Linux环境下Redis 集群部署
Linux环境下Redis 集群部署
- 1.单机Redis部署
- 2.Redis 集群配置
- 2.1 创建redis集群安装目录
- 2.2 将redis单机部署目录下的redis.confi文件复制到每个目录下
- 2.3 修改每个文件夹下的redis.conf
- 2.4 修改完六个配置内容后开始启动
- 2.5 启动完后查看进程
- 2.6 建集群
1.单机Redis部署
Linux下redis安装并设置开机自启
2.Redis 集群配置
具体是参考这篇文章(由于在搭建过程中仍遇到很多问题,所以在其基础上补充):
Linux下redis集群搭建与部署
2.1 创建redis集群安装目录
cd /home/xh/hadoop/
mkdir myredis
cd myredis
mkdir 7000 7001 7002 7003 7004 7005
2.2 将redis单机部署目录下的redis.confi文件复制到每个目录下
cp /home/xh/hadoop/redis-3.2.5/redis.conf /home/xh/hadoop/myredis/7000
cp /home/xh/hadoop/redis-3.2.5/redis.conf /home/xh/hadoop/myredis/7001
cp /home/xh/hadoop/redis-3.2.5/redis.conf /home/xh/hadoop/myredis/7002
cp /home/xh/hadoop/redis-3.2.5/redis.conf /home/xh/hadoop/myredis/7003
cp /home/xh/hadoop/redis-3.2.5/redis.conf /home/xh/hadoop/myredis/7004
cp /home/xh/hadoop/redis-3.2.5/redis.conf /home/xh/hadoop/myredis/7005
2.3 修改每个文件夹下的redis.conf
#例如
vim myredis/7000/redis.conf#修改如下
#端口号
port 7000
#后台启动
daemonize yes
#开启集群
cluster-enabled yes
#集群节点配置文件(注意需要跟端口号一样)
cluster-config-file nodes-7000.conf
#数据文件存放位置(注意此处的路径需要自己创建好)
dir /usr/local/redis/redis-cluster/7000/data/
#集群连接超时时间
cluster-node-timeout 5000
#进程pid的文件位置 (注意需要跟端口号一样)
pidfile /var/run/redis-7000.pid
#开启aof
appendonly yes
#aof文件路径
appendfilename “appendonly-7000.aof”
#rdb文件路径
dbfilename dump-7000.rdb
注意:需要补充如下设置,否则java连接报错
#保护模式设为no
protected-mode no
#绑定ip
bind 192.168.240.128
2.4 修改完六个配置内容后开始启动
cd /usr/local/redis
#这里闲一个个启动麻烦的话可以自己配置一个配置文件启动
bin/redis-server myredis/7000/redis.conf
bin/redis-server myredis/7001/redis.conf
bin/redis-server myredis/7002/redis.conf
bin/redis-server myredis/7003/redis.conf
bin/redis-server myredis/7004/redis.conf
bin/redis-server myredis/7005/redis.conf
2.5 启动完后查看进程
[root@hadoop myredis]# ps -ef|grep redis
#显示有六个则是启动成功
root 63262 1 0 11:08 ? 00:00:00 redis-server 192.168.240.128:7000 [cluster]
root 63264 1 0 11:08 ? 00:00:00 redis-server 192.168.240.128:7001 [cluster]
root 63266 1 0 11:08 ? 00:00:00 redis-server 192.168.240.128:7002 [cluster]
root 63270 1 0 11:08 ? 00:00:00 redis-server 192.168.240.128:7003 [cluster]
root 63276 1 0 11:08 ? 00:00:00 redis-server 192.168.240.128:7004 [cluster]
root 63278 1 0 11:08 ? 00:00:00 redis-server 192.168.240.128:7005 [cluster]
root 63287 62960 0 11:08 pts/2 00:00:00 grep redis
2.6 建集群
到这里只是启动了六个单进程的redis,开始创建集群,先安装好ruby
yum install ruby rubygems -y
使用gem要先镜像一下
#这里需要镜像一下
gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/#确保镜像成功
[root@hadoop myredis]# gem sources -l*** CURRENT SOURCES ***
https://gems.ruby-china.com/
然后执行连接ruby-redis
[root@hadoop myredis]# gem install redis
上面步骤有可能报错查了资料发现是版本太低
解决办法是 先安装rvm,再把ruby版本提升
ERROR: Error installing redis:
redis requires Ruby version >= 2.3.0.
ruby版本提升(若没有报错不需要进行此步骤)
#安装curl
sudo yum install curl#安装rvm
curl -L get.rvm.io | bash -s stable(如出现错误参考: http://blog.csdn.net/qq_30242987/article/details/99727838)
source /usr/local/rvm/scripts/rvm
#查看rvm库中已知的ruby版本
rvm list known#安装一个ruby版本
rvm install 2.4.0#使用一个ruby版本
rvm use 2.4.0#卸载一个已知版本
rvm remove 2.3.0#查看版本
ruby --version#再安装redis就可以了
gem install redis
创建集群
#进入src下面
cd /home/xh/hadoop/redis-3.2.5/src
# 创建集群
[root@hadoop src]# ./redis-trib.rb create --replicas 1 192.168.240.128:7000 192.168.240.128:7001 192.168.240.128:7002 192.168.240.128:7003 192.168.240.128:7004 192.168.240.128:7005
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.240.128:7000
192.168.240.128:7001
192.168.240.128:7002
Adding replica 192.168.240.128:7003 to 192.168.240.128:7000
Adding replica 192.168.240.128:7004 to 192.168.240.128:7001
Adding replica 192.168.240.128:7005 to 192.168.240.128:7002
M: b553b5ed57b5d152dc1819c1818e61eba77b867f 192.168.240.128:7000slots:0-5460 (5461 slots) master
M: d3bb8e329319f90d42f3a6163d0dcb2059cbeb47 192.168.240.128:7001slots:5461-10922 (5462 slots) master
M: 40a44e92c9644e0366abb3aa2f18222b7d255b93 192.168.240.128:7002slots:10923-16383 (5461 slots) master
S: 330be48eaa9bd676720738f0efe8007b2421944e 192.168.240.128:7003replicates b553b5ed57b5d152dc1819c1818e61eba77b867f
S: ba1195fe77df429079e34cb6c296878b1d0c7dcb 192.168.240.128:7004replicates d3bb8e329319f90d42f3a6163d0dcb2059cbeb47
S: 674176635075d82369ebba73060eadf8e4e1d701 192.168.240.128:7005replicates 40a44e92c9644e0366abb3aa2f18222b7d255b93
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.....
>>> Performing Cluster Check (using node 192.168.240.128:7000)
M: b553b5ed57b5d152dc1819c1818e61eba77b867f 192.168.240.128:7000slots:0-5460 (5461 slots) master1 additional replica(s)
M: d3bb8e329319f90d42f3a6163d0dcb2059cbeb47 192.168.240.128:7001slots:5461-10922 (5462 slots) master1 additional replica(s)
S: ba1195fe77df429079e34cb6c296878b1d0c7dcb 192.168.240.128:7004slots: (0 slots) slavereplicates d3bb8e329319f90d42f3a6163d0dcb2059cbeb47
M: 40a44e92c9644e0366abb3aa2f18222b7d255b93 192.168.240.128:7002slots:10923-16383 (5461 slots) master1 additional replica(s)
S: 330be48eaa9bd676720738f0efe8007b2421944e 192.168.240.128:7003slots: (0 slots) slavereplicates b553b5ed57b5d152dc1819c1818e61eba77b867f
S: 674176635075d82369ebba73060eadf8e4e1d701 192.168.240.128:7005slots: (0 slots) slavereplicates 40a44e92c9644e0366abb3aa2f18222b7d255b93
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
到这里集群就安装好了,测试一下
[xh@hadoop myredis]$ redis-cli -c -h 192.168.240.128 -p 7000
192.168.240.128:7000> set name frank
-> Redirected to slot [5798] located at 192.168.240.128:7001
OK
192.168.240.128:7001> get name
"frank"
在启动时会发现一个个启动太麻烦,这里配置一下启动关闭文件
#进入安装redis的路径
cd /home/xh/hadoop/myredis#编写关闭文件
vi stop-all.sh#加入下面内容,编辑完之后按esc键输入 :wq 退出保存
#这里得找到自己配置启动得地方,我得是在bin下面
redis-cli -p 7000 -h 192.168.240.128 shutdown
redis-cli -p 7001 -h 192.168.240.128 shutdown
redis-cli -p 7002 -h 192.168.240.128 shutdown
redis-cli -p 7003 -h 192.168.240.128 shutdown
redis-cli -p 7004 -h 192.168.240.128 shutdown
redis-cli -p 7005 -h 192.168.240.128 shutdown#赋值权限
chmod u+x stop-all.sh#编写启动文件
vi start-all.sh#加入下面内容,编辑完之后按esc键输入 :wq 退出保存
#这里得找到自己配置启动得地方,我得是在bin下面
redis-server myredis/7000/redis.conf
redis-server myredis/7001/redis.conf
redis-server myredis/7002/redis.conf
redis-server myredis/7003/redis.conf
redis-server myredis/7004/redis.conf
redis-server myredis/7005/redis.conf#赋值权限
chmod u+x start-all.sh
其中在java连接时出现问题,通过参考如下文章解决:
1.本地虚拟机搭建的Redis集群,Jedis可以连接,JedisCluster连接不上
2.Redis错误:[ERR] Sorry, can‘t connect to node 192.168.10.3:6379
3.彻底解决:[ERR] Node is not empty. Either the node already knows other nodes
相关文章:

Linux环境下Redis 集群部署
Linux环境下Redis 集群部署 1.单机Redis部署2.Redis 集群配置2.1 创建redis集群安装目录2.2 将redis单机部署目录下的redis.confi文件复制到每个目录下2.3 修改每个文件夹下的redis.conf2.4 修改完六个配置内容后开始启动2.5 启动完后查看进程2.6 建集群 1.单机Redis部署 Linu…...

html iframe 框架有哪些优缺点?
目录 前言: 用法: 理解: 优点: 嵌套外部内容: 独立性: 分离安全性: 跨平台兼容性: 方便维护: 缺点: 性能开销: 用户体验问题…...

git 版本管理
标签管理 git tag: 标签的操作 用于给某次提交打个标签 命令:git tag B08P09 为当前提交打上 B08P09 的标签 命令:git tag B08P09 ab1591eb4e06c1e93fdd50126b9fab8a88d89155 为这个节点打上 B08P09 的标签 命令:git tag -a <tagname>…...

hyperf框架接入pgsql扩展包
文章目录 hyperf2.2安装 hyperf3.0安装 配置 环境版本支持 hyperf框架版本php版本database版本2.2>7.4~2.2.03.0>8.1~3.0.0 hyperf2.2 https://github.com/hyperf/database-pgsql-incubator 安装 hyperf/database 组件版本必须大于等于 v2.2.26 composer require hype…...
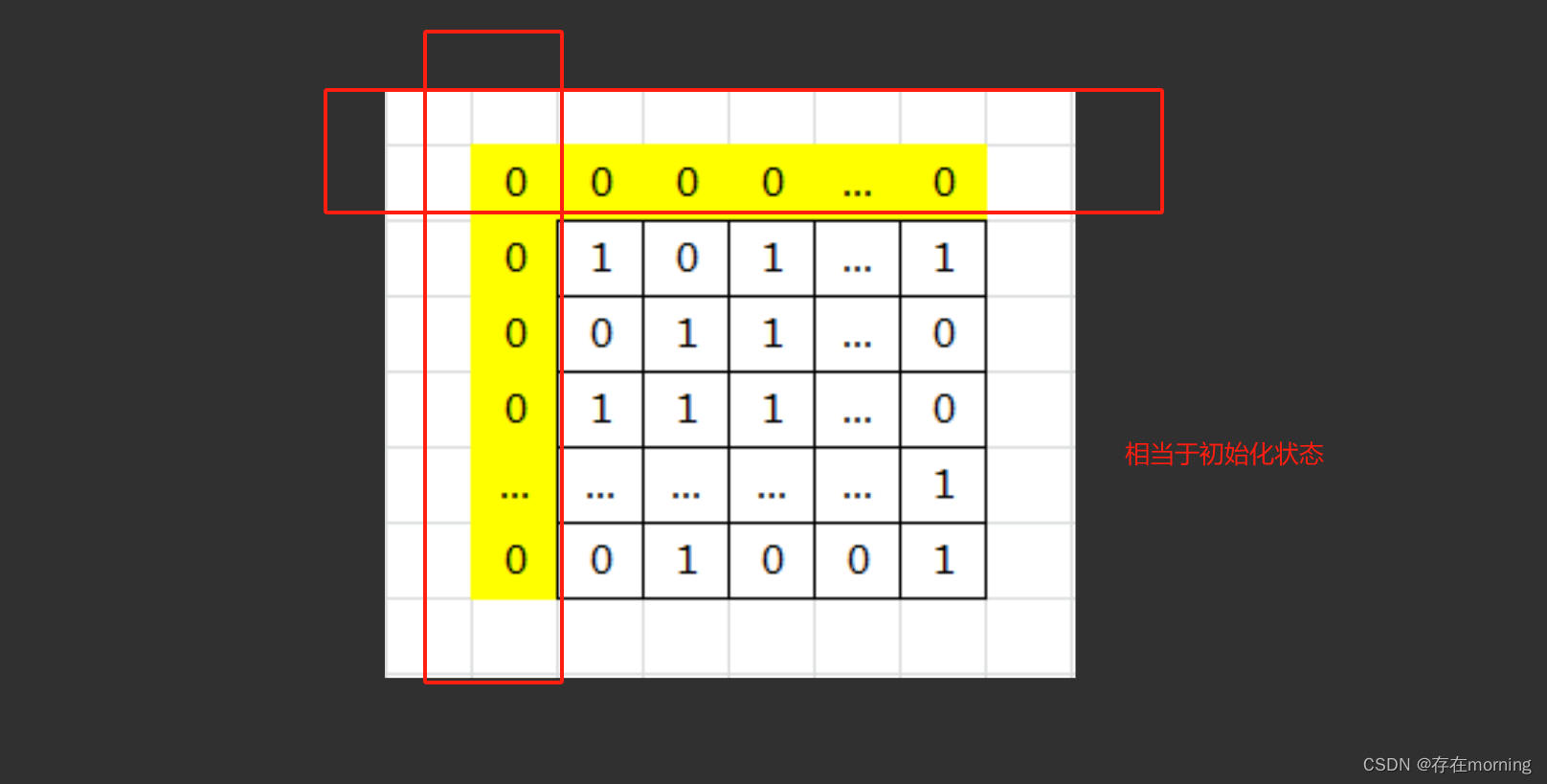
【算法训练-动态规划 五】【二维DP问题】最大正方形
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【动态规划】,使用【数组】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为&…...

20.Node-Express框架的用法
题记 node.js中express框架的用法 Express框架的特点 可以设置中间件来响应 HTTP 请求。 定义了路由表用于执行不同的 HTTP 请求动作。 可以通过向模板传递参数来动态渲染 HTML 页面。 安装Express模块 npm install express --save 安装重要模块 npm install body-parser --…...

cuda卸载
去查看你的电脑显卡对应的cuda版本,不然还是一整个用不到gpu的情况嘿嘿. 啊啊啊啊打开控制面板看一下,驱动不要乱卸载: 这些东西不能全部卸载了哦,只能卸载含有“CUDA”的那几个(其实其他的可能也没有用 但是不懂的哇 …...
怎么选择好的游戏平台开发商?
选择好的游戏平台开发商需要考虑以下几个方面: 开发经验 了解游戏开发公司的历史和经验是找到靠谱公司的重要步骤。查看公司的官方网站、社交媒体账号等渠道,了解公司的发展历程、团队规模、客户案例等。同时,了解公司是否有相关的游戏开发经…...
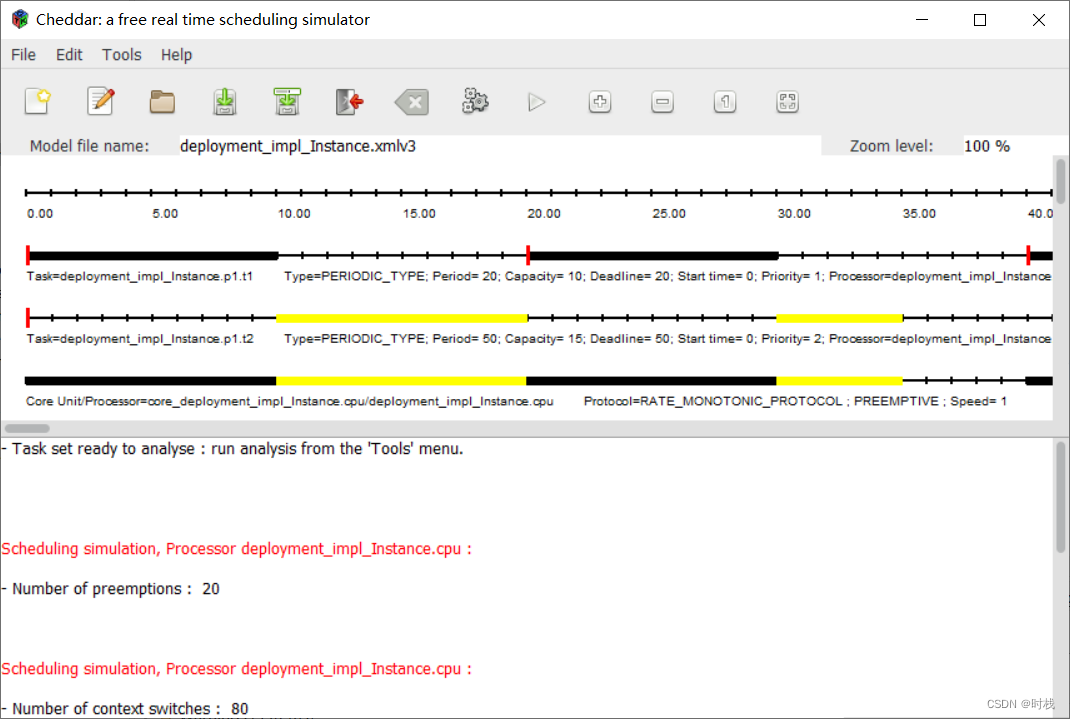
OSATE 插件 Cheddar 的安装与简单使用
一、Cheddar简介 Cheddar是一个开源的实时系统任务调度模拟器/分析仪,可以使用Cheddar进行任务的可调度性分析以及相关的性能分析。对于Cheddar的详细信息可以参考其官网: Cheddar - open-source real-time scheduling simulator/analyzer (univ-brest…...
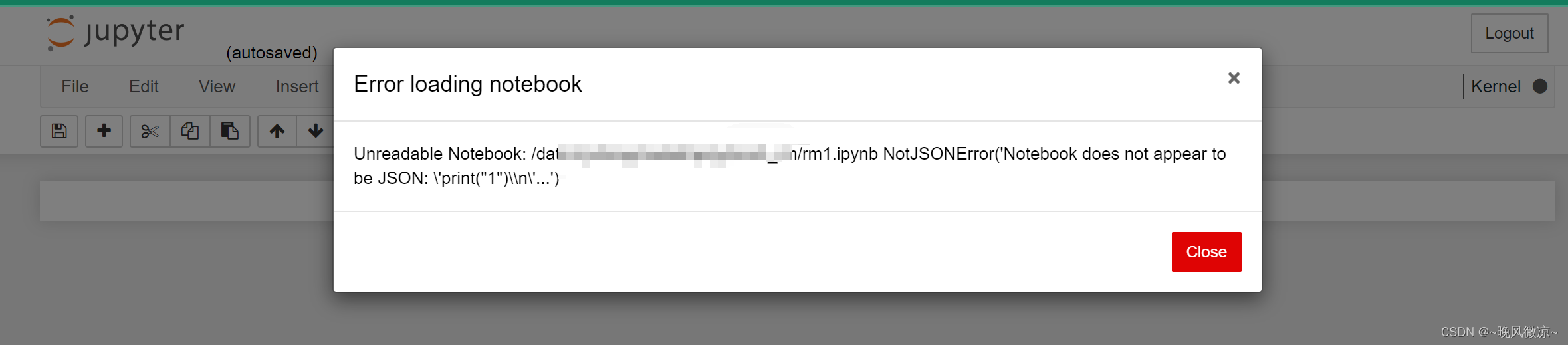
解决:vscode和jupyter远程连接无法创建、删除文件的问题(permission denied)
目录 问题:vscode和jupyter远程连接服务器无法创建、删除文件的问题原因:代码文件的权限不够解决方法:1.ls -l查看目录所在组,权限2.chown修改拥有者和所在组 问题:vscode和jupyter远程连接服务器无法创建、删除文件的…...

Android Studio模拟器/虚拟设备连接互联网的方法
如图,无线、网络都无法联网 找到本机的DNS 找到emu-launch-params.txt,添加DNS -dns-server 192.168.124.1 重启虚拟机,关闭无线...

linux 内存检测工具 kfence 详解
版本基于: Linux-5.10 约定: PAGE_SIZE:4K 内存架构:UMA 0. 前言 本文 kfence 之外的代码版本是基于 Linux5.10,最近需要将 kfence 移植到 Linux5.10 中,本文借此机会将 kfence 机制详细地记录一下。 k…...

虚拟机VMware Workstation Pro安装配置使用服务器系统ubuntu-22.04.3-live-server-amd64.iso
虚拟机里安装ubuntu-23.04-beta-desktop-amd64开启SSH(换源和备份)配置中文以及中文输入法等 一、获取Ubuntu服务器版 获取Ubuntu服务器版 二、配置虚拟机 选择Custom(advanced): 选择Workstation 17.x: 选择“I will install the operating system later.”…...
)
《C程序设计》笔记(ch1-2)
第1章 程序设计和C语言 1.2 什么是计算机语言 人和计算机都能识别的语言,就是计算机语言。 符号语言用一些英文字母和数字表示一个指令。汇编程序:符号语言的指令→机器指令。 编译程序:源程序→机器指令。 1.4 最简单的C语言程序 每一…...
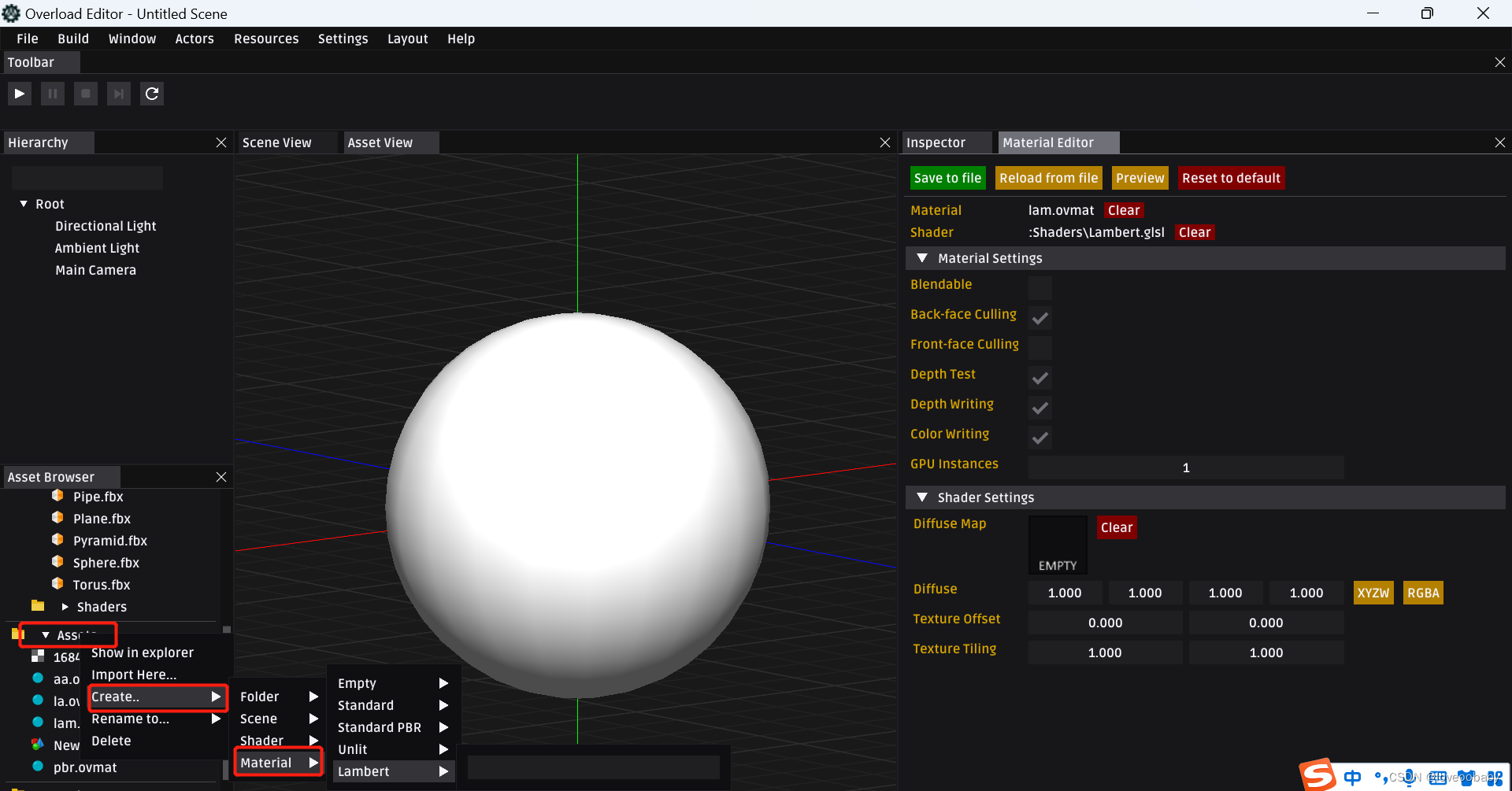
【Overload游戏引擎细节分析】Lambert材质Shader分析
一、经典光照模型:Phong模型 现实世界的光照是极其复杂的,而且会受到诸多因素的影响,这是以目前我们所拥有的处理能力无法模拟的。经典光照模型冯氏光照模型(Phong Lighting Model)通过单独计算光源成分得到综合光照效果,然后添加…...
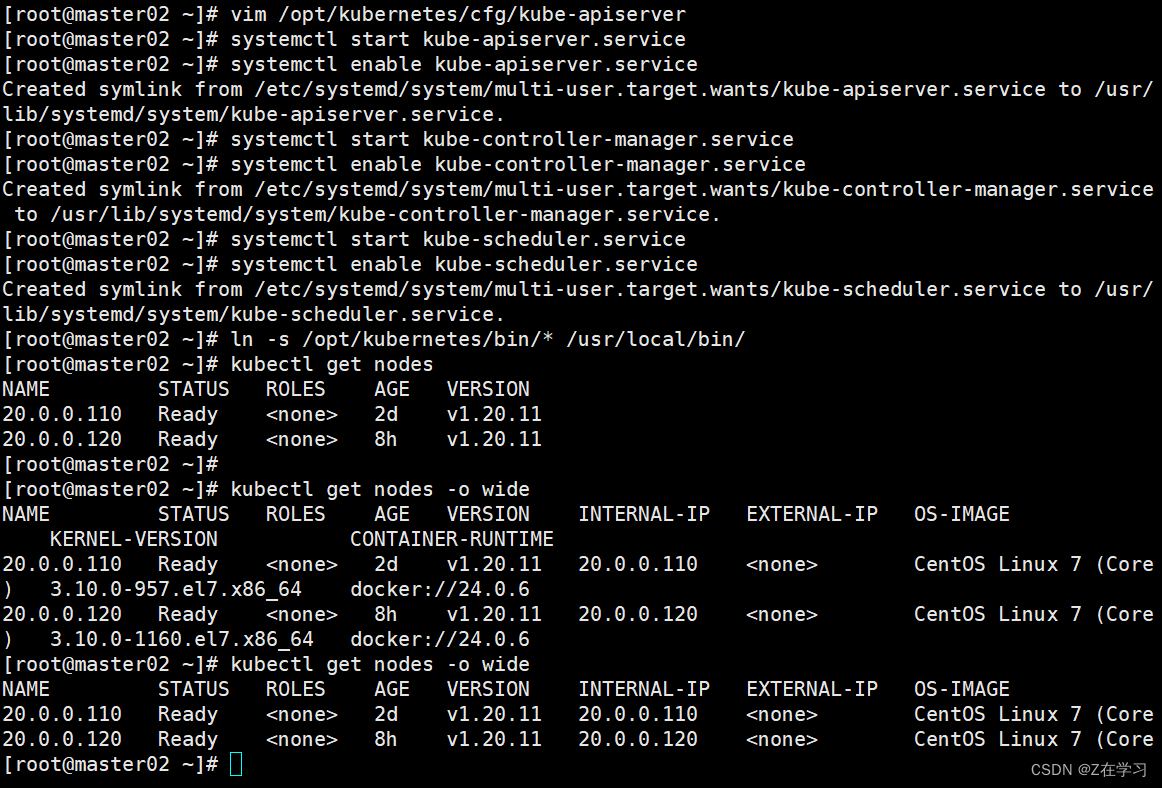
二进制搭建 Kubernetes+部署网络组件+部署CornDNS+负载均衡部署+部署Dashboard
二进制搭建 Kubernetes v1.20 k8s集群master01:20.0.0.50 kube-apiserver kube-controller-manager kube-scheduler etcd k8s集群master02:20.0.0.100k8s集群node01:20.0.0.110 kubelet kube-proxy docker etcd k8s集群node02:20.…...
】)
【 OpenGauss源码学习 —— 列存储(update_pages_and_tuples_pgclass)】
列存储(update_pages_and_tuples_pgclass) 概述update_pages_and_tuples_pgclass 函数ReceivePageAndTuple 函数estimate_cstore_blocks 函数get_attavgwidth 函数get_typavgwidth 函数 vac_update_relstats 函数 测试案例 声明:本文的部分内…...
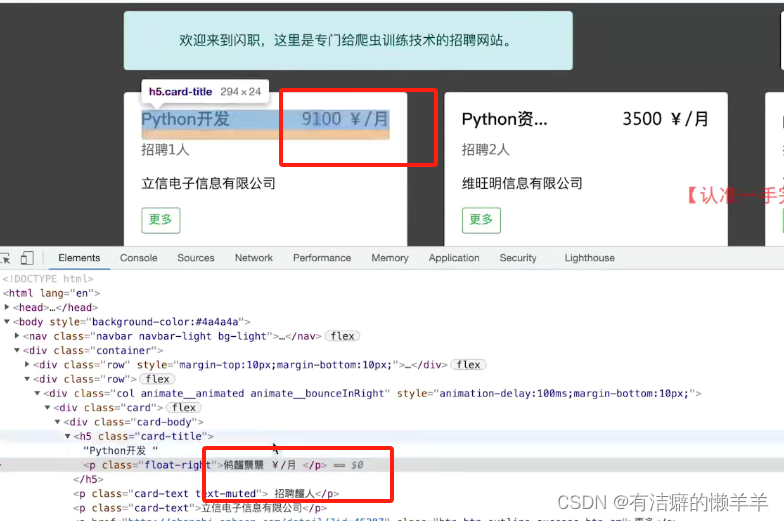
爬虫进阶-反爬破解7(逆向破解被加密数据:全方位了解字体渲染的全过程+字体文件的检查和数据查看+字体文件转换并实现网页内容还原+完美还原上百页的数据内容)
目录 一、全方位了解字体渲染的全过程 1.加载顺序 2.实践操作:浏览器中调试字体渲染 3.总结: 二、字体文件的检查和数据查看 1.字体文件的操作软件 2.映射关系的建立 3.实践操作:翻找样式和真实内容 4.总结: 三、字体文…...

系统架构设计师之RUP软件开发生命周期
系统架构设计师之RUP软件开发生命周期...
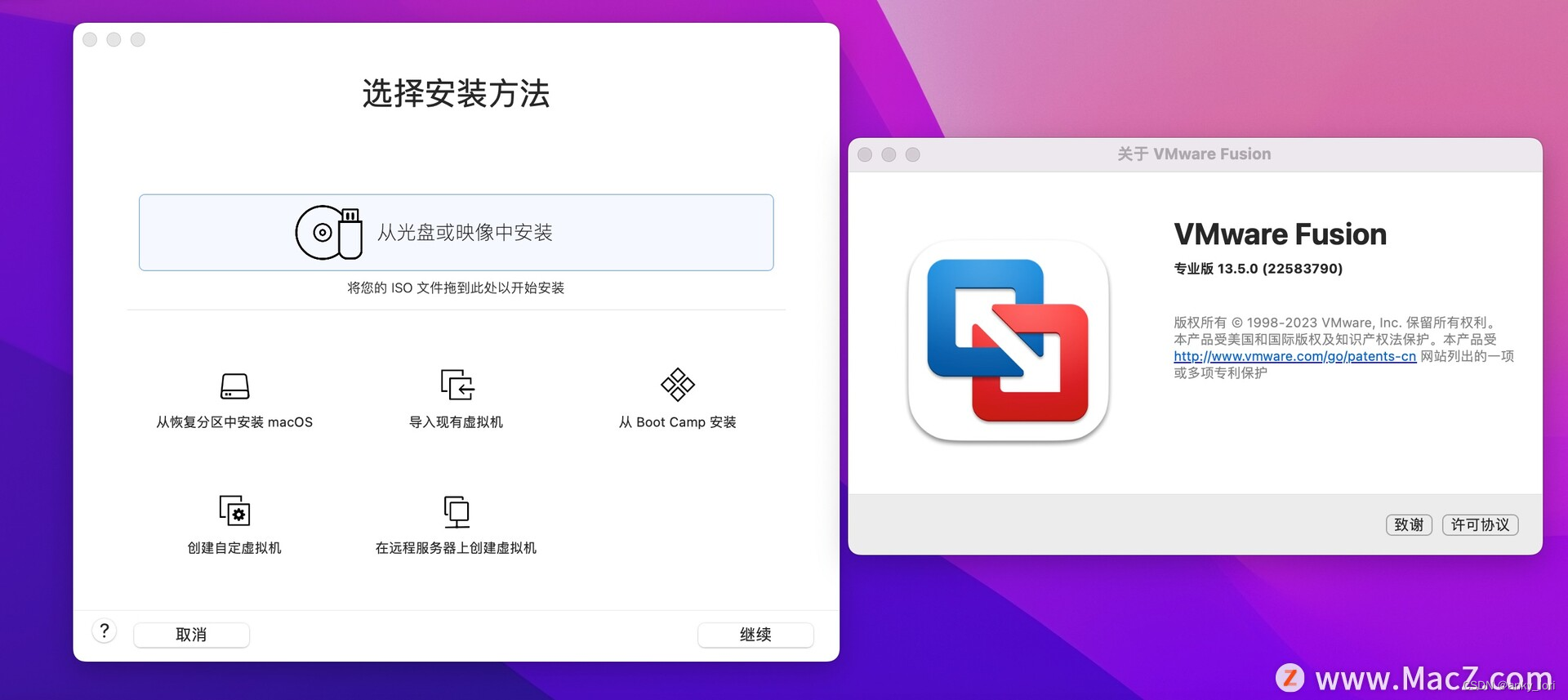
VM虚拟机 13.5 for Mac
VMware Fusion Pro for Mac是一款强大的虚拟机软件,可以在Mac操作系统中创建、运行和管理多个虚拟机,使用户可以在一台Mac电脑上同时运行多个操作系统和应用程序。 以下是VMware Fusion Pro for Mac的主要特点: 1. 支持多种操作系统ÿ…...
实战:从零部署企业级WEB前后端项目)
TongWEB(东方通)实战:从零部署企业级WEB前后端项目
1. 环境准备:银河麒麟系统下的基础搭建 在银河麒麟桌面系统V10(SP1)兆芯版上部署企业级WEB项目,环境准备是第一步。我遇到过不少开发者直接跳过环境检查就急着部署,结果浪费大量时间排查兼容性问题。这里分享几个关键点: 首先是系…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager
5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是经常在右键文件时,面对几十个…...

AI Agent执行链路的安全机制:权限控制与沙箱隔离方案
AI Agent执行链路安全深度解析:权限控制与沙箱隔离全栈落地方案 摘要/引言 你有没有遇到过这些场景:刚上线的企业内部运维Agent被恶意Prompt注入后,直接调用了删除生产库的工具;你做的数据分析Agent被诱导执行了恶意Python代码,把公司的用户隐私数据传到了境外黑客服务器…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...

如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程
如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本(Onmyoji Auto Script,…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

模拟电路布局优化:多智能体强化学习实践
1. 模拟电路布局优化的挑战与机遇在集成电路设计领域,模拟电路布局一直是个令人头疼的问题。作为一名从业十余年的模拟电路设计师,我深刻体会到传统布局方法在面对现代工艺挑战时的局限性。每次手工调整晶体管位置时,那种"差之毫厘&…...