Flink CDC 2.0 主要是借鉴 DBLog 算法
DBLog 算法原理

DBLog 这个算法的原理分成两个部分,第一部分是分 chunk,第二部分是读 chunk。分 chunk 就是把一张表分为多个 chunk(桶/片)。我可以把这些 chunk 分发给不同的并发的 task 去做。例如:有 reader1 和 reader2,不同的 reader 负责读不同的 chunk。其实只要保证每个 reader 读的那个 chunk 是完整的,也能跟最新的 Binlog 能够匹配在一起就可以了。在读 chunk 的过程中,会同时读属于这个 chunk的历史数据,也会读这个 chunk 期间发生的 Binlog 事件,然后来做一个 normalize。

首先是 chunk 的划分。一张表,它的 ID 字段是主键 PK。通过 query 能够知道最大的 PK 也能知道最小的 PK。然后根据最大最小的 PK 设定一个步长,那么就能把这个表分成一些 chunk。每个 chunk 是一个左闭右开的区间,这样可以实现 chunk 的无缝衔接。第一个 chunk 和最后一个 chunk 最后一个字段,是一个正无穷和负无穷的表示, 即所有小于 k1 的 key 由第一个 chunk 去读,所有大于 K104 的 key 由最后一个chunk去读。

chunk 的读取,首先有一个 open 打点的过程,还有一个 close 打点的过程。例如,读属于这个 chunk1 的所有数据时,橘色的 K1 到 K7 是这些全量数据。橘黄色里面有下划线的数据,是在读期间这些 Binlog 在做改变。比如 K2 就是一条 update,从 100 变成 108,K3 是一条 delete。K2 后面又变成 119。还有 K5 也是一个update。在 K2、K3、K5 做标记,说明它们已经不是最新的数据了,需要从 Binlog 里面读出来,做一个 merge 获取最新的数据, 最后读出来的就是在 close 位点时刻的最新数据。最后的效果就是,将 update 最新的数据最终输出,将 delete 的数据如 K3 不输出。所以在 chunk1 读完的时候,输出的数据是 K0、K2、K4、K5、K6、K7 这些数据,这些数据也是在 close 位点时数据库中该 chunk 的数据。

接下来是 chunk 的分发。一张表切成了 N 个 chunk 后,SourceEnumerator 会将这些 chunk 分给一些 SourceReader 并行地读取,并行读是用户可以配置的,这就是水平扩展能力。

每一个 Snapshot chunk 读完了之后有一个信息汇报过程,这个汇报非常关键,包含该 chunk 的基本信息和该 chunk 是在什么位点读完的(即 close 位点)。在进入 Binlog 读取阶段之后, 在 close 位点之后且属于这个 chunk 的 binlog 数据,是要需要继续读取的,从而来保证数据的完整性。

在所有的 Snapshot chunk 读完之后会发一个特殊的 Binlog chunk,该 chunk 里包含刚刚所有 Snapshot chunk 的汇报信息。Binlog Reader 会根据所有的 Snapshot chunk 汇报信息按照各自的位点进行跳读,跳读完后再进入一个纯粹的 binlog 读取。跳读就是需要考虑各个 snapshot chunk 读完全量时的 close 位点进行过滤,避免重复数据,纯 binlog 读就是在跳读完成后只要是属于目标表的 changelog 都读取。

Flink CDC 增量快照算法流程为,首先,一张表按 key 分成一个个 chunk,Binlog在不断地写,全量阶段由 SourceReader 去读,进入增量阶段后,SourceReader 中会启一个 BinlogReader 来读增量的部分。全量阶段只会有 insert only 的数据,增量阶段才会有 update、delete 数据。SourceReader 中具体去负责读 chunk 的 reader 会根据收到的分片类型,决定启动 SnapshotReader 还是 BinlogReader。

Flink CDC 增量快照算法的核心价值包括:
第一,实现了并行读取,水平扩展的能力,即使十亿百亿的大表,只要资源够,那么水平扩展就能够提升效率;
第二,实现 Dblog 算法的变动,它能够做到在保证一致性的情况下,实现无锁切换;
第三,基于 Flink 的 state 和 checkpoint 机制,它实现了断点续传。比如 task 1 失败了,不影响其它正在读的task,只需要把 task 1 负责的那几个 chunk 进行重读;
第四,全增量一体化,全增量自动切换。


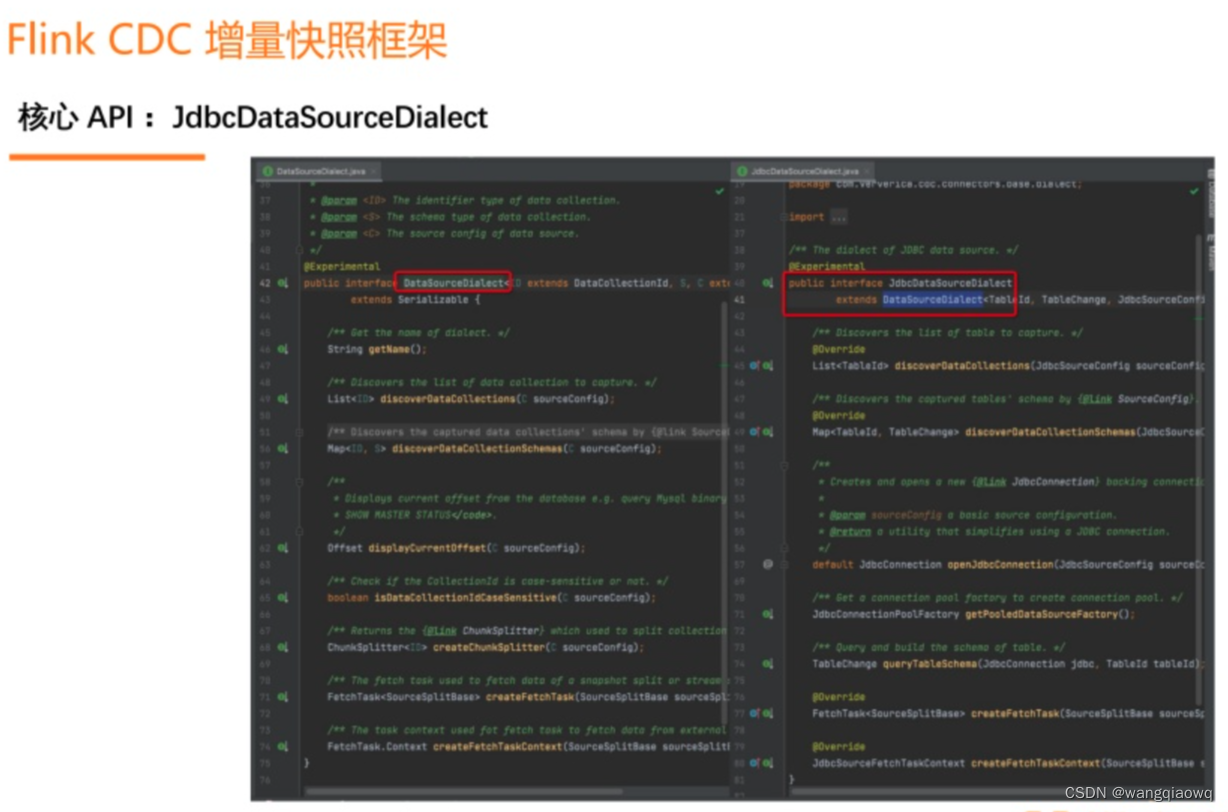
增量快照框架的设计围绕一个核心的 API 展开,这个核心的 API 就是DataSourceDialect(数据源方言),这个方言关心的就是面向某个数据源特有的,在接入全增量框架时需要实现的方法。

比较常见的CDC工具大都有过使用经验:
Debezium是国外⽤户常⽤的CDC组件,单机对于分布式来说,在数据读取能力的拓展上,没有分布式的更具有优势,在大数据众多的分布式框架中(Hive、Hudi等)Flink CDC 的架构能够很好地接入这些框架。
DataX无法支持增量同步。如果一张Mysql表每天增量的数据是不同天的数据,并且没有办法确定它的产生时间,那么如何将数据同步到数仓是一个值得考虑的问题。DataX支持全表同步,也支持sql查询的方式导入导出,全量同步一定是不可取的,sql查询的方式没有可以确定增量数据的字段的话也不是一个好的增量数据同步方案。
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。Canal主要支持了MySQL的Binlog解析,将增量数据写入中间件中(例如kafka,Rocket MQ等),但是无法同步历史数据,因为无法获取到binlog的变更。
Sqoop主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递。Sqoop将导入或导出命令翻译成mapreduce程序来实现,这样的弊端就是Sqoop只能做批量导入,遵循事务的一致性,Mapreduce任务成功则同步成功,失败则全部同步失败。
Apache SeaTunnel是一个当前也非常受欢迎的数据集成同步组件。其可以支持全量和增量,支持流批一体。SeaTunnel的使用是非常简单的,零编写代码,只需要写一个配置文件脚本提交命令即可,同时也使用分布式的架构,可以依托于Flink,Spark以及自身的Zeta引擎的分布式完成一个任务在多个节点上运行。其内部也有类似Flink checkpoint的状态保存机制,用于故障恢复,sink阶段的两阶段提交机制也可以做到精准一次性Excatly-once。对于大部分的场景,SeaTunnel都能完美支持,但是SeaTunnel只能支持简单的数据转换逻辑,对于复杂的数据转换场景,还是需要Flink、Spark任务来完成。
Flink CDC 基本都弥补了以上框架的不足,将数据库的全量和增量数据一体化地同步到消息队列和数据仓库中;也可以用于实时数据集成,将数据库数据实时入湖入仓;无需像其他的CDC工具一样需要在服务器上进行部署,减少了维护成本,链路更少;完美套接Flink程序,CDC获取到的数据流直接对接Flink进行数据加工处理,一套代码即可完成对数据的抽取转换和写出,既可以使用flink的DataStream API完成编码,也可以使用较为上层的FlinkSQL API进行操作。
DBlog paper 论文的 chunk 切分算法。
该算法在数据库中维护了一张watermark(信号)表,记录每个chunk块的区间值位点LW和HW。

Flink CDC2.x 并没有维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能。
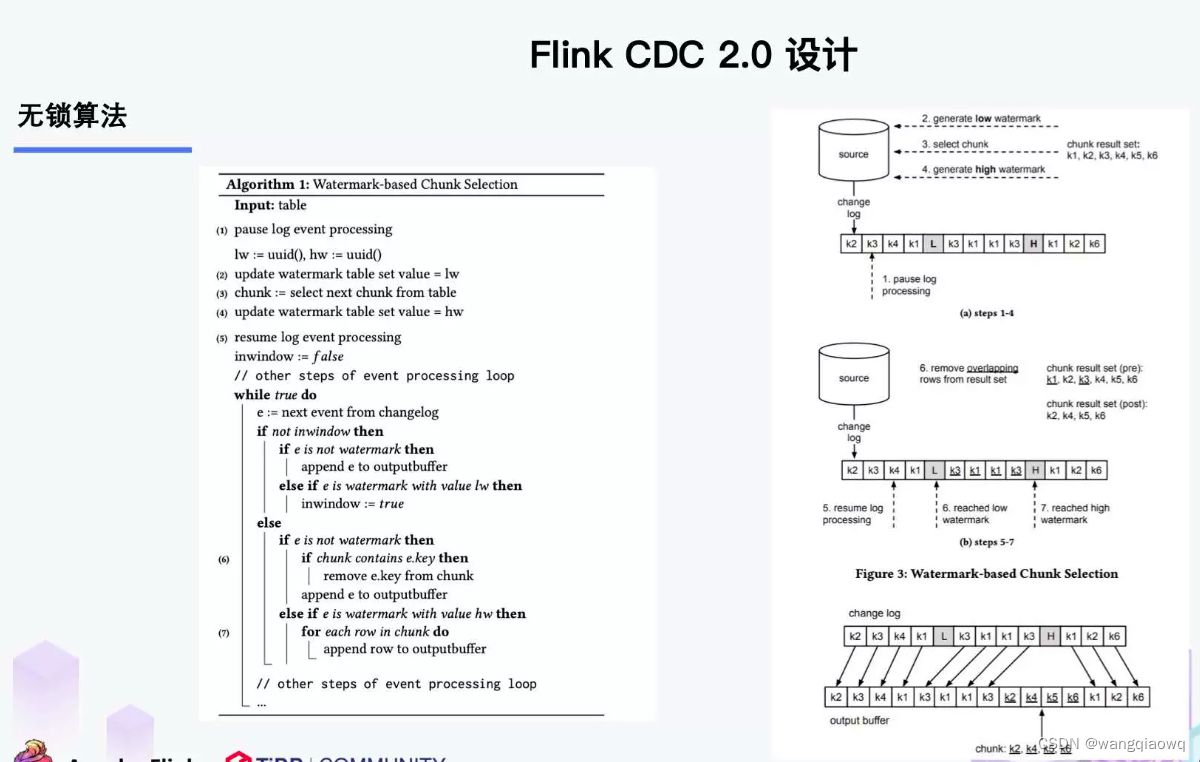
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。

因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
Netflix 的 DBLog 论文中 Chunk 读取算法是通过在 DB 维护一张信号表,再通过信号表在 binlog 文件中打点,记录每个 chunk 读取前的 Low Position (低位点) 和读取结束之后 High Position (高位点) ,在低位点和高位点之间去查询该 Chunk 的全量数据。在读取出这一部分 Chunk 的数据之后,再将这 2 个位点之间的 binlog 增量数据合并到 chunk 所属的全量数据,从而得到高位点时刻,该 chunk 对应的全量数据。
Flink CDC 结合自身的情况,在 Chunk 读取算法上做了去信号表的改进,不需要额外维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能,整体的 chunk 读算法描述如下图所示:
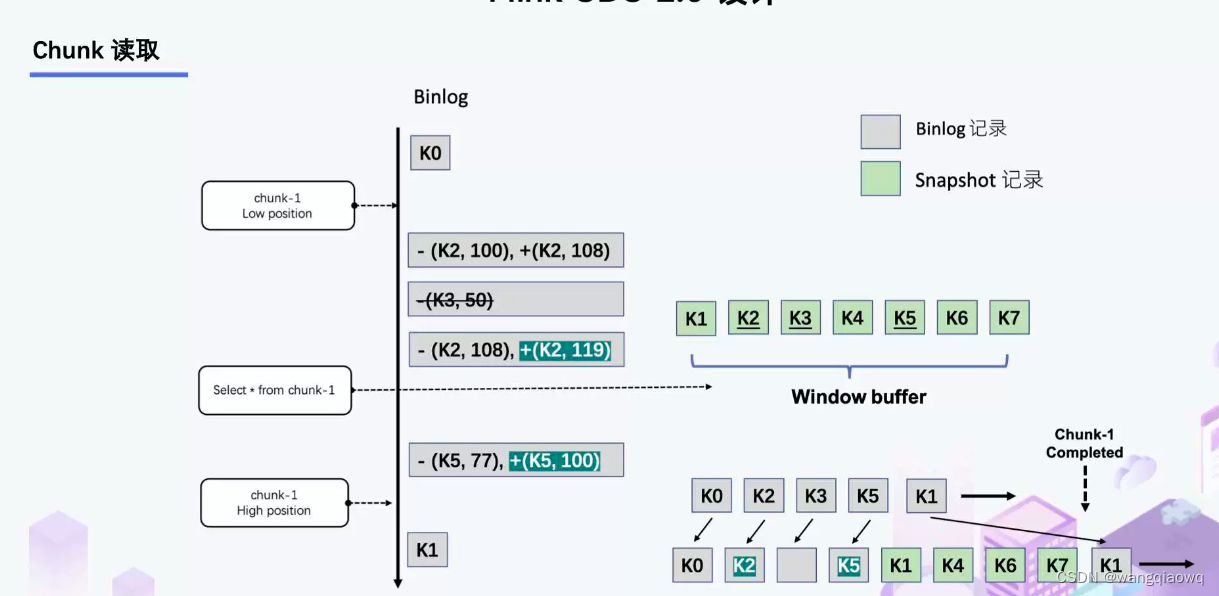
比如正在读取 Chunk-1,Chunk 的区间是 [K1, K10],首先直接将该区间内的数据 select 出来并把它存在 buffer 中,在 select 之前记录 binlog 的一个位点 (低位点),select 完成后记录 binlog 的一个位点 (高位点)。然后开始增量部分,消费从低位点到高位点的 binlog。
- 图中的 - ( k2,100 ) + ( k2,108 ) 记录表示这条数据的值从 100 更新到 108;
- 第二条记录是删除 k3;
- 第三条记录是更新 k2 为 119;
- 第四条记录是 k5 的数据由原来的 77 变更为 100。
观察图片中右下角最终的输出,会发现在消费该 chunk 的 binlog 时,出现的 key 是k2、k3、k5,我们前往 buffer 将这些 key 做标记。
- 对于 k1、k4、k6、k7 来说,在高位点读取完毕之后,这些记录没有变化过,所以这些数据是可以直接输出的;
- 对于改变过的数据,则需要将增量的数据合并到全量的数据中,只保留合并后的最终数据。例如,k2 最终的结果是 119 ,那么只需要输出 +(k2,119),而不需要中间发生过改变的数据。
通过这种方式,Chunk 最终的输出就是在高位点是 chunk 中最新的数据。
上图描述的是单个 Chunk 的一致性读,但是如果有多个表分了很多不同的 Chunk,且这些 Chunk 分发到了不同的 task 中,那么如何分发 Chunk 并保证全局一致性读呢?
有 SourceEnumerator 的组件,这个组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 我们能较为方便地做到 chunk 粒度的 checkpoint。
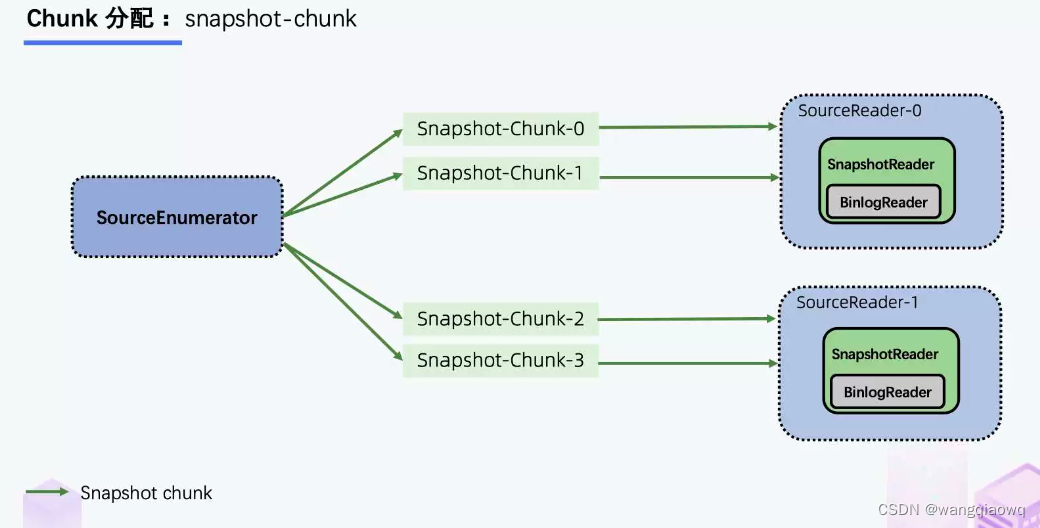
当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。
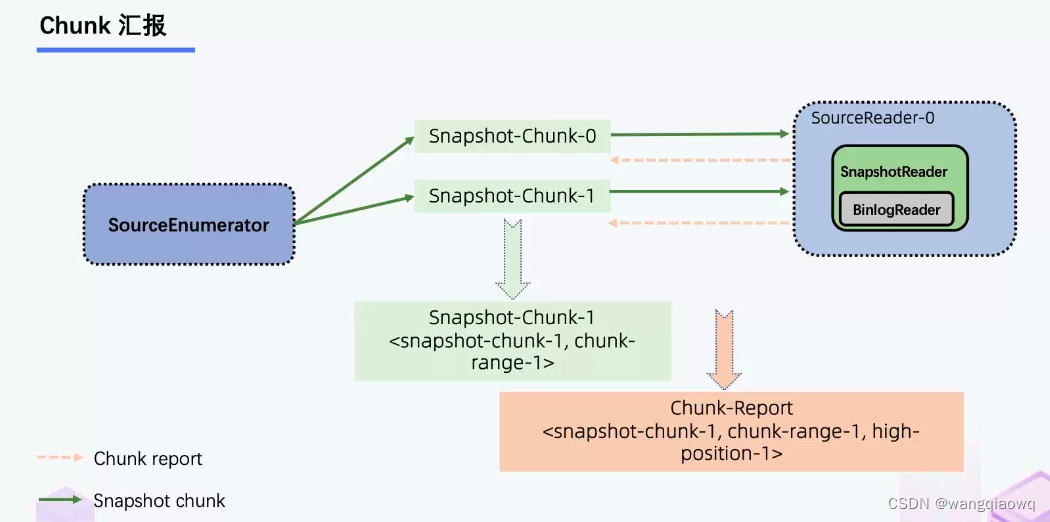
汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。

整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:

MySQL CDC 2.0,核心feature 包括
- 并发读取,全量数据的读取性能可以水平扩展;
- 全程无锁,不对线上业务产生锁的风险;
- 断点续传,支持全量阶段的 checkpoint。
SQL server CDC
CDC实现的原理:
① 数据源:监控的源表所有操作都会进入日志。日志为变更表提供数据源,作为捕获进程的输入来源。
② 捕获进程:扫描日志并将列数据以及与事务有关的信息写入变更数据捕获更改表中。
③ 捕获进程将在每个扫描周期内打开并提交其自己的事务。它检测何时为表新启用了变更数据捕获,并自动将这些表加入到当前在日志中监视更改项的表集中。 同样,它还会检测禁用的变更数据捕获,进而从当前监视更改数据的表集中删除源表。 在处理完日志的某个部分后,捕获进程将通知服务器日志截断逻辑,后者使用此信息来确定适合截断的日志项,所以采用完整备份和简单备份日志方式对CDC捕获不会产生影响。
SQL Server CDC 长什么样?
原始日志
常见的数据库往往存在以下两种日志
- redo 日志
- 记录数据的正向变更,简单来说,事务的 commit 通常先记录在这个文件,再返回应用程序成功,可确保数据 持久性
- undo 日志
- 用于保证事务的 原子性,如执行 rollback 命令即反向执行 undo 日志中内容以达成数据回滚
一条 DML 语句写入数据库流程如下

- 大部分关系型数据库中,一个或多个变更会被隐式或显式包装成一个事务
- 事务开始,数据库引擎定位到数据行所在的 文件位置 并根据已有的数据生成 前镜像 和 后镜像
- 后镜像 数据记录到 redo 日志中,前镜像 数据记录到 undo 日志中
- 事务提交后,日志提交位点(检查点)向前推进,已提交的日志内容即可能被覆盖或者释放
SQL Server redo/undo 日志采用了 ldf 格式 ,文件循环使用。
- ldf 日志文件由多个 VLF(逻辑日志) 组合在一起,这些 VLF 首尾相连形成完整的数据库日志记录
- ldf 在逻辑日志末端到达物理日志文件末端时,新的日志记录将回到物理日志文件开始,复写旧的数据
ldf 文件即 CDC 所分析的增量日志文件。
- cdc.console_capture
- 负责分析 ldf 日志 并解析 console 数据库事件,再将其写入到 CDC 表中
- 间隔 5 秒钟执行一次扫描,每次扫描 10 轮,每轮扫描最多 500 个事务
- cdc.console_cleanup
- 负责定期清理 CDC 表中较老的数据
- 默认保留 3 天 CDC 日志数据(4320秒)
开启 CDC 功能后,SQL Server 数据库会多出一个名称为 cdc 的 schema,里面会多出下列这些表。
- change_tables
- 记录每一个启用了 CDC 的 源表 及其对应的 捕获表
- captured_columns
- 记录对应 捕获表 中每个列的信息
- index_columns
- 记录 源表 含有的主键信息(如果有)
- lsn_time_mapping
- 记录每个事务的开始/结束时间及 LSN 位置信息
- ddl_history
- 记录源表发生的 增/减列 对应的 DDL 信息,除此之外的 DDL 都不会被记录
有了上述准备动作和信息,即可开始对原始表开启 change data capture(CDC),即增量数据捕获了。
+I 表示新增、-U 表示记录更新前的值、+U 表示记录更新后的值,-D 表示删除
相关文章:
Flink CDC 2.0 主要是借鉴 DBLog 算法
DBLog 算法原理 DBLog 这个算法的原理分成两个部分,第一部分是分 chunk,第二部分是读 chunk。分 chunk 就是把一张表分为多个 chunk(桶/片)。我可以把这些 chunk 分发给不同的并发的 task 去做。例如:有 reader1 和 re…...
win10 + VS2017 编译libjpeg(jpeg-9b)--更新
刚刚写了一篇“win10 VS2017 编译libjpeg(jpeg-9b)”, 然后就发现,还有一个更好的方法。因此,重新更新了一篇,作为对比与参考。 需要用到的文件: jpeg-9b.zip win32.mak 下载链接链接…...
使用pycharm远程调试
使用pycharm 专业版, 在设置解释器中,具备ssh 解释器功能; 一般在本地无法调试远程端代码,机械性的scp传输文件十分影响工作效率,PyCharm的Pro支持远程Run,Debug,等可视化的功能。 操作系统&…...
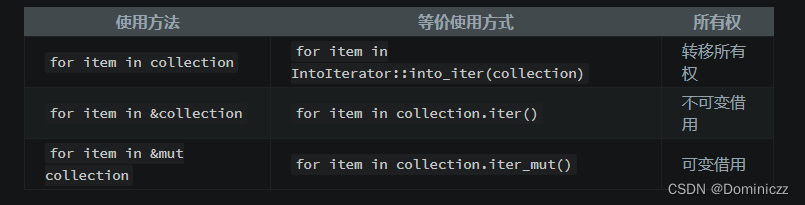
rust学习
rust学习 String类型clone和copy结构体的内存分布for循环(<font color red>important!)堆和栈数据结构vector panic失败就 panic: unwrap 和 expect传播错误 模式匹配忽略模式的值绑定 泛型特征Trait定义特征为类型实现特征孤儿规则使…...
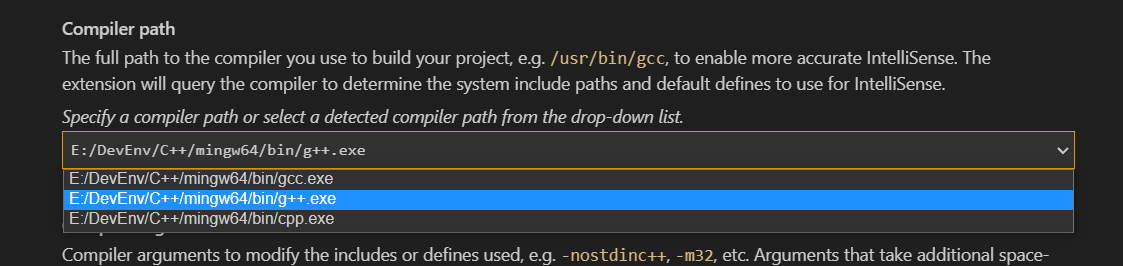
GCC、g++、gcc的关系
GCC、g、gcc的关系 引言 VsCode中对编译环境进行配置的时选择编译器时发现有多种不同的编译器 GNU计划和GCC GNU的全称 GNU’s Not UNIX GNU是一个计划 Q:为什么会有这个计划 因为当时的Unix开始收费和商业闭源,有人觉得不爽→ 想要自己开发和Unix类似的→GNU计划 GUN计划目…...

IP应用场景API的反欺诈潜力:保护在线市场不受欺诈行为侵害
前言 在数字化时代,网络上的商业活动迅速增长,但与之同时,欺诈行为也在不断演化。欺诈者不断寻找新方法来窃取个人信息、进行金融欺诈以及实施其他不法行为。为了应对这一威胁,企业和组织需要强大的工具,以识别和防止…...
常用的主流音乐编曲软件有哪些?
FL Studio是一款备受音乐人喜爱的超强编曲软件。最新的FL Studio版本将所有音频形式都视为采样,使得它在各个领域都有出色的表现。该软件操作简单,界面友好,非常适合新手全面学习和使用。此外,FL Studio完美支持Windows和Mac操作系…...
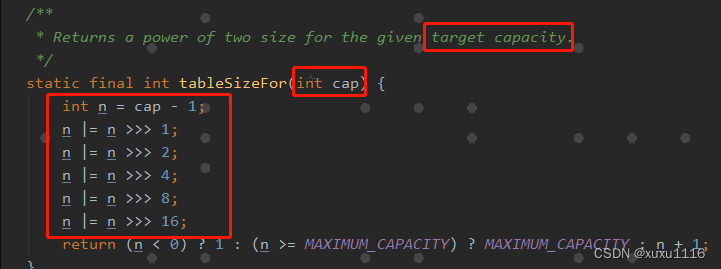
面试题:为什么HashMap 使用的时候指定容量?
文章目录 前言正文为什么要指定容量? 前言 其实可以看到我写了这么久的博客,很少去写hashMap的东西。 为什么?因为这个东西感觉是java面试必备的,我感觉大家都看到腻了,所以一直没怎么去写hashMap相关的。 本篇内容&…...

基于C/C++的UG二次开发流程
文章目录 基于C/C的UG二次开发流程1 环境搭建1.1 新建工程1.2 项目属性设置1.3 添加入口函数并生成dll文件1.4 执行程序1.5 ufsta入口1.5.1 创建程序部署目录结构1.5.2 创建菜单文件1.5.3 设置系统环境变量1.5.4 制作对话框1.5.5 创建代码1.5.6 部署和执行 基于C/C的UG二次开发…...
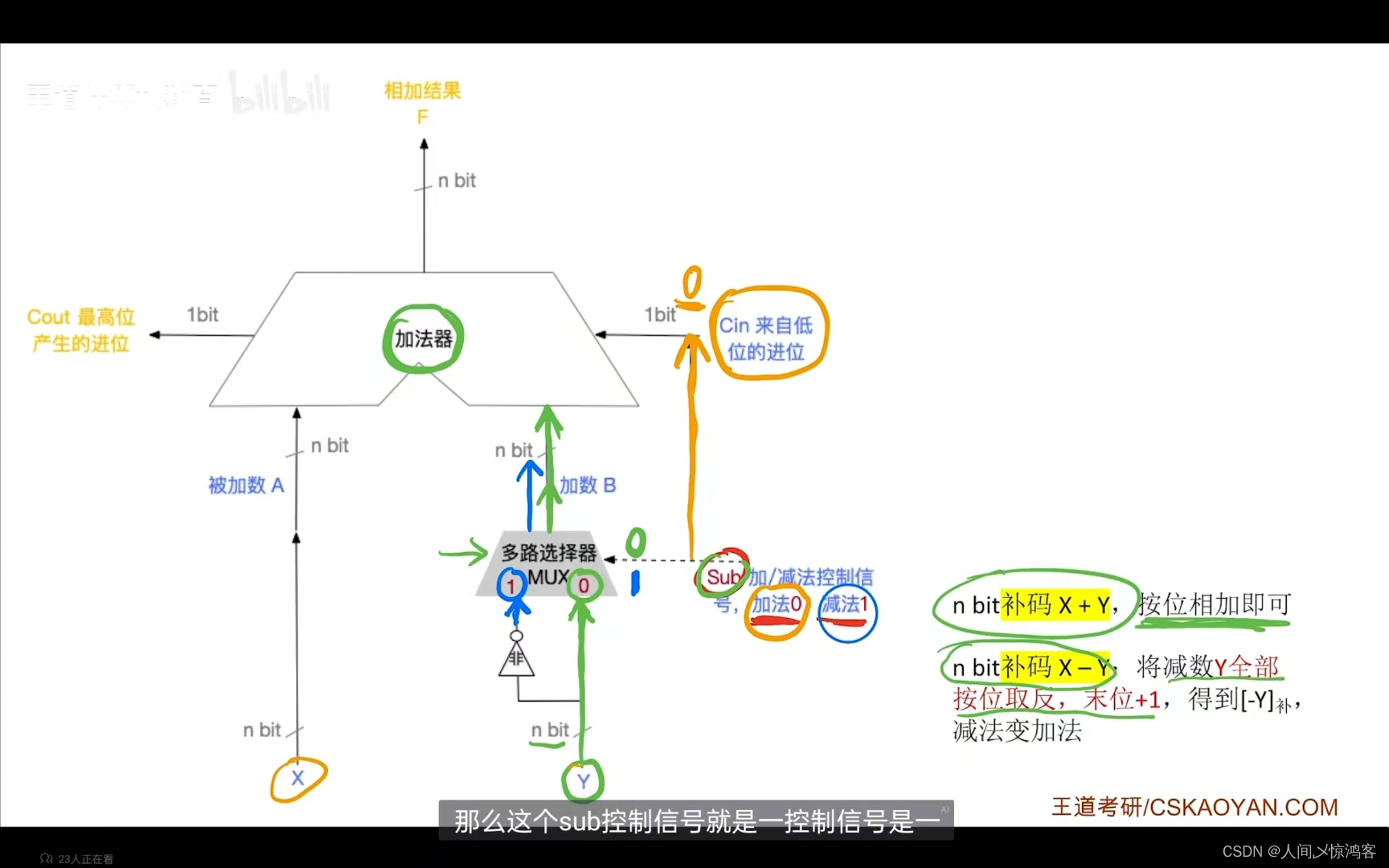
“第五十二天”
算术逻辑单元: 之前提过的运算器包括MQ,ACC,ALU,X,PSW;运算器可以实现运算以及一些辅助功能(移位,求补等)。 其中ALU负责运算,运算包括算术运算(加减乘除等)和逻辑运算(…...
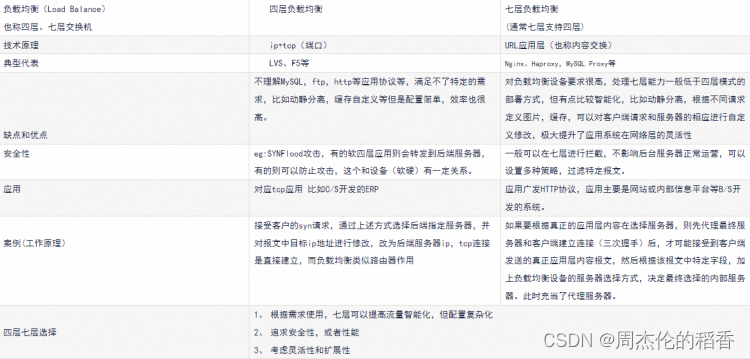
Lvs+Nginx+NDS
什么是?为什么?需要负载均衡 一个网站在创建初期,一般来说都是只有一台服务器对用户提供服务 从图里可以看出,用户经过互联网直接连接了后端服务器,如果这台服务器什么时候突然 GG 了,用户将无法访问这…...

JavaWeb——Servlet原理、生命周期、IDEA中实现一个Servlet(全过程)
6、servlet 6.1、什么是servlet 在JavaWeb中,Servlet是基于Java编写的服务器端组件,用于处理客户端(通常是Web浏览器)发送的HTTP请求并生成相应的HTTP响应。Servlet运行在Web服务器上,与Web容器(如Tomcat&…...

Android 12.0 ota升级之SettingsProvider新增和修改系统数据相关功能实现
1. 前言 在12.0的系统rom定制化开发中,在解决一些已经上线的bug后,进行ota升级的过程中,由于在SettingsProvider中新增了系统属性和修改某项系统属性值,但是在ota升级以后发现没有 更新,需要恢复出厂设置以后才会更改,但是恢复出厂设置 会丢掉一些数据,这是应为系统数据…...
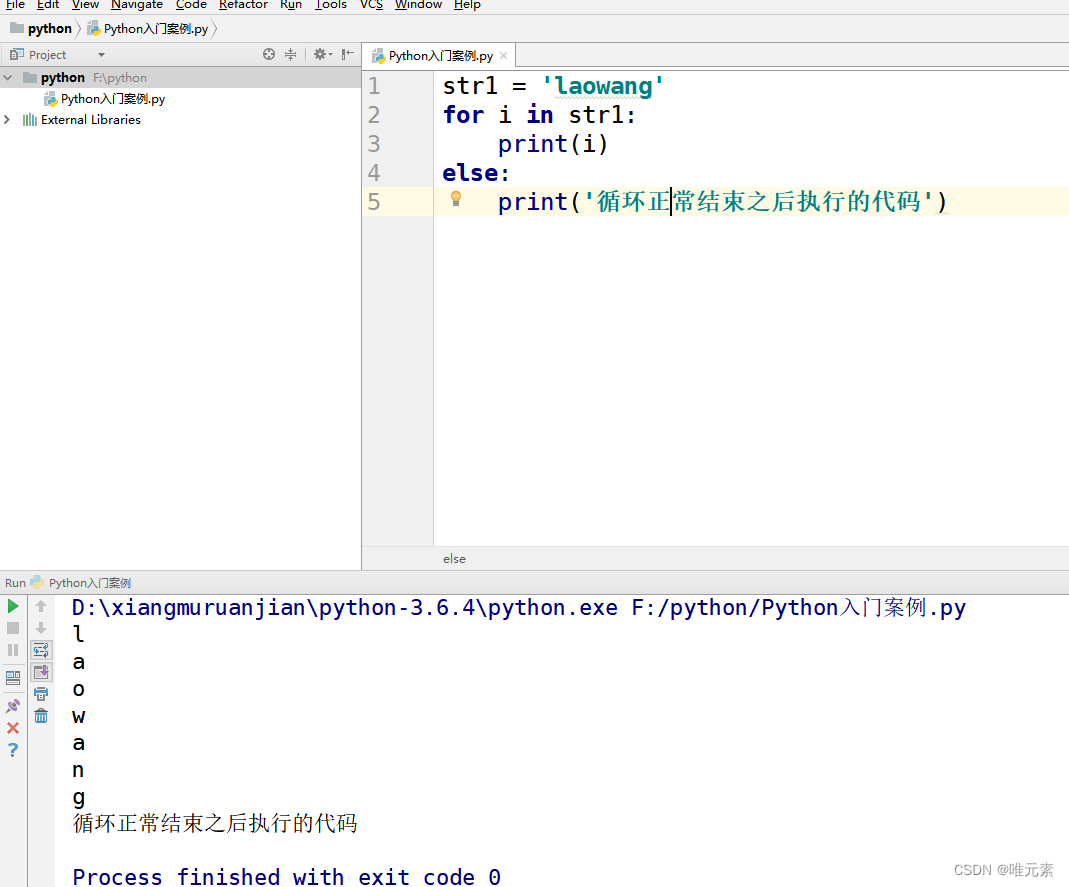
python---for循环结构中的else结构(是同级关系)
为什么需要在for循环中添加else结构 循环可以和else配合使用, else下方缩进的代码指的是当循环正常结束之后要执行的代码。 强调: 循环 正常结束,else之后要执行的代码。 非正常结束,其else中的代码是不会执行的。…...

XLua中lua读写cs对象的原理
LuaCallCS 1. 传递C#对象到Lua XLua在C#维护了两个数据结构,ObjectPool和ReverseMap。 首次传递一个C#对象obj到Lua时,对象被加入到ObjectPool中,并为它创建一个唯一标识objId,建立obj和objId的双向映射。 ObjectPool: objId-…...

新手小白怎么选择配音软件?
现在的配音软件软件很多,各种类型的都比较多,对于新手小白来说不知该如何选择,今天就来给你分享几款好用的配音软件。不论是制作短视频还是制作平常音频都完全可以。 第一款:悦音配音 这是一款专业的视频配音软件,多端…...

linux查看硬件信息命令
文章目录 cpu内核版本内存硬盘主板服务器参考链接 cpu cat /proc/cpuinfo 一个物理CPU可以有1个或者多个物理内核,一个物理内核可以作为1个或者2个逻辑CPU。 物理CPU数就是主板上实际插入的CPU数量。 在Linux上cat /proc/cpuinfo,会打印每个cpu的信息 …...
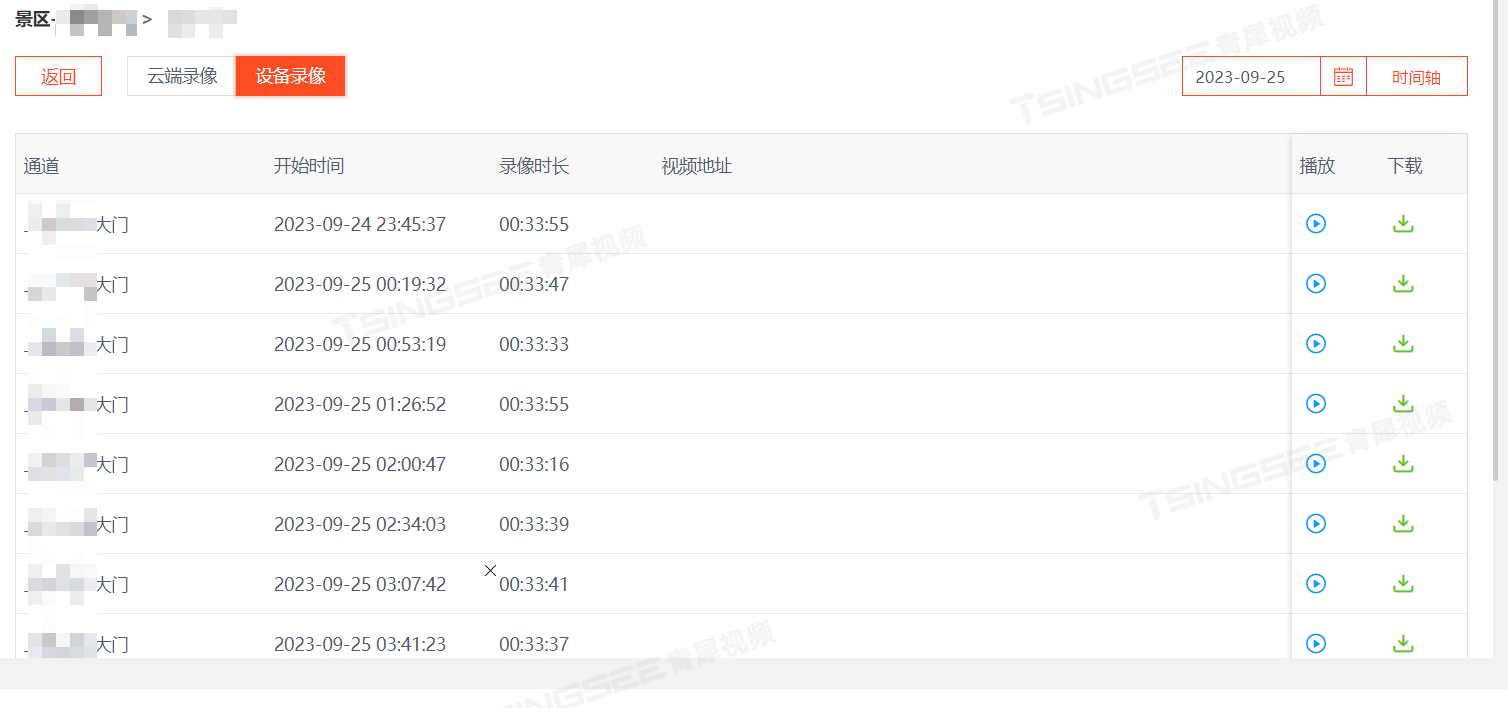
TSINGSEE青犀省级高速公路视频上云联网方案:全面实现联网化、共享化、智能化
一、需求背景 随着高速铁路的建设及铁路管理的精细化,原有的模拟安防视频监控系统已经不能满足视频监控需求,越来越多站点在建设时已开始规划高清安防视频监控系统。高速公路视频监控资源非常丰富,需要对其进行综合管理与利用。通过构建监控…...
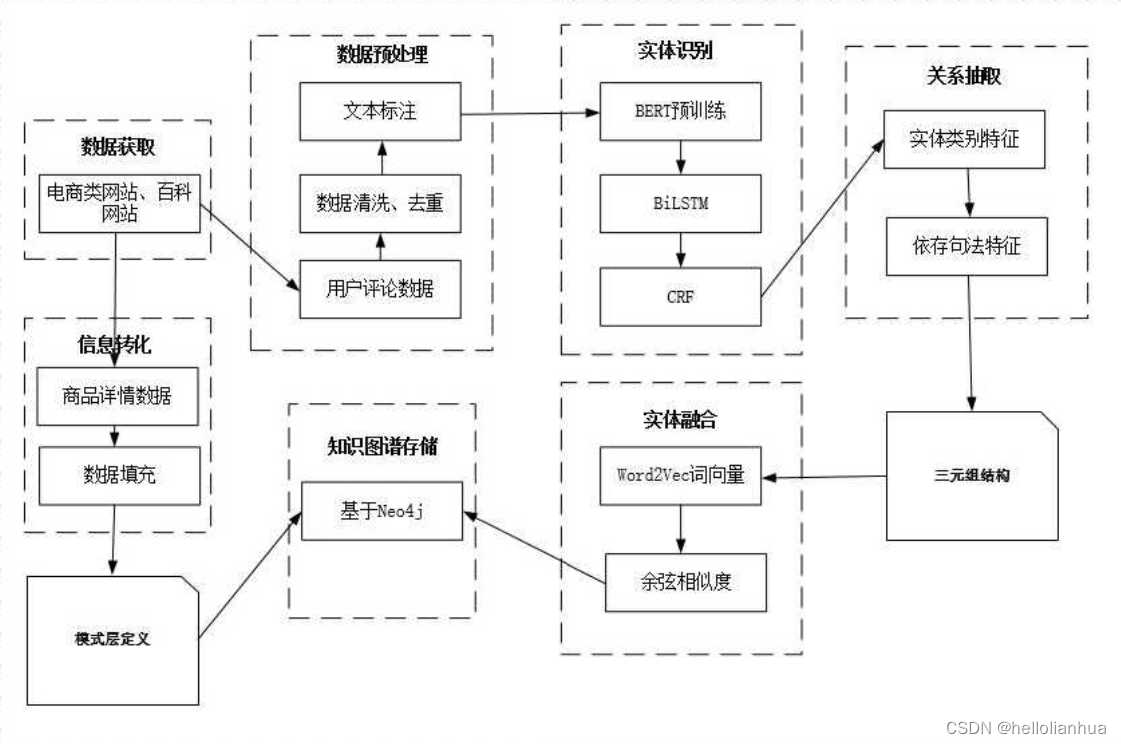
知识图谱相关的操作
微软生成自己的图谱:GitHub - microsoft/SmartKG: This project accepts excel files as input which contains the description of a Knowledge Graph (Vertexes and Edges) and convert it into an in-memory Graph Store. This project implements APIs to searc…...
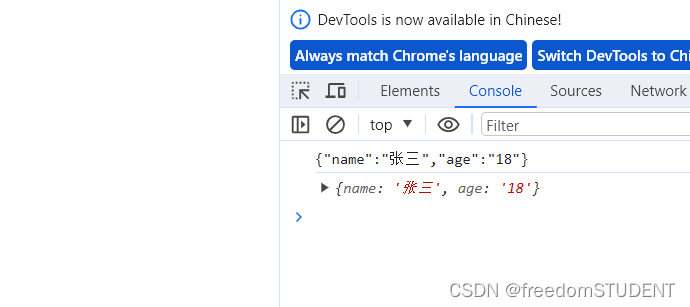
【Javascript】json
目录 什么是json? 书写格式 json 序列化和反序列化 序列化 反序列化 什么是json? JSON(JavaScript Object Notation)是⼀种轻量级的数据交换格式,它基于JavaScript的⼀个⼦集,易于⼈的编写和阅读,也易于机器解析…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...
)
Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环)
更多请点击: https://kaifayun.com 第一章:Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环) Lovable 方法论的核心不是交付功能,而是培育“工具依赖感”——当一线工程师在凌晨三点调试线上问题时&am…...

安卓用户如何免费获取大模型API密钥并开始调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 安卓用户如何免费获取大模型API密钥并开始调用 对于安卓开发者或移动端技术爱好者而言,直接体验和调用多种大模型的能力…...

VisualCppRedist AIO:Windows系统依赖问题终极解决方案,一键修复所有VC++运行库
VisualCppRedist AIO:Windows系统依赖问题终极解决方案,一键修复所有VC运行库 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经…...