Linux网络基础2 -- 应用层相关
一、协议
- 引例:编写一个网络版的计算器
1.1 约定方案:“序列化” 和 “反序列化”
- 方案一:客户端发送形如“1+1”的字符串,再去解析其中的数字和计算字符,并且设限(如数字和运算符之间没有空格; 运算符只能是“
+,-,*,/,%”等) - 方案二:“序列化” 和 “反序列化”
- 定义结构体来表示我们需要交互的信息;
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
// proto.h 定义通信的结构体
typedef struct Request{int a; //操作数a和bint b; char op;//操作符
} Request; typedef struct Response { int result;//运算结果int code;//该次运算是否出错(默认没出错为0;出错需要原因)
} Response;
- 相较于方案一,传结构化对象的方案二更好,可以“直接发送结构化数据”这么写,但应用层一般不这么写:
- ①可扩展性太差:因为采用结构化数据,若未来代码中想做扩展,修改一点协议旧客户端就可能无法使用了。
- ②对于这种纯正的结构化数据,不同编译器下对结构体大小的观点视角可能都不同(比如客户端就分各种平台,有移动端、有Windows桌面环境的;服务端大部分是Linux。而由于大小端和内存对齐的影响,在不同平台下,会对结构体对齐方式不同,大小也就有差,按照二进制发送会容易造成各种读写方面的问题)
- ③故一般不直接发送结构化数据,而是先将结构化数据中的所有字段都统一转为一个整体的序列化数据(相当于意味着转成字符串或字节流) ,再以字符串或字节流的方式向对方发送 ==> 该过程为“序列化”(多变一)
- ==> 对方接收到序列化数据,将序列化数据拆分成不同字段的结构化数据的过程,为“反序列化”(一变多)
- 但实际协议定制时基本传的就是这种结构化的数据。
- ①因为一般底层协议定好后基本不动,除非对操作系统直接进行升级,而且升级需要兼容旧协议。底层协议被改动的概率比较低。
- ②因为网络协议栈的对齐与大小端问题,在内核源代码是有各样的条件编译策略的,会自动去识别源码,可以根据当前编译源码的平台自动去识别你的平台是32位/64位,从而设置好对齐规则。
- 所以最终内核级的协议定制解决了这样的问题,但是应用层不一样。应用层更重要的是我们写出来的代码一定要有高可靠、高可维护性,对于想调整随时变的需求,可以很快调整出来。
1.2 序列化和反序列化的优势
-
①降低编写代码的难度,解决通信的成本问题
-
②业务逻辑和网络通信实现一定程度的解耦
- 结构化的数据一般是给上层业务去使用的,属于上层的业务(比如结构体或者类,直接点操作就可以访问到某个字段),上层业务提取这种结构化的数据是最简单;
- 下层的反序列化,通信时以字节流(或理解为字符串)的通信方式,更多是网络比较适合传输字节流式的数据。
- 而“序列化和反序列化”的工作相当于在上层业务和网络通信的中间,加了一层软件层来实现,从而业务逻辑和网络通信实现一定程度的解耦。

-
反序列化能得到结构化数据,便于上层能直接取出处理
1.3 协议定制
- 本质1:定义请求以及未来响应中的字段都需要哪些。
- 字段本身就是协议的一部分。协议是约定,那在计算机语言中该如何去表述这种约定呢?==>其中就取决于曾经发送到request结构化数据中的字段。
- 比如说约定好a永远在操作符左侧,b在操作符右侧(如做除法,a就是被除数,b是除数),op代表是操作,所以把这个字段发给对方后,对方就立马能意识到可以把对应发的反序列化出的结构化对象按a除以b的方式组织起来。
1.4(🔺重要)基于“序列和反序列化”和“TCP套接字”的网络版本计算器的代码编写
-
目标:实现一个基于序列和反序列化方式,且基于TCP套接字的自定义应用层协议的网络版本计算器
-
学习“序列化和反序列化”的思路:
- 基本的网络套接字代码,实现基于网络式的通信
- ==> 先自主实现。手动定制协议
- ==> 再使用现成的方案。看看别人较成熟的序列/反序列方案
1.4.1 自己定制协议
-
文件准备:
- TCP套接字:
Sock.hpp - 日志文件:
Log.hpp - 客户端:
CalClient.cc - 服务端:
CalServer.cc - 基于套接字接口封装的:
TcpServer.hpp - 定制协议:
Protocol.hpp
- TCP套接字:
-
参数设计的一般经验
const std::string &: 输入型参数std::string*: 输出型参数std::string &: 输入输出型参数
-
类内成员函数名末尾习惯带
_,如
private: int listensock_;Sock sock_;
1.4.2 代码部分的细节
-
当服务端读取客户端数据请求,可能读取失败,也可能是客户端退出连接断开而导致没读到数据。对于后者,若不进行处理,就会发生由于服务端没读到数据,于是向客户端发送表示错误的状态码的情况,而客户端已经关闭了,向关闭的服务器发送数据属于是“非法写入”的问题,对此的处理方式:
- ①忽略信号:
signal(SIGPIPE, SIG_IGN); - ②完善代码逻辑的角度:在服务端,对读取客户端的结果进行判断是否成功,只有读取成功且数据符合要求,才会进行进一步的处理(本例中是进行计算) ==> 判断读到的数据是否为空,不为空就对数据进行处理;为空时,不论是读取失败的情况,还是连接关闭的情况,都直接break
- 以上两个方法都会使用。
- 一般经验:server在编写的时候,要有较为严谨性的判断逻辑
- 一般服务器,都是要忽略SIGPIPE信号的,防止在运行中出现非法写入的问题:
signal(SIGPIPE, SIG_IGN);
- ①忽略信号:
-
“协议是一种约定”在代码中的体现:
- 知道计算顺序是
x_ op y_,而非y_ op x_ - 知道
result_代表计算结果;code_代表随计算结果返回的状态码; - 知道
code_分别为0/1/2/3时,对应的不同含义
- 知道计算顺序是
-
客户端发出request,获取response;服务器获取request,发出response ==> 对于request和response,都会经历被发出和被获取 ==> 故对request和response都要进行序列化和反序列化的操作。
-
TCP字节流和UDP数据报的理解
- TCP(传输控制协议):
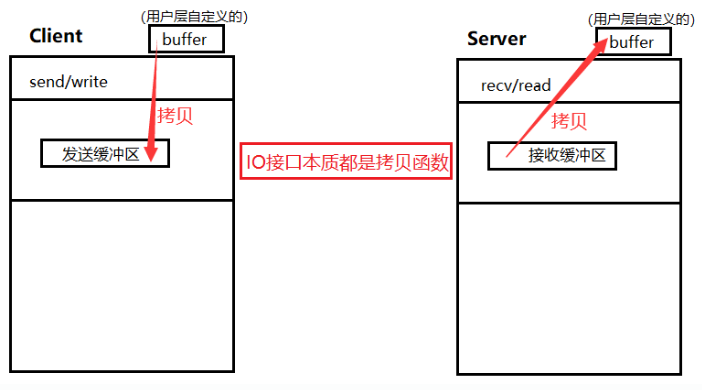
- 在TCP协议中,实际Client用户端和Server服务端各自是包含一对接收和发送缓冲区的,为方便起见,本次先只理解单向,即Client用户端仅设置一个发送缓冲区,Server服务端仅设置一个接收缓冲区。
- ① IO接口:本质都是拷贝函数 ==> 故IO函数亦称为拷贝函数
- “
客户端调用send或write这类接口时,是把数据发送到网络,甚至是对方主机中”的认识是错误的 - 正确认识:实际客户端调用send/write时,只是将要写入的数据,从应用层自定义的buffer缓冲区中,拷贝了一份发送到Client客户端的发送缓冲区中;而服务端调用recv/read时,只是将要接受的数据,从Server服务端的接收缓冲区中,拷贝了一份到调用recv/read时产生的上层用户所定义的缓冲区中
- 诸如:客户端什么时候把用户层buffer内的数据发到发送缓冲区中?发多少?出错了怎么办?……等此类问题都属于传输控制层,由TCP传输控制协议来决定和处理
- “
- ② TCP发送的次数和接受的次数之间,没有任何关系 ==> 面向字节流
- ③ TCP是面向字节流的,意味着服务端接受数据时可能收到的数据是1份报文、十多个报文、也可能是2.5份的报文。比如,对于"1234 + 5678",可能读到:
- “1234 +”
- “1234 + 5678” “123 + 99”
- "1234 "
- UDP是发几次就读几次(不考虑丢包情况下),能保证每次读到的都是完整的报文;而TCP字节流不能保证
recv读到的inbuffer是一个完整完善的请求 - 又由于该题的计算数值大小不受限,无法确定计算字符串的长短(如不确定有“1234 + 5678”这么长;还是“1 + 1”这么长),该怎么保证TCP能读到完整的请求呢?==> 单纯的recv是无法解决该问题,需要进一步定制协议
- TCP(传输控制协议):
-
进一步定制协议:保证
recv读取完整的报文- 提取报文的原则:要么就不提取,提取一定要提取完整的一个报文
length\r\nx_ op_ y_\r\n:直接标明运算字符串的长度- 如:
9\r\n123 + 456\r\n length:表示正文长度(“x_ op_ y_”,不包含\r\n)的整数, ==> 协议报头x_ op_ y_:运算字符串 ==> 应用层的有效载荷- 使用特殊字符(本例中指
\r\n),以区分内容(本例中指区分length和x_ op_ y_)- 由于length为整数,所以能保证其内部不会出现
\r\n的特殊字符 \r\n:虽然也能采用\a\b作为特殊字符,但采用\r\n能使得将来定出的协议可读性很好。末尾的\r\n可以不加,不影响效果,但加了可以提高协议的可读性
- 由于length为整数,所以能保证其内部不会出现
- 如:
length\r\nx_ op_ y_\r\nlength\r\nx_ op_ y_\r\nlength\r\nx_ op_ y_\r\n……:未来读取到的字符串类似这样- 具体读取过程:根据
length读取一定长度的字符串后,再丢弃末尾的\r\n,再继续读取length与字符串;若读不到完整length长度的字符串,就先对能完整读取的字符串做处理 - 读取方案①:先读取length,再根据length读取一定字符串
- 读取方案②:一次性都先读完缓冲区所有内容,读到后再根据length做字符串分析 ==> 目前更推荐该种,有利于底层网络再发送新数据
- 具体读取过程:根据
-
定义字符串长度要用
strlen(),不能是sizeof(),否则sizeof("\r\n" )==3,因为会把\0统计上
#define SEP "\r\n" // 定义分隔符
#define SEP_LEN strlen(SEP) // 不能是sizeof,
- send部分代码中待完善的问题( #待补充 讲多路转接时补充):
- ①发送数据时,网络很拥塞/服务端接收缓冲区满了塞不下了,客户端发送缓冲区的数据发不出去得等一等;
- ②客户端发送缓冲区被写满了,所以不一定要把发送缓冲区中的一大串(好多份报文)的数据一次性发出
1.4.3 现有方案json
-
json:是一种网络通信的格式,可以用于进行序列化和反序列化,从而让我们不用写出非常冗余的代码 -
json的结构介绍- 基本:用KV式的结构==>
{"key":"value"} - 若有多个可采用逗号作为分隔符,如:
{"key":"value","key":"value","key":"value","key":"value"} - 支持数组:
{"key":"value","key":"value",["key":"value","key":"value",]} - 采用Json若要拓展协议,比较便利
- 基本:用KV式的结构==>
-
结构化的数据本身就是key-value的
如对于:
struct AAA{int x;int y;char op;
}
AAA a;
a.x =100;则可以理解作:
a.x -> key
100 -> value
json的具体使用:- 在C++中使用json需要采用
jsoncpp的库 - Linux云服务器中安装库:
sudo yum install jsoncpp-devel - 导入头文件:
#include <jsoncpp/json/json.h>
- 在C++中使用json需要采用
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>int main()
{int a = 10;int b = 20;char c = '+';//将abc三个对象分别放入json的value对象中//一般json中放的都是原生类型(即abc一般都为整数/浮点数/字符串等)Json::Value root;root["aa"] = a;root["bb"] = b;root["op"] = c;Json::Value sub;sub["other"] = 200;sub["other1"] = "hello";root["sub"] = sub;Json::StyledWriter writer;//创建一个对象// Json::FastWriter writer;//更常用std::string s = writer.write(root);//write方法用于将value所对应的root对象填充好(只要把它传递给root对象就好),返回值就会自动将value转成序列化的字符串风格std::cout << s << std::endl;
}
- 若输入a=10;b=20;c=‘+’,采用
Json::StyledWriter;返回值就有:
{"aa" : 10,"bb" : 20,"op" : 43
}
- 若输入a=10;b=20;c=‘+’,采用
Json::FastWriter;返回值就有:- 实际中
FastWriter更常用,其与StyledWriter仅不同于转换序列化后字符串格式的不同
- 实际中
{"aa" : 10,"bb" : 20,"op" : 43}
- Json的其他用法:套接使用
Json::Value sub;
sub[ "other"] = 200;
sub[ "other1"] = "hello";Json::Value root;
root[ "aa" ] = a;
root[ "bb" ] = b;
root[ "op" ] = c;root[ "sub"] = sub; //把整个sub放入root中//root最后显示:
{"aa" : 10, "bb" : 20, "op":43, "sub" : {"other":200, "other1" :"hello"}}二、 守护进程
2.1 前置知识
- 目前学习到的服务器全部都是在前台运行的
- 前台进程:和终端关联的进程,就称为前台进程。==> 判断是否是前台进程:该进程能否正常获取你的输入?能否正常处理从你这获取到的内容? ==> bash本身就是前台进程
- 任何XShell登陆,只允许一个前台进程和多个后台进程 ==> 只能有一个前台进程来获取输入
- 进程除了有自己的pid、ppid,还有一个组ID
- 在命令行中,同时用管道启动多个进程,多个进程是兄弟关系,父进程都是bash ==> 可以用匿名管道来进行通信
- 同时被创建的多个进程可以成为一个进程组的概念,组长一般是组内第一个创建的进程
- 任何一次登陆,登陆的用户需要有多个进程(组),来给这个用户提供服务的(bash),用户自己可以启动很多进程或进程组。我们把给用户提供服务的进程,或者用户自己启动的所有的进程或服务,整体都是要属于一个叫做会话的机制中的 ==> 每次登陆,操作系统都会给用户创建一个会话,内部有bash+终端和进程组,bash自成一组;退出登陆(注销)一般会话相关的任务就会被释放(但不同操作系统处理方式可能不同)
- 若在登录时创建了一个进程,退出登陆后不希望该进程随着会话被释放,就需要拎出该进程,让其自成一个会话,对于这种“自成一个会话”的进程我们称为“守护进程”
- 如何将自己自称会话呢?==>
setsid() setsid若想成功被调用,必须保证当前进程不是进程组的组长 > 怎么保证我不是组长呢?> 通过fork();,不是第一个创建的进程即可- 守护进程不能直接向显示器打印消息,一旦打印会被暂停(在有的操作系统上会被终止)
2.2 如何在Linux中正确写一个让进程守护进程化的代码?
方式1:直接采用系统提供的方案daemon
- 但在很多项目中,该方案并不常采用。一般更习惯自己去写、定制一个守护进程。
方式2:自行定制守护进程
-
想通过自己写一个函数,让进程通过调用该函数,能自动变成守护进程
-
重定向到
/dev/null:这个文件一定会存在的,往devnull里写的东西(如cout等)全部都被自动丢弃。- 对
/dev/null随便进行操作,而不影响系统的正常运行 - 由于使用cout等写的数据会被丢弃,所以得采用向文件当中写入的方式,来写日志才能被保留
- 对
-
守护进程的父进程就是1号进程,属于被领养 ==> 守护进程本质是孤儿进程的一种 ==> 守护进程和孤儿进程的区别:守护进程自成一个会话;而孤儿进程可能属于某个会话

-
将守护进程添加到如上写的网络版计算器中,就能让连接上该服务的随时可以运行了 ==> 电脑/手机里的应用后端就是采用守护进程等待接收用户登录信号的
三、HTTP超文本传输协议
- 应用层:就是程序员基于socket接口之上编写的具体逻辑,做的很多工作,都是和文本处理有关的 ==> 文本格式?序列化?反序列化?都和“协议分析与处理”相关
- 同理,可推测,若学习http协议其有关细节(而非局限于使用),一定会具有大量的文本分析和协议处理
3.1 认识URL
-
定位互联网中唯一的一个资源 ==> URL(统一资源定位符)
-
所有的资源:全球范围内,只要找到它的URL就能访问该资源。
- 基于该形式获取资源的方式,称作“www万维网”
-
举例:
https://blog.csdn.net/SHIE_Ww/article/details/132864436?spm=1001.2014.3001.5501https://:协议方案名。获取资源采用的协议版本blog.csdn.net:域名,对域名解析后即服务器ip地址(将域名解析成ip地址,是由浏览器自动完成的)- 端口号:ip地址后总会跟着端口号,但在URL中端口号被省略,因为我们所请求的网络服务对应的端口号是所有客户端由共识的(比如用Edge浏览器或火狐浏览器,请求网络服务,对应端口号它们都知道是80号/443号端口)
http绑定端口号是80https绑定端口号是443
/:域名后跟的第一个/,称为web根目录,通常代表着某一资源的起始- web根目录在Linux下该路径并非是绝对路径。> 一般http都要有自己的web根目录(例如:
#define ROOT "./wwwroot")> 我们访问的文件一般都会基于此,往后找(例如:./wwwroot/index.html)
- web根目录在Linux下该路径并非是绝对路径。> 一般http都要有自己的web根目录(例如:
/SHIE_Ww/article/details/132864436:- 细节说明可见:上网的两大行为
SHIE_Ww/article/details/:代表的就是后端Linux机器上的路径132864436:代表的就是后端Linux路径下的文件名/:从路径分隔符的样式可见,其和Linux下的分隔符是一样的,所以由此也可知其后台就是Linux操作系统
?spm=1001.2014.3001.5501:带参 #待补充
-
总结基本URL:
协议名称://server ip[:80]/a/b/c/d/e.htmlserver ip地址:用以确定互联网中唯一的机器端口号:标识了该机器上给我们提供服务的进程,即根据路径和文件名找到文件后,想通过哪个服务将对应资源交给客户端(通过端口号确定哪个服务)- 客户要得资源
/a/b/c/d/:标识了客户想访问的资源路径e.html:客户想要的文件名
3.2 urlencode和urldecode
- URL中的特殊字符需要被编码:若用户想在URL中包含“URL本身用来作为特殊字符”的字符,则URL在形成时,浏览器会自动给我们进行编码encode
- 如
/会转成%2F;?会转成%3F;+会转成%2B- 转义规则:将需要转码的字符转为16进制(共8个比特位),然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY 格式
- 一般服务端收到之后,需要进行转回特殊字符,进行解码
- url在线转码工具
- 如
3.3 http请求和响应的格式是什么样的
- 前置知识
-
- 交互的就是双方通信时的报文
-
- http协议式应用层的协议,底层采用的式TCP
- http在正常经历request请求和response响应之前,就已经经历了三次握手的过程,建立好了连接。在此基础上,双方才开始正常通信
-
-
快速构建HTTP请求和响应的报文格式
- 单纯在报文角度,http可以是基于行的文本协议:
- 对于客户端发起的request:
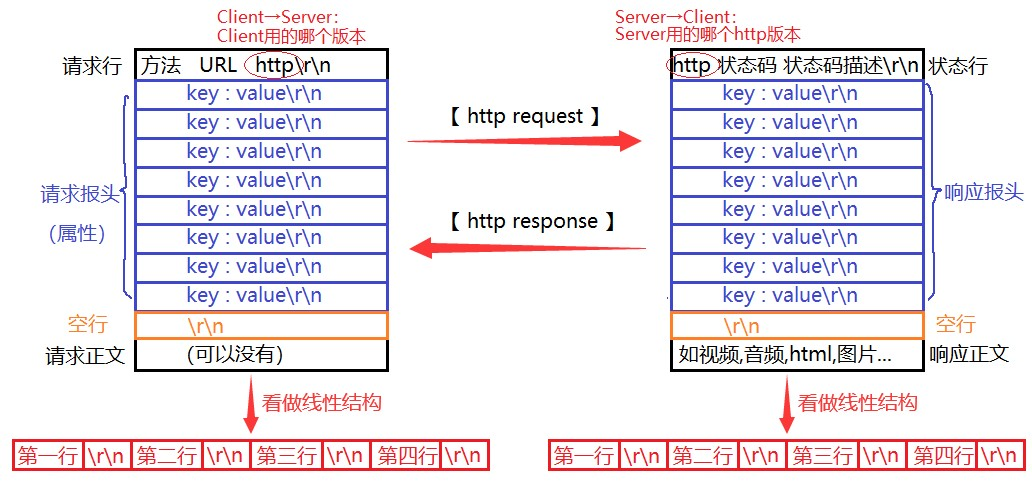
- 第一行“请求行”:包含http请求的方法、URL和版本(一般是http,比如/1.1),三部分之间分别用一个空格分隔开,如
方法 URL http\r\n - 第二行“请求报头”:由多个行(一般6-8个)构成,其中填充该次请求的相关属性(如该次请求用的长/短连接?期望接受的编码格式?发起该次请求的客户端信息有哪些?) ,均为K-V结构
- 第三行“空行”:该部分仅有
\r\n - 第四行“请求正文”:可以没有
- 第一行“请求行”:包含http请求的方法、URL和版本(一般是http,比如/1.1),三部分之间分别用一个空格分隔开,如
- 对于服务端接收回应的response
- 第一行"状态行":
http 状态码 状态码描述\r\n。状态码如成功:200;失败404;状态码描述如not found - 第二行和第三行同request
- 第四行“响应正文”:其中有视频、音频、html、图片等
- 第一行"状态行":
- 对于客户端发起的request:
- 单纯在报文角度,http可以是基于行的文本协议:
-
如何看待http请求 :看成线性结构
-
-
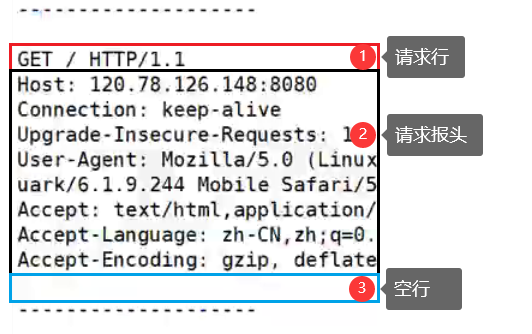
如下仅有三部分:
-
-
共识:该协议如何封装和解包?如何向上交付( #待补充 )?
- http如何区分报头和有效载荷?>
\r\n:通过空行的方式区分>一定能保证把报头读完 ==> 接下来再读就是正文了 > 如何得知正文的大小?> 报头中有如Content-Length: 123的字段,根据其数值,可确定正文大小,再以此读取正文
- http如何区分报头和有效载荷?>
3.4 http demo
- 浏览器的编写难度是属于弱于操作系统的第二梯队(第一梯队属于操作系统,浏览器属于第二梯队,但同属于第二梯队的也有很多),若操作系统难度为10,浏览器至少能有7分左右,甚至会难于编译器。
- 一般http都要有自己的web根目录,不是单纯直接就在后台Linux根目录下访问的。若客户端只请求了一个
/,我们就会返回默认首页(类比百度打开时,会显示的默认主页)
细节说明1:上网的两大行为
- ① 想获取(从服务器端拿下来资源数据)==> GET方法:可能获取的是一张图片、一个视频、一段文字等资源,这些资源在未被获取时,都在服务器上(后端服务器基本都是Linux)。若想获取,则需要客户端想后端服务器发送请求申请,从而获取资源。
- 一个服务器上可能存在很多的资源 ==> 资源在Linux上都是文件的形式 ==> 请求资源拿到本地 ==> 即让服务器进程打开我们要访问的文件,读取该文件,通过网络发送给Client ==> 要打开文件,需要先找到文件,而Linux中标识一个文件,是通过路径标识的
- ② 想上传(把客户端的数据提交到服务器)==> POST方法、GET方法
- http的应用场景当中,八九成的、最常见的请求方法就是“POST和GET方法”,其他方法要么被服务端禁用,要么服务端不支持,因为web服务器推送资源是直接推送给客户的,而客户有好的客户和非法的客户,所以除了要以最小的接口、最小的成本给用户提供它最基本的服务之外,它还要尽量减少自己无用服务的暴露,进而减少自己服务器出现漏洞的可能性。所以即使web服务器支持比较多的方法,但一般web服务器能禁用的方法尽量都是关掉的,不一定就能够对用户拿到这些方法。
- 总体认识:不论是获取还是上传,总归都是在服务器和客户端之间进行资源数据(诸如视频、图片、文档等)的传递,进一步的理解就是服务器进程和客户端进程之间在进行通信。
- 而对于http,只是说明在通信的时候,它需要更具体的通信方案:先通过GET方法获取表单(本例中表单就是这个静态网页),即从服务器把资源拿下来,然后根据表单再把数据提交给服务器,提交方法有两种,分别为通过URL传参的GET方法和通过正文传参的POST方法。
细节说明2:GET方法、POST方法、表单
-
表单:
- POST和GET方法想提交数据给服务器,就必须依托于网页的表单。
- 表单的作用:给用户提供输入框和提交按钮。让用户填充好数据(即表单收集用户数据)后,就把用户数据推送给服务器 ==> 具体的推送:表单的数据会被转成http request的一部分
- 表单也要提交,需要指明提交方法(最常见的就是“GET”和“POST”)
-
GET方法和POST方法的不同
- GET方法通过URL传参
- 浏览器会自动把表单中内容拆分出来,构建诸如name="value"这样的值;若有多个参数,则采用“
&”符号来作为分隔符构建一个长字符串作为请求,把参数提交上去。最终的参数会直接回显到URL当中,所以GET方法最重大的特性就是会将所对应的参数直接回显到所对应的URL(即整个参数作为URL的一部分来进行传参的) - 如:
http://120.78.126.148:8080/a/b/haha.html?user=list&pwd=12345abcde - 由于GET方法是以行为单位获取参数,并回显到URL中,所以大小方面会有一定受限(不同协议受限程度不同,没有具体数值)。
- 浏览器会自动把表单中内容拆分出来,构建诸如name="value"这样的值;若有多个参数,则采用“
- POST方法通过正文提交参数
- POST方法不会将用户填充的参数回显到URL中,但会显示在http的正文中
- 相较于GET方法,POST通过正文提交参数并不会将用户填充信息直接回显到URL上,所以可论POST方法的私密性相对较好 ==> △注意:私密性并不意味着安全性。私密性仅是让小白看不到信息,但只要传送数据时通过的是明文传送,不论POST还是GET,在网络传送时,没有经过加密/解密,数据照样可以被人拿到,所以只有对数据经过加密/解密,才能说是安全的。
- 使用场景:
- GET获取:获取众所周知的网页、图片、视频、音频等资源
- GET提交:传参的数据一般不怎么重要或私密。如搜索引擎中用户填充关键字,就会采用GET提交,回显到URL上。
- POST提交:
- ①参数比较隐私性:登录、注册等
- ②提交文件比较大:若文件较大,采用GET传参不好处理换行等;并且采用POST传送大文件,报头里能写清文件大小。如网盘上传视频、音频等
- GET方法通过URL传参
细节说明3:HTTP其他方法
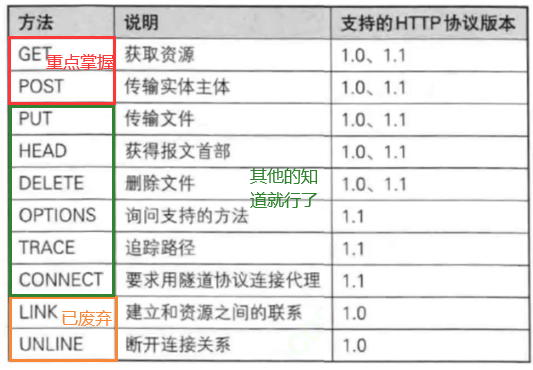
- HEAD方法:只想拿到报文的首部,并不关心整个的有效载荷(即只要空行之前的,不要空行之后的)
- DELETE方法:一般都是不公开的(不然就会造成,腾讯刚上线个功能,就被web服务器给删除了)
- OPTIONS方法:询问你支持什么样的方法。
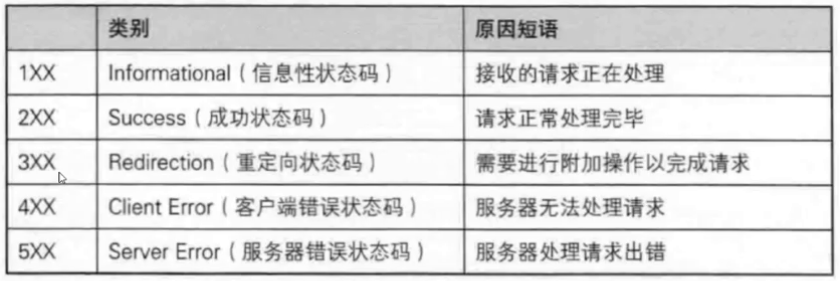
3.5 HTTP状态码
- 举例:
- 1XX状态码表示“当前正在处理请求,但由于请求较大,需要等待”,比较少见
- 200(OK):很常见的请求成功状态码
- 404(Not Found):很常见的请求失败状态码
- 向特定的服务器请求资源,所请求的资源一定要在其特定的能力之内,若超过了它的能力你的请求就是无理请求、非法请求,因此4XX称作客户端错误,而不是服务端错误(类比找家长要10块会给,要1亿就会吵起来)
- 403(Forbidden):因为平常访问的多是公网,故很少见。在公司中,访问公司内网时可能会由于权限,遇到请求被禁止访问
- 302(Redirect, 重定向):跳转到其他网页时会出现
- 504(Bad Gateway):
- 5XX也比较少见,因为有时即便是服务器后台的内部错误,一般也会打成4XX或3XX,因为公司不愿意将服务器内部错误暴露出去给他人
- 状态码和状态码描述是有规定对照的,但不一定前端编写的人严格遵守规则(谁也不服谁的规则):http response code(HTTP状态码对照表)
临时重定向(302/307) VS 永久重定向(301)
-
临时重定向:不影响用户后续的请求策略
- 举例:所有人在登录时,不论谁登陆、什么时候登陆,都是先打开登录界面,再跳转到特定的服务
- 客户端浏览器发起请求
http request>服务端会返回302状态码,并告知临时重定向的新地址>客户端浏览器自动向新地址发起请求 ==> 新地址会返回客户端想要的内容 - 服务端是怎么告诉客户端临时重定向后的新地址呢?
-
永久重定向:影响用户后续的请求策略
- 例如:公司域名变更、业务拓展有新的网站和域名了,这类情况下想把老客户搬运过来,就会采用永久重定向
- 永久重定向在编码方面,比临时重定向多做的一步是,需要更新一下本地的缓存
3.6 HTTP常见的报头
- Content-Type: 数据类型(text/html等)
- 每种资源都有对应后缀,服务器会根据客户端发起的请求资源的后缀,识别Content-Type是什么类型:HTTP Content-type 对照表 - 常用参考表对照表
- 现在有的浏览器很聪明,即使没有写明Content-Type是什么类型,浏览器也能根据正文内容对文件类型做自动识别(不是所有浏览器都能识别,Chrome可以做到)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
3.7 HTTP的特征
- 简单快速:
- 无连接(HTTP在协议这层不维护连接,直接向对方发送请求和响应;是TCP维护连接)
- 无状态(HTTP不会记录下用户历史或上一次的请求),即HTTP不会对用户的行为做任何的记录==>实际上在进行使用时,一般网站会记录下我们的状态的(比如某网站登录一次后,叉掉该网站重进时,无需再次登录)
- HTTP协议不记录状态,并不意味着网站不会提供这样的服务。
- HTTP协议只关心诸如要请求什么资源?什么格式?大小是多少?等问题,HTTP协议与其说是超文本(即传的文件多一点,能是文本,也能是视频、音频、网页等)传输,更确切是文件传输协议。
- HTTP只要负责网络特性,把网络功能搞定即可;至于网页如何渲染、用户是否在登录状态等等是交给上层的业务逻辑去维护的,不是交给HTTP处理的
- HTTP为了更好地支持常规用户的回话管理,它的报头属性里有“Cookie(请求当中涵盖)”和“Set-Cookie(相应当中设置)”
四、会话管理 – Cookie相关
-
会话管理:保证用户登录,及维持他登录状态的一套策略。
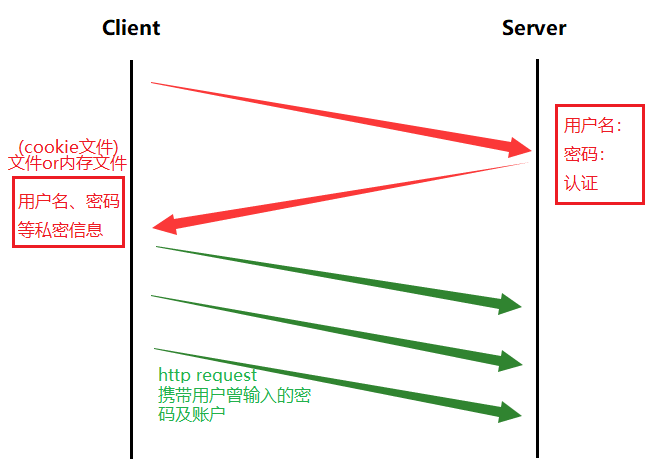
-
客户端第一次向浏览器发起登陆请求,会将用户名、密码信息发送给服务器,经过服务器认证通过后就允许客户端访问,并且认证通过的用户名及密码的私密信息会以文件或者内存文件的方式在客户端保存起来,成为Cookie文件,保存在浏览器中。此后客户端再向服务端发起,需要用户登录或vip登录后才能访问的界面时,就能直接访问了(因为http request携带用户曾经输入的密码和账户)。
-
-
判断Cookie文件是文件形式还是内存文件形式?当网页关闭后,重新进入,①若能够免登录,就是文件形式的;②若需要重新填写用户名及密码。则是内存文件。
-
-
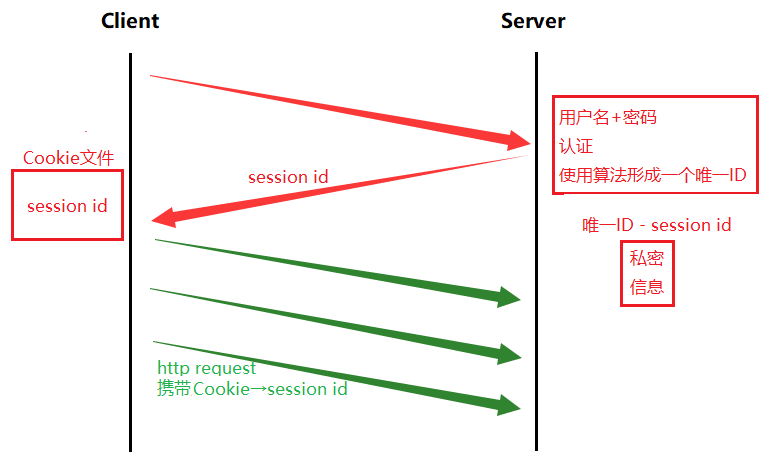
直接用账户及密码传输,容易被人直接劫取私密信息,于是有了以下改进:
-
-
服务器对用户名及密码认证通过后,就使用算法形成一个唯一ID,并在服务端维护起一个文件==>文件命名采用形成的唯一ID“
session id”;文件内容保存私密信息。> “session id”会返回给客户端,并被保存在客户端的Cookie文件中(也会保存其它诸如session id有效时长等,但核心的就是session id)> 而后客户端再访问已登录过的网页时,http request就携带用户Cookie->session id即可 ==> 服务端再次接受到http request时,只要证明session id在服务端存在,就知道其是合法的、已登录用户 -
session id虽然依旧有被不法分子获取到,并拿着访问网站的风险,但是session id并不是确切的用户名及密码,私密信息在一定程度上得到了保护。
-
-
Connection选项介绍
- Connection:keep-alive 是长连接 ==> 发起一个连接,就可以对应多次请求
- Connection:close 是短连接 ==> 每次请求,都要Connect发起连接
- 一个完整的网页,是由非常多的资源构成的。当网页由很多资源构成,有的资源(如高清图片)又比较厚重,若使用短连接,次次建立连接的成本太高了,所以使用长连接能提高效率
-
两个http相关工具介绍
- Postman:可以让客户端手动地向目标服务器构建http请求(可用于向任何网站发起请求)
- Fiddler:进行转包的工具(抓到客户端发出去的请求
http request)
相关文章:
Linux网络基础2 -- 应用层相关
一、协议 引例:编写一个网络版的计算器 1.1 约定方案:“序列化” 和 “反序列化” 方案一:客户端发送形如“11”的字符串,再去解析其中的数字和计算字符,并且设限(如数字和运算符之间没有空格; 运算符只…...

【Python机器学习】零基础掌握SkewedChi2Sampler内核近似特征
有没有遇到这样的困扰:即使在拥有大量数据的条件下,传统的机器学习模型表现依然不佳?这时,数据预处理和特征工程成了解决问题的关键步骤。那么,有没有一种算法能够优化特征,提升模型性能呢? 假设一个在线商城希望通过用户行为(比如点击、购买等)来预测用户是否会成为…...
Unity Meta Quest 一体机开发(三):Oculus Integration 基本原理、概念与结构+玩家角色基本配置
文章目录 📕教程说明📕输入数据📕Oculus Integration 处理手部数据的推荐流程📕VR 中交互的基本概念📕Oculus Integration 中的交互流程📕配置一个基本的玩家物体⭐OVRCameraRig⭐OVRInteraction⭐OVRHandP…...

excel 拼接字符 单元格
需要将单元格作为字符串拼接,使用 & 符号,拼接逗号,分号,冒号,横杠等,需要用英文双引号。...
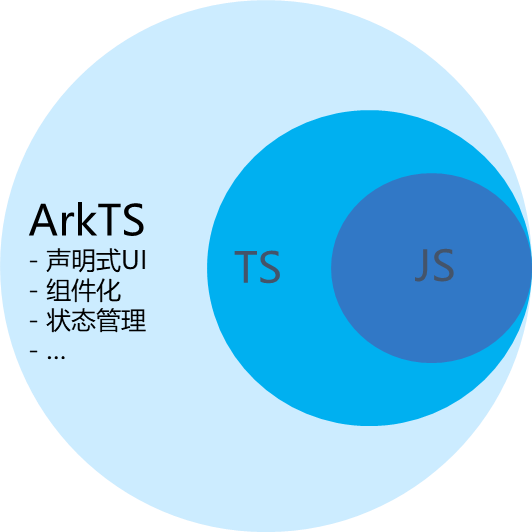
HarmonyOS 快速入门TypeScript
1.什么是TypeScript,它和JavaScript,ArkTs有什么区别 ArkTS是HarmonyOS优选的主力应用开发语言。它在TypeScript(简称TS)的基础上,匹配ArkUI框架,扩展了声明式UI、状态管理等相应的能力,让开发…...
ChatGPT扩展系列之ChatExcel
文章目录 ChatGPT扩展系列之ChatExcel对某一列的文字进行处理对数据进行排序对数据进行计算微软官方又推出Excel AI插件ChatGPT扩展系列之ChatExcel 自从ChatGPT很空出世之后,很多基于ChatGPT的应用便如雨后春笋般应用而生,这些应用的底层本质就是利用了ChatGPT对自然语言的…...

AM@微元法和定积分的应用@平面图形面积@立体体积@曲线弧长
文章目录 abstract微元法平面图形的面积极坐标上图形面积曲边扇形面积 平行截面面积为已知的立体体积旋转体的体积绕 x x x轴旋转绕 y y y轴旋转另一类型旋转体积 曲线弧长参数方程表示的曲线弧长直角坐标方程表示的曲线弧长极坐标方程表示得曲线弧长小结 abstract 微元法定积…...
SparkStreaming【实例演示】
前言 1、环境准备 启动Zookeeper和Kafka集群导入依赖: <dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.4</version></dependency><dependency>&l…...

提高抖音小店用户黏性和商品销量的有效策略
抖音小店是抖音平台上的电商模式,用户可以在抖音上购买各类商品。要提高用户黏性和商品销量,四川不若与众帮你整理了需要注意以下几个方面。 首先,提供优质的商品和服务。在抖音小店中,用户会通过观看商品展示视频和用户评价来选…...

提高公众意识:共同防范AI诈骗
随着人工智能技术的飞速发展,AI诈骗成为了一个不容忽视的威胁,影响到我们的社交、金融和个人隐私安全。在这个数字时代,提高公众对AI诈骗的意识至关重要,以下是一些关于如何提高公众意识以防范AI诈骗的观点: 认知AI诈…...

MES的物料管理
----物料管理的定义和作用---- 物料管理在制造执行系统(MES)中扮演着至关重要的角色。通过有效的物料管理,企业可以实现生产过程的高效性、准确性和可靠性,从而提高生产效率并降低成本。 一、物料管理的定义 物料管理是指对生产过…...
正点原子嵌入式linux驱动开发——Linux 多点电容触摸屏
随着智能手机的发展,电容触摸屏也得到了飞速的发展。相比电阻触摸屏,电容触摸屏有很多的优势,比如支持多点触控、不需要按压,只需要轻轻触摸就有反应。ALIENTEK的三款RGB LCD屏幕都支持多点电容触摸,本章就以ATK7016这…...
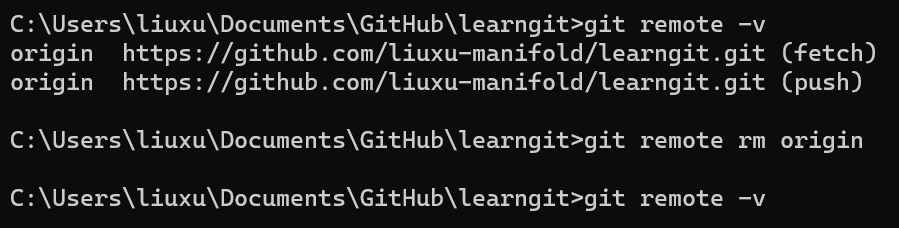
Git基础命令实践
文章目录 简介git的安装配置git的安装git的配置 git使用的基本流程创建版本库时光机穿梭版本回退工作区和暂存区管理修改撤销修改删除文件 远程仓库添加远程库从远程库克隆 总结 简介 本文主要记录了我在学习git操作的过程,以及如何使用GitHub。建议先参考廖雪峰的…...
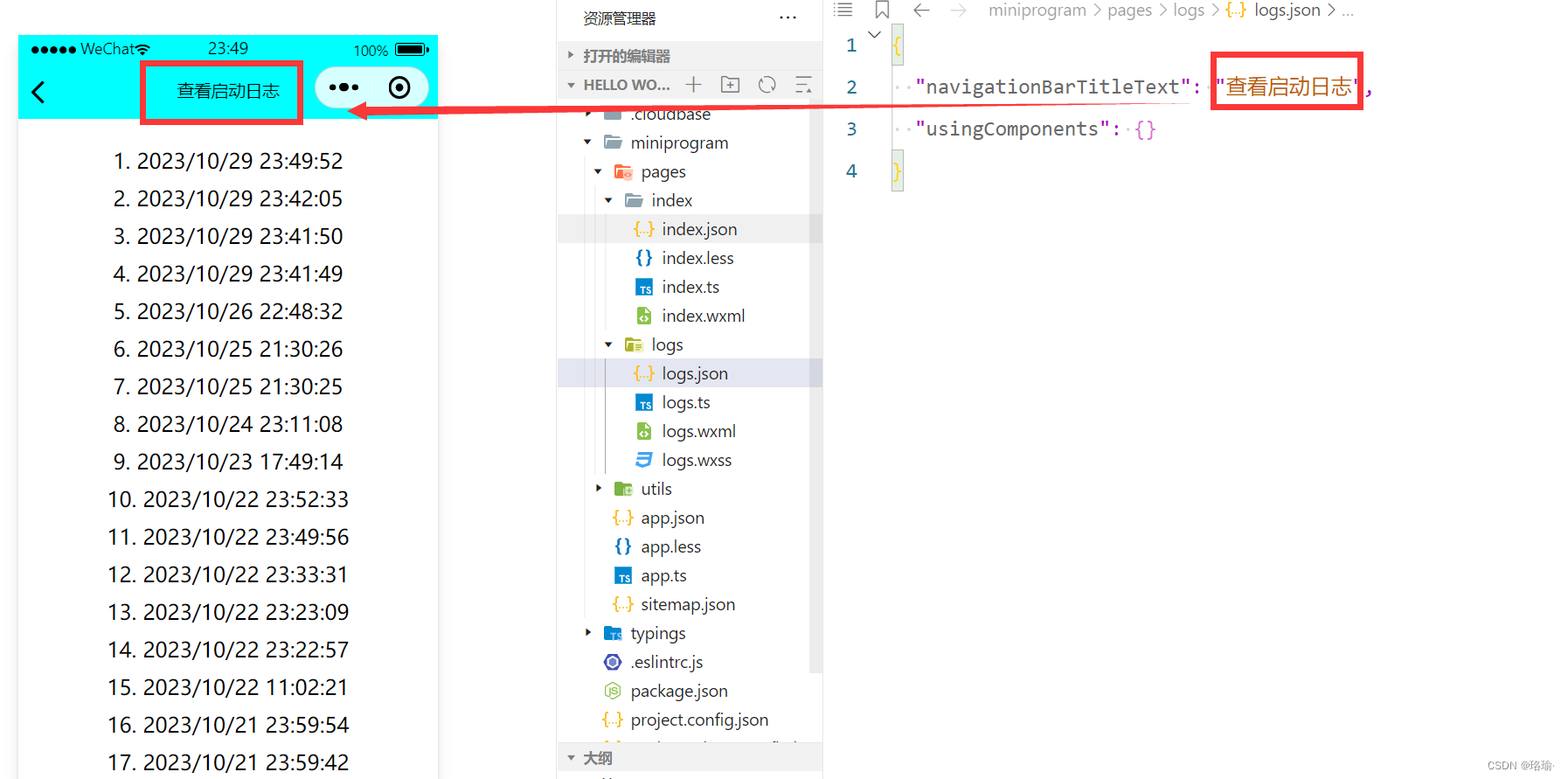
微信小程序设计之页面文件pages
一、新建一个项目 首先,下载微信小程序开发工具,具体下载方式可以参考文章《微信小程序开发者工具下载》。 然后,注册小程序账号,具体注册方法,可以参考文章《微信小程序个人账号申请和配置详细教程》。 在得到了测…...
VScode 自定义主题各参数解析
参考链接: vscode自定义颜色时各个参数的作用(史上最全)vscode编辑器,自己喜欢的颜色 由于 VScode 搜索高亮是在是太不起眼了,根本看不到此时选中到哪个搜索匹配了,所以对此进行了配置,具体想增加更多可配置项可参考…...

Linux进程等待
文章目录 1. 为什么要进程等待2. 进程等待的方法waitwaitpid非阻塞轮询 1. 为什么要进程等待 子进程退出,如果父进程还未结束,没有管这个子进程,那么就可能会造成“僵尸进程”问题,进而出现内存泄漏 如果这个进程变成了“僵尸进程…...
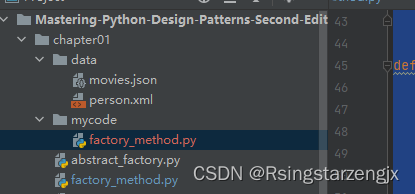
python设计模式笔记1:创建型模式 工厂模式和抽象工厂模式
1.工厂模式 (1) 导入所需的模块( json 和 ElementTree )。 (2) 定义 JSON数据提取器类( JSONDataExtractor )。 (3) 定义 XML数据提取器类( XMLDataExtractor )。 (4) 添加工厂函数 dataextraction_factor…...

第五章 I/O管理 一、I/O设备的基本概念和分类
目录 一、什么是I/O设备 1、定义: 2、按特性分类: 3、按传输速率分类: 4、按信息交换的方式分类: 二、总结 一、什么是I/O设备 1、定义: I/O设备就是可以将数据输入到计算机,或者可以接收计算机输出…...
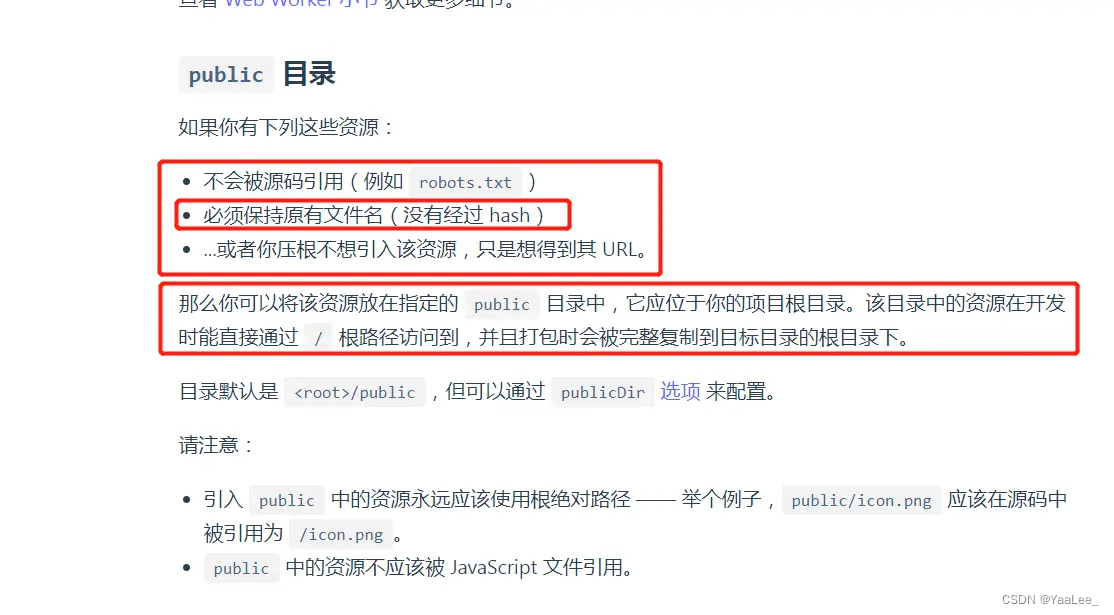
vue3动态引入图片(:src)
vite 官方默认的配置,如果资源文件在assets文件夹打包后会把图片名加上 hash值,但是直接通过 :src"imgSrc"方式引入并不会在打包的时候解析,导致开发环境可以正常引入,打包后却不能显示的问题 实际上我们不希望资源文…...
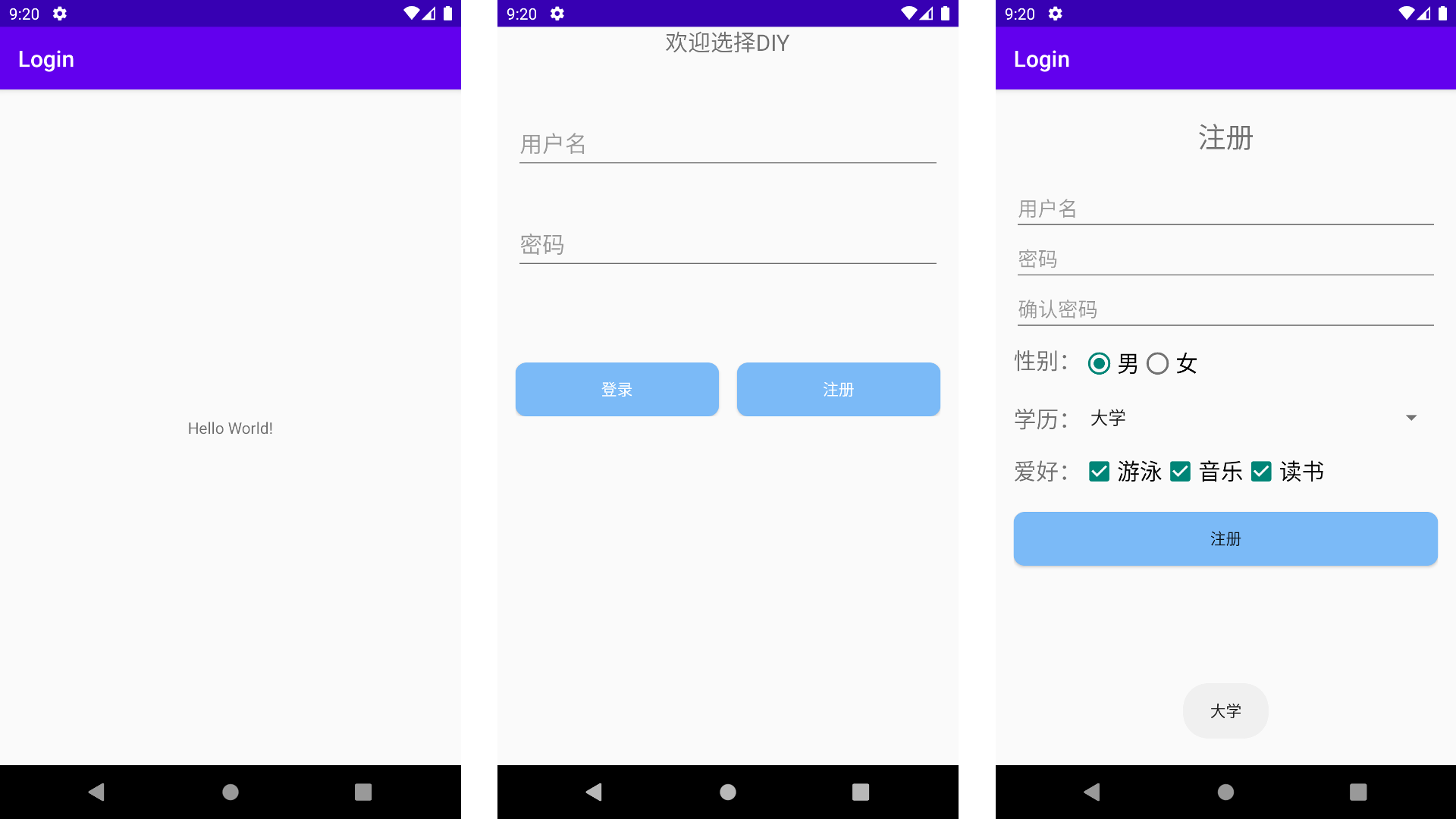
Android-登录注册页面(第三次作业)
第三次作业 - 登录注册页面 题目要求 嵌套布局。使用线性布局的嵌套结构,实现登录注册的页面。(例4-3) 创建空的Activity 项目结构树如下图所示: 注意:MainActivity.java文件并为有任何操作,主要功能集中…...

Qwen2.5-7B+Tools应用场景解析:智能客服、信息查询等实战案例
Qwen2.5-7BTools应用场景解析:智能客服、信息查询等实战案例 1. 引言:当大语言模型遇上工具 想象一下,你正在运营一家电商平台,每天要处理上千条客户咨询。人工客服团队疲于应对,而客户等待时间越来越长。这时&#…...

深度解析:智能体认知动力学
引言:智能体认知的变革在人工智能从 "大炼模型" 转向 "大用模型" 的关键时期,张家林的《智能体认知动力学导论:从生成式控制到拓扑几何求解》(2026 年版)如同一颗投入平静湖面的巨石,激…...

告别手动切图:用快马ai生成脚本,自动化ps设计稿导出与标注
作为一名长期与PS打交道的设计师,我深知重复性切图标注的痛苦。每次设计稿调整后,手动导出图层、记录样式、测量间距的过程不仅枯燥,还容易出错。最近尝试用InsCode(快马)平台的AI辅助生成自动化脚本,意外发现效率提升显著。以下是…...

别再死记硬背BPSK公式了!用Python+NumPy手把手带你仿真2PSK信号生成与解调全过程
用Python实战BPSK:从信号生成到误码率分析的完整指南 通信工程专业的学生常常被各种调制公式搞得晕头转向,尤其是BPSK(二进制相移键控)这类基础但抽象的概念。今天,我们将彻底改变这种学习方式——通过Python代码和可视…...

Nanbeige 4.1-3B专属UI实战:一键部署沉浸式游戏风格聊天应用
Nanbeige 4.1-3B专属UI实战:一键部署沉浸式游戏风格聊天应用 1. 项目概述与核心价值 南北阁(Nanbeige)4.1-3B是一款性能优异的中英双语大语言模型,而今天我们要介绍的是为其量身打造的专属Web交互界面。这个界面最特别之处在于&…...

PDF-Parser-1.0智能办公:告别手动复制粘贴的PDF处理方案
PDF-Parser-1.0智能办公:告别手动复制粘贴的PDF处理方案 1. 为什么需要智能PDF解析工具 在日常办公场景中,PDF文档处理是一个高频且痛苦的工作环节。根据统计,职场人士平均每周需要处理15-20份PDF文件,包括合同、报告、发票等各…...

ESP32无线心情记录仪设计与物联网应用
1. 基于ESP32的无线心情记录仪设计与实现1.1 项目背景与功能概述现代工程师工作压力大,情绪波动频繁,需要有效的情绪管理工具。本项目设计了一款基于无线射频技术的情绪记录装置,通过物理按键触发和云端数据记录的方式,帮助用户量…...

05-OpenClaw 自动生成 PPT 实战:每天节省 3 小时
作者:程序员小明儿 字数:约 9000 字 阅读时间:约 25 分钟 难度:⭐⭐⭐ 中级 系列:OpenClaw 实战 16 例(第 5 篇) 前置条件:已完成 OpenClaw 环境部署和基础配置写在前面 你是不是也这…...

深度解析IDM激活脚本:注册表锁定技术的完整实现指南
深度解析IDM激活脚本:注册表锁定技术的完整实现指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM&…...

Win11Debloat实战指南:3步彻底清理Windows 11系统臃肿
Win11Debloat实战指南:3步彻底清理Windows 11系统臃肿 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以简化和改…...