rust学习
rust学习
- String类型
- clone和copy
- 结构体的内存分布
- for循环(<font color = red>important!)
- 堆和栈
- 数据结构
- vector
- panic
- 失败就 panic: unwrap 和 expect
- 传播错误
- 模式匹配
- 忽略模式的值
- @绑定
- 泛型
- 特征Trait
- 定义特征
- 为类型实现特征
- 孤儿规则
- 使用特征作为函数参数
- 特征约束(trait bound)
- 函数返回中的impl Trait
- 自定义类型打印输出
- 关联类型
- 方法和关联函数
- 线程学习
- 1.多线程的风险
- 2.使用spawn创建线程
- 等待子线程结束
- move 关键字强制闭包获取其使用的环境值的所有权
Ok,Let’s rust !
String类型
String 类型
let mut s = String::from("hello world");
&String类型
let mut s1 = &s
字符串切片类型是&str
let s = String::from("hello");
let len = s.len();let slice = &s[0..len];
let slice = &s[..];
clone和copy
参考链接!link
结构体的内存分布
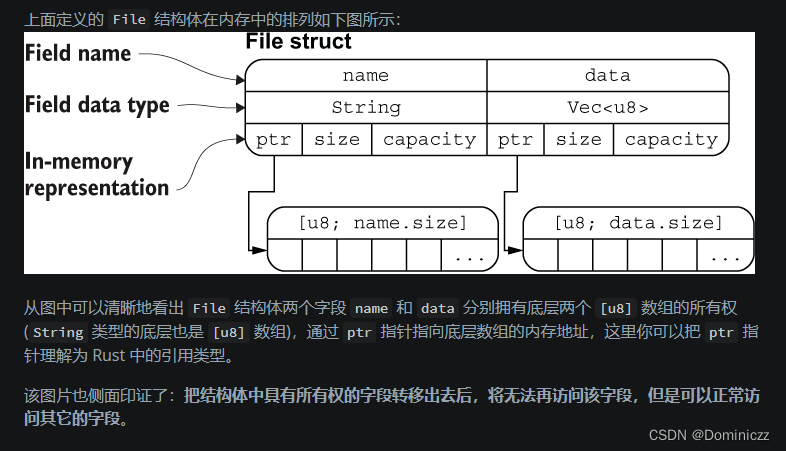
for循环(important!)
1..=5 代表 1 2 3 4 5
1..5 代表1 2 3 4
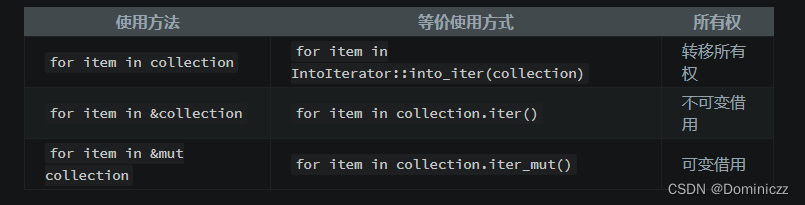
for in 结构能以几种方式与 Iterator 互动。在 迭代器 trait 一节将会谈到,如果没有特别指定,for 循环会对给出的集合应用 into_iter 函数,把它转换成一个迭代器。这并不是把集合变成迭代器的唯一方法,其他的方法有 iter 和iter_mut 函数。
下列三种情况刚好对应上面的表格!
- iter
在每次迭代中借用集合中的一个元素。这样集合本身不会被改变,循环之后仍可以使用。
fn main() {let names = vec!["Bob", "Frank", "Ferris"];for name in names.iter() {match name {&"Ferris" => println!("There is a rustacean among us!"),_ => println!("Hello {}", name),}}
}
- info_iter
会消耗集合。在每次迭代中,集合中的数据本身会被提供。一旦集合被消耗了,之后就无法再使用了,因为它已经在循环中被 “移除”(move)了。
fn main() {let names = vec!["Bob", "Frank", "Ferris"];for name in names.into_iter() {match name {"Ferris" => println!("There is a rustacean among us!"),_ => println!("Hello {}", name),}}
}- iter_mut
可变地(mutably)借用集合中的每个元素,从而允许集合被就地修改。
fn main() {let mut names = vec!["Bob", "Frank", "Ferris"];for name in names.iter_mut() {*name = match name {&mut "Ferris" => "There is a rustacean among us!",_ => "Hello",}}println!("names: {:?}", names);
}堆和栈
在很多语言中,你并不需要经常考虑到栈与堆。不过在像 Rust 这样的系统编程语言中,值是位于栈上还是堆上在更大程度上影响了语言的行为以及为何必须做出这样的抉择。我们会在本章的稍后部分描述所有权与栈和堆相关的内容,所以这里只是一个用来预热的简要解释。
栈和堆都是代码在运行时可供使用的内存,但是它们的结构不同。栈以放入值的顺序存储值并以相反顺序取出值。这也被称作 后进先出(last in, first out)。想象一下一叠盘子:当增加更多盘子时,把它们放在盘子堆的顶部,当需要盘子时,也从顶部拿走。不能从中间也不能从底部增加或拿走盘子!增加数据叫做 进栈(pushing onto the stack),而移出数据叫做 出栈(popping off the stack)。栈中的所有数据都必须占用已知且固定的大小。在编译时大小未知或大小可能变化的数据,要改为存储在堆上。 堆是缺乏组织的:当向堆放入数据时,你要请求一定大小的空间。内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。这个过程称作 在堆上分配内存(allocating on the heap),有时简称为 “分配”(allocating)。(将数据推入栈中并不被认为是分配)。因为指向放入堆中数据的指针是已知的并且大小是固定的,你可以将该指针存储在栈上,不过当需要实际数据时,必须访问指针。想象一下去餐馆就座吃饭。当进入时,你说明有几个人,餐馆员工会找到一个够大的空桌子并领你们过去。如果有人来迟了,他们也可以通过询问来找到你们坐在哪。
入栈比在堆上分配内存要快,因为(入栈时)分配器无需为存储新数据去搜索内存空间;其位置总是在栈顶。相比之下,在堆上分配内存则需要更多的工作,这是因为分配器必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。继续类比,假设有一个服务员在餐厅里处理多个桌子的点菜。在一个桌子报完所有菜后再移动到下一个桌子是最有效率的。从桌子 A 听一个菜,接着桌子 B 听一个菜,然后再桌子 A,然后再桌子 B 这样的流程会更加缓慢。出于同样原因,处理器在处理的数据彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。
当你的代码调用一个函数时,传递给函数的值(包括可能指向堆上数据的指针)和函数的局部变量被压入栈中。当函数结束时,这些值被移出栈。
跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据的数量,以及清理堆上不再使用的数据确保不会耗尽空间,这些问题正是所有权系统要处理的。一旦理解了所有权,你就不需要经常考虑栈和堆了,不过明白了所有权的主要目的就是为了管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
fn main() {let mut x = 5;let mut y = x;x = 6;println!("{},{}", x, y)
}
输出6,5
为什么y不是6呢?因为普通i32变量在赋值的时候,只是值的拷贝,实际上他们的两个不同的5
数据结构
vector
使用宏自动推断类型
fn main() {let v = vec![1, 2, 3];
}更新
fn main() {let mut v = Vec::new();v.push(5);v.push(6);v.push(7);v.push(8);
}panic
vscode默认打开的是powershell
查看更多运行错误信息的命令:$env:RUST_BACKTRACE=1;cargo run
失败就 panic: unwrap 和 expect
use std::fs::File;fn main() {let f = File::open("hello.txt").unwrap();
}
use std::fs::File;fn main() {let f = File::open("hello.txt").expect("Failed to open hello.txt");
}
expect 跟 unwrap 很像,也是遇到错误直接 panic, 但是会带上自定义的错误提示信息,相当于重载了错误打印的函数
传播错误
一般的错误
use std::fs::File;
use std::io::{self, Read};fn read_username_from_file() -> Result<String, io::Error> {// 打开文件,f是`Result<文件句柄,io::Error>`let f = File::open("hello.txt");let mut f = match f {// 打开文件成功,将file句柄赋值给fOk(file) => file,// 打开文件失败,将错误返回(向上传播)Err(e) => return Err(e),};// 创建动态字符串slet mut s = String::new();// 从f文件句柄读取数据并写入s中match f.read_to_string(&mut s) {// 读取成功,返回Ok封装的字符串Ok(_) => Ok(s),// 将错误向上传播Err(e) => Err(e),}
}
传播界的大明星 ?
use std::fs::File;
use std::io;
use std::io::Read;fn read_username_from_file() -> Result<String, io::Error> {let mut f = File::open("hello.txt")?;let mut s = String::new();f.read_to_string(&mut s)?;Ok(s)
}
**?**其实是一个宏,它的作用跟上面的match几乎一样
let mut f = match f {// 打开文件成功,将file句柄赋值给fOk(file) => file,// 打开文件失败,将错误返回(向上传播)Err(e) => return Err(e),
};
想象一下,一个设计良好的系统中,肯定有自定义的错误特征,错误之间很可能会存在上下级关系,例如标准库中的 std::io::Error 和 std::error::Error,前者是 IO 相关的错误结构体,后者是一个最最通用的标准错误特征,同时前者实现了后者,因此 std::io::Error 可以转换为 std:error::Error。
明白了以上的错误转换,? 的更胜一筹就很好理解了,它可以自动进行类型提升(转换):
fn open_file() -> Result<File, Box<dyn std::error::Error>> {let mut f = File::open("hello.txt")?;Ok(f)
}
上面代码中 File::open 报错时返回的错误是 std::io::Error 类型,但是 open_file 函数返回的错误类型是 std::error::Error 的特征对象,可以看到一个错误类型通过 ? 返回后,变成了另一个错误类型,这就是 ? 的神奇之处。
根本原因是在于标准库中定义的 From 特征,该特征有一个方法 from,用于把一个类型转成另外一个类型,? 可以自动调用该方法,然后进行隐式类型转换。因此只要函数返回的错误 ReturnError 实现了 From 特征,那么 ? 就会自动把 OtherError 转换为 ReturnError。
这种转换非常好用,意味着你可以用一个大而全的 ReturnError 来覆盖所有错误类型,只需要为各种子错误类型实现这种转换即可。
模式匹配
忽略模式的值
_s 和 _ 有些微妙的不同:_s 会将值绑定到变量,而**_** 则完全不会绑定
fn main() {let s = Some(String::from("Hello!"));if let Some(_s) = s {println!("found a string");}println!("{:?}", s);
}
s 是一个拥有所有权的动态字符串,在上面代码中,我们会得到一个错误
因为 s 的值会被转移给 _s,在 println! 中再次使用 s 会报错但是如果使用_去匹配,则不会绑定值,因为s没有被移动到_
@绑定
@(读作 at)运算符允许为一个字段绑定另外一个变量。下面例子中,我们希望测试 Message::Hello 的 id 字段是否位于 3…=7 范围内,同时也希望能将其值绑定到 id_variable 变量中以便此分支中相关的代码可以使用它。我们可以将 id_variable 命名为 id,与字段同名,不过出于示例的目的这里选择了不同的名称。
enum Message {Hello { id: i32 },
}let msg = Message::Hello { id: 5 };match msg {Message::Hello { id: id_variable @ 3..=7 } => {println!("Found an id in range: {}", id_variable)},Message::Hello { id: 10..=12 } => {println!("Found an id in another range")},Message::Hello { id } => {println!("Found some other id: {}", id)},
}
@绑定到底有什么用呢,注意看第一个匹配和第二个匹配,当范围匹配的时候,无法直接得到这个值,这个时候,就可以使用@绑定,得到具体的值。
泛型
一个报错的泛型
fn largest<T>(list: &[T]) -> T {let mut largest = list[0];for &item in list.iter() {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest(&char_list);println!("The largest char is {}", result);
}error[E0369]: binary operation `>` cannot be applied to type `T` // `>`操作符不能用于类型`T`--> src/main.rs:5:17|
5 | if item > largest {| ---- ^ ------- T| || T|
help: consider restricting type parameter `T` // 考虑对T进行类型上的限制 :|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T {| ++++++++++++++++++++++因为 T 可以是任何类型,但不是所有的类型都能进行比较,因此上面的错误中,编译器建议我们给 T 添加一个类型限制:使用 std::cmp::PartialOrd 特征(Trait)对 T 进行限制,特征在下一节会详细介绍,现在你只要理解,该特征的目的就是让类型实现可比较的功能。
简单的add例子,不是所有 T 类型都能进行相加操作,因此我们需要用 std::ops::Add<Output = T> 对 T 进行限制:
fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {a + b
}
否则报错
error[E0369]: cannot add `T` to `T` // 无法将 `T` 类型跟 `T` 类型进行相加--> src/main.rs:2:7|
2 | a + b| - ^ - T| || T|
help: consider restricting type parameter `T`|
1 | fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {| +++++++++++++++++++++++++++感觉这里的泛型跟java c++的还是不太一样,更抽象一点
特征Trait
特征类似于其他语言中的接口。在之前的代码中,我们也多次见过特征的使用,例如 #[derive(Debug)],它在我们定义的类型(struct)上自动派生 Debug 特征,接着可以使用 println!(“{:?}”, x) 打印这个类型;再例如:
fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {a + b
}
通过 std::ops::Add 特征来限制 T,只有 T 实现了 **std::ops::Add **才能进行合法的加法操作,毕竟不是所有的类型都能进行相加。
这些都说明一个道理,特征定义了一组可以被共享的行为,只要实现了特征,你就能使用这组行为。
定义特征
使用trait关键字来声明一个特征
pub trait Summary {fn summarize(&self) -> String;
}
这里使用 trait 关键字来声明一个特征,Summary 是特征名。在大括号中定义了该特征的所有方法,在这个例子中是: fn summarize(&self) -> String。
特征只定义行为看起来是什么样的,而不定义行为具体是怎么样的。因此,我们只定义特征方法的签名,而不进行实现,此时方法签名结尾是 ;而不是一个 {}
为类型实现特征
pub trait Summary {fn summarize(&self) -> String;
}
pub struct Post {pub title: String, // 标题pub author: String, // 作者pub content: String, // 内容
}impl Summary for Post {fn summarize(&self) -> String {format!("文章{}, 作者是{}", self.title, self.author)}
}impl Summary for Post {}
孤儿规则
关于特征实现与定义的位置,有一条非常重要的原则:如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的! 例如我们可以为上面的 Post 类型实现标准库中的 Display 特征,这是因为 Post 类型定义在当前的作用域中。同时,我们也可以在当前包中为 String 类型实现 Summary 特征,因为 Summary 定义在当前作用域中。
但是你无法在当前作用域中,为 String 类型实现 Display 特征,因为它们俩都定义在标准库中,其定义所在的位置都不在当前作用域,跟你半毛钱关系都没有,看看就行了。
该规则被称为孤儿规则,可以确保其它人编写的代码不会破坏你的代码,也确保了你不会莫名其妙就破坏了风马牛不相及的代码。
使用特征作为函数参数
pub fn notify(item: &impl Summary) {println!("Breaking news! {}", item.summarize());
}
impl Summary,只能说想出这个类型的人真的是起名鬼才,简直太贴切了,顾名思义,它的意思是 实现了Summary特征 的 item 参数。
特征约束(trait bound)
形如T: Summary 被称为特征约束
pub fn notify<T: Summary>(item: &T)pub fn notify(item1: &impl Summary, item2: &impl Summary) {}pub fn notify(item: &(impl Summary + Display)) {}pub fn notify<T: Summary + Display>(item: &T) {}fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {}fn some_function<T, U>(t: &T, u: &U) -> i32where T: Display + Clone,U: Clone + Debug
{}
函数返回中的impl Trait
fn returns_summarizable() -> impl Summary {Weibo {username: String::from("sunface"),content: String::from("m1 max太厉害了,电脑再也不会卡",)}
}
因为 Weibo 实现了 Summary,因此这里可以用它来作为返回值。要注意的是,虽然我们知道这里是一个 Weibo 类型,但是对于 returns_summarizable 的调用者而言,他只知道返回了一个实现了 Summary 特征的对象,但是并不知道返回了一个 Weibo 类型。
自定义类型打印输出
#![allow(dead_code)] // 允许未使用的代码use std::fmt;
use std::fmt::{Display};#[derive(Debug,PartialEq)]
enum FileState {Open,Closed,
}#[derive(Debug)]
struct File {name: String,data: Vec<u8>,state: FileState,
}impl Display for FileState {// 第一个参数,当前实例的引用// 第二个参数引用类型,用于接收一个正在被修改的格式化输出流fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {match *self {FileState::Open => write!(f, "OPEN"),FileState::Closed => write!(f, "CLOSED"),}}
}impl Display for File {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {write!(f, "<{} ({})>", self.name, self.state)}
}impl File {fn new(name: &str) -> File {File {name: String::from(name),data: Vec::new(),state: FileState::Closed,}}
}/*** &self:表示这个函数接受一个指向当前实例的引用。* * &mut fmt::Formatter:表示这个函数接受一个指向一个可以写入的 fmt::Formatter 的引用* fmt::Formatter 是用于格式化字符串的一种结构体。* * -> fmt::Result:表示这个函数返回一个 fmt::Result 值* fmt::Result 是 write!() 函数的返回类型,它表示是否成功地将数据写入到指定的 fmt::Formatter 上。* * write!(f, "<{} ({})>", self.name, self.state):* 这是调用 write!() 函数来将格式化的字符串写入到指定的 fmt::Formatter 中* 这个字符串包含了 self.name(即文件名)和 self.state(即文件状态* 其中,<...> 是一个字符串插槽,它会在运行时被替换为我们想要显示的内容* {} 后面的内容会被替换为对应的变量或表达式的值。在这个例子中,self.name 和 self.state 就是这些内容。*/fn main() {let f6 = File::new("f6.txt"); // 创建一个名为"f6.txt"的新文件对象println!("{:?}", f6); // 打印调试信息,输出文件对象的调试表示println!("{}", f6); // 打印文件对象的字符串表示
}{:?} 使用的是 Debug 特性,会输出 File 对象的详细信息,包括其所有的字段及其值。
{} 使用的是 Display 特性,会输出 File 对象的字符串表示形式。在上面的例子中,由于我们为 File 类型实现了 Display 特性,所以 {} 会输出 <f6.txt (Open)> 这样的字符串
关联类型
type关键字可以用来取别名,但是在结合泛型使用的时候,是关联类型
关联类型是 trait 定义中的类型占位符。定义的时候,并不定义它的具体的类型是什么。在 impl 这个 trait 的时候,才为这个关联类型赋予确定的类型。也就是说,在实现的时候,才知道它的具体类型是什么。
pub trait Converter {type Output;fn convert(&self) -> Self::Output;
}struct MyInt;impl Converter for MyInt {type Output = i32;fn convert(&self) -> Self::Output {42}
}fn main() {let my_int = MyInt;let output = my_int.convert();println!("output is: {}", output);
}输出:output is: 42参考
方法和关联函数
new 是关联函数,width是方法
pub struct Rectangle {width: u32,height: u32,
}impl Rectangle {pub fn new(width: u32, height: u32) -> Self {Rectangle { width, height }}pub fn width(&self) -> u32 {return self.width;}
}fn main() {let rect1 = Rectangle::new(30, 50);println!("{}", rect1.width());
}// let rect1 = Rectangle::new(30, 50);
线程学习
1.多线程的风险
由于多线程的代码是同时运行的,因此我们无法保证线程间的执行顺序,这会导致一些问题:
- 竞态条件(race conditions),多个线程以非一致性的顺序同时访问数据资源
- 死锁(deadlocks),两个线程都想使用某个资源,但是又都在等待对方释放资源后才能使用,结果最终都无法继续执行
- 一些因为多线程导致的很隐晦的 BUG,难以复现和解决
虽然 Rust 已经通过各种机制减少了上述情况的发生,但是依然无法完全避免上述情况,因此我们在编程时需要格外的小心,同时本书也会列出多线程编程时常见的陷阱,让你提前规避可能的风险。
2.使用spawn创建线程
use std::thread;
use std::time::Duration;fn main() {thread::spawn(|| {for i in 1..10 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}
}但是打印顺序是随机的,主线程和子线程会随机打印。有可能主线程执行完了,子线程还没有创建,这取决于操作系统的调度。
等待子线程结束
use std::thread;
use std::time::Duration;fn main() {let handle = thread::spawn(|| {for i in 1..5 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});handle.join().unwrap();for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}
}
通过调用 handle.join,可以让当前线程阻塞,直到它等待的子线程的结束
在上面代码中,由于 main 线程会被阻塞,因此它直到子线程结束后才会输出自己的 1..5:
move 关键字强制闭包获取其使用的环境值的所有权
use std::thread;fn main() {let v = vec![1, 2, 3];let handle = thread::spawn(|| {println!("Here's a vector: {:?}", v);});handle.join().unwrap();
}
子线程要v的所有权,但是子线程和主线程执行顺序随机。在主线程丢弃,使用drop也不行。根本原因在于存在所有权冲突。
正确写法——添加move关键字
直接将所有权转移到子线程
use std::thread;fn main() {let v = vec![1, 2, 3];let handle = thread::spawn(move || {println!("Here's a vector: {:?}", v);});handle.join().unwrap();// 下面代码会报错borrow of moved value: `v`// println!("{:?}",v);
}
相关文章:
rust学习
rust学习 String类型clone和copy结构体的内存分布for循环(<font color red>important!)堆和栈数据结构vector panic失败就 panic: unwrap 和 expect传播错误 模式匹配忽略模式的值绑定 泛型特征Trait定义特征为类型实现特征孤儿规则使…...
GCC、g++、gcc的关系
GCC、g、gcc的关系 引言 VsCode中对编译环境进行配置的时选择编译器时发现有多种不同的编译器 GNU计划和GCC GNU的全称 GNU’s Not UNIX GNU是一个计划 Q:为什么会有这个计划 因为当时的Unix开始收费和商业闭源,有人觉得不爽→ 想要自己开发和Unix类似的→GNU计划 GUN计划目…...

IP应用场景API的反欺诈潜力:保护在线市场不受欺诈行为侵害
前言 在数字化时代,网络上的商业活动迅速增长,但与之同时,欺诈行为也在不断演化。欺诈者不断寻找新方法来窃取个人信息、进行金融欺诈以及实施其他不法行为。为了应对这一威胁,企业和组织需要强大的工具,以识别和防止…...
常用的主流音乐编曲软件有哪些?
FL Studio是一款备受音乐人喜爱的超强编曲软件。最新的FL Studio版本将所有音频形式都视为采样,使得它在各个领域都有出色的表现。该软件操作简单,界面友好,非常适合新手全面学习和使用。此外,FL Studio完美支持Windows和Mac操作系…...
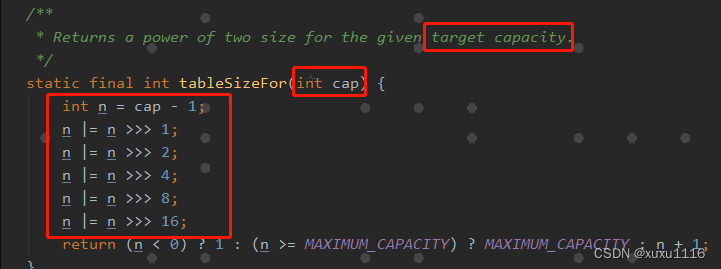
面试题:为什么HashMap 使用的时候指定容量?
文章目录 前言正文为什么要指定容量? 前言 其实可以看到我写了这么久的博客,很少去写hashMap的东西。 为什么?因为这个东西感觉是java面试必备的,我感觉大家都看到腻了,所以一直没怎么去写hashMap相关的。 本篇内容&…...

基于C/C++的UG二次开发流程
文章目录 基于C/C的UG二次开发流程1 环境搭建1.1 新建工程1.2 项目属性设置1.3 添加入口函数并生成dll文件1.4 执行程序1.5 ufsta入口1.5.1 创建程序部署目录结构1.5.2 创建菜单文件1.5.3 设置系统环境变量1.5.4 制作对话框1.5.5 创建代码1.5.6 部署和执行 基于C/C的UG二次开发…...
“第五十二天”
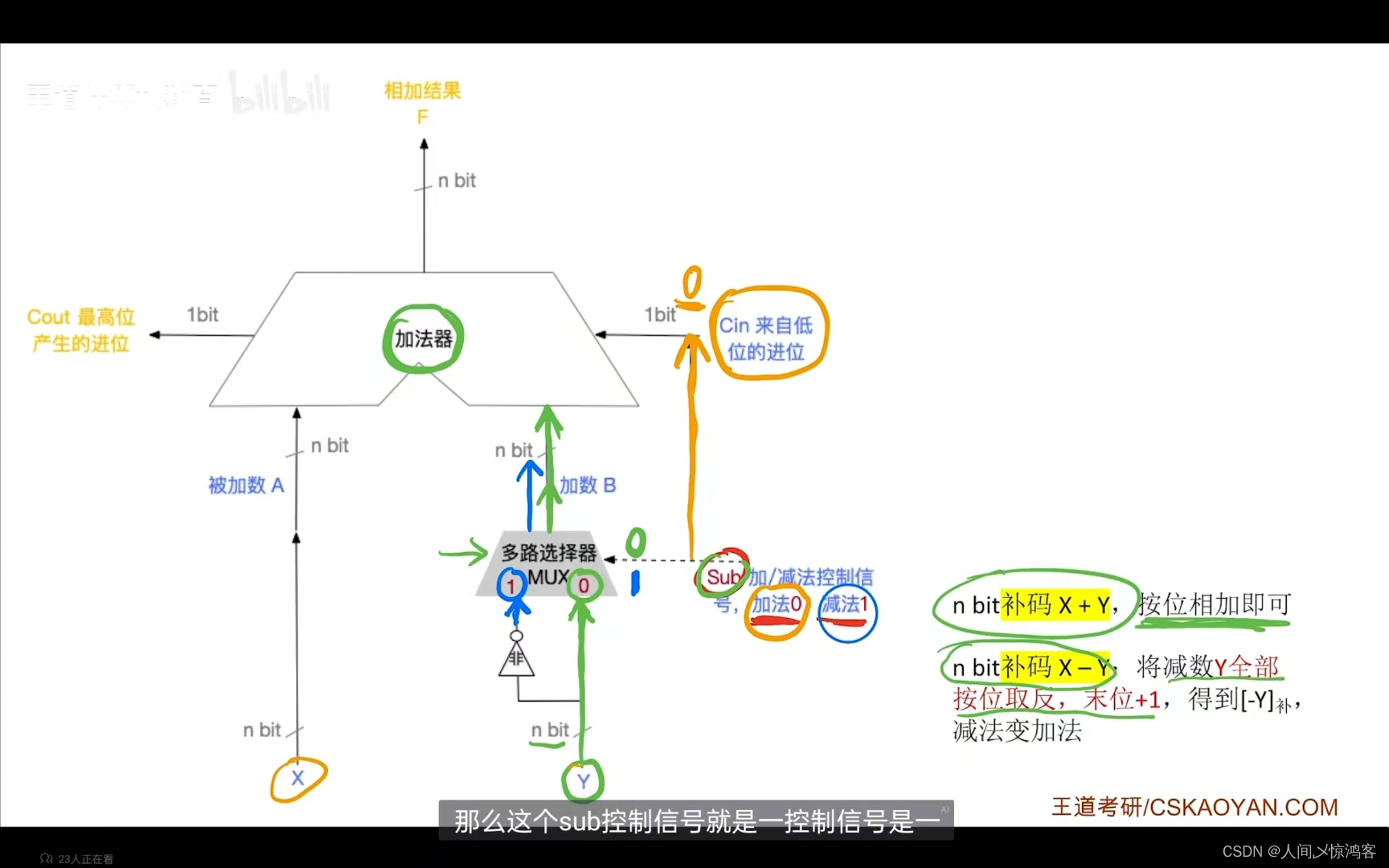
算术逻辑单元: 之前提过的运算器包括MQ,ACC,ALU,X,PSW;运算器可以实现运算以及一些辅助功能(移位,求补等)。 其中ALU负责运算,运算包括算术运算(加减乘除等)和逻辑运算(…...
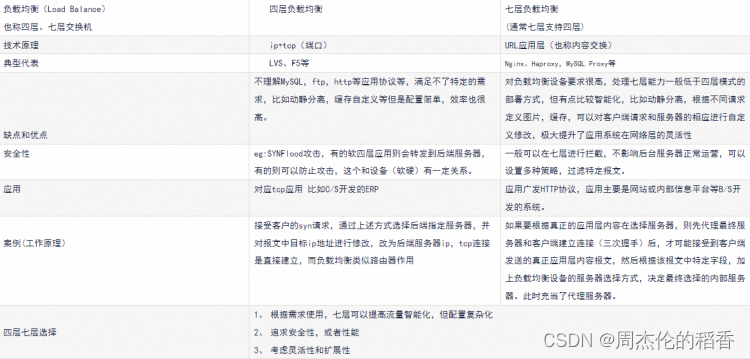
Lvs+Nginx+NDS
什么是?为什么?需要负载均衡 一个网站在创建初期,一般来说都是只有一台服务器对用户提供服务 从图里可以看出,用户经过互联网直接连接了后端服务器,如果这台服务器什么时候突然 GG 了,用户将无法访问这…...

JavaWeb——Servlet原理、生命周期、IDEA中实现一个Servlet(全过程)
6、servlet 6.1、什么是servlet 在JavaWeb中,Servlet是基于Java编写的服务器端组件,用于处理客户端(通常是Web浏览器)发送的HTTP请求并生成相应的HTTP响应。Servlet运行在Web服务器上,与Web容器(如Tomcat&…...

Android 12.0 ota升级之SettingsProvider新增和修改系统数据相关功能实现
1. 前言 在12.0的系统rom定制化开发中,在解决一些已经上线的bug后,进行ota升级的过程中,由于在SettingsProvider中新增了系统属性和修改某项系统属性值,但是在ota升级以后发现没有 更新,需要恢复出厂设置以后才会更改,但是恢复出厂设置 会丢掉一些数据,这是应为系统数据…...
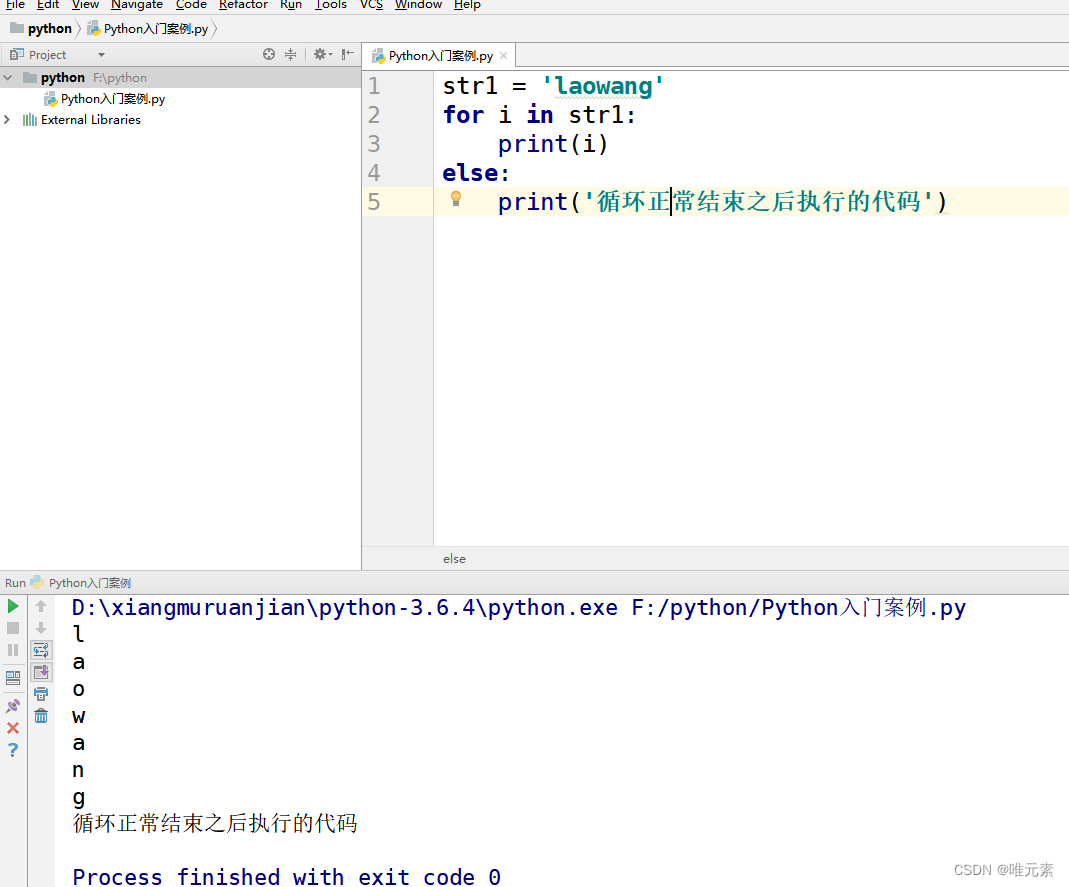
python---for循环结构中的else结构(是同级关系)
为什么需要在for循环中添加else结构 循环可以和else配合使用, else下方缩进的代码指的是当循环正常结束之后要执行的代码。 强调: 循环 正常结束,else之后要执行的代码。 非正常结束,其else中的代码是不会执行的。…...

XLua中lua读写cs对象的原理
LuaCallCS 1. 传递C#对象到Lua XLua在C#维护了两个数据结构,ObjectPool和ReverseMap。 首次传递一个C#对象obj到Lua时,对象被加入到ObjectPool中,并为它创建一个唯一标识objId,建立obj和objId的双向映射。 ObjectPool: objId-…...

新手小白怎么选择配音软件?
现在的配音软件软件很多,各种类型的都比较多,对于新手小白来说不知该如何选择,今天就来给你分享几款好用的配音软件。不论是制作短视频还是制作平常音频都完全可以。 第一款:悦音配音 这是一款专业的视频配音软件,多端…...

linux查看硬件信息命令
文章目录 cpu内核版本内存硬盘主板服务器参考链接 cpu cat /proc/cpuinfo 一个物理CPU可以有1个或者多个物理内核,一个物理内核可以作为1个或者2个逻辑CPU。 物理CPU数就是主板上实际插入的CPU数量。 在Linux上cat /proc/cpuinfo,会打印每个cpu的信息 …...
TSINGSEE青犀省级高速公路视频上云联网方案:全面实现联网化、共享化、智能化
一、需求背景 随着高速铁路的建设及铁路管理的精细化,原有的模拟安防视频监控系统已经不能满足视频监控需求,越来越多站点在建设时已开始规划高清安防视频监控系统。高速公路视频监控资源非常丰富,需要对其进行综合管理与利用。通过构建监控…...
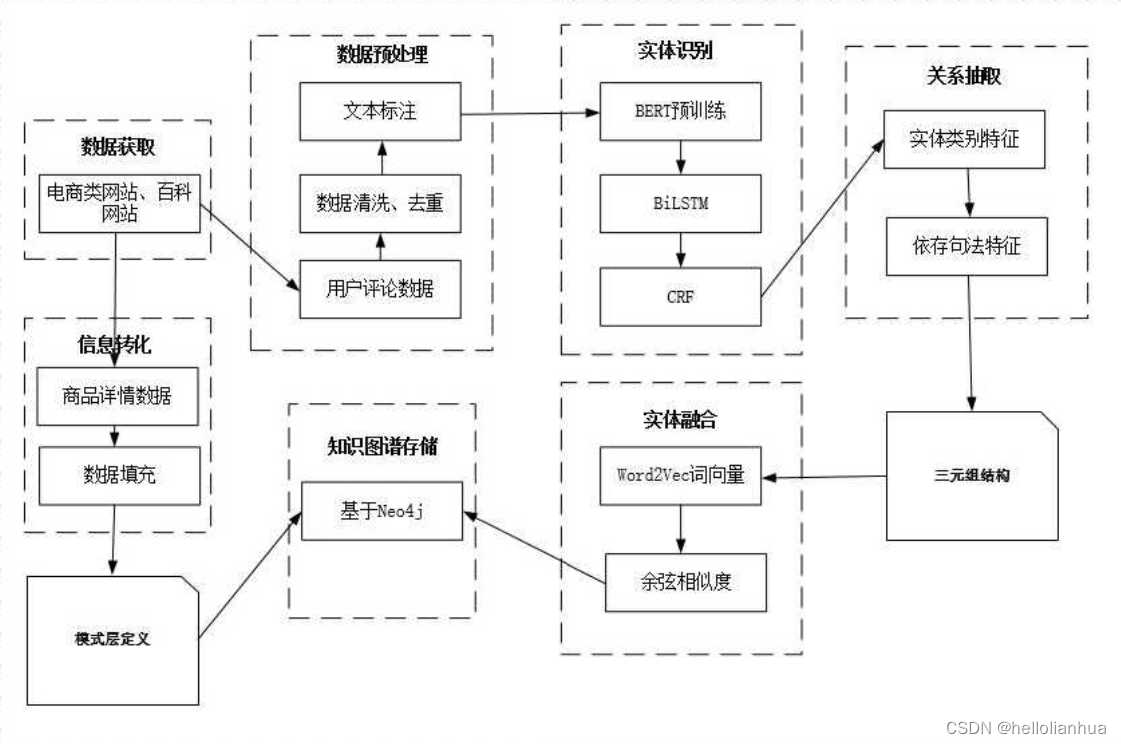
知识图谱相关的操作
微软生成自己的图谱:GitHub - microsoft/SmartKG: This project accepts excel files as input which contains the description of a Knowledge Graph (Vertexes and Edges) and convert it into an in-memory Graph Store. This project implements APIs to searc…...
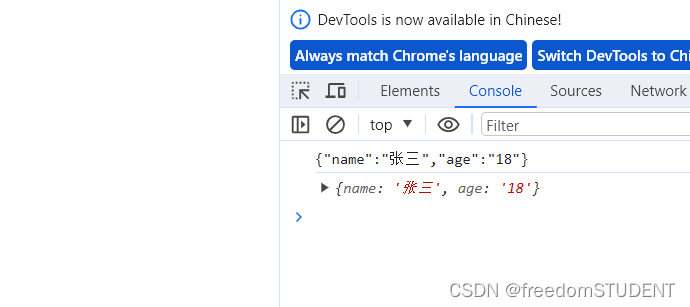
【Javascript】json
目录 什么是json? 书写格式 json 序列化和反序列化 序列化 反序列化 什么是json? JSON(JavaScript Object Notation)是⼀种轻量级的数据交换格式,它基于JavaScript的⼀个⼦集,易于⼈的编写和阅读,也易于机器解析…...

零资源的大语言模型幻觉预防
零资源的大语言模型幻觉预防 摘要1 引言2 相关工作2.1 幻觉检测和纠正方法2.2 幻觉检测数据集 3 方法论3.1 概念提取3.2 概念猜测3.2.1 概念解释3.2.2 概念推理 3.3 聚合3.3.1 概念频率分数3.3.2 加权聚合 4 实验5 总结 摘要 大语言模型(LLMs)在各个领域…...

智能终端界面自动化测试操作工具 - Appium常见用法
1. Appium 是什么可以做什么? Appium 是一款开源的移动应用自动化测试框架,用于测试移动应用程序的功能和用户界面。它支持多种移动平台,包括 Android 和 iOS,可以使用多种编程语言进行脚本编写,如 Python、Java、Jav…...
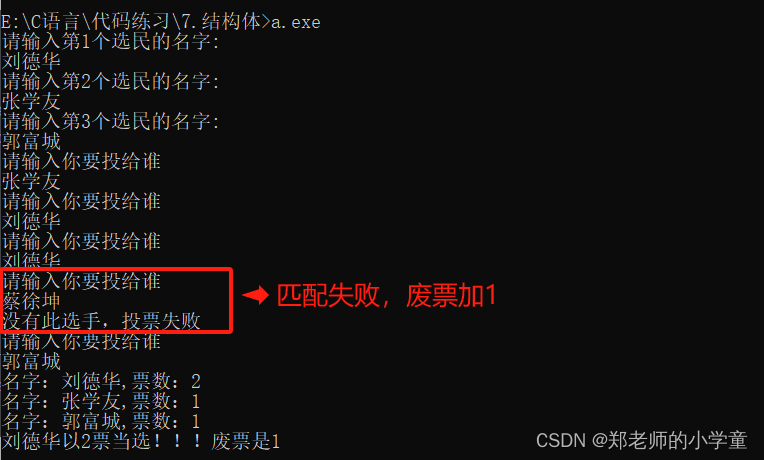
结构体数组经典运用---选票系统
结构体的引入 1、概念:结构体和其他类型基础数据类型一样,例如int类型,char类型,float类型等。整型数,浮点型数,字符串是分散的数据表示,有时候我们需要用很多类型的数据来表示一个整体&#x…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...