【2023CANN训练营第二季】——通过一份入门级算子开发代码了解Ascend C算子开发流程
本次博客讲解的代码是Gitee代码仓的Ascend C加法算子开发代码,代码地址为:
quick-start
打开Add文件,可以看到文件结构如下:
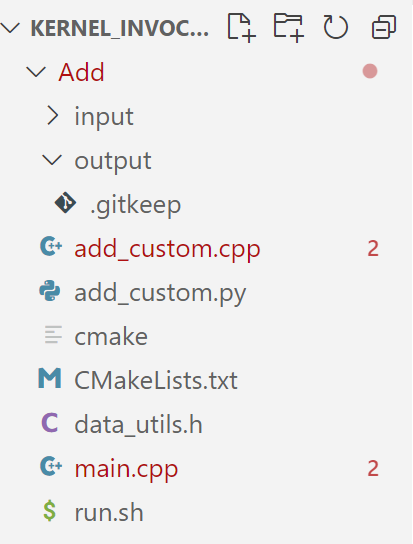
其中add_custom.cpp是算子开发的核心文件,包括了核函数的实现,展示了如何在Ascend平台上使用Ascend C编写算子以及如何在CPU和NPU上运行算子。
main.cpp的作用是用于调用名为 add_custom 的算子进行向量相加操作,根据定义的宏 CCE_KT_TEST 来选择执行哪个部分。
CMakeLists.txt是编译cpu侧或npu侧运行的算子的编译工程文件
run.sh 编译运行算子的脚本
下面我们重点看add_custom.cpp文件和main.cpp文件,以此了解核函数的开发流程和进行CPU侧和NPU侧验证
在进行核函数开发之间,我们先分析算子的表达式:
1.算子分析
Add算子的算子分析如下:
数学表达式:
Add算子的数学表达式为 z = x + y,即将输入x和y逐元素相加,得到输出z。
输入和输出:
算子有两个输入:x和y。
输入数据类型为half(float16)。
输入数据形状(shape)为(8, 2048),即一个8x2048的二维数组。
输入数据格式(format)为ND(N-Dimensional),表示通用的多维数组格式。
算子有一个输出:z。
输出数据类型与输入数据类型相同,为half(float16)。
输出数据形状与输入形状相同,为(8, 2048)。
核函数名称和参数:
核函数的名称为 add_custom。
核函数有三个参数:x、y、z。
x和y是输入在全局内存(Global Memory)上的内存地址。
z是输出在全局内存上的内存地址。
实现所需接口:
数据搬移接口:需要使用 DataCopy 来实现输入数据的搬运,将数据从全局内存搬移到AI Core的局部内存。
矢量计算接口:通过使用矢量双目指令接口 Add 来完成x和y的逐元素相加。
内存管理接口:使用 AllocTensor 和 FreeTensor 来申请和释放Tensor数据结构,用于存储中间变量和计算结果。
队列管理接口:通过队列管理接口 EnQue 和 DeQue 来进行并行流水任务之间的通信和同步。
计算逻辑:
Add算子采用一种分块计算策略,用于在AI Core上执行向量加法操作。主要的计算逻辑包括以下步骤:
初始化核函数 add_custom,其中核函数初始化包括获取每个核的起始索引和初始化队列等。
执行计算过程,计算过程由多个循环组成,每次循环处理一个小块数据。
在每个循环中,分为以下三个步骤:
数据拷贝(CopyIn):将输入数据x和y从全局内存搬移到本地队列(Local Queue)。
计算(Compute):执行向量加法操作,将x和y逐元素相加得到z。
数据拷贝(CopyOut):将计算得到的z从本地队列搬回到全局内存。
循环处理完所有小块数据后,完成整个向量相加操作。
2.核函数开发
2.1核函数定义
这个核函数的主要作用是创建 KernelAdd 类对象,初始化并执行向量相加的计算过程,调用 Process 方法来实际执行向量相加的操作。
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{KernelAdd op;op.Init(x, y, z);op.Process();
}
extern “C”: 这是一个C++编译指示,用于告诉编译器要使用C链接规范,以便在C/C++混编时,能够正确链接核函数。
__global__: 这是一个GPU编程的关键字,表示核函数可以在GPU上执行。这个关键字通常用于CUDA编程,表明这是一个全局函数,可以在GPU上调用。
__aicore__: 这是针对AI Core的编程关键字,表示这是AI Core上的核函数,用于AI Core的编程模型。
void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z): 这是核函数的定义,它接受三个参数 x、y 和 z,分别代表输入向量 x、输入向量 y 和输出向量 z 的内存地址。这些内存地址是在全局内存中的,而不是在核函数的局部内存中。
KernelAdd op;: 在核函数的开头,创建了一个名为 op 的 KernelAdd 类的对象,用于执行向量相加的计算。
op.Init(x, y, z);: 调用 KernelAdd 类的 Init 方法,初始化 op 对象,将输入向量 x 和 y 的内存地址传递给 op 对象,以及将输出向量 z 的内存地址传递给 op 对象。
op.Process();: 调用 KernelAdd 类的 Process 方法,执行向量相加的计算。这一步会根据Add算子的计算逻辑,将输入数据从全局内存拷贝到本地队列,执行向量加法操作,再将计算结果从本地队列拷贝回全局内存。
2.2算子类定义
KernelAdd 类是用于执行Add算子计算的核心类。
class KernelAdd {
public:__aicore__ inline KernelAdd() {}__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){// get start index for current core, core parallelxGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);// pipe alloc memory to queue, the unit is Bytespipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));}__aicore__ inline void Process(){// loop count need to be doubled, due to double bufferconstexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;// tiling strategy, pipeline parallelfor (int32_t i = 0; i < loopCount; i++) {CopyIn(i);Compute(i);CopyOut(i);}}
Init方法
Init 方法通过 GM_ADDR 类型的参数 x、y 和 z,将输入向量和输出向量的地址传入该方法。
首先,通过 GetBlockIdx() 方法获取当前AI Core的起始索引,这是为了在AI Core并行处理中计算每个核心需要处理的数据范围。
接下来,使用 xGm、yGm 和 zGm 对象,通过 SetGlobalBuffer 方法将输入向量 x、y 和输出向量 z 与AI Core的局部内存进行关联。这确保了每个核心的计算都在局部内存中进行,提高了计算效率。
然后,通过 pipe 对象,使用 InitBuffer 方法初始化了 inQueueX、inQueueY 和 outQueueZ 队列,这些队列将用于数据的输入和输出。BUFFER_NUM 和 TILE_LENGTH 用于确定队列的深度和每个队列的大小。
Process方法
Process 方法用于执行Add算子的计算逻辑。在该方法中:
通过循环处理数据,loopCount 表示循环的次数。TILE_NUM 和 BUFFER_NUM 的乘积决定了总共有多少次循环。因为采用了双缓冲策略,所以需要循环两次。
CopyIn 方法用于将数据从全局内存拷贝到本地队列,执行输入操作。
Compute 方法执行Add算子的计算,将数据从 inQueueX 和 inQueueY 队列中取出,执行相加操作。
CopyOut 方法用于将计算结果从本地队列拷贝回全局内存,执行输出操作。
CopyIn函数实现
__aicore__ inline void CopyIn(int32_t progress){// alloc tensor from queue memoryLocalTensor<half> xLocal = inQueueX.AllocTensor<half>();LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();// copy progress_th tile from global tensor to local tensorDataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);// enque input tensors to VECIN queueinQueueX.EnQue(xLocal);inQueueY.EnQue(yLocal);}
它用于将数据从全局内存(Global Memory)复制到局部内存(Local Memory)并将数据放入输入队列,为Add算子的计算做准备。以下是对该方法的解释:
CopyIn 方法接受一个整数参数 progress,表示当前执行的迭代进度。这个参数在循环中用于确定从全局内存复制的数据位置。
首先,使用 inQueueX 和 inQueueY 队列的 AllocTensor 方法,为每个输入数据创建一个 LocalTensor 对象 xLocal 和 yLocal。这些 LocalTensor 对象用于在局部内存中存储全局内存中的部分数据。
接下来,使用 DataCopy 方法,将全局内存中的数据从 xGm 和 yGm 复制到 xLocal 和 yLocal 中。这里 progress * TILE_LENGTH 用于确定要复制的全局内存数据的位置。
然后,使用 EnQue 方法,将 xLocal 和 yLocal 放入输入队列 inQueueX 和 inQueueY 中,以便后续的计算操作可以从这些队列中获取数据。
Compute函数实现
__aicore__ inline void Compute(int32_t progress){// deque input tensors from VECIN queueLocalTensor<half> xLocal = inQueueX.DeQue<half>();LocalTensor<half> yLocal = inQueueY.DeQue<half>();LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();// call Add instr for computationAdd(zLocal, xLocal, yLocal, TILE_LENGTH);// enque the output tensor to VECOUT queueoutQueueZ.EnQue<half>(zLocal);// free input tensors for reuseinQueueX.FreeTensor(xLocal);inQueueY.FreeTensor(yLocal);}
Compute 方法接受一个整数参数 progress,表示当前执行的迭代进度。这个参数在循环中用于确定从输入队列中获取数据以及将结果放入输出队列的位置。
首先,使用 inQueueX 和 inQueueY 队列的 DeQue 方法,从输入队列中获取 LocalTensor 对象 xLocal 和 yLocal,这些对象包含了之前在 CopyIn 方法中准备好的输入数据。
接下来,使用 outQueueZ 队列的 AllocTensor 方法,创建一个 LocalTensor 对象 zLocal,用于存储计算结果。
然后,使用 Add 方法,对 xLocal 和 yLocal 中的数据执行加法操作,将结果存储在 zLocal 中。TILE_LENGTH 参数表示每次计算的元素数量。
使用 outQueueZ 队列的 EnQue 方法,将计算结果 zLocal 放入输出队列中,以便后续的步骤可以从输出队列中获取计算结果。
最后,使用 inQueueX 和 inQueueY 队列的 FreeTensor 方法,释放 xLocal 和 yLocal 对象,以便它们可以在后续的迭代中被重用。
CopyOut函数实现
__aicore__ inline void CopyOut(int32_t progress){// deque output tensor from VECOUT queueLocalTensor<half> zLocal = outQueueZ.DeQue<half>();// copy progress_th tile from local tensor to global tensorDataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);// free output tensor for reuseoutQueueZ.FreeTensor(zLocal);}
首先,从 outQueueZ 队列中出队(DeQue)一个 LocalTensor 对象 zLocal,这是之前计算的结果存储在本地内存中的对象。
然后,使用 DataCopy 函数将 zLocal 中的数据复制到全局内存中的 zGm 中,复制的数据长度为 TILE_LENGTH。
最后,通过 outQueueZ.FreeTensor(zLocal) 释放 zLocal 对象,以便在下一个迭代中重新使用。
3.核函数运行验证
通过对__CCE_KT_TEST__宏定义的判断来区分CPU和NPU侧的运行程序。
3.1CPU侧运行验证
完成算子核函数CPU侧运行验证的步骤如下:
分配共享内存,并进行数据初始化;
调用ICPU_RUN_KF调测宏,完成核函数CPU侧的调用;
释放申请的资源。
#ifdef __CCE_KT_TEST__uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize);uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize);uint8_t* z = (uint8_t*)AscendC::GmAlloc(outputByteSize);ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);AscendC::SetKernelMode(KernelMode::AIV_MODE);ICPU_RUN_KF(add_custom, blockDim, x, y, z); // use this macro for cpu debugWriteFile("./output/output_z.bin", z, outputByteSize);AscendC::GmFree((void *)x);AscendC::GmFree((void *)y);AscendC::GmFree((void *)z);
内存分配:首先,分配了三块内存,x、y 和 z,这些内存用于存储输入数据和输出数据。这些内存分配使用 AscendC::GmAlloc 函数。
数据读取:使用 ReadFile 函数,从外部文件(如 “./input/input_x.bin” 和 “./input/input_y.bin”)读取输入数据(x 和 y)。
核函数模式设置:调用 AscendC::SetKernelMode 函数,将核函数执行模式设置为 KernelMode::AIV_MODE。这表明代码将在AI Core上执行。
核函数运行:通过宏 ICPU_RUN_KF 来运行核函数,add_custom 核函数将被执行。此核函数将输入数据 x 和 y 作为参数传递,并计算结果存储在 z 中。这一步是在AI Core上执行的。
结果写入文件:使用 WriteFile 函数,将计算的结果 z 写入输出文件(如 “./output/output_z.bin”),以便进一步分析和验证。
内存释放:最后,使用 AscendC::GmFree 函数,释放之前分配的内存,包括输入数据 x 和 y,以及输出数据 z。这是为了确保不会发生内存泄漏。
3.2NPU侧验证
在NPU侧验证主要分为以下步骤:
1.初始化Device设备;
2.创建Context绑定设备;
3.分配Host内存,并进行数据初始化;
4.分配Device内存,并将数据从Host上拷贝到Device上;
5.用内核调用符<<<>>>调用核函数完成指定的运算;
6.将Device上的运算结果拷贝回Host;
7.释放申请的资源。
代码如下:
#elseCHECK_ACL(aclInit(nullptr));aclrtContext context;int32_t deviceId = 0;CHECK_ACL(aclrtSetDevice(deviceId));CHECK_ACL(aclrtCreateContext(&context, deviceId));aclrtStream stream = nullptr;CHECK_ACL(aclrtCreateStream(&stream));uint8_t *xHost, *yHost, *zHost;uint8_t *xDevice, *yDevice, *zDevice;CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize));CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice);CHECK_ACL(aclrtSynchronizeStream(stream));CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));WriteFile("./output/output_z.bin", zHost, outputByteSize);CHECK_ACL(aclrtFree(xDevice));CHECK_ACL(aclrtFree(yDevice));CHECK_ACL(aclrtFree(zDevice));CHECK_ACL(aclrtFreeHost(xHost));CHECK_ACL(aclrtFreeHost(yHost));CHECK_ACL(aclrtFreeHost(zHost));CHECK_ACL(aclrtDestroyStream(stream));CHECK_ACL(aclrtDestroyContext(context));CHECK_ACL(aclrtResetDevice(deviceId));CHECK_ACL(aclFinalize());
总结:以上就是整个Ascend C算子开发的流程,接下来就可以执行一键式编译运行脚本,编译和运行应用程序。总的来说,通过这个简单的例子,可以知道Ascend C算子开发的工作主要分为:环境准备、算子分析、核函数开发、核函数运行验证、编译运行脚本这就几个步骤,核函数开发和核函数验证运行需要重点掌握,里面涉及到了算子开发核心知识。
相关文章:
【2023CANN训练营第二季】——通过一份入门级算子开发代码了解Ascend C算子开发流程
本次博客讲解的代码是Gitee代码仓的Ascend C加法算子开发代码,代码地址为: quick-start 打开Add文件,可以看到文件结构如下: 其中add_custom.cpp是算子开发的核心文件,包括了核函数的实现,展示了如何在Asc…...
建模仿真软件 Comsol Multiphysics mac中文版软件介绍
COMSOL Multiphysics mac是一款全球通用的基于高级数值方法和模拟物理场问题的通用软件,拥有、网格划分、研究和优化、求解器、可视化和后处理、仿真 App等相关功能,轻松实现各个环节的流畅进行,它能够解释耦合或多物理现象。 附加产品扩展了…...

深入理解强化学习——强化学习的历史:近代强化学习的发展
分类目录:《深入理解强化学习》总目录 在《深入理解强化学习——强化学习的历史》前面的文章中我们讨论了最优控制和试错学习学习的思想,接下来,我们将讨论一些在20世纪60年代和70年代,在试错学习计算和理论研究被相对忽视的时候&…...

移动端ViT新利器!苹果提出稀疏专家混合模型Mobile V-MoEs
文章链接:https://arxiv.org/abs/2309.04354 最近,专家混合模型MoE受到了学术界和工业界的广泛关注,其能够对任意输入来激活模型参数中的一小部分来将模型大小与推理效率分离,从而实现模型的轻量化设计。目前MoE已经在自然语言处理…...

【linux系统】服务器安装Pycharm
文章目录 安装pycharm步骤1. 进入pycharm官网2. 上传到服务器3. 安装过程 摘要:pycharm是Python语言的图形化开发工具。因为如果在Linux环境下的Python shell 中直接进行编程,其无法保存与修改,在大型项目当中这是很不方便的,而py…...

便利连锁:如何增加收益?教你一招轻松搞定!
自动售货机,作为零售行业的一项颠覆性技术,正逐渐改变着我们的购物方式和商业格局。这一创新技术不仅重新定义了零售业务模式,还为企业提供了更多的机会来满足不断演变的消费者需求。 客户案例 便利连锁店 成都某便利连锁店面临一系列挑战&am…...
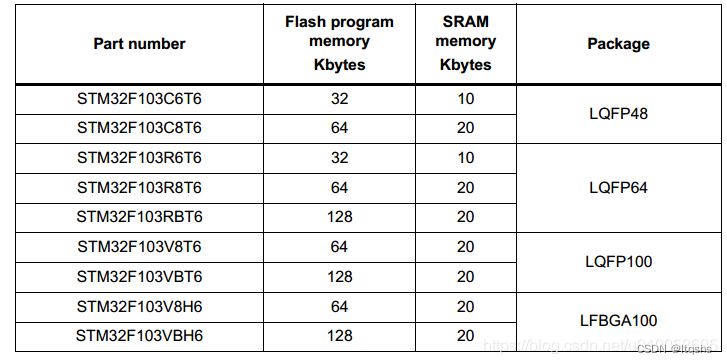
STM32-程序占用内存大小计算
STM32中程序占用内存容量 Keil MDK下Code, RO-data,RW-data,ZI-data这几个段: Code存储程序代码。 RO-data存储const常量和指令。 RW-data存储初始化值不为0的全局变量。 ZI-data存储未初始化的全局变量或初始化值为0的全局变量。 占用的FlashCode RO Data RW Data; 运行消…...
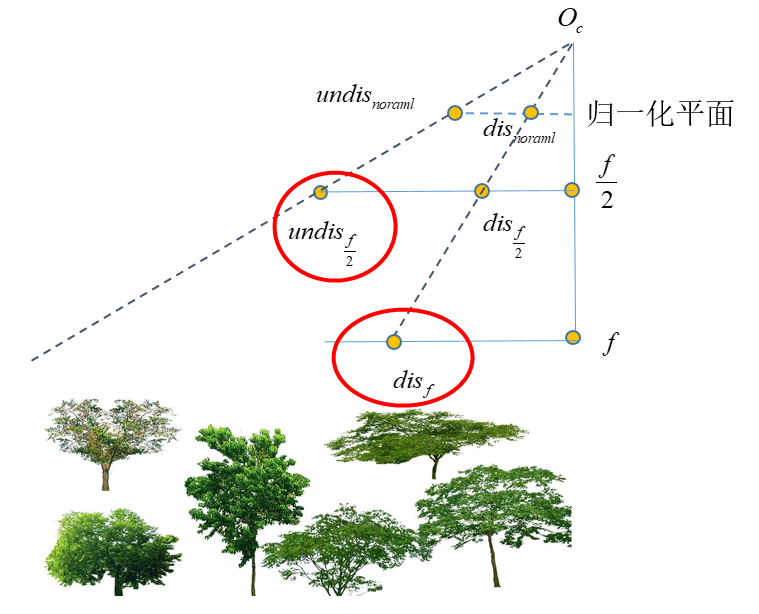
鱼眼图像去畸变python / c++
#鱼眼模型参考链接 本文假设去畸变后的图像与原图大小一样大。由于去畸变后的图像符合针孔投影模型,因此不同的去畸变焦距得到不同的视场大小,且物体的分辨率也不同。可以见上图,当焦距缩小为一半时,相同大小的图像(横…...
文心一言简单体验
百度正式发布文心一言,文心一言 这里的插件模式挺有意思: 测试了一下图解说明,随意上传了一张图片: 提供图解让反过来画,抓住了部分重点,但是还是和原图有比较大的差异! 百宝箱 暂未逐个体验&am…...

css正确的语法
Cascading Style Sheets (CSS) 是一种用于定义网页元素外观和样式的标记语言。以下是正确的 CSS 语法要点: 选择器 (Selector): 选择器用于指定要应用样式的 HTML 元素。例如,选择器可以是标签名、类名、ID、属性等。例如: 标签名选择器&…...

【PG】PostgresSQL角色管理
目录 角色概念 查询现有角色 列出当前角色 创建角色 删除角色 更改角色 创建角色举例 预定义角色 角色属性 登陆角色 超级用户角色 创建数据库角色 创建role角色 复制角色 创建带有密码的角色 角色成员关系 角色组概念 角色组增加成员 角色组移除成员 删除角…...

百度智能云获评Forrester中国市场人工智能/机器学习平台领导者
写在前面百度智能云AI平台,打造企业智能化转型的基础设施大模型时代,百度智能云AI平台迎来全面升级 写在前面 日前,国际权威咨询机构 Forrester 发布了最新的《The Forrester Wave™:中国市场人工智能/机器学习平台厂商评测&…...
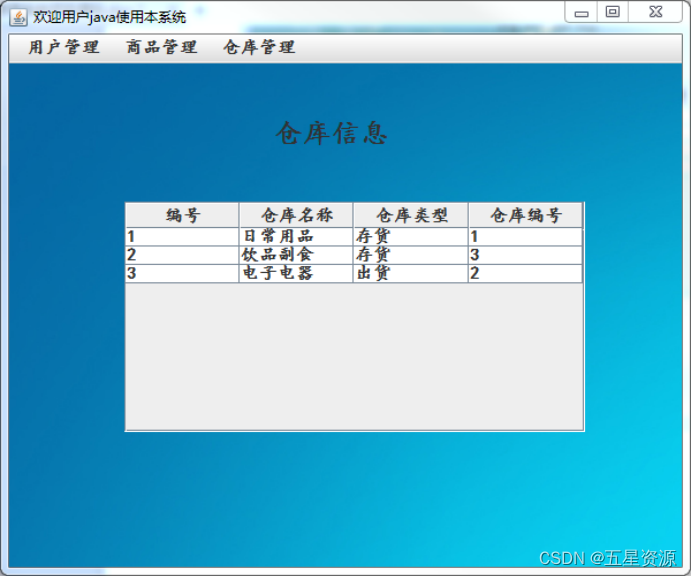
基于java+swing+mysql实现的仓库商品管理系统
JavaSwingmysql用户信息管理系统 一、系统介绍二、功能展示三、项目相关3.1 乱码问题3.2 如何将GBK编码系统修改为UTF-8编码的系统? 四、其它1.其他系统实现 五、源码下载 一、系统介绍 本系统实现了两个角色层面的功能,管理员可以管理用户、仓库、商品…...

深入理解Spring Boot AOP:CGLIB代理与JDK动态代理的完全指南
深入理解Spring Boot AOP:CGLIB代理与JDK动态代理的完全指南 前言第一:AOP和代理模式AOP(面向切面编程):代理模式: 第二:深入分析CGLIB代理,包括其实现原理和内部机制CGLIB的实现原理…...

【无标题】读书笔记之《智能化社会:未来人们如何生活、相爱和思考》
《智能化社会:未来人们如何生活、相爱和思考》:Digital vs Human_ how well live, love, and think in the future ,由中信出版社于2017年06月出版。作者是澳大利亚的理查德沃特森(Richard Watson)。Richard Watson在伦敦帝国理工学院从事未来…...

华为云双十一服务器数据中心带宽全动态BGP和静态BGP区别
2023华为云双十一优惠活动中提供多款云服务器选择,需要注意的是:西南-贵阳一和华北-北京一数据中心是静态BGP带宽,其他数据中心配置全动态独享BGP带宽。 静态BGP和全动态BGP带宽有什么区别?全动态BGP网络线路可用性保障更高&…...
STM32 HAL库串口使用printf
STM32 HAL库串口使用printf 背景配置说明在usart.h中添加在usart.c中添加在工程中选中微库: 测试 背景 在我们使用CubeMX生成好STM32 HAL库工程之后,我们想使用printf函数来打印一些信息,配置如下: 配置说明 在usart.h中添加 …...
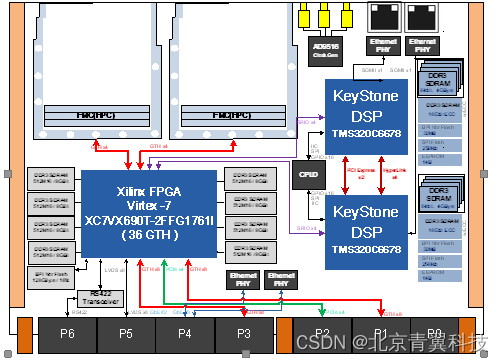
【VPX610】 青翼科技基于6U VPX总线架构的高性能实时信号处理平台
板卡概述 VPX610是一款基于6U VPX架构的高性能实时信号处理平台,该平台采用2片TI的KeyStone系列多核DSP TMS320C6678作为主处理单元,采用1片Xilinx的Virtex-7系列FPGA XC7VX690T作为协处理单元,具有2个FMC子卡接口,各个处理节点之…...

Parity 战略转型引热议,将如何推动波卡生态去中心化?
Polkadot 生态的区块链基础设施公司 Parity Technologies,最近宣布了一项重要的战略调整,即正在寻求在未来几个月内,将部分现有的市场职能转移给 Polkadot 生态系统内的多个去中心化团队,这将影响 Parity Technologies 未来几个月…...
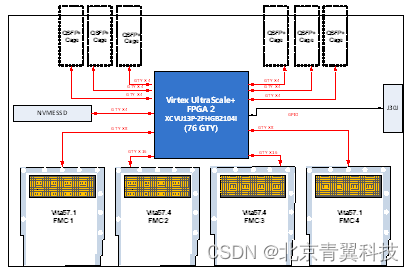
【TES641】基于VU13P FPGA的4路FMC接口基带信号处理平台
板卡概述 TES641是一款基于Virtex UltraScale系列FPGA的高性能4路FMC接口基带信号处理平台,该平台采用1片Xilinx的Virtex UltraScale系列FPGA XCVU13P作为信号实时处理单元,该板卡具有4个FMC子卡接口(其中有2个为FMC接口)&#x…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...

空洞骑士模组管理器Scarab:2024年最全面的安装与管理指南
空洞骑士模组管理器Scarab:2024年最全面的安装与管理指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...

从开源物理拼图游戏学习Unity 2D物理引擎与游戏架构设计
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“openclaw-puzzle-game”。光看名字,你可能会觉得这又是一个普通的开源拼图游戏,但点进去仔细研究后,我发现它的设计思路和实现方式,对于想学习游戏开…...