基于PyTorch的中文情绪分析器设计与开发
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、相关基础理论
- 2.1 主流深度学习框架
- 2.2 神经网络
- 2.2.1 神经网络基础
- 二、中文情感分类模型构建
- 3.1 开发环境
- 3.2 数据部分
- 3.3 文本特征提取
- 3.3.1、过滤标点符号
- 3.3.2 中文分词、单词过滤
- 三 运行结果与分析
- 五 结 论
- 目录
概要
情感分析在最近的十年内得到了快速的发展,这归功于大数据的支持。相较于英语而言,中文的使用同样广泛。如何把握中文里的情感也是服务行业所关注的问题。本文旨在研究中文情绪分析的设计与开发,意在基于Pytorch平台,利用深度学习去构建神经网络模型从而去判断中文文本数据中所蕴含的情绪,试图通过迁移学习的方式,把电影评价数据的模型应用在教育评价的数据上。本文先是通过了对文献的分析,得到了迁移学习的基础,再是通过深度神经网络模型的搭建以及网上电影评价数据来训练,最终得到一个对于电影评价、教育评价都适用的模型。
【关键词】:Pytorch;神经网络;情感分析;迁移学习
一、相关基础理论
2.1 主流深度学习框架
Pytorch是Facebook在2017年推出的开源深度学习框架,源于torch更新后的一种新产品。因其是原生的python包,所以它与python是无缝集成的,同样使用了命令式编码风格。其易于上手、入门的缘故,非专业人士同样可以使用该平台来提高工作效率。Pytorch及其扩展函数库构成了一个丰富、完整的神经网络构建、应用平台,开源,免费,学习和使用方便[10]。相较于TensorFlow,Pytorch具有动态计算图表、精简的后端与高度可拓展等优势,深度学习专业人员可以利用该平台进行深度学习领域项目的设计与应用。
2.2 神经网络
2.2.1 神经网络基础
人工神经网络(Artificial Neural Networks),简称为神经网络(NNs)是一种受人脑的生物神经网络启发而设计的计算模型。这种网络基于系统的复杂程序,善于从输入的数据和标签中学习到相关映射关系,从而达成完成预测或者解决分类问题的目的。人工神经网络本质上是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型,用于拟合任意映射,因此也被称为通用拟合器。神经网络的运行包含前馈的预测过程和反馈的学习过程。
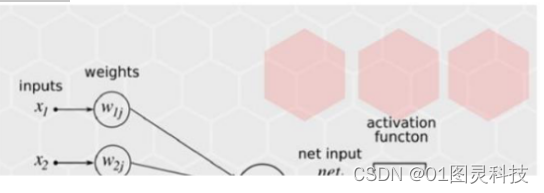
如图2-1所示,在前馈的预测过程中,信号(Inputs)从输入单元输入,并沿着网络连边传输,每个信号会与连边上的权重(Weights)进行乘积,从而得到隐含层单元的输入;接下来,隐含层单元对所有连边输入的信号进行汇总(通过transfer function进行求和),然后经过一定的处理(激活函数)进行输出( );这些输出的信号再乘以从隐含层到输出的那组连线上的权重( ),从而得到输入给输出单元的信号;最后,输出单元再对每一条输入连边的信号进行汇总,并进行加工处理再输出。最后的输出就是整个神经网络的输出。神经网络在训练阶段会通过优化函数调节每条连边上的权重 数值。
在反馈的学习过程中,每个输出神经元会首先计算出它的预测误差,然后将这个误差沿着网络的所有连边进行反向传播,得到每个隐含层节点的误差。最后,根据每条连边所连通的两个节点的误差计算连边上的权重更新量,从而完成网络的学习与调整。
二、中文情感分类模型构建
3.1 开发环境
模型是在系统WIN10、1TB+256G(SSD)、内存16G 、INTEL酷睿I7-7700HQ的CPU以及英伟达GTX1070(8G)显卡的PC机上通过python3.8版本和Anaconda1.9.12版本来使用pytorch构建深度学习模型。Anaconda是一个开源的python包管理器,包含了python、conda等180多个科学包及其依赖项。它支持Windows、Linux和Mac三种系统。由于它提供了包管理与环境管理的功能,能够很方便地解决多版本python切换、并存以及下载安装各种第三方包等问题。使用自带的jupyter notebooks应用程序,可以直接在谷歌网页页面编写、运行和调试代码。
构建神经网络模型中使用到的python模块的功能介绍:
1、Re—python独有的通过正则表达式对字符串匹配操作的模块。
2、Jieba—一款基于python的强大的分词库,完美支持中文分词。
3、Collections—包括了dict、set、list、tuple以外的一些特殊容器类型。
4、Matplotlib—将数据可视化。
3.2 数据部分
本模型中所使用的用于训练模型的数据均来自于网上的开源数据包,其包括了豆瓣在2018年之前约13万部电影数据以及105万条左右的电影评论。其中评论数据中包含评论者的ID、电影的ID、评论内容、点赞次数、评论时间和评论等级。由于文本信息均为不等长的序列,可能会出现内存不足、无法训练模型的情况,因此我们对电影评价数据做以下预处理,过程保证全随机:
1.抽取5000条评价星级为4~5的评价作为满意度高的评价存放在comment_good.txt文件中。
2. 抽取5000条评价星级为1~2的评价作为满意度低的评价存放在comment_bad.txt文件中。
3.对comment_good.txt和comment_bad.txt中的文本进行去噪处理。
3.3 文本特征提取
3.3.1、过滤标点符号
通过filter_punc函数对文本的标点符号中进行过滤操作,它通过调用正则表达式的相应程序包,替换掉了所有中英文的标点符号。#将文本中的标点符号过滤掉def filter_punc(sentence): sentence = re.sub( “[\s+.!/_,$%^(+"'“”《》?“]+|[+——!,。?、~@#¥%……&():]+”, “”, sentence)
return(sentence)
3.3.2 中文分词、单词过滤
中文分词是对文本数据分析的一种重要环节,主要的目的是将一个连续的中文句子按照汉语语言的规则组合成分开的词组的过程(脚注)。在python中,通过调用“jieba”模块来对原始文本进行分词。jieba模块拥有一个自带的词典,调用jieba.lcut(x)函数就将x中的字符分成若干个词,并存储在列表all_words[]中。x为一条评论文本数据。由于jieba自带的词典不足以满足我们的需求,因此我们根据已知数据的特性,通过调用Python的字典(diction)来建立自己专用的单词表,其中diction中存储了每个单词作为键(key),一对数字分别表示词的编号以及词在整个语料中出现的次数作为值(value)。存储第一个数值的目的是用数字来替换文字,存储第二个数值的目的是方便查看不同词的频率(TF)。根据公式(2-5)、2(6)统计训练集中评价的条数、以及包含某个特征词的评论条数,用于计算IDF。通过“TF-IDF”指标过滤常见无用词语,保留 重要的词语,从而得到更优质的词袋。
三 运行结果与分析

图3-3 优化函数SDG、学习率为0.01下的三条曲线分布
图3-3中蓝色的Train Loss表示训练集上的损失函数,橘色的Valid Loss表示校验集上的损失函数,绿色的Valid Accuracy表示校验集上的分类准确度。可以观察到,随着训练周期的增加,训练数据和校验数据的损失函数曲线并没有发现明显下降趋势,甚至于在第10周期之后训练数据的损失函数一直高于校验数据的损失函数值,且模型准确率一直不超过70%,这说明模型并没有训练成功。将学习率调整为0.001后再次训练模型。
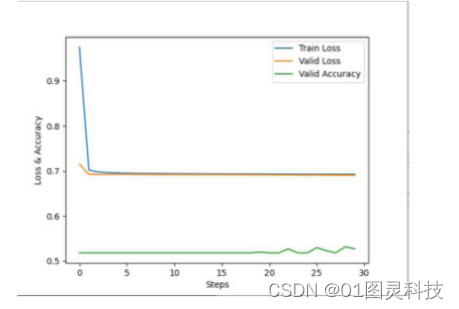
图3-4 优化函数SDG、学习率为0.001下的三条曲线分布
观察图3-4可知,训练数据的损失函数曲线在第一个周期之后与校验数据损失函数曲线持平,也就意味着SGD在学习率为0.001并没有起到做到作用,且模型准确率低达0.53。将学习率调整为0.1后再次训练模型。

图3-5 优化函数SDG、学习率为0.1下的三条曲线分布
观察图3-5可知,虽然模型的准确率在稳步上升,但训练数据的损失函数值一直高于校验数据的损失函数值,这说明30步训练并没有成功的训练模型。试着将循环调整为15次后对模型进行训练。
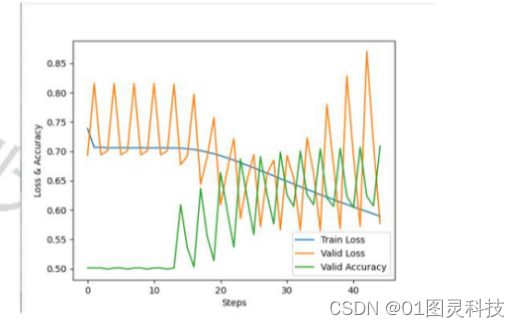
图3-6 优化函数SDG、学习率为0.1下的三条曲线分布
观察图3-6可知,模型准确率一直止步于70%,虽然校验数据的损失函数值一直围绕着训练数据的损失函数进行波动,但是该损失值过大,不足以证明模型被训练好。究其原因,问题可能出现在使用的激活函数为Relu,因为第二章提到的学习率的问题引发了Dead ReLU problem,极大可能由于SGD是固定学习率的缘故。因此我们试着采用之前介绍的学习率不固定的Adam优化算法训练模型,初始设置学习率为0.1。
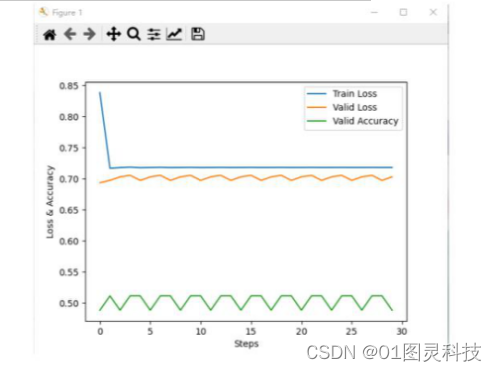
图3-7 优化函数Adam、学习率为0.1下的三条曲线分布
五 结 论
通过利用影视作品的评价数据去训练模型可以得知,对于好作品而言,人们一般不会从电影好的方面去评价一个作品的好坏,更多的是抒发自己看完电影后的感悟,大部分描述的词汇与电影的本身内容没有直接的关联,这也证实了电影评价的数据确实不好用一般的分类模型去分析。此外,模型的精确度还可以通过针对性的对数据清洗来提高。
另一方面“大数据”与“教育”的相结合可能远远的会比我们现在所搭建的神经网络分类器要复杂的许多,我们的分类器暂时也只能做到对文本情绪的好坏进行分类。在情感领域内,情感的分类远远不是非黑即白这么简单,教育工作者会需要评价文本中蕴含的情感建立更加具有针对性的教育方针的改变,所以我们模型还远远达不到这方面的要求。但现在所搭建的神经网络模型,是更加高级的神经网络(RNN模型或者LSTM模型)的基础。路漫漫其修远兮,拥有扎实的基础理论才有可能再往上继续延伸,这是起点,却不是终点。
目录
目录
1 绪论5
1.1 研究背景5
1.2 国内外研究现状5
1.3 研究问题6
1.4 研究方法与手段7
2 相关基础理论8
2.1 主流深度学习框架8
2.2 神经网络8
2.2.1 神经网络基础8
2.2.2 神经网络的分类任务9
2.2.3 激活函数9
2.2.4 损失函数10
2.2.5 过拟合现象11
2.2.6 泛化能力12
2.2.7 超参数12
2.3 词袋模型12
2.4 词频逆文档频率(TF-IDF)13
3 中文情感分类模型构建13
3.1 开发环境13
3.2 数据部分14
3.3 文本特征提取14
3.3.1 过滤标点符号14
3.3.2 中文分词及单词过滤14
3.3.3 文本数据向量化14
3.3.4 数据划分15
3.4 神经网络的搭建15
3.5 运行结果与分析16
3.6 优化与改进模型20
4 方案拓展以及总结21
4.1 方案拓展21
4.2 方案总结22
参考文献23
致谢24
相关文章:
基于PyTorch的中文情绪分析器设计与开发
收藏和点赞,您的关注是我创作的动力 文章目录 概要 一、相关基础理论2.1 主流深度学习框架2.2 神经网络2.2.1 神经网络基础 二、中文情感分类模型构建3.1 开发环境3.2 数据部分3.3 文本特征提取3.3.1、过滤标点符号3.3.2 中文分词、单词过滤 三 运行结果与分析五 结…...
HT5010 音频转换器工作原理
HT5010是一款低成B的立体声DA转换器,内部集成了内插滤波器、DA转换器和输出模拟滤波等电路。其可支持多种音频数字输入格式,支持24-bit字节。 该HT5010 基于一个多比特位的Δ-Σ调制器,将数字信号转化成两个声道的模拟信号并经过模拟滤波器滤…...

ubuntu18.04如何更新到22.04
将linux系统中的Ubuntu 18.04更新到22.04,按照以下步骤操作: 打开终端并更新系统,使用以下命令: sudo apt update sudo apt upgrade sudo apt dist-upgrade 确保系统是最新的,然后备份数据,以防万一。执…...

嵌入式软件开发:第二部分–七个步骤计划
使用一种工具(仅一种工具)武装自己,您可以在下一个嵌入式项目的质量和交付时间上做出巨大的改进。点击领取嵌入式物联网学习路线 该工具是:绝对承诺对开发代码的方式进行一些小而基本的更改 。 有了改变的意志,今天您…...
什么是IPA,和RPA有啥区别和联系?
∵ IPA中包含了RPA的“PA”,AI的“I” ∴IPARPAAI,等式成立! AI:或人工智能,是一种复杂的计算机技术,旨在模仿人类智能行为和决策的能力。它涵盖了多种技术和方法,包括:机器学习&am…...

内涝积水监测仪怎么样?万宾科技城市内涝积水监测的作用
在城市建设发展过程中,道路基础设施的建设永远都占据着重要一席,因为人们出行一旦受阻便会影响城市进展,也会影响经济发展。在城市之中有隧道,下穿式立交桥等容易存积水的地方,一旦出现恶劣暴雨天气,这些地…...
【java】命令行,包
文件夹情况: HelloWorld.java package com.demo; public class HelloWorld{public static void print(){System.out.println("HelloWorld!");}public static void main(String[] args){print();} } import.java import com.demo.HelloWorld; public cla…...

Generative AI 新世界 | 文生图(Text-to-Image)领域论文解读
在上期文章,我们开始探讨生成式 AI(Generative AI)的另一个进步迅速的领域:文生图(Text-to-Image)领域。概述了 CLIP、OpenCLIP、扩散模型、DALL-E-2 模型、Stable Diffusion 模型等文生图(Text…...

03.从简单的sql开始
从简单的sql开始 一、sql语句的种类二、oracle的工作原理三、oracle数据库常见基础命令 一、sql语句的种类 下面是SQL语句的分类、常用语句、使用方法: 分类语句使用方法解释数据查询SELECTSELECT column1, column2, … FROM table_name WHERE condition;用于从表…...

JS加密/解密之jsjiami在线js加密的效率问题
故事背景 经常有客户反馈,v7加密的效率比v6低,但是安全性更好。这里我给大家科普一下关于jsjiami的优化诀窍。 示例源代码 // 伪代码 while (1) {var name ‘张三’ }优化后 var _name 张三; while (1) {var name _name }优化原理 相信很多朋…...
解决【spring boot】Process finished with exit code 0的问题
文章目录 1. 复现错误2. 分析错误3. 解决问题 1. 复现错误 今天从https://start.spring.io下载配置好的spring boot项目: 启动后却报出如下错误: 即Process finished with exit code 0 2. 分析错误 Process finished with exit code 0翻译成中文进程已完…...
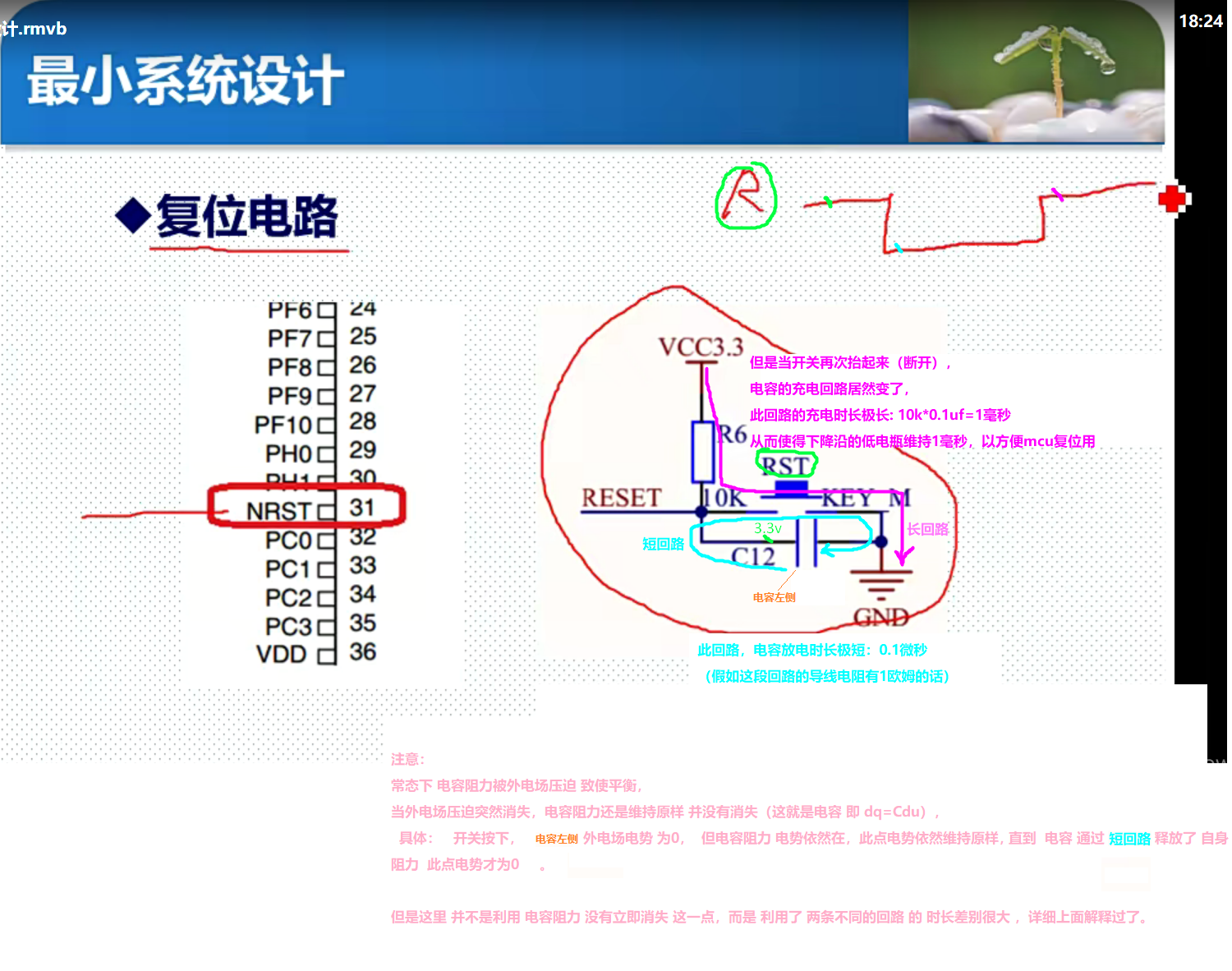
模电学习路径
交流通路实质 列出电路方程1,方程1对时刻t做微分 所得方程1‘ 即为 交流通路 方程1对时刻t做微分:两个不同时刻的方程1相减,并 令两时刻差为 无穷小 微分 改成 差 模电学习路径: 理论 《电路原理》清华大学 于歆杰 朱桂萍 陆文…...
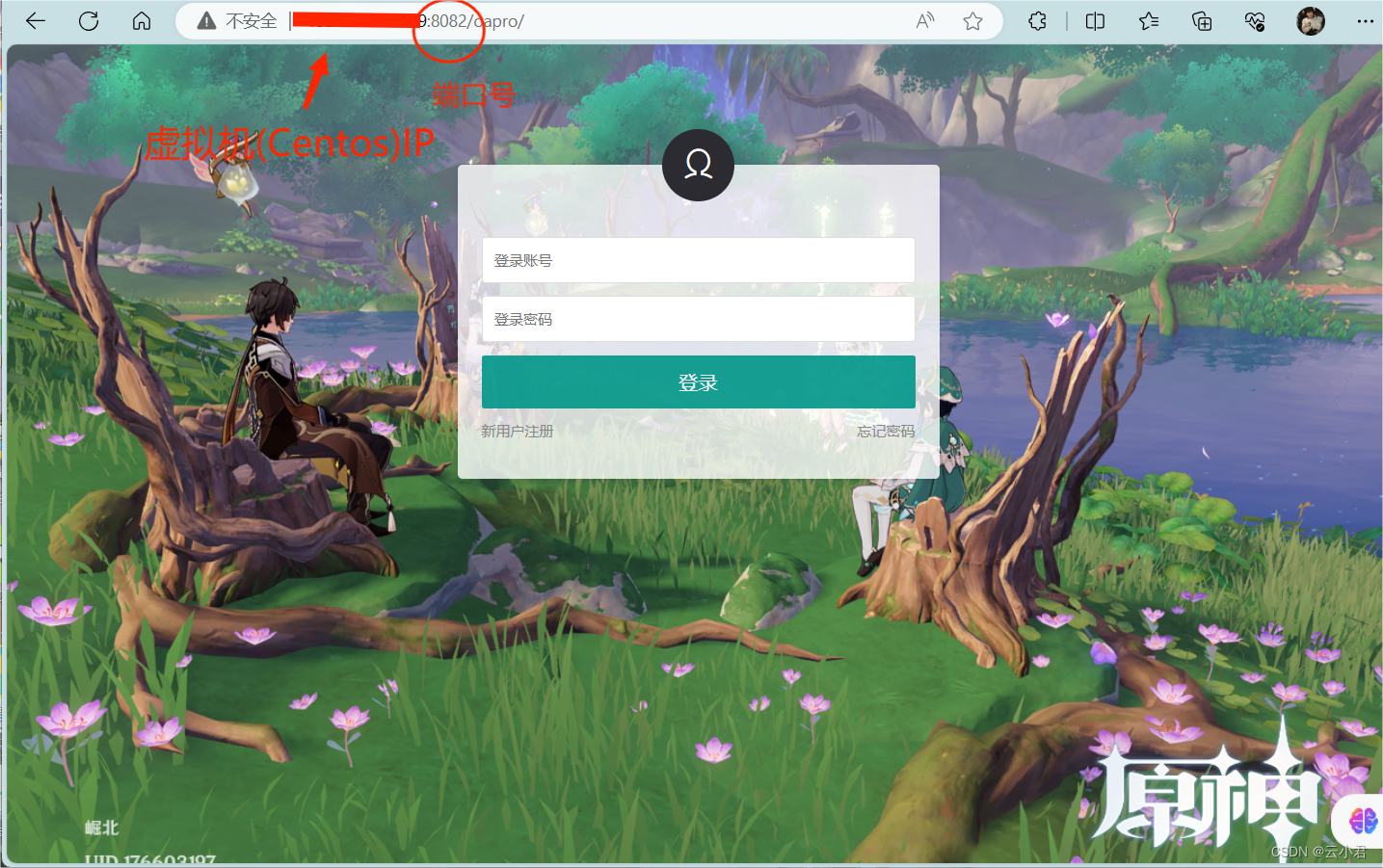
【Linux】配置JDKTomcat开发环境及MySQL安装和后端项目部署
目录 一、jdk安装配置 1. 传入资源 2. 解压 3. 配置 二、Tomcat安装 1. 解压开启 2. 开放端口 三、MySQL安装 1. 解压安装 2. 登入配置 四、后端部署 1. 数据库 2. 导入.war包 3. 修改端口 4.开启访问 一、jdk安装配置 打开虚拟机 Centos 登入账号ÿ…...

Modelsim 使用教程(3)——Projects
目录 一、概述 二、设计文件及tb 2.1 设计文件 counter.v 2.2 仿真文件 tcounter.v 三、操作流程 3.1 Create a New Project(创建一个新的工程) 3.2 Add Objects to the Project(把代码加入项目) 3.3 Compile the …...
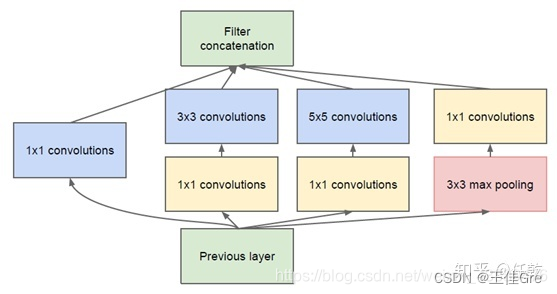
pytorch复现3_GoogLenet
背景: GoogLeNeta是2014年提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。GoogLeNet通过引入i…...

CH09_重新组织数据
拆分变量(Split Variable) 曾用名:移除对参数的赋值(Remove Assignments to Parameters) 曾用名:分解临时变量(Split Temp) let temp 2 * (height width); console.log(temp); t…...

最新 IntelliJ IDEA 旗舰版和社区版下载安装教程(图解)
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
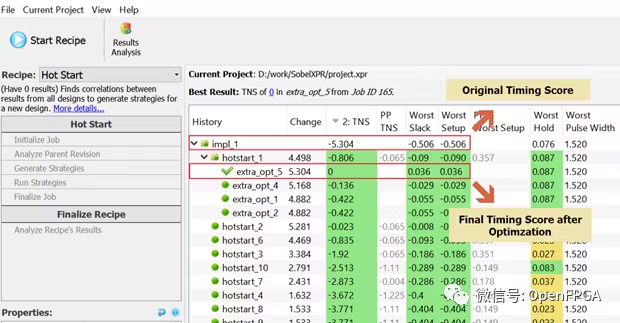
优化 FPGA HLS 设计
优化 FPGA HLS 设计 用工具用 C 生成 RTL 的代码基本不可读。以下是如何在不更改任何 RTL 的情况下提高设计性能。 介绍 高级设计能够以简洁的方式捕获设计,从而减少错误并更容易调试。然而,经常出现的问题是性能权衡。在高度复杂的 FPGA 设计中实现高性…...

LVGL库入门 01 - 样式
一、LVGL样式概述 1、创建样式 在 LVGL 中,样式都是以对象的方式存在,一个对象可以描述一种样式。每个控件都可以独立添加样式,创建的样式之间互不影响。 可以使用 lv_style_t 类型创建一个样式并初始化: static lv_style_t s…...

酷克数据出席永洪科技用户大会 携手驱动商业智能升级
10月27日,第7届永洪科技全国用户大会在北京召开。酷克数据作为国内云原生数仓代表企业,受邀出席本次大会,全面展示了云数仓领域最新前沿技术,并进行主题演讲。 携手合作 助力企业释放数据价值 数据仓库是商业智能(BI…...
)
TVA驱动智能家居的视觉范式革命(11)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

单一职责原则 登录功能重构笔记
核心定义单一职责原则:一个类只干一件事,只有一个修改的理由,避免功能杂糅、代码耦合。原有问题原始 Login 登录类,把界面展示、数据库连接、数据查询、登录校验、程序启动全部堆在一个类里,职责混乱,任何小…...

CANN-ATB量化推理-昇腾NPU上W8A8量化为什么比W4A16更实用
Llama2-70B 权重 140GB,8 卡 TP 刚好放得下但没什么余量给 KV Cache。W8A8 量化把权重从 fp16 压到 int8,权重体积减半,4 卡就能跑 70B。W4A16 理论上压得更狠(4 倍压缩),但精度损失在实际业务里往往不可接…...

【无人机通信】无线通信网络中无人机UAV定位与带宽分配的优化算法在确保地面用户服务质量QoS约束的同时,最大化网络吞吐量附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

AI写论文真给力!4款AI论文生成工具,开启高效论文写作模式!
AI论文写作工具评测 还在为撰写期刊论文、毕业论文或职称论文而感到烦恼吗?在人工写作的过程中,面对那海量的文献资料,犹如在茫茫大海中捞针,而那些繁琐的格式要求更是让我们无从下手,不断的修改反复消耗我们的耐心&a…...

windows VS工具判断动态库是32位还是64位
dumpbin /headers yourfile.dll | findstr "machine"...

门店数据采集如何做质量控制:LBS、图片质检、去重和人工复核
门店数据采集项目的难点,不是“采不到数据”,而是采回来的数据能不能被业务相信、被系统处理、被管理层复盘。质量控制通常要覆盖位置与时间校验、图片质量检测、图片去重、字段标准化和人工复核。一个全国项目可能涉及几百到几万家门店,图片…...

MPC5604B/C Memory Map 内存映射全解析
一、前言 本文章主要说明底层开发、寄存器操作、Boot、Flash 编程,告诉你Flash 在哪、RAM 在哪、每个外设寄存器基地址是多少、保留区是哪些。 用途: 写寄存器头文件 写链接脚本 .ld Flash 擦写、Boot 跳转 调试定位非法地址 外设地址计算 二、MPC5604B 地址空间总规则(Pow…...

RK3588核心板开发全解析:从8K编解码到NPU AI应用实战
1. 项目概述:当“八核”遇上“8K”,一块核心板能做什么?最近拿到了一块RK3588的核心板套件,这玩意儿在圈子里热度一直不低。RK3588这颗芯片,从发布之初就被贴上了“旗舰”、“全能”的标签,八核CPU、8K编解…...

终极免费指南:如何用Wand-Enhancer深度解锁WeMod完整功能与远程控制
终极免费指南:如何用Wand-Enhancer深度解锁WeMod完整功能与远程控制 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer Wand-Enhancer是一个开源…...