【Redis】认识Redis-特点特性应用场景对比MySQL重要文件及作用
文章目录
- 认识redis
- redis的主要特点
- redis的特性(优点)
- redis是单线程模型,为什么效率这么高,访问速度这么快
- redis应用场景
- redis不可以做什么
- MySQL和Redis对比
- 启动Redis
- Redis客户端
- Redis重要文件及作用
认识redis
redis里面相关的小命令 fulshall:清空redis数据库,类似于mysql里面的drop database;
-
一. 内存中存储数据(内存级数据库)
-
redis相比MySQL的优势:MySQL数据库最大的问题在于访问速度是比较慢的(很多互联网产品中,对于性能要求是很高的)。redis作为数据库使用,定性的角度来看是很快的,但是很难定量去衡量。
-
redis相比MySql的劣势:存储空间是有限的(内存的空间毕竟是少的)。
- 虽然有不少互联网产品,对于性能的要求是比较高的。更多的互联网产品对于性能的要求没那么高。
- 所以要设计又大又快的数据库:典型的方案是,可以把redis和mysql结合起来使用(“二八原则”,20%的热点数据,能满足80%的访问需要)。虽然结合起来使用使得系统的复杂度程度大大提升了。而且,如果数据发生修改,还涉及到redis和mysql之间的数据同步的问题。
-
二. cache
- 速度快。可能会有人问:定义变量,不就是在内存中存储数据吗? => redis是在分布式系统中,才能发挥威力的~~如果只是单机程序,直接通过变量存储数据的方式,确实是比使用redis更优的选择。
- 为什么在分布式系统中会更有优势的呢?
不同的主机之间的通信,其实还是不同的进程之间的通信。又因为进程之间具有隔离性(利用网络),redis就是基于网络的,可以把自己内存中的变量给别的进程,甚至别的主机的进程进行使用。
-
三. redis的初心
- 最初就是用来作为一个“消息中间件”的(消息队列)。分布式系统下的生产者消费者模型。当前很少会直接使用redis作为消息中间件(业界有更多更专业的消息中间件使用)。
Redis(Remote Dictionary Server)是一个基于客户端-服务器架构的存储数据的中间件。它是一种内存数据库,属于NoSQL(非关系型数据库)的一种,可用于作为数据库,缓存/会话存储,消息队列。它通常被用作中间缓存层,将频繁访问的数据存储在内存中,从而大幅提升读取性能。上文所说的主从分离/冷热分离架构中的缓存服务器就可以用Redis来实现,以提高热点数据的读取性能
redis的主要特点
1.键值存储:Redis使用简单的键值对**(K-V)数据模型**。每个键都与一个唯一的值相关联,通过键可以快速访问和操作对应的值。
2.内存存储:Redis将数据保存在内存中,以实现高速的读写操作(还引入了IO多路复用,一个线程管理多个socket)。这使得Redis能够实现非常低延迟和高吞吐量的数据访问
3.可编程的:可直接通过简单的交互式命令进行操作,也可通过脚本的方式,批量执行操作
4.可扩展:Redis提供了一组API,在原有的功能上进行扩展(以支持更多的数据结构,命令),通过几个语言编写Redis扩展,本质上是一个动态链接库(windows:dll Linux:.so)
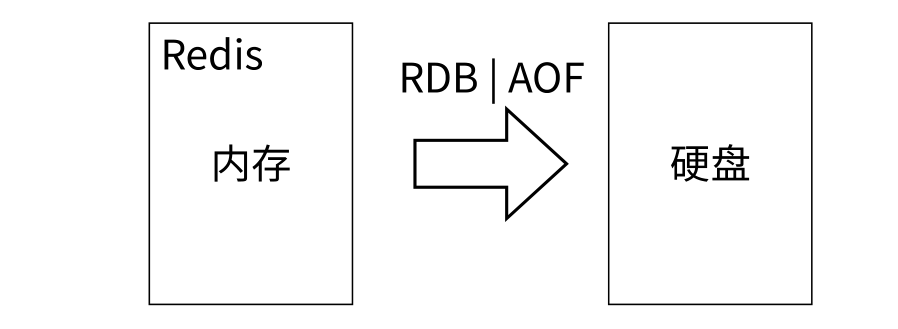
5.持久化与备份:提供持久化功能,将数据写入磁盘或其他持久存储介质。此外,一些RDS还支持数据备份和恢复功能,以防止数据丢失
- Redis提供了两种持久化⽅式:RDB和AOF,即可以⽤两种策略将内存的数据保存到硬盘中
6.支持集群:支持水平扩展(类似于分库分表),将数据分片到多个节点上,以提高存储和处理能力
7.高可用性:Redis支持主从复制(Master-Slave Replication)和哨兵(Sentinel)机制,以提供数据的高可用性和容错能力。通过配置主从复制和哨兵节点,Redis可以实现自动故障恢复和故障转移
redis的特性(优点)
1.通过数据结构在内存当中存储数据
- MySQL主要是通过
表的方式来存储组织数据的,它是关系型数据库 - Redis主要是通过
键值对的方式来存储组织数据的,它是非关系型数据库
2.可编程的
- 针对redis的操作,可以直接通过简单的交互式命令来操作,也可以通过一些脚本的方式执行一些操作
3.可拓展性
- Redis提供了一组api,可以在redis原有的功能基础上再进行拓展,比如:redis本身已经提供了很多数据结构和命令,但是通过拓展,可以让redis支持更多的数据结构和命令
4.持久化
- 因为redis为了快速访问是把数据存储到内存上的,然而内存的数据是比较容易丢失的,进程退出/系统重启,都可能会导致内存数据丢失,但是Redis还会把数据存储到硬盘上,硬盘相当于对内存当中的数据备份了一下,如果redis重启了,就会在重启的时候加载硬盘当中的备份数据,使redis的内存数据恢复到重启前的状态
- 但是主要的CRUD操作还是在内存当中进行的,为的是保证访问速度
5.集群
- redis作为一个分布式系统的中间件,一个redis能存储的数据使有限的,因为内存的空间是有限的,引入多个主机,部署多个redis节点,每个redis存储数据的一部分
6.高可用 => 冗余 / 备份
- redis自身也是支持 主从结构的,从节点相当于是主节点的备份
redis是单线程模型,为什么效率这么高,访问速度这么快
1.因为redis数据存储到内存当中,就比访问硬盘的数据库要快很多
2.redis的核心功能都是比较简单的逻辑,都是比较简单的操作内存的数据结构,并且redis是单线程模型,避免了不必要的线程竞争开销
3.从网络角度上,处理网络IO的时候,redis使用了IO多路复用的方式(epoll),使用一个线程管理很多个socket
4.使⽤了单线程,预防了多线程可能产⽣的竞争问题,减少了不必要的线程之间的竞争开销
- Redis在6.0版本引⼊了多线程机制,但主要也是在处理⽹络和IO,不涉及到数据命令,即命令的执⾏仍然采⽤了单线程模式
- 多线程提高效率的前提是CPU密集型的任务,此时使用多个线程可以充分的利用CPU多核资源
5.redis是使用C语言实现的,距离”操作系统更近,执⾏速度相对会更快 【但是MySQL也是用C语言实现的,但是MySQL比redis慢,在同样都是C语言实现的前提下,很难说是因为redis基于C语言实现的所以redis执行速度更快】
redis应用场景
1.实时的数据存储(Real-time data store),可以将 Redis 当作数据库。适用于对性能要求高的业务场景
- 大多数情况,考虑到数据存储,有限考虑的是存储空间足够大,但是有一些场景考虑的是
快,如果把redis作为数据库,那么此时redis存储的是全量数据,数据不能随便丢失
2.作为缓存/会话存储(Caching & session storage),MySql存储数据空间大,但是读取速度慢,满足不了缓存的要求,所以可以将热点数据放到redis当中
- 此时redis存储的是部分数据,全量数据以MySQL为主,哪怕redis当中数据没了,仍然可以从MySQL再加载回来
例子:会话存储
会话存储时,使用cookie用来存储用户信息的身份标识(sessionId) => 存储在浏览器这边的身份标识,但是还需要session配合 => 存储在应用服务器当中的
如果在应用服务器当中保存会话信息
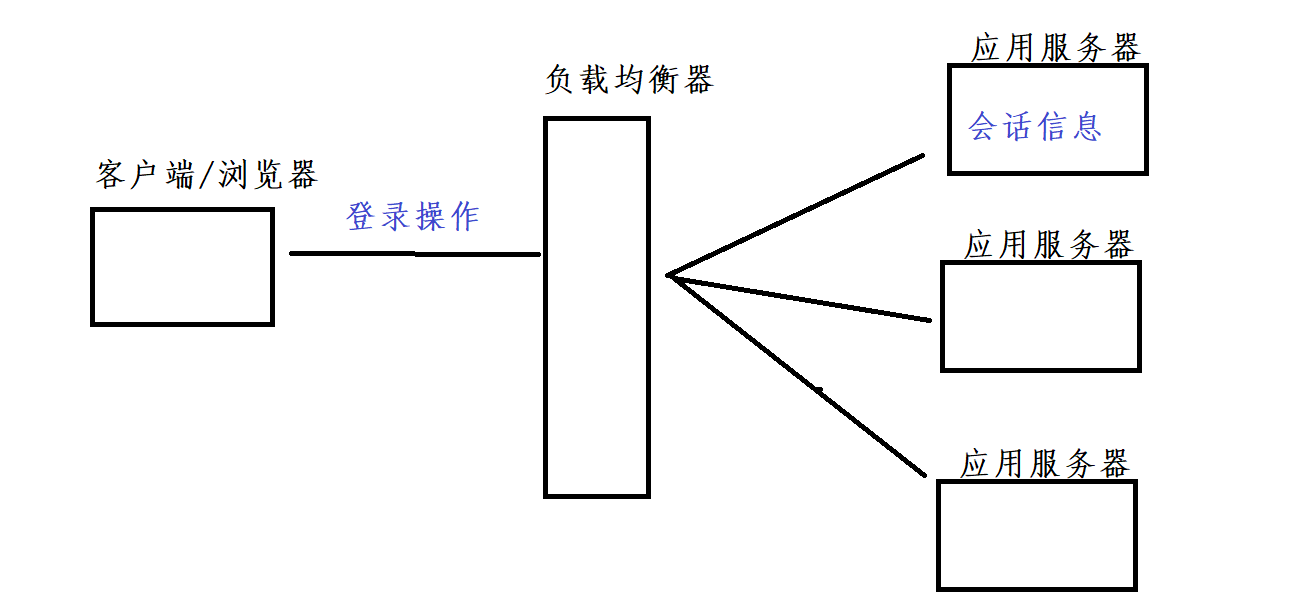
此时导致的问题:当客户端通过负载均衡器访问到服务器,进行登录操作,登录成功之后,在服务器当中生成一个session会话信息,但是当客户端再次访问服务器的时候,通过负载均衡器可能会将该请求派发到其它服务器当中,而该服务器可能并没有该用户的会话信息
解决办法:
1.更改负载均衡算法,将同一个用户的请求始终打到同一个机器上
2.将会话数据单独放到一台机器上进行存储,好处是:如果应用程序重启了,会话并不会丢失

Redis真正存储了用户信息。无论负载均衡器将登录请求分担给哪个应用服务器,都能从Redis中获取到会话
3.消息队列(服务器)(Streaming & messaging),可以实现网络版的生产者-消费者模型(优势:解耦合;削峰填谷)
注意:由于是使用内存来存储数据,不能使用Redis存储大规模数据,考虑使用其它数据库
场景1:排行榜系统
排⾏榜系统⼏乎存在于所有的⽹站,例如按照热度排名的排⾏榜,按照发布时间的排⾏榜,按照各种复杂维度计算出的排⾏榜,Redis提供了列表和有序集合的结构,合理地使⽤这些数据结构可以很⽅便地构建各种排⾏榜系统
场景2:计数器应用
计数器在⽹站中的作⽤⾄关重要,例如视频⽹站有播放数、电商⽹站有浏览数,为了保证数据的实时性,每⼀次播放和浏览都要做加1的操作,如果并发量很⼤对于传统关系型数据的性能是⼀种挑战。Redis天然⽀持计数功能⽽且计数的性能也⾮常好,可以说是计数器系统的重要选择
场景3:社交网络
赞?踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交⽹站的必备功能,由于社交⽹站访问量通常⽐较⼤,⽽且传统的关系型数据不太合适保存这种类型的数据,Redis提供的数据结构可以相对⽐较容易地实现这些功能
redis不可以做什么
站在数据规模的⻆度看,数据可以分为⼤规模数据和⼩规模数据。Redis的数据是存放在内存中的,虽然现在内存已经⾜够便宜,但是如果数据量⾮常⼤,例如每天有⼏亿的⽤⼾⾏为数据,使⽤Redis来存储的话,基本上是个⽆底洞,经济成本相当⾼
- 因为redis是使用内存来存储数据的,所以redis不能存储大规模数据
站在数据冷热的⻆度,数据分为热数据和冷数据,热数据通常是指需要频繁操作/访问的数据,反之为冷数据。如果将这些冷数据放在Redis上,基本上是对于内存的⼀种浪费,但是对于⼀些热数据可以放在Redis中加速读写,也可以减轻后端存储的负载
MySQL和Redis对比
Redis属于一种NoSQL数据库
1.数据模型
- MySQL是关系型数据库管理系统(RDBMS),使用表格来组织数据,并使用结构化查询语言(SQL)进行数据操作。数据以行和列的形式存储,且需预定义数据模式和数据类型。
- NoSQL是非关系型数据库,其数据模型可以是键值对(Key-Value)、文档(Document)、列族(Wide-Column)或图形(Graph)等。NoSQL数据库更加灵活,不需要预定义固定的数据模式
2.拓展性
- MySQL在水平扩展时存在一些限制,常规部署通常是单机或主从复制架构。虽然可以通过分区和分片等技术来提高性能和可伸缩性,但相对较复杂。
- NoSQL数据库通常天生具备可伸缩性,易于构建分布式集群,可以通过添加更多节点来水平扩展,以应对大规模数据和高并发访问的需求。
3.强一致性和灵活性
- MySQL支持强一致性,即保证所有读取操作都能看到最新的写入操作。通过事务和锁机制,确保数据一致性和完整性。
- NoSQL数据库中的一些类型,如键值对存储,可能会放宽一致性要求以换取更高的性能和可用性。这种弱一致性模型在某些场景下更加适用。
4.查询复杂性
- MySQL作为关系型数据库,支持SQL语言进行复杂查询,可以执行连接操作、聚合函数和多表关联等。
- NoSQL数据库的查询方式相对简单,通常使用键值对或类似于JSON的查询语法。它们更适合于数据访问模式简单、数据结构扁平化的场景。
如果需要强大的事务支持、复杂查询和一致性保证,以及已经有现有的SQL架构和工具链,那么MySQL是一个不错的选择。对于大规模数据、高并发和灵活的数据模型,以及更容易进行水平扩展的需求,可以考虑使用NoSQL数据库。也可以在特定场景中将两者结合使用,如使用MySQL作为主数据库,然后使用NoSQL数据库作为辅助或缓存数据库来提升性能。
启动Redis
centos启动redis命令:sudo redis-server /etc/redis/redis.conf
- ping:与redis服务做心跳测试,服务端正常的话会返回pong

如果想要关闭redis:使用netstat或者ps查询得到redis的服务器的进程id,再进行kill即可
注意:修改了配置文件,需要重启redis才能生效
Ubuntu:
- 重新启动redis服务器:
service redis-server restart - 查看redis服务器的状态:
service redis-server status
Centos:
通过netstat 或者ps查询redis服务器的进程id,然后再使用kill杀掉该进程
Redis客户端
Redis也是一个基于客户端-服务器(Client-Server)架构的内存数据库,自带的命令行客户端,可通过命令直接启动
redis-cli -h <host> -p <port>
<host> 是Redis服务器的主机名或IP地址,<port> 是Redis服务器监听的端口号。由于当前我们连接的服务器位于127.0.0.1,端口默认使用的是6379,所以可以直接使用redis-cli来启动Redis客户端
注意:redis的“快”是相对于mysql这类关系型数据库的,如果是直接和内存中的操作变量相比就没有优势甚至更慢了
比如针对单机系统,应用程序要存储K-V结构的数据,那么使用redis还是map更好呢?引入redis,一定是比直接使用map更慢的,因为map是直接操作内存,redis是先通过网络再操作内存的
Redis重要文件及作用
/usr/bin/redis-benchmark
/usr/bin/redis-check-aof -> /usr/bin/redis-server
/usr/bin/redis-check-rdb -> /usr/bin/redis-server
/usr/bin/redis-cli
/usr/bin/redis-sentinel -> /usr/bin/redis-server
/usr/bin/redis-server
/usr/libexec/redis-shutdown
redis-server是Redis服务器程序 , redis-check-aof是修复AOF⽂件⽤的⼯具 ,redis-check-rdb是修复RDB⽂件的⼯具,redis-sentinel是Redis哨兵程序,redis-benchmark⽤于对Redis做性能基准测试的⼯具,redis-shutdown是⽤于停⽌Redis的专⽤脚本
配置文件
/etc/redis-sentinel.conf 是Redis Sentinel的配置⽂件
/etc/redis.conf 是Redis服务器的配置⽂件
持久化⽂件存储⽬录
/var/lib/redis/ Redis持久化⽣产的RDB和AOF⽂件都默认⽣成于该⽬录下
相关文章:
【Redis】认识Redis-特点特性应用场景对比MySQL重要文件及作用
文章目录 认识redisredis的主要特点redis的特性(优点)redis是单线程模型,为什么效率这么高,访问速度这么快redis应用场景redis不可以做什么MySQL和Redis对比启动RedisRedis客户端Redis重要文件及作用 认识redis redis里面相关的小…...
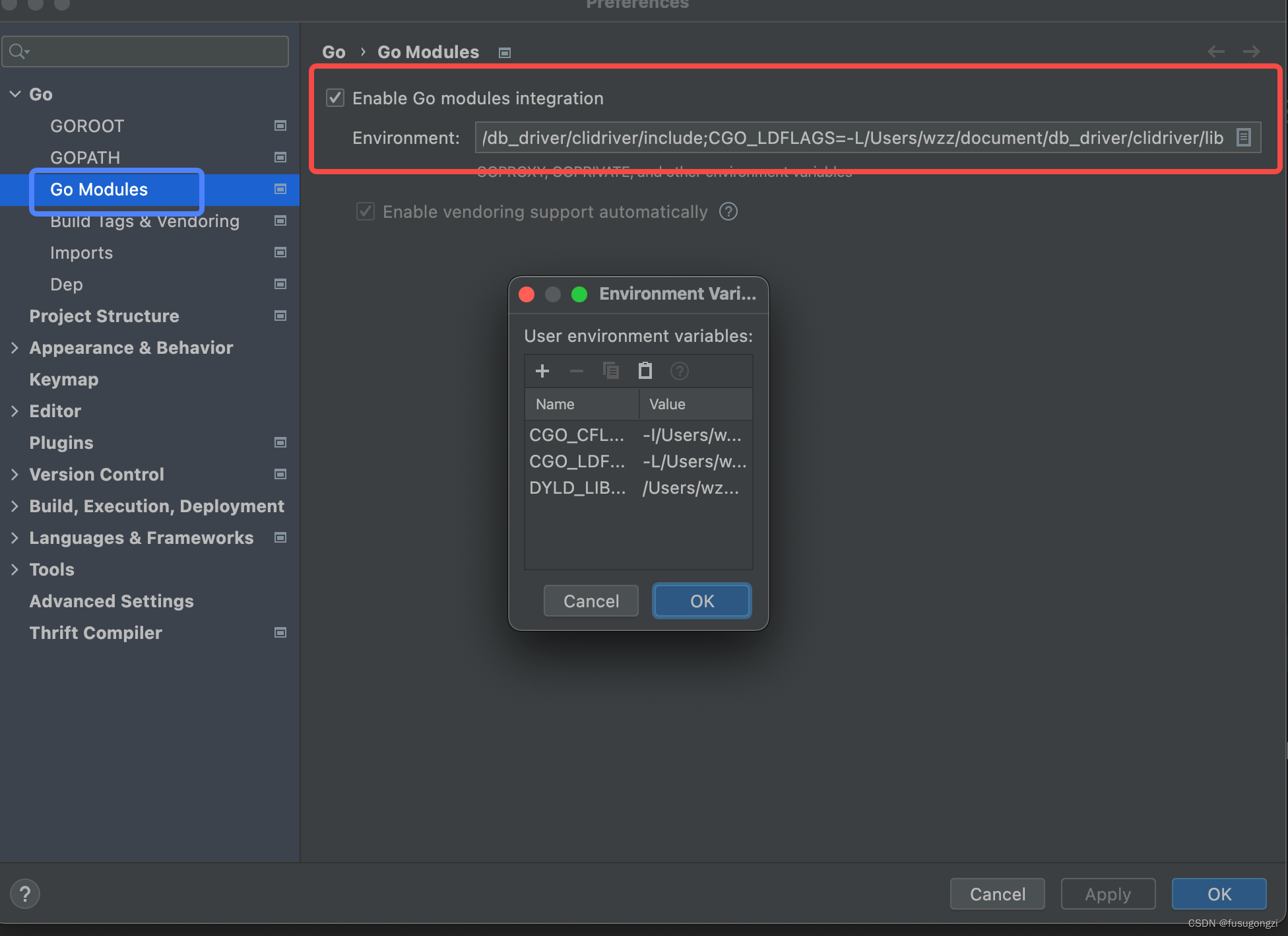
goland setup go env
go env -w设置的变量,在goland中不生效,需要额外配置。 点击goland->preference,在go module里,设置go环境变量即可。...

如何打造一支敏捷测试团队
文章目录 摘要01 从测试角度理解敏捷理念什么是敏捷?测试人员应该怎样理解敏捷理念?敏捷宣言对于测试活动的启发与思考总结如下。敏捷原则12条敏捷实践框架为什么要做敏捷 02 什么是敏捷测试03 敏捷测试为什么会失败04 诊断脑暴会的成果示例敏捷测试原则…...

STM32F40EZT6 PWM可控制电压原理
PWM可控制电压原理 主要通过PWM 输入模式根据控制单位时间内输出的平均电压,以调节电压大小。而PWM输出模式通过调节占空比,控制平均电压大小; 设置TIM为PWM输出模式 第一步:时钟使能: GPIO,TIM; 第二步&a…...
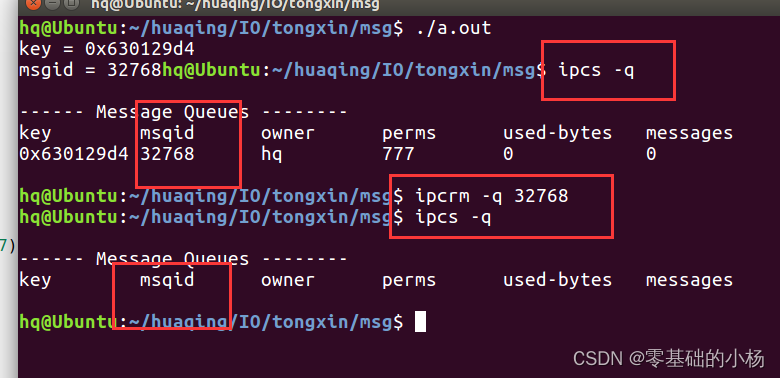
信号灯集,消息队列
信号灯集 1、概念 信号灯(semaphore),也叫信号量。它是不同进程间或一个给定进程内部不同线程间同步的机制;System V的信号灯是一个或者多个信号灯的一个集合。其中的每一个都是单独的计数信号灯。而Posix信号灯指的是单个计数信号灯。 通过信号灯集实现…...
我在Vscode学OpenCV 初步接触
OpenCV是一个开源的计算机视觉库,可以处理图像和视频数据。它包含了超过2500个优化过的算法,用于对图像和视频进行处理,包括目标识别、面部识别、运动跟踪、立体视觉等。OpenCV支持多种编程语言,包括C、Python、Java等,…...

[threejs]让导入的gltf模型显示边框
边框1效果图如下: 代码如下: const gltfLoader1 new GLTFLoader();gltfLoader1.load( "/assets/box/1/scene.gltf" ,function(gltf){let model gltf.scene;model.scale.set(3,3,3)// scene1.add(model);// renderer1.render(scene1, camera…...
YOLOv5优化:独家创新(SC_C_Detect)检测头结构创新,实现涨点 | 检测头新颖创新系列
💡💡💡本文独家改进:独家创新(SC_C_Detect)检测头结构创新,适合科研创新度十足,强烈推荐 SC_C_Detect | 亲测在多个数据集能够实现大幅涨点 目录 1. SC_C_Detect介绍 2. SC_C_Detect加入YOLOv5 2.1 新建models/head_improve.py...
作物模型--土壤数据制备过程
作物模型–土壤数据制备过程 首先打开FAO网站 下载下面这两个 Arcgis打开.bil文件 .mdb文件在access中转成.xls格式 Arcgis中对.bil文件定义投影...

学习笔记|单样本t检验|无统计学意义|规范表达|《小白爱上SPSS》课程:SPSS第四讲 | 单样本T检验怎么做?很单纯很简单!
目录 学习目的软件版本原始文档一、实战案例二、案例解析本案例之目的 四、SPSS操作1、正态性检验Tips:无统计学意义 2、t检验结果 五、结果解读六、规范报告1、规范表格2、规范文字 注意划重点 学习目的 SPSS第四讲 | 单样本T检验怎么做?很单纯很简单&…...

Bug管理规范
1BUG定义 1.1Bug状态 BUG状态标记BUG当前所处的状态,是用来处理BUG流程的主要参数,JIRA缺陷管理平台有以下一些状态: 新增(New):测试人员新发现的系统Bug; 打开(Open…...

剑指JUC原理-8.Java内存模型
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码🔥如果感觉博主的文章还不错的话,请👍三连支持&…...

Azure 机器学习 - 使用 AutoML 和 Python 训练物体检测模型
目录 一、Azure环境准备二、计算目标设置三、试验设置四、直观呈现输入数据五、上传数据并创建 MLTable六、配置物体检测试验适用于图像任务的自动超参数扫描 (AutoMode)适用于图像任务的手动超参数扫描作业限制 七、注册和部署模型获取最佳试用版注册模型配置联机终结点创建终…...
【深度学习】pytorch——快速入门
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ pytorch快速入门 简介张量(Tensor)操作创建张量向量拷贝张量维度张量加法函数名后面带下划线 _ 的函数索引和切片Tensor和Numpy的数组之间的转换张量(tensor)与标量…...

git本地项目同时推送提交到github和gitee同步
git本地项目同时推送提交到github和gitee同步 同时推送到GitHub和Gitee(码云)可以通过设置多个远程仓库地址来实现。具体步骤如下: 一、分别推送 # 初始化仓库 git init# 添加远程仓库 git remote add gitee gitgitee.com:bealei/test.git…...

结构体数据类型使用的一些注意点
1.结构体定义时的注意事项: 1.错误定义结构体: struct students {char name[9] "Mike";int height 185; }; 这是不对的,在 C 语言中,这是由语言的设计原则所决定的。结构体的定义(struct declaration&…...

Serverless化云产品超40款 阿里云发布全球首款容器计算服务
10月31日,杭州云栖大会上,阿里云宣布推出全球首款容器计算服务ACS,大幅提升操作的易用性并节省20%资源成本,真正将Serverless理念大规模落地,同时阿里云 Serverless化进程进入快车道,有超40款云产品提供了S…...
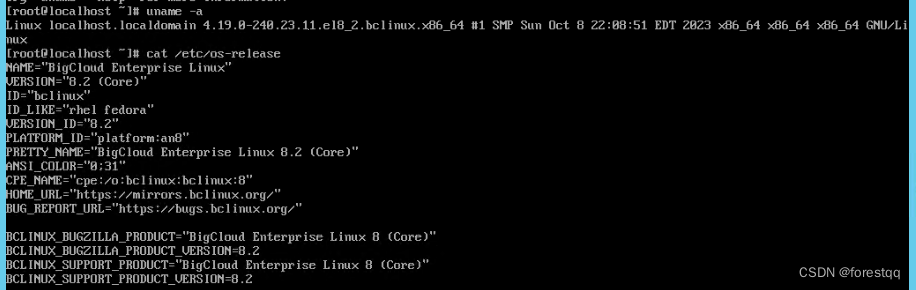
最小化安装移动云大云操作系统--BCLinux-R8-U2-Server-x86_64-231017版
有个业务系统因为兼容性问题,需要安装el8.2的系统,因此对应安装国产环境下的BCLinuxR8U2系统来满足用户需求。BCLinux-R8-U2-Server是中国移动基于AnolisOS8.2深度定制的企业级X86服务器通用版操作系统。本文记录在DELL PowerEdge R720xd服务器上最小化安…...

索引创建的原则
索引的创建是数据库优化中非常重要的一部分,正确创建索引可以大大提高查询效率。以下是一些创建索引时需要考虑的原则: 根据查询频率创建索引: 频繁用于检索的列: 那些频繁用于查询的列或经常出现在 WHERE、JOIN、ORDER BY 和 GR…...
动态表单生成Demo(Vue+elment)
摘要:本文将介绍如何使用vue和elment ui组件库实现一个简单的动态表单生成的Demo。主要涉及两个.vue文件的书写,一个是动态表单生成的组件文件,一个是使用该动态表单生成的组件。 1.动态表单生成组件 这里仅集成了输入框、选择框、日期框三种…...

SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析
SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser&…...

当卫星在天上“读懂”人间:ICLR 2025 论文深度解读师玉娇、昃向辉的CS2S
把一张卫星图变成一张街景照片,就像把一个俯视棋盘拼成一面看台——不仅要摆对每一枚棋子,还要看懂整场比赛想象这样一个场景:你在城市规划部门工作,需要快速生成某条街道在不同季节、不同天气条件下的真实渲染效果,以…...

Python之encode-cli包语法、参数和实际应用案例
Python encode-cli包完整使用指南 encode-cli 是Python生态中轻量、高效的命令行编码/解码工具包,专注于提供主流编码格式的快速转换,支持命令行直接调用,无需编写复杂Python代码,适用于数据加密、文本转码、URL处理、Base64转换等…...

ZYNQ PS-SPI驱动W25Q80 Flash避坑指南:从寄存器配置到逻辑分析仪抓包全流程
ZYNQ PS-SPI驱动W25Q80 Flash实战避坑手册:从寄存器配置到信号抓包全解析 当你在Vitis Standalone环境下调试ZYNQ的PS-SPI与W25Q80 Flash通信时,是否遇到过这些场景:SPI时钟信号看似正常但数据始终对不上、擦除操作耗时远超预期、FIFO缓冲区莫…...

STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南
STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南 在嵌入式系统开发中,ADC(模数转换器)的稳定性直接关系到整个系统的测量精度。特别是对于STM32F407这类高性能MCU,当应用于电源监控、医疗设备或工业传感…...

SuperMap iDesktop中BIM模型缓存生成全攻略:从性能调优到Web端流畅加载的避坑指南
SuperMap iDesktop中BIM模型缓存生成全攻略:从性能调优到Web端流畅加载的避坑指南 当你在深夜加班处理一个大型商业综合体的BIM模型时,iDesktop突然闪退,进度条停留在87%——这种崩溃瞬间是否似曾相识?作为经历过数十个大型BIM项目…...
并计算卫星坐标)
保姆级教程:用Python解析北斗广播星历文件(RINEX 3.04格式)并计算卫星坐标
北斗卫星坐标计算实战:Python解析RINEX 3.04星历全流程 当我们需要获取北斗卫星的精确位置时,广播星历文件是最直接的数据来源。这份看似晦涩的文本文件,实际上包含了计算卫星位置所需的所有轨道参数。本文将带你从零开始,完整实现…...

E-ROBOT:融合熵正则化与鲁棒截断的最优传输新框架
1. E-ROBOT框架:从理论动机到核心思想拆解在机器学习和统计学中,我们常常需要比较和度量两个概率分布之间的差异。最优传输(Optimal Transport, OT)为此提供了一个优雅且几何直观的数学框架:它寻找一个“运输计划”&am…...

别再只盯着电池百分比了!Windows 11 这个隐藏命令,一键生成你的笔记本电池“体检报告”
别再只盯着电池百分比了!Windows 11 这个隐藏命令,一键生成你的笔记本电池“体检报告”每次看到笔记本电量只剩20%就焦虑地找充电器?你可能忽略了更重要的数据——电池健康度就像人体的体检报告,能告诉你电池真实的"身体状况…...
别再用Sprite了!用UE Niagara条带渲染器制作能量射线与流体轨迹的实战指南
别再用Sprite了!用UE Niagara条带渲染器制作能量射线与流体轨迹的实战指南在游戏特效制作中,能量射线和流体轨迹一直是技术美术师们面临的挑战。传统的Sprite粒子系统虽然简单易用,但在表现连续、方向性强的动态效果时往往力不从心。想象一下…...