Hive表优化、表设计优化、Hive表数据优化(ORC)、数据压缩、存储优化
文章目录
- Hive表优化
- Hive表设计优化
- 分区表结构 - 分区设计思想
- 分桶表结构 - Join问题
- Hive中的索引
- Hive表数据优化
- 常见文件格式
- TextFile
- SequenceFile
- Parquet
- ORC
- 数据压缩
- 存储优化 - 避免小文件生成
- 存储优化 - 合并输入的小文件
- 存储优化 - ORC文件索引
- Row Group Index
- Bloom Filter Index
- 存储优化 - ORC矢量化查询
Hive表优化
- 当执行查询计划时,Hive会使用表的最后一级目录作为底层处理数据的输入,即全表扫描。
- Step1:先根据表名在元数据中进行查询表对应的HDFS目录
- Step2:然后将整个HDFS中表的目录作为底层查询的输入,可以通过explain命令查看执行计划依赖的数据
Hive表设计优化
分区表结构 - 分区设计思想
- 设计思想:根据查询需求,将数据按照查询的条件(一般以时间)进行分区存储,将不同分区的数据单独使用一个HDFS目录存储。
- 分区表的构建和使用可见本专栏对应的文章。
分桶表结构 - Join问题
- 分桶表是按一定规则将数据划分到不同的文件中存储(分区表是分到不同目录)
- 如果有两张表按照相同的划分规则(按照Join的关联字段)将各自的数据进行划分,Join时就可以实现桶于桶之间的Join,避免不必要的比较。
- 分桶表的构建和操作相关SQL可见本专栏对应的文章。
Hive中的索引
- Hive的索引与关系型数据库中的索引并不相同,Hive不支持主键或外键索引。
- 索引功能从Hive0.7开始,到Hive3.0后不再支持。
- 建立索引时,Hive中会自动创建一张索引表,该表记录了该字段每个值与数据实际物理位置之间的关系。
- 当Hive中原始数据表的数据更新时,索引表不会自动更新
- 必须手动执行ALTER INDEX命令实现更新索引表,整体性能较差。
- 在实际应用中推荐使用ORC文件格式中的索引、物化视图来代替Hive Index提高查询性能。
- 语法:
- 创建索引
CREATE INDEX idx_user_id_login ON TABLE tb_login_part(userid) AS 'COMPACT' WITH deferred REBUILD;
- 构建索引:通过运行一个MapReduce程序来构建索引
ALTER INDEX idx_user_id_login ON tb_login_part REBUILD;
Hive表数据优化
- 为了提高对HDFS文件读写的性能,Hive提供了多种文件存储格式:TextFile、SequenceFile、ORC、Parquet等;
- 不同的文件存储格式具有不同的存储特点,有的可以降低存储空间,有的可以提高查询性能。
- Hive的文件格式在建表时指定,默认是TextFile,对应语法为:
STORED AS file_format
常见文件格式
TextFile
- TextFile是Hive中默认的文件格式,存储形式为按行存储。
- 优点:最简单的数据格式,可以直接查看,可以用任意分隔符进行分割,便于共享数据,可以搭配压缩一起使用。
- 缺点:耗费存储空间,I/O性能较低;结合压缩时Hive不进行数据切分合并,不能进行并行操作,查询效率低;按行存储,读取列的性能差。
- 适合小量数据的存储查询,一般用作第一层数据加载和测试使用。
SequenceFile
- 是Hadoop里用来存储序列化的键值对即二进制的一种文件格式。
- 也可以作为MapRrduce作业的输入和输出,Hive也支持这种格式。
- 加载数据时不能直接用load,因为load不经过MR程序,就实现不了SequenceFile。
- SequenceFile使用方法:
- 创建表
CREATE TABLE tb_sogou_seq(stime STRING,userid STRING
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS SEQUENCEFILE;
- 导入数据(不能直接load,需要通过INSERT调用MR程序实现压缩)
INSERT INTO TABLE tb_sogou_seq
SELECT * FROM tb_sogou_source;
Parquet
- 是一种支持嵌套结构的列式存储文件格式。
- 使用方法:(和SequenceFile一样不能直接load)
CREATE TABLE tb_sogou_parquet(stime STRING,userid STRING
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS PARQUET;INSERT INTO TABLE tb_sogou_parquet
SELECT * FROM tb_sogou_source;
ORC
- 是一种列式存储格式
- 优点:
- 列式存储效率非常高
- 可压缩,高效的列存取
- 查询效率较高,支持索引
- 支持矢量化查询
- 缺点:
- 加载时性能消耗较大
- 需要通过textFile文件转化生成
- 读取全量数据时性能较差
- 适合Hive中大型的存储、查询。
- ORC不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。
- ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能地压缩以降低存储空间的消耗。
- 用法和SequenceFile相同:
CREATE TABLE tb_sogou_parquet(stime STRING,userid STRING
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORC;INSERT INTO TABLE tb_sogou_orc
SELECT * FROM tb_sogou_source;
数据压缩
- Hive的数据压缩实际上是MapReduce的压缩
- Hive的压缩就是使用了Hadoop中的压缩实现的,Hadoop中支持的压缩在Hive中都可以直接使用。
- Hive中压缩配置:
- 开启Hive中间传输数据压缩功能
-- 1) 开启hive中间传输数据压缩功能:
SET hive.exec.compress.intermediate=true;
-- 2) 开启mapreduce中map输出压缩功能
SET mapreduce.map.output.compress=true;
-- 3) 设置mapreduce中map输出数据的压缩方式
SET mapreduce.map.output.compress.codec=org.apache.io.compress.SnappyCodec;
- 开启Reduce输出阶段压缩
-- 1) 开启hive最终输出数据压缩功能
SET hive.exec.compress.output=true;
-- 2) 开启mapreduce最终输出数据压缩
SET mapreduce.output.fileoutputformat.compress=true;
-- 3) 设置mapreduce最终数据输出压缩方式
SET mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
-- 4) 设置mapreduce最终数据输出压缩为块压缩
SET mapreduce.output.fileoutputformat.compress.type=BLOCK;
- 配合文件存储格式使用:
CREATE TABLE tb_sogou_orc_snappy
STORED AS ORC tblproperties ("orc.compress"="SNAPPY")
AS SELECT * FROM tb_sogou_source;
存储优化 - 避免小文件生成
- Hive的存储本质还是HDFS,由于每个小文件在HDFS中都会产生一条元数据信息,HDFS不利于小文件存储,且不利于MR程序的处理。
- MapReduce中每个小文件会启动一个MapTask计算处理,导致资源的浪费。
- Hive可以自动判断是否是小文件,如果是,则自动合并小文件。
- 参数设置:
-- 如果hive程序只有maptask,将MapTask产生的所有小文件进行合并
SET hive.merge.mapfiles=true;
-- 如果hive程序有Map和ReduceTask,将ReduceTask产生的所以小文件进行合并
SET hive.merge.mapredfiles=true;
-- 每一个合并的文件的大小
SET hive.merge.size.per.task=256000000;
-- 平均每个文件的大小,如果小于这个值就会进行合并
SET hive.merge.smallfiles.avgsize=16000000;
存储优化 - 合并输入的小文件
- 数据处理时输入小文件的情况下,Hive中提供一种输入类CombineHiveInputFormat,用于将小文件合并以后,再进行处理。
- 参数设置:
-- 设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入
SET hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
存储优化 - ORC文件索引
- 使用ORC文件时,为了加快读取ORC文件中的数据内容,ORC提供了两种索引机制:
- Row Group Index
- Bloom Filter Index
- 当数据写入数据时,可以指定构建索引,当用户查询数据时,可以根据索引提前对数据进行过滤,避免不必要的数据扫描。
Row Group Index
- 一个ORC文件包含一个或多个stripes(groups of row data即行组),每个stripe中包含了每个column的min/max值得索引数据;
- 当查询中有大于等于小于得操作时,会根据min/max值,跳过不包含在内得stripes。
- 建立ORC表时,指定参数’orc.create.index’='true’之后,便会建立Row Group Index;
- 向表中加载数据时,对需要使用索引的字段进行排序可以提高使用效率。
- 例:
-- 1. 开启索引配置
SET hive.optimize.index.filter=true;
-- 2. 创建表并设置构建索引
CREATE TABLE tb_sogou_orc_indexSTORED AS ORC TBLPROPERTIES("orc.create.index"="true")
AS SELECT * FROM tb_sogou_sourceDISTRIBUTE BY stimeSORT BY stime;
-- 3. 当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
SELECT COUNT(*) FROM tb_sogou_orc_index WHERE stime > '12:00:00' AND stime < '18:00:00';
Bloom Filter Index
- 建表时通过表参数"orc.bloom.filter.columns"="columnName…"来指定为哪些字段建立BloomFilter索引,在生成数据时,会在每个stripe中为该字段建立BloomFilter的数据结构;
- 当查询条件中包含对该字段的等值过滤时,先从BloomFilter中获取以下stripe是否包含该值,如果不包含,则跳过该stripe。
- 例:
-- 创建表并设置构建布隆索引
CREATE TABLE tb_sogou_orc_indexSTORED AS ORC TBLPROPERTIES
("orc.create.index"="true","orc.bloom.filter.columns"="stime,userid")
AS SELECT * FROM tb_sogou_sourceDISTRIBUTE BY stimeSORT BY stime;
-- 当stime进行范围查询(<,>)时可以走row group index,userid等值查询时走bloom filter index
SELECT COUNT(*) FROM tb_sogou_orc_index WHERE stime > '12:00:00' AND stime < '18:00:00' AND userid = '123345';
存储优化 - ORC矢量化查询
- Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive’针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录集整合应用操作。
- 要使用矢量化查询,必须以ORC格式存储数据。
- 矢量化查询设置;
SET hive.vectorized.execution.enabled = ture;
SET hive.vectorized.execution.reduce.enabled = true;
相关文章:
、数据压缩、存储优化)
Hive表优化、表设计优化、Hive表数据优化(ORC)、数据压缩、存储优化
文章目录Hive表优化Hive表设计优化分区表结构 - 分区设计思想分桶表结构 - Join问题Hive中的索引Hive表数据优化常见文件格式TextFileSequenceFileParquetORC数据压缩存储优化 - 避免小文件生成存储优化 - 合并输入的小文件存储优化 - ORC文件索引Row Group IndexBloom Filter …...

LearnOpenGL-入门-着色器
本人刚学OpenGL不久且自学,文中定有代码、术语等错误,欢迎指正 我写的项目地址:https://github.com/liujianjie/LearnOpenGLProject LearnOpenGL中文官网:https://learnopengl-cn.github.io/ 文章目录着色器GLSL数据类型输入与输…...
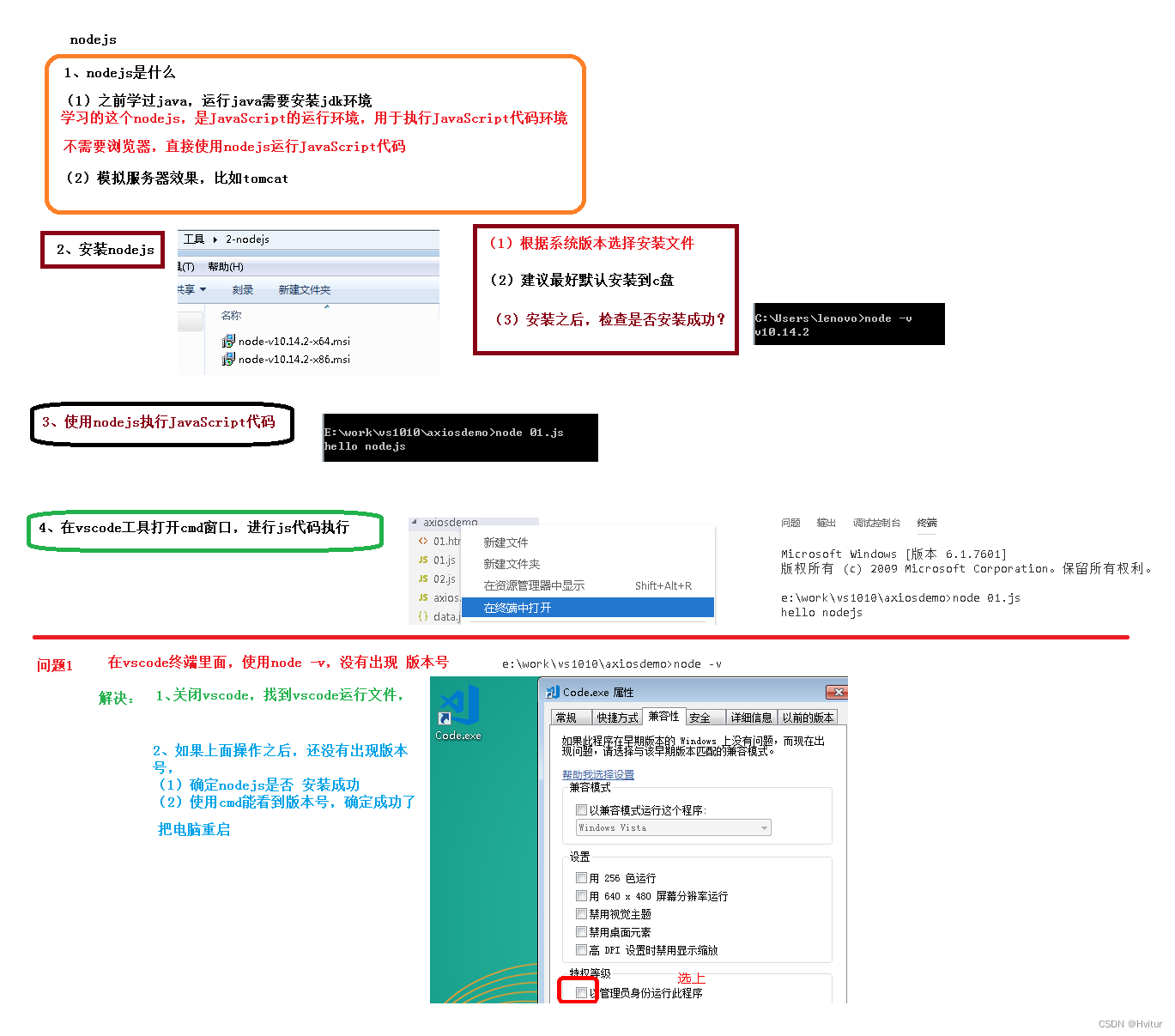
【谷粒学院】vue、axios、element-ui、node.js(44~58)
44.前端技术-vue入门 🧨Vue.js 是什么 Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。 Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具…...

【一些回忆】2022.02.26-2023.02.26 一个普通男孩的365天
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:一些回忆 为什么选择在这个时间节点回忆一下呢? 一是因为今天距离2023高考仅剩1…...
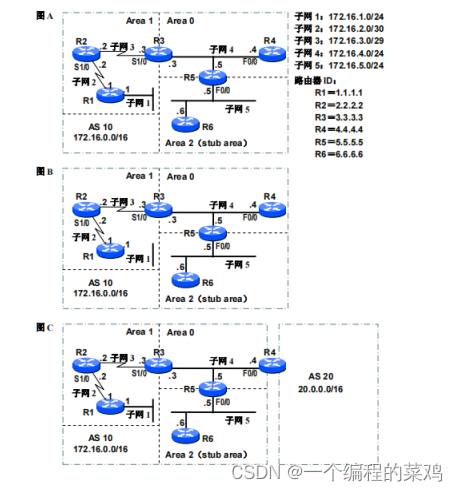
OSPF的多区域特性 (电子科技大学TCP/IP实验三)
一.实验目的 1、掌握OSPF 协议中区域的类型、特征和作用 2、掌握OSPF 路由器的类型、特征和作用 3、掌握OSPF LSA 分组的类型、特征和作用 4、理解OSPF 区域类型、路由器类型和OSPF LSA 分组类型间的相互关系 二.预备知识 1、静态路由选择和动态路…...
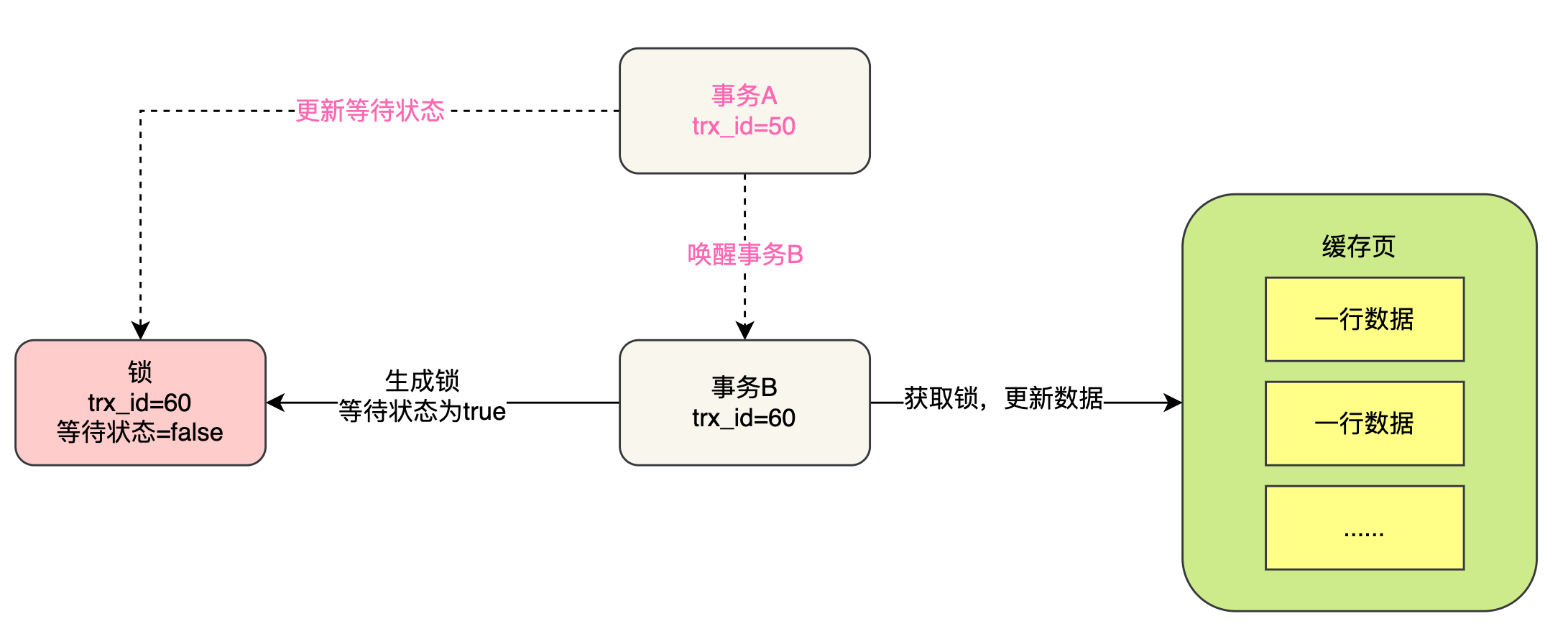
(四十四)多个事务更新同一行数据时,是如何加锁避免脏写的?
之前我们已经用很多篇幅给大家讲解了多个事务并发运行的时候,如果同时要读写一批数据,此时读和写时间的关系是如何协调的,毕竟要是你不协调好的话,可能就会有脏读、不可重复读、幻读等一系列的问题。 简单来说,脏读、…...

【数据库】第十二章 数据库管理
第12章 数据库管理 数据库的物理存储 关于内存、外存、磁盘、硬盘、软盘、光盘的区别_Allenzyg的博客-CSDN博客_磁盘和硬盘的区别 数据库记录在磁盘上的存储 定长,变长跨块,非跨快 文件的组织方方法: 无序记录文件(堆文件heap或pile file…...
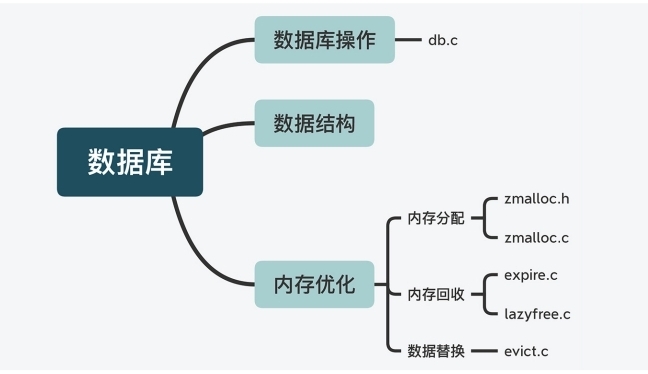
Redis源码---整体架构
目录 前言 Redis目录结构 前言 deps目录 src 目录 tests 目录 utils 目录 重要的配置文件 Redis 功能模块与源码对应 前言 服务器实例 数据库数据类型与操作 高可靠性和高可扩展性 辅助功能 前言 以先面后点的方法推进无特殊说明,都是基于 Redis 5.0.…...
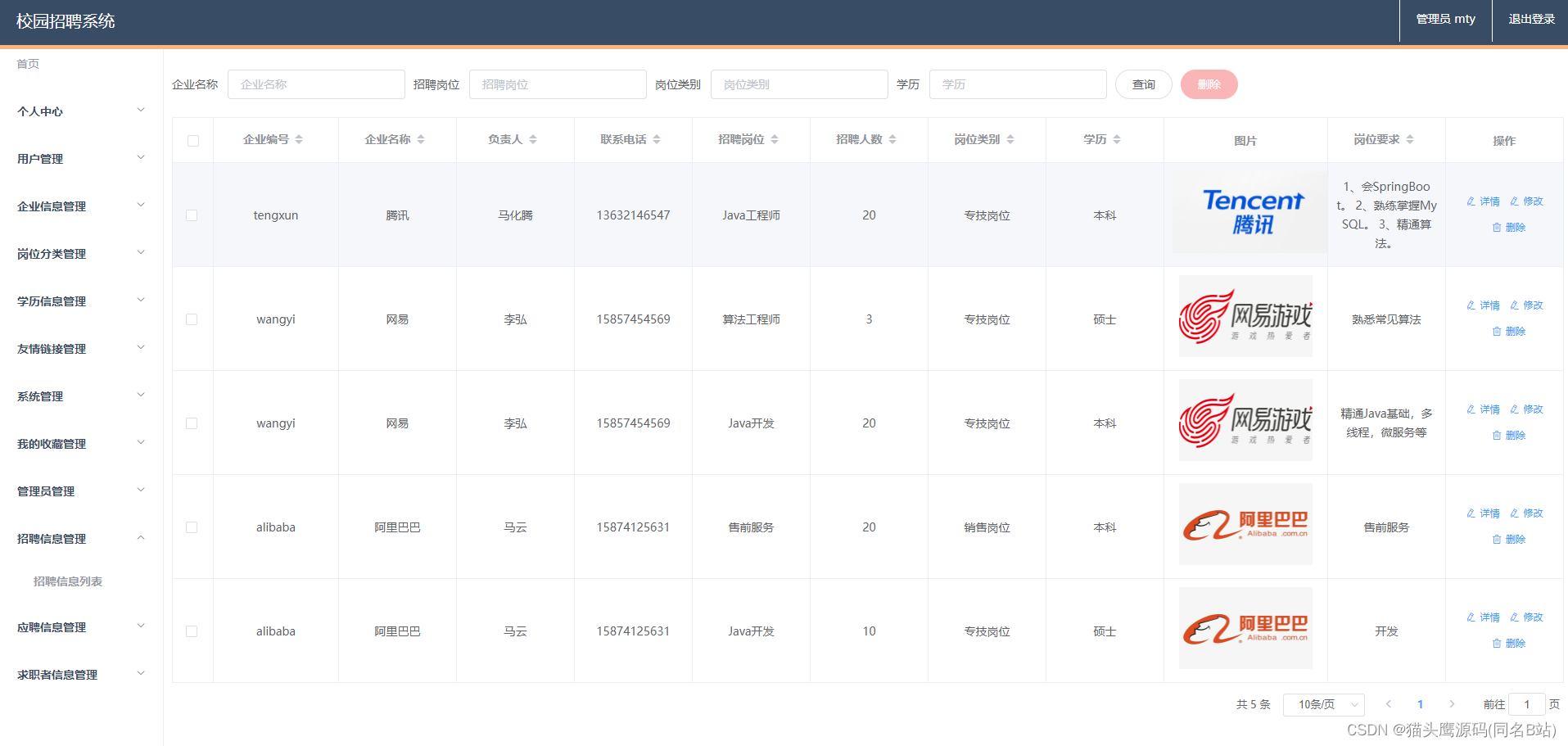
基于springboot+vue的校园招聘系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...
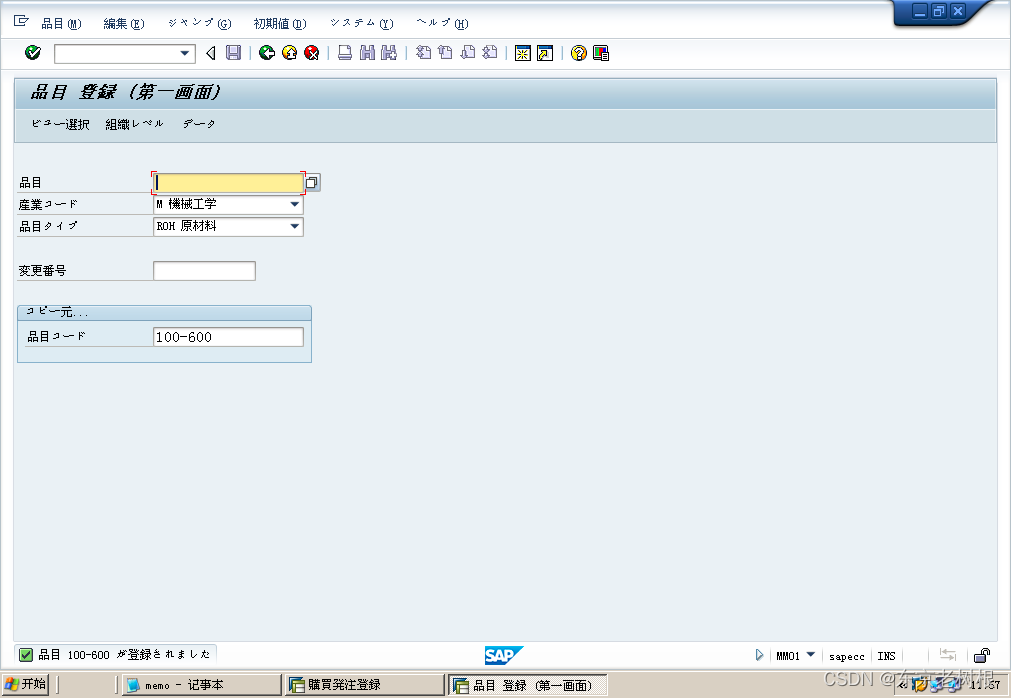
SAP MM学习笔记1-SAP中扩张的概念,如何将一个物料从工厂A扩张到工厂B
MM中在创建物料的时候,最低也得创建如下5个view。 基本数据1 基本数据2 购买管理 会计1 会计2 1,扩张是什么 有时候,你想增加其他的View,比如保管场所 等,你不能用MM02来做编辑,要用MM01来做扩张。这就是扩…...
【Python】Numpy数组的切片、索引详解:取数组的特定行列
【Python】Numpy数组的切片、索引详解:取数组的特定行列 文章目录【Python】Numpy数组的切片、索引详解:取数组的特定行列1. 介绍2. 切片索引2.1 切片索引先验知识2.1 一维数组的切片索引2.3 多维数组的切片索引3. 数组索引(副本)…...

2023年全国最新交安安全员精选真题及答案6
百分百题库提供交安安全员考试试题、交安安全员考试预测题、交安安全员考试真题、交安安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 51.安全生产资金保障制度建立后关键在于落实,各施工企业在落实安全生…...
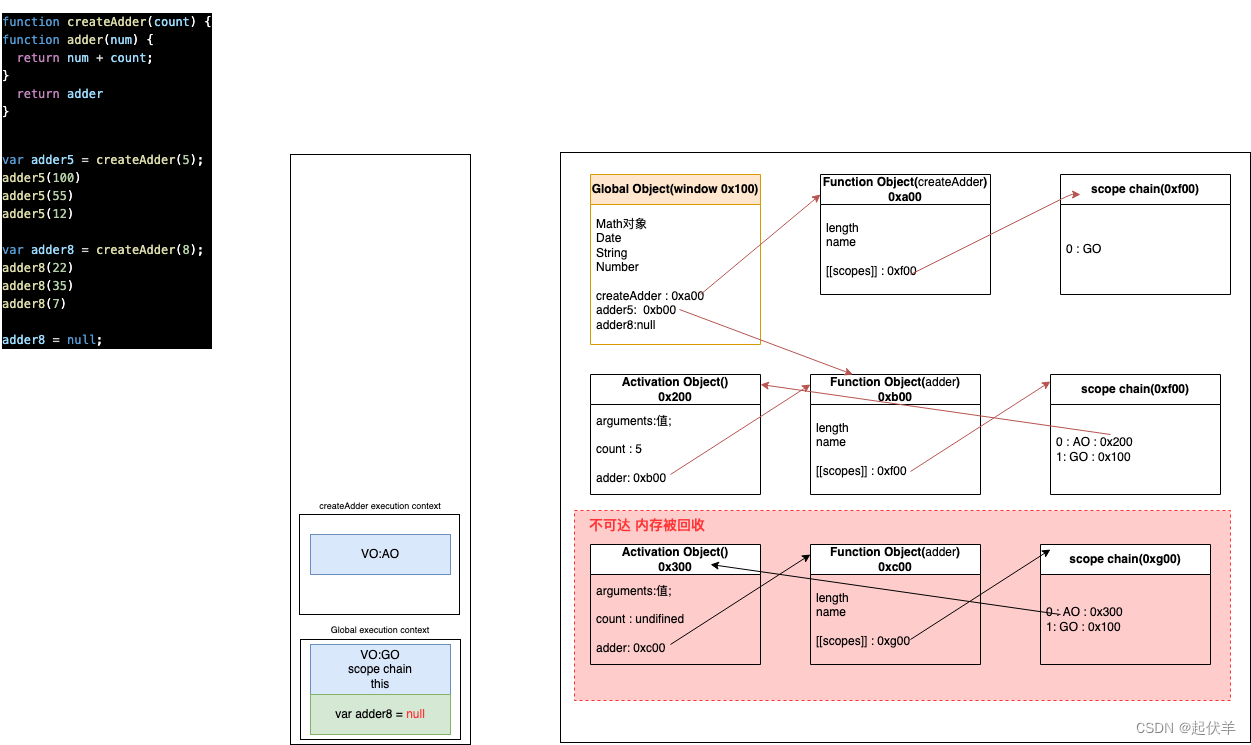
JavaScript 闭包【自留】
闭包的概念理解 闭包的定义 ✅ 这里先来看一下闭包的定义,分成两个:在计算机科学中和在JavaScript中。 ✅ 在计算机科学中对闭包的定义(维基百科): 闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures);是在支持头等函数…...
【MySQL】什么是意向锁 IS IX 及值得学习的思想
文章目录前言行锁和表锁使用意向锁意向锁的算法意向锁的思想JDK 中相似的思想前言 之前看 MySQL 都刻意忽略掉了 IS 和 IX 锁,今天看 《MySQL 是怎样运行的》,把意向锁讲的很通透,本篇博文提炼一下思想。 I: Intention Lock(意向…...

python多线程实现
用于线程实现的Python模块 Python线程有时称为轻量级进程,因为线程比进程占用的内存少得多。 线程允许一次执行多个任务。 在Python中,以下两个模块在一个程序中实现线程 - _thread模块threading模块 这两个模块之间的主要区别在于_thread模块将线程视…...
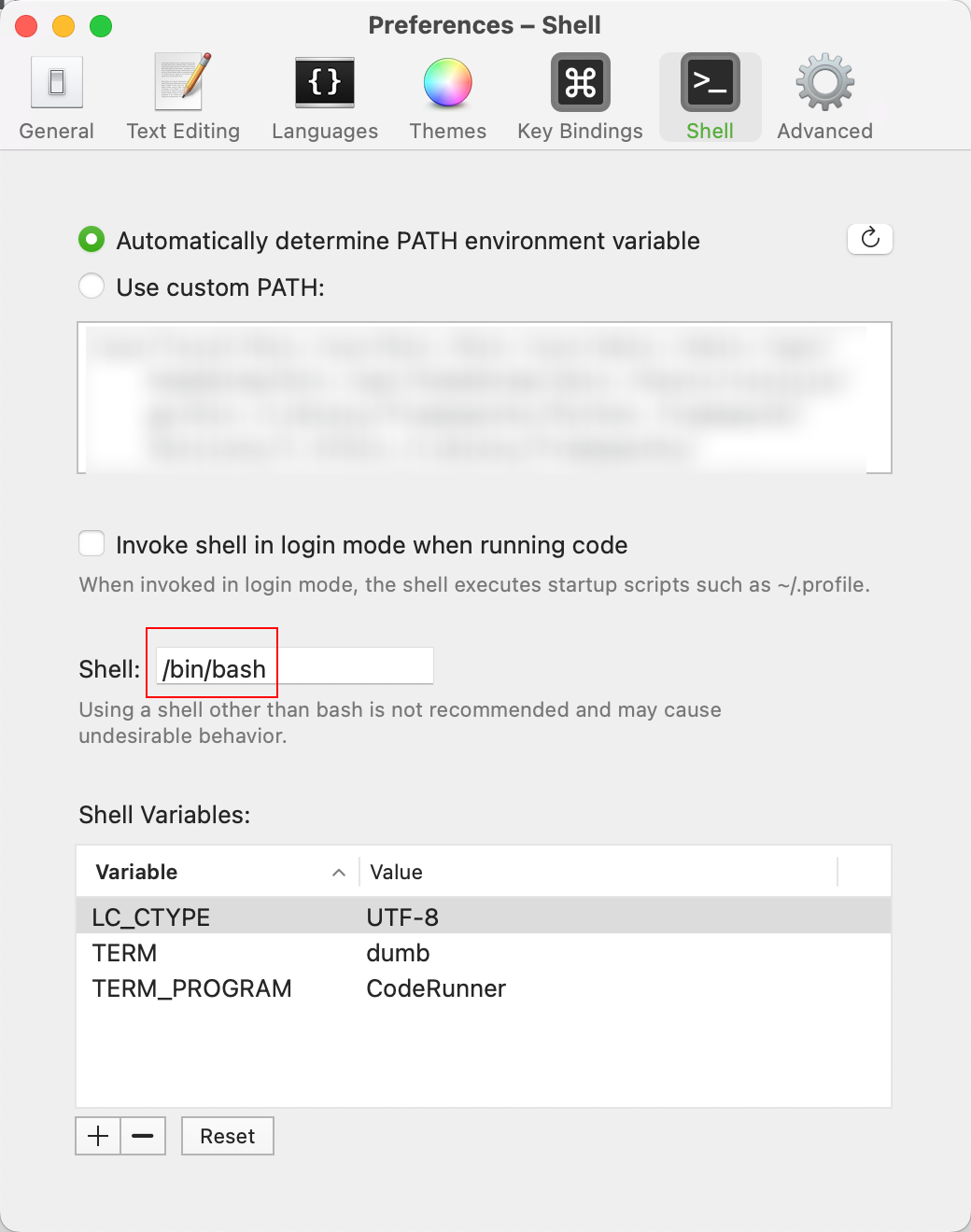
macOS使用CodeRunner快速配置fortran环境
个人网站:xzajyjs.cn 由于一些项目的缘故,需要有fortran的需求,但由于是M1 mac的缘故,不能像windows那样直接使用vsivf这种经典配置。搜了一下网上主流的跨平台方案,主要是gfortran,最近用Coderunner(主要…...
【云原生】k8s 离线部署讲解和实战操作
文章目录一、概述二、前期准备1)节点信息2)修改主机名和配置hosts3)配置ssh互信4)时间同步5)关闭防火墙6)关闭 swap7)禁用SELinux8)允许 iptables 检查桥接流量三、开始部署1&#x…...

【Kubernetes】第十一篇 - 滚动发布的介绍与实现
一,前言 上一篇,介绍了灰度发布和流量切分的集中方式,以及如何实现 k8s 的灰度发布; 本篇,介绍滚动发布的实现; 二,滚动发布简介 滚动发布 滚动发布,则是我们一般所说的无宕机发…...

【尊享版】如何系统构建你的思维认知模型?
超友们,早上好,国庆节快乐~ 今天为你带来的分享是《如何系统构建你的思维认知模型?》,主要分为三个部分: 第一部分:【实现爆发式成长的 10 个思维模型】 第二部分:【6 个不可不知的…...

urho3D编码约定
缩进样式类似于Allman(BSD),即在控制语句的下一行使用大括号,在同一级别缩进。在switch-case语句中,case与switch语句处于相同的缩进级别。 缩进使用4个空格而不是制表符。不应保留空行上的缩进。 类和结构名称以大写…...

基于多智能体协作的AI开发流程:三人团队模式解析与实践
1. 项目概述与核心痛点如果你和我一样,在日常开发中深度依赖像Claude这样的AI编码助手,那你一定也经历过那种“又爱又恨”的时刻。爱的是它强大的代码生成和理解能力,恨的是它时不时会“放飞自我”——比如你只想让它修改一个函数,…...

深度强化学习在航天控制中的仿真到实物迁移挑战
1. 深度强化学习在航天控制领域的应用背景卫星近距离操作是航天任务中的一项关键技术挑战,涉及轨道交会、在轨服务、空间目标检测等多种场景。传统基于模型预测控制(MPC)的方法需要精确的环境动力学模型,而实际太空环境中存在诸多…...

ImageGlass:Windows平台最强图像浏览器,90+格式全支持
ImageGlass:Windows平台最强图像浏览器,90格式全支持 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 你是否曾因Windows自带照片应用无法打开专业RA…...

芯片晶圆平面度如何测量?半导体制造中的光学形貌检测方案
晶圆作为集成电路的核心承载基片,表面形貌的精度直接关系到光刻聚焦质量、芯片电学性能及最终良率。从8英寸到12英寸的大尺寸晶圆制造中,平面度、翘曲度(Warp)、总厚度变化(TTV)及局部平面度(SF…...

202X年CSDN年度技术趋势大预测
好的,以下是一篇关于CSDN年度技术趋势预测的技术文章大纲:202X年CSDN年度技术趋势预测:引领未来的技术变革一、引言技术发展的加速与变革年度技术趋势对行业的影响本文预测的依据与方法论二、人工智能与生成式AI的深化应用大模型技术的演进方…...

N41 SRS与LTE共用XPXT开关的一些考虑
n41 SRS 与 LTE 共存冲突分析与工程设计指南 核心结论:在 n41 与 LTE 共用 XSPxT(DPDT / DP3T / DP4T)架构下,冲突是物理必然;硬件目标是将干扰压缩至软件可调度范围,系统稳定性最终取决于软件互斥策略。 一、问题本质:为什么 n41 SRS 会和 LTE 冲突? 1️⃣ n41 SRS 的…...

浏览器运行Cursor AI编辑器:Docker+KasmVNC部署全攻略
1. 项目概述:在浏览器中运行 Cursor AI 编辑器如果你是一名开发者,大概率听说过或者正在使用 Cursor——这款集成了强大 AI 辅助编程能力的编辑器。它基于 VS Code,但深度整合了类似 ChatGPT 的对话和代码生成功能,能极大提升编码…...

Pega Helm Charts:Kubernetes上自动化部署Pega平台的完整指南
1. 项目概述与核心价值如果你正在或即将在Kubernetes上部署Pega Platform,那么pegasystems/pega-helm-charts这个项目绝对是你绕不开的“官方说明书”和“自动化工具箱”。简单来说,这是Pega官方维护的一套Helm Chart,专门用于将Pega Platfor…...

Articuler.Ai 技术深度解析:海量人脉匹配、数字足迹解析与高转化冷触达引擎
摘要Articuler.Ai 是一款面向商业人脉精准匹配与高效触达的 AI 引擎,核心定位为 “商业关系搜索引擎 智能触达工作台”,彻底重构传统关键词搜索失效背景下的 B2B 人脉连接逻辑。本文从9.8 亿级公开档案数据底座、语义匹配引擎架构、Playbook 深度解析技…...

Linux fanotify vs inotify:如何为你的监控需求选择正确的工具?
Linux文件监控技术选型:fanotify与inotify深度对比与实践指南 在构建需要实时感知文件系统变化的应用程序时,开发者常面临监控工具的选择困境。无论是开发安全扫描工具、持续备份系统还是智能IDE,文件监控都是核心需求。Linux平台提供了inoti…...