MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL2:MySQL中一条查询SQL是如何执行的?
- MySQL中一条查询SQL是如何执行的?
- 1.连接
- 怎么查看MySQL当前有多少个连接?
- 思考:为什么连接数是查看线程?客户端的连接和服务端的线程有什么关系?
- MySQL参数级别说明
- 2.查询缓存
- 3.解析器(Parser)
- 词法解析
- 语法解析
- 4.预处理器(Preprocessor)
- 5.查询优化器(Query Optimizer)
- 什么是查询优化器?
- 优化器可以做什么?
- 6.执行计划
- EXPLAIN査看MySQL的执行计划
- EXPLAIN FORMAT=JSON输出详细JSON格式的的执行计划
- 开启optimizer trace
- 7.存储引擎
- MySQL表数据存在磁盘什么位置
- 存储引擎是怎么选择的?可以修改吗?
- MySQL为什么支持这么多存储引擎呢?
- MySQL常见存储引擎
- MylSAM (3个文件)
- InnoDB (2个文件)
- Memory (1个文件)
- CSV (3个文件)
- Archive (2 个文件)
- 如何选择存储引擎?
- 8.执行引擎(Query Execution Engine),返回结果
- MySQL体系结构总结
- MySQL合集
MySQL中一条查询SQL是如何执行的?
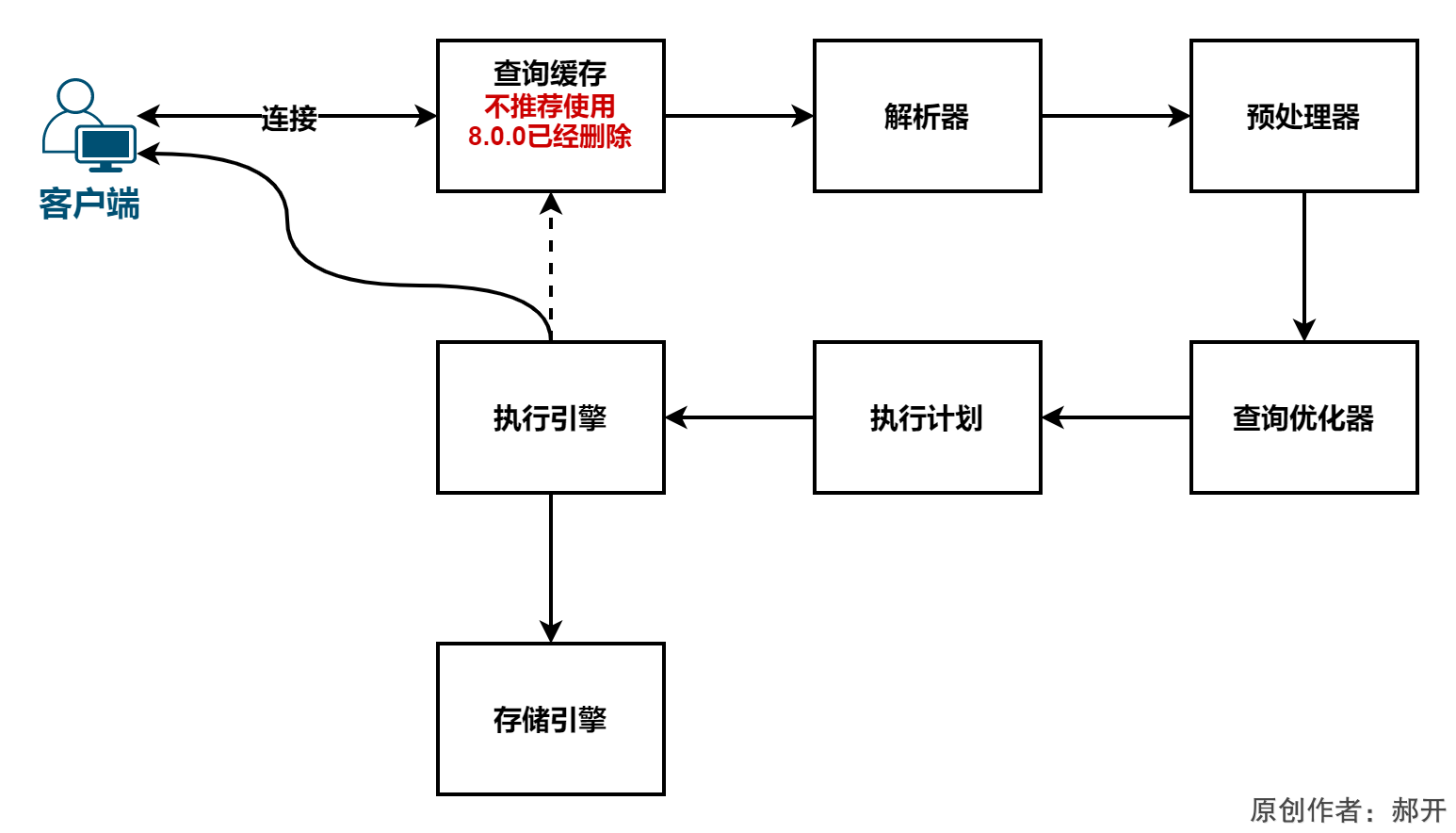
1.连接
MySQL服务监听的端口默认是3306,客户端连接服务端的方式有很多:
- 通信类型:同步/异步
通信类型可以是同步的,也可以是异步的,服务端都支持,只不过具体采用哪种方式取决于客户端的代码编写,通常我们都采用同步的方式,因为异步的方式编程会更加复杂,可能会造成客户端数据的混淆 - 连接方式:长连接/短连接
连接方式可以是长连接,也可以是短连接,服务端都支持。短连接就是用完直接将这个连接close掉,长连接用完之后连接可以保持,可以给其它的客户端继续使用,那么为了节省资源,在大部分情况下,我们都会采用长连接这样的方式 - 协议:TCP/Unix Socket
TCP:从协议上来讲,MySQL服务端支持客户端和它使用TCP ip的通信协议和它进行交互,我们Java代码,包括其它程序语言,都是使用TCP这种方式Unix Socket:本机的客户端连本机的服务端的时候,也就是说,你的Linux本机安装了MySQL,访问的时候不指定host直接访问,那么用到的就是一种文件的方式,这个文件叫做Unix Socket文件共享、命名空间:你的Windows本机安装了MySQL,就可以在界面上看到最后是否启用这两个选项
怎么查看MySQL当前有多少个连接?
可以用show status命令,模糊查询Thread:
show global status like 'Thread%';

字段含义
Threads_cached:缓存中的线程连接数
Threads_connected:当前打开的连接数
Threads_created:为处理连接创建的线程数
Threads_running:非睡眠状态的连接数,通常指并发连接数
思考:为什么连接数是查看线程?客户端的连接和服务端的线程有什么关系?
MySQL服务端是一个单进程多线程的模型,也就是说:
客户端每产生一个连接或者一个会话(session),在服务端就会创建一个线程来处理。既然如此, 如果要杀死会话,就是Kill线程。
既然是分配线程的话,保持连接肯定会消耗服务端的资源,因此,必然有一个定时的回收长时间不用的线程的资源的操作,MySQL会把那些长时间不活动的(SLEEP)连接自动断开,有两个参数wait timeout和interactive timeout,也
可以叫做系统的变量:
show global VARIABLES like 'wait_timeout'; ## 非交互式超时时间,如 JDBC 程序show global VARIABLES like 'interactive_timeout'; ## 交互式超时时间,如数据库连接工具

默认都是28800秒,8小时。
既然连接消耗资源,MySQL服务允许的最大连接数(也就是并发数)默认是多少呢?
show variables like 'max_connections';

在5.7版本中默认是151个,最大可以设置成100000
MySQL参数级别说明
MySQL中的参数(变量)分为session和global级别,分别是在当前会话中生效和全局生效,但是并不是每个参数都有两个级别,比如max_connections就只有全局级别。
当没有带参数的时候,默认是session级别,包括查询和修改。
比如修改了一个参数以后,在本窗口査询已经生效,但是其他窗口不生效:
所以,如果只是临时修改,建议修改session级别。 如果需要在其他会话中生效,必须显式地加上global参数。
执行一条查询语句,客户端跟服务端建立连接之后呢?下一步要做什么?
2.查询缓存
MySQL内部自带了一个缓存模块。MySQL的缓存默认是关闭的。
默认关闭的意思就是不推荐使用,为什么MySQL不推荐使用它自带的缓存呢?
主要是因为MySQL自带的缓存的应用场景有限,很鸡肋
- 第一个是它要求SQL语句必须一 模一样,中间多一个空格,字母大小写不同都被认为是不同的的SQL
- 第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对于有大量数据更新的应用,也不适合
所以缓存这一块,我们还是交给ORM框架(比如MyBatis默认开启了一级缓存),或者独立的缓存服务,比如Redis来处理更合适。
MySQL 8.0中,查询缓存已经被移除了。
没有使用缓存的话,就会跳过缓存的模块,下一步要做什么呢?
3.解析器(Parser)
一条SQL语句是如何被识别的呢?假如随便执行一个字符串aaa,服务器会报了一个1064的错:
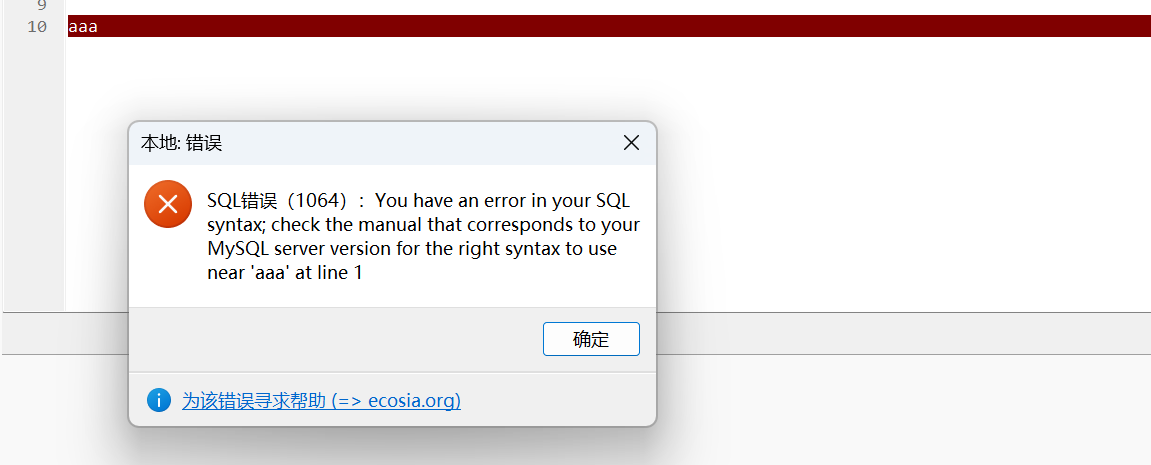
那么MySQL是如何知道输入的内容是错误的?
这个就是MySQL的Parser解析器和Preprocessor预处理模块。
解析器主要做的事情是:对语句基于SQL语法,进行词法解析和语法解析。
词法解析
词法解析就是把一个完整的SQL语句打碎成一个个的单词。
比如一个简单的SQL语句:
select name from stu where id = 1001;
它会打碎成8个符号,每个符号是什么类型,从哪里开始到哪里结束。
语法解析
第二步就是语法解析,语法解析会对SQL做一些语法检查,比如单引号有没有闭合,然后根据MySQL定义的语法规则,根据SQL语句生成一个数据结构,这个数据结构,我们把它叫做解析树(select lex)。
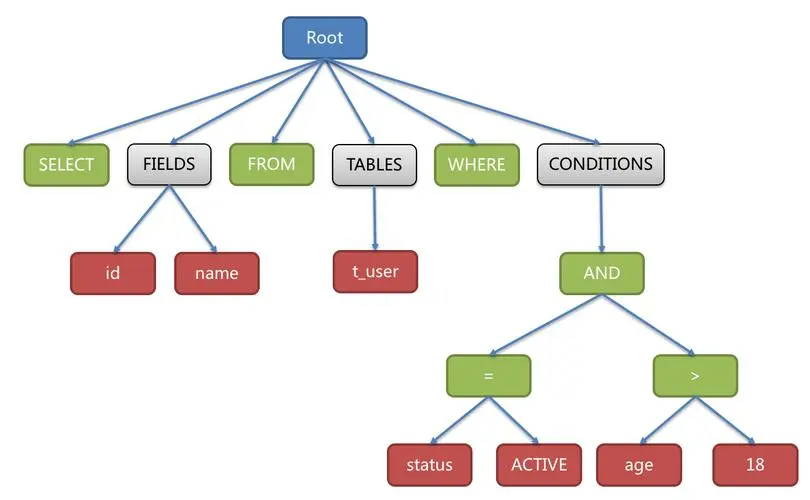
词法、语法分析是一个非常基础的功能,Java的编译器、百度搜索引擎如果要识别语句,必须也要有词法语法分析功能。
任何数据库的中间件,要解析SQL完成路由功能,也必须要有词法和语法分析功能,比如Mycat,Sharding-JDBC (用到了 Druid Parser)。在市面上也有很多的开源的词法解析的工具(比如LEX, Yacc)
解析器可以分析语法,但是它怎么知道数据库里面有什么表,表里面有什么字段呢?
4.预处理器(Preprocessor)
问题:如果我写了一个词法和语法都正确的SQL,但是表名或者字段不存在,会在哪里报错?是在数据库的执行层还是解析器?比如:
select * from tbl1;
实际上还是在解析的时候报错,解析SQL的环节里面有个预处理器。
它会检査生成的解析树,解决解析器无法解析的语义。比如,它会检査表和列名是否存在,检査名字和别名,保证没有歧义。
预处理之后得到一个新的解析树。
5.查询优化器(Query Optimizer)
将解析树变为执行计划。
什么是查询优化器?
得到解析树之后,是不是执行SQL语句了呢?
这里我们有一个问题,一条SQL语句是不是只有一种执行方式?或者说数据库最终 执行的SQL是不是就是我们发送的SQL?
这个答案是否定的。
一条SQL语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。比如索引有好几个,那么最终选择哪一个索引;或者是多张表进行关联查询的时候,使用哪个表作为基准表,以及其它的语法方面的一些优化等。
有多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
这个就是MySQL的査询优化器的模块(Optimizer)。
査询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选 择一种最优的执行计划,MySQL里面使用的是基于开销(cost)的优化器,哪种执行计划开销最小,就用哪种。
可以使用这个命令査看査询的开销:
show status like Last query cost';
优化器可以做什么?
MySQL的优化器能处理哪些优化类型呢?
6.执行计划
优化完之后,得到一个什么东西呢?
优化器最终会把解析树变成一个査询执行计划,查询执行计划是一个数据结构。
EXPLAIN査看MySQL的执行计划
如何査看MySQL的执行计划呢?比如多张表关联查询,先査询哪张表?在执行査询的时候可能用到哪些索引,实际上用到了什么索引?
MySQL提供了一个执行计划的工具。我们在SQL语句前面加上EXPLAIN,就可以
看到执行计划的信息。
EXPLAIN select name from stu where id=1001;

为什么执行EXPLAIN很快,而执行一条SQL语句执行很慢?
因为EXPLAIN并没有真正执行SQL语句,而是一个参考,有一些值是不精准的。
EXPLAIN FORMAT=JSON输出详细JSON格式的的执行计划
如果要得到详细的信息,还可以在EXPLAIN后面加上FORMAT=JSON,这样会输出详细的JSON格式
EXPLAIN FORMAT=JSON select name from stu where id=1001;
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "1.20"},"table": {"table_name": "stu","access_type": "ALL","rows_examined_per_scan": 1,"rows_produced_per_join": 1,"filtered": "100.00","cost_info": {"read_cost": "1.00","eval_cost": "0.20","prefix_cost": "1.20","data_read_per_join": "16"},"used_columns": ["id","name"],"attached_condition": "(`test`.`stu`.`id` = 1001)"}}
}
开启optimizer trace
如果要得到详细的信息,还有一种方式,开启optimizer trace,默认是关闭的,开启之后,会消耗性能。

SHOW VARIABLES LIKE 'optimizer_trace';
SET optimizer_trace = 'ENABLED=ON';select name from stu where id=1001; ## 执行SQL语句select * from information_schema.optimizer_trace; ## 执行之后会记录在这张表内
7.存储引擎
得到执行计划以后,SQL语句是不是终于可以执行了?
问题又来了:
1、从逻辑的角度来说,我们的数据是放在哪里的,或者说放在一个什么结构里面?
2、执行计划在哪里执行?是谁去执行?查询总归是要知道数据在哪里存放着的,才能去查,因此先了解存储引擎,看数据都存在哪里。
MySQL表数据存在磁盘什么位置
这些位置可能因具体的MySQL版本和安装方式而有所不同,用户可以通过MySQL的配置文件(my.cnf)来设置MySQL数据库文件的位置。
MySQL数据库文件的位置是由datadir参数决定的,下面命令可以查看到数据文件存储的位置。
show global variables like 'datadir%';
我这里用的是Windows的

可以看到,在Windows系统中,数据文件是在C:\ProgramData\MySQL\MySQL Server 5.7\Data
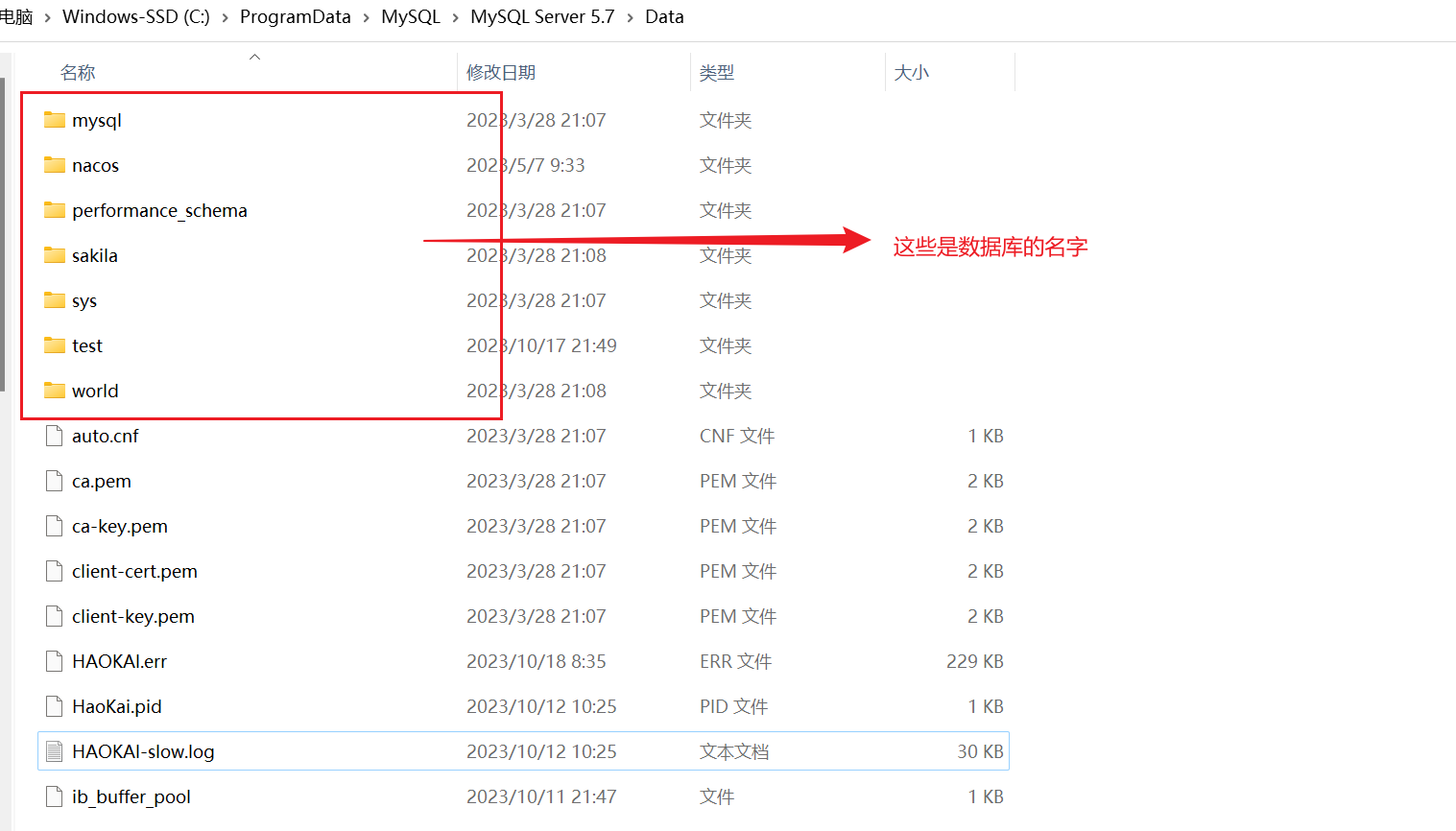
在MySQL的数据目录下,每个数据库对应一个文件夹,对应数据库的表文件就存在对应命名的文件夹中,以test数据库为例,点击进入该文件夹,可以发现数据表文件
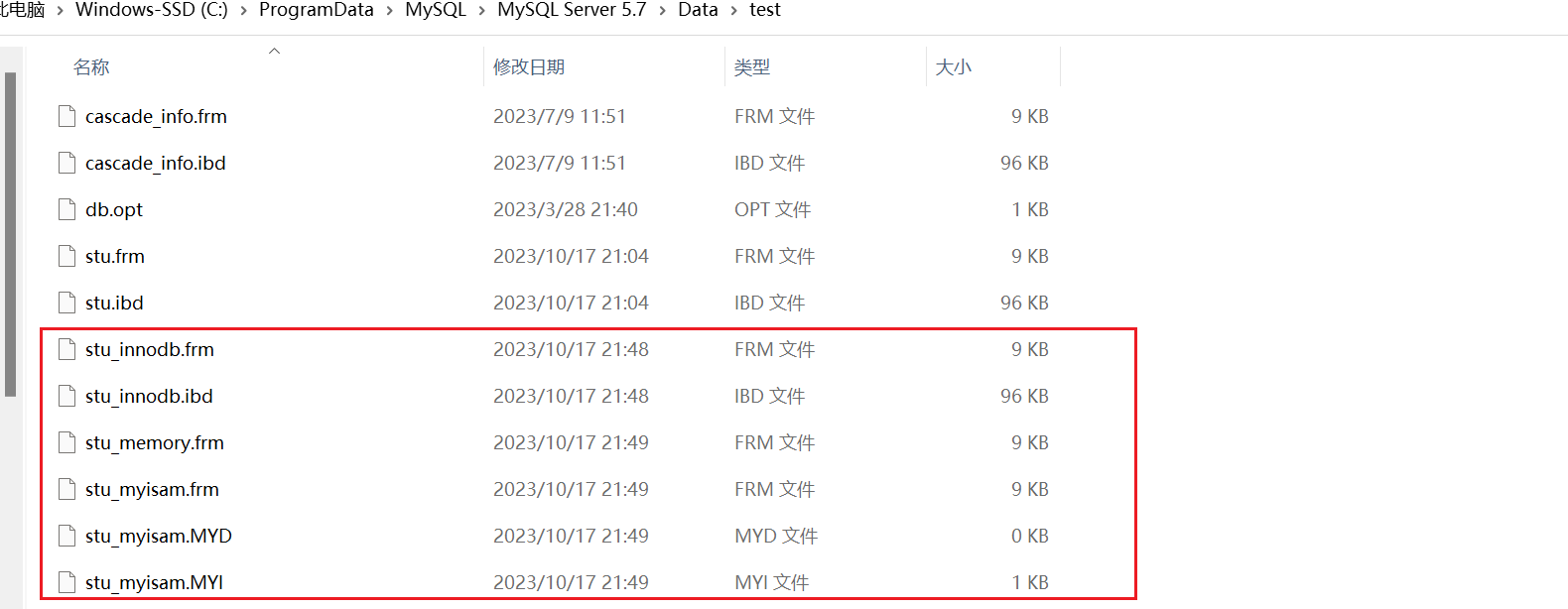
图中红框中列出三种常用的存储引擎的表存储方式。
存储引擎是怎么选择的?可以修改吗?
我们在建表的时候,可以发现MySQL提供了多种存储引擎选项。
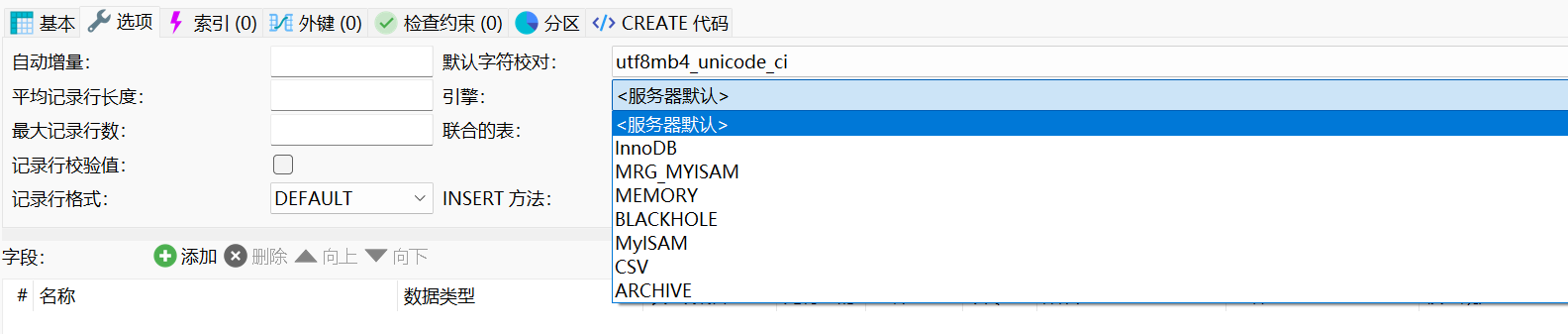
一张表的存储引擎,也叫表类型,是在创建表的时候指定的,使用ENGINE关键字来指定。
CREATE TABLE `stu_innodb` (`id` INT(11) NULL DEFAULT NULL,`name` INT(11) NULL DEFAULT NULL,`sex` INT(11) NULL DEFAULT NULL,`age` INT(11) NULL DEFAULT NULL
)
COLLATE='utf8mb4_unicode_ci'
ENGINE=InnoDB
没有指定的时候,数据库就会使用默认的存储引擎,5.5.5之前,默认的存储引擎是MylSAM, 5.5.5之后,默认的存储引擎是InnoDB。
存储引擎是可以修改的,很多时候,我们在做测试,需要插入大量的测试数据,就可以先将表的存储引擎改为MylSAM ,插入完成之后,再改为InnoDB。
MySQL为什么支持这么多存储引擎呢?
- 如果有一张表,需要很高的访问速度,而不需要考虑持久化的问题,丢了就丢了,是不是只需要要把数据放在内存就可以了?
- 如果一张表,是用来做历史数据存档的,不需要修改,也不需要索引,那它是不是要支持数据的压缩?
- 如果一张表用在读写并发很多的业务中,是不是要支持读写不干扰,而且要保证比较高的数据一致性呢?
说到这里大家应该明白了,MySQL之所以支持这么多的存储引擎,就是因为我们有不同的业务需求,对表有不同的访问要求、存储要求、管理要求,而一种存储引擎是不能提供所有的特性。
MySQL常见存储引擎
MylSAM (3个文件)
These tables have a small footprint. Table-level locking limits the performance in read/write workloads, so it is often used in read-only or read-mostly workloads in Web and data warehousing configurations.
应用范围比较小。表级锁定限制了读/写的性能,因此在Web和数据仓库配置中,
它通常用于只读或以读为主的工作。
特点:
- 支持表级别的锁(插入和更新会锁表)。
- 不支持事务。
- 拥有较高的插入(insert)和查询(select)速度。比如:怎么快速向数据库插入100万条数据?我们可以先用MylSAM插入数据,然后修改存储引擎为InnoDB的操作。
- 存储了表的行数(count速度更快)。
适合:只读之类的数据分析的项目。
数据文件:
每个MyISAM表由三个文件组成:.frm文件、.MYD文件和.MYI文件。
- .frm文件:是表结构定义文件,它存储了表的元数据信息,包括表的字段、索引等。
- .MYD文件:是数据文件,它存储了实际的表数据。
- .MYI文件:是索引文件,它存储了表的索引信息,用于加快查询速度。
InnoDB (2个文件)
The default storage engine in MySQL 5.7. InnoDB is a transaction-safe (ACID compliant) storage engine for MySQL that has commit, rollback, and crash-recovery capabilities to protect user data. InnoDB row-level locking (without escalation to coarser granularity locks) and Oracle-style consistent nonlocking reads increase multi-user concurrency and performance. InnoDB stores user data in clustered indexes to reduce I/O for common queries based on primary keys. To maintain data integrity, InnoDB also supports FOREIGN KEY referential-integrity constraints.
mysql 5.7中的默认存储引擎。InnoDB是一个事务安全(与ACID兼容)的MySQL 存储引擎,它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁(不升级
为更粗粒度的锁)和Oracle风格的一致非锁读提高了多用户并发性和性能。InnoDB将
用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性, InnoDB还支持外键引用完整性约束。
InnoDB本来是InnobaseOy公司开发的,它和MySQL AB公司合作开源了InnoDB的代码。但是MySQL的竞争对手Oracle把InnobaseOy收购了。后来08年Sun公司(开发Java语言的Sun)收购了MySQL AB,09年Sun公司又被Oracle收购了,所以MySQL,InnoDB又是一家了。有人觉得MySQL越来越像Oracle,其实也是这个原因。
特点:
- 支持事务,支持外键,因此数据的完整性、一致性更高。
- 支持行级别的锁和表级别的锁。
- 支持读写并发,写不阻塞读(MVCC)。
- 特殊的索引存放方式,可以减少IO,提升査询效率。
适合:经常更新的表,存在并发读写或者有事务处理的业务系统。
数据文件:
- .ibd文件:InnoDB将每个表,存储在以表名命名的文件中,这些文件的后缀名为.ibd。
Memory (1个文件)
Stores all data in RAM, for fast access in environments that require quick lookups of non-critical data. This engine was formerly known as the HEAP engine. Its use cases are decreasing; InnoDB with its buffer pool memory area provides a general-purpose and durable way to keep most or all data in memory, and DBCLUSTER provides fast key-value lookups for huge distributed data sets.
将所有数据存储在RAM中,以便在需要快速查找非关键数据的环境中快速访问。这
个引擎以前被称为堆引擎。其使用案例正在减少;InnoDB及其缓冲池内存区域提供了一
种通用、持久的方法来将大部分或所有数据保存在内存中,而ndbduster为大型分布式 数据集提供了快速的键值查找。
特点:把数据放在内存里面,读写的速度很快,但是数据库重启或者崩溃,数据会全部消失。
适合:适合做临时表。将表中的数据存储到内存中。
CSV (3个文件)
Its tables are really text files with comma-separated values. CSV tables let you import or dump data in CSV format, to exchange data with scripts and pplications that read and write that same format. Because CSV tables are not indexed, you typically keep the data in InnoDB tables during normal operation, and only use CSV tables during the import or export stage.
它的表实际上是带有逗号分隔值的文本文件。csv表允许以CSV格式导入或转储数据,
以便与读写相同格式的脚本和应用程序交换数据。因为CSV表没有索引,所以通常在正
常操作期间将数据保存在innodb表中,并且只在导入或导出阶段使用csv表。
特点:不允许空行,不支持索引。格式通用,可以直接编辑。
适合:在不同数据库之间导入导出。
Archive (2 个文件)
These compact, unindexed tables are intended for storing and
retrieving large amounts of seldom-referenced historical, archived, or
security audit information.
这些紧凑的未索引的表用于存储和检索大量很少引用的历史、存档或安全审计信息。
特点:不支持索引,不支持update、delete。
如何选择存储引擎?
不同的存储引擎有各自的特性,它们有不同的存储机制、索引方式、锁定水平等功能。我们在不同的业务场景中对数据操作的要求不同,就可以选择不同的存储引擎来满足我们的需求,这个就是MySQL支持这么多存储引擎的原因。
如果对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
如果需要一个用于查询的临时表,可以选择Memory。
如果所有的存储引擎都不能满足你的需求,并且技术能力足够,可以根据官网内部 手册用C语言开发一个存储引擎
这个开发规范,实现相应的接口,给执行器操作。
也就是说,为什么能支持这么多存储引擎,还能自定义存储引擎,表的存储引擎改 了对Server访问没有任何影响,就是因为大家都遵循了一定了规范,提供了相同的操作 接口。
每个存储引擎都有自己的服务。
show engine innodb status;
这些存储引擎用不同的方式管理数据文件,提供不同的特性,但是为上层提供相同 的接口。
为什么我们修改了表的存储引擎,操作方式不需要做任何改变?
因为不同功能的存储引擎实现的API是相同的。
MySQL中文帮助文档:https://www.mysqlzh.com/doc/213.html
8.执行引擎(Query Execution Engine),返回结果
存储引擎分析完了,它是我们存储数据的形式,那么是谁使用执行计划去操作存储引擎呢?
这个东西就是执行引擎,它利用存储引擎提供的相应的API来完成操作。最后把数据返回给客户端。
MySQL体系结构总结

基于上面分析的流程,总体上,我们可以把MySQL分成三层:
- 跟客户端对接的连接层:客户端要连接到MySQL服务器3306端口,必须要跟服务端建立连接,那么管理所有的连接,验证客户端的身份和权限,这些功能就在连接层完成
- 真正执行操作的服务层:连接层会把SQL语句交给服务层,这里面又包含一系列的流程:
- 比如查询缓存的判断
- 根据SQL调用相应的接口
- 对我们的SQL语句进行词法和语法的解析(比如关键字怎么识别,别名怎么识别,语法有没有错误等等)
- 然后是优化器,MySQL底层会根据一定的规则对我们的SQL语句进行优化,最后再交给执行器去执行
- 和跟硬件打交道的存储引擎层:存储引擎就是我们的数据真正存放的地方,在MySQL里面支持不同的存储引擎。再往下就是内存或者磁盘。
MySQL合集
MySQL1:MySQL发展史,MySQL流行分支及其对应存储引擎
MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL4:索引是什么;索引类型;索引存储模型发展:1.二分查找,2.二叉查找树,3.平衡二叉树,4.多路平衡查找树,5. B+树,6.索引为什么不用红黑树?7.InnoDB的hash索引指什么?
相关文章:
MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL2:MySQL中一条查询SQL是如何执行的? MySQL中一条查询SQL是如何执行的?1.连接怎么查看MySQL当前有多少个连接?思考:为什么连接数是查看线程?客户端的连接和服务端的线程有什么关系?MySQL参数…...
C++入门01—从hello word!开始
1.第一个C程序 1.1 创建项目 第一次使用Visual Studio时: 1.2 创建文件 1.3 编写代码 编写第一个代码: #include<iostream> using namespace std; int main() {cout << "hello word!" << endl;system("pause"…...
Mingw下载---运行vscodeC++文件
下载 下载网址: https://sourceforge.net/projects/mingw-w64/files/mingw-w64/mingw-w64-release/ 翻到最下面,选择win64的安装: 下载完,解压到没有空格和中文字符的路径。不然在vscode中运行不了C代码。...

数据安全与PostgreSQL:最佳保护策略
在当今数字化时代,数据安全成为了企业不可或缺的一环。特别是对于使用数据库管理系统(DBMS)的组织来说,确保数据的完整性、保密性和可用性至关重要。在众多DBMS中,PostgreSQL作为一个强大而灵活的开源数据库系统&#…...

火山引擎实时、低延时拥塞控制算法的优化实践
摘要 火山引擎智能拥塞控制算法 VICC(Volcano Intelligent Congestion Control)是一种自适应的拥塞控制算法,旨在解决全球不同网络环境下,不同音视频应用对带宽利用率和延时的差异化要求。它结合了传统拥塞控制算法(如…...

adb设备调试常用命令
自从工作越来越忙后,越来越懒得写文章了,趁着1024程序员节,仪式性地写篇文章,分享一下最近调试设备经常用到的adb指令~ 1.查看应用内存占用 1.1 dumpsys meminfo package dumpsys是查看系统服务信息的一个常用指令,可…...

ubuntu下Docker的简单使用并利用主机显示
首先分享一个docker镜像的网站:https://hub.docker.com/search?q 这个网站里面有很多配置好的镜像,可以直接拉取。 下面介绍一下docker的安装和使用。 1、docker得到安装: sudo apt-get install docker 2、docker拉取一个镜像到本地,这里我…...

第12章 PyTorch图像分割代码框架-1
从本章开始,本书将会进行深度学习图像分割的实战阶段。PyTorch作为目前最为流行的一款深度学习计算框架,在计算机视觉和图像分割任务中已经广泛使用。本章将介绍基于PyTorch的深度学习图像分割代码框架,在总体框架的基础上,基于PA…...

2023CSPJ 旅游巴士 —— dijkstra
This way 题意: 给你一个有向图,1号点为起点,n为终点。你可以在k的倍数的时间点在起点开始,每条边的边长为1,同时,每条边有一个限定时间ai,表示你必须在大于等于ai的时间点才能走这条边。 …...
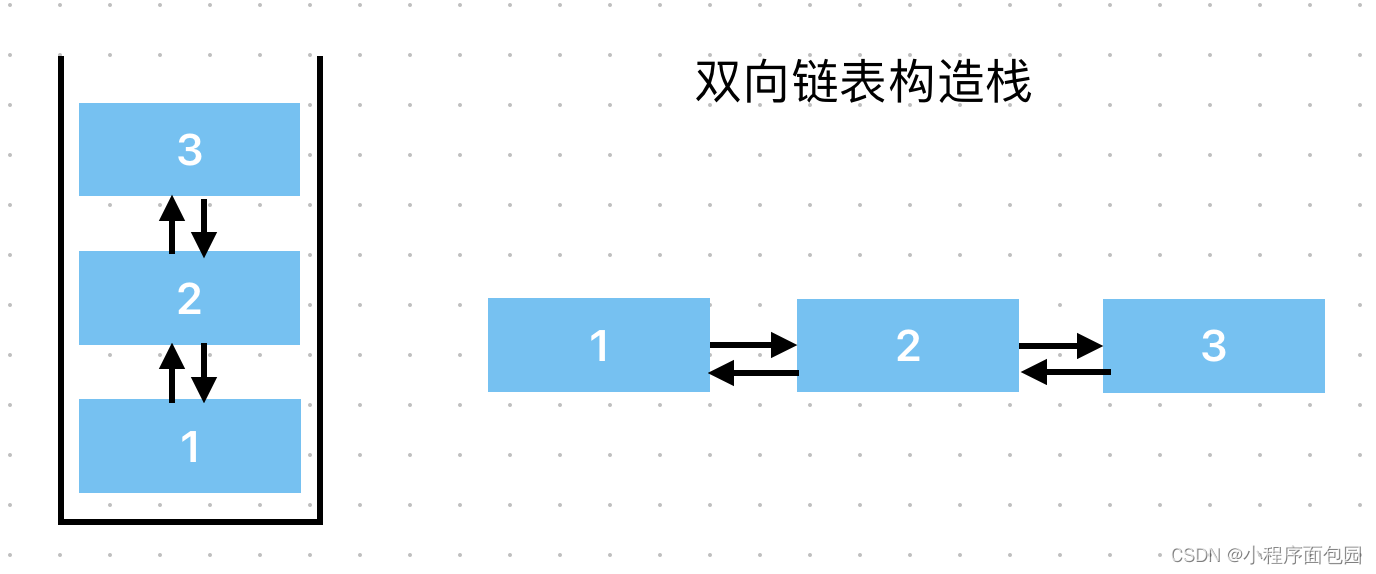
数据结构之栈的讲解(源代码+图解+习题)
我们在学习过顺序表和链表之后,了解了使用数组存储数据,使用结构体来存储数据和有关的指针,这些都是底层的东西,链表是靠指针的链接,顺序表是靠数组的下标才能得以实现增删查改。众多数据结构其实底层都离不开数组&…...
内网渗透-内网信息收集
内网信息收集 前言 当我们进行外网信息收集,漏洞探测以及漏洞利用后,获得了主机的权限后,我们需要扩大渗透的战果时,这是我们就要进行内网的渗透了,内网渗透最重要的还是前期的信息收集的操作了,就是我们的…...

LeetCode解法汇总2520. 统计能整除数字的位数
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你一个整…...

Lua语言编写爬虫程序
以下是一个使用luasocket-http库和Lua语言编写的爬虫程序。此程序使用了https://www.duoip.cn/get_proxy的代码。 -- 引入所需的库 local http require("socket.http") local ltn12 require("ltn12") local json require("json") -- 获取…...

安防监控项目---概要
文章目录 前言一、项目需求二、环境介绍三、关键点四、主框架分析总结 前言 各位小伙伴,在蛰伏了将近有半年的时间又要和大家分享新的知识了,这次和大家分享的是一个项目,因此呢我准备分项目阶段去和大家分享,希望大家都能够在每…...

数仓经典面试题
1.什么是数据仓库?请谈谈你对数据仓库的理解。 数据仓库是一个用于存储和管理数据的系统,它可以将分散的、异构的数据源中的数据进行抽取、转换、清洗和整合,然后按照一定的模型和架构进行组织和存储,以便更好地支持决策分析和业…...

【ARM Coresight 系列文章 15.2 – components power domain 详细介绍】
文章目录 1.1. Coresight 电源域模型1.1.1 CDBGPWRUPREQ 和 CDBGPWRUPACK1.1.2 CSYSPWRUPREQ 和 CSYSPWRUPACK1.1.3 Power Domain ID In RomTable1.1.4 Power domain entries1.1.5 Algorithm to discover power domain IDs1.1.6 Debug power requests1.1.7 System power reques…...

Flutter Android IOS 获取通讯录联系人列表
1.在pubspec.yaml 文件中添加 contacts_service 和 permission_handler 插件的依赖: dependencies:contacts_service: ^0.6.3 #获取联系人permission_handler: ^11.0.1 #权限请求2.在你的 Dart 代码中,导入 contacts_service 插件: impo…...
Spring Boot集成SpringFox 3.0与Pageable参数处理
Springfox 3.0有多个模块,提供了spring boot starter,与Spring Boot集成时仅需引入springfox-boot-starter,如下: <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter<…...

2、基于pytorch lightning的fabric实现pytorch的多GPU训练和混合精度功能
文章目录 承接 上一篇,使用原始的pytorch来实现多GPU训练和混合精度,现在对比以上代码,我们使用Fabric来实现相同的功能。关于Fabric,我会在后续的博客中继续讲解,是讲解,也是在学习。通过fabric,可以减少代码量&#…...

python版opencv人脸训练与人脸识别
1.人脸识别准备 使用的两个opencv包 D:\python2023>pip list |findstr opencv opencv-contrib-python 4.8.1.78 opencv-python 4.8.1.78数据集使用前一篇Javacv的数据集,网上随便找的60张图片,只是都挪到了D:\face目录下方便遍历 D:\face\1 30张刘德华图片…...

【Polars 2.0数据清洗成本控制白皮书】:20年ETL专家亲授5大降本增效实战模式,92%企业忽略的内存泄漏陷阱
第一章:Polars 2.0数据清洗成本控制全景认知在现代数据工程实践中,数据清洗不再仅关乎逻辑正确性,更深度绑定计算资源消耗、内存占用与执行延迟。Polars 2.0 通过零拷贝语义、惰性执行引擎重构与 Arrow-native 内存布局优化,将清洗…...

【部署】windows下虚拟机OpenClaw Ubuntu 24.04.4 安装指南
未来已来,只需一句指令,养龙虾专栏导航,持续更新ing… 概述 前置环境:win10/11、vmware等虚拟机(安装时注意勾选VMware Tools、cpu可以分配2C,内存建议4G,硬盘空间建议给40G) 系统要求 Node.js 22+:安装脚本可自动检测并安装(下文补充手动安装方案); Ubuntu 24.0…...

自媒体人的秘密武器:OpenClaw+nanobot自动生成视频字幕文件
自媒体人的秘密武器:OpenClawnanobot自动生成视频字幕文件 1. 为什么我们需要自动化字幕生成 作为一个长期在视频创作领域摸索的自媒体人,我深知字幕制作这个环节有多折磨人。曾经为了给一段10分钟的视频添加字幕,我需要反复暂停播放、手动…...

AI辅助开发:用提示词让快马AI自动生成技术职级成长路径分析应用
AI辅助开发:用提示词让快马AI自动生成技术职级成长路径分析应用 最近在研究技术职级体系时,发现很多开发者对阿里P10这类高级职位的成长路径特别感兴趣。但手动整理这些信息费时费力,于是尝试用AI辅助开发的方式快速生成一个可视化分析工具。…...

Oracle数据库架构入门概述
本文分为四个部分简单概述 一、入门概述 二、数据库实例简述 三、数据库物理存储和逻辑存储结构简述 四、网络体系结构概述 入门概述 Oracle 数据库服务器包括一个数据库和至少一个数据库实例 (通常是指只有一个实例)。 因为实例和数据库关联紧密&#x…...

17 种 RAG 优化策略
RAG 完整解析 本文适合小白入门,全程用「公司员工手册查病假」为统一实例,清晰讲解 RAG 是什么、工作流程,以及 17 种 RAG 优化策略(含标准英文术语),所有内容可直接复制用于分享,实例均精确到具…...

COMSOL中固态锂离子电池的电-热-力耦合仿真:考虑扩散诱导应力、热应力及外部挤压应力的影响
COMSOL 固态锂离子电池仿真 固态锂离子电池电-热-力耦合仿真,考虑了扩散诱导应力,热应力以及外部挤压应力。固态电池鼓包变形的时候,工程师老张盯着屏幕上的应力云图直挠头。这玩意儿明明充满电就膨胀,放完电又缩回去,…...

RAG深度解析一:从参数化知识到检索增强的范式重构
【内容定位】深度技术原理【文章日期】2026-03-27【场景引入】进入2026年3月,一场围绕大语言模型“可信性”的讨论在技术社区再度升温。开发者们早已不再争论模型参数量,而是转向一个更实际的问题:如何让动辄千亿参数的大模型,在回…...

mmsegmentation训练策略调优全攻略:从学习率预热到迭代次数计算
mmsegmentation训练策略调优实战:从参数配置到显存优化 在图像分割领域,mmsegmentation框架因其模块化设计和丰富的预训练模型而广受欢迎。但真正决定模型性能上限的,往往是那些容易被忽视的训练策略细节。本文将带您深入AdamW优化器的参数微…...

GBase 8a云数仓存算分离,“柔性搭建数仓”
传统分析型MPP数据库的搭建,就像装修一套毛坯房,从规划格局到水电改造,从墙面处理到家具进场,每一步都离不开专业师傅,稍有不慎就得返工重来。南大通用(gbase database)GBase 8a云数仓(GCDW&…...