Generative AI 新世界 | 文生图(Text-to-Image)领域论文解读
在上期文章,我们开始探讨生成式 AI(Generative AI)的另一个进步迅速的领域:文生图(Text-to-Image)领域。概述了 CLIP、OpenCLIP、扩散模型、DALL-E-2 模型、Stable Diffusion 模型等文生图(Text-to-Image)的基本内容。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点 这里让它成为你的技术宝库!
本期内容将进行文生图(Text-to-Image)方向的主要论文解读。
变分自编码器 VAE (Variational Auto-Encoder) 论文解读
自编码器 (Auto-Encoder) 架构
自编码器(Auto-Encoder)是一种无监督学习的神经网络,用于学习输入数据的压缩表示。具体而言,可以将其分为两个部分:
编码器:负责将数据压缩为低维表示;
解码器:负责将低维表示恢复为原始数据。
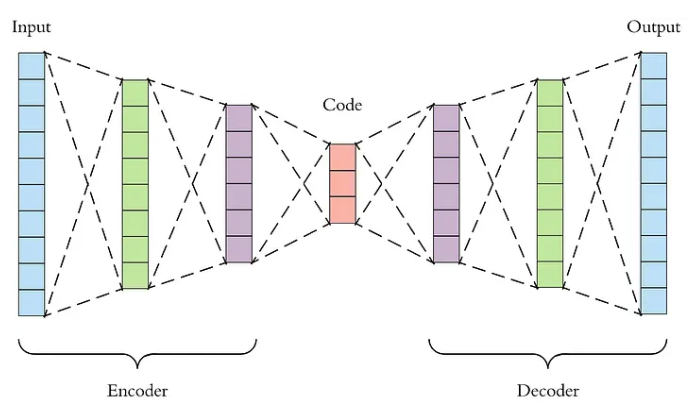
Source:https://towardsdatascience.com/applied-deep-learning-part-3-a...
读到这里,可能有读者会问:既然解码器只需要输入某些低维向量,就能够输出高维的图片数据;那我们是否可以把解码器模型直接当做生成模型呢?比如:在低维空间中随机生成某些向量,再送给解码器来生成图片。
不这样做的原因是,绝大多数随机生成是无意义的噪声,由于没有显性的对分布进行建模,我们并不知道那些向量能够生成有用的图片;我们用来训练的数据集通常是有限的,因此只会具有有限响应。而整个低维空间很大,如果只在这个空间上随机采样的话,恰好采样到能够生成有用图片的概率不高。
而 VAE(自变分编码器,Variational Auto-Encoders)就是在 AE 的基础上,显性对分布进行建模,帮助自编码器成为一个合格甚至优秀的生成模型。
降维(Dimensionality Reduction)和潜在空间(latent space)
上一节中我们谈到了一个降维(Dimensionality Reduction)的概念,这个概念在所有生成式 AI 领域都非常重要。在本节中我会做一个通俗的解释。
在机器学习中,降维是减少描述某些数据的特征数量的过程。这种减少可以通过选择(仅保留部分现有特征)或提取(减少基于旧特征创建的新要素数量)来实现,在许多需要低维数据的情况下(数据可视化、数据存储、大量计算等)很有用。
首先,让我们称编码器为从 “旧特征” 表示形式(通过选择或提取)生成 “新特征” 表示的过程,并对反向过程进行解码。然后,降维可以解释为数据压缩,其中编码器压缩数据(从初始空间到编码空间,也称为潜在空间,即 latent space),而解码器则对其进行解压缩。当然,根据初始数据分布、潜在空间维度和编码器定义,这种压缩可能会有损失,这意味着部分信息在编码过程中会丢失,在解码时无法恢复。

Source: https://theaisummer.com/latent-variable-models/?trk=cndc-detail
而自编码器(Auto-Encoder)使用了神经网络来降低维度。自动编码器的总体思路非常简单,包括将编码器和解码器设置为神经网络,并使用迭代优化过程学习最佳的编码解码方案。因此,在每次迭代中,我们向自动编码器架构(编码器后面是解码器)提供一些数据,将编码解码后的输出与初始数据进行比较,然后通过架构反向传播错误以更新网络的权重。
整个自动编码器架构确保了只有信息的主要结构部分才能通过和重建。从总体框架来看,考虑的编码器家族 E 由编码器网络架构定义,考虑的解码器 D 族由解码器网络架构定义;而以最大限度地减少重构误差,是通过对这些网络的参数进行梯度下降(Gradient Decent)来完成的。如下图所示:
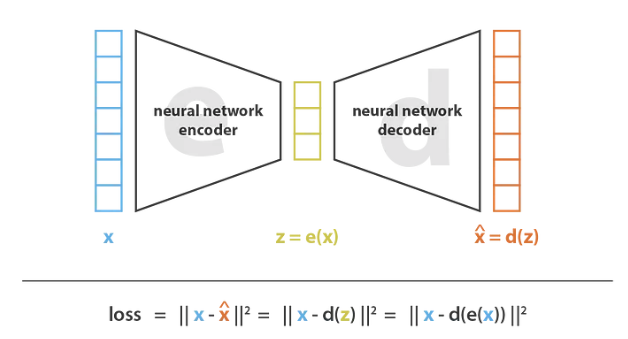
Source:https://towardsdatascience.com/understanding-variational-auto...
这种自动编码器结构,在现实世界中会面临两个主要挑战。
首先,在没有重建损失的情况下进行重要的降维往往是有代价的,潜在空间中缺乏可解释和可利用的结构,或者更简单来说,缺乏规律性;
其次,在大多数情况下,降维的最终目的不仅是减少数据的维度数,同时也将数据结构信息的大部分保留在简化表示中。基于这两个原因,在现实世界中我们必须根据降维的最终目的,仔细控制和调整潜在空间的尺寸和自动编码器(定义压缩程度和质量)的 “深度”。如下图所示:
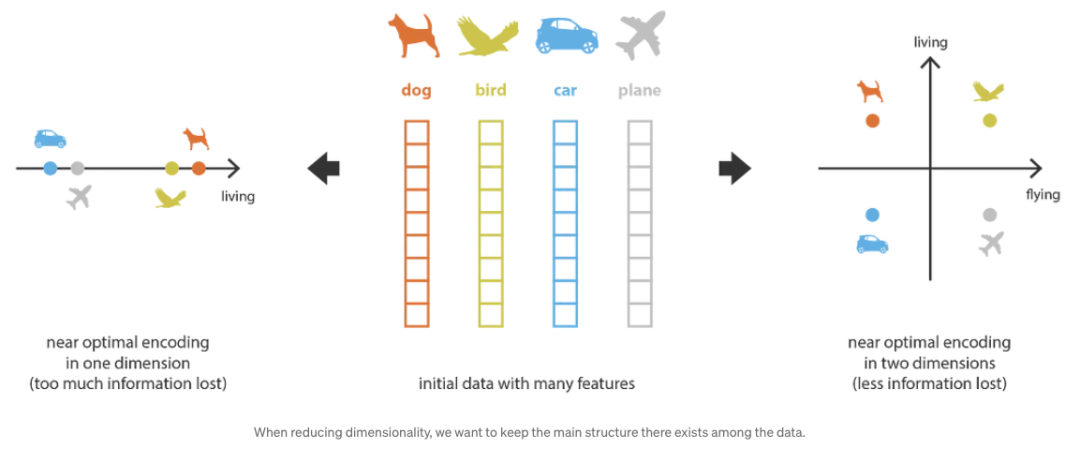
Source:https://towardsdatascience.com/understanding-variational-auto...
变分自编码器 Variational Auto-Encoder
铺垫完前面的知识基础,终于可以来探究 VAE 这篇论文的精华了。

Source: https://arxiv.org/pdf/1312.6114.pdf?trk=cndc-detail
到目前为止,我们已经讨论了降维问题,并介绍了自动编码器,这些编码器是可以通过梯度下降进行训练的编码器-解码器架构。现在让我们把内容生成问题的关联起来,看看自动编码器在解决这个问题时的局限性,然后请变分自编码器(Variational Auto-Encoder)闪亮登场。
关于内容生成和自动编码器的结合,我们可能会想到,如果潜在空间有足够规则,我们是否可以从潜在空间中随机取点解码以获得新的内容?如下图所示:
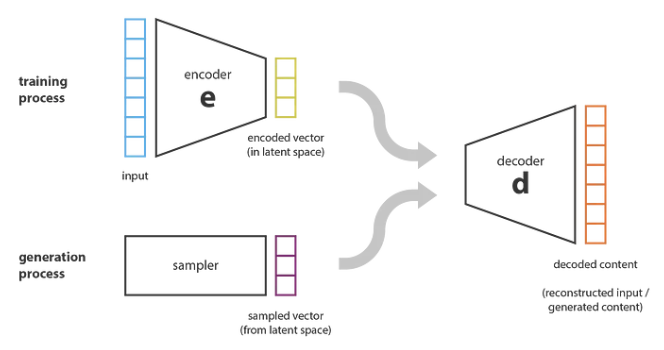
Source:https://towardsdatascience.com/understanding-variational-auto...
变分自编码器的定义
因此,为了能够将自动编码器的解码器用于生成目的,我们必须确保潜在空间足够规律。获得这种规律性的一个可能的解决方案是在训练过程中引入明确的正则化。变分自动编码器可以定义为自动编码器,其训练经过正则化,以避免过度拟合,并确保潜在空间具有良好的特性,从而实现生成过程。
就像标准的自动编码器一样,变分自动编码器是一种由编码器和解码器组成的架构,经过训练可以最大限度地减少编码解码的数据和初始数据之间的重建错误。但是,为了对潜在空间进行一些正则化,我们对编码-解码过程进行了细微的修改:我们没有将输入编码为单点,而是将其编码为潜在空间上的分布。然后按如下方式训练模型:
- 输入被编码为在潜在空间上的分布
- 潜在空间中的一个点是从该分布中采样的
- 对采样点进行解码,可以计算出重构误差
- 重构误差通过网络反向传播
如下图所示:
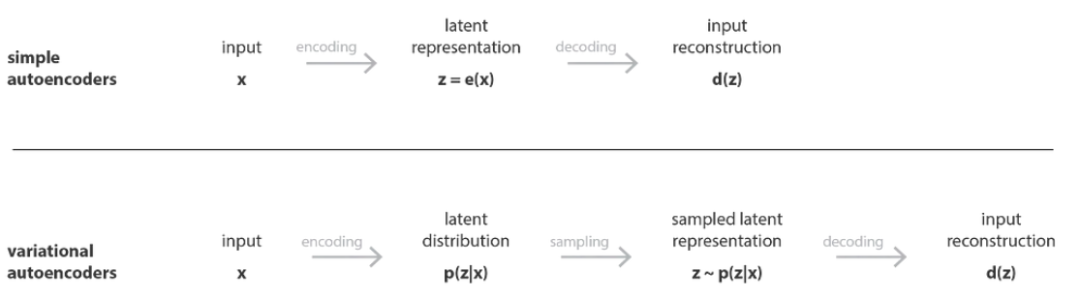
Source:https://towardsdatascience.com/understanding-variational-auto...
实际上,选择编码分布为正态分布,这样就可以训练编码器返回描述这些高斯分布的均值和协方差矩阵。之所以将输入编码为具有一定方差的分布而不是单点分布,是因为它可以非常自然地表达潜在空间正则化。通过这种方式,确保了潜在空间的局部正则化和全局正则化(方差控制局部正则化,均值控制全局正则化)。
因此,训练 VAE 时最小化的损失函数由 “重构项”(位于最后一层)和 “正则化”(位于潜在层)组成,后者倾向于通过使编码器返回的分布接近标准正态分布来规范潜在空间的组织。该正则化表示为返回分布和标准高斯分布之间的 KL 散度(Kulback-Leibler Divergence),由于两个高斯分布之间的 KL 散度具有封闭形式,可以直接用两个分布的均值和协方差矩阵表示。如下图所示:
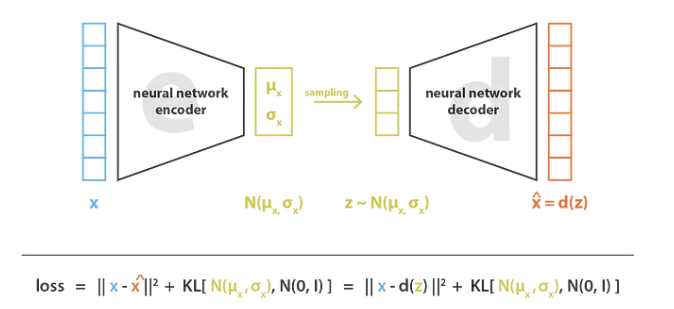
Source:https://towardsdatascience.com/understanding-variational-auto...
关于 VAE 我个人的理解是:VAE 架构的核心是两个 Encoder,一个用来计算均值,一个用来计算方差;这个均值和方差,VAE 架构会用神经网络来计算。
VAE 本质上就是在我们常规的自编码器的基础上,对 Encoder 的结果(在 VAE 中对应着计算均值的网络)加上了“高斯噪声”,使得结果 Decoder 能够对噪声有鲁棒性;而额外的 KL loss(目的是让均值为 0,方差为 1),事实上就是相当于对 Encoder 的一个正则项,希望 Encoder 出来的东西均有零均值。
另外一个 Encoder(对应着计算方差的网络)用来动态调节噪声强度。当 Decoder 还没有训练好时(重构误差远大于 KL loss,KL 是 Kullback-Leibler 的缩写,它作为经典函数用来度量概率分布相似度的指标),就会适当降低噪声(KL loss 增加),使得拟合更容易(重构误差开始下降);反之,如果 Decoder 训练得还不错时(重构误差小于 KL loss),这时噪声就会增加(KL loss 减少),使得拟合更困难(重构误差开始增加),推动 Decoder 想办法提高它的生成能力。
这个本质,在 VAE 的论文中它用了一个精妙的数学公式来做了阐述,如下论文截图:
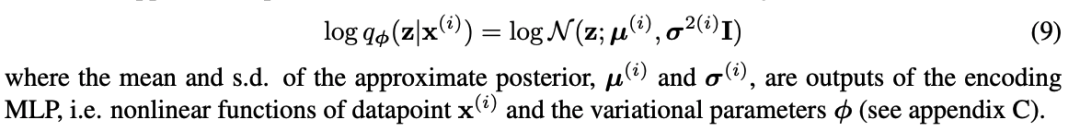
Source: https://arxiv.org/pdf/1312.6114.pdf?trk=cndc-detail
VAE 论文的观点
VAE 这篇论文的主要观点有:
- 降维是减少描述某些数据的特征数量的过程(要么仅选择初始特征的子集,要么将它们合并为减少数量的新要素),因此,可以将其视为编码过程
- 自动编码器是由编码器和解码器组成的神经网络架构,编码器和解码器构成了数据穿越的瓶颈,并且经过训练,可以在编码-解码过程中丢失最少量的信息(通过梯度下降迭代进行训练,目的是减少重建错误)
- 由于过度拟合,自动编码器的潜在空间可能非常不规则(潜在空间中的近点可以提供截然不同的解码数据,潜在空间的某些点解码后可能会提供毫无意义的内容);而且我们无法真正定义一个生成过程,该过程仅包括从潜在空间采样一个点并使其通过解码器获得新数据变
- 分自动编码器 (VAE) 是自动编码器,它通过使编码器返回潜在空间上的分布而不是单点的分布,并在损失函数中添加针对该返回分布的正则化项来解决潜在空间不规则性问题,以确保更好地组织潜在空间
- 假设使用简单的底层概率模型来描述我们的数据,则可以特别使用变分推理(variational inference)的统计技术(因此被命名为变分自动编码器)谨慎地推导出由重构项和正则化项组成的 VAE 的损失函数
扩散模型(Diffusion Models)系列论文解读
在扩散模型成为文生图领域的主流模型之前,曾经出现过三种类型的生成模型。它们是:
- GAN(Generative Adversarial Network)
- VAE (Variational Auto-Encode)
- 基于流的模型(Flow-based models)
这些模型在生成高质量样本方面都取得过巨大成功,但每个样本都有其自身的局限性。众所周知,由于其对抗训练性质,GAN 模型的训练可能不稳定,生成多样性较低;VAE 依赖于代理损失(Surrogate Loss)函数;而流模型必须使用专门的架构来构造可逆变换。
- 代理损失(Surrogate Loss)函数:https://baike.baidu.com/item/%E4%BB%A3%E7%90%86%E6%8D%9F%E5%A...
扩散模型(Diffusion Models)受到非平衡热力学的启发。他们定义了马尔可夫扩散链,以缓慢地向数据添加随机噪声,然后学会逆向扩散过程,从噪声中构造出所需的数据样本。与 VAE 或基于流的模型不同,扩散模型是通过固定的过程学习的,潜在变量(Latent Variable)具有高维度(与原始数据的维度相同)。如下图所示:
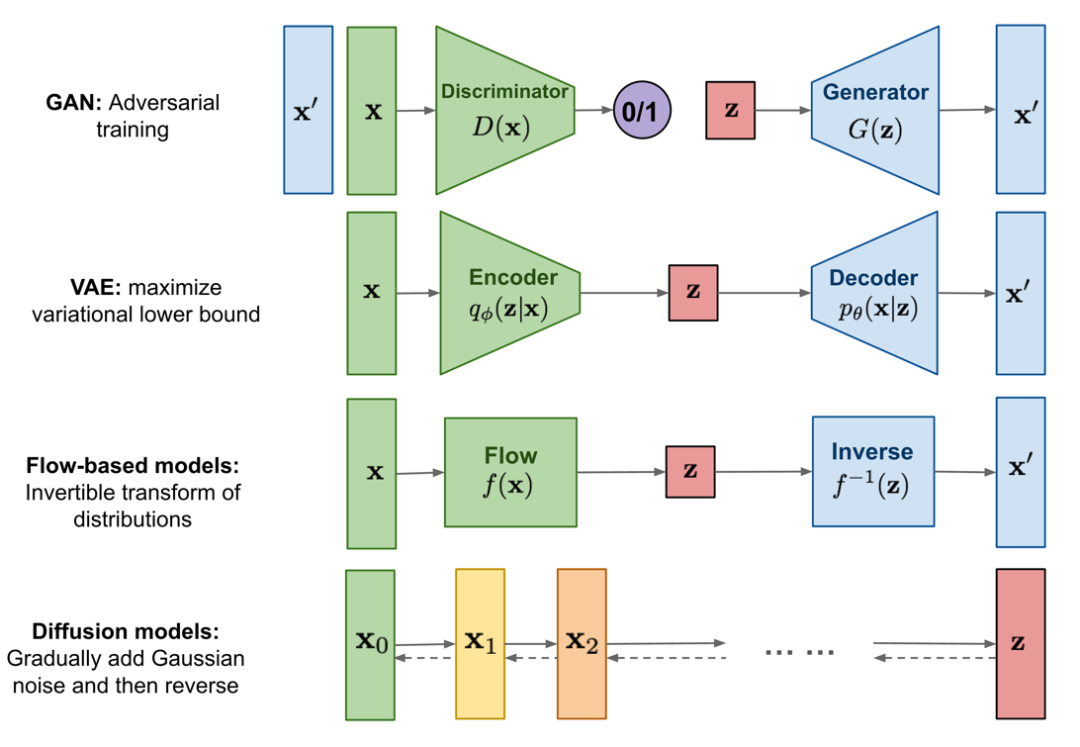
Source: https://lilianweng.github.io/posts/2021-07-11-diffusion-model...
而扩散模型的重要贡献之一就是:在训练的过程中(例如 DDPM 的训练过程),通过噪声估计模型 ϵθ(xt,t) 来预测真实噪声,以最小化估计噪声与真实噪声之间的差距。后面我们会详细阐述这一贡献。
扩散模型概述
基于扩散生成模型的主要几篇论文,其思想都比较相似,包括扩散概率模型(Sohl-Dickstein 等人,2015 年)、噪声条件评分网络(NCSN;Yang & Ermon,2019 年)和去噪扩散概率模型(DDPM;Ho 等人,2020 年)。
-
Sohl-Dickstein 等人,2015 年:
https://arxiv.org/abs/1503.03585?trk=cndc-detail
-
Yang & Ermon,2019 年:
https://arxiv.org/abs/1907.05600?trk=cndc-detail
-
Ho 等人,2020 年:
https://arxiv.org/abs/2006.11239?trk=cndc-detail
1. 正向扩散过程 Forward diffusion process
给定从真实数据分布中采样的数据点 x0∼q(x),让我们定义一个正向扩散过程。在该过程中,我们在步骤 T 时添加少量的高斯噪声到样本中,以产生一系列嘈杂的样本 x1,…,xT, 其步长由方差计划控制
![]()
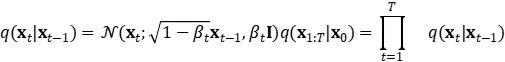
数据样本 x0 随着步骤 t 变大,逐渐失去其显著特征。当 T→∞ 时,xT 等同于各向同性高斯分布。如下图所示:
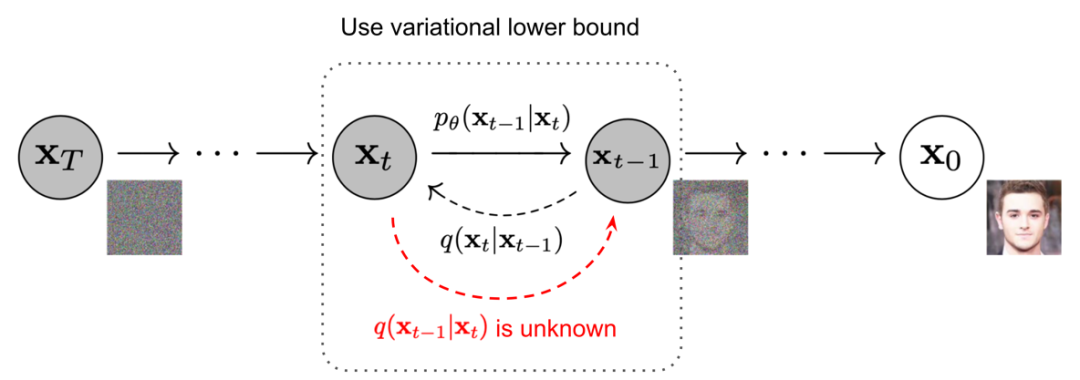
The Markov chain of forward (reverse) diffusion process of generating a sample by slowly adding (removing) noise. (Image source: Ho et al. 2020 with a few additional annotations)
正向扩散和逆扩散过程都是马尔可夫过程,唯一的区别就是:
正向扩散过程里每一个条件概率的高斯分布的均值和方差都是已经确定的(依赖于 βt 和 x0 ),而逆扩散过程里面的均值和方差需要通过神经网络学出来。
-
马尔可夫过程:
https://zhuanlan.zhihu.com/p/426290103?trk=cndc-detail
上述过程的还有一个不错的特性是:可以使用重新参数化技巧(Reparameterised trick)以封闭形式对任意时间步骤 xt 进行采样,如下图所示:
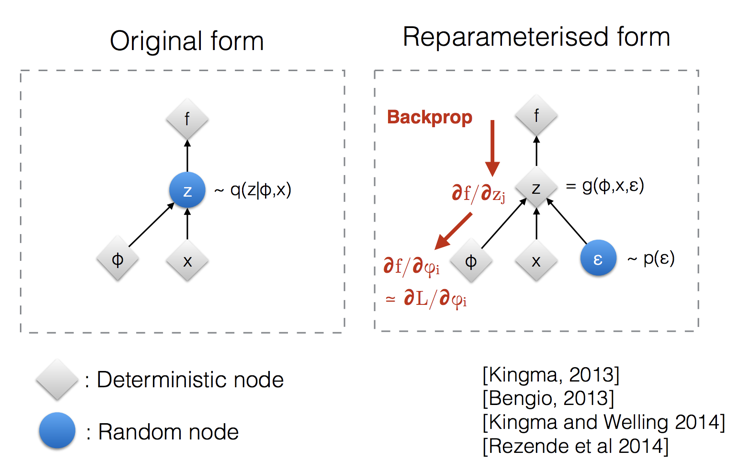
Illustration of how the reparameterization trick makes the � sampling process trainable.(Image source: Slide 12 in Kingma’s NIPS 2015 workshop talk)
重新参数化技巧也适用于其他类型的分布,而不仅仅是高斯分布。在多变量高斯的情况下,通过使用如上图描述的重新参数化技巧,以及学习分布的均值 μ 和方差 σ 来使模型可训练,而随机性在随机变量 ∈~Ν(0,Ι) 中体现。下图就是使用多变量高斯假设的变分自动编码器模型示意图,这个变分自动编码器模型,我在前一章里曾详细探讨过。
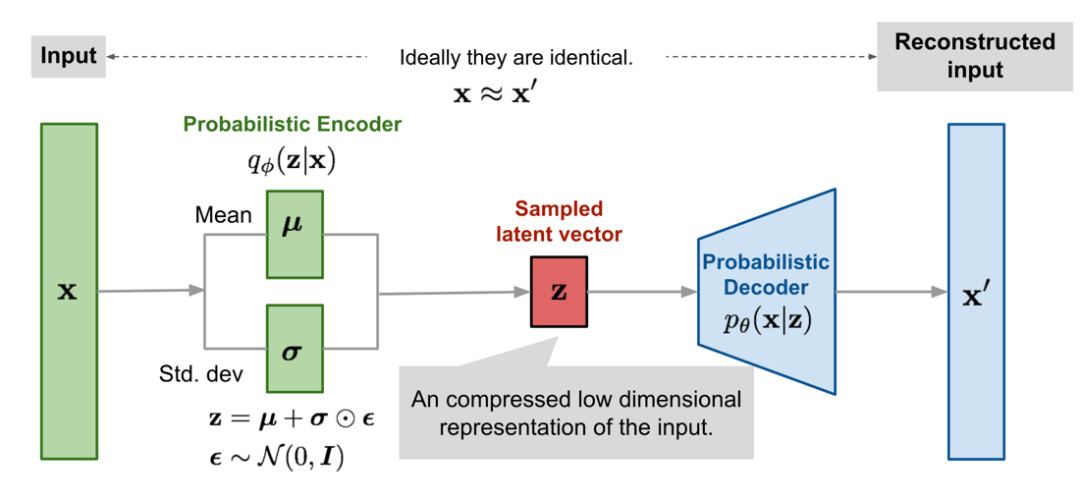
Source: https://lilianweng.github.io/posts/2018-08-12-vae/#reparamete...
正向扩散过程的数学推导过程,我就不在这个篇幅里详细展开了,有兴趣的同学可以参考以下文章的 “Forward diffusion process” 这个小节的内容: https://lilianweng.github.io/posts/2021-07-11-diffusion-model...
此处仅做小结:
与标准随机梯度下降(SGD)的方法相比,扩散模型中参考了随机梯度 Langevin 动力学(stochastic gradient Langevin dynamics)的方法,该方法可以在参数更新中注入高斯噪声,以避免崩溃为局部最小值。
2. 反向扩散过程 Reverse diffusion process
如果能逆转上述过程并从 q(x(t−1)∣xt) 中取样,就能够从高斯噪声输入 xT N(0,I) 中重新创建真实样本。请注意,如果 βt 足够小,q(x(t−1)∣xt) 也将是高斯分布。但是,由于无法轻易估算出 q(x(t−1)∣xt) ,因为估算它需要使用整个数据集,如下图所示:
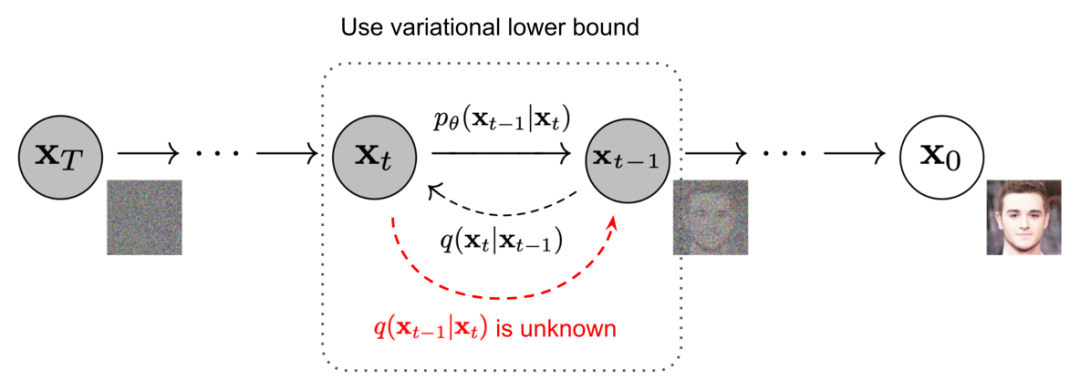
Image source: Ho et al. 2020 with a few additional annotations
因此需要训练一个模型 ρθ,来近似出这些条件概率,以运行反向扩散过程:
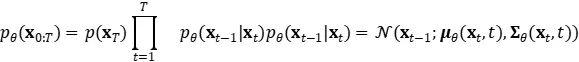
下图为 “Sohl-Dickstein et al., 2015” 论文中,训练扩散模型以建模二维瑞士轧辊数据的示例。
-
Sohl-Dickstein et al., 2015
https://arxiv.org/abs/1503.03585?trk=cndc-detail
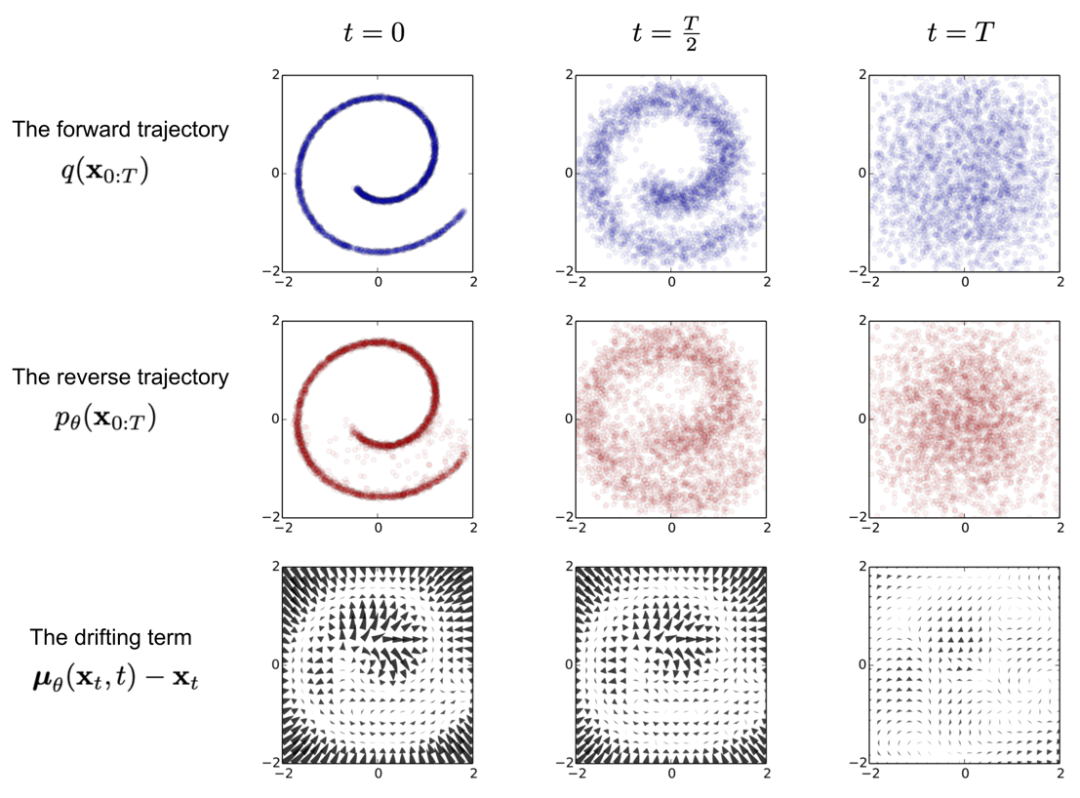
Image source: Sohl-Dickstein et al., 2015
第一行显示了从正向轨迹 q(x(0:T)) 开始的时间片段。数据分布从左侧经历高斯扩散,在右侧高斯扩散逐渐将其转换为特征协方差高斯分布(identity-covariance Gaussian)。
中间一行显示了经过训练的反向轨迹 ρθ(x0:T) 的相应时间片段。特征协方差高斯分布(右)通过学到的均值和协方差函数经历高斯扩散过程,并逐渐转换还原回原始数据分布(左)。
最后一行显示了相同反向扩散过程的漂移项 μθ(xt,t)—xt 的情况。
3. DDPM 论文和参数化 Lt
如前所述,我们需要学习一个神经网络来近似逆向扩散过程中的条件概率分布:
![]()
我们想训练 μθ 来预测:
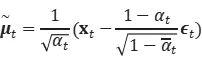
由于 xt 在训练时可用作输入,因此可以改为重新参数化高斯噪声项,使其在时间步骤 t 从输入 xt 中预测 ∈t:
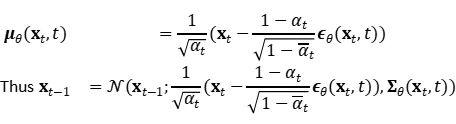
后面还可以通过一些数学公式做简化,具体的数学推导过程有兴趣的读者可以参考以下文章:
https://lilianweng.github.io/posts/2021-07-11-diffusion-model...
简化的结果可以参考如下 DDPM 论文:

Source: https://arxiv.org/abs/2006.11239?trk=cndc-detail

The training and sampling algorithms in DDPM (Image source: Ho et al. 2020)
以上简化结果的得出的原因,在 DDPM 这篇论文中提到,主要是 Ho 等人(2020)根据经验发现,如果使用忽略加权(weighting)项的简化目标,则训练扩散模型效果更好:
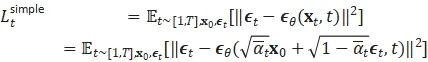
最终的简化公式是:
![]()
其中 C 是一个不依赖于 θ 的常数。
-
Ho 等人(2020):
https://arxiv.org/abs/2006.11239?trk=cndc-detail
扩散模型的加速采样 Speed up Diffusion Model Sampling
1. DDIM 论文解读
通过遵循反向扩散过程的马尔可夫链(Markov chain)从 DDPM 生成样本非常缓慢,因为最多可以是几千步。来自 Song 等人的 2020 年 DDIM 论文中的数据指出:“例如,从 DDPM 采样 5 万张大小为 32×32 的图像大约需要 20 个小时,但从 Nvidia 2080 Ti GPU 上的 GAN 采样不到一分钟。”
-
Song 等人的 2020 年 DDIM 论文:
https://arxiv.org/abs/2010.02502?trk=cndc-detail

Source: https://arxiv.org/pdf/2010.02502.pdf?trk=cndc-detail
DDIM 具有相同的边际噪声分布,但会确定性地将噪声映射回原始数据样本。在生成过程中,我们仅对扩散步骤的子集 {τ1,…,τS} 进行采样,DDIM 的推理过程变为:
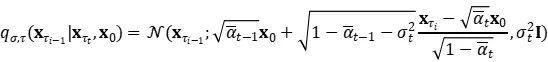
虽然所有模型在实验中都使用 Τ=1000 扩散步长进行训练,但他们观察到,当 S 较小时 DDIM (η=0) 可以产生最优质的样本,而 DDPM (η=1) 在小 S 上的表现要差得多。当我们有能力运行完全的反向马尔可夫扩散步骤 (S=Τ=1000) 时,DDPM 的表现会更好。
而使用 DDIM 之后,可以将扩散模型训练到任意数量的前进步数,但只能从生成过程中的一部分步骤中采样。DDPM 和 DDIM 在论文中的对比测试结果,如下图所示:
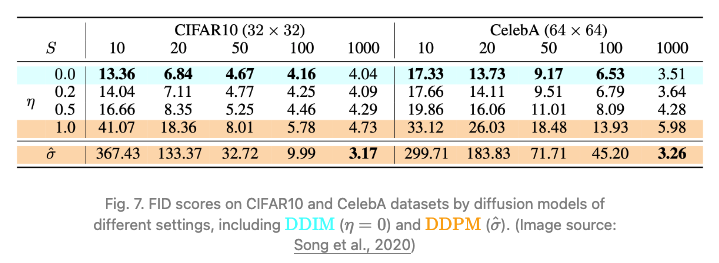
Source: https://arxiv.org/pdf/2010.02502.pdf?trk=cndc-detail
DDIM 和 DDPM 的对比小结如下:
- 使用更少的步骤生成更高质量的样本
- 因为生成过程确定,意味着以同一个潜在变量为条件的多个样本具有相似的高级特征
- 由于一致性,DDIM 可在潜在变量中进行有意义的语义插值(meaningful interpolation)
2. LDM 论文解读
另一篇重要论文是潜在扩散模型(LDM: Rombach & Blattmann 等人,2022)的论文(如下图所示),该论文提出在潜在空间而不是像素空间中运行扩散过程,从而降低训练成本,加快推理速度。
-
LDM: Rombach & Blattmann 等人,2022
https://arxiv.org/abs/2112.10752?trk=cndc-detail

Source: https://arxiv.org/pdf/2112.10752.pdf?trk=cndc-detail
论文动机是观察到图像的大部分都是感知细节,而语义和概念构图在积极压缩后仍然存在。LDM 通过生成建模学习松散地分解感知压缩和语义压缩,方法是首先使用自动编码器削减像素级冗余,然后在学习的潜在上使用扩散过程操作/生成语义概念。

说明感知和语义压缩(illustrating perceptual and semantic compression)
数字图像的大多数部分对应于难以察觉的细节。尽管扩散模型已经通过最大限度地减少损失项,来抑制这些在语义上毫无意义的信息,但仍需要在所有像素上评估梯度(训练期间)和神经网络主干(训练和推断),这会导致多余的计算和不必要的昂贵的优化和推断。
因此,DDIM 论文建议将潜在扩散模型 (LDM) 作为有效的生成模型,并采用单独的轻度压缩阶段。
DDIM 感知压缩过程依赖于自动编码器模型。编码器用于将输入图像 x∈RH×W×3 压缩为较小的 2D 潜在矢量 z=ε(x)∈Rh×w×c,其中向下采样率 f=H/h=W/w=2m,m∈N,然后解码器 D 从潜在矢量 x ̃=D(z) 中重建图像。
扩散和去噪过程发生在潜在向量 Z 上。去噪模型是一种时效条件下的 U-Net,增强了交叉注意力机制,用于处理图像生成的灵活条件信息(例如类别标签、语义地图、图像的模糊变体)。该设计等同于通过交叉注意力机制将不同模态的表示融合到模型中。每种类型的调理信息都与特定领域编码器 τθ 配对,用于将调理输入 y 投影为中间表示形式,该中间表示形式可以映射到交叉注意力分量 τθ(y)∈R(M×dτ ):

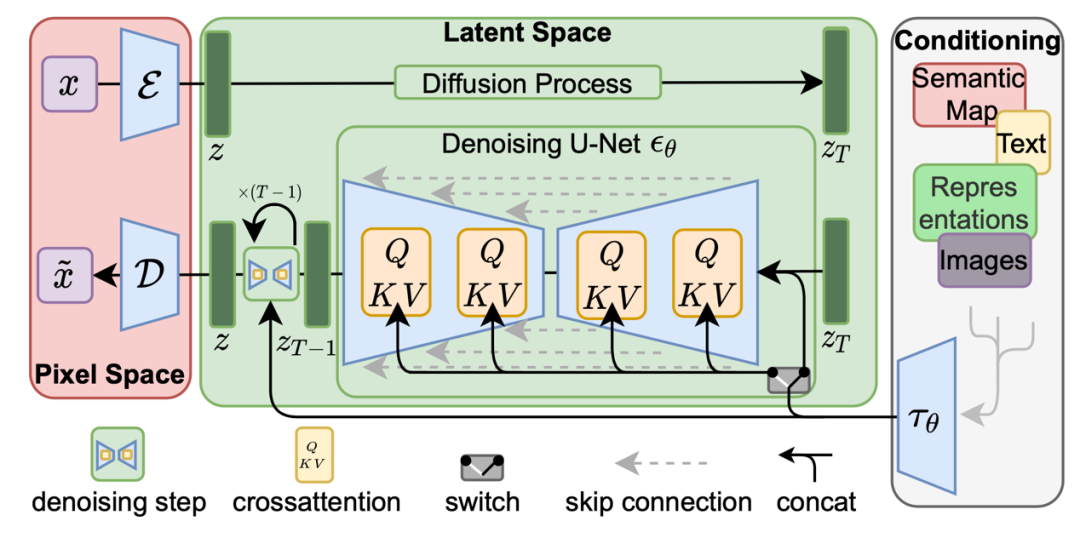
The architecture of latent diffusion model. (Image source: Rombach & Blattmann, et al. 2022)
扩散模型的条件生成 (Conditioned Generation)
在使用 ImageNet 数据集等条件信息的图像上训练生成模型时,通常会根据类别标签或一段描述性文本生成样本。
1. 扩散模型的分类器指导(Classifier Guided Diffusion)
GLIDE 论文(如下图所示)阐述了它在扩散模型的分类器指导领域的最新工作。

Source: https://arxiv.org/pdf/2112.10741.pdf?trk=cndc-detail
为了将类别信息明确纳入模型扩散过程,Dhariwal & Nichol (2021) 在噪声图像 xt 上训练了分类器 fϕ(y∣xt,t),并使用梯度 ∇xlogfϕ(y∣xt) 通过改变噪声预测来引导扩散采样过程向条件信息 y(例如目标类别标签)发展。由此产生的消融扩散模型 (ADM) 和具有额外分类器指导的模型 (ADM-G) 能够获得比 SOTA 生成模型(例如 BigGAN)更好的结果。
-
Dhariwal & Nichol (2021)
https://arxiv.org/abs/2105.05233?trk=cndc-detail

The algorithms use guidance from a classifier to run conditioned generation with DDPM and DDIM. (Image source: Dhariwal & Nichol, 2021])
2. 扩散模型的无分类指导(Classifier-Free Guidance)
另外,GLIDE 论文中,还阐述了使用无分类器指导从 GLIDE 中选择样本。从论文提供的样本图像数据中可以观察到,GLIDE 模型可以生成带有阴影和反射的逼真图像,可以组合多个概念,生成新概念的艺术渲染等。


Source: https://arxiv.org/pdf/2112.10741.pdf?trk=cndc-detail
GLIDE 论文中,还详细探讨了指导策略、CLIP 指导和无分类指导,发现后者更受欢迎。
扩散模型的高分辨率和图像质量
1. CDM 论文
论文 “Cascaded Diffusion Models for High Fidelity Image Generation” 建议使用一系列分辨率更高的多个扩散模型。流水线模型之间的噪声调节增强(Noise conditioning augmentation)对最终图像质量至关重要,即对每个超分辨率模型 pθ(x∣z) 的调节输入 z 应用强大的数据增强,调节噪声有助于减少管道设置中的复合误差。
-
Cascaded Diffusion Models for High Fidelity Image Generation:
https://arxiv.org/abs/2106.15282?trk=cndc-detail

Source: https://arxiv.org/pdf/2106.15282.pdf?trk=cndc-detail
在生成高分辨率图像的扩散建模中,U-Net 是模型架构的常见选择。论文里谈到在级联扩散模型(Cascaded Diffusion Models)的管道中,其每个模型都是使用的 U-Net 架构。如下图所示:
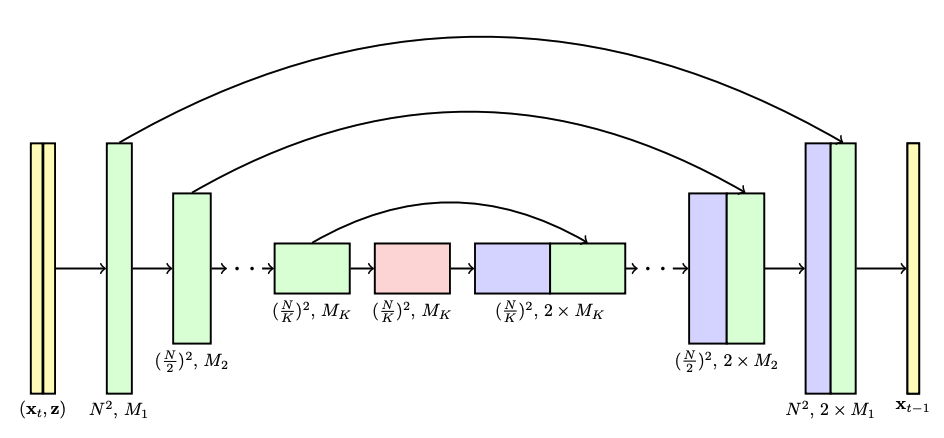
Source: https://arxiv.org/pdf/2106.15282.pdf?trk=cndc-detail
该论文还指出,他们发现最有效的噪声是在低分辨率下施加高斯噪声(Gaussian noise),在高分辨率下施加高斯模糊(Gaussian blur)。此外,他们还探索了两种形式的条件增强,需要对训练过程进行少量修改。条件噪声仅适用于训练,不适用于推理。
2. UnCLIP 论文
在两阶段扩散模型 UnCLIP(Ramesh et al. 2022)论文中,其建议利用 CLIP 文本编码器来生成高质量的文本引导图像。
-
Ramesh et al. 2022
https://arxiv.org/abs/2204.06125?trk=cndc-detail

Source: https://arxiv.org/abs/2204.06125?trk=cndc-detail
给定预训练的 CLIP 模型 c 和扩散模型 (x, y) 的配对训练数据,其中 x 是图像,y 是相应的标题,我们可以分别计算 CLIP 文本和图像的向量表示 Ct(y) 和 Ci(x) 。
UnCLIP 同时学习两个模型:
- 先验模型 p(ci∣y):给定文本 y,输出 ci 的 CLIP 图像向量表示;
- 解码器 p(x∣ci,[y]) :给定 CLIP 图像向量表示 ci 以及原始文本 y(可选),输出图像 x。
这两个模型支持条件生成,因为:
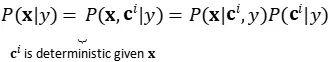
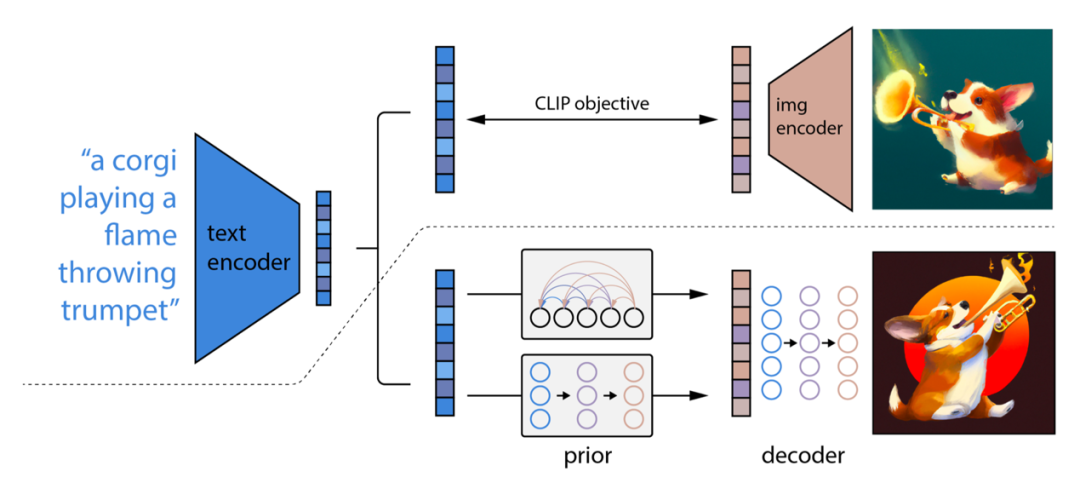
The architecture of unCLIP. (Image source: Ramesh et al. 2022)
3. Imagen 论文
而 Imagen 的论文 Imagen (Saharia et al. 2022) 却未使用 CLIP 模型,而是使用预先训练的大型 LM(冻结的 T5-XXL 文本编码器)对文本进行编码以生成图像。
-
Saharia et al. 2022
https://arxiv.org/abs/2205.11487?trk=cndc-detail

Source: https://arxiv.org/pdf/2205.11487.pdf?trk=cndc-detail
普遍的趋势是,较大的模型尺寸可以带来更好的图像质量和文本图像对齐方式。该论文研究团队发现 T5-XXL 和 CLIP 文本编码器在 MS-COCO 上实现了相似的性能。

Source: https://arxiv.org/pdf/2205.11487.pdf?trk=cndc-detail
Imagen 修改了 U-net 中的多项设计以使其高效 U-Net。例如:
- 通过为较低的分辨率添加更多的残差锁(residual locks),将模型参数从高分辨率模块转移到低分辨率模块
- 扩大 skip connections 的规模到 1/√2 倍
- 调转向下采样(在卷积之前移动)和向上采样操作(卷积后移动)的顺序,以提高向前传递的速度
该论文团队的经验总结包括:
- 噪声调节增强、动态阈值和高效的 U-Net 对图像质量至关重要
- 缩放文本编码器大小比 U-Net 大小更重要
小结
本期我们开始探讨了文生图(Text-to-Image)方向的主要论文解读,包括:VAE、DDPM、DDIM、GLIDE、Imagen、UnCLIP、CDM、LDM 等主要扩散模型领域的发展状况。
由我们的分析可知,扩散模型的主要优点和缺点如下:
优点:可追溯性和灵活性是生成建模中两个相互矛盾的目标。可处理的模型可以通过分析进行评估并有效地拟合数据(例如通过高斯或拉普拉斯),但它们无法轻松描述丰富数据集中的结构。灵活的模型可以拟合数据中的任意结构,但是从这些模型中进行评估、训练或采样通常很昂贵。而扩散模型,则可以在分析上既可实现可追溯性,又不失灵活性;
缺点:扩散模型依赖于长链的马尔可夫扩散步骤来生成样本,因此在时间和计算方面可能较昂贵。虽然目前已经出现一些使过程加速的新方法,但采样速度仍然比 GAN 慢。
下期我们将进入动手实践环节,我会带领大家使用亚马逊云科技的 SageMaker 等服务,在云中体验构建文生图(Text-to-Image)领域大模型的应用,敬请期待。
请持续关注 Build On Cloud 微信公众号,了解更多面向开发者的技术分享和云开发动态!
往期推荐
机器学习洞察
架构模型最佳实践
GitOps 最佳实践

文章来源:
https://dev.amazoncloud.cn/column/article/64702f06182e6e537ca4bd7c7?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN
相关文章:
Generative AI 新世界 | 文生图(Text-to-Image)领域论文解读
在上期文章,我们开始探讨生成式 AI(Generative AI)的另一个进步迅速的领域:文生图(Text-to-Image)领域。概述了 CLIP、OpenCLIP、扩散模型、DALL-E-2 模型、Stable Diffusion 模型等文生图(Text…...

03.从简单的sql开始
从简单的sql开始 一、sql语句的种类二、oracle的工作原理三、oracle数据库常见基础命令 一、sql语句的种类 下面是SQL语句的分类、常用语句、使用方法: 分类语句使用方法解释数据查询SELECTSELECT column1, column2, … FROM table_name WHERE condition;用于从表…...

JS加密/解密之jsjiami在线js加密的效率问题
故事背景 经常有客户反馈,v7加密的效率比v6低,但是安全性更好。这里我给大家科普一下关于jsjiami的优化诀窍。 示例源代码 // 伪代码 while (1) {var name ‘张三’ }优化后 var _name 张三; while (1) {var name _name }优化原理 相信很多朋…...
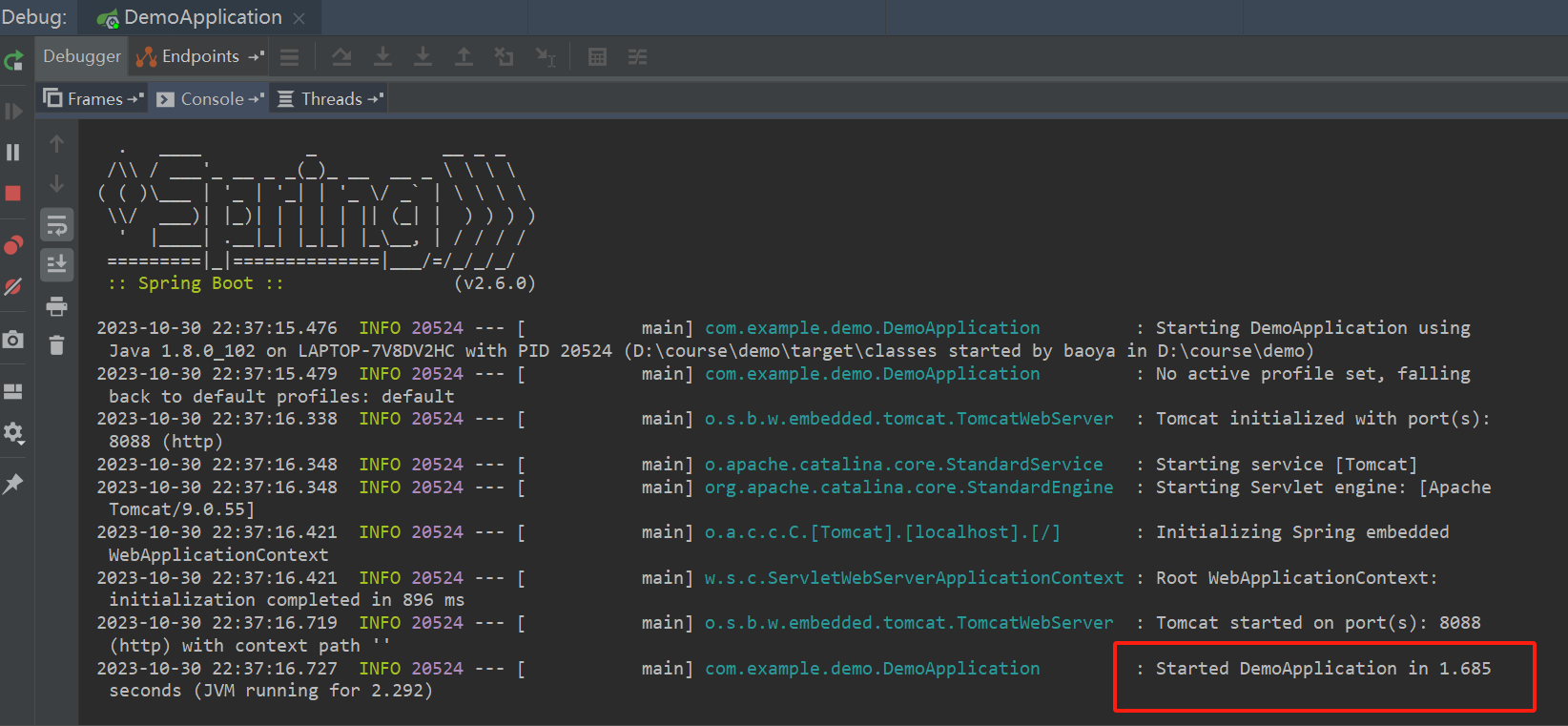
解决【spring boot】Process finished with exit code 0的问题
文章目录 1. 复现错误2. 分析错误3. 解决问题 1. 复现错误 今天从https://start.spring.io下载配置好的spring boot项目: 启动后却报出如下错误: 即Process finished with exit code 0 2. 分析错误 Process finished with exit code 0翻译成中文进程已完…...
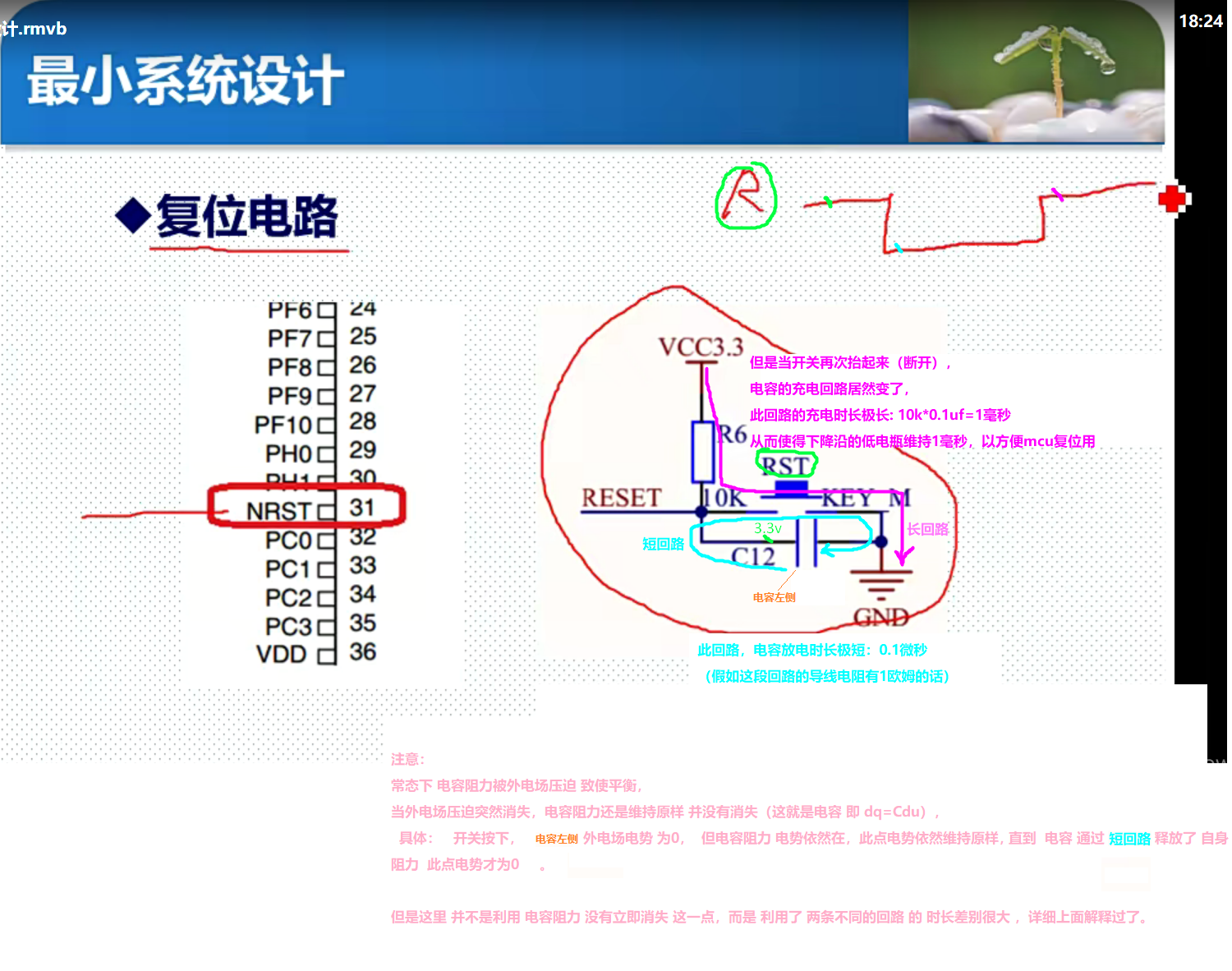
模电学习路径
交流通路实质 列出电路方程1,方程1对时刻t做微分 所得方程1‘ 即为 交流通路 方程1对时刻t做微分:两个不同时刻的方程1相减,并 令两时刻差为 无穷小 微分 改成 差 模电学习路径: 理论 《电路原理》清华大学 于歆杰 朱桂萍 陆文…...
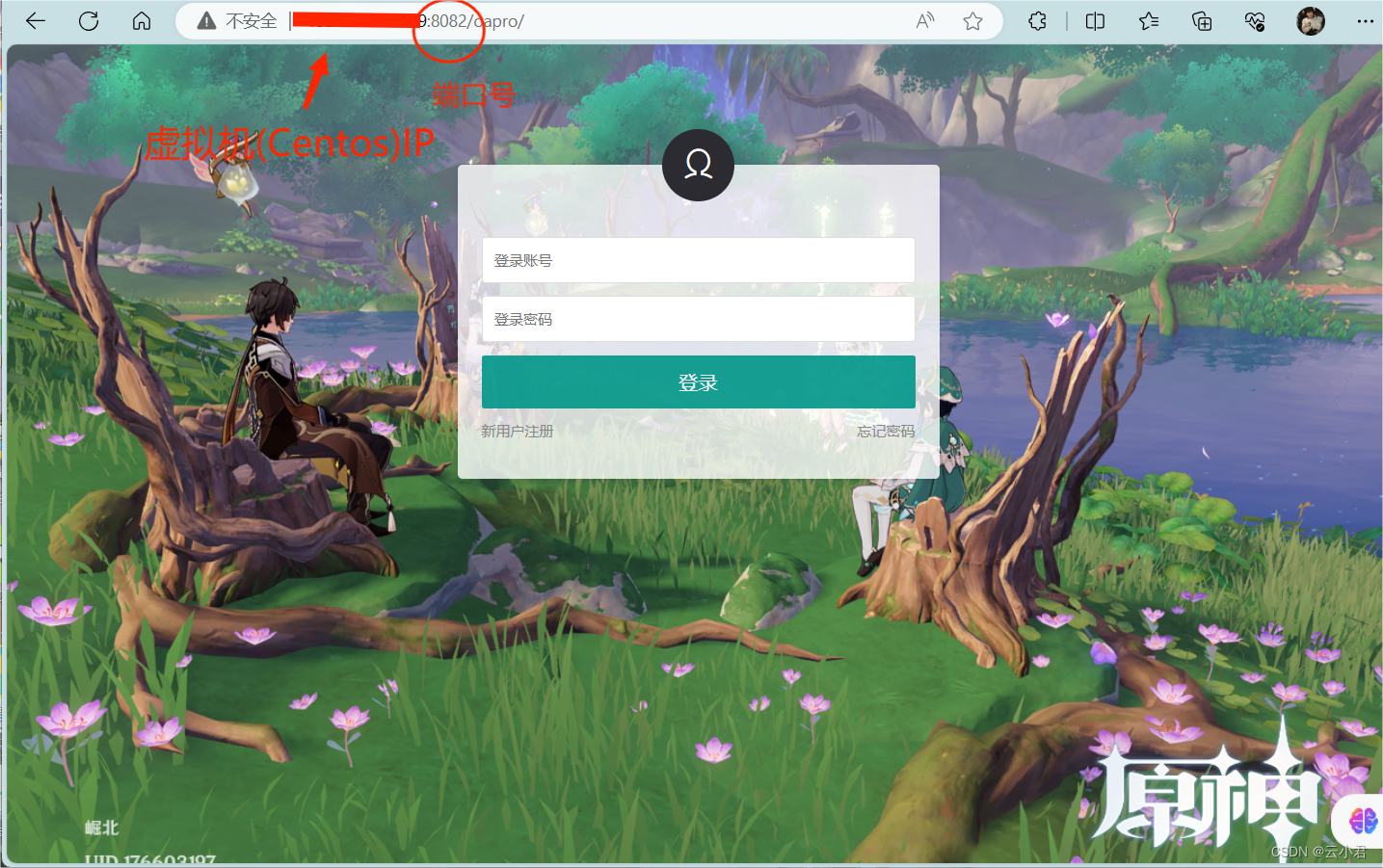
【Linux】配置JDKTomcat开发环境及MySQL安装和后端项目部署
目录 一、jdk安装配置 1. 传入资源 2. 解压 3. 配置 二、Tomcat安装 1. 解压开启 2. 开放端口 三、MySQL安装 1. 解压安装 2. 登入配置 四、后端部署 1. 数据库 2. 导入.war包 3. 修改端口 4.开启访问 一、jdk安装配置 打开虚拟机 Centos 登入账号ÿ…...

Modelsim 使用教程(3)——Projects
目录 一、概述 二、设计文件及tb 2.1 设计文件 counter.v 2.2 仿真文件 tcounter.v 三、操作流程 3.1 Create a New Project(创建一个新的工程) 3.2 Add Objects to the Project(把代码加入项目) 3.3 Compile the …...
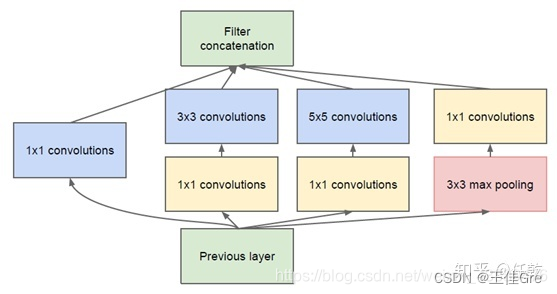
pytorch复现3_GoogLenet
背景: GoogLeNeta是2014年提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。GoogLeNet通过引入i…...

CH09_重新组织数据
拆分变量(Split Variable) 曾用名:移除对参数的赋值(Remove Assignments to Parameters) 曾用名:分解临时变量(Split Temp) let temp 2 * (height width); console.log(temp); t…...

最新 IntelliJ IDEA 旗舰版和社区版下载安装教程(图解)
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
优化 FPGA HLS 设计
优化 FPGA HLS 设计 用工具用 C 生成 RTL 的代码基本不可读。以下是如何在不更改任何 RTL 的情况下提高设计性能。 介绍 高级设计能够以简洁的方式捕获设计,从而减少错误并更容易调试。然而,经常出现的问题是性能权衡。在高度复杂的 FPGA 设计中实现高性…...

LVGL库入门 01 - 样式
一、LVGL样式概述 1、创建样式 在 LVGL 中,样式都是以对象的方式存在,一个对象可以描述一种样式。每个控件都可以独立添加样式,创建的样式之间互不影响。 可以使用 lv_style_t 类型创建一个样式并初始化: static lv_style_t s…...

酷克数据出席永洪科技用户大会 携手驱动商业智能升级
10月27日,第7届永洪科技全国用户大会在北京召开。酷克数据作为国内云原生数仓代表企业,受邀出席本次大会,全面展示了云数仓领域最新前沿技术,并进行主题演讲。 携手合作 助力企业释放数据价值 数据仓库是商业智能(BI…...

英语教育目标转变:更加注重实际应用能力培养
今年九月份,北京市教委发布了《关于深入推进高中阶段学校考试招生改革的实施意见》。按照该意见,北京市2024年初三年级学生的初中学业水平考试英语科目听力口语考试与笔试将分离,首次计算机考试将于2023年12月17日进行。 根据《意见》规定,听力口语计算机考试共有两次考试机会…...

Java中的继承和多态
目录 1. 继承 1.1 为什么需要继承 1.2 继承概念 1.3 继承的语法 1.4 父类成员访问 1.4.1 子类中访问父类的成员变量 1.4.2 子类中访问父类的成员方法 1.5 super关键字 1.6 子类构造方法 1.7 super和this 1.8 再谈初始化 1.9 protected 关键字 1.10 继承方式…...

海外问卷调查现在还可以做吗?
可以做,海外问卷调查是一个稳定长期的互联网创业项目。 大家好,我是橙河,这篇文章讲一讲海外问卷调查现在还可以做吗? 海外问卷调查,简单来说,就是外国的商业公司对外发放的付费调查问卷,按照…...

CA证书与服务器证书
服务器证书和CA证书是网络通信中使用的两种重要的证书。服务器证书是用于验证服务器身份的证书,而CA证书是用于验证证书颁发机构(Certificate Authority)身份的证书。 服务器证书是由网站服务器申请并由CA机构颁发的。它包含了服务器的公钥和其他相关信息ÿ…...

AI智能语音识别模块(二)——基于Arduino的语音控制MP3播放器
文章目录 简介离线语音控制模块Mini MP3模块0.96寸 OLED模块实验准备安装库接线定义主要程序实验效果注意事项总结 简介 在前面一篇文章里我们对AI智能语音识别模块进行了介绍,并对离线语音模组下载固件的过程进行了一个简单描述,不知道大家还记不记得&…...

CentOS部署Minikube
基本介绍 Minikube是本地的Kubernetes,专注于使其易于为Kubernete学习和开发。 官方地址:https://minikube.sigs.k8s.io/docs/start/ 部署安装 # CentOS 7.6# 前置条件:安装好Docker或其他容器引擎或虚拟机 参见《CentOS一键部署Docker》…...

第5章_排序与分页
文章目录 1 排序数据1.1 排序规则1.2 单列排序1.3 多列排序排序演示代码 2 分页2.1 背景2.2 实现规则2.3 拓展分页演示代码 3 课后练习 1 排序数据 1.1 排序规则 使用 ORDER BY 子句排序 ASC(ascend): 升序DESC(descend):降序 …...

《离别的最后》的内容入口:收尾场景如何被记住
从内容传播角度看,《离别的最后》的入口在“最后”这个收束动作。它不是笼统告别,而是写到一段关系、一个阶段或一次转身即将落下尾音的时刻。这首歌不适合被写成普通伤感推荐。更准确的角度,是把它放在收尾场景里:删掉草稿、收起…...
的转矩分配函数(TSF)控制仿真)
手把手教你学 Simulink-- 开关磁阻电机(SRM)的转矩分配函数(TSF)控制仿真
目录 手把手教你学 Simulink-- 开关磁阻电机(SRM)的转矩分配函数(TSF)控制仿真 🔥 前言:为什么选 SRM+TSF? 一、SRM 基础:12/8 极结构与数学模型 1.1 电压方程(第 k 相) 1.2 转矩方程(强非线性) 二、TSF 核心原理:一句话讲透 2.1 四种常用 TSF 公式(含参数…...

Unity XLua调试Could not load source问题根因与四层排查法
1. 为什么UnityXLua调试总在“Could not load source”上卡死三年?做Unity热更的开发者,大概率都见过这个红色报错:Could not load source xxx.lua。它不崩溃、不闪退,但断点永远进不去,Lua调用栈里全是问号࿰…...

Unity C#方法设计实战:从参数传递到跨脚本调用
1. 这不是语法课,是写代码时每天要面对的“沟通现场”刚带完一批Unity新手做小项目,有个现象特别明显:很多人能背出“方法就是函数”“参数分值传递和引用传递”,但一到实际写代码就卡壳——比如想让角色跳跃时播放音效࿰…...

气象水文耦合模式WRF-Hydro建模技术应用
WRF-Hydro模型是一个分布式水文模型,它基于WRF陆面过程部分独立发展而来,旨在模拟大气和水文相互作用及过程。该模型采用FORTRAN90开发,具有良好的扩展性和支持大规模并行计算的与传统水文模型相比,WRF-Hydro模型具有以下…...

【限时解密】Lindy自动化方案未公开的4层权限熔断机制:为什么92%的企业跳过这步就触发合规雷区?
更多请点击: https://kaifayun.com 第一章:Lindy人力资源自动化方案的合规性底层逻辑 Lindy人力资源自动化方案并非简单地将流程数字化,而是以全球主流劳动法规为约束边界,将合规性内化为系统架构的刚性层。其底层逻辑建立在“规…...

UPS电源部分
1.法国最好的ups 施耐德电器 美国最好的ups 伊顿 瑞士最好的ups ABB 日本最好的ups 三菱电器 台湾是 台达电子 对的吗2.施耐德电气 (Schneider Electric):虽然公司总部在法国,但其UPS业务的核心是旗下的APC(美国电力转换公司&…...

ViGEmBus虚拟手柄驱动深度解析与实战指南
ViGEmBus虚拟手柄驱动深度解析与实战指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的困境:手头有一款独特的游戏控制…...

如何快速配置大麦抢票自动化工具:5个步骤实现高效网络诊断与抓包分析
如何快速配置大麦抢票自动化工具:5个步骤实现高效网络诊断与抓包分析 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否曾因大麦网抢…...

如何高效使用开源Spotify音乐下载工具:完整的实战操作指南
如何高效使用开源Spotify音乐下载工具:完整的实战操作指南 【免费下载链接】spotify-downloader Download your Spotify playlists and songs along with album art and metadata (from YouTube if a match is found). 项目地址: https://gitcode.com/gh_mirrors/…...