《动手学深度学习 Pytorch版》 10.4 Bahdanau注意力
10.4.1 模型
Bahdanau 等人提出了一个没有严格单向对齐限制的可微注意力模型。在预测词元时,如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
新的基于注意力的模型与 9.7 节中的模型相同,只不过 9.7 节中的上下文变量 c \boldsymbol{c} c 在任何解码时间步 t ′ \boldsymbol{t'} t′ 都会被 c t ′ \boldsymbol{c}_{t'} ct′ 替换。假设输入序列中有 T \boldsymbol{T} T 个词元,解码时间步 t ′ \boldsymbol{t'} t′ 的上下文变量是注意力集中的输出:
c t ′ = ∑ t = 1 T α ( s t ′ − 1 , h t ) h t \boldsymbol{c}_{t'}=\sum^T_{t=1}{\alpha{(\boldsymbol{s}_{t'-1},\boldsymbol{h}_t)\boldsymbol{h}_t}} ct′=t=1∑Tα(st′−1,ht)ht
参数字典:
-
遵循与 9.7 节中的相同符号表达
-
时间步 t ′ − 1 \boldsymbol{t'-1} t′−1 时的解码器隐状态 s t ′ − 1 \boldsymbol{s}_{t'-1} st′−1 是查询
-
编码器隐状态 h t \boldsymbol{h}_t ht 既是键,也是值
-
注意力权重 α \alpha α 是使用上节所定义的加性注意力打分函数计算的

从图中可以看到,加入注意力机制后:
-
将编码器对每次词的输出作为 key 和 value
-
将解码器对上一个词的输出作为 querry
-
将注意力的输出和下一个词的词嵌入合并作为解码器输入
import torch
from torch import nn
from d2l import torch as d2l
10.4.2 定义注意力解码器
AttentionDecoder 类定义了带有注意力机制解码器的基本接口
#@save
class AttentionDecoder(d2l.Decoder):"""带有注意力机制解码器的基本接口"""def __init__(self, **kwargs):super(AttentionDecoder, self).__init__(**kwargs)@propertydef attention_weights(self):raise NotImplementedError
在 Seq2SeqAttentionDecoder 类中实现带有 Bahdanau 注意力的循环神经网络解码器。初始化解码器的状态,需要下面的输入:
-
编码器在所有时间步的最终层隐状态,将作为注意力的键和值;
-
上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态;
-
编码器有效长度(排除在注意力池中填充词元)。
class Seq2SeqAttentionDecoder(AttentionDecoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args): # 新增 enc_valid_lens 表示有效长度# outputs的形状为(batch_size,num_steps,num_hiddens).# hidden_state的形状为(num_layers,batch_size,num_hiddens)outputs, hidden_state = enc_outputsreturn (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)def forward(self, X, state):# enc_outputs的形状为(batch_size,num_steps,num_hiddens).# hidden_state的形状为(num_layers,batch_size,num_hiddens)enc_outputs, hidden_state, enc_valid_lens = state# 输出X的形状为(num_steps,batch_size,embed_size)X = self.embedding(X).permute(1, 0, 2)outputs, self._attention_weights = [], []for x in X:# query的形状为(batch_size,1,num_hiddens)query = torch.unsqueeze(hidden_state[-1], dim=1) # 解码器最终隐藏层的上一个输出添加querry个数的维度后作为querry# context的形状为(batch_size,1,num_hiddens)context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens) # 编码器的输出作为key和value# 在特征维度上连结x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1) # 并起来当解码器输入# 将x变形为(1,batch_size,embed_size+num_hiddens)out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)outputs.append(out)self._attention_weights.append(self.attention.attention_weights) # 存一下注意力权重# 全连接层变换后,outputs的形状为 (num_steps,batch_size,vocab_size)outputs = self.dense(torch.cat(outputs, dim=0))return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,enc_valid_lens]@propertydef attention_weights(self):return self._attention_weights
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))
10.4.3 训练
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
loss 0.020, 7252.9 tokens/sec on cuda:0

engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est mouillé ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
训练结束后,下面通过可视化注意力权重会发现,每个查询都会在键值对上分配不同的权重,这说明在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中。
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((1, 1, -1, num_steps))# 加上一个包含序列结束词元
d2l.show_heatmaps(attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),xlabel='Key positions', ylabel='Query positions')

练习
(1)在实验中用LSTM替换GRU。
class Seq2SeqEncoder_LSTM(d2l.Encoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqEncoder_LSTM, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size, embed_size)self.lstm = nn.LSTM(embed_size, num_hiddens, num_layers, # 更换为 LSTMdropout=dropout)def forward(self, X, *args):X = self.embedding(X)X = X.permute(1, 0, 2)output, state = self.lstm(X)return output, stateclass Seq2SeqAttentionDecoder_LSTM(AttentionDecoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqAttentionDecoder_LSTM, self).__init__(**kwargs)self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.LSTM(embed_size + num_hiddens, num_hiddens, num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):outputs, hidden_state = enc_outputsreturn (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)def forward(self, X, state):enc_outputs, hidden_state, enc_valid_lens = stateX = self.embedding(X).permute(1, 0, 2)outputs, self._attention_weights = [], []for x in X:query = torch.unsqueeze(hidden_state[-1][0], dim=1) # 解码器最终隐藏层的上一个输出添加querry个数的维度后作为querrycontext = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)outputs.append(out)self._attention_weights.append(self.attention.attention_weights)outputs = self.dense(torch.cat(outputs, dim=0))return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,enc_valid_lens]@propertydef attention_weights(self):return self._attention_weights
embed_size_LSTM, num_hiddens_LSTM, num_layers_LSTM, dropout_LSTM = 32, 32, 2, 0.1
batch_size_LSTM, num_steps_LSTM = 64, 10
lr_LSTM, num_epochs_LSTM, device_LSTM = 0.005, 250, d2l.try_gpu()train_iter_LSTM, src_vocab_LSTM, tgt_vocab_LSTM = d2l.load_data_nmt(batch_size_LSTM, num_steps_LSTM)
encoder_LSTM = Seq2SeqEncoder_LSTM(len(src_vocab_LSTM), embed_size_LSTM, num_hiddens_LSTM, num_layers_LSTM, dropout_LSTM)
decoder_LSTM = Seq2SeqAttentionDecoder_LSTM(len(tgt_vocab_LSTM), embed_size_LSTM, num_hiddens_LSTM, num_layers_LSTM, dropout_LSTM)
net_LSTM = d2l.EncoderDecoder(encoder_LSTM, decoder_LSTM)
d2l.train_seq2seq(net_LSTM, train_iter_LSTM, lr_LSTM, num_epochs_LSTM, tgt_vocab_LSTM, device_LSTM)
loss 0.021, 7280.8 tokens/sec on cuda:0

engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq_LSTM = d2l.predict_seq2seq(net_LSTM, eng, src_vocab_LSTM, tgt_vocab_LSTM, num_steps_LSTM, device_LSTM, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => puis-je <unk> <unk> ., bleu 0.000
i'm home . => je suis chez moi ., bleu 1.000
attention_weights_LSTM = torch.cat([step[0][0][0] for step in dec_attention_weight_seq_LSTM], 0).reshape((1, 1, -1, num_steps_LSTM))# 加上一个包含序列结束词元
d2l.show_heatmaps(attention_weights_LSTM[:, :, :, :len(engs[-1].split()) + 1].cpu(),xlabel='Key positions', ylabel='Query positions')

(2)修改实验以将加性注意力打分函数替换为缩放点积注意力,它如何影响训练效率?
class Seq2SeqAttentionDecoder_Dot(AttentionDecoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)self.attention = d2l.DotProductAttention( # 替换为缩放点积注意力num_hiddens, num_hiddens, num_hiddens, dropout)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):outputs, hidden_state = enc_outputsreturn (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)def forward(self, X, state):enc_outputs, hidden_state, enc_valid_lens = stateX = self.embedding(X).permute(1, 0, 2)outputs, self._attention_weights = [], []for x in X:query = torch.unsqueeze(hidden_state[-1], dim=1)context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)outputs.append(out)self._attention_weights.append(self.attention.attention_weights)outputs = self.dense(torch.cat(outputs, dim=0))return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,enc_valid_lens]@propertydef attention_weights(self):return self._attention_weights
embed_size_Dot, num_hiddens_Dot, num_layers_Dot, dropout_Dot = 32, 32, 2, 0.1
batch_size_Dot, num_steps_Dot = 64, 10
lr_Dot, num_epochs_Dot, device_Dot = 0.005, 250, d2l.try_gpu()train_iter_Dot, src_vocab_Dot, tgt_vocab_Dot = d2l.load_data_nmt(batch_size_Dot, num_steps_Dot)
encoder_Dot = Seq2SeqEncoder_LSTM(len(src_vocab_Dot), embed_size_LSTM, num_hiddens_Dot, num_layers_Dot, dropout_Dot)
decoder_Dot = Seq2SeqAttentionDecoder_LSTM(len(tgt_vocab_Dot), embed_size_Dot, num_hiddens_Dot, num_layers_Dot, dropout_Dot)
net_Dot = d2l.EncoderDecoder(encoder_Dot, decoder_Dot)
d2l.train_seq2seq(net_Dot, train_iter_Dot, lr_Dot, num_epochs_Dot, tgt_vocab_Dot, device_Dot)
loss 0.021, 7038.8 tokens/sec on cuda:0

engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq_Dot = d2l.predict_seq2seq(net_Dot, eng, src_vocab_Dot, tgt_vocab_Dot, num_steps_Dot, device_Dot, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est riche ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
attention_weights_Dot = torch.cat([step[0][0][0] for step in dec_attention_weight_seq_Dot], 0).reshape((1, 1, -1, num_steps_Dot))# 加上一个包含序列结束词元
d2l.show_heatmaps(attention_weights_Dot[:, :, :, :len(engs[-1].split()) + 1].cpu(),xlabel='Key positions', ylabel='Query positions')

相关文章:
《动手学深度学习 Pytorch版》 10.4 Bahdanau注意力
10.4.1 模型 Bahdanau 等人提出了一个没有严格单向对齐限制的可微注意力模型。在预测词元时,如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现…...

iOS_Crash 四:的捕获和防护
文章目录 1.Crash 捕获1.2.NSException1.2.C异常1.3.Mach异常1.4.Unix 信号 2.Crash 防护2.1.方法未实现2.2.KVC 导致 crash2.3.KVO 导致 crash2.4.集合类导致 crash2.5.其他需要注意场景: 1.Crash 捕获 根据 Crash 的不同来源,分为以下三类:…...

spring boot项目运行jar包读取包内resources目录下的文件
spring boot项目运行jar包读取包内resources目录下的文件 摘要码代码相关文章 摘要 Spring Boot 项目打包成 jar 包后,resources 目录下的文件将会被打包到 jar 包中。如果需要在 Spring Boot 项目运行 jar 包后读取 resources 目录下的文件,可以使用 t…...
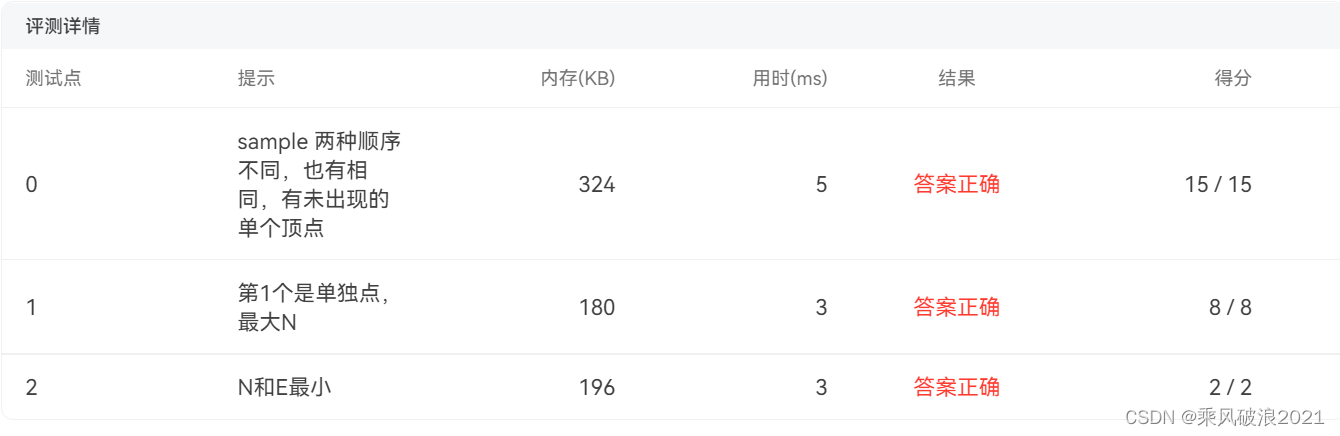
浙大陈越何钦铭数据结构06-图1 列出连通集
题目 给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集。假设顶点从0到N−1编号。进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。 输入格式: 输入第1行给出2个整数N(0<N≤10)和E&…...
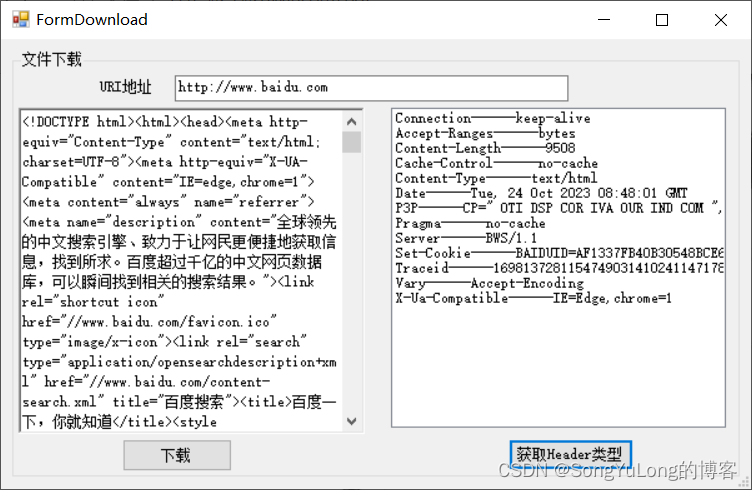
C# Winform编程(9)网络编程
网络编程 HTTP网络编程IPAddress IP地址类WebClient类WebRequest类和WebResponse类 WebBrowser网页浏览器控件TCP网络编程TcpClient类TcpListener类NetworkStream类Socket类 HTTP网络编程 IPAddress IP地址类 IPAddress类代表IP地址,可在十进制表示法和实际的整数…...

RabbitMQ中方法channel.basicAck的使用说明
方法channel.basicAck的作用 在RabbitMQ中,channel.basicAck方法用于确认已经接收并处理了消息。 方法的参数说明 public void basicAck(long deliveryTag,boolean multiple) 参数: long deliveryTag 消息的唯一标识。每条消息都有自己的ID号&#x…...

Jenkins+Python自动化测试持续集成详细教程
Jenkins安装 Jenkins安装 Jenkins是一个开源的软件项目,是基于java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能。由于是基于java开发因此它也依赖java环境&…...
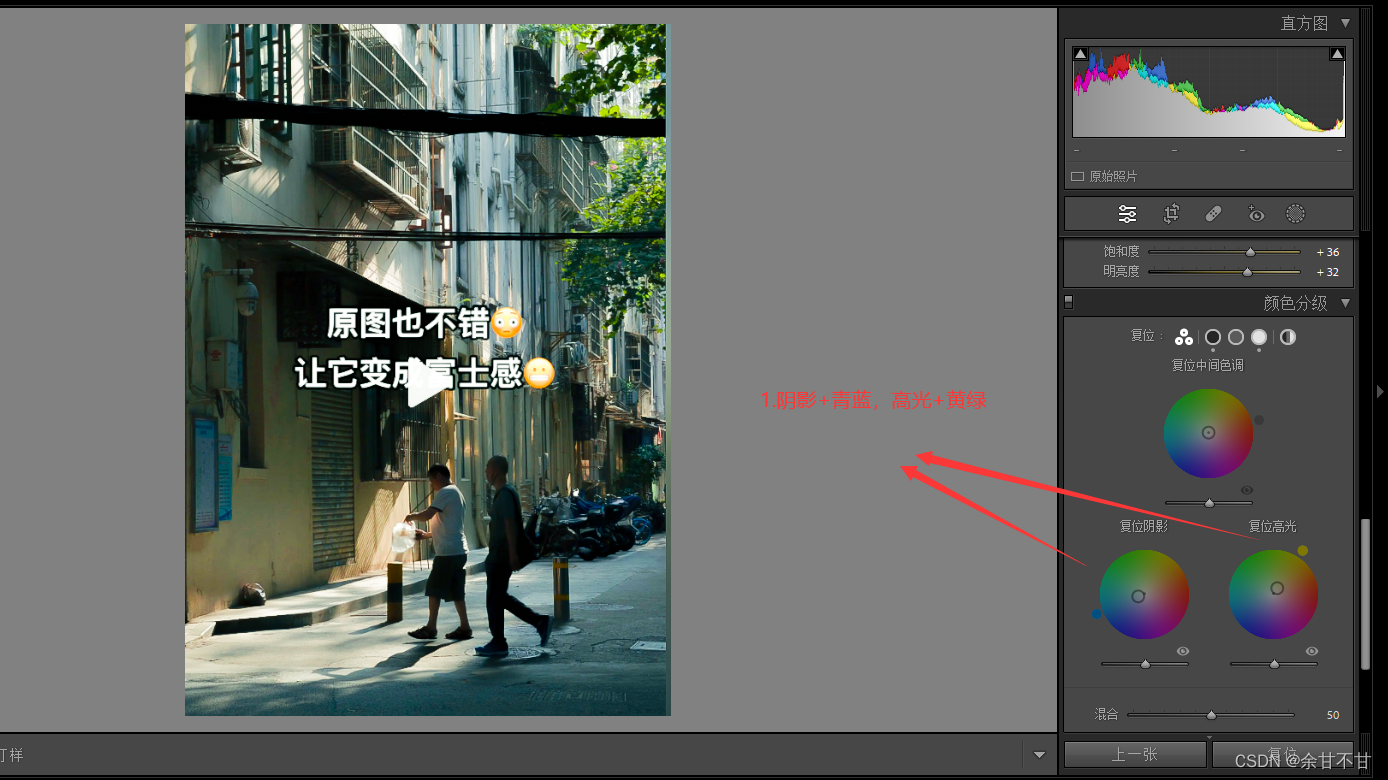
Lightroom学习之路
基础知识 常用快捷键 双击修改图片下右边布局的属性,快速回到初始值 B站学习笔记 1、导入到图库为图片标星级,后期优先处理星级高的图片 2、修改照片-基础-白平衡有吸管吸颜色会自动平衡照片颜色 3、直方图左右上角三角形,选中后照片会显示…...

Day 2 Abp框架下,MySQL数据迁移时,添加表和字段注释
后端采用Abp框架,当前最新版本是7.4.0。 数据库使用MySQL,在执行数据库迁移时,写在Domain层的Entity类上的注释通通都没有,这样查看数据库字段的含义时,就需要对照代码来看,有些不方便。今天专门来解决这个…...
传智教育研究院重磅发布Java学科新研发《智慧养老》项目
在招聘Java开发人才的过程中,企业往往对候选人的项目经验有着严格的要求,项目经验成为顺利就业的重要敲门砖之一。而在数字化技术的学习中,如何让学员通过项目课程有效地积累实战开发经验,就成了数字化技术职业教育的一个重大难点…...
Fiddler抓包VSCode和探索
前言: 最近在使用 VSCode 调试 web 程序时,遇到一些问题,当时不知道如何是好。所以决定抓看来看一看,然后一顿操作猛如虎,成功安装了抓包软件 – Fiddler Classic。我并没有使用 Postman 这种重量级的 HTTP 测试软件&a…...

Pytorch指定数据加载器使用子进程
torch.utils.data.DataLoader(train_dataset, batch_sizebatch_size, shuffleTrue,num_workers4, pin_memoryTrue) num_workers 参数是 DataLoader 类的一个参数,它指定了数据加载器使用的子进程数量。通过增加 num_workers 的数量,可以并行地读取和预处…...

【科普】干货!带你从0了解移动机器人(六) (底盘结构类型)
牵引式移动机器人(AGV/AMR),通常由一个牵引车和一个或多个被牵引的车辆组成。牵引车是机器人的核心部分,它具有自主导航和定位功能,可以根据预先设定的路径或地标进行导航,并通过传感器和视觉系统感知周围环…...
爆肝整理,Pytest+Allure+Jenkins自动化测试集成实战(图文详细步骤)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、简介 pytesta…...
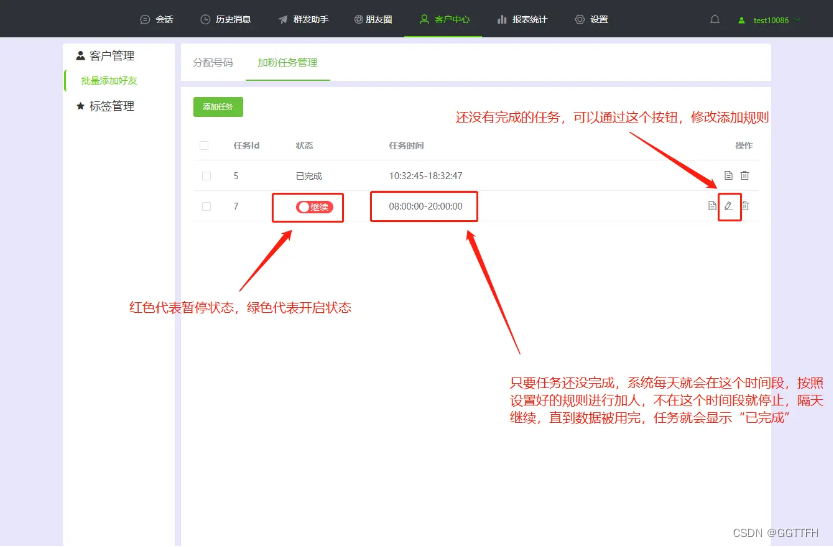
微信批量添加好友,让你的人脉迅速增长
在这个数字化时代,微信作为中国最流行的社交平台之一,已经成为了人们生活中不可或缺的一部分。它的广泛使用为我们提供了无限的社交可能性。你是否曾为了扩大人脉圈子而犯愁?今天,我将向你揭示一个高效添加微信好友的秘密武器&…...
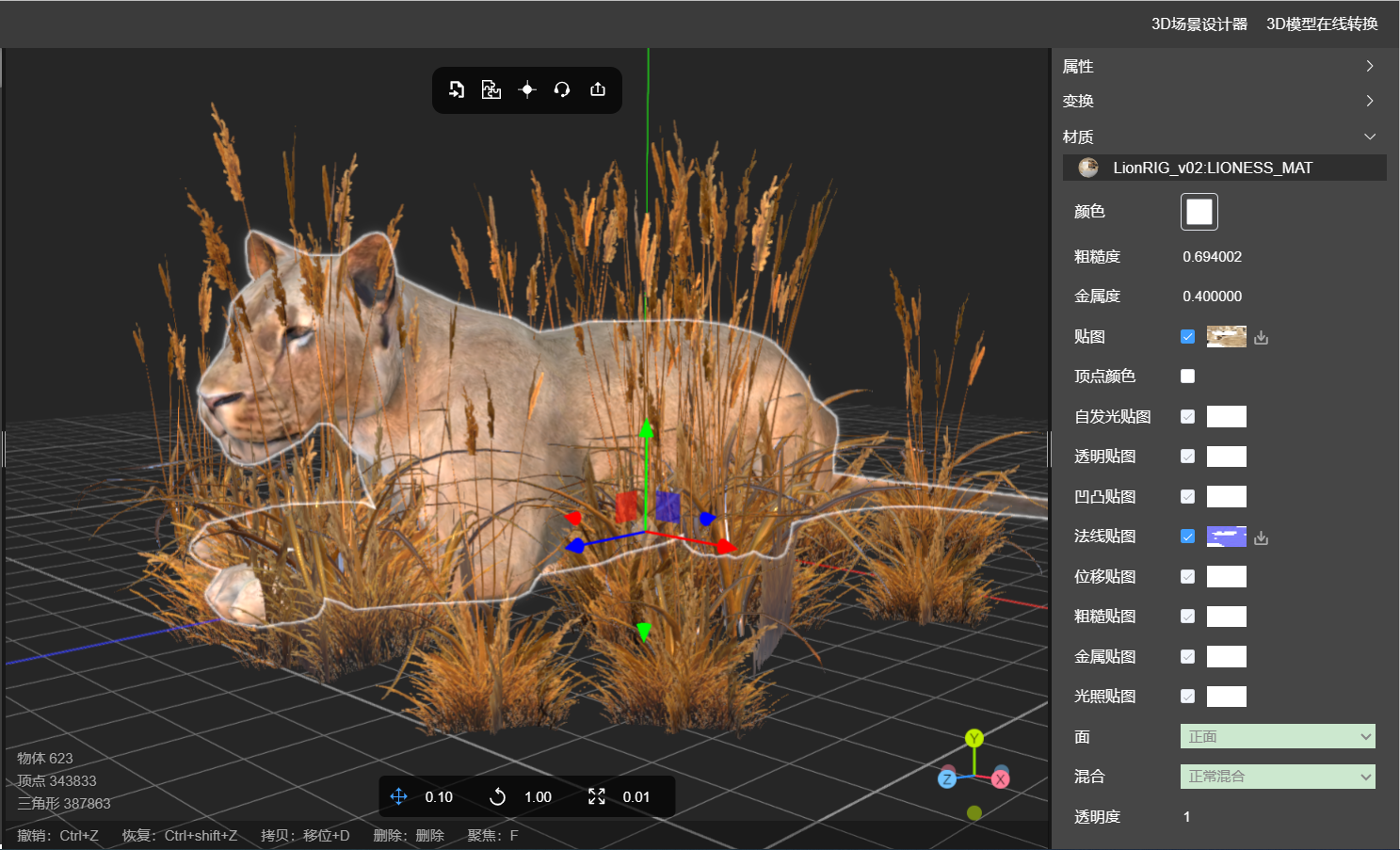
3D模型怎么贴法线贴图?
1、法线贴图的原理? 法线贴图(normal mapping)是一种计算机图形技术,用于在低多边形模型上模拟高多边形模型的细节效果。它通过在纹理坐标上存储和应用法线向量的信息来实现。 法线贴图的原理基于光照模型。在渲染过程中&#x…...

QT中文乱码解决方案与乱码的原因
相信大家应该都遇到过中文乱码的问题,有时候改一改中文就不乱码了,但是有时候用同样的方式还是乱码,那么这个乱码到底是什么原因,又该如何彻底解决呢? 总结 先总结一下: Qt5中,将QString()的构…...
sam9x60 boot
...
3D模型格式转换工具HOOPS Exchange:支持国际标准STEP格式!
HOOPS Exchange SDK是一组C软件库,使开发团队能够快速将可靠的2D和3D CAD导入和导出添加到其应用程序中,访问广泛的数据,包括边界表示 (B-REP)、产品制造信息 (PMI)、模型树、视图、持久 ID、样式、构造几何、可视化等,无需依赖任…...

java--死循环与循环嵌套
1.死循环 可以一直执行下去的一种循环,如果没有干预不会停下来的 2.死循环的写法 3.循环嵌套 循环中又包含循环 4.循环嵌套的特点 外部循环每循环一次,内部循环会全部执行完一轮...

A-59F 多功能语音处理模组:覆盖全场景人群,让每一次语音都清晰无噪
在门禁对讲、会议扩音、车载通话、导游喊话、监护设备、智能工牌等各类语音设备中,啸叫刺耳、环境嘈杂、回音不断、拾音模糊、通话断续是所有人共同的痛点。一款真正解决问题的核心硬件 ——A-59F 多功能语音处理模组,它集成扩音防啸叫、AI ENC 降噪、AE…...

从CUDA核心到Tensor Core:GPU计算单元的演进与实战解析
1. CUDA核心:通用计算的基石 我第一次接触CUDA核心是在2012年做图像处理项目时。当时用GTX 680显卡做图像渲染,发现它比CPU快了近20倍,这个性能差距让我震惊。后来才知道,这要归功于显卡里密密麻麻的CUDA核心。 CUDA核心本质上就是…...

终极Ghidra安装指南:5分钟在Ubuntu系统快速部署逆向工程神器
终极Ghidra安装指南:5分钟在Ubuntu系统快速部署逆向工程神器 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 想要…...

解决Docker容器中英伟达GPU驱动报错:nvidia-container-toolkit安装指南
1. 为什么Docker容器无法识别英伟达GPU? 最近在帮朋友调试一个深度学习项目时,遇到了一个典型问题:当尝试在Docker容器中运行需要GPU加速的应用时,系统报错提示无法找到NVIDIA驱动。错误信息是这样的: Error response …...

避坑指南:S-Function参数传递中mxArray操作的3个典型错误
S-Function开发实战:mxArray参数传递的3大陷阱与防御性编程技巧 在Simulink的S-Function开发中,mxArray作为MATLAB与C/C之间的数据桥梁,其正确操作直接关系到模块的稳定性和可靠性。许多开发者在参数传递环节频繁遭遇段错误、内存泄漏和类型误…...

FlatBuffers游戏开发终极指南:如何实现零解析实时数据传输
FlatBuffers游戏开发终极指南:如何实现零解析实时数据传输 【免费下载链接】flatbuffers FlatBuffers: Memory Efficient Serialization Library 项目地址: https://gitcode.com/gh_mirrors/flat/flatbuffers 在游戏开发中,数据传输的效率直接影响…...

HP-Socket技术债务管理成熟度提升计划:行动项与时间表
HP-Socket技术债务管理成熟度提升计划:行动项与时间表 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket作为高性能TCP/UDP/HTTP通信组件,随…...
)
JDK17下Lombok报错?手把手教你解决IllegalAccessError问题(附最新版本配置)
JDK17与Lombok兼容性实战:彻底解决IllegalAccessError的终极指南 最近在将项目迁移到JDK17时,不少开发者反馈遇到了一个棘手的错误:java.lang.IllegalAccessError,特别是与Lombok相关的模块访问问题。这个错误看似简单,…...

Windows下OpenClaw全流程指南:GLM-4.7-Flash模型接入与自动化测试
Windows下OpenClaw全流程指南:GLM-4.7-Flash模型接入与自动化测试 1. 为什么选择OpenClawGLM-4.7-Flash组合 去年我在处理一个Python数据分析项目时,每天要重复执行十几个脚本并整理结果。当我第三次因为手工操作失误导致数据错乱后,终于决…...

如何高效使用开源工具:3个实战技巧快速上手WebPlotDigitizer图表数据提取
如何高效使用开源工具:3个实战技巧快速上手WebPlotDigitizer图表数据提取 【免费下载链接】WebPlotDigitizer WebPlotDigitizer: 一个基于 Web 的工具,用于从图形图像中提取数值数据,支持 XY、极地、三角图和地图。 项目地址: https://gitc…...