0基础学习PyFlink——用户自定义函数之UDTAF
大纲
- UDTAF
- TableAggregateFunction的实现
- 累加器
- 定义
- 创建
- 累加
- 返回
- 类型
- 计算
- 完整代码
在前面几篇文章中,我们分别介绍了UDF、UDTF和UDAF这三种用户自定义函数。本节我们将介绍最后一种函数:UDTAF——用户自定义表值聚合函数。
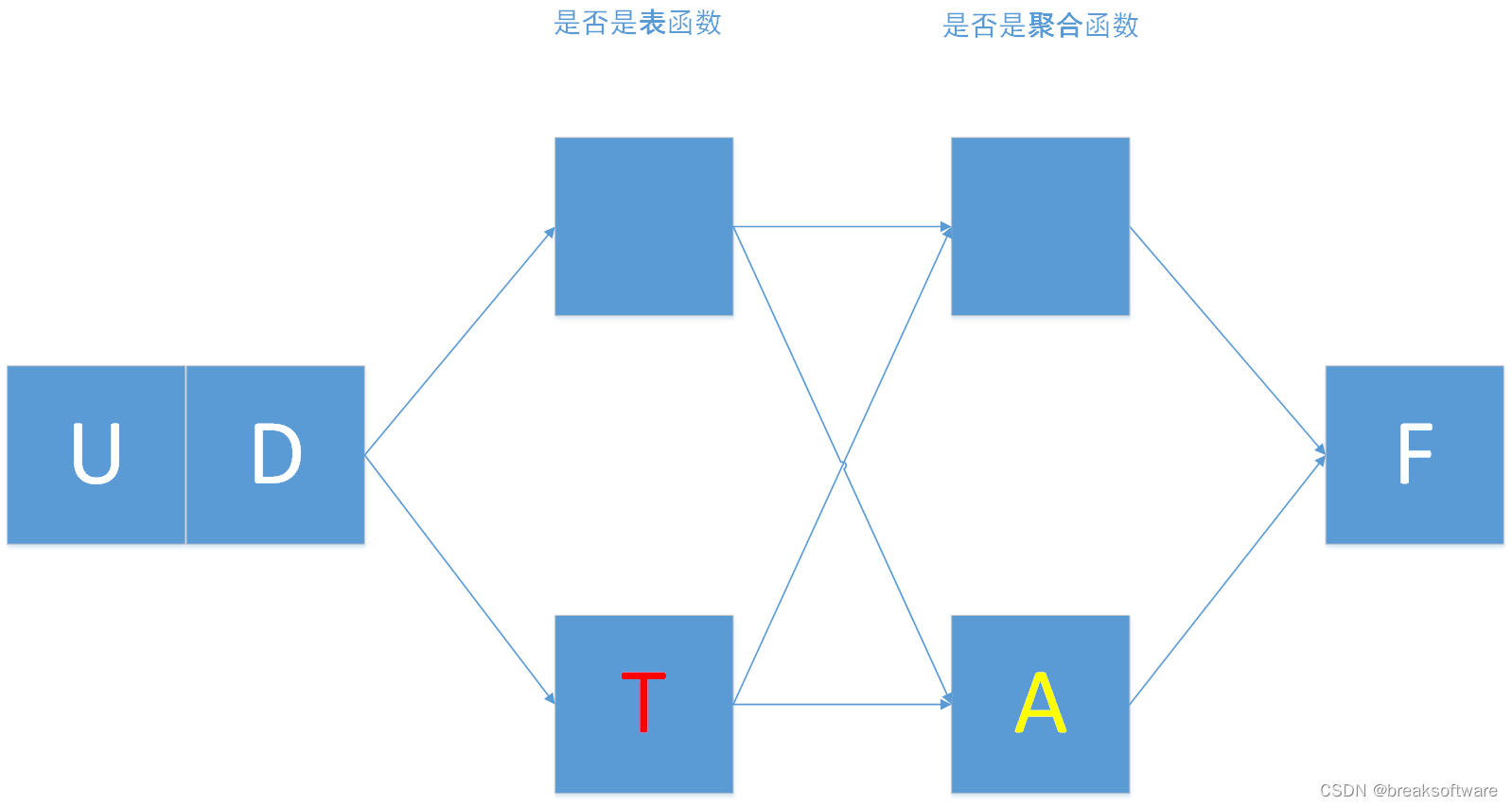
UDTAF
UDTAF函数即具备了UDTF的特点,也具备UDAF的特点。即它可以像《0基础学习PyFlink——用户自定义函数之UDTF》介绍的UDTF那样可以返回任意数量的行作为输,又可以像《0基础学习PyFlink——用户自定义函数之UDAF》介绍的UDAF那样通过聚合的数据(多组)计算出一个值。
举一个例子:我们拿到一个学生成绩表,每行包括:
- 学生姓名
- 英语成绩
- 数学成绩
- 年级
现在我们需要把这张表调整为:
- 学生姓名
- 成绩
- 科目
- 科目年级平均成绩
- 年级
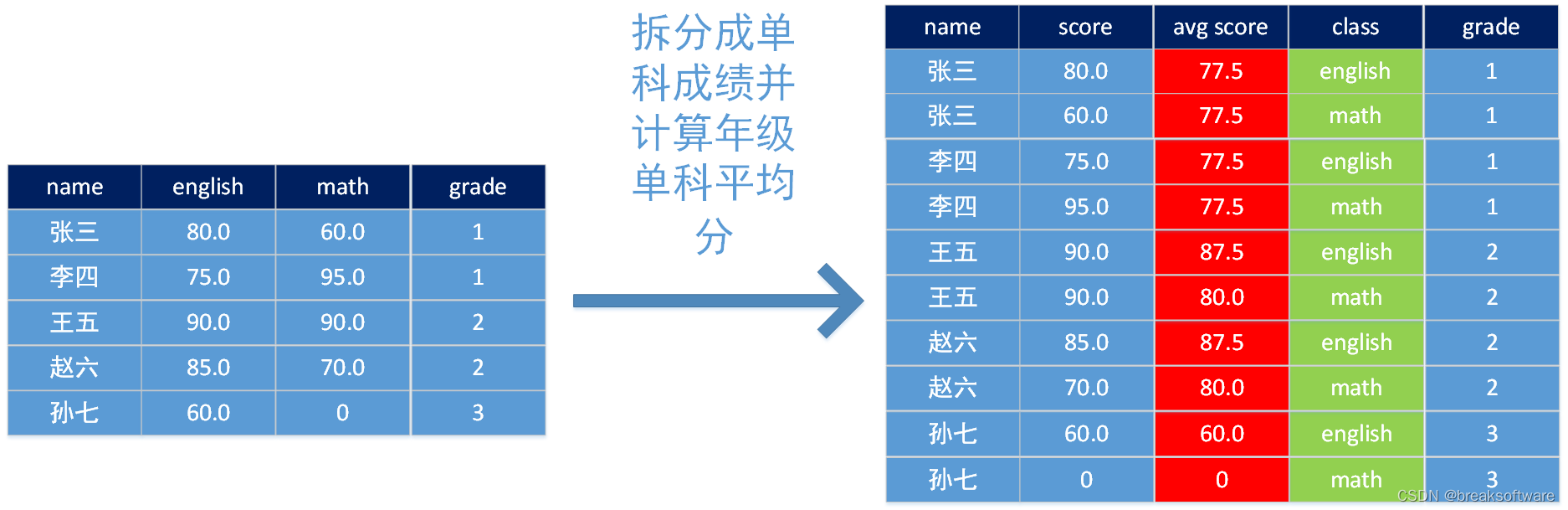
将一行中的“英语成绩”和“数学成绩”,拆成“成绩”和“科目”,相当于把一行数据拆解成多行,如上图左侧“张三”只有一行,而右侧有两行“张三”信息。这种拆解操作就需要T类型的用户自定义函数,比如UDTF和UDTAF。
而我们需要计算一个年级一科的平均成绩,比如1年级英语的平均成绩,则需要按年级聚合之后再做计算。这个就需要A类型的用户自定义函数,比如UDAF和UDTAF。
同时要满足上述两种技术方案的就是UDTAF。我们先看下主体代码,它和《0基础学习PyFlink——用户自定义函数之UDAF》中的很像。但是有两个重要区别: - 要设置成in_streaming_mode模式,否则会报错;
- udtaf要修饰一个对象,而非一个方法;
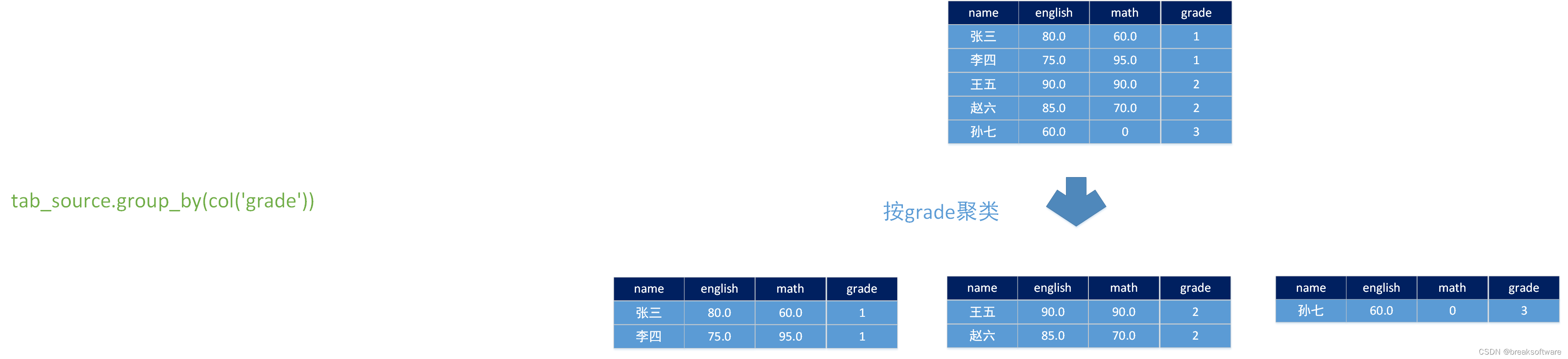
def calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_streaming_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('english', DataTypes.FLOAT()), DataTypes.FIELD('math', DataTypes.FLOAT()), DataTypes.FIELD('grade', DataTypes.STRING())])students_score = [("张三", 80.0, 60.0, "1"),("李四", 75.0, 95.0, "1"),("王五", 90.0, 90.0, "2"),("赵六", 85.0, 70.0, "2"),("孙七", 60.0, 0.0, "3"),]tab_source = t_env.from_elements(students_score, row_type_tab_source)split_class = udtaf(SplitClass())tab_source.group_by(col('grade')) \.flat_aggregate(split_class) \.select(col('*')) \.execute().print()
TableAggregateFunction的实现
用于计算的类要继承于TableAggregateFunction,即UDTAF中的TAF。
class SplitClass(TableAggregateFunction):_class_keys = ["english", "math"]
我们需要通过get_result_type告诉框架,UDTAF函数返回的是什么类型的数据。一般我们都是构造一个行类型——ROW,然后定义其每个字段的值和类型:
- name:string类型,用户姓名;
- score:float类型,考分;
- avg score:float类型,科目年级平均分数;
- class:sting类型,科目名称;
累加器
accumulator(累加器)是用于参与计算的中间数据。比如这个案例中,我们会向让accumulator保存拆解后的数据(即一行拆解成多行后的数据),然后再计算各年级每科的平均成绩。
定义
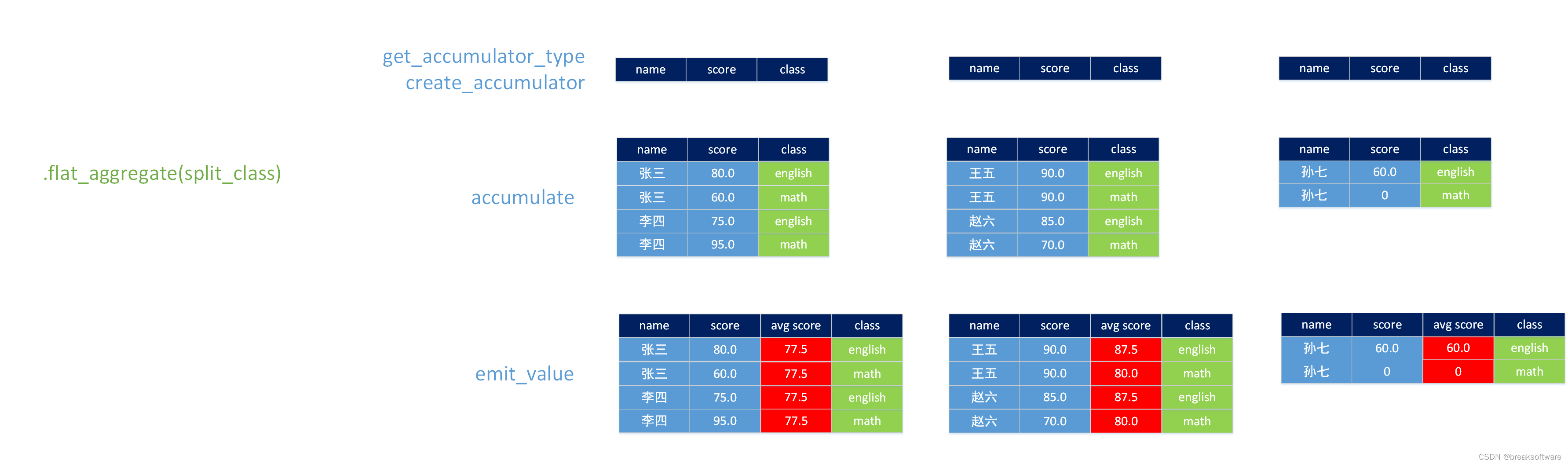
def get_accumulator_type(self):return DataTypes.ARRAY(DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())]))
因为只是为了保存展开的数据,于是我们只用定义均值计算之前的字段:
- name:string类型,姓名;
- score:float类型,分数;
- class:string类型,科目名称;
创建
刚开始时,我们让其是一个空数组,对应上定义中的ARRAY类型。
def create_accumulator(self):return []
累加
我们对科目进行遍历,进行行的拆分。即将(“张三”, 80.0, 60.0, “1”)拆解成(“张三”, 80.0, “english”)和(“张三”, 60.0, “math”)这样的两组数据。
def accumulate(self, accumulator, row):for i in self._class_keys:accumulator.append(Row(row["name"], row[i], i))
返回
类型
def get_result_type(self):return DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("avg score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())])
可以看到result_type(返回类型)和accumulator_type(累加器类型)是不一样的(也可以一样,主要看怎么计算规则)。前者比后者多了“学科年级平均分”(avg score),这就更加接近我们希望获得的最终结果。
这些字段和我们目标字段只差一个grade(年级)。因为原始表中有grade,且我们会通过grade聚类,所以最终我们可以获得这个信息,而不用在这儿定义。
需要注意的是,虽然表值类型函数返回的是一组数据(若干Row),但是这儿只是返回Row的具体定义,而不是ARRAY[Row]。
计算
def emit_value(self, accumulator):rows = []for i in self._class_keys: total = 0.0student_count = 0for y in accumulator:# y[2] y[]"class"]if i == y[2]:# y[1] y["score"]total = total + y[1]student_count = student_count + 1avg_score = total / student_countfor y in accumulator:if i == y[2]:rows.append(Row(y[0], y[1], avg_score, y[2]))for x in rows: yield x
这个函数会在最后执行,它会通过累加器中的数据计算“学科年级平均分”,然后构造和“返回类型”一直的Row到rows数组中。最后通过yeild关键字返回一个生成器,我们可以将其看成还是一组Row,即拆解后的结果。
最后我们看下结果
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | grade | name | score | avg score | class |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 1 | 张三 | 80.0 | 77.5 | english |
| +I | 1 | 李四 | 75.0 | 77.5 | english |
| +I | 1 | 张三 | 60.0 | 77.5 | math |
| +I | 1 | 李四 | 95.0 | 77.5 | math |
| +I | 2 | 王五 | 90.0 | 87.5 | english |
| +I | 2 | 赵六 | 85.0 | 87.5 | english |
| +I | 2 | 王五 | 90.0 | 80.0 | math |
| +I | 2 | 赵六 | 70.0 | 80.0 | math |
| +I | 3 | 孙七 | 60.0 | 60.0 | english |
| +I | 3 | 孙七 | 0.0 | 0.0 | math |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
10 rows in set

完整代码
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf,TableAggregateFunction
import pandas as pd
from pyflink.table.udf import UserDefinedFunction
from typing import Listclass SplitClass(TableAggregateFunction):_class_keys = ["english", "math"]def emit_value(self, accumulator):rows = []for i in self._class_keys: total = 0.0student_count = 0for y in accumulator:if i == y[2]:total = total + y[1]student_count = student_count + 1avg_score = total / student_countfor y in accumulator:if i == y[2]:rows.append(Row(y[0], y[1], avg_score, y[2]))return rowsdef create_accumulator(self):return []def accumulate(self, accumulator, row):for i in self._class_keys:accumulator.append(Row(row["name"], row[i], i))def get_accumulator_type(self):return DataTypes.ARRAY(DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())])) def get_result_type(self):return DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("avg score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())])def calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_streaming_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('english', DataTypes.FLOAT()), DataTypes.FIELD('math', DataTypes.FLOAT()), DataTypes.FIELD('grade', DataTypes.STRING())])students_score = [("张三", 80.0, 60.0, "1"),("李四", 75.0, 95.0, "1"),("王五", 90.0, 90.0, "2"),("赵六", 85.0, 70.0, "2"),("孙七", 60.0, 0.0, "3"),]tab_source = t_env.from_elements(students_score, row_type_tab_source)split_class = udtaf(SplitClass())tab_source.group_by(col('grade')) \.flat_aggregate(split_class) \.select(col('*')) \.execute().print()if __name__ == '__main__':calc()
相关文章:
0基础学习PyFlink——用户自定义函数之UDTAF
大纲 UDTAFTableAggregateFunction的实现累加器定义创建累加 返回类型计算 完整代码 在前面几篇文章中,我们分别介绍了UDF、UDTF和UDAF这三种用户自定义函数。本节我们将介绍最后一种函数:UDTAF——用户自定义表值聚合函数。 UDTAF UDTAF函数即具备了…...
SQLi靶场
SQLi靶场 less1- less2 (详细讲解) less 1 Error Based-String (字符类型注入) 思路分析 判断是否存在SQL注入 已知参数名为id,输入数值和‘ 单引号‘’ 双引号来判断,它是数值类型还是字符类型 首先输入 1 , 发现…...

重庆开放大学学子们的好帮手
作为一名电大学员,我有幸目睹了一个令人惊叹的学习工具的诞生——电大搜题微信公众号。这个创新应用为重庆开放大学(广播电视大学)的学子们提供了便捷、高效的学习资源,成为他们的得力助手。 重庆开放大学是一所为全日制在职人员提…...
机器学习-学习率:从理论到实战,探索学习率的调整策略
目录 一、引言二、学习率基础定义与解释学习率与梯度下降学习率对模型性能的影响 三、学习率调整策略常量学习率时间衰减自适应学习率AdaGradRMSpropAdam 四、学习率的代码实战环境设置数据和模型常量学习率时间衰减Adam优化器 五、学习率的最佳实践学习率范围测试循环学习率&a…...
【Vue3-Flask-BS架构Web应用】实践笔记1-使用一个bat脚本自动化完整部署环境
前言 近年来,Web开发已经成为计算机科学领域中最热门和多产的领域之一。Python和Vue.js是两个备受欢迎的工具,用于构建现代Web应用程序。在本教程中,我们将探索如何使用这两个工具来创建一个完整的Web项目。我们将完成从安装Python和Vue.js到…...

工作小计-GPU硬编以及依赖库 nvcuvidnvidia-encode
工作小计-GPU编码以及依赖库 已经是第三篇关于编解码的记录了。项目中用到GPU编码很久了,因为yuv太大,所以编码显得很重要。这次遇到的问题是环境的搭建问题。需要把开发机上的环境放到docker中,以保证docker中同样可以进行GPU的编码。 1 定…...
)
前端 JS 经典:宏任务、微任务、事件循环(EventLoop)
1. 前言概览 js 是一门单线程的非阻塞的脚本语言 单线程:只有一个主线程处理所有任务 非阻塞:有异步任务,主线程挂起这个任务,等异步返回结果再根据一定规则执行 2. 宏任务与微任务 都是异步任务宏任务:script 标签&a…...
电子邮件发送接收原理(附 go 语言实现发送邮件)
前言 首先要了解电子邮件的发送接收,不是点到点的。我想给你传达个消息,不是直接我跑到你家里喊你:“嘿,xxx,是你的益达,快拿走”。 而是类似快递的发送收取方式,是有服务器的中转的。我先将我…...
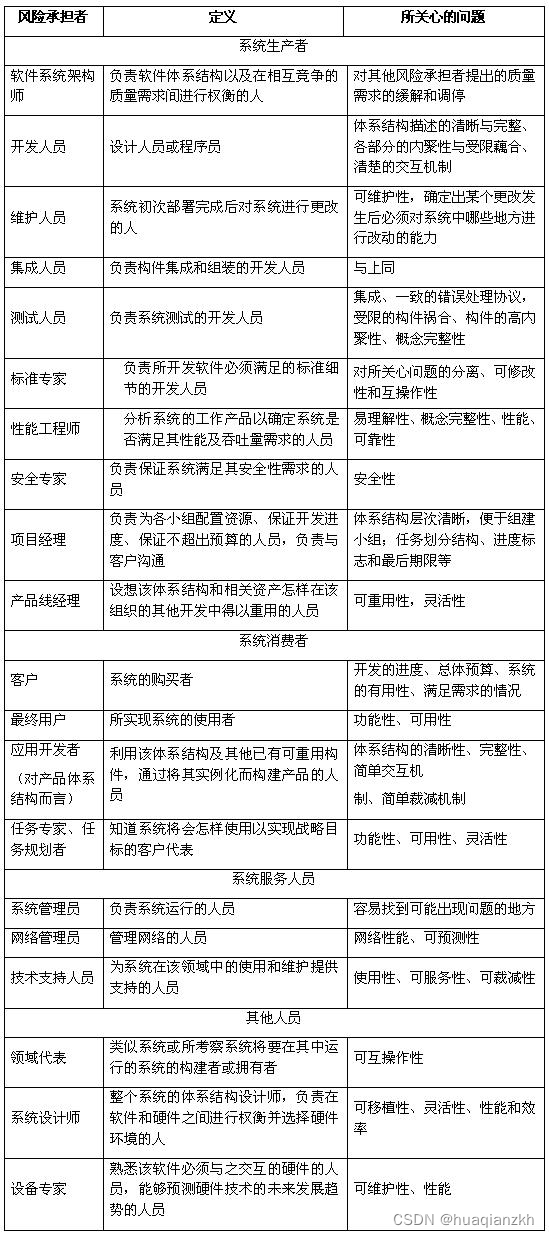
体系结构评估——(三)风险承担者
风险承担者分为系统生产者、系统消费者、系统服务人员和其他四大类。 其中系统生产者有:软件系统架构师、开发人员、维护人员、集成人员、测试人员、标准专家、 性能工程师、安全专家、项目经理、产品线经理。 系统消费者有:客户、最终用户、应用开发…...
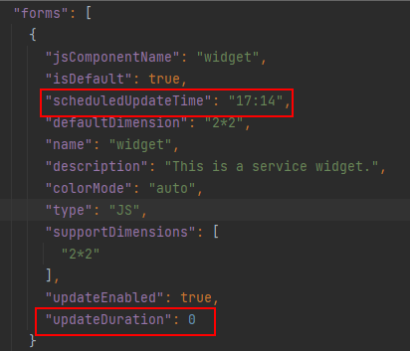
【HarmonyOS】元服务卡片展示动态数据,并定点更新卡片数据
【关键字】 元服务卡片、卡片展示动态数据、更新卡片数据 【写在前面】 本篇文章主要介绍开发元服务卡片时,如何实现卡片中动态显示数据功能,并实现定时数据刷新。本篇文章通过实现定时刷新卡片中日期数据为例,讲述展示动态数据与更新数据功…...

SaveFileDialog.OverwritePrompt
SaveFileDialog.OverwritePrompt 获取或设置一个值,该值指示如果用户指定的文件名已存在,Save As 对话框是否显示警告。 public bool OverwritePrompt { get; set; } OverwritePrompt 控制在将要在改写现在文件时是否提示用户 https://vimsky.com/…...

oracle统计信息
1. 查看表的统计信息 1.建表 SQL> create table test as select * from dba_objects;2.查看表的统计信息 select owner, table_name, num_rows, blocks, avg_row_lenfrom dba_tableswhere owner SCOTTand table_name TEST; OWNER TABLE_NAME NUM_ROWS BLO…...

LeetCode 面试题 16.01. 交换数字
文章目录 一、题目二、C# 题解 一、题目 编写一个函数,不用临时变量,直接交换 numbers [a, b] 中 a 与 b 的值。 示例: 输入: numbers [1,2] 输出: [2,1] 提示: numbers.length 2-2147483647 < numbers[i] < 214748364…...
手机apn介绍
公司遇到一件很棘手的事情,app发版之后,长江以北地方的用户网络信号很好,但是打开app之后网络连接不上,而长江以南的用户网络却很好。大家找了很多资料,提出一些方案: 1、是不是运营商把我们公司的ip给限制…...
垃圾回收系统小程序
在当今社会,废品回收不仅有利于环境保护,也有利于资源的再利用。随着互联网技术的发展,个人废品回收也可以通过小程序来实现。本文将介绍如何使用乔拓云网制作个人废品回收小程序。 1. 找一个合适的第三方制作平台/工具,比如乔拓云…...
【随机过程】布朗运动
这里写目录标题 Brownian motion Brownian motion The brownian motion 1D and brownian motion 2D functions, written with the cumsum command and without for loops, are used to generate a one-dimensional and two-dimensional Brownian motion, respectively. 使用cu…...

基于机器视觉的车道线检测 计算机竞赛
文章目录 1 前言2 先上成果3 车道线4 问题抽象(建立模型)5 帧掩码(Frame Mask)6 车道检测的图像预处理7 图像阈值化8 霍夫线变换9 实现车道检测9.1 帧掩码创建9.2 图像预处理9.2.1 图像阈值化9.2.2 霍夫线变换 最后 1 前言 🔥 优质竞赛项目系列,今天要分…...

C语言文件读写,文件相关操作
文章目录 C语言文件读写,文件相关操作1.C语言万物皆是地址,文件读操作2.文件的写3.文件的复制4.获取文件的大小5.文件的加密解密 C语言文件读写,文件相关操作 1.C语言万物皆是地址,文件读操作 // // Created by MagicBook on 20…...

竞赛选题 深度学习卷积神经网络的花卉识别
文章目录 0 前言1 项目背景2 花卉识别的基本原理3 算法实现3.1 预处理3.2 特征提取和选择3.3 分类器设计和决策3.4 卷积神经网络基本原理 4 算法实现4.1 花卉图像数据4.2 模块组成 5 项目执行结果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基…...

CMake教程 - basic point
CMake教程 - basic point 1 - Building a Basic Project 最基本的CMake项目是由单个源代码文件构建的可执行文件。对于像这样简单的项目,只需要一个带有三个命令的CMakeLists.txt文件。 注意:尽管CMake支持大写、小写和混合大小写命令,但小…...

Figma设计稿自动化生成Markdown文档:从API调用到CI/CD集成
1. 项目概述:从设计稿到结构化文档的自动化桥梁如果你是一名前端开发者、产品经理或是UI设计师,一定经历过这样的场景:Figma里精心打磨的设计稿终于定稿,接下来需要将其转化为开发文档、产品需求文档或者设计规范文档。这个过程&a…...

OpenAI GPT Image 2文字准确率95%,企业视觉硬核生产力4大核心升级与商业落地路径
GPT Image 2的4大核心升级能力1. 文字渲染准确率接近95%,多语言直出即用过去用AI生图,最头疼的就是文字。写个中文标题,十次有八次是乱码,英文稍微长一点也会出错。而GPT Image 2的文字渲染准确率做到了接近95%,支持中…...

RT-Thread SMP启动流程深度解析:从多核同步到调度就绪
1. 项目概述:从单核到多核,RT-Thread的启动逻辑变迁如果你是从RT-Thread 3.x版本一路用过来的老用户,或者刚开始接触RT-Thread 4.x,可能会发现一个显著的变化:启动流程变“复杂”了。以前,一个main函数或者…...

TMP006红外热电堆传感器:从塞贝克效应到Arduino/Python实战应用
1. 项目概述:从“摸”到“看”的温度测量革命在嵌入式开发和物联网项目中,温度测量是个再常见不过的需求。传统上,我们习惯用DS18B20这类接触式传感器,需要把探头紧贴被测物体,甚至用导热硅脂来确保热传导。但有些场景…...

Nuxt.js Tailwind CSS 模块:零配置快速启动现代Web开发
Nuxt.js Tailwind CSS 模块:零配置快速启动现代Web开发 【免费下载链接】tailwindcss Tailwind CSS module for Nuxt 项目地址: https://gitcode.com/gh_mirrors/tai/tailwindcss Nuxt.js Tailwind CSS 模块是一个专为Nuxt框架设计的Tailwind CSS集成解决方案…...

暗黑3终极按键助手D3KeyHelper:图形化配置解放你的双手
暗黑3终极按键助手D3KeyHelper:图形化配置解放你的双手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑破坏神3中繁琐的技能按…...
)
为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败?——2024最新L10n兼容性白皮书首发(附实测RTT延迟对比数据)
更多请点击: https://intelliparadigm.com 第一章:为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败? ElevenLabs 官方文档明确声明支持僧伽罗文(Sinhala),但实际部署中,斯里兰卡本地政…...

番茄小说下载器:从网页到电子书的完整离线阅读解决方案
番茄小说下载器:从网页到电子书的完整离线阅读解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款基于Rust语言开发的开源工具ÿ…...

Linux服务器安全基线自动化实践:基于Ansible的加固方案
1. 项目概述与核心价值“安全加固”这个词,对于任何一个负责线上系统运维、应用部署或者个人服务器管理的朋友来说,都绝不陌生。它就像给自家房子装防盗门、安监控一样,是基础且必要的工作。然而,现实情况往往是:我们面…...

终极NGA论坛浏览体验优化指南:5分钟打造你的专属摸鱼神器
终极NGA论坛浏览体验优化指南:5分钟打造你的专属摸鱼神器 【免费下载链接】NGA-BBS-Script NGA论坛增强脚本,给你完全不一样的浏览体验 项目地址: https://gitcode.com/gh_mirrors/ng/NGA-BBS-Script 还在为NGA论坛繁杂的界面和低效的浏览体验烦恼…...