强化学习------PPO算法
目录
- 简介
- 一、PPO原理
- 1、由On-policy 转化为Off-policy
- 2、Importance Sampling(重要性采样)
- 3、off-policy下的梯度公式推导
- 二、PPO算法两种形式
- 1、PPO-Penalty
- 2、PPO-Clip
- 三、PPO算法实战
- 四、参考
简介
PPO 算法之所以被提出,根本原因在于 Policy Gradient 在处理连续动作空间时 Learning rate 取值抉择困难。
Learning rate 取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。除此之外,Policy Gradient 因为在线学习的性质,进行迭代策略时原先的采样数据无法被重复利用,每次迭代都需要重新采样;
同样地置信域策略梯度算法(Trust Region Policy Optimization,TRPO)虽然利用重要性采样(Important-sampling)、共轭梯度法求解提升了样本效率、训练速率等,但在处理函数的二阶近似时会面临计算量过大,以及实现过程复杂、兼容性差等缺陷。
而PPO 算法具备 Policy Gradient、TRPO 的部分优点,采样数据和使用随机梯度上升方法优化代替目标函数之间交替进行,虽然标准的策略梯度方法对每个数据样本执行一次梯度更新,但 PPO 提出新目标函数,可以实现小批量更新。
PPO 算法可依据 Actor 网络的更新方式细化为:
- 含有自适应 KL-散度
(KL Penalty)的 PPO-Penalty - 含有
Clippped Surrogate Objective函数的 PPO-Clip
下面我们一次介绍PPO算法的基本原理,以及 PPO-Penalty 和PPO-Clip两种形式的PPO算法
一、PPO原理
1、由On-policy 转化为Off-policy
- 如果被训练的
agent和与环境做互动的agent(生成训练样本)是同一个的话,那么叫做on-policy(同策略)。 - 如果被训练的
agent和与环境做互动的agent(生成训练样本)不是同一个的话,那么叫做off-policy(异策略)。
PPO算法是在Policy Gradient算法的基础上由来的,Policy Gradient是一种on-policy的方法,他首先要利用现有策略和环境互动,产生学习资料,然后利用产生的资料,按照Policy Gradient的方法更新策略参数。然后再用新的策略去交互、更新、交互、更新,如此重复。这其中有很多的时间都浪费在了产生资料的过程中,所以我们应该让PPO算法转化为Off-Policy。
Off-Policy的目的就是更加充分的利用actor产生的交互资料,增加学习效率。
2、Importance Sampling(重要性采样)
重要性采样(Importance Sampling)推导过程
Importance Sampling 是一种用于估计在一个分布下的期望值的方法。在强化学习中,我们需要估计由当前策略产生的样本的值函数,然后利用该估计值来优化策略。然而,在训练过程中,我们通常会使用一些已经训练好的旧策略来采集样本,而不是使用当前的最新策略。这就导致了采样样本和当前策略不匹配的问题,也就是所谓的“策略偏移”。
为什么要在PPO算法中使用Importance Sampling?
我们看一下Policy Gradient的梯度公式:
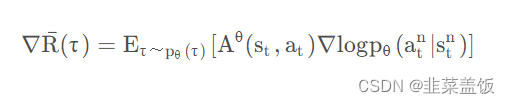
问题在于上面的式子是基于 τ ~ p θ ( τ ) τ ~p_θ (τ) τ~pθ(τ)采样的,一旦更新了参数,从θ到θ ′ ,这个概率 P θ P_{\theta} Pθ就不对了。而Importance Sampling解决的正是从 τ ~ p θ ( τ ) \tau~p_\theta(\tau) τ~pθ(τ)采样,计算θ '的 ∇ R ˉ ( τ ) \nabla\bar{R}(\tau) ∇Rˉ(τ)的问题。
重要性采样(Importance Sampling)推导过程的推导可以点击链接查看,这里直接给出公式:
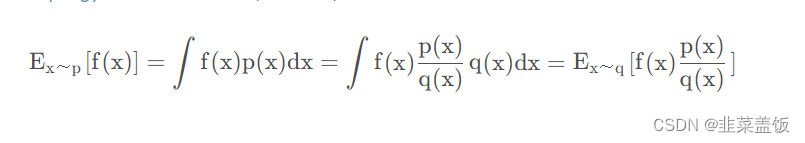
上面的式子表示,已知x服从分布p,我们要计算f(x),但是p不方便采样,我们就可以通过q去采样,计算期望。
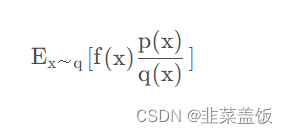
这里我们用q做采样, p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)叫做重要性权重,用来修正q与p两个分布的差异。理论上利用重要性采样的方法我们可以用任何q来完成采样,但是由于采样数量的限制,q与p的差异不能太大。如果差异过大 E x ~ q [ f ( x ) p ( x ) q ( x ) ] E _{x~q} [f(x) \frac{p(x)}{q(x)} ] Ex~q[f(x)q(x)p(x)]与 E x ~ q [ f ( x ) ] E _{x~q} [f(x) ] Ex~q[f(x)]的差异也会很大。
3、off-policy下的梯度公式推导
在on-policy情况下,Policy Gradient公式为:
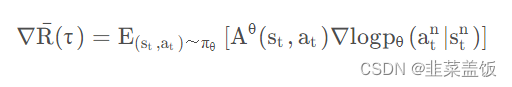
由上面的推导可得,我们利用 θ ′ \theta' θ′ ,优化 θ \theta θ时的公式为:
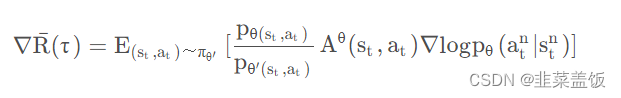
其中 A θ ( s t , a t ) A^{\theta}(s_t, a_t) Aθ(st,at)为比较优势,从该项的推导过程可以知道,它是由采样样本决定的,所以应该用 A θ ′ ( s t , a t ) A^{\theta'}(s_t, a_t) Aθ′(st,at)表示,所以式子变为:
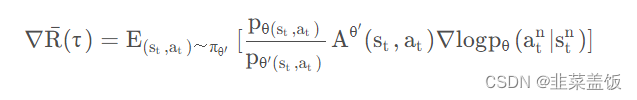
将 p θ ( s t , a t ) p_{\theta(s_t,a_t)} pθ(st,at) 展开可得:
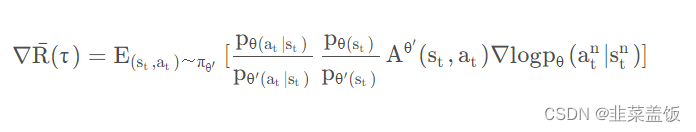
我们认为某一个状态 s t s_t st出现的概率与策略函数无关,只与环境有关,所以可以认为 p θ ( s t ) ≈ p θ ′ ( s t ) p_{\theta(s_t)} \approx p_{\theta'(s_t)} pθ(st)≈pθ′(st),由此得出如下公式:
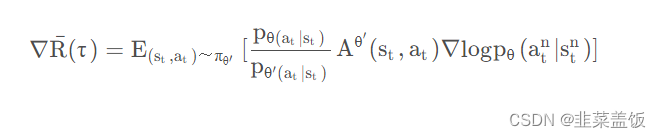
根据上面的式子,我们就可以完成off-policy的工作,反推出目标函数为:
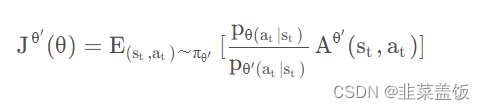
二、PPO算法两种形式
1、PPO-Penalty
PPO-Penalty 基于 KL散度惩罚项优化目标函数。
PPO-Penalty 的主要思想是将非负约束视为一种奖惩机制。具体来说,当一个行为不符合约束条件(比如动作小于0)时,我们会对策略进行惩罚。这种惩罚采用了一种类似于强化学习中的奖励机制的方式,即在损失函数中引入一个 penalty term。
例如,在 PPO-Penalty 中,我们可以将惩罚项添加到 PPO 算法的损失函数中,可以是在 KL 散度约束项的后面添加一个 penalty term 或者在损失函数中添加一个额外的 penalty term。这个 penalty term 会根据动作的非负性来惩罚那些不符合约束条件的行为,从而强制策略学会产生符合约束条件的行为。
用拉格朗日乘数法直接将KL散度的限制放入目标函数,变成一个无约束的优化问题。同时还需要更新KL散度的系数。
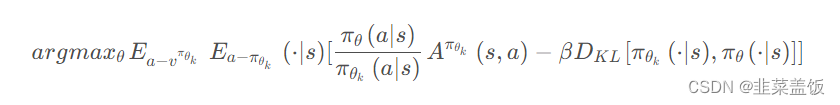
令 d k = D K L v π θ k [ π θ k ( ⋅ ∣ s ) , π θ ( ⋅ ∣ s ) ] d_k=D^{v^{\pi_{\theta_k}}}_{KL}[\pi_{\theta_k}(\cdot|s), \pi_{\theta}(\cdot|s)] dk=DKLvπθk[πθk(⋅∣s),πθ(⋅∣s)]
- 如果 d k < δ / 1.5 d_k < \delta /1.5 dk<δ/1.5, 那么 β k + 1 = β k / 2 \beta_{k+1} = \beta_k/2 βk+1=βk/2
- 如果 d k > δ ∗ 1.5 d_k > \delta *1.5 dk>δ∗1.5, 那么 β k + 1 = β k / 2 \beta_{k+1} = \beta_k/2 βk+1=βk/2
- 否则 β k + 1 = β k \beta_{k+1} = \beta_k βk+1=βk
相对PPO-Clip来说计算还是比较复杂,我们在之后的例子使用PPO-Clip
2、PPO-Clip
PPO-Clip 的目标是在优化策略的同时,控制策略更新的幅度,以避免更新过大导致策略发生剧烈变化。这可以提供算法的稳定性,并且有助于收敛到一个比较好的策略。
具体来说,PPO-Clip 在优化过程中使用一个剪切函数来限制新旧策略之间的差异。这个剪切函数用于计算出新旧策略在每个动作样本上的比例,并将其与一个预先设定的范围进行比较。
剪切函数使用的是一个剪切比例,通常表示为 clip_ratio,它是一个介于0和1之间的数值。比如,如果 clip_ratio 设置为0.2,那么在计算新旧策略比例时,会将比例限制在0.8到1.2之间。
使用剪切函数,PPO-Clip 有两个重要的优点:
- 剪切目标:
PPO-Clip使用剪切函数来确保新策略更新不超过一个预定的范围,从而避免了过大的策略变化。这可以防止策略的不稳定性和发散,同时保证算法的收敛性。 - 改进策略更新:
PPO-Clip可以通过剪切目标的方式改进策略更新的效果。在优化过程中,通过比较新旧策略在每个样本上的比例,并选择较小的那个,可以保留原始策略中已经表现良好的部分,从而提高策略的稳定性和性能。
PPO-Clip直接在目标函数中进行限制,保证新的参数和旧的参数的差距不会太大。
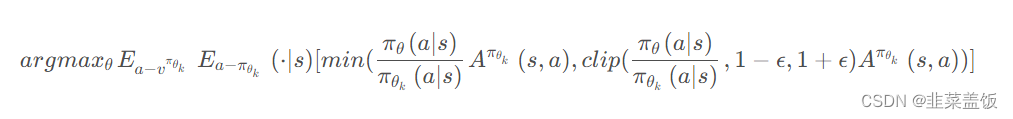
本质就是将新旧动作的差异限定在 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ]。
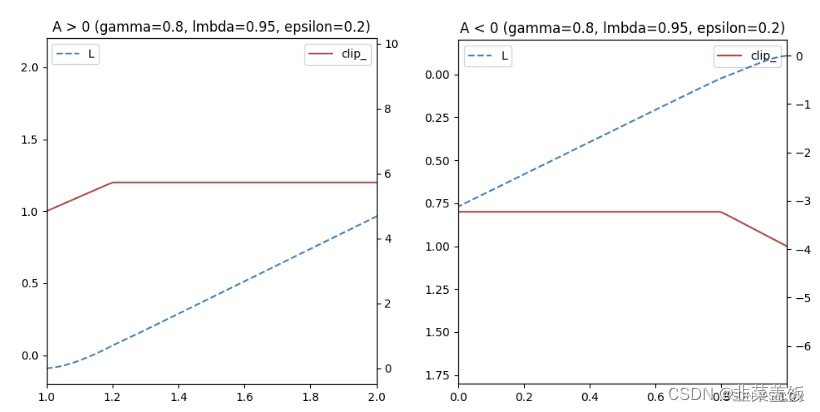
如果A > 0,说明这个动作的价值高于平均,最大化这个式子会增大 π θ ( a ∣ s ) π θ k ( a ∣ s ) \frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)} πθk(a∣s)πθ(a∣s)但是不会让超过 1 + ϵ 1+\epsilon 1+ϵ。反之,A<0,最大化这个式子会减少 π θ ( a ∣ s ) π θ k ( a ∣ s ) \frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)} πθk(a∣s)πθ(a∣s)但是不会让超过 1 − ϵ 1-\epsilon 1−ϵ
可以简单绘制如下:
算法流程如下:

三、PPO算法实战
PPO-Clip更加简洁,同时大量的实验也表名PPO-Clip总是比PPO-Penalty 效果好。所以我们就用PPO-Clip算法进行代码实战。
我们使用使用的环境是OpenAI gym中的CartPole-v0环境
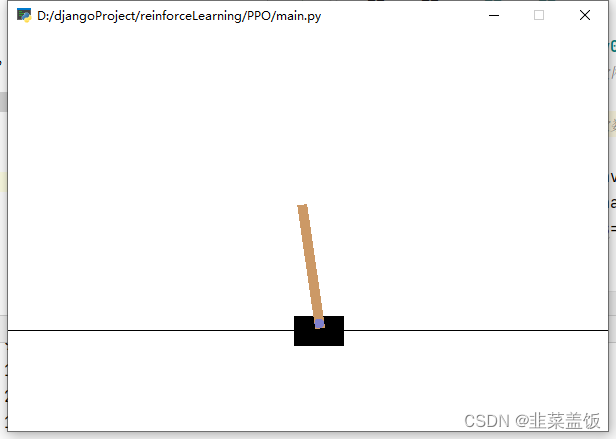
代码解释可以看代码中的注释,这里不再赘述
ppo_torch.py
import os
import numpy as np
import torch as T
import torch.nn as nn
import torch.optim as optim
from torch.distributions.categorical import Categoricalclass PPOMemory:"""经验池"""def __init__(self, batch_size):self.states = []self.probs = []self.vals = []self.actions = []self.rewards = []self.dones = []self.batch_size = batch_sizedef generate_batches(self):n_states = len(self.states)batch_start = np.arange(0, n_states, self.batch_size)indices = np.arange(n_states, dtype=np.int64)np.random.shuffle(indices)batches = [indices[i:i + self.batch_size] for i in batch_start]return np.array(self.states), \np.array(self.actions), \np.array(self.probs), \np.array(self.vals), \np.array(self.rewards), \np.array(self.dones), \batchesdef store_memory(self, state, action, probs, vals, reward, done):self.states.append(state)self.actions.append(action)self.probs.append(probs)self.vals.append(vals)self.rewards.append(reward)self.dones.append(done)def clear_memory(self):self.states = []self.probs = []self.actions = []self.rewards = []self.dones = []self.vals = []class ActorNetwork(nn.Module):"""构建策略网络--actor"""def __init__(self, n_actions, input_dims, alpha,fc1_dims=256, fc2_dims=256, chkpt_dir='tmp/ppo'):super(ActorNetwork, self).__init__()self.checkpoint_file = os.path.join(chkpt_dir, 'actor_torch_ppo')self.actor = nn.Sequential(nn.Linear(*input_dims, fc1_dims),nn.ReLU(),nn.Linear(fc1_dims, fc2_dims),nn.ReLU(),nn.Linear(fc2_dims, n_actions),nn.Softmax(dim=-1))self.optimizer = optim.Adam(self.parameters(), lr=alpha)self.device = T.device('cuda:0' if T.cuda.is_available() else 'cpu')self.to(self.device)def forward(self, state):"""返回动作的概率分布:param state::return:"""dist = self.actor(state)dist = Categorical(dist)return dist # 返回动作的概率分布def save_checkpoint(self):"""保存模型:return:"""T.save(self.state_dict(), self.checkpoint_file)def load_checkpoint(self):"""加载模型:return:"""self.load_state_dict(T.load(self.checkpoint_file))class CriticNetwork(nn.Module):"""构建价值网络--critic"""def __init__(self, input_dims, alpha, fc1_dims=256, fc2_dims=256,chkpt_dir='tmp/ppo'):super(CriticNetwork, self).__init__()self.checkpoint_file = os.path.join(chkpt_dir, 'critic_torch_ppo')self.critic = nn.Sequential(nn.Linear(*input_dims, fc1_dims),nn.ReLU(),nn.Linear(fc1_dims, fc2_dims),nn.ReLU(),nn.Linear(fc2_dims, 1))self.optimizer = optim.Adam(self.parameters(), lr=alpha)self.device = T.device('cuda:0' if T.cuda.is_available() else 'cpu')self.to(self.device)def forward(self, state):value = self.critic(state)return valuedef save_checkpoint(self):"""保存模型:return:"""T.save(self.state_dict(), self.checkpoint_file)def load_checkpoint(self):"""加载模型:return:"""self.load_state_dict(T.load(self.checkpoint_file))class Agent:def __init__(self, n_actions, input_dims, gamma=0.99, alpha=0.0003, gae_lambda=0.95,policy_clip=0.2, batch_size=64, n_epochs=10):self.gamma = gammaself.policy_clip = policy_clipself.n_epochs = n_epochsself.gae_lambda = gae_lambda# 实例化策略网络self.actor = ActorNetwork(n_actions, input_dims, alpha)# 实例化价值网络self.critic = CriticNetwork(input_dims, alpha)# 实例化经验池self.memory = PPOMemory(batch_size)def remember(self, state, action, probs, vals, reward, done):"""记录轨迹:param state::param action::param probs::param vals::param reward::param done::return:"""self.memory.store_memory(state, action, probs, vals, reward, done)def save_models(self):print('... saving models ...')self.actor.save_checkpoint()self.critic.save_checkpoint()def load_models(self):print('... loading models ...')self.actor.load_checkpoint()self.critic.load_checkpoint()def choose_action(self, observation):"""选择动作:param observation::return:"""# 维度变换 [n_state]-->tensor[1,n_states]state = T.tensor([observation], dtype=T.float).to(self.actor.device)# 当前状态下,每个动作的概率分布 [1,n_states]dist = self.actor(state)# 预测,当前状态的state_value [b,1]value = self.critic(state)# 依据其概率随机挑选一个动作action = dist.sample()probs = T.squeeze(dist.log_prob(action)).item()action = T.squeeze(action).item()value = T.squeeze(value).item()return action, probs, valuedef learn(self):# 每次学习需要更新n_epochs次参数for _ in range(self.n_epochs):# 提取数据集state_arr, action_arr, old_prob_arr, vals_arr, \reward_arr, dones_arr, batches = \self.memory.generate_batches()values = vals_arradvantage = np.zeros(len(reward_arr), dtype=np.float32)# 计算优势函数for t in range(len(reward_arr) - 1): # 逆序时序差分值 axis=1轴上倒着取 [], [], []discount = 1a_t = 0for k in range(t, len(reward_arr) - 1):a_t += discount * (reward_arr[k] + self.gamma * values[k + 1] * \(1 - int(dones_arr[k])) - values[k])discount *= self.gamma * self.gae_lambdaadvantage[t] = a_tadvantage = T.tensor(advantage).to(self.actor.device)# 估计状态的值函数的数组values = T.tensor(values).to(self.actor.device)for batch in batches:# 获取数据states = T.tensor(state_arr[batch], dtype=T.float).to(self.actor.device)old_probs = T.tensor(old_prob_arr[batch]).to(self.actor.device)actions = T.tensor(action_arr[batch]).to(self.actor.device)# 用当前网络进行预测dist = self.actor(states)critic_value = self.critic(states)critic_value = T.squeeze(critic_value)# 每一轮更新一次策略网络预测的状态new_probs = dist.log_prob(actions)# 新旧策略之间的比例prob_ratio = new_probs.exp() / old_probs.exp()# prob_ratio = (new_probs - old_probs).exp()# 近端策略优化裁剪目标函数公式的左侧项weighted_probs = advantage[batch] * prob_ratio# 公式的右侧项,ratio小于1-eps就输出1-eps,大于1+eps就输出1+epsweighted_clipped_probs = T.clamp(prob_ratio, 1 - self.policy_clip,1 + self.policy_clip) * advantage[batch]# 计算损失值进行梯度下降actor_loss = -T.min(weighted_probs, weighted_clipped_probs).mean()returns = advantage[batch] + values[batch]critic_loss = (returns - critic_value) ** 2critic_loss = critic_loss.mean()total_loss = actor_loss + 0.5 * critic_lossself.actor.optimizer.zero_grad()self.critic.optimizer.zero_grad()total_loss.backward()self.actor.optimizer.step()self.critic.optimizer.step()self.memory.clear_memory()main.py
import gym
import numpy as np
from ppo_torch import Agent
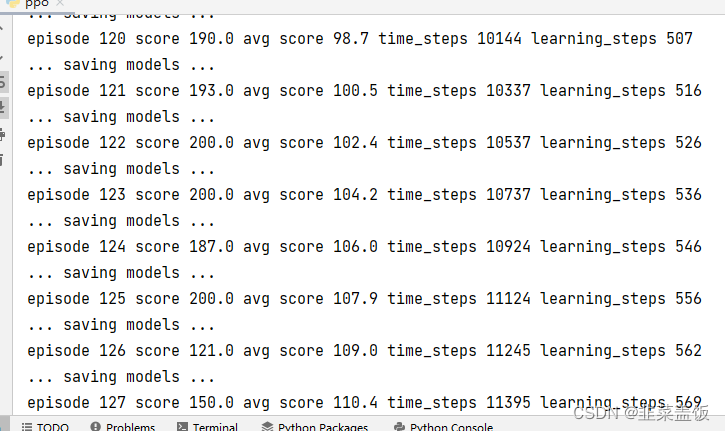
from utils import plot_learning_curveif __name__ == '__main__':print('开始训练!')env = gym.make('CartPole-v0')# 每经过N步就更新一次网络N = 20batch_size = 5# 每次更新的次数n_epochs = 4# 学习率alpha = 0.0003# 初始化智能体agent = Agent(n_actions=env.action_space.n, batch_size=batch_size,alpha=alpha, n_epochs=n_epochs,input_dims=env.observation_space.shape)# 训练轮数n_games = 300# 统计图figure_file = 'plots/cartpole.png'# 存储最佳得分best_score = env.reward_range[0]# 存储历史分数score_history = []# 更新网络的次数learn_iters = 0# 每一轮的得分avg_score = 0# 总共在环境中走的步数n_steps = 0# 开始玩游戏for i in range(n_games):observation = env.reset()done = Falsescore = 0while not done:action, prob, val = agent.choose_action(observation)observation_, reward, done, info = env.step(action)env.render()n_steps += 1score += reward# 存储轨迹agent.remember(observation, action, prob, val, reward, done)if n_steps % N == 0:# 更新网络agent.learn()learn_iters += 1observation = observation_score_history.append(score)avg_score = np.mean(score_history[-100:])# 比较最佳得分 保存最优的策略if avg_score > best_score:best_score = avg_scoreagent.save_models()print('episode', i, 'score %.1f' % score, 'avg score %.1f' % avg_score,'time_steps', n_steps, 'learning_steps', learn_iters)x = [i+1 for i in range(len(score_history))]plot_learning_curve(x, score_history, figure_file)画图工具
utils.py
import numpy as np
import matplotlib.pyplot as pltdef plot_learning_curve(x, scores, figure_file):running_avg = np.zeros(len(scores))for i in range(len(running_avg)):running_avg[i] = np.mean(scores[max(0, i-100):(i+1)])plt.plot(x, running_avg)plt.title('Running average of previous 100 scores')plt.savefig(figure_file)
效果如下:

四、参考
PPO实践(Pendulum-v1)
PyTorch实现PPO代码
PPO 模型解析,附Pytorch完整代码
详解+推导!!PPO 近端策略优化
Policy Gradient 策略梯度法
蒙特卡洛方法、接受拒绝采样、重要性采样、MCMC方法
机器学习:KL散度详解
相关文章:
强化学习------PPO算法
目录 简介一、PPO原理1、由On-policy 转化为Off-policy2、Importance Sampling(重要性采样)3、off-policy下的梯度公式推导 二、PPO算法两种形式1、PPO-Penalty2、PPO-Clip 三、PPO算法实战四、参考 简介 PPO 算法之所以被提出,根本原因在于…...
express框架)
node(三)express框架
文章目录 1.express介绍2.express初体验3.express路由3.1什么是路由?3.2路由的使用 1.express介绍 是一个基于Node平台的极简、灵活的WEB应用开发框架,官网地址:https://www.expressjs.com.cn/ 简单来说,express是一个封装好的工…...

linux find命令搜索日志内容
linux find命令搜索日志内容 查询服务器log日志 find /opt/logs/ -name "filename.log" | xargs grep -a "这里是要查询的字符"加上-a 是为了不报查出 binary 的错 服务器会返回 包含所查字符的整行日志信息...

CentOS 编译安装TinyXml2
安装 TinyXml2 Git 源码下载地址:https://github.com/leethomason/tinyxml2 步骤1:首先,你需要下载tinyxml2的源代码。你可以从Github或者源代码官方网站下载。并上传至/usr/local/source_code/ 步骤2:下载完成后,需要将源代码解…...

竞赛选题 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的人体跌倒检测算法研究与实现 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满…...

使用gson将复杂的树型结构转Json遇到的问题,写入文件为空
某个项目需要用到一个较为复杂的数据结构。定义成一个树型链表。 public class TreeNode { private String name; public String getName() { return name; } public void setName(String name) { this.name name; } public String getPartType() { retur…...

JavaScript异步编程:提升性能与用户体验
目录 什么是异步编程? 回调函数 Promise Async/Await 总结 在Web开发中,处理耗时操作是一项重要的任务。如果我们在执行这些操作时阻塞了主线程,会导致页面失去响应,用户体验下降。JavaScript异步编程则可以解决这个问题&…...
lossBN
still tips for learning classification and regression关于softmax的引入和作用分类问题损失函数 - MSE & Cross-entropy⭐Batch Normalization(BN)⭐想法:直接改error surface的landscape,把山铲平feature normalization那…...

【微信小程序】数字化会议OA系统之投票模块(附源码)
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《微信小程序开发实战》。🎯Ἲ…...

clang-前端插件-给各种无花括号的“块”加花括号-基于llvm15--clang-plugin-add-brace
处理的语句 case 术语约定或备忘 case起止范围: 从冒号到下一个’case’开头, 简称有: case内 、case内容Ast: Abstract syntax tree: 抽象语法树没插入花括号的case 若case内, 以下任一条成立,则 跳过该case 即 不会对该case内容用花括号包裹. 有#define、有#include、有…...
实例小记)
python爬虫-某政府网站加速乐(简单版)实例小记
# -*- coding:utf-8 -*- # Time : 2023/10/23 17:06 # Author: 水兵没月 # File : 哈哈哈哈.py # Software: PyCharm ####################import random import requests# 代理 def get_proxy(proxy_typerandom.choice([1,2,3,4,5])):url "http://ZZZZZZZZZZZZZZZZZZ&qu…...
stable diffusion简介和原理
Stable Diffusion中文的意思是稳定扩散,本质上是基于AI的图像扩散生成模型。 Stable Diffusion是一个引人注目的深度学习模型,它使用潜在扩散过程来生成图像,允许模型在生成图像时考虑到文本的描述。这个模型的出现引起了广泛的关注和讨论&am…...
【机器学习】模型平移不变性/等变性归纳偏置Attention机制
Alphafold2具有旋转不变性吗——从图像识别到蛋白结构预测的旋转对称性实现 通过Alphafold2如何预测蛋白质结构,看有哪些机制或tricks可以利用? 一、等变Transformer 等变Transformer是Transformer众多变体的其中一种,其强调等变性。不变性…...
c++的4中类型转换操作符(static_cast,reinterpret_cast,dynamic_cast,const_cast),RTTI
目录 引入 介绍 static_cast 介绍 使用 reinterpret_cast 介绍 使用 const_cast 介绍 使用 dynamic_cast 介绍 使用 RTTI(运行时确定类型) 介绍 typeid运算符 dynamic_cast运算符 type_info类 引入 原本在c中,我们就已经接触到了很多类型转换 -- 隐式类型转…...
)
CNN实现与训练--------------以cifar10数据集为例进行演示(基于Tensorflow)
本文以cifar10数据集为例进行演示 (cifar10数据集有5万张3232像素点的彩色图片,用于训练有1万张3232像素点的彩色图片,用于测试) import tensorflow as tf import os import numpy as np from matplotlib import pyplot as plt from tensorflow.keras.layers import Conv2…...

YOLOv5算法改进(21)— 添加CA注意力机制 + 更换Neck网络之BiFPN + 更换损失函数之EIoU
前言:Hello大家好,我是小哥谈。通过上节课的学习,相信同学们一定了解了组合改进的核心。本节课开始,就让我们结合论文来对YOLOv5进行组合改进(添加CA注意力机制+更换Neck网络之BiFPN+更换损失函数之EIoU),希望同学们学完本节课可以有所启迪,并且后期可以自行进行YOLOv5…...

面对6G时代 适合通信专业的 毕业设计题目
对于通信专业的本科生来说,选择一个与学习内容紧密相关的毕业设计题目十分重要。 以下是东枫科技建议的题目,它们涵盖了通信技术的不同方面: 高校老师可以申请东枫科技工程师共同对学生指导,完成毕业设计。 基于5G/6G的通信技术…...
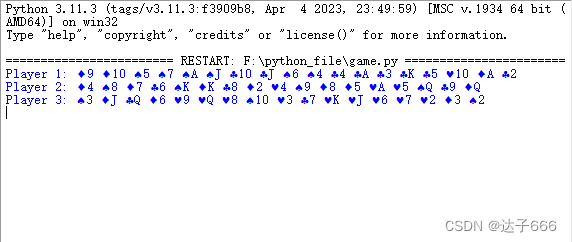
使用Python实现一个简单的斗地主发牌
使用Python实现一个简单的斗地主发牌 1.源代码实现2.实现效果 1.源代码实现 import random# 定义扑克牌的花色和大小 suits [♠, ♥, ♣, ♦] ranks [2, 3, 4, 5, 6, 7, 8, 9, 10, J, Q, K, A]# 初始化一副扑克牌 deck [suit rank for suit in suits for rank in ranks]# …...
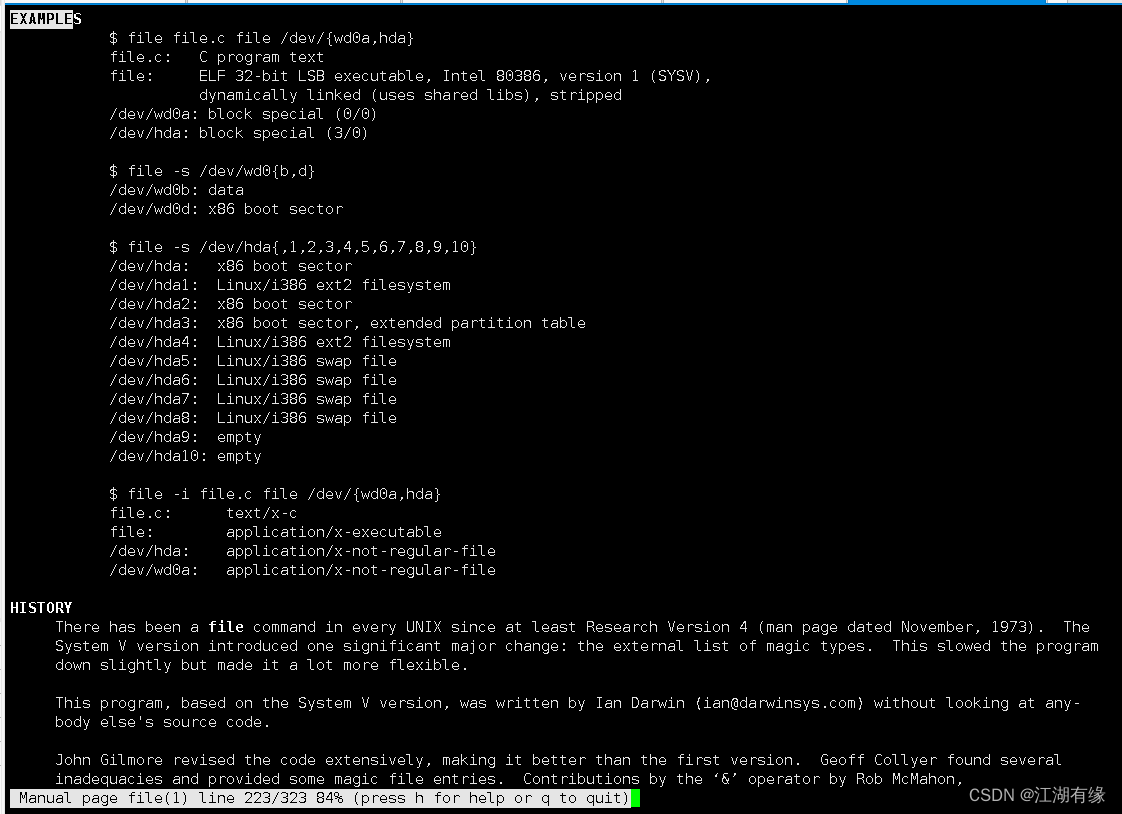
Linux系统之file命令的基本使用
Linux系统之file命令的基本使用 一、file命令介绍1.1 Linux简介1.2 file命令简介 二、file命令的使用帮助2.1 file命令的help帮助信息2.2 file命令的语法解释2.3 file命令的man手册 三、文件类型介绍四、file命令的基本使用4.1 查询file版本4.2 显示文件类型4.3 输出时不显示文…...

【智能大数据分析】实验1 MapReduce实验:单词计数
【智能大数据分析】实验1 MapReduce实验:单词计数 文章目录 【智能大数据分析】实验1 MapReduce实验:单词计数一、实验目的二、实验要求三、实验原理1 MapReduce编程2 Java API解析 四、实验步骤1 启动Hadoop2 验证HDFS上没有wordcount的文件夹3 上传数据…...

当Cox回归的比例风险假定被违背时,除了时依协变量还能怎么办?
当Cox回归的比例风险假定被违背时的五维解决方案 在生存分析领域,Cox比例风险模型因其半参数特性和对基准风险函数形式不做假设的优势,成为医学研究、工程可靠性分析等领域的标配工具。但当这个金标准遇到比例风险假定(PH假定)被违背的情况时,…...

桌面级机械臂DIY全攻略:从运动学建模到PID控制实战
1. 项目概述:一个桌面级机械臂的诞生最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“ClawPuter”。光看名字,你可能会有点摸不着头脑,Claw是爪子,Puter是计算机,合起来是“爪式计算机”&am…...

Cursor智能体学习工具:构建专属AI编程知识库的完整指南
1. 项目概述:一个为开发者量身定制的Cursor智能体学习工具如果你是一名开发者,并且最近正在尝试使用Cursor这款AI编程工具,那么你很可能和我一样,经历过一个既兴奋又有点迷茫的阶段。Cursor的强大毋庸置疑,它能理解上下…...

基于全志T527开发板的手势识别:OpenCV部署与轮廓匹配实战
1. 项目概述与硬件平台选择最近在做一个嵌入式视觉项目,需要在一块开发板上实现实时的手势识别功能。选型时,我重点考察了算力、接口丰富度和社区支持。最终,米尔电子的MYD-LT527开发板进入了我的视线。这块板子核心是全志T527处理器…...

Claude思维拟真度已达人类青少年水平?斯坦福HAI联合实测数据+5项认知心理学验证指标
更多请点击: https://intelliparadigm.com 第一章:Claude思维拟真度已达人类青少年水平?斯坦福HAI联合实测数据5项认知心理学验证指标 实验设计与评估框架 斯坦福大学以人为本人工智能研究院(HAI)联合加州大学伯克利…...
全攻略)
手把手教你配置Jitsi Meet的.env文件:从安全密码生成到Nginx反代(含SSL证书)全攻略
Jitsi Meet生产级部署实战:安全配置与Nginx反代全解析 当内部测试的Jitsi Meet需要面向公网提供服务时,.env文件的精细配置与Nginx反向代理的深度整合就成为关键分水岭。许多团队在过渡阶段常遇到视频卡顿、安全漏洞或证书配置错误等问题,本…...

5分钟掌握百度网盘高速下载神器:完全免费的开源解析工具终极指南
5分钟掌握百度网盘高速下载神器:完全免费的开源解析工具终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘非会员下载速度只有几十KB而烦恼吗…...
注入失败,除了配置文件还有这8个地方要检查)
SpringBoot新手避坑:@Value(“${xxx}“)注入失败,除了配置文件还有这8个地方要检查
SpringBoot配置注入深度排查:当Value("${xxx}")失效时的8个关键检查点 刚接触SpringBoot的开发者往往会被其"约定优于配置"的理念所吸引,直到在控制台看到那个令人困惑的Could not resolve placeholder错误。这个看似简单的配置问题…...

别再为OSGB数据导入SuperMap iDesktop发愁了!手把手教你搞定倾斜摄影配置文件生成与常见报错
三维GIS实战:从OSGB到SuperMap iDesktop的完整避坑指南 当无人机航拍的倾斜摄影数据第一次在SuperMap iDesktop中成功加载时,那种从二维平面跃入三维空间的震撼感,是每个GIS从业者都难忘的体验。然而,这份喜悦往往被配置文件生成失…...

如何用 curl 命令快速测试 Taotoken 的 API 是否连通
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用 curl 命令快速测试 Taotoken 的 API 是否连通 在接入大模型服务时,直接使用 curl 命令测试 API 是最基础、最直…...