0基础学习PyFlink——用户自定义函数之UDTF
大纲
- 表值函数
- 完整代码
在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF
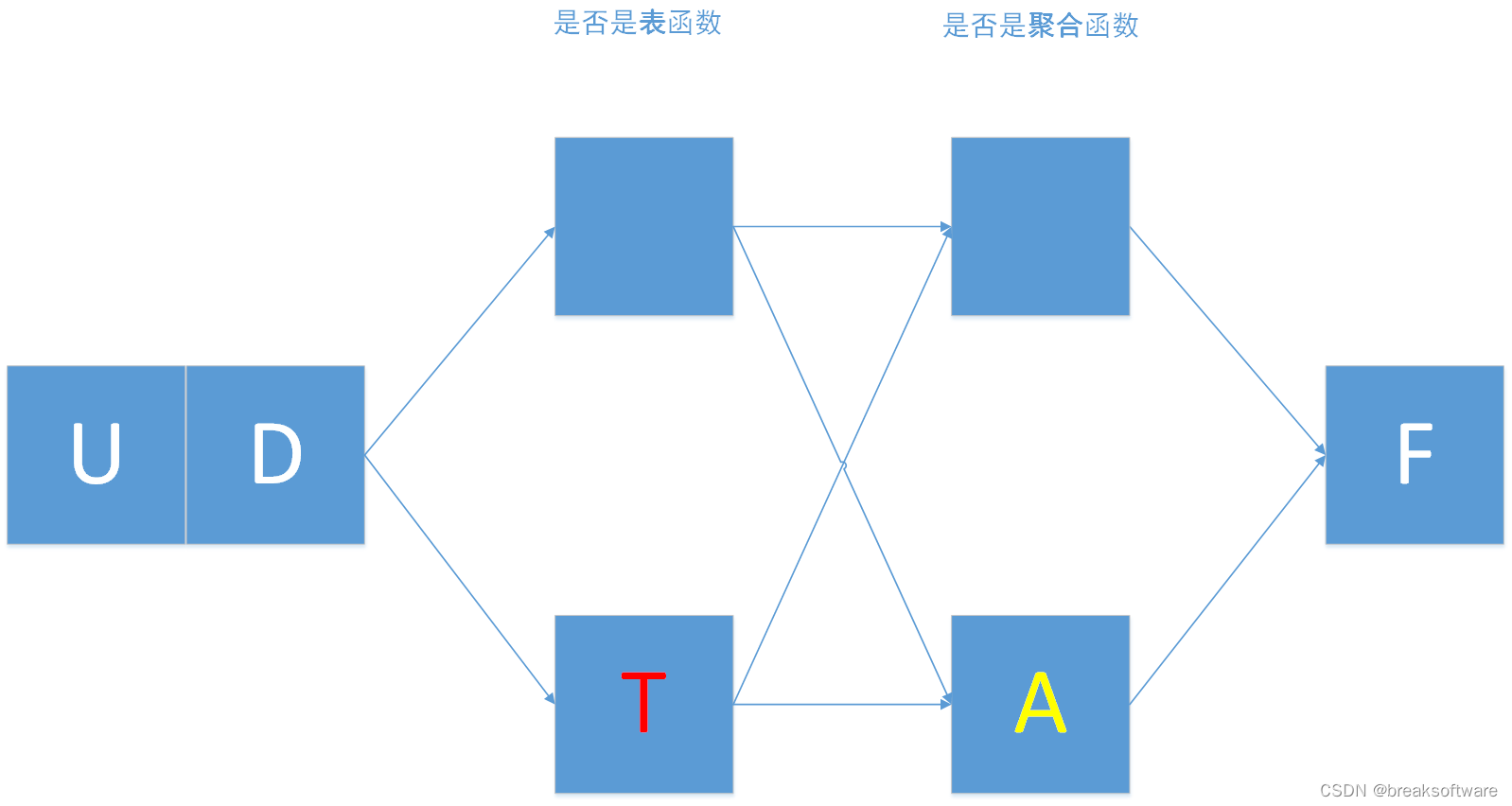
表值函数
我们对比下UDF和UDTF
def udf(f: Union[Callable, ScalarFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_type: Union[DataType, str] = None,deterministic: bool = None, name: str = None, func_type: str = "general",udf_type: str = None) -> Union[UserDefinedScalarFunctionWrapper, Callable]:
def udtf(f: Union[Callable, TableFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_types: Union[List[DataType], DataType, str, List[str]] = None,deterministic: bool = None,name: str = None) -> Union[UserDefinedTableFunctionWrapper, Callable]:
可以发现:
- UDF比UDTF多了func_type和udf_type参数;
- UDTF的返回类型比UDF的丰富,多了两个List类型:List[DataType]和List[str];
特别是最后一点,可以认为是UDF和UDTF在应用上的主要区别。
换种更容易理解的说法是:UDTF可以返回任意数量的行作为输出而不是像UDF那样返回单个值(行)。
举一个例子:
word_count_data = ["A", "B", "C", "a", "C"]
我们希望统计上面这些字符的个数,以及小写后字符的个数。这样A的个数是1,a的个数是2(因为a算一个,A小写后又算一个)。C的个数是2,g的个数是2。
这就要求统计算法在遇到大写字母时,需要统计大小写两种字母;而遇到小写字母时,只需要统计小写字母。
@udtf(result_types=[DataTypes.STRING()], input_types=row_type_tab_source)def rowFunc(row):if row[0].isupper():yield row[0]yield row[0].lower()else:yield row[0]
yield关键字返回的是generator生成器。Table API对rowFunc的调用最终会生成[“A”,“a”,“B”,“b”,“C”,“c”,“a”,“C”,“c”]。
和调用UDF不同的是,需要使用flat_map来调用UDTF。flat即为“打平”,可以生动的理解为将多维降为一维。
tab_trans=tab_source.flat_map(rowFunc)tab_trans.execute().print()
+--------------------------------+
| f0 |
+--------------------------------+
| A |
| a |
| B |
| b |
| C |
| c |
| a |
| C |
| c |
+--------------------------------+
9 rows in set
由于我们没有指定经过处理的值所属的字段名称,于是会使用默认的f0作为字段名。我们可以使用alias来给它别名下。
tab_trans_alias=tab_trans.alias('trans_word')tab_trans_alias.execute().print()
+--------------------------------+
| trans_word |
+--------------------------------+
| A |
| a |
| B |
| b |
| C |
| c |
| a |
| C |
| c |
+--------------------------------+
9 rows in set
最后我们就可以用这个新的表做字数统计计算
tab_trans_alias.group_by(col('trans_word')) \.select(col('trans_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
+I[A, 1]
+I[a, 2]
+I[B, 1]
+I[b, 1]
+I[C, 2]
+I[c, 2]
完整代码
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctionword_count_data = ["A", "B", "C", "a", "C"] def word_count():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('word', DataTypes.STRING())])tab_source = t_env.from_elements(map(lambda i: Row(i), word_count_data), row_type_tab_source)# define the sink schemasink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector('print')\.schema(sink_schema) \.build()t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)@udtf(result_types=[DataTypes.STRING()], input_types=row_type_tab_source)def rowFunc(row):if row[0].isupper():yield row[0]yield row[0].lower()else:yield row[0]tab_trans=tab_source.flat_map(rowFunc)tab_trans.execute().print()tab_trans_alias=tab_trans.alias('trans_word')tab_trans_alias.execute().print()tab_trans_alias.group_by(col('trans_word')) \.select(col('trans_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()if __name__ == '__main__':word_count()
相关文章:
0基础学习PyFlink——用户自定义函数之UDTF
大纲 表值函数完整代码 在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF 表值函数 我们对比下UDF和UDTF def udf(f: Union[Callable, ScalarFunction, Type] None,input_types: Union[List[DataType], DataTy…...

【Java 进阶篇】Java Request 原理详解
在网络应用开发中,HTTP请求是一项常见而关键的任务。当我们使用Java编写网络应用时,了解HTTP请求的工作原理变得至关重要。本文将详细介绍Java中HTTP请求的原理,包括请求的结构、发送请求的方法以及处理请求的过程。 HTTP请求的基本结构 HT…...

13 结构性模式-装饰器模式
1 装饰器模式介绍 在软件设计中,装饰器模式是一种用于替代继承的技术,它通过一种无须定义子类的方式给对象动态的增加职责,使用对象之间的关联关系取代类之间的继承关系. 2 装饰器模式原理 //抽象构件类 public abstract class Component{public abstract void operation(); }…...
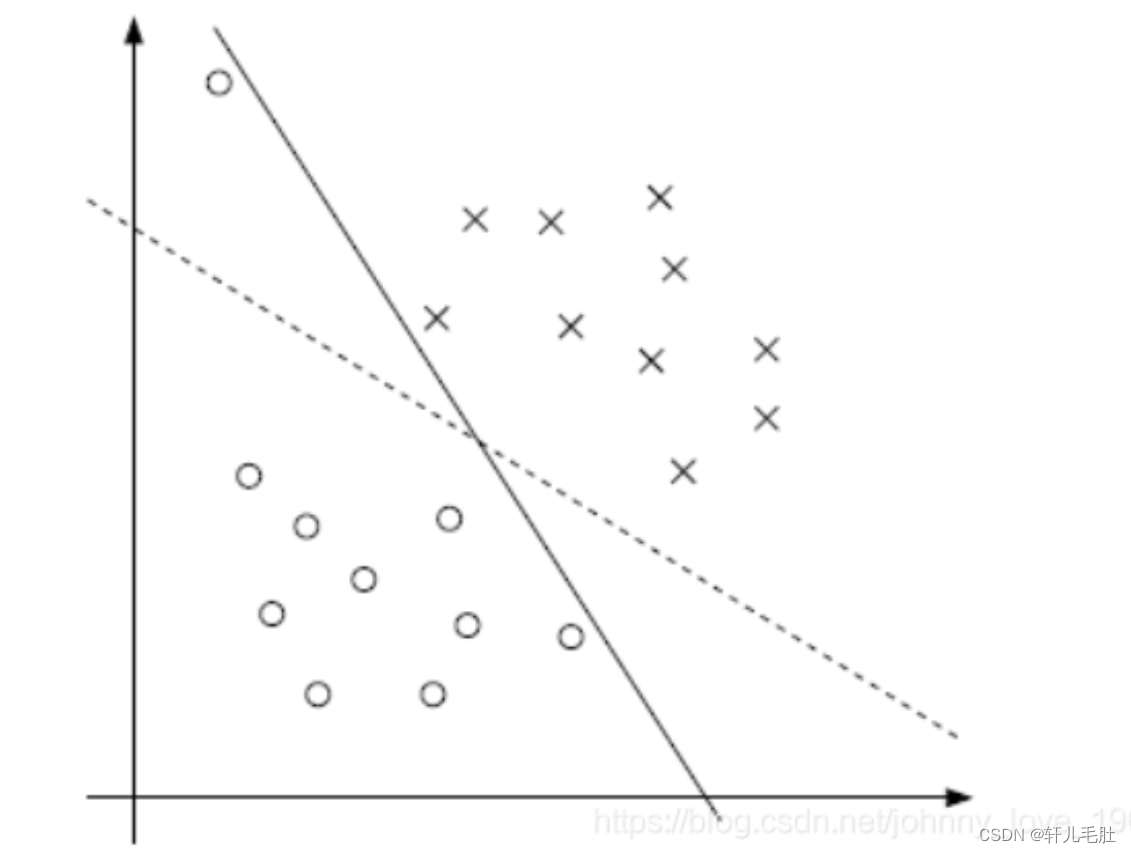
支持向量机(SVM)
一. 什么是SVM 1. 简介 SVM,曾经是一个特别火爆的概念。它的中文名:支持向量机(Support Vector Machine, 简称SVM)。因为它红极一时,所以关于它的资料特别多,而且杂乱。虽然如此,只要把握住SV…...

Rabbitmq----分布式场景下的应用
服务异步通信-分布式场景下的应用 如果单机模式忘记也可以看看这个快速回顾rabbitmq,在做学习 消息队列在使用过程中,面临着很多实际问题需要思考: 1.消息可靠性 消息从发送,到消费者接收,会经理多个过程: 其中的每一…...
springboot + redis实现签到与统计功能
在很多项目中都会有签到与统计功能,最容易想到的方案是创建一个签到表来记录每个用户的签到记录,比如设计一个mysql数据库表: CREATE TABLE tb_sign id bigint(20) unsigned NOT NULL AUTOINCREMENT COMMENT 主键, user_id bigint(20) unsig…...

Redis | 数据结构(02)SDS
一、键值对数据库是怎么实现的? 在开始讲数据结构之前,先给介绍下 Redis 是怎样实现键值对(key-value)数据库的。 Redis 的键值对中的 key 就是字符串对象,而 value 可以是字符串对象,也可以是集合数据类型…...

Linux C语言开发-D7D8运算符
算术运算符:-*/%,浮点数可以参与除法运算,但不能参与取余运算 a%b:表示取模或取余 关系运算符:<,>,>,<,,! 逻辑运算符:!,&&,|| &&,||逻辑运算符是从左到右,依次运算&#…...
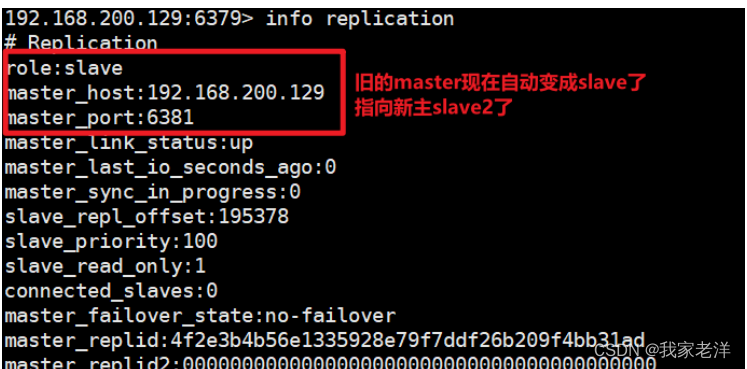
redis 配置主从复制,哨兵模式案例
哨兵(Sentinel)模式 1 . 什么是哨兵模式? 反客为主的自动版,能够自动监控master是否发生故障,如果故障了会根据投票数从slave中挑选一个 作为master,其他的slave会自动转向同步新的master,实现故障自动转义 2 . 原理…...
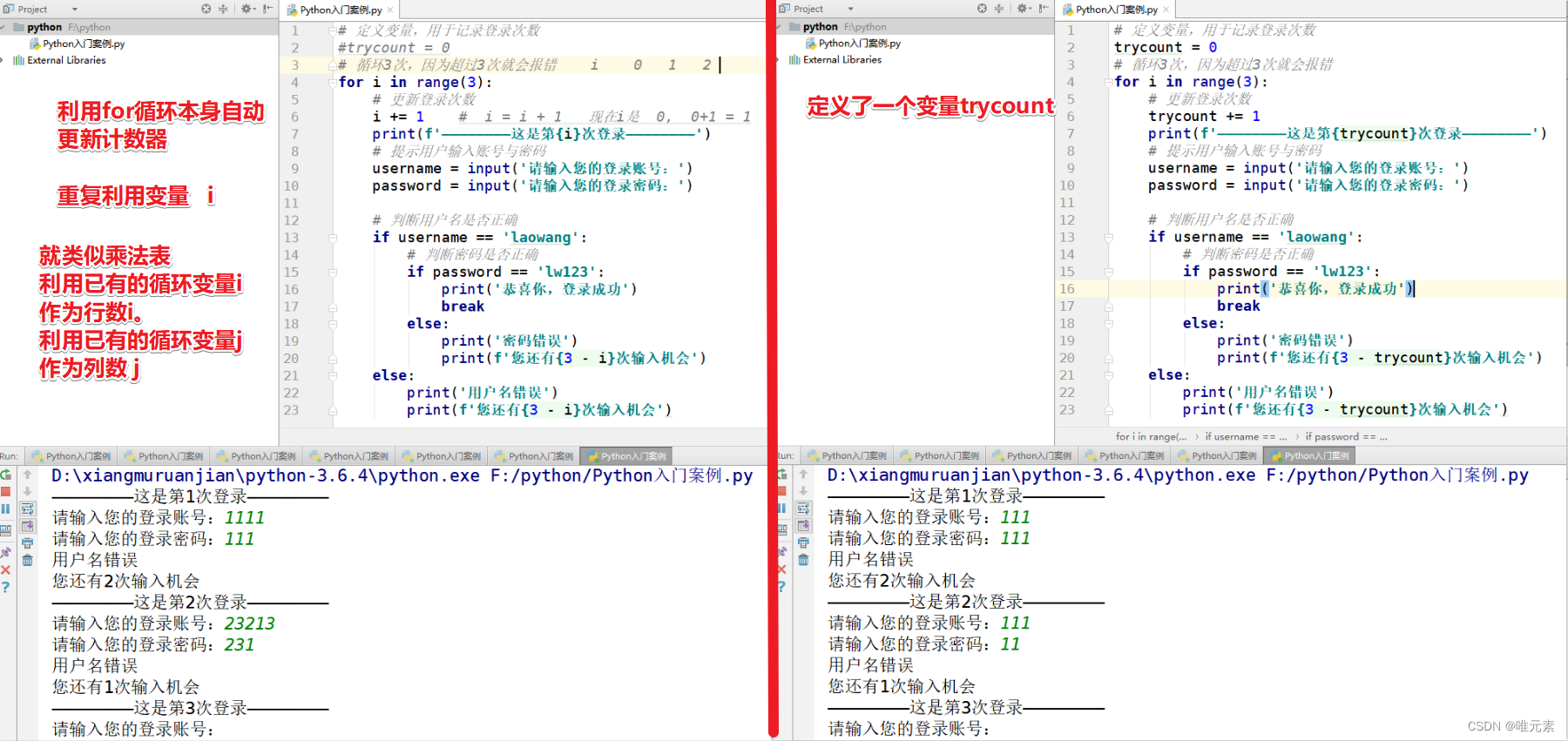
Python---练习:使用for循环实现用户名+密码认证
案例: 用for循环实现用户登录 ① 输入用户名和密码 ② 判断用户名和密码是否正确(usernamelaowang,passwordlw123) ③ 登录仅有三次机会,超过3次会报错 思考: 用户登陆情况有3种: ① 用户名错误(此时…...

react中使用jquery 语法
react中使用jquery 语法 npm install jquery引入 import $ from ‘jquery’ import React from react; import ./css/App.css import { Button } from antd; import $ from jquerylet slider_img [https://cdn.jsdelivr.net/gh/xaoxuu/cdn-wallpaper/abstract/41F215B9-261F…...

服务器中了360后缀勒索病毒怎么解决,勒索病毒解密,数据恢复
近期,网络上的各种病毒都比较猖獗,而其中较为明显的就是360后缀勒索病毒,从这个月开始云天数据恢复中心接到很多企业的求助,企业的服务器遭到了360后缀勒索病毒的攻击,通过给用户的服务器检测与加密病毒的分析…...
使用字节流读取文件中的数据的几种方式
public class FileReader02_ {public static void main(String[] args) {}Testpublic void m1() {String filePath "e:\\hello.txt";FileReader fileReader null;int date0;try {fileReader new FileReader(filePath);//循环读取 使用readwhile ((datefileReader.…...
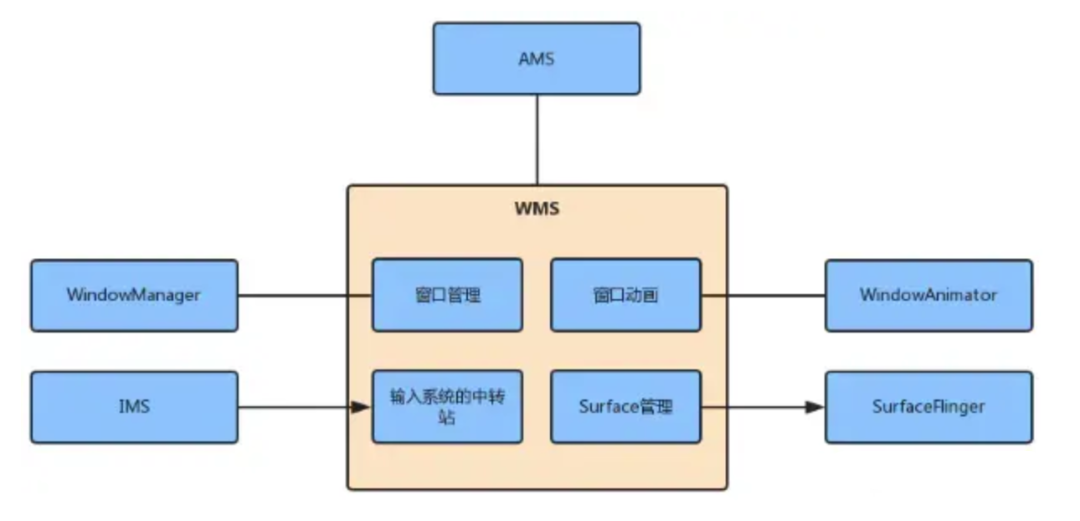
Android WMS——概述(一)
Android 中的 WMS 指的是 Window Manager Service(窗口管理服务)。WMS 是 Android 系统中的核心服务,主要分为四大部分,分别是窗口管理,窗口动画,输入系统中转站和 Surface 管理 。负责管理应用程序窗口的创建、移动、调整大小和显示等操作。 一、功能简介 WMS 的职责可…...
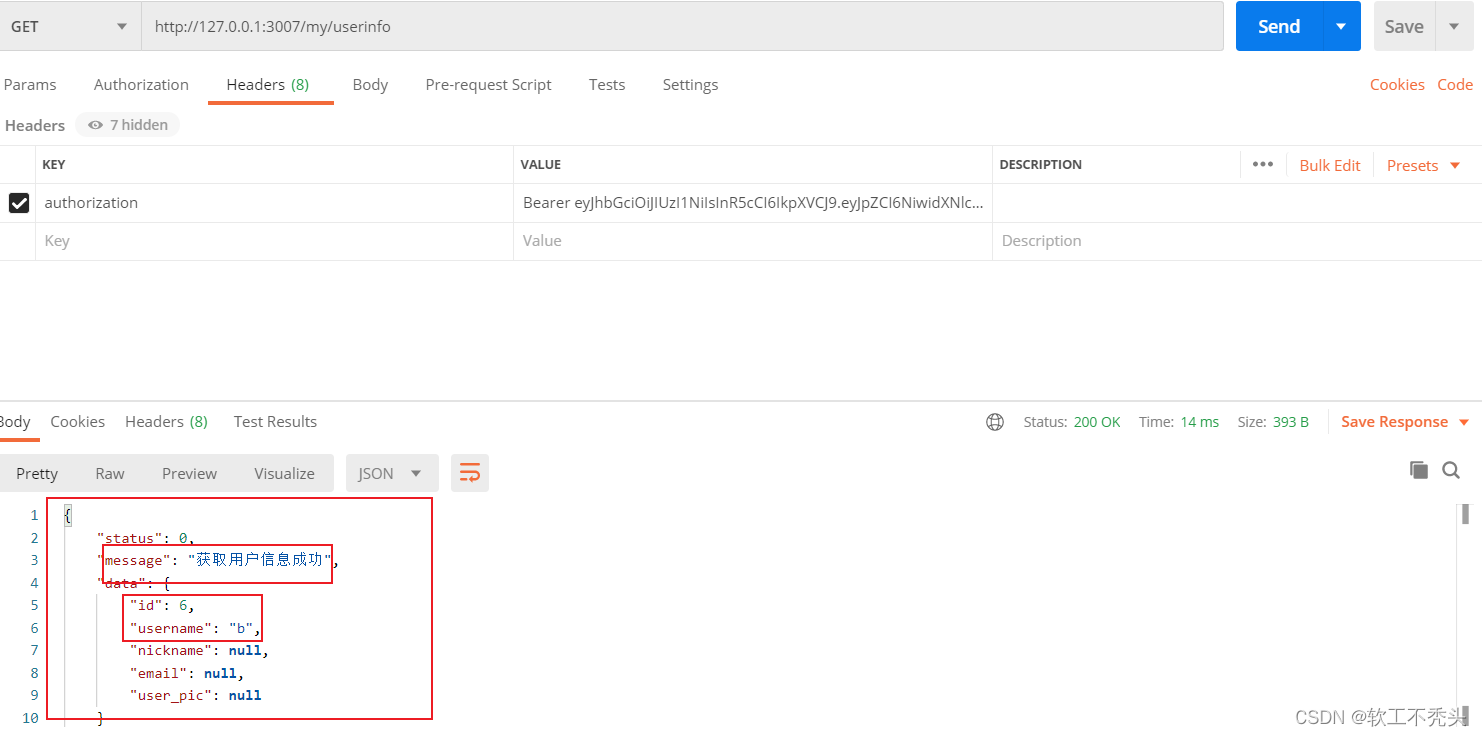
Node编写获取用户信息接口
目录 前言 初始化路由模块 使用postman发送get获取用户信息请求 初始化路由处理函数模块 获取用户基本信息 前言 在前两篇文章中已经介绍了如何编写用户注册接口以及用户登录接口,这篇文章介绍如何获取用户信息,本篇文章建立在Node编写用户登录接口…...

【从0到1设计一个网关】自研网关的设计要点以及架构设计
文章目录 请求的流程架构设计设计要点项目架构流程设计源码地址: 源码地址 请求的流程 一个HTTP请求发送到网关并完成整个生命周期通常包括以下步骤: 客户端请求: 请求始于客户端,客户端通过HTTP请求(例如GET、POST等)发送请求到API网关的入口点。 API网关接收: API…...

论文-分布式-分布式计算|容错-分布式控制下的自稳定系统
参考文献Self-stabilizing systems in spite of distributed control可以把松散耦合的 循环序列过程 间的同步任务,看成是要保持一个这样的不变性:“系统要处于一种合法状态”因此每个进程在运行每一个可能会改变不变性的步骤之前都要先检查一下是可以执…...

C#压缩图片的方法
/// <summary> /// 图片压缩 /// </summary> /// <param name"imagePath">图片文件路径</param> /// <param name"targetFolder">保存文件夹</param> /// <param name"quality">压缩质量</param&g…...

安装 fcitx + 搜狗/谷歌输入法 之后导致 死机,重启后黑屏只有鼠标可以移动
一般的原因就是 : fcitx 导致的问题 方法就是 先卸载搜狗,再卸载fcitx 解决办法: 首先:ctrlaltF6 进入命令行界面,如果进不去就 ctrlaltF2 接下来执行: sudo apt-get remove sogoupinyin sudo apt-get …...

Maven项目转为SpringBoot项目
Maven项目转为SpringBoot项目 前言创建一个maven项目前的软件的一些通用设置Maven仓库的设置其他的设置字符编码编译器注解支持 创建的Maven项目修改为Spring Boot项目修改pom.xml文件修改启动类-Main新建WAR包所需的类 添加核心配置文件 测试的控制器最后整个项目的目录结构
拓世AI决策系统白皮书
拓世AI决策系统白皮书——基于六元结构的双环自适应决策架构版权与所有权声明本技术系统所有知识产权归拓世网络技术开发室(Tuoshi Network Technology Development Studio)独家所有。本系统由拓世网络技术开发室唯一技术开发者独立完成,未接…...
)
别再被网站当机器人了!手把手教你编译一个‘隐身版’Chromedriver(绕过Selenium检测)
从源码到隐身:深度定制Chromedriver绕过检测的工程实践 当你的Selenium脚本突然被目标网站拦截,熟悉的"Access Denied"页面赫然出现时,那种挫败感每个爬虫开发者都深有体会。网站的反爬系统越来越智能,常规的UserAgent轮…...

OpenClaw技能市场盘点:Qwen3-4B模型支持的十大实用自动化模块
OpenClaw技能市场盘点:Qwen3-4B模型支持的十大实用自动化模块 1. 为什么需要关注OpenClaw技能市场? 去年冬天,当我第一次在个人笔记本上部署OpenClaw时,最让我惊喜的不是框架本身的基础能力,而是它背后那个充满可能性…...
你用了吗?)
Verdi波形调试效率翻倍指南:除了拖信号,这些隐藏功能(信号计数、逻辑运算、模拟波形)你用了吗?
Verdi波形调试效率翻倍指南:解锁隐藏的高级功能 在数字验证工程师的日常工作中,Verdi作为业界主流的波形查看工具,其基础功能可能早已被大家所熟悉。但你是否知道,Verdi还隐藏着一系列能大幅提升调试效率的高级功能?本…...

OpenClaw+Phi-3-vision-128k-instruct:电商商品截图自动比价系统
OpenClawPhi-3-vision-128k-instruct:电商商品截图自动比价系统 1. 为什么需要自动化比价系统 作为一个经常网购的技术爱好者,我发现自己花在比价上的时间越来越多。每次看到心仪的商品,都要手动打开多个电商平台,截图保存价格信…...

直方图均衡化:从理论到实践——MATLAB代码实现与效果对比
1. 直方图均衡化基础概念 直方图均衡化是数字图像处理中最基础也最实用的技术之一。简单来说,它就像给照片做了一次"智能美颜",能够自动调整图像的对比度,让暗部更清晰、亮部更细腻。想象一下你拍摄了一张背光的人像照片࿰…...

spring boot apm生态
一、spring boot actuatorSpring Boot Actuator Micrometer Prometheus Grafana组合1、spring boot actuator ,提供实时指标查询2、prometheus(美/ proˈmiθɪəs /),定期(比如每15秒)去调用应用的接口,把数据拉取…...

电路接口技术解析:从TTL到无线通信的演进
1. 电路接口概述:信号传输的关键桥梁在嵌入式系统和电子电路设计中,接口技术就像城市之间的高速公路系统。当不同模块需要通信时,就像不同方言的人群需要找到共同语言。我曾参与过一个工业控制器项目,CPU与传感器间的通信故障导致…...

2026届学术党必备的六大AI写作方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为先进的大语言模型,能够为学术论文写作给予系统性辅助。研究者理应首…...

Claude Code 进阶攻略:搞定内置 /loop,用大白话玩转 Cron,一行搞定自动化任务
每天免费领 1亿 Token,白嫖DeepSeek、GLM、MiniMax、Kimi等大模型! 本文写给:天天跟 Claude Code 打交道的程序员们,教你把那些烦人的监控活儿从“肉眼盯着”变成“系统自动报”。 等代码构建的时候,你通常在干嘛&…...