scrapy+selenium框架模拟登录
目录
二、模拟登录方法-Requests模块Cookie实现登录
四、selenium使用基本代码
五、scrapy+selenium实现登录
一、cookie和session实现登录原理
cookie:1.网站持久保存在浏览器中的数据2.可以是长期永久或者限时过期

session:1.保存在服务器中的一种映射关系2.在客户端以Cookie形式储存Session_ID

二、模拟登录方法-Requests模块Cookie实现登录
import requestsurl = 'http://my.cheshi.com/user/'headers = {"User-Agent":"Mxxxxxxxxxxxxxxxxxxxxxx"
}
cookies = "pv_uid=16xxxxx;cheshi_UUID=01xxxxxxxxx;cheshi_pro_city=xxxxxxxxxxx"
cookies = {item.split("=")[0]:item.split("=")[1] for item in cookies.split(";")}
cookies = requests.utils.cookiejar_from_dict(cookies)
res = requests.get(url, headers=headers, cookies=cookies)with open("./CO8L02.html","w") as f:f.write(res.text)三、cookie+session实现登录并获取数据
如下两种方法:
import requestsurl = "https://api.cheshi.com/services/common/api.php?api=login.Login"
headers = {"User-Agent":"Mxxxxxxxxxxxxx"
}
data = {"act":"login","xxxx":"xxxx"........
}
res = requests.post(url, headers=headers, data=data)
print(res.cookies)admin_url = "http://my.cheshi.com/user/"
admin_res = requests.get(admin_url, headers=headers, cookies=res.cookies)with open("./C08L03.html","w") as f:f.write(admin_res.text)import requestsurl = "https://api.cheshi.com/services/common/api.php?api=login.Login"
headers = {"User-Agent":"Mxxxxxxxxxxxxx"
}
data = {"act":"login","xxxx":"xxxx"........
}
session = requests.session()
session.post(url, headers=headers, data=data)admin_url = "http://my.cheshi.com/user/"
admin_res = session.get(admin_url, headers=headers)
with open("./C08L03b.html","w") as f:f.write(admin_res.text)四、selenium使用基本代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 实现交互的方法
from selenium.webdriver import ActionChains
import timeservice = Service(executable_path="../_resources/chromedriver")
driver = webdriver.Chrome(service=service)
driver.get("http://www.cheshi.com/")# print(drive.page_source)
# print(driver.current_url)
# with open("./C08L05.html", "w") as f:
# f.write(drive.page_source)# # 屏幕截图
# driver.save_screenshot("C08L05.png")"""元素定位方法."""
# 注意:不要在xpath里面写text()会报错
h1 = driver.find_element(By.XPATH, "//h1")
h1_text = h1.text# 虽然是//p 但是text后只能拿到第一个元素,若拿所有元素需要用find_elements后循环遍历
#items = driver.find_element(By.XPATH, "//p")
# print(items.text)items = driver.find_elements(By.XPATH, "//p")
print(items.text)
for item in items:print(item.text)p = driver.find_element(By.XPATH, '//p[@id="primary"]')
print(p.text)
print(p.get_attribute("another-attr"))# 为了防止报错,可以用try,except方法防止中断程序"""元素交互方法."""
username = driver.find_element(By.XPATH, '//*[@id="username"]')
password = driver.find_element(By.XPATH, '//*[@id="password"]')ActionChains(driver).click(username).pause(1).send_keys("abcde").pause(0.5).perform()
ActionChains(driver).click(password).pause(1).send_keys("12345").pause(0.5).perform()
time.sleep(1)div = driver.find_element(By.XPATH, '//*[@id="toHover"]')
ActionChains(driver).pause(0.5).move_to_element("div").pause(2).perform()
time.sleep(1)div = driver.find_element(By.XPATH, '//*[@id="end"]')
ActionChains(driver).scroll_to_element("div").pause(2).perform()
time.sleep(1)
ActionChains(driver).scroll_by_amount(0,200).perform()
time.sleep(1)time.sleep(2)
driver.quit()五、scrapy+selenium实现登录
在scrapy中的爬虫文件(app.py)中修改如下代码(两种方法):
import scrapyclass AppSpider(scrapy.Spider):name = "app"# allowed_domains = ["my.cheshi.com"]# start_urls = ["http://my.cheshi.com/user/"]def start_requests(self):url = "http://my.cheshi.com/user/"cookies = "pv_uid=16xxxxx;cheshi_UUID=01xxxxxxxxx;cheshi_pro_city=xxxxxxxxxxx"cookies = {item.split("=")[0]:item.split("=")[1] for item in cookies.split(";")}yield scrapy.Request(url=url, callback=self.parse,cookies=cookies)def parse(self,response):print(response.text)import scrapyclass AppSpider(scrapy.Spider):name = "app"# allowed_domains = ["my.cheshi.com"]# start_urls = ["http://my.cheshi.com/user/"]def start_requests(self):url = "https://api.cheshi.com/services/common/api.php?api=login.Login"data = {"act":"login","xxxx":"xxxx"........}yield scrapy.FormRequest(url=url, formdata=data,callback=self.parse)def parse(self,response):url = "http://my.cheshi.com/user/"yield scrapy.Request(url=url, callback=self.parse_admin)def parse_admin(self, response):print(response.text) 相关文章:
scrapy+selenium框架模拟登录
目录 一、cookie和session实现登录原理 二、模拟登录方法-Requests模块Cookie实现登录 三、cookiesession实现登录并获取数据 四、selenium使用基本代码 五、scrapyselenium实现登录 一、cookie和session实现登录原理 cookie:1.网站持久保存在浏览器中的数据2.可以是长期…...

【实验五】题解
T1:缺失的数字 题目描述; 我是敦立坤的爹!!! 一个整数集合中含有n个数字,每个数字都在0n之间。假设0n的n1个数字中有且仅有一个数字不在该集合中,请找出这个数字。 分析: 这里引用一个桶的思…...
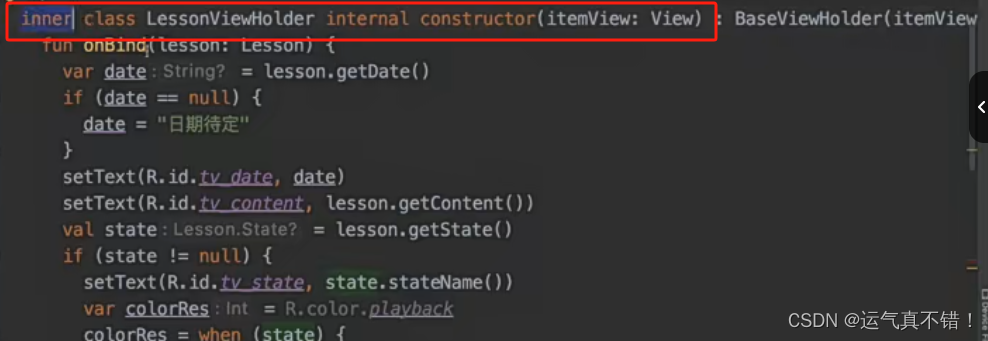
Android开发知识学习——Kotlin基础
函数声明 声明函数要用用 fun 关键字,就像声明类要用 class 关键字一样 「函数参数」的「参数类型」是在「参数名」的右边 函数的「返回值」在「函数参数」右边使用 : 分隔,没有返回值时可以省略 声明没有返回值的函数: fun main(){println…...
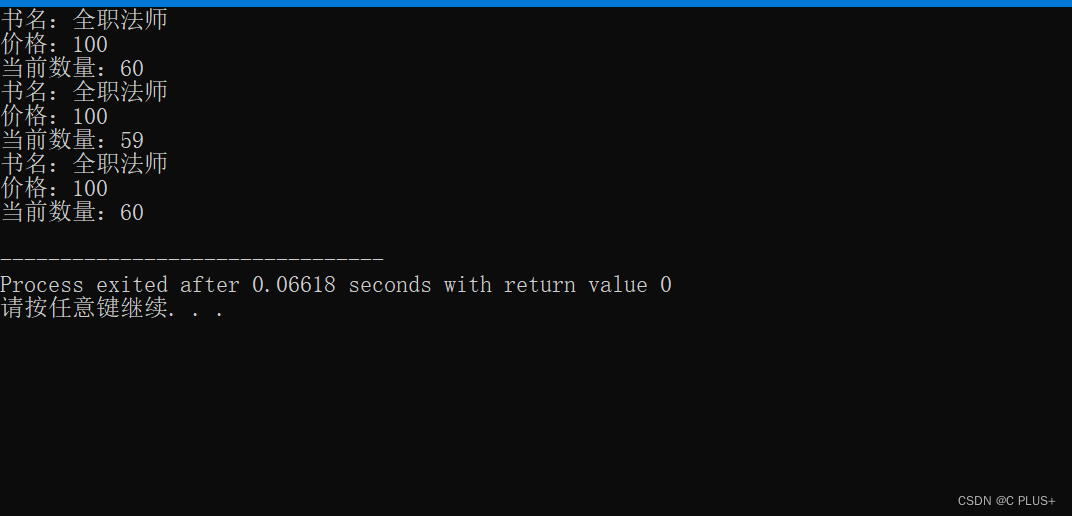
C++——定义一个 Book(图书)类
完整代码: /*定义一个 Book(图书)类,在该类定义中包括数据成员和成员函数 数据成员:book_name (书名)、price(价格)和 number(存书数量); 成员函数:display()显示图书的 情况;borro…...
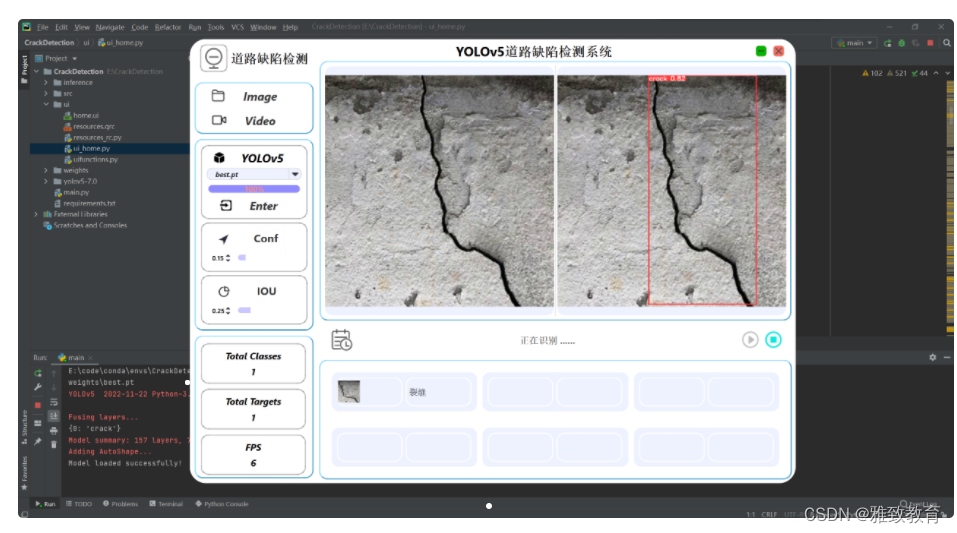
深度学习之基于YoloV5的道路地面缺陷检测系统(UI界面)
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、道路地面缺陷检测系统四. 总结 一项目简介 基于YoloV5的道路地面缺陷检测系统利用深度学习中的目标检测算法,特别是YoloV5算法&am…...

AcWing94. 递归实现排列型枚举:输出1~n的全排列
题目 把 1∼ n n n 这 n n n 个整数排成一行后随机打乱顺序,输出所有可能的次序。 输入格式 一个整数 n n n。 输出格式 按照从小到大的顺序输出所有方案,每行 1 个。 首先,同一行相邻两个数用一个空格隔开。 其次,对于两…...

神经网络多种注意力机制原理和代码讲解
多种注意力表格: 大神参考仓库链接: 魔鬼面具 对应 name 就是目录,点击即可跳转到对应学习。 nameneed_chaneelpaper SE (2017) Truehttps://arxiv.org/abs/1709.01507 BAM (2018) Truehttps://arxiv.org/pdf/1807.06514.pdf CBAM (2018) Tr…...
前端HTML
文章目录 一、什么是前端前端后端 前端三剑客1.什么是HTML2.编写前端的步骤1.编写服务端2.浏览器充当客户端访问服务端 3.浏览器无法正常展示服务端内容(因为服务端的数据没有遵循标准)4.HTTP协议>>>:最主要的内容就是规定了浏览器与服务端之间数据交互的格式 3. 前…...

Jenkins安装(Jenkins 2.429)及安装失败解决(Jenkins 2.222.4)
敏捷开发与持续集成 敏捷开发 敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。在敏捷开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备可视、可集成和可运行使用的特征。…...

vue中哪些数组操作可以重排
以下是Vue中可以重排数组的常用方法的示例: push():在数组末尾添加一个或多个元素 // 初始化数组 let myArray [1, 2, 3]; // 在数组末尾添加一个元素4 myArray.push(4); console.log(myArray); // [1, 2, 3, 4] // 在数组末尾添加多个元素5和6 myArr…...

订单创建订单确认、收货创建收货确认取消收货、生成库存和领用单发料
本人详解 作者:王文峰,参加过 CSDN 2020年度博客之星,《Java王大师王天师》 公众号:山JAVA开发王大师,专注于天道酬勤的 Java 开发问题中国国学、传统文化和代码爱好者的程序人生,期待你的关注和支持!本人外号:神秘小峯 山峯 转载说明:务必注明来源(注明:作者:王文…...

yolox转rknn
使用瑞芯微版本的yolox:https://github.com/airockchip/YOLOXpip install torch1.8.1 torchvision0.9.1 torchaudio0.8.1 --no-cache -i https://pypi.tuna.tsinghua.edu.cn/simplepip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --…...
llava1.5模型安装、预测、训练详细教程
引言 本博客介绍LLava1.5多模态大模型的安装教程、训练教程、预测教程,也会涉及到hugging face使用与wandb使用。 源码链接:点击这里 demo链接:点击这里 论文链接:点击这里 一、系统环境 ubuntu 20.04 gpu: 2*3090 cuda:11.6 二、LLava环境安装 1、代码下载…...
一个ppt带你读懂网络安全行业四大顶会之一的ndss论文<<Large Language Model guided Protocol Fuzzing>>
论文下载地址: Large Language Model guided Protocol Fuzzing...
ajax调用springboot后台接口
工具 api测试工具 由于后台接口不是同一个团队编写的,在文档缺失的情况下,需要测试后台接口接收参数类型,可以使用这个工具,注册很方便 页面如下所示,可以选择请求方法是get,或者post 重点介绍两种&…...
2021-arxiv-LoRA Low-Rank Adaptation of Large Language Models
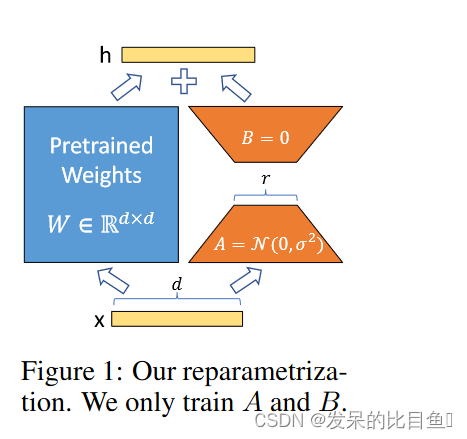
2021-arxiv-LoRA Low-Rank Adaptation of Large Language Models Paper: https://arxiv.org/abs/2106.09685 Code: https://github.com/microsoft/LoRA 大型语言模型的LoRA低秩自适应 自然语言处理的一个重要范式包括对通用领域数据的大规模预训练和对特定任务或领域的适应。…...
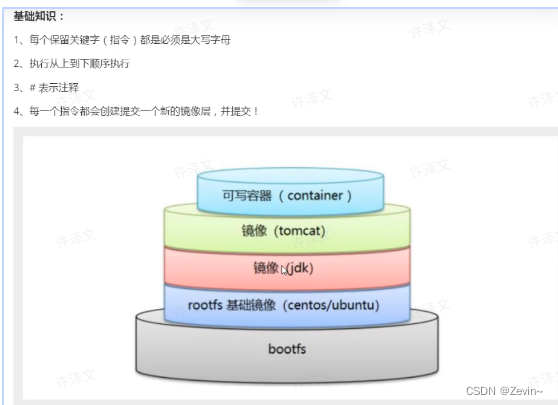
dockefile
文章目录 应用的部署MySql的部署Tomcat的部署 dockerfileDocker原理镜像的制作容器转镜像Dockerfile 服务编排Docker Compose Docker 私有仓库 应用的部署 搜索app的镜像拉去app的镜像创建容器操作容器中的app MySql的部署 容器内的网络服务和外部机器无法直接通信外部机器和…...

rpc入门笔记 0x02 protobuf的杂七杂八
syntax "proto3"; // 这是个proto3的文件message HelloRequest{ // 创建数据对象string name 1; // name表示名称,编号是1 }生成python文件 安装grpcio和grpcio-tools库 pip install grpcio #安装grpc pip install grpcio-tools #安装grpc tools生成…...
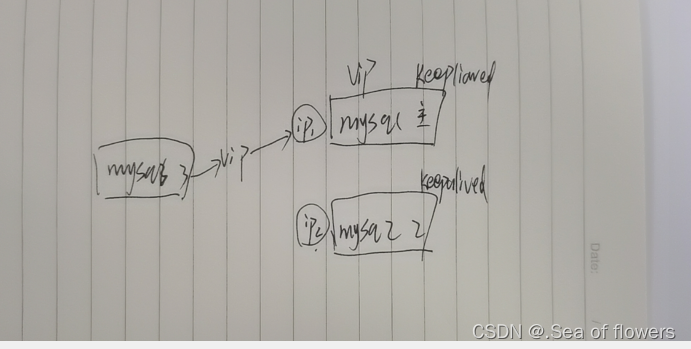
keepalived与nginx与MySQL
keepalived VRRP介绍 集群(cluster)技术是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能、可靠性、灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技术。 集群组成后,可…...

Pod基础概念
Pod是kubernetes中最小的资源管理组件,Pod也是最小化运行容器化应用的资源对象。一个Pod代表着集群中运行的一个进程。kubernetes中其他大多数组件都是围绕着Pod来进行支撑和扩展Pod功能的,例如,用于管理Pod运行的StatefulSet和Deployment等控…...

2026年十家小程序开发公司榜单及全面解读
数字经济全行业渗透的当下,权威的小程序开发服务商排名,早已成为企业筛选技术合作方的核心参考坐标。市面上服务商定位差异大、水平参差不齐,企业如何才能找到技术实力过硬、同时匹配自身成本预期的合作方?本文结合2024-2025年行业…...

浮动油封市场深度研判:预计2032年将攀升至4.57亿美元
浮动油封,也叫机械端面密封或永久密封,是一种特殊类型的机械密封,主要由一对耐磨的金属浮封环和配套的橡胶密封圈组成,它通过橡胶圈的弹力使两个金属环端面紧密贴合、相对滑动,实现对油、水、泥沙等介质的动态密封&…...

终极指南:Visual C++运行库合集AIO - 一站式解决Windows程序依赖问题
终极指南:Visual C运行库合集AIO - 一站式解决Windows程序依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在运行某些软件或游戏时…...
)
软考 系统架构设计师系列知识点之杂项集萃(155)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(154) 第293题 给定关系R(A1, A2, A3, A4, A5)上的函数依赖集F={A1->A2A5, A2->A3A4, A3->A2},R的候选关键字()。函数依赖()∈F+。 第1空 A. A1 B. A1A2 C. A1A3 D. A1A2A3 正确答案:A。 第2空…...

利用 AI 导出鸭将 DeepSeek 内容一键转为 PDF
在日常使用 AI 助手进行技术调研或文档整理时,我们常常会遇到一个痛点:生成的优质内容往往停留在网页对话框中,难以直接转化为便于归档、打印或离线阅读的格式。尤其是像 DeepSeek 这样输出结构清晰、代码片段丰富的长文,如果只能…...
 企业级部署方案-Docker-Compose-K8s集群化实践)
LangChain-Chatchat 开发与应用(十) 企业级部署方案-Docker-Compose-K8s集群化实践
企业级部署方案:Docker Compose / K8s 集群化实践标签:Docker | Kubernetes | 高可用 | 生产部署 | DevOps一、从"单机玩具"到"生产系统" 前面九篇,咱们从 0 到 1 搭起了 Chatchat,做了二次开发,优…...

NoFences:免费开源的Windows桌面整理神器,让杂乱图标瞬间归位
NoFences:免费开源的Windows桌面整理神器,让杂乱图标瞬间归位 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上堆积如山的图标而烦…...
【简洁版】)
Java 高级特性高频面试题 30 道(含答案)【简洁版】
覆盖泛型、反射、注解、Lambda/Stream、函数式接口、动态代理、JDK8 新特性、线程池、JVM、IO/NIO、序列化等核心高频考点,适合中高级 Java 工程师面试。一、泛型(3 题)什么是 Java 泛型?泛型的作用是什么?答案&#…...

曼德勃罗集的 Three.js 实现
效果预览 经典的曼德勃罗集(Mandelbrot Set)分形渲染,配合动态缩放动画探索分形边界的无限细节。使用线性插值平滑着色,呈现出彩虹般的色彩过渡。 👉 点击查看《曼德勃罗集的》完整源码与效果演示 Shader 实现原理…...

三国杀卡牌DIY终极指南:5分钟打造你的专属武将
三国杀卡牌DIY终极指南:5分钟打造你的专属武将 【免费下载链接】Lyciumaker 在线三国杀卡牌制作器 项目地址: https://gitcode.com/gh_mirrors/ly/Lyciumaker 还在羡慕别人能设计出酷炫的三国杀武将卡牌吗?Lyciumaker这个免费开源的三国杀卡牌制作…...