【大数据】Kafka 实战教程(一)
Kafka 实战教程(一)
- 1.Kafka 介绍
- 1.1. 主要功能
- 1.2. 使用场景
- 1.3 详细介绍
- 1.3.1 消息传输流程
- 1.3.2 Kafka 服务器消息存储策略
- 1.3.3 与生产者的交互
- 1.3.4 与消费者的交互
- 2.Kafka 生产者
- 3.Kafka 消费者
- 3.1 Kafka 消费模式
- 3.1.1 At-most-once(最多一次)
- 3.1.2 At-least-once(最少一次)
- 3.1.3 Exactly-once(正好一次)
- 3.2 消费组与分区重平衡
- 4.Broker
- 5.Topic
- 5.1 Topic 中 Partition 存储分布
- 5.2 Partiton 中文件存储方式
- 5.3 Partiton 中 Segment 文件存储结构
- 5.4 在 Partition 中如何通过 Offset 查找 Message
- 5.5 读写 Message 总结
应用往 Kafka 写数据的原因有很多:用户行为分析、日志存储、异步通信 等。多样化的使用场景带来了多样化的需求:消息是否能丢失?是否容忍重复?消息的吞吐量?消息的延迟?
1.Kafka 介绍
Kafka 属于 Apache 组织,是一个高性能跨语言分布式发布订阅消息队列系统。它的主要特点有:
- 以时间复杂度 O ( 1 ) O(1) O(1) 的方式提供消息持久化能力,并对大数据量能保证常数时间的访问性能。
- 高吞吐率,单台服务器可以达到每秒几十万的吞吐速率。
- 支持服务器间的消息分区,支持分布式消费,同时保证了每个分区内的消息顺序。
- 轻量级,支持实时数据处理和离线数据处理两种方式。
1.1. 主要功能
根据官网的介绍,Apache Kafka 是一个分布式流媒体平台,它主要有 3 种功能:
- 发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 归类为消息队列框架的原因。
- 以容错的方式记录消息流,Kafka 以文件的方式来存储消息流。
- 可以在消息发布的时候进行处理。
1.2. 使用场景
- 消息队列功能,在系统或应用程序之间构建可靠的用于传输实时数据的管道。
- 数据处理功能,构建实时的流数据处理程序来变换或处理数据流。
1.3 详细介绍
Kafka 目前主要作为一个分布式的发布订阅式的消息系统使用,下面简单介绍一下 Kafka 的基本机制。
1.3.1 消息传输流程

Producer:生产者。生产者向 Kafka 集群发送消息,在发送消息之前,会对消息进行分类,即 Topic。上图展示了两个 producer 发送了分类为 topic1 的消息,另外一个发送了 topic2 的消息。
Topic:主题。通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的 Topic 中的消息。
Consumer:消费者。消费者通过与 Kafka 集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个 Topic 下的消费者和生产者的数量并不是对应的。
1.3.2 Kafka 服务器消息存储策略

谈到 Kafka 的存储,就不得不提到分区,即 Partitions,创建一个 Topic 时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,Kafka 在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。

在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
Kafka 中的 Message 以 Topic 的形式存在,Topic 在物理上又分为很多的 Partition,Partition 物理上由很多 Segment 组成,Segment 是存放 Message 的真正载体。
下面具体介绍下 Segment 文件:
- 每个 Partition(目录)相当于一个巨型文件被平均分配到多个大小相等 Segment(段)数据文件中。但每个段 Segment File 消息数量不一定相等,这种特性方便 Old Segment File 快速被删除。
- 每个 Partiton 只需要支持顺序读写就行了,Segment 文件生命周期由服务端配置参数决定。
- Segment File 组成:由 2 大部分组成,分别为
index file和data file,此 2 个文件一一对应,成对出现,后缀.index和.log分别表示为 Segment 索引文件、数据文件。 - Segment 文件命名规则:Partion 全局的第一个 Segment 从 0 0 0 开始,后续每个 Segment 文件名为上一个 Segment 文件最后一条消息的 Offset 值。数值最大为 64 64 64 位
long大小, 19 19 19 位数字字符长度,没有数字用 0 0 0 填充。

.index 文件存放的是 Message 逻辑相对偏移量( 相对 o f f s e t = 绝对 o f f s e t − b a s e o f f s e t 相对 offset = 绝对offset - base\ offset 相对offset=绝对offset−base offset)以及在相应的 .log 文件中的物理位置(Position)。
但 .index 并不是为每条 Message 都指定到物理位置的映射,而是以 entry 为单位,每条 entry 可以指定连续 n n n 条消息的物理位置映射。
例如:假设有 20000 ~ 20009 共 10 条消息,.index 文件可配置为每条 entry 指定连续 10 10 10 条消息的物理位置映射,该例中,index entry 会记录偏移量为 20000 的消息到其物理文件位置,一旦该条消息被定位,20001 ~ 20009 可以很快查到。
每个 entry 大小 8 8 8 字节,前 4 4 4 个字节是这个 Message 相对于该 log segment 第一个消息 offset(base offset)的相对偏移量,后 4 4 4 个字节是这个消息在 .log 文件中的物理位置。
1.3.3 与生产者的交互

生产者在向 Kafka 集群发送消息的时候,可以通过指定分区来发送到指定的分区中。也可以通过指定均衡策略来将消息发送到不同的分区中。如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中。
1.3.4 与消费者的交互

在消费者消费消息时,Kafka 使用 Offset 来记录当前消费的位置。
在 Kafka 的设计中,可以有多个不同的 Group 来同时消费同一个 Topic 下的消息。如上图,我们有两个不同的 Group 同时消费,他们的消费的记录位置 Offset 各不项目,不互相干扰。
对于一个 Group 而言,消费者的数量不应该多于分区的数量,因为在一个 Group 中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费。因此,若一个 Group 中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
2.Kafka 生产者

首先,创建 ProducerRecord 必须包含 Topic 和 Value,Key 和 Partition 可选。然后,序列化 Key 和 Value 对象为 ByteArray,并发送到网络。
接下来,消息发送到 Partitioner。如果创建 ProducerRecord 时指定了 Partition,此时 Partitioner 啥也不用做,简单的返回指定的 Partition 即可。如果未指定 Partition,Partitioner 会基于 ProducerRecord 的 Key 生成 Partition。Producer 选择好 Partition后,增加 record 到对应 Topic 和 Partition 的 Batch Record。最后,专有线程负责发送 Batch Record 到合适的 Kafka Broker。
当 Broker 收到消息时,它会返回一个应答(response)。如果消息成功写入 Kafka,Broker 将返回 RecordMetadata 对象(包含 Topic,Partition 和 Offset);相反,Broker 将返回 error。这时 Producer 收到 error 会尝试重试发送消息几次,直到 Producer 返回 error。
实例化 Producer 后,接着发送消息。这里主要有 3 种发送消息的方法:
- 立即发送:只管发送消息到 Server 端,不关心消息是否成功发送。大部分情况下,这种发送方式会成功,因为 Kafka 自身具有高可用性,Producer 会自动重试,但有时也会丢失消息。
- 同步发送:通过
send()方法发送消息,并返回 Future 对象。get()方法会等待 Future 对象,看send()方法是否成功。 - 异步发送:通过带有回调函数的
send()方法发送消息,当 Producer 收到 Kafka Broker 的response会触发回调函数。
以上所有情况,一定要时刻考虑发送消息可能会失败,想清楚如何去处理异常。
通常我们是一个 Producer 起一个线程开始发送消息。为了优化 Producer 的性能,一般会有下面几种方式:单个 Producer 起多个线程发送消息;使用多个 Producer。
3.Kafka 消费者
3.1 Kafka 消费模式
Kafka 的消费模式总共有 3 种:最多一次,最少一次,正好一次。为什么会有这 3 种模式,是因为客户端 处理消息,提交反馈(commit)这两个动作不是原子性。
- 最多一次:客户端收到消息后,在处理消息前自动提交,这样 Kafka 就认为 Consumer 已经消费过了,偏移量增加。
- 最少一次:客户端收到消息,处理消息,再提交反馈。这样就可能出现消息处理完了,在提交反馈前,网络中断或者程序挂了,那么 Kafka 认为这个消息还没有被 Consumer 消费,产生重复消息推送。
- 正好一次:保证消息处理和提交反馈在同一个事务中,即有原子性。
本文从这几个点出发,详细阐述了如何实现以上三种方式。
3.1.1 At-most-once(最多一次)
(1)设置 enable.auto.commit 为 ture。
(2)设置 auto.commit.interval.ms 为一个较小的时间间隔。
(3)Client 不要调用 commitSync(),Kafka 在特定的时间间隔内自动提交。
3.1.2 At-least-once(最少一次)
方法一
(1)设置 enable.auto.commit 为 false。
(2)Client 调用 commitSync(),增加消息偏移。
方法二
(1)设置 enable.auto.commit 为 ture。
(2)设置 auto.commit.interval.ms 为一个较大的时间间隔。
(3)Client 调用 commitSync(),增加消息偏移。
3.1.3 Exactly-once(正好一次)
如果要实现这种方式,必须自己控制消息的 offset,自己记录一下当前的 offset,对消息的处理和 offset 的移动必须保持在同一个事务中,例如在同一个事务中,把消息处理的结果存到 MySQL 数据库,同时更新此时的消息的偏移。
(1)设置 enable.auto.commit 为 false。
(2)保存 ConsumerRecord 中的 Coffset 到数据库。
(3)当 Partition 分区发生变化的时候需要再均衡(Rebalance),有以下几个事件会触发分区变化:
- Consumer 订阅的 Topic 中的分区大小发生变化。
- Topic 被创建或者被删除。
- Consuer 所在 Group 中有个成员挂了。
- 新的 Consumer 通过调用
join加入了 Group。
(4)此时 Consumer 通过实现 ConsumerRebalanceListener 接口,捕捉这些事件,对偏移量进行处理。
(5)Consumer 通过调用 seek(TopicPartition, long) 方法,移动到指定的分区的偏移位置。
3.2 消费组与分区重平衡
当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为 重平衡(Rebalance)。重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。后面我们会讨论如何安全的进行重平衡以及如何尽可能避免。
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的 Broker 来保持在消费组内存活。这个 Broker 不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
在 0.10.1 0.10.1 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
4.Broker
Kafka 是一个高吞吐量分布式消息系统,采用 Scala 和 Java 语言编写,它提供了快速、可扩展的、分布式、分区的和可复制的日志订阅服务。它由 Producer、Broker、Consumer 三部分构成.
Producer 向某个 Topic 发布消息,而 Consumer 订阅某个 Topic 的消息。 一旦有某个 Topic 新产生的消息,Broker 会传递给订阅它的所有 Consumer,每个 Topic 分为多个分区,这样的设计有利于管理数据和负载均衡。
- Broker:消息中间件处理结点,一个 Kafka 节点就是一个 Broker,多个 Broker 可以组成一个 Kafka 集群。
- Controller:中央控制器 Control,负责管理分区和副本状态并执行管理着这些分区的重新分配(里面涉及到 Partition Leader 选举)。
- ISR(
In-Sync Replicas,同步副本组):Kafka 为某个分区维护的一组同步集合,即每个分区都有自己的一个 ISR 集合,处于 ISR 集合中的副本,意味着 Follower 副本与 Leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 Leader。一条 Kafka 消息,只有被 ISR 中的副本都接收到,才被视为 “已同步” 状态。这跟 ZK 的同步机制不一样,ZK 只需要超过半数节点写入,就可被视为已写入成功。
5.Topic
在 Kafka 中,消息是按 Topic 组织的。
- Partition:Topic 物理上的分组,一个 Topic 可以分为多个 Partition,每个 Partition 是一个有序的队列。
- Segment:Partition 物理上由多个 Segment 组成
- Offset:每个 Partition 都由一系列有序的、不可变的消息组成,这些消息被连续的追加到 Partition 中。Partition 中的每个消息都有一个连续的序列号叫做 Offset,用于 Partition 唯一标识一条消息。
5.1 Topic 中 Partition 存储分布
在 Kafka 文件存储中,同一个 Topic 下有多个不同 Partition,每个 Partition 为一个目录,Partiton 命名规则为 Topic 名称 + 有序序号,第一个 Partiton 序号从 0 0 0 开始,序号最大值为 Partitions 数量减 1 1 1。
├── data0
│ ├── cleaner-offset-checkpoint
│ ├── client_mblogduration-35
│ │ ├── 00000000000004909731.index
│ │ ├── 00000000000004909731.log // 1G 文件--Segment
│ │ ├── 00000000000005048975.index // 数字是 Offset
│ │ ├── 00000000000005048975.log
│ ├── client_mblogduration-37
│ │ ├── 00000000000004955629.index
│ │ ├── 00000000000004955629.log
│ │ ├── 00000000000005098290.index
│ │ ├── 00000000000005098290.log
│ ├── __consumer_offsets-33
│ │ ├── 00000000000000105157.index
│ │ └── 00000000000000105157.log
│ ├── meta.properties
│ ├── recovery-point-offset-checkpoint
│ └── replication-offset-checkpoint
cleaner-offset-checkpoint:存了每个日志最后清理的 Offset。记录当前清理到哪里了,这时候 Kafka 就知道哪部分是已经清理的,哪部分是未清理的。meta.properties:broker.id信息。recovery-point-offset-checkpoint:表示已经刷写到磁盘的记录。日志恢复点(recoveryPoint)以下的数据都是已经刷到磁盘上的了。replication-offset-checkpoint:用来存储每个 Replica 的 High Watermark(HW)。High Watermark 表示已经被commited的 Message,HW 以下的数据都是各个 Replicas 间同步的,一致的。

5.2 Partiton 中文件存储方式
每个 Partion(目录)由多个大小相等 Segment(段)数据文件组成。但每个段 Segment File 消息数量不一定相等,这种特性方便 Old Segment File 快速被删除。
每个 Partiton 只需要支持顺序读写就行了,Segment 文件生命周期由服务端配置参数决定。
5.3 Partiton 中 Segment 文件存储结构
Segment File 组成:由 2 大部分组成,分别为 index file 和 data file,此 2 个文件一一对应,成对出现,后缀 .index 和 .log 分别表示为 Segment 的索引文件、数据文件。
Segment 文件命名规则:Partion 全局的第一个 Segment 从 0 0 0 开始,后续每个 Segment 文件名为上一个 Segment 文件最后一条消息的 Offset 值。数值最大为 64 64 64 位 long 大小, 19 19 19 位数字字符长度,没有数字用 0 0 0 填充。
以一对 Segment File 文件为例,说明 Segment 中 index file、data file 对应关系物理结构如下:
index文件存储大量元数据,指向对应log文件中message的物理偏移地址。log数据文件存储大量消息。
其中以 index 文件中元数据 3 , 497 3,497 3,497 为例,依次在数据文件中表示第 3 3 3 个 message(在全局 Partiton 表示第 368772 368772 368772 个 message)、以及该消息的物理偏移地址为 497 497 497。
segment data file 由许多 message 组成,下面详细说明 message 物理结构如下:
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 该 message 在 partition 的 offset |
| 4 byte message size | message 大小 |
| 4 byte CRC32 | 用 crc32 校验 message |
| 1 byte “magic” | 表示本次发布 Kafka 服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型 |
| 4 byte key length | 表示 key 的长度,当 key 为 − 1 -1 −1 时,K byte key 字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据 |
5.4 在 Partition 中如何通过 Offset 查找 Message
例如读取 offset = 368776 的 Message,需要通过下面 2 个步骤查找。
(1)第一步查找 segment file
00000000000000000000.index 表示最开始的文件,起始偏移量(offset)为 0 0 0。第二个文件00000000000000368769.index 的消息量起始偏移量为 368770 = 368769 + 1。同样,第三个文件 00000000000000737337.index 的起始偏移量为 737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据 offset 二分查找文件列表,就可以快速定位到具体文件。
当 offset=368776 时定位到 00000000000000368769.index|log
(2)第二步通过 segment file 查找 message
通过第一步定位到 segment file,当 offset=368776 时,依次定位到 00000000000000368769.index 的元数据物理位置(这个较小,可以放在内存中,直接操作)和 00000000000000368769.log 的物理偏移地址,然后再通过 00000000000000368769.log 顺序查找直到 offset=368776 为止。
segment index file 采取稀疏索引存储方式,它减少索引文件大小,通过 Map 可以直接内存操作,稀疏索引为数据文件的每个对应 Message 设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
5.5 读写 Message 总结
- 写
message- 消息从 Java 堆转入 page cache(即物理内存)。
- 由异步线程刷盘,消息从 page cache 刷入磁盘。
- 读
message- 消息直接从 page cache 转入 socket 发送出去。
- 当从 page cache 没有找到相应数据时,此时会产生磁盘 IO,从磁盘 Load 消息到 page cache,然后直接从 socket 发出去。
Kafka 高效文件存储设计特点
- Topic 中一个 Parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位 message 和确定 response 的最大大小。
- 通过
index元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。 - 通过索引文件稀疏存储,可以大幅降低
index文件元数据占用空间大小。
相关文章:
【大数据】Kafka 实战教程(一)
Kafka 实战教程(一) 1.Kafka 介绍1.1. 主要功能1.2. 使用场景1.3 详细介绍1.3.1 消息传输流程1.3.2 Kafka 服务器消息存储策略1.3.3 与生产者的交互1.3.4 与消费者的交互 2.Kafka 生产者3.Kafka 消费者3.1 Kafka 消费模式3.1.1 At-most-once(…...

求臻医学:肺癌患者就诊指南及基因检测意义
2023年国家癌症中心公布的最新的数据显示,中国癌症新发病例数前十的癌症分别是:肺癌82万,结直肠癌56万,胃癌48万,乳腺癌42万,肝癌41万,食管癌32万,甲状腺癌22万,胰腺癌12…...

【项目管理】项目中如何进行风险管理
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉公众号👈:测试开发自动化【获取源码商业合作】 👉荣__誉👈:阿里云博客专家博主、5…...

【算法题】得到K个半回文串的最小修改次数
题目: 给你一个字符串 s 和一个整数 k ,请你将 s 分成 k 个 子字符串 ,使得每个 子字符串 变成 半回文串 需要修改的字符数目最少。 请你返回一个整数,表示需要修改的 最少 字符数目。 注意: 如果一个字符串从左往…...
)
C# 通过IP获取Mac地址(ARP)
C# 通过IP获取Mac地址 [DllImport("Iphlpapi.dll")] private static unsafe extern int SendARP(Int32 dest, Int32 host, ref Int32 mac, ref Int32 length);[DllImport("Ws2_32.dll")] private static extern Int32 inet_addr(string ip);public static…...

【QT】信号和槽
一、前置示例代码 main.cpp #include "widget.h"#include <QApplication>int main(int argc, char *argv[]) {QApplication a(argc, argv); // 应用程序对象a,在Qt中,应用程序对象,有且仅有一个。Widget w; // 窗口对…...

有话则长,无话则短
有话则长,无话则短...

云台/稳定器/无人机姿态控制之欧拉角与四元数控制优缺点分析
基于欧拉角的姿态控制简述: 通过陀螺仪数据解算出姿态:pitch,roll,yaw(相对航向),根据目标 姿态:dst_pitch,dst_roll,dst_yaw计算出误差姿态pitch_err,roll_err,yaw_err。将误差姿态转换为目标速度e_pitch_rate,e_roll_rate,e_yaw_rate。然后…...
:依赖管理神器)
Go 工具链详解(六):依赖管理神器
go mod 是 Golang 的官方依赖管理工具,从 Go 1.11 版本开始引入。go mod 使用一种被称为模块(modules)的方式来管理依赖,每个模块都包含了一组 Golang 包。一个 Go 程序可以由多个模块组成,每个模块都可以有自己的 go.…...

C语言解决约瑟夫环问题
约瑟夫环问题是一个经典的数学问题,它的描述如下:有n个人围成一圈,从第1个人开始报数,数到第m个人出列,然后从出列的下一个人开始重新报数,数到第m个人出列,如此循环,直到最后一个人…...
6.6 Elasticsearch(六)京淘项目改造
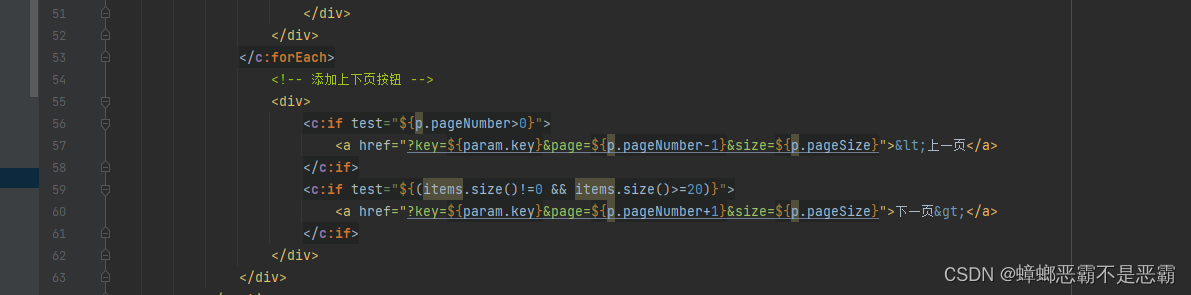
文章目录 1.项目准备2.基础配置2.1 添加pom.xml依赖2.2 yml配置es服务器地址列表 3.具体实现3.1 item实体类封装3.2 添加接口3.3 SearchController 4.search.jsp界面4.1 搜索内容展示4.2 高亮内容样式设置4.3 搜索框内容回填4.4 添加上下页按钮 1.项目准备 我们切换回到此前的…...

Socks5代理:数字化时代的技术支柱
随着数字化时代的到来,技术不仅改变了我们的日常生活,还重新定义了商业、通信、娱乐和全球互联。在这一浪潮中,Socks5代理技术崭露头角,成为跨界电商、爬虫数据分析、企业出海和游戏体验的关键推动力。这项技术不仅在实现数字化愿…...
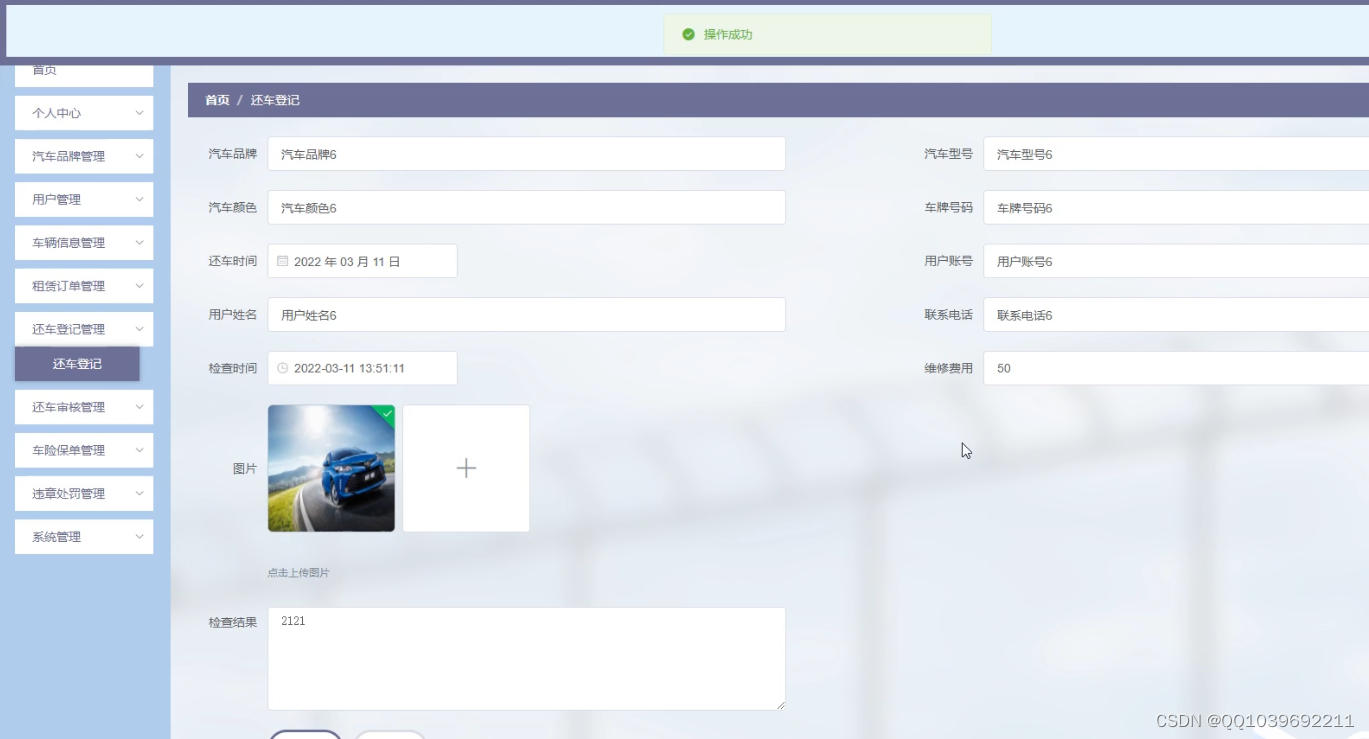
基本微信小程序的汽车租赁公司小程序
项目介绍 任何系统都要遵循系统设计的基本流程,本系统也不例外,同样需要经过市场调研,需求分析,概要设计,详细设计,编码,测试这些步骤,基于Java语言、微信小程序技术设计并实现了汽…...
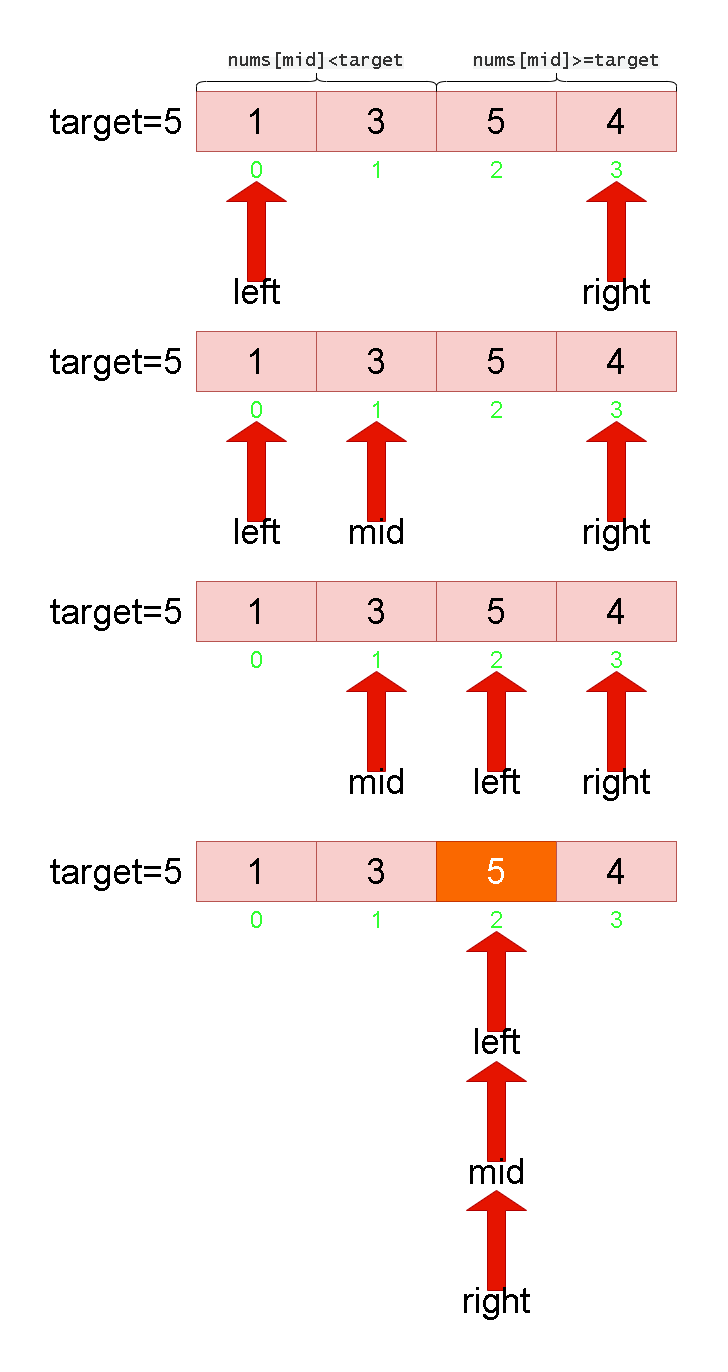
Leetcode刷题详解——搜索插入位置
1. 题目链接:35. 搜索插入位置 2. 题目描述: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。…...

centos升级openssh
注意: openssh升级异常会造成服务失联,如果在允许的情况下可以安装talent服务,使用talent升级; 如果不能安装talent服务,可以打开多个终端,启动ping命令,防止升级终端失败后,作为备用…...

架构、框架、模式,极简文字介绍
1、架构、框架、模式是一种从大到小的关系,也是一种组合关系 2、架构一般针对一个行业或一类应用,是技术和应用的完美组合 3、框架比较小,很多表现为中间件,框架一般是从技术角度解决同类问题,从技术的横切面来解决实…...

Java实现Fisher‘s Exact Test 的置信区间的计算
实现代码 package com.bgi.aigi.common.utils;public class FisherExactUtils {public static double[] getConfidenceInterval(double[][] data) {if (datanull||data.length!2||data[0].length!2||data[1].length!2) {return null;}double[] intervalnew double[2];double …...
,即插即用,助力小目标检测 | NeurIPS2022)
YOLOv8改进:全网原创首发 | 新颖的多尺度卷积注意力(MSCA),即插即用,助力小目标检测 | NeurIPS2022
💡💡💡本文全网首发独家改进:多尺度卷积注意力(MSCA),有效地提取上下文信息,新颖度高,创新十足。 1)作为注意力MSCA使用; 推荐指数:五星 MSCA | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。 💡💡💡Yolov8魔术师,独家首发…...
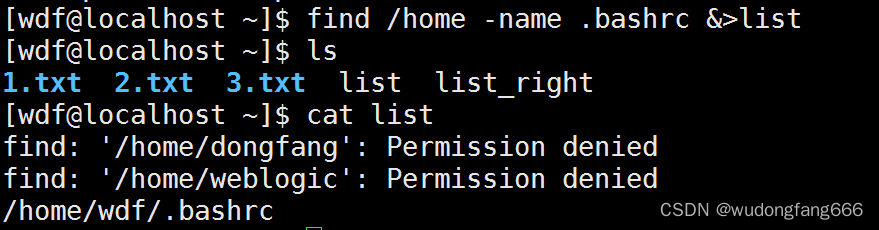
linux中好玩的数据流定向和管道命令一
知识点复习: 什么是数据流定向,个人理解就是将 一些结果信息不打印在屏幕上,而是定位在某一个文件里面 ll /wdf > file 会覆盖file的原内容 ll /wdf >> 会追加到原文件后面 比如在自己的目录新建1.TXT, 2.txt ll /…...

tesseract-ocr-w64-setup-5.3.3.20231005.exe 百度网盘下载
链接:https://pan.baidu.com/s/1q6u-nRvj2S8n6jSYz2iqig?pwdbtm4 提取码:btm4...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南
Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否经常因为…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...

如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案
如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

终极指南:如何在Mac上免费备份和导出微信聊天记录
终极指南:如何在Mac上免费备份和导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而懊恼?或是需要…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...