python爬虫入门(三)正则表达式
开源中国提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了
常用的匹配规则如下
| 模 式 | 描 述 |
|---|---|
| \w | 匹配字母、数字及下划线 |
| \W | 匹配不是字母、数字及下划线的字符 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结尾,如果存在换行,同时还会匹配换行符 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 匹配任意字符,除了换行符,当 re.DOTALL 标记被指定时,则可以匹配包括换行符的任意字符 |
| […] | 用来表示一组字符,单独列出,比如 [amk] 匹配 a、m 或 k |
| 不在 [] 中的字符,比如 匹配除了 a、b、c 之外的字符 | |
| * | 匹配 0 个或多个表达式 |
| + | 匹配 1 个或多个表达式 |
| ? | 匹配 0 个或 1 个前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配 n 个前面的表达式 |
| {n, m} | 匹配 n 到 m 次由前面正则表达式定义的片段,贪婪方式 |
| a | b |
| ( ) | 匹配括号内的表达式,也表示一个组 |
match
match 方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回 None。
例如句子‘Hello 123 4567 World_This is a Regex Demo’,接下来我们写一个正则表达式:
^Hello\s\d\d\d\s\d{4}\s\w{10}
开头的 ^ 是匹配字符串的开头,也就是以 Hello 开头;然后 \s 匹配空白字符,用来匹配目标字符串的空格;\d 匹配数字,3 个 \d 匹配 123;然后再写 1 个 \s 匹配空格;后面还有 4567,我们其实可以依然用 4 个 \d 来匹配,但是这么写比较烦琐,所以后面可以跟 {4} 以代表匹配前面的规则 4 次,也就是匹配 4 个数字;然后后面再紧接 1 个空白字符,最后 \w{10} 匹配 10 个字母及下划线。
调用match函数:
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
结果为:<_sre.SRE_Match object; span=(0, 25), match=‘Hello 123 4567 World_This’>
结果是 SRE_Match 对象,这证明成功匹配。
该对象有两个方法:group 方法可以输出匹配到的内容,结果是 Hello 123 4567 World_This,这恰好是正则表达式规则所匹配的内容;span 方法可以输出匹配的范围,结果是 (0, 25),这就是匹配到的结果字符串在原字符串中的位置范围。
匹配目标
用 match 方法可以得到匹配到的字符串内容,如果想从字符串中提取一部分内容。可以使用 () 括号将想提取的子字符串括起来。() 实际上标记了一个子表达式的开始和结束位置,被标记的每个子表达式会依次对应每一个分组,调用 group 方法传入分组的索引即可获取提取的结果。
仍然是上面的例子:Hello 1234567 World_This is a Regex Demo
这里我们想把字符串中的1234567提取出来,此时可以将数字部分的正则表达式用 () 括起来,然后调用了 group(1) 获取匹配结果。
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result.group(1))
group(1),它与 group() 有所不同,后者会输出完整的匹配结果,而前者会输出第一个被 () 包围的匹配结果。如果还有()包裹的内容,依次用group(1),group(2)输出。
通用匹配
上面的正则表达式可以简化,.(点)可以匹配任意字符(除换行符),*代表匹配前面的字符无限次,组合在一起就可以匹配任意字符了。
对上式进行改写:result = re.match('^Hello.Demo$', content),将中间部分直接省略,全部用 . 来代替,最后加一个结尾字符串就好了。
贪婪与非贪婪
使用上面的通用匹配 .* 时,可能有时候匹配到的并不是我们想要的结果。看下面的例子:
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+).*Demo$', content)<_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
7
只得到了 7 这个数字。
在贪婪匹配下,. *会匹配尽可能多的字符。正则表达式中.* 后面是 \d+,也就是至少一个数字,并没有指定具体多少个数字,因此,.* 就尽可能匹配多的字符,这里就把 123456 匹配了,给 \d + 留下一个可满足条件的数字 7,最后得到的内容就只有数字 7 了。
这里只需要使用非贪婪匹配就好了。非贪婪匹配的写法是 .*?,多了一个 ?
此时就可以成功获取 1234567 了。非贪婪匹配就是尽可能匹配少的字符。当 .? 匹配到 Hello 后面的空白字符时,再往后的字符就是数字了,而 \d + 恰好可以匹配,那么这里 .? 就不再进行匹配,交给 \d+ 去匹配后面的数字。
这里需要注意,如果匹配的结果在字符串结尾,.*? 就有可能匹配不到任何内容了,因为它会匹配尽可能少的字符。
修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。
content = '''Hello 1234567 World_This
is a Regex Demo
'''
result = re.match('^He.*?(\d+).*?Demo$', content)
在字符串中加了换行符,正则表达式还是一样的,用来匹配其中的数字。运行直接报错,也就是说正则表达式没有匹配到这个字符串,返回结果为 None,而我们又调用了 group 方法导致 AttributeError。
匹配的是除换行符之外的任意字符,当遇到换行符时,.*? 就不能匹配了,所以导致匹配失败。这里只需加一个修饰符 re.S,即可修正这个错误。
result = re.match('^He.*?(\d+).*?Demo$', content, re.S)
这个 re.S 在网页匹配中经常用到。因为 HTML 节点经常会有换行,加上它,就可以匹配节点与节点之间的换行了。
修饰符
| 修饰符 | 描 述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据 Unicode 字符集解析字符。这个标志影响 \w、\W、\b 和 \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
转义匹配
如果目标字符串里面就包含.,要用到转义匹配,例如:
content = '(百度) www.baidu.com'
result = re.match('\(百度 \) www\.baidu\.com', content)
当遇到用于正则匹配模式的特殊字符时,在前面加反斜线转义一下即可。
search
match 方法是从字符串的开头开始匹配的,一旦开头不匹配,那么整个匹配就失败了。它更适合用来检测某个字符串是否符合某个正则表达式的规则。
这里就有另外一个方法 search,它在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果。也就是说,正则表达式可以是字符串的一部分,在匹配时,search 方法会依次扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容,如果搜索完了还没有找到,就返回 None。
首先,这里有一段待匹配的 HTML 文本,接下来写几个正则表达式实例来实现相应信息的提取:
html = '''<div id="songs-list">
<h2 class="title"> 经典老歌 </h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2"> 一路上有你 </li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐"> 沧海一声笑 </a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦"> 往事随风 </a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond"> 光辉岁月 </a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳"> 记事本 </a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君"> 但愿人长久 </a>
</li>
</ul>
</div>'''
尝试提取 class 为 active 的 li 节点内部的超链接包含的歌手名和歌名,此时需要提取第三个 li 节点下 a 节点的 singer 属性和文本。
此时正则表达式可以以 li 开头,然后寻找一个标志符 active,中间的部分可以用 .? 来匹配。接下来,要提取 singer 这个属性值,所以还需要写入 singer="(.?)",这里需要提取的部分用小括号括起来,以便用 group 方法提取出来,它的两侧边界是双引号。然后还需要匹配 a 节点的文本,其中它的左边界是 & gt;,右边界是 & lt;/a>。然后目标内容依然用 (.*?) 来匹配,所以最后的正则表达式就变成了:
<li.*?active.*?singer="(.*?)">(.*?)</a>
调用 search 方法,它会搜索整个 HTML 文本,找到符合正则表达式的第一个内容返回。另外,由于代码有换行,所以这里第三个参数需要传入 re.S。
findall
如果想要获取匹配正则表达式的所有内容,就要借助 findall 方法了。该方法会搜索整个字符串,然后返回匹配正则表达式的所有内容。
还是上面的 HTML 文本,如果想获取所有 a 节点的超链接、歌手和歌名,就可以将 search 方法换成 findall 方法。如果有返回结果的话,就是列表类型,所以需要遍历一下来依次获取每组内容。
[('/2.mp3', ' 任贤齐 ', ' 沧海一声笑 '), ('/3.mp3', ' 齐秦 ', ' 往事随风 '), ('/4.mp3', 'beyond', ' 光辉岁月 '), ('/5.mp3', ' 陈慧琳 ', ' 记事本 '), ('/6.mp3', ' 邓丽君 ', ' 但愿人长久 ')]
<class 'list'>
('/2.mp3', ' 任贤齐 ', ' 沧海一声笑 ')
/2.mp3 任贤齐 沧海一声笑
('/3.mp3', ' 齐秦 ', ' 往事随风 ')
/3.mp3 齐秦 往事随风
('/4.mp3', 'beyond', ' 光辉岁月 ')
/4.mp3 beyond 光辉岁月
('/5.mp3', ' 陈慧琳 ', ' 记事本 ')
/5.mp3 陈慧琳 记事本
('/6.mp3', ' 邓丽君 ', ' 但愿人长久 ')
/6.mp3 邓丽君 但愿人长久
sub
想要把一串文本中的所有数字都去掉,如果只用字符串的 replace 方法,那就太烦琐了,这时可以借助 sub 方法。
content = '54aK54yr5oiR54ix5L2g'
content = re.sub('\d+', '', content)
结果如下:
aKyroiRixLg
这里只需要给第一个参数传入 \d+ 来匹配所有的数字,第二个参数为替换成的字符串(如果去掉该参数的话,可以赋值为空)。
在上面的 HTML 文本中,如果想获取所有 li 节点的歌名,直接用正则表达式来提取可能比较烦琐。比如,可以写成这样子:
results = re.findall('<li.*?>\s*?(<a.*?>)?(\w+)(</a>)?\s*?</li>', html, re.S)
for result in results:print(result[1])
此时借助 sub 方法就比较简单了。可以先用 sub 方法将 a 节点去掉,只留下文本,然后再利用 findall 提取就好了:
html = re.sub('<a.*?>|</a>', '', html)
print(html)
results = re.findall('<li.*?>(.*?)</li>', html, re.S)
for result in results:print(result.strip())
去除后html如下:
<div id="songs-list"><h2 class="title"> 经典老歌 </h2><p class="introduction">经典老歌列表</p><ul id="list" class="list-group"><li data-view="2"> 一路上有你 </li><li data-view="7">沧海一声笑</li><li data-view="4" class="active">往事随风</li><li data-view="6"> 光辉岁月 </li><li data-view="5"> 记事本 </li><li data-view="5">但愿人长久</li></ul>
</div>
compile
compile 方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
content1 = '2016-12-15 12:00'
content2 = '2016-12-17 12:55'
content3 = '2016-12-22 13:21'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result2 = re.sub(pattern, '', content2)
result3 = re.sub(pattern, '', content3)
这里有 3 个日期,我们想分别将 3 个日期中的时间去掉,这时可以借助 sub 方法。compile 还可以传入修饰符,例如 re.S 等修饰符。
相关文章:
正则表达式)
python爬虫入门(三)正则表达式
开源中国提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了 常用的匹配规则如下 模 式描 述\w匹配字母、数字及下划线\W匹配不是字母、数字及下划线的…...

fabric.js介绍
fabric.js是可以简化canvas编写的js库,提供canvas缺少的对象模型,包含动画、数据序列化和反序列化的等高级功能的js库,开源项目,在GitHub有很多人贡献。 官网:Fabric.js Javascript Canvas Library (fabricjs.com) 文档…...

YOLOv5源码中的参数超详细解析(3)— 训练部分(train.py)| 模型训练调参
前言:Hello大家好,我是小哥谈。YOLOv5项目代码中,train.py是用于模型训练的代码,是YOLOv5中最为核心的代码之一,而代码中的训练参数则是核心中的核心,只有学会了各种训练参数的真正含义,才能使用YOLOv5进行最基本的训练。🌈 前期回顾: YOLOv5源码中的参数超详细解析…...

Linux高性能编程学习-TCP/IP协议族
一、TCP/IP协议族结构与主要协议 分层:数据链路层、网络层、传输层、应用层 1. 数据链路层 功能:实现网卡驱动程序,处理数据在不同物理介质的传输 协议: ARP:将目标机器的IP地址转成MAC地址RARP:将MAC地…...

用爬虫代码爬取高音质音频示例
目录 一、准备工作 1、安装Python和相关库 2、确定目标网站和数据结构 二、编写爬虫代码 1、导入库 2、设置代理IP 3、发送HTTP请求并解析HTML页面 4、查找音频文件链接 5、提取音频文件名和下载链接 6、下载音频文件 三、完整代码示例 四、注意事项 1、遵守法律法…...
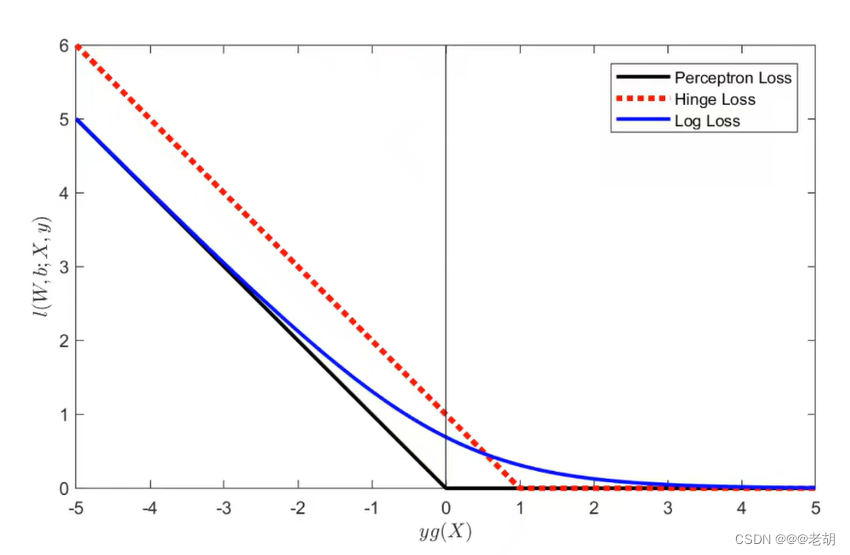
深度学习与计算机视觉(一)
文章目录 计算机视觉与图像处理的区别人工神经元感知机 - 分类任务Sigmoid神经元/对数几率回归对数损失/交叉熵损失函数梯度下降法- 极小化对数损失函数线性神经元/线性回归均方差损失函数-线性回归常用损失函数使用梯度下降法训练线性回归模型线性分类器多分类器的决策面 soft…...
【vector题解】杨辉三角 | 删除有序数组中的重复项 | 只出现一次的数字Ⅱ
杨辉三角 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1…...
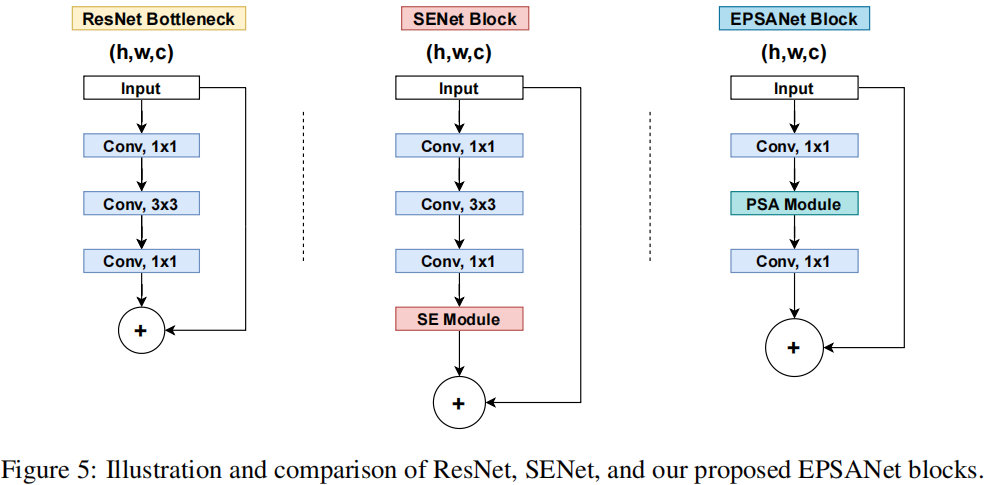
金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度…...
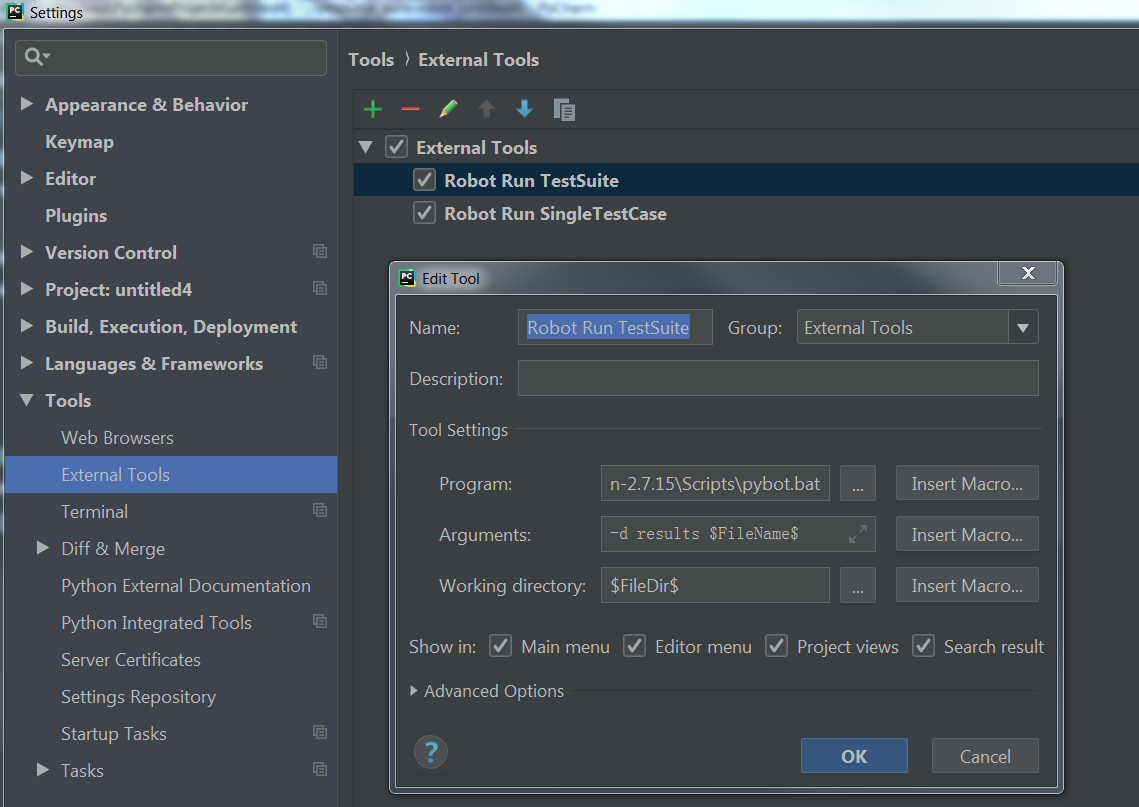
Jenkins自动化测试
学习 Jenkins 自动化测试的系列文章 Robot Framework 概念Robot Framework 安装Pycharm Robot Framework 环境搭建Robot Framework 介绍Jenkins 自动化测试 1. Robot Framework 概念 Robot Framework是一个基于Python的,可扩展的关键字驱动的自动化测试框架。 它…...

python 字典dict和列表list的读取速度问题, range合并
嗨喽,大家好呀~这里是爱看美女的茜茜呐 python 字典和列表的读取速度问题 最近在进行基因组数据处理的时候,需要读取较大数据(2.7G)存入字典中, 然后对被处理数据进行字典key值的匹配,在被处理文件中每次…...
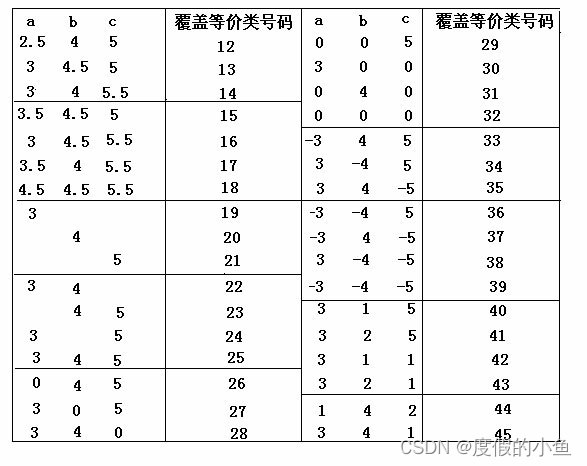
测试用例的设计方法(全):等价类划分方法
一.方法简介 1.定义 是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。 2.划分等价类: 等价类是指某个输入域的…...
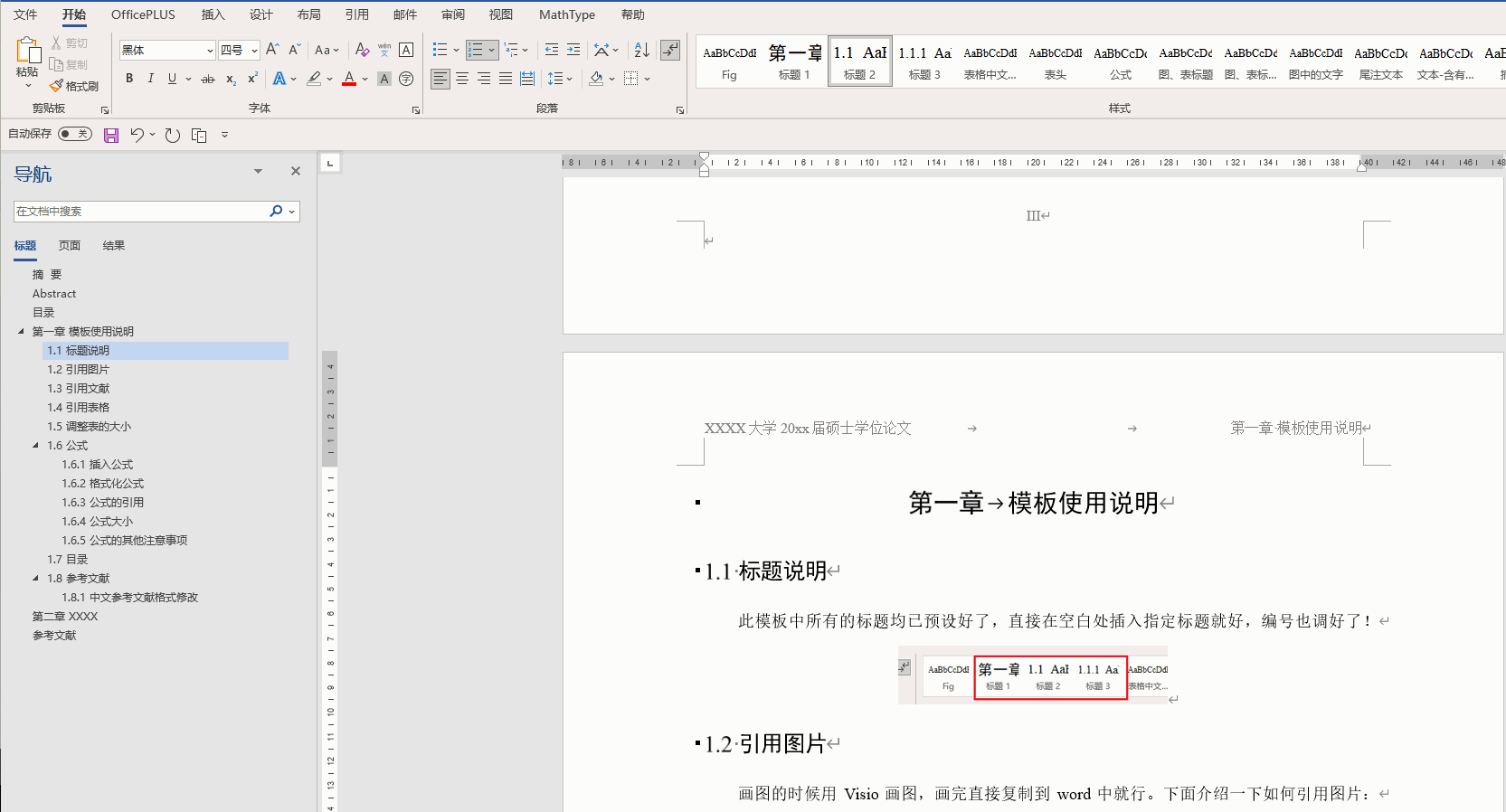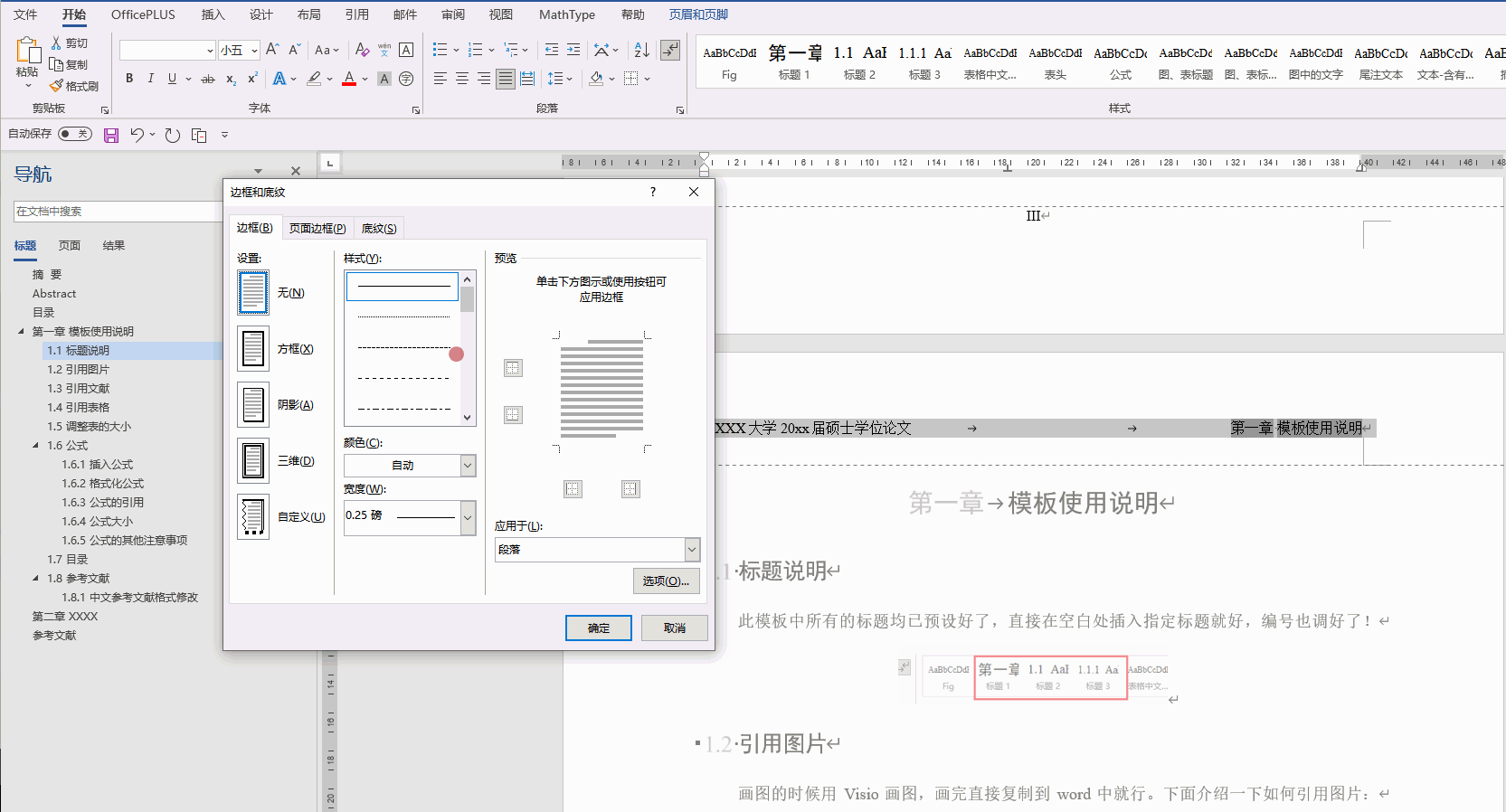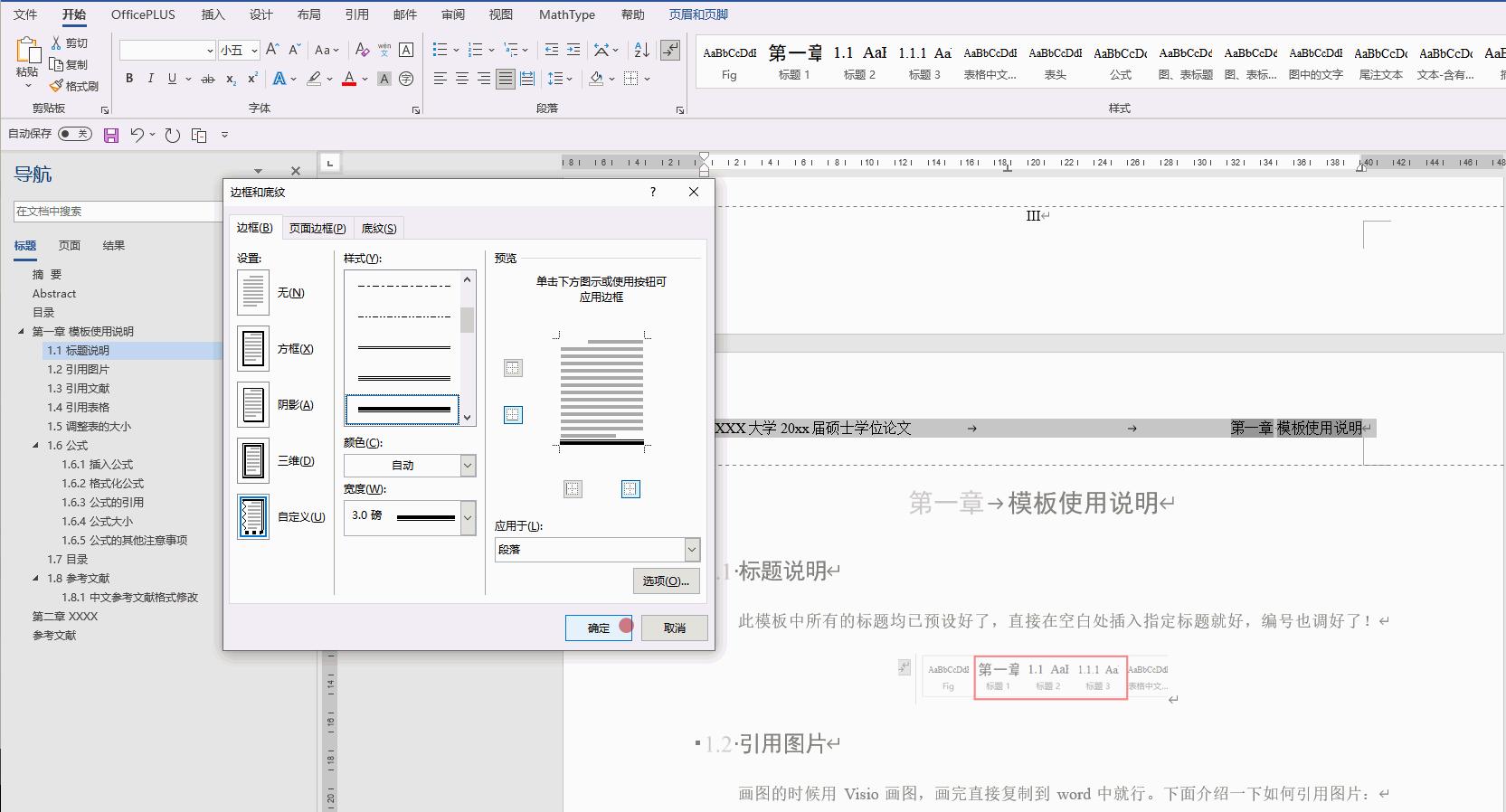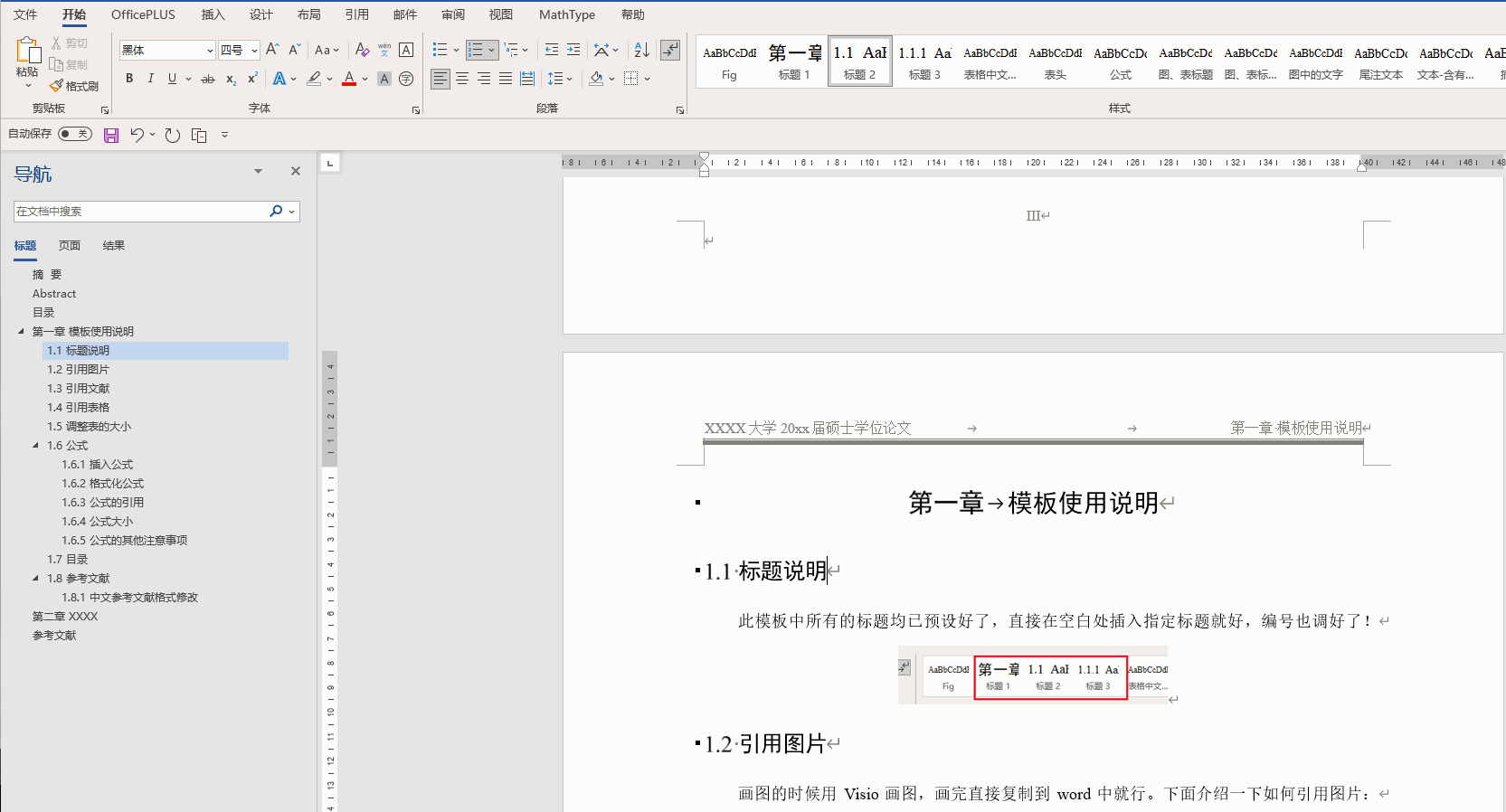
Office技巧(持续更新)(Word、Excel、PPT、PowerPoint、连续引用、标题、模板、论文)
1. Word 1.1 标题设置为多级列表 选住一级标题,之后进行“定义新的多级列表” 1.2 图片和表的题注自动排序 正常插入题注后就可以了。如果一级标题是 “汉字序号”,那么需要对题注进行修改: 从原来的 图 { STYLEREF 1 \s }-{ SEQ 图 \* A…...
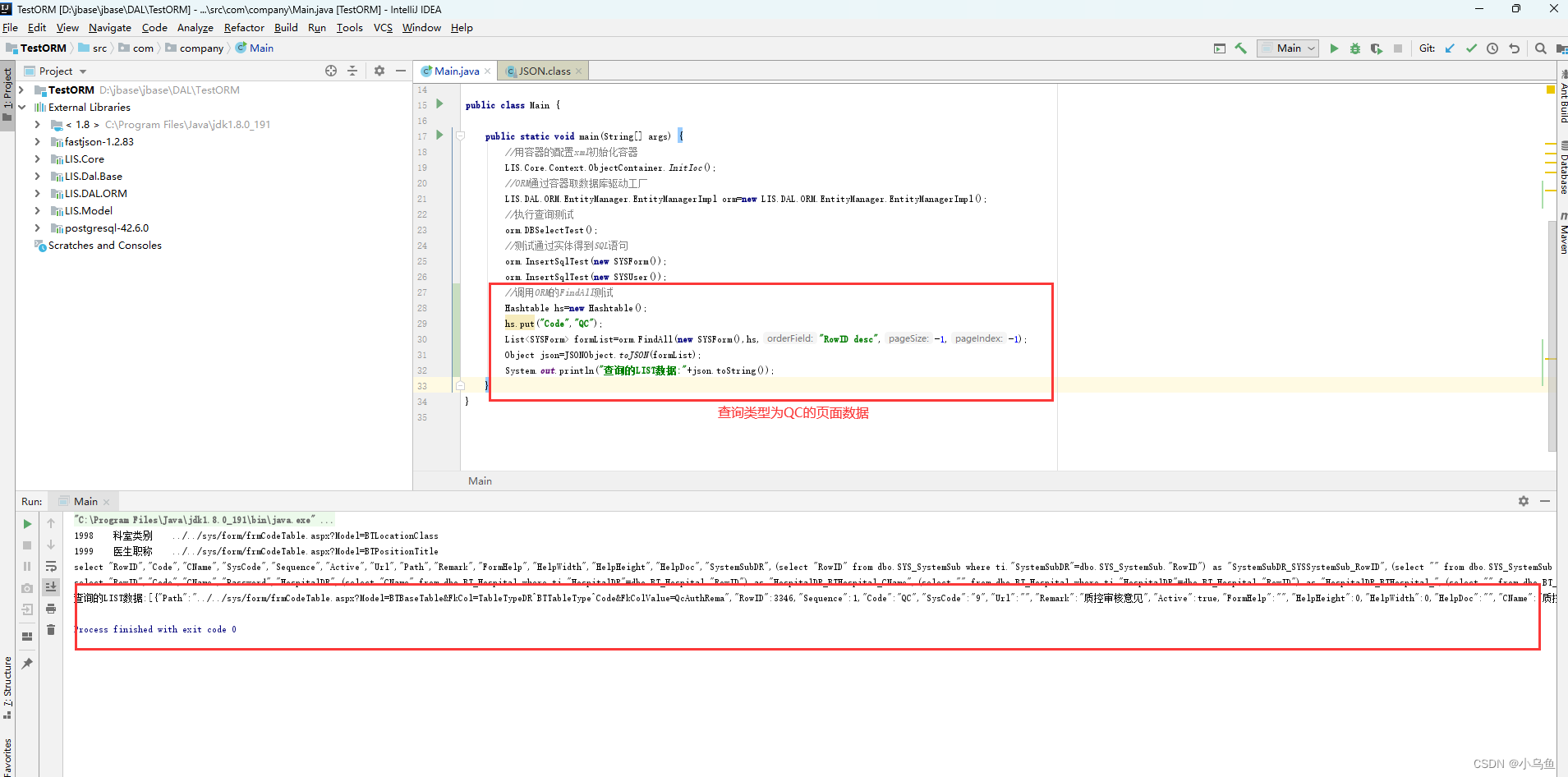
Java实现ORM第一个api-FindAll
经过几天的业余开发,今天终于到ORM对业务api本身的实现了,首先实现第一个查询的api 老的C#定义如下 因为Java的泛型不纯,所以无法用只带泛型的方式实现api,对查询类的api做了调整,第一个参数要求传入实体对象 首先…...

HFSS笔记——求解器和求解分析
文章目录 1、求解器2、求解类型3、自适应网格剖分4、求解频率选择4.1 求解设置项的含义4.2 扫频类型 1、求解器 自从ANSYS将HFSS收购后,其所有的求解器都集成在一起了,点击Project,会显示所有的求解器类型。 其中, HFSS design&…...
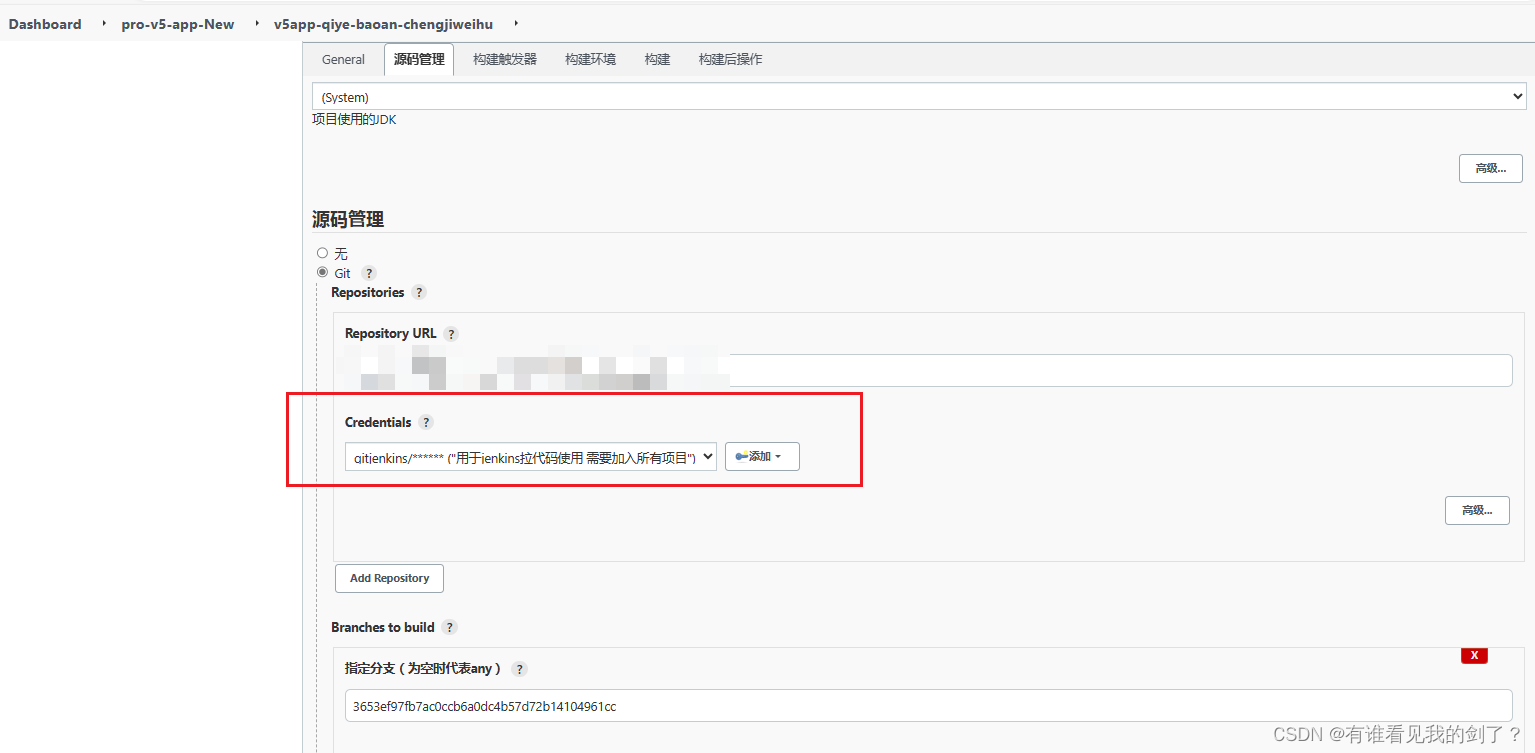
jenkins配置gitlab凭据
下载Credentials Binding插件(默认是已经安装了) 在凭据配置里添加凭据类型 点击保存 Username with password: 用户名和密码 SSH Username with private 在凭据管理里面添加gitlab账号和密码 点击全局 点击添加凭据(版本不同…...
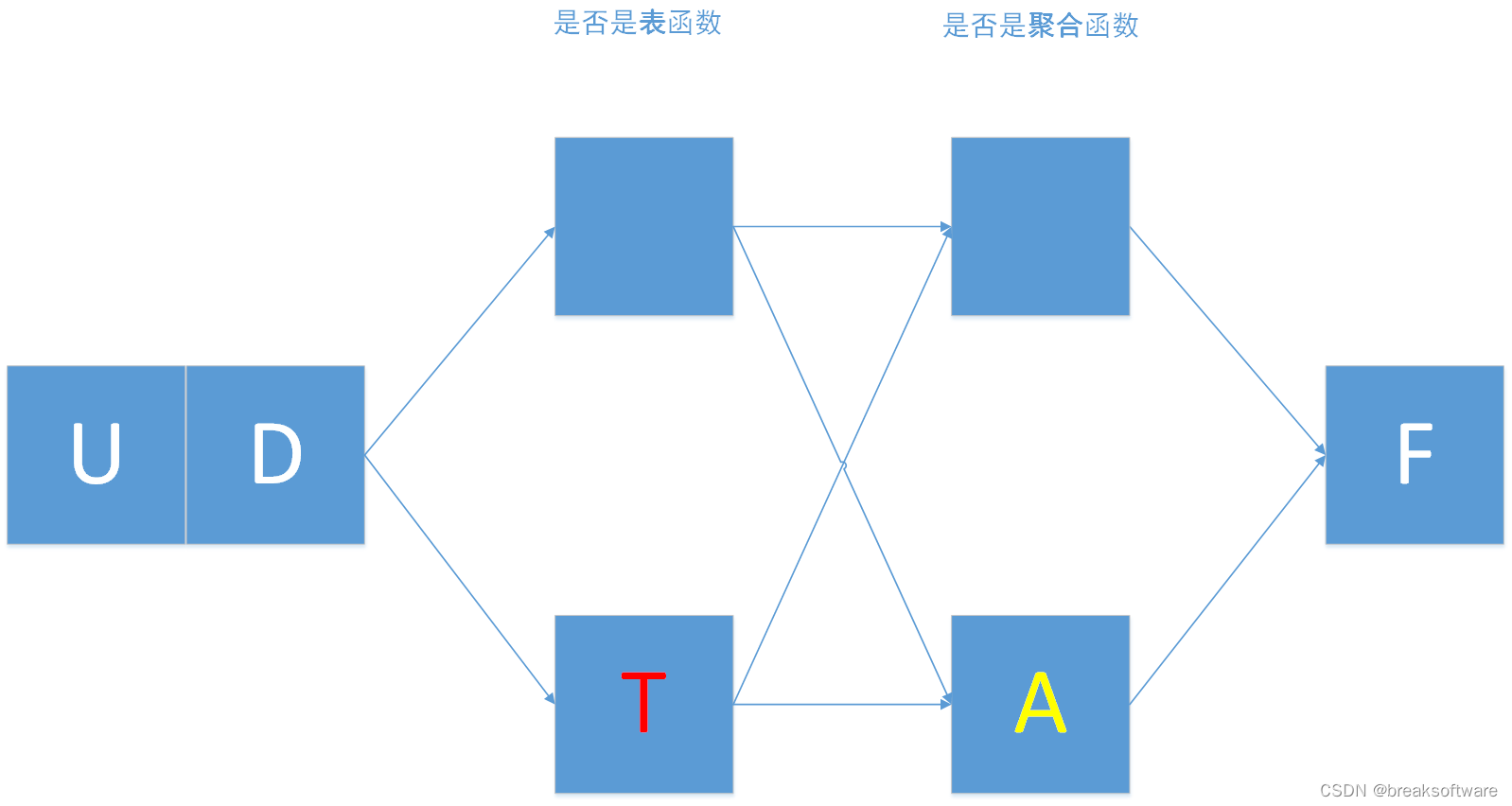
0基础学习PyFlink——用户自定义函数之UDTF
大纲 表值函数完整代码 在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF 表值函数 我们对比下UDF和UDTF def udf(f: Union[Callable, ScalarFunction, Type] None,input_types: Union[List[DataType], DataTy…...

【Java 进阶篇】Java Request 原理详解
在网络应用开发中,HTTP请求是一项常见而关键的任务。当我们使用Java编写网络应用时,了解HTTP请求的工作原理变得至关重要。本文将详细介绍Java中HTTP请求的原理,包括请求的结构、发送请求的方法以及处理请求的过程。 HTTP请求的基本结构 HT…...

13 结构性模式-装饰器模式
1 装饰器模式介绍 在软件设计中,装饰器模式是一种用于替代继承的技术,它通过一种无须定义子类的方式给对象动态的增加职责,使用对象之间的关联关系取代类之间的继承关系. 2 装饰器模式原理 //抽象构件类 public abstract class Component{public abstract void operation(); }…...
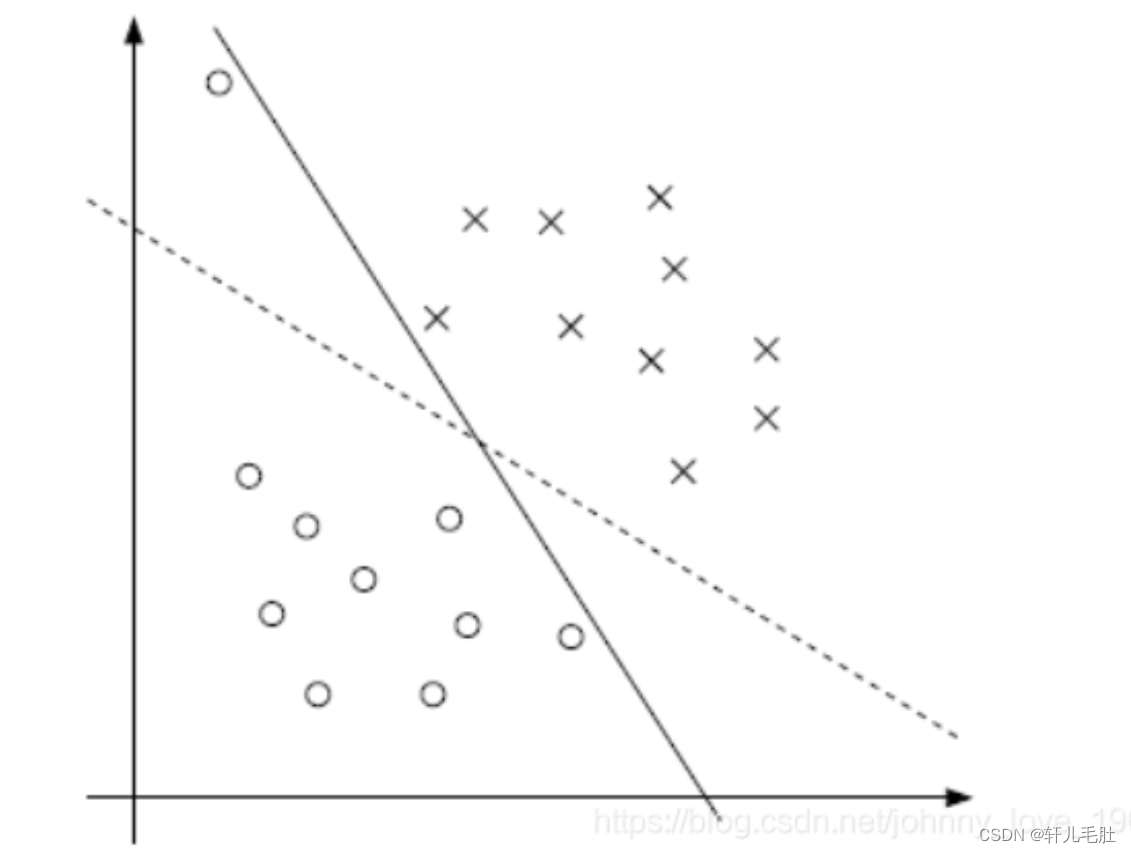
支持向量机(SVM)
一. 什么是SVM 1. 简介 SVM,曾经是一个特别火爆的概念。它的中文名:支持向量机(Support Vector Machine, 简称SVM)。因为它红极一时,所以关于它的资料特别多,而且杂乱。虽然如此,只要把握住SV…...

Rabbitmq----分布式场景下的应用
服务异步通信-分布式场景下的应用 如果单机模式忘记也可以看看这个快速回顾rabbitmq,在做学习 消息队列在使用过程中,面临着很多实际问题需要思考: 1.消息可靠性 消息从发送,到消费者接收,会经理多个过程: 其中的每一…...

SEO 舆情处理中数据分析的作用是什么
SEO 舆情处理中数据分析的作用 在当今数字化社会,搜索引擎优化(SEO)和舆情处理已经成为企业品牌管理的重要组成部分。尤其是在网络信息迅速传播的今天,舆情的好坏直接影响到企业的声誉和市场竞争力。因此,如何有效地进…...

如何在5分钟内成为资源下载高手:res-downloader的终极指南
如何在5分钟内成为资源下载高手:res-downloader的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader res-do…...

Fujitsu空调本地化控制:ESP32协议逆向与硬件隔离方案
1. FujitsuAC 开源库深度解析:面向嵌入式工程师的 Fujitsu 空调本地化控制方案1.1 项目定位与工程价值FujitsuAC 是一个专为 ESP32 平台设计的开源固件库,其核心目标是完全替代 Fujitsu 原厂 UTY-TFSXW1 / UTY-TFSXF3 WiFi 通信模块,实现对 F…...

SEO标题优化与内容营销的关系是什么
SEO标题优化与内容营销的关系:深度解析与实践指南 在数字营销的世界里,SEO标题优化与内容营销之间的关系日益紧密,两者共同塑造了网站的可见性和用户参与度。究竟SEO标题优化与内容营销的关系是什么呢?本文将深入解析这一关系&am…...

Java集成LibreOffice实现高效Office文档批量转PDF方案
1. 为什么选择LibreOffice进行文档转换 在企业日常办公中,我们经常需要处理大量的Office文档。想象一下这样的场景:财务部门每月要生成上百份报表,人力资源部门要处理大量简历,而市场部门则需要频繁修改和分享各种方案文档。这些文…...

深入解析Anaconda中的pkgs文件夹:功能、管理与优化策略
1. pkgs文件夹的核心功能解析 第一次打开Anaconda安装目录时,很多人都会被那个占据几个GB空间的pkgs文件夹吓一跳。这个看似普通的文件夹,其实是Anaconda生态系统的"心脏"。它不仅仅是存放安装包的仓库,更承担着环境管理的关键角色…...
)
QQ 第三方登录(Django)
QQ 第三方登录(Django) 本篇教程完全面向 Django 开发者,从 QQ 互联原理、三端交互流程,到完整代码实现,一步到位,新手可直接复制粘贴跟着操作,避开所有常见踩坑点,兼顾教学和实战需…...
)
从Hyper-V到内核隔离:手把手教你为eNSP在Win11 24H2上‘清场’(安全功能关闭指南)
从Hyper-V到内核隔离:Win11 24H2深度虚拟化冲突解决手册 当你在Windows 11 24H2上启动eNSP模拟器时,那个令人沮丧的"版本不兼容"提示背后,隐藏着一场现代系统安全机制与传统虚拟化工具的无声战争。这不是简单的软件冲突,…...
读懂?)
claw-code 源码详细分析:子系统目录地图——几十个顶层包如何用五条轴(会话 / 工具 / 扩展 / 入口 / 桥接)读懂?
范围:src/ 下 顶层包(含 */__init__.py 的目录)与 与会话/runtime 强相关的根模块;与 result/01_start.md 第十三节、「清单—路由—会话」叙事一致。1. 为什么用五条轴 src/ 里同时存在: 大量占位包(读 re…...

【RAG】【vector_stores001】阿里云OpenSearch向量存储完整案例
本案例演示如何使用 LlamaIndex 与阿里云 OpenSearch 向量搜索版集成,实现向量存储和检索功能,用于构建基于文档的问答系统。1. 案例目标本案例的主要目标是:设置阿里云 OpenSearch 向量存储:配置 LlamaIndex 以使用阿里云 OpenSe…...