机器学习可解释性一(LIME)
随着深度学习的发展,越来越多的模型诞生,并且在训练集和测试集上的表现甚至于高于人类,但是深度学习一直被认为是一个黑盒模型,我们通俗的认为,经过训练后,机器学习到了数据中的特征,进而可以正确的预测结果,但是,对于机器到底学到了什么,仍然是个黑盒模型,我们迫切想要知道机器所学习到的特征,这就需要对模型的可解释性进行研究。
本文主要介绍一下机器学习可解释性的相关内容与实现方法,并回答以下问题。
- 什么是机器学习可解释性?
- 为什么要进行可解释性的研究
- Lime可解释性的原理
- Lime可解释性的代码实现
什么是机器学习可解释性?
对于机器学习的用户而言,模型的可解释性是一种较为主观的性质,我们无法通过严谨的数学表达方法形式化定义可解释性。通常,我们可以认为机器学习的可解释性刻画了“人类对模型决策或预测结果的理解程度”,即用户可以更容易地理解解释性较高的模型做出的决策和预测。
从哲学的角度来说,为了理解何为机器学习的可解释性,我们需要回答以下几个问题:首先,我们应该如何定义对模型的“解释”,怎样的解释才足够好?许多学者认为,要判断一个解释是否足够好,取决于这个解释需要回答的问题是什么。对于机器学习任务而言,我们最感兴趣的两类问题是“为什么会得到该结果”和“为什么结果应该是这样”。而理想状态下,如果我们能够通过溯因推理的方式恢复出模型计算出输出结果的过程,就可以实现较强的模型解释性。
实际上,我们可以从“可解释性”和“完整性”这两个方面来衡量一种解释是否合理。“可解释性”旨在通过一种人类能够理解的方式描述系统的内部结构,它与人类的认知、知识和偏见息息相关;而“完整性”旨在通过一种精确的方式来描述系统的各个操作步骤(例如,剖析深度学习网络中的数学操作和参数)。然而,不幸的是,我们很难同时实现很强的“可解释性”和“完整性”,这是因为精确的解释术语往往对于人们来说晦涩难懂。同时,仅仅使用人类能够理解的方式进行解释由往往会引入人类认知上的偏见。
此外,我们还可以从更宏大的角度理解“可解释性人工智能”,将其作为一个“人与智能体的交互”问题。如图 1所示,人与智能体的交互涉及人工智能、社会科学、人机交互等领域。

为什么要进行可解释性的研究
在当下的深度学习浪潮中,许多新发表的工作都声称自己可以在目标任务上取得良好的性能。尽管如此,用户在诸如医疗、法律、金融等应用场景下仍然需要从更为详细和具象的角度理解得出结论的原因。为模型赋予较强的可解释性也有利于确保其公平性、隐私保护性能、鲁棒性,说明输入到输出之间个状态的因果关系,提升用户对产品的信任程度。下面,我们从“完善深度学习模型”、“深度学习模型与人的关系”、“深度学习模型与社会的关系”3 个方面简介研究机器学习可解释性的意义。
(1)完善深度学习模型
大多数深度学习模型是由数据驱动的黑盒模型,而这些模型本身成为了知识的来源,模型能提取到怎样的知识在很大程度上依赖于模型的组织架构、对数据的表征方式,对模型的可解释性可以显式地捕获这些知识。
尽管深度学习模型可以取得优异的性能,但是由于我们难以对深度学习模型进行调试,使其质量保证工作难以实现。对错误结果的解释可以为修复系统提供指导。
(2)深度学习模型与人的关系
在人与深度学习模型交互的过程中,会形成经过组织的知识结构来为用户解释模型复杂的工作机制,即「心理模型」。为了让用户得到更好的交互体验,满足其好奇心,就需要赋予模型较强的可解释性,否则用户会感到沮丧,失去对模型的信任和使用兴趣。
人们希望协调自身的知识结构要素之间的矛盾或不一致性。如果机器做出了与人的意愿有出入的决策,用户则会试图解释这种差异。当机器的决策对人的生活影响越大时,对于这种决策的解释就更为重要。
当模型的决策和预测结果对用户的生活会产生重要影响时,对模型的可解释性与用户对模型的信任程度息息相关。例如,对于医疗、自动驾驶等与人们的生命健康紧密相关的任务,以及保险、金融、理财、法律等与用户财产安全相关的任务,用户往往需要模型具有很强的可解释性才会谨慎地采用该模型。
(3)深度学习模型与社会的关系
由于深度学习高度依赖于训练数据,而训练数据往往并不是无偏的,会产生对于人种、性别、职业等因素的偏见。为了保证模型的公平性,用户会要求深度学习模型具有检测偏见的功能,能够通过对自身决策的解释说明其公平。
深度学习模型作为一种商品具有很强的社会交互属性,具有强可解释性的模型也会具有较高的社会认可度,会更容易被公众所接纳。
Lime可解释性的原理
Lime(Local Interpretable Model-Agnostic Explanations)是使用训练的局部代理模型来对单个样本进行解释。假设对于需要解释的黑盒模型,取关注的实例样本,在其附近进行扰动生成新的样本点,并得到黑盒模型的预测值,使用新的数据集训练可解释的模型(如线性回归、决策树),得到对黑盒模型良好的局部近似。值得注意的是,可解释性模型是黑盒模型的局部近似,而不是全局近似。

实现步骤
- 如上图是一个非线性的复杂模型,蓝/粉背景的交界为决策函数;
- 选取关注的样本点,如图粗线的红色十字叉为关注的样本点X;
- 定义一个相似度计算方式,以及要选取的K个特征来解释;
- 在该样本点周围进行扰动采样(细线的红色十字叉),按照它们到X的距离赋予样本权重;
- 用原模型对这些样本进行预测,并训练一个线性模型(虚线)在X的附近对原模型近似。
其数学表示如下:
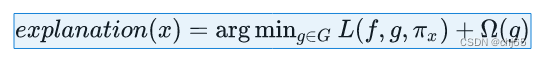
对于实例x的解释模型g,我们通过最小化损失函数来比较模型g和原模型f的近似性,其中,代表了解释模型g的模型复杂度,G表示所有可能的解释模型(例如我们想用线性模型解释,则G表示所有的线性模型),定义了x的邻域。我们通过最小化L使得模型f变得可解释。其中,模型g,邻域范围大小,模型复杂度均需要定义。
对于结构化数据,首先确定可解释性模型,兴趣点x,邻域的范围。LIME首先在全局进行采样,然后对于所有采样点,选出兴趣点x的邻域,然后利用兴趣点的邻域范围拟合可解释性模型。如图。

其中,背景灰色为负例,背景蓝色为正例,黄色为兴趣点,小粒度黑色点为采样点,大粒度黑点为邻域范围,右下图为LIME的结果。
LIME的优点我们很容易就可以看到,原理简单,适用范围广,可解释任何黑箱模型。
Lime可解释性的代码实现
算法流程
宏观来看:

首先,在待解释的模型中取一个待解释样本,之后随机生成扰动样本,并以与待解释样本的距离作为标准附加权重,再将得到的结果作为输入投入待解释模型中,同时选择在局部考察的待训练可解释模型(如决策树、逻辑回归等等),最终即可训练出在可解释特征维度上的可解释性模型。
微观来看:

选取待解释样本X,并转换为可解释特征维度上的样本X’。

通过随机扰动,得到其余在可解释特征维度上的样本Z’。
将Z’恢复至原始维度,计算f(z)与相似度。
利用自适应相似度对各个样本点进行加权。

以X’作为特征,f(z)作为标准训练局部可解释模型(如图虚线)。
import sklearn
import sklearn.datasets
import sklearn.ensemble
import numpy as np
import lime
import lime.lime_tabular
#读取数据
x = np.array(data[feats].fillna(-99999))
y = np.array(data['target'])
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state = 400)
# 以XGBoost模型为例
model_xgb = xgb.XGBClassifier(learning_rate =0.05,n_estimators=50,max_depth=3,min_child_weight=1,gamma=0.3,subsample=0.8,colsample_bytree=0.8,objective= 'multi:softprob',nthread=4,scale_pos_weight=1,num_class=2,seed=27).fit(X_train, y_train)
# 生成解释器
explainer = lime.lime_tabular.LimeTabularExplainer(X_train, feature_names=feats,class_names=[0,1], discretize_continuous=True)
# 对局部点的解释
i = np.random.randint(0, X_test.shape[0])
#参数解释
#image:待解释图像
#classifier_fn:分类器
#labels:可解析标签
#hide_color:隐藏颜色
#top_labels:预测概率最高的K个标签生成解释
#num_features:说明中出现的最大功能数
#num_samples:学习线性模型的邻域大小
#batch_size:批处理大小
#distance_metric:距离度量
#model_regressor:模型回归器,默认为岭回归
#segmentation_fn:分段,将图像分为多个大小
#random_seed:随机整数,用作分割算法的随机种子
exp = explainer.explain_instance(X_test[i], model_xgb.predict_proba, num_features=6)
# 显示详细信息图
exp.show_in_notebook(show_table=True, show_all=True)
# 显示权重图
exp.as_pyplot_figure()
结果示例:


相关文章:
机器学习可解释性一(LIME)
随着深度学习的发展,越来越多的模型诞生,并且在训练集和测试集上的表现甚至于高于人类,但是深度学习一直被认为是一个黑盒模型,我们通俗的认为,经过训练后,机器学习到了数据中的特征,进而可以正…...

CV学习笔记-MobileNet
MobileNet 文章目录MobileNet1. MobileNet概述2. 深度可分离卷积(depthwise separable convolution)2.1 深度可分离卷积通俗理解2.2 深度可分离卷积对于参数的优化3. MobileNet网络结构4. 代码实现4.1 卷积块4.2 深度可分离卷积块4.3 MobileNet定义4.4 完…...

C++进阶——继承
C进阶——继承 1.继承的概念及定义 面向对象三大特性:封装、继承、多态。 概念: 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特 性的基础上进行扩展,增加功能,这…...
数据结构---单链表
专栏:数据结构 个人主页:HaiFan. 专栏简介:从零开始,数据结构!! 单链表前言顺序表的缺陷链表的概念以及结构链表接口实现打印链表中的元素SLTPrintphead->next!NULL和phead!NULL的区别开辟空间SLTNewNod…...

redis数据结构的底层实现
文章目录一.引言二.redis的特点三.Redis的数据结构a.字符串b.hashc.listd.sete.zset(有序集合)一.引言 redis是一个开源的使用C语言编写、支持网络、可基于内存亦可持久化的日志型、key-value的NoSQL数据库。 通常使用redis作为缓存中间件来降低数据库的压力,除此…...
【JavaSE】复习(进阶)
文章目录1.final关键字2.常量3.抽象类3.1概括3.2 抽象方法4. 接口4.1 接口在开发中的作用4.2类型和类型之间的关系4.3抽象类和接口的区别5.包机制和import5.1 包机制5.2 import6.访问控制权限7.Object7.1 toString()7.2 equals()7.3 String类重写了toString和equals8.内部类8.1…...

Java 主流日志工具库
日志系统 java.util.logging (JUL) JDK1.4 开始,通过 java.util.logging 提供日志功能。虽然是官方自带的log lib,JUL的使用确不广泛。 JUL从JDK1.4 才开始加入(2002年),当时各种第三方log lib已经被广泛使用了JUL早期存在性能问题&#x…...

产品经理有必要考个 PMP吗?(含PMP资料)
现在基本上做产品的都有一个PMP证件,从结果导向来说,不对口不会有这么大范围的人来考,但是需要因地制宜,在公司内部里,标准程序并不流畅,产品和项目并不规范,关系错综复杂。 而产品经理的职能又…...
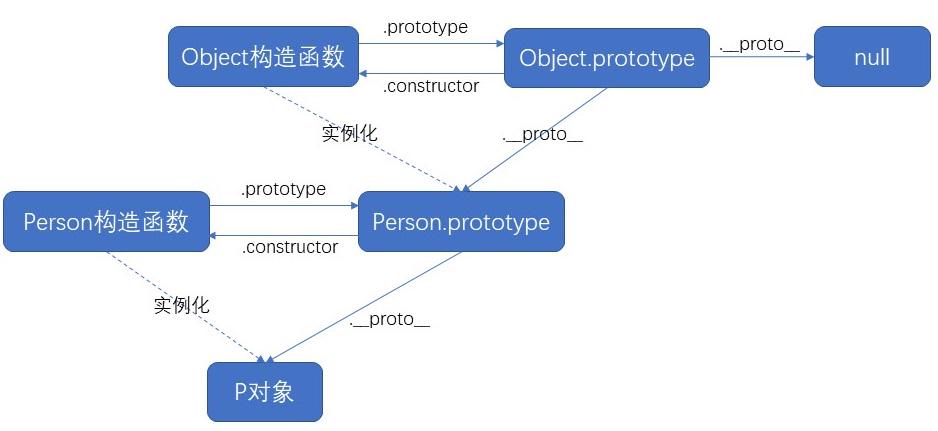
什么是原型、原型链?原型和原型链的作用
1、ES6之前,继承都用构造函数来实现;对象的继承,先申明一个对象,里面添加实例成员<!DOCTYPE html> <html><head><meta charset"utf-8" /><title></title></head><body><script…...

条件期望4
条件期望例题----快排算法的分析 快速排序算法的递归定义如下: 有n个数(n≥2n\geq 2n≥2), 一开始随机选取一个数xix_ixi, 并将xix_ixi和其他n-1个数进行比较, 记SiS_iSi为比xix_ixi小的元素构成的集合, Siˉ\bar{S_i}Siˉ为比xix_ixi大的元素构成的集合, 然后分…...

网络协议分析(2)判断两个ip数据包是不是同一个数据包分片
一个节点收到两个IP包的首部如下:(1)45 00 05 dc 18 56 20 00 40 01 bb 12 c0 a8 00 01 c0 a8 00 67(2)45 00 00 15 18 56 00 b9 49 01 e0 20 c0 a8 00 01 c0 a8 00 67分析并判断这两个IP包是不是同一个数据报的分片&a…...

6.2 负反馈放大电路的四种基本组态
通常,引入交流负反馈的放大电路称为负反馈放大电路。 一、负反馈放大电路分析要点 如图6.2.1(a)所示电路中引入了交流负反馈,输出电压 uOu_OuO 的全部作为反馈电压作用于集成运放的反向输入端。在输入电压 uIu_IuI 不变的情况下,若由于…...

MySQL进阶之锁
锁是计算机中协调多个进程或线程并发访问资源的一种机制。在数据库中,除了传统的计算资源竞争之外,数据也是一种提供给许多用户共享的资源,如何保证数据并发访问的一致性和有效性是数据库必须解决堆的一个问题,锁冲突也是影响数据…...

【Mac 教程系列】如何在 Mac 上破解带有密码的 ZIP 压缩文件 ?
如何使用 fcrackzip 在 Mac 上破解带有密码的 ZIP 压缩文件? 用 markdown 格式输出答案。 在 Mac 上破解带有密码的 ZIP 压缩文件 使用解压缩软件,如The Unarchiver,将文件解压缩到指定的文件夹。 打开终端,输入 zip -er <zipfile> &…...
【Acwing 周赛复盘】第92场周赛复盘(2023.2.25)
【Acwing 周赛复盘】第92场周赛复盘(2023.2.25) 周赛复盘 ✍️ 本周个人排名:1293/2408 AC情况:1/3 这是博主参加的第七次周赛,又一次体会到了世界的参差(这次周赛记错时间了,以为 19:15 开始&…...

L1-087 机工士姆斯塔迪奥
在 MMORPG《最终幻想14》的副本“乐欲之所瓯博讷修道院”里,BOSS 机工士姆斯塔迪奥将会接受玩家的挑战。 你需要处理这个副本其中的一个机制:NM 大小的地图被拆分为了 NM 个 11 的格子,BOSS 会选择若干行或/及若干列释放技能,玩家…...

本周大新闻|索尼PS VR2立项近7年;传腾讯将引进Quest 2
本周大新闻,AR方面,传立讯精密开发苹果初代AR头显,第二代低成本版将交给富士康;iOS 16.4代码曝光新的“计算设备”;EM3推出AR眼镜Stellar Pro;努比亚将在MWC2023推首款AR眼镜。VR方面,传闻腾讯引…...
aws console 使用fargate部署aws服务快速跳转前端搜索栏
测试过程中需要在大量资源之间跳转,频繁的点击不如直接搜索来的快,于是写了一个搜索框方便跳转。 前端的静态页面可以通过s3静态网站托管实现,但是由于中国区需要备案的原因,可以使用ecs fargate部署 步骤如下: 编写…...

Redis实战之Redisson使用技巧详解
一、摘要什么是 Redisson?来自于官网上的描述内容如下!Redisson 是一个在 Redis 的基础上实现的 Java 驻内存数据网格客户端(In-Memory Data Grid)。它不仅提供了一系列的 redis 常用数据结构命令服务,还提供了许多分布…...

SQLAlchemy
文章目录SQLAlchemy介绍SQLAlchemy入门使用原生sql使用orm外键关系一对多关系多对多关系基于scoped_session实现线程安全简单表操作实现方案CRUDFlask 集成 sqlalchemySQLAlchemy 介绍 SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系…...
成最优之选)
2026年AI大模型接口加速站亲测:六家平台横评,诗云API(ShiyunApi)成最优之选
在进行AI开发时,一个现实问题摆在眼前:如何接入模型厂商的官方API?对于海外开发者而言,注册、绑卡、调用这三步便能轻松解决。然而,国内开发者却面临着诸多难题,如跨境网络波动、外币支付门槛、发票合规需求…...

计算机视觉模型选型实战:四维战场决策法
1. 项目概述:这不是一场技术选型,而是一次实战能力的现场测验 “计算机视觉的战场:选择你的冠军”——这个标题乍看像游戏海报,实则精准戳中了当前CV工程落地最真实的痛点。它不谈论文指标、不堆模型参数,而是把镜头直…...

Foundation Sites响应式设计原理:5个核心断点系统详解,打造完美移动优先体验
Foundation Sites响应式设计原理:5个核心断点系统详解,打造完美移动优先体验 【免费下载链接】foundation-sites The most advanced responsive front-end framework in the world. Quickly create prototypes and production code for sites that work …...

Mac用户的跨平台文件交换终极解决方案:免费NTFS读写工具Nigate完整指南
Mac用户的跨平台文件交换终极解决方案:免费NTFS读写工具Nigate完整指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, a…...

clawhealth:本地化Garmin健康数据同步与自动化分析工具实践
1. 项目概述:打造你的本地健康数据中心如果你和我一样,手腕上常年戴着一块Garmin手表,每天看着它记录步数、心率、睡眠,但总觉得这些数据只是躺在Garmin Connect的云端,自己没法真正“拥有”和分析,那么cla…...

3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南
3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II 如果你在使用Reloaded-I…...
pc手机通用)
明末:渊虚之羽加修改器2026.5.12最新破解版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)pc手机通用
游戏本体下载链接 修改器链接 由成都灵泽科技(Leenzee Games)开发,505 Games发行的动作角色扮演游戏《明末:渊虚之羽》(WUCHANG: Fallen Feathers)在近年来备受动作游戏玩家的关注。作为一款扎根于中国历…...

智能网联汽车窄路车流预测与协同通行【附仿真】
✨ 长期致力于智能网联汽车、窄路段、短时车流量预测、协同通行研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)窄路车流时空异质图特征构建ÿ…...

5分钟极简安装:免费Ghidra逆向工程工具完整配置指南
5分钟极简安装:免费Ghidra逆向工程工具完整配置指南 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 你是否曾因复…...

5个简单步骤:用DXVK在Linux上流畅运行Windows游戏
5个简单步骤:用DXVK在Linux上流畅运行Windows游戏 【免费下载链接】dxvk Vulkan-based implementation of D3D8, 9, 10 and 11 for Linux / Wine 项目地址: https://gitcode.com/gh_mirrors/dx/dxvk 你是否曾经想在Linux系统上玩Windows游戏,却被…...