【whisper】在python中调用whisper提取字幕或翻译字幕到文本
最近在做视频处理相关的业务。其中有需要将视频提取字幕的需求,在我们实现过程中分为两步:先将音频分离,然后就用到了whisper来进行语音识别或者翻译。本文将详细介绍一下whisper的基本使用以及在python中调用whisper的两种方式。
一、whisper简介
whisper 是一款用于语音识别的开源库,支持多种语言,其中包括中文。在本篇文章中,我们将介绍如何安装 whisper 以及如何使用它来识别中文字幕。
二、安装 whisper
首先,我们需要安装 whisper。根据操作系统,可以按照以下步骤进行安装:
-
对于 Windows 用户,可以从 whisper 的 GitHub 页面 (https://github.com/qingzhao/whisper) 下载适用的 Python 版本的whisper 安装包,然后运行安装程序。
-
对于 macOS 用户,可以使用 Homebrew (https://brew.sh/) 进行安装。在终端中运行以下命令:
brew install python@3.10 whisper。 -
对于 Linux 用户,可以使用包管理器 (如 apt 或 yum) 进行安装。例如,对于使用 Python 3.10 的 Ubuntu 用户,在终端中运行以下命令:
sudo apt install python3.10 whisper。
当然,我们还需要配置环境,这里我们可以参考这篇文章,这篇文章是使用控制台的方式来进行字幕翻译,比较适合非开发人员。
三、使用Whisper提取视频字幕并生成文件
3.1 安装Whisper库
首先,我们需要安装Whisper库。可以使用以下命令在命令行中安装:
pip install whisper
3.2 导入所需的库和模块
import whisper
import arrow
import time
from datetime import datetime, timedelta
import subprocess
import re
import datetime
参考 python生成requirements.txt的两种方法
生成失败参考 这里
对应版本生成的requirements.txt信息
arrow==1.3.0
asposestorage==1.0.2
numpy==1.25.0
openai_whisper==20230918
3.3 提取字幕并生成文件
下面是一个函数,用于从目标视频中提取字幕并生成到指定文件:
1.在python中直接调库的方式
def extract_subtitles(video_file, output_file, actual_start_time=None):# 加载whisper模型model = whisper.load_model("medium") # 根据需要选择合适的模型subtitles = []# 提取字幕result = model.transcribe(video_file)start_time = arrow.get(actual_start_time, 'HH:mm:ss.SSS') if actual_start_time is not None else arrow.get(0)for segment in result["segments"]:# 计算开始时间和结束时间start = format_time(start_time.shift(seconds=segment["start"]))end = format_time(start_time.shift(seconds=segment["end"]))# 构建字幕文本subtitle_text = f"【{start} -> {end}】: {segment['text']}"print(subtitle_text)subtitles.append(subtitle_text)# 将字幕文本写入到指定文件中with open(output_file, "w", encoding="utf-8") as f:for subtitle in subtitles:f.write(subtitle + "\n")
2.在python中调用控制台命令
"""
从目标视频中提取字幕并生成到指定文件
参数:video_file (str): 目标视频文件的路径
output_file (str): 输出文件的路径
actual_start_time (str): 音频的实际开始时间,格式为'时:分:秒.毫秒'(可选)
target_lang (str): 目标语言代码,例如'en'表示英语,'zh-CN'表示简体中文等(可选)
"""def extract_subtitles_translate(video_file, output_file, actual_start_time=None, target_lang=None):# 指定whisper的路径whisper_path = r"D:\soft46\AncondaSelfInfo\envs\py39\Scripts\whisper"subtitles = []# 构建命令行参数command = [whisper_path, video_file, "--task", "translate", "--language", target_lang, "--model", "large"]if actual_start_time is not None:command.extend(["--start-time", actual_start_time])print(command)try:# 运行命令行命令并获取字节流输出output = subprocess.check_output(command)output = output.decode('utf-8') # 解码为字符串subtitle_lines = output.split('\n') # 按行分割字幕文本start_time = time_to_milliseconds(actual_start_time) if actual_start_time is not None else 0for line in subtitle_lines:line = line.strip()if line: # 空行跳过# 解析每行字幕文本match = re.match(r'\[(\d{2}:\d{2}.\d{3})\s+-->\s+(\d{2}:\d{2}.\d{3})\]\s+(.+)', line)if match:# 这是秒转时间# start = seconds_to_time(start_time + time_to_seconds(match.group(1)))# end = seconds_to_time(start_time + time_to_seconds(match.group(2)))start = start_time + time_to_milliseconds(match.group(1))end = start_time + time_to_milliseconds(match.group(2))text = match.group(3)# 构建字幕文本 自定义输出格式subtitle_text = f"【{start} -> {end}】: {text}"print(subtitle_text)subtitles.append(subtitle_text)# 将字幕文本写入指定文件with open(output_file, "w", encoding="utf-8") as f:for subtitle in subtitles:f.write(subtitle + "\n")except subprocess.CalledProcessError as e:print(f"命令执行失败: {e}")
3.4 辅助函数
在上述代码中,还使用了一些辅助函数,用于处理时间格式的转换和格式化:
def time_to_milliseconds(time_str):h, m, s = time_str.split(":")seconds = int(h) * 3600 + int(m) * 60 + float(s)return int(seconds * 1000)def format_time(time):return time.format('HH:mm:ss.SSS')def format_time_dot(time):return str(timedelta(seconds=time.total_seconds())).replace(".", ",")[:-3]# 封装一个计算方法运行时间的函数
def time_it(func, *args, **kwargs):start_time = time.time()print("开始时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(start_time)))result = func(*args, **kwargs)end_time = time.time()total_time = end_time - start_timeminutes = total_time // 60seconds = total_time % 60print("结束时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(end_time)))print("总共执行时间: {} 分 {} 秒".format(minutes, seconds))return result
3.5 调用函数提取字幕
可以使用以下代码调用上述函数,并提取字幕到指定的输出文件中:
if __name__ == '__main__':video_file = "C:/path/to/video.mp4" # 替换为目标视频文件的路径output_file = "C:/path/to/output.txt" # 替换为输出txt文件的路径actual_start_time = '00:00:00.000' # 替换为实际的音频开始时间,格式为'时:分:秒.毫秒',如果未提供则默认为00:00:00.000时刻# 直接在main方法中调用# extract_subtitles(video_file, output_file, actual_start_time)time_it(extract_subtitles_translate, video_file, output_file, None, 'en')
注意替换video_file和output_file为实际的视频文件路径和输出文件路径。如果有实际的音频开始时间,可以替换actual_start_time参数。
在上面的代码中,我们首先导入 whisper 库,然后定义一个名为 recognize_chinese_subtitle 的函数,该函数接受一个音频文件路径作为输入,并使用 whisper 客户端进行语音识别。识别结果保存在 result 字典中,其中 text 字段包含了识别出的字幕文本。
在 if __name__ == "__main__" 块中,我们调用 recognize_chinese_subtitle 函数,传入一个音频文件路径,然后打印识别出的字幕。
3.6 模型的选择,参考如下
_MODELS = {"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt","tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt","base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt","base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt","small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt","small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt","medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt","medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt","large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt","large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt","large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
}# 1.
# tiny.en / tiny:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03 / tiny.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 65147644
# a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9 / tiny.pt
# - 优点:模型体积较小,适合在资源受限的环境中使用,推理速度较快。
# - 缺点:由于模型较小,可能在处理复杂或长文本时表现不如其他大型模型。 -------------错误较多
#
# 2.
# base.en / base:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 25
# a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead / base.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e / base.pt
# - 优点:具有更大的模型容量,可以处理更复杂的对话和文本任务。
# - 缺点:相对于较小的模型,推理速度可能会稍慢。
#
# 3.
# small.en / small:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872 / small.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 9
# ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794 / small.pt
# - 优点:模型规模适中,具有一定的表现能力和推理速度。
# - 缺点:在处理更复杂的对话和文本任务时,可能不如较大的模型表现出色。
#
# 4.
# medium.en / medium:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f / medium.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 345
# ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1 / medium.pt
# - 优点:更大的模型容量,可以处理更复杂的对话和文本任务。
# - 缺点:相对于较小的模型,推理速度可能会较慢。 ---断句很长 【00:00:52.000 -> 00:01:03.000】: 嗯,有一个那个小箱子,能看到吗?上面有那个白色的泡沫,那个白色塑料纸一样盖着,把那个白色那个塑料纸拿起来,下面就是。
#
# 5.
# large - v1 / large - v2 / large:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a / large - v1.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 81
# f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524 / large - v2.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 81
# f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524 / large - v2.pt
# - 优点:最大的模型容量,具有最强大的表现能力,可以处理复杂的对话和文本任务。
# - 缺点:相对于其他较小的模型,推理速度较慢,占用更多的内存。# whisper C:/Users/Lenovo/Desktop/whisper/luyin.aac --language Chinese --task translate
四、结论
通过以上步骤,已经成功安装了 whisper 并实现了识别中文字幕的功能。在实际应用中,可能需要根据实际情况对代码进行一些调整,例如处理音频文件路径、识别结果等。希望这篇文章对你有所帮助!
相关文章:

【whisper】在python中调用whisper提取字幕或翻译字幕到文本
最近在做视频处理相关的业务。其中有需要将视频提取字幕的需求,在我们实现过程中分为两步:先将音频分离,然后就用到了whisper来进行语音识别或者翻译。本文将详细介绍一下whisper的基本使用以及在python中调用whisper的两种方式。 一、whispe…...

git diff对比差异时指定或排除特定的文件和目录
文章目录 前言git diff指定或者排除文件指定文件和目录排除文件和目录 番外篇总结 前言 你一般什么时候会用GPT? 居然会有这种话题,答案就是作为程序员的我天天在用,虽然GPT有个胡说八道的毛病,但试试总没错的,就比如今天题目中这…...
数据结构介绍与时间、空间复杂度
数据结构介绍 什么是数据结构?什么是算法?数据结构和算法的重要性 数据结构定义 数据结构是计算机科学中研究数据组织、存储和管理的一门学科。数据结构描述了数据对象之间的关系,以及对数据对象进行操作的方法和规则。 常见的数据结构 数…...
(c语言进阶)字符串函数、字符分类函数和字符转换函数
一.求字符串长度 1.strlen() (1)基本概念 头文件:<string.h> (2)易错点:strlen()的返回值为无符号整形 #include<stdio.h> #include<string.h> int main() {const char* str1 "abcdef";const char* str2 "bbb&q…...
解决MySQL大版本升级导致.Net(C#)程序连接报错问题
数据库版本从MySQL 5.7.21 升级到 MySQL8.0.21 数据升级完成后,直接修改程序的数据库连接配置信息 <connectionStrings> <add name"myConnectionString" connectionString"server192.168.31.200;uidapp;pwdFgTDkn0q!75;databasemail;&q…...

Java 将对象List转为csv文件并上传远程文件服务器实现方案
问题情景: 最近项目中遇到了根据第三方系统传递过来的参数,封装为List<实体类对象>后,将该实体类转换为csv文件,然后上传到远程的sftp服务器指定目录的需求。 实现思路: List<实体类对象>转为csv文件的…...
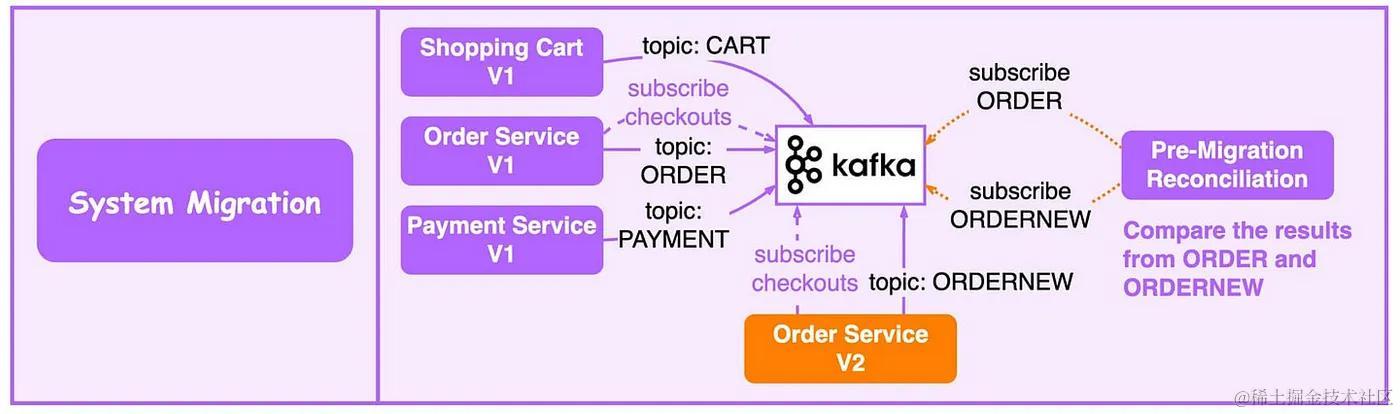
分享8个分布式Kafka的使用场景
Kafka 最初是为海量日志处理而构建的。它保留消息直到过期,并让消费者按照自己的节奏提取消息。与它的前辈不同,Kafka 不仅仅是一个消息队列,它还是一个适用于各种情况的开源事件流平台。 1. 日志处理与分析 下图显示了典型的 ELK࿰…...

【再见了暗恋对象 朋友们看完之后的一些感悟】
【再见了暗恋对象】写完之后魏野是我的第一个读者,魏野的反应是:这就是青春啊,喜欢了一个不喜欢自己的人而且男生觉得很困扰女孩子喜欢被牵引着走,但是男孩子牵引就是因为不喜欢这个女孩子,好可怜!青春就这…...

JSON和Protobuf序列化
文章目录 一、粘包和拆包1、半包问题2、半包现象原理 二、JSON协议通信1、通用类库2、JSON传输的编码器和解码器 三、Protobuf协议通信1、一个简单的proto文件的实践案例2、生成POJO和Builder3、消息POJO和Builder的使用案例1)构造POJO消息对象2)序列化和…...
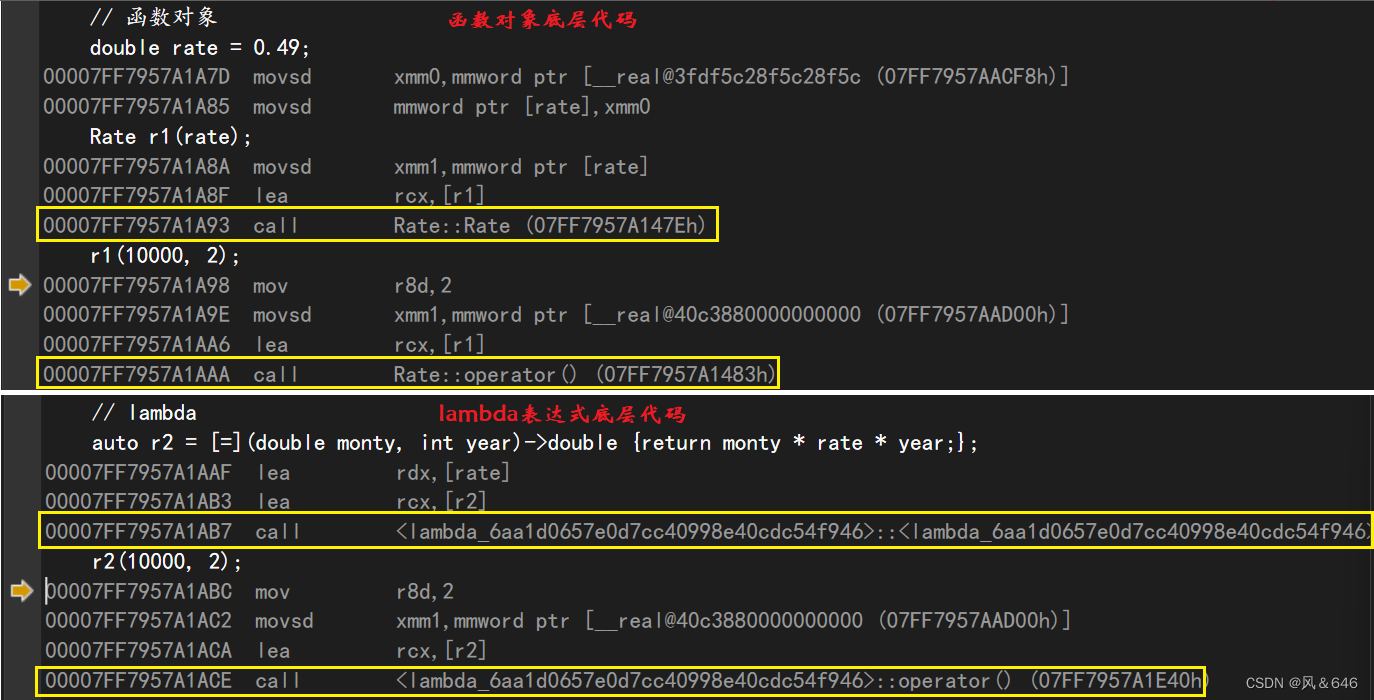
lambda表达式 - c++11
文章目录: lambda表达式概念lambda表达式语法函数对象与lambda表达式 lambda表达式概念 lambda 表达式是 c11 中引入的一种匿名函数,它可以在需要函数对象的地方使用,可以用作函数参数或返回值。lambda 表达式可以看作是一种局部定义的函数对…...

509. 斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n - 1) F(n - 2),其中 n > 1给定 n &a…...

四、[mysql]索引优化-1
目录 前言一、场景举例1.联合索引第一个字段用范围查询不走索引(分情况)2.强制走指定索引3.覆盖索引优化4.in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描5.like 后% 一般情况都会走索引(索引下推) 二、Mysql如何选择合适的索…...
:神经网络-最大池化使用)
PyTorch入门学习(九):神经网络-最大池化使用
目录 一、数据准备 二、创建神经网络模型 三、可视化最大池化效果 一、数据准备 首先,需要准备一个数据集来演示最大池化层的应用。在本例中,使用了CIFAR-10数据集,这是一个包含10个不同类别图像的数据集,用于分类任务。我们使…...
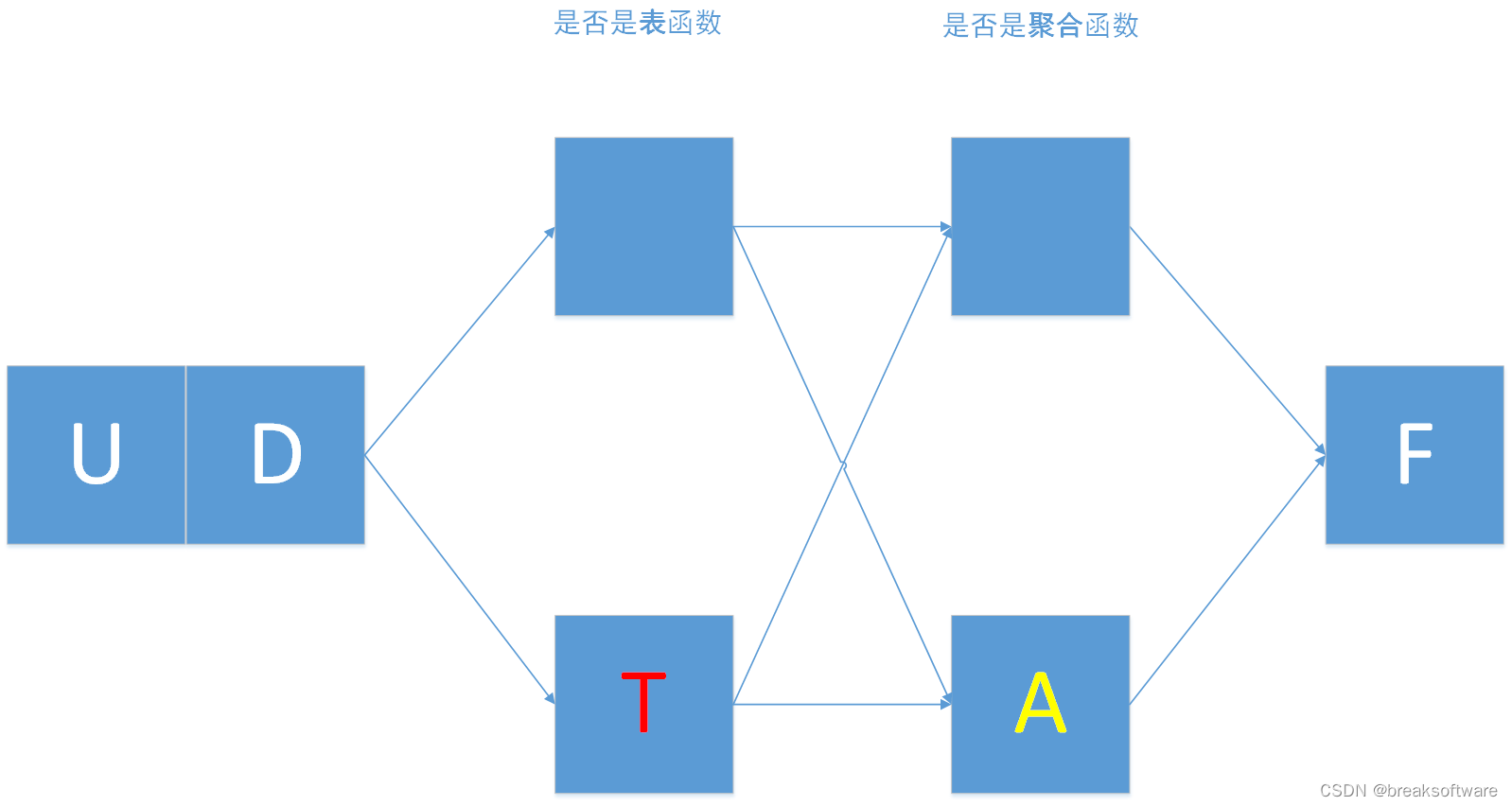
0基础学习PyFlink——用户自定义函数之UDF
大纲 标量函数入参并非表中一行(Row)入参是表中一行(Row)alias PyFlink中关于用户定义方法有: UDF:用户自定义函数。UDTF:用户自定义表值函数。UDAF:用户自定义聚合函数。UDTAF&…...

英语小作文模板(06求助+描述;07描述+建议)
06 求助描述: 题目背景及要求 第一段 第二段 第三段 翻译成中文 07 描述+建议: 题目背景及要求 第一段 第二段...

为什么感觉假期有时候比上班还累?
假期比上班还累的感觉可能由以下几个原因造成: 计划过度:在假期里,人们往往会制定各种计划,如旅游、聚会、休息等,以充分利用这段时间。然而,如果这些计划过于紧张或安排得过于紧密,就会导致身…...
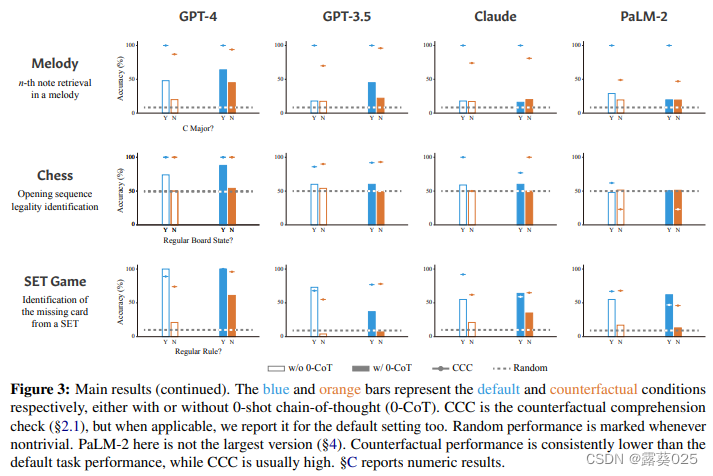
推理还是背诵?通过反事实任务探索语言模型的能力和局限性
推理还是背诵?通过反事实任务探索语言模型的能力和局限性 摘要1 引言2 反事实任务2.1 反事实理解检测 3 任务3.1 算术3.2 编程3.3 基本的句法推理3.4 带有一阶逻辑的自然语言推理3.5 空间推理3.6 绘图3.7 音乐3.8 国际象棋 4 结果5 分析5.1 反事实条件的“普遍性”5…...
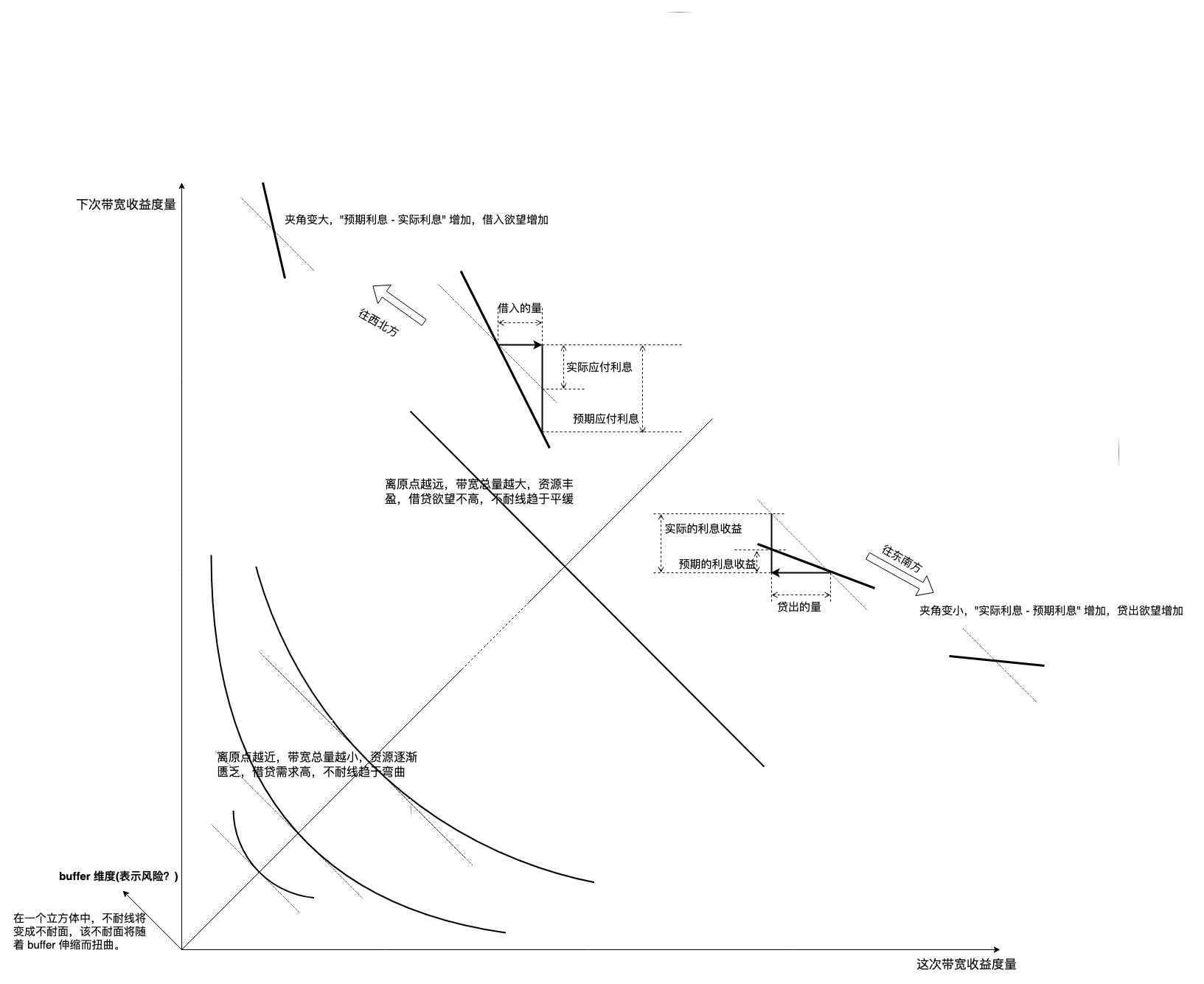
《利息理论》指导 TCP 拥塞控制
欧文费雪《利息原理》第 10 章,第 11 章对利息的几何说明是普适的,任何一个负反馈系统都能引申出新结论。给出原书图示,本文依据于此,详情参考原书: 将 burst 看作借贷是合理的,它包含成本(报文)…...
)
Bsdiff,Bspatch 的差分增量升级(基于Win和Linux)
目录 背景 内容 准备工作 在windows平台上 在linux平台上 正式工作 生成差分文件思路 作用差分文件思路 在保持相同目录结构进行差分增量升级 服务端(生成差分文件) 客户端(作用差分文件) 背景 像常见的Android 的linux平台,游戏,系统更新都…...

【3妹教我学历史-秦朝史】2 秦穆公-韩原之战
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 3妹:2哥,今天下班这么早&#…...

PUBG终极雷达系统免费搭建:从战场盲人到战术大师的完整指南
PUBG终极雷达系统免费搭建:从战场盲人到战术大师的完整指南 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-m…...

Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型 对于需要在项目中集成大语言模型的 Python 开发者而言,逐…...

代码锁:极简主义下的单例模式与模块化设计实践
1. 项目概述:一个极简主义者的代码锁最近在GitHub上看到一个挺有意思的项目,叫cdotlock/the_only。光看这个名字,你可能有点摸不着头脑,cdotlock是什么?the_only又是什么意思?这其实是一个典型的极简主义开…...
)
CentOS 7/8下Nginx报`unknown directive “stream“`?可能是你的安装方式不对(附完整修复流程)
CentOS下Nginx报unknown directive "stream"的深度解析与解决方案 当你在CentOS系统上配置Nginx的stream模块时,突然遇到unknown directive "stream"的错误提示,这往往意味着你的Nginx安装并不完整。这个问题看似简单,背…...

动态光照技术在视觉触觉传感器中的应用与优化
1. 视觉触觉传感器技术概述 视觉触觉传感器(Vision-Based Tactile Sensors, VBTS)是机器人触觉感知领域的重要技术突破。这类传感器通过光学成像方式捕捉弹性体接触面的微观变形,将机械接触转化为可视化数据。与传统力传感器相比,…...

【ZYNQ】AXI4总线协议实战:从握手时序到PS-PL高效通信
1. AXI4总线协议基础:从握手信号到通道架构 第一次接触ZYNQ的PS-PL通信时,我被AXI4协议里那些VALID/READY信号搞得头晕眼花。直到在示波器上抓到真实的握手波形,才突然理解这个看似复杂的协议其实像极了我们日常的对话机制——只有当说话方准…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

Godot游戏集成Discord状态:RPC插件原理与实战指南
1. 项目概述:在Godot引擎中点亮你的Discord状态 如果你是一名独立游戏开发者,或者正在用Godot引擎捣鼓一些有趣的个人项目,你可能会想让你的朋友或社区成员知道你现在正在“玩”什么。不是通过截图发到社交媒体,而是更实时、更优…...

从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程
从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程 在开源硬件社区,GitHub上每天都有大量优秀的STM32项目被分享——从智能家居控制器到四轴飞行器飞控系统。但当开发者满怀期待地git clone后,却常常在第一步"编译通过&…...
:多智能体沙箱与工具配置)
OpenClaw从入门到应用——工具(Tools):多智能体沙箱与工具配置
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 概述 在多智能体设置中,每个智能体现在可以拥有自己的: 沙箱配置(agents.list[].sandbox 会覆盖 agents.defaults.sandbox&…...