大数据技术笔记
1. 大数据技术简介
大数据技术是一系列的工具和方法,它们可以帮助我们收集、存储和分析大量的数据,并将结果呈现给我们。
2. 大数据计算模式
我们需要一些方法来处理这些数据,就像我们需要各种各样的厨具来处理食材一样。这些方法被称为大数据计算模式,包括批处理计算、流计算、图计算和查询分析计算等。
批处理计算
静态数据是那些不会随时间改变的数据,比如企业为了决策分析而构建的数据仓库系统中的大量历史数据。这些数据来自不同的数据源,经过ETL(提取、转换、加载)工具的处理后被加载到数据仓库中,并不会发生变化。技术人员可以用数据挖掘和OLAP(联机分析处理)工具从这些静态数据中找出对企业有价值的信息。
批量计算是以静态数据为对象,可以在很充裕的时间内对大量数据进行处理,提取有价值的信息,Hadoop就是典型的批处理模型。
流计算
流数据则是近年来在各种领域,如网络监控、传感监测、电子商务等,常见的一种数据形式。这类数据以大量、快速、持续变化的流形式不断产生,比如,一个PM 2.5传感器会实时监测大气中PM 2.5的浓度并将数据实时传回数据中心。流数据的特点是数据快速持续到达、数据来源众多、数据量大且注重整体价值而非单个数据。
流计算的核心理念是数据的价值会随着时间的流逝而降低,所以当数据出现时就应该立即处理它,而不是缓存起来等待批量处理。流计算系统需要满足高性能、海量数据、实时性、分布式、易用性和可靠性等要求。
流计算的处理流程包括数据实时采集、数据实时计算和实时查询服务。首先,我们需要采集数据并实时分析和计算,然后提供实时查询服务。不同于传统的数据处理流程,用户不需要主动发出查询请求,实时查询服务可以主动将实时结果推送给用户。
查询分析计算
查询分析计算就像是我们在查询图书馆的书籍一样,我们需要在大量的数据中快速找到我们需要的信息。比如Dremel和Impala就是两个常用的查询分析计算工具,它们能够在短时间内完成对大量数据的查询和分析。
3. 大数据相关框架
3.1 Hadoop
让我们把Hadoop想象成一个大型的购物中心,其中有各种各样的商店,每个商店都提供不同种类的商品和服务,合在一起,就形成了一个完整的购物体验。
-
Hadoop的商场里,HDFS是这个购物中心的仓库管理员,负责保管商品。如同一个大型仓库,HDFS将大量数据(商品)拆分为小块,然后将这些小块散布到许多分布式的仓库中,即使某些仓库发生问题,仍然能保证整体商品的可用性和可靠性。
-
MapReduce就像购物中心的运输系统,它把商品从仓库送到顾客手中。它把大量的商品拆分为小块,然后分发给各个商店来处理。这就是“分而治之”的原理,通过分割数据并行处理,最后再把结果汇总起来。
-
HBase就像一个大型的百货公司,它能高效地处理大量的商品,包括实时读取和写入数据。它就像一个巨大的电子表格,可以无限扩展,只要增加更多的服务器。
-
Hive就像是购物中心里的信息查询台,它可以查询和分析存储在Hadoop文件中的数据。Hive使用类似于SQL的查询语言"HiveQL",让你能快速找到你需要的商品。
-
Pig就像是购物中心的一个智能机器人,它能通过一种简单的脚本语言,自动帮你从大数据集中找到你需要的商品。
-
Mahout就像是购物中心的专业购物顾问,它能通过机器学习,根据你的购物记录和喜好,为你推荐你可能感兴趣的商品。
-
ZooKeeper就像是购物中心的管理者,它协调和管理各个商店,以确保整个购物中心的正常运行。
-
Flume就像是购物中心的物流系统,它负责收集、聚合和传输大量的商品信息。
-
Sqoop就像是购物中心的一个快速通道,它能快速地将商品数据从传统数据库转移到Hadoop,或者从Hadoop转移到传统数据库。
-
最后,Ambari就像是购物中心的安保系统,它管理和监控整个Hadoop的运行情况,以确保整个系统的稳定运行。
3.2 Spark
让我们把 Spark 想象成一辆超级跑车,那么 Hadoop 就好比一辆普通轿车。当两车在一条道路上进行百公里加速竞速时,Spark 只需 23 分钟就能完成,而 Hadoop 则需要 72 分钟。而且,Spark 的燃油效率更高,需要的燃油只有 Hadoop 的十分之一。这表明了 Spark 的性能更强、效率更高。
这辆超级跑车(Spark)的优势在于它的四个主要特点:
1)它的引擎(DAG 执行引擎)非常先进,可以支持循环数据流和内存计算,使其运行速度比轿车(Hadoop)快上百倍,甚至千倍。
2)它的操控性非常好,支持使用多种语言进行编程,用户可以轻松地驾驭这辆跑车。
3)它的功能非常全面,提供了完整而强大的技术栈,包括 SQL 查询、机器学习和图算法等,这些功能就像跑车的各种豪华配置,让你应对各种驾驶场景。
4)它的运行模式多样,可以独立运行,也可以运行于其他环境中,如云环境等。这就好比跑车既可以在赛道上独自飞驰,也可以在公路上与其他车辆并行。
总的来说,Spark就像一辆超级跑车,它的性能和效率都比轿车(Hadoop)更出色。虽然轿车(Hadoop)也有自己的优势,比如它更适合长途旅行(大数据批处理),但如果你想要快速、高效地处理数据,那么你可能更需要一辆超级跑车(Spark)。
3.3 Spark Streaming
Spark Streaming是一个基于Spark的实时数据处理工具,它增强了Spark在处理大数据流方面的能力。这个工具可以同时处理批量数据和进行交互查询,特别适合在需要同时分析历史数据和实时数据的场合使用。
Spark Streaming是Spark的主要组件之一,它让Spark具有了可以扩展、高速传输和容错的流计算能力。这个工具可以整合许多不同类型的输入数据源,如Kafka、Flume、HDFS等,甚至是常见的TCP套接字。经过处理之后,数据可以存储到文件系统、数据库,或者显示在仪表盘上。
Spark Streaming的工作原理是把实时输入的数据流分解为一秒一段的时间片,然后用Spark引擎按照批处理的方式处理每一段时间片的数据。
在Spark Streaming中,主要的概念是所谓的离散化数据流,也就是DStream,代表了连续不断的数据流。在内部实现上,Spark Streaming会把输入的数据按照一段一段的时间片分解成DStream,每一段数据都会转化为Spark中的RDD。所有对DStream的操作都最终会变成对相应的RDD的操作。例如,在进行单词统计的时候,每一段时间片的数据(存储了句子的RDD)会经过flatMap操作,生成了存储单词的RDD。整个流式计算可以根据业务需要对这些中间结果进行进一步处理,或者存储到外部设备中。
3.4 Flink
Flink是一个基于流处理的大数据处理框架,它同时支持批处理和实时流处理,这使得Flink能够灵活处理大规模数据。Flink特别适合需要对历史数据和实时数据同时进行分析的应用场景。
Flink是大数据处理的主要工具之一,提供了可扩展、高效、和容错的数据处理能力。Flink可以整合各种输入数据源,如Kafka、HDFS等,甚至是常见的TCP套接字。经过处理后,数据可以存储到文件系统、数据库,或者显示在仪表盘上。
Flink的工作原理是基于事件驱动的方式处理实时输入数据流,它不需要像Spark Streaming那样将数据切分为时间片进行处理,而是根据数据的到达时间进行处理,这样能够保证更高的实时性。
在Flink中,主要的概念是DataStream(数据流)和DataSet(数据集),它们都代表了一种连续不断的数据流。在内部实现上,Flink会把输入的数据转化为DataStream或DataSet,并且对这些数据的操作都会转变为对DataStream或DataSet的操作。例如,在进行单词统计的时候,每一段数据(存储了句子的DataStream或DataSet)会经过flatMap操作,生成了存储单词的DataStream或DataSet。整个流式计算可以根据业务需要对这些中间结果进行进一步处理,或者存储到外部设备中。
相比其他大数据处理工具,Flink的优势在于其实时性,因为Flink是基于事件驱动的方式处理数据,所以,Flink可以实现毫秒级的流计算,这是其它大部分流处理工具不能做到的。Flink的另一个优势是其能很好地处理时间和事件驱动的应用场景,例如,Flink可以处理事件时间和处理时间,对延迟数据可以进行有效的管理。
总结来说,Flink是一个强大的大数据处理工具,它不仅可以处理大规模的数据,还能实现实时性的处理,非常适合需要大规模数据处理和实时性要求比较高的应用场景。
相关文章:

大数据技术笔记
1. 大数据技术简介 大数据技术是一系列的工具和方法,它们可以帮助我们收集、存储和分析大量的数据,并将结果呈现给我们。 2. 大数据计算模式 我们需要一些方法来处理这些数据,就像我们需要各种各样的厨具来处理食材一样。这些方法被称为大…...

Vue 3 中的 Composition API
✨理解 Vue 3 中的 Composition API 🎃 Vue 3 引入了全新的 Composition API,相较于传统的 Options API,它具备许多优势和适用场景。下面将介绍 Composition API 的优势和使用场景,并为你带来更好的开发体验。 🎁 Co…...

《TCP/IP详解 卷一:协议》第5章的IPv4数据报的总长度字段出现“不需要大于576字节的IPv4数据报“相关内容的解释
《TCP/IP详解 卷一:协议》第5章的IPv4数据报的总长度字段的一些解释,出现以下内容(有省略): ....另外,主机不需要接收大于576字节的IPv4数据报.....以避免576字节的IPv4限制。 英文原文的内容(有…...

PO-java客户端连接错误can not connect to server
问题描述: 换电脑或者网络环境改变了,PO下载EST ID的jnlp提示can not connect to server*** ;**message server***这类错误 原因分析: 基本上都是PO消息服务器连接不上导致的错误,原理有均衡负载对应的IP转接后端口不…...

PM2 vs Kubernetes:在部署 Node.js 服务时使用哪个?
Node.js 已成为 Web 开发中的热门技术之一,但如果我们想成功地将 Node.js 应用程序交付给用户,我们需要考虑部署和管理这些应用程序。两个常见的选项是 PM2 和 Kubernetes。PM2 是一个用于运行和管理 Node.js 应用程序的进程管理器,它能够创建…...
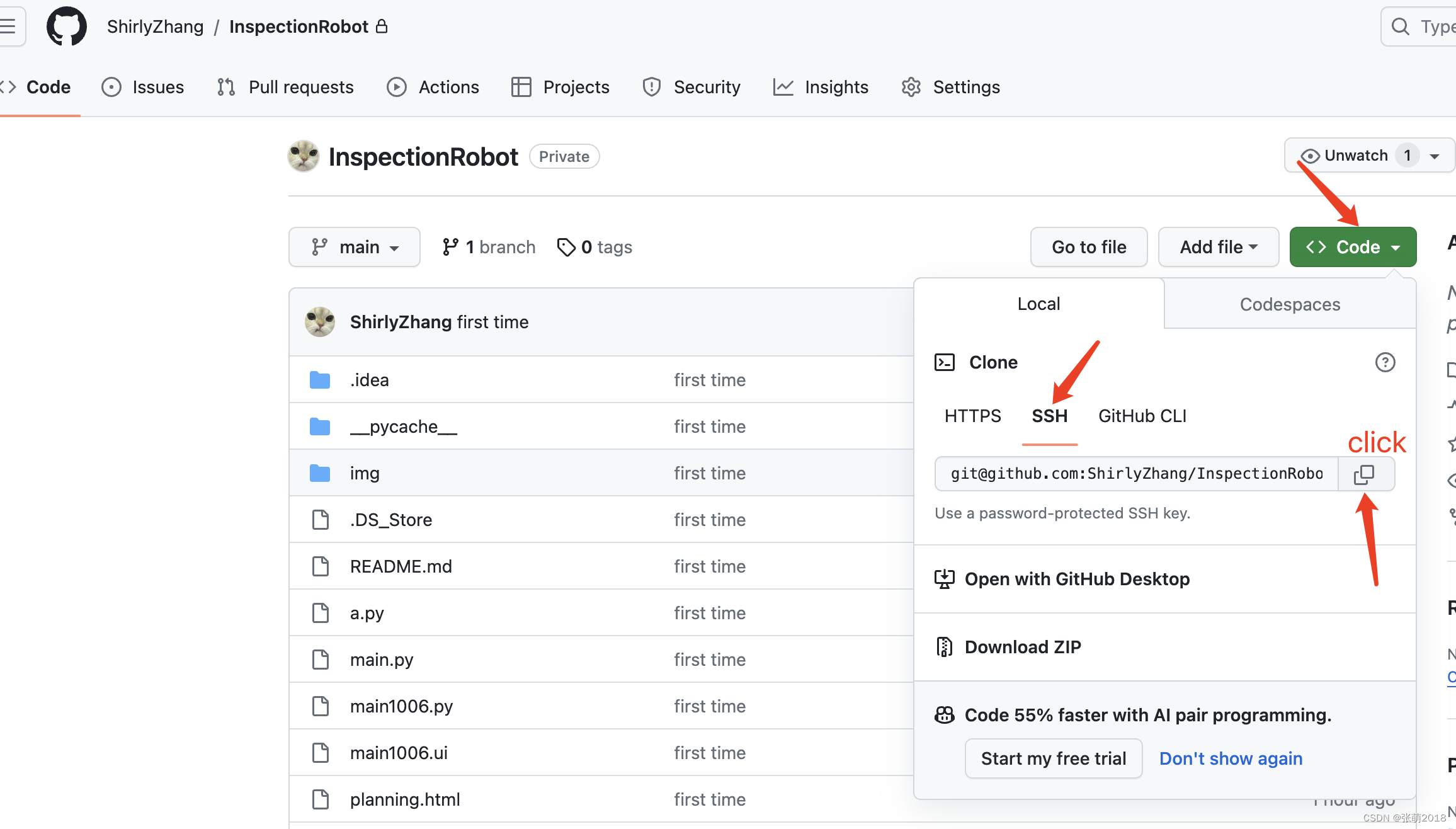
配置git并把本地项目连接github
一.配置git 1.下载git(Git),但推荐使用国内镜像下载(CNPM Binaries Mirror) 选好64和版本号下载,全部点下一步 下载完成后打开终端,输入 git --version 出现版本号则说明安装成功 然后继续…...
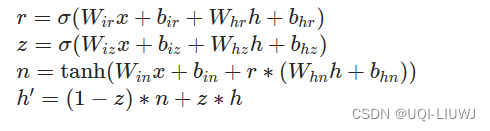
pytorch笔记 GRUCELL
1 介绍 GRU的一个单元 2 基本使用方法 torch.nn.GRUCell(input_size, hidden_size, biasTrue, deviceNone, dtypeNone) 输入:(batch,input_size) 输出和隐藏层:(batch,hidden_size…...

不解压,也能列出文件信息
gz文件,不解压,查看压缩前文件的大小: gzip -l ~$ ll -rw-r--r-- 1 fee fee 17343450 Nov 2 12:02 xxx.log.2023-11-02T04-02-56.000.1 -rw-r--r-- 1 fee fee 3150599 Nov 2 12:02 xxx.log.2023-11-02T04-02-56.000.1.gz ~$ gzip -l gb…...
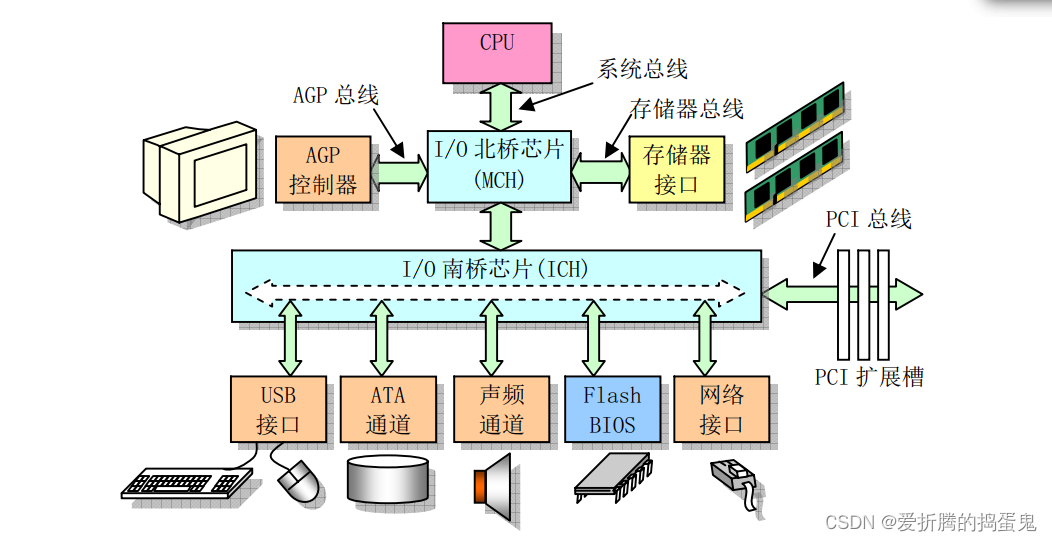
微型计算机组成原理
1、微型计算机组成 一个传统微型计算机硬件组成如下图 CPU通过地址线、数据线和控制信号线组成的本地总线(内部总线)与系统其他部分进行数据通信。 地址线用于提供内存或I/O设备的地址,即指明需要读/写数据的具体位置;数据线用…...
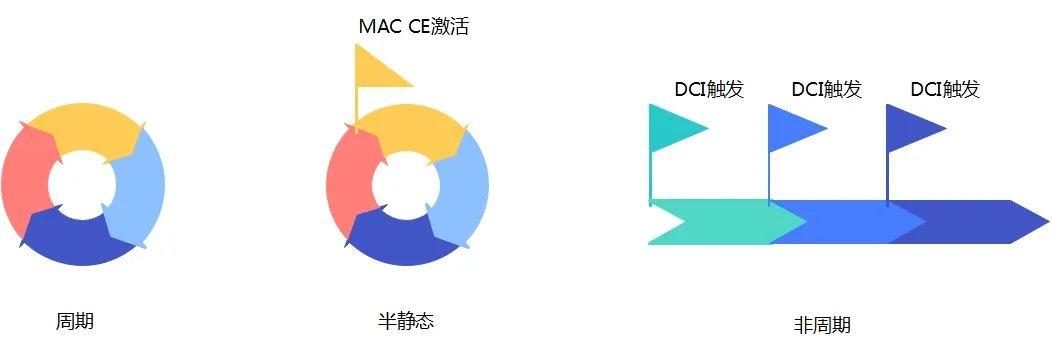
基站/手机是怎么知道信道情况的?
在无线通信系统中,信道的情况对信号的发送起到至关重要的作用,基站和手机根据信道的情况选择合适的资源配置和发送方式进行通信,那么基站或者手机是怎么知道信道的情况呢? 我们先来看生活中的一个例子,从A地发货到B地…...

进程/线程
进程是资源单位, 线程是执行单位。 每一个进程至少要有一个线程,启动每一个程序默认都会有一个主线程 1.多线程的两种实现 from threading import Thread#方法一 def func(name):for i in range(10):print(name, i)if __name__ __main__:t Thread(targetfunc, …...
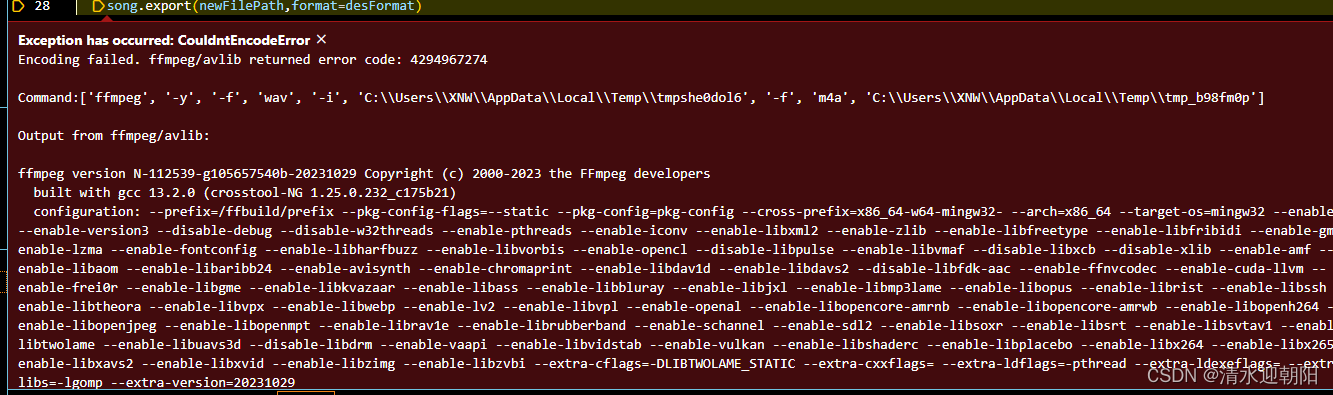
Python 应用 之 转换音频格式
目录 一、python音频转换 1、pydub 音频包安装 2、 ffmpeg安装 1)、解压后,添加到环境变量中 2)、可以直接放在python安装目录下 3、python程序 1)、引入相关包 2)、重命名 3)、to Mp3 4…...

Oracle JDK 和OpenJDK两者有什么异同点
Oracle JDK 和 OpenJDK 是两种不同版本的 Java Development Kit(Java 开发工具包),它们都提供了用于开发 Java 程序的一系列工具和库。以下是它们之间的一些主要异同点: 相同点: 功能:在大多数情况下&…...
GPT引发智能AI时代潮流
最近GPT概念爆火,许多行业开始竞相发展AI ,工作就业也将面临跳转,目前测试就业形势就分为了两大类,一类是测试行业如功能、性能、自动化综合性人才就业技能需求,另一类便是AI测试行业的需求普遍增长,原本由…...

FreeSWITCH mrcp-v2小记
最近得知有人受mrcp的困扰,于是写了这篇小文,希望能有所帮助 FreeSWITCH版本选择 目前当然选择1.10.10,不建议老版本,差别在于老版本用到的libmrcp比较旧,是1.2版本,bug比较多,有时会crash&am…...
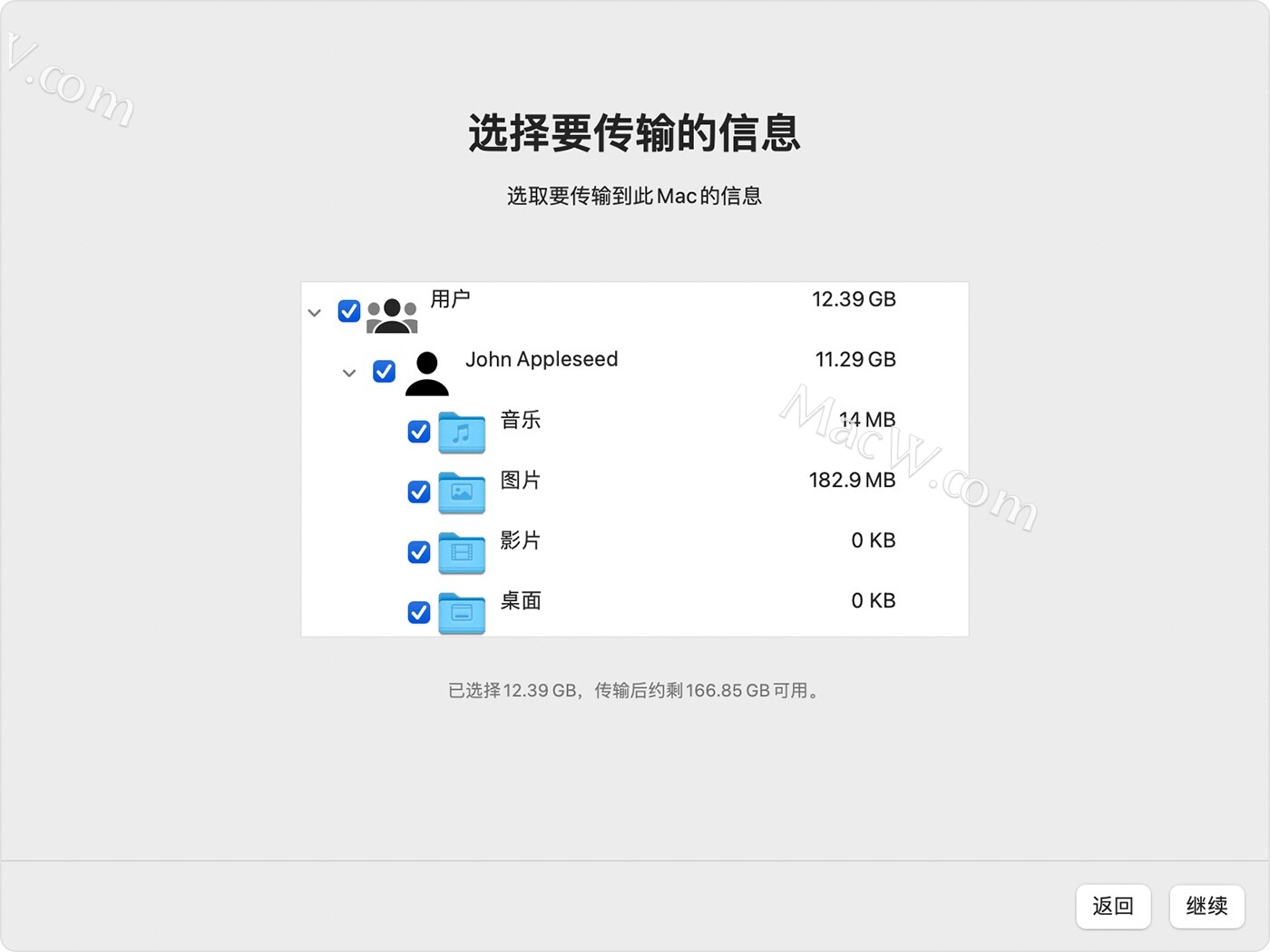
如何将你的PC电脑数据迁移到Mac电脑?使用“迁移助理”从 PC 传输到 Mac的具体操作教程
有的小伙伴因为某一项工作或者其它原因由Windows电脑换成了Mac电脑,但是数据和文件都在原先的Windows电脑上,不知道怎么传输。接下来小编就为大家介绍使用“迁移助理”将你的通讯录、日历、电子邮件帐户等内容从 Windows PC 传输到 Mac 上的相应位置。 在…...

Elasticsearch集群搭建、数据分片以及位置坐标实现附近的人搜索
集群搭建、数据分片 es使用两种不同的方式来发现对方: 广播单播也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成 一 广播方式 当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328。而其他的es实例使用同样的集群名称响应了这个请求。 一般这…...

深度学习_3 数据操作之线代,微分
线代基础 标量 只有一个元素的张量。可以通过 x torch.tensor(3.0) 方式创建。 向量 由多个标量组成的列表(一维张量)。比如 x torch.arange(4) 就是创建了一个1*4的向量。可以通过下标获取特定元素(x[3]),可以通…...
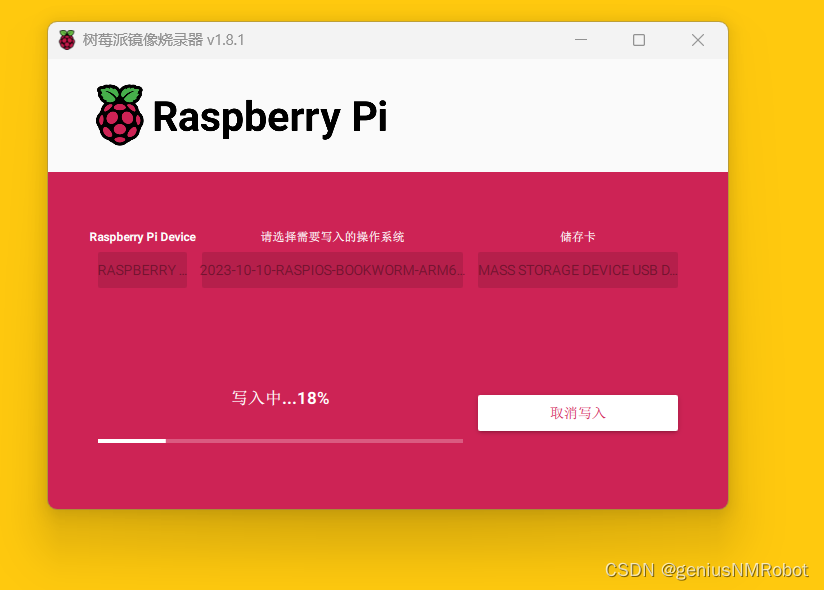
树莓派安装Ubuntu22.04LTS桌面版
工具:树莓派4B Raspberry Pi 自己下载的ubuntu22.04LTS img磁盘镜像文件 这里有一个小技巧:这个Raspberry Pi的选择镜像的时候在最后面一行可以选择自定义的镜像,哈哈哈哈,这就使得我们可以自己下载,而且知道那个文…...
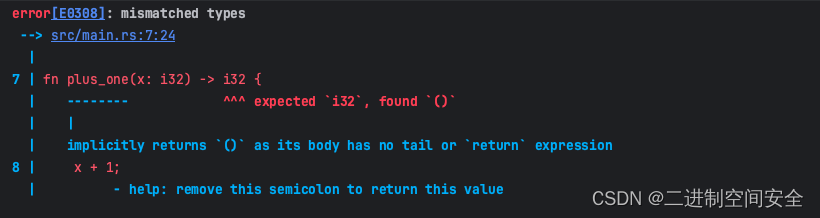
Rust编程基础之函数和表达式
1.Rust函数 在之前的文章中,我们已经见到了一个函数:main函数, 它是很多程序的入口点。也见过 fn 关键字,它用来声明新函数。 Rust 代码中的函数和变量名使用 snake case 规范风格。在 snake case 中,所有字母都是小写并使用下划线分隔单词。这是一个包…...

2026营销策划岗位学数据分析能提升职场能力吗
一、数据分析在营销策划中的核心价值数据驱动决策取代经验主义,精准定位用户需求与行为模式 实时监测市场趋势与竞品动态,优化营销策略的敏捷性 量化评估活动效果,提升ROI与资源分配效率二、2026年营销策划岗位的数据分析技能需求基础能力&am…...

OpenSSH CVE-2024-6387 漏洞原理与实战修复指南
1. 这不是普通补丁:CVE-2024-6387 是 OpenSSH 里埋了二十年的“定时炸弹”你有没有遇到过这种情况:凌晨三点,监控告警疯狂闪烁,SSH 登录失败率突然飙升到98%,但服务器负载、内存、磁盘一切正常;运维同事反复…...

FanControl:重新定义Windows风扇控制,告别恼人噪音与散热烦恼
FanControl:重新定义Windows风扇控制,告别恼人噪音与散热烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/…...

如何为Hermes Agent自定义配置Taotoken作为模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为Hermes Agent自定义配置Taotoken作为模型提供商 对于使用Hermes Agent框架的开发者而言,直接对接多个大模型厂商…...

基于国产可控硅LTH16-08的电风扇无极调速方案设计与实践
1. 项目概述:当可控硅遇上电风扇 最近在帮一个做小家电的朋友优化一款电风扇的电路板,核心需求是想实现一个无极调速功能,让风扇的风量可以从微风到强风平滑过渡,而不是传统的三档或五档机械开关。这个需求听起来简单,…...

CANN 生态工具链:ATC、ACL 与 MindX 全景
一、CANN 工具链全景 1.1 工具链架构 ┌──────────────────────────────────────────────────┐ │ CANN 工具链全景 │ ├──────────────────────────────…...

从状态机视角理解程序:形式化方法如何保证复杂系统正确性
1. 从数学视角审视程序:为什么我们需要形式化思维在软件开发的日常里,我们常常埋头于代码的细节:这个循环边界对不对?那个指针会不会为空?这个API调用返回错误该怎么处理?我们依赖编译器、静态分析工具、单…...

星露谷物语SMAPI模组加载器:从新手到专家的终极指南
星露谷物语SMAPI模组加载器:从新手到专家的终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾梦想为星露谷物语添加全新的游戏体验?SMAPI模组加载器正是实现这…...

AI双轨制实战指南:MoE架构、异构模态与弹性推理的工程落地
1. 这不是新闻简报,而是一份AI地缘技术格局的实操观察手记你点开这篇文字,大概率不是为了读一篇“本周AI大事件汇总”。如果你真需要那种信息,直接刷Twitter或Hugging Face的Weekly Digest就够了。我写这个,是因为过去三个月里&am…...

谷歌推YouTube Shorts Remix功能:借Gemini重设计视频,创作者可自主开关
YouTube Shorts Remix:借Gemini开启视频重塑新玩法谷歌新推出的YouTube Shorts Remix功能引人注目,借助Gemini Omni,用户能对视频片段进行重新设计。在YouTube Shorts视频底部点击混音图标,便出现“重新构思”选项。用户可让Gemin…...