高性能消息中间件 - Kafka3.x(三)
文章目录
- 高性能消息中间件 - Kafka3.x(三)
- Kafka Broker ⭐
- Kafka Broker概念
- Zookeeper(新版本可以不使用zk了)⭐
- Zookeeper的作用
- Kafka的选举1:Broker选举Leader⭐
- Broker核心参数⭐
- 案例:服役新节点和退役旧节点(重要)⭐
- 服役新节点⭐
- 退役旧节点⭐
- Kafka的副本⭐
- 副本的基本概念⭐
- Kafka的选举2:副本选举Leader⭐
- 手动调整分区副本⭐
- 分区自动再平衡机制
- 增加kafka的副本⭐
- Kafka的存储
- 基本概念
- 文件清理策略
- Kafka高效读取数据⭐
- 1:顺序写磁盘
- 2:页缓存与零拷贝
- Kafka消费者⭐
- Kafka消费者的消费模式
- 消费者组⭐
- Kafka的选举3:消费者组选举Leader⭐
- Java Api消费者的重要参数⭐
- Java Api操作消费者⭐
- 手动提交Offset⭐
- 生产调优5:消息积压⭐
高性能消息中间件 - Kafka3.x(三)
Kafka Broker ⭐
Kafka Broker概念
- kafka broker说白了就是kafka服务器。我们在生产环境下通常要搭建kafka broker集群。
- partition(分区)和replica(副本)的区别:
- 前提条件:假设我们的kafka集群数量(broker)为3。(也就是说我们集群只有3台kafka)。
- 此时Partition分区可以指定的数量是(无限制)的(也就是说可以指定10、100)。
- 但是replica副本数最多只能指定为3(3、2、1),否则就会报错。(因为我们的kafka broker数量就是3,replica不能超过这个值!!!!!)
- 前提条件:假设我们的kafka集群数量(broker)为3。(也就是说我们集群只有3台kafka)。
大致图如下:(partition和replica和kafka broker的关系图)

Zookeeper(新版本可以不使用zk了)⭐
Zookeeper的作用
- zookeeper的作用有:
- 1:保存kafka元数据。
- 2:保存broker注册信息。(有哪些broker可用)
- 3:记录每一个分区副本有哪些?并且每一个分区副本的leader是谁?
- 4:辅助选举leader。
- 5:保存主题、分区信息,等等。
Kafka的选举1:Broker选举Leader⭐
- broker选举leader规则:
- 每一个broker都有一个唯一的broker id,broker在启动后会去zookeeper的controller节点中竞争注册,哪个broker先注册,那这个broker就是leader。
Broker核心参数⭐
| 参数 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR,并移动到OSR。该时间阈值,默认 30s |
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡(再平衡)。 |
| leader.imbalance.per.broker.percentage | **默认是 10%。**每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log日志划分 成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index文件里面记录一个索引 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。 |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。 |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50%的 1/3 |
案例:服役新节点和退役旧节点(重要)⭐
服役新节点⭐
先只启动kafka01和kafka02机器,然后创建topic,副本数设置为2。然后再启动kafka03机器,然后让这个kafka03节点服役到集群中。
- 1:只启动kafka01和kafka02机器,并创建topic:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --partitions=3 --replication-factor=2 --create
- 2:查询mytopic001详情(发现副本只存在于kafka01和kafka02节点上):
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe

- 3:启动kafka03机器的zk和kafka,再次查询mytopic001详情(发现还是一样,副本只存在于kafka01和kafka02节点上,而不存在于kafka03节点上):
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe

- 4:开始服役新节点了!!
vim topics-to-move.json
内容如下:(topics下面的topic设置为想要服役的topic主题名称,其他不变)
{"topics": [{"topic": "mytopic001"}],"version": 1
}
- 5:生成新的负载均衡计划:(并复制下面如图所示的计划)
- –bootstrap-server:kafka集群地址
- –topics-to-move-json-file:刚刚创建的json文件名
- –broker-list:假如服役节点后的broker编号列表(3为kafka03的broker编号)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --topics-to-move-json-file topics-to-move.json --broker-list "1,2,3" --generate

- 6:创建副本存储计划:
vim increase-replication-factor.json
内容如下:(就是刚刚复制的新的负载均衡计划)
{"version":1,"partitions":[{"topic":"mytopic001","partition":0,"replicas":[3,2],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":1,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":2,"replicas":[2,1],"log_dirs":["any","any"]}]}
- 7:执行副本计划:(–reassignment-json-file负载均衡计划文件)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file increase-replication-factor.json --execute
- 8:再次查看mytopic001详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe

退役旧节点⭐
- 1:经过上面的服役新节点,我们可以看到副本被分配到1、2、3号机器上了。下面我们要把kafka03节点删去。
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe

- 2:开始退役节点了!!
vim topics-to-move.json
内容如下:(topics下面的topic设置为想要退役的topic主题名称,其他不变)
{"topics": [{"topic": "mytopic001"}],"version": 1
}
- 3:生成新的负载均衡计划:(并复制下面如图所示的计划)
- –bootstrap-server:kafka集群地址
- –topics-to-move-json-file:刚刚创建的json文件名
- –broker-list:假如服役节点后的broker编号列表(1、2代表着kafka03节点要退役了)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --topics-to-move-json-file topics-to-move.json --broker-list "1,2" --generate

- 6:创建副本存储计划:
vim decr-replication-factor.json
内容如下:(就是刚刚复制的新的负载均衡计划)
{"version":1,"partitions":[{"topic":"mytopic001","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":1,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":2,"replicas":[1,2],"log_dirs":["any","any"]}]}
- 7:执行副本计划:(–reassignment-json-file负载均衡计划文件)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file decr-replication-factor.json --execute
- 8:再次查看mytopic001详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe

Kafka的副本⭐
副本的基本概念⭐
-
replica(副本):为了防止集群中机器故障导致数据丢失,所以副本出现了。kafka的每一个topic在每一个分区都可以有多个replica副本,副本分为leader副本和follower副本。
- leader副本:生产者和消费者只于leader副本交互。每一个topic中的每一个分区都有一个leader副本。
- follower副本:负责实时从leader副本同步数据,当leader副本故障了,则会重新选举,使follower副本变成leader副本。
-
AR:分区中的所有 Replica 统称为 AR = ISR +OSR
-
ISR:所有与 Leader 副本保持一定程度同步的Replica(包括 Leader 副本在内)组成 ISR
-
OSR:与 Leader 副本同步滞后过多的 Replica 组成了 OSR
Kafka的选举2:副本选举Leader⭐
-
选举规则:以ISR队列存在为前提,选举AR队列中的第一个副本为leader副本。
-
如果leader副本故障下线,则也会以ISR队列存在为前提,选举AR队列第一个为leader(第一个不行则第二个,一直轮询直到选出leader)。
手动调整分区副本⭐
- 1:创建一个新的topic:(指定为3个分区1个副本)
kafka-topics.sh --bootstrap-server kafka01:9092 --create --partitions 3 --replication-factor 1 --topic mytopic002
- 2:查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe

- 3:创建副本存储计划:
vim increase-replication-factor.json
内容如下:(修改topic和replicas)
{
"version":1,
"partitions":[{"topic":"mytopic002","partition":0,"replicas":[1,2]},
{"topic":"mytopic002","partition":1,"replicas":[1,2]},
{"topic":"mytopic002","partition":2,"replicas":[1,2]} ]}
- 4:执行副本存储计划:
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file increase-replication-factor.json --execute
- 5:再次查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe

分区自动再平衡机制
一般情况下,我们的分区都是平衡散落在broker的,随着一些broker故障,会慢慢出现leader集中在某台broker上的情况,造成集群负载不均衡,这时候就需要分区平衡。
- 为了解决上述问题kafka出现了自动平衡的机制。kafka提供了下面几个参数进行控制:
- auto.leader.rebalance.enable:自动leader parition平衡,默认是true;
- leader.imbalance.per.broker.percentage:每个broker允许的不平衡的leader的比率,默认是10%,如果超过这个值,控制器将会触发leader的平衡
- leader.imbalance.check.interval.seconds:检查leader负载是否平衡的时间间隔,默认是300秒
- 但是在生产环境中是不开启这个自动平衡,因为触发leader partition的自动平衡会损耗性能,或者可以将触发自动平和的参数leader.imbalance.per.broker.percentage的值调大点。
增加kafka的副本⭐
- 1:创建一个新的topic:(指定为3个分区1个副本)
kafka-topics.sh --bootstrap-server kafka01:9092 --create --partitions 3 --replication-factor 1 --topic mytopic002
- 2:查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe

- 3:创建副本存储计划:
vim increase-replication-factor.json
内容如下:(修改topic和replicas)
{
"version":1,
"partitions":[{"topic":"mytopic002","partition":0,"replicas":[1,2]},
{"topic":"mytopic002","partition":1,"replicas":[1,2]},
{"topic":"mytopic002","partition":2,"replicas":[1,2]} ]}
- 4:执行副本存储计划:
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file increase-replication-factor.json --execute
- 5:再次查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe

Kafka的存储
基本概念
-
每一个partition分区都对应着一个log文件。Producer生产的数据会被不断追加到该log文件末端
-
kafka为了提高效率,把每一个log文件拆分成多个segment(每个segment大小默认是1G),可以通过
log.segment.bytes去修改。 -
该文件命名规则为:topic名称+分区号
-
当log文件写入4kb大小数据(这里可以通过
log.index.interval.bytes设置),就会写入一条索引信息到index文件中,这样的index索引文件就是一个稀疏索引,它并不会每条日志都建立索引信息。
文件清理策略
-
日志清理策略有两个:
- 日志删除(delete) :按照一定的保留策略直接删除不符合条件的日志分段。
- 日志压缩(compact) :针对每个消息的key进行整合,对于有相同key的不同value值,只保留最后一个版本。
- 可以通过修改broker端参数
log.cleanup.policy来进行配置
-
kafka中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间。
- log.retention.hours:最低优先级小时,默认7天
- log.retention.minutes:分钟
- log.retention.ms:最高优先级毫秒
- log.retention.check.interval.ms:负责设置检查周期,默认5分钟
- file.delete.delay.ms:延迟执行删除时间
- log.retention.bytes:当设置为-1时表示运行保留日志最大值(相当于关闭);当设置为1G时,表示日志文件最大值
Kafka高效读取数据⭐
- kafka之所以读写性能高,是因为:
- 1:kafka是一个分布式的中间件,采用了多分区架构、以及消费者集群(消费者组),有利于抗住高并发、大流量场景。
- 2:kafka底层存储采用稀疏索引(每写入4kb数据才会加上1条索引),不仅能够节约索引占用的空间,也可以让我们快速定位数据。
- 3:顺序写磁盘
- 4:采用页缓存和零拷贝
1:顺序写磁盘
- kafka底层写入log日志数据采用的就是末尾追加的方式写入数据(这种就是顺序写磁盘),顺序写磁盘的效率比随机写磁盘的效率高了很多。
2:页缓存与零拷贝
-
kafka大量使用了页缓存(PageCache),分为以下两个场景:
- 1:读操作:当我们要读取数据的时候,首先会去页缓存里面找有没有该数据,如果有则返回,如果没有则会去磁盘中寻找,并把数据存到页缓存中。
- 2:写操作:首先会判断如果页缓存没有该条数据,则会把数据写入页缓存。如果有这条数据则修改这个页缓存数据,此时这个页缓存中的数据页就是脏页,操作系统会在特定时间把脏页写入磁盘,保证了数据一致性。
-
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。
- 当数据从磁盘经过DMA 拷贝到内核缓存(页缓存)后,为了减少CPU拷贝的性能损耗,操作系统会将该内核缓存与用户层进行共享,减少一次CPU copy过程,同时用户层的读写也会直接访问该共享存储,本身由用户层到Socket缓存的数据拷贝过程也变成了从内核到内核的CPU拷贝过程,更加的快速,这就是零拷贝。
Kafka消费者⭐
Kafka消费者的消费模式
- 1:poll(拉):消费者主动从kafka broker中拉取数据。(kafka默认采用)
- 2:push(推):kafka broker主动推送数据给消费者。
消费者组⭐
-
一个相同消费者组的消费者,它们的groupid是相同的。
-
一个分区只能由同一个消费者组的一个消费者所消费。
-
消费者组之间互不影响。
Kafka的选举3:消费者组选举Leader⭐
-
首先要选择出coordinator,如下:
- groupid的hashcode值%50(-consumer_offsets的分区数)。
- 比如groupid的hashcode值为2,则2%50=2,也就是说coordinator的2号分区在哪个kafka broker上就选择哪个节点的coordinator作为这个消费者组的boss,以后这个消费者组提交的所有offsets就往这个分区提交。
-
后面由coordinator负责选出消费组中的Leader
Java Api消费者的重要参数⭐
| 参数 | 描述 |
|---|---|
| bootstrap.servers | Kafka集群地址列表。 |
| key.deserializer 和value.deserialize | 反序列化类型。要写全类名 |
| group.id | 消费者组id。标记消费者所属的消费者组 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka提交的频率,默认 5s。 |
| auto.offset.reset | earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。 |
| max.poll.records | 一次 poll拉取数据返回消息的最大条数,默认是 500 条 |
Java Api操作消费者⭐
- 注意:指定消费者组id。注意指定my-consumer-group01会出现无反应现象。最好别加数字。例如:my-consumer-group 这个就可以运行
package com.kafka02.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;public class MyConsumer {public static void main(String[] args) {Properties properties = new Properties();//1:基本配置properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.201:9092");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//2:指定消费者组id。注意指定my-consumer-group01会出现无反应现象。最好别加数字。my-consumer-groupproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"my-consumer-group");KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);// 存放需要消费的topic名称Set<String> topicSet=new HashSet<>();topicSet.add("java-api-test");// 订阅这个topic集合kafkaConsumer.subscribe(topicSet);System.out.println("等待拉取数据------");//循环消费消息while (true){//kafka消费者的消费模式就是poll。指定1s拉取一次数据ConsumerRecords<String, String> consumerRecords =kafkaConsumer.poll(Duration.ofSeconds(1));//输出消息consumerRecords.forEach(record -> {System.out.println("--");System.out.println(record);});}}}
手动提交Offset⭐
- 手动提交offset有两个方法:(二选一)
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。 阻塞线程,一直到提交到成功,会进行失败重试
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。没有失败重试机制,会提交失败
package com.kafka02.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;public class MyConsumerCommit {public static void main(String[] args) {Properties properties = new Properties();//1:基本配置properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.201:9092");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//2:指定消费者组id。注意指定my-consumer-group01会出现无反应现象。最好别加数字。my-consumer-groupproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"my-consumer-group");//3:关闭自动提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 存放需要消费的topic名称Set<String> topicSet=new HashSet<>();topicSet.add("java-api-test");// 订阅这个topic集合kafkaConsumer.subscribe(topicSet);System.out.println("等待拉取数据------");//循环消费消息while (true){//kafka消费者的消费模式就是poll。指定1s拉取一次数据ConsumerRecords<String, String> consumerRecords =kafkaConsumer.poll(Duration.ofSeconds(1));//消费消息consumerRecords.forEach(record -> {System.out.println("--");System.out.println(record);});//消费结束后手动提交offsetkafkaConsumer.commitSync(); //同步提交}}
}
生产调优5:消息积压⭐
-
解决方案1:可以增加partition分区数和增加消费者组中的消费者数量,使partition分区数=消费者组中的消费者数量。
-
解决方案2:提高每批次拉取消息的数量(
max.poll.records),默认是500条,可以提高到1000条。
相关文章:
高性能消息中间件 - Kafka3.x(三)
文章目录 高性能消息中间件 - Kafka3.x(三)Kafka Broker ⭐Kafka Broker概念Zookeeper(新版本可以不使用zk了)⭐Zookeeper的作用 Kafka的选举1:Broker选举Leader⭐Broker核心参数⭐案例:服役新节点和退役旧…...

【八】Linux成神之路
Linux成神之路 简介:最近梳理了一下自己linux系统的学习历程,感觉整个成长过程就很顺利,并没有走弯路,于是想着可以不可以把自己linux系统学习的路线记录下来,能够在大家成长的路上有一点帮助,就在这样的一…...

功能测试用例,需要详细到什么程度?
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...
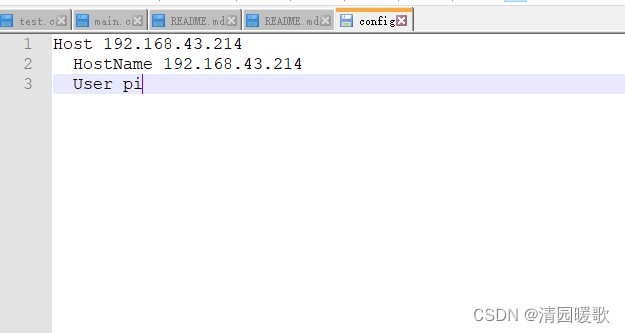
VScode远程连接错误:进程试图写入不存在的管道
使用VScode连接树莓派时,出现远程连接错误:进程试图写入不存在的管道 解决方案: (1)可以进入config所在文件夹,删除文件 (2)无法解决的化尝试下述方法 输入 Remotting-SSH:Settin…...
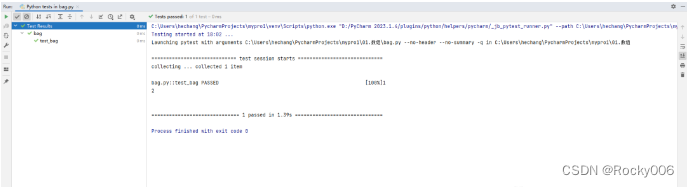
Python测试之Pytest详解
概要 当涉及到python的测试框架时,pytest是一个功能强大且广泛应用的第三方库。它提供简洁而灵活的方式来编写和执行测试用例,并具有广泛的应用场景。下面是pytest的介绍和详细使用说明: pytest是一个用于python单元测试的框架,它…...
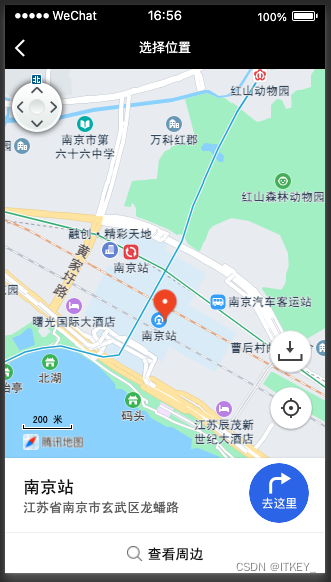
uni-app微信小程序打开第三方地图
需求 小程序中有个按钮点击以后会调用手机中第三方地图进行导航。参数 位置信息 经度 与纬度。 实现方法 uni.openLocation({latitude: Number(地址纬度),longitude: Number(地址经度),name: 地址名称,address: 地址详情,success: function (res) {console.log(打开系统位置地…...

Android NDK开发详解之NDK 使用入门
Android NDK开发详解之NDK 使用入门 下载 NDK 和工具创建或导入原生项目 原生开发套件 (NDK) 是一套工具,使您能够在 Android 应用中使用 C 和 C 代码,并提供众多平台库,您可使用这些平台库管理原生 activity 和访问实体设备组件,…...

nmap指纹识别要点以及又快又准之方法
nmap指纹识别要点以及又快又准之方法 一. 前言:二. nmap识别实验:一. 实验一:IP配置:空间配置:扫描结果:详细输出二. 实验二:IP配置:空间配置:扫描结果:详细输出三. 实验三:IP配置:空间配置:扫描结果:详细输出四. 实验四:IP...
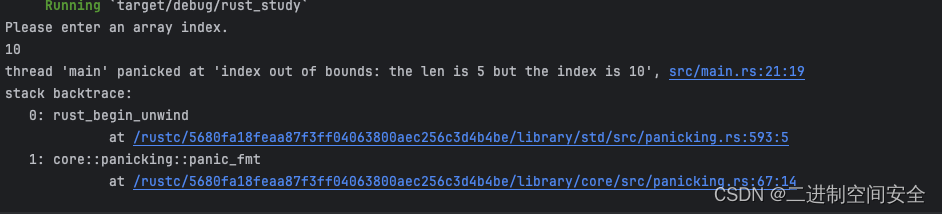
Rust编程基础之6大数据类型
1.Rust数据类型 在 Rust 中, 每一个值都属于某一个 数据类型(data type), 这告诉 Rust 它被指定为何种数据,以便明确数据处理方式。我们将看到两类数据类型子集:标量(scalar)和复合(compound&a…...
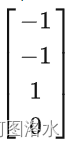
06 MIT线性代数-线性无关,基和维数Independence, basis, and dimension
1. 线性无关 Independence Suppose A is m by n with m<n (more unknowns than equations) Then there are nonzero solutions to Ax0 Reason: there will be free variables! A中具有至少一个自由变量,那么Ax0一定具有非零解。A的列向量可以线性组合得到零向…...
Kubernetes 概述以及Kubernetes 集群架构与组件
目录 Kubernetes概述 K8S 是什么 为什么要用 K8S K8S 的特性 Kubernetes 集群架构与组件 核心组件 Master 组件 Node 组件 编辑 Kubernetes 核心概念 常见的K8S按照部署方式 Kubernetes概述 K8S 是什么 K8S 的全称为 Kubernetes,Kubernetes 是一个可移植、可扩…...

GZ035 5G组网与运维赛题第9套
2023年全国职业院校技能大赛 GZ035 5G组网与运维赛项(高职组) 赛题第9套 一、竞赛须知 1.竞赛内容分布 竞赛模块1--5G公共网络规划部署与开通(35分) 子任务1:5G公共网络部署与调试(15分) 子…...

使用Jasypt3.0.3版本对SpringBoot配置文件加密
时间 2023-11-01 使用Jasypt3.0.3版本对SpringBoot配置文件加密 目录 引入依赖使用密钥生成密文配置yml验证是否自动解密 引入依赖 <!--yml 文件加解密--><dependency><groupId>com.github.ulisesbocchio</groupId><artifactId>jasypt-spring-b…...

生成一篇博客,详细讲解springboot的单点登录功能,有流程图,有源码demo
SpringBoot是目前非常流行的一个Java开发框架,它以简洁的配置和快速的开发效率著称。在实际应用中,单点登录是一个非常重要的功能,它可以让用户在多个应用系统中使用同一个账号登录,提高用户体验和安全性。本文将详细讲解如何在Sp…...
Hadoop、Hive安装
一、 工具 Linux系统:Centos,版本7.0及以上 JDK:jdk1.8 Hadoop:3.1.3 Hive:3.1.2 虚拟机:VMware mysql:5.7.11 工具下载地址: https://pan.baidu.com/s/1JYtUVf2aYl5–i7xO6LOAQ 提取码: xavd…...

PHP自定义函数--输入起始日期和解算日期返回日期差几天和 上一个周期的起始结束日期
/** 日期差几天* param beginDate:2018-01-26 endDatee:2018-01-26* return int days* */ function dateDiff($beginDate, $endDate) {$diff date_diff(date_create($beginDate), date_create($endDate))->format(%R%a);return (int)$diff; }/** 返回上一周期的起始和结束日…...

.net 7 上传文件踩坑
(Name “file”) 没加上这个传不进文件 /// <summary>/// 上传单个文件/// </summary>/// <param name"formFile"></param>/// <returns></returns>[HttpPost("UploadFiles")][FunctionAttribute(MuType.Btn, "…...
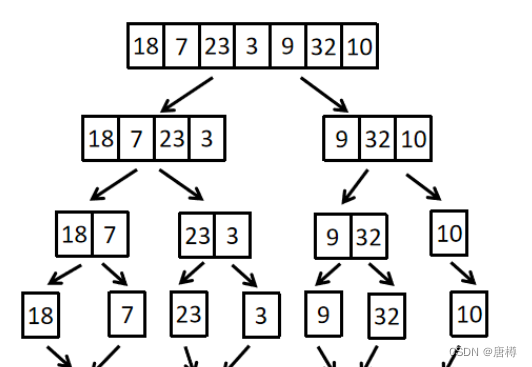
C++基础算法④——排序算法(快速、归并附完整代码)
快速排序 快速排序是对冒泡排序的一种改进。 它的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,以达到整个序列有序。 假设我们现在对 …...

高防CDN如何在防护cc上大显神通
高级防御CDN(Content Delivery Network)在对抗CC(HTTP Flood)攻击方面扮演着关键的角色,具备以下重要职能和作用: 流量分散:CC攻击的目标是通过大规模的HTTP请求使服务器过载,从而导…...

解决CSS中height:100%失效的问题
出现BUG的场景,点击退出到登录页面,发现高度不对 上面出现了一种只是占了内容的高度,没有占满100%,为什么会出现这种情况呐? 让div的height"100%",执行网页时,css先执行到࿰…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

Win11Debloat:Windows系统精简与隐私保护的专业解决方案
Win11Debloat:Windows系统精简与隐私保护的专业解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

初创公司如何通过Taotoken快速为产品原型注入多种AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何通过Taotoken快速为产品原型注入多种AI能力 对于初创公司而言,资源有限、时间紧迫是常态。产品原型的快速…...

终极空洞骑士模组管理器 Lumafly:跨平台一键安装与智能依赖管理指南
终极空洞骑士模组管理器 Lumafly:跨平台一键安装与智能依赖管理指南 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly Lumafly 是一款基于 Avalonia 框…...