pytorch 入门 (五)案例三:乳腺癌识别识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章
- 🍨 本文为🔗小白入门Pytorch中的学习记录博客
- 🍦 参考文章:【小白入门Pytorch】乳腺癌识别
- 🍖 原作者:K同学啊
在本案例中,我将带大家探索一下深度学习在医学领域的应用–完成乳腺癌识别,乳腺癌是女性最常见的癌症形式,浸润性导管癌 (IDC) 是最常见的乳腺癌形式。准确识别和分类乳腺癌亚型是一项重要的临床任务,利用深度学习方法识别可以有效节省时间并减少错误。 我们的数据集是由多张以 40 倍扫描的乳腺癌 (BCa) 标本的完整载玻片图像组成。
关于环境配置请看我之前缩写博客:https://blog.csdn.net/qq_33489955/article/details/132890434?spm=1001.2014.3001.5501
数据集:链接:https://pan.baidu.com/s/1xkqsqsRRwlBOl5L9t_U0UA?pwd=vgqn
提取码:vgqn
–来自百度网盘超级会员V4的分享
目录
- 一、 前期准备
- 1. 设置GPU
- 2. 导入数据
- 3. 划分数据集
- 二、手动搭建VGG-16模型
- 1. 搭建模型
- 2. 查看模型详情
- 三、 训练模型
- 1. 编写训练函数
- 3. 编写测试函数
- 3. 正式训练
- 四、 结果可视化
- 1. Loss与Accuracy图
- 2. 指定图片进行预测
- 3. 模型评估
一、 前期准备
import torchprint(torch.__version__) # 查看pytorch版本
2.0.1+cu118
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2. 导入数据
import os,PIL,random,pathlibdata_dir = './data/2-data/'
data_dir = pathlib.Path(data_dir)
提问:已经有路径不是直接使用就可以了吗,为什么还要将其转化为路径对象。
回答:当我们使用传统的字符串来表示文件路径时,确实可以工作,但pathlib提供的对象方法对于文件路径的操作更为简洁和直观。
以下是使用pathlib的一些优点:
- 跨平台兼容性:
pathlib自动处理不同操作系统的路径分隔符问题。例如,Windows使用\,而Unix和Mac使用/。使用pathlib,你不需要关心这些细节。 - 链式操作:你可以方便地使用链式方法来处理路径。例如,
path.parent返回父目录,path.stem返回文件的基本名称(不带扩展名)等。 - 读写简便:
pathlib.Path对象有read_text(),write_text(),read_bytes(), 和write_bytes()等方法,可以直接读写文件,而无需再使用open函数。 - 创建和删除目录:使用
pathlib, 你可以很容易地创建 (mkdir()) 或删除 (rmdir()) 目录。
以下是一个简单的例子来比较两者:
使用传统的os模块:
import os
file_path = os.path.join("folder1", "folder2", "myfile.txt")
使用pathlib:
from pathlib import Path
file_path = Path("folder1") / "folder2" / "myfile.txt"
所以,虽然直接使用字符串路径是可以的,但使用pathlib可以使代码更加简洁、可读和跨平台兼容。
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 13403Root location: data\2-dataStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
total_data.class_to_idx
{'0': 0, '1': 1}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x14191aec850>,<torch.utils.data.dataset.Subset at 0x141c3e693d0>)
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=8)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=8)
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
提问:为什么结果只输出一次,是因为测试数据集只有一个批次,即32张图片吗
回答:不,结果只输出一次是因为您的代码中包含了一个 break 语句。这个 break 会在第一次迭代后立即退出 for 循环,因此您只看到了第一个批次的输出。
如果您想确认 test_dl 中有多少批次,您可以尝试以下代码:
num_batches = len(test_dl)
print("Number of batches in test_dl:", num_batches)
这将告诉您 test_dl 中有多少个批次。如果这个数字是1,那么确实只有32张图片。但是,如果这个数字大于1,那么 test_dl 会包含更多的图片。每个批次都有32张图片(除了可能的最后一个批次,它可能包含少于32张图片,取决于数据集的总数)。
二、手动搭建VGG-16模型
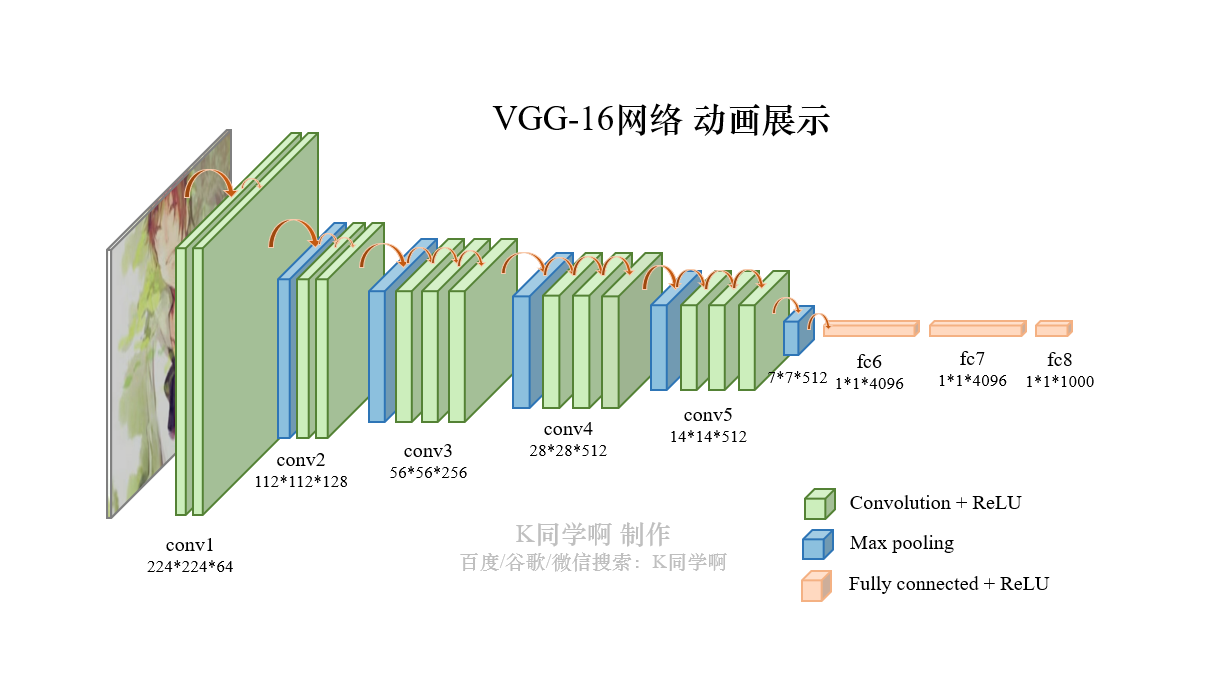
VGG-16结构说明:
- 13个卷积层(Convolutional Layer),分别用
blockX_convX表示; - 3个全连接层(Fully connected Layer),用
classifier表示; - 5个池化层(Pool layer)。
VGG-16包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
1. 搭建模型
import torch.nn.functional as Fclass vgg16(nn.Module):def __init__(self):super(vgg16, self).__init__()# 卷积块1self.block1 = nn.Sequential( # # 这定义了一个名为block1的属性。nn.Sequential是一个容器,它按照它们被添加到容器中的顺序执行其中的层或操作。nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), # 这添加了一个2D卷积层。它接受3个通道的输入(例如RGB图像),并产生64个通道的输出。它使用3x3的卷积核,步长为1,和1的填充。nn.ReLU(), # 这添加了一个ReLU激活函数。它将所有的负值变为0,其他值保持不变。nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), # 这是另一个2D卷积层。它接受上一个卷积层的64个通道的输出,并产生64个通道的输出。nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)) # # 这添加了一个2D最大池化层。它使用2x2的窗口和2的步长来减少每个通道的尺寸的一半。)# 卷积块2self.block2 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 卷积块3self.block3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 卷积块4self.block4 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 卷积块5self.block5 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=512*7*7, out_features=4096),nn.ReLU(),nn.Linear(in_features=4096, out_features=4096),nn.ReLU(),nn.Linear(in_features=4096, out_features=2))def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = vgg16().to(device)
model
Using cuda device
vgg16((block1): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block2): Sequential((0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block3): Sequential((0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): ReLU()(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block4): Sequential((0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): ReLU()(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block5): Sequential((0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): ReLU()(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU()(2): Linear(in_features=4096, out_features=4096, bias=True)(3): ReLU()(4): Linear(in_features=4096, out_features=2, bias=True))
)
2. 查看模型详情
!pip install torchsummary
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: torchsummary in c:\users\cheng\appdata\roaming\python\python310\site-packages (1.5.1)
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 224, 224] 1,792ReLU-2 [-1, 64, 224, 224] 0Conv2d-3 [-1, 64, 224, 224] 36,928ReLU-4 [-1, 64, 224, 224] 0MaxPool2d-5 [-1, 64, 112, 112] 0Conv2d-6 [-1, 128, 112, 112] 73,856ReLU-7 [-1, 128, 112, 112] 0Conv2d-8 [-1, 128, 112, 112] 147,584ReLU-9 [-1, 128, 112, 112] 0MaxPool2d-10 [-1, 128, 56, 56] 0Conv2d-11 [-1, 256, 56, 56] 295,168ReLU-12 [-1, 256, 56, 56] 0Conv2d-13 [-1, 256, 56, 56] 590,080ReLU-14 [-1, 256, 56, 56] 0Conv2d-15 [-1, 256, 56, 56] 590,080ReLU-16 [-1, 256, 56, 56] 0MaxPool2d-17 [-1, 256, 28, 28] 0Conv2d-18 [-1, 512, 28, 28] 1,180,160ReLU-19 [-1, 512, 28, 28] 0Conv2d-20 [-1, 512, 28, 28] 2,359,808ReLU-21 [-1, 512, 28, 28] 0Conv2d-22 [-1, 512, 28, 28] 2,359,808ReLU-23 [-1, 512, 28, 28] 0MaxPool2d-24 [-1, 512, 14, 14] 0Conv2d-25 [-1, 512, 14, 14] 2,359,808ReLU-26 [-1, 512, 14, 14] 0Conv2d-27 [-1, 512, 14, 14] 2,359,808ReLU-28 [-1, 512, 14, 14] 0Conv2d-29 [-1, 512, 14, 14] 2,359,808ReLU-30 [-1, 512, 14, 14] 0MaxPool2d-31 [-1, 512, 7, 7] 0Linear-32 [-1, 4096] 102,764,544ReLU-33 [-1, 4096] 0Linear-34 [-1, 4096] 16,781,312ReLU-35 [-1, 4096] 0Linear-36 [-1, 2] 8,194
================================================================
Total params: 134,268,738
Trainable params: 134,268,738
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.52
Params size (MB): 512.19
Estimated Total Size (MB): 731.29
----------------------------------------------------------------
三、 训练模型
1. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3. 编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
3. 正式训练
1. model.train()
model.train()的作用是启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
2. model.eval()
model.eval()的作用是不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
import copyoptimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数epochs = 10train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)print('Done')
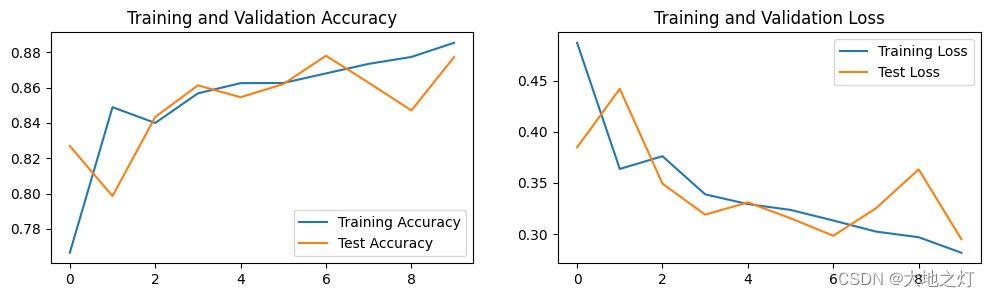
Epoch: 1, Train_acc:76.6%, Train_loss:0.487, Test_acc:82.7%, Test_loss:0.385, Lr:1.00E-04
Epoch: 2, Train_acc:84.9%, Train_loss:0.364, Test_acc:79.9%, Test_loss:0.442, Lr:1.00E-04
Epoch: 3, Train_acc:84.0%, Train_loss:0.376, Test_acc:84.3%, Test_loss:0.349, Lr:1.00E-04
Epoch: 4, Train_acc:85.7%, Train_loss:0.339, Test_acc:86.1%, Test_loss:0.319, Lr:1.00E-04
Epoch: 5, Train_acc:86.3%, Train_loss:0.329, Test_acc:85.5%, Test_loss:0.331, Lr:1.00E-04
Epoch: 6, Train_acc:86.3%, Train_loss:0.324, Test_acc:86.2%, Test_loss:0.315, Lr:1.00E-04
Epoch: 7, Train_acc:86.8%, Train_loss:0.313, Test_acc:87.8%, Test_loss:0.298, Lr:1.00E-04
Epoch: 8, Train_acc:87.3%, Train_loss:0.302, Test_acc:86.3%, Test_loss:0.325, Lr:1.00E-04
Epoch: 9, Train_acc:87.7%, Train_loss:0.297, Test_acc:84.7%, Test_loss:0.363, Lr:1.00E-04
Epoch:10, Train_acc:88.5%, Train_loss:0.282, Test_acc:87.7%, Test_loss:0.295, Lr:1.00E-04
Done
四、 结果可视化
1. Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2. 指定图片进行预测
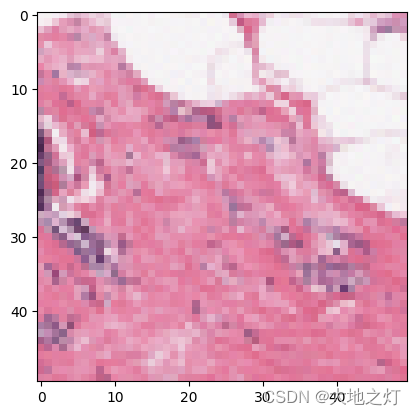
from PIL import Image classes = ["正常细胞", "乳腺癌细胞"]def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./data/2-data/0/8863_idx5_x451_y501_class0.png', model=model, transform=train_transforms, classes=classes)
预测结果是:正常细胞
3. 模型评估
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss
(0.8780305856023871, 0.29799242158021244)
# 查看是否与我们记录的最高准确率一致
epoch_test_acc
0.8780305856023871
相关文章:
pytorch 入门 (五)案例三:乳腺癌识别识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参考文章:【小白入门Pytorch】乳腺癌识别🍖 原作者:K同学啊 在本案例中,我将带大家探索一下深…...
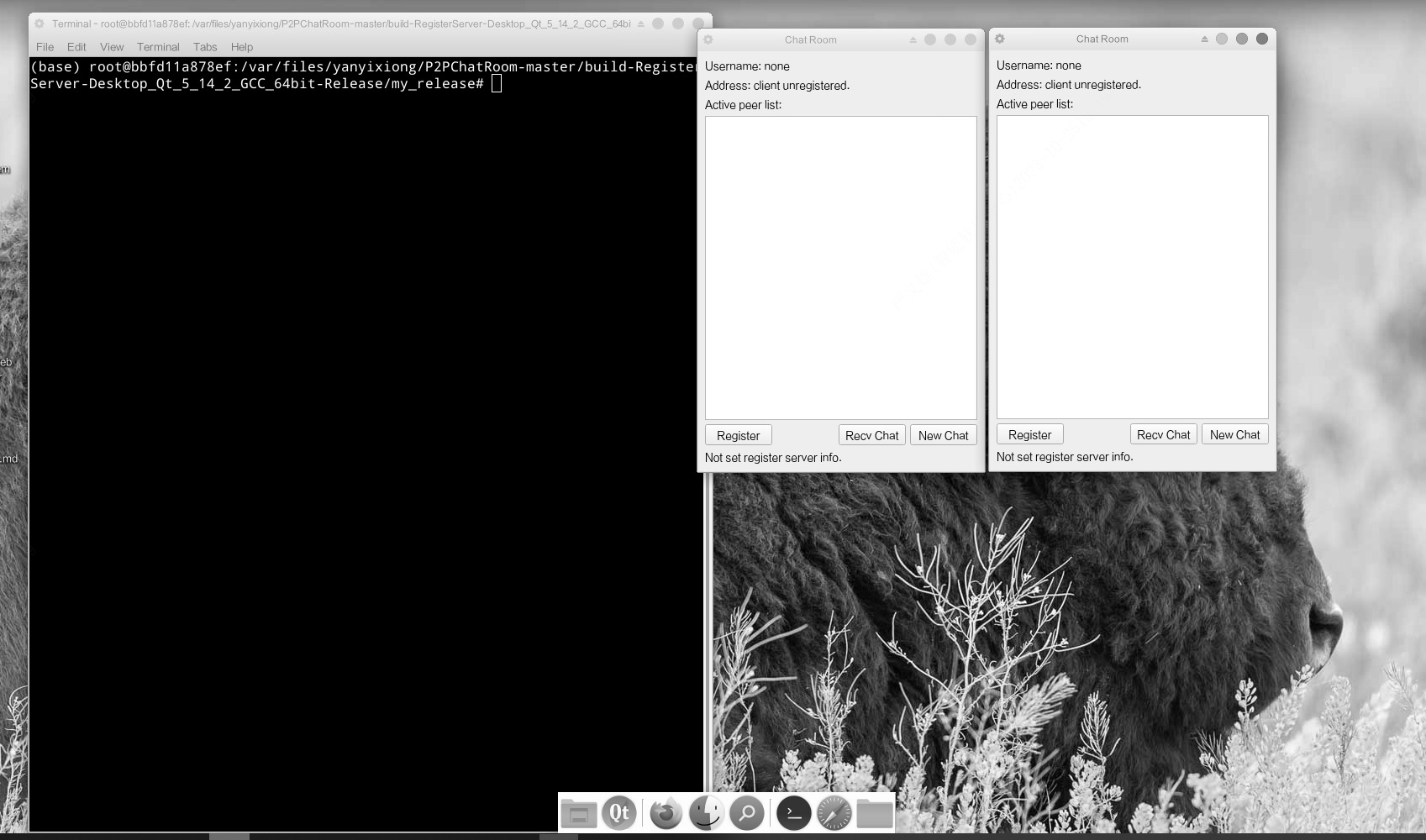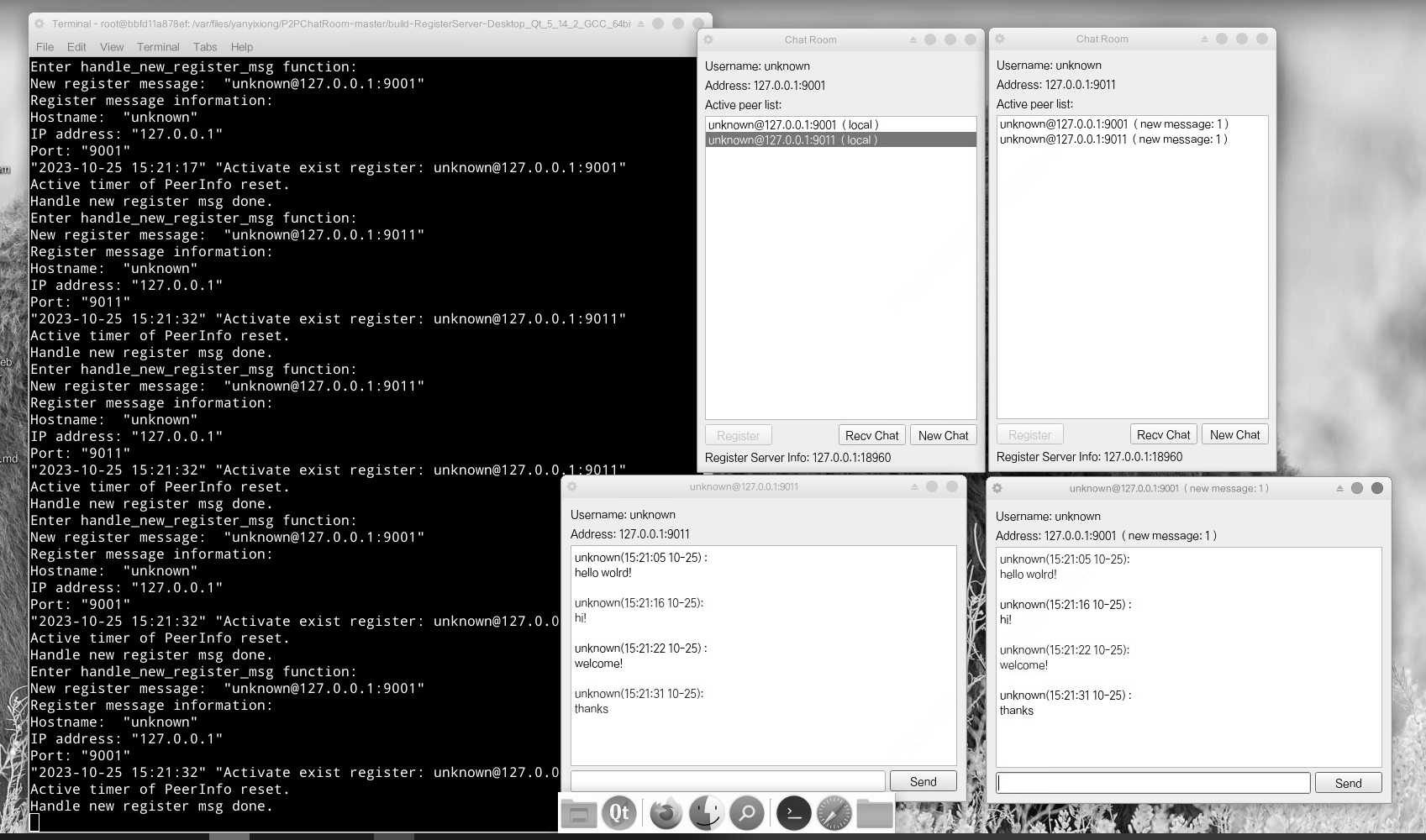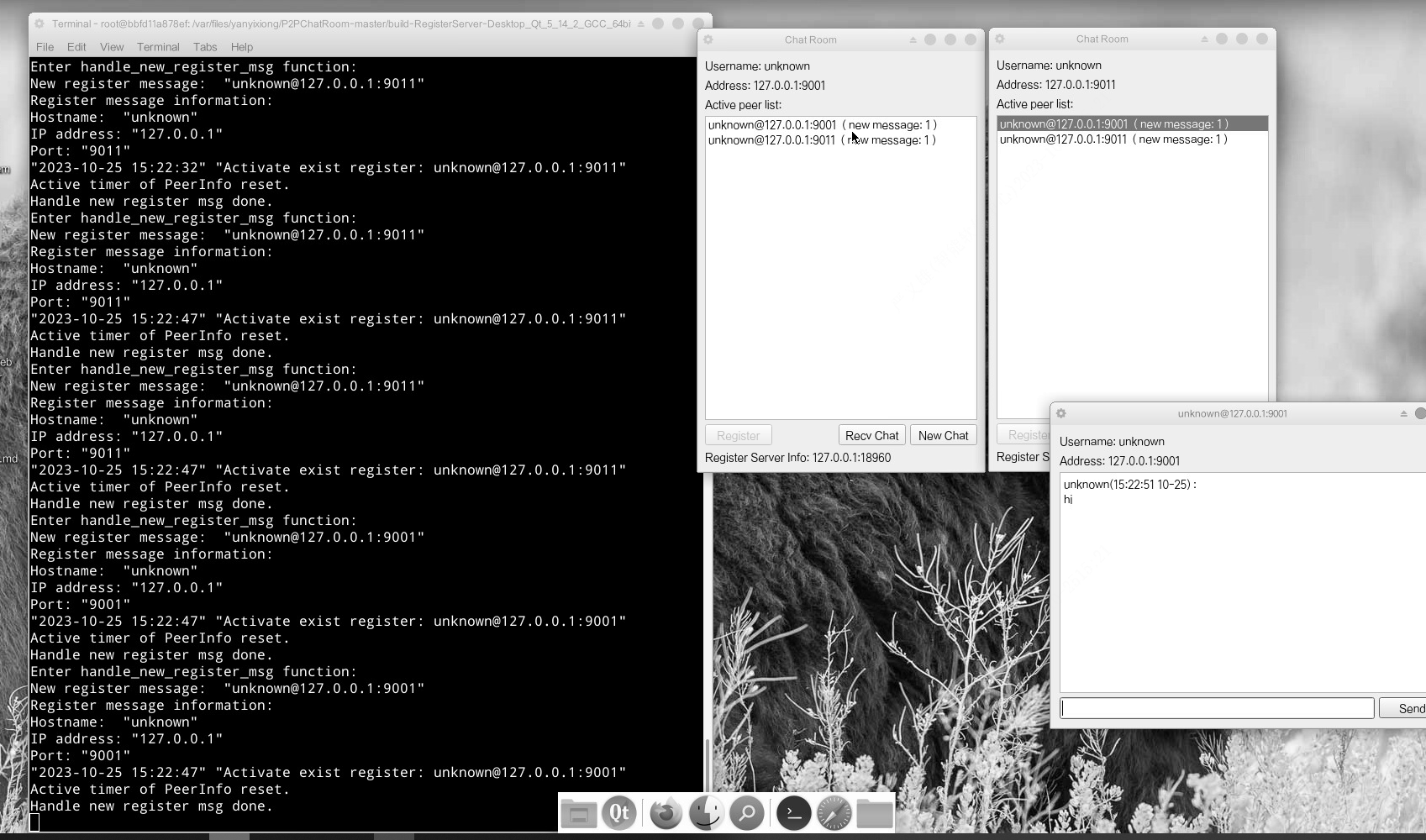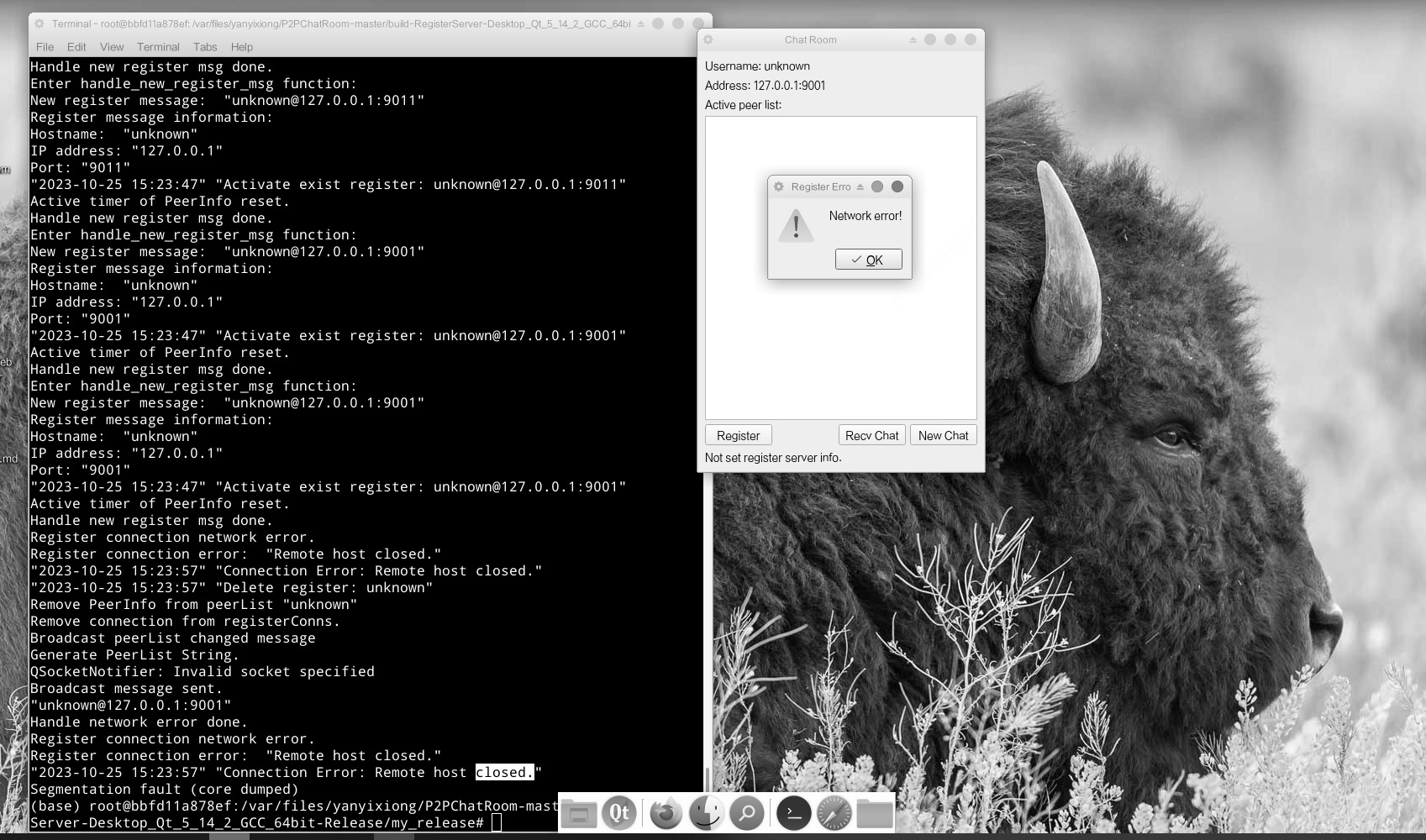
【QT开发(14)】QT P2P chat 聊天
在【P2P学习(2)】P2P 通信,主要存在四种不同的网络模型的第一阶段:集中式P2P 模式 最简单的路由方式就是集中式,即存在一个中心节点保存了其他所有节点的索引信息,索引信息一般包括节点 IP 地址、端口、节…...

解决adb root命令时错误 adbd cannot run as root in production builds
我测试的手机是小米8,root权限已经刷过了,但是在pc端使用adb root命令的时候,会报错"adbd cannot run as root in production builds" 后来查资料发现是因为Magisk和安卓9版本的问题 https://www.cnblogs.com/jeason1997/p/124105…...

操作系统中套接字和设备独立性软件的关系
网络编程就是编写程序让两台联网的计算机相互交换数据。在我们不需要考虑物理连接的情况下,我们只需要考虑如何编写传输软件。操作系统提供了名为“套接字”,套接字是网络传输传输用的软件设备。 这是对软件设备的解释: 在操作系统中&#…...
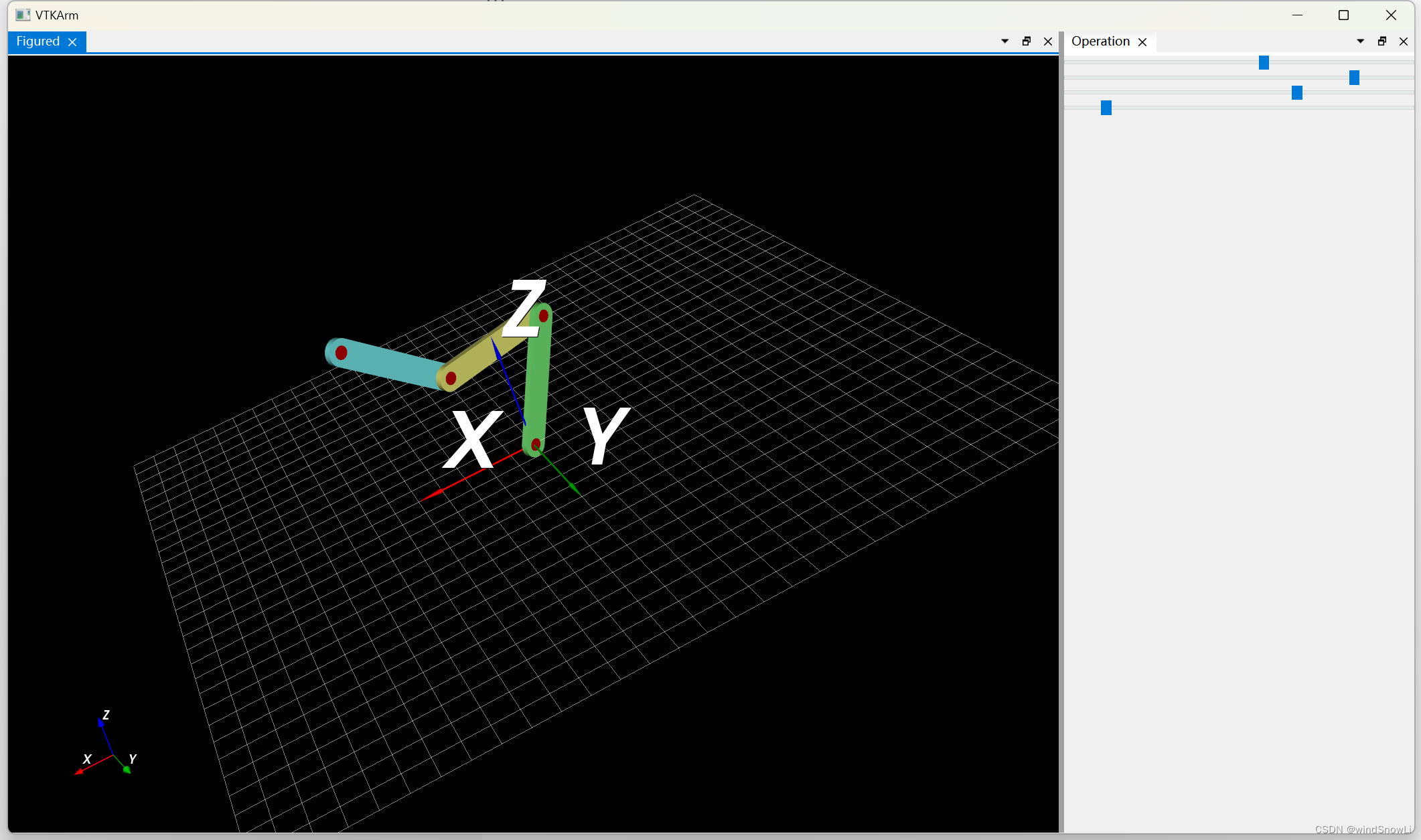
C++ Qt/VTK装配体组成联动连接杆
效果 关键代码 #include "View3D.h" #include "Axis.h"#include <vtkActor.h> #include <vtkAppendPolyData.h > #include <vtkAreaPicker.h> #include <vtkAxesActor.h> #include <vtkBox.h> #include <vtkCamera.h>…...
File文件查找
用的是递归调用, (递归死循环的结果是导致栈内存溢出错误) 一.代码 package org.example;import java.io.File;public class day03 {public static void main(String[] args) {//文件查找,在d:temp下查找改名.mp4sea…...

小程序 wxml2canvas开发文档
wxml: <view class"share__canvas share__canvas1"><view class"share__canvas1-text draw_canvas" data-type"text" data-text"这是一段无边距文字">这是一段无边距文字</view> </view> <canvas canvas-…...

SpringCloud微服务 【实用篇】| 认识微服务
目录 一:认识微服务 1. 微服务框架介绍 2. 服务架构演变 3. 微服务技术对比 4. SpringCloud 图书推荐:《巧用ChatGPT快速提高职场晋升力》 一:认识微服务 本课程学习于黑马,会通过分层次学习,分为三部分去讲解微…...
Csdn文章编写参考案例
这里写自定义目录标题 欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants 创建一个自定义列表如何创建一个…...

Jmeter性能测试:高并发分布式性能测试
一、为什么要进行分布式性能测试 当进行高并发性能测试的时候,受限于Jmeter工具本身和电脑硬件的原因,无法满足我们对大并发性能测试的要求。 基于这种场景下,我们就需要采用分布式的方式来实现我们高并发的性能测试要求。 二、分布式性能…...

2015年亚太杯APMCM数学建模大赛B题城市公共交通服务水平动态评价模型求解全过程文档及程序
2015年亚太杯APMCM数学建模大赛 B题 城市公共交通服务水平动态评价模型 原题再现 城市公共交通服务评价是城市公共交通系统建设和提高公共交通运营效率的重要组成部分。对于公交企业,管理和规划部门,传统公交车站、线路和换乘枢纽的规划数据只是基于主…...

CCF CSP认证历年题目自练 Day40
题目 试题编号: 201412-3 试题名称: 集合竞价 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 某股票交易所请你编写一个程序,根据开盘前客户提交的订单来确定某特定股票的开盘价和开盘成交量…...

闲聊一下写技术博客的一些感想
大家好,我是阿赵。 在我的163博客关闭之后,我就把一部分的博文移到了CSDN这边。不过实际上我有好几年都没有写过博客,所以这个博客的浏览量和粉丝数一直都不高。直到今年2023年的2月底开始,打算总结一下3DsMax的MaxScript的用…...
单片机为什么一直用C语言,不用其他编程语言?
单片机为什么一直用C语言,不用其他编程语言? 51 单片机规模小得拮据,C 的优势几乎看不到。放个类型信息进去都费劲,你还想用虚函数?还想模板展开?程序轻松破 10k。最近很多小伙伴找我,说想要一些…...

利用HTTP2,新型DDoS攻击峰值破纪录
亚马逊、Cloudflare 和谷歌周二联合发布消息称,一种依赖于 HTTP/2 快速重置技术的攻击行为对它们造成了破纪录的分布式拒绝服务 (DDoS) 攻击。 根据披露的信息,该攻击自8月下旬以来便一直存在,所利用的漏洞被跟踪为CVE-2023-44487,…...

android鼠标滚轮事件监听方法
Overridepublic boolean onGenericMotionEvent(MotionEvent event) { //The input source is a pointing device associated with a display. //输入源为可显示的指针设备,如:mouse pointing device(鼠标指针),stylus pointing device(尖笔设备)if (0 ! …...

【C语言|关键字】C语言32个关键字详解(4)——其他(typedef、sizeof)
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
Hafnium简介和构建
安全之安全(security)博客目录导读 目录 一、Hafnium简介 二、Hafnium构建 2.1.1 先决条件 2.1.1.1 构建Host 2.1.1.2 工具链 2.1.1.3 依赖 2.1.1.4 获取源码 2.1.2 构建 一、Hafnium简介 可信固件为Armv8-A、Armv9-A和Armv8-M提供了安全软件的参考实现。它为SoC开发人…...
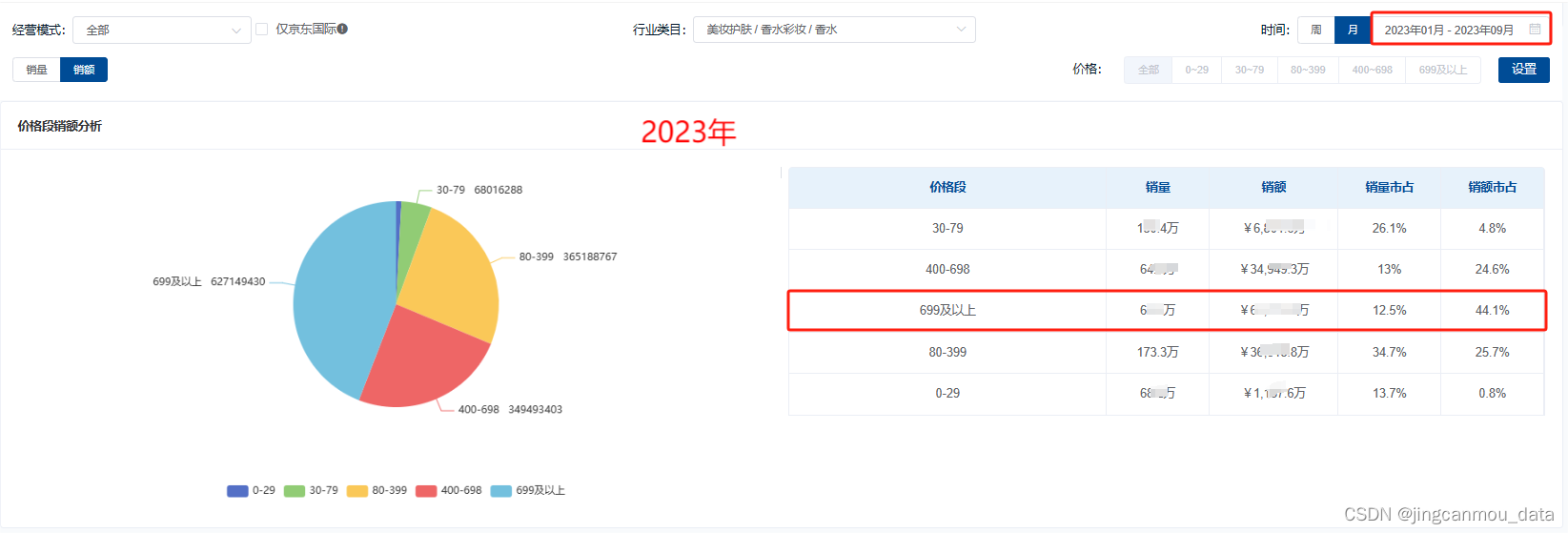
2023年香水行业数据分析:国人用香需求升级,高端香水高速增长
在人口结构变迁的背景下,“Z世代”作为当下我国的消费主力,正在将“悦己”消费推动成为新潮流。具备经济基础的“Z世代”倡导“高颜值”、“个性化”、“精致主义”,这和香水、香氛为代表的“嗅觉经济”的特性充分契合,因此&#…...
这可能是最简单的Page Object库
做过web自动化测试的同学,对Page object设计模式应该不陌生。 Page object库应该根据以下目标开发: Page object应该易于使用 清晰的结构 PageObjects 对于页面对象 PageModules对于页面内容 只写测试,而不是基础。 在可能的情况下防止…...

Python FIT文件解析终极指南:3分钟掌握运动数据分析技巧
Python FIT文件解析终极指南:3分钟掌握运动数据分析技巧 【免费下载链接】python-fitparse Python library to parse ANT/Garmin .FIT files 项目地址: https://gitcode.com/gh_mirrors/py/python-fitparse 你是否拥有Garmin、Suunto等运动手表,却…...

XGBoost处理缺失值:构建面向天文大数据的极冷矮星智能发现系统
1. 项目概述:当机器学习遇见“暗弱”的宇宙居民在广袤的宇宙中,除了那些明亮耀眼的主序星和星系,还存在着一个庞大而“低调”的群体——极冷矮星。它们涵盖了光谱型晚于M6的恒星(如M型矮星)以及质量不足以点燃稳定氢聚…...
)
别再为立体匹配发愁了!手把手教你用Fusiello法搞定双目相机极线校正(附Python代码)
双目视觉实战:Fusiello极线校正算法详解与Python实现在计算机视觉领域,立体匹配是获取三维场景信息的关键步骤。但原始双目图像由于相机位置差异,导致匹配搜索空间复杂,计算效率低下。本文将深入解析Fusiello极线校正算法的数学原…...

人工智能通识课:深度学习框架 PyTorch
深度学习框架是连接算法理论与工程实践的重要工具。它让开发者不必从零实现张量运算、自动求导、参数更新、GPU 调度和模型保存等底层细节,而可以把主要精力放在数据处理、模型结构设计、训练策略和实验验证上。在众多深度学习框架中,PyTorch 凭借直观的…...

基于静态动态障碍物DWA、DWA+RRT*、改进A*、RRT* 2D和3D的路径规划算法Matlab代码
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

FPG平台:信息透明度建设的深度解析
FPG平台:信息透明度建设的深度解析金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。FPG平台经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的…...

K210开发板固件烧录:使用kflash_gui图形化工具的完整指南
K210开发板固件烧录:使用kflash_gui图形化工具的完整指南 【免费下载链接】kflash_gui Cross platform GUI wrapper for kflash.py (download(/burn) tool for k210) 项目地址: https://gitcode.com/gh_mirrors/kf/kflash_gui 在K210开发板生态系统中&#x…...

哈夫曼树:高效压缩数据的秘密武器
引言在前面的树系列中,我们学习了二叉搜索树、AVL 树和红黑树——它们都是为了高效查找而设计的。今天要讲的哈夫曼树,目的完全不同:它是为了压缩数据而生。哈夫曼树(Huffman Tree),又称最优二叉树…...
)
【教育科技爆款内容生产核心】:用ChatGPT批量生成带答案解析+难度分级+认知维度标签的脑筋急转弯(附可商用JSON Schema)
更多请点击: https://kaifayun.com 第一章:教育科技爆款内容生产的底层逻辑重构 教育科技领域的“爆款”并非偶然产物,而是内容价值、用户认知路径与算法分发机制三者深度耦合的结果。传统以课程大纲为中心的线性生产范式,正被“…...

【Java EE】IPv6
IPv6引言IPv6 地址表示IPv6 地址类型地址范围详解多播地址结构IPv6 与 IPv4 的主要区别IPv6 首部格式扩展首部IPv6 地址配置方式无状态地址自动配置(SLAAC)有状态配置(DHCPv6)手动配置邻居发现协议(NDP)IPv…...