Python四种基本结构的操作
列表
列表的创建有两种方法
SampleList = []
SampleList = list()
列表中元素的添加
append(obj):在列表末尾添加元素obj
extend(seq):在列表末尾添加多个值,使用extend()函数,seq是一个可迭代对象,否则报错。
Insert(index,obj):将元素obj添加到列表的index位置处。
Sample = [1,2,3,4,5]
Sample.append(1)
#[1,2,3,4,5,6]
s = [7,8]
Sample.extend(s)
#[1,2,3,4,5,6,7,8]
Sample.insert(0,0)
#[0,1,2,3,4,5,6,7,8]
列表中元素删除
pop(index=-1):删除列表index位置处元素,默认是-1,即最后一个,并且返回该元素值。
remove(obj):删除列表中第一次出现的obj元素。
clear():列表清空
两个删除函数,如果没有找到对应元素的话,则报错。
s = [1,2,3,4]
s.pop()
#[1,2,3]
s.remove(2)
#[1,3]
s.clear()
#[]
查找元素位置
index(obj,start=0,end=1)函数
index函数从列表中查找元素,在下标索引为0到下标索引为1区间内查找obj元素,并且返回索引值。
如果没有则报错。
s = [1,2,3,4]
print(s.index(2))
#1
元素排序
sort(reverse=True)函数
如果不加reverse默认为从小到大排序。
s = [2,3,1,6]
s.sort()
#[1,2,3,6]
s.sort(reverse=True)
#[6,3,2,1]
列表元素倒置
使用reverse()函数
s = [1,2,3,4]
s.reverse()
#[4,3,2,1]
统计元素格式
count(obj)函数可以统计列表中obj元素出现的次数,如果没有则返回0。
s = [1,2,3,4,1]
s.count(1)
#2
集合
集合的创建只有一种方法
t = set()
不能使用t = {},因为{}默认是创建字典。
集合的性质1:(去重)
集合自身不能存在重复元素,决定了集合可以去重。
s = [1,1,2,3,4,5,5]
print(set(s))
#{1,2,3,4,5}
增加、删除元素
s = set([1,2,3])
s.add(4)
#{1,2,3,4}
s.pop()
#{2,3,4},集合pop与列表的pop是不同的,列表的pop默认删除最后一个,而集合默认删除第一个。
s.remove(2)
#{3,4}
s.update([1,2])
#{1,2,3,4},这里有一个小细节,在使用update,add添加元素的时候,集合会根据元素的大小按升序自动排列好,并且插入到合适的位置。
求两个集合间交集
使用“&”符号,返回的也是一个集合。
s1 = set([1,2,3])
s2 = set([2,3,4,5])
print(s1 & s2)
#{2,3}
求两个集合间并集
使用 "|"符号,返回的是一个集合。
s1 = set([1,2,3])
s2 = set([2,3,4,5[)
print(s1 | s2)
#{1,2,3,4,5}
求两个集合的差集
使用"-"符号,返回一个集合。
s1 = set([1,2,3])
s2 = set([2,3,4,5])
print(s1 - s2)
#{1}
元组
元组一旦被定义就不允许再改变了,可以存储任意类型数据。
值得注意的是,如果元组中包含一个列表,那么列表中的元素可以改变。
元组的创建
直接使用小括号创建。
不过有一个小细节,当元组中只有一个元素的时候,必须要在最后加一个","来区分。
否则就会被认为是一个整数,而不是一个元组。
s = (1,2)
print(s)
#(1,2)
s = (1)
print(s)
#1,注意此时s被当作一个整数而不是一个元组了。
s = (1,)
print(s)
#(1,),此时s才被当作一个元组。
元组的连接
值得注意的是,元组虽然不能改变,但是元组可以做连接。
s = (1,2)
print((1,2) + s)
#(1,2,1,2)
元组计数、索引、排序
元组的计数、索引、排序都跟列表的使用方法一致。
count(),index(),sort()
接收多个参数(解包)
在元组解包中比较有意思。
scores = (65,89,59,78,100)
minscore,*middlescore,maxscore = scores ##将第一个参数赋值给minscore,最后一个参数赋值给maxscore,其余参数所有赋给middlescore
print(minscore)#65
print(middlescore)#[89,59,78]
print(maxscore)#100
字典
字典是四种结构中,读取速度最快的一种结构。
字典创建
d = {'name':'xiaohong','age':18}
d = dict()
字典的增加
字典[新的key] = 值。
如果key在原字典中已经存在则修改,否则则添加。
update()函数,一般用作两个字典的拼接,如果update的字典中已存在某个键值对,则修改。
d = {'name':'xiaoming', 'age': 18}
d['gender'] = '男'
print(d)
#{'name': 'xiaoming', 'age': 18, 'gender': '男'}
d.update({'id': '001', 'color': 'yellow', 'name': 'rose'})
print(d)
#{'name': 'rose', 'age': 18, 'gender': '男', 'id': '001', 'color': 'yellow'}
字典的删除
del()在字典中遵循查找"键"的方式进行删除,并且返回这一个键所对应的值!
clear()清空字典。
pop(obj)删除指定键的键值对,必须有一个obj参数否则报错,而且必须是键,不能是一个索引!
popitem()删除最后一个键值对。并且以元组的形式返回键值对。
d = {'name': 'xiaoming', 'age': 18}
d.pop('name')
print(d)
#{'age':18}
d = {'name': 'xiaoming', 'age': 18}
print(d.popitem())
#('age': 18)
字典的查询,重要!!!!
get(key,None)函数,查询一个键,返回这个键的值,不存在时不报错,可以默认返回None,也可以指定返回大小。
keys()函数,获取所有键。
values()函数,获取所有值。
items()函数,获取所有键值对并且以元组的格式返回。
d = {'name': '小明', 'age': 18, 'gender': '男', 'id': '001'}
print(d.get('name')) #小明
print(d.get('2b',520)) #520,指定返回值,返回为520.
print(d.keys()) #dict_keys(['name', 'age', 'gender', 'id'])
print(d.values()) #dict_values(['小明', 18, '男', '001'])
print(d.items()) #dict_items([('name', '小明'), ('age', 18), ('gender', '男'), ('id', '001')])
相关文章:

Python四种基本结构的操作
列表 列表的创建有两种方法 SampleList [] SampleList list() 列表中元素的添加 append(obj):在列表末尾添加元素obj extend(seq):在列表末尾添加多个值,使用extend()函数,seq是一个可迭代对象,否则报错。 Inser…...

Eureka:com.netflix.discovery.TimedSupervisorTask - task supervisor timed out
1、原因是spring cloud netflix中,某个服务挂掉了或者是执行某个任务时间过长,而没有发送给Eureka心跳 ,导致调用不到指定的服务,所以检查被调用服务器是否有问题。 2、有可能是某一个微服务自身内部G了,导致没有向eu…...

1.spark standalone环境安装
概述 环境是spark 3.2.4 hadoop版本 3.2.4,所以官网下载的包为 spark-3.2.4-bin-hadoop3.2.tgz 在具体安装部署之前,需要先下载Spark的安装包,进到 spark的官网,点击download按钮 使用Spark的时候一般都是需要和Hadoop交互的&a…...
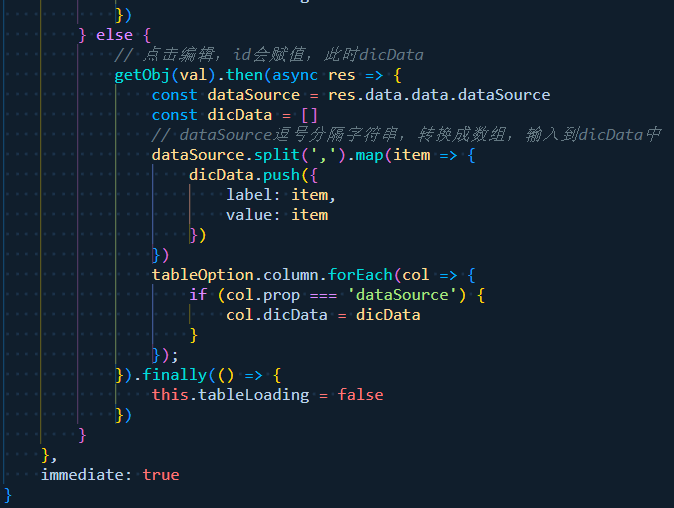
【问题解决】 avue dicUrl 动态参数加载字典数据(已解决)
事情是这样的,用了avue-crud组件,配置了一个option。 现在有一列source属性要展示为 多选的下拉框 ,当然问题不在这而在于,选项是需要根据同级别属性id去拿的。也就是option.column.source 的配置中 需要该行的option.col…...

学习一下,什么是预包装食品?
预包装食品,指预先定量包装或者制作在包装材料和容器中的食品;包括预先定量包装以及预先定量制作在包装材质和容器中并且在一定量限范围内具有统一的质量或体积标识的食品。简单说, 就是指在包装完成后即具有确定的量值,这一确定的…...

从零开始学习搭建量化平台笔记
从零开始学习搭建量化平台笔记 本笔记由纯新手小白开发学习记录,欢迎大佬请教指点留言,有空的话还可以认识一下,来上海请您喝咖啡~~ 2023/10/30:上份工作辞职并休息了几个月后,打算开始找个关于量化投资相关的工作。面…...

【whisper】在python中调用whisper提取字幕或翻译字幕到文本
最近在做视频处理相关的业务。其中有需要将视频提取字幕的需求,在我们实现过程中分为两步:先将音频分离,然后就用到了whisper来进行语音识别或者翻译。本文将详细介绍一下whisper的基本使用以及在python中调用whisper的两种方式。 一、whispe…...

git diff对比差异时指定或排除特定的文件和目录
文章目录 前言git diff指定或者排除文件指定文件和目录排除文件和目录 番外篇总结 前言 你一般什么时候会用GPT? 居然会有这种话题,答案就是作为程序员的我天天在用,虽然GPT有个胡说八道的毛病,但试试总没错的,就比如今天题目中这…...
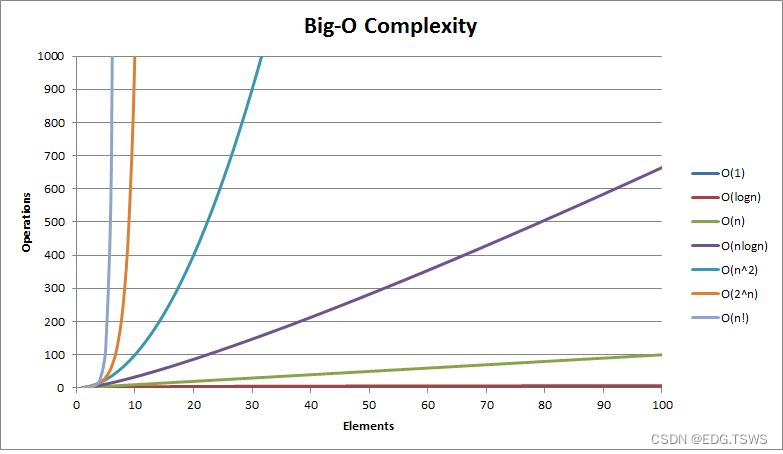
数据结构介绍与时间、空间复杂度
数据结构介绍 什么是数据结构?什么是算法?数据结构和算法的重要性 数据结构定义 数据结构是计算机科学中研究数据组织、存储和管理的一门学科。数据结构描述了数据对象之间的关系,以及对数据对象进行操作的方法和规则。 常见的数据结构 数…...
(c语言进阶)字符串函数、字符分类函数和字符转换函数
一.求字符串长度 1.strlen() (1)基本概念 头文件:<string.h> (2)易错点:strlen()的返回值为无符号整形 #include<stdio.h> #include<string.h> int main() {const char* str1 "abcdef";const char* str2 "bbb&q…...
解决MySQL大版本升级导致.Net(C#)程序连接报错问题
数据库版本从MySQL 5.7.21 升级到 MySQL8.0.21 数据升级完成后,直接修改程序的数据库连接配置信息 <connectionStrings> <add name"myConnectionString" connectionString"server192.168.31.200;uidapp;pwdFgTDkn0q!75;databasemail;&q…...

Java 将对象List转为csv文件并上传远程文件服务器实现方案
问题情景: 最近项目中遇到了根据第三方系统传递过来的参数,封装为List<实体类对象>后,将该实体类转换为csv文件,然后上传到远程的sftp服务器指定目录的需求。 实现思路: List<实体类对象>转为csv文件的…...
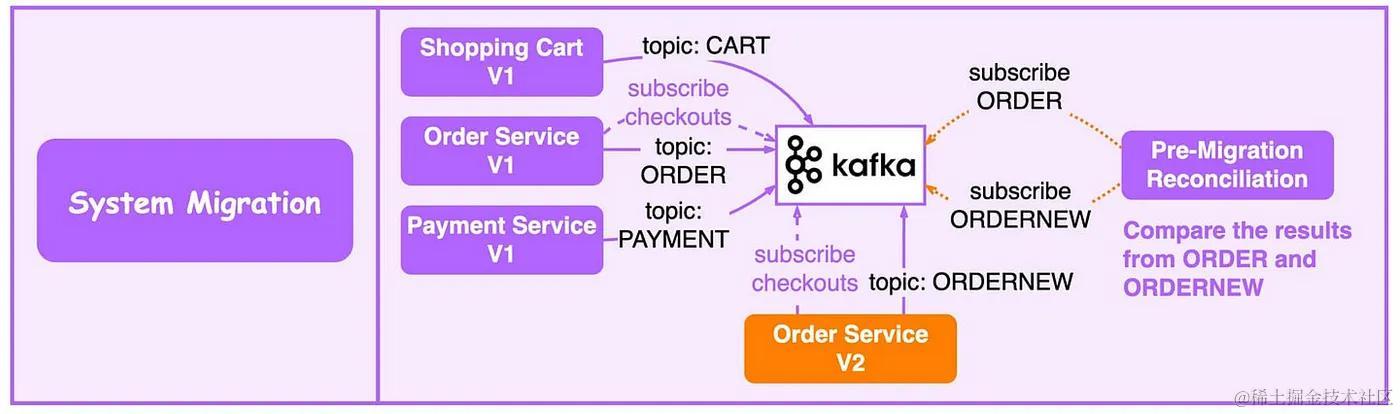
分享8个分布式Kafka的使用场景
Kafka 最初是为海量日志处理而构建的。它保留消息直到过期,并让消费者按照自己的节奏提取消息。与它的前辈不同,Kafka 不仅仅是一个消息队列,它还是一个适用于各种情况的开源事件流平台。 1. 日志处理与分析 下图显示了典型的 ELK࿰…...

【再见了暗恋对象 朋友们看完之后的一些感悟】
【再见了暗恋对象】写完之后魏野是我的第一个读者,魏野的反应是:这就是青春啊,喜欢了一个不喜欢自己的人而且男生觉得很困扰女孩子喜欢被牵引着走,但是男孩子牵引就是因为不喜欢这个女孩子,好可怜!青春就这…...

JSON和Protobuf序列化
文章目录 一、粘包和拆包1、半包问题2、半包现象原理 二、JSON协议通信1、通用类库2、JSON传输的编码器和解码器 三、Protobuf协议通信1、一个简单的proto文件的实践案例2、生成POJO和Builder3、消息POJO和Builder的使用案例1)构造POJO消息对象2)序列化和…...
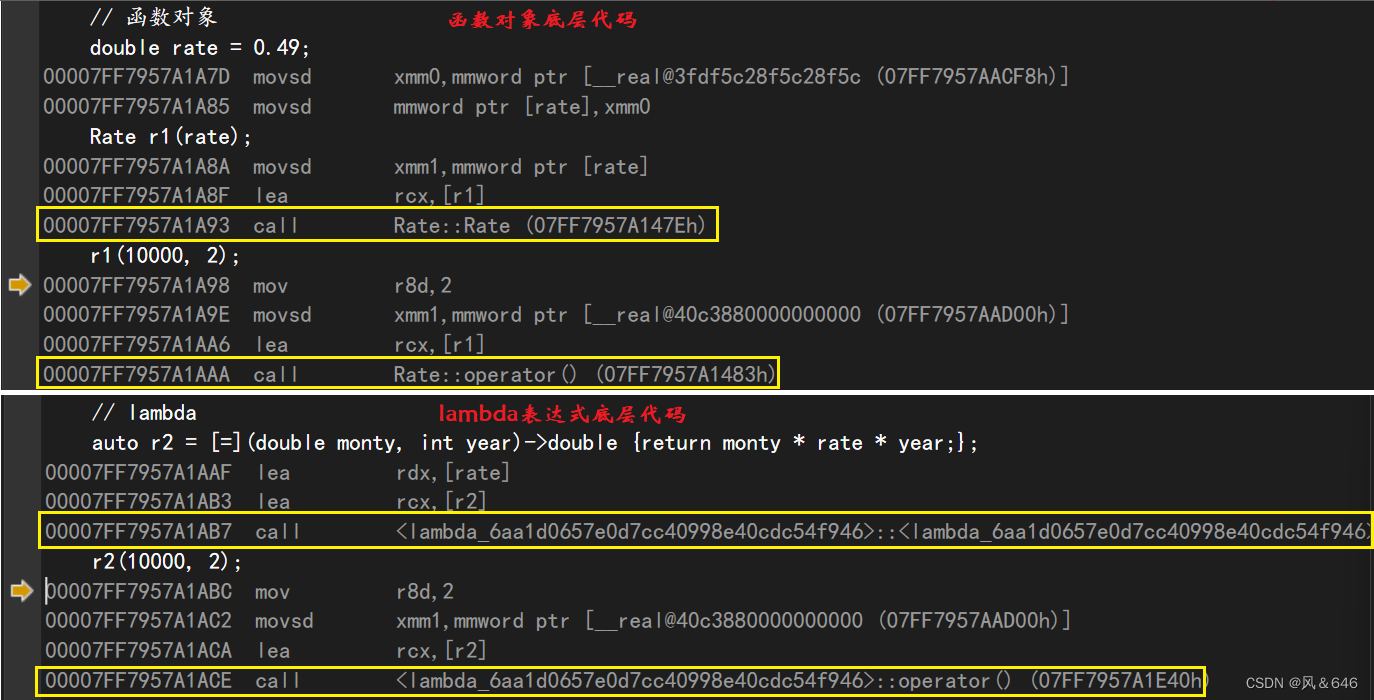
lambda表达式 - c++11
文章目录: lambda表达式概念lambda表达式语法函数对象与lambda表达式 lambda表达式概念 lambda 表达式是 c11 中引入的一种匿名函数,它可以在需要函数对象的地方使用,可以用作函数参数或返回值。lambda 表达式可以看作是一种局部定义的函数对…...

509. 斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n - 1) F(n - 2),其中 n > 1给定 n &a…...

四、[mysql]索引优化-1
目录 前言一、场景举例1.联合索引第一个字段用范围查询不走索引(分情况)2.强制走指定索引3.覆盖索引优化4.in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描5.like 后% 一般情况都会走索引(索引下推) 二、Mysql如何选择合适的索…...
:神经网络-最大池化使用)
PyTorch入门学习(九):神经网络-最大池化使用
目录 一、数据准备 二、创建神经网络模型 三、可视化最大池化效果 一、数据准备 首先,需要准备一个数据集来演示最大池化层的应用。在本例中,使用了CIFAR-10数据集,这是一个包含10个不同类别图像的数据集,用于分类任务。我们使…...
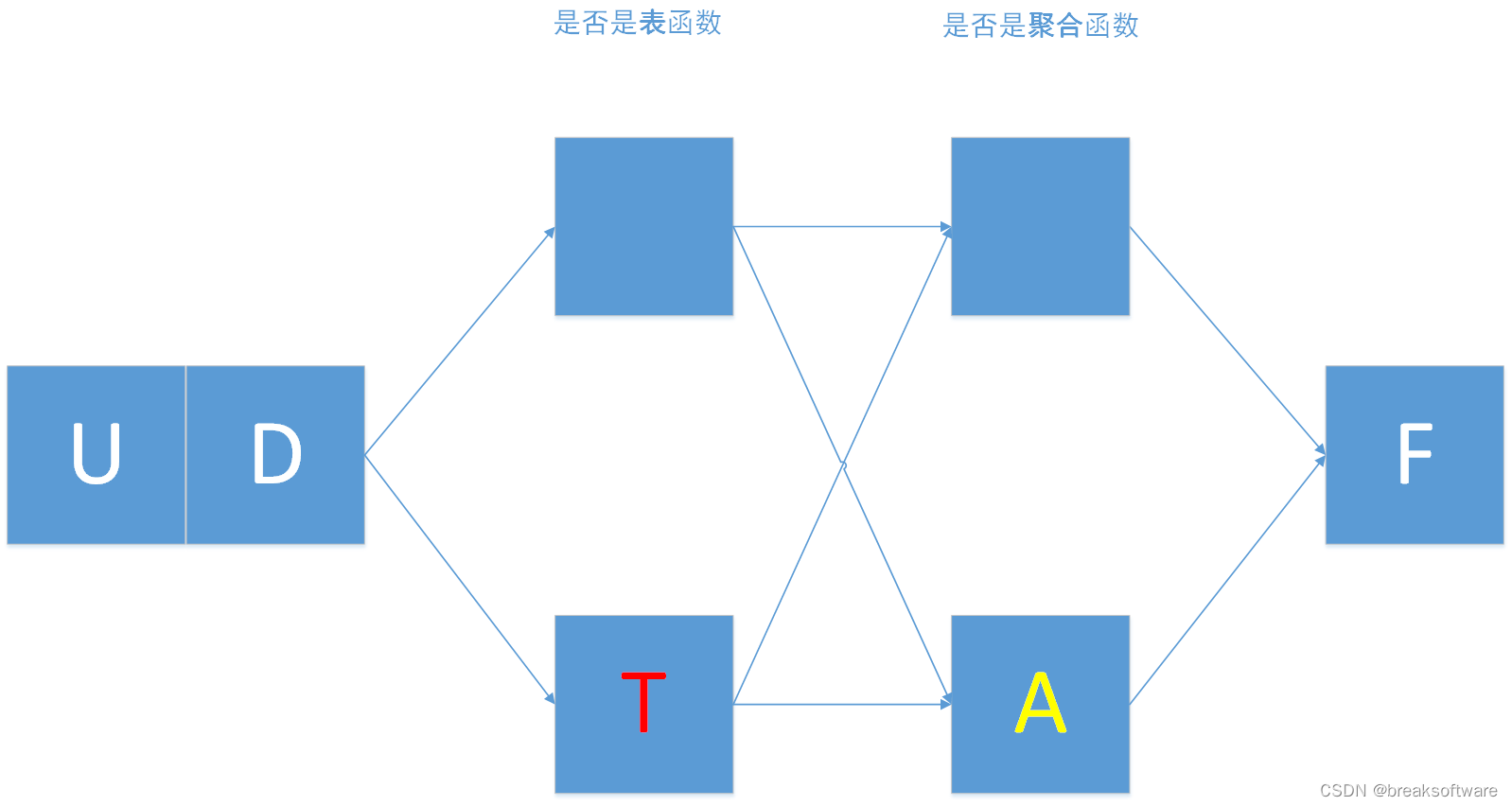
0基础学习PyFlink——用户自定义函数之UDF
大纲 标量函数入参并非表中一行(Row)入参是表中一行(Row)alias PyFlink中关于用户定义方法有: UDF:用户自定义函数。UDTF:用户自定义表值函数。UDAF:用户自定义聚合函数。UDTAF&…...

PaddleOCR-VL 1.5 + ROCm:让开发者从文档解析 Demo 走向高性能生产部署
很多文档解析 Demo 看起来都很惊艳:上传一张图片,模型识别出文字、表格、公式,甚至还能输出 Markdown。但真正进入生产环境后,问题很快就会暴露出来。企业里的文档不是干净样例,而是 PDF、扫描件、合同、票据、财报、检…...

HPM6750 CAN FD实战:从波特率配置到高效收发,避坑指南
1. 项目概述:从经典CAN到CAN FD的实战入门作为一名长期在嵌入式领域摸爬滚打的开发者,我深知现场总线技术,尤其是CAN总线,在工业控制、汽车电子等领域的核心地位。随着数据吞吐量需求的激增,经典CAN的1Mbps带宽逐渐捉襟…...

Power BI主题模板完全指南:35+ JSON模板快速构建专业数据可视化方案
Power BI主题模板完全指南:35 JSON模板快速构建专业数据可视化方案 【免费下载链接】PowerBI-ThemeTemplates Snippets for assembling Power BI Themes 项目地址: https://gitcode.com/gh_mirrors/po/PowerBI-ThemeTemplates 在数据驱动的商业决策时代&…...

B站视频解析API架构解析:PHP实现的高效视频流获取方案
B站视频解析API架构解析:PHP实现的高效视频流获取方案 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 在视频内容生态蓬勃发展的今天,开发者经常面临一个技术挑战:…...

AI健身教练开源项目:用代码实现个性化训练与健康追踪
1. 项目概述:当AI健身教练遇上开源代码库最近在GitHub上闲逛,发现了一个挺有意思的项目,叫ClaireAICodes/gym-workout-health-longevity。光看名字,你可能会觉得这又是一个普通的健身计划分享,但点进去之后,…...

Kubernetes轻量级服务网格Cetus:核心流量治理与Sidecar代理实践
1. 项目概述:一个为Kubernetes而生的智能代理如果你正在管理一个规模不小的Kubernetes集群,并且对服务网格(Service Mesh)的复杂性望而却步,或者觉得像Istio这样的“巨无霸”方案有些杀鸡用牛刀,那么你很可…...

紧急通知:NotebookLM v2.3将移除手动标签覆盖功能!立即执行这5项存量标签加固操作,否则知识链永久断裂
更多请点击: https://intelliparadigm.com 第一章:NotebookLM标签管理方法 NotebookLM 原生不提供显式的“标签(Tags)”UI 控件,但可通过其底层的 source 元数据机制实现语义化标签管理。核心思路是将标签作为自定义…...

零成本替代 Zendesk,个人 / 小团队专属开源客服系统
零成本替代 Zendesk,个人 / 小团队专属开源客服系统 前言 在线客服这个赛道,Intercom、Zendesk 这些产品做得确实成熟,但价格对于小团队来说始终是个门槛。随便看一家,每月订阅费基本从几百到几千不等,企业版功能更是直…...

AWS实战|从零搭建高可用Web应用网络架构
1. 为什么需要高可用Web应用架构? 最近帮朋友公司迁移电商平台到AWS时,他们最担心的就是大促期间服务器挂掉。这让我想起三年前自己踩过的坑——当时用单可用区部署的官网,因为一次区域级故障直接宕机8小时。现在回头看,其实只要在…...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...