6.6 Elasticsearch(六)京淘项目改造
文章目录
- 1.项目准备
- 2.基础配置
- 2.1 添加pom.xml依赖
- 2.2 yml配置es服务器地址列表
- 3.具体实现
- 3.1 item实体类封装
- 3.2 添加接口
- 3.3 SearchController
- 4.search.jsp界面
- 4.1 搜索内容展示
- 4.2 高亮内容样式设置
- 4.3 搜索框内容回填
- 4.4 添加上下页按钮
1.项目准备
我们切换回到此前的京淘项目,对京淘项目使用Elasticsearch技术进行改造:

此前我们在pd-web和pd-web-consumer中做了订单削峰,此次的改造,我们不涉及订单的相关业务,只需要对pd-web做改造,对商品完成搜索操作即可,首先运行pd-web模块,测试运行是否正常;
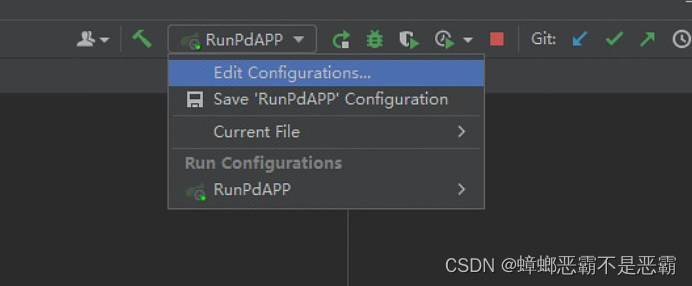
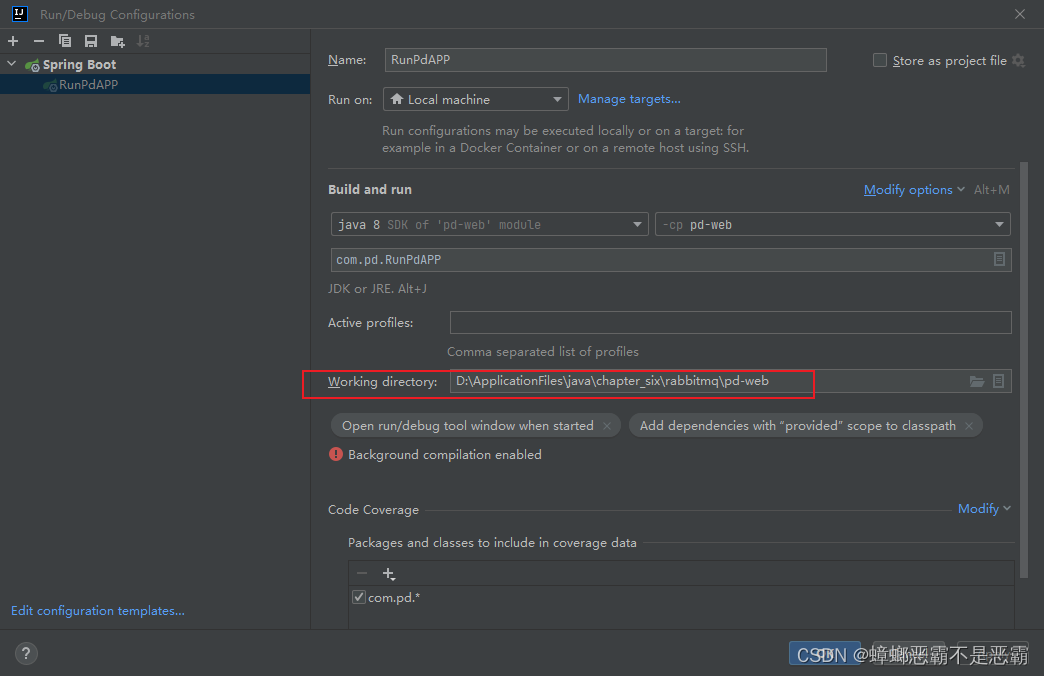
正常启动后,需要设置其工作空间为pd-web文件夹目录:
设置完成后重新启动,访问http://localhost/测试能否成功访问:
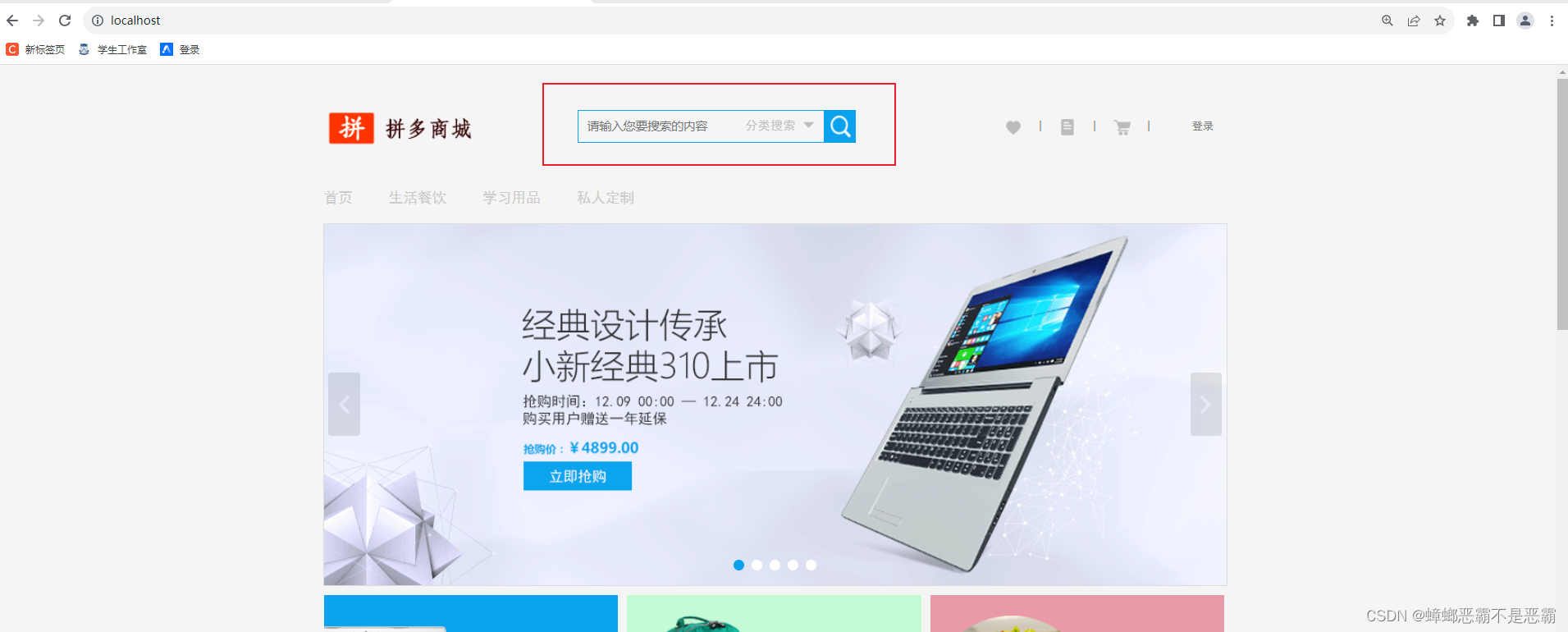
此次,我们就是要完成上方搜索功能的实现;
2.基础配置
2.1 添加pom.xml依赖
在pd-web项目的pom.xml中添加Elasticsearch和lombok的依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
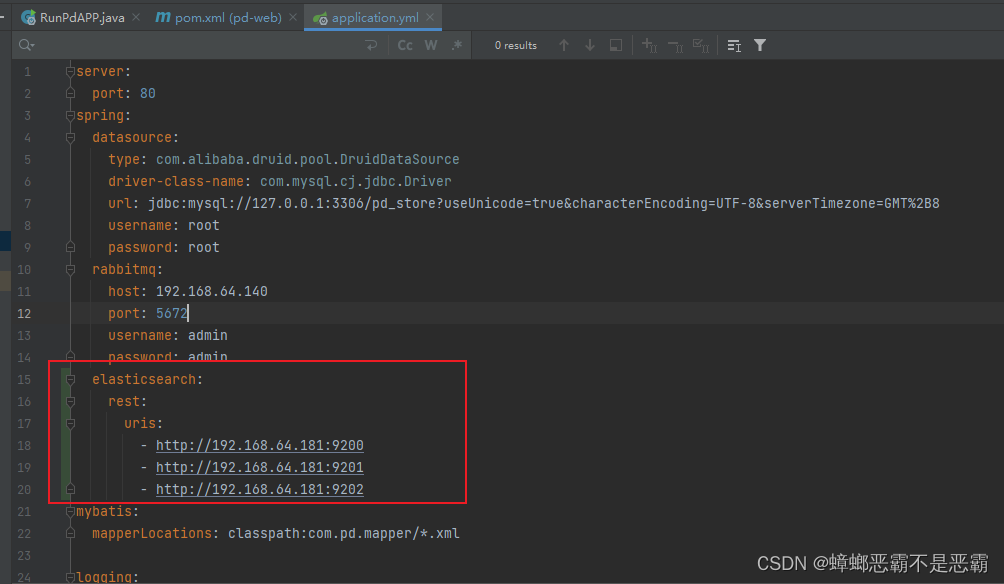
2.2 yml配置es服务器地址列表
在application.yml配置文件中添加es服务器地址列表:
3.具体实现
3.1 item实体类封装
package com.pd.pojo;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;@Document(indexName = "pditems")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Item {@Idprivate Long id;private String brand;private String title;@Fieldprivate String sellPoint;private String price;private String image;
}
我们通过@Document(indexName = "pditems")注解来确定实体类的索引数据具体来自哪里,通过@Id注解来表明当前字段为ID;当实体类中的名字与索引中的字段不一致时,通过@Field("sell_point")注解来建立俩者间的联系;
3.2 添加接口
我们添加ItemRepository接口,定义商品搜索方法:
package com.pd.es;import com.pd.pojo.Item;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.annotations.Highlight;
import org.springframework.data.elasticsearch.annotations.HighlightField;
import org.springframework.data.elasticsearch.annotations.HighlightParameters;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;public interface ItemRepository extends ElasticsearchRepository<Item,Long> {//在title和sellpoint俩个字段中搜索@Highlight(parameters = @HighlightParameters(preTags = "<em>" ,postTags = "</em>"),fields = {@HighlightField(name = "title")})List<SearchHit<Item>> findByTitleOrSellPoint(String key1, String key2, Pageable pageable);
}
接口中需要继承ElasticsearchRepository,并给定访问数据类型与ID的类型;
然后再添加SearchService定义具体的搜索方法:
package com.pd.service;import com.pd.pojo.Item;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.SearchHit;
import java.util.List;public interface SearchService {List<SearchHit<Item>> search(String key, Pageable pageable);
}
以及其实现类SearchServiceImpl:
package com.pd.service.impl;import com.pd.es.ItemRepository;
import com.pd.pojo.Item;
import com.pd.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class SearchServiceImpl implements SearchService {@Autowiredprivate ItemRepository itemRepository;@Overridepublic List<SearchHit<Item>> search(String key, Pageable pageable) {return itemRepository.findByTitleOrSellPoint(key, key, pageable);}
}
用户在搜索框中输入关键词进行搜索时,实际只输入了一个关键词,但是我们要将关键词发送俩次,使用俩个key来接收它,用户商品搜索中名字以及卖点的关键字:
3.3 SearchController
package com.pd.controller;import com.pd.pojo.Item;
import com.pd.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.ArrayList;
import java.util.List;@Controller
public class SearchController {@Autowiredprivate SearchService searchService;//?key=手机&page=0&size=20@GetMapping("/search/toSearch.html")public String search(Model model, String key, Pageable pageable) {// model对象用来向jsp传递数据的工具List<SearchHit<Item>> list = searchService.search(key, pageable);List<Item> items = zhuanHuan(list); //转换// items 集合传递到 jsp 进行显示// pageable 对象传递到 jsp 显示翻页model.addAttribute("items", items);model.addAttribute("p", pageable);return "/search.jsp";}private List<Item> zhuanHuan(List<SearchHit<Item>> list) {List<Item> items = new ArrayList<>();for (SearchHit<Item> sh : list) {Item item = sh.getContent(); //原始数据,没有高亮List<String> hlTitle = sh.getHighlightField("title"); //高亮titleitem.setTitle(pinJie(hlTitle));//高亮title替换原始的title数据items.add(item);}return items;}private String pinJie(List<String> hlTitle) {StringBuilder s = new StringBuilder();for (String s1 : hlTitle) {s.append(s1);}return s.toString();}
}
4.search.jsp界面
我们这里的项目不是前后端分离的项目,这里我们直接使用在webapp目录下的search.jsp界面,上面SearchController 中也将数据直接返回给了search.jsp;
4.1 搜索内容展示
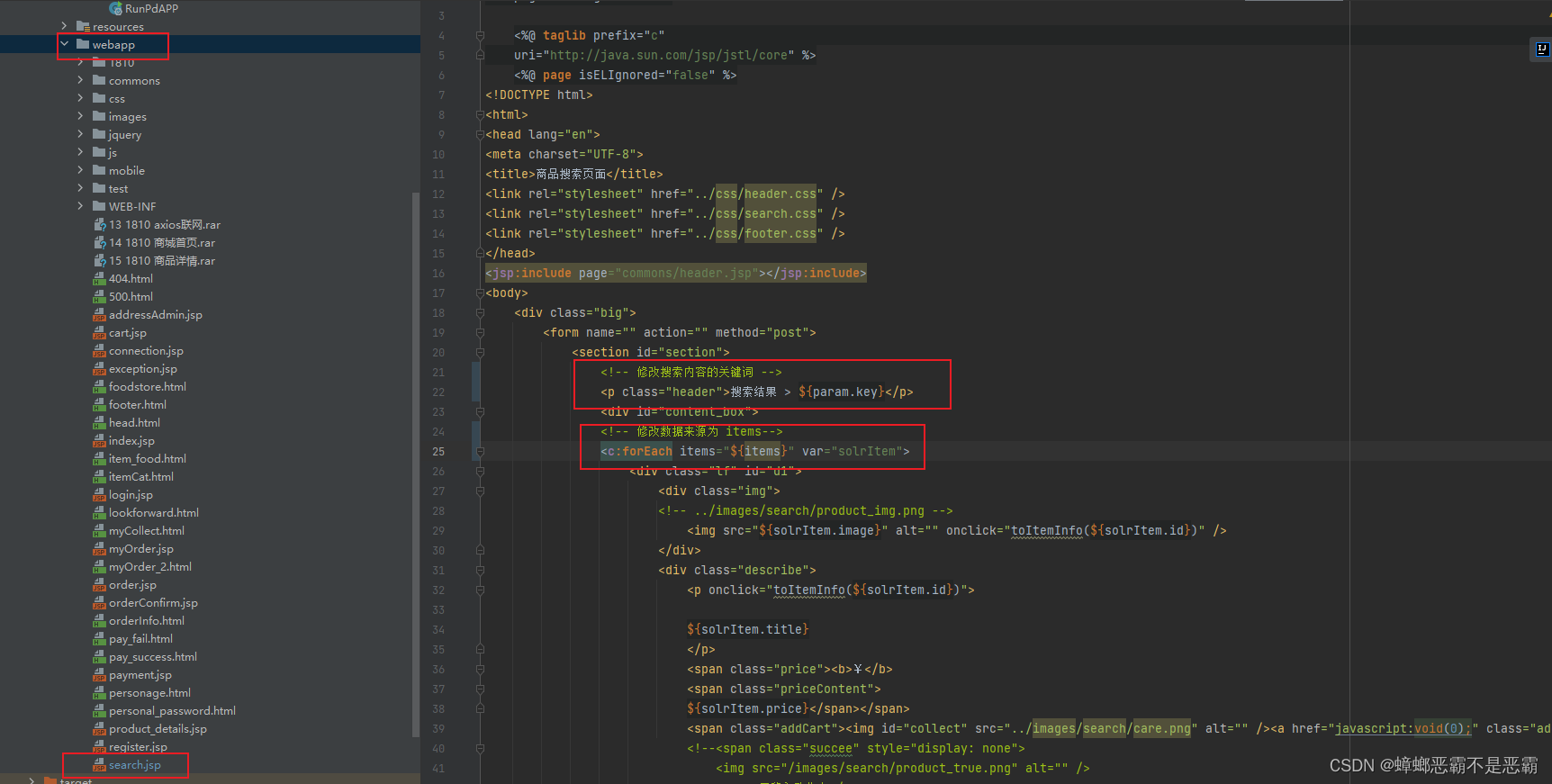
接下来我们调整jsp页面的相关代码:
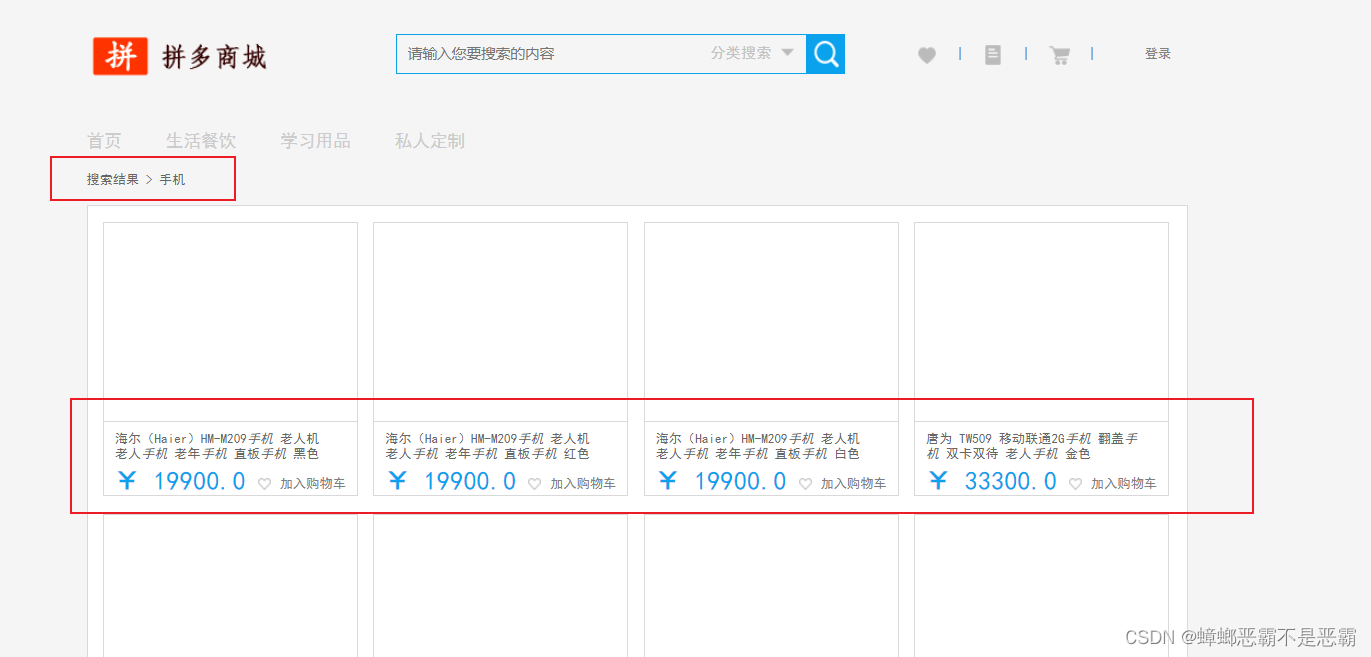
此时搜索结果已可以正确显示:
4.2 高亮内容样式设置
但是此时,我们设置的高亮显示的内容只是变为了斜体,并没有其他特殊样式,我们通过css样式设置来进行优化:,通过定位网页源代码我们可以看到,高亮显示的内容是在一个<div>标签中,且通过class分类为describe,内部在<p>标签中,且被<em>标签包裹着:
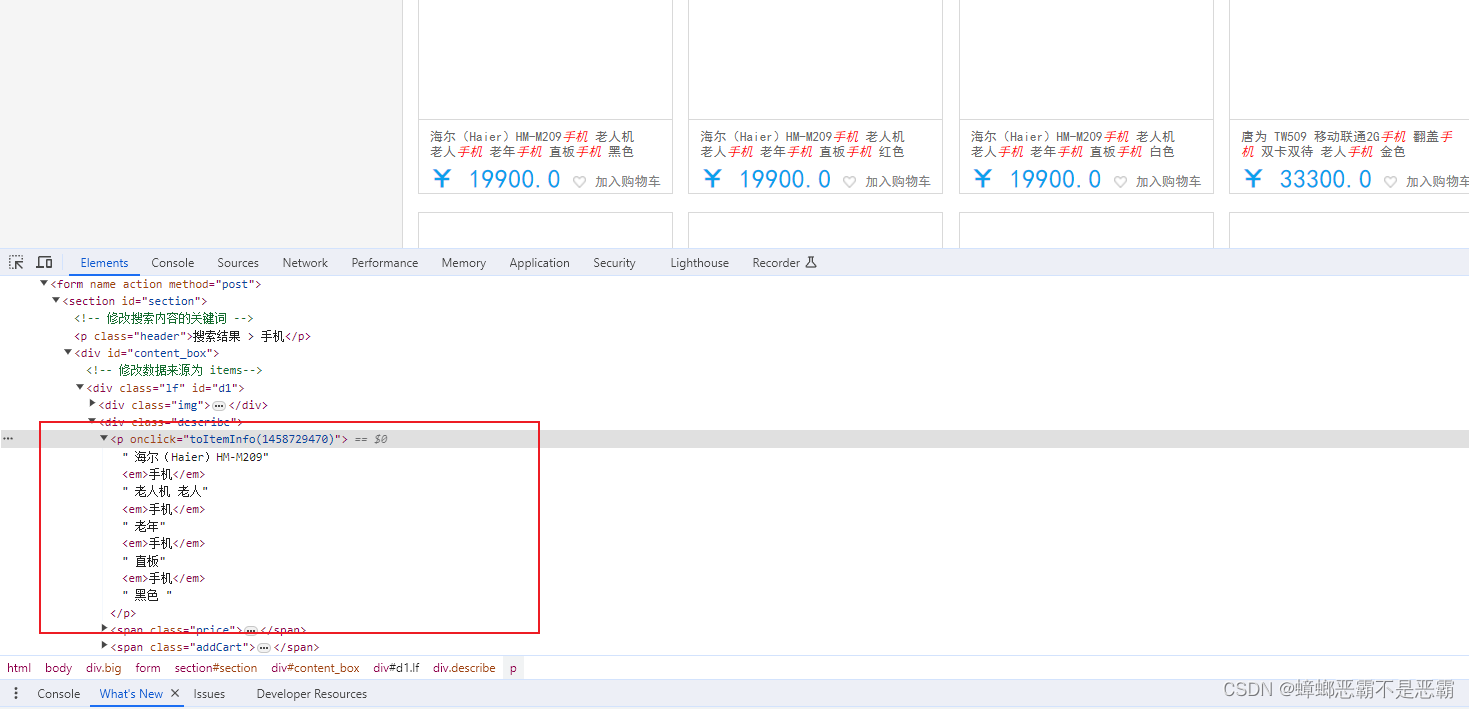
我们通过<style>标签并选择相关的标签内容进行颜色的css样式设置:
<style>div.describe p em {color: #f00;}
</style>
通过在search.jsp文件中添加css样式代码 ,重启项目后我们可以发现,我们设置的高亮显示内容已可以成功展现:
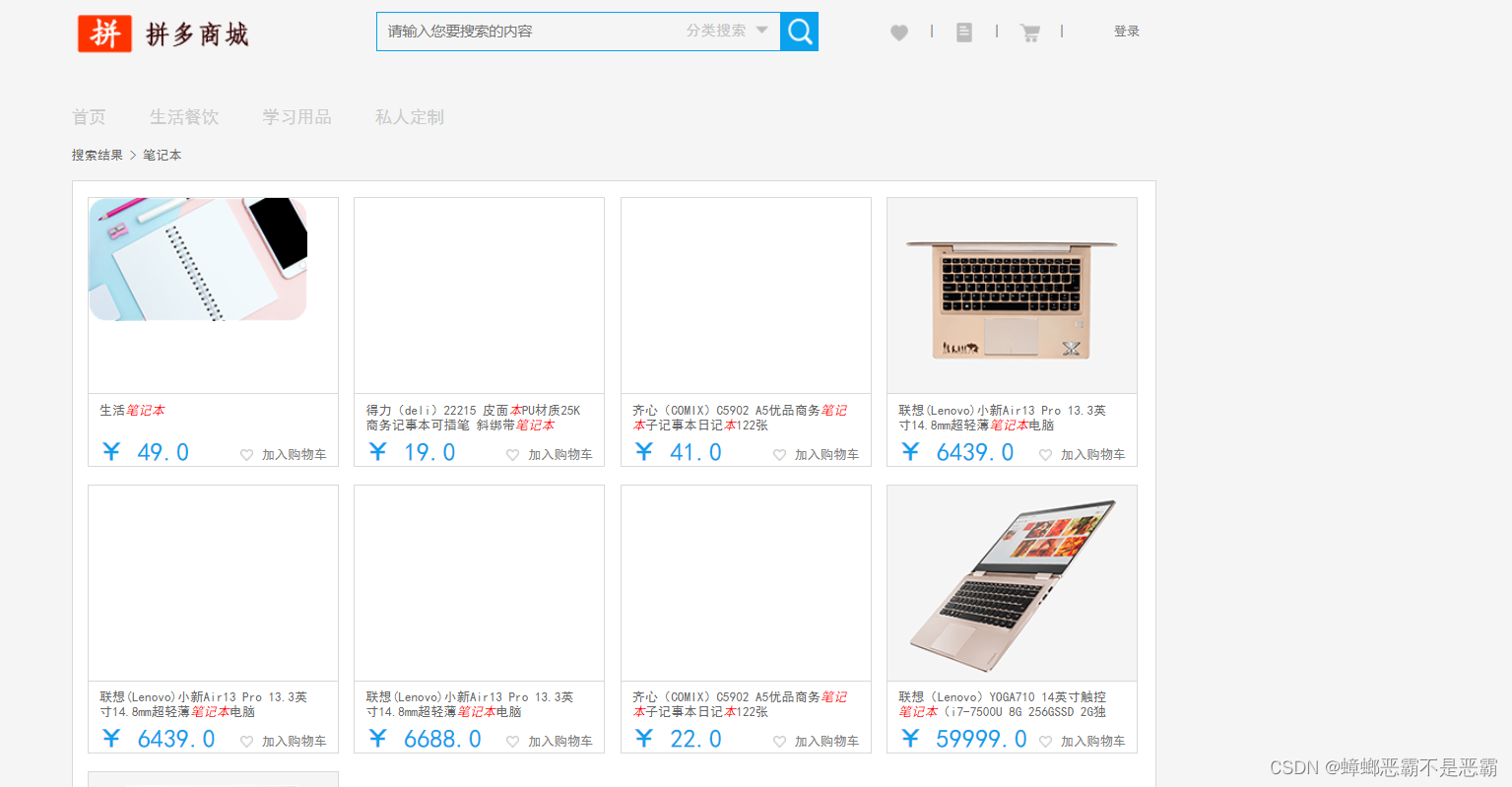
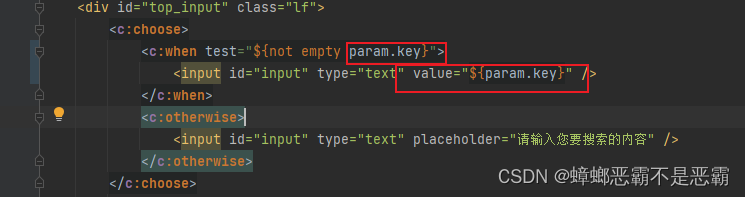
4.3 搜索框内容回填
我们可以看到,搜索框中的内容是通过包含另外一个header.jsp引入的:
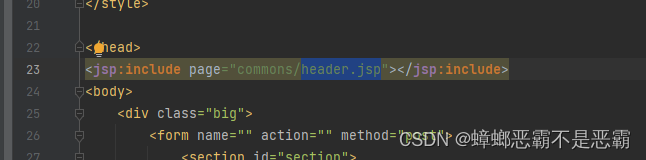
通过一个判断语句,有关键词回填关键词,没有关键词回填提示语句:
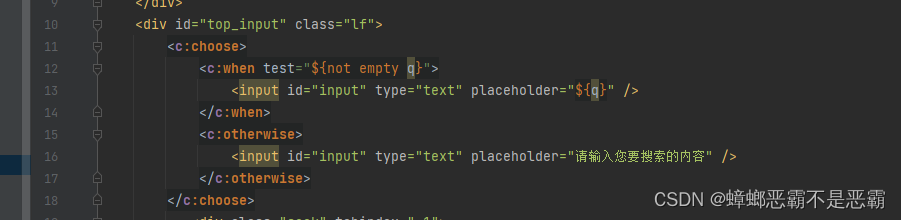
我们将判断语句中的关键词匹配更改为正确的:
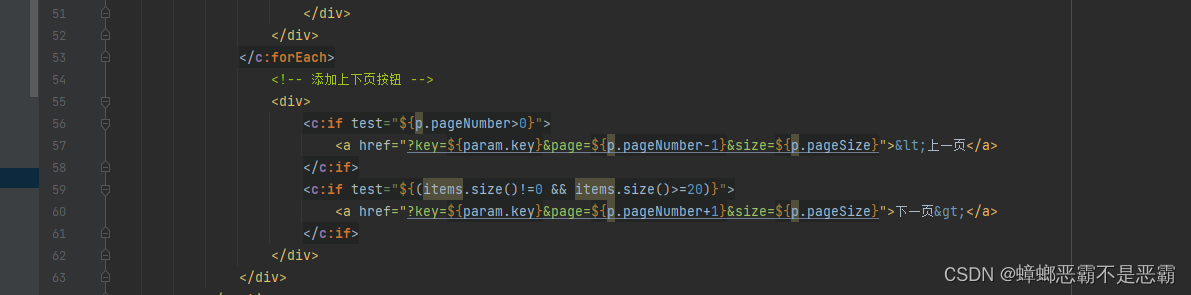
4.4 添加上下页按钮
我们通过判断当前页面在是否在第一页以后来添加上一页按钮;
通过判断当前页面数据大于等于20且页面数据不为0时添加下一页按钮;
相关文章:
6.6 Elasticsearch(六)京淘项目改造
文章目录 1.项目准备2.基础配置2.1 添加pom.xml依赖2.2 yml配置es服务器地址列表 3.具体实现3.1 item实体类封装3.2 添加接口3.3 SearchController 4.search.jsp界面4.1 搜索内容展示4.2 高亮内容样式设置4.3 搜索框内容回填4.4 添加上下页按钮 1.项目准备 我们切换回到此前的…...

Socks5代理:数字化时代的技术支柱
随着数字化时代的到来,技术不仅改变了我们的日常生活,还重新定义了商业、通信、娱乐和全球互联。在这一浪潮中,Socks5代理技术崭露头角,成为跨界电商、爬虫数据分析、企业出海和游戏体验的关键推动力。这项技术不仅在实现数字化愿…...
基本微信小程序的汽车租赁公司小程序
项目介绍 任何系统都要遵循系统设计的基本流程,本系统也不例外,同样需要经过市场调研,需求分析,概要设计,详细设计,编码,测试这些步骤,基于Java语言、微信小程序技术设计并实现了汽…...
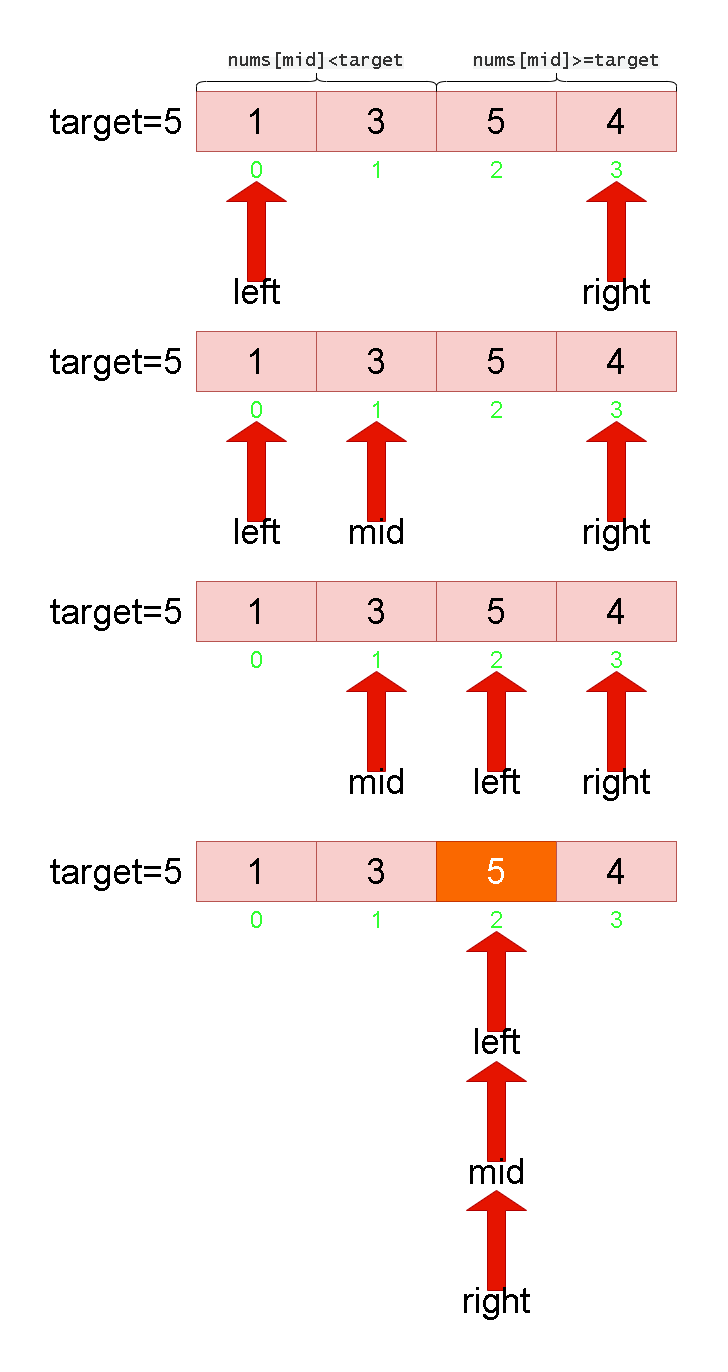
Leetcode刷题详解——搜索插入位置
1. 题目链接:35. 搜索插入位置 2. 题目描述: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。…...

centos升级openssh
注意: openssh升级异常会造成服务失联,如果在允许的情况下可以安装talent服务,使用talent升级; 如果不能安装talent服务,可以打开多个终端,启动ping命令,防止升级终端失败后,作为备用…...

架构、框架、模式,极简文字介绍
1、架构、框架、模式是一种从大到小的关系,也是一种组合关系 2、架构一般针对一个行业或一类应用,是技术和应用的完美组合 3、框架比较小,很多表现为中间件,框架一般是从技术角度解决同类问题,从技术的横切面来解决实…...

Java实现Fisher‘s Exact Test 的置信区间的计算
实现代码 package com.bgi.aigi.common.utils;public class FisherExactUtils {public static double[] getConfidenceInterval(double[][] data) {if (datanull||data.length!2||data[0].length!2||data[1].length!2) {return null;}double[] intervalnew double[2];double …...
,即插即用,助力小目标检测 | NeurIPS2022)
YOLOv8改进:全网原创首发 | 新颖的多尺度卷积注意力(MSCA),即插即用,助力小目标检测 | NeurIPS2022
💡💡💡本文全网首发独家改进:多尺度卷积注意力(MSCA),有效地提取上下文信息,新颖度高,创新十足。 1)作为注意力MSCA使用; 推荐指数:五星 MSCA | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。 💡💡💡Yolov8魔术师,独家首发…...
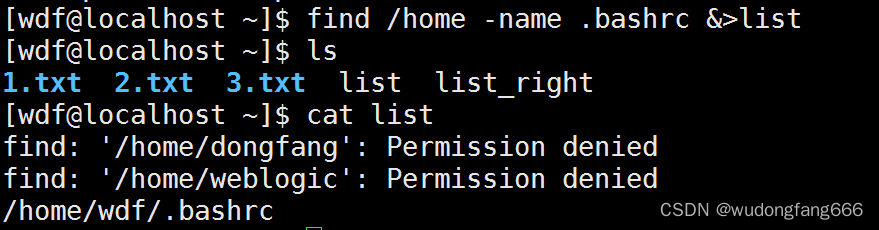
linux中好玩的数据流定向和管道命令一
知识点复习: 什么是数据流定向,个人理解就是将 一些结果信息不打印在屏幕上,而是定位在某一个文件里面 ll /wdf > file 会覆盖file的原内容 ll /wdf >> 会追加到原文件后面 比如在自己的目录新建1.TXT, 2.txt ll /…...

tesseract-ocr-w64-setup-5.3.3.20231005.exe 百度网盘下载
链接:https://pan.baidu.com/s/1q6u-nRvj2S8n6jSYz2iqig?pwdbtm4 提取码:btm4...

Linux环境下Redis 集群部署
Linux环境下Redis 集群部署 1.单机Redis部署2.Redis 集群配置2.1 创建redis集群安装目录2.2 将redis单机部署目录下的redis.confi文件复制到每个目录下2.3 修改每个文件夹下的redis.conf2.4 修改完六个配置内容后开始启动2.5 启动完后查看进程2.6 建集群 1.单机Redis部署 Linu…...

html iframe 框架有哪些优缺点?
目录 前言: 用法: 理解: 优点: 嵌套外部内容: 独立性: 分离安全性: 跨平台兼容性: 方便维护: 缺点: 性能开销: 用户体验问题…...

git 版本管理
标签管理 git tag: 标签的操作 用于给某次提交打个标签 命令:git tag B08P09 为当前提交打上 B08P09 的标签 命令:git tag B08P09 ab1591eb4e06c1e93fdd50126b9fab8a88d89155 为这个节点打上 B08P09 的标签 命令:git tag -a <tagname>…...

hyperf框架接入pgsql扩展包
文章目录 hyperf2.2安装 hyperf3.0安装 配置 环境版本支持 hyperf框架版本php版本database版本2.2>7.4~2.2.03.0>8.1~3.0.0 hyperf2.2 https://github.com/hyperf/database-pgsql-incubator 安装 hyperf/database 组件版本必须大于等于 v2.2.26 composer require hype…...
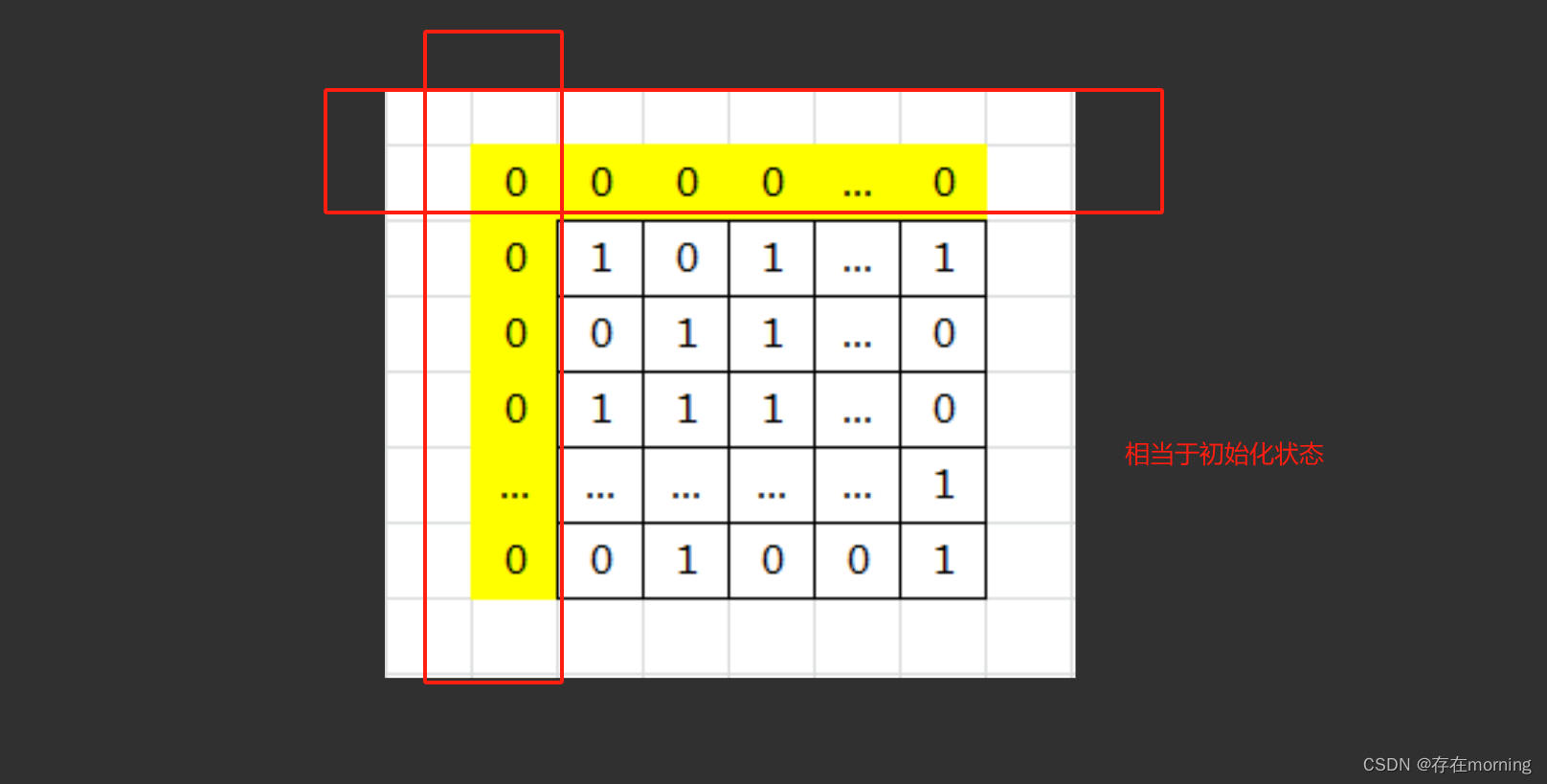
【算法训练-动态规划 五】【二维DP问题】最大正方形
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【动态规划】,使用【数组】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为&…...

20.Node-Express框架的用法
题记 node.js中express框架的用法 Express框架的特点 可以设置中间件来响应 HTTP 请求。 定义了路由表用于执行不同的 HTTP 请求动作。 可以通过向模板传递参数来动态渲染 HTML 页面。 安装Express模块 npm install express --save 安装重要模块 npm install body-parser --…...

cuda卸载
去查看你的电脑显卡对应的cuda版本,不然还是一整个用不到gpu的情况嘿嘿. 啊啊啊啊打开控制面板看一下,驱动不要乱卸载: 这些东西不能全部卸载了哦,只能卸载含有“CUDA”的那几个(其实其他的可能也没有用 但是不懂的哇 …...
怎么选择好的游戏平台开发商?
选择好的游戏平台开发商需要考虑以下几个方面: 开发经验 了解游戏开发公司的历史和经验是找到靠谱公司的重要步骤。查看公司的官方网站、社交媒体账号等渠道,了解公司的发展历程、团队规模、客户案例等。同时,了解公司是否有相关的游戏开发经…...
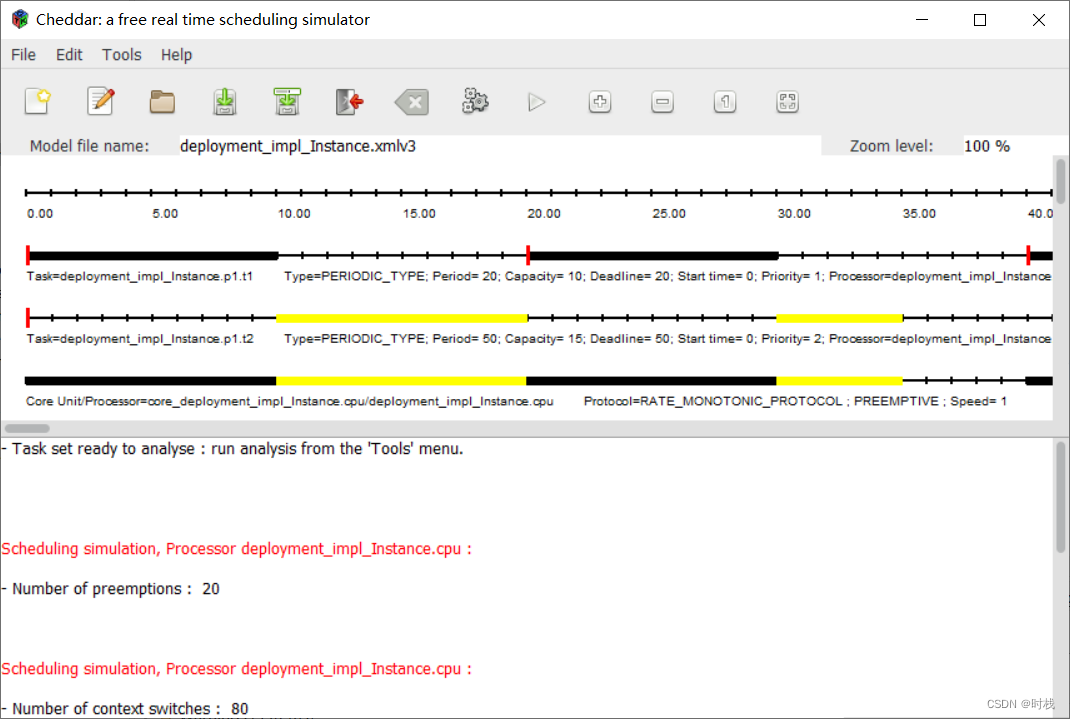
OSATE 插件 Cheddar 的安装与简单使用
一、Cheddar简介 Cheddar是一个开源的实时系统任务调度模拟器/分析仪,可以使用Cheddar进行任务的可调度性分析以及相关的性能分析。对于Cheddar的详细信息可以参考其官网: Cheddar - open-source real-time scheduling simulator/analyzer (univ-brest…...
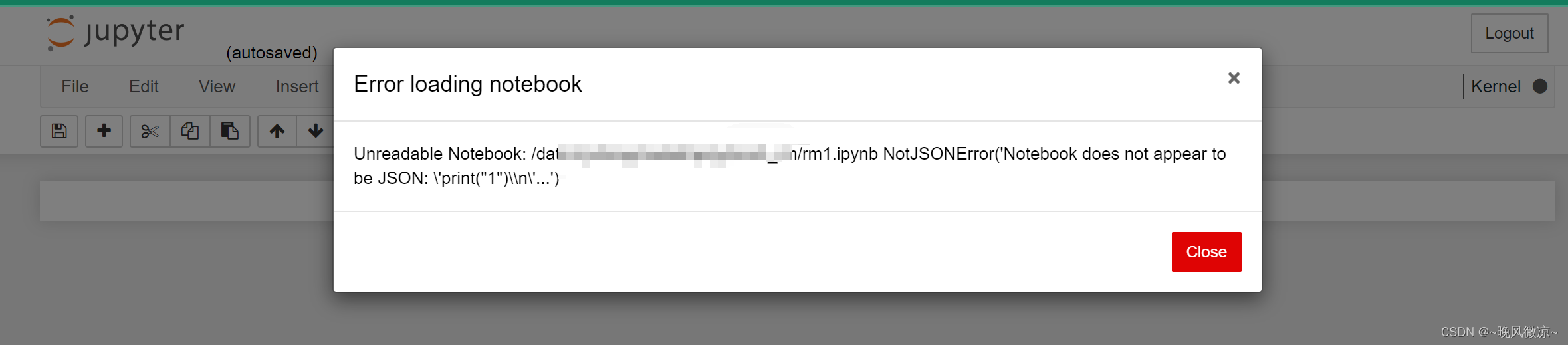
解决:vscode和jupyter远程连接无法创建、删除文件的问题(permission denied)
目录 问题:vscode和jupyter远程连接服务器无法创建、删除文件的问题原因:代码文件的权限不够解决方法:1.ls -l查看目录所在组,权限2.chown修改拥有者和所在组 问题:vscode和jupyter远程连接服务器无法创建、删除文件的…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程
OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程
怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的旧Mac重新焕发活力吗…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...

符号链接批量管理工具 linko:声明式配置与自动化实践
1. 项目概述与核心价值最近在折腾一些自动化脚本和工具链,发现一个挺有意思的仓库:monsterxx03/linko。乍一看这个名字,你可能会有点懵,这到底是干嘛的?是链接管理工具,还是某种网络代理的客户端࿱…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...