JVM进阶(1)
一)JVM是如何运行的?
1)在程序运行前先将JAVA代码转化成字节码文件也就是class文件,JVM需要通过类加载器将字节码以一定的方式加载到JVM的内存运行时数据区,将类的信息打包分块填充在运行时数据区;
2)但是字节码文件是JVM的一套指令运行规范,并不能直接交给底层的操作系统来执行,因此需要特殊的命令解析器,也就是JVM的执行引擎会将字节码翻译成底层的操作系统指令也就是0 1的二进制操作系统指令数据交给CPU执行,因为操作系统只认机器码,不认识字节码
3)执行引擎在进行执行的过程中也会调用其它语言的接口,比如说调用本地库接口调用本地方法来实现整个程序的运行;
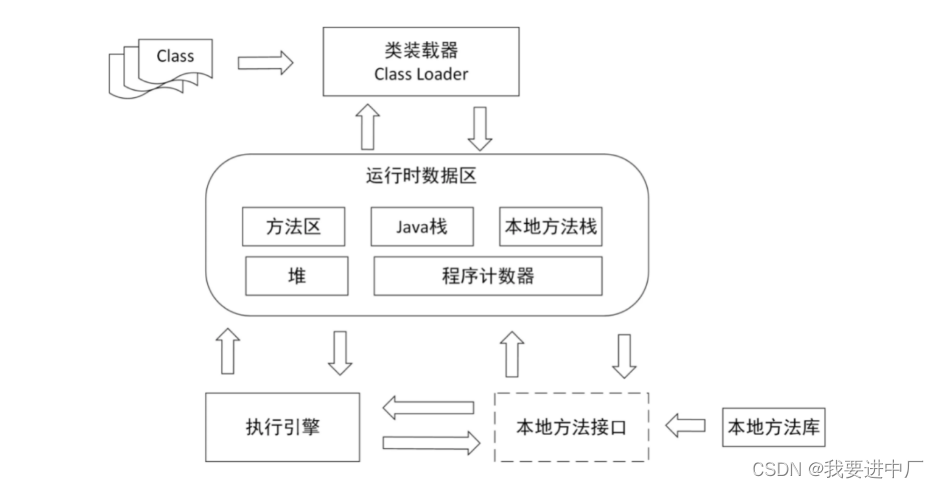
JVM=类加载器+运行时数据区+执行引擎+本地库接口
1)本地方法接口:简单来说就是一个本地方法就是一个JAVA调用,非JAVA代码的一个接口,方法体不是由JAVA代码写的,设置优先级之类的,简单来说一个本地方法就是一个JAVA调用非JAVA代码的接口,一个本地方法的方法并不是由JAVA方法实现的,比如说C,本地接口的作用就是融合不同的编程语言为JAVA所用。本地方法不是抽象方法,native方法是存在方法体,但是abstract不存在方法体,标识符native可以和其它所有的java标识符连用,但是不可以和abstract连用
2)因为本身JAVA的实现非常简单,但是有些层次的任务使用JAVA实现就非常不容易了,或者对于程序执行的执行效率很在意的时候,问题就出现了
2.1)需要和JAVA外部的环境进行交互:有的时候JAVA应用需要和外部的环境进行交互,这是本地方法存在的主要的原因,JAVA需要和底层的操作系统,交互系统或者是某一些硬件交换信息的时候,本地方法提供了一些交互机制
1)类加载器:加载class字节玛的内容到内存中
2)运行时数据区:负责管理JVM使用到的内存,比如说创建对象和销毁对象
3)方法区:常量,域信息,只有HotSpot虚拟机才有
4)执行引擎:将字节码文件中的内容解析成机器码,同时使用即时编译优化性能
5)本地方法接口:调用本地已经编译的方法,比如说虚拟机中已经提供好的C/C++的方法
6)翻译字节码:针对于字节码的指令进行解释执行
7)JIT编译器:针对于热点代码进行二次编译(将字节码中的字节码指令编译成机器指令)并将其缓存起来缓存在方法区中
字符串常量池的底层实现是依靠C++的map来实现的,C++的hashmap也是需要存放局部变量的,存放C++本地方法的方法调用和局部变量
JMM:一种内存模型,为了提升CPU的读写效率,充分利用CPU资源

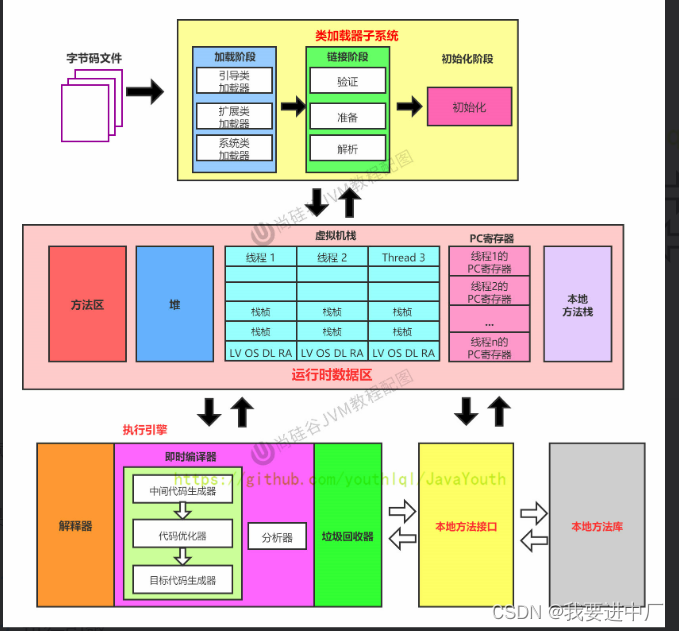

二)类加载子系统,类加载的过程=类的生命周期
init方法:成员变量真正进行赋值,之前是0,并且调用对象的构造方法
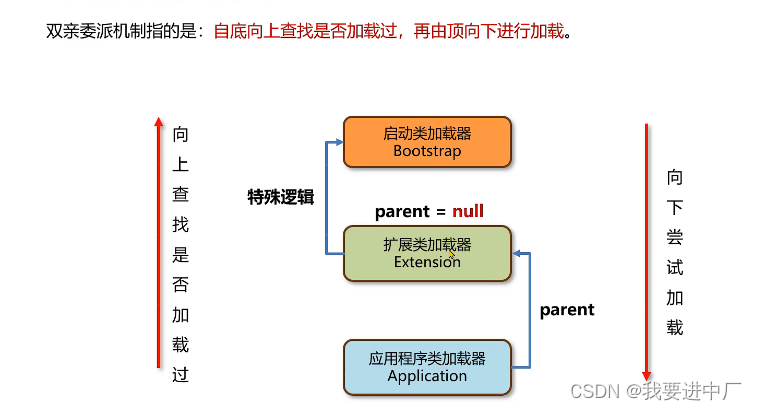
双亲委派模型
1)沙箱安全机制:自己写的类不会加载,这样便可以防止JAVA的核心API不会被修改
2)避免类的重复加载:当父亲已经加载之后,子类就没有必要再加载一次
类加载子系统的作用:是一种JAVA虚拟机提供给应用程序去实现获取类和接口字节码的技术,类加载器只是参与加载过程中的字节码获取并加载到内存的这一部分
类的生命周期描述了一个类加载使用卸载的过程,加载---链接---初始化----使用----卸载
一)loadding:
a)根据包的全限定包名+类名通过不同的渠道来找到对应的.class文件加载到内存中;
b)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构,就是将字节码的信息存放到方法区里面,方法区就是用来存放已被加载的类信息,常量,静态变量
c)在方法区中生成这个类的类对象,作为方法区中这个类的各种数据的访问入口;
二)链接:
2.1)验证:class文件是以特定的文件符开始的,校验内容是否满足JAVA虚拟机规范;
a)文件格式验证:验证文件是否已特定字符开头,就是以特定的二进制文件开头
b)原信息校验:就是对一些基本信息进行校验,比如说类必须有父类
c)验证程序执行的语义:比如说方法中的指令执行中跳转到不正确的位置
d)符号引用验证:例如说有没有类中访问private修饰的方法
e)版本号检测:如果返回值是true,代表验证成功,就是检测JDK的版本
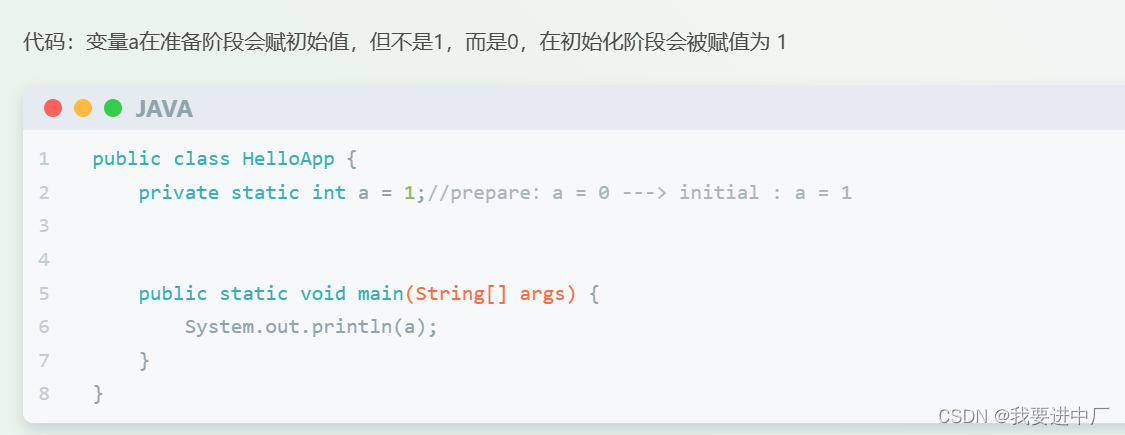
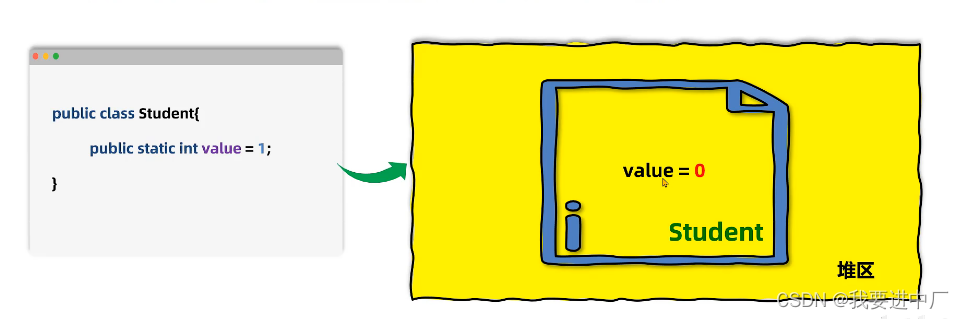
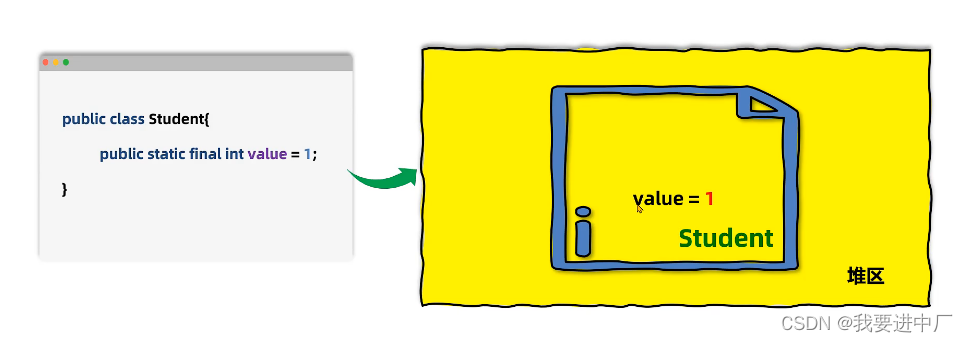
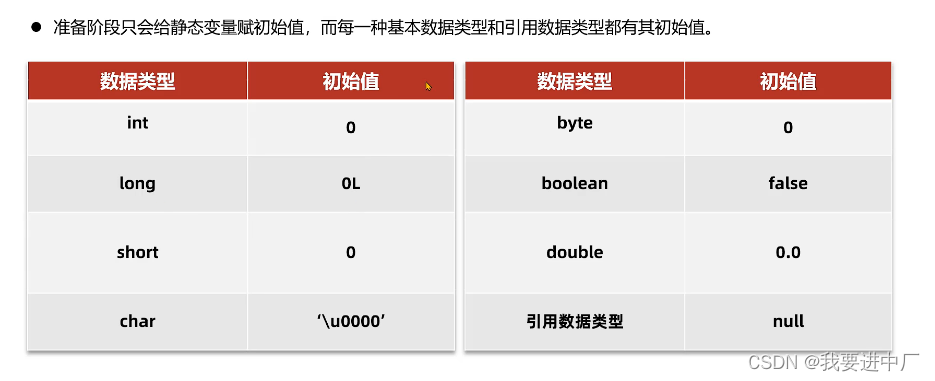
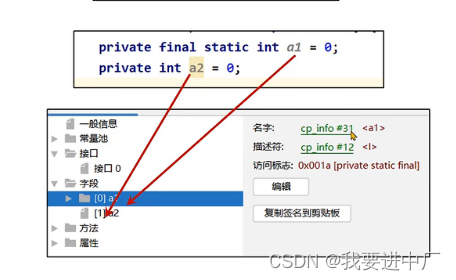
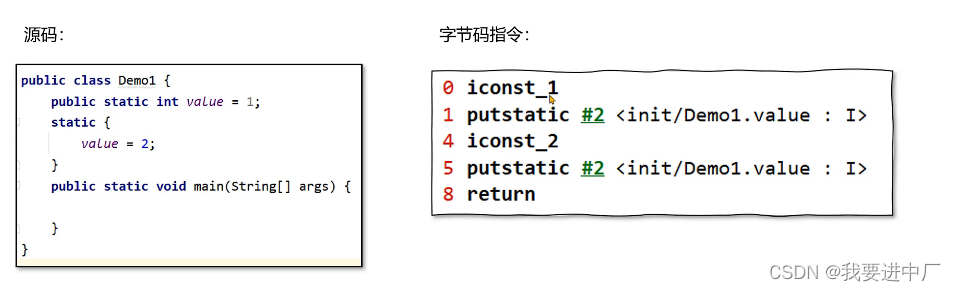
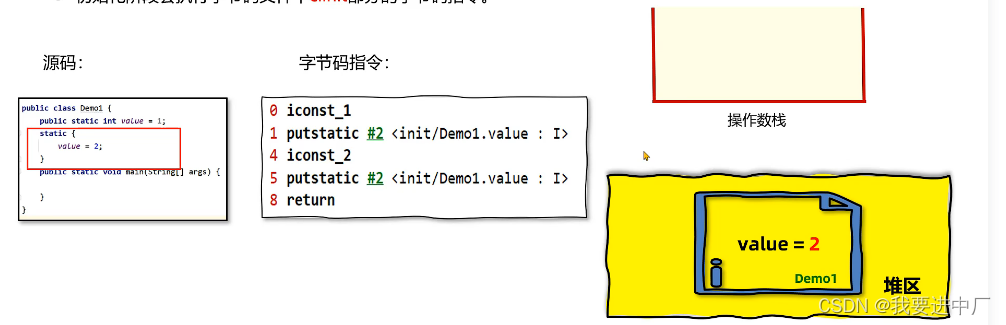
2.2)准备:为静态变量分配内存并设置初始化值为0值,是默认值的初值,就是防止程序员写出脑残代码,比如说给一个a没有赋初值,如果程序员进行后续操作打印a;
final修饰的静态变量,在准备阶段就直接复制初始值了,因为在编译期的时候直接就可以确定值,不会针对于实例变量进行初始化,实例变量会随着对象一起被分配到JAVA的堆里面
下面是准备阶段,下面分别是两个变量在内存中的状态
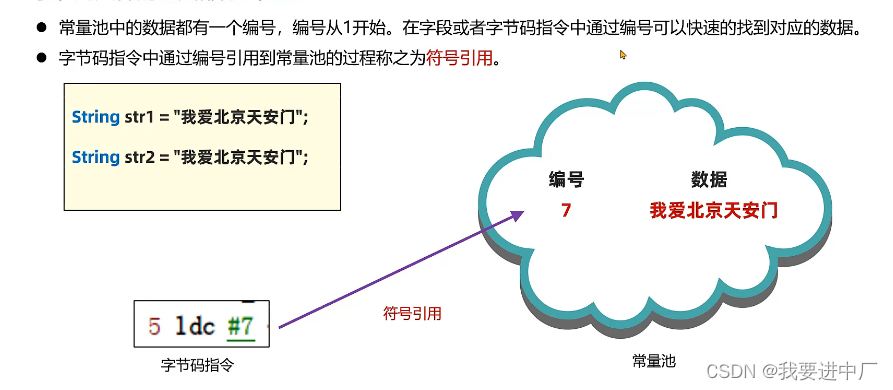
2.3)解析:解析所作的操作就是将常量池中的符号引用替换成直接引用
符号引用就是在字节码文件中使用编号来访问字符串常量池中的内容,而直接引用不再使用编号,而是使用内存地址来直接访问具体的数据
3)初始化阶段:执行静态代码块中的代码并且会给静态变量赋初值
其实本质上初始化就是在执行字节码部分的中的clinit部分的字节码指令
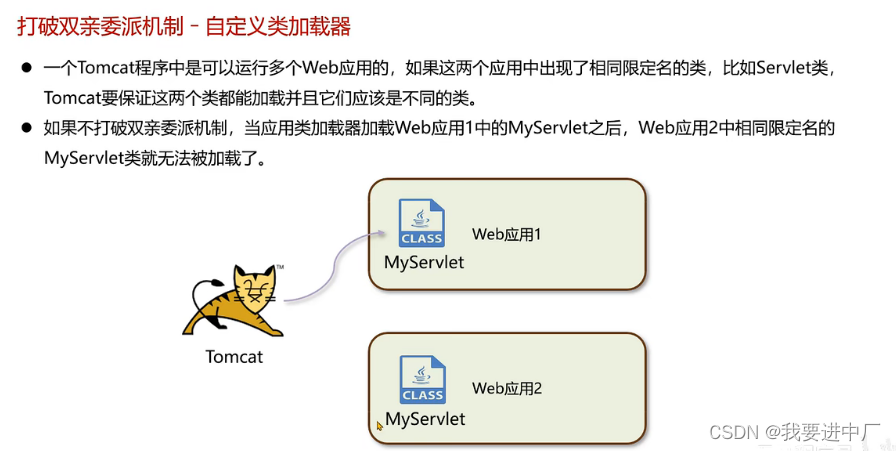
java虚拟机针对于class文件采用的是按需加载的方式,也就是说当需要使用该类的时候才会将他的class文件加载到内存中生成类对象,而且家在某一个类的class文件的时候,JAVA虚拟机采用的是双亲委派模型,会把请求交给父亲来处理,是一种任务委派模式
在类加载中使用synchronized加锁,向上委托检查,向下加载
1)避免类的重复加载
2)保护程序安全,防止核心API被随意篡改
在JVM中表示两个Class对象是否是同一个需要满足两个条件
1)两个类的完整类名必须完全一致,全限定包名和类名
2)加载这个类的classloader实例对象必须相同
换句话说,在JVM中,即使这两个类对象Class对象来源于同一个Class文件,即使一个虚拟机所加载,但是只要加载他们的ClassLoader实例对象不同,两个类对象也是不相同的
三)字节码文件的组成:
1)基础信息:魔数,字节码文件对应的java版本号,访问表示public final以及父类和接口
2)常量池:保存了字符串常量,类或者是接口名,字段名,主要在接口中使用
3)字段:当前类或者是接口声明的字段信息
方法:当前类或者接口声明的方法信息,字节码指令
属性:指的是类的属性,源码的文件名以及类的列表
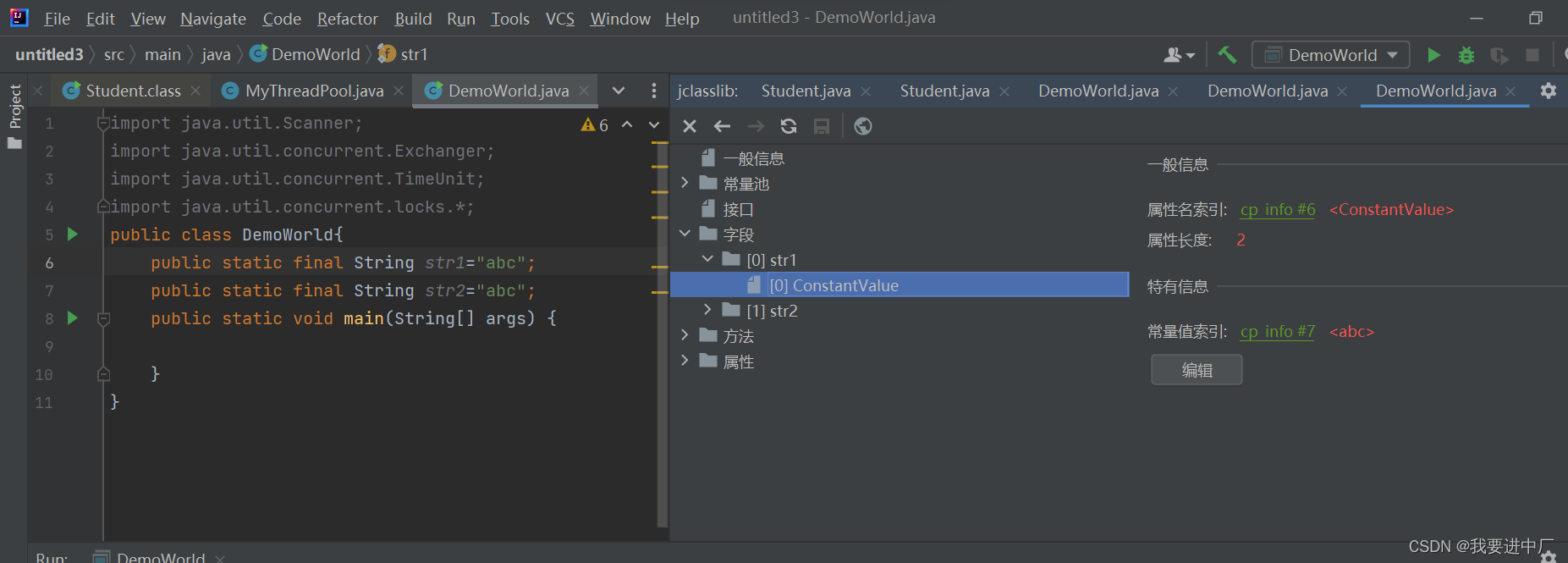
字节码文件中常量池的作用:避免相同的内容同时定义节省空间,不仅会使文件变得非常大,况且读取也会非常慢,通过常量池节省字节码文件中的一部分空间避免同样的数据出现多次
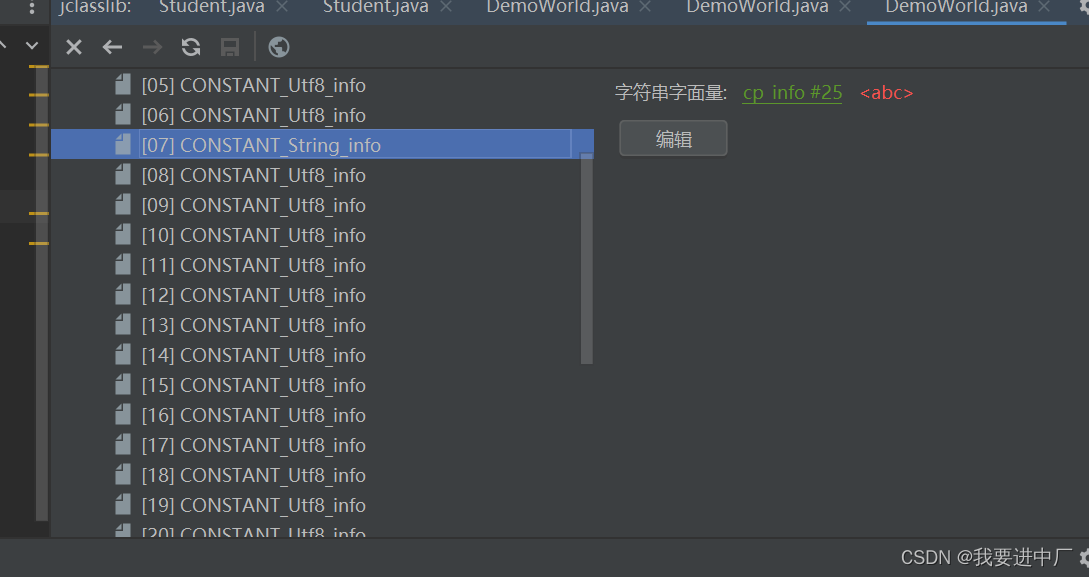
可以看到字符串的引用存放的是7号的索引,点击常量池的索引,发现又是一个字面量
最后点击25就可以找到最终的字面量了
iconst:将数字放入到操作数栈中
putstatic:将操作数栈中的数据放到静态变量中
如果将代码进行颠倒,clinit字节码指令执行的顺序和java中编写的顺序是一致的
但是为什么字节码文件再进行设计这一块的时候,先通过字符串的引用找到字符串,再来通过字符串找到字面量呢?能不能直接通过字段来找到字面量呢?因为JAVA里面的字符串解析并加载中,需要将String类型加载到字符串常量池中
从下到上查找是否加载过,再从上向下进行记载


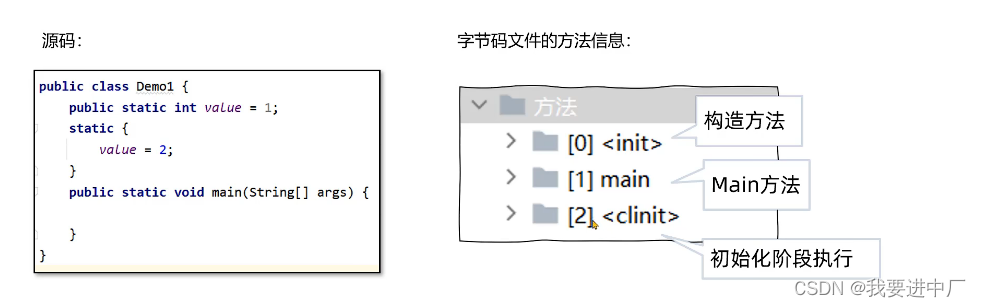






下面来看一下哪几种方式会导致类的初始化:
1)当访问到一个类的静态变量或者是静态方法,注意变量是final修饰的并且等号右边是常量不会触发初始化
2)调用Class.forName(String className)获取到这个类的类对象的时候
3)new一个该类的对象的时候
4)执行Main方法的当前类
添加-XX:+TraceClassLoading参数可以打印出加载并且初始化的类
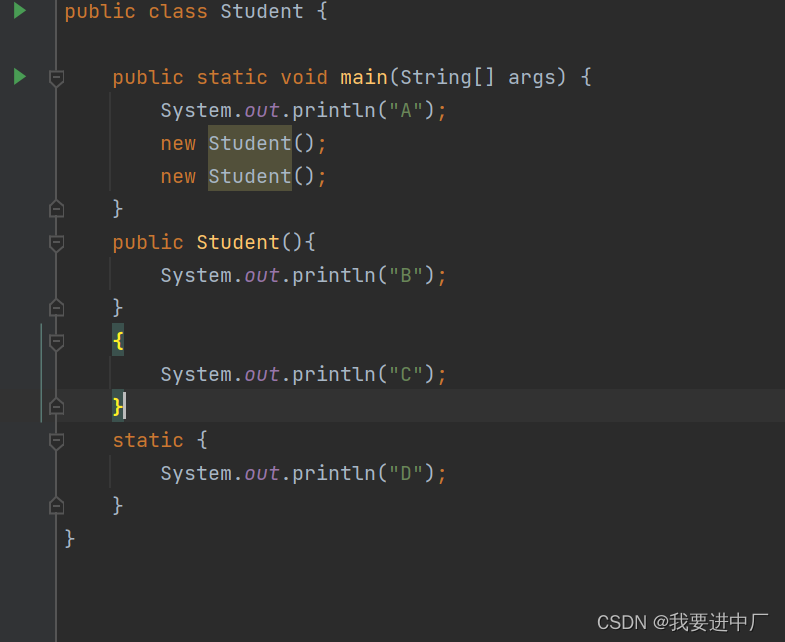
下面程序的输出结果是:
执行main函数,况且类加载只会执行一次,所以静态代码块也只会执行一次,先进行类加载DACBCB
clinit方法在特定的条件下不会出现,如下面几种情况是不会执行初始化指令的,也就不会生成clinit方法,在下面的情况下不会执行初始化操作
1)没有静态代码块况且没有静态变量赋值语句;
2)有静态变量的声明但是没有赋值语句,public static int a在类加载的准备阶段就会赋值成0
3)静态变量的定义使用final关键字况且这份变量会在准备阶段直接进行初始化
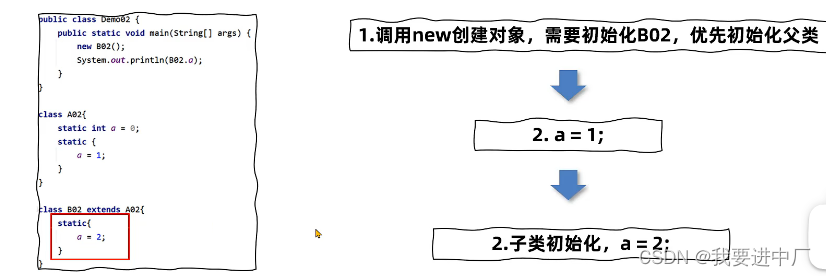
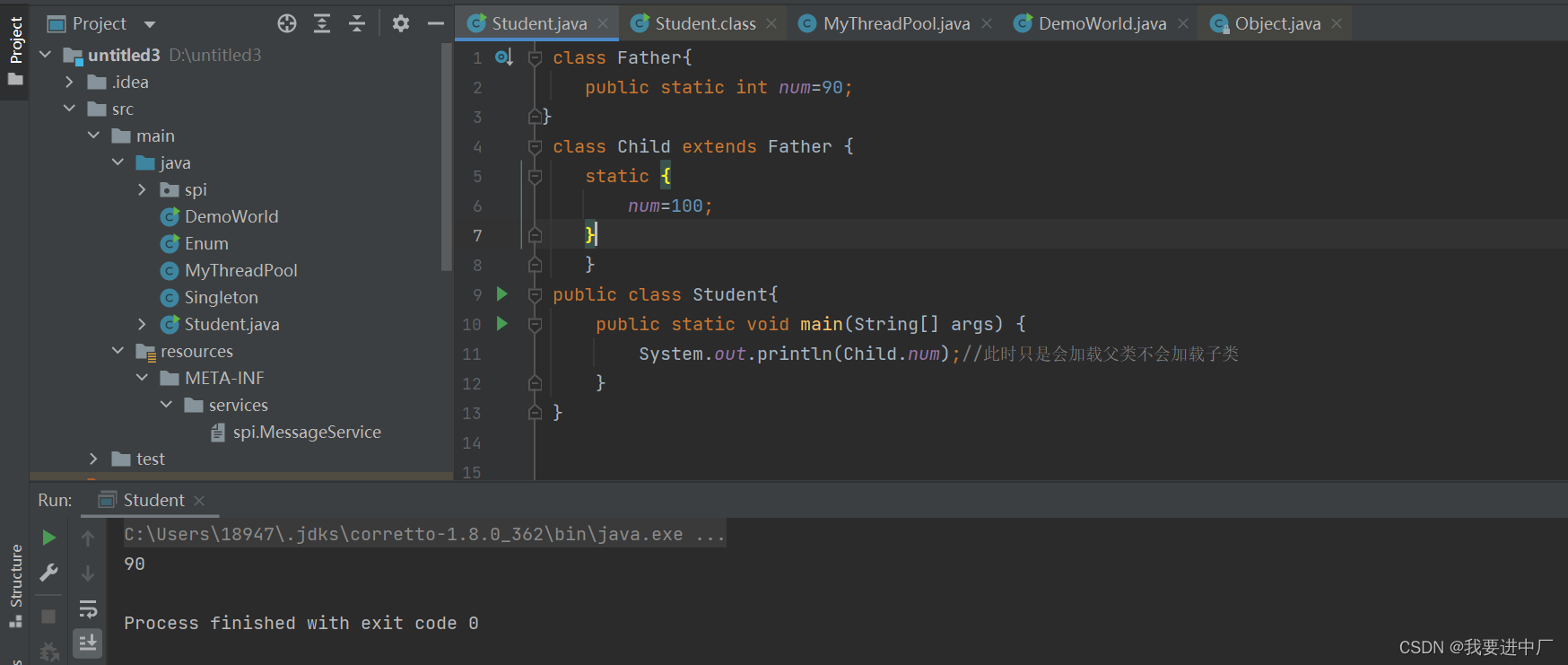
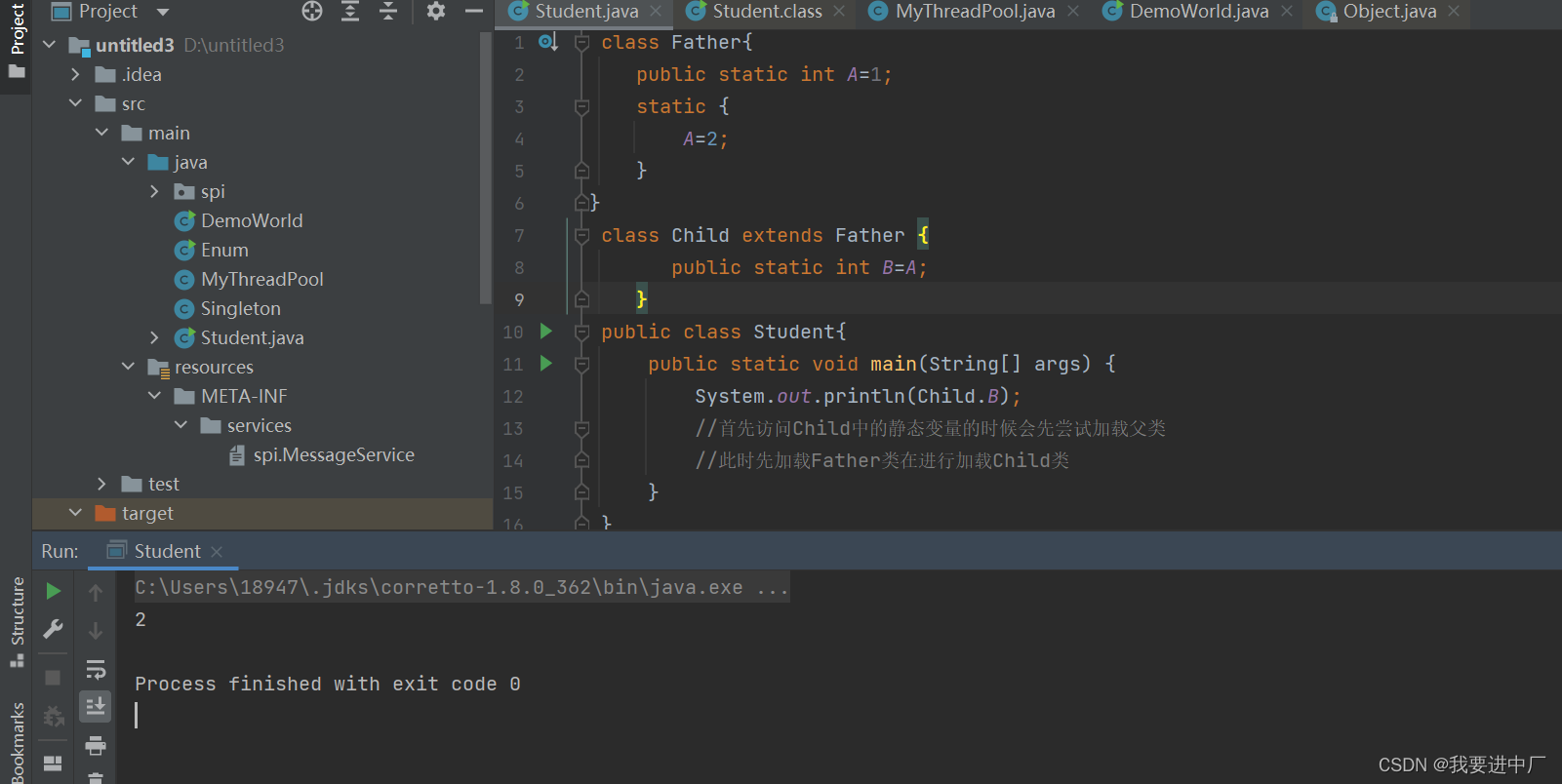
1)直接访问父类的静态变量,不会触发到子类的初始化,子类的clinit方法执行前会先执行父类的clinit方法
2)声明一个类以后,内部至少会存在一个这个类的构造器,也就是一定会出现init方法
访问父类的初始化变量只会初始化父类,因为a只是在父类中,此时打印的是a=1
第五步就是为了防止多个线程多次加载同一个类,从下面的代码中而可以看到类加载中的静态代码块只会执行一次,就相当于是一个加锁的过程,一个类在内存中加载一次即可,方法区在JDK1.8使用的是元空间,会使用直接内存缓存起来了,也就是说JAVA虚拟机在执行类加载的时候只会执行一次,只会调用一次clinit()方法;
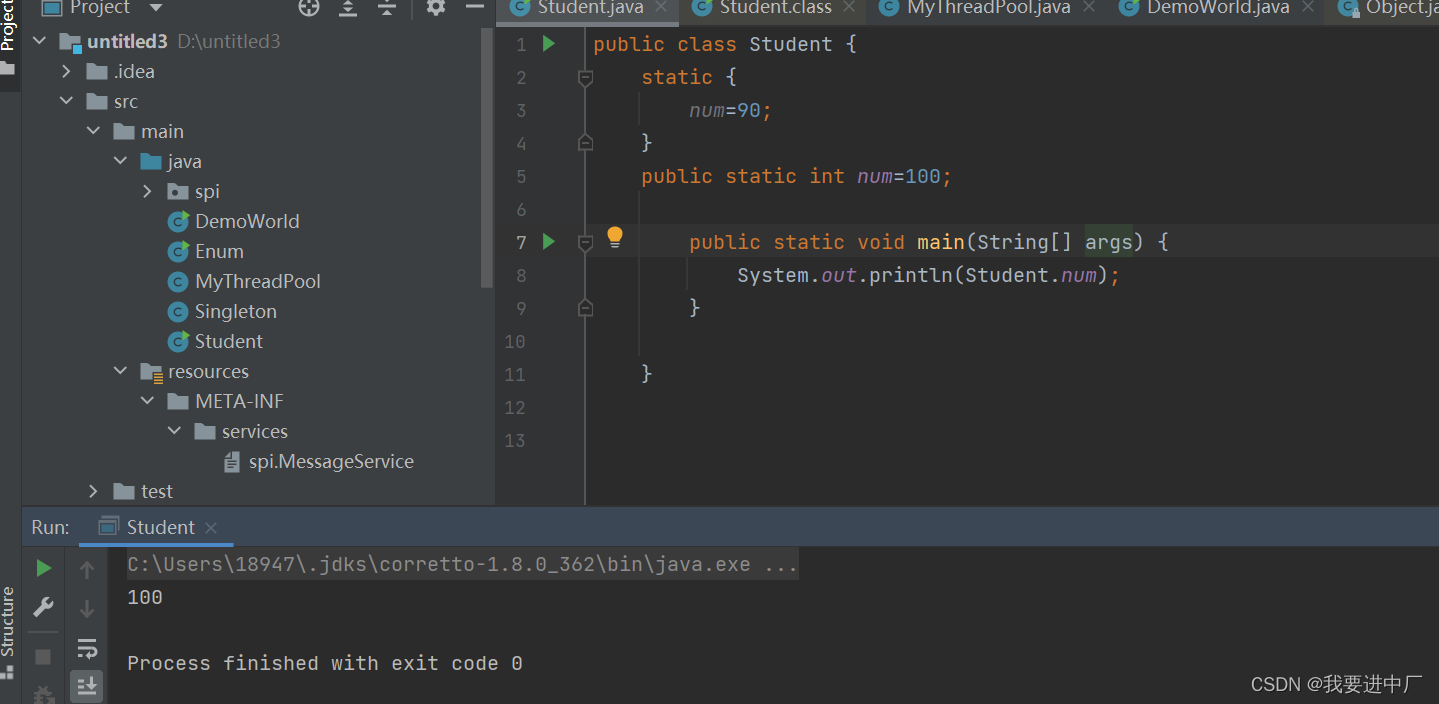
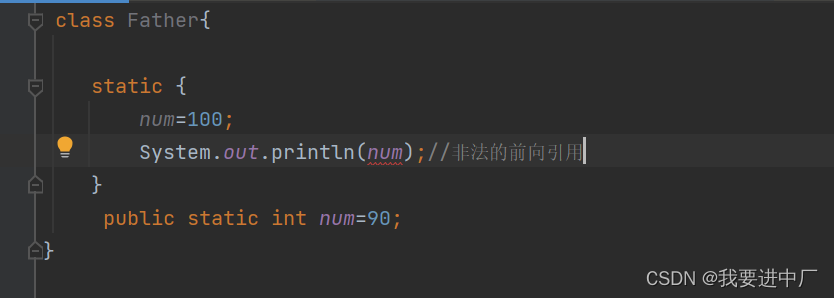
非法的前向引用:当一个定义的变量出现在静态代码块之后,是可以在静态代码块中赋值的,但是是不可以打印这个静态代码块的







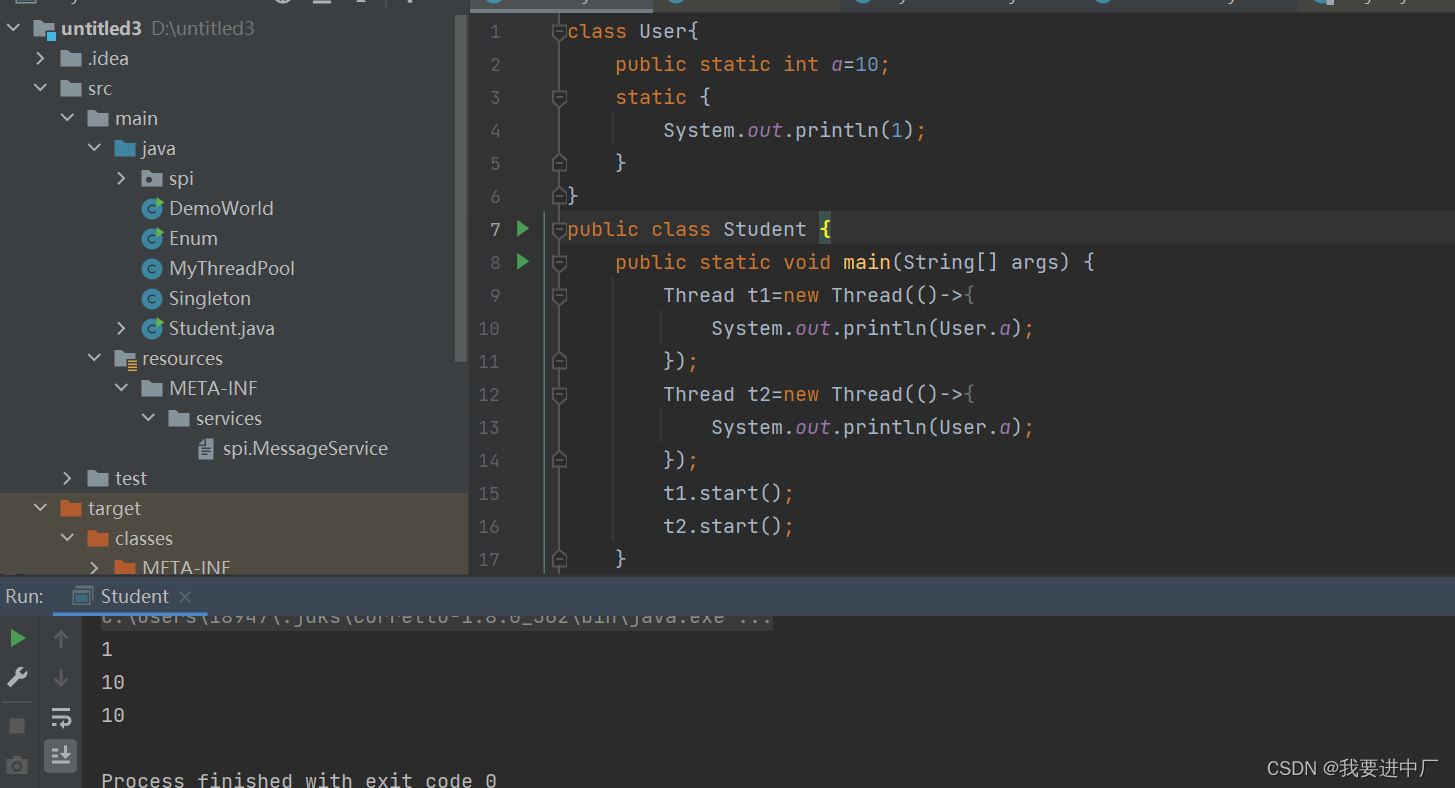
四)如何打破双亲委派模型?
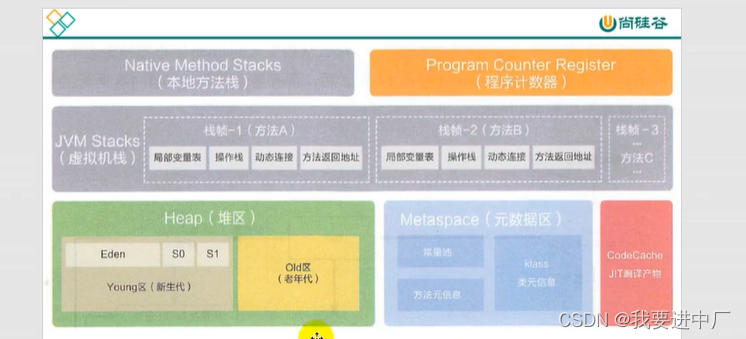
五) JAVA的运行时数据区
1)网络中的数据和硬盘上面的数据要想能够被CPU运算,需要先把数据加载到内存中,CPU直接交互的对象就是内存,内存充当着磁盘和CPU的桥梁,一个JVM实例对应着一个RunTime实例,内存是非常重要的系统资源,是硬盘和CPU的中间仓库以及桥梁,承载着操作系统和应用程序的实时运行,JVM的内存布局规定了JAVA在运行过程中内存申请,分配和管理的策略,保证了JVM的高效稳定运行;
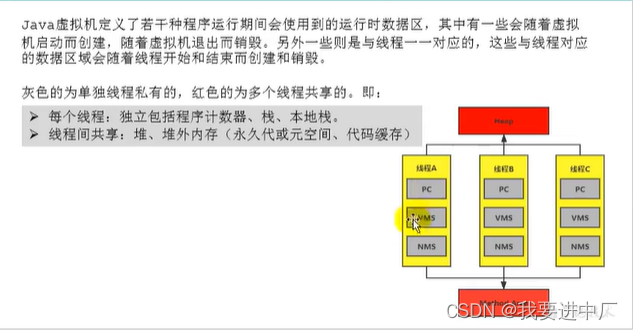
2)JAVA虚拟机定义了若干种程序运行期间会使用到的运行时数据区,其中有一些随着虚拟机的启动而创建,随着虚拟机的退出而销毁,另外一些则是和线程是一一对应的,这些线程对应的数据区域会随着县城开始和结束而创建或者销毁
3)线程是一个程序中的运行单元,JVM允许一个应用有多个线程并行的执行
在Hotspot虚拟机JVM里面,每一个线程都和操作系统本地线程直接映射,当一个Java线程准备好执行以后,此时一个操作系统的本地线程也会创建,Java线程终止以后,本地线程一会回收,操作系统负责所有的线程的安排调度到任何一个可用的CPU上,一旦本地线程初始化成功,他就会调用Java线程的run()方法
4)如果使用jconsole或者是任何一个调试工具,都可以看到在后台有很多线程在运行,这些后台线程不包括调用main线程以及所有这个main线程自己所创建的线程
java虚拟机规范白皮书是给JVM开发厂商去看的,指导开发厂商实现JVM,默认的JVM是hotSpot
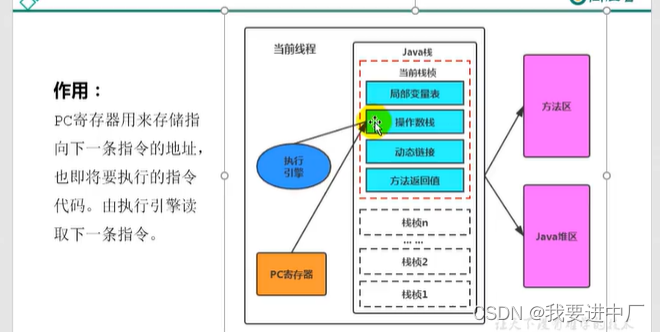
1)程序计数器:当前线程执行的字节码指令的地址,CPU的个数有限,但是任务很多,CPU会频繁进行线程切换,某一块程序会一直经历执行,暂停,再继续执行,就需要有个东西来记录当前线程执行到哪一步,用于存储当前线程执行的执行的字节码的指令的地址,在多线程环境下,程序计数器用于实现线程切换,保证线程恢复执行的时候能够继续从正确的位置开始执行代码
2)JAVA虚拟机栈:用于存储JAVA方法调用和局部变量(方法内部调用的变量),局部变量的生命周期是和方法的生命周期是一模一样的,当方法执行完成,方法调用出栈,局部变量也会销毁,为什么JAVA虚拟机栈也是线程私有的呢?因为线程执行方法的局部变量只会有线程本身使用,当前线程执行方法的局部变量,其他线程是不会使用到这个变量,使用到这个方法
JAVA虚拟机栈,每一个线程在进行创建的时候会创建一个JAVA虚拟机栈,它的内部保留的是一个一个的栈帧,一个栈帧就对应着一个JAVA方法,对应是一次一次的方法调用就对应着栈帧的入栈和出栈操作,是线程私有的,它本身对应的是一次一次的方法调用,生命周期是和线程保持一致的,它是主管JAVA程序的运行,保存方法中的局部变量(8种基本数据类型和对象的引用地址),部分结果以及参与方法的调用和返回,JAVA虚拟机栈随着线程的创建而创建,随着线程的销毁而销毁;


六)JAVA中的程序计数器:被执行引擎来进行解释执行
每执行完一行代码,字节码执行引擎都会动态修改程序计数器里面的值
1)程序计数器是一块很小的内存空间,几乎可以忽略不记,它也是运行速度最快的内存区域
2)在JVM规范中,每一个线程都有着它自己的程序计数器,是线程私有的,生命周期和线程的生命周期保持一致
3)任何时间一个线程只会有一个方法在执行,也就是说所谓的当前方法程序计数器会存储对应的线程正在执行的JVM指令地址,他是程序控制流的指示器,分支,循环,异常处理线程恢复等基础功能都是需要这个程序计数器来完成,字节码解释器工作的时候就是按照改变这个计数器的值来选取下一条需要执行的字节码指令
4)他也是唯一一个在JAVA虚拟机规范中没有规定任何OutOfMemory的区域
5)程序计数器就相当于是行号指示器,相当于是迭代器和游标
1)操作局部变量表和操作数栈
2)将字节码指令翻译成CPU指令
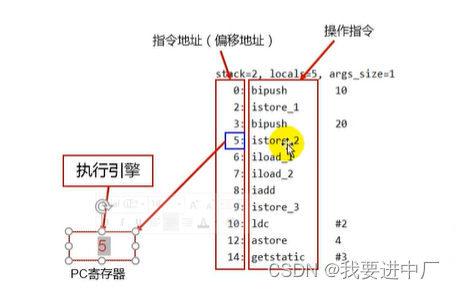
1)使用PC寄存器存储字节码指令地址有什么用呢?
为什么使用PC寄存器来记录当前线程执行的地址呢?
CPU需要不停的进行切换各个线程,这时候切换回来之后,就得知道下一条从哪里开始继续执行,JVM的字节码解释器就需要通过改变PC寄存器的值来确定下一条该执行啥样的字节码
CPU时间片就是CPU分配给各个程序的时间,每一个线程被分配一个时间段,称作是它的时间片,在宏观上可以同时打开多个应用程序,每一个程序并行同时运行,但是在微观上,由于只是有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,每一个线程交替执行
串行:用户线程和垃圾回收线程不能同时执行,排队执行,同一个时间点只能有一个线程执行,垃圾回收线程只有一条执行逻辑
并行:线程可以并行同时地去执行
并发:一个CPU核心快速的切换几个线程,让他们串行执行,看着像是并行
并行:垃圾回收线程可以并行同时地去执行,可以有多条,但是执行用户线程的程序用户线程必须是一个停止的状态
并发:垃圾回收线程和用户线程是同时执行,同时不一定是并行,还有可能是交替执行,不会是得用户线程出现Stop The World


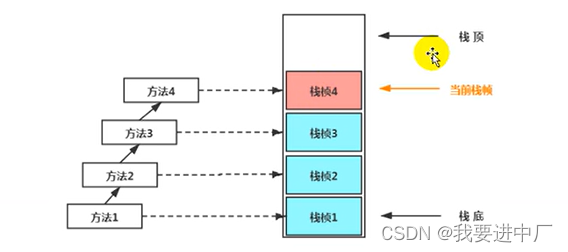
七)JAVA中的栈:
栈的特点:栈是一种快速有效的分配内存方式,访问速度仅仅次于程序计数器
JVM对于JAVA虚拟机栈的操作只有两个:每一个方法执行都伴随着进栈,压栈和入栈
执行方法完成之后的出栈操作,栈和程序计数器不存在垃圾回收问题,虽然会溢出,但是不需要GC,资源会自动释放
1)每一个线程都有自己的栈,栈中的数据都是依靠栈帧为基本单位格式进行存储的,在这个线程上每一个执行的方法都是对应着一个栈帧,栈帧是一个内存区块,是一个数据集,维持着方法执行的各种的存放的数据信息,一个方法的执行对应着栈帧的入栈,一个方法的结束对应着一个栈帧的出栈,方法执行完成就出栈,况且一个栈帧不可以调用另一个栈帧
这里面的抛出异常是未处理的异常,会沿着栈向下抛出,最后交给main函数
变量的分类:
按照数据类型划分分为基本数据类型和引用数据类型
按照在类中声明的位置来进行划分:
1)成员变量:在使用之前都默认经历过初始化赋值
静态成员变量也叫做类变量:在链接的准备阶段会给类变量赋初值并分配内存空间,在初始化阶段给类变量进行赋值或者是静态代码块赋值
实例变量:随着对象的创建,会在堆空间中分配实例变量空间,并进行默认赋值;
2)局部变量:在使用之前必须要显示赋值,否则编译不通过
JAVA虚拟机规范中允许JAVA栈的大小是动态的或者是固定不变的,
1)如果采用固定大小的JAVA虚拟机栈,那么每一个线程的JAVA虚拟机栈容量可以在线程创建的时候独立选定,如果线程请求分配的栈容量超过虚拟机栈允许的最大容量,JAVA虚拟机将会抛出一个StackOverFlower异常;
2)如果JAVA虚拟机栈可以进行动态扩展,并且在尝试扩展的过程中无法申请到足够的内存,或者在进行创建新的线程的时候没有足够的内存去创建对应的虚拟机栈,那么JAVA虚拟机将会抛出一个OutOfMemory异常,是整体虚拟机内存都不够的情况下才执行;
可以使用-Xss选项来进行设置现成的最大栈空间,栈的大小直接决定了函数调用的最大可达深度,是以字节为单位,-Xss256K






1)栈溢出的情况:StackOverFlow,当加栈帧的时候,栈空间不足,会发生StackOverFlow
2)调整栈大小,就能保证栈不溢出吗?
能,当进行有限递归的情况下,可以解决;
不能,对于死循环来说,循环递归只能增加递归的深度,但是最终还是会溢出,只能降低递归最后出现的时间,增加栈的大小,对于有限的递归来说,可能会避免堆溢出;
3)垃圾回收不会涉及到虚拟机栈,程序计数器没有GC也没有error,虚拟机栈没有GC出栈就是垃圾回收,但是存在error,本地方法栈不存在GC,存在error,方法区会存在GC和error,方法区放时间比较长的数据,有error和GC;
4)分配的栈越多越好吗?
避免出现StackOverFlow的概率会降低,整个JVM分配内存空间有限的,可能会挤占其他的空间
堆和栈有什么区别?
1)存放的数据内容不同
2)大小不同
3)访问数据性能不同:因为堆很大,进行查询对象的时候需要进行寻址和内存管理,但是栈存放基本数据类型,内存固定,不需要有动态数据的变化,不需要进行访问,再多大部分情况下,从栈上面寻找数据是很快的,不需要寻址和内存管理;
4)功能侧重点不同:堆是JAVA虚拟机的主要存储单位,JAVA中的对象和数组都是保存在这个区域的,而栈式JAVA虚拟机基本的运行单位,也就是说,堆主要解决的是数据的存储,数据怎么放,放在哪里的问题,但是栈主要解决的是JVM程序方法运行的调用关系,以及运算在哪里进行运算在那里进行存储数据,如何处理数据的;
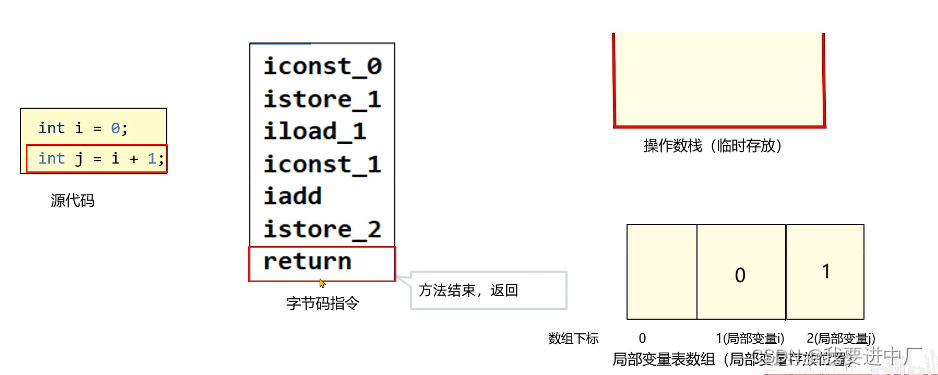
栈是运行时的基本单位,而堆是存储的单位栈解决的是程序的运行问题,就是程序如何执行,如何处理数据,把相关的一些指令通过栈的局部变量表和操作数栈来进行体现,但是主体的数据都放在堆中,左上是局部变量,左下是字节码指令,右边是堆空间
符号引用:符号引用是一种字面上的引用,它使用符号来描述所引用的对象,比如说类名,方法名和字段名,符号引用在编译时期就已经存在了它是一种无法直接定位到内存地址的引用,直接进行编译,还没有进行类加载,就是一个占位符,标记着内存的一个位置
直接引用定义:直接引用就是直接指向对象内存地址的引用,它包括创建对象的new操作符,获取对象的引用或者是实例变量的操作,直接引用在运行时才存在,他是可以直接定位到内存地址的引用,根据内存地址可以直接拿到对象的引用,直接可以定位到字面量的引用地址
字面量:实际的字符串,判断字符串常量池是否存在该字符串的依据,如果key存在,那么直接就把value值赋值给实际的引用,如果没有就现存
从HotSpot虚拟机来说,字符串常量池是依靠C++的HashMap来实现的,key是字符串常量的字面量,value是字符串对象的引用
编译期常量池:在编译期间可以确定的常量
运行期常量池:在运行期间可以确定的常量,String的intern()方法,将动态生成的东西就是放在运行期常量池的
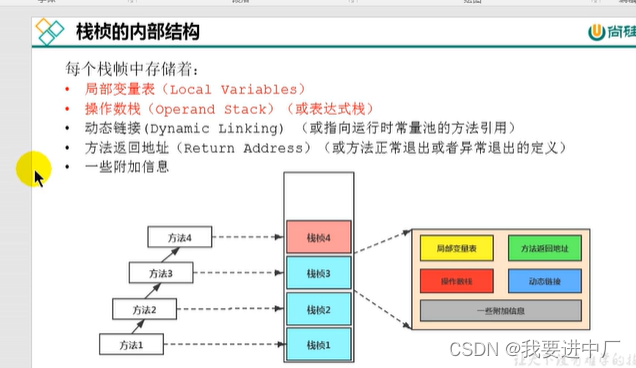
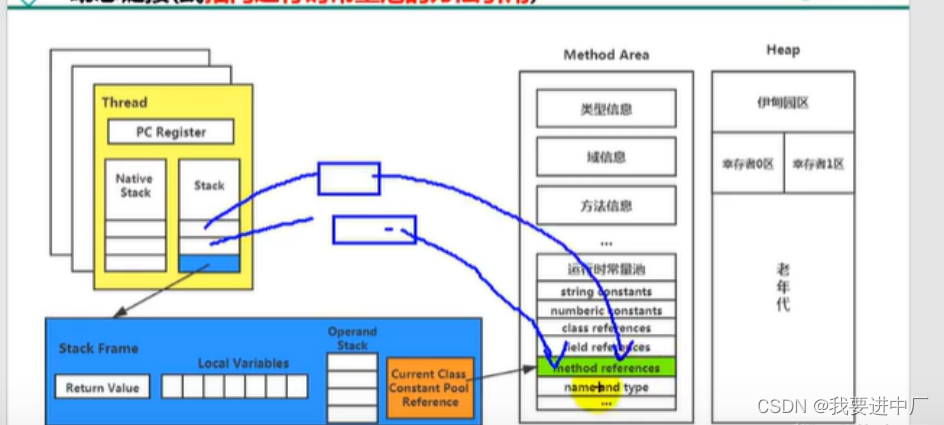
一)栈帧:
一个栈桢的入栈对应着方法的调用,一个栈桢的出栈,对印着方法的执行的结束,如果发生异常,还会将异常抛给方法调用者,栈帧的大小决定了栈中能存放栈帧的个数,每一个栈帧中存放着局部变量表,操作数栈(或者是表达式栈),动态链接是指向运行时常量池的方法引用,方法返回地址是方法正常退出或者异常退出的定义,还有一些附加信息
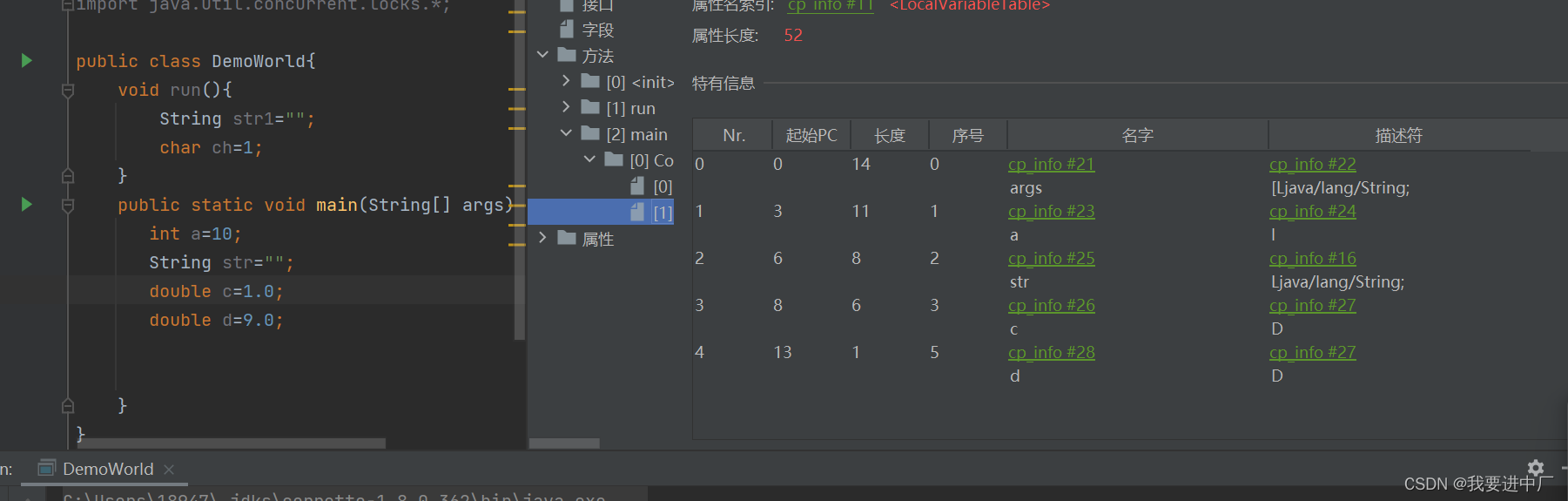
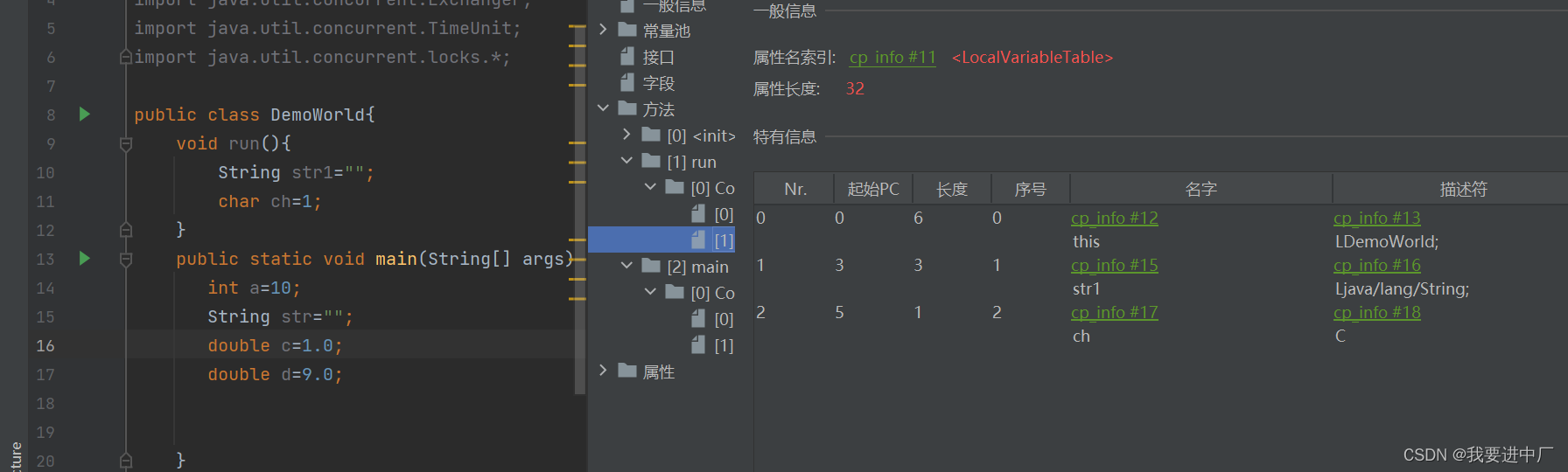
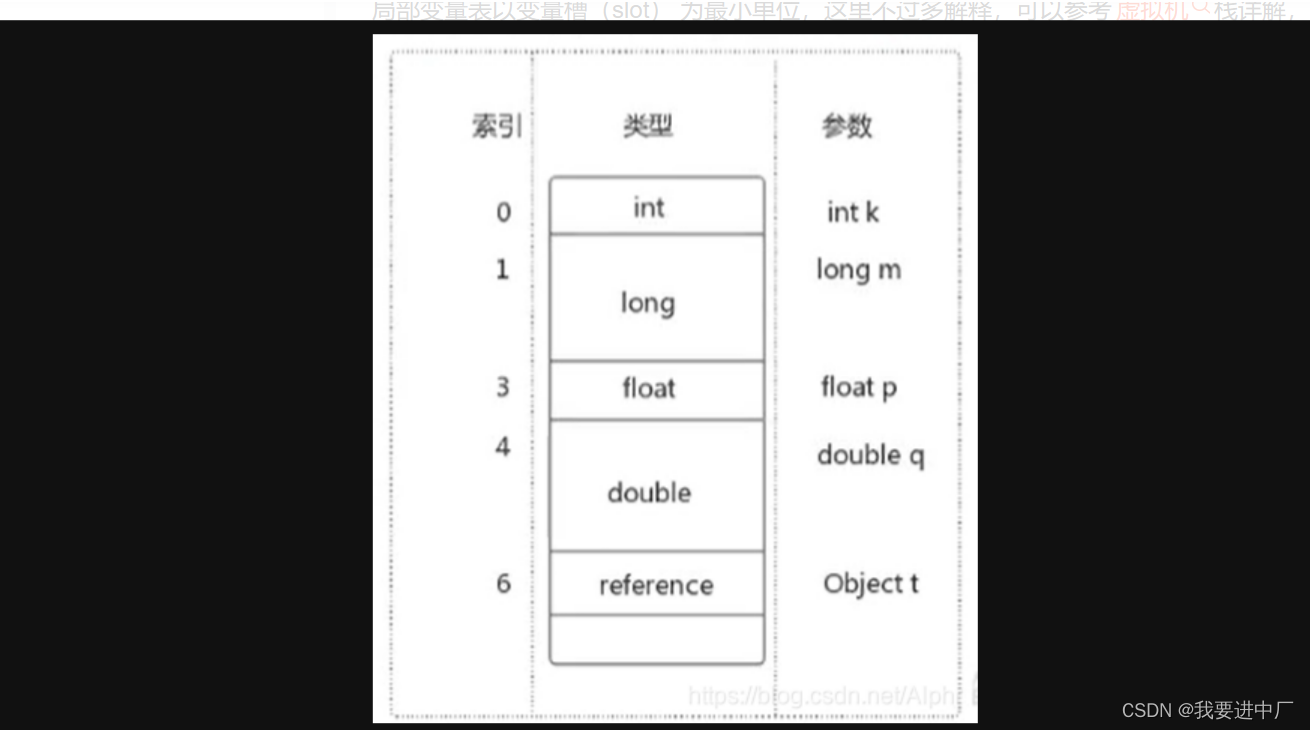
二)局部变量表:局部变量表又被称之为是局部变量数组或者是本地变量表
对于int double float本身就是数值,char有对应的ASCILL值,可以看作数值,存储可以转化成int,bool类型,8中基本数据类型和引用类型都可以使用数值类型来表示,不会涉及到线程安全问题,局部变量表大小一旦确定下来是不会更改的,本质上来说就是一个数字数组用于存储方法参数和本地的局部变量,这些数据类型包括各种基本数据类型,对象引用以及各种返回值类型,由于局部变量表是建立在线程的栈上面,是线程的私有数据,因此不存在线程安全问题,还有就是局部变量表的大小是在编译时期确定下来的,在方法运行期间是不会修改局部变量表的大小的
方法返回值类型,访问标识是public static,上面包含着方法声明的所有信息
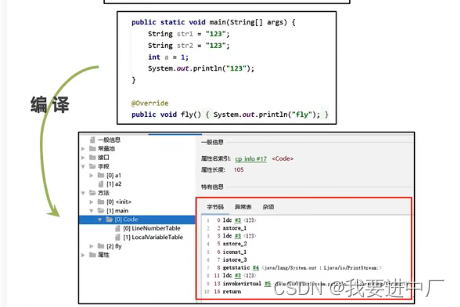
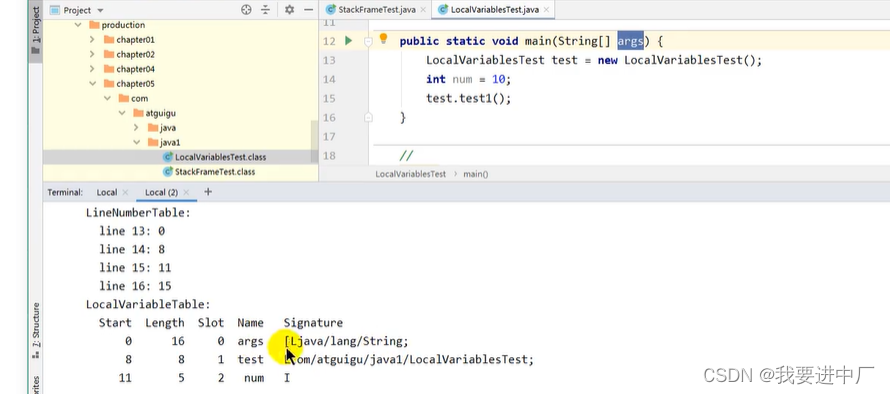
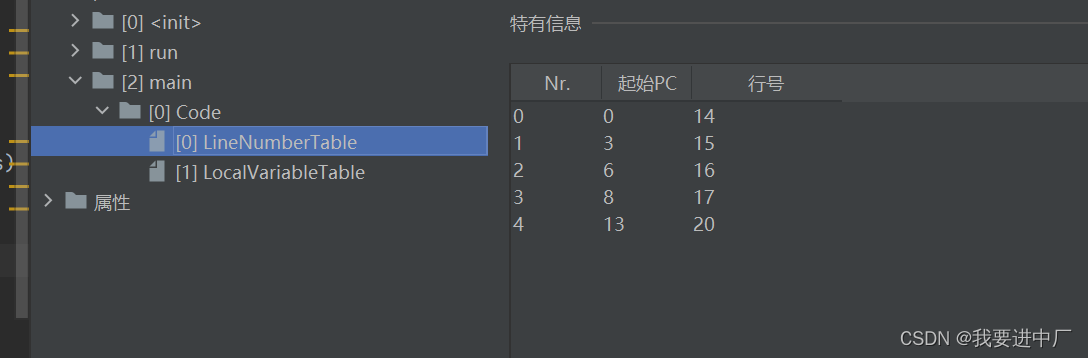
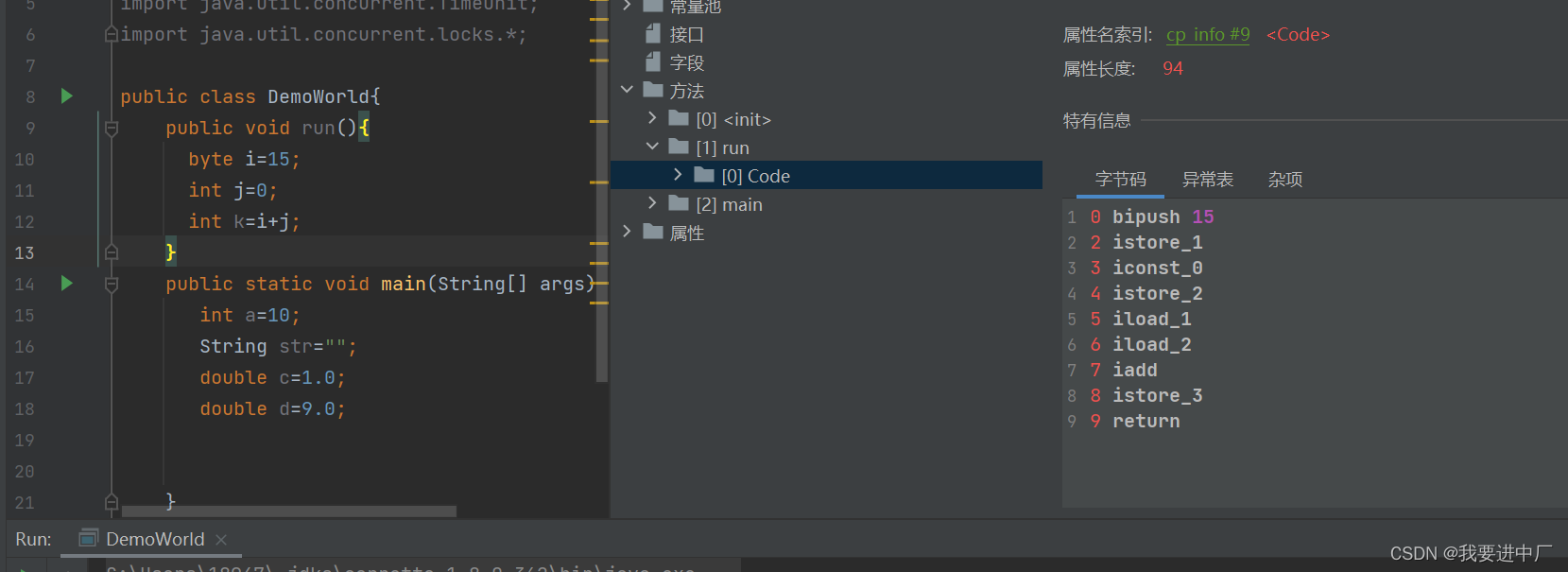
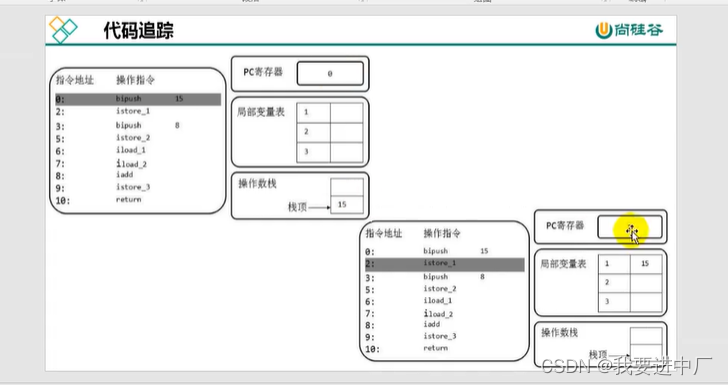
下面字节码指令行号和源代码行号的对应关系
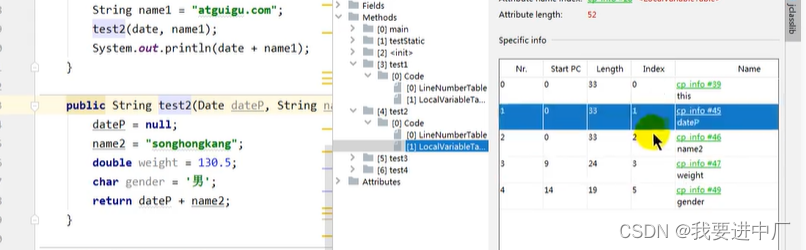
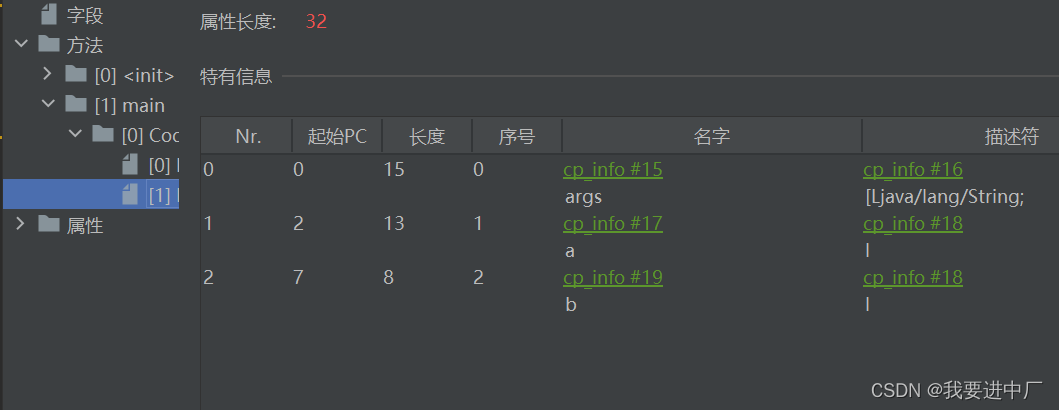
按照变量声明的位置依次占据着索引位置,根据索引位置来使用变量,Descibler:表示变量类型,length:描述当前变量作用域的范围
起始PC:字节码执行的行号,也是表示变量作用域的起始位置,也就是变量声明完以后
起始PC+length=代码的长度=CodeLength
变量槽:this变量存在与普通方法和构造方法的局部变量表,但是静态方法没有this,序号就是局部变量表的位置,引用数据类型是一个槽位;
index:代表变量所占槽位的起始位置
三)操作数栈:底层是使用数组结构来实现的,
3.1)方法执行过程中就是在执行字节码的指令,操作数栈都是临时存储数据,弹出栈栈中的数据也就没了,但是局部变量表中的数据永远都是存在的
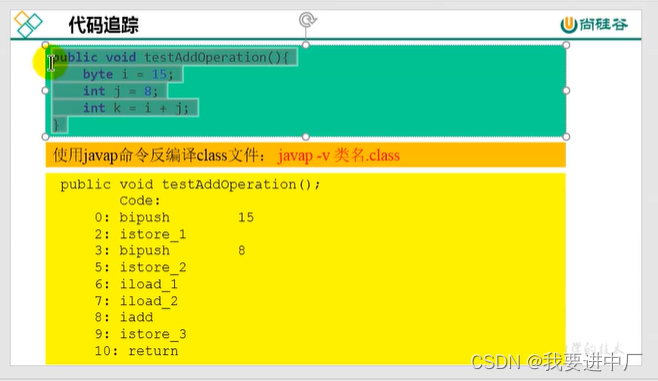
3.2)操作数栈是存放临时数据的地方,两个数相加运算都要放在操作数栈,最终结果都放在操作数栈中,也就是在编译期间确定了大小,只能由入栈出栈操作,不能通过索引调用
一些字节码指令向操作数栈中存放数据,也可以从操作数栈中取出数据
3.3)局部变量表是存放方法中局部变量的位置,在编译期间就确定了数组的长度,是在方法中声明的局部变量,局部变量表,方法形参,方法内部定义的变量,底层是依靠数组来实现的,实际上是依靠定义变量的顺序来声明数组下标的
每一个独立的栈桢中除了包含局部变量表以外,还包含着一个先进先出的操作数栈,也可以称之为是表达式栈,操作数栈在方法执行过程中向栈中写入数据或者是提取数据,就是入栈或者是出栈,比如说操作数栈在执行某一些字节码指令的时候,向栈中写入数据也就是将值压入操作数栈中,其余的字节码指令再将将操作数取出操作数栈中,执行复制交换,求和等操作的时候再将它们写回到操作数栈中;
byte short int boolean都以int型来保存
执行引擎要把字节码指令翻译成机器指令再来进行操作操作数栈
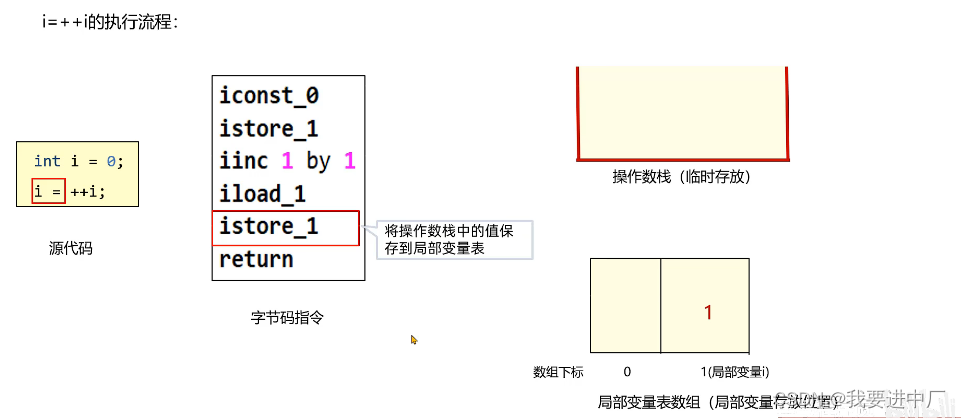
istore_i:将操作数栈中的数据取出来放到局部变量表中的对应位置i,那么到底应该放在哪一个位置呢?应该在istrore后面加上一个数组下标,比如说istore_1就会将操作数栈中的内容放到局部变量表中的1号位置,局部变量表中的数据取出来之后,就没了
iload_i:从局部变量表的i位置复制一份取出数放到操作数栈中,最终操作数栈和局部变量表都是会有这个数据的;
iconst_data:将data数据放入操作数栈中
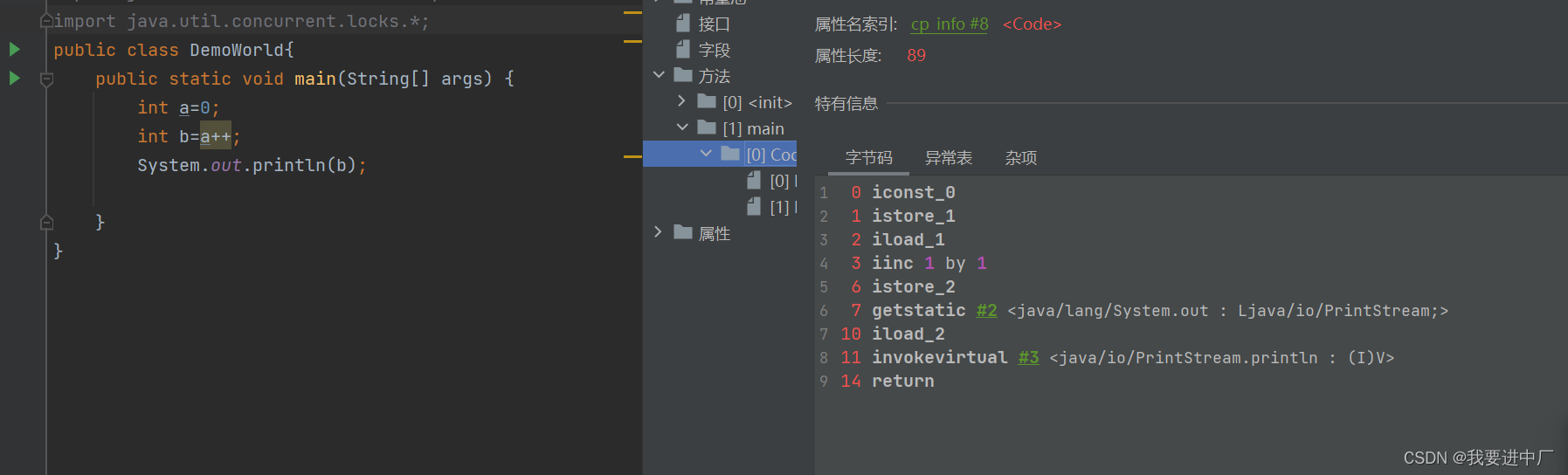
int i=0会拆解出iconst_0和istore_1这两个指令
i_add:将操作数栈中的顶部的两个数据进行相加,并将结果放入到操作数栈中
iinc 1 by 1:将局部变量表中的1号位置加1
操作数栈的指令非常多,缓存一般缓存在物理寄存器中,从而来提升CPU的读写效率,执行速度快,就比如说add操作
三)动态链接:指向常量池的方法引用
重点:每一个栈帧内部包含着一个指向运行时常量池的该栈帧所述方法的引用,包含这个引用的目的就是为了支持当前的方法可以实现动态链接,因为JAVA源文件被编译成字节码文件的时候,所有的变量和方法引用都作为符号引用保存在class文件的常量池里面,比如说一个方法调用了另外的其他方法的时候,就是通过常量池中指向的方法的符号引用来表示的,所以动态链接的作用就是为了将符号引用替换成直接引用
大部分字节码指令执行的时候都是要对常量池中的访问,在桢数据区中,就保存着能够进行访问的常量池的一个指针,方便访问常量池
在编译时时常量池里面,包含着类似于键值对的信息,key是符号引用就是带有#的,value是真实的字面量或者是接口信息等真实结构,返回值类型void,数据类型int,父类信息,System结构的加载,比如说很多方法都是没有返回值类型的,那么这些函数就是都可以引用void的符号引用,方法名字,value后面可能还是包含着符号引用,类加载过程中的使用到的信息都作为一个符号声明出来;
运行时常量池:就是为了提供一些符号和常量,便于指令的识别
五)方法返回地址:记录PC寄存器存储的值作为返回地址
PC寄存器的地址值=方法调用者调用该方法的下一条指令地址



















八)JAVA中的堆
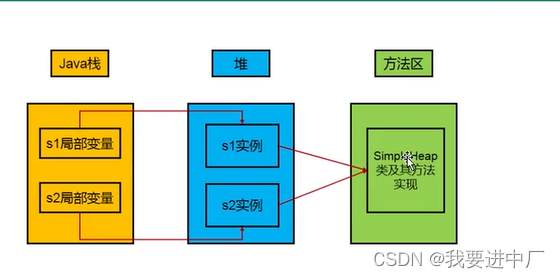
1)一个java进程对应这个一个JVM实例,堆是JAVA内存管理的核心区域,Runtime,就对应着一个运行时数据区,一个进程中的多个线程,共享同一份堆空间和方法区,而栈和程序计数器使每一个线程私有的,JAVA堆区在JVM启动的时候就被创建了,它的空间大小也被确定了,是JVM管理的最大的一块内存区域,JAVA虚拟机规范中规定,对可以处于不连续的物理内存空间中,但是在逻辑上应该是连续的,所有的线程共享JAVA堆空间,在这里还可以划分出线程私有的缓冲区;
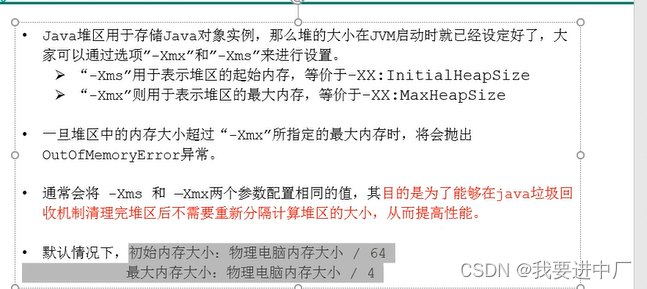
2)通过-Xms10m -Xmx10m是初始堆空间和最大堆空间
3)堆空间在物理上可以不连续,逻辑上是连续的,而栈只存在入栈和出栈,不会有垃圾回收
4)堆上面有着各个线程的缓冲区,每一个线程都有着自己的小空间,这个小空间就是TLB,这个时候并发性会更好;
5)不是没有引用指向对象,对象就立即回收,只有说堆中快满了不足了,才会执行GC垃圾回收,不是栈中的引用弹出栈,对象就立即被回收了,否则GC的频率过高,就会影响用户线程的执行,如果一直进行垃圾回收,就会影响用户线程的执行,所以应该将堆空间的区域设置的大一些合理的分配,减少GC,让用户线程执行时间长一些,提升吞吐量,频繁的GC会影响性能,都是Throwable的子类,error不可控,exception一般需要手动去捕获,比如说javaheapspace
6)-Xms10m -Xmx10m -XX:+PrintGCDetails(打印GC的详细信息),注意-Xms是用来设置堆空间,年轻代+老年代的最大内存大小
7)JAVA虚拟机规范对于堆的描述是:所有的对象实例和数据都应该当运行时分配在堆上,当方法结束以后,堆中的对象不会马上移除,仅仅是在垃圾收集的时候才会被移除
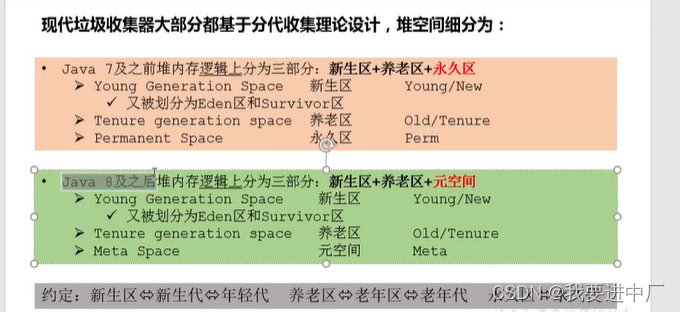
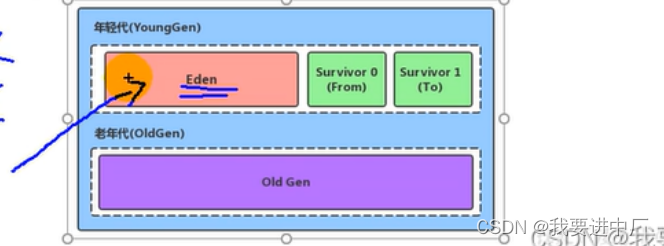
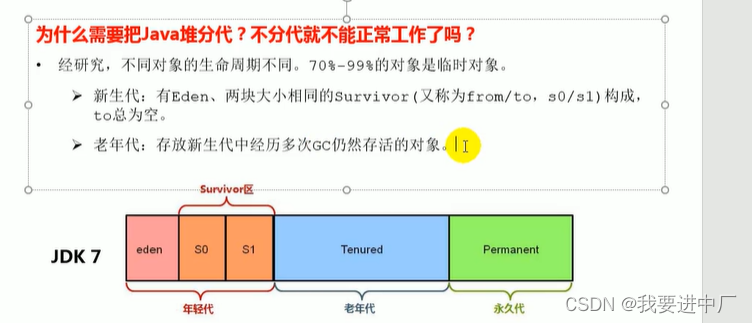
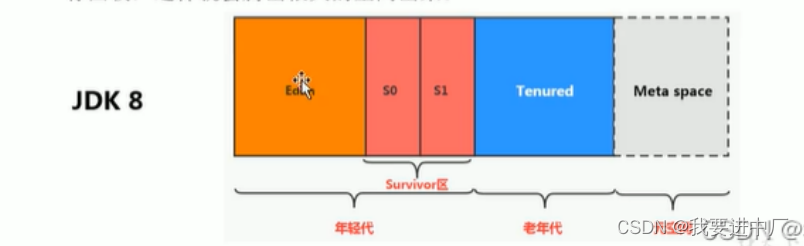
8)存储在JVM的JAVA对象可以被分成两类,一类是生命周期比较短的对象,这类对象的创建和消亡都十分的迅速,但是另一类的对象的生命周期非常长,在某一些极端的情况下还可以和JVM的生命周期保持一致,JAVA堆进一步划分可以划分成年轻代和老年代,年轻代又可以分成Eden区,Survivor1区和Survivor0区空间,有时候也叫做from区和to区;
查看堆占用的情况:
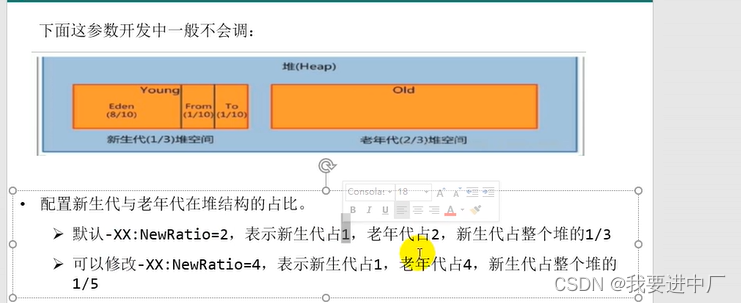
伊甸园区:幸存者1区:幸存者2区=8:1:1
默认新生代和老年代的占比是2:1
新生代:伊甸园区+幸存者1区+幸存者2区
yonggc/minor GC:触发条件时伊甸园区满了,幸存者区满了不会触发yonggc,但是yongGC回收的过程中会顺便带上回收幸存者区,伊甸园区满了之后再来对象,这个时候再次进行垃圾回收,会产生STW,需要进行判断各个对象是否是垃圾,不是垃圾的移动到幸存者1区或者是幸存者2区,放在空的区,空的幸存者区是to(从伊甸园区的对象首先放到幸存者1区),不空的是from;
什么时候执行垃圾回收:任何时候都可能,当系统觉得你内存不足了就会开始回收常见的比如分配对象内存不足时这里的内存不足有可能,不是占用真的很高,可能是内存足够,但是没有连续内存空间去放这个对象,当前堆内存占用超过阈值时,手动调用 System.gc() 建议开始GC时,系统整体内存不足时等
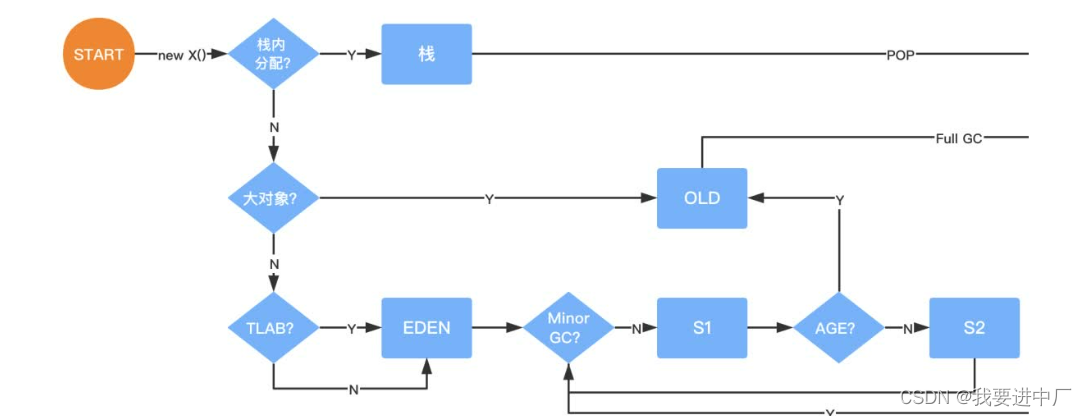
1)如果幸存者0区或者是幸存者1区放不下伊甸区的对象,直接将对象放到老年代
如果说伊甸园区和幸存区的比例比较大的话,也就是说幸存者1区和幸存者2区所占的空间比较小,理想情况下所有的伊甸区中的垃圾对象都被回收了,很少的对象存活到幸存区,但是一般情况下,幸存区的对象比较少,如果再向伊甸园区放对象,很容易导致伊甸园区对象放在幸存区,幸村区容易存不下,于是直接给放到old区,会导致minorGC失去意义,因为正常进行yongGC的时候幸存者1区和幸存者2区也会进行垃圾回收,而现在有些对象没有达到阈值15就直接到达老年代了,minorGC意义不大况且尽量说先把对象在新生代回收,分代意义更小
2)如果伊甸园区比较小,那么yonggc会频繁触发,会影响用户进程,影响STW的时间
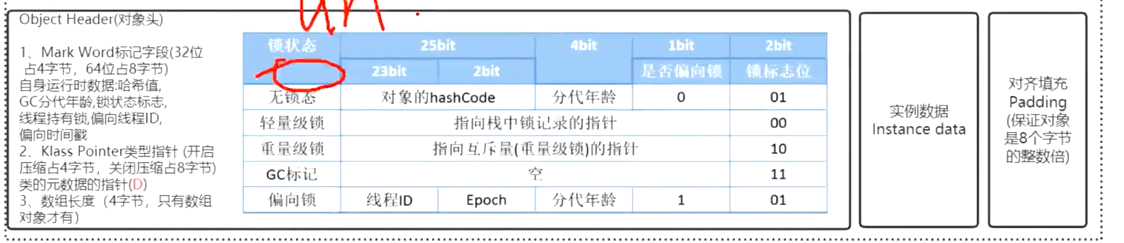
MarkWord里面存放对象的GC年龄只有4位,所以最大也只是15
3)复制之后有交换,谁空谁是to
图解对象分配的过程 - 掘金 (juejin.cn)



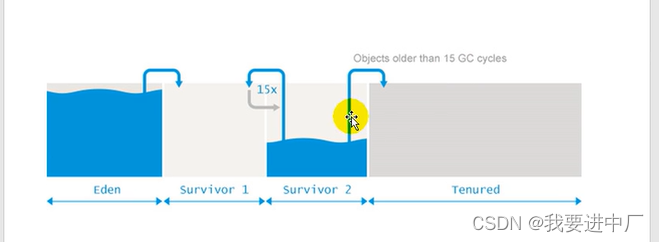



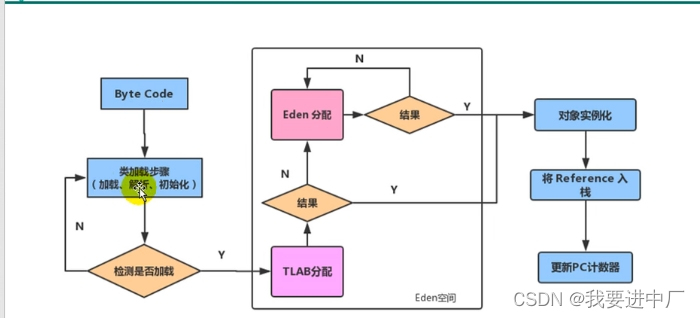
1)当创建一个新的对象的时候,首先进行判断伊甸区是否可以存放的下,如果放得下就为其分配内存,如果放不下的话,那么就开始yongGc;
2)然后再进行判断伊甸区是否可以存放的下,如果放得下的话,就为其分配内存,如果放不下的话,说明这个对象比伊甸园区的对象还要大,此时说明这个对象是一个超级大的对象,此时就直接放在老年代,如果老年代也是放不下,就直接进行FullGC,然后进行判断老年代是否可以存放的下,如果放得下就直接进行存放,如果还是村放不下就是直接报OOM异常
3)有的时候进行YGC的时候,幸存的对象会进入到幸存区,此时会进行判断是否存放的下,如果存的下就存放,存不下就直接放入到老年代;
4)JVM调优:GC回收能够少一些,GC扫描的过程中会出现STW,用户线程终止
从频率上看大部分情况下都是回收的是新生代,只有伊甸园区满的时候才会触发youngGC,只有触发yongGC,才会顺便回收幸存者1区或者是幸存者2区
5)年轻代GC触发机制:当年轻代空间不足的时候,就会触发minorGC,
TLAB:默认给每一个线程开辟一块内存空间存放线程自己的对象
Class对象是存放在堆区的,不是方法区,类的元数据元数据并不是类的Class对象,Class对象是加载的最终产品,类的方法代码,变量名,方法名,访问权限,返回值等等都是在方法区的,代码信息只是在方法区;
对齐填充:方便计算机寻址存取方便,是计算机寻址最优的一种方式


1)大对象直接放到老年代:可以设置参数
1.1)如果你知道系统创建的对象比较大,况且这些对象不会被垃圾收集的就可以配置此参数,提早进入老年代;
JVM会直接判断对象大小,就是为了降低大对象分配内存的时候复制对象而降低效率
1.2)大对象就是需要大量连续内存空间的对象,比如说数组和字符串,JVM参数-XX:PretenureThreshold可以设置大对象的大小,如果对象设置超过大小会直接进入到老年代,不会进入到年轻代,这个参数只是在Serial和ParNew两个收集器下面有效
1.3)比如说设置JVM参数: -XX:PretenureThreshold(单位是字节) -XX:+UseSerialGC,设置这个参数以后会发现大对象直接进入到老年代,况且这个大对象占用空间还比较大,可能触发频繁的YGC,早早的被回收腾出更多的空间给朝生夕死,还有为了大对象是分配内存时候的复制操作而降低效率;
2)达到分代年龄存放到老年代:可以设置参数,默认值是15
什么时候这个参数设置的比较小一点呢?
大概知道很多new对象生命周期不是特别长,这些对象可能做几次GC就会被垃圾回收掉,对象new出来以后可能要用一段时间,程序员大概可以估算到一个方法中有一个大对象,但是方法结束非常快,对象可能一两次GC就被干掉,分代年龄尽量设置的短一些,这个参数设置的比较小,说明系统中的对象大多数经历一次或者是两次GC就会被干掉,要么经历很多次GC都不会被干掉,就可以把分代年龄设置比较小,已经知道大多数对象明明生命周期很长,这时候分代年龄设置的短一些,就不要白白的在新生代复制来复制去浪费性能,趁早滚去老年代,早早的在伊甸区腾出空间

3)对象动态年龄判断机制:
当前放对象的Survior区域里面(其中一块区域,放对象的那一块S区),一批对象的总大小大于这块Survior区域的50%(-XX:TargetSurivorRatio可以指定),那么此时大于等于这一批年龄对象的年龄最大值的对象,就可以直接存放到老年代了,假设现在幸存者区里面有一批对象,年龄1+年龄2+年龄N的多个年龄对象超过了Surivor区域的50%,此时就会把年龄N以上的对象全部放在老年代,这个规则是希望那些可能长期存活的对象尽早地进入到老年代,对象动态年龄判断机制其实是在minor GC以后触发的;
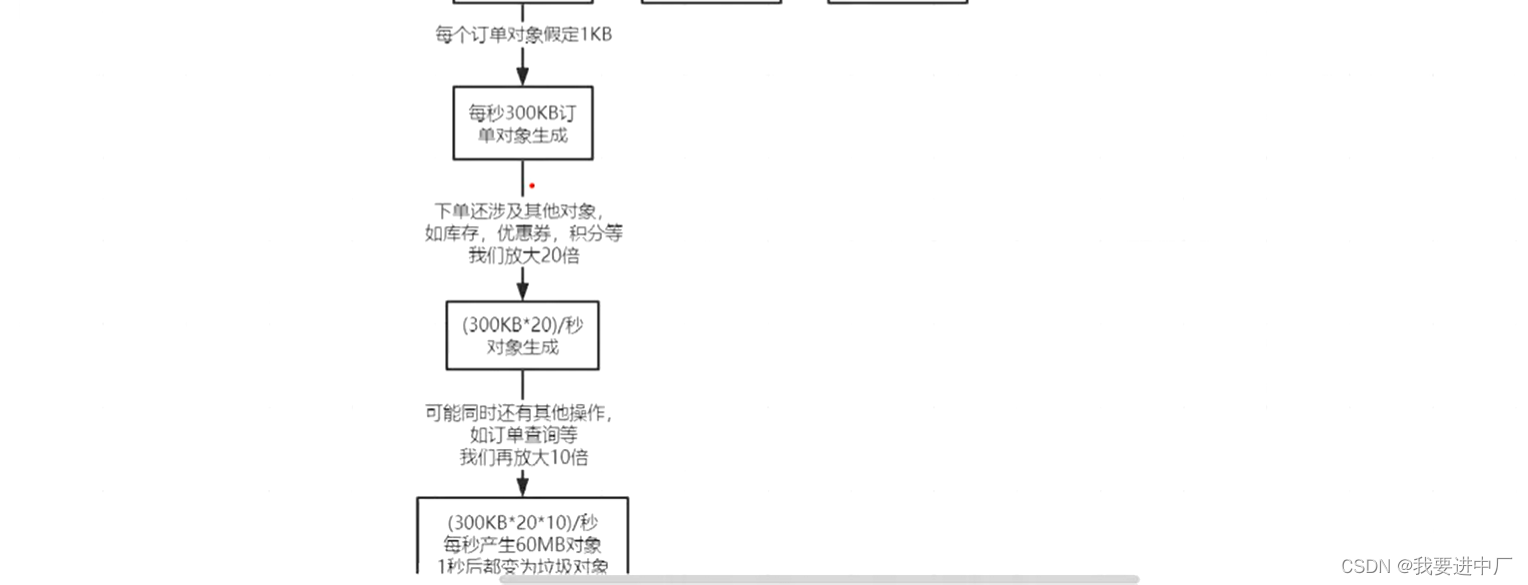
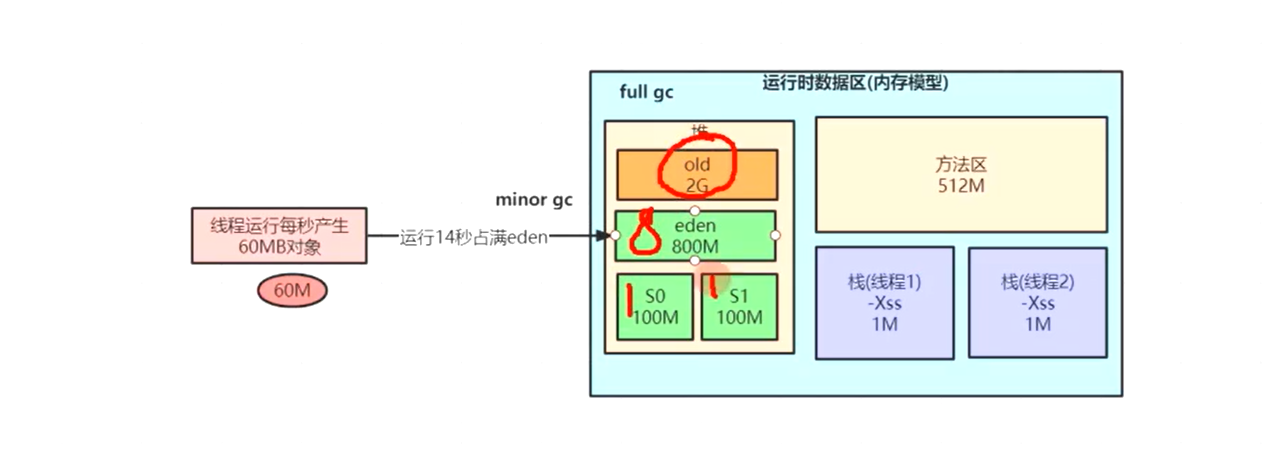
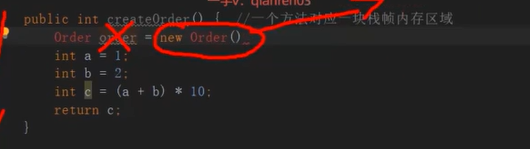
为什么1s之后就会变成垃圾对象呢?因为生成订单对象只是一个方法,方法很快就会结束的,GCroots很快被销毁,这个Order引用所指向的对象也会很快地变成垃圾,如果是按照上面的参数进行设置的话,可能会频繁的触发FullGC,FullGC是需要优先解决的,对于订单系统来说,每秒钟有60M对象会向伊甸园区里面存放,1S以后变成垃圾对象
1)因为每一秒钟大概有60M的对象要往伊甸园区进行存放,因为伊甸园区大概是800M,大概13秒或者14s来说伊甸园区就会被放满,第14s的对象尝试存放到伊甸园区,会触发minorGC,会把伊甸区的对象全部进行垃圾回收,前面13s的对象做minor GC的时候都是可以回收掉的,但是伊甸区第14s产生的对象这一时刻尝试放到伊甸园区会触发minorGC,因为此时订单正在执行过程中,第14S会发生STW,第14s产生的对象都被GCROOTS引用着,所以此时这60M对象会被存放到S0幸存者区域,但是前面13s产生的对象(因为方法已经结束了,况且已经知道1s以后对象会被回收)会被伊甸园区GC直接被干掉,因为之前伊甸区的方法已经结束了,生成订单非常快;
2)按照上一步的分析,第14s产生的对象会被直接存放到幸存者区域,因为幸存者区域此时还可以存放的下;
3)但是最终情况是由于动态年龄判断机制,这60M对象会被分配到老年代(即使幸存者区域可以存放100M的对象),每隔14s就有60M对象放到老年代(前13s产生的对象在新生代,第14s产生的对象直接放到老年代),等到一段时间5 6min老年代放满,就会发生一次FullGC,但是其实这些老年代的对象其实早就变成垃圾了,因为正常的订单对象早就变成垃圾了,因为垃圾对象频繁的进行FullGC肯定不太好,现在根据空间分配担保机制来看,第14s的60M对象, 已经超过了这块Survior区域的50%,此时这60M对象很快就会进入到老年代;
4)这个时候朝生夕死的对象太多,于是就适当提高年轻代的空间大小,因为在这种情况下,系统会产生大量的朝生夕死的对象,频繁导致FullGC的原因就是动态年龄判断机制,使用两种机制来优化,一种是调整surivor区域,一种是把整个年轻代调整的大一些,几乎不发生FullGC;
适当提升新生代的比例之后,第24s以后对象的空间已经满了,那么此时这个25S产生的60M对象会直接存放到幸存区,此时触发minorGC会进行回收伊甸园区和幸存者区,不光13s产生的对象被回收了,第14s产生的60M对象也被回收了;
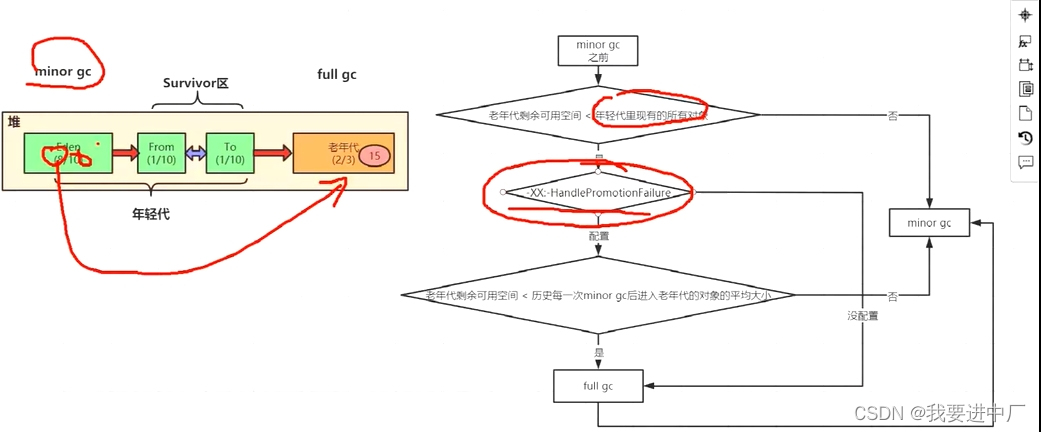
4)老年代动态分配担保机制:本质上是保证年轻代的非垃圾对象做了FullGC到了老年代以后避免老年代空间存放满而触发FullGC;
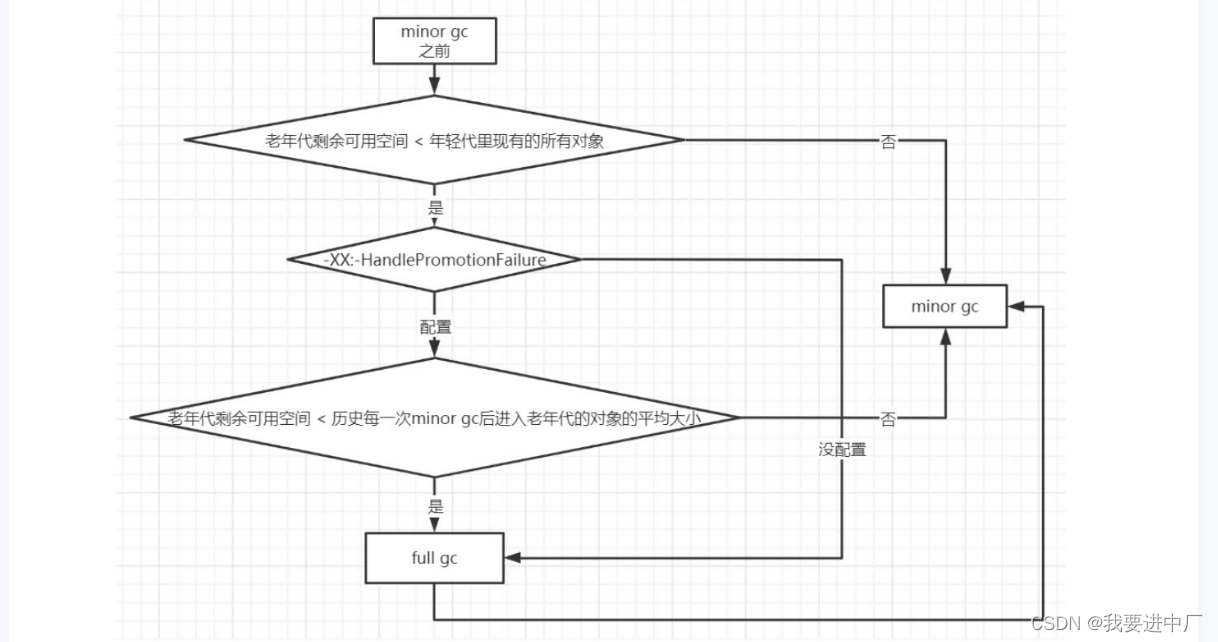
年轻代每一次做minorGC之前,JVM都会做校验计算一下老年代的剩余可用空间大小
1)首先会进行校验如果老年代的可用空间大小小于年轻代现有的所有对象之和包括垃圾对象,就是看看老年代剩余可用的空间是否容纳年轻代的所有对象,如果可以容纳的下,直接做minorGC,如果容纳不下,也就是说老年代所剩空间不多了,就会看一个参数,如果这个参数没有设置,就会触发FullGC,将老年代和年轻代一起进行回收,如果回收完成还没有空间存放新对象就会发生OOM;
2)如果这个参数设置了,就会看看老年代的可用内存大小,是否大于之前所有每一次minor gc后进入老年代的对象的平均大小,如果小于,就会触发FullGC,将老年代和年轻代一起进行回收,如果回收完成还没有空间存放新对象就会发生OOM,节省一次MinorGC;
3)当然如果minorGC以后剩余存活的需要挪动到老年代的对象大小还是大于老年代可用空间,那么也是会触发FullGC,然后再来一次monor GC,如果FullGC之后还是没有足够的空间来存放minor GC以后的存活对象,此时就会发生OOM;
实质:就是在minorGC之前,判断是否大概率发生FullGC,如果大概率发生FullGC
如果调整完新生代的大小之后将晋升到老年代的空间调整成5了,因为这种情况是每25S触发一次minorGC,触发一次GC,分代年龄+1,分代年龄达到5,说明已经过去了好几分钟了,所以说这些已经达到5的对象早就已经变成垃圾了,要么赶紧被清理掉,如果分代年龄达到5,说明这样的对象肯定不是简单的GC对象肯定不容易被收集,这样的对象肯定是系统中的缓存对象,Spring Bean对象,线程池的引用对象,对于这些对象可以让她尽量的早点老年代,不要再年轻代里面占用过多的那些朝生夕死的对象的空间了,订单对象库存对象,优惠劵对象的空间了,让那些年轻代的对象能够在年轻代就被干掉
什么时候发生FullGC?
1)system.gc:此方法的调用是建议JVM进行Full GC,虽然只是建议但是不一定,但是很多情况下他会触发Full GC,从而增加FullGC的频率,既增加了间歇性停顿的次数,强烈建议能不使用该方法就不使用该方法,让虚拟机自己去管理他的内存,可以通过-XX:+DisableExplicitGC来禁止JVM调用System.gc();
2)老年代空间不足:老年代空间只有在新生代空间转入以及创建大对象,大数组的时候才会出现空间不足的状况,当执行Full GC之后如果空间还是不足,那么抛出以下错误:
java.lang.OutOfMemory,java heap space,为了避免以上两个状况引起的Full GC,调优的时候尽量做到让对象在minor GC阶段被回收,让对象在新生代多存货一段时间以及不要创建大对象或者是大数组
进行minorGC的时候要将新生代的对象往老年代里面进行存放,先看看老年代的最大可用连续空间是否大于新生代所有对象的总空间,如果比他大那么说明这里面最坏的情况就是新生代的对象没有一个是垃圾,老年代肯定都是可以放得下,如果小于,说明此时minorGC不安全,那么继续判断这个参数,如果这个参数是true,那么会进行继续检查老年代最大可用连续空间是否大于历次晋升到老年代的对象的平均大小老年代GC垃圾回收慢,STW时间太长
为什么要进行分代呢?
其实部分带也完全可以,因为分代的唯一理由就是来优化性能,如果没有分代,那么所有的对象都在一起,就好像把一个学校的所有人都关在教室里面,GC要找到那些对象没有使用,这样子就会对堆的所有区域进行扫描,但是很多对象都是朝生夕死的,如果进行分代的话,吧新创建的对象放在一个地方,当GC的时候就把这块存储朝生夕死的对象的区域进行回收,这样子就会腾出很大的空间来;
因为使用G1垃圾回收器,内部算法耗费的性能比CMS要高,CMS触发FullGC比例可能会导致部分空间不可用,如果FullGC发生频率很低,这时就可以启动serial Old来进行清理,设置参数是0,每一次FullGC,serial Old会清理一次内存碎片,但是如果出现秒杀活动,就尽量减少内存碎片的整理,因为不敢让用户线程停止,这时候就可以配置5次FullGC一次清理,如果长时间不做内存清理,那么老年代的连续可用内存空间会越来越少;
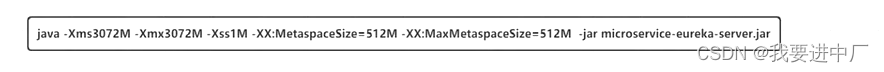





逃逸分析:
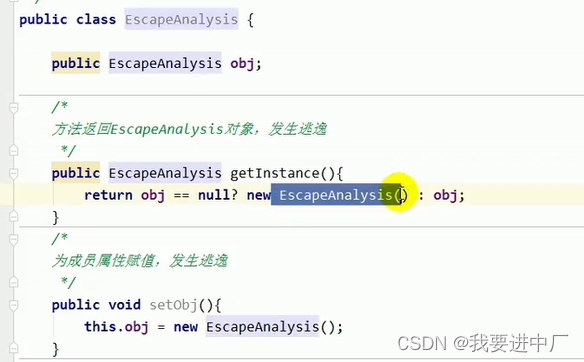
1)因为JVM内存分配都是在堆上面进行分配,当对象没有引用的时候,需要依靠GC来进行回收,如果对象数量比较多的时候,就会给GC带来巨大压力,也间接影响了GC的性能,为了减少临时对象在堆中分配的数量,JVM本身就会通过逃逸分析确定对象不会被外部访问,如果不会逃逸那么可以将对象在栈上分配内存,这样子对象所占用的内存空间就可以随着栈帧出栈而销毁,从而减轻了垃圾回收的压力
2)对象的逃逸分析:对于一个对象来说,如果采取栈上分配,不会new一个对象在栈上面,而是将它的成员变量属性剥离开存放分配在栈上,分开存,这几个字段会进行标识是属于哪一个对象的,前提是开启了逃逸分析,减少GC的压力,线程结束方法结束对象就被销毁,对象的逃逸分析就是动态的进行分析对象的作用域,当一个对象在方法中定义的时候,他可能被外部方法所引用,比如说调用参数传递到其他方法里面
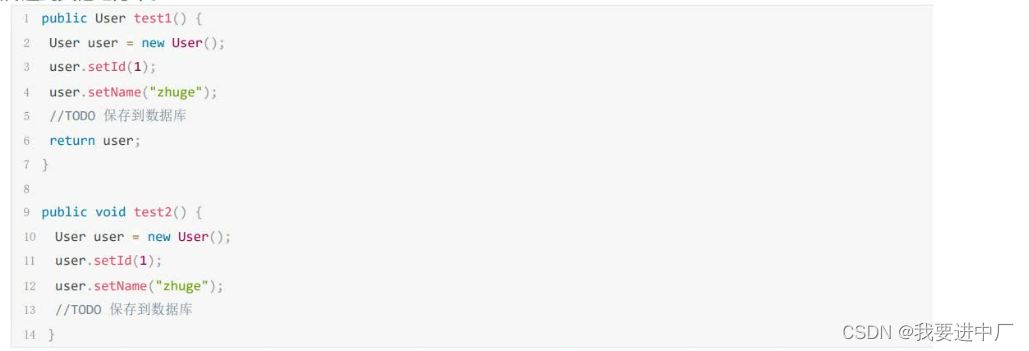
很显然Test1中的user对象被返回了,这个对象的作用域的范围是不确定的,Test2中的方法中的user对象可以确定方法结束以后对象在栈上面就被销毁了,就是一个无用的对象,这样的对象其实我们就可以把他分配到栈空间上面,让方法结束以后随着栈内存一起释放掉
JVM对于这种情况可以可以开启逃逸分析参数(XX:+DoEscapeAnalysis)来优化对象内存分配位置,通过标量替换优先分配在栈上,JDK7之后默认开启逃逸分析,如果要关闭使用参数(-XX:-DoEscapeAnalysis)
1)标量替换:通过逃逸分析以后发现确定该对象不会被外部访问,并且对象可以进一步被分解的情况下,JVM不会创建该对象,而是将对象的成员变量拆解成若干个被这个方法所使用的成员变量所代替,这些所代替的成员变量在站镇上或者是寄存器上面分配空间,这样就会保证不会有一大快连续的内存空间导致对象内存不够分配,开启标量替换参数;(XX:+EliminateAllocations),JDK7之后默认开启,这个时候不是在栈上开辟一个对象,而是将对象的成员变量拆分开存放,拆分成成员属性分配到栈上面;
2)标量和聚合量:标量是不可以进一步被分解的量,JAVA中的基本数据类型就是标量,比如说int double 引用数据类型,而聚合量就是可以进一步被分解的量,这种量称之为是聚合量,在JAVA中对象就是一种可以被分解的聚合量,栈上分配依赖于逃逸分析和标量替换;
没有发生逃逸的对象,就可以分配在栈上,随着方法的结束,栈空间就会被移除,
1)栈空间是每一个线程一份,不会涉及到同步的问题,可以并行地去执行
2)每一个栈都是放的是栈帧,当方法执行完,栈帧弹出栈,空间被释放,内存自动释放,不会涉及到GC
//1.不会发生逃逸分析 public static String createStringBuffer(String s1,String s2){StringBuffer s=new StringBuffer();s.append("abc");s.append("bcd");return s.toString();} //2.会发生逃逸分析 public static StringBuffer createStringBuffer(String s1,String s2){StringBuffer s=new StringBuffer();s.append("abc");s.append("bcd");return s;}
如何快速判断发生了逃逸分析:只是看new的对象实体是否在方法外部使用
使用逃逸分析,编译器可以对以下代码进行优化:
1)栈上分配:将堆分配转化成栈上分配,如果一个对象在子程序中被分配,要使得指向该对象的指针永远不会发生逃逸,对象可能是栈分配的首选,而不是堆分配,栈上分配,减少垃圾回收
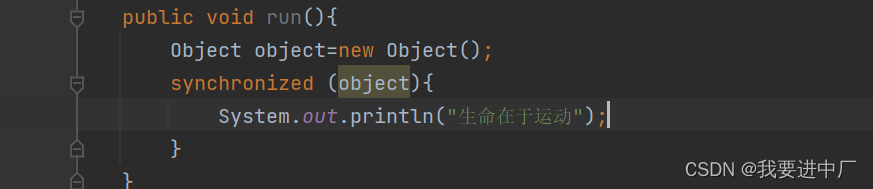
2)同步省略:如果一个对象被发现只能被一个线程被访问,那么对于这个对象的操作可以不考虑同步多个线程来起不到同步的效果,纯看字节码文件还是有锁的,但是程序会自动优化掉
因为线程同步的代价是相当高的,同步的后果就是降低并发性和性能,再进行动态编译同步代码块的时候,JIT即时编译器还会借助逃逸分析来判断同步代码块使用到的锁对象是否只能被一个线程访问而没有被发布到其他线程,如果没有那么JIT即时编译器就会在编译这个同步代码块的时候会取消对于这段代码的同步,这样就可以大大提高并发访问的性能,这个取消同步的过程就叫做同步省略,也叫做锁销除;
代码中针对object这个对象进行加锁,但是object对象生命周期,只会在方法中使用到,并不会被其他线程访问到,所以在JIT即时编译过程中就会被优化掉,优化成:
3)分离对象或者是标量替换:有的对象可能不需要作为一个连续的内存就可以被访问到,那么对象的部分或者是全部可以不存储在内存,而是存储在CPU寄存器中;
把一个对象替换成两个局部变量放到局部变量表里面了,将对象打散了分配到栈上
java中的引用类型一般分为四种:
1)强引用:public static User user=new User(),在JAVA程序中最常见的引用类型就是强引用,也就是最常见的普通对象引用,也是默认的引用类型,在JAVA语言中使用一个new关键字操作符创建一个新的对象的时候,并将其赋值给一个变量的时候,这个引用就是指向该对象的一个强引用,强引用的对象是可达的,垃圾回收器永远也不会回收此类对象,对于一个普通对象来说,只要超过了引用的作用域或者显示的将强引用的引用赋值为null,也就是可以当作垃圾来收集了,当然具体回收策略还是依靠垃圾收集策略
2)软引用:将对象使用SoftReference软引用类型对象包裹起来的,正常情况下不会进行垃圾回收,但是GC做完以后发现释放不出新的空间来进行存放新的对象,这时GC就可以将这些软引用的对象直接进行回收掉,软引用可以用来实现内存敏感的高速缓存
pulic static SoftReference<User> referenece =new SoftRefernce<User>(user);
软引用在实际中有一个重要的应用就是,比如说浏览器的后退按钮,按下后退的时候,这个后退的时候所显示的网页是重新进行请求还是从缓存中取出呢?这要看具体的实现策略了
如果一个网页在浏览结束以后就进行内存的回收,那么后退查看前面所浏览的网页的时候需要重新进行构建,如果浏览到的网页结构存储到内存中会造成内存的大量浪费,可能会造成空间溢出
3)弱引用:将对象使用WeakReference软引用的类型进行包裹,弱引用和没引用差不多,只要出现垃圾回收就会被回收掉
4)虚引用,又被称之为是幽灵引用或者是幻影引用,几乎不用
5)finalize方法来判断对象是否存活
1)即使在可达性分析算法中不可达的对象,也并非是非死不可的,这个时候他们正在处于缓刑阶段,要想宣告一个对象真正的死亡,至少要经历两次标记过程,标记的前提就是对象在进行可达性分析算法以后发现没有和Gc Roots相连接的引用链
2)第一次标记并进行一次筛选:筛选的条件就是此对象是否有必要执行finalize()方法,如果当前该对象没有重写finalize方法,那么对象直接被回收
3)第二次标记,如果这个对象重写了finalize方法,finalize方法是对象脱逃死亡命运的最后一次机会,如果对象要在finalize中成功拯救自己,只要重新和引用恋上面的任何的一个对象建立关联即可,假设说把自己赋值给某一个类变量或者是某一个对象的成员变量,那么在第二次标记是将他移除掉即将被回收的集合,如果这时候对象还没有被回收,那么此时就真的被回收了,注意一个对象的finalize方法只会被执行一次,也就是说调用finalize方阿飞自我救命的方式只有一次;
public class Demo {static List<User> list=null;static class User{public String username;public String password;@Overrideprotected void finalize() throws Throwable {System.out.println("对象即将被回收");}}public static void main(String[] args) {list=new ArrayList<>();while(true){list.add(new User());new User();}}
fullGC回收类元信息和堆空间没有类原信息,对象的对象头已经没有指针指向这个类原信息
三种类加载器不会被回收,所以加载的类不会被回收,类加载器会维护他所有加载过的类,所有的classLoader都会记录着所有它加载过的类信息,但是JSP的类加载器和自定义的类加载器是可以回收,第三条Class对象也应该被回收因为Class对象可以创建出新的对象;
6)为什么要有TLAB
1)堆区是线程共享的区域,任何线程都是可以访问到堆区的共享数据,由于对象的实例的创建在JVM中非常频繁,那么在并发环境下从堆区中分配内存空间是线程不安全的,TLAB的作用就是为了避免多个线程操作同一块地址空间,需要使用到加锁等机制,进而影响分配速度
2)从内存模型而不是垃圾收集的角度,他会针对于Eden区会继续进行划分,JVM为每一个线程都分配了一个私有的缓存区域,它被包含在伊甸园区里面
3)多线程同时分配内存的时候,使用TLAB是可以避免一系列的非线程安全问题,同时还可以提升内存分配的吞吐量,因此我们可以见这种内存分配策略称之为是快速内存分配策略
1)尽管不是所有的对象实例都能够在TLAB中能够重新分配内存,但是JVM确实是将TLAB作为内存分配的首选
2)在程序中,开发人员可以通过选项"-XX:UseTLAB"设置是否开启TLAB空间
3)默认情况下,TLAB空间的内存非常小,仅占用TLAB空间所占用的Eden区空间的百分比大小的1%,当然也是可以通过"-XX:TLABWateTargetPercent"来设置TLAB空间所占用的Eden空间的百分比大小;
4)一旦对象在TLAB空间分配内存失败的时候,JVM就会尝试通过加锁机制来确保数据操作的也,从而直接在伊甸园区空间分配内存

















相关文章:
JVM进阶(1)
一)JVM是如何运行的? 1)在程序运行前先将JAVA代码转化成字节码文件也就是class文件,JVM需要通过类加载器将字节码以一定的方式加载到JVM的内存运行时数据区,将类的信息打包分块填充在运行时数据区; 2)但是字节码文件是JVM的一套指…...
【AICFD案例操作】汽车外气动分析
AICFD是由天洑软件自主研发的通用智能热流体仿真软件,用于高效解决能源动力、船舶海洋、电子设备和车辆运载等领域复杂的流动和传热问题。软件涵盖了从建模、仿真到结果处理完整仿真分析流程,帮助工业企业建立设计、仿真和优化相结合的一体化流程&#x…...

Hadoop 请求数据长度 Requested Data length 超过配置的最大值
一、问题 现象 Spark 任务速度变慢,也不失败。 DataNode 内存足够 CPU 负载不高 GC 时间也不长。 查看 DataNode 日志,发现有些日志出现很多 Netty RPC 超时。超时的 destination 是一个 NameNode 节点,然后查看 NameNode 节点的日志&…...

搜索与图论:染色法判定二分图
将所有点分成两个集合,使得所有边只出现在集合之间,就是二分图 二分图:一定不含有奇数个点数的环;可能包含长度为偶数的环, 不一定是连通图 染色可以使用1和2区分不同颜色,用0表示未染色 遍历所有点&…...

磁场设备主要有哪些
磁学是物理学最古老的研究领域之一,目前仍然充满了生机活力。对于磁性物理的科学研究、磁性材料相关的探索来说,磁场设备必不可少,因为在外加磁场的作用下,样品会表现出特殊的物理性质,并带来了巨大的应用前景…...

【wespeaker】模型ECAPA_TDNN介绍
本次主要介绍开源项目wespeaker模型介绍 1. 模型超参数 model_args: feat_dim: 80 embed_dim: 192 pooling_func: “ASTP” projection_args: project_type: “softmax” # add_margin, arc_margin, sphere, softmax scale: 32.0 easy_margin: False 2. 模型结构 2.1 Layer…...

GPT技术的广泛使用
GPT技术的广泛使用确实引发了一些关于其潜在影响的讨论,包括可能导致某些职业失业以及对一些互联网公司构成竞争压力的问题。然而,这个问题涉及到多个方面,而且不容易一概而论。 潜在影响: 自动化任务: GPT等自然语言…...

银河麒麟V10安装MySQL8.0.28并实现远程访问
参考资料: 银河麒麟V10安装MySQL8.0.28并实现远程访问-数据库运维技术服务 银河麒麟高级服务器操作系统V10安装mysql数据库_麒麟v10安装mysql-CSDN博客...
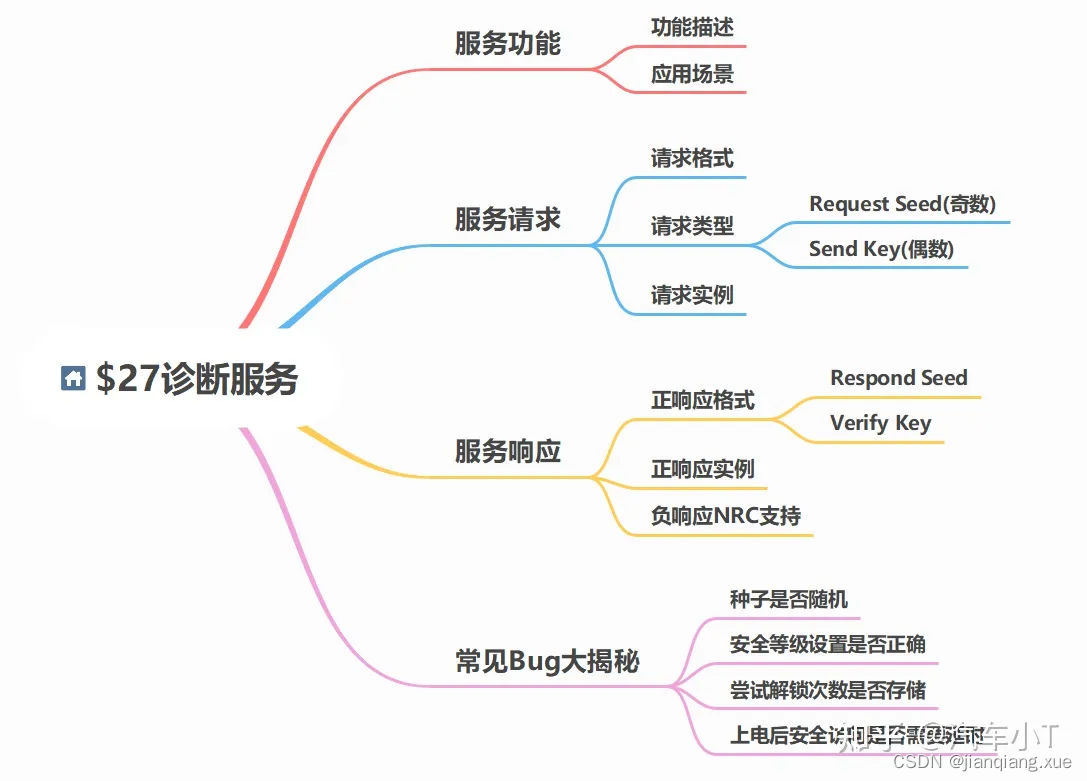
[AUTOSAR][诊断管理][ECU][$27] 安全访问
文章目录 一、简介$27服务有何作用,为什么要有27服务呢?功能描述应用场景安全解锁基本原理服务请求服务响应Verify Key负响应NRC支持二、常见Bug大揭秘三、示例代码uds27_security_access.c一、简介 $27服务有何作用,为什么要有27服务呢? 功能描述 根据ISO14119-1标准中…...

Android Studio编译旧的app代码错误及解决方法
‘android.injected.build.density’ is deprecated. The option ‘android.injected.build.density’ is deprecated. It was removed in version 8.0 of the Android Gradle plugin. Density property injection from Android Studio has been removed. 解决 app/build.gr…...

Docker的架构与自制镜像的发布
一. Docker 是什么 Docker与自动化测试及其测试实践 大家都知道虚拟机吧,windows 上装个 linux 虚拟机是大部分程序员的常用方案。公司生产环境大多也是虚拟机,虚拟机将物理硬件资源虚拟化,按需分配和使用,虚拟机使用起来和真实操…...

嵌入式系统中C++ 类的设计和实现分析
C代码提供了足够的灵活性,因此对于大部分工程师来说都很难把握。 本文介绍了写好C代码需要遵循的10个最佳实践,并在最后提供了一个工具可以帮助我们分析C代码的健壮度。 原文:10 Best practices to design and implement a C class。 1. 尽…...

【torch高级】一种新型的概率学语言pyro(02/2)
前文链接:【torch高级】一种新型的概率学语言pyro(01/2) 七、Pyro 中的推理 7.1 背景:变分推理 引言中的每项计算(后验分布、边际似然和后验预测分布)都需要执行积分,而这通常是不可能的或计算…...
Git基本概念与使用
一、Git基本概念 git,是一种分布式版本控制软件,与CVS、Subversion这类的集中式版本控制工具不同,它采用了分布式版本库的作法,不需要服务器端软件,就可以运作版本控制,使得源代码的发布和交流极其方便。g…...

Kubernetes数据卷Volume和数据卷分类(emptyDir、nfs、hostPath、ConfigMap)详解
Kubernetes数据卷Volume和数据卷分类详解 数据卷概述 Kubernetes Volume(数据卷)主要解决了如下两方面问题: 数据持久性:通常情况下,容器运行起来之后,写入到其文件系统的文件暂时性的。当容器崩溃后&am…...
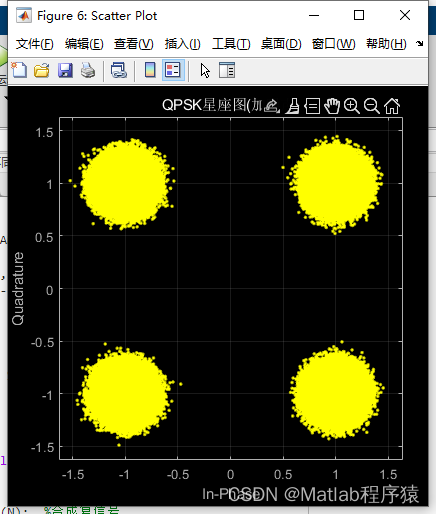
【MATLAB源码-第59期】基于matlab的QPSK,16QAM164QAM等调制方式误码率对比,调制解调函数均是手动实现未调用内置函数。
操作环境: MATLAB 2022a 1、算法描述 正交幅度调制(QAM,Quadrature Amplitude Modulation)是一种在两个正交载波上进行幅度调制的调制方式。这两个载波通常是相位差为90度(π/2)的正弦波,因此…...
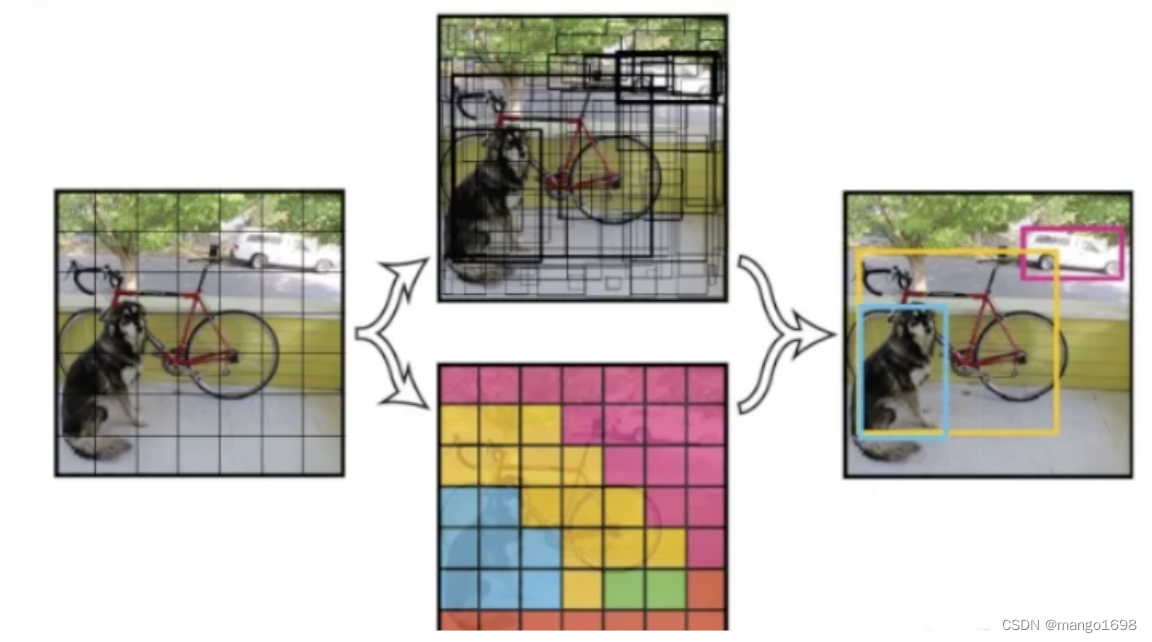
经典目标检测神经网络 - RCNN、SSD、YOLO
文章目录 1. 目标检测算法分类2. 区域卷积神经网络2.1 R-CNN2.2 Fast R-CNN2.3 Faster R-CNN2.4 Mask R-CNN2.5 速度和精度比较 3. 单发多框检测(SSD)4. YOLO 1. 目标检测算法分类 目标检测算法主要分两类:One-Stage与Two-Stage。One-Stage与…...

mysql存在10亿条数据,如何高效随机返回N条纪录,sql如何写
1 低效方案 1.使用ORDER BY RAND(): SELECT * FROM your_table ORDER BY RAND() LIMIT 1; 这将随机排序表中的所有行,并且通过LIMIT 1仅返回第一行,从而返回一个随机记录。然而,对于大型表来说,ORDER BY RAND()可能会…...
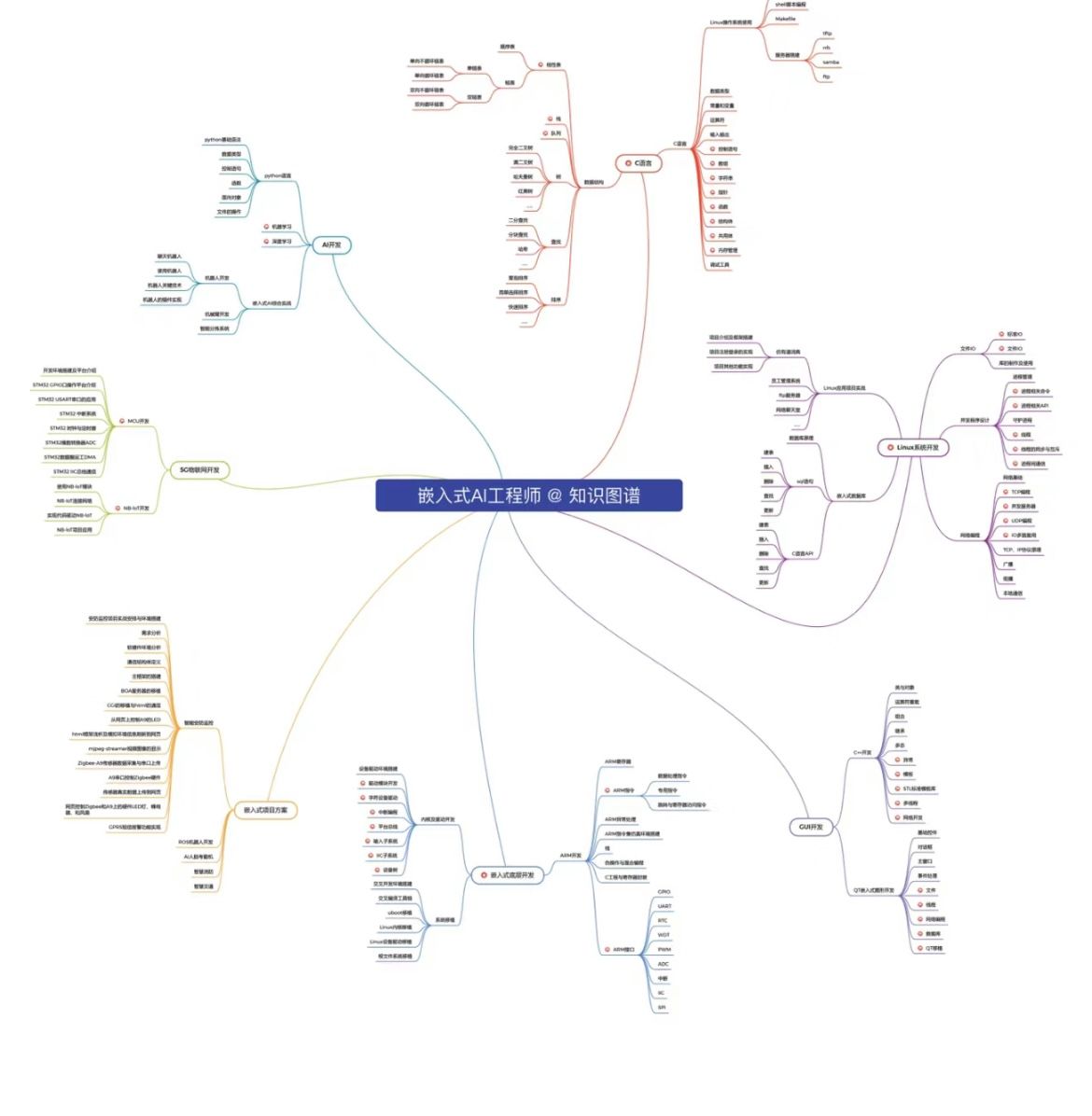
c语言中啥时候用double啥时候用float?
c语言中啥时候用double啥时候用float? 一般来说,可以使用double来表示具有更高精度要求的浮点数,因为它可以存储更大范围的数值并且具有更高的精度。 最近很多小伙伴找我,说想要一些c语言资料,然后我根据自己从业十年…...
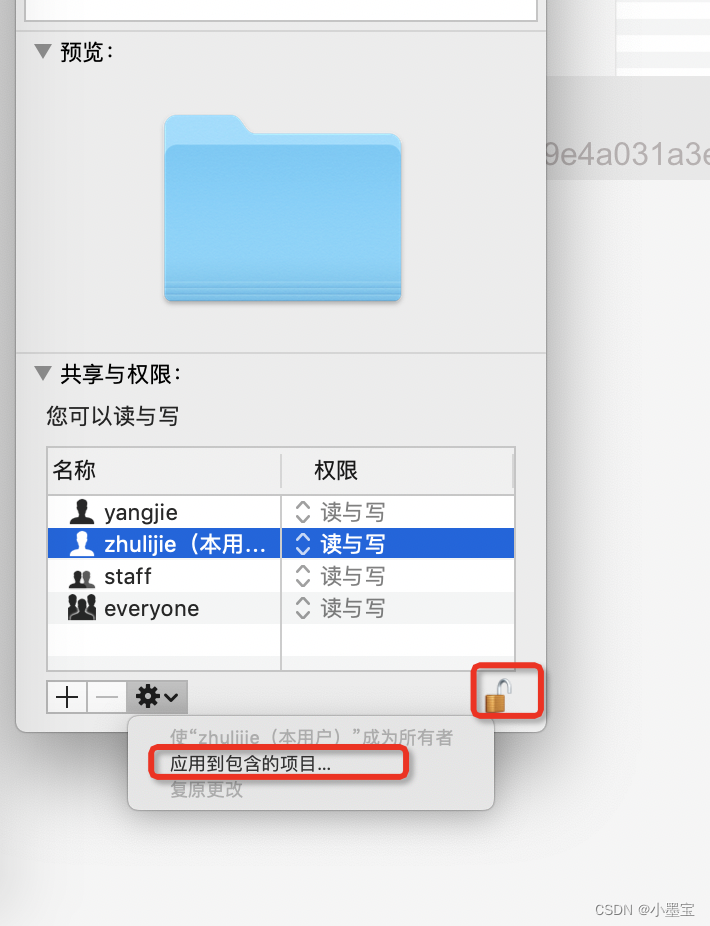
vscode 保存 “index.tsx“失败: 权限不足。选择 “以超级用户身份重试“ 以超级用户身份重试。
vscode 保存 "index.tsx"失败: 权限不足。选择 “以超级用户身份重试” 以超级用户身份重试。 操作:mac在文件夹中创建文件,sudo 创建umiJs项目 解决:修改文件夹权限 右键文件夹...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...

Midjourney V6锐化失控?3步诊断+5组--sref/--stylize协同参数公式,立竿见影修复模糊与锯齿
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6锐化失控的本质归因 Midjourney V6 引入的全新扩散架构与隐式细节增强机制,导致图像生成过程中高频纹理被过度强化,其根本原因并非参数误配,而是模型在…...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...

ESP32搭建TFT_LCD中文字库,附常用字库
(一)简介 在使用ESP32的时候,我们知道OLED屏幕是有中文库的,里面有非常多的常用字,但是LCD屏幕只有取模才能得到中文字体,那我们本期教程就来教大家如何搭建自己的字体库,使用中文字体更加方便快…...

C++的单例模式及其作用
什么是单例模式?无论是在面向对象编程还是软件架构中,单例模式都扮演着至关重要的角色。它不仅能够确保一个类只有一个实例存在,还能够提供全局访问点,使得我们可以方便地在程序的任何地方使用该实例。但有几个设计模式并非解决抽…...

从无人机到自动驾驶:一文读懂ROS中ENU、NED、相机坐标系到底怎么用
从无人机到自动驾驶:ROS中ENU、NED与相机坐标系实战指南 当你在无人机上安装Realsense相机时,是否遇到过相机数据与飞控数据"对不上"的情况?或者在自动驾驶项目中,GPS的北东地坐标如何与激光雷达的东北天坐标对齐&#…...

QKeyMapper完整指南:Windows上最强大的免费按键映射解决方案
QKeyMapper完整指南:Windows上最强大的免费按键映射解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&…...

3PEAK思瑞浦 TPA6532-VS1R MSOP8 运算放大器
特性 供电电压:1.75伏至5.5伏 偏移电压:土1.5mV(最大) 通用峰值电压:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1Hz至10Hz电压噪声:1Vpp 开机和关机电流期间无明显输出抖动 低功耗:每通道最大25安培工作温度范围:-40C至125C...