python自动化测试工具selenium
概述
selenium是网页应用中最流行的自动化测试工具,可以用来做自动化测试或者浏览器爬虫等。官网地址为:Selenium。相对于另外一款web自动化测试工具QTP来说有如下优点:
- 免费开源轻量级,不同语言只需要一个体积很小的依赖包
- 支持多种系统,包括Windows,Mac,Linux
- 支持多种浏览器,包括Chrome,FireFox,IE,safari,opera等
- 支持多语言,包括Java,C,python,c#等主流语言
- 支持分布式测试用例执行
python+selenium环境安装
首先需要安装python(推荐3.7+)环境,然后直接用pip install selenium安装依赖包即可。
另外还需要下载浏览器相应的webdriver驱动程序,注意下载的驱动版本一定要匹配浏览器版本。
- Firefox浏览器驱动:geckodriver
- Chrome浏览器驱动:chromedriver
- IE浏览器驱动:IEDriverServer
- Edge浏览器驱动:MicrosoftWebDriver
- Opera浏览器驱动:operadriver
下载以后可以把驱动程序加到环境变量,这样使用时就不用手动指定驱动程序路径。
使用selenium启动浏览器
可以在python中使用下面的代码启动一个Chrome浏览器,然后控制这个浏览器的行为或者读取数据。
from selenium import webdriver# 启动Chrome浏览器,要求chromedriver驱动程序已经配置到环境变量
# 将驱动程序和当前脚本放在同一个文件夹也可以
driver = webdriver.Chrome()# 手动指定驱动程序路径
driver = webdriver.Chrome(r'D:/uusama/tools/chromedriver.exe')driver = webdriver.Ie() # Internet Explorer浏览器
driver = webdriver.Edge() # Edge浏览器
driver = webdriver.Opera() # Opera浏览器
driver = webdriver.PhantomJS() # PhantomJSdriver.get('http://uusama.com') # 打开指定路径的页面
启动的时候还可以设置启动参数,比如下面的代码实现启动时添加代理,并且忽略https证书校验。
from selenium import webdriver# 创建chrome启动选项对象
options = webdriver.ChromeOptions()options.add_argument("--proxy-server=127.0.0.1:16666") # 设置代理
options.add_argument("---ignore-certificate-errors") # 设置忽略https证书校验
options.add_experimental_option("excludeSwitches", ["enable-logging"]) # 启用日志# 设置浏览器下载文件时保存的默认路径
prefs = {"download.default_directory": get_download_dir()}
options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(options=options)
一些非常有用的启动选项,下面使用的options = webdriver.ChromeOptions():
options.add_argument("--proxy-server=127.0.0.1:16666"): 设置代理,可以结合mitmproxy进行抓包等option.add_experimental_option('excludeSwitches', ['enable-automation']): 设置绕过selenium检测options.add_argument("---ignore-certificate-errors"): 设置忽略https证书校验options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}): 设置不请求图片模式加快页面加载速度chrome_options.add_argument('--headless'): 设置无头浏览器
selenium页面加载等待和检测
使用selenium打开页面以后,还不能立刻操作,需要等到待处理页面元素加载完成,这时就需要检测和等待页面元素加载。
使用time.sleep()等待
最简单的方法就是打开页面以后,使用time.sleep()强制等待一定时间,该方法只能设置一个固定时间等待,如果页面提前加载完成,则会空等阻塞。
from time import sleep
from selenium import webdriverdriver = webdriver.Chrome()
driver.get('http://uusama.con')
time.sleep(10)
print('load finish')
使用implicitly_wait设置最长等待时间
另外还可以使用implicitly_wait设置最长等待时间,如果在给定时间内页面加载完成或者已经超时,才会执行下一步。该方法会等到所有资源全部加载完成,也就是浏览器标签栏的loading图表不再转才会执行下一步。有可能页面元素已经加载完成,但是js或者图片等资源还未加载完成,此时还需要等待。
另需注意使用implicitly_wait只需设置一次,且对整个driver生命周期都起作用,凡是遇到页面正在加载都会阻塞。
示例如下:
from selenium import webdriverdriver = webdriver.Chrome()
driver.implicitly_wait(30) # 设置最长等30秒
driver.get('http://uusama.com')
print(driver.current_url)driver.get('http://baidu.com')
print(driver.current_url)
使用WebDriverWait设置等待条件
使用WebDriverWait(selenium.webdriver.support.wait.WebDriverWait)能够更加精确灵活地设置等待时间,WebDriverWait可在设定时间内每隔一段时间检测是否满足某个条件,如果满足条件则进行下一步操作,如果超过设置时间还不满足,则抛出TimeoutException异常,其方法声明如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
其中各参数含义如下:
driver:浏览器驱动timeout:最长超时时间,默认以秒为单位poll_frequency:检测的间隔(步长)时间,默认为0.5秒ignored_exceptions:忽略的异常,即使在调用until()或until_not()的过程中抛出给定异常也不中断
WebDriverWait()一般配合until()或until_not()方法使用,表示等待阻塞直到返回值为True或者False,需要注意这两个方法的参数都需是可调用对象,即方法名称,可以使用expected_conditions模块中的方法或者自己封装的方法。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditionsdriver = webdriver.Chrome()
driver.get("http://baidu.com")# 判断id为`input`的元素是否被加到了dom树里,并不代表该元素一定可见,如果定位到就返回WebElement
element = WebDriverWait(driver, 5, 0.5).until(expected_conditions.presence_of_element_located((By.ID, "s_btn_wr")))# implicitly_wait和WebDriverWait都设置时,取二者中最大的等待时间
driver.implicitly_wait(5)# 判断某个元素是否被添加到了dom里并且可见,可见代表元素可显示且宽和高都大于0
WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.ID, 'su')))# 判断元素是否可见,如果可见就返回这个元素
WebDriverWait(driver,10).until(EC.visibility_of(driver.find_element(by=By.ID, value='kw')))
下面列出expected_conditions常用的一些方法:
title_is: 判断当前页面title是否精确等于预期title_contains: 判断当前页面title是否包含预期字符串presence_of_element_located: 判断某个元素是否被加到了dom树里,并不代表该元素一定可见visibility_of_element_located: 判断某个元素是否可见(元素非隐藏,并且元素的宽和高都不等于0)visibility_of: 跟上面的方法做一样的事情,只是上面的方法要传入locator,这个方法直接传定位到的element就好了presence_of_all_elements_located: 判断是否至少有1个元素存在于dom树中。举个例子,如果页面上有n个元素的class都是'column-md-3',那么只要有1个元素存在,这个方法就返回Truetext_to_be_present_in_element: 判断某个元素中的text是否包含了预期的字符串text_to_be_present_in_element_value: 判断某个元素中的value属性是否包含了预期的字符串frame_to_be_available_and_switch_to_it: 判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回Falseinvisibility_of_element_located: 判断某个元素中是否不存在于dom树或不可见element_to_be_clickable: 判断某个元素中是否可见并且是enable的,这样的话才叫clickablestaleness_of: 等某个元素从dom树中移除,注意,这个方法也是返回True或Falseelement_to_be_selected: 判断某个元素是否被选中了,一般用在下拉列表element_selection_state_to_be: 判断某个元素的选中状态是否符合预期element_located_selection_state_to_be: 跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator
检测document是否加载完成
另外还可以使用driver.execute_script('return document.readyState;') == 'complete'来检测document是否加载完成。
注意document加载完成,是不包括那种异步加载ajax请求动态渲染dom的,这种需要使用WebDriverWait检测某个元素是否渲染完成。
selenium元素定位和读取
查找元素
selenium提供了一系列api方便获取chrome中的元素,这些API都返回WebElement对象或其列表,如:
find_element_by_id(id): 查找匹配id的第一个元素find_element_by_class_name(): 查找匹配class的第一个元素find_elements_by_xpath(): 查找匹配xpath的所有元素find_elements_by_css_selector(): 查找匹配css选择器的所有元素
其实可以看WebDriver类里面的实现源码,其核心实现都是调用两个基本函数:
find_element(self, by=By.ID, value=None): 查找匹配策略的第一个元素find_elements(self, by=By.ID, value=None): 查找匹配策略的所有元素
其中by参数可以是ID, CSS_SELECTOR, CLASS_NAME, XPATH等。下面举几个简单的例子:
- 通过xpath查询包含文本
登录的第一个元素:find_element_by_xpath("//*[contains(text(),'登录')]") - 查询包含类名
refresh的所有元素:find_elements_by_class_name('refresh') - 查询
table表格的第二行:find_element_by_css_selector('table tbody > tr:nth(2)')
dom元素交互
上面介绍的元素查找结果WebElement对象,常用的api有:
element.text: 返回元素的文本内容(包括所有后代节点的内容),注意如果元素display=none则返回为空字符串element.screenshot_as_png: 元素的截图element.send_keys("input"): 元素输入框输入input字符串element.get_attribute('data-v'): 获取data-v名称属性值,除了自定义节点属性,还可以获取如textContent等属性element.is_displayed(): 判断元素是否用户可见element.clear(): 清除元素文本element.click(): 点击元素,如果元素不可点击会抛出ElementNotInteractableException异常element.submit(): 模拟表单提交
查找元素失败处理
如果找不到指定元素,则会抛出NoSuchElementException异常,而且需要注意,display=none的元素是可以获取到的,凡是在dom节点中的元素都可以获取到。
而且实际使用的时候要注意一些js代码动态创建的元素,可能需要轮询获取或者监控。
一个检查是否存在指定元素的方法如下:
def check_element_exists(xpath):try:driver.find_element_by_xpath(xpath)except NoSuchElementException:return Falsereturn True
selenium交互控制
ActionChains动作链
webdriver通过ActionChains对象来模拟用户操作,该对象表示一个动作链路队列,所有操作会依次进入队列但不会立即执行,直到调用perform()方法时才会执行。其常用方法如下:
click(on_element=None): 单击鼠标左键click_and_hold(on_element=None): 点击鼠标左键,不松开context_click(on_element=None): 点击鼠标右键double_click(on_element=None): 双击鼠标左键send_keys(*keys_to_send): 发送某个键到当前焦点的元素send_keys_to_element(element, *keys_to_send): 发送某个键到指定元素key_down(value, element=None): 按下某个键盘上的键key_up(value, element=None): 松开某个键drag_and_drop(source, target): 拖拽到某个元素然后松开drag_and_drop_by_offset(source, xoffset, yoffset): 拖拽到某个坐标然后松开move_by_offset(xoffset, yoffset): 鼠标从当前位置移动到某个坐标move_to_element(to_element): 鼠标移动到某个元素move_to_element_with_offset(to_element, xoffset, yoffset): 移动到距某个元素(左上角坐标)多少距离的位置perform(): 执行链中的所有动作release(on_element=None): 在某个元素位置松开鼠标左键
模拟鼠标事件
下面代码模拟鼠标移动,点击,拖拽等操作,注意操作时需要等待一定时间,否则页面还来不及渲染。
from time import sleep
from selenium import webdriver
# 引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChainsdriver = webdriver.Chrome()
driver.get("https://www.baidu.cn")
action_chains = ActionChains(driver)target = driver.find_element_by_link_text("搜索")
# 移动鼠标到指定元素然后点击
action_chains.move_to_element(target).click(target).perform()
time.sleep(2)# 也可以直接调用元素的点击方法
target.click()
time.sleep(2)# 鼠标移动到(10, 50)坐标处
action_chains.move_by_offset(10, 50).perform()
time.sleep(2)# 鼠标移动到距离元素target(10, 50)处
action_chains.move_to_element_with_offset(target, 10, 50).perform()
time.sleep(2)# 鼠标拖拽,将一个元素拖动到另一个元素
dragger = driver.find_element_by_id('dragger')
action.drag_and_drop(dragger, target).perform()
time.sleep(2)# 也可以使用点击 -> 移动来实现拖拽
action.click_and_hold(dragger).release(target).perform()
time.sleep(2)
action.click_and_hold(dragger).move_to_element(target).release().perform()
模拟键盘输入事件
通过send_keys模拟键盘事件,常用有:
send_keys(Keys.BACK_SPACE): 删除键(BackSpace)send_keys(Keys.SPACE): 空格键(Space)send_keys(Keys.TAB): 制表键(Tab)send_keys(Keys.ESCAPE): 回退键(Esc)send_keys(Keys.ENTER): 回车键(Enter)send_keys(Keys.F1): 键盘 F1send_keys(Keys.CONTROL,'a'): 全选(Ctrl+A)send_keys(Keys.CONTROL,'c'): 复制(Ctrl+C)send_keys(Keys.CONTROL,'x'): 剪切(Ctrl+X)send_keys(Keys.CONTROL,'v'): 粘贴(Ctrl+V)
示例:定位到输入框,然后输入内容
# 输入框输入内容
driver.find_element_by_id("kw").send_keys("uusamaa")# 模拟回车删除多输入的一个字符a
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
警告框处理
用于处理调用alert弹出的警告框。
driver.switch_to_alert(): 切换到警告框text:返回alert/confirm/prompt中的文字信息,比如js调用alert('failed')则会获取failed字符串accept():接受现有警告框dismiss():关闭现有警告框send_keys(keysToSend):将文本发送至警告框
selenium浏览器控制
基本常用api
下面列出一些非常实用的浏览器控制api:
driver.current_url: 获取当前活动窗口的urldriver.switch_to_window("windowName"): 移动到指定的标签窗口driver.switch_to_frame("frameName"): 移动到指定名称的iframedriver.switch_to_default_content(): 移动到默认文本内容区driver.maximize_window(): 将浏览器最大化显示driver.set_window_size(480, 800): 设置浏览器宽480、高800显示driver.forword(),driver.back(): 浏览器前进和后退driver.refresh(): 刷新页面driver.close(): 关闭当前标签页driver.quiit(): 关闭整个浏览器driver.save_screenshot('screen.png'): 保存页面截图driver.maximize_window(): 将浏览器最大化显示browser.execute_script('return document.readyState;'): 执行js脚本
selenium读取和加载cookie
使用get_cookies和add_cookie可以实现将cookie缓存到本地,然后启动时加载,这样可以保留登录态。实现如下
import os
import json
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://www.baidu.cn")# 读取所有cookie并保存到文件
cookies = driver.get_cookies()
cookie_save_path = 'cookie.json'
with open(cookie_save_path, 'w', encoding='utf-8') as file_handle:json.dump(cookies, file_handle, ensure_ascii=False, indent=4)# 从文件读取cookie并加载到浏览器
with open(cookie_save_path, 'r', encoding='utf-8') as file_handle:cookies = json.load(file_handle)for cookie in cookies:driver.add_cookie(cookie)
selenium打开新的标签页窗口
使用driver.get(url)会默认在第一个标签窗口打开指定连接,点击页面中的_blank的链接时也会打开一个新的标签窗口。
还可以用下面的方式手动打开一个指定页面的标签窗口,需要注意打开新窗口或者关闭以后,还需要手动调用switch_to.window切换当前活动的标签窗口,否则会抛出NoSuchWindowException异常。
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://www.baidu.cn")new_tab_url = 'http://uusama.com'
driver.execute_script(f'window.open("{new_tab_url}", "_blank");')
time.sleep(1)# 注意:必须调用switch_to.window手动切换window,否则会找不到tab view
# 聚焦到新打开的tab页面,然后关闭
driver.switch_to.window(driver.window_handles[1])
time.sleep(2)
driver.close() # 关闭当前窗口# 手动回到原来的tab页面
driver.switch_to.window(driver.window_handles[0])
time.sleep(1)
除了使用execute_script外,还可以使用模拟打开新tab页按键的方式新建一个标签页窗口:
driver.find_element_by_tag_name('body').send_keys(Keys.CONTROL + 't')ActionChains(driver).key_down(Keys.CONTROL).send_keys('t').key_up(Keys.CONTROL).perform()
selenium一些问题记录
获取隐藏元素的文本内容
如果一个元素是隐藏的,即display=none,虽然可以通过find_element查找到该元素,但是用element.text属性是获取不到该元素文本内容的,其值是空字符串,这时可以用下面的方式获取:
element = driver.find_element_by_id('uusama')
driver.execute_script("return arguments[0].textContent", element)
driver.execute_script("return arguments[0].innerHTML", element)# 相应的也可以把隐藏的元素设置为非隐藏
driver.execute_script("arguments[0].style.display = 'block';", element)
浏览器崩溃WebDriverException异常处理
比如在Chrome中长时间运行一个页面会出现Out Of Memory内存不足的错误,此时WebDriver会抛出WebDriverException异常,基本所有api都会抛出这个异常,这个时候需要捕获并进行特殊处理。
我的处理方式是记录页面的一些基本信息,比如url,cookie等,并定期写入到文件中,如果检测到该异常,则重启浏览器并且加载url和cookie等数据。
selenium抓取页面请求数据
网上有通过driver.requests或者通过解析日志来获取页面请求的方式,但是我感觉都不是很好使。最后使用mitmproxy代理进行抓包处理,然后启动selenium时填入代理来实现。
proxy.py为在mitmproxy基础上封装的自定义代理请求处理,其代码如下:
import os
import gzip
from mitmproxy.options import Options
from mitmproxy.proxy.config import ProxyConfig
from mitmproxy.proxy.server import ProxyServer
from mitmproxy.tools.dump import DumpMaster
from mitmproxy.http import HTTPFlow
from mitmproxy.websocket import WebSocketFlowclass ProxyMaster(DumpMaster):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)def run(self, func=None):try:DumpMaster.run(self, func)except KeyboardInterrupt:self.shutdown()def process(url: str, request_body: str, response_content: str):# 抓包请求处理,可以在这儿转存和解析数据passclass Addon(object):def websocket_message(self, flow: WebSocketFlow):# 监听websockt请求passdef response(self, flow: HTTPFlow):# 避免一直保存flow流,导致内存占用飙升# flow.request.headers["Connection"] = "close"# 监听http请求响应,并获取请求体和响应内容url = flow.request.urlrequest_body = flow.requestresponse_content = flow.response# 如果返回值是压缩的内容需要进行解压缩if response_content.data.content.startswith(b'\x1f\x8b\x08'):response_content = gzip.decompress(response_content.data.content).decode('utf-8')Addon.EXECUTOR.submit(process, url, request_body, response_content)def run_proxy_server():options = Options(listen_host='0.0.0.0', listen_port=16666)config = ProxyConfig(options)master = ProxyMaster(options, with_termlog=False, with_dumper=False)master.server = ProxyServer(config)master.addons.add(Addon())master.run()if __name__ == '__main__':with open('proxy.pid', mode='w') as fin:fin.write(os.getpid().__str__())run_proxy_server()
在使用mitmproxy过程中,随着时间推移proxy.py会出现占用内存飙升的问题,在github的issue区有人也遇到过,有说是因为http连接keep-alive=true请求会一直保存不会释放,导致请求越多越占用内存,然后通过添加flow.request.headers["Connection"] = "close"来手动关闭连接,我加了以后有一定缓解,但还是不能从根本上解决。
最后通过写入proxy.pid记录代理程序进程,然后用另外一个程序定时重启proxy.py来解决内存泄漏的问题。
Python接口自动化测试零基础入门到精通(2023最新版)
相关文章:

python自动化测试工具selenium
概述 selenium是网页应用中最流行的自动化测试工具,可以用来做自动化测试或者浏览器爬虫等。官网地址为:Selenium。相对于另外一款web自动化测试工具QTP来说有如下优点: 免费开源轻量级,不同语言只需要一个体积很小的依赖包支持…...
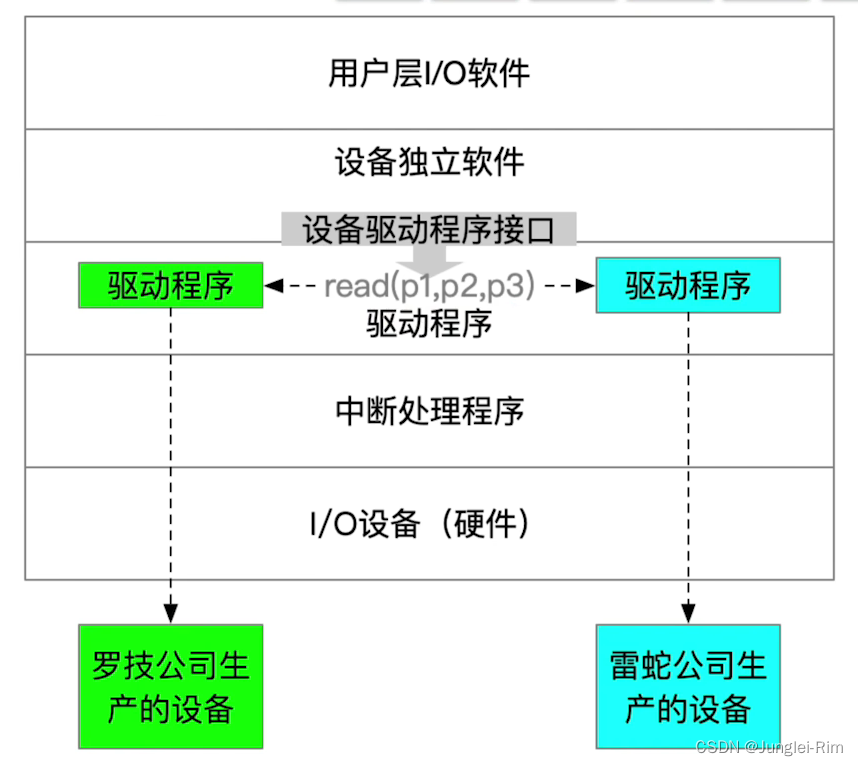
输入/输出应用程序接口和设备驱动程序接口
文章目录 1.输入/输出应用程序接口1.字符设备接口2.块设备接口3.网络设备接口1.网络设备套接字通信 4.阻塞/非阻塞I/O 2.设备驱动程序接口1.统一标准的设备驱动程序接口 1.输入/输出应用程序接口 1.字符设备接口 get/put系统调用:向字符设备读/写一个字符 2.块设备接口 read/wr…...

Python---Socket 网络通信
Socket :进程之间通信的工具,进程之间想要进行网络通信需要Socket,两个进程之间通过socket进行相互通讯,就必须有服务端和客服端。 Socket服务端编程 # 1.创建socket对象 import socketsocket_server socket.socket()# 2. 绑定socket_server到指定IP和…...
使用 jdbc 技术升级水果库存系统(优化版本)
抽取执行更新方法抽取查询方法 —— ResultSetMetaData ResultSetMetaData rsmd rs.getMetaData();//元数据,结果集的结构数据 抽取查询方法 —— 解析结果集封装成实体对象提取 获取连接 和 释放资源 的方法将数据库配置信息转移到配置文件 <dependencies><depend…...
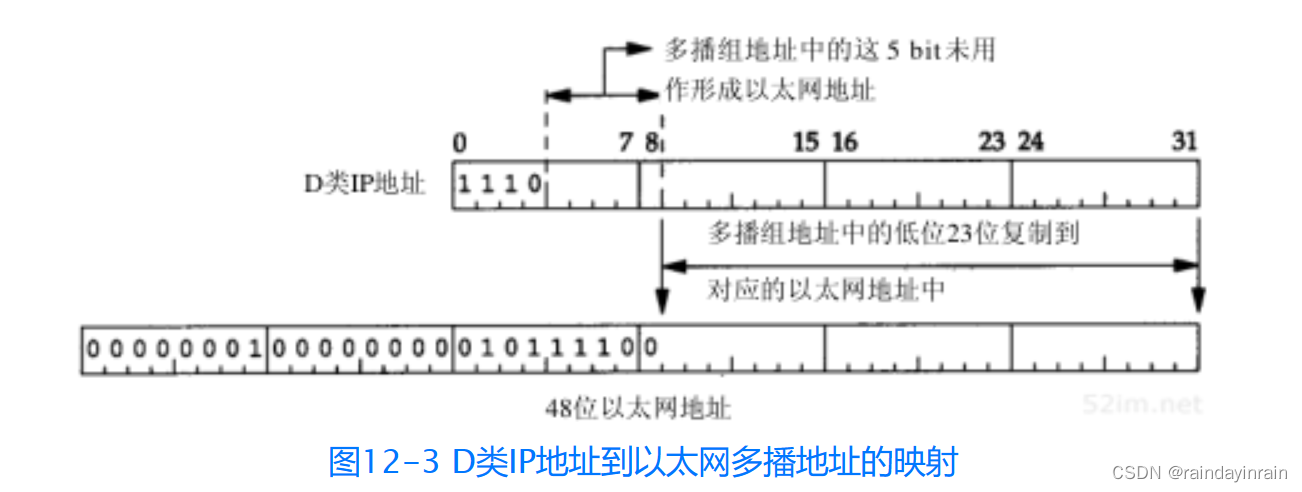
网络协议--广播和多播
12.1 引言 在第1章中我们提到有三种IP地址:单播地址、广播地址和多播地址。本章将更详细地介绍广播和多播。 广播和多播仅应用于UDP,它们对需将报文同时传往多个接收者的应用来说十分重要。TCP是一个面向连接的协议,它意味着分别运行于两主…...
正则表达式)
python爬虫入门(三)正则表达式
开源中国提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了 常用的匹配规则如下 模 式描 述\w匹配字母、数字及下划线\W匹配不是字母、数字及下划线的…...

fabric.js介绍
fabric.js是可以简化canvas编写的js库,提供canvas缺少的对象模型,包含动画、数据序列化和反序列化的等高级功能的js库,开源项目,在GitHub有很多人贡献。 官网:Fabric.js Javascript Canvas Library (fabricjs.com) 文档…...

YOLOv5源码中的参数超详细解析(3)— 训练部分(train.py)| 模型训练调参
前言:Hello大家好,我是小哥谈。YOLOv5项目代码中,train.py是用于模型训练的代码,是YOLOv5中最为核心的代码之一,而代码中的训练参数则是核心中的核心,只有学会了各种训练参数的真正含义,才能使用YOLOv5进行最基本的训练。🌈 前期回顾: YOLOv5源码中的参数超详细解析…...

Linux高性能编程学习-TCP/IP协议族
一、TCP/IP协议族结构与主要协议 分层:数据链路层、网络层、传输层、应用层 1. 数据链路层 功能:实现网卡驱动程序,处理数据在不同物理介质的传输 协议: ARP:将目标机器的IP地址转成MAC地址RARP:将MAC地…...

用爬虫代码爬取高音质音频示例
目录 一、准备工作 1、安装Python和相关库 2、确定目标网站和数据结构 二、编写爬虫代码 1、导入库 2、设置代理IP 3、发送HTTP请求并解析HTML页面 4、查找音频文件链接 5、提取音频文件名和下载链接 6、下载音频文件 三、完整代码示例 四、注意事项 1、遵守法律法…...
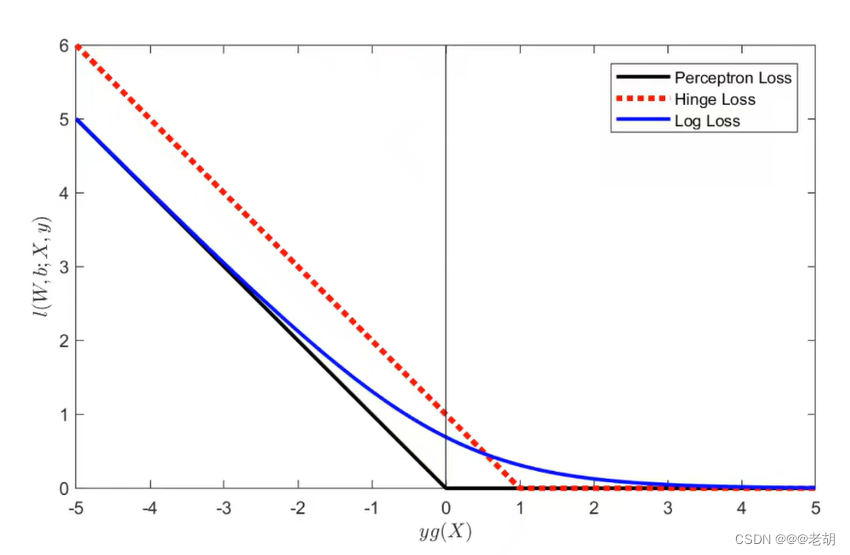
深度学习与计算机视觉(一)
文章目录 计算机视觉与图像处理的区别人工神经元感知机 - 分类任务Sigmoid神经元/对数几率回归对数损失/交叉熵损失函数梯度下降法- 极小化对数损失函数线性神经元/线性回归均方差损失函数-线性回归常用损失函数使用梯度下降法训练线性回归模型线性分类器多分类器的决策面 soft…...
【vector题解】杨辉三角 | 删除有序数组中的重复项 | 只出现一次的数字Ⅱ
杨辉三角 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1…...
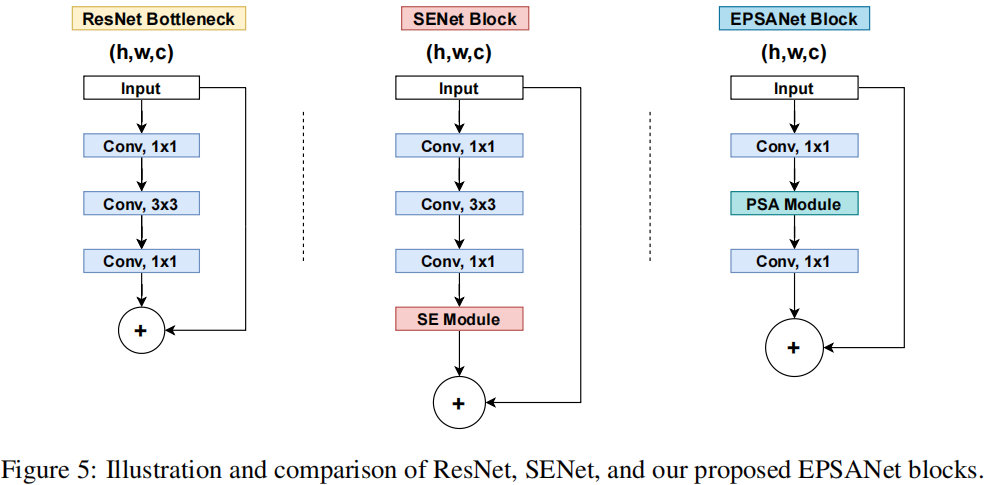
金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度…...
Jenkins自动化测试
学习 Jenkins 自动化测试的系列文章 Robot Framework 概念Robot Framework 安装Pycharm Robot Framework 环境搭建Robot Framework 介绍Jenkins 自动化测试 1. Robot Framework 概念 Robot Framework是一个基于Python的,可扩展的关键字驱动的自动化测试框架。 它…...

python 字典dict和列表list的读取速度问题, range合并
嗨喽,大家好呀~这里是爱看美女的茜茜呐 python 字典和列表的读取速度问题 最近在进行基因组数据处理的时候,需要读取较大数据(2.7G)存入字典中, 然后对被处理数据进行字典key值的匹配,在被处理文件中每次…...
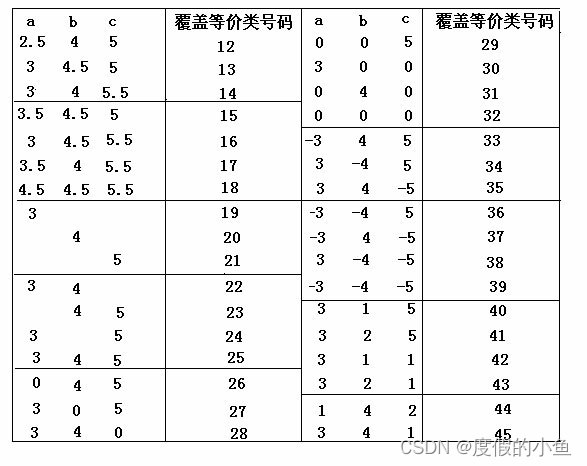
测试用例的设计方法(全):等价类划分方法
一.方法简介 1.定义 是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。 2.划分等价类: 等价类是指某个输入域的…...
Office技巧(持续更新)(Word、Excel、PPT、PowerPoint、连续引用、标题、模板、论文)
1. Word 1.1 标题设置为多级列表 选住一级标题,之后进行“定义新的多级列表” 1.2 图片和表的题注自动排序 正常插入题注后就可以了。如果一级标题是 “汉字序号”,那么需要对题注进行修改: 从原来的 图 { STYLEREF 1 \s }-{ SEQ 图 \* A…...
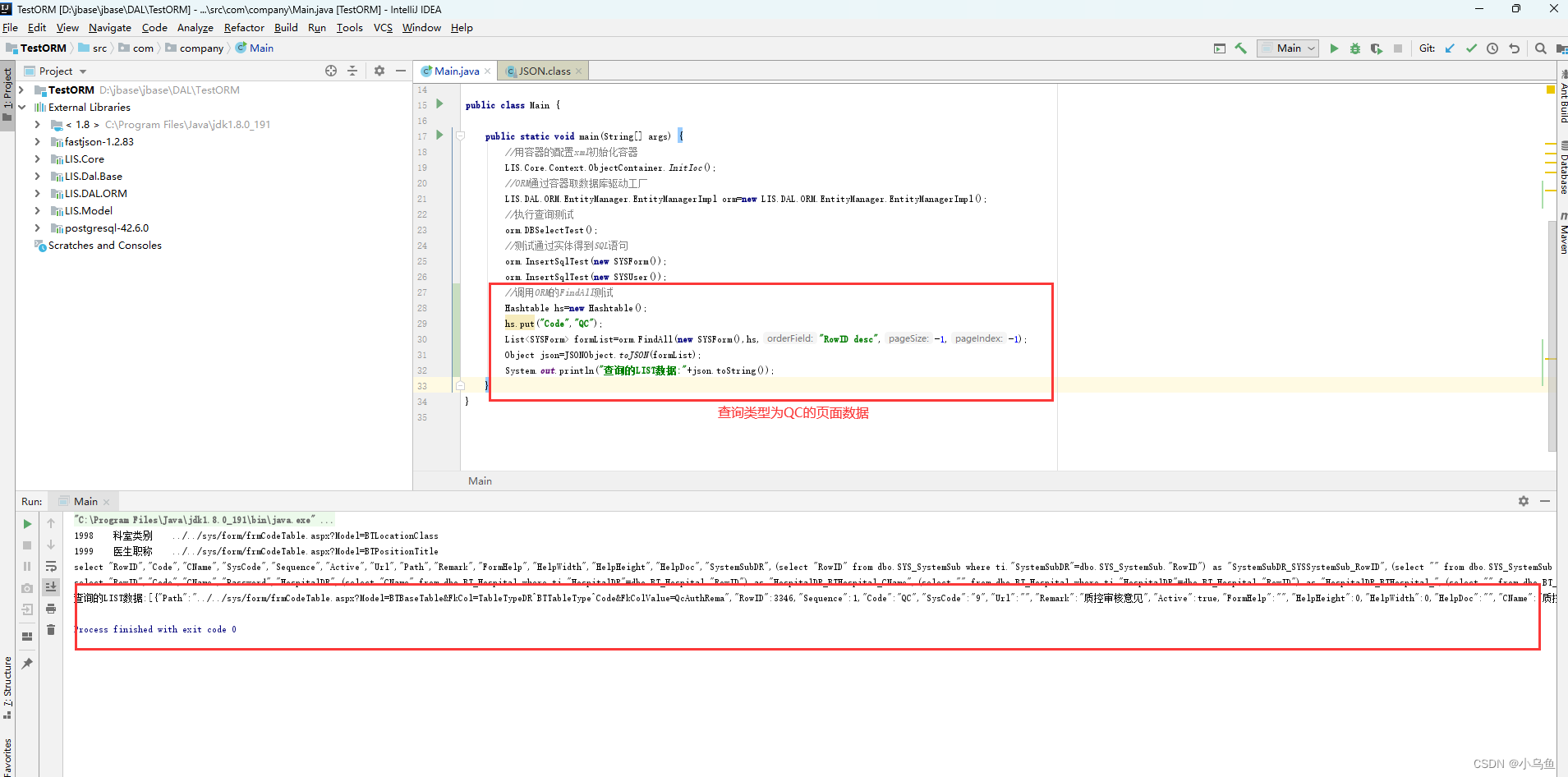
Java实现ORM第一个api-FindAll
经过几天的业余开发,今天终于到ORM对业务api本身的实现了,首先实现第一个查询的api 老的C#定义如下 因为Java的泛型不纯,所以无法用只带泛型的方式实现api,对查询类的api做了调整,第一个参数要求传入实体对象 首先…...

HFSS笔记——求解器和求解分析
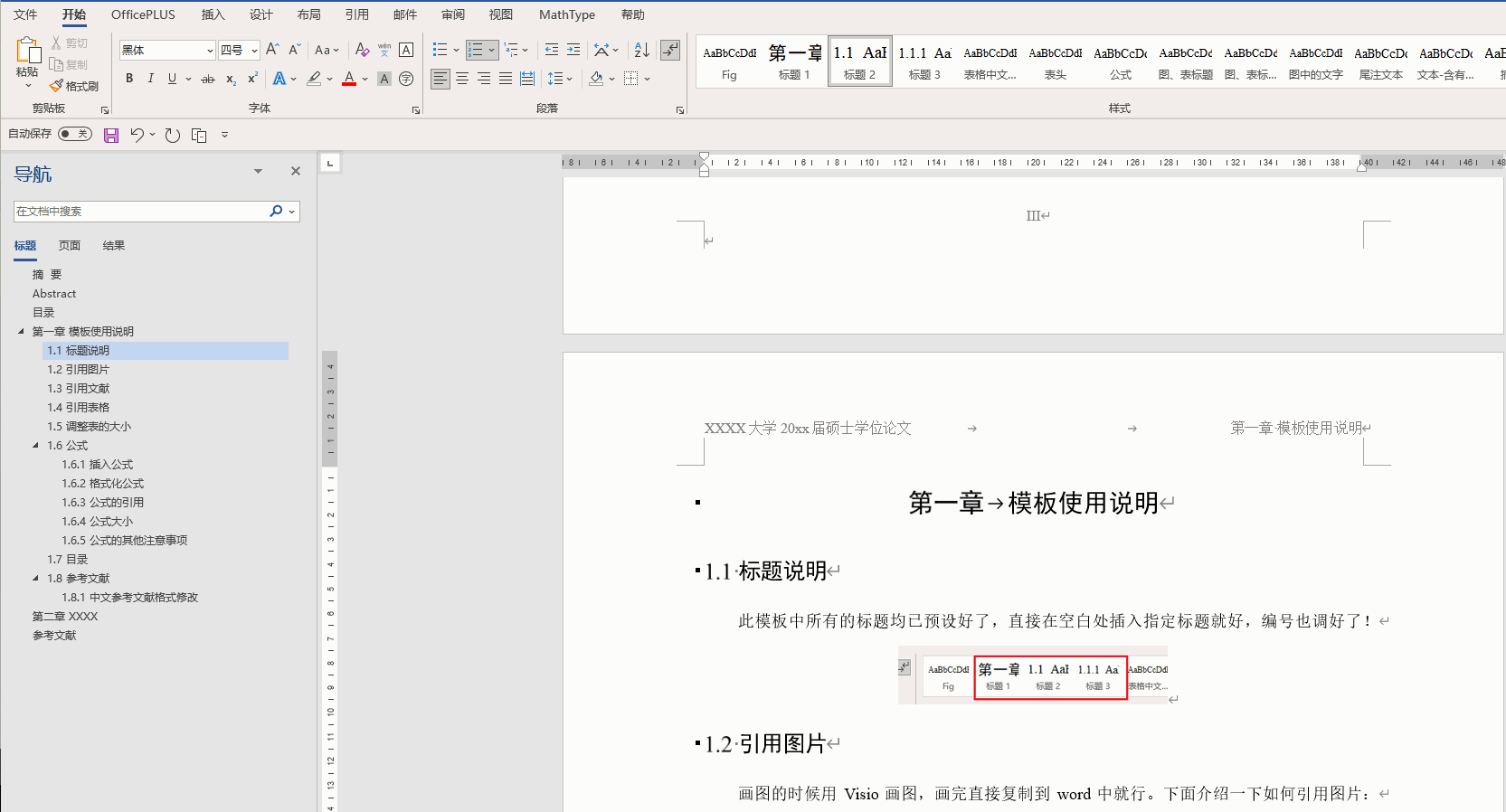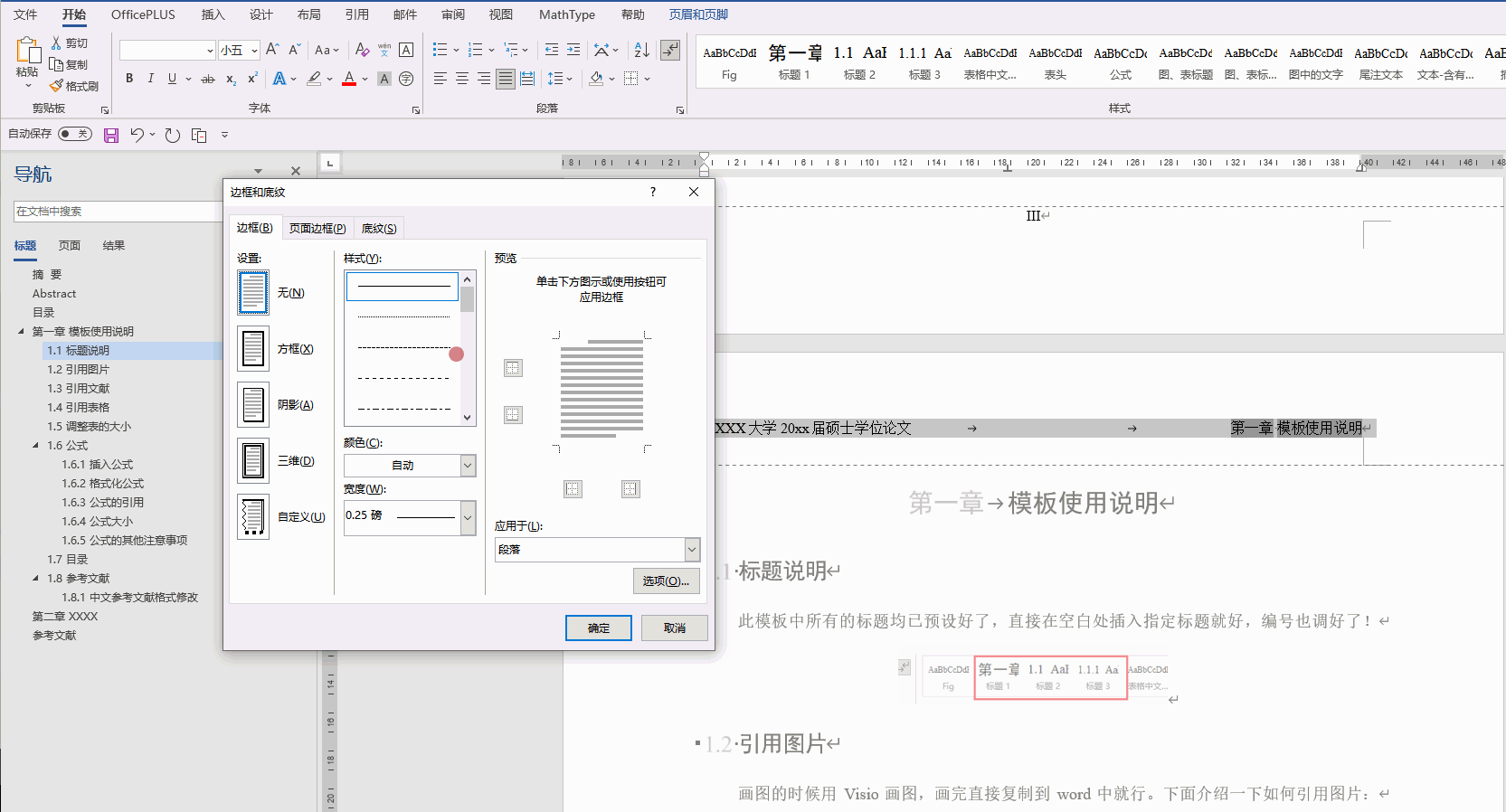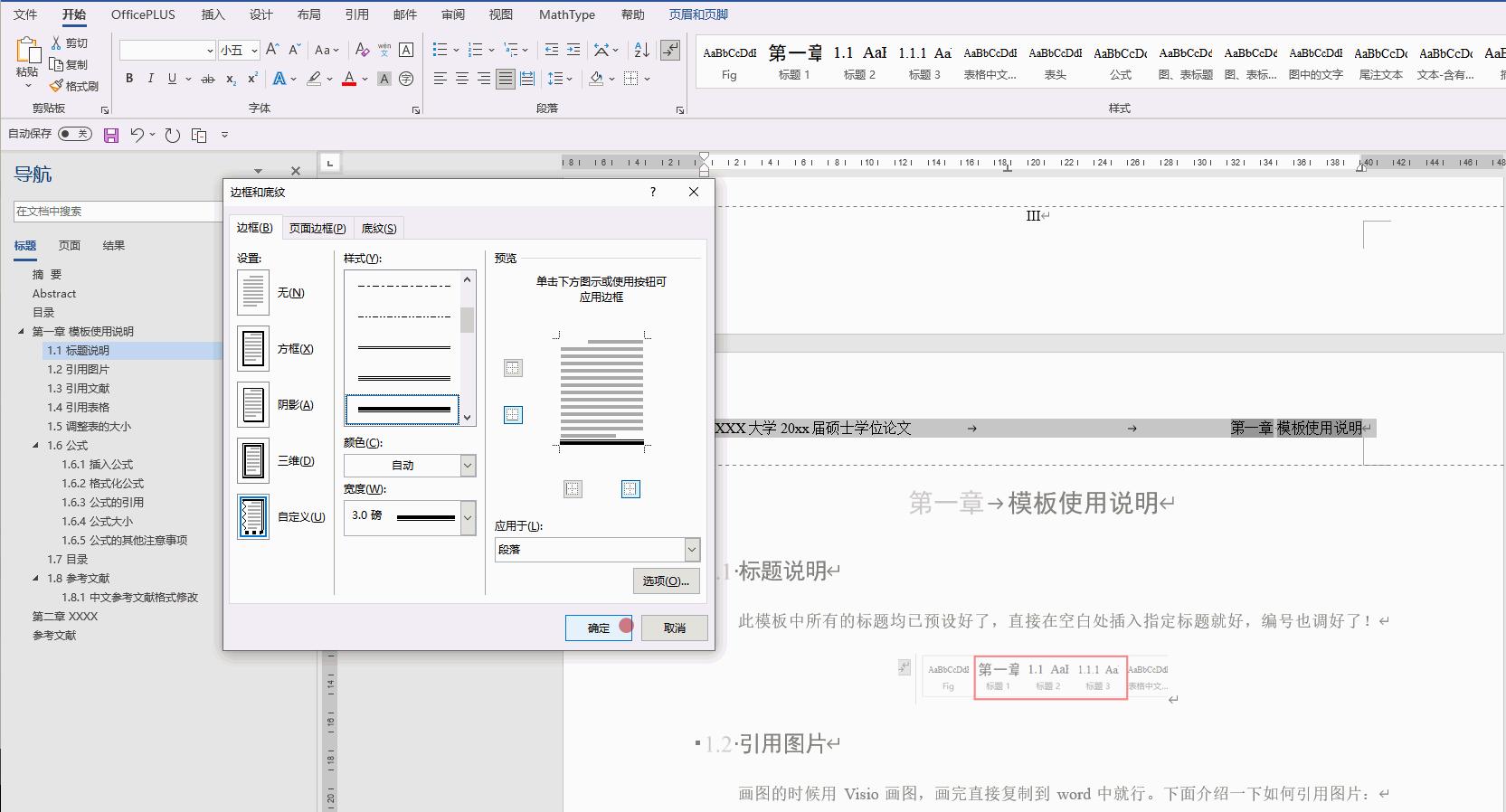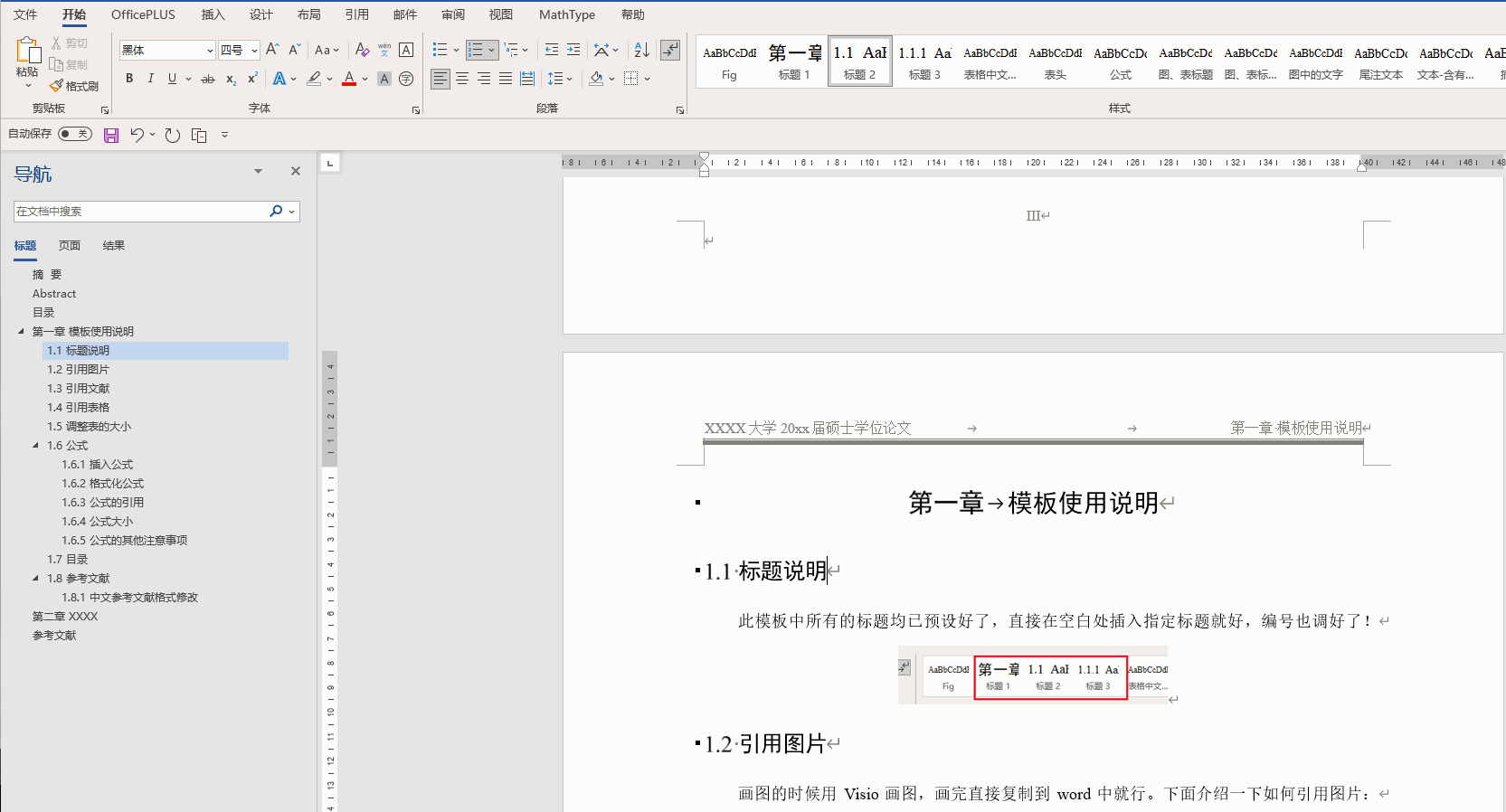
文章目录 1、求解器2、求解类型3、自适应网格剖分4、求解频率选择4.1 求解设置项的含义4.2 扫频类型 1、求解器 自从ANSYS将HFSS收购后,其所有的求解器都集成在一起了,点击Project,会显示所有的求解器类型。 其中, HFSS design&…...
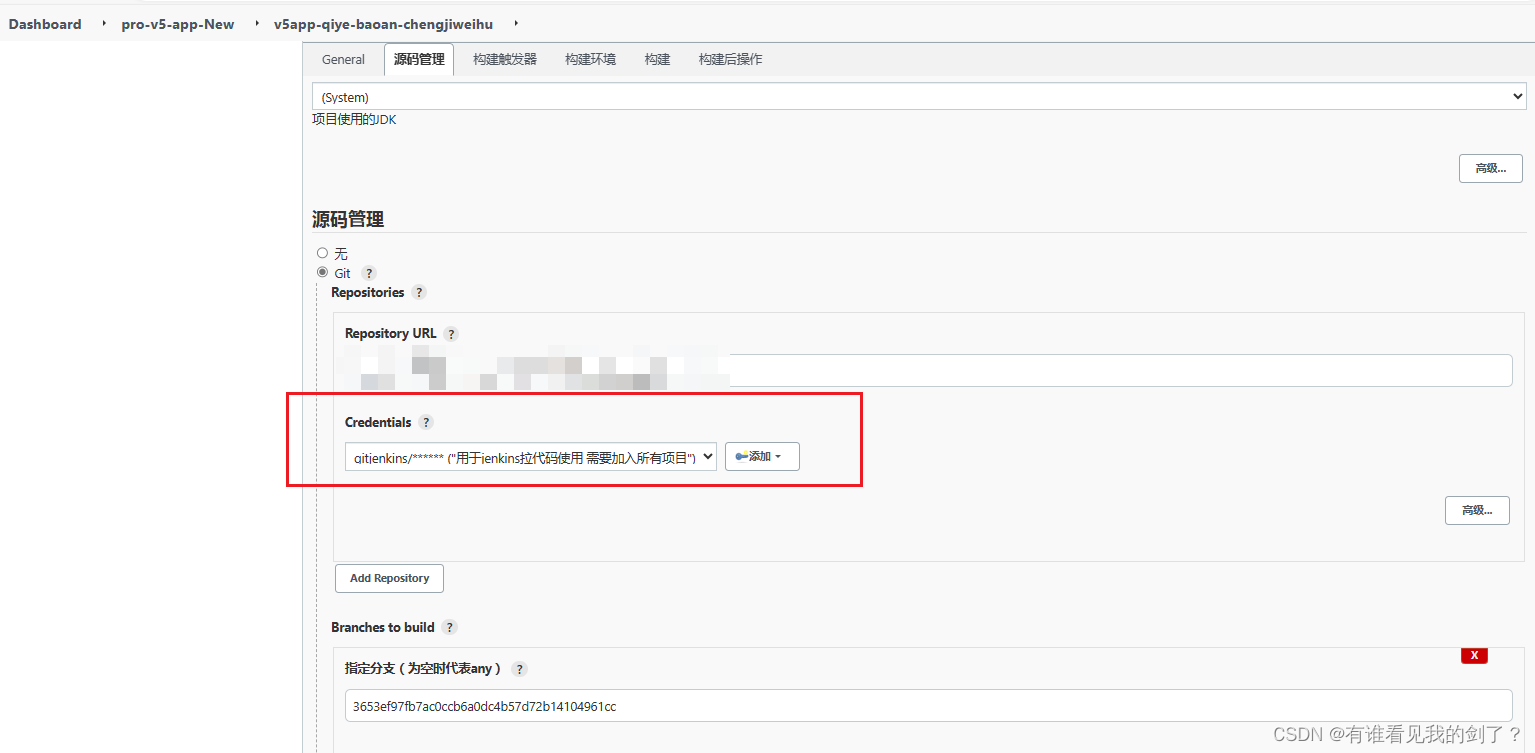
jenkins配置gitlab凭据
下载Credentials Binding插件(默认是已经安装了) 在凭据配置里添加凭据类型 点击保存 Username with password: 用户名和密码 SSH Username with private 在凭据管理里面添加gitlab账号和密码 点击全局 点击添加凭据(版本不同…...

SQL复杂报表如何通过窗口函数优化_减少子查询提升性能
窗口函数可高效替代关联子查询,适用于累计值、移动平均、并列排名等场景,性能提升3–10倍;须注意RANK()与ROW_NUMBER()语义差异、ORDER BY的强制性、ROWS优于RANGE、窗口函数不可用于WHERE/HAVING等关键规则。窗口函数替代关联子查询的典型场…...

正则表达式元字符详解:learn-regex-zh 进阶教程
正则表达式元字符详解:learn-regex-zh 进阶教程 【免费下载链接】learn-regex-zh :cn: 翻译: 学习正则表达式的简单方法 项目地址: https://gitcode.com/gh_mirrors/le/learn-regex-zh 正则表达式是一种强大的文本处理工具,而元字符是构建正则表达…...

技术面试终极指南:10个反向面试技巧助你问对公司问题
技术面试终极指南:10个反向面试技巧助你问对公司问题 【免费下载链接】reverse-interview Questions to ask the company during your interview 项目地址: https://gitcode.com/gh_mirrors/re/reverse-interview 在技术面试中,反向面试ÿ…...

seo网上教程有哪些常见错误
SEO网上教程有哪些常见错误 在互联网时代,SEO(搜索引擎优化)已经成为网站流量和排名提升的关键因素。很多人在学习SEO过程中,常常会遇到一些误区,甚至在网上找到的一些教程中也包含了不少错误。本文将详细介绍一些常见…...

在FreeRTOS上为Zynq CAN驱动添加任务间通信:一个实用的数据收发框架搭建
在FreeRTOS上为Zynq CAN驱动构建高效任务间通信框架 当我们在Zynq平台上开发基于FreeRTOS的CAN总线应用时,如何安全高效地在中断服务程序(ISR)与任务之间传递数据,是构建稳定系统的关键挑战。本文将深入探讨一个经过实战检验的解决方案——通过消息队列和…...

运放稳定性补偿实战:从Riso到双反馈,如何为你的MOSFET驱动电路‘降噪’
运放稳定性补偿实战:从Riso到双反馈的MOSFET驱动电路降噪方案 在高速开关电源和电机驱动系统中,工程师们经常需要面对一个令人头疼的问题——当MOSFET栅极电容与PCB寄生参数形成复杂网络时,电路会出现难以消除的振铃和过冲。这种现象不仅影响…...

WebGL/Three.js性能优化实战:你的3D模型为什么卡?从理解栅格化与渲染管线开始
WebGL/Three.js性能优化实战:从栅格化原理到渲染管线调优 当你用Three.js加载一个精致的3D模型时,是否遇到过页面突然卡顿、风扇狂转的情况?这背后往往与浏览器如何将矢量图形转换为屏幕像素的过程密切相关。今天我们就从栅格化的底层原理出发…...

棕榈酰化修饰:从基础研究到癌症治疗的5个关键突破点
棕榈酰化修饰:从基础研究到癌症治疗的5个关键突破点 在肿瘤免疫治疗领域,蛋白质翻译后修饰的调控机制正成为突破性疗法的新靶点。棕榈酰化修饰——这种将16碳棕榈酸共价连接到蛋白质半胱氨酸残基上的动态过程,近年来因其在癌细胞信号传导中的…...

一文详解RPC,深入浅出从原理到主流框架
什么是RPC? RPC 全称 Remote Procedure Call,即远程过程调用。它的核心目标非常简单:让开发者调用远程机器上的函数/方法,就像调用本地函数一样简单,无需关注底层的网络连接、数据传输、序列化与反序列化等繁琐细节[1]…...

深入解析Dify中的RAG内容检索:Rerank模型与权重计算的实战对比
1. RAG内容检索的核心挑战与Rerank的价值 当你用Dify搭建一个智能问答系统时,最头疼的问题往往是:明明数据库里有正确答案,但系统总是返回一堆不相关的文档。这就像在图书馆用关键词搜索书籍,结果管理员给你搬来了整个书架——这时…...