Azure - 机器学习:使用 Apache Spark 进行交互式数据整理
目录
- 本文内容
- 先决条件
- 使用 Apache Spark 进行交互式数据整理
- Azure 机器学习笔记本中的无服务器 Spark 计算
- 从 Azure Data Lake Storage (ADLS) Gen 2 导入和整理数据
- 从 Azure Blob 存储导入和处理数据
- 从 Azure 机器学习数据存储导入和整理数据
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

本文内容
数据整理已经成为机器学习项目中最重要的步骤之一。 Azure 机器学习与 Azure Synapse Analytics 集成,提供对 Apache Spark Pool(由 Azure Synapse 支持)的访问,以便使用 Azure 机器学习笔记本进行交互式数据整理。
先决条件
- 一个 Azure 订阅;如果你没有 Azure 订阅,请在开始之前创建一个免费帐户。
- Azure 机器学习工作区。 请参阅创建工作区资源。
- Azure Data Lake Storage (ADLS) Gen 2 存储帐户。 请参阅创建 Azure Data Lake Storage (ADLS) Gen 2 存储帐户。
- (可选):Azure Key Vault。 请参阅创建 Azure 密钥保管库。
- (可选):服务主体。 请参阅创建服务主体。
- (可选)Azure 机器学习工作区中附加的 Synapse Spark 池。
在开始数据整理任务之前,请了解存储机密的过程
- Azure Blob 存储帐户访问密钥
- 共享访问签名 (SAS) 令牌
- Azure Data Lake Storage (ADLS) Gen 2 服务主体信息
在 Azure 密钥保管库中。 还需要了解如何在 Azure 存储帐户中处理角色分配。 下面的部分讨论以下概念。 然后,我们将详细了解如何使用 Azure 机器学习笔记本中的 Spark 池进行交互式数据整理。
使用 Apache Spark 进行交互式数据整理
Azure 机器学习在 Azure 机器学习笔记本中提供无服务器 Spark 计算和附加的 Synapse Spark 池,用于与 Apache Spark 进行交互式数据整理。 无服务器 Spark 计算不需要在 Azure Synapse 工作区中创建资源。 相反,在 Azure 机器学习笔记本中可以直接使用完全托管的无服务器 Spark 计算。 要访问 Azure 机器学习中的 Spark 群集,最简单的方法是使用无服务器 Spark 计算。
Azure 机器学习笔记本中的无服务器 Spark 计算
默认情况下,Azure 机器学习笔记本中提供了无服务器 Spark 计算。 若要在笔记本中访问它,请从“计算”选择菜单的“Azure 机器学习无服务器 Spark”下选择“无服务器 Spark 计算”。
笔记本 UI 还为无服务器 Spark 计算提供了 Spark 会话配置选项。 配置 Spark 会话:
-
选择屏幕顶部的“配置会话”。
-
从下拉菜单中选择“Apache Spark 版本”。
重要
适用于 Apache Spark 的 Azure Synapse 运行时:公告
- 适用于 Apache Spark 3.2 的 Azure Synapse 运行时:
- EOLA 公告日期:2023 年 7 月 8 日
- 支持结束日期:2024 年 7 月 8 日。 在此日期之后,将会禁用运行时。
- 为了获取持续支持和最佳性能,建议迁移到 Apache Sark 3.3。
- 适用于 Apache Spark 3.2 的 Azure Synapse 运行时:
-
从下拉菜单中选择“实例类型”。 当前支持以下实例类型:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
-
输入 Spark 会话超时值(以分钟为单位)。
-
选择是否动态分配执行程序
-
选择 Spark 会话的执行程序数量。
-
从下拉菜单中选择“执行程序大小”。
-
从下拉菜单中选择“驱动程序大小”。
-
要使用 Conda 文件配置 Spark 会话,请选中“上传 conda 文件”复选框。 然后,选择“浏览”,并选择具有所需 Spark 会话配置的 Conda 文件。
-
添加“配置设置”属性,在“属性”和“值”文本框中输入值,然后选择“添加”。
-
选择“应用”。
-
在“配置新会话?”弹出窗口中选择“停止会话”。
会话配置更改将被保存,并可用于使用无服务器 Spark 计算启动的另一个笔记本会话。
提示
如果使用会话级 Conda 包,并将配置变量 spark.hadoop.aml.enable_cache 设置为 true,则可以改善 Spark 会话冷启动时间。 会话首次启动时,具有会话级别 Conda 包的会话冷启动通常需要 10 到 15 分钟。 但是,配置变量设置为 true 时的后续会话冷启动通常需要 3 到 5 分钟。
从 Azure Data Lake Storage (ADLS) Gen 2 导入和整理数据
可以使用 abfss:// 数据 URI 按照以下两种数据访问机制之一访问和处理存储在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中的数据:
- 用户标识传递
- 基于服务主体的数据访问
提示
要使用无服务器 Spark 计算进行数据整理、对 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中的数据进行用户标识直通访问,需要的配置步骤是最少的。
若要使用用户标识传递开始交互式数据整理,请执行以下命令:
-
验证用户身份是否在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中获得了“参与者”和“存储 Blob 数据参与者”角色。
-
要使用无服务器 Spark 计算,请在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”。
-
要使用附加的 Synapse Spark 池,请从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
这个 Titanic 数据整理代码示例显示了
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>格式的数据 URI 与pyspark.pandas和pyspark.ml.feature.Imputer的搭配使用。import pyspark.pandas as pd from pyspark.ml.feature import Imputerdf = pd.read_csv("abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv",index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy("mean" ) # Replace missing values in Age column with the mean value df.fillna(value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv("abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled",index_col="PassengerId", )备注
此 Python 代码示例使用
pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
若要通过服务主体按照访问权限来整理数据,请执行以下操作:
-
验证服务主体是否在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中获得了“参与者”和“存储 Blob 数据参与者”角色。
-
为服务主体租户 ID、客户端 ID 和客户端机密值创建 Azure 密钥保管库机密。
-
在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”,或者从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
若要在配置中设置服务主体租户 ID、客户端 ID 和客户端密码,请执行以下代码示例。
-
代码中的
get_secret()调用取决于 Azure 密钥保管库的名称,以及为服务主体租户 ID、客户端 ID 和客户端密码创建的 Azure 密钥保管库机密的名称。 在配置中设置这些相应的属性名称/值:- 客户端 ID 属性:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 客户端机密属性:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 租户 ID 属性:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 租户 ID 值:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSessionsc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary# Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>")# Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net","org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net",client_id, ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net",client_secret, ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net","https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", ) - 客户端 ID 属性:
-
-
使用
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>格式的数据 URI 导入和转换数据,如使用 Titanic 数据的代码示例所示。

从 Azure Blob 存储导入和处理数据
可以使用存储帐户访问密钥或共享访问签名 (SAS) 令牌访问 Azure Blob 存储数据。 应将这些凭据作为机密存储在 Azure 密钥保管库中,并在会话配置中将其设置为属性。
若要开始交互式数据整理,请执行以下操作:
-
在左侧Azure 机器学习工作室面板中,选择“笔记本”。
-
在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”,或者从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
若要配置存储帐户访问密钥或共享访问签名 (SAS) 令牌以便在 Azure 机器学习笔记本中访问数据,请执行以下操作:
-
对于访问密钥,请设置属性
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net,如以下代码片段所示:from pyspark.sql import SparkSessionsc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key ) -
对于 SAS 令牌,请设置属性
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net,如以下代码片段所示:from pyspark.sql import SparkSessionsc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set("fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net",sas_token, )备注
上述代码片段中的
get_secret()调用需要 Azure 密钥库的名称,以及为 Azure Blob 存储帐户访问密钥或 SAS 令牌创建的机密的名称
-
-
在同一笔记本中执行数据整理代码。 将数据 URI 的格式设置为
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>,类似于此代码片段所示:import pyspark.pandas as pd from pyspark.ml.feature import Imputerdf = pd.read_csv("wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv",index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy("mean" ) # Replace missing values in Age column with the mean value df.fillna(value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv("wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled",index_col="PassengerId", )备注
此 Python 代码示例使用
pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
从 Azure 机器学习数据存储导入和整理数据
若要从 Azure 机器学习数据存储访问数据,请使用 URI 格式azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>定义数据存储上数据的路径。 若要在笔记本会话中以交互方式处理 Azure 机器学习数据存储中的数据,请执行以下操作:
-
在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”,或者从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
此代码示例显示了如何使用
azureml://数据存储 URIpyspark.pandas和pyspark.ml.feature.Imputer从 Azure 机器学习数据存储中读取和处理大量数据。import pyspark.pandas as pd from pyspark.ml.feature import Imputerdf = pd.read_csv("azureml://datastores/workspaceblobstore/paths/data/titanic.csv",index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy("mean" ) # Replace missing values in Age column with the mean value df.fillna(value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv("azureml://datastores/workspaceblobstore/paths/data/wrangled",index_col="PassengerId", )备注
此 Python 代码示例使用
pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
Azure 机器学习数据存储可以使用 Azure 存储帐户凭据访问数据
- 访问密钥
- SAS 令牌
- 服务主体 (service principal)
或提供无凭据的数据访问。 根据数据存储类型和基础 Azure 存储帐户类型,选择适当的身份验证机制来确保数据访问。 下表总结了用于访问 Azure 机器学习数据存储中的数据的身份验证机制:
| 存储帐户类型 | 无凭据数据访问 | 数据访问机制 | 角色分配 |
|---|---|---|---|
| Azure Blob | 否 | 访问密钥或 SAS 令牌 | 不需要角色分配 |
| Azure Blob | 是 | 用户标识传递* | 用户标识应在 Azure Blob 存储帐户中具有适当的角色分配 |
| Azure Data Lake Storage (ADLS) Gen 2 | 否 | 服务主体 | 服务主体应在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中具有适当的角色分配 |
| Azure Data Lake Storage (ADLS) Gen 2 | 是 | 用户标识传递 | 用户标识应在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中具有适当的角色分配 |
只有在未启用软删除的情况下,* 用户标识直通才适用于指向 Azure Blob 存储帐户的无凭据数据存储。
默认文件共享挂载到无服务器 Spark 计算和附加的 Synapse Spark 池。
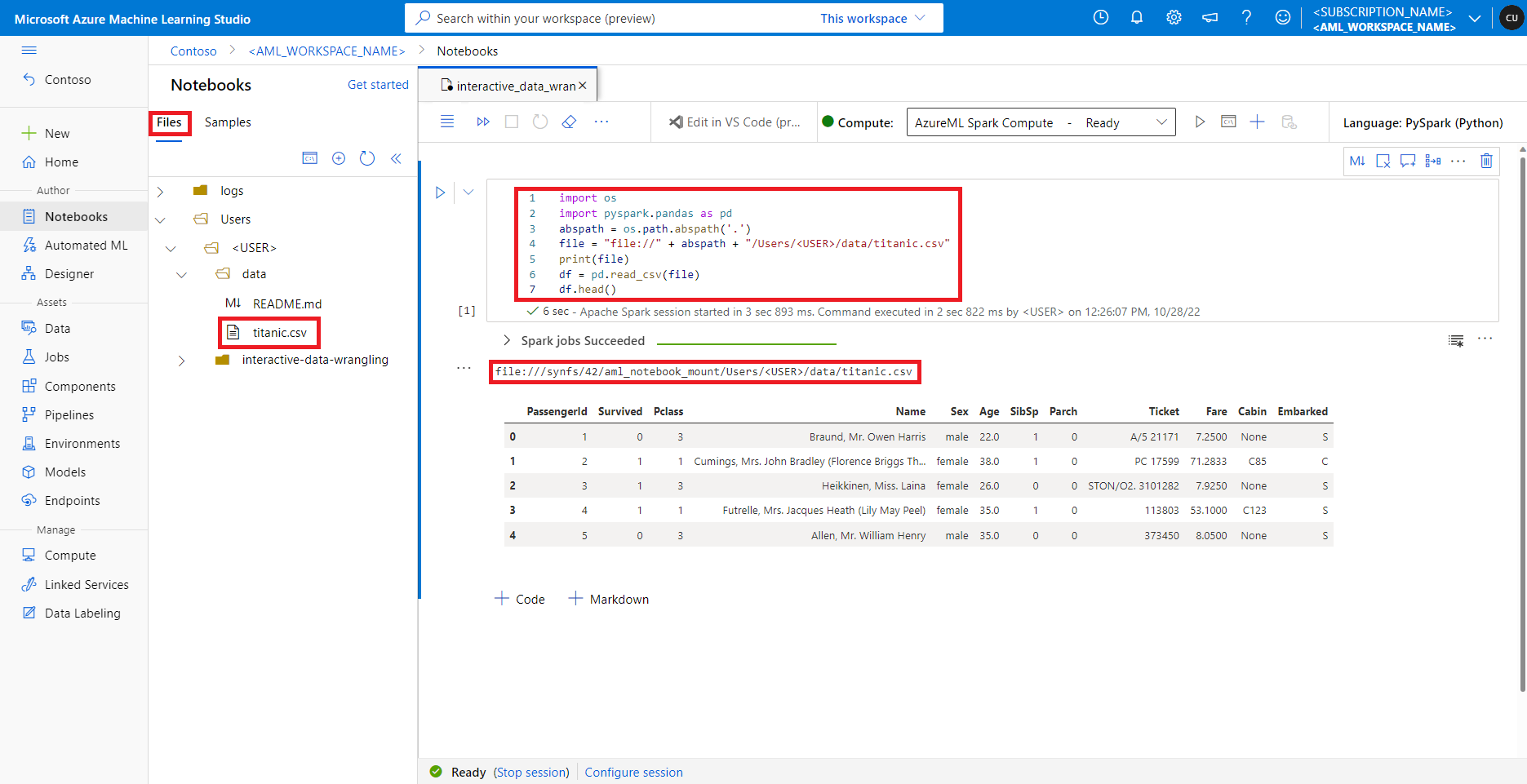
在 Azure 机器学习工作室中,默认文件共享中的文件显示在“文件”选项卡下的目录树中。笔记本代码可以使用 file:// 协议以及文件的绝对路径直接访问此文件共享中存储的文件,而无需进行更多配置。 此代码片段演示如何访问存储在默认文件共享上的文件:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputerabspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"],outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
备注
此 Python 代码示例使用 pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
Azure - 机器学习:使用 Apache Spark 进行交互式数据整理
目录 本文内容先决条件使用 Apache Spark 进行交互式数据整理Azure 机器学习笔记本中的无服务器 Spark 计算从 Azure Data Lake Storage (ADLS) Gen 2 导入和整理数据从 Azure Blob 存储导入和处理数据从 Azure 机器学习数据存储导入和整理数据 关注TechLead,分享AI…...
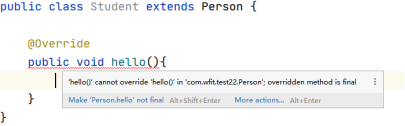
4.5 final修饰符
在Java中,final修饰符可以修饰类、属性和方法,final有“最终”、“不可更改”的含义,所以在使用final关键字时需要注意以下几点: 使用final修饰类,则该类就为最终类,最终类不能被继承。 使用final修饰方法…...

Clickhouse数据库部署、Python3压测实践
Clickhouse数据库部署、Python3压测实践 一、Clickhouse数据库部署 版本:yandex/clickhouse-server:latest 部署方式:docker 内容 version: "3"services:clickhouse:image: yandex/clickhouse-server:latestcontainer_name: clickhouse …...

探索控制领域:从电视遥控器到自动驾驶【基础概念理解、应用实例】
当谈到控制学和控制系统时,你可能会联想到电视遥控器、自动驾驶汽车、飞机自动驾驶系统以及许多其他自动化系统。但控制学是一个更广泛的学科,它涵盖了各种领域,从工程到生物学,从经济学到环境科学。让我们深入了解控制学的基本概…...

在R中安装CmdStanR的步骤-R4.3.1-CmdStanR-0.6.1.900
报错未安装cmdstanr 安装包官网详细介绍: R Interface to CmdStan • cmdstanrhttps://mc-stan.org/cmdstanr/ 以下是在R中安装CmdStanR的步骤: 1. 首先,需要下载和安装C编译器 例如gcc。如果您已经安装了C编译器,则可以跳过此…...

安信可小安派AiPi 代码下载
安信可小安派AiPi 代码下载笔记记录 AiPi 代码下载(直接使用命令行操作,仅需要Type-C接口线即可) 在完成环境搭建,和代码编写前提下,使用Type-C接口线下载代码,当然可以自己使用usb-ttl串口线下载程序&am…...
level2行情数据源接入)
程序化交易(二)level2行情数据源接入
WEBSOCKET行情接入 行情在线测试 websocket行情接口 交易在线测试 在线交易接口 官方文档地址 行情交易接口用户文档 分配服务器 注意:每次分配的服务器地址会发生变化,连接服务前,请务必调用该接口获取最新的服务器地址。 获取服务器:…...

4.6 static修饰符
static是一个修饰符,用于修饰类的成员属性和成员方法,还可以编写static代码块来优化程序性能。 1. static修饰属性 在Java程序中使用static修饰属性,则该属性称为静态属性(也称全局属性),静态属性可以使用…...

C++头文件定义变量
1.在进行头文件学习时,犯了不少错误,记录一下,先贴代码. .h头文件 #ifndef MY_FIRST_H_ #define MY_FIRST_H_struct Person {std::string name;int age;char8_t gender; };//需要使用extern来声明,否则在多个文件中引入该头文件会出现重定义…...

[蓝桥杯-610]分数
题面 解答 这一题如果不知道数论结论的话,做这个题会有两种天壤之别的体验 此题包含以下两个数论知识 1. 2^02^12^2...2^(n-1)2^n-1 2. 较大的数如果比较小的数的两倍大1或者小1,则两者互质 所以答案就是2^n-1/2^(n-1) 标程1 我的初次解答 #in…...

Vue指令大全:深入探索Vue提供的强大指令功能
目录 v-bind指令 v-on指令 v-if和v-show指令 v-for指令 自定义指令 其他常用指令 总结 Vue.js是一款流行的JavaScript框架,具备丰富的指令系统。Vue指令允许开发者直接在模板中添加特殊属性,以实现DOM操作、事件绑定、样式控制等功能。在本文中&a…...

x210项目重新回顾之十七升级到linux4.19.114 +buildroot2018再讨论
代码参考https://github.com/colourfate/x210_bsp/ 他的是linux_4.10(dtb为 s5pv210-x210..dtb)我打算用linux4.19.114(dtb为 s5pv210-smdkv210.dtb) ,所以修改build.sh ------------------------------------------------------------------------------ 5 M…...

shell_56.Linux永久重定向
永久重定向 1.脚本中有大量数据需要重定向,那么逐条重定向所有的 echo 语句会很烦琐。 这时可以用 exec 命令,它会告诉 shell 在脚本执行期间重定向某个特定文件描述符: $ cat test10 #!/bin/bash # redirecting all output to a file ex…...
CN考研真题知识点二轮归纳(1)
本轮开始更新真题中涉及过的知识点,总共不到20年的真题,大致会出5-10期,尽可能详细的讲解并罗列不重复的知识点~ 目录 1.三类IP地址网络号的取值范围 2.Socket的内容 3.邮件系统中向服务器获取邮件所用到的协议 4.RIP 5.DNS 6.CSMA/CD…...
hadoop使用简介
git clone hadoop源码地址:https://gitee.com/CHNnoodle/hadoop.git git clone错误: Filename too long错误,使用git config --global core.longpaths true git clone https://gitee.com/CHNnoodle/hadoop.git -b rel/release-3.2.2 拉取指定…...

WebSocketClient objects are not reuseable
好久没写东西,夜深了来冒个泡,先啰嗦几句。今天测试 Android App 的时候,发现推到后台不到一分钟再唤醒直接闪退,初次以为网络和GPS信号弱导致的(当时是在地铁上进行的测试),之后在网络与GPS 信…...

分享54个ASP.NET源码总有一个是你想要的
分享54个ASP.NET源码总有一个是你想要的 链接:https://pan.baidu.com/s/1khPzxtOFP0wUHpg7TBDitg?pwd8888 提取码:8888 项目名称 (ASP.Net)基于三层架构的企业信息管理系统 asp .net mvc编写的房产管理系统 asp.net core mvc 病人管理后台 asp.ne…...
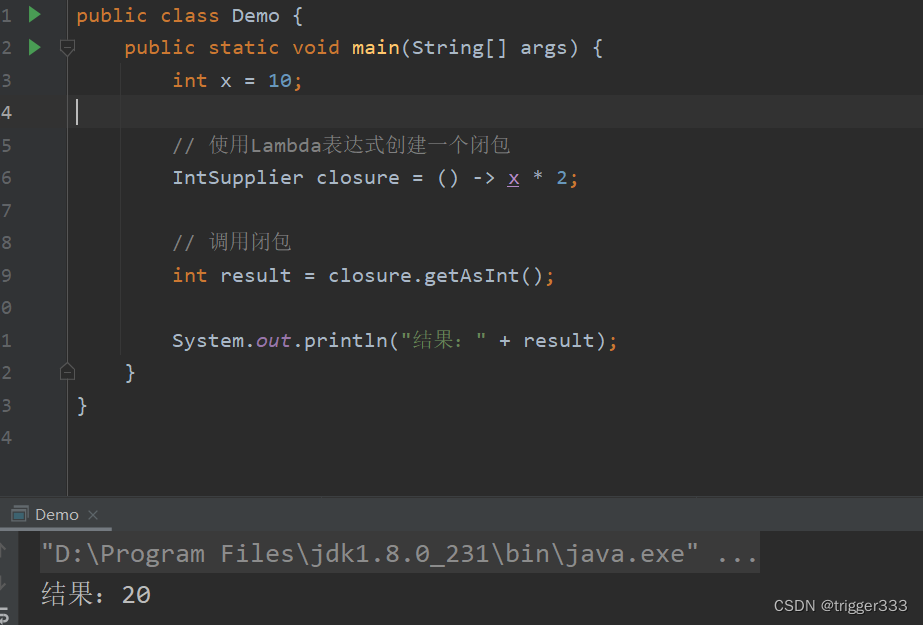
闭包通俗解释,Demo(Go Java Python)
闭包的概念 想象一下,你有一个包裹着变量的函数,就像是一个封闭的包裹。这个包裹里有一个变量,而这个函数(或包裹)本身就是一个完整的单元。当你把这个函数传递给其他地方,就像是把这个包裹传递出去。 这…...
Linux部署Redis Cluster高可用集群(附带集群节点添加删除以及槽位分配操作详解)
目录 一、前言二、下载安装Redis2.1、选择需要安装的Redis版本2.2、下载并解压Redis2.3、编译安装Redis 三、部署Redis Cluster高可用集群3.1、准备配置文件3.2、启动Redis服务3.3、创建Redis集群3.4、查看集群关系3.5、连接集群Redis进行数据读写以及重定向测试3.6、故障转移和…...

【PWN · heap | Off-By-One】Asis CTF 2016 b00ks
萌新进度太慢了,才真正开始heap,还是从简单的Off-By-One开始吧 前言 步入堆的学习。堆的知识复杂而多,于是想着由wiki从简单部分逐个啃。 b00ks是经典的堆上off-by-one漏洞题目。刚开始看很懵(因为确实连堆的管理机制都没有完全…...

对比直接使用官方API体验Taotoken在稳定接入上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API体验Taotoken在稳定接入上的优势 在长期将大模型能力集成到生产系统的实践中,开发者通常会面临一个…...

简单说明--程序系统如何对用户身份证实名认证接口api
程序系统对注册用户身份认证,接口将【身份证号码、姓名】上传至接口API判断是否匹配 请求数据: bodys.put("idNo", "330421190210182345"); bodys.put("name", "张某某");响应数据: {"name&quo…...

《纳瓦尔宝典》幸福篇精读:程序员如何在敲码之余获得内心的平静与幸福
本文是《纳瓦尔宝典》第三部分"学习幸福"的完整精读笔记,专为程序员群体量身打造。结合技术职场高压、内卷严重的现状,拆解纳瓦尔关于幸福的核心哲学,提供可落地的日常实践方法。引言:为什么程序员更需要学习幸福&#…...

【纳瓦尔宝典】财富篇精读:程序员实现财富自由的底层逻辑
本文是《纳瓦尔宝典》第一部分"财富"与第二部分"判断力"的完整精读笔记,专为程序员群体量身打造。结合技术职场实际,拆解每一个核心观点,提供可落地的行动指南。一、积累财富:不是靠打工,而是靠创…...

从任务栏消失到界面混乱:如何用ExplorerPatcher拯救你的Windows 11体验
从任务栏消失到界面混乱:如何用ExplorerPatcher拯救你的Windows 11体验 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 你是否经历…...

实测:把Ubuntu 22.04装进移动固态硬盘,读写速度到底怎么样?附性能优化技巧
移动固态硬盘上的Ubuntu 22.04性能实测与深度调优指南 当我们将完整的Ubuntu系统装进移动固态硬盘时,最令人忐忑的莫过于性能表现——这个装在口袋里的系统能否像内置硬盘一样流畅?本文将通过一系列严谨测试,揭示移动固态硬盘运行Ubuntu的真…...

如何快速完成AI智能图像分层:layerdivider完整使用指南
如何快速完成AI智能图像分层:layerdivider完整使用指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对复杂的插画设计&#x…...

Richard Socher创业公司获6.5亿美元融资,欲让AI自动化研发引领底层范式转移
Richard Socher创业公司获巨额融资一家创业公司获得了GV(Alphabet旗下VC)和Greycroft共同领投的6.5亿美元早期融资,NVIDIA和AMD也参与本轮融资,它的估值达到了46.5亿美元。这家公司的创始人是Richard Socher,他是AI领域…...

QQ音乐加密音频一键解密:qmcdump终极指南
QQ音乐加密音频一键解密:qmcdump终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾为QQ音乐下…...
)
Spring Boot项目实战:手把手教你集成银联B2B无卡支付(SM2国密证书版)
Spring Boot实战:银联B2B无卡支付集成全流程解析(SM2国密证书版) 在企业级应用开发中,支付功能是不可或缺的核心模块。银联B2B无卡支付作为国内企业间交易的重要渠道,其安全性和稳定性备受开发者关注。本文将带你从零开…...