDD# 参数2,指定列名,通过list的形式指定,按照顺序依次提供字符串名称即可df = spark.createDataFrame(rdd, schema=schema)df.printSchema()df.show()

③通过RDD的toDF方法创建RDD
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
if __name__ == '__main__':# 构建执行环境对象Spark Sessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()# 构建SparkContextsc = spark.sparkContext# 基于RDD转换为DataFramerdd = sc.textFile('../input/people.txt').\map(lambda x: x.split(',')).\map(lambda x: (x[0], int(x[1])))# toDF构建DataFrame# 第一种构建方式,只能设置列名,列类型靠RDD推断,默认允许为空df1 = rdd.toDF(['name', 'name'])df1.printSchema()df1.show()# toDF方式2:通过StructType来构造# 设置全面,能设置列名、列数据类型、是否为空# 构建表结构的描述对象:StructType 对象# 参数1,列名# 参数2,列数据类型# 参数3,是否允许为空schema = StructType().add('name', StringType(), nullable=True).\add('age', IntegerType(), nullable=False)df2 = rdd.toDF(schema=schema)df2.printSchema()df2.show()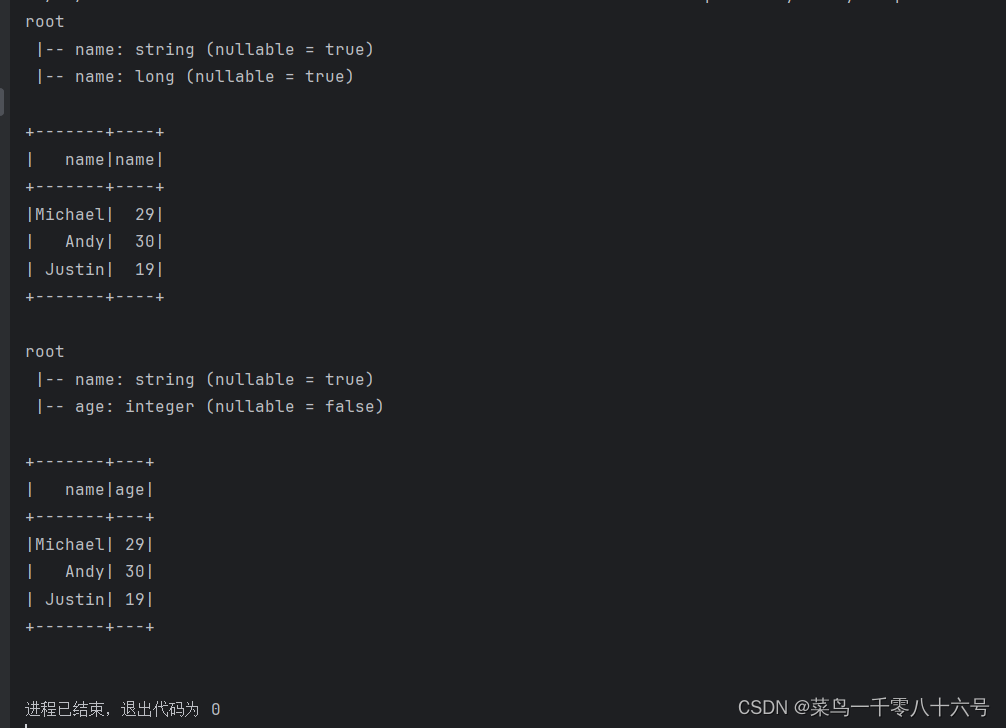
④基于Pandas的DataFrame创建DataFrame
# cording:utf8from pyspark.sql import SparkSession
import pandas as pdif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContext# 基于pandas的DataFrame构建SparkSQL的DataFrame对象pdf = pd.DataFrame({'id': [1, 2, 3],'name': ['张大仙', '王晓晓', '吕不韦'],'age': [1, 2, 3]})df = spark.createDataFrame(pdf)df.printSchema()df.show()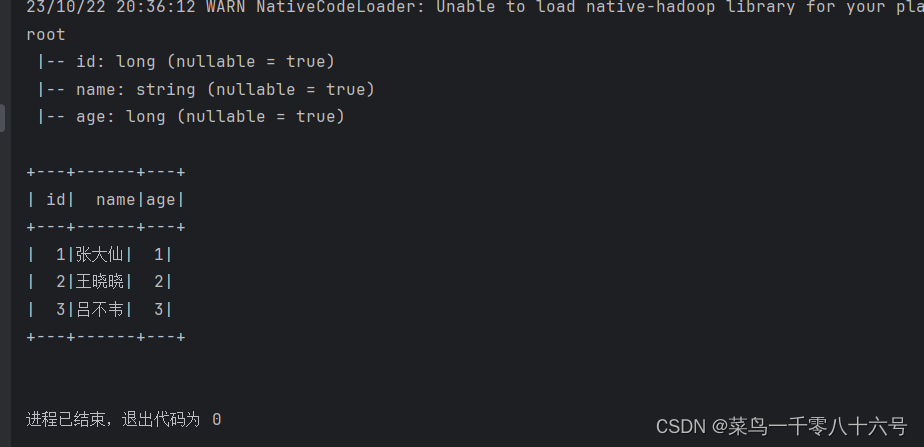
(3)DataFrame创建方式(标准API读取)
统一API示例代码:

①读取本地text文件
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringTypeif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContext# 构建StructType,text数据源,# text读取数据的特点是:将一整行只作为一个列读取,默认列名是value 类型是Stringschema = StructType().add('data', StringType(),nullable=True)df = spark.read.format('text').\schema(schema=schema).\load('../input/people.txt')df.printSchema()df.show()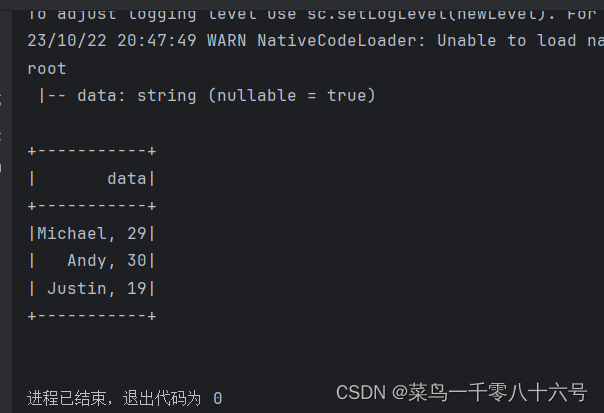
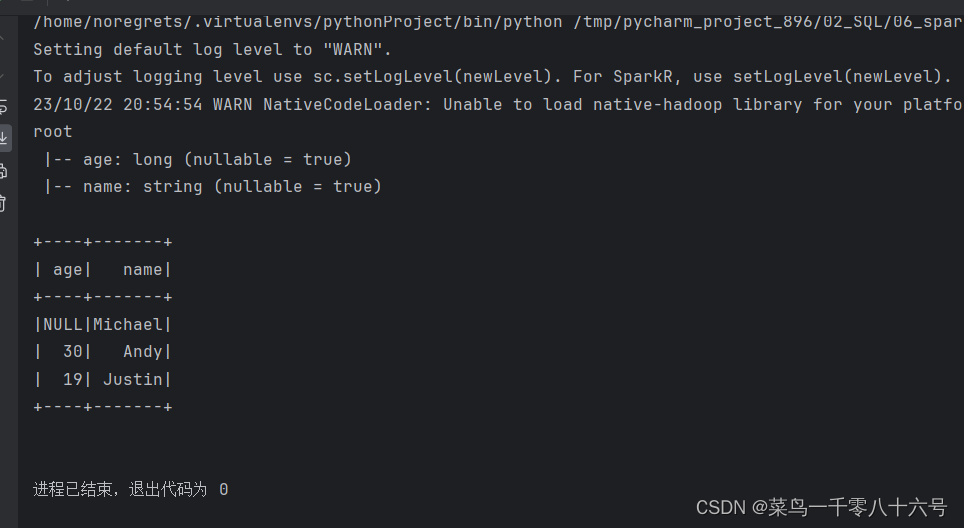
②读取json文件
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringTypeif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContext# json文件类型自带Schema信息df = spark.read.format('json').load('../input/people.json')df.printSchema()df.show()
③读取csv文件

# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringTypeif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContext# 读取csv文件df = spark.read.format('csv').\option('sep', ';').\option('header', True).\option('encoding', 'utf-8').\schema('name STRING, age INT, job STRING').\load('../input/people.csv')df.printSchema()df.show()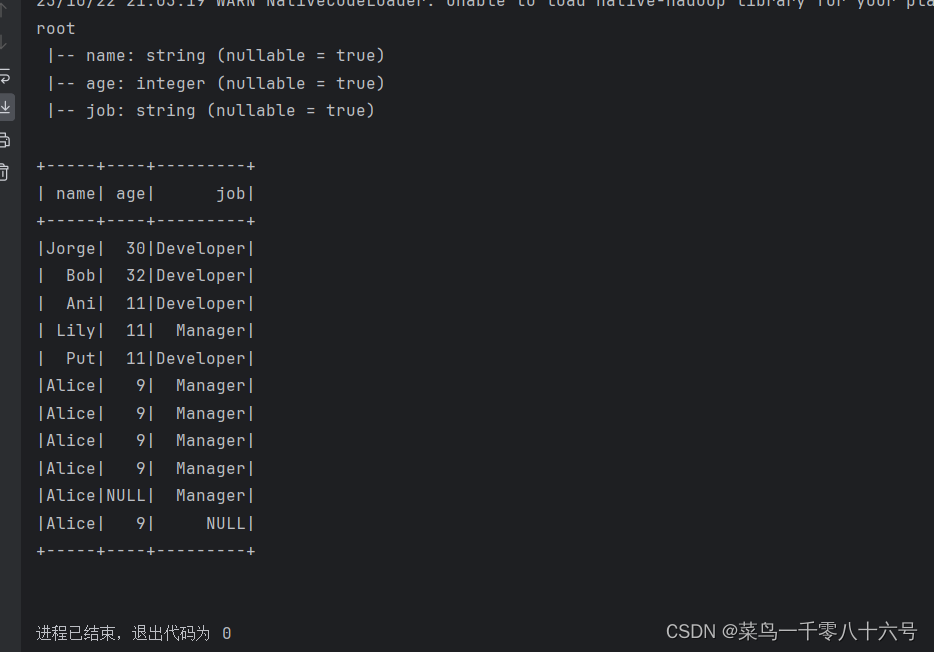
④读取parquet文件
parquet文件:是Spark中常用的一种列式存储文件格式,和Hive中的ORC差不多,他们都是列存储格式。
parquet对比普通的文本文件的区别:
①parquet内置schema(列名、列类型、是否为空)
②存储是以列作为存储格式
③存储是序列化存储在文件中的(有压缩属性体积小)
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringTypeif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContext# 读取parquet文件df = spark.read.format('parquet').load('../input/users.parquet')df.printSchema()df.show()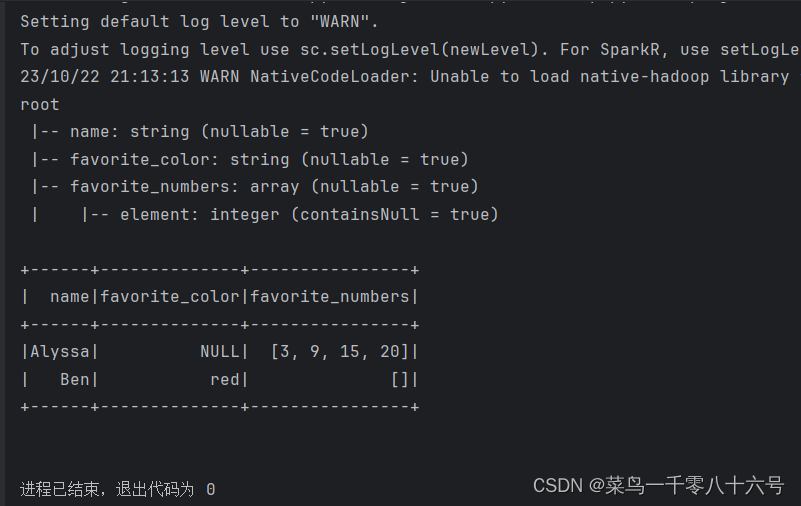
四、DataFrame编程
(1)DSL语法风格
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringTypeif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContextdf = spark.read.format('csv').\schema('id INT, subject STRING, score INT').\load('../input/stu_score.txt')# Column对象的获取id_column = df['id']subject_column = df['subject']# DLS风格df.select(['id', 'subject']).show()df.select('id', 'subject').show()df.select(id_column, subject_column).show()# filter APIdf.filter('score < 99').show()df.filter(df['score'] < 99).show()# where APIdf.where('score < 99').show()df.where(df['score'] < 99).show()# group By API# df.groupBy API的返回值为 GroupedData类型1# GroupedData对象不是DataFrame# 它是一个 有分组关系的数据结构,有一些API供我们对分组做聚合# SQL:group by 后接上聚合: sum avg count min max# GroupedData 类似于SQL分组后的数据结构,同样由上述5中聚合方法# GroupedData 调用聚合方法后,返回值依旧是DayaFrame# GroupedData 只是一个中转的对象,最终还是会获得DataFrame的结果df.groupBy('subject').count().show()df.groupBy(df['subject']).count().show()(2)SQL语法风格
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql()来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
df.createTempView( "score") #注册一个临时视图(表)
df.create0rReplaceTempView("score") #注册一个临时表,如果存在进行替换。
df.createGlobalTempView( "score") #注册一个全局表 全局表:跨SparkSession对象使用,在一个程序内的多个SparkSession中均可调用,查询前带上前缀:
global_temp.
临时表:只在当前SparkSession中可用
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringTypeif __name__ == '__main__':# 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName('test').\master('local[*]').\getOrCreate()sc = spark.sparkContextdf = spark.read.format('csv').\schema('id INT, subject STRING, score INT').\load('../input/stu_score.txt')# 注册成临时表df.createTempView('score') # 注册临时视图(表)df.createOrReplaceTempView('score_2') # 注册或者替换为临时视图df.createGlobalTempView('score_3') # 注册全局临时视图 全局临时视图使用的时候 需要在前面带上global_temp. 前缀# 可以通过SparkSession对象的sql api来完成sql语句的执行spark.sql("SELECT subject, COUNT(*) AS cnt FROM score GROUP BY subject").show()spark.sql("SELECT subject, COUNT(*) AS cnt FROM score_2 GROUP BY subject").show()spark.sql("SELECT subject, COUNT(*) AS cnt FROM global_temp.score_3 GROUP BY subject").show()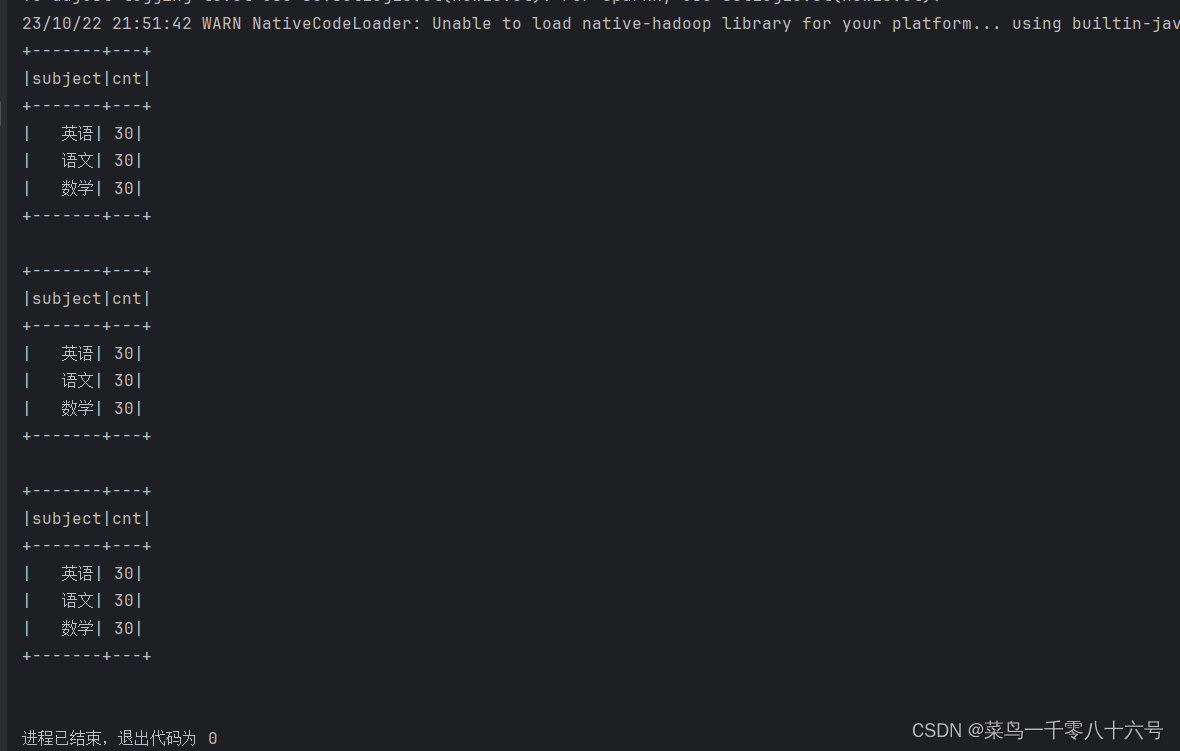
五、Spark SQL——wordcount代码示例
(1)pyspark.sql.functions包
这个包里面提供了一系列的计算函数供SparkSQL使用
导包:from pyspark.sql import functions as F
这些函数返回值多数都是Column对象。

(2)代码示例
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql import functions as Fif __name__ == '__main__':spark = SparkSession.builder.appName('wordcount').master('local[*]').getOrCreate()sc = spark.sparkContext# TODO 1:SQL风格进行处理rdd = sc.textFile('../input/words.txt').\flatMap(lambda x: x.split(' ')).\map(lambda x: [x])df = rdd.toDF(['word'])# 注册DF为表格df.createTempView('words')spark.sql('SELECT word,COUNT(*) AS cnt FROM words GROUP BY word ORDER BY cnt DESC').show()# TODO 2:DSL 风格处理df = spark.read.format('text').load('../input/words.txt')# withColumn 方法# 方法功能:对已存在的列进行操作,返回一个新的列,如果名字和老列相同,那么替换,否则作为新列存在df2 = df.withColumn('value', F.explode(F.split(df['value'], ' ')))df2.groupBy('value').\count().\withColumnRenamed('value', 'word').\withColumnRenamed('count', 'cnt').\orderBy('cnt', ascending=False).show()# withColumnRenamed() 对列名进行重命名# orderBy() 排序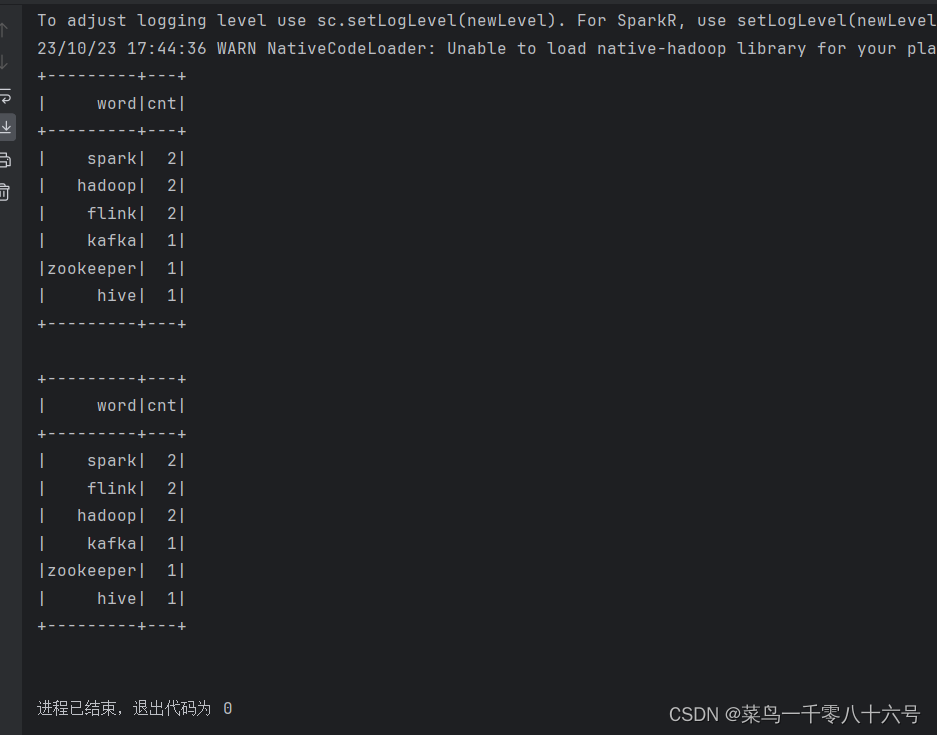
相关文章:
Spark SQL概述与基本操作
目录 一、Spark SQL概述 (1)概念 (2)特点 (3)Spark SQL与Hive异同 (4)Spark的数据抽象 二、Spark Session对象执行环境构建 (1)Spark Session对象 (2)代码演…...
KDChart3.0编译过程-使用QT5.15及QT6.x编译
文章目录 参考原文一、下载KDChart源文件二、下载安装CMake三、编译Qt5.15.0 编译Qt6.x 编译使用Qt6.X编译的直接看这最快 四、使用测试方法一:测试方法二: 参考原文 记录我的KDChart3.0编译过程 系统:win11,Qt5.15 ,编…...
一、PHP环境搭建[phpstorm]
一、安装 1.php编写工具 地址:https://www.jetbrains.com/phpstorm/download/#sectionwindows 图示: 2.php环境 解释:建议使用phpstudy进行安装,安装较为简单 链接:https://www.xp.cn/ 图示: 二、第…...

光影之梦2:动画渲染前后对比,揭示视觉艺术的惊人转变!
动画渲染是影视艺术中不可或缺的一环,它赋予了角色和场景鲜活的生命。渲染过程中的光影、色彩、材质等元素,像是画家的调色板,将平淡无奇的线条和形状转化为充满韵味与情感的画面。动画角色仿佛拥有了自己的灵魂,无论是一颦一笑&a…...

pytorch_lightning:Validation sanity check: 0%| | 0/2 [00:00<?, ?it/s]
在使用Lighting架构辅助训练时,对于出现的下述情况的原因: 解释: 注意到“ Validation sanity check ”。这是因为Lightning在开始训练之前进行了两批验证。这是一种单元测试,以确保如果你在验证循环中有一个bug,你不…...
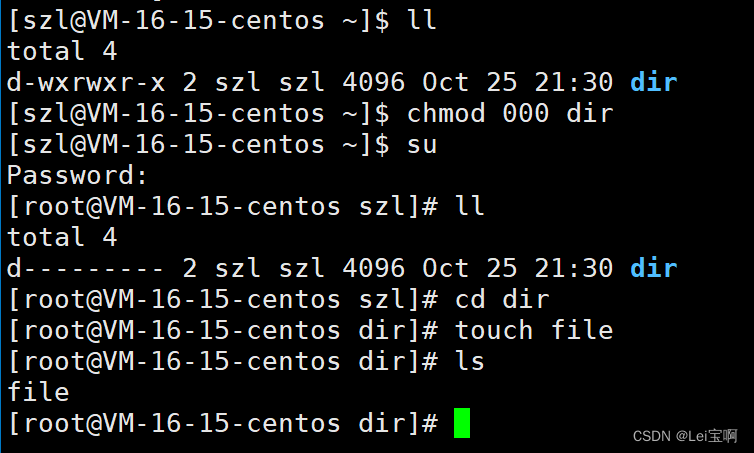
2、Linux权限理解
个人主页:Lei宝啊 愿所有美好如期而遇 目录 前言 Linux权限的概念 1.文件访问者的分(人) 2.文件类型和访问权限(事物属性) 3.文件权限值的表示方法 4.文件访问权限的相关设置方法 file指令 目录的权限 粘滞位 关于权限的总结 前言 在开始Linux权限理…...

Linux 通过 sed 命令过滤指定日期的日志文件并输出到新文件
sed -n /2023-10-18T09:00:00/,/2023-10-18 12:00:00/p mysql_slow.log > out.log...

景联文科技:针对敏感数据的安全转录服务,护航信息安全
针对数据的安全转录服务,主要是为了确保数据在转录过程中的安全性和隐私保护。这些服务通常会采用一系列严格的安全措施,如数据加密、访问控制、数据脱敏等,以确保敏感数据不会被泄露或滥用。 景联文科技提供特定的数据转录服务,以…...

Excel宏(VBA)自动化标准流程代码
自动化流程 我们对一个报表进行自动化改造会经历的固定流程,这里称为“流水线”,通常包含以下流程: 打开一个表格选择打开的表格选择表格中的Sheet选择Sheet中的单元格区域 (有时候需要按条件筛选)复制某个区域 粘贴…...

vue vue3开发 vue2和vue3的选择
现在vue新建项目,官方给出的命令是 npm create vuelatest项目默认vue3,他是不支持IE11 如果想支持IE11用下面方法,项目vue2.7.7 npm create vuelegacy他们的打包工具默认vite,不是webpack。老手要注意生成的项目中的示例组件使…...
【java】A卷+B卷)
华为OD 数列描述(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应往年部分考题以及新出的题目。 我将持续更新最新题目 我精选了一部分题目免费分享给大家,可前往夸克网盘转存,请点击以下链接进入: 我用夸克网盘分享了「华为OD题库J…...
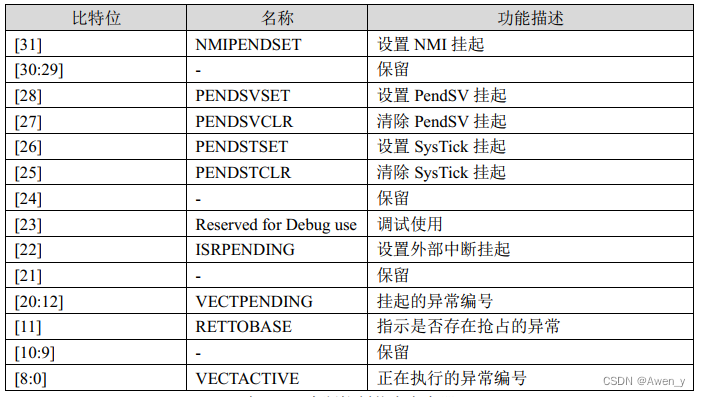
μCOS-Ⅲ中断管理,这样理解非常简单!
μCOS-Ⅲ中断管理,这样理解非常简单! 文章目录 μCOS-Ⅲ中断管理,这样理解非常简单!前言一、中断源与中断优先级二、μCOS-Ⅲ的中断管理方式三、中断屏蔽与中断控制1、μCOS-Ⅲ中断开关2、μCOS-Ⅲ中断屏蔽应用——临界区4、μCOS…...
Vue 项目进行 SEO 优化
SSR 服务器渲染 服务端渲染, 在服务端 html 页面节点, 已经解析创建完了, 浏览器直接拿到的是解析完成的页面解构 关于服务器渲染:Vue 官网介绍 ,对 Vue 版本有要求,对服务器也有一定要求,需要支持 nodejs 环境。 优势: 更好的 …...

【C++入门篇】保姆级教程篇【上】
目录 一、第一个C程序 二、C命名空间 1)什么是命名空间? 2)命名空间的使用 3) std库与namespace展开 4)命名空间的嵌套使用 三、输入输出方式 四、缺省参数 1)什么是缺省参数? 2࿰…...

用傲梅分区软件分割分区重启系统蓝屏BAD_SYSTEM_CONFIG_INFO,八个解决参考方案
环境: Win11 专业版 HP 笔记本 傲梅分区软件 闪迪16G U盘 Win10 官方镜像文件 Win11PE 系统安装U盘 USB固态硬盘盒 问题描述: 起因 开始使用windows自动磁盘管理工具压缩不了磁盘,提示无法将卷压缩到超出任何不可移动的文件所在点,关闭系统保护还原,删除系统创建…...

7-1、S曲线加减速原理【51单片机控制步进电机-TB6600系列】
摘要:本节介绍步进电机S曲线相关内容,总共分四个小节讨论步进电机S曲线相关内容 根据上节内容,步进电机每一段的速度可以任意设置,但是每一段的速度都会跳变,当这个跳变值比较大的时候,电机会发生明显的…...

golang 通過ssh連接遠程服務器 控制
1.下載依賴 go get golang.org/x/crypto/ssh 2.import import ("fmt""log""time""golang.org/x/crypto/ssh" )3.使用 func pwdConnect(sshHost, sshUser, sshPassword string, sshPort int) (*ssh.Client, error) {// 创建ssh登录…...
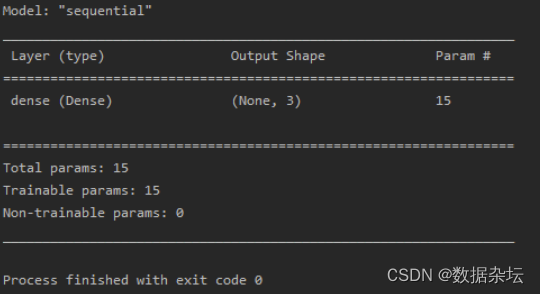
Python深度学习实战-基于tensorflow.keras六步法搭建神经网络(附源码和实现效果)
实现功能 第一步:import tensorflow as tf:导入模块 第二步:制定输入网络的训练集和测试集 第三步:tf.keras.models.Sequential():搭建网络结构 第四步:model.compile():配置训练方法 第五…...

单片机核心/RTOS必备 (ARM汇编)
ARM汇编概述 一开始,ARM公司发布两类指令集: ARM指令集,这是32位的,每条指令占据32位,高效,但是太占空间。Thumb指令集,这是16位的,每条指令占据16位,节省空间。 要节…...

2023/10/25
如果你越来越冷漠 你以为你成长了 但其实没有 长大应该是变得温柔 对全世界都温柔...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

单元体幕墙计算方法研究
单元体幕墙计算方法研究 一、单元板块计算 选择隔离的单个单元进行计算,不需要考虑周边单元的影响。 单元之间的相互影响,来自于左右立柱的变形不一致,在截面选择上反应的就是左右立柱的截面参数的不同。 所以,单元间的相互影响,可以通过控制左右立柱截面参数的相近而进…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...

3分钟完成30分钟任务:词达人自动化助手终极指南
3分钟完成30分钟任务:词达人自动化助手终极指南 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否厌倦了每周在词达人平台上花费数小时完成枯燥的…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...