金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度的特征图的空间信息,丰富特征空间。二是通道注意力或者或空间注意力只能有效捕获局部信息,而不能建立长期的依赖关系。最新的一些方法虽然能有效解决上述问题,但是他们同时会带来巨大的计算负担。基于此,本文首先提出了一种新颖的轻量且高效的PSA注意力模块。PSA模块可以处理多尺度的输入特征图的空间信息并且能够有效地建立多尺度通道注意力间的长期依赖关系。然后,我们将PSA 模块替换掉ResNet网络Bottleneck中的3x3x卷积,其余保持不变,最后得到了新的EPSA(efficient pyramid split attention) block.基于EPSA block我们构建了一个新的骨干网络称作:EPSANet。它既可以提供强有力的多尺度特征表示能力。与此同时,EPSANet不仅在图像识别任务中的Top-1 Acc大幅度优于现有技术,而且在计算参数量上有更加高效。具体效果:如下图所示,

论文地址:https://arxiv.org/pdf/2105.14447v1.pdf
代码地址:https://gitcode.com/mirrors/murufeng/epsanet/blob/master/models/epsanet.py
1.是什么?
Pyramid Split Attention (PSA)是一种基于注意力机制的模块,它可以用于图像分类、目标检测等任务中。PSA模块通过将不同大小的卷积核的卷积结果进行拼接,形成一个金字塔状的特征图,然后在这个特征图上应用注意力机制,以提取更加丰富的特征信息。与其他注意力模块相比,PSA模块具有轻量、简单高效等特点,可以与ResNet等主流网络结构结合使用,提高模型的性能。
2.为什么?
1. SE仅仅考虑了通道注意力,忽略了空间注意力。
2. BAM和CBAM考虑了通道注意力和空间注意力,但仍存在两个最重要的缺点:(1)没有捕获不同尺度的空间信息来丰富特征空间。(2)空间注意力仅仅考虑了局部区域的信息,而无法建立远距离的依赖。
3. 后续出现的PyConv,Res2Net和HS-ResNet都用于解决CBAM的这两个缺点,但计算量太大。
基于以上三点分析,提出了Pyramid Split Attention。
3.怎么样?
3.1网络结构

PSA模块主要通过四个步骤实现
- 首先,利用SPC模块来对通道进行切分,然后针对每个通道特征图上的空间信息进行多尺度特征提取;
- 其次,利用SEWeight模块提取不同尺度特征图的通道注意力,得到每个不同尺度上的通道注意力向量;
- 第三,利用Softmax对多尺度通道注意力向量进行特征重新标定,得到新的多尺度通道交互之后的注意力权重。
- 第四,对重新校准的权重和相应的特征图按元素进行点乘操作,输出得到一个多尺度特征信息注意力加权之后的特征图。该特征图多尺度信息表示能力更丰富。
3.2 SPC module
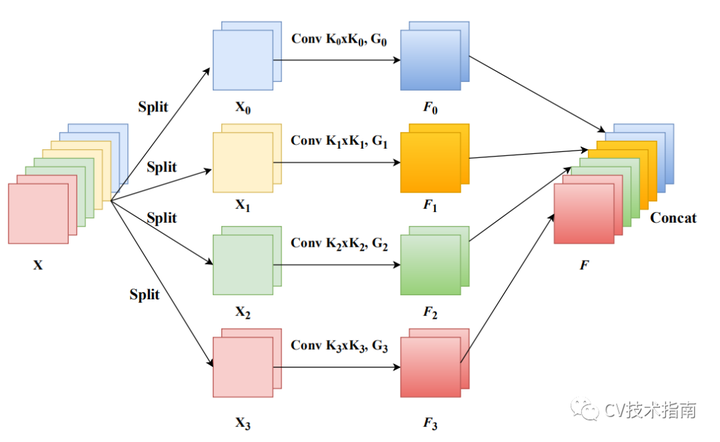
从前面我们了解到:PSA的关键在于多尺度特征提取,即SPC模块。假设输入为X,我们先将其拆分为S部分,然后对不同部分提取不同尺度特征,最后将所提取的多尺度特征通过Concat进行拼接。上述过程可以简单描述如下:
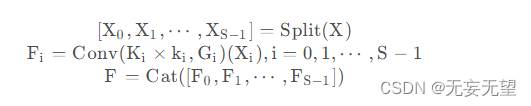
在上述特征基础上,我们对不同部分特征提取注意力权值,公式如下:
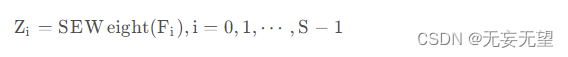
为更好的实现注意力信息交互并融合跨维度信息,我们将上述所得注意力向量进行拼接,即.然后,我们再对所得注意力权值进行归一化,定义如下:
![]()
最后,我们即可得到校正后的特征:Y = F ⊙ att
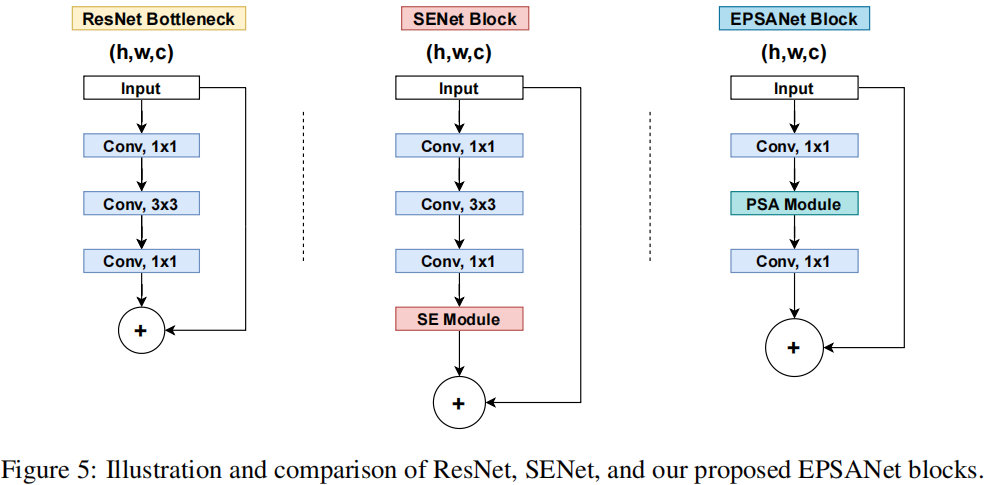
3.3 框图
3.4 代码实现
SEWeightModule
import torch.nn as nnclass SEWeightModule(nn.Module):def __init__(self, channels, reduction=16):super(SEWeightModule, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc1 = nn.Conv2d(channels, channels//reduction, kernel_size=1, padding=0)self.relu = nn.ReLU(inplace=True)self.fc2 = nn.Conv2d(channels//reduction, channels, kernel_size=1, padding=0)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.avg_pool(x)out = self.fc1(out)out = self.relu(out)out = self.fc2(out)weight = self.sigmoid(out)return weightPSAModule
def conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):"""standard convolution with padding"""return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=False)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class PSAModule(nn.Module):def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):super(PSAModule, self).__init__()self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,stride=stride, groups=conv_groups[0])self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,stride=stride, groups=conv_groups[1])self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,stride=stride, groups=conv_groups[2])self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,stride=stride, groups=conv_groups[3])self.se = SEWeightModule(planes // 4)self.split_channel = planes // 4self.softmax = nn.Softmax(dim=1)def forward(self, x):batch_size = x.shape[0]x1 = self.conv_1(x)x2 = self.conv_2(x)x3 = self.conv_3(x)x4 = self.conv_4(x)feats = torch.cat((x1, x2, x3, x4), dim=1)feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])x1_se = self.se(x1)x2_se = self.se(x2)x3_se = self.se(x3)x4_se = self.se(x4)x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)attention_vectors = self.softmax(attention_vectors)feats_weight = feats * attention_vectorsfor i in range(4):x_se_weight_fp = feats_weight[:, i, :, :]if i == 0:out = x_se_weight_fpelse:out = torch.cat((x_se_weight_fp, out), 1)return outEPSANET
import torch
import torch.nn as nn
import math
from .SE_weight_module import SEWeightModuledef conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):"""standard convolution with padding"""return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=False)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class PSAModule(nn.Module):def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):super(PSAModule, self).__init__()self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,stride=stride, groups=conv_groups[0])self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,stride=stride, groups=conv_groups[1])self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,stride=stride, groups=conv_groups[2])self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,stride=stride, groups=conv_groups[3])self.se = SEWeightModule(planes // 4)self.split_channel = planes // 4self.softmax = nn.Softmax(dim=1)def forward(self, x):batch_size = x.shape[0]x1 = self.conv_1(x)x2 = self.conv_2(x)x3 = self.conv_3(x)x4 = self.conv_4(x)feats = torch.cat((x1, x2, x3, x4), dim=1)feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])x1_se = self.se(x1)x2_se = self.se(x2)x3_se = self.se(x3)x4_se = self.se(x4)x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)attention_vectors = self.softmax(attention_vectors)feats_weight = feats * attention_vectorsfor i in range(4):x_se_weight_fp = feats_weight[:, i, :, :]if i == 0:out = x_se_weight_fpelse:out = torch.cat((x_se_weight_fp, out), 1)return outclass EPSABlock(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None, conv_kernels=[3, 5, 7, 9],conv_groups=[1, 4, 8, 16]):super(EPSABlock, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2d# Both self.conv2 and self.downsample layers downsample the input when stride != 1self.conv1 = conv1x1(inplanes, planes)self.bn1 = norm_layer(planes)self.conv2 = PSAModule(planes, planes, stride=stride, conv_kernels=conv_kernels, conv_groups=conv_groups)self.bn2 = norm_layer(planes)self.conv3 = conv1x1(planes, planes * self.expansion)self.bn3 = norm_layer(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass EPSANet(nn.Module):def __init__(self,block, layers, num_classes=1000):super(EPSANet, self).__init__()self.inplanes = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layers(block, 64, layers[0], stride=1)self.layer2 = self._make_layers(block, 128, layers[1], stride=2)self.layer3 = self._make_layers(block, 256, layers[2], stride=2)self.layer4 = self._make_layers(block, 512, layers[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _make_layers(self, block, planes, num_blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample))self.inplanes = planes * block.expansionfor i in range(1, num_blocks):layers.append(block(self.inplanes, planes))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)return xdef epsanet50():model = EPSANet(EPSABlock, [3, 4, 6, 3], num_classes=1000)return modeldef epsanet101():model = EPSANet(EPSABlock, [3, 4, 23, 3], num_classes=1000)return model参考:
EPSANet: 一种高效的多尺度通道注意力机制,主要提出了金字塔注意力模块,即插即用,效果显著,已开源!
EPSANet:金字塔拆分注意力模块
相关文章:
金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度…...
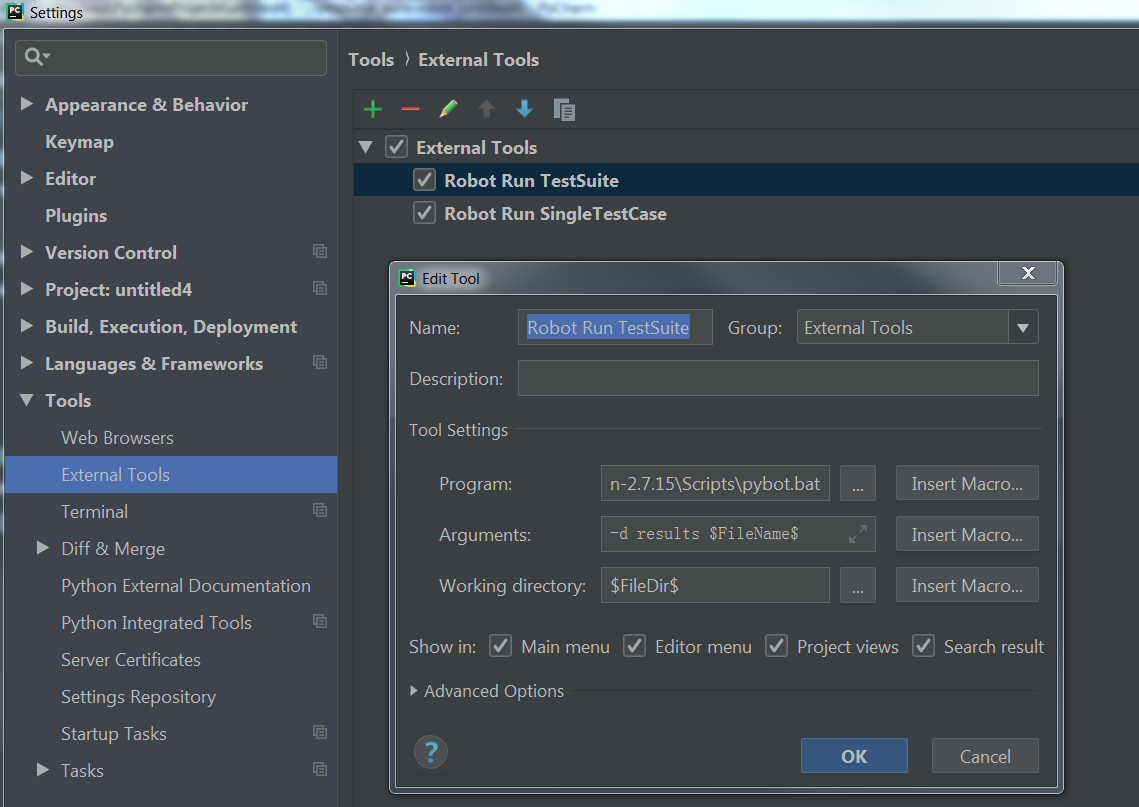
Jenkins自动化测试
学习 Jenkins 自动化测试的系列文章 Robot Framework 概念Robot Framework 安装Pycharm Robot Framework 环境搭建Robot Framework 介绍Jenkins 自动化测试 1. Robot Framework 概念 Robot Framework是一个基于Python的,可扩展的关键字驱动的自动化测试框架。 它…...

python 字典dict和列表list的读取速度问题, range合并
嗨喽,大家好呀~这里是爱看美女的茜茜呐 python 字典和列表的读取速度问题 最近在进行基因组数据处理的时候,需要读取较大数据(2.7G)存入字典中, 然后对被处理数据进行字典key值的匹配,在被处理文件中每次…...
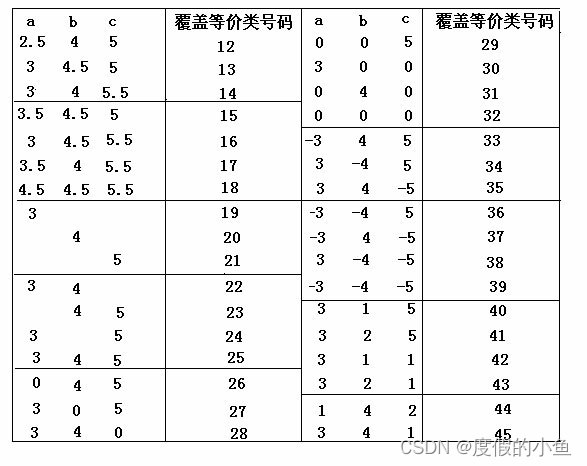
测试用例的设计方法(全):等价类划分方法
一.方法简介 1.定义 是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。 2.划分等价类: 等价类是指某个输入域的…...
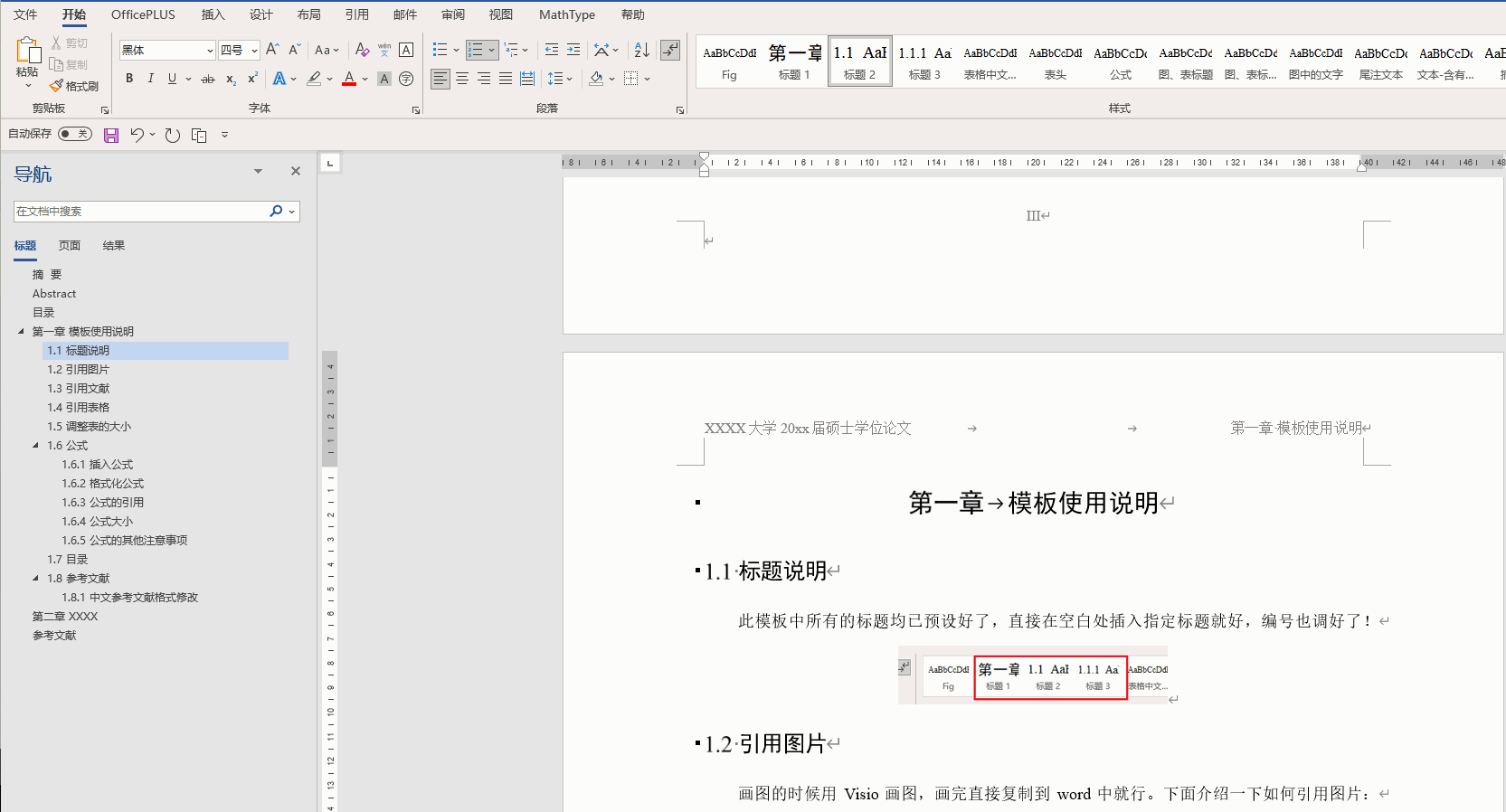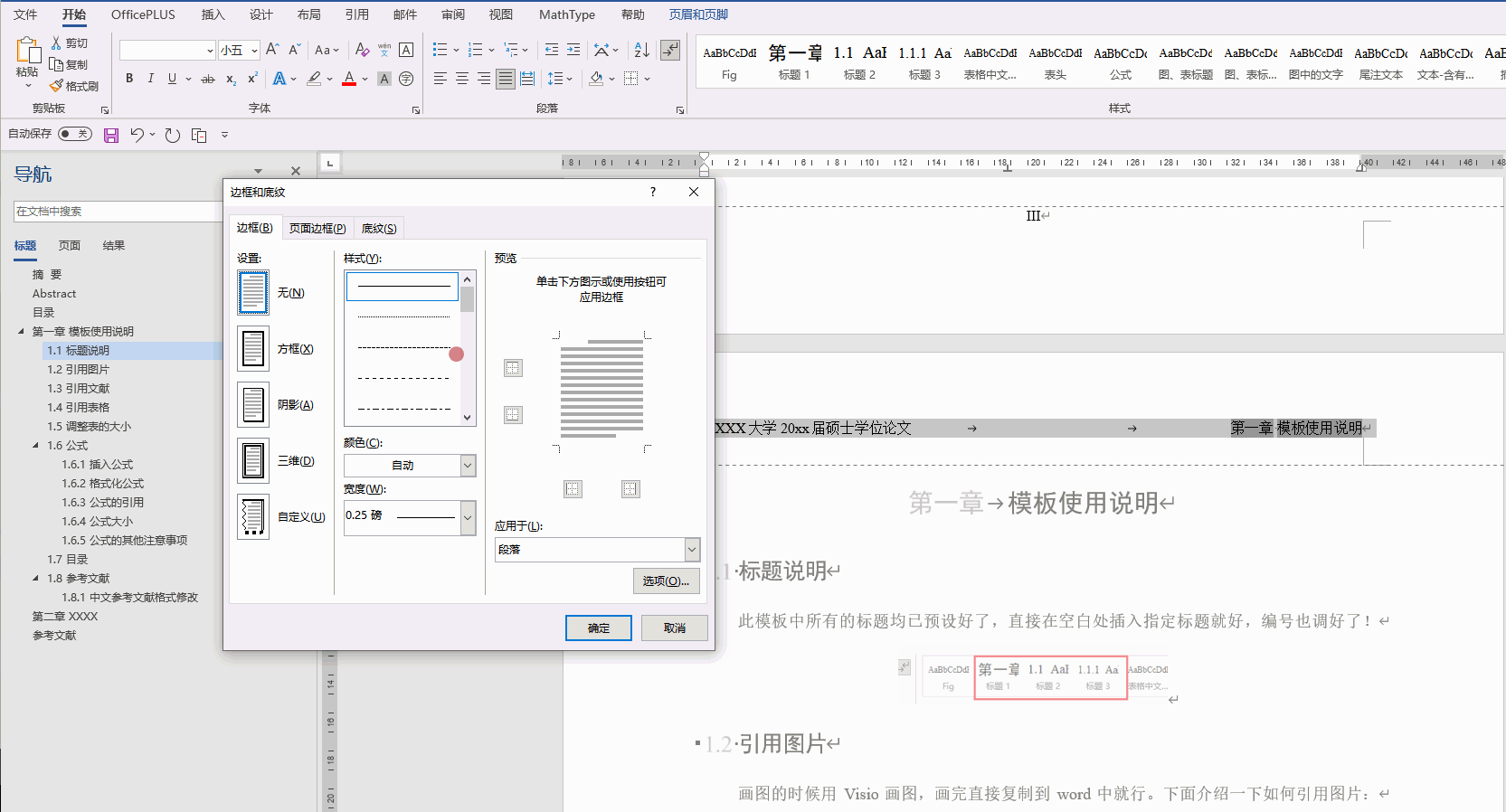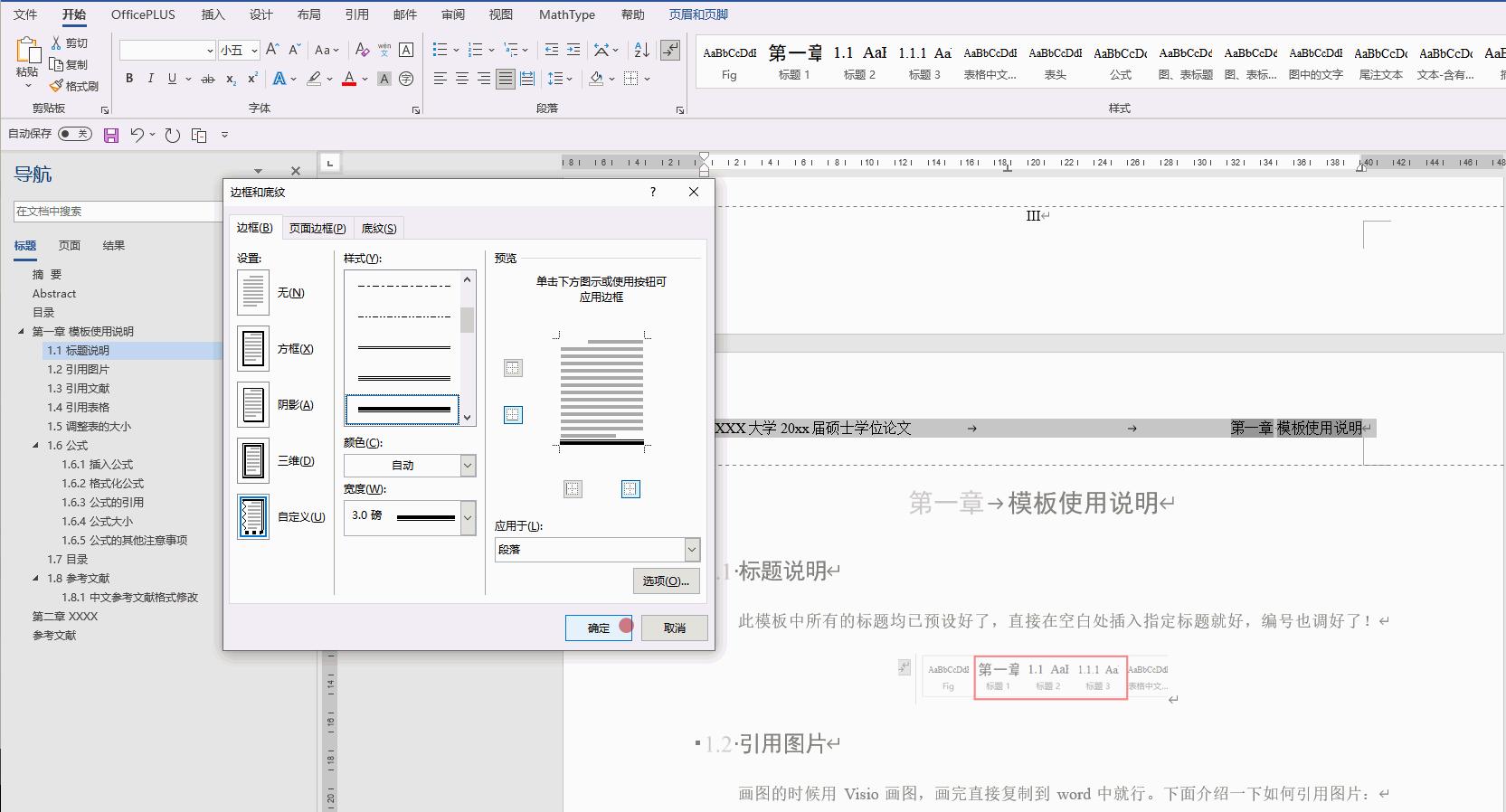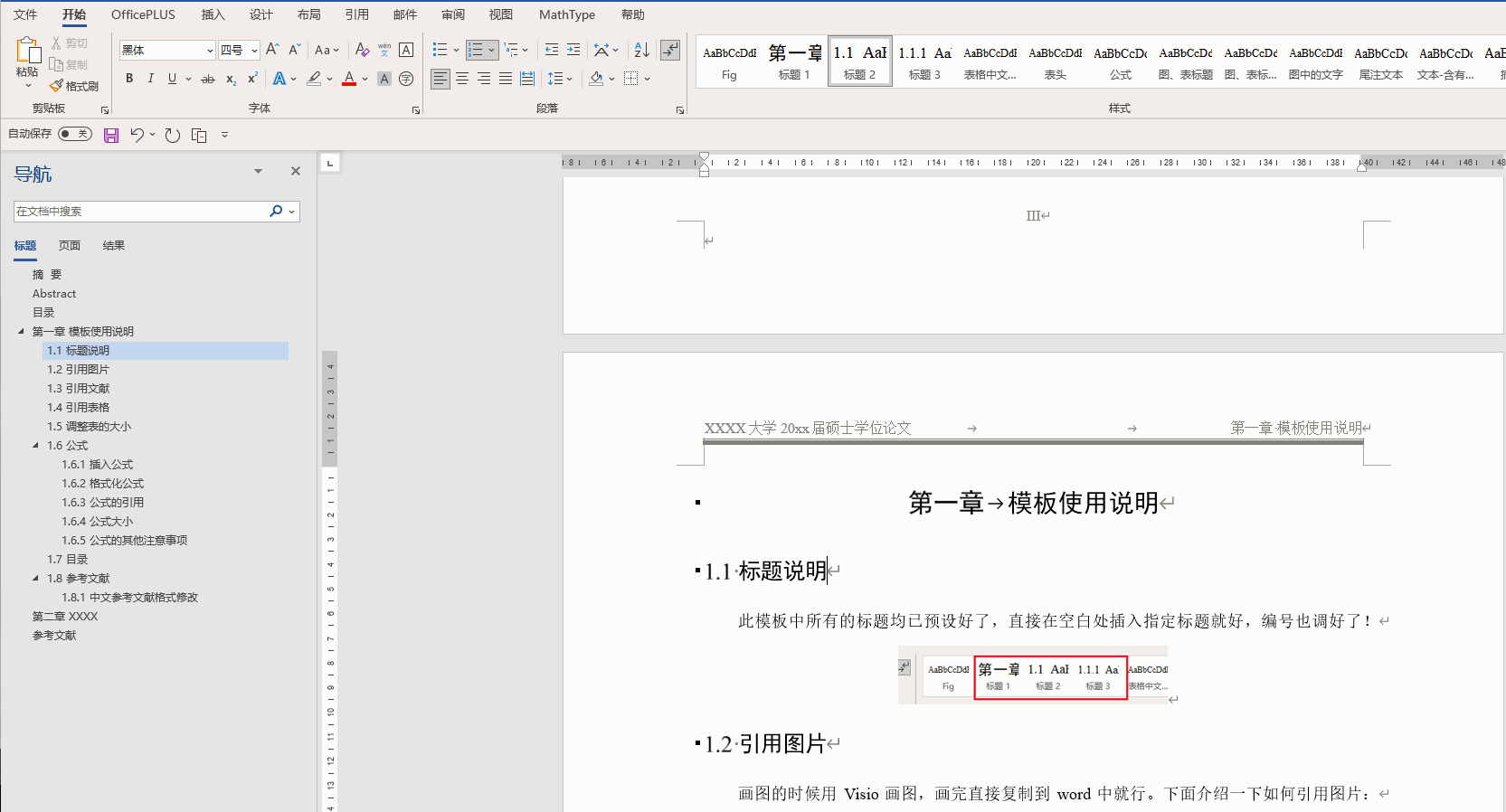
Office技巧(持续更新)(Word、Excel、PPT、PowerPoint、连续引用、标题、模板、论文)
1. Word 1.1 标题设置为多级列表 选住一级标题,之后进行“定义新的多级列表” 1.2 图片和表的题注自动排序 正常插入题注后就可以了。如果一级标题是 “汉字序号”,那么需要对题注进行修改: 从原来的 图 { STYLEREF 1 \s }-{ SEQ 图 \* A…...
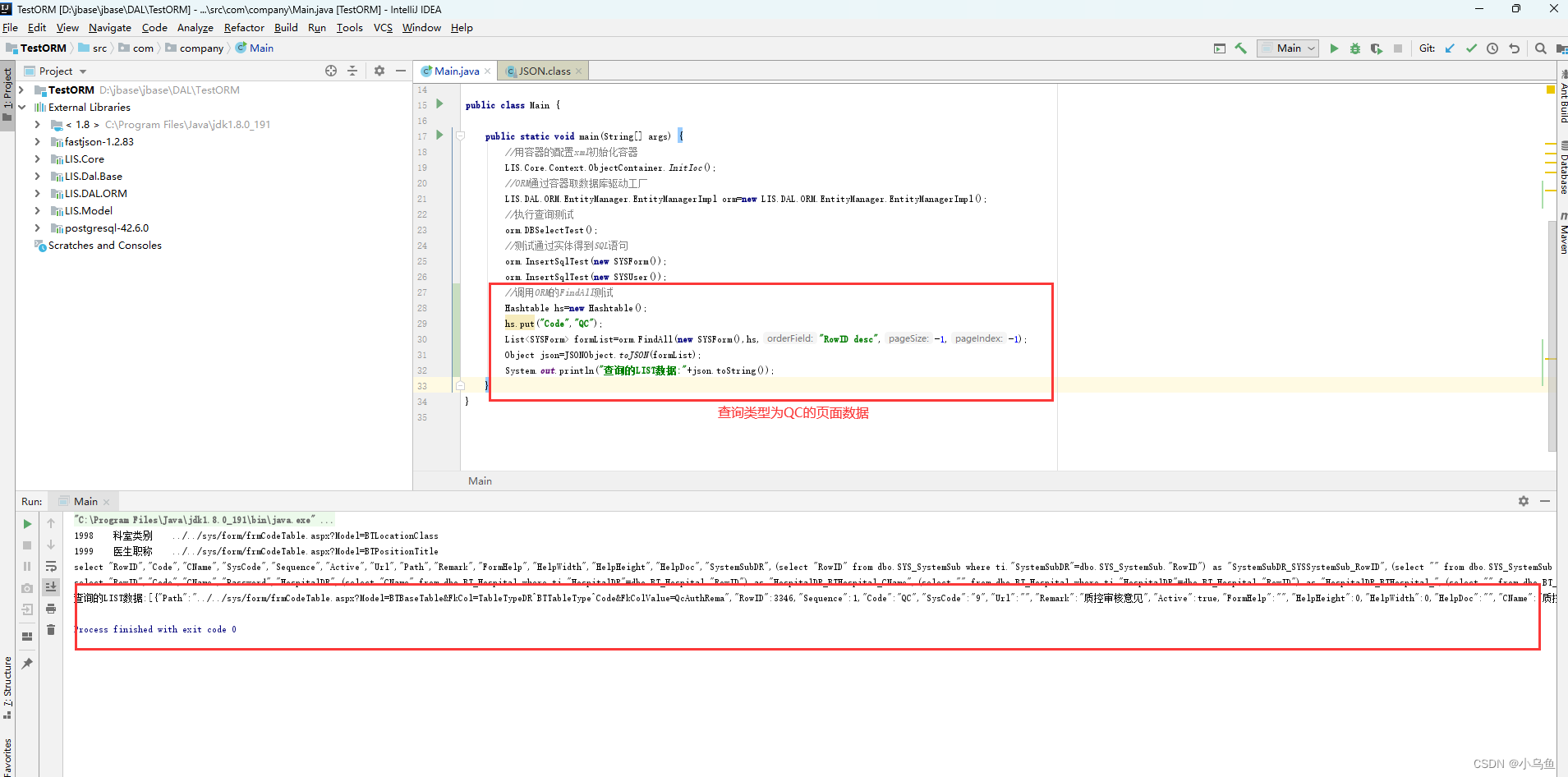
Java实现ORM第一个api-FindAll
经过几天的业余开发,今天终于到ORM对业务api本身的实现了,首先实现第一个查询的api 老的C#定义如下 因为Java的泛型不纯,所以无法用只带泛型的方式实现api,对查询类的api做了调整,第一个参数要求传入实体对象 首先…...

HFSS笔记——求解器和求解分析
文章目录 1、求解器2、求解类型3、自适应网格剖分4、求解频率选择4.1 求解设置项的含义4.2 扫频类型 1、求解器 自从ANSYS将HFSS收购后,其所有的求解器都集成在一起了,点击Project,会显示所有的求解器类型。 其中, HFSS design&…...
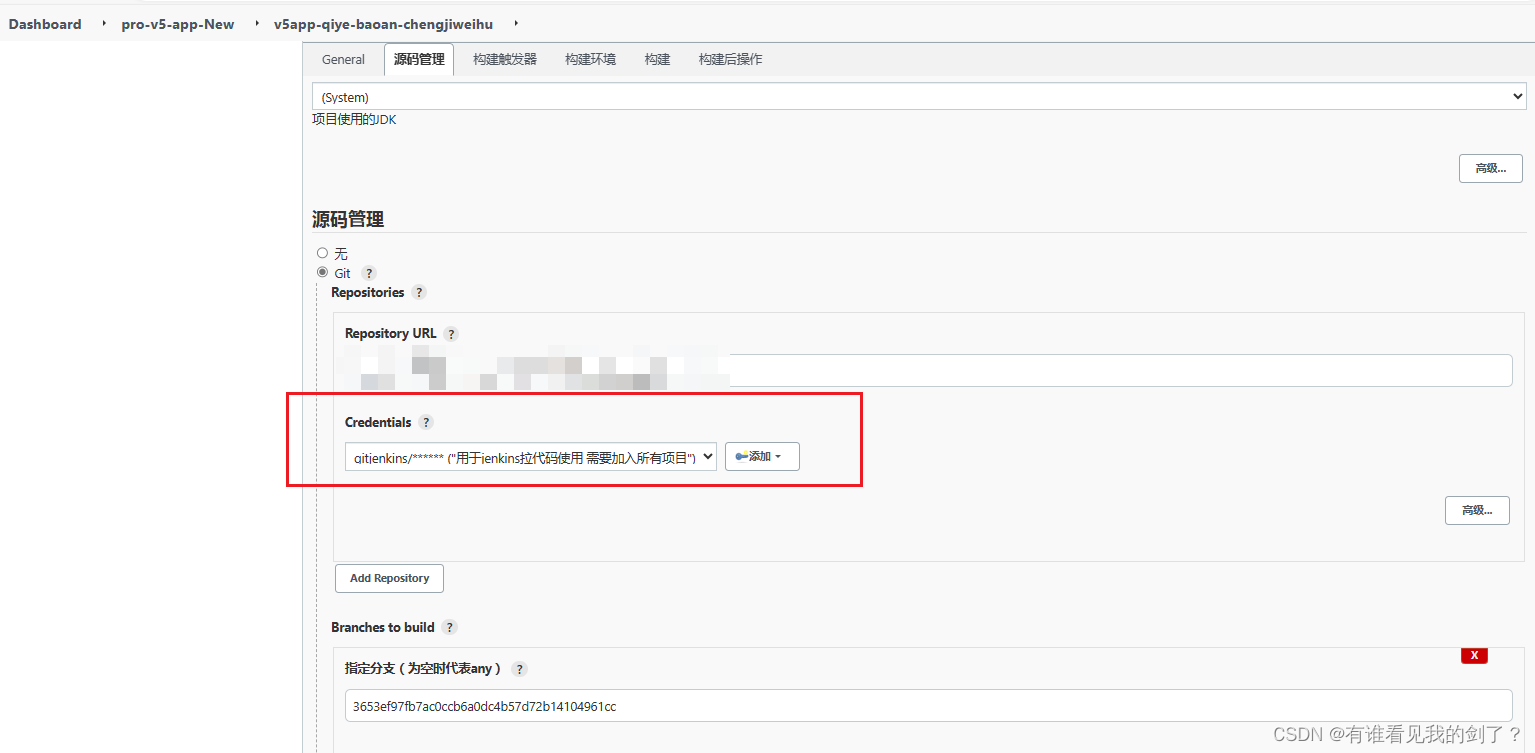
jenkins配置gitlab凭据
下载Credentials Binding插件(默认是已经安装了) 在凭据配置里添加凭据类型 点击保存 Username with password: 用户名和密码 SSH Username with private 在凭据管理里面添加gitlab账号和密码 点击全局 点击添加凭据(版本不同…...
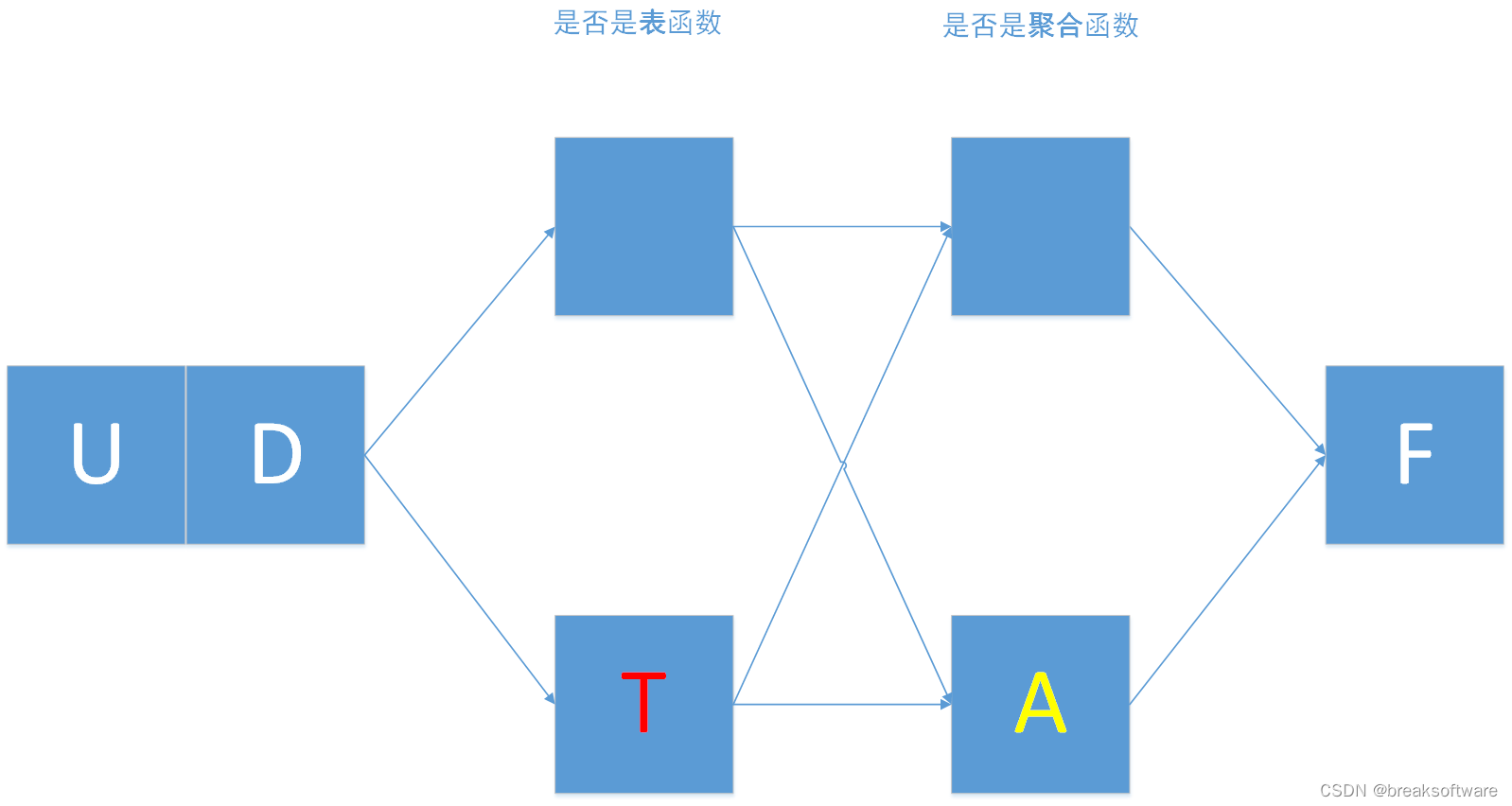
0基础学习PyFlink——用户自定义函数之UDTF
大纲 表值函数完整代码 在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF 表值函数 我们对比下UDF和UDTF def udf(f: Union[Callable, ScalarFunction, Type] None,input_types: Union[List[DataType], DataTy…...

【Java 进阶篇】Java Request 原理详解
在网络应用开发中,HTTP请求是一项常见而关键的任务。当我们使用Java编写网络应用时,了解HTTP请求的工作原理变得至关重要。本文将详细介绍Java中HTTP请求的原理,包括请求的结构、发送请求的方法以及处理请求的过程。 HTTP请求的基本结构 HT…...

13 结构性模式-装饰器模式
1 装饰器模式介绍 在软件设计中,装饰器模式是一种用于替代继承的技术,它通过一种无须定义子类的方式给对象动态的增加职责,使用对象之间的关联关系取代类之间的继承关系. 2 装饰器模式原理 //抽象构件类 public abstract class Component{public abstract void operation(); }…...
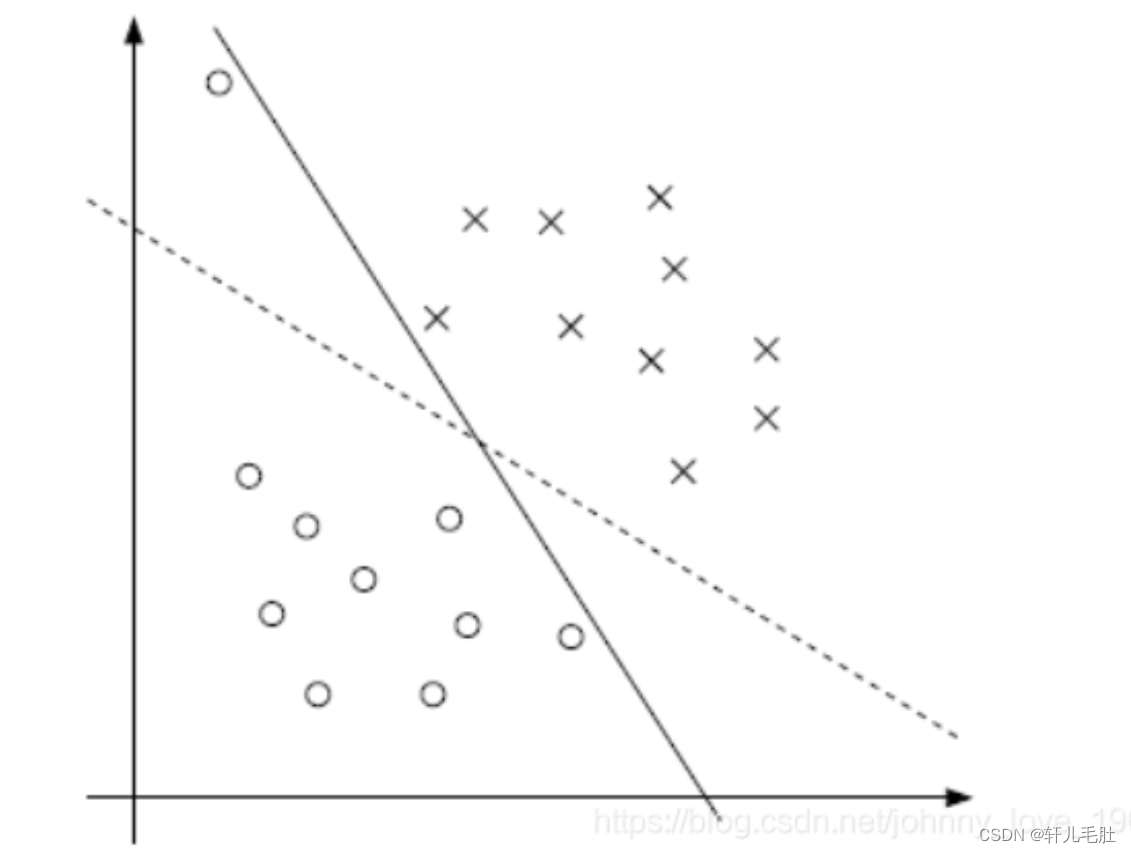
支持向量机(SVM)
一. 什么是SVM 1. 简介 SVM,曾经是一个特别火爆的概念。它的中文名:支持向量机(Support Vector Machine, 简称SVM)。因为它红极一时,所以关于它的资料特别多,而且杂乱。虽然如此,只要把握住SV…...

Rabbitmq----分布式场景下的应用
服务异步通信-分布式场景下的应用 如果单机模式忘记也可以看看这个快速回顾rabbitmq,在做学习 消息队列在使用过程中,面临着很多实际问题需要思考: 1.消息可靠性 消息从发送,到消费者接收,会经理多个过程: 其中的每一…...
springboot + redis实现签到与统计功能
在很多项目中都会有签到与统计功能,最容易想到的方案是创建一个签到表来记录每个用户的签到记录,比如设计一个mysql数据库表: CREATE TABLE tb_sign id bigint(20) unsigned NOT NULL AUTOINCREMENT COMMENT 主键, user_id bigint(20) unsig…...

Redis | 数据结构(02)SDS
一、键值对数据库是怎么实现的? 在开始讲数据结构之前,先给介绍下 Redis 是怎样实现键值对(key-value)数据库的。 Redis 的键值对中的 key 就是字符串对象,而 value 可以是字符串对象,也可以是集合数据类型…...

Linux C语言开发-D7D8运算符
算术运算符:-*/%,浮点数可以参与除法运算,但不能参与取余运算 a%b:表示取模或取余 关系运算符:<,>,>,<,,! 逻辑运算符:!,&&,|| &&,||逻辑运算符是从左到右,依次运算&#…...
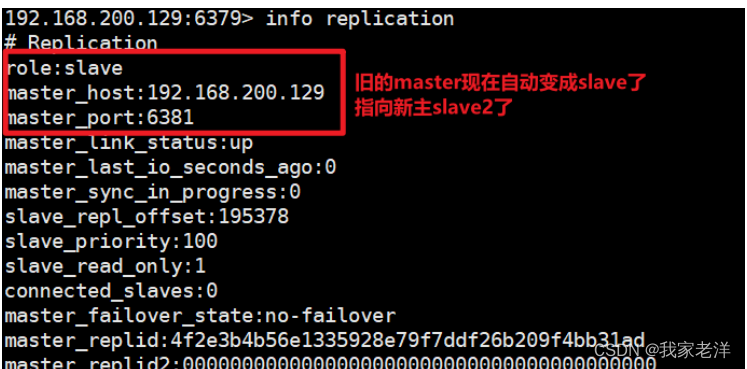
redis 配置主从复制,哨兵模式案例
哨兵(Sentinel)模式 1 . 什么是哨兵模式? 反客为主的自动版,能够自动监控master是否发生故障,如果故障了会根据投票数从slave中挑选一个 作为master,其他的slave会自动转向同步新的master,实现故障自动转义 2 . 原理…...
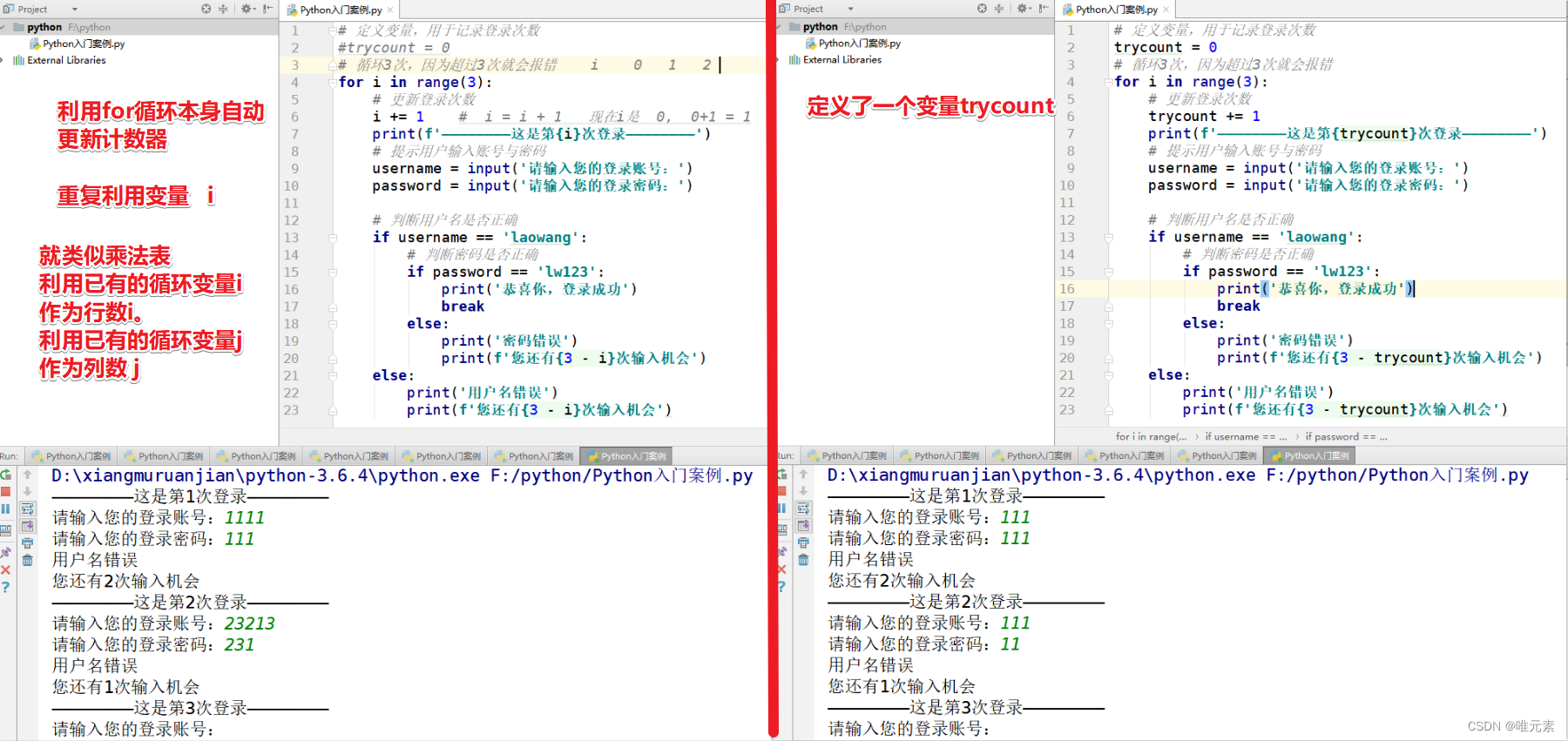
Python---练习:使用for循环实现用户名+密码认证
案例: 用for循环实现用户登录 ① 输入用户名和密码 ② 判断用户名和密码是否正确(usernamelaowang,passwordlw123) ③ 登录仅有三次机会,超过3次会报错 思考: 用户登陆情况有3种: ① 用户名错误(此时…...

react中使用jquery 语法
react中使用jquery 语法 npm install jquery引入 import $ from ‘jquery’ import React from react; import ./css/App.css import { Button } from antd; import $ from jquerylet slider_img [https://cdn.jsdelivr.net/gh/xaoxuu/cdn-wallpaper/abstract/41F215B9-261F…...

服务器中了360后缀勒索病毒怎么解决,勒索病毒解密,数据恢复
近期,网络上的各种病毒都比较猖獗,而其中较为明显的就是360后缀勒索病毒,从这个月开始云天数据恢复中心接到很多企业的求助,企业的服务器遭到了360后缀勒索病毒的攻击,通过给用户的服务器检测与加密病毒的分析…...

OpenClaw云端体验指南:星图平台Qwen3-14B镜像+OpenClaw沙盒部署
OpenClaw云端体验指南:星图平台Qwen3-14B镜像OpenClaw沙盒部署 1. 为什么选择云端沙盒体验? 第一次接触OpenClaw时,我尝试在本地MacBook上部署,结果被复杂的依赖关系和环境配置劝退。直到发现星图平台的Qwen3-14B镜像OpenClaw沙…...

在AutoDL云平台高效部署YOLO训练:从零到一的实战避坑指南
1. 为什么选择AutoDL跑YOLO训练? 第一次接触YOLO目标检测项目时,我像大多数开发者一样被本地显卡性能劝退。直到发现AutoDL这个云GPU平台,才真正体会到什么叫"用多少付多少"的灵活。相比动辄上万的游戏显卡,AutoDL上每小…...

嵌入式设备参数存储优化方案与实践
1. 嵌入式设备参数存储的痛点与常见方案在嵌入式系统开发中,参数存储是个看似简单却暗藏玄机的基础功能。我经历过多个量产项目,发现参数管理不当导致的现场问题占比高达30%。最常见的场景是:设备运行多年后需要功能升级,新增几个…...

基于光伏出力利用率的电动汽车充电站能量调度策略:动态评估充放电灵活性,优化准入规则与电价制定...
考虑光伏出力利用率的电动汽车充电站能量调度策略。 程序注释非常非常详细 针对间歇性能源利用的问题,构建电动汽车的充放电灵活度指标,用以评估电动汽车参与光伏充电站能量调度的能力; 令充电站在饥饿模式或饱和模式下运行,并根据…...

Node.js——dns模块
dns模块1、resolve方法将域名解析为DNS记录2、lookup方法查询IP地址3、reverse方法反向解析IP地址4、dns模块中的各种错误代码在网络编程中,开发者更倾向于使用域名,而不是IP地址来指定网络连接的目标地址。在Node.js中,提供dns模块ÿ…...

res-downloader:全平台网络资源下载工具的高效使用指南
res-downloader:全平台网络资源下载工具的高效使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 当你在微信…...

多年研究图像增强算法,包括但不限于:retinex,gamma,clahe,滤波算法。如果有需要此方面的需要,可以找我哦,理论算法打包带走
多年研究图像增强算法,包括但不限于:retinex,gamma,clahe,滤波算法。如果有需要此方面的需要,可以找我哦,理论算法打包带走...

ai辅助开发新场景:让快马生成基于tailscale exposure的内网设备探测工具
今天想和大家分享一个最近用AI辅助开发的实用小工具——基于Tailscale Exposure的内网设备探测工具。这个项目特别适合需要监控内部网络设备状态的场景,而且整个过程在InsCode(快马)平台上实现起来非常顺畅。 项目背景与需求 作为一个经常需要维护内部网络的人&am…...

基于Vivado的AD9680 FPGA芯片测试程序开发之旅
基于vivado的ad9680 FPGA芯片测试1g采样率lane4 verilog编写,包括配置ad,配置时钟,jesd204b接收 在FPGA开发领域,与高速ADC芯片如AD9680协同工作是一项充满挑战但又极具乐趣的任务。今天咱们就聊聊基于Vivado平台,针对…...

如何用ESP32打造你的个性化智能网络收音机:YoRadio完全指南
如何用ESP32打造你的个性化智能网络收音机:YoRadio完全指南 【免费下载链接】yoradio Web-radio based on ESP32-audioI2S library 项目地址: https://gitcode.com/GitHub_Trending/yo/yoradio 你是否厌倦了传统收音机有限的功能和单调的操作界面?…...