尚硅谷Flume(仅有基础)
q
1 概述
1.1 定义
Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
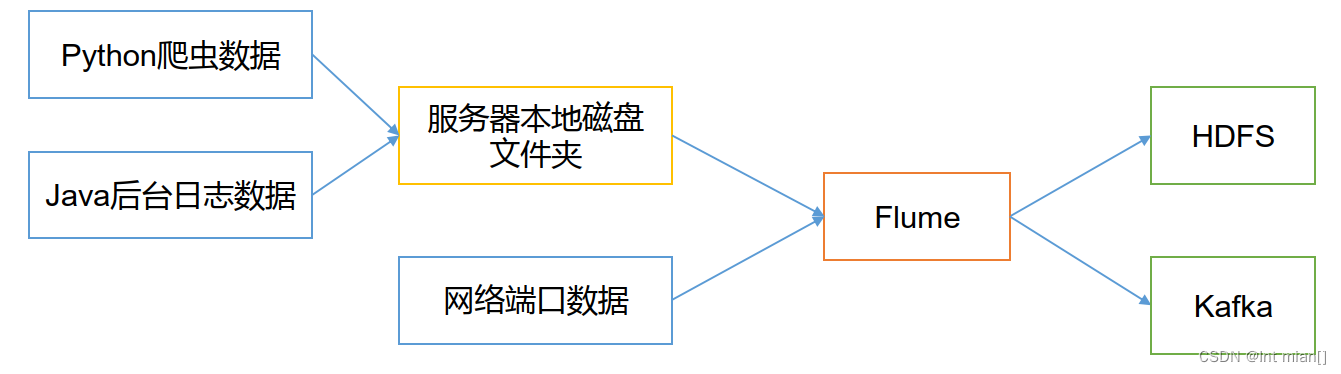
1.2 架构

1.2.1 Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成,Source、Channel、Sink。
1.2.2 Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、taildir、sequence generator、syslog、http、legacy。
1.2.3 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
1.2.4 Channel
Channel是位于Source 和Sink 之间的缓冲区。因此,Channel允许 Source和Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和 File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
1.2.5 Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。
Event由Header 和Body 两部分组成,Header用来存放该 event的一些属性,为K-V 结构,Body用来存放该条数据,形式为字节数组。

2 Flume基本操作
2.1 安装部署
http://www.apache.org/dyn/closer.lua/flume/1.9.0/apache-flume-1.9.0-tar.gz
直接解压
将lib文件夹下的guava-11.0.2.jar删除以兼容 Hadoop 3.1.3
2.2 案例
2.2.1 监控端口数据官方案例
Flume 1.9.0 User Guide — Apache Flume
使用 Flume监听一个端口,收集该端口数据,并打印到控制台

(1)安装netcat工具
[atguigu@hadoop102 software]$ sudo yum install -y nc
(2)判断4444端口是否被占用
[atguigu@hadoop102 flume-telnet]$ sudo netstat -nlp | grep 4444
(3)创建Flume Agent配置文件flume-netcat-logger.conf
(4)在flume目录下创建 job文件夹并进入job文件夹。
[atguigu@hadoop102 flume]$ mkdir job
[atguigu@hadoop102 flume]$ cd job/
(5)在job文件夹下创建 Flume Agent配置文件flume-netcat-logger.conf。
[atguigu@hadoop102 job]$ vim flume-netcat-logger.conf
(6)在flume-netcat-logger.conf文件中添加如下内容# name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 4444# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1

原神启动
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
or
bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -flume.root.logger=INFO,console --conf/-c:表示配置文件存储在 conf/目录 --name/-n:表示给 agent 起名为 a1 --conf-file/-f:flume 本次启动读取的配置文件是在 job 文件夹下的 flume-telnet.conf文件。 -Dflume.root.logger=INFO,console :-D 表示 flume 运行时动态修改 flume.root.logge参数属性值,并将控制台日志打印级别设置为 INFO 级别。日志级别包括:log、info、warn、error。 另一台nc启动
nc localhost 4444
然后发消息
2023-10-25 14:03:53,633 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 30
2.2.2 实时监控单个追加文件
实时监控 Hive 日志,并上传到HDFS中
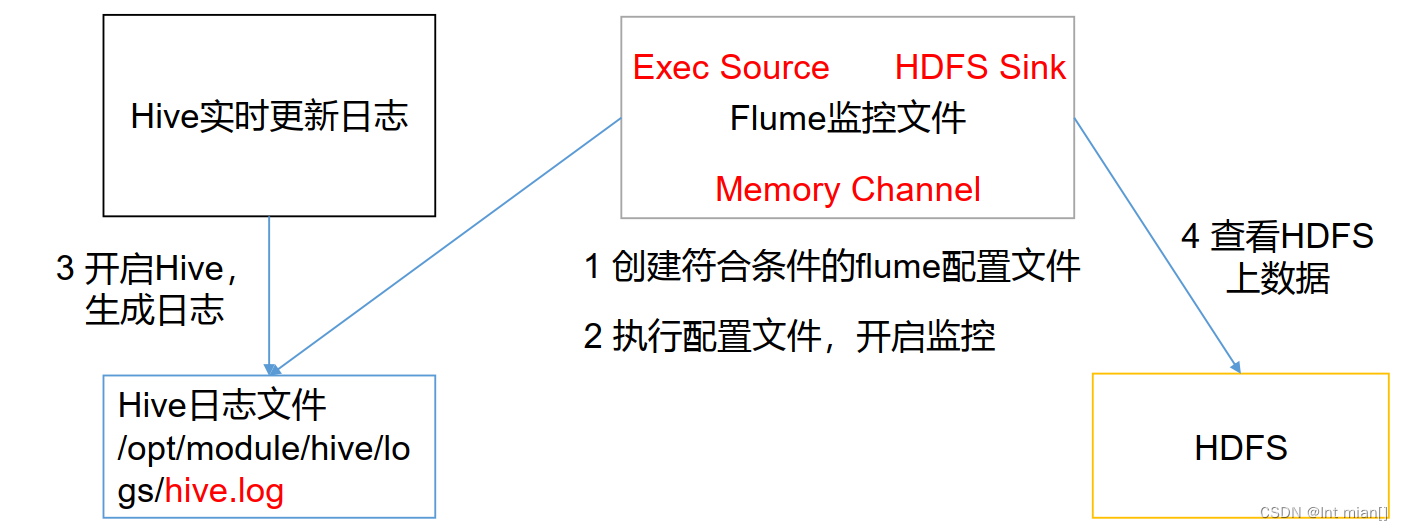
开启hadoop集群
start-all.sh
开启hive
/export/servers/hive/bin/hive --service metastore & nohup /export/servers/hive/bin/hive
vim flume-file-hdfs.conf
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /export/server/hive/logs/hive.log(要监控拉取的文件)# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop1:8020/flume/%Y%m%d/%H(这里的端口要和hadoop配置里hdfs的一样!!!!!!!!!)
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event 才flush 到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
启动
bin/flume-ng agent -n a2 -c conf -f job/flume-file-hdfs.conf
ctrl+Z退出
在HDFS上查看文件。
2.2.3 实时监控目录下多个新文件
使用Flume监听整个目录的文件,并上传至 HDFS

在使用 Spooling Directory Source 时,不要在监控目录中创建并持续修改文件;上传完成的文件会以.COMPLETED结尾;被监控文件夹每 500毫秒扫描一次文件变动。
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.confa3.sources = r3
a3.sinks = k3
a3.channels = c3# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /export/server/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop1:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀:
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event 才flush 到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3在/opt/module/flume 目录下创建upload文件夹
向 upload文件夹中添加文件

2.2.4 实时监控目录下的多个追加文件
Exec source适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。

a3.sources = r3
a3.sinks = k3
a3.channels = c3 # Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.* # Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://hadoop102:9820/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event 才flush 到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3Taildir 说明:
Taildir Source维护了一个 json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下
3 Flume 高级
相关文章:

尚硅谷Flume(仅有基础)
q 1 概述 1.1 定义 Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。 Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HD…...

JS中this的绑定规则
如果有人问你this指向哪里?但又不给你说调用位置,那他就是在耍流氓。 – 龚港浩 1、默认绑定 首先要介绍的是最常用的函数调用类型:独立函数调用。可以把这条规则看作是无法应用其他规则时的默认规则。 function foo() {console.log( this…...
酷开科技 | 酷开系统大屏电视,打造精彩家庭场景
在信息资讯不发达的年代,电视机一直都是个人及家庭重要的信息获取渠道和家庭娱乐中心,是每个家庭必不可少的大家电之一!在快节奏的现代生活中,受手机和平板的冲击,电视机这个曾经的客厅“霸主”一度失去了“主角光环”…...

GDPU 数据结构 天码行空6
一、实验目的 1、掌握串的顺序存储结构 2、掌握顺序串的基本操作方法(插入、删除等)。 3、掌握串的链式存储结构。 4、掌握链式串的几种基本操作(插入、删除等)。 5、掌握Brute-Force算法 二、实验内容 1、编写函数BFIndex(Str…...
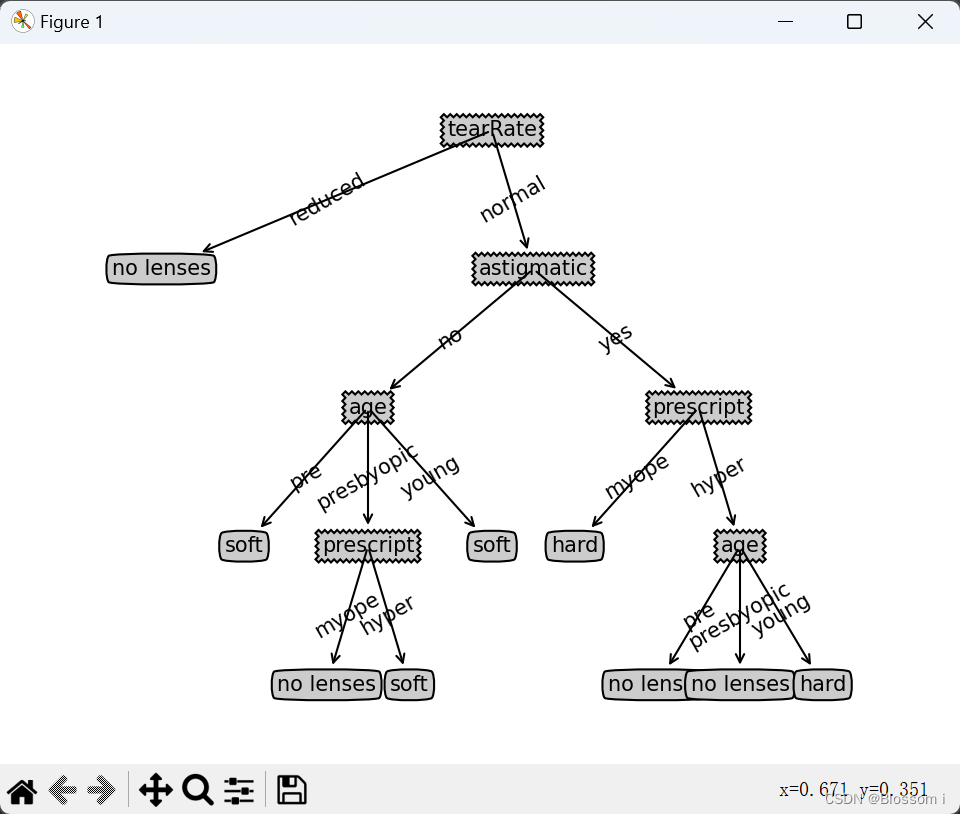
机器学习实验三:决策树-隐形眼镜分类(判断视力程度)
决策树-隐形眼镜分类(判断视力程度) Title : 使用决策树预测隐形眼镜类型 # Description :隐形眼镜数据是非常著名的数据集 ,它包含很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型 。 # 隐形眼镜类型包括硬材质 、软材质以及不适合佩…...

广州华锐互动:VR技术应用到工程项目施工安全培训的好处
随着科技的飞速发展,虚拟现实(VR)技术已经深入到各个领域。在建筑施工领域,VR技术的应用为工程项目施工安全培训带来了许多好处。本文将探讨VR技术在这方面的优势和应用。 首先,VR技术能够提供沉浸式的安全培训体验。通过VR设备,学…...

Hadoop3.0大数据处理学习1(Haddop介绍、部署、Hive部署)
Hadoop3.0快速入门 学习步骤: 三大组件的基本理论和实际操作Hadoop3的使用,实际开发流程结合具体问题,提供排查思路 开发技术栈: Linux基础操作、Sehll脚本基础JavaSE、Idea操作MySQL Hadoop简介 Hadoop是一个适合海量数据存…...
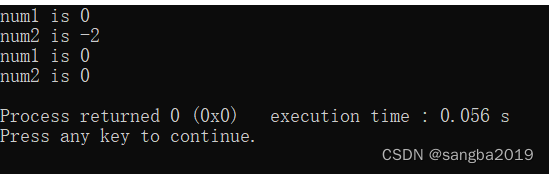
C笔记:引用调用,通过指针传递
代码 #include<stdio.h> int max1(int num1,int num2) {if(num1 < num2){num1 num2;}else{num2 num1;} } int max2(int *num1,int *num2) {if(num1 < num2){*num1 *num2; // 把 num2 赋值给 num1 }else{*num2 *num1;} } int main() {int num1 0,num2 -2;int…...
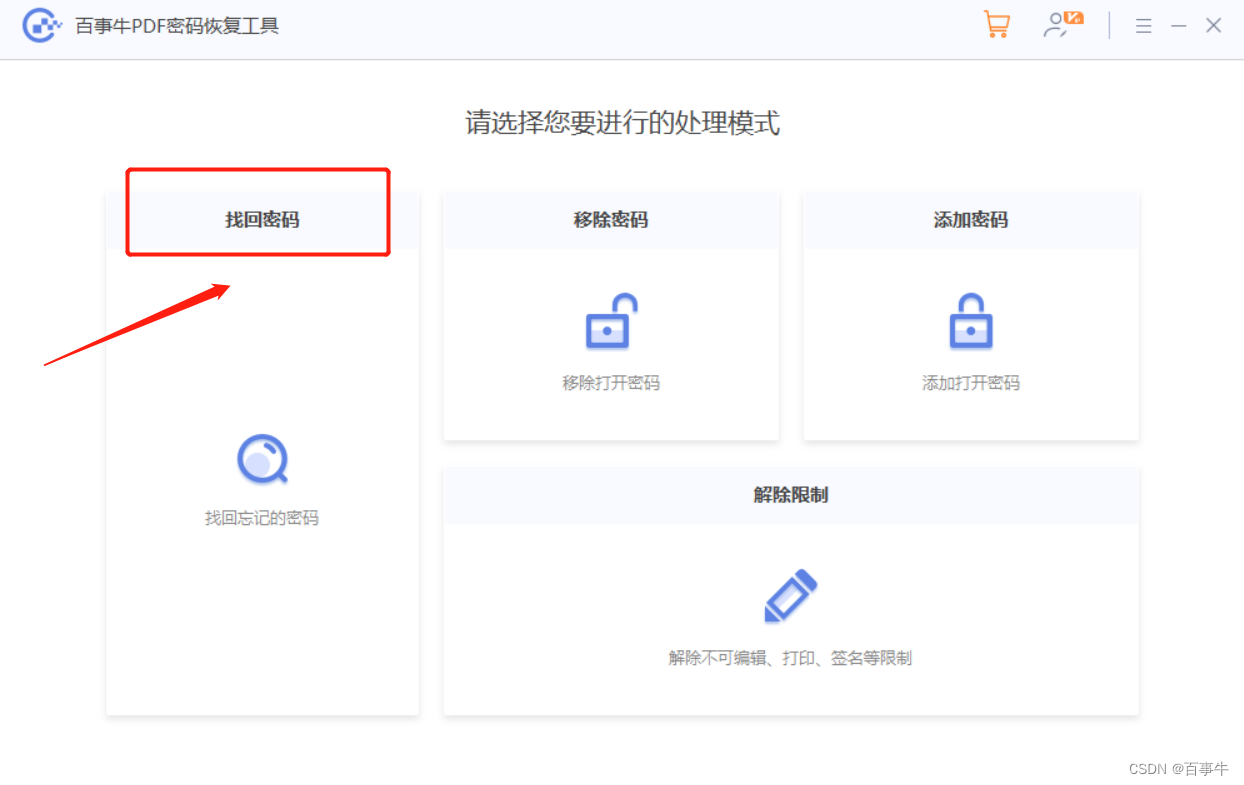
【方法】如何给PDF文件添加“打开密码”?
PDF文件可以在线浏览,但如果想要给文件添加“打开密码”,就需要用到软件工具,下面小编分享两种常用的工具,小伙伴们可以根据需要选择。 工具一:PDF编辑器 PDF阅读器一般是没有设置密码的功能模块,PDF编辑器…...
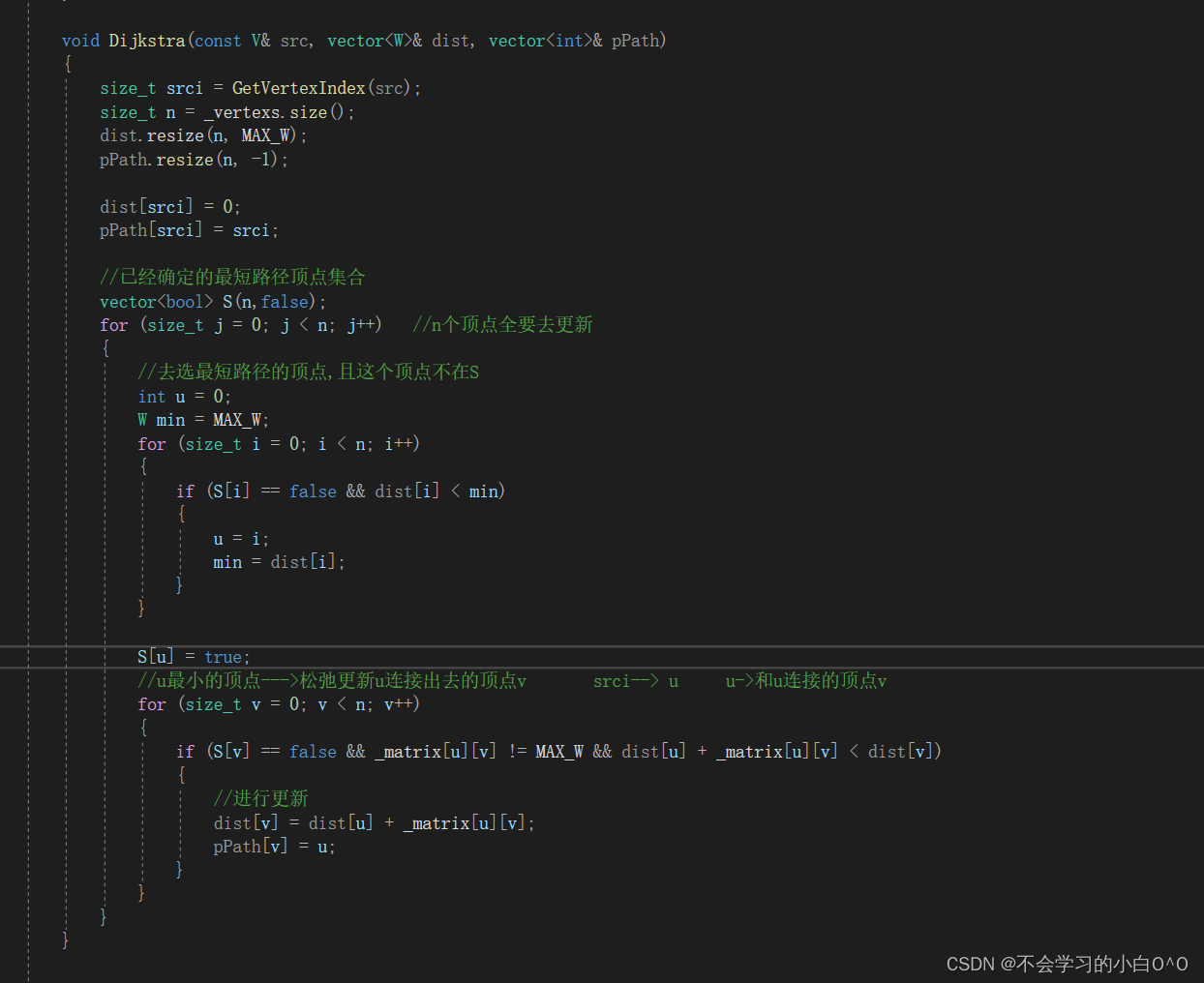
单源最短路径 -- Dijkstra
Dijkstra算法就适用于解决带权重的有向图上的单源最短路径问题 -- 同时算法要求图中所有边的权重非负(这个很重要) 针对一个带权有向图G , 将所有节点分为两组S和Q , S是已经确定的最短路径的节点集合,在初始时为空&…...

Java--多态及抽象类与接口
1.多态 以不同参数调用父类方法,可以得到不同的处理,子类中无需定义相同功能的方法,避免了重复代码编写,只需要实例化一个继承父类的子类对象,即可调用相应的方法,而只需要维护附父类方法即可。 package c…...
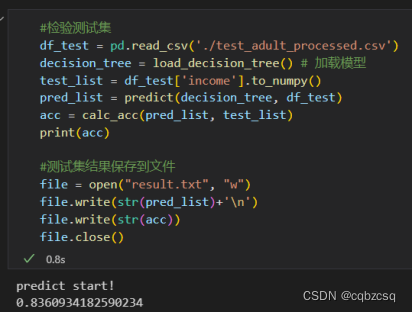
Python手搓C4.5决策树+Azure Adult数据集分析
前言 课上的实验 由于不想被抄袭,所以暂时不放完整代码 Adult数据集可以在Azure官网上找到 Azure 开放数据集中的数据集 - Azure Open Datasets | Microsoft Learn 数据集预处理 删除难以处理的权重属性fnlwgt与意义重复属性educationNum去除重复行与空行删除…...

【tg】6: MediaManager的主要功能
【tg】2:视频采集的输入和输出 的管理者是 media manager‘ media 需要 network的支持:NetworkInterface friend class MediaManager::NetworkInterfaceImpl;NetworkInterfaceImpl 直接持有 MediaManager 的指针即可:发送rtp包、rtcp包、设置socket选项?...

NPM-安装报错connect ETIMEDOUT
报错信息request to https://registry.npm.taobao.org/yarn failed, reason: connect ETIMEDOUT 解决方案: 1、npm set strict-ssl false 2、设置代理 npm config set proxy http://xxx:xxxopenproxy.ali.com:8080npm如何在安装的时候指定源 npm install -g yarn1.…...

机器学习之查准率、查全率与F1
文章目录 查准率(Precision):查全率(Recall):F1分数(F1 Score):实例P-R曲线F1度量python实现 查准率(Precision): 定义: …...
*Django中的Ajax 纯js的书写样式1
搭建项目 建立一个Djano项目,建立一个app,建立路径,视图函数大多为render, Ajax的创建 urls.py path(index/,views.index), path(index2/,views.index2), views.py def index(request):return render(request,01.html) def index2(requ…...

谈谈node架构中的线程进程的应用场景、事件循环及任务队列
本文作者系360奇舞团前端开发工程师 文章标题:谈谈node架构中的线程进程的应用场景、事件循环及任务队列 Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,nodejs是单线程执行的,它基于事件驱动和非阻塞I/O模型进行多任务的执行。在理…...

http代理IP它有哪些应用场景?如何提升访问速度?
随着互联网的快速发展,越来越多的人开始关注网络速度和安全性。其中,代理IP技术作为一种有效的网络加速和安全解决方案,越来越受到人们的关注。那么,http代理IP有哪些应用场景?又如何提升访问速度呢? 一、h…...

Armv8/Armv9的VIPT的别名问题是如何解决的
https://www.cse.unsw.edu.au/~cs9242/02/lectures/03-cache/node8.html https://developer.arm.com/documentation/ddi0406/b/System-Level-Architecture/Virtual-Memory-System-Architecture–VMSA-/Address-mapping-restrictions...
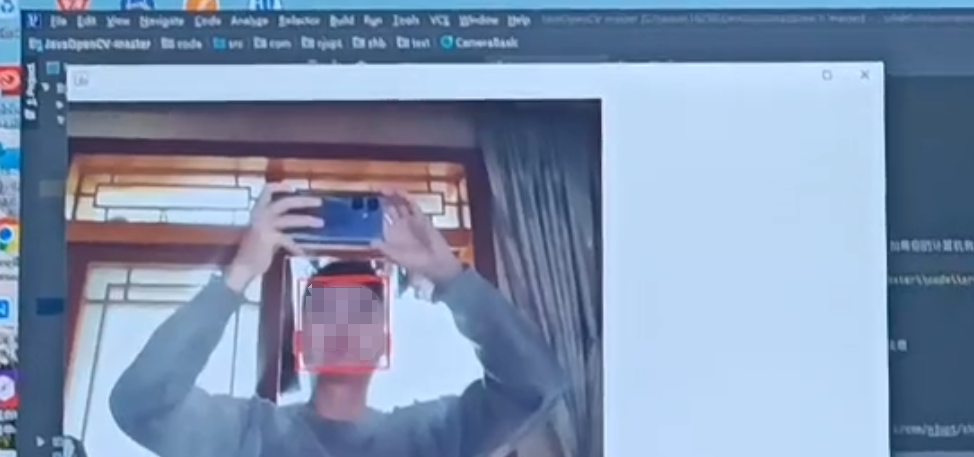
java/javaswing/窗体程序,人脸识别系统,人脸追踪,计算机视觉
源码下载地址 支持:远程部署/安装/调试、讲解、二次开发/修改/定制 源码下载地址...

颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式
颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式 【免费下载链接】upkie Open-source wheeled biped robots 项目地址: https://gitcode.com/gh_mirrors/up/upkie 在传统机器人设计面临轮式与足式两难选择的今天,一个革命性…...

Excel MCP Server终极指南:让AI成为你的Excel自动化助手
Excel MCP Server终极指南:让AI成为你的Excel自动化助手 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了重复的Excel操作&…...

轻量级爬虫框架slacrawl:基于规则驱动的模块化数据采集实践
1. 项目概述:一个轻量级、模块化的网页爬虫框架最近在做一个需要从多个网站定时抓取结构化数据的小项目,找了一圈现成的工具,要么太重(像Scrapy,学起来成本高),要么太死板(很多脚本只…...

LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼
LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼 【免费下载链接】LrcHelper 从网易云音乐下载带翻译的歌词 Walkman 适配 项目地址: https://gitcode.com/gh_mirrors/lr/LrcHelper 你是否曾为找不到心爱歌曲的歌词而烦恼?或…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Wand-Enhancer:零成本解锁WeMod高级功能的完整指南
Wand-Enhancer:零成本解锁WeMod高级功能的完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫不决吗…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...

GURU-Ai:面向开发者的AI命令行工具集,提升代码理解与运维效率
1. 项目概述:一个面向开发者的AI助手工具集最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个大而全的AI模型或者聊天机器人,但点进去仔细研究后,我发现它的定位其实非常…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...