Pytorch指定数据加载器使用子进程
torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=4, pin_memory=True)num_workers 参数是 DataLoader 类的一个参数,它指定了数据加载器使用的子进程数量。通过增加 num_workers 的数量,可以并行地读取和预处理数据,从而提高数据加载的速度。
通常情况下,增加 num_workers 的数量可以提高数据加载的效率,因为它可以使数据加载和预处理工作在多个进程中同时进行。然而,当 num_workers 的数量超过一定阈值时,增加更多的进程可能不会再带来更多的性能提升,甚至可能会导致性能下降。
这是因为增加 num_workers 的数量也会增加进程间通信的开销。当 num_workers 的数量过多时,进程间通信的开销可能会超过并行化所带来的收益,从而导致性能下降。
此外,还需要考虑到计算机硬件的限制。如果你的计算机 CPU 核心数量有限,增加 num_workers 的数量也可能会导致性能下降,因为每个进程需要占用 CPU 核心资源。
因此,对于 num_workers 参数的设置,需要根据具体情况进行调整和优化。通常情况下,一个合理的 num_workers 值应该在 2 到 8 之间,具体取决于你的计算机硬件配置和数据集大小等因素。在实际应用中,可以通过尝试不同的 num_workers 值来找到最优的配置。
综上所述,当 num_workers 的值从 4 增加到 8 时,如果你的计算机硬件配置和数据集大小等因素没有发生变化,那么两者之间的性能差异可能会很小,或者甚至没有显著差异。
测试代码如下
import torch
import torchvision
import matplotlib.pyplot as plt
import torchvision.models as models
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
import timeif __name__ == '__main__':mp.freeze_support()train_on_gpu = torch.cuda.is_available()if not train_on_gpu:print('CUDA is not available. Training on CPU...')else:print('CUDA is available! Training on GPU...')device = torch.device("cuda" if torch.cuda.is_available() else "cpu")batch_size = 4# 设置数据预处理的转换transform = torchvision.transforms.Compose([torchvision.transforms.Resize((512,512)), # 调整图像大小为 224x224torchvision.transforms.ToTensor(), # 转换为张量torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化])dataset = torchvision.datasets.ImageFolder('C:\\Users\\ASUS\\PycharmProjects\\pythonProject1\\cats_and_dogs_train',transform=transform)val_ratio = 0.2val_size = int(len(dataset) * val_ratio)train_size = len(dataset) - val_sizetrain_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])train_dataset = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=4, pin_memory=True)val_dataset = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True,num_workers=4, pin_memory=True)model = models.resnet18()num_classes = 2for param in model.parameters():param.requires_grad = Falsemodel.fc = nn.Sequential(nn.Dropout(),nn.Linear(model.fc.in_features, num_classes),nn.LogSoftmax(dim=1))optimizer = optim.Adam(model.parameters(), lr=0.001)criterion = nn.CrossEntropyLoss().to(device)model.to(device)filename = "recognize_cats_and_dogs.pt"def save_checkpoint(epoch, model, optimizer, filename):checkpoint = {'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'loss': loss,}torch.save(checkpoint, filename)num_epochs = 3train_loss = []for epoch in range(num_epochs):running_loss = 0correct = 0total = 0epoch_start_time = time.time()for i, (inputs, labels) in enumerate(train_dataset):# 将数据放到设备上inputs, labels = inputs.to(device), labels.to(device)# 前向计算outputs = model(inputs)# 计算损失和梯度loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()# 更新模型参数optimizer.step()# 记录损失和准确率running_loss += loss.item()train_loss.append(loss.item())_, predicted = torch.max(outputs.data, 1)correct += (predicted == labels).sum().item()total += labels.size(0)accuracy_train = 100 * correct / total# 在测试集上计算准确率with torch.no_grad():running_loss_test = 0correct_test = 0total_test = 0for inputs, labels in val_dataset:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)running_loss_test += loss.item()_, predicted = torch.max(outputs.data, 1)correct_test += (predicted == labels).sum().item()total_test += labels.size(0)accuracy_test = 100 * correct_test / total_test# 输出每个 epoch 的损失和准确率epoch_end_time = time.time()epoch_time = epoch_end_time - epoch_start_timeprint("Epoch [{}/{}], Time: {:.4f}s, Loss: {:.4f}, Train Accuracy: {:.2f}%, Loss: {:.4f}, Test Accuracy: {:.2f}%".format(epoch + 1, num_epochs,epoch_time,running_loss / len(val_dataset),accuracy_train, running_loss_test / len(val_dataset), accuracy_test))save_checkpoint(epoch, model, optimizer, filename)plt.plot(train_loss, label='Train Loss')# 添加图例和标签plt.legend()plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Training Loss')# 显示图形plt.show()不同num_workers的结果如下



相关文章:
Pytorch指定数据加载器使用子进程
torch.utils.data.DataLoader(train_dataset, batch_sizebatch_size, shuffleTrue,num_workers4, pin_memoryTrue) num_workers 参数是 DataLoader 类的一个参数,它指定了数据加载器使用的子进程数量。通过增加 num_workers 的数量,可以并行地读取和预处…...

【科普】干货!带你从0了解移动机器人(六) (底盘结构类型)
牵引式移动机器人(AGV/AMR),通常由一个牵引车和一个或多个被牵引的车辆组成。牵引车是机器人的核心部分,它具有自主导航和定位功能,可以根据预先设定的路径或地标进行导航,并通过传感器和视觉系统感知周围环…...
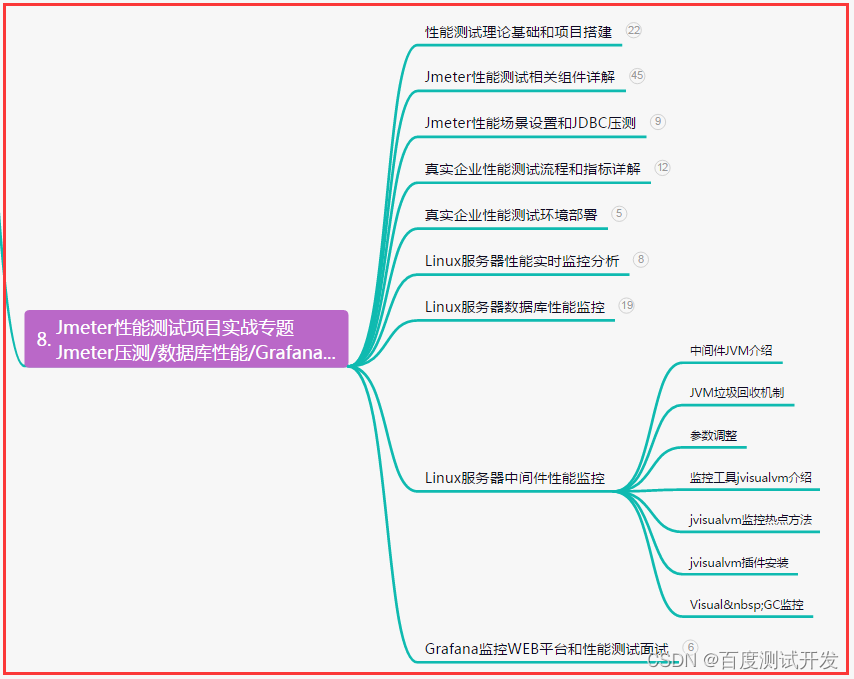
爆肝整理,Pytest+Allure+Jenkins自动化测试集成实战(图文详细步骤)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、简介 pytesta…...
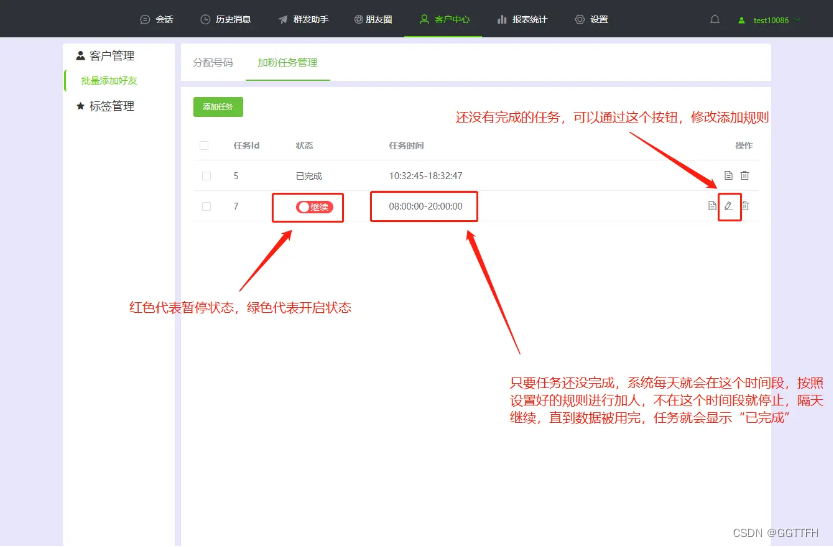
微信批量添加好友,让你的人脉迅速增长
在这个数字化时代,微信作为中国最流行的社交平台之一,已经成为了人们生活中不可或缺的一部分。它的广泛使用为我们提供了无限的社交可能性。你是否曾为了扩大人脉圈子而犯愁?今天,我将向你揭示一个高效添加微信好友的秘密武器&…...
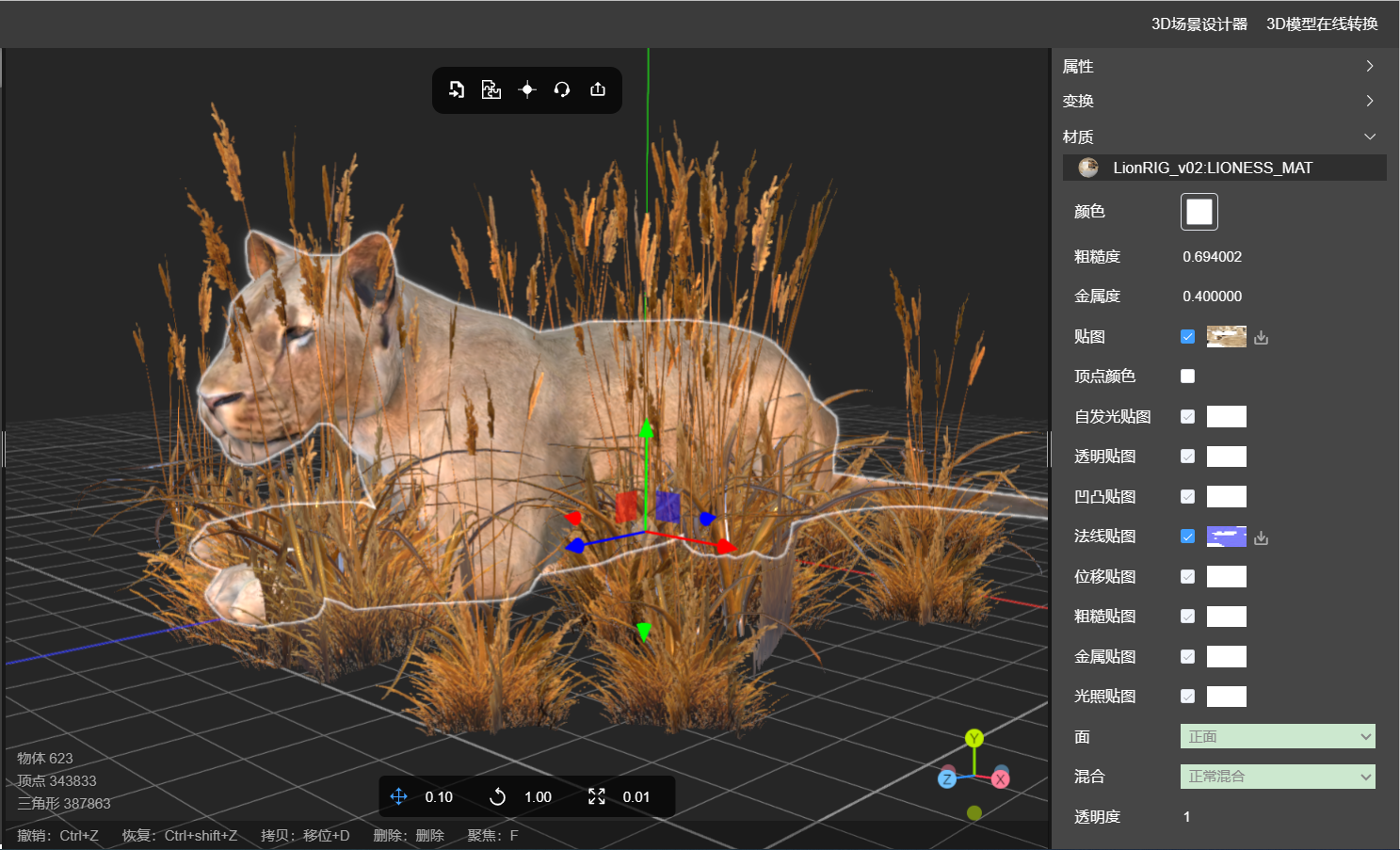
3D模型怎么贴法线贴图?
1、法线贴图的原理? 法线贴图(normal mapping)是一种计算机图形技术,用于在低多边形模型上模拟高多边形模型的细节效果。它通过在纹理坐标上存储和应用法线向量的信息来实现。 法线贴图的原理基于光照模型。在渲染过程中&#x…...

QT中文乱码解决方案与乱码的原因
相信大家应该都遇到过中文乱码的问题,有时候改一改中文就不乱码了,但是有时候用同样的方式还是乱码,那么这个乱码到底是什么原因,又该如何彻底解决呢? 总结 先总结一下: Qt5中,将QString()的构…...
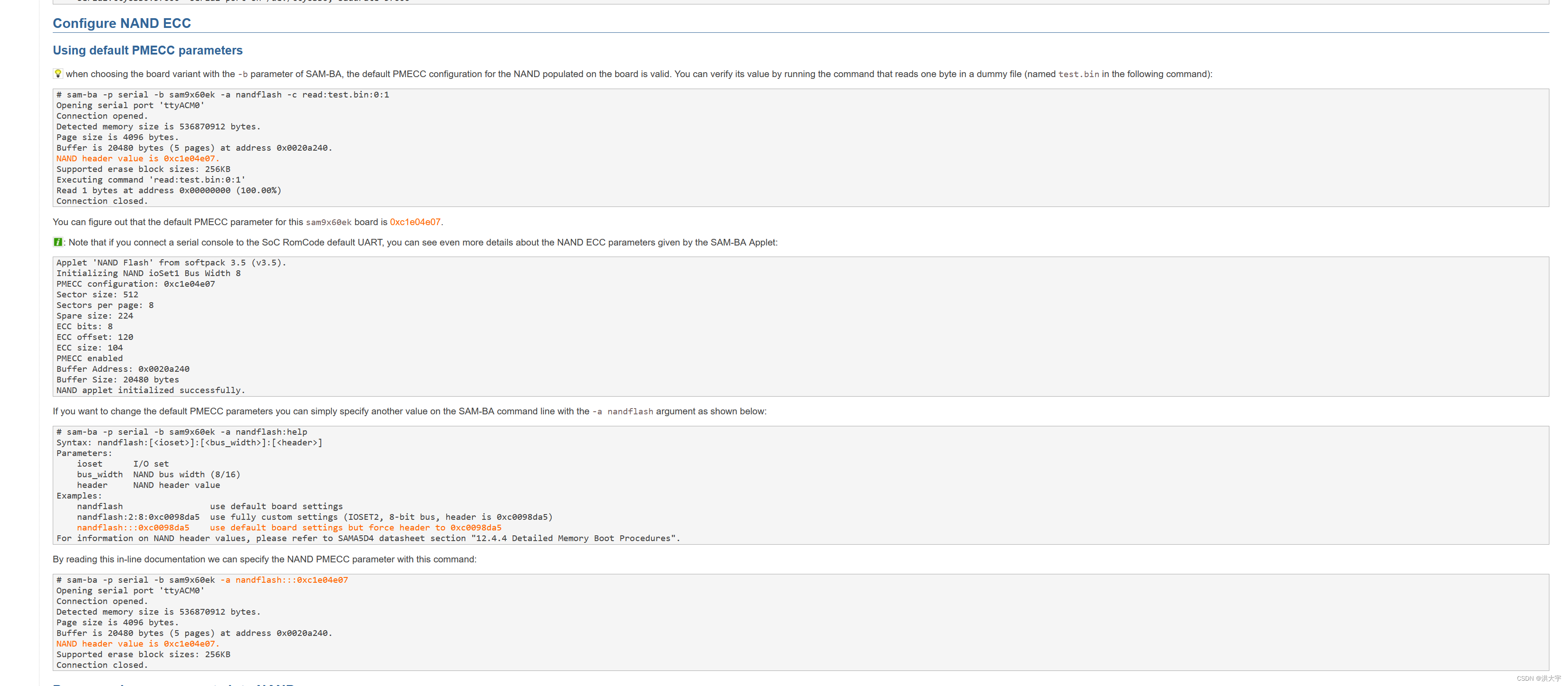
sam9x60 boot
...
3D模型格式转换工具HOOPS Exchange:支持国际标准STEP格式!
HOOPS Exchange SDK是一组C软件库,使开发团队能够快速将可靠的2D和3D CAD导入和导出添加到其应用程序中,访问广泛的数据,包括边界表示 (B-REP)、产品制造信息 (PMI)、模型树、视图、持久 ID、样式、构造几何、可视化等,无需依赖任…...

java--死循环与循环嵌套
1.死循环 可以一直执行下去的一种循环,如果没有干预不会停下来的 2.死循环的写法 3.循环嵌套 循环中又包含循环 4.循环嵌套的特点 外部循环每循环一次,内部循环会全部执行完一轮...

基于机器视觉的图像拼接算法 计算机竞赛
前言 图像拼接在实际的应用场景很广,比如无人机航拍,遥感图像等等,图像拼接是进一步做图像理解基础步骤,拼接效果的好坏直接影响接下来的工作,所以一个好的图像拼接算法非常重要。 再举一个身边的例子吧,…...

基于arduino uno + L298 的直流电机驱动proteus仿真设计
一、L298简介: L298是一个集成的单片电路,采用15个导线多瓦和PowerSO20封装。它是一个高电压、高电流双全桥驱动器,旨在接受标准TTL逻辑电平和驱动感应负载,如继电器、螺线管、直流和加速电机。提供两个使输入来使独立于输入信号的…...
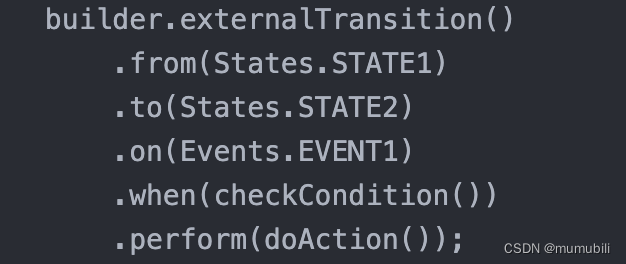
cola架构:有限状态机(FSM)源码分析
目录 0. cola状态机简述 1.cola状态机使用实例 2.cola状态机源码解析 2.1 语义模型源码 2.1.1 Condition和Action接口 2.1.2 State 2.1.3 Transition接口 2.1.4 StateMachine接口 2.2 Builder模式 2.2.1 StateMachine Builder模式 2.2.2 ExternalTransitionBuilder-…...
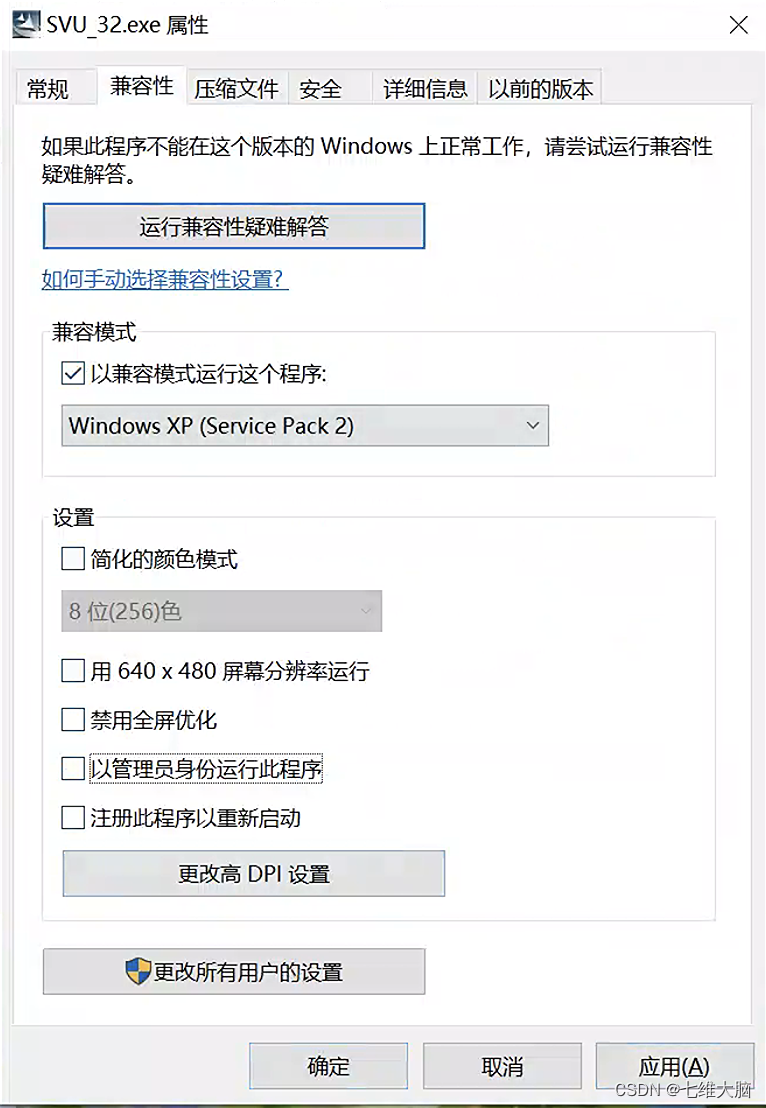
通信仿真软件SystemView安装教程(超详细)
介绍 system view是一种电子仿真工具。它是一个信号级的系统仿真软件,主要用于电路与通信系统的设计和仿真,是一个强有力的动态系统分析工具,能满足从数字信号处理,滤波器设计,直到复杂的通信系统等不同层次的设计&am…...
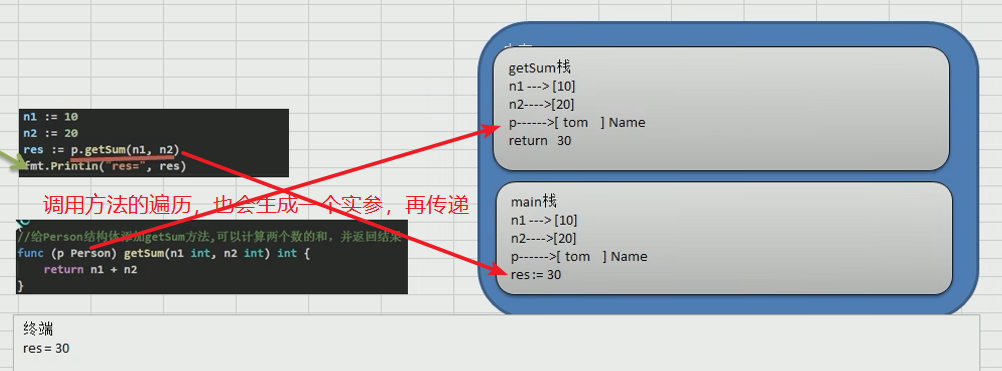
Go学习第八章——面向“对象”编程(入门——结构体与方法)
Go面向“对象”编程(入门——结构体与方法) 1 结构体1.1 快速入门1.2 内存解析1.3 创建结构体四种方法1.4 注意事项和使用细节 2 方法2.1 方法的声明和调用2.2 快速入门案例2.3 调用机制和传参原理2.4 注意事项和细节2.5 方法和函数区别 3 工厂模式 Gola…...

「滚雪球学Java」:方法函数(章节汇总)
🏆本文收录于「滚雪球学Java」专栏,专业攻坚指数级提升,助你一臂之力,带你早日登顶🚀,欢迎大家关注&&收藏!持续更新中,up!up!up!…...
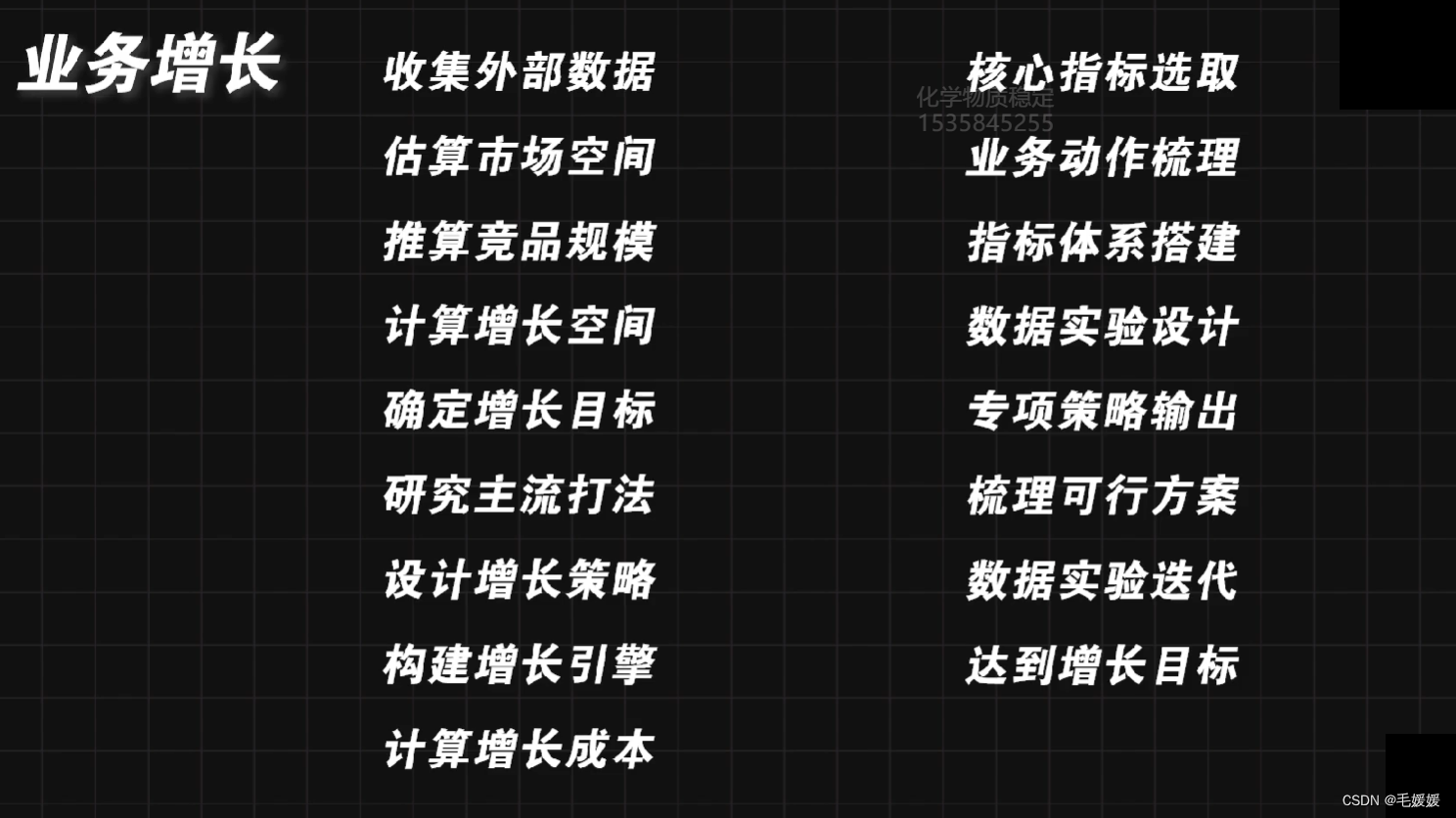
数据分析必备原理思路(二)
文章目录 三、主流的数据分析方法与框架使用1. 五个数据分析领域关键的理论基础(1)大数定律(2)罗卡定律(3)幸存者偏差(4)辛普森悖论(5)帕累托最优(…...
)
分布式ID系统设计(1)
分布式ID系统设计(1) 在分布式服务中,需要对data和message进行唯一标识。 比如订单、支付等。然后在数据库分库分表之后也需要一个唯一id来表示。 基于DB的自增就肯定不能满足了。这个时候能够生成一个Global的唯一ID的服务就很有必要我们姑且把它叫做id-server 。…...

机器学习(python)笔记整理
目录 一、数据预处理: 1. 缺失值处理: 2. 重复值处理: 3. 数据类型: 二、特征工程: 1. 规范化: 2. 归一化: 3. 标准化(方差): 三、训练模型: 如何计算精确度,召…...

微客云霸王餐系统 1.0 : 全面孵化+高额返佣
1、业务简介。业务模式是消费者以5-10元吃到原价15-25元的外卖,底层逻辑是帮外卖商家做推广,解决新店基础销量、老店增加单量、品牌打万单店的需求。 因为外卖店的平均生命周期只有6个月,不断有新店愿意送霸王餐。部分老店也愿意做活动&…...

极智开发 | Hello world for Manim
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文分享一下 Hello world for Manim。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq Manim 是什么呢?Manim 是一个用于创…...

s2-pro GPU显存优化实践:FP16推理+动态批处理降低30%显存占用
s2-pro GPU显存优化实践:FP16推理动态批处理降低30%显存占用 1. 引言 语音合成技术正在快速改变内容创作的方式,但专业级模型的显存占用问题一直困扰着开发者。Fish Audio开源的s2-pro作为专业级语音合成模型镜像,虽然提供了出色的音质和音…...

保姆级教程:NLI-DistilRoBERTa快速部署与简单调用指南
保姆级教程:NLI-DistilRoBERTa快速部署与简单调用指南 1. 项目概述与核心能力 NLI-DistilRoBERTa是基于DistilRoBERTa模型的自然语言推理(Natural Language Inference)Web服务,专门用于分析两个句子之间的逻辑关系。这个轻量级模型保留了RoBERTa模型90…...

如何将Uvicorn部署到Azure Functions Premium Plan:完整指南
如何将Uvicorn部署到Azure Functions Premium Plan:完整指南 【免费下载链接】uvicorn An ASGI web server, for Python. 🦄 项目地址: https://gitcode.com/GitHub_Trending/uv/uvicorn Uvicorn是Python生态中备受推崇的ASGI Web服务器ÿ…...

搭建专属汽车电子测试 AI 助手
专栏:《AI 汽车电子测试实战》第 15 篇 作者:一线汽车电子测试工程师 适合人群:想搭建私有 AI 助手的测试团队、关注数据安全的工程师开篇:为什么需要专属 AI 助手? 这是我上个月在某车企的 AI 部署项目中的真实经历。…...
)
ESP32-S3 OV2640摄像头从AP模式到STA模式的保姆级切换教程(附完整代码)
ESP32-S3 OV2640摄像头从AP模式到STA模式的保姆级切换教程(附完整代码) 当你第一次拿到ESP32-S3开发板和OV2640摄像头模块时,可能会被官方例程中的AP(热点)模式所困扰。虽然AP模式让设备快速上线,但在实际家…...

Linux驱动开发实战:从设备树到内核调试全解析
Linux驱动工程师实战经验分享:从入门到进阶的技术要点解析1. 设备树系统的深入理解1.1 设备树的基本概念在Linux驱动开发初期,大多数工程师都是从最简单的模块开发开始。典型的入门流程包括:#include <linux/module.h> #include <li…...
开发中,EEG实时预处理流程设计与避坑指南)
从实验室到产品:脑机接口(BCI)开发中,EEG实时预处理流程设计与避坑指南
从实验室到产品:脑机接口(BCI)开发中EEG实时预处理流程设计与避坑指南 在咖啡馆见到那位渐冻症患者用脑电波操控机械臂喝咖啡时,我意识到脑机接口技术正从实验室走向真实世界。但鲜有人提及的是,这套酷炫系统背后藏着怎样的信号处理炼狱——当…...
)
AutoSAR实战:NVRAM Manager配置避坑指南(附完整代码示例)
AutoSAR实战:NVRAM Manager配置避坑指南(附完整代码示例) 在汽车电子开发领域,AutoSAR框架的NVRAM Manager(NvM)模块是管理非易失性数据的关键组件。许多工程师在初次配置时容易陷入性能陷阱和功能误区&…...

OpenClaw内容创作流:nanobot辅助生成技术文章草稿
OpenClaw内容创作流:nanobot辅助生成技术文章草稿 1. 从灵感到初稿的自动化尝试 去年冬天,当我面对第五篇技术博客的空白文档时,突然意识到一个残酷事实:写作最耗时的不是码字本身,而是前期资料搜集和结构搭建。就像…...

nanomsg性能基准测试终极指南:不同消息大小下的吞吐量对比分析
nanomsg性能基准测试终极指南:不同消息大小下的吞吐量对比分析 【免费下载链接】nanomsg nanomsg library 项目地址: https://gitcode.com/gh_mirrors/na/nanomsg nanomsg是一个轻量级、高性能的消息传递库,专为解决常见的通信模式而设计。作为na…...