用爬虫代码爬取高音质音频示例
目录
一、准备工作
1、安装Python和相关库
2、确定目标网站和数据结构
二、编写爬虫代码
1、导入库
2、设置代理IP
3、发送HTTP请求并解析HTML页面
4、查找音频文件链接
5、提取音频文件名和下载链接
6、下载音频文件
三、完整代码示例
四、注意事项
1、遵守法律法规和网站规定
2、不要过于频繁地访问网站
3、不要忽略网站的反爬虫机制
4、尊重网站的robots.txt文件
总结
网络爬虫是一种自动化程序,用于从网络上获取数据。在本文中,我们将介绍如何使用Python编写一个简单的网络爬虫,以从特定的音乐网站上爬取高音质音频文件。我们将使用BeautifulSoup库进行HTML解析和数据提取,使用requests库发送HTTP请求,以及使用selenium库模拟浏览器行为。

一、准备工作
1、安装Python和相关库
确保您的计算机上已安装Python,并且已安装requests、beautifulsoup4和selenium等库。可以使用以下命令在终端中安装它们:
pip install requests beautifulsoup4 selenium2、确定目标网站和数据结构
我们需要确定要爬取的目标网站以及网站上的数据结构。在本例中,我们将爬取一个提供高音质音频文件的音乐网站。我们需要了解网站的HTML结构和音频文件的URL地址结构。
二、编写爬虫代码
1、导入库
首先,我们导入所需的库:
python
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
2、设置代理IP
这里我们使用Chrome浏览器和Selenium库来实现自动化浏览器行为。为了模拟真实用户行为,我们还需要设置Chrome浏览器选项以隐藏浏览器窗口和禁用JavaScript。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # 定义代理IP和端口号 ,可以从站大爷网站获取代理IP
proxy_ip = "168.88.88.88"
proxy_port = 16888 # 创建Chrome浏览器选项并设置代理
options = Options()
options.add_argument("--headless") # 隐藏浏览器窗口
options.add_argument("--disable-dev-shm-usage") # 解决内存问题
options.add_argument("--no-sandbox") # 禁用沙盒模式
options.add_argument(f"--proxy-server={proxy_ip}:{proxy_port}") # 设置代理服务器地址和端口号
driver = webdriver.Chrome(options=options) # 打开目标网站
driver.get("目标网站URL")
3、发送HTTP请求并解析HTML页面
接下来,我们发送HTTP请求并解析HTML页面以获取所需数据。在本例中,我们需要找到包含音频文件URL的HTML元素。这里我们使用BeautifulSoup库进行HTML解析和数据提取:
url = "目标网站URL" # 替换为您要爬取的网站URL
response = requests.get(url) # 发送HTTP请求并获取响应内容
soup = BeautifulSoup(response.text, "html.parser") # 解析响应内容为BeautifulSoup对象4、查找音频文件链接
接下来,我们需要查找包含音频文件链接的HTML元素。在本例中,音频文件链接存储在一个包含多个下载链接的列表中。我们可以使用BeautifulSoup库的select方法来查找包含所需数据的HTML元素:
# 查找包含音频文件链接的HTML元素
download_links = soup.select("div.download-links-container a") # 遍历下载链接并查找音频文件链接
for link in download_links: href = link["href"] if "audio" in href or "mp3" in href: # 检查链接中是否包含音频文件扩展名 audio_link = href break5、提取音频文件名和下载链接
现在,我们可以提取音频文件名和下载链接:
# 提取音频文件名和下载链接
filename = audio_link.split("/")[-1] # 获取文件名
download_link = f"{url}/{audio_link}" # 构建完整的下载链接6、下载音频文件
最后,我们可以使用requests库来下载音频文件:
# 下载音频文件
response = requests.get(download_link)
with open(filename, "wb") as file: file.write(response.content)三、完整代码示例
以下是完整的代码示例:
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time options = Options()
options.add_argument("--headless") # 隐藏浏览器窗口
options.add_argument("--disable-dev-shm-usage") # 解决内存问题
options.add_argument("--no-sandbox") # 禁用沙盒模式
driver = webdriver.Chrome(options=options) url = "目标网站URL" # 替换为您要爬取的网站URL
driver.get(url) # 打开网站页面
time.sleep(3) # 等待页面加载完成,根据实际情况适当调整等待时间
response = driver.page_source # 获取页面源代码
soup = BeautifulSoup(response, "html.parser") # 解析页面源代码为BeautifulSoup对象 # 查找包含音频文件链接的HTML元素并提取音频文件名和下载链接
download_links = soup.select("div.download-links-container a")
for link in download_links: href = link["href"] if "audio" in href or "mp3" in href: # 检查链接中是否包含音频文件扩展名 audio_link = href break
filename = audio_link.split("/")[-1] # 获取文件名
download_link = f"{url}/{audio_link}" # 构建完整的下载链接 # 下载音频文件并保存到本地磁盘上
response = requests.get(download_link) # 使用requests库下载音频文件,可以根据实际情况设置请求头和代理等参数
with open(filename, "wb") as file: # 将响应内容保存到本地磁盘上,可以根据实际情况设置保存路径和文件名等参数 file.write(response.content) # 将响应内容写入文件中,保存为二进制格式的文件流数据(byte array)形式。四、注意事项
1、遵守法律法规和网站规定
在编写爬虫代码之前,请确保您已经了解了相关法律法规和网站规定,并遵守它们。在爬取网站数据时,请尊重网站的隐私政策和使用条款,不要侵犯他人的合法权益。
2、不要过于频繁地访问网站
在爬取网站数据时,请注意不要过于频繁地访问网站。如果您的爬虫程序过于频繁地访问网站,可能会被网站封禁或被视为恶意攻击。为了防止这种情况发生,您可以在爬虫程序中添加适当的延迟时间,以模拟真实用户行为。
3、不要忽略网站的反爬虫机制
许多网站都配备了反爬虫机制,以防止恶意攻击或过度访问。在编写爬虫代码时,请注意不要忽略这些机制。如果网站检测到您正在进行爬虫操作,可能会采取措施限制您的访问权限或封禁您的IP地址。因此,您需要在编写爬虫代码时采取相应的防护措施,以避免触发这些机制。
4、尊重网站的robots.txt文件
网站的robots.txt文件通常用于告诉爬虫程序如何访问网站。在编写爬虫代码时,请尊重网站的robots.txt文件,遵循其中的规定和限制。这样可以避免不必要的纠纷和问题。
总结
通过使用BeautifulSoup库进行HTML解析和数据提取,以及使用requests库发送HTTP请求和Selenium库模拟浏览器行为,我们可以实现自动化地爬取所需数据并下载音频文件。但是,在编写爬虫代码之前,请确保您已经了解了相关法律法规和网站规定,并遵守它们。
相关文章:
用爬虫代码爬取高音质音频示例
目录 一、准备工作 1、安装Python和相关库 2、确定目标网站和数据结构 二、编写爬虫代码 1、导入库 2、设置代理IP 3、发送HTTP请求并解析HTML页面 4、查找音频文件链接 5、提取音频文件名和下载链接 6、下载音频文件 三、完整代码示例 四、注意事项 1、遵守法律法…...
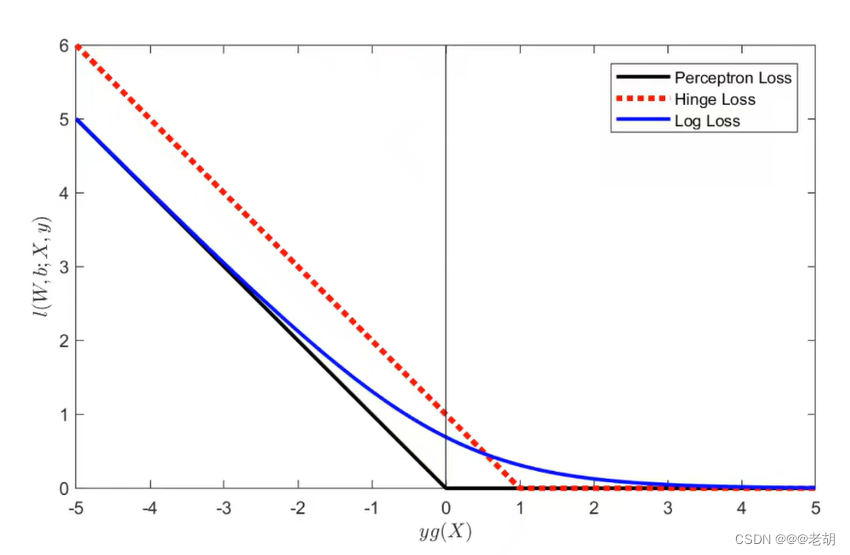
深度学习与计算机视觉(一)
文章目录 计算机视觉与图像处理的区别人工神经元感知机 - 分类任务Sigmoid神经元/对数几率回归对数损失/交叉熵损失函数梯度下降法- 极小化对数损失函数线性神经元/线性回归均方差损失函数-线性回归常用损失函数使用梯度下降法训练线性回归模型线性分类器多分类器的决策面 soft…...
【vector题解】杨辉三角 | 删除有序数组中的重复项 | 只出现一次的数字Ⅱ
杨辉三角 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1…...
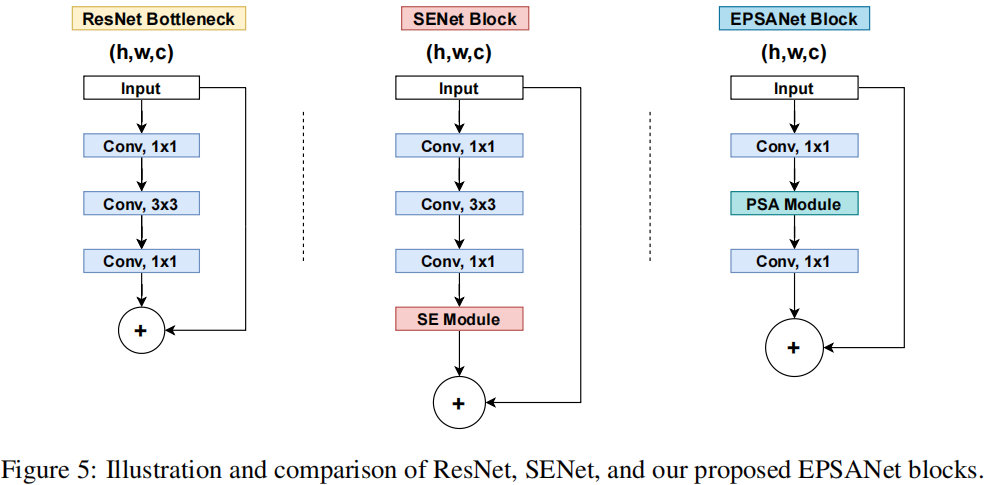
金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度…...
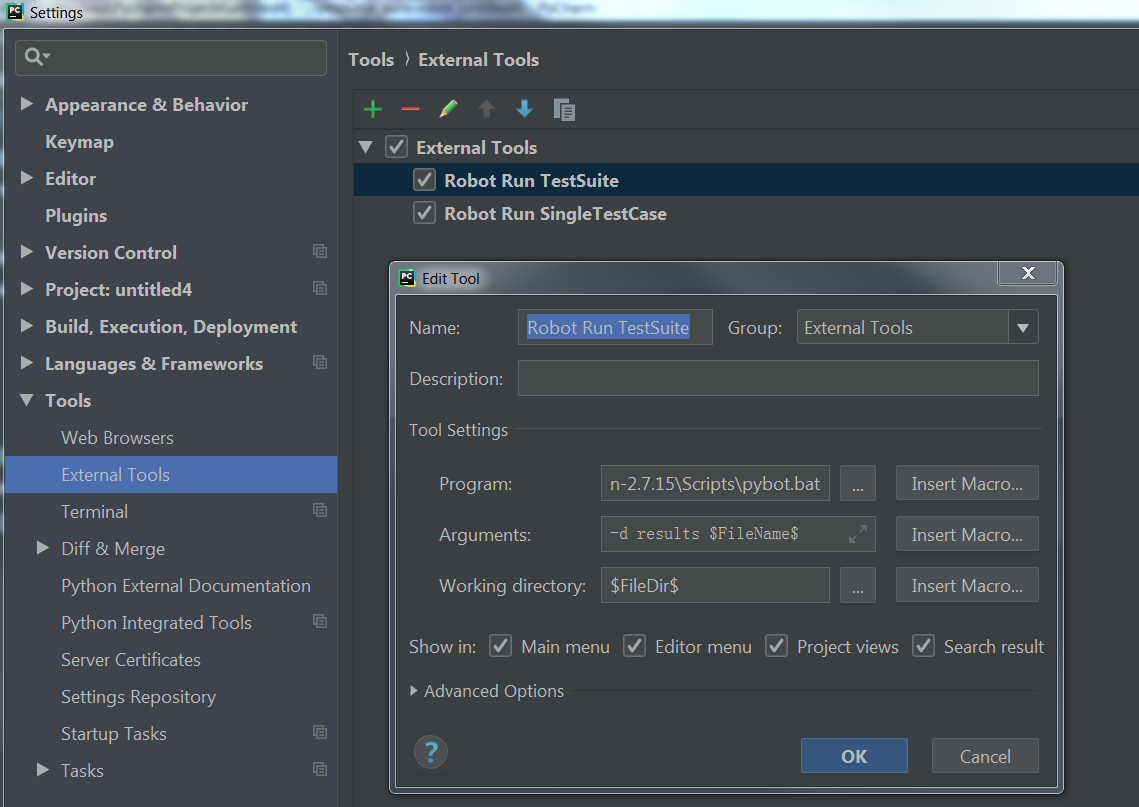
Jenkins自动化测试
学习 Jenkins 自动化测试的系列文章 Robot Framework 概念Robot Framework 安装Pycharm Robot Framework 环境搭建Robot Framework 介绍Jenkins 自动化测试 1. Robot Framework 概念 Robot Framework是一个基于Python的,可扩展的关键字驱动的自动化测试框架。 它…...

python 字典dict和列表list的读取速度问题, range合并
嗨喽,大家好呀~这里是爱看美女的茜茜呐 python 字典和列表的读取速度问题 最近在进行基因组数据处理的时候,需要读取较大数据(2.7G)存入字典中, 然后对被处理数据进行字典key值的匹配,在被处理文件中每次…...
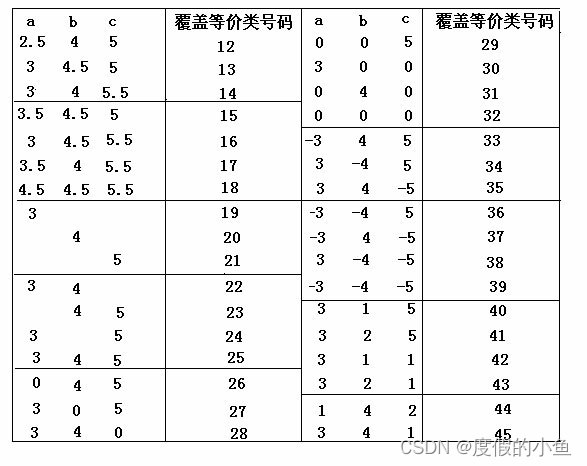
测试用例的设计方法(全):等价类划分方法
一.方法简介 1.定义 是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。 2.划分等价类: 等价类是指某个输入域的…...
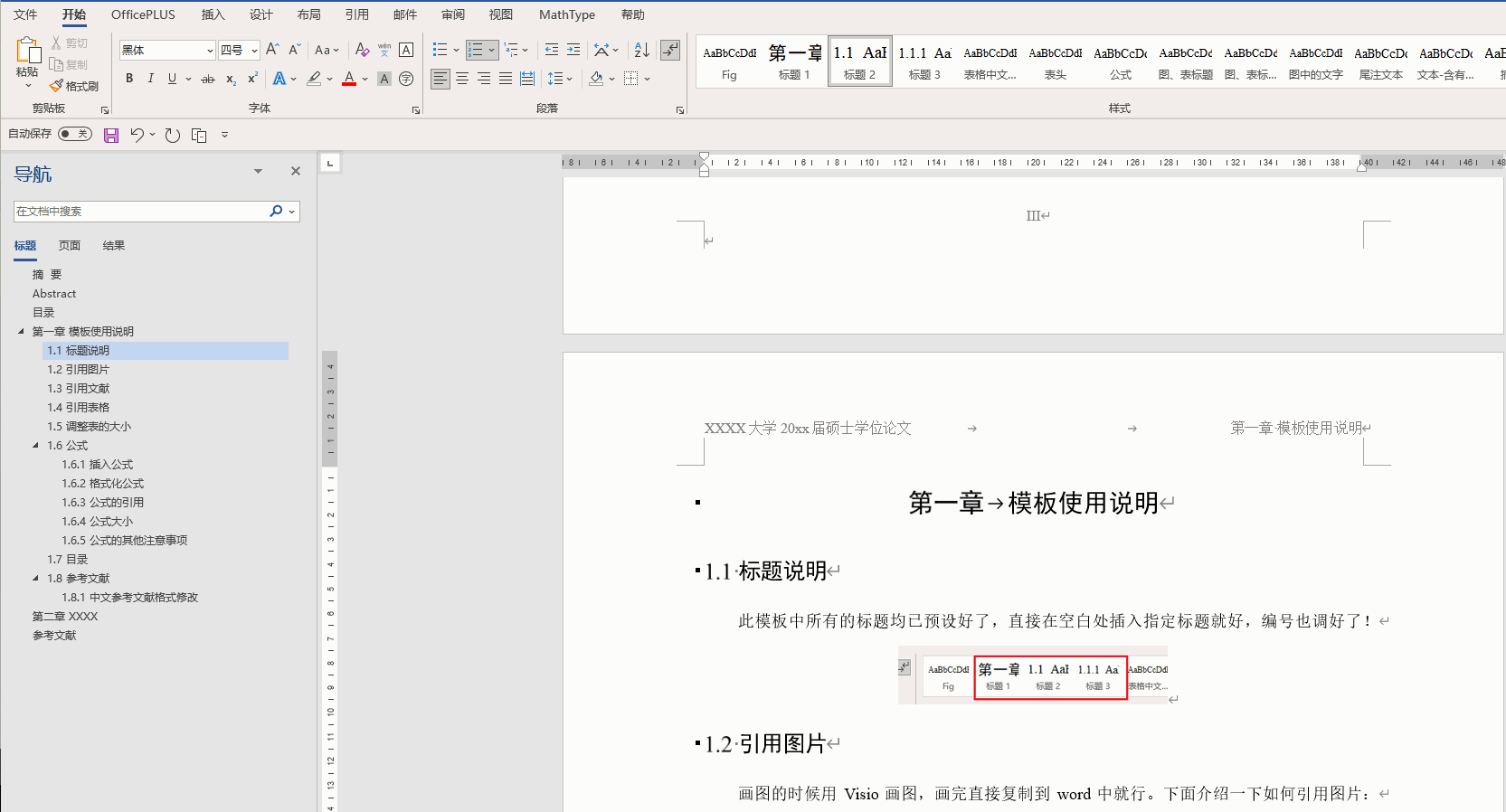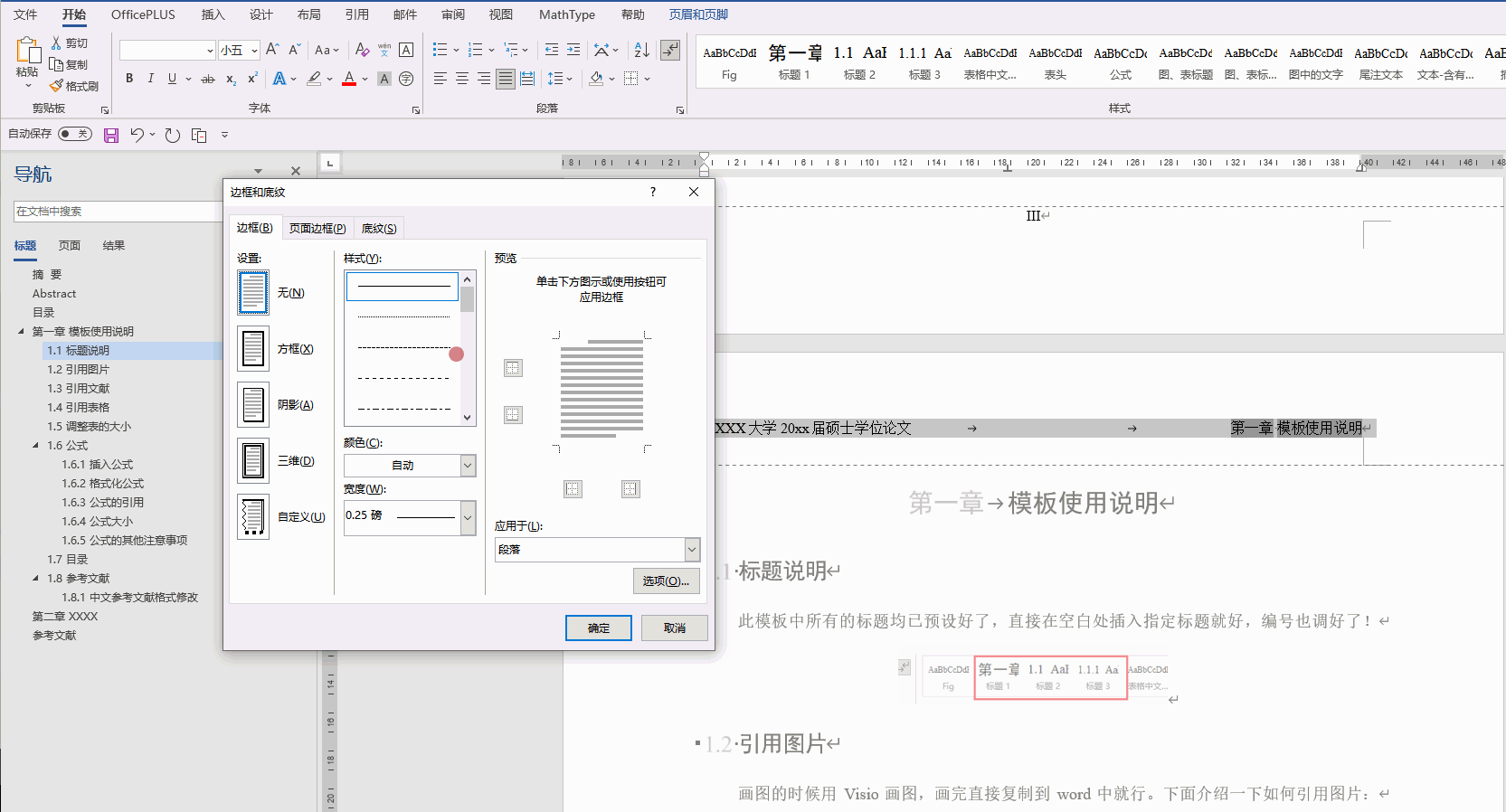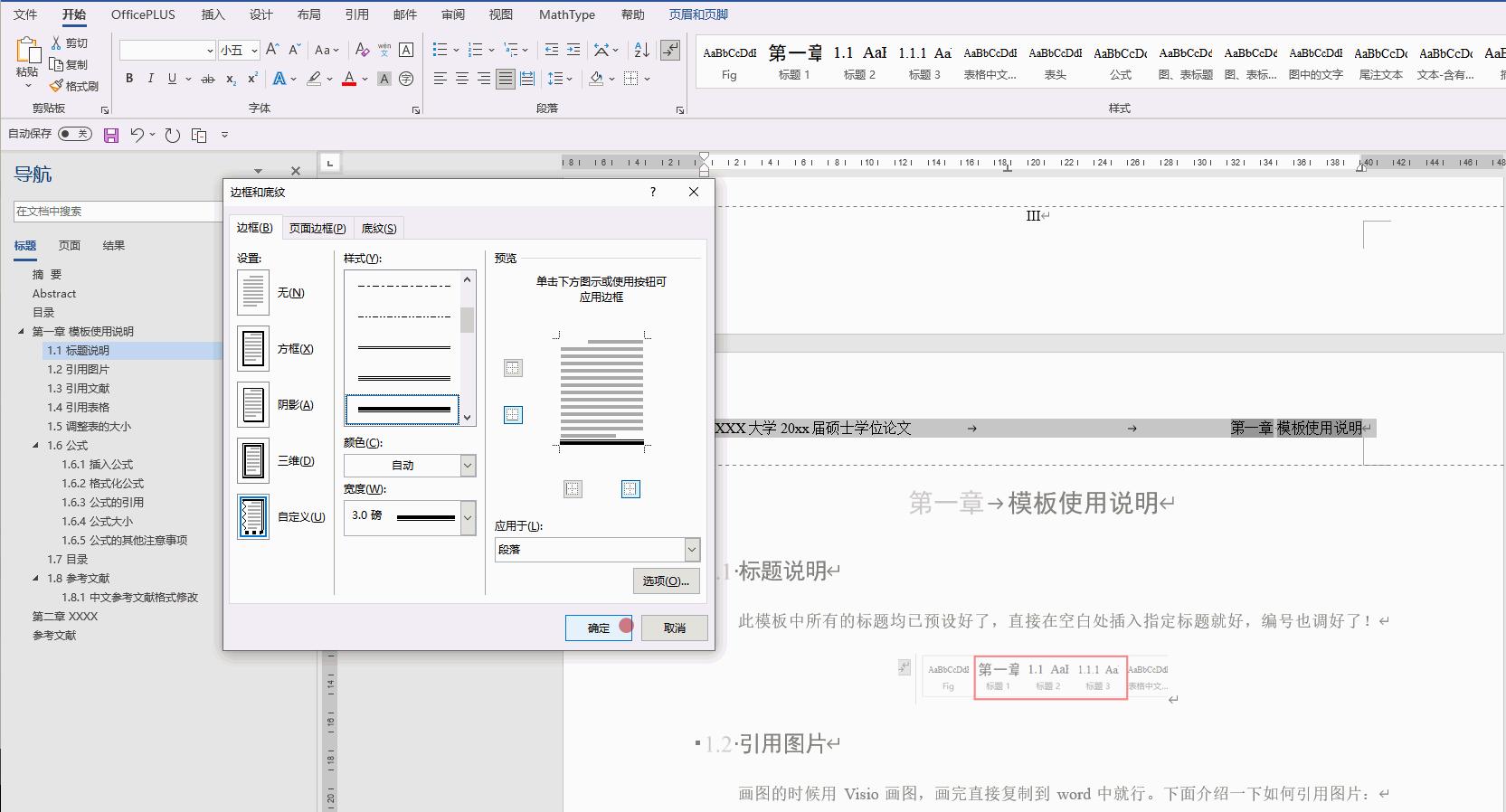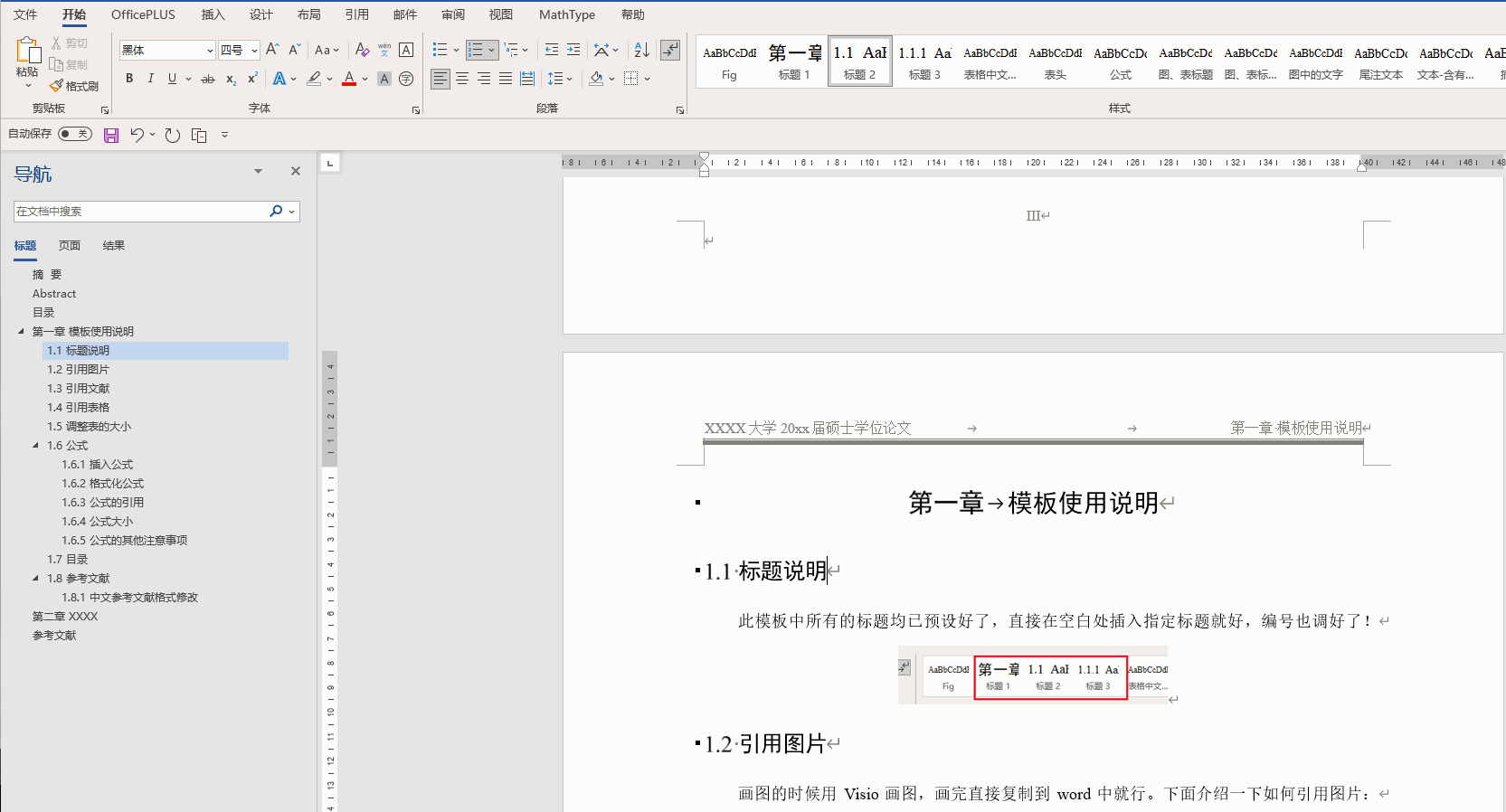
Office技巧(持续更新)(Word、Excel、PPT、PowerPoint、连续引用、标题、模板、论文)
1. Word 1.1 标题设置为多级列表 选住一级标题,之后进行“定义新的多级列表” 1.2 图片和表的题注自动排序 正常插入题注后就可以了。如果一级标题是 “汉字序号”,那么需要对题注进行修改: 从原来的 图 { STYLEREF 1 \s }-{ SEQ 图 \* A…...
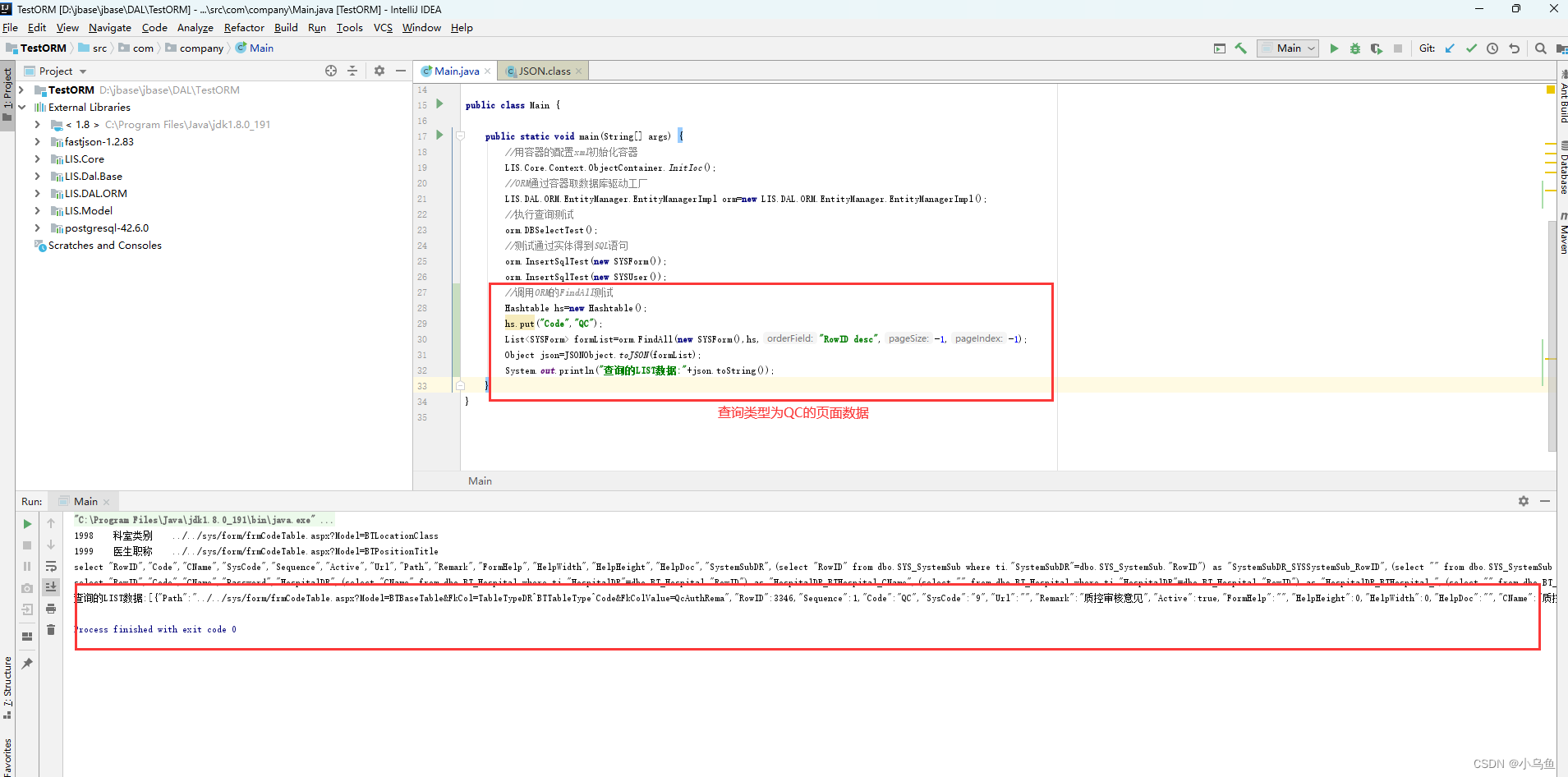
Java实现ORM第一个api-FindAll
经过几天的业余开发,今天终于到ORM对业务api本身的实现了,首先实现第一个查询的api 老的C#定义如下 因为Java的泛型不纯,所以无法用只带泛型的方式实现api,对查询类的api做了调整,第一个参数要求传入实体对象 首先…...

HFSS笔记——求解器和求解分析
文章目录 1、求解器2、求解类型3、自适应网格剖分4、求解频率选择4.1 求解设置项的含义4.2 扫频类型 1、求解器 自从ANSYS将HFSS收购后,其所有的求解器都集成在一起了,点击Project,会显示所有的求解器类型。 其中, HFSS design&…...
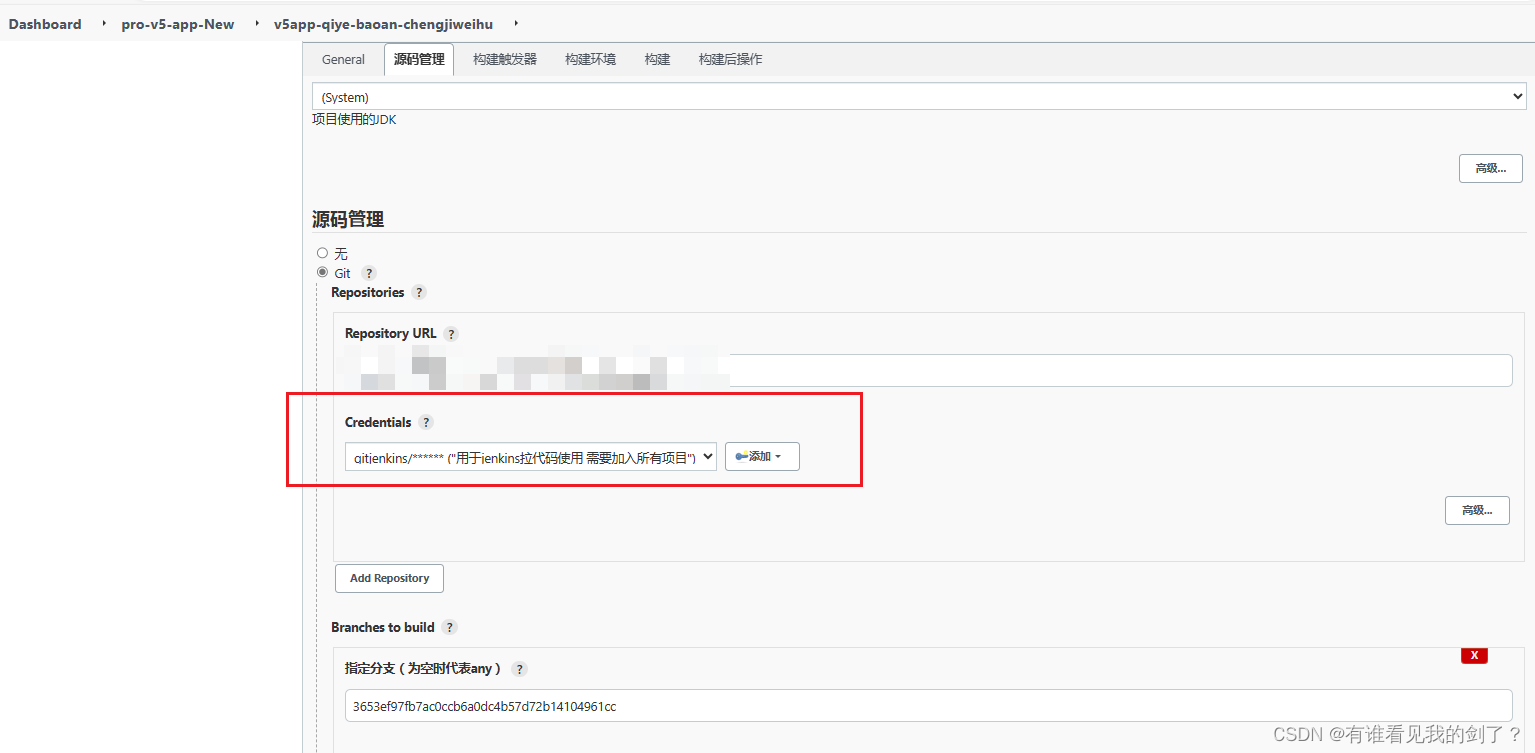
jenkins配置gitlab凭据
下载Credentials Binding插件(默认是已经安装了) 在凭据配置里添加凭据类型 点击保存 Username with password: 用户名和密码 SSH Username with private 在凭据管理里面添加gitlab账号和密码 点击全局 点击添加凭据(版本不同…...
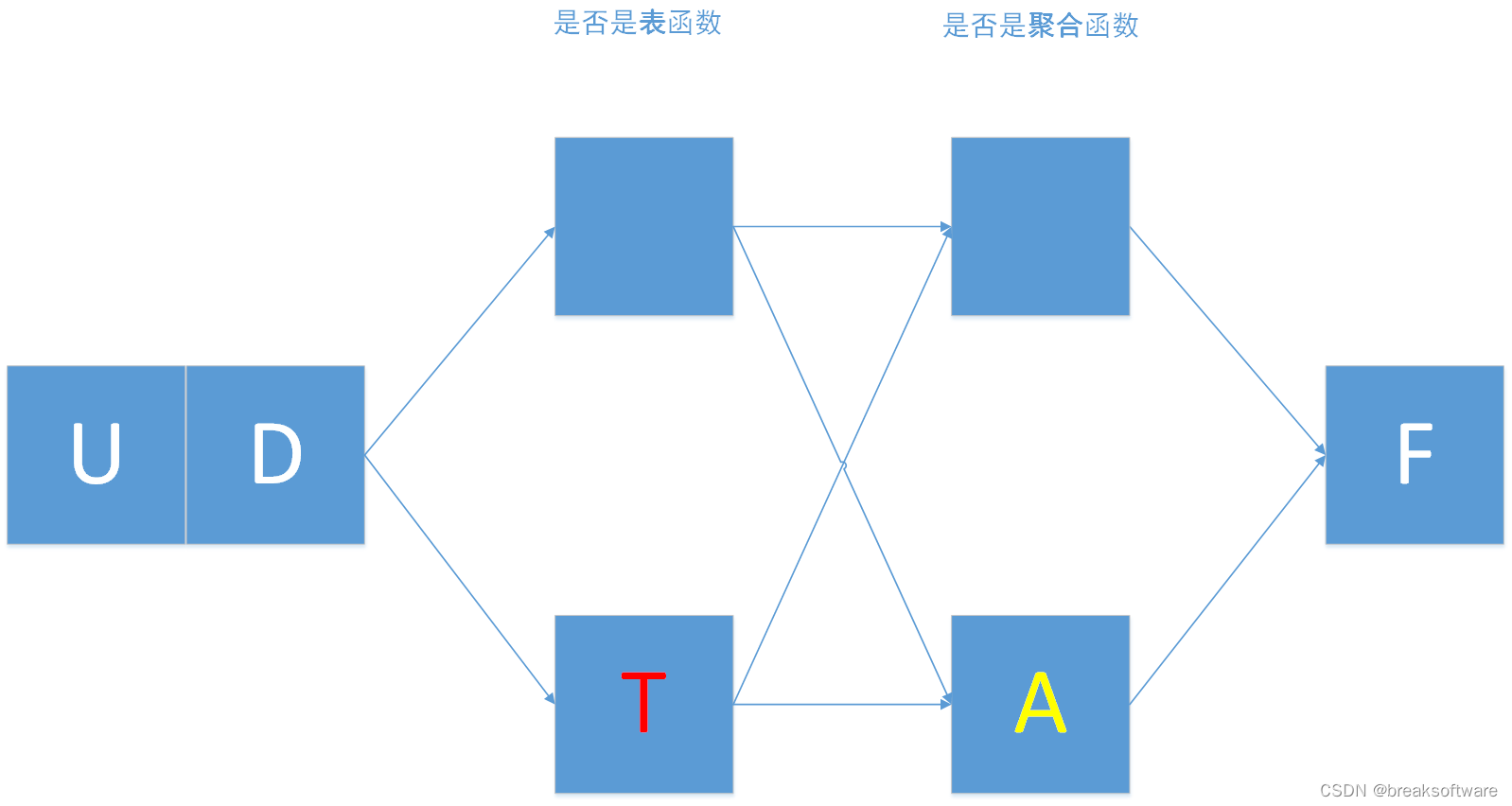
0基础学习PyFlink——用户自定义函数之UDTF
大纲 表值函数完整代码 在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF 表值函数 我们对比下UDF和UDTF def udf(f: Union[Callable, ScalarFunction, Type] None,input_types: Union[List[DataType], DataTy…...

【Java 进阶篇】Java Request 原理详解
在网络应用开发中,HTTP请求是一项常见而关键的任务。当我们使用Java编写网络应用时,了解HTTP请求的工作原理变得至关重要。本文将详细介绍Java中HTTP请求的原理,包括请求的结构、发送请求的方法以及处理请求的过程。 HTTP请求的基本结构 HT…...

13 结构性模式-装饰器模式
1 装饰器模式介绍 在软件设计中,装饰器模式是一种用于替代继承的技术,它通过一种无须定义子类的方式给对象动态的增加职责,使用对象之间的关联关系取代类之间的继承关系. 2 装饰器模式原理 //抽象构件类 public abstract class Component{public abstract void operation(); }…...
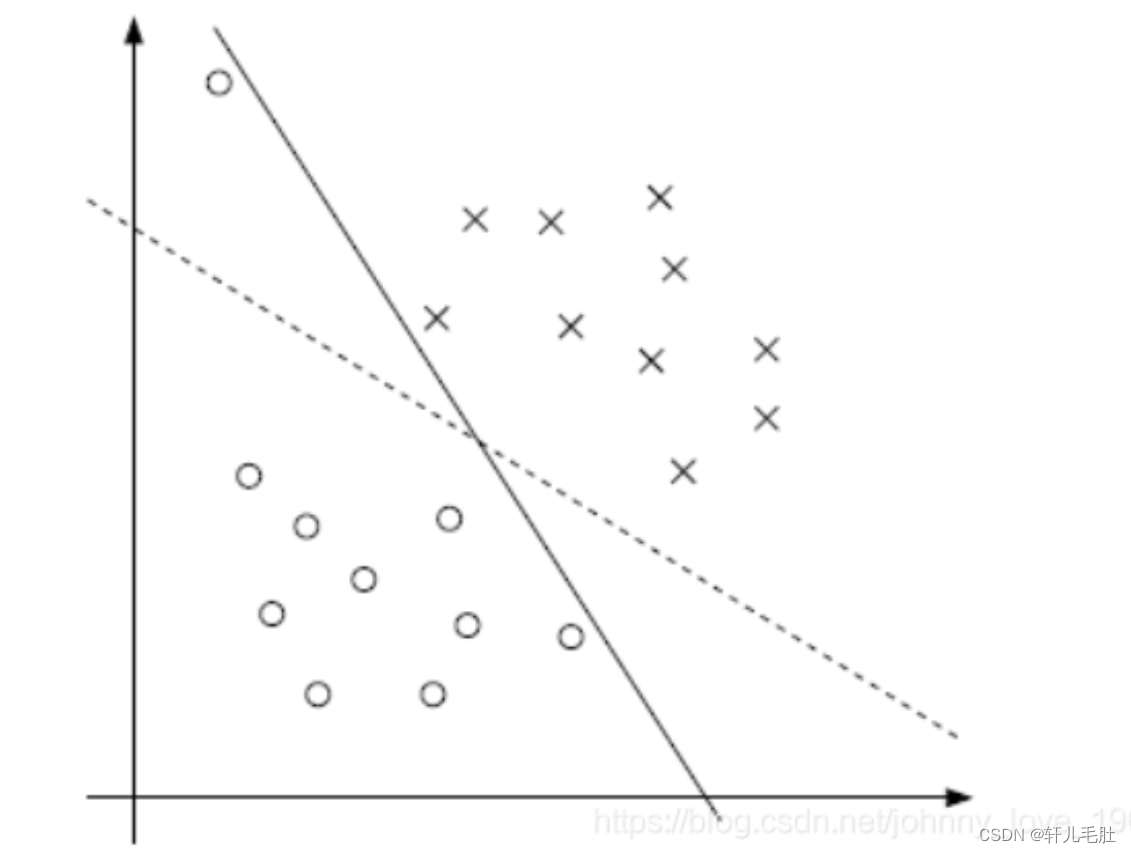
支持向量机(SVM)
一. 什么是SVM 1. 简介 SVM,曾经是一个特别火爆的概念。它的中文名:支持向量机(Support Vector Machine, 简称SVM)。因为它红极一时,所以关于它的资料特别多,而且杂乱。虽然如此,只要把握住SV…...

Rabbitmq----分布式场景下的应用
服务异步通信-分布式场景下的应用 如果单机模式忘记也可以看看这个快速回顾rabbitmq,在做学习 消息队列在使用过程中,面临着很多实际问题需要思考: 1.消息可靠性 消息从发送,到消费者接收,会经理多个过程: 其中的每一…...
springboot + redis实现签到与统计功能
在很多项目中都会有签到与统计功能,最容易想到的方案是创建一个签到表来记录每个用户的签到记录,比如设计一个mysql数据库表: CREATE TABLE tb_sign id bigint(20) unsigned NOT NULL AUTOINCREMENT COMMENT 主键, user_id bigint(20) unsig…...

Redis | 数据结构(02)SDS
一、键值对数据库是怎么实现的? 在开始讲数据结构之前,先给介绍下 Redis 是怎样实现键值对(key-value)数据库的。 Redis 的键值对中的 key 就是字符串对象,而 value 可以是字符串对象,也可以是集合数据类型…...

Linux C语言开发-D7D8运算符
算术运算符:-*/%,浮点数可以参与除法运算,但不能参与取余运算 a%b:表示取模或取余 关系运算符:<,>,>,<,,! 逻辑运算符:!,&&,|| &&,||逻辑运算符是从左到右,依次运算&#…...
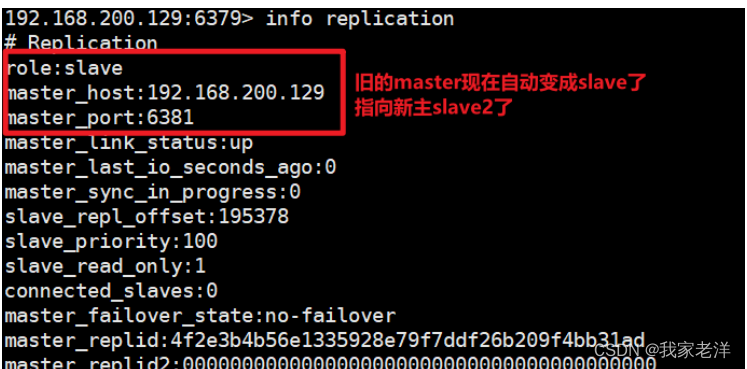
redis 配置主从复制,哨兵模式案例
哨兵(Sentinel)模式 1 . 什么是哨兵模式? 反客为主的自动版,能够自动监控master是否发生故障,如果故障了会根据投票数从slave中挑选一个 作为master,其他的slave会自动转向同步新的master,实现故障自动转义 2 . 原理…...

OpenClaw+Phi-3-vision-128k-instruct:个人知识库自动化建设方案
OpenClawPhi-3-vision-128k-instruct:个人知识库自动化建设方案 1. 为什么需要自动化知识管理 作为一个长期与技术文档打交道的开发者,我发现自己陷入了一个典型的知识管理困境:每天接触大量优质内容——技术博客、论文PDF、会议视频、截图…...

C语言核心特性与工程实践详解
1. C语言核心特性解析C语言作为一门经典的编程语言,其核心特性决定了它在系统编程和嵌入式开发中的不可替代地位。让我们从底层机制开始剖析:1.1 静态类型与编译执行C语言采用静态类型系统,这意味着所有变量必须在编译前明确声明其类型。这种…...

OpenClaw多模型对比:Qwen3.5-9B与Llama3本地接口性能实测
OpenClaw多模型对比:Qwen3.5-9B与Llama3本地接口性能实测 1. 测试背景与实验设计 去年在搭建个人自动化工作流时,我尝试用OpenClaw对接了多个开源大模型。当需要处理不同复杂度任务时,发现模型选择会显著影响最终效果。这次我决定用相同硬件…...

大学生保护动物网页——web网页期末大作业
(文件先保存到自己网盘,谨防文件丢失!!) 源码获取地址 链接: https://pan.baidu.com/s/1bz6nL9WPBBsxxWVmBAfGXw?pwdrcwi提取码: rcwihtml个人网页源码 ✅ 网页一共4个页面 ✅ 网页使用html css完成 布局简单 ✅ 文…...
 模块,可以直接加载和运行,通过PyTorch AI框架训练好的模型,而不需要安装PyTorch AI框架)
[具身智能-229]:OpenCV 的 DNN (Deep Neural Networks) 模块,可以直接加载和运行,通过PyTorch AI框架训练好的模型,而不需要安装PyTorch AI框架
OpenCV 的 DNN (Deep Neural Networks) 模块确实是工业界和边缘计算领域非常推崇的推理引擎。它的核心定位不是“训练模型”,而是“让训练好的模型跑得更快、更轻、更通用”。它允许开发者在不依赖庞大的 TensorFlow 或 PyTorch 库的情况下,直接在生产环…...

CSS 语音参考
CSS 语音参考 概述 CSS(层叠样式表)是网页设计中的核心组成部分,它允许开发者控制网页元素的样式,包括颜色、布局、字体等。在网页设计中,有时我们需要为特定的元素添加语音提示,以便于视觉障碍者或需要语音辅助的用户使用。本文将详细探讨CSS中语音参考的实现方法,包…...

云原生环境中的DevOps实践
云原生环境中的DevOps实践 🔥 硬核开场 各位技术老铁,今天咱们聊聊云原生环境中的DevOps实践。别跟我扯那些理论,直接上干货!在云原生时代,DevOps已经不是可选选项,而是必须掌握的生存技能。不搞DevOps&…...
)
Tomcat里同时部署静态资源和SpringBoot应用,跨域配置冲突了?一个配置搞定(附排查思路)
Tomcat混合部署中的跨域困局:静态资源与SpringBoot应用的配置博弈 当静态HTML页面上的AJAX请求突然返回Access-Control-Allow-Origin缺失的错误时,我正调试一个企业级知识管理系统。这个系统采用经典架构——Tomcat同时托管Vue前端静态资源和SpringBoot…...

Gson序列化LocalDateTime的3种方案对比:原生支持vs自定义适配器vs第三方库
Gson序列化LocalDateTime的3种方案对比:原生支持vs自定义适配器vs第三方库 在Java生态中,时间日期处理一直是个让人头疼的问题。特别是当你需要将LocalDateTime这样的现代时间类型通过Gson进行JSON序列化时,往往会遇到各种兼容性问题。作为一…...

JetBrains IDE试用期重置终极指南:如何轻松实现30天无限续杯
JetBrains IDE试用期重置终极指南:如何轻松实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目冲刺的关键时刻,突然被JetBrains IDE弹出的"试用期已结束…...