TensorFlow案例学习:简单的音频识别
前言
以下内容均来源于官方教程:简单的音频识别:识别关键字
音频识别
下载数据集
下载地址:http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip
可以直接浏览器访问下载。
下载完成后将其解压到项目里,从文件夹里可以看到有8个子文件夹,文件夹的名称就是8个语音命令。
注意:我们只需要mini_speech_commands文件夹,其他的不需要
加载数据集
# 加载训练数据集、验证集
train_ds, val_ds = tf.keras.utils.audio_dataset_from_directory(directory='./data/mini_speech_commands', # 数据集路径batch_size=64, # 批次validation_split=0.2, # 验证集占数据集的20%seed=0, # 指定随机生成数据集的种子# 每个样本的输出序列长度。音频剪辑在 1kHz 时为 16 秒或更短。将较短的填充到正好 1 秒(并且会修剪较长的填充),以便可以轻松批量处理output_sequence_length=16000,subset='both' # 训练集和验证集两者同时使用
)
获取类别
# 获取命令的类别
label_names = np.array(train_ds.class_names)
print("命令类别:", label_names)

刚好与子文件的名称和顺序一致。
维度压缩
文档中说,此数据集仅包含单声道音频,因此需要 对输入的音频数据进行维度压缩
-
单声道(mono)音频只有一个声道。这意味着所有的音频信号被混合到一个通道中,不区分左右声道。在单声道音频中,所有的声音通过单个扬声器播放。单声道音频适用于大部分音频应用,如电话通信、语音录音等。
-
多声道(stereo)音频有两个声道,左声道(left channel)和右声道(right channel)。通过左右声道的不同信号,可以在音频空间上创建立体声效果。多声道音频提供了更加丰富的音频体验,可以更好地模拟现实环境中的声音分布。常见的应用包括音乐播放、电影声音、游戏音效等。
def squeeze(audio,labels):audio = tf.squeeze(audio,axis=-1)return audio,labelstrain_ds = train_ds.map(squeeze,tf.data.AUTOTUNE)
val_ds = val_ds.map(squeeze,tf.data.AUTOTUNE)
拆分验证集
这块没太看明白在干嘛
test_ds = val_ds.shard(num_shards=2, index=0)
val_ds = val_ds.shard(num_shards=2, index=1)
for example_audio, example_labels in train_ds.take(1):print(example_audio.shape)print(example_labels.shape)
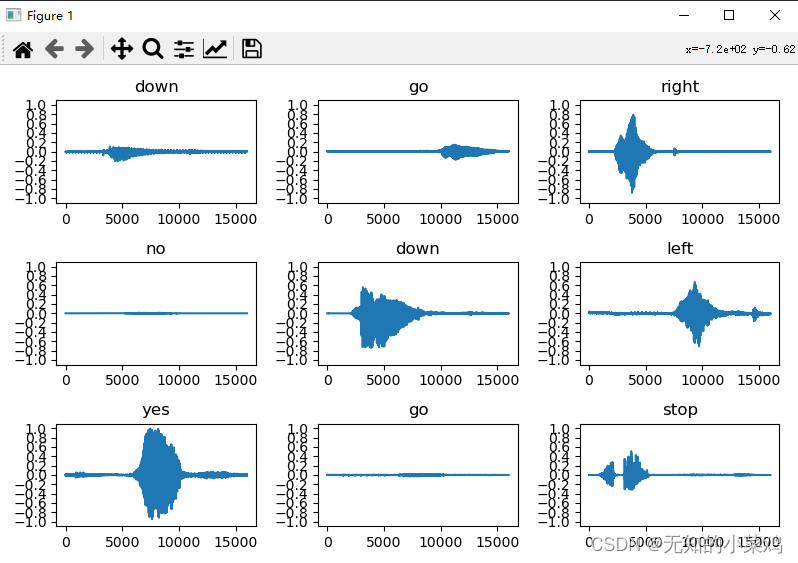
绘制音频波形
这块只是让我们可视化的观察音频的波形,这块后面可以注释掉
plt.figure(figsize=(8, 5))
rows = 3
cols = 3
n = rows * cols
for i in range(n):plt.subplot(rows, cols, i+1)audio_signal = example_audio[i]plt.plot(audio_signal)plt.title(label_names[example_labels[i]])plt.yticks(np.arange(-1.2, 1.2, 0.2))plt.ylim([-1.1, 1.1])
plt.tight_layout()
plt.show()
将波形转换为频谱图
将波形转换为频谱图的目的是为了更好地分析和理解音频信号。
波形是时域上的表示,它展示了音频信号在时间轴上的变化。然而,频谱图是频域上的表示,它将音频信号分解为不同的频率成分,并显示每个频率成分的能量或振幅。
通过将波形转换为频谱图,我们可以更清晰地看到音频信号中哪些频率成分对于特定的声音或事件是重要的。这对于音频处理任务(如语音识别、音频分类、音频分割等)以及音频信号理解和分析非常有帮助。
def get_spectrogram(waveform):spectrogram = tf.signal.stft(waveform, frame_length=255, frame_step=128)spectrogram = tf.abs(spectrogram)spectrogram = spectrogram[..., tf.newaxis]return spectrogram
浏览数据
打印一个示例的张量化波形和相应频谱图的形状,并播放原始音频:
for i in range(3):label = label_names[example_labels[i]]waveform = example_audio[i]spectrogram = get_spectrogram(waveform)print('Label:', label)print('Waveform shape:', waveform.shape)print('Spectrogram shape:', spectrogram.shape)print('Audio playback')display.display(display.Audio(waveform, rate=16000))
从音频数据集创建频谱图数据集
# 从音频数据集创建频谱图数据集
def make_spec_ds(ds):return ds.map(map_func=lambda audio,label: (get_spectrogram(audio), label),num_parallel_calls=tf.data.AUTOTUNE)train_spectrogram_ds = make_spec_ds(train_ds)
val_spectrogram_ds = make_spec_ds(val_ds)
test_spectrogram_ds = make_spec_ds(test_ds)
减少训练模型时的读取延迟
train_spectrogram_ds = train_spectrogram_ds.cache().shuffle(10000).prefetch(tf.data.AUTOTUNE)
val_spectrogram_ds = val_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)
test_spectrogram_ds = test_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)
使用卷积神经网络创建并训练模型
# 使用卷积神经网络创建模型
input_shape = example_spectrograms.shape[1:]
print('Input shape:', input_shape)
num_labels = len(label_names)
norm_layer = tf.keras.layers.Normalization() # 创建规范化层,便于更好的进行模型训练和推断
norm_layer.adapt(data=train_spectrogram_ds.map(map_func=lambda spec, label: spec))model = tf.keras.models.Sequential([tf.keras.layers.Input(shape=input_shape),tf.keras.layers.Resizing(32, 32),norm_layer,tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.Conv2D(64, 3, activation='relu'),tf.keras.layers.MaxPool2D(),tf.keras.layers.Dropout(0.25),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(num_labels),
])model.summary()# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(), # 优化器loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数metrics=['accuracy'] # 准确率作为评估标准
)# 训练模型,并记录训练的日志
history = model.fit(train_spectrogram_ds,validation_data=val_spectrogram_ds,epochs=10,callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
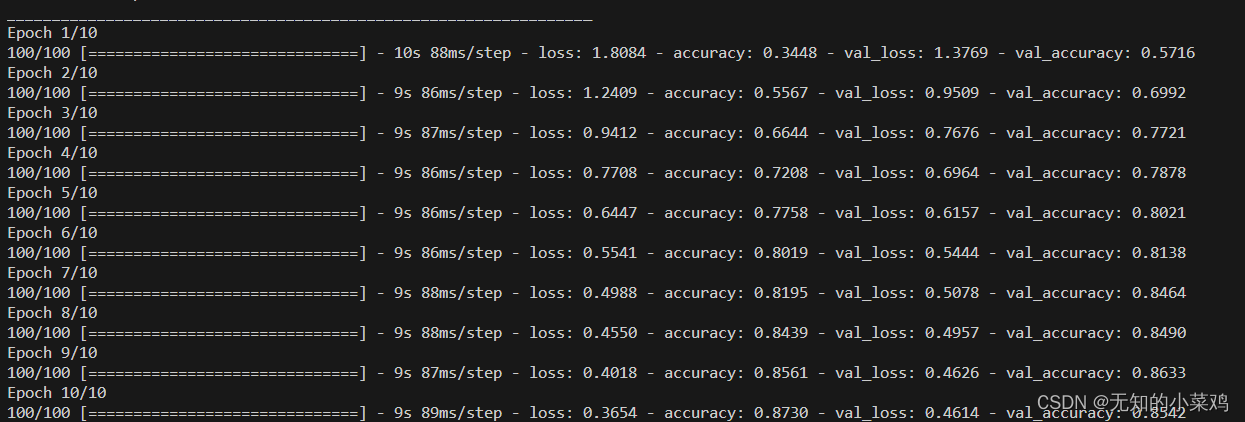
评估性能
model.evaluate(test_spectrogram_ds, return_dict=True)
导出模型
class ExportModel(tf.Module):def __init__(self, model):self.model = model# Accept either a string-filename or a batch of waveforms.# YOu could add additional signatures for a single wave, or a ragged-batch.self.__call__.get_concrete_function(x=tf.TensorSpec(shape=(), dtype=tf.string))self.__call__.get_concrete_function(x=tf.TensorSpec(shape=[None, 16000], dtype=tf.float32))@tf.functiondef __call__(self, x):# If they pass a string, load the file and decode it.if x.dtype == tf.string:x = tf.io.read_file(x)x, _ = tf.audio.decode_wav(x, desired_channels=1, desired_samples=16000,)x = tf.squeeze(x, axis=-1)x = x[tf.newaxis, :]x = get_spectrogram(x)result = self.model(x, training=False)class_ids = tf.argmax(result, axis=-1)class_names = tf.gather(label_names, class_ids)return {'predictions': result,'class_ids': class_ids,'class_names': class_names}export = ExportModel(model)
export(tf.constant('./data/mini_speech_commands/no/012c8314_nohash_0.wav'))tf.saved_model.save(export, "saved")
下面是保存的模型
完整代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from IPython import display# 加载训练数据集、验证集
train_ds, val_ds = tf.keras.utils.audio_dataset_from_directory(directory='./data/mini_speech_commands', # 数据集路径batch_size=64, # 批次validation_split=0.2, # 验证集占数据集的20%seed=0, # 指定随机生成数据集的种子# 每个样本的输出序列长度。音频剪辑在 1kHz 时为 16 秒或更短。将较短的填充到正好 1 秒(并且会修剪较长的填充),以便可以轻松批量处理output_sequence_length=16000,subset='both' # 训练集和验证集两者同时使用
)# 获取命令的类别
label_names = np.array(train_ds.class_names)
print("命令类别:", label_names)# 输入数据压缩def squeeze(audio, labels):audio = tf.squeeze(audio, axis=-1)return audio, labelstrain_ds = train_ds.map(squeeze, tf.data.AUTOTUNE)
val_ds = val_ds.map(squeeze, tf.data.AUTOTUNE)# 拆分验证集
test_ds = val_ds.shard(num_shards=2, index=0)
val_ds = val_ds.shard(num_shards=2, index=1)for example_audio, example_labels in train_ds.take(1):print(example_audio.shape)print(example_labels.shape)# 绘制音频波形
# plt.figure(figsize=(8, 5))
# rows = 3
# cols = 3
# n = rows * cols
# for i in range(n):
# plt.subplot(rows, cols, i+1)
# audio_signal = example_audio[i]
# plt.plot(audio_signal)
# plt.title(label_names[example_labels[i]])
# plt.yticks(np.arange(-1.2, 1.2, 0.2))
# plt.ylim([-1.1, 1.1])
# plt.tight_layout()
# plt.show()# 将波形转换为频谱图
def get_spectrogram(waveform):spectrogram = tf.signal.stft(waveform, frame_length=255, frame_step=128)spectrogram = tf.abs(spectrogram)spectrogram = spectrogram[..., tf.newaxis]return spectrogram# 浏览数据
for i in range(3):label = label_names[example_labels[i]]waveform = example_audio[i]spectrogram = get_spectrogram(waveform)print('Label:', label)print('Waveform shape:', waveform.shape)print('Spectrogram shape:', spectrogram.shape)print('Audio playback')display.display(display.Audio(waveform, rate=16000))# 从音频数据集创建频谱图数据集def make_spec_ds(ds):return ds.map(map_func=lambda audio, label: (get_spectrogram(audio), label),num_parallel_calls=tf.data.AUTOTUNE)train_spectrogram_ds = make_spec_ds(train_ds)
val_spectrogram_ds = make_spec_ds(val_ds)
test_spectrogram_ds = make_spec_ds(test_ds)# 检查数据集的不同示例的频谱图
for example_spectrograms, example_spect_labels in train_spectrogram_ds.take(1):break# 减少训练模型时的读取延迟
train_spectrogram_ds = train_spectrogram_ds.cache().shuffle(10000).prefetch(tf.data.AUTOTUNE)
val_spectrogram_ds = val_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)
test_spectrogram_ds = test_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)# 使用卷积神经网络创建模型
input_shape = example_spectrograms.shape[1:]
print('Input shape:', input_shape)
num_labels = len(label_names)
norm_layer = tf.keras.layers.Normalization() # 创建规范化层,便于更好的进行模型训练和推断
norm_layer.adapt(data=train_spectrogram_ds.map(map_func=lambda spec, label: spec))model = tf.keras.models.Sequential([tf.keras.layers.Input(shape=input_shape),tf.keras.layers.Resizing(32, 32),norm_layer,tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.Conv2D(64, 3, activation='relu'),tf.keras.layers.MaxPool2D(),tf.keras.layers.Dropout(0.25),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(num_labels),
])model.summary()# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(), # 优化器loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数metrics=['accuracy'] # 准确率作为评估标准
)# 训练模型,并记录训练的日志
history = model.fit(train_spectrogram_ds,validation_data=val_spectrogram_ds,epochs=10,callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)# 评估性能
model.evaluate(test_spectrogram_ds, return_dict=True)# 导出模型class ExportModel(tf.Module):def __init__(self, model):self.model = modelself.__call__.get_concrete_function(x=tf.TensorSpec(shape=(), dtype=tf.string))self.__call__.get_concrete_function(x=tf.TensorSpec(shape=[None, 16000], dtype=tf.float32))@tf.functiondef __call__(self, x):if x.dtype == tf.string:x = tf.io.read_file(x)x, _ = tf.audio.decode_wav(x, desired_channels=1, desired_samples=16000,)x = tf.squeeze(x, axis=-1)x = x[tf.newaxis, :]x = get_spectrogram(x)result = self.model(x, training=False)class_ids = tf.argmax(result, axis=-1)class_names = tf.gather(label_names, class_ids)return {'predictions': result,'class_ids': class_ids,'class_names': class_names}export = ExportModel(model)
export(tf.constant('./data/mini_speech_commands/no/012c8314_nohash_0.wav'))tf.saved_model.save(export, "saved")
加载使用导出的模型
使用模型预测down的音频
import tensorflow as tf# 直接加载模型的目录
new_model = tf.saved_model.load("./saved")
res = new_model('./data/mini_speech_commands/down/004ae714_nohash_0.wav')
print("结果:",res)class_names = ['down', 'go', 'left', 'no', 'right', 'stop', 'up', 'yes']
class_index = res['class_ids'].numpy()[0]
class_name = class_names[class_index]
print("类别名称:", class_name)

相关文章:
TensorFlow案例学习:简单的音频识别
前言 以下内容均来源于官方教程:简单的音频识别:识别关键字 音频识别 下载数据集 下载地址:http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 可以直接浏览器访问下载。 下载完成后将其解压到项目…...

css小程序踩坑记录
写标签设置距离 一直设置不动 写个双层 设置动了 神奇 好玩...

Android sqlite分页上传离线订单后删除
1、判断订单表的的总数是否大于0,如果大于0开始上传订单 public int getOrderCount() {String query "SELECT COUNT(*) FROM " TABLE_NAME;Cursor cursor db.rawQuery(query, null);int count 0;if (cursor.moveToFirst()) {count cursor.getInt(0);…...
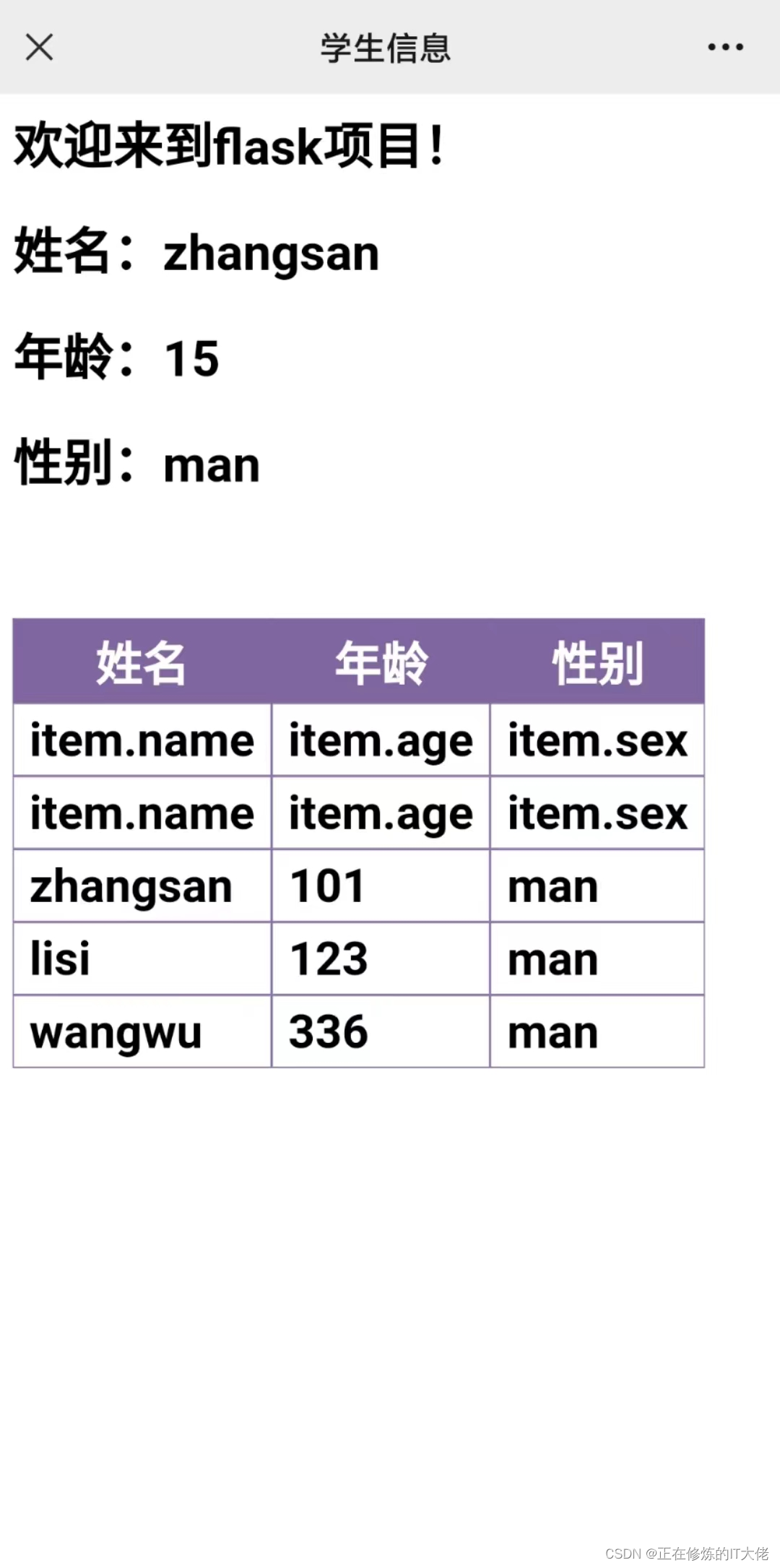
Flask基本教程以及Jinjia2模板引擎简介
flask基本使用 直接看代码吧,非常容易上手: # 创建flask应用 app Flask(__name__)# 路由 app.route("/index", methods[GET]) def index():return "FLASK:欢迎访问主页!"if __name__ "__main__"…...
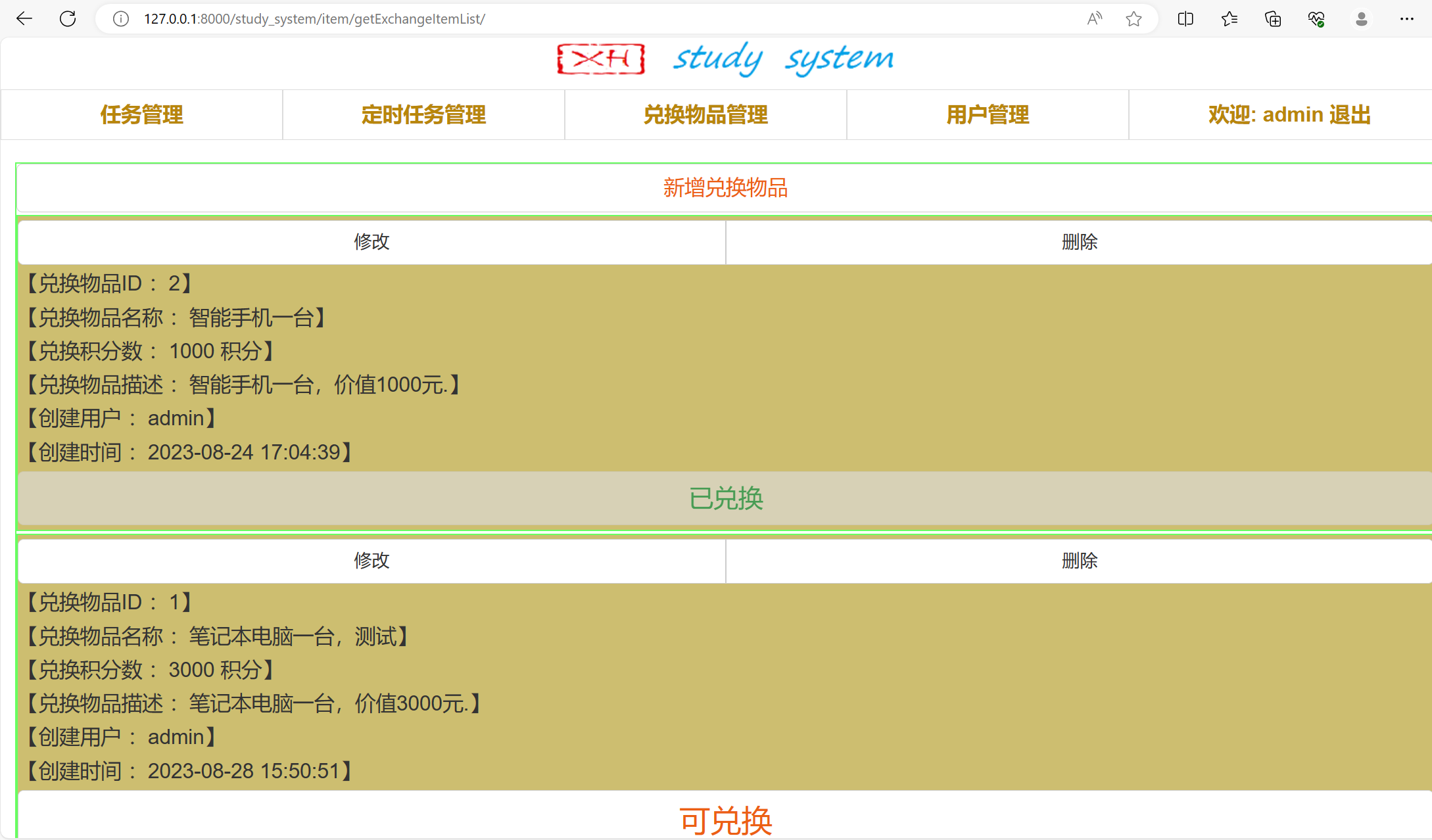
Django实战项目-学习任务系统-兑换物品管理
接着上期代码框架,开发第5个功能,兑换物品管理,再增加一个学习兑换物品表,主要用来维护兑换物品,所需积分,物品状态等信息,还有一个积分流水表,完成任务奖励积分,兑换物品…...

jmeter和postman你选哪个做接口测试?
软件测试行业做功能测试和接口测试的人相对比较多。在测试工作中,有高手,自然也会有小白,但有一点我们无法否认,就是每一个高手都是从小白开始的,所以今天我们就来谈谈一大部分人在做的接口测试,小白变高手…...

mac版本 Adobe总是弹窗提示验证问题如何解决
来自: mac软件下载macsc站 mac电脑使用过程中总是弹出Adobe 的弹窗提示,尤其是打开Adobe的软件,更是频繁的弹出提示: Your Adobe app is not genuine. Adobe reserves the right to disable this software after a 0 grace period…...

钡铼技术ARM工控机在机器人控制领域的应用
ARM工控机是一种基于ARM架构的工业控制计算机,用于在工业自动化领域中进行数据采集、监控、控制和通信等应用。ARM(Advanced RISC Machine)架构是一种低功耗、高性能的处理器架构,广泛应用于移动设备、嵌入式系统和物联网等领域。…...

HTML+CSS+JS实现计算器
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 ps:点赞👍是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全栈,…...
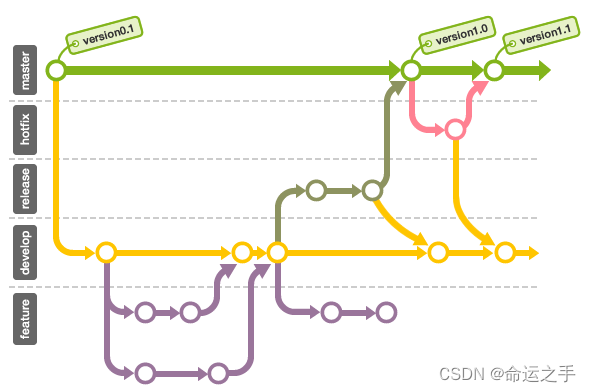
Git工作原理和常见问题处理方案
博客定位Git工作区域工作区域划分暂存区设计目的 Git基本操作核心操作初始化和配置指令 HEAD指针Git版本回滚指令介绍reset模式reset hard使用场景reset soft使用场景reset mixed使用场景reset使用注意事项checkout使用场景 Git分支管理什么是分支分支应用场景分支相关指令被合…...
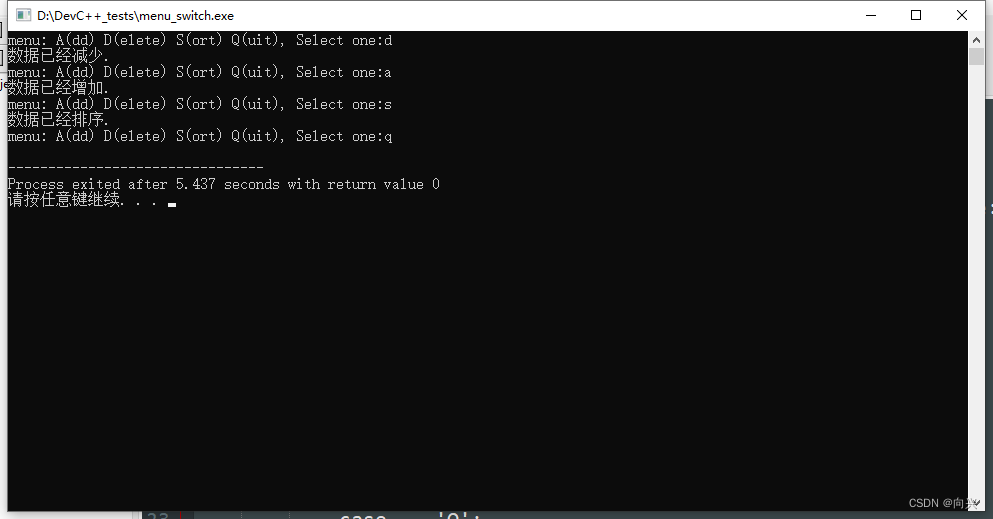
C++-实现一个简单的菜单程序
C-实现一个简单的菜单程序 1,if-else语句实现1.1,代码实现1.2,功能检测 2,switch语句实现2.1,代码实现2.2,功能检测 1,if-else语句实现 实现一个简单的菜单程序,运行时显示"Men…...

Git更新 fork 的仓库
文章目录 确保本地仓库是最新的配置上游存储库(remote upstream)获取上游存储库的更改合并上游存储库的更改推送更改到你 fork 的仓库 确保本地仓库是最新的 在命令行中,导航到存储库的本地副本所在的目录,并执行以下命令: # 切换到主分支 …...

chorme安装esay scholar及chrome 无法从该网站添加应用、扩展程序和用户脚本解决方案
问题描述 如题,博主想安装easy scholar用于查询论文的分区,结果安装了半天一直出现chrome 无法从该网站添加应用、扩展程序和用户脚本解决方案的问题。 解决方案 先从这个网址下载:https://www.easyscholar.cc/download 然后对下载好的文…...
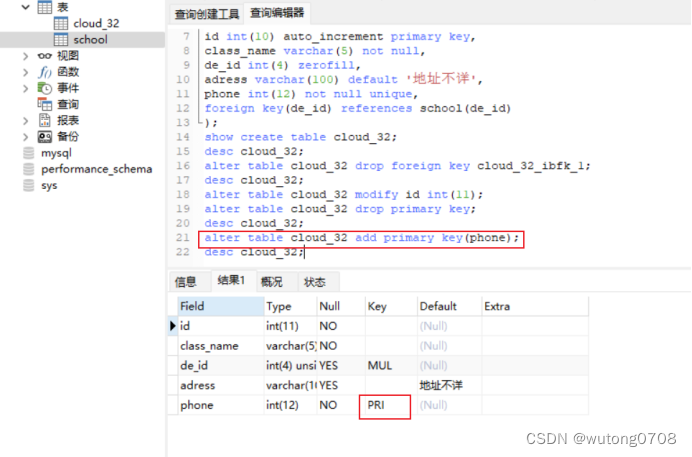
数据库-扩展语句,约束方式
扩展语句: 例: 自增长: auto_increment:表示该字段可以自增长,默认从一开始,每条记录会自动递增1 复制: 通过like这个语法直接复制ky32的表结构,只能复制表结构,不能复制表里面的…...
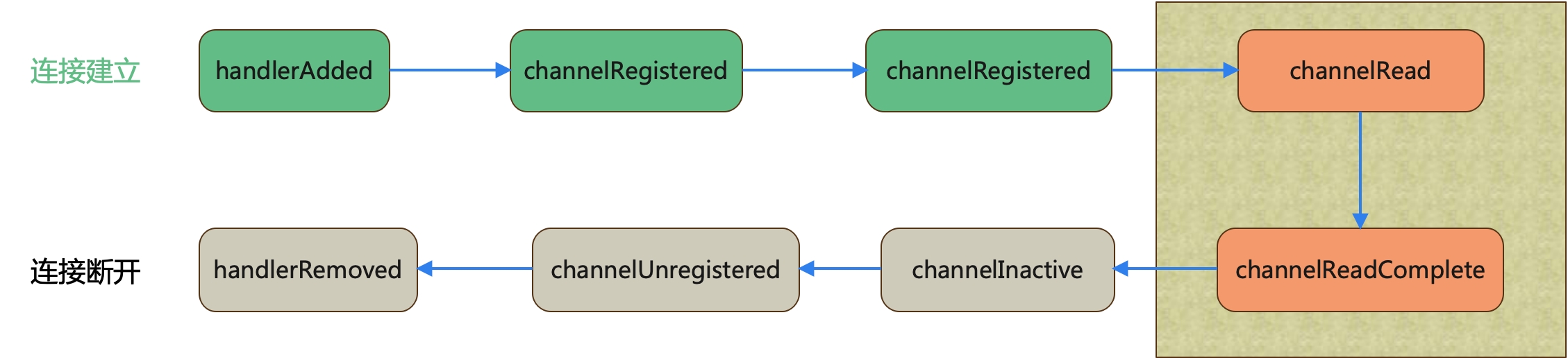
精密数据工匠:探索 Netty ChannelHandler 的奥秘
通过上篇文章(Netty入门 — Channel,把握 Netty 通信的命门),我们知道 Channel 是传输数据的通道,但是有了数据,也有数据通道,没有数据加工也是没有意义的,所以今天学习 Netty 的第四…...

Python四种基本结构的操作
列表 列表的创建有两种方法 SampleList [] SampleList list() 列表中元素的添加 append(obj):在列表末尾添加元素obj extend(seq):在列表末尾添加多个值,使用extend()函数,seq是一个可迭代对象,否则报错。 Inser…...

Eureka:com.netflix.discovery.TimedSupervisorTask - task supervisor timed out
1、原因是spring cloud netflix中,某个服务挂掉了或者是执行某个任务时间过长,而没有发送给Eureka心跳 ,导致调用不到指定的服务,所以检查被调用服务器是否有问题。 2、有可能是某一个微服务自身内部G了,导致没有向eu…...

1.spark standalone环境安装
概述 环境是spark 3.2.4 hadoop版本 3.2.4,所以官网下载的包为 spark-3.2.4-bin-hadoop3.2.tgz 在具体安装部署之前,需要先下载Spark的安装包,进到 spark的官网,点击download按钮 使用Spark的时候一般都是需要和Hadoop交互的&a…...
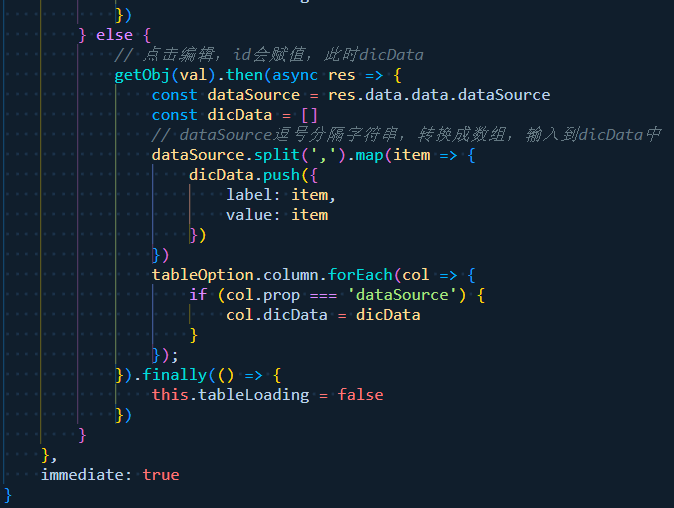
【问题解决】 avue dicUrl 动态参数加载字典数据(已解决)
事情是这样的,用了avue-crud组件,配置了一个option。 现在有一列source属性要展示为 多选的下拉框 ,当然问题不在这而在于,选项是需要根据同级别属性id去拿的。也就是option.column.source 的配置中 需要该行的option.col…...

学习一下,什么是预包装食品?
预包装食品,指预先定量包装或者制作在包装材料和容器中的食品;包括预先定量包装以及预先定量制作在包装材质和容器中并且在一定量限范围内具有统一的质量或体积标识的食品。简单说, 就是指在包装完成后即具有确定的量值,这一确定的…...
)
CentOS 7/8下Nginx报`unknown directive “stream“`?可能是你的安装方式不对(附完整修复流程)
CentOS下Nginx报unknown directive "stream"的深度解析与解决方案 当你在CentOS系统上配置Nginx的stream模块时,突然遇到unknown directive "stream"的错误提示,这往往意味着你的Nginx安装并不完整。这个问题看似简单,背…...

[安全攻防实验] 环境变量:Set-UID程序中的隐形攻击向量
1. 环境变量与Set-UID程序的安全隐患 在Linux系统中,环境变量就像是一个随身携带的"工具箱",里面装着各种程序运行时需要的信息。但你可能不知道,这个看似普通的工具箱,在遇到Set-UID程序时,可能会变成黑客…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

PowerInfer:基于热点神经元预测的LLM高性能推理引擎部署指南
1. 项目概述:当推理速度成为AI落地的瓶颈最近在折腾本地大模型推理的朋友,估计都绕不开一个核心痛点:速度。模型效果再好,生成一句话要等上十几秒,那种“卡顿感”足以劝退绝大多数想把它集成到实际应用里的开发者。我自…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...

云原生安全工具:保护云原生环境
云原生安全工具:保护云原生环境 一、云原生安全工具概述 1.1 云原生安全工具的定义 云原生安全工具是指专为云原生环境设计的安全工具和解决方案。它们用于保护容器、Kubernetes集群、微服务和Serverless应用的安全。 1.2 云原生安全工具的价值 安全防护:…...