词向量模型Word2Vec
Word2Vec
- CBOW连续词袋模型
- 例子
- CBOW模型的embeddings层
- CBOW模型的线性层
- 总结
- skip-gram跳字模型
- 例子
- Skip-Gram模型的结构
CBOW和skip-gram的目标都是迭代出词向量字典(嵌入矩阵)——embeddings
CBOW连续词袋模型
根据上下文词汇预测目标词汇
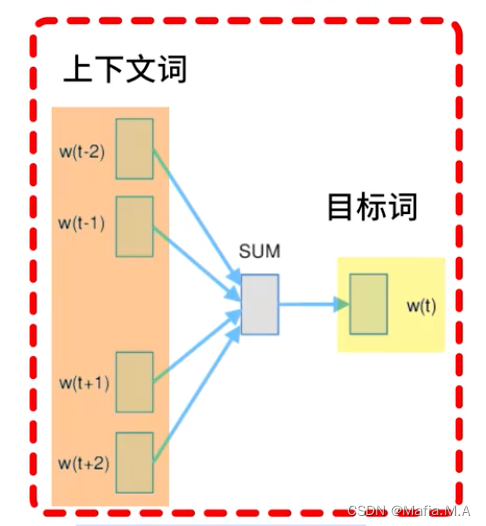
例子
使用study的上下文,表示出study
例句:We are about to study the idea of deep learning.
- 某个词的上下文,需要提前设置一个上下文窗口长度
窗口长度为1:We are about to study the idea of deep learning. (上下文分别问to和the)
窗口长度为2:We are about to study the idea of deep learning. (上下文分别为about to 和 the idea)
- 设置好窗口的长度后,需要通过窗口内的词语,预测目标词:
窗口长度为2时,则有如下对应关系:
We、are、to、study -预测> about
are、about、study、the -预测> to
about、to、the、idea -预测> study
- CBOW模型是一个神经网络:该神经网络会将接收上下文词语,将上下文词语转换为最有可能得到的目标词。
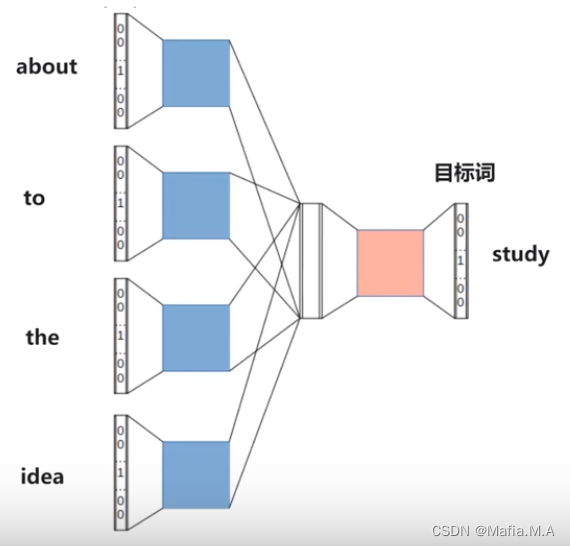
eg.如果向神经网络输入 about、to、the、idea四个词,神经网络则输出study这个词。
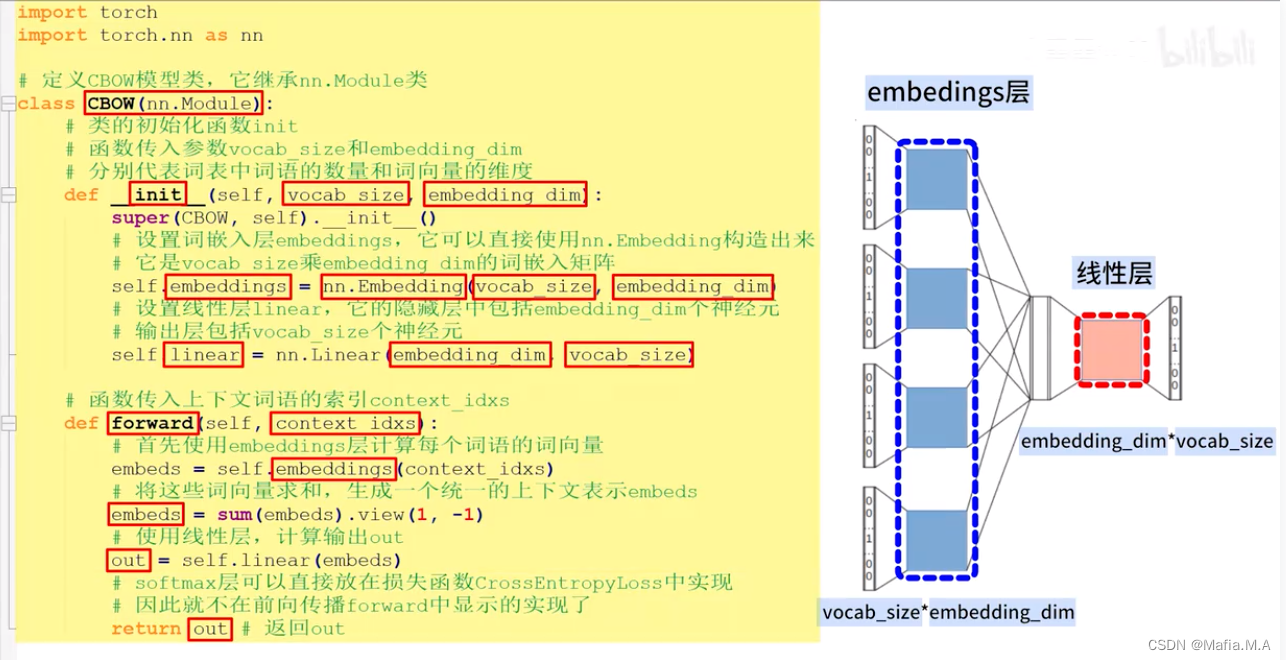
CBOW模型的embeddings层
CBOW模型中有一个特殊的层——embeddings层
embeddings层是一个N*V的矩阵
N——词表中的词语个数;
V——词向量的维度
他就是我们最终希望得到的嵌入矩阵
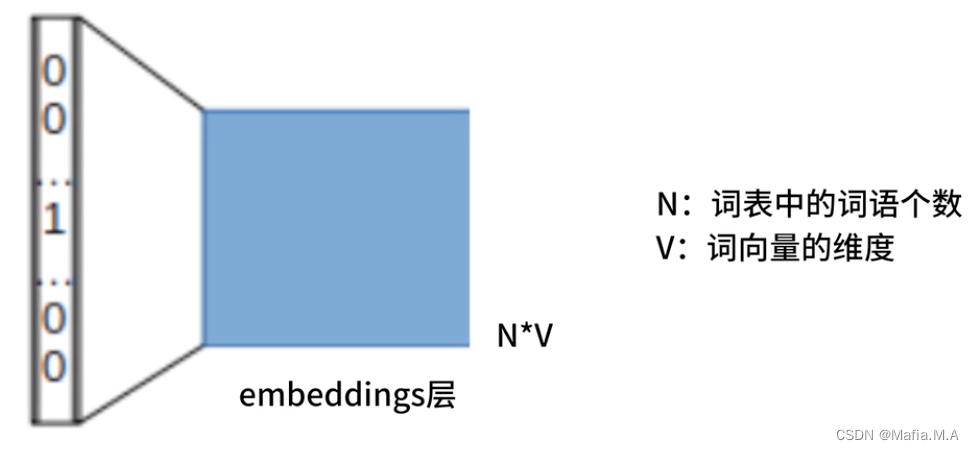
embeddings层的作用是将我们输入的词语转换成词向量
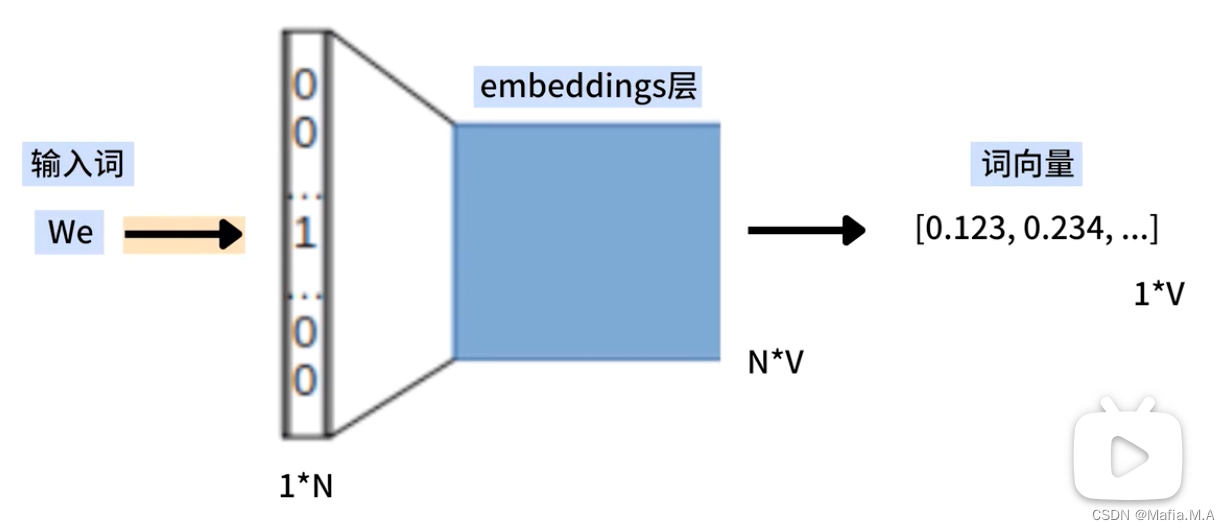
1.将词语we输入至CBOW,将we转换为One-Hot编码形式,是一个1xN的向量,其中只有与We对应的位置是1,其余位置都是0
2.将we的One-Hot编码(1xN的向量)与embeddings(NxV的矩阵)相乘,得到we的词向量(1xV的向量)
相当于从矩阵中选择一个特定的行,从embeddings中查找we的词向量。
由于某个词的上下文中包括了多个词语,这些词语会同时输入embeddings层,每个词语都会被转换为一个词向量。
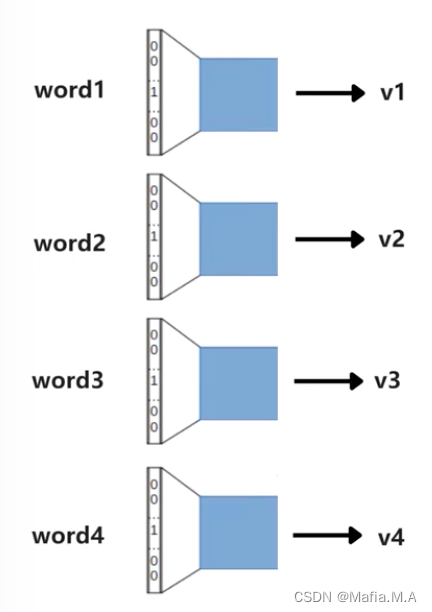
多个上下文词的一个统一表示:v=(v1+v2+v3+v4)/ 4
embeddings层的输出结果:是一个将语义信息平均的向量v
CBOW模型的线性层
在embeddings层后会连接一个线性层
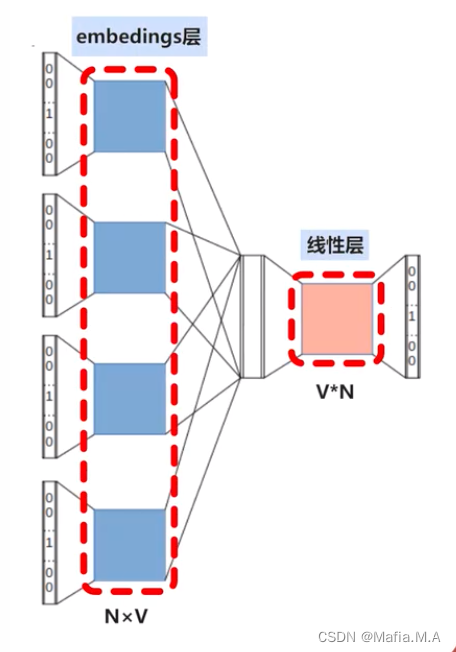
橙色标记的线性层
不设置激活函数
权重矩阵的维度:VxN
词向量维度:V
词表中词语的个数:N
V个隐藏神经元、N个输出神经元的神经网络
- 我们将所有上下文词向量的平均值(向量V),输入该线性层
- 通过线性层的计算得到一个1xN的向量
- 将1xN的向量再输入至softmax层,最终计算出一个最有可能的输出词,这个词就是CBOW模型的预测目标词
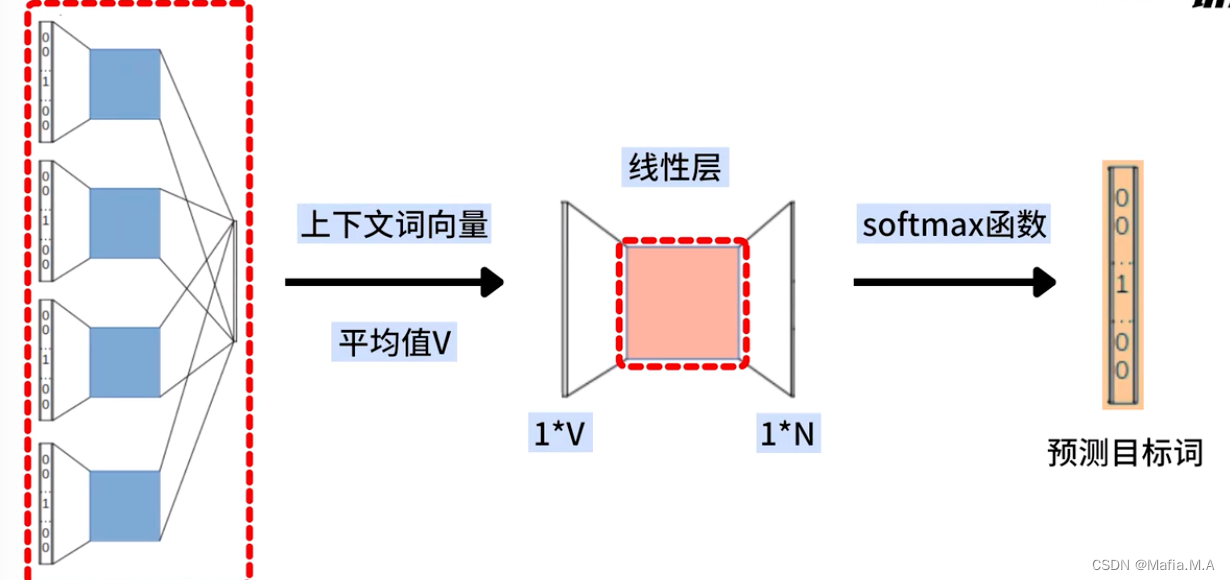
总结
CBOW模型包括两部分:embeddings层和线性层
embeddings层:将输入的上下文词语,都转换为一个上下文词向量,并继续求出这些上下文词向量的平均值(代表整个上下文的向量)
线性层:接收该向量,并将其转换为一个输出向量(输出向量的维度与词汇表的大小相同)
最后使用softmax函数,将输出向量转换为一个概率分布,表示每个词作为目标词的概率,概率最大的词就是CBOW模型的预测结果
skip-gram跳字模型
根据目标词汇预测上下文
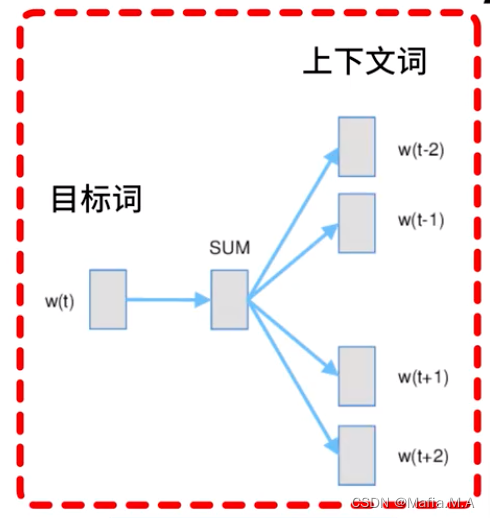
例子
使用词语study,预测出它的上下文
例句:We are about to study the idea of deep learning.
- 某个词的上下文,需要提前设置一个上下文窗口长度
设置窗口长度为2后,根据目标词,预测窗口内的上下文词,study -预测-> about、to、the、idea
如何使用一个词预测另一个词:
使用一个词,预测另一个词,尽量使这两个词的词向量接近
Skip-gram在迭代时,调整词向量:
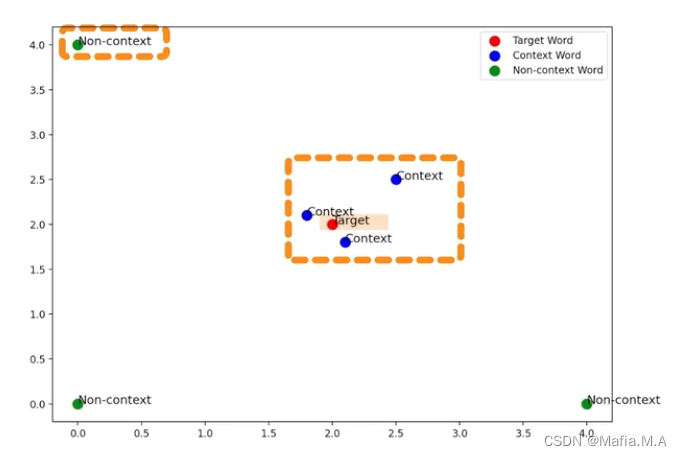
使目标词的词向量与其上下文的词向量尽可能的接近;
使目标词的词向量与非上下文词的词向量尽可能的远离。
因此我们对于给定的目标词,它与它的上下文的词向量相似,与非上下文词的词向量不相似。
在skip模型中,判断两个词向量是否相似,使用向量点积:
A·B=a1b1+a2b2+…+anbn
A=(a1,a2,…,an)
B=(b1,b2,…,bn)
向量的点积:衡量了两个向量在同一方向上的强度,点积越大——两个向量越相似,它们对应的词语语义就越接近

需要想办法让study与about的词向量的点积尽可能大
Skip-Gram模型的结构
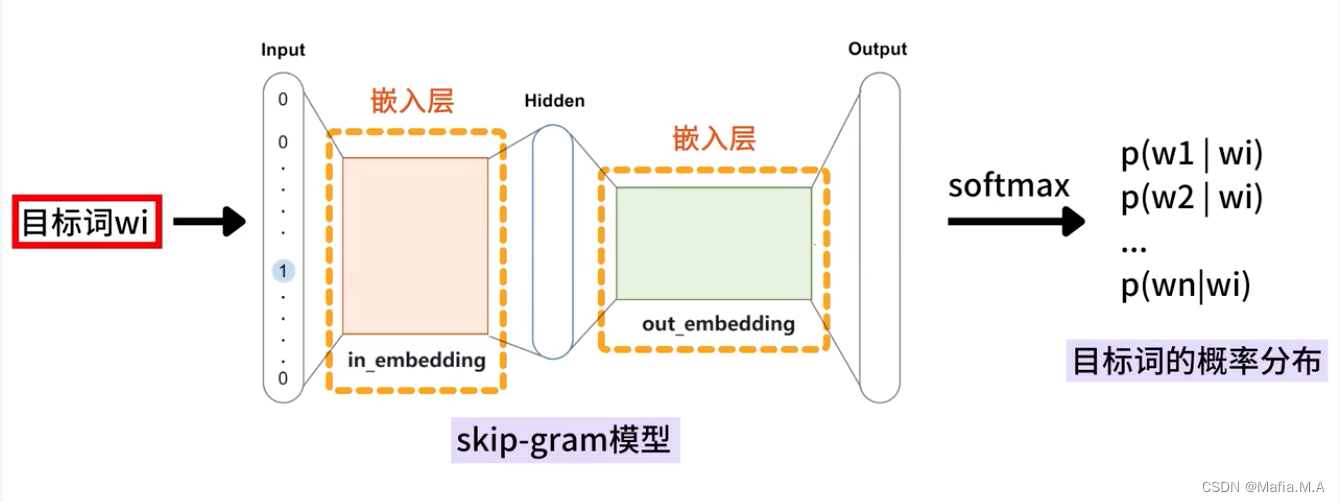
目标词的概率分布——词汇表中的每个词是目标词的上下文的可能性

词表中的词,与目标词有两种关系:
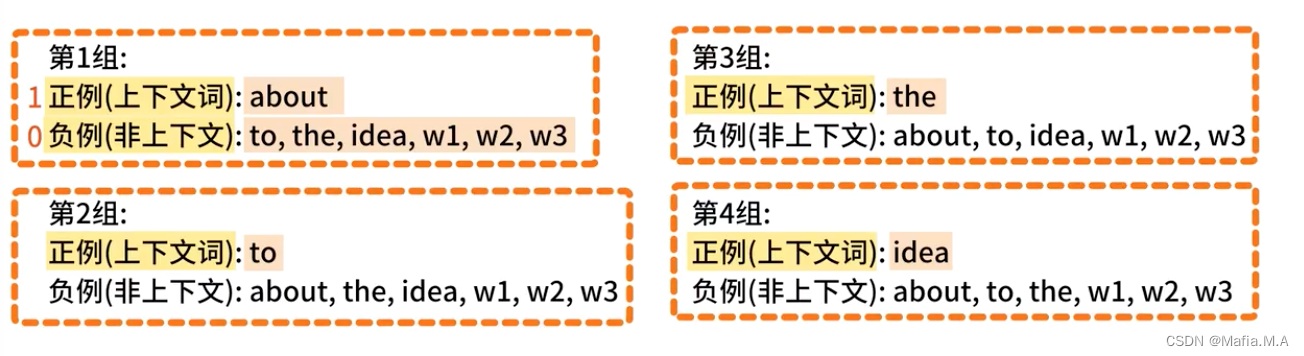
- 上下文词——正样本,标记为1
- 非上下文词——负样本,标记为0
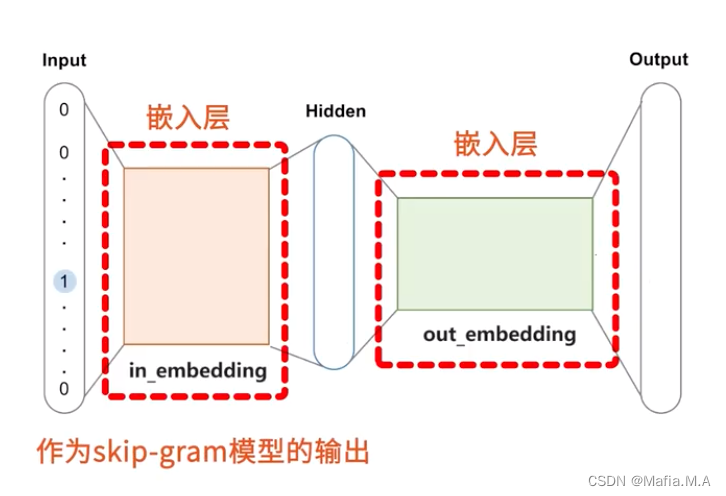
基于这一点来优化模型中两个嵌入层——in_embedding和out_embedding
最后将in_embedding作为skip-gram模型的输出

由此产生的训练数据:有4个上下文词,因此产生4组训练数据
相关文章:
词向量模型Word2Vec
Word2Vec CBOW连续词袋模型例子CBOW模型的embeddings层CBOW模型的线性层 总结 skip-gram跳字模型例子Skip-Gram模型的结构 CBOW和skip-gram的目标都是迭代出词向量字典(嵌入矩阵)——embeddings CBOW连续词袋模型 根据上下文词汇预测目标词汇 例子 使…...

公会发展计划(GAP):经过实战考验的 Web3 任务模式
2020 年 12 月,Yield Guild Games 踏上了一段征程,以表彰兢兢业业的 Web3 游戏玩家所付出的时间和努力,同时为他们提供利用自己的技能促进个人成长的机会。这一旅程的第一步是于 2022 年 7 月推出的公会发展计划(GAP)。…...
)
网络工程师基础知识(2)
一、端口可以分为系统端口、登记端口、客户端使用端口。 (1) 系统端口。该端口的取值范围为[0,1023]. (2) 登记端口。登记端口是为没有熟知端口号的应用程序使用的,端口范围为[1024,49151]。这些端口必须在 IANA 登记以避免重复。 (3) 客户端使用端口。这类端口仅…...

创建ABAP数据库表和ABAP字典对象-理解表字段02
理解表字段 这一步,您将定义表字段。首先,你需要了解你的需求: 内置的ABAP类型和新定义的字段类型 下面我们将会创建3个字段类型在数据库表中。 ●内置字段类型:最快的方法:应用系统已经提供好的字段类型,基本类型、长度和描述…...
2021-arxiv-GPT Understands, Too
2021-arxiv-GPT Understands, Too Paper: https://arxiv.org/abs/2103.10385 Code: https://github.com/THUDM/P-tuning Prompt 简单理解 举例来讲,今天如果有这样两句评论: 1. 什么苹果啊,都没有苹果味,…...

【Spark】What is the difference between Input and Shuffle Read
Spark调参过程中 保持每个task的 input shuffle read 量在300-500M左右比较合适 The Spark UI is documented here: https://spark.apache.org/docs/3.0.1/web-ui.html The relevant paragraph reads: Input: Bytes read from storage in this stageOutput: Bytes written …...

redis相关的一些面试题?
1.什么是缓存穿透,什么是缓存雪崩,什么是缓存击穿? 缓存穿透:假如某一时刻访问redis的大量key都在redis中不存在(比如黑客故意伪造一些乱七八糟的key),那么也会给数据造成压力,这就是缓存穿透,解决方案是使…...

什么是Babel?它的主要作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
【APP】go-musicfox - 一款网易云音乐命令行客户端, 文件很小Mac版本只有16.5M
go-musicfox 是用 Go 写的又一款网易云音乐命令行客户端,支持各种音质级别、UnblockNeteaseMusic、Last.fm、MPRIS 和 macOS 交互响应(睡眠暂停、蓝牙耳机连接断开响应和菜单栏控制等)等功能特性。 预览 启动 启动界面 主界面 主界面 通…...

P1284 三角形牧场
Portal. 首先,我们需要一些初中数学知识——秦九韶公式(又名海伦公式): p a b c 2 S p ( p − a ) ( p − b ) ( p − c ) \begin{align} &p\dfrac{abc}{2}\\ &S\sqrt{p(p-a)(p-b)(p-c)} \end{align} p2abcSp(p…...
【Linux】:Linux开发工具之Linux编辑器vim的使用
🔫1.Linux编辑器-vim使用 📤 vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以…...

PFMEA详解结构分析——Sun FMEA软件
FMEA从1949年诞生到今天已经发生过多次更新,最新版本是2019年6月发布的《AIAG VDA FMEA手册》。新手册借鉴了AIAG的方框图、参数图、流程图等工具的运用,也借鉴了VDA的五步过程导向法,并在此基础上头尾各增加一步,形成了FMEA七步法…...

Qt扫盲-QFutureWatcher理论总结
QFutureWatcher理论总结 一、概述二、转态 一、概述 QFutureWatcher类允许我们使用信号槽的方式去监控QFuture。 QFutureWatcher提供关于QFuture的信息和通知。使用 setFuture() 函数开始监视特定的QFuture。 future()函数通过setFuture()返回 QFuture 集合。 为了方便起见…...
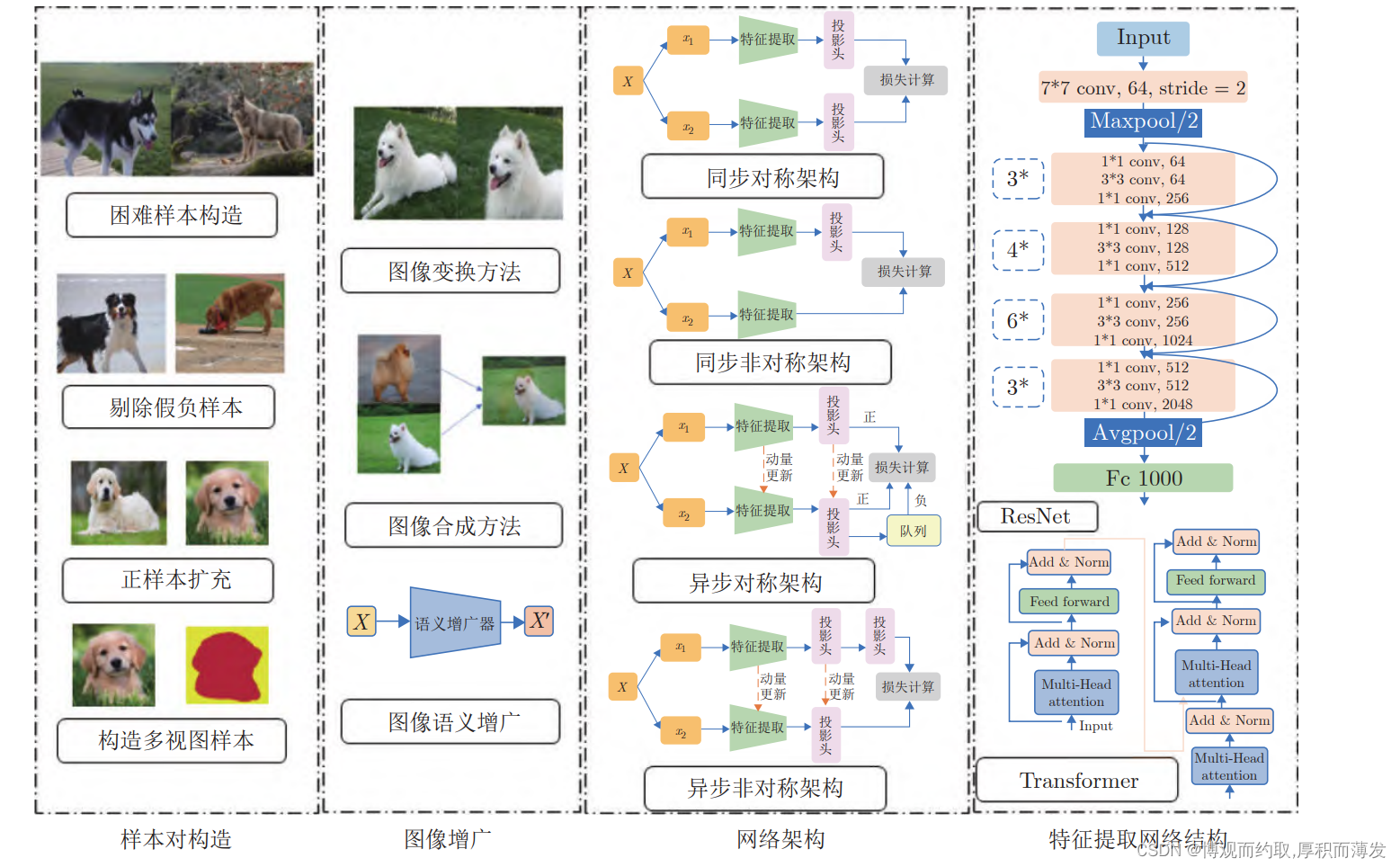
对比学习(contrastive Learning)
起源和定义 自监督学习又可以分为对比学习(contrastive learning)和生成学习(generative learning)两条主要的技术路线。 比学习的核心思想是将正样本和负样本在特征空间对比,从而学习样本的特征表示,使得样本与正样本的特征表示尽可能接近。正样本和负…...
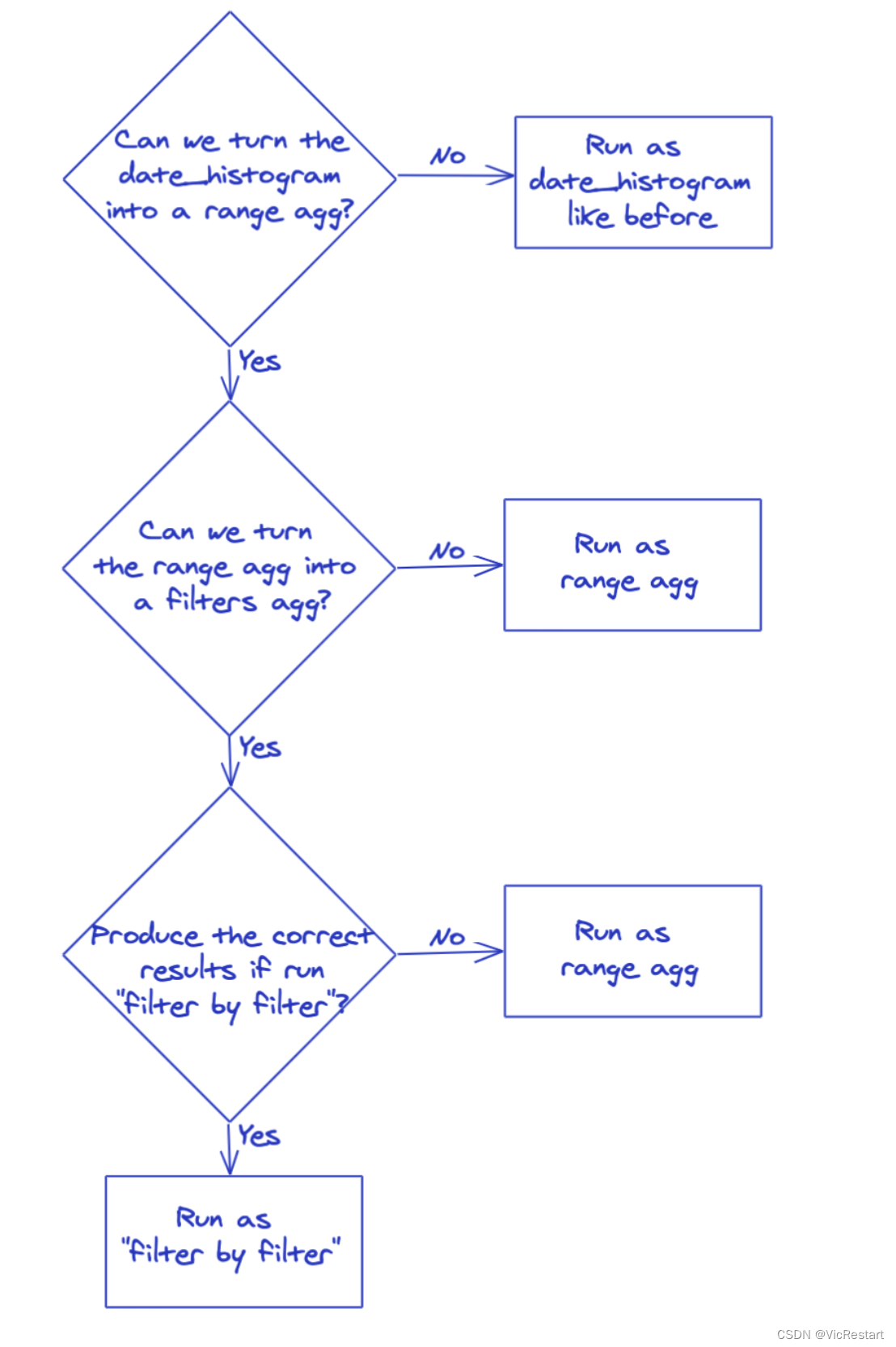
译文:我们如何使 Elasticsearch 7.11 中的 date_histogram 聚合比以往更快
这篇文章是ES7.11版本的文章,主要学习的是思路,记录在这里留作以后参考用。 原文地址:https://www.elastic.co/cn/blog/how-we-made-date-histogram-aggregations-faster-than-ever-in-elasticsearch-7-11 正文开始: Elasticsea…...

python设计模式4:适配器模式
使用适配器模式使用两个或是多个不兼容的接口兼容。在不修改不兼容代码的情况下使用适配器模式实现接口一致性。通过Adapter 类实现。 例子: 一个俱乐部类Club,艺术加被请到俱乐部在表演节目: organize_performance()…...
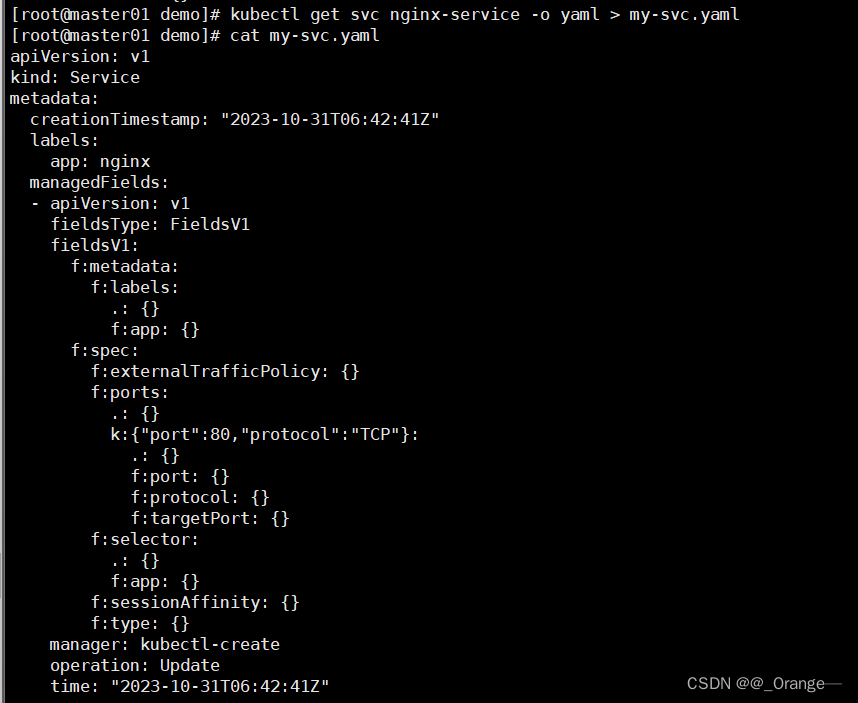
kubectl资源管理命令---声明式
目录 一、yaml和json介绍 1、yuml语言介绍 2、k8s支持的文件格式 二、声明式对象管理 1、deployment.yaml文件详解 2、Pod yaml文件详解 3、Service yaml文件详解 三、编写资源配置清单 1、 编写yaml文件 2、 创建并查看pod资源 3、创建service服务对外提供访问并测试…...
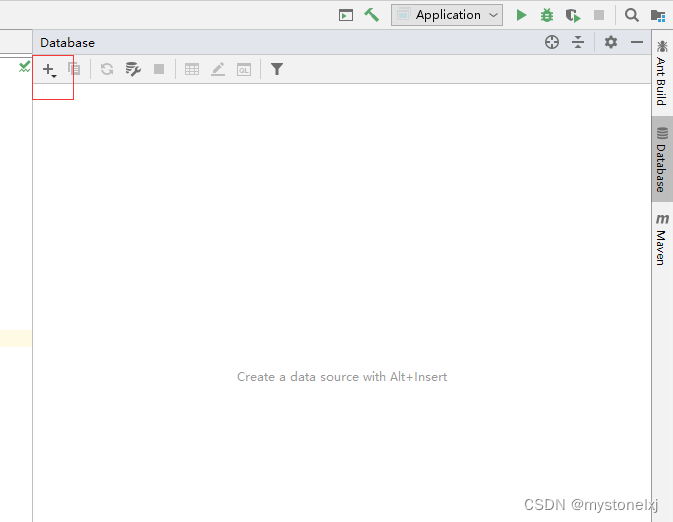
IDEA使用-通过Database面板访问数据库
文章目录 前言操作过程注意事项1.无法下载驱动2.“Database”面板不显示数据库表总结前言 作为一款强大IDE工具,IDEA具有很多功能,本文将以MariaDB数据库访问为例,详细介绍如何通过IDE工具的Database面板来访问数据库。 操作过程 不同的版本操作会略有差异,这里我们用于演…...

单片机如何写好一个模块的驱动文件
搞单片机,MCU:STM32/GD32/HC32,通讯模组:4G/WIFI/BT/433,总线:USB/CAN/K/232/485,各种常见的传感器,都接触过。 一开始学习单片机的时候没有形成很好的编写习惯,如LED点亮/熄灭/闪烁…...

【C++笔记】C++多态
【C笔记】C多态 一、多态的概念及实现1.1、什么是多态1.2、实现多态的条件1.3、实现继承与接口继承1.4、多态中的析构函数1.5、抽象类 二、多态的实现原理 一、多态的概念及实现 1.1、什么是多态 多态的概念: 在编程语言和类型论中,多态(英…...
)
仅剩72小时!Claude ROI计算模型企业定制版限时开放API对接权限(含AWS/Azure/GCP原生适配器)
更多请点击: https://codechina.net 第一章:Claude ROI计算模型企业定制版核心价值与限时策略 Claude ROI计算模型企业定制版并非通用模板的简单参数调整,而是基于客户实际业务流、成本结构与AI应用成熟度深度耦合的量化决策引擎。其核心价值…...

量子态估计新突破:超越置乱时间,QELM稳健实现高效信息提取
1. 项目概述 量子态估计,简单来说,就是“看清”一个未知量子系统内部状态的过程。这好比在完全黑暗的房间里,你需要通过有限的光线(测量)来推断房间内物体的精确形状和位置。在量子计算、量子通信和量子传感等领域&…...

[智能体-42]:深度解读:Python 免编译 + 动态执行,支撑智能体落地大模型决策
一、先厘清核心概念无需编译执行:Python 属于解释型语言,区别于 C/C、Java 编译型语言。编译型语言必须先将源码整体编译成机器码 / 字节码文件,才能运行;Python 无需手动编译,源码可逐行边解析边执行,即时…...

机器学习模型监控实战:KS检验与BC系数在大数据供应链预测中的应用
1. 项目概述:为什么模型上线后,监控比训练更重要?在机器学习项目里,我们常常把80%的精力花在数据清洗、特征工程和模型调优上,觉得模型一旦上线,任务就完成了。但真实的生产环境会给你上一课:一…...

Keil串口调试与程序共享端口的解决方案
1. 串口调试中的端口复用问题解析 在嵌入式开发过程中,使用Keil Vision的Monitor模式进行硬件调试时,开发板上的串口资源往往会被调试器独占。这个问题困扰过不少开发者——当我们需要在调试过程中通过串口输入测试数据时,却发现串口已经被Mo…...

ES 模块:JavaScript 模块化的标准方案
ES 模块:JavaScript 模块化的标准方案 什么是 ES 模块? ES 模块(ES Modules,简称 ESM)是 ECMAScript 2015(ES6)引入的官方模块化规范。 ES 模块 vs CommonJS 特性CommonJSES Modules加载方式同步…...

毕业论文神器!2026年必备AI论文软件榜单,免费版也能写合规初稿
2026 年实测 10 款主流 AI 论文工具,千笔AI以全流程覆盖 语义级降重 免费查重领跑综合榜;ThouPen 稳坐留学生毕业全流程工具头把交椅;免费工具中DeepSeek Scholar、豆包学术版表现亮眼,30 分钟即可生成万字高质量初稿࿰…...

HTML 零基础入门:从概念到常用标签详解,前端入门超详细版
一、HTML介绍HTML 全称超文本标记语言(HyperText Markup Language),是搭建网页的基础骨架语言,也是前端开发最入门、最核心的语言。它不属于编程语言,没有逻辑运算、没有变量,只是一套标记标签,…...

Shutter Encoder:构建高效媒体工作流的FFmpeg图形化解决方案
Shutter Encoder:构建高效媒体工作流的FFmpeg图形化解决方案 【免费下载链接】shutter-encoder A professional video compression tool accessible to all, mostly based on FFmpeg. 项目地址: https://gitcode.com/gh_mirrors/sh/shutter-encoder 在数字媒…...

SQL 能包打天下吗?多少比例的产品只需 SQL,何时需要引入其他存储?
引言 在数据驱动的时代,SQL(结构化查询语言)作为关系型数据库的标准查询语言,其地位无可撼动。它以其强大的数据操作能力、清晰的声明式语法和广泛的生态支持,成为绝大多数应用开发者的首选。然而,随着业务场景的日益复杂和数据形态的多样化,一个灵魂拷问随之而来:SQL…...