【ARM Cortex-M 系列 4 番外篇 -- 常用 benchmark 介绍】
文章目录
- 1.1 CPU 性能测试 MIPS 计算
- 1.1.1 Cortex-M7 CPI
- 1.2 benchmark 小节
- 1.3.1 Geekbenck 介绍
- 1.3 编译参数配置
1.1 CPU 性能测试 MIPS 计算
每秒百万指令数 (MIPS):在数据压缩测试中,MIPS 每秒测量一次 CPU 执行的低级指令的数量。越高越好,但是在比较不同代的 CPU 时,则要对得分持保留态度,因为执行指令的方式有所不同。比如CoreMark或者Dhrystone之类,然后用处理器自带的PMU(Performance Monitor Unit)计算下某段函数实际跑了多少指令周期,然后除以这段函数有多少条指令。这就计算出来了。原理很简单,操作起来可能有点费劲。
1.1.1 Cortex-M7 CPI
关于Cortex-M7 CPI 的计算,系统有一个专门的系统外设 DWT(Data Watchpoint and Trace Unit),这个外设提供了一个Clock Cycle Counter(CYCCNT),可以方便的用来计算CPI(ARMv7-M Architecture Reference Manual)。
DWT 中除了 CYCCNT 外的 counter,都只有 8bit 的 register。所以如果一段程序稍长一点的话就溢出了,既然 CPI 是统计的话,一段一端的测程序好像会不太准的样子。需要知道的是这个 overflow DWT 本身就是个低成本的东西,设计目的就是应对局部。大程序(运行时间长的)要用高精度的示波器(或者逻辑分析仪)配合IO口翻转来测量时间(在测量开始的时候拉低电平,在测量结束的时候拉高电平,最终计算的时候,由拉低电平引入的误差基本忽略不计)。
关于 DWT 见文章:【ARM Coresight 系列文章 14 - Cortex-M DWT 详细介绍】
Cortex-M7 就无法提供准确的指令执行周期信息,因为 Cortex-M7的 流水线是超标量的(Super-scalar),对于前后满足条件的两条指令来说,Cortex-M7的流水线可以同时执行。在这种情况下,如何计算指令的平均周期呢?
实际上,这个问题比想象的要略微复杂一点。因为前后两条指令还可能存在数据依赖(Data Dependency)或者是资源竞争(Structural Hazard)的情况。所以,指令执行周期的平均值也是根据前后指令的组合不同而变动的。
两条指令之所以安排他们同时执行,就是因为两条指令同时的执行时间小于二者之和啊。应该说,和最长的那条指令执行时间一样长——你会发现,双发射的流水线连回答“他的执行时间与一条指令单独执行相比如何?”都是不容易做到的。
如果你从MIPS过来,应该更多接触过超标量,甚至是 Out of Order 的流水线。超标量,甚至是Out of Order 的流水线理论上都无法精确的标注一条指令的执行周期,这种情况下,为了评估系统吞吐量,往往用另外一个概念,也就是CPI(Cycle per Instruction)或者IPC(Instruction per Cycle)。对于Cortex-M0这种顺序执行的流水线来说,CPI一定是 >= 1的,但是对于超标量以及OOO的流水线来说,CPI是可以做到 < 1的。
1.2 benchmark 小节
项目预研和产品开发中经常有性能评估的需求,性能benchmark是评估性能最常用的手段。本文小结下之前用过的 benchmark。
| 工具名称 | 测试项目 | summary | 项目地址 |
|---|---|---|---|
| coremark | cpu | 测评cpu的整体性能(列举、矩阵运算、状态机、CRC) | https://github.com/eembc/coremark |
| coremark_pro | cpu | coremark的升级版,测评cpu整体性能 | |
| super PI | cpu | 测评PI的计算 | ftp://pi.super-computing.org/Linux/ |
| SPEC | cpu | 测评cpu性能 | http://www.spec.org/spec/ |
| dhrystone | cpu | 测评CPU整形计算 | |
| whetstone | cpu | 测评CPU浮点运算 | |
| stressapptest | cpu&mem | 主要ddr压力测试,也可以提高cpu负载 | https://github.com/stressapptest/stressapptest |
| nbench | cpu&mem | 测评CPU运算性能(整数运算、双精度浮点运算)/mem指数主要体现处理器总线、cache和存储器性能 | http://www.tux.org/~mayer/linux/bmark.html |
| utest_mem | mem | 测评mem bandwidth | |
| cachebench | mem | 测评mem&cache bandwidth | http://icl.cs.utk.edu/projects/llcbench/cachebench.html |
| copybw | mem | 测评mem bandwidth | http://www.tux.org/pub/benchmarks/CPU/copybw.c |
| ramspeed | mem | 测评cache有效带宽 | |
| bonnie | IO | 测评IO性能 | http://www.textuality.com/bonnie/ |
| Fio | IO | 测评文件系统IO性能 | http://freshmeat.net/projects/fio/ |
| iozone | IO | 测评文件系统IO性能 | http://www.iozone.org/ |
| lmbench | CPU/mem/IO | 测评cpu/mem/IO bandwidth & latency | http://lmbench.sourceforge.net/ |
| sysbench | CPU/mem/IO | 多线程性能测试 | https://github.com/akopytov/sysbench |
| cyclictest | 实时性 | git.kernel.org/pub/scm/linux/kernel/git/clrkwllms/rt-tests.git |
芯片厂商发布SOC时评估算力习惯与Geekbench 数据库中测评结果进行比较,国内安卓手机厂商一般都会在Antutu跑个分。除这两个之外,还有3DMark,PCMark等,这些会更关注GPU和其它多媒体处理的性能了。
1.3.1 Geekbenck 介绍
Geekbench是一个广泛使用的跨平台处理器基准测试工具,由Primate Labs开发。它可以对单核和多核性能进行全面的测量和评估,为用户提供一个快速而准确的衡量和比较计算设备(如桌面,笔记本电脑,手机,平板电脑等)性能的方法。
以下是Geekbench的主要特性:
-
跨平台:Geekbench可在各种设备和操作系统上运行,包括Windows,Mac,Linux,iOS,Android等。
-
单核和多核性能测试:Geekbench可以同时测试处理器的单核和多核性能,从而提供全面的处理器性能评估。
-
实际场景测试:Geekbench采用的是实际应用场景的模拟测试,比如图像处理,文本压缩等,以模拟实际使用情况中的设备性能。
-
结果比较:Geekbench提供了一个在线的测评结果数据库,用户可以将自己设备的得分与全球其他设备进行比较,更好地理解设备性能。
下图是Geekbench 6 排行:

详情见:
https://browser.geekbench.com/v6/cpu/singlecore
https://browser.geekbench.com/v6/cpu/singlecore
1.3 编译参数配置
GCC编译参数可以对程序的性能产生显著的影响,因此也就影响了跑分测试的结果。一些GCC编译参数可以对程序的执行速度,内存使用情况等进行优化。
以下是一些GCC编译参数及其对跑分测试可能产生的影响:
-
-O1、-O2、-O3:这些参数用于控制编译器优化级别,级别越高,编译器会尝试进行更多的代码优化,以提高程序的运行速度。这些优化可能包括循环展开、常量折叠等。但是级别越高,编译时间也越长。 -
-march=native:这个参数告诉GCC产生优化以适应本地机器类型的代码。如果你在本地运行跑分测试,这个参数将使GCC生成针对你的CPU特性进行优化的代码。 -
-ffast-math:这个参数让GCC对浮点数学运算做一些假设(即假设不会出现NaN,Inf和Denorms等),使其可以进行更多的优化。如果你的程序大量使用浮点运算,这个参数可能会带来性能的提升。 -
-funroll-loops:这个参数让GCC对较小的循环进行循环展开,以减少循环开销。这可能会提高程序的性能,但也可能会增加程序的大小。 -
-fprefetch-loop-arrays:如果目标平台支持,则使用该选项将导致预取循环数组以减少缓存未命中的数量。这可能会提高程序的性能。
这里需要注意的是,虽然这些编译参数可能会影响程序的性能,但具体影响取决于很多因素,包括程序的具体代码、硬件环境等。并且,并非所有的优化都会带来性能提升,有时候甚至会导致性能下降。因此,使用这些参数时需要根据具体情况进行测试和调整。
关于编译参数的详细介绍见:ARM GCC 编译系列学习
相关文章:
【ARM Cortex-M 系列 4 番外篇 -- 常用 benchmark 介绍】
文章目录 1.1 CPU 性能测试 MIPS 计算1.1.1 Cortex-M7 CPI 1.2 benchmark 小节1.3.1 Geekbenck 介绍 1.3 编译参数配置 1.1 CPU 性能测试 MIPS 计算 每秒百万指令数 (MIPS):在数据压缩测试中,MIPS 每秒测量一次 CPU 执行的低级指令的数量。越高越好&…...
web安全-原发抗抵赖
原发抗抵赖 原发抗抵赖也称不可否认性,主要表现以下两种形式: 数据发送者无法否认其发送数据的事实。例如,A向B发信,事后,A不能否认该信是其发送的。数据接收者事后无法否认其收到过这些数据。例如,A向B发…...

强化学习------PPO算法
目录 简介一、PPO原理1、由On-policy 转化为Off-policy2、Importance Sampling(重要性采样)3、off-policy下的梯度公式推导 二、PPO算法两种形式1、PPO-Penalty2、PPO-Clip 三、PPO算法实战四、参考 简介 PPO 算法之所以被提出,根本原因在于…...
express框架)
node(三)express框架
文章目录 1.express介绍2.express初体验3.express路由3.1什么是路由?3.2路由的使用 1.express介绍 是一个基于Node平台的极简、灵活的WEB应用开发框架,官网地址:https://www.expressjs.com.cn/ 简单来说,express是一个封装好的工…...

linux find命令搜索日志内容
linux find命令搜索日志内容 查询服务器log日志 find /opt/logs/ -name "filename.log" | xargs grep -a "这里是要查询的字符"加上-a 是为了不报查出 binary 的错 服务器会返回 包含所查字符的整行日志信息...

CentOS 编译安装TinyXml2
安装 TinyXml2 Git 源码下载地址:https://github.com/leethomason/tinyxml2 步骤1:首先,你需要下载tinyxml2的源代码。你可以从Github或者源代码官方网站下载。并上传至/usr/local/source_code/ 步骤2:下载完成后,需要将源代码解…...

竞赛选题 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的人体跌倒检测算法研究与实现 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满…...

使用gson将复杂的树型结构转Json遇到的问题,写入文件为空
某个项目需要用到一个较为复杂的数据结构。定义成一个树型链表。 public class TreeNode { private String name; public String getName() { return name; } public void setName(String name) { this.name name; } public String getPartType() { retur…...

JavaScript异步编程:提升性能与用户体验
目录 什么是异步编程? 回调函数 Promise Async/Await 总结 在Web开发中,处理耗时操作是一项重要的任务。如果我们在执行这些操作时阻塞了主线程,会导致页面失去响应,用户体验下降。JavaScript异步编程则可以解决这个问题&…...
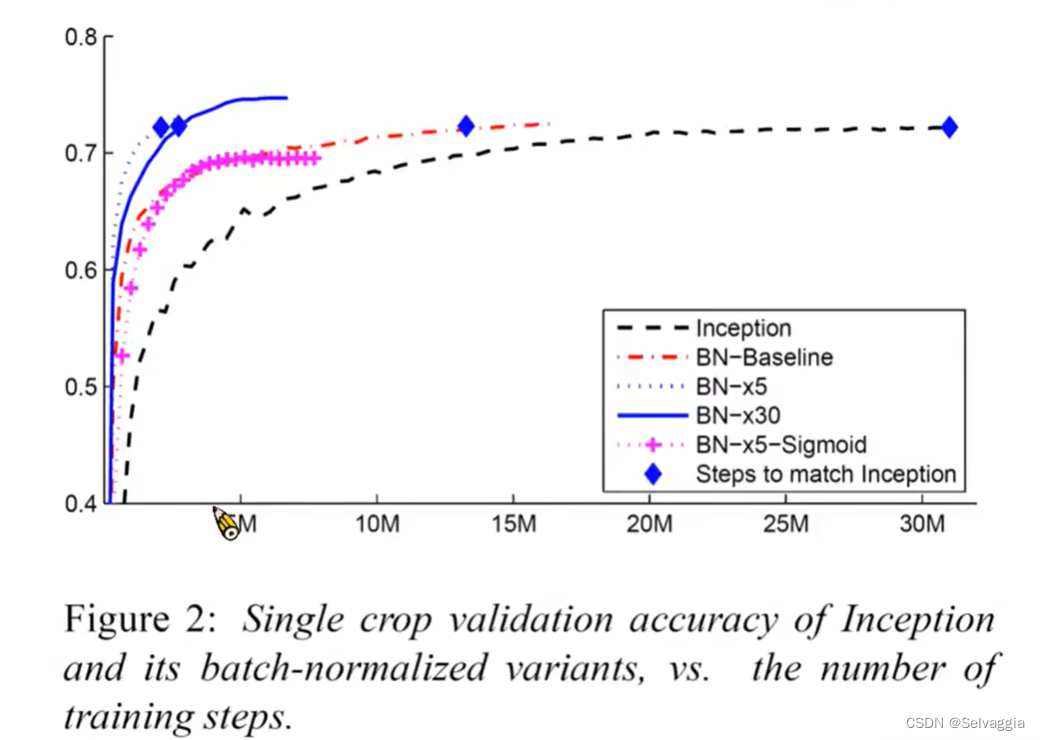
lossBN
still tips for learning classification and regression关于softmax的引入和作用分类问题损失函数 - MSE & Cross-entropy⭐Batch Normalization(BN)⭐想法:直接改error surface的landscape,把山铲平feature normalization那…...

【微信小程序】数字化会议OA系统之投票模块(附源码)
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《微信小程序开发实战》。🎯Ἲ…...

clang-前端插件-给各种无花括号的“块”加花括号-基于llvm15--clang-plugin-add-brace
处理的语句 case 术语约定或备忘 case起止范围: 从冒号到下一个’case’开头, 简称有: case内 、case内容Ast: Abstract syntax tree: 抽象语法树没插入花括号的case 若case内, 以下任一条成立,则 跳过该case 即 不会对该case内容用花括号包裹. 有#define、有#include、有…...
实例小记)
python爬虫-某政府网站加速乐(简单版)实例小记
# -*- coding:utf-8 -*- # Time : 2023/10/23 17:06 # Author: 水兵没月 # File : 哈哈哈哈.py # Software: PyCharm ####################import random import requests# 代理 def get_proxy(proxy_typerandom.choice([1,2,3,4,5])):url "http://ZZZZZZZZZZZZZZZZZZ&qu…...
stable diffusion简介和原理
Stable Diffusion中文的意思是稳定扩散,本质上是基于AI的图像扩散生成模型。 Stable Diffusion是一个引人注目的深度学习模型,它使用潜在扩散过程来生成图像,允许模型在生成图像时考虑到文本的描述。这个模型的出现引起了广泛的关注和讨论&am…...
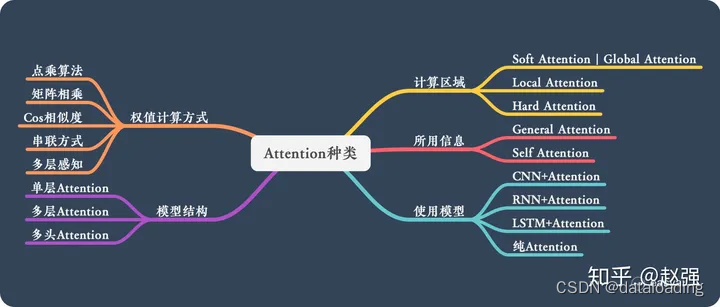
【机器学习】模型平移不变性/等变性归纳偏置Attention机制
Alphafold2具有旋转不变性吗——从图像识别到蛋白结构预测的旋转对称性实现 通过Alphafold2如何预测蛋白质结构,看有哪些机制或tricks可以利用? 一、等变Transformer 等变Transformer是Transformer众多变体的其中一种,其强调等变性。不变性…...
c++的4中类型转换操作符(static_cast,reinterpret_cast,dynamic_cast,const_cast),RTTI
目录 引入 介绍 static_cast 介绍 使用 reinterpret_cast 介绍 使用 const_cast 介绍 使用 dynamic_cast 介绍 使用 RTTI(运行时确定类型) 介绍 typeid运算符 dynamic_cast运算符 type_info类 引入 原本在c中,我们就已经接触到了很多类型转换 -- 隐式类型转…...
)
CNN实现与训练--------------以cifar10数据集为例进行演示(基于Tensorflow)
本文以cifar10数据集为例进行演示 (cifar10数据集有5万张3232像素点的彩色图片,用于训练有1万张3232像素点的彩色图片,用于测试) import tensorflow as tf import os import numpy as np from matplotlib import pyplot as plt from tensorflow.keras.layers import Conv2…...

YOLOv5算法改进(21)— 添加CA注意力机制 + 更换Neck网络之BiFPN + 更换损失函数之EIoU
前言:Hello大家好,我是小哥谈。通过上节课的学习,相信同学们一定了解了组合改进的核心。本节课开始,就让我们结合论文来对YOLOv5进行组合改进(添加CA注意力机制+更换Neck网络之BiFPN+更换损失函数之EIoU),希望同学们学完本节课可以有所启迪,并且后期可以自行进行YOLOv5…...

面对6G时代 适合通信专业的 毕业设计题目
对于通信专业的本科生来说,选择一个与学习内容紧密相关的毕业设计题目十分重要。 以下是东枫科技建议的题目,它们涵盖了通信技术的不同方面: 高校老师可以申请东枫科技工程师共同对学生指导,完成毕业设计。 基于5G/6G的通信技术…...
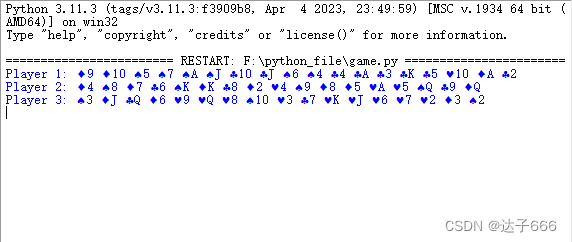
使用Python实现一个简单的斗地主发牌
使用Python实现一个简单的斗地主发牌 1.源代码实现2.实现效果 1.源代码实现 import random# 定义扑克牌的花色和大小 suits [♠, ♥, ♣, ♦] ranks [2, 3, 4, 5, 6, 7, 8, 9, 10, J, Q, K, A]# 初始化一副扑克牌 deck [suit rank for suit in suits for rank in ranks]# …...

基于树莓派的智能直播状态指示器:物联网与API轮询实践
1. 项目概述与核心价值 如果你和我一样,经常在Ustream或Google Hangouts上观看固定的直播节目,或者自己就是一名内容创作者,那你肯定理解那种“直播是否开始了”的焦虑。是继续刷新页面,还是去做点别的?对于家庭或小型…...

2026 电子招投标全流程操作指南:环境搭建→签章→上传→解密全避坑
据安华招标 2025 年度电子招投标技术白皮书显示,全国公共资源交易平台电子标覆盖率已达98.7%,但因纯技术操作失误导致的废标率仍高达22%。其中环境配置错误、签章失效、解密失败三大问题,占所有技术类废标的85% 以上。很多企业投入数月打磨标…...

如何快速配置阅读APP书源:26个高质量小说资源一键导入指南
如何快速配置阅读APP书源:26个高质量小说资源一键导入指南 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 阅读APP作为一款开源的小说阅读工具,本身不提供小说内容,而…...

终极指南:如何用BookGet快速下载全球50+图书馆古籍资源
终极指南:如何用BookGet快速下载全球50图书馆古籍资源 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget BookGet是一款强大的数字古籍图书下载工具,支持全球50多个知名数字图书馆的…...

Cursor Free VIP:如何轻松突破AI编程助手限制的完整指南
Cursor Free VIP:如何轻松突破AI编程助手限制的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

SLCAN协议实战:从脚本编写到自动化测试全解析
1. SLCAN协议基础:嵌入式开发者的文本化CAN接口 第一次接触SLCAN协议时,我正为一个汽车电子项目头疼——需要快速验证CAN总线设备却找不到合适的调试工具。直到发现抽屉里吃灰的LAWICEL CANUSB适配器,这个基于SLCAN协议的小玩意彻底改变了我…...
)
Android性能分析新利器:Perfetto一站式抓Trace攻略(附超大文件处理技巧)
Android性能分析新利器:Perfetto一站式抓Trace攻略(附超大文件处理技巧) 在移动应用开发领域,性能优化始终是开发者面临的核心挑战之一。随着Android系统架构的不断演进,传统的性能分析工具链已难以满足现代复杂应用场…...
上电自动重枚举的两种实现方法)
告别反复拔插!STM32F103 USB Device(CDC/MSC)上电自动重枚举的两种实现方法
STM32F103 USB设备免拔插重枚举技术深度解析 引言 在嵌入式开发领域,STM32F103系列微控制器因其出色的性价比和丰富的外设资源,成为众多工程师的首选。其中,USB接口的开发应用尤为广泛,从虚拟串口(CDC)到大容量存储设备(MSC)&…...

基于全志T527开发板的手势识别:OpenCV部署与轮廓匹配实战
1. 项目概述与硬件平台选择最近在做一个嵌入式视觉项目,需要在一块开发板上实现实时的手势识别功能。选型时,我重点考察了算力、接口丰富度和社区支持。最终,米尔电子的MYD-LT527开发板进入了我的视线。这块板子核心是全志T527处理器…...

题解:学而思编程 3或5的倍数
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...