JSON和Protobuf序列化
文章目录
- 一、粘包和拆包
- 1、半包问题
- 2、半包现象原理
- 二、JSON协议通信
- 1、通用类库
- 2、JSON传输的编码器和解码器
- 三、Protobuf协议通信
- 1、一个简单的proto文件的实践案例
- 2、生成POJO和Builder
- 3、消息POJO和Builder的使用案例
- 1)构造POJO消息对象
- 2)序列化和反序列化
- 四、Protobuf编解码的实践案例
- 1、Protobuf编码器和解码器的原理
- 2、示例
- 五、Protobuf协议语法
- 1、头部声明
- 2、消息结构体
- 3、其他的语法规范
因为像TCP和UDP这种底层协议只能发送字节流,因此当我们在开发一些远程过程调用(RPC)的程序时,需要将应用层的Java POJO对象序列化成字节流,数据接收端再反序列化成Java POJO对象。序列化一定会设计编码和格式化,目前常见的编码方式有:
- JSON:将Java POJO对象转换成JSON结构化字符串。基于HTTP协议,是常用的编码方式,可读性较强,性能稍差
- XML:和JSON一样数据在序列化成字节流之前都转换成字符串,可读性强但是性能差
- Java内置的编码和序列化机制,可移植性强,性能稍差,无法跨平台(语言)
- 其他开源的序列化/反序列化机制,例如Apache Avro,Apache Thrift,这两个框架和Protobuf相比性能非常接近,且设计原理如出一辙。其中Avro在大数据存储时比较常用,Thrift的亮点在于内置了RPC机制,所以在开发一些RPC交互式应用时,客户端和服务端的开发和部署都非常简单
评价一个序列化框架的优缺点:
- 结果数据大小:序列化后的数据越小,传输效率越高
- 结构复杂度:这会影响序列化/反序列化的效率,结构越复杂,越耗时
理论上对于性能要求不是太高的服务器程序可以选择JSON系列的序列化框架,而对于性能要求较高的服务器程序则应该选择传输效率更高的二进制序列化框架如Protobuf。
一、粘包和拆包
每一次发送就是向通道写入一个ByteBuf。发送数据时先填好ByteBuf,然后通过通道发出去。对于接收端每一次读取就是通过Handler业务处理器的入站方法,从通道读到一个ByteBuf。最理想的情况就是发送端每发送一个ByteBuf缓冲区,接收端就能接收到一个ByteBuf,并且发送端和接收端的ByteBuf内容能一模一样。
1、半包问题
然而事实是接收方收到的数据包并不总按我们的预期,而是可能存在三种情况:
- 全包:读到一个完整的ByteBuf
- 粘包:读到多个ByteBuf输入,粘在了一起
- 半包:只读到部分ByteBuf内容,并且有乱码
粘包就是接收端收到一个ByteBuf,但是包含了多个发送端的ByteBuf,即多个ByteBuf粘在了一起。半包就是接收端将一个发送端的ByteBuf拆开了,收到了多个破碎的包。为了简单起见,也可以将粘包的情况看成特殊的半包,粘包和半包可以统称为传输的半包问题,都是指一次不正常的ByteBuf缓存区接收。
2、半包现象原理
寻根粘包和半包的来源得从操作系统底层说起。底层网络都是以二进制字节报文的形式来传输数据的,读数据的大致流程为:当IO可读时,Netty会从底层网络将二进制数据读到ByteBuf缓冲区中,再交给Netty程序转换成Java POJO对象。
在发送端Netty的应用层进程缓冲区,程序以ByteBuf为单位来发送数据,但是到了底层操作系统的内核缓冲区 ,底层会按照协议的规范对数据包进行二次封装,拼成传输层TCP协议报文再进行发送。在接收端收到传输层的二进制包后,首先保存在内核缓冲区,Netty读取ByteBuf时才复制到进程缓冲区。
在接收端当Netty程序将数据从内核缓冲区复制到Netty进程缓冲区的ByteBuf时,问题就来了:
- 首先每次读取底层缓冲的数据容量是有限制的,当TCP底层缓冲的数据包比较大时,会将一个底层包分成多个ByteBuf进行赋值,进而造成进程缓冲区读到的是半包
- 当TCP底层缓冲的数据包比较小时,一次复制的却不止一个内核缓冲区包,进而造成进程缓冲区读取到的是粘包
那么解决的基本思路就是在接收端Netty程序根据自定义协议,将读取到的进程缓冲区ByteBuf,在应用层进行二次拼装,重新组装我们应用层的数据包。接收端的这个过程通常也称为分包,或者叫做拆包。
在Netty中分包的方法主要有两种:
- 自定义解码器分包器:基于ByteToMessageDecoder或ReplayingDecoder,定义自己的进程缓冲区分包器
- 使用Netty内置的解码器,如DelimiterBasedFrameDecoder或LengthFieldBasedFrameDecoder等解码器
二、JSON协议通信
1、通用类库
Java处理JSON数据有三个比较流行的开源类库:
- 阿里的FastJson
- 谷歌的Gson
- 开源社区的Jackson
Jackson是一个简单的、基于JavadeJSON开源库,可以轻松地将Java POJO对象转换成JSON、XML格式字符串,同样也可以方便地将JSON、XML字符串转换成Java POJO对象。它的优点是依赖的jar包较少,简单易用,性能也还不错。但是缺点是对于复杂的Pojo类型、复杂的集合Map、List的转换结果不是标准的JSON格式,或者会出现一些问题。
Google的Gson开源库是一个功能齐全的JSON解析库,可以完成复杂类型的POJO和JSON字符串的相互转换,转换能力非常的强。
阿里巴巴的FastJson是一个高性能的JSON库,采用独创的算法,将JSON转换成POJO的速度提升到极致,超过其他JSON开源库。
在实际开发中,目前主流的策略是使用Gson将POJO序列化成JSON字符串,用FastJson将JSON字符串反序列化成POJO对象。下面是使用这两个类库封装出来的Json通用工具类。
public class JsonUtil {// 谷歌的GsonBuilder构造器static GsonBuilder gb = new GsonBuilder();static {gb.disableHtmlEscaping();}public static String pojoToJson(Object obj) {return gb.create().toJson(obj);}public static <T> T jsonToPojo(String json, Class<T> tClass) {return JSONObject.parseObject(json, tClass);}
}
2、JSON传输的编码器和解码器
本质上JSON格式仅仅是字符串的一种组织形式,所以传输JSON所用到的协议和传输普通文本所使用的协议没什么不同。下面使用采用的Head-Content协议来介绍一下JSON传输。
解码过程:先使用LengthFieldBasedFrameDecoder(Netty内置的自定义长度数据包解码器)解码Head-Content二进制数据包,解码出Content字段的二进制内容。然后使用StringDecoder字符串解码器(Netty内置的解码器)将二进制内容解码成JSON字符串。最后使用JsonMsgDecoder(自定义的解码器)将JSON字符串解码成POJO对象。
编码过程:先使用StringEncoder编码器(Netty内置)将JSON字符串编码成二进制字节数组,然后使用LengthFieldPrepender编码器(Netty内置)将二进制字节数组编码成Head-Content二进制数据包。
LengthFieldPrepender编码器的作用是在数据包的前面加上内容的二进制字节数组的长度,和LengthFieldBasedFrameDecoder解码器是配对使用的。构造器需要传入两个参数:
- int lengthFieldLength:表示Head长度字段所占用的字节数
- boolean lengthIncludesLengthFieldLength:表示Head字段的总长度值是否包含长度字段自身的字节数(默认为false)
三、Protobuf协议通信
Protobuf是Google提出的一种数据交换的格式,是一套类似JSON或者XML的数据传输格式和规范,用于不同应用或进程之间进行通信。Protobuf的编码过程为:使用预先定义的Message数据结构的传输数据进行打包,然后编码成二进制的码流进行传输或存储。Protobuf的解码过程则是将二进制码流解码成Protobuf自己定义的Message结构的POJO实例。
Protobuf既独立于语言,又独立于平台。Google官方提供了多种语言的实现:Java、C#、C++、Go、JavaScript和Python。Protobuf数据包是一种二进制的格式,相对于文本格式的数据交换(JSON、XML)来说速度要快很多。由于Protobuf优异的性能,使得它更加适用于分布式应用场景下的数据通信或异构环境下的数据交换。
JSON和XML是文本格式,数据具有可读性,而Protobuf是二进制数据格式,数据本身不具有可读性,只有反序列化之后才能得到真正可读的数据。正因为Protobuf是二进制数据格式,数据序列化之后体积相比JSON和XML药效,更加适合网络传输。
总的来说,在一个需要大量数据传输的应用场景,因为数据量很大,那么选择Protobuf可以明显地减少传输的数据量和提升网络IO的速度。对于打造一款高性能的通信服务器来说,Protobuf传输协议是最高性能的传输协议之一,微信的消息传输就采用了Protobuf协议。
1、一个简单的proto文件的实践案例
Protobuf使用proto文件来预先定义的消息格式。数据包是按照proto文件所定义的消息格式完成二进制码流的编码和解码。proto文件简单来说就是一个消息的协议文件,这个协议文件的后缀文件名为“.proto”。如下为简单的示例:
// [开始头部声明]
syntax = "proto3";
package cn.ken.netty.protocol;
// [结束头部声明]// [开始java选项配置]
option java_package = "cn.ken.netty.protocol";
option java_outer_classname = "MsgProtos";
// [结束java选项配置]// [开始消息定义]
message Msg {uint32 id = 1; // 消息IDstring content = 2; // 消息内容
}
// [结束消息定义]
-
在“.proto”文件的头部声明中,需要声明“.proto”所使用的Protobuf协议版本,默认的协议版本为“proto2”
-
Protobuf支持很多语言,所以它为不同的语言提供了一些可选的声明选项,选项的前面有option关键字
- “java_package"选项的作用为:在生成“proto”文件中消息的POJO类和Builder(构造者)的Java代码时,将Java代码放入指定的package中
- “java_outer_classname”选项的作用为:在生成“proto”文件所对应的Java代码时,所生产的Java外部类的名称
-
在“proto”文件中,使用message这个关键字来定义消息的结构体。在生成“proto”对应的Java代码时,每个具体的消息结构体都对应于一个最终的Java POJO类。消息结构提的字段对应到POJO类的属性。message中可以内嵌message,就像Java的内部类一样
-
每一个消息结构体可以有多个字段。定义一个字段的格式,简单来说就是“类型名称=编号”。字段序号表示为在Protobuf数据包的序列化、反序列化时,该字段的具体排序
在每一个“.proto”文件中,可以声明多个“message”。大部分情况下,会把有依赖关系或者包含关系的message消息结构体写入一个.proto文件。将那些没有关联关系的message消息结构体分别写入不同的文件,这样便于管理。
2、生成POJO和Builder
完成“.proto”文件定义后,下一步就是生成消息的POJO类和Builder类。有两种方式生成Java类:一种是通过控制台命令的方式,一种是使用Maven插件的方式。
-
控制台生成:protoc.exe --java_out=./src/main/java/ ./Msg.proto,该命令表示“proto”文件的名称为./Msg.proto,所生产的POJO类和构造者类的输出文件为./src/main/java/
-
maven生成:protobuf-maven-plugin插件
-
<plugin><groupId>org.xolstice.maven.plugins</groupId><artifactId>protobuf-maven-plugin</artifactId><version>0.5.0</version><extensions>true</extensions><configuration><!--proto文件路径--><protoSourceRoot>${project.basedir}/protobuf</protoSourceRoot><!--目标路径--><outputDirectory>${project.build.sourceDirectory}</outputDirectory><!--设置是否在生成Java文件之前情况outputDirectory的文件--><clearOutputDirectory>false</clearOutputDirectory><!--临时目录--><temporaryProtoFileDirectory>${project.build.directory}/protoc-temp</temporaryProtoFileDirectory><!--protoc可执行文件路径--><protocExecutable>${project.basedir}/protobuf/protoc3.6.1.exe</protocExecutable></configuration><executions><execution><goals><goal>compile</goal><goal>test-compile</goal></goals></execution></executions> </plugins>
-
3、消息POJO和Builder的使用案例
1)构造POJO消息对象
public static MsgProtos.Msg buildMsg() {MsgProtos.Msg.Builder builder = MsgProtos.Msg.newBuilder();builder.setId(100).setContent("hello");return builder.build();
}
protobuf为每个message消息结构体生成的Java类中,包含了一个POJO类,一个Builder类。构造POJO消息,首先需要使用POJO类的newBuilder静态方法获得一个Builder构造者。。每一个POJO字段的值,需要通过Builder的setter方法去设置(消息POJO对象并没有setter方法)。字段值设置完成之后哦,使用构造者的build方法构造出POJO消息对象。
2)序列化和反序列化
public class ProtoTest {@Testpublic void test1() throws IOException {MsgProtos.Msg msg = buildMsg();// 将protobuf对象序列化为二进制字节数组byte[] bytes = msg.toByteArray();ByteArrayOutputStream stream = new ByteArrayOutputStream();stream.write(bytes);// 反序列化MsgProtos.Msg inMsg = MsgProtos.Msg.parseFrom(stream.toByteArray());System.out.println(inMsg.getId());System.out.println(inMsg.getContent());}@Testpublic void test2() throws IOException {MsgProtos.Msg msg = buildMsg();// 将protobuf对象序列化为二进制字节数组byte[] bytes = msg.toByteArray();ByteArrayOutputStream stream = new ByteArrayOutputStream();msg.writeTo(stream);// 反序列化MsgProtos.Msg inMsg = MsgProtos.Msg.parseFrom(stream.toByteArray());System.out.println(inMsg.getId());System.out.println(inMsg.getContent());}@Testpublic void test3() throws IOException {MsgProtos.Msg msg = buildMsg();// 将protobuf对象序列化为二进制字节数组byte[] bytes = msg.toByteArray();ByteArrayOutputStream stream = new ByteArrayOutputStream();msg.writeDelimitedTo(stream);// 反序列化ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);MsgProtos.Msg inMsg = MsgProtos.Msg.parseDelimitedFrom(inputStream); System.out.println(inMsg.getId());System.out.println(inMsg.getContent());}
}方法三类似于Head-Content协议,在序列化的字节码之前添加了字节数组的长度,反序列化时protubuf从输入流中先读取varint32类型的长度值,然后根据长度值读取此消息的二进制字节,在反序列化得到POJO新的实例。
Protobuf做了优化,长度类型不是固定长度的int类型,而是可变长度varint32类型
这种方式可以用于异步操作的NIO应用场景中,解决了粘包/半包问题。
四、Protobuf编解码的实践案例
Netty默认支持Protobuf的编码和解码,内置了一套基础的Protobuf编码和解码器。
1、Protobuf编码器和解码器的原理
Netty内置的Protobuf专用的基础编码器/解码器为ProtobufEncoder编码器和ProtobufDecoder解码器。
- ProtobufEncoder编码器:直接使用了message.toByteArray()方法将Protobuf的POJO消息对象编码成二进制字节,数据放入Netty的Bytebuf数据包中,然后交给下一个编码器
- ProtobufDecoder解码器:该类的构造函数需要传入一个POJO消息的对象实例,以此来将二进制的字节解析为Protobuf POJO消息对象
- ProtobufVarint32LengthFieldPrepender长度编码器:在ProtobufEncoder生成的字节数组之前,前置一个varint32数字,表示序列化的二进制字节数
- ProtobufVarint32FrameDecoder长度解码器:根据数据包中varint32中的长度值,解码一个足额的字节数组,然后将字节数组交给下一站的解码器ProtobufDecoder
什么是varint32类型的长度,为什么不用int类型?
varint32是一种紧凑地表示数字的方式,它不是一种具体的数据类型。varint32使用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数,值越大使用的字节数越多。varint32根据值的大小自动进行长度的收缩,这能减少用于保存长度的字节数。也就是说varint32不是固定长度,为了更好地减少通信过程中的传输量,消息头中的长度尽量采用varint32格式。
2、示例
服务端:
public class ProtobufServer {public void runServer() throws InterruptedException {ServerBootstrap bootstrap = new ServerBootstrap();NioEventLoopGroup bossLoopGroup = new NioEventLoopGroup(1);NioEventLoopGroup workerLoopGroup = new NioEventLoopGroup(0);// 1.设置反应器线程组bootstrap.group(bossLoopGroup, workerLoopGroup);// 2.设置nio类型的通道bootstrap.channel(NioServerSocketChannel.class);// 3.设置监听端口bootstrap.localAddress(8000);// 4.设置通道的参数bootstrap.option(ChannelOption.SO_KEEPALIVE, true);bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ch.pipeline().addLast(new ProtobufVarint32FrameDecoder()).addLast(new ProtobufDecoder(MsgProtos.Msg.getDefaultInstance())).addLast(new ProtobufBusinessDecoder());}});ChannelFuture bind = bootstrap.bind().sync();bind.channel().closeFuture().sync();bossLoopGroup.shutdownGracefully();workerLoopGroup.shutdownGracefully();}static class ProtobufBusinessDecoder extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {MsgProtos.Msg protoMsg = (MsgProtos.Msg) msg;System.out.println(protoMsg.getId());System.out.println(protoMsg.getContent());}}public static void main(String[] args) throws InterruptedException {new ProtobufServer().runServer();}
}客户端:
public class ProtobufClient {public static void main(String[] args) throws InterruptedException {Bootstrap bootstrap = new Bootstrap();NioEventLoopGroup workerLoopGroup = new NioEventLoopGroup();bootstrap.group(workerLoopGroup);bootstrap.channel(NioSocketChannel.class);bootstrap.remoteAddress(new InetSocketAddress("localhost", 8000));bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);bootstrap.handler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ch.pipeline().addLast(new ProtobufVarint32LengthFieldPrepender()).addLast(new ProtobufEncoder());}});ChannelFuture connect = bootstrap.connect();connect.sync();Channel channel = connect.channel();for (int i = 0; i < 1000; i++) {MsgProtos.Msg user = MsgProtos.Msg.newBuilder().setId(i).setContent("hello" + i).build();channel.writeAndFlush(user).sync();}workerLoopGroup.shutdownGracefully();}
}五、Protobuf协议语法
在Protobuf中,通信协议的格式是通过“.proto”文件定义的。一个“.proto”文件有两大组成部分:头部声明、消息结构体的定义。
1、头部声明
-
协议的版本:syntax
-
包名:package(用于避免信息名字冲突)
-
特定语言的选项设置:option
-
option java_package:表示Protobuf编译器在生成Java POJO消息类时,生成类所在的Java包名,如果没有设置该选项,会以头部声明中的package作为Java包名
-
option java_multiple_files:表示在生成Java类时的打包方式,有两种方式:
- 一个消息对应一个独立的Java类
- 所有的消息都作为内部类,打包到一个外部类中
- 默认值为false也就是方法2
-
2、消息结构体
可以定义一个或多个消息结构体。定义Protobuf消息结构体的关键字为message。一个信息结构体由一个或者多个消息字段组合而成。
Protobuf消息字段的格式为:
-
限定修饰符
-
repeated:表示该字段可以包含0-N个元素值,相当于Java中的List
-
singular:表示该字段可以包含0-1个元素值,是默认的字段修饰符
-
reserved:用来保留字段名称和分配标识符号,用于将来的扩展
- reserved 12, 5, 9 to 11; // 预留将来使用的分配标识号
- reserved “foo”, “bar”; // 预留将来使用的字段名
-
-
数据类型
- double
- Float
- int32:使用变长编码,对于负值的效率很低,如果字段有可能有负值,使用sint64代替
- uint32:使用变长编码
- uint64:使用变长编码
- sint32:使用变长编码,在负值时比int32高效得多
- sint64:使用变长编码,有符号的整型值,编码时比通常的int64高效
- fixed32:固定4个字节,如果数值总是大于228,这个类型会比uint32高效
- fixed64:固定8个字节,如果数值总是大于256,这个类型会比uint64高效
- sfixed32
- sfixed64
- Bool
- String
- Bytes
-
字段名称:建议采用下划线分割
-
=
-
分配标识号:在消息定义中,每个字段都有唯一的一个数字标识符,可以理解为字段的编码值。通过该值,通信双方才能互相识别对方的字段。相同的编码值的限定修饰符和数据类型必须相同。
- 分配标识号是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能再改变
- 一个消息结构体中的标识号是无需连续的
- 同一个消息结构体中,不同的字段不能使用相同的标识号
- 取值范围为4个字节的整数,且1900-2000之内的标识号为Google Protobuf系统的内部保留值,建议不要在自己的项目中使用
fixed32的打包效率比int32的效率高,但是使用的空间一般比int32多。根据项目的实际情况,一般选择fixed32,如果遇到对于传输数据量要求比较苛刻的环境,则可以选择int32。如果数值较小,如在0-127时,其只需要使用一个字节打包。
3、其他的语法规范
-
import声明:在需要多个消息结构体时,“.proto”文件可以像Java语言的类文件一样分离为多个,在需要时通过import导入需要的文件。导入的操作和Java的import操作大致相同
-
嵌套消息:“.protp”支持嵌套消息,消息中可以包含另一个消息作为其字段,也可以在消息中定义一个新的消息。如果想在父消息类型的外部重复使用内部的消息类型,可以使用Parent.Type的形式来使用。如:
-
message Outer{message Middle{message Inner{int64 ival = 1;bool booly = 2;}} } message SomeOtherMessage{Outer.Middle.Inner ref = 1; }
-
-
enum枚举:枚举的定义和Java相同,但是有一些限制。枚举值必须大于等于0的整数。使用分号分割枚举变量而不是Java中的逗号
相关文章:

JSON和Protobuf序列化
文章目录 一、粘包和拆包1、半包问题2、半包现象原理 二、JSON协议通信1、通用类库2、JSON传输的编码器和解码器 三、Protobuf协议通信1、一个简单的proto文件的实践案例2、生成POJO和Builder3、消息POJO和Builder的使用案例1)构造POJO消息对象2)序列化和…...
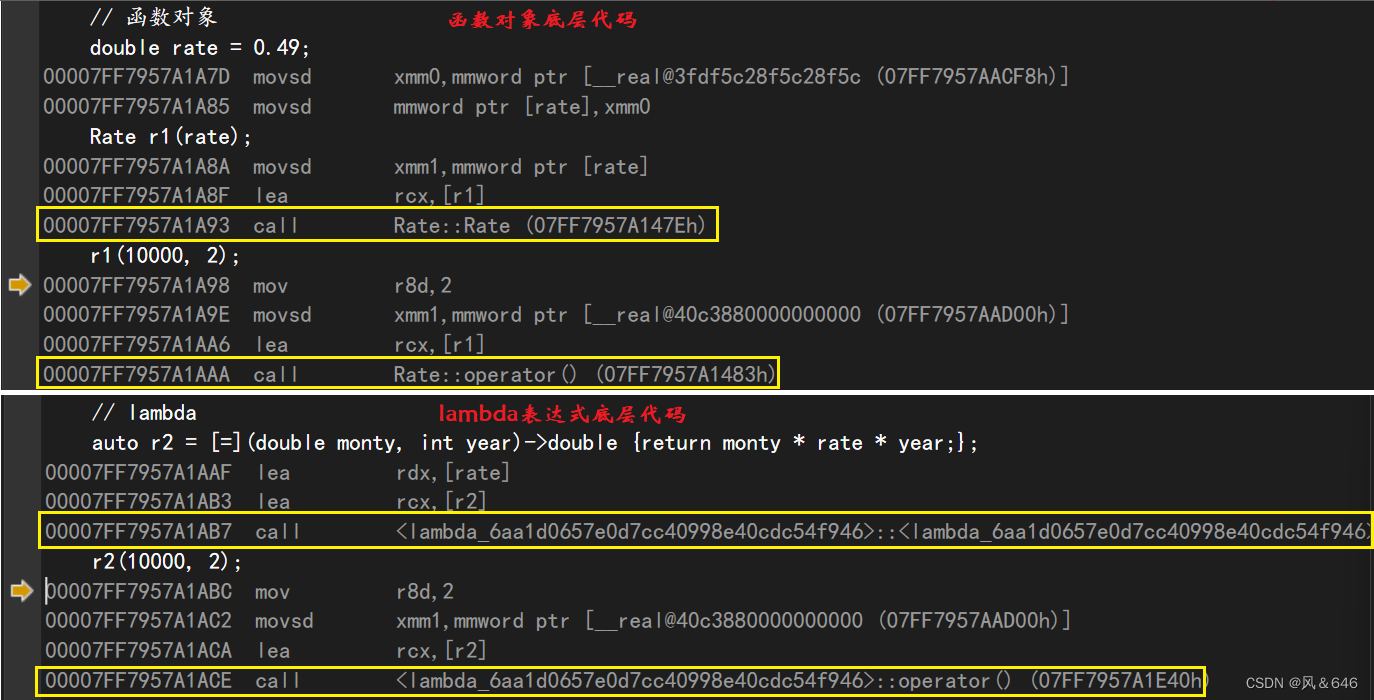
lambda表达式 - c++11
文章目录: lambda表达式概念lambda表达式语法函数对象与lambda表达式 lambda表达式概念 lambda 表达式是 c11 中引入的一种匿名函数,它可以在需要函数对象的地方使用,可以用作函数参数或返回值。lambda 表达式可以看作是一种局部定义的函数对…...

509. 斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n - 1) F(n - 2),其中 n > 1给定 n &a…...

四、[mysql]索引优化-1
目录 前言一、场景举例1.联合索引第一个字段用范围查询不走索引(分情况)2.强制走指定索引3.覆盖索引优化4.in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描5.like 后% 一般情况都会走索引(索引下推) 二、Mysql如何选择合适的索…...
:神经网络-最大池化使用)
PyTorch入门学习(九):神经网络-最大池化使用
目录 一、数据准备 二、创建神经网络模型 三、可视化最大池化效果 一、数据准备 首先,需要准备一个数据集来演示最大池化层的应用。在本例中,使用了CIFAR-10数据集,这是一个包含10个不同类别图像的数据集,用于分类任务。我们使…...
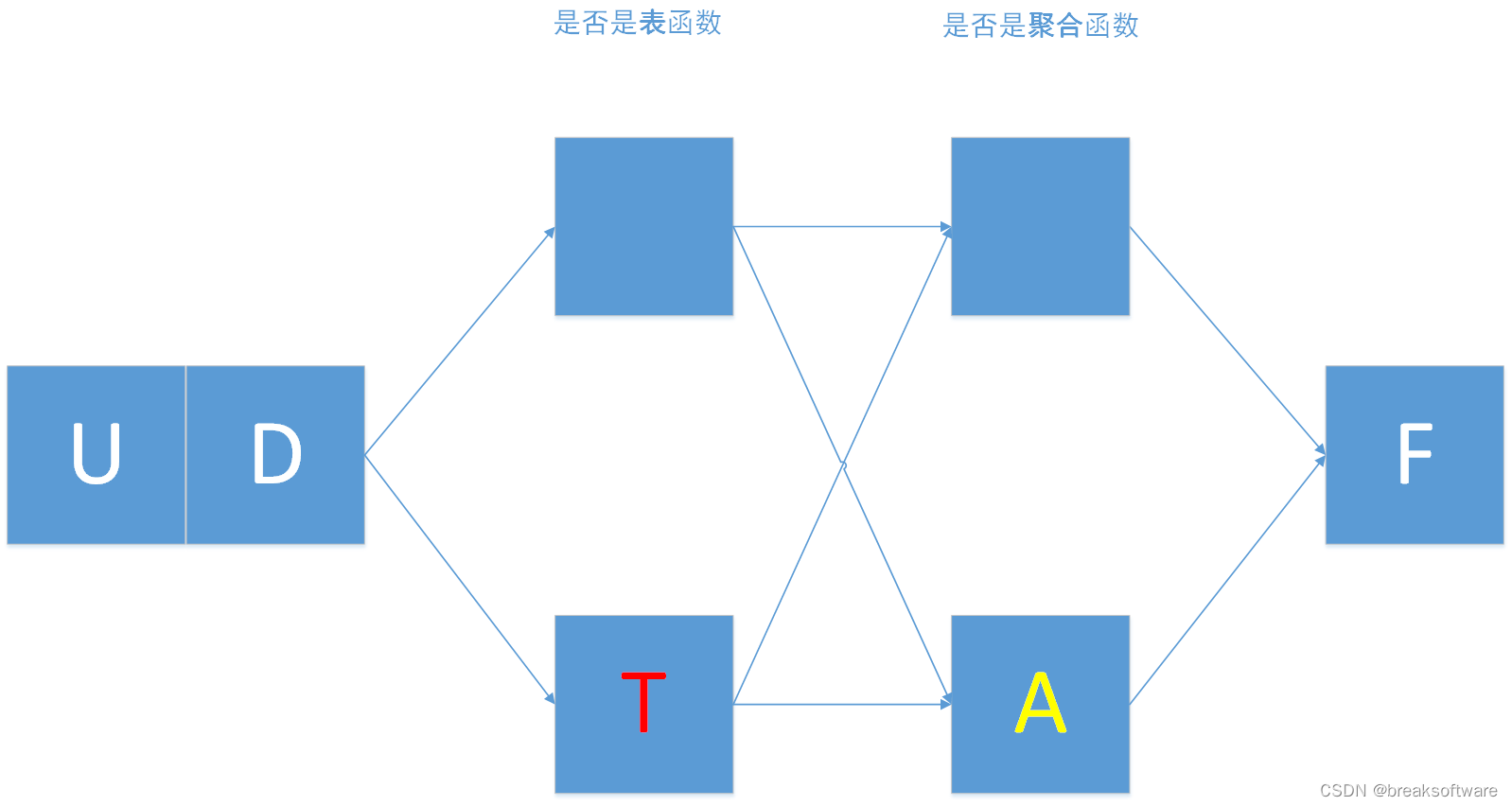
0基础学习PyFlink——用户自定义函数之UDF
大纲 标量函数入参并非表中一行(Row)入参是表中一行(Row)alias PyFlink中关于用户定义方法有: UDF:用户自定义函数。UDTF:用户自定义表值函数。UDAF:用户自定义聚合函数。UDTAF&…...

英语小作文模板(06求助+描述;07描述+建议)
06 求助描述: 题目背景及要求 第一段 第二段 第三段 翻译成中文 07 描述+建议: 题目背景及要求 第一段 第二段...

为什么感觉假期有时候比上班还累?
假期比上班还累的感觉可能由以下几个原因造成: 计划过度:在假期里,人们往往会制定各种计划,如旅游、聚会、休息等,以充分利用这段时间。然而,如果这些计划过于紧张或安排得过于紧密,就会导致身…...
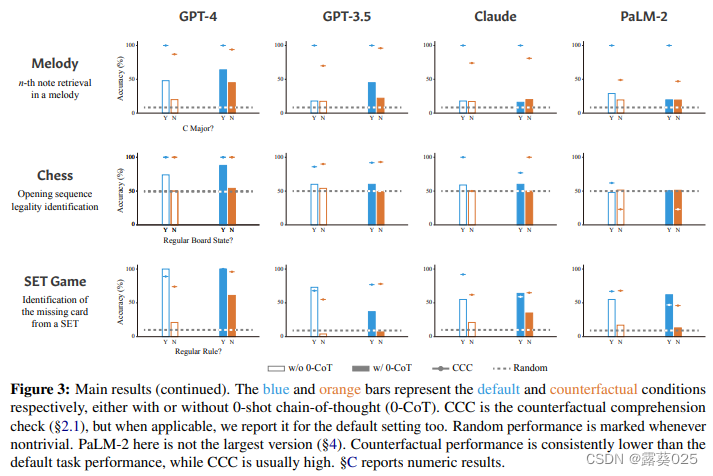
推理还是背诵?通过反事实任务探索语言模型的能力和局限性
推理还是背诵?通过反事实任务探索语言模型的能力和局限性 摘要1 引言2 反事实任务2.1 反事实理解检测 3 任务3.1 算术3.2 编程3.3 基本的句法推理3.4 带有一阶逻辑的自然语言推理3.5 空间推理3.6 绘图3.7 音乐3.8 国际象棋 4 结果5 分析5.1 反事实条件的“普遍性”5…...
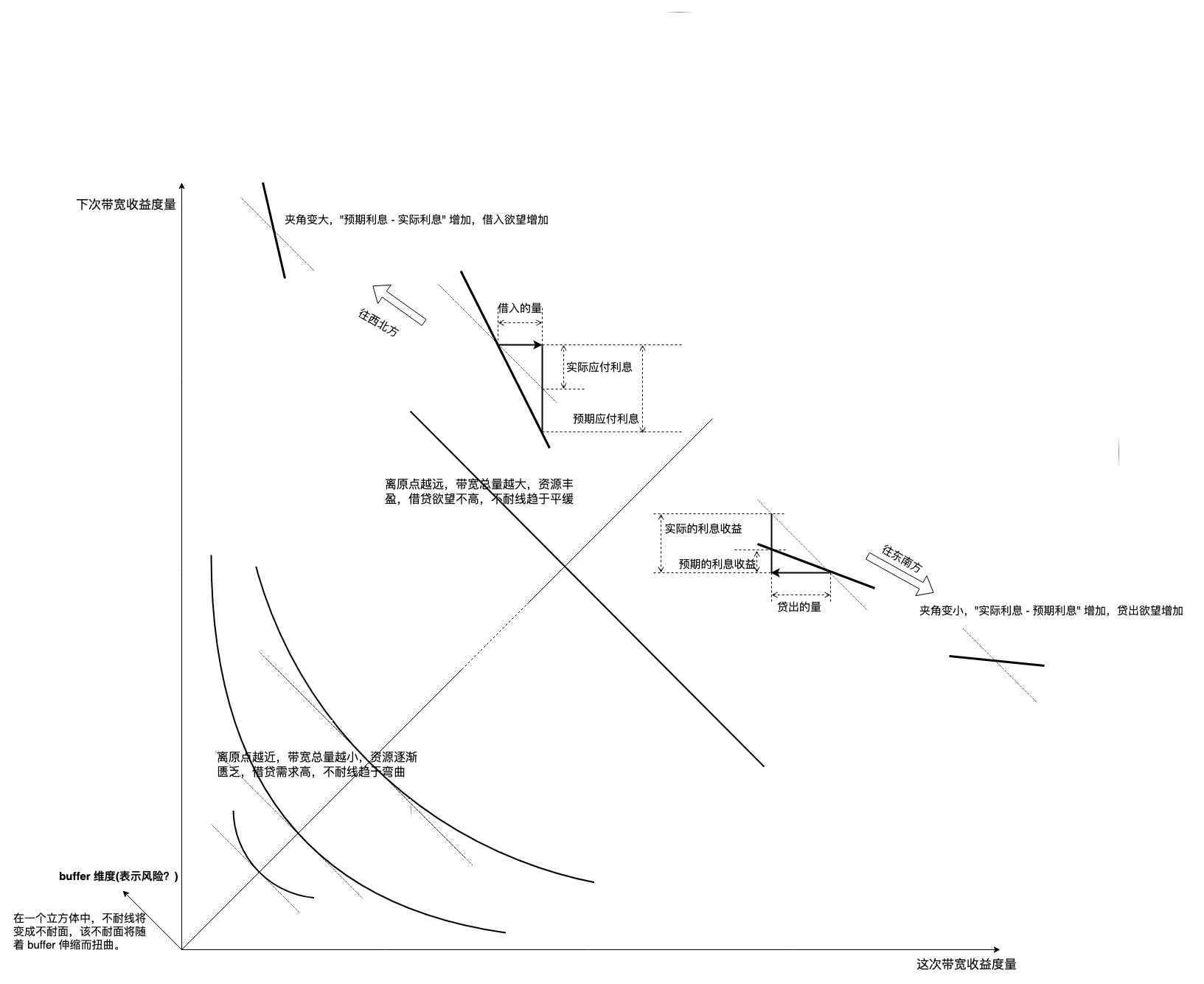
《利息理论》指导 TCP 拥塞控制
欧文费雪《利息原理》第 10 章,第 11 章对利息的几何说明是普适的,任何一个负反馈系统都能引申出新结论。给出原书图示,本文依据于此,详情参考原书: 将 burst 看作借贷是合理的,它包含成本(报文)…...
)
Bsdiff,Bspatch 的差分增量升级(基于Win和Linux)
目录 背景 内容 准备工作 在windows平台上 在linux平台上 正式工作 生成差分文件思路 作用差分文件思路 在保持相同目录结构进行差分增量升级 服务端(生成差分文件) 客户端(作用差分文件) 背景 像常见的Android 的linux平台,游戏,系统更新都…...

【3妹教我学历史-秦朝史】2 秦穆公-韩原之战
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 3妹:2哥,今天下班这么早&#…...

车载控制器
文章目录 车载控制器电动汽车上都有什么ECU 车载控制器 智能汽车上的控制器数量因车型和制造商而异。一般来说,现代汽车可能有50到100个电子控制单元(ECU)或控制器。这些控制器负责管理各种系统,如发动机管理、刹车、转向、空调、…...
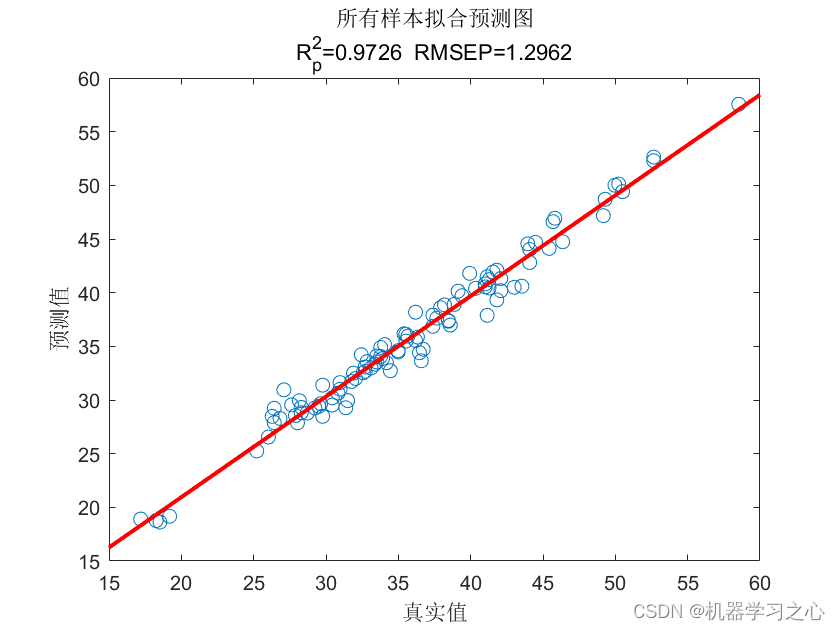
回归预测 | Matlab实现RIME-CNN-SVM霜冰优化算法优化卷积神经网络-支持向量机的多变量回归预测
回归预测 | Matlab实现RIME-CNN-SVM霜冰优化算法优化卷积神经网络-支持向量机的多变量回归预测 目录 回归预测 | Matlab实现RIME-CNN-SVM霜冰优化算法优化卷积神经网络-支持向量机的多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.RIME-CNN-SVM霜冰优化算…...

使用Jaeger进行分布式跟踪:学习如何在服务网格中使用Jaeger来监控和分析请求的跟踪信息
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

添加多个单元对象
开发环境: Windows 11 家庭中文版Microsoft Visual Studio Community 2019VTK-9.3.0.rc0vtk-example参考代码 demo解决问题:不同阶段添加多个单元对象。 定义一个点集和一个单元集合,单元的类型可以是点、三角形、矩形、多边形等基本图形。只…...
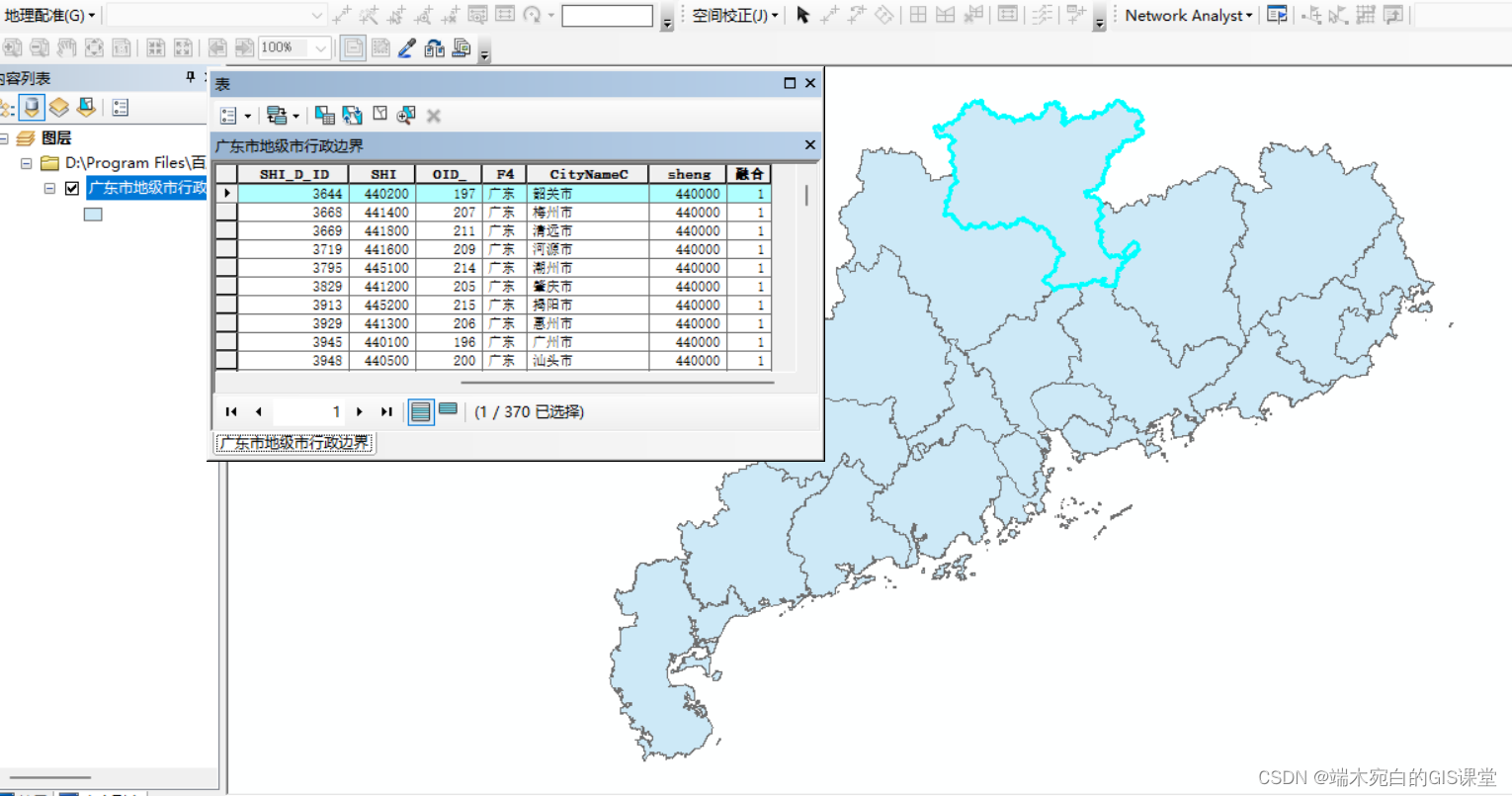
十八、模型构建器(ModelBuilder)快速提取城市建成区——批量掩膜提取夜光数据、夜光数据转面、面数据融合、要素转Excel(基于参考比较法)
一、前言 前文实现批量投影栅格、转为整型,接下来重点实现批量提取夜光数据,夜光数据转面、夜光数据面数据融合、要素转Excel。将相关结果转为Excel,接下来就是在Excel中进行阈值的确定,阈值确定无法通过批量操作,除非采用其他方式,但是那样的学习成本较高,对于参考比较…...

HarmonyOS开发:基于http开源一个网络请求库
前言 网络封装的目的,在于简洁,使用起来更加的方便,也易于我们进行相关动作的设置,如果,我们不封装,那么每次请求,就会重复大量的代码逻辑,如下代码,是官方给出的案例&am…...
【杂记】Ubuntu20.04装系统,安装CUDA等
装20.04系统 安装系统的过程中,ROG的B660G主板,即使不关掉Secure boot也是可以的,不会影响正常安装,我这边出现问题的主要原因是使用了Ventoy制作的系统安装盘,导致每次一选择使用U盘的UEFI启动,就会跳回到…...

040-第三代软件开发-全新波形抓取算法
第三代软件开发-全新波形抓取算法 文章目录 第三代软件开发-全新波形抓取算法项目介绍全新波形抓取算法代码小解 关键字: Qt、 Qml、 抓波、 截获、 波形 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object …...

如何通过3个步骤掌握iOS游戏修改神器H5GG
如何通过3个步骤掌握iOS游戏修改神器H5GG 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 你是否曾想在iOS设备上修改游戏数值却苦于没有越狱?是否觉得传统游戏修改工具操作…...

Flutter聊天UI组件库flutter_chat_ui:快速构建高质量聊天界面
1. 项目概述与核心价值如果你正在用Flutter开发一个聊天应用,并且不想从零开始手搓UI组件,那么flyerhq/flutter_chat_ui这个开源库,绝对值得你花时间研究一下。它不是一个完整的聊天SDK,不负责消息的发送、接收和存储,…...

2026年抠图app有哪些?一篇避坑指南告诉你哪款最好用
最近身边朋友经常问我:"抠图app有哪些?"、"免费抠图app有哪些工具推荐?",我决定整理一份完整的对比指南,基于我的实际使用经验,为你揭开各款抠图工具的真实面目。说实话,现…...

基于本地大模型的字幕翻译:LM Studio集成方案与实战优化
1. 项目概述:当本地大模型遇上字幕翻译最近在折腾本地大模型应用时,发现了一个挺有意思的场景:字幕翻译。很多朋友喜欢看海外影视剧或学习资料,但苦于没有高质量的中文字幕。在线翻译工具要么有字数限制,要么担心隐私泄…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化
英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟排位赛中,你是否曾因错过接受对局而懊恼不已&a…...

开源机械爪OpenClaw:从设计到力控抓取的完整实现指南
1. 项目概述:从“OpenClaw”看开源机械爪的无限可能最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“MeyerZhou/openclaw”。光看名字,你大概能猜到这是个关于机械爪的开源项目。没错,这是一个旨在提供低成本、模块…...