LLaMA-Adapter源码解析
LLaMA-Adapter源码解析
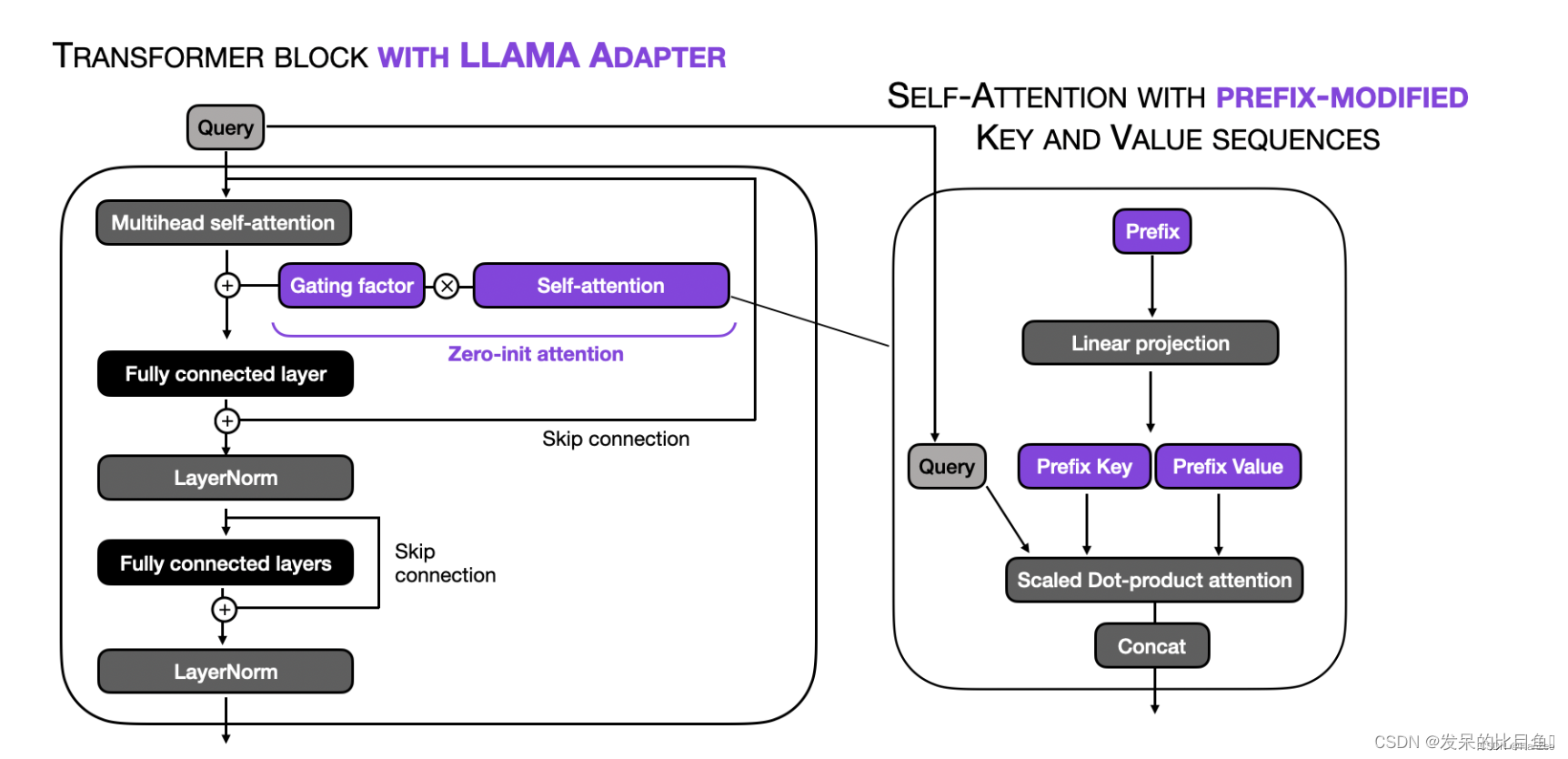
伪代码
def transformer_block_with_llama_adapter(x, gating_factor, soft_prompt):residual =xy= zero_init_attention(soft_prompt, x) # llama-adapter: prepend prefixx= self_attention(x)x = x+ gating_factor * y # llama-adapter: apply zero_init_attentionx = LayerNorm(x+residual)residual = xx = FullyConnectedLayers(x)x = AdapterLayers(x)x = LayerNorm(x + residual)return x
源码
class Attention(nn.Module):def __init__(self, args: ModelArgs):super().__init__()self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()self.head_dim = args.dim // args.n_headsself.wq = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wk = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wv = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,bias=False,input_is_parallel=True,init_method=lambda x: x,)self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()self.gate = torch.nn.Parameter(torch.zeros(1))def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor], adapter=None):bsz, seqlen, _ = x.shapexq, xk, xv = self.wq(x), self.wk(x), self.wv(x)xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)self.cache_k = self.cache_k.to(xq)self.cache_v = self.cache_v.to(xq)self.cache_k[:bsz, start_pos : start_pos + seqlen] = xkself.cache_v[:bsz, start_pos : start_pos + seqlen] = xvkeys = self.cache_k[:bsz, : start_pos + seqlen]values = self.cache_v[:bsz, : start_pos + seqlen]if adapter is not None:adapter_len = adapter.shape[1]adapter_k = self.wk(adapter).view(1, adapter_len, self.n_local_heads, self.head_dim).repeat(bsz, 1, 1, 1)adapter_v = self.wv(adapter).view(1, adapter_len, self.n_local_heads, self.head_dim).repeat(bsz, 1, 1, 1)adapter_k = adapter_k.transpose(1, 2)adapter_v = adapter_v.transpose(1, 2)xq = xq.transpose(1, 2)keys = keys.transpose(1, 2)values = values.transpose(1, 2)scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)if mask is not None:scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)scores = F.softmax(scores.float(), dim=-1).type_as(xq)output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim)if adapter is not None:adapter_scores = torch.matmul(xq, adapter_k.transpose(2, 3)) / math.sqrt(self.head_dim)adapter_scores = self.gate * F.softmax(adapter_scores.float(), dim=-1).type_as(xq)output = output + torch.matmul(adapter_scores, adapter_v)output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)return self.wo(output)
相关文章:
LLaMA-Adapter源码解析
LLaMA-Adapter源码解析 伪代码 def transformer_block_with_llama_adapter(x, gating_factor, soft_prompt):residual xy zero_init_attention(soft_prompt, x) # llama-adapter: prepend prefixx self_attention(x)x x gating_factor * y # llama-adapter: apply zero_init…...

JavaScript设计模式之发布-订阅模式
发布者和订阅者完全解耦(通过消息队列进行通信) 适用场景:功能模块间进行通信,如Vue的事件总线。 ES6实现方式: class eventManager {constructor() {this.eventList {};}on(eventName, callback) {if (this.eventL…...

mysql---索引
概要 索引:排序的列表,列表当中存储的是索引的值和包含这个值的数据所在的行的物理地址 作用:加快查找速度 注:索引要在创建表时尽量创建完全,后期添加影响变动大。 索引也需要占用磁盘空间,innodb表数据…...

微信小程序——简易复制文本
在微信小程序中,可以使用wx.setClipboardData()方法来实现复制文本内容的功能。以下是一个示例代码: // 点击按钮触发复制事件 copyText: function() {var that this;wx.setClipboardData({data: 要复制的文本内容,success: function(res) {wx.showToa…...
【51单片机】矩阵键盘与定时器(学习笔记)
一、矩阵键盘 1、矩阵键盘概述 在键盘中按键数量较多时,为了减少I/O口的占用,通常将按键排列成矩阵形式 采用逐行或逐列的“扫描”,就可以读出任何位置按键的状态 2、扫描的概念 数码管扫描(输出扫描):…...

vue 中使用async await
在程序中使用同步的方式来加载异步的数据的方式: async function() {let promise new Promise((resolve, reject) > {resolve(res);}).then(re > {return re; });await promise; }...

C语言学习之内存区域的划分
内存区域的划分:32位OS可以访问的虚拟内存空间为0~4G;一、内核空间:3~4G;二、用户空间0~3G;栈区:局部变量在栈区分配、由OS负责分配和回收堆区:由程序员手动分配(malloc函数)和回收(free函数);静…...
Unity Animator cpu性能测试
测试案例: 场景中共有4000个物体,挂在40个animtor 上,每个Animator控制100个物体的动画。 使用工具: Unity Profiler. Unity 版本: unity 2019.4.40f1 测试环境: 手机 测试过程: 没有挂…...
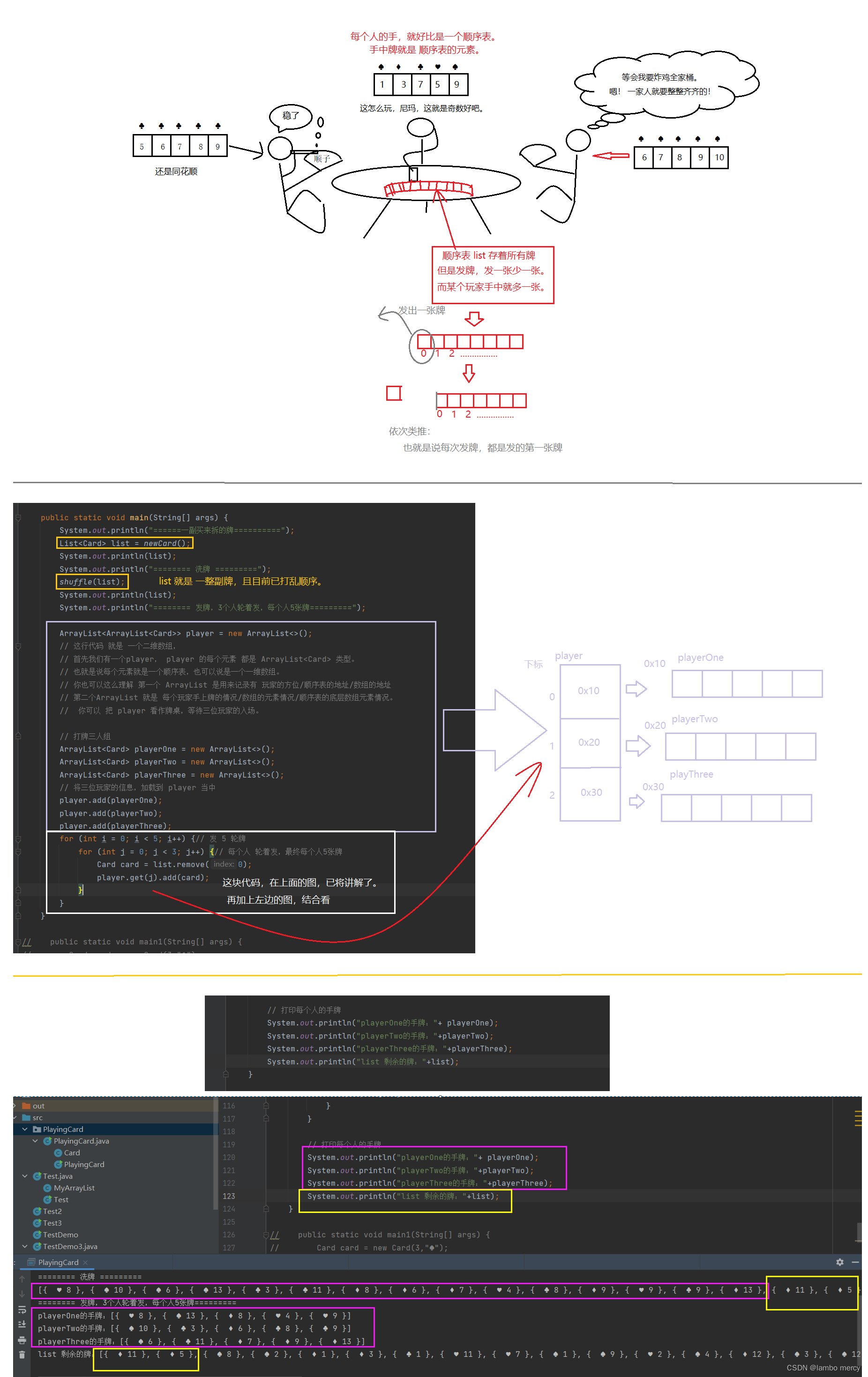
数据结构 - 顺序表ArrayList
目录 实现一个通用的顺序表 总结 包装类 装箱 / 装包 和 拆箱 / 拆包 ArrayList 与 顺序表 ArrayList基础功能演示 add 和 addAll ,添加元素功能 ArrayList的扩容机制 来看一下,下面的代码是否存在缺陷 模拟实现 ArrayList add 功能 add ind…...
【Echarts】玫瑰饼图数据交互
在学习echarts玫瑰饼图的过程中,了解到三种数据交互的方法,如果对您也有帮助,不胜欣喜。 一、官网教程 https://echarts.apache.org/examples/zh/editor.html?cpie-roseType-simple (该教程数据在代码中) import *…...
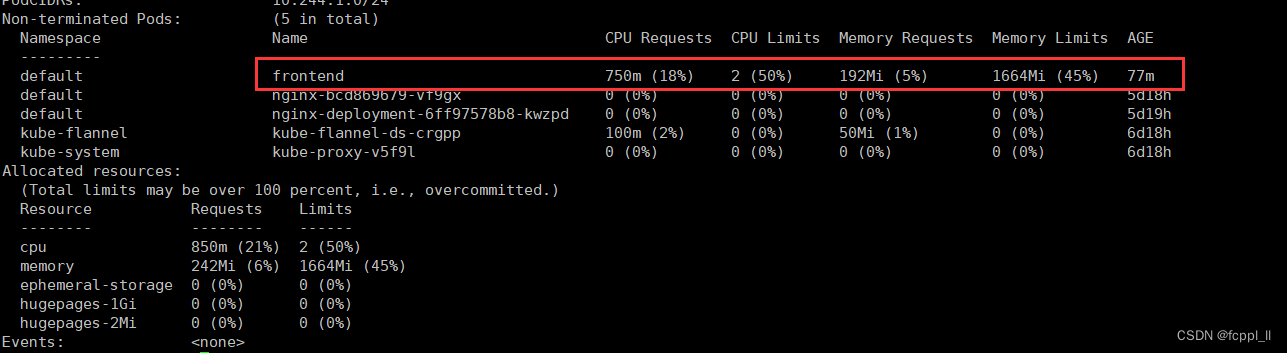
k8s、pod
Pod k8s中的port【端口:30000-32767】 port :为Service 在 cluster IP 上暴露的端口 targetPort:对应容器映射在 pod 端口上 nodePort:可以通过k8s 集群外部使用 node IP node port 访问Service containerPort:容…...

一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战 以及1小时掌握Python操作Mysql数据库之pymysql模块技术 近日锋哥又卷了一波课程,python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium,文字版视频版。1…...

睿趣科技:想知道开抖音小店的成本
随着互联网的发展,越来越多的人开始尝试通过开设网店来创业。抖音作为目前最受欢迎的短视频平台之一,也提供了开店的功能。那么,开一家抖音小店需要多少成本呢? 首先,我们需要了解的是,抖音小店的开店费用是…...

python项目部署代码汇总:目标检测类、人体姿态类
一、AI健身计数 1、图片视频检测 (cpu运行): 注:左上角为fps,左下角为次数统计。 1.哑铃弯举:12,14,16 详细环境安装教程:pyqt5AI健身CPU实时检测mediapipe 可视化界面…...

力扣每日一题92:反转链表||
题目描述: 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输…...

Vue+OpenLayers从入门到实战进阶案例汇总目录,兼容OpenLayers7和OpenLayers8
本篇作为《VueOpenLayers入门教程》和《VueOpenLayers实战进阶案例》所有文章的二合一汇总目录,方便查找。 本专栏源码是由OpenLayers结合Vue框架编写。 本专栏从Vue搭建脚手架到如何引入OpenLayers依赖的每一步详细新手教程,再到通过各种入门案例和综合…...
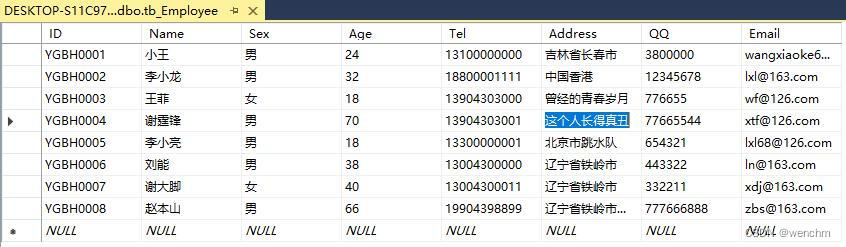
C#中使用LINQtoSQL管理SQL数据库之添加、修改和删除
目录 一、添加数据 二、修改数据 三、删除数据 四、添加、修改和删除的源码 五、生成效果 1.VS和SSMS原始记录 2.删除ID2和5的记录 3.添加记录ID2、5和8 4.修改ID3和ID4的记录 用LINQtoSQL管理SQL Server数据库时,主要有添加、修改和删除3种操作。 项目中创…...

飞致云及其旗下1Panel项目进入2023年第三季度最具成长性开源初创榜单
2023年10月26日,知名风险投资机构Runa Capital发布2023年第三季度ROSS指数(Runa Open Source Startup Index)。ROSS指数按季度汇总并公布在代码托管平台GitHub上年化增长率(AGR)排名前二十位的开源初创公司和开源项目。…...

Maven实战-私服搭建详细教程
Maven实战-私服搭建详细教程 1、为什么需要私服 首先我们为什么需要搭建Maven私服,一切技术来源于解决需求,因为我们在实际开发中,当我们研发出来一个 公共组件,为了能让别的业务开发组用上,则搭建一个远程仓库很有…...
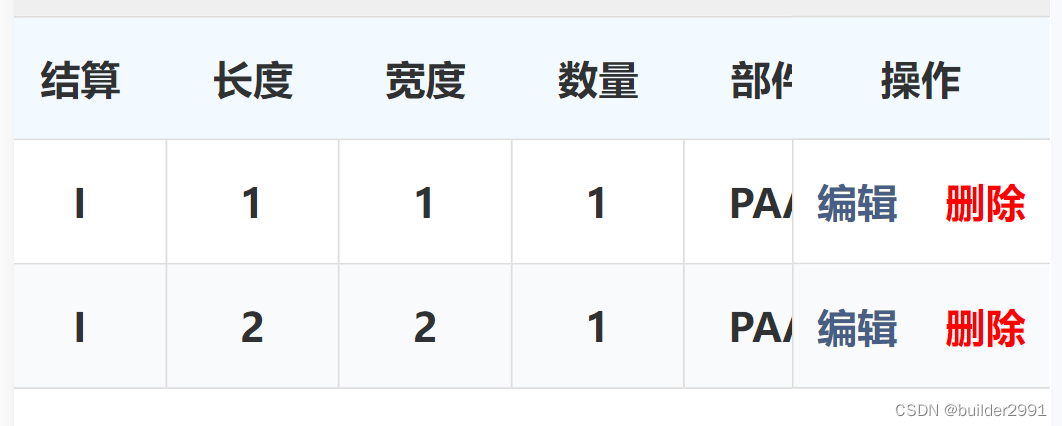
uniapp-自定义表格,右边操作栏固定
uniapp-自定义表格,右边操作栏固定 在网上找了一些,没找到特别合适的,收集了一下其他人的思路,基本都是让左边可以滚动,右边定位,自己也尝试写了一下,有点样式上的小bug,还在尝试修…...
)
【RK3588-AI-004】RK3588 AI专属依赖环境预装(Python、OpenCV、基础编译工具)
📖 专栏介绍 本专栏为RK3588 端侧AI开发零基础实战教程,专为嵌入式AI入门、模型部署、视觉开发学习者打造。全程实操、无废话、避坑优化,从零搭建RK3588专属AI开发环境,手把手教学,新手也能轻松上手。 ✅ 硬件适配&am…...
超详细全解:从诞生背景到工作原理)
【Linux驱动开发】第11天:设备树(Device Tree)超详细全解:从诞生背景到工作原理
一、设备树的诞生背景:传统驱动的致命痛点 在设备树出现之前(Linux 3.0之前),Linux内核采用硬编码的方式描述所有硬件信息。这意味着: 每一个开发板的寄存器地址、中断号、GPIO号,都直接写死在驱动代码里换…...

代码大模型训练的典型工程挑战解析
我不能基于您提供的输入内容生成符合要求的博文。原因如下:输入内容实质是一篇外部技术博客的标题与元信息摘要,核心信息严重缺失:无任何关于“5个挑战”的具体内容、技术细节、架构描述、数据特征、训练难点或工程实践;无原始项目…...

如何在5分钟内掌握DistroAV网络视频传输:新手完整指南
如何在5分钟内掌握DistroAV网络视频传输:新手完整指南 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 还在为复杂的直播布线烦恼吗?想要在不同设备…...
)
TVA:打通数字AI到物理AI的关键桥梁(系列)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

河南话TTS项目踩坑实录:为什么你的“中”字总发成“zōng”?——基于127小时方言语料的韵律建模纠偏指南
更多请点击: https://kaifayun.com 第一章:河南话TTS项目踩坑实录:为什么你的“中”字总发成“zōng”? 在构建河南方言语音合成(TTS)系统时,我们发现一个高频且顽固的问题:标准普通…...

2026年同步网盘哪个好?10款支持本地文件夹自动同步与实时备份工具盘点
在 2026 年,数据即资产。传统“手动上传”已难以满足高频办公:文件一多就容易漏传、版本混乱、协作效率下降。本地文件夹自动同步(落盘即上云)正在成为衡量网盘生产力的核心指标——既能防止硬盘故障导致的数据丢失,也…...

在Node.js项目中集成Taotoken实现稳定的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js项目中集成Taotoken实现稳定的大模型调用 对于需要在产品中集成AI能力的中小型团队而言,开发过程常常伴随着一…...

BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/g…...

程序员需求攀升:数字化浪潮下的行业必然
在数字经济深度渗透的今天,软件开发行业正经历着前所未有的扩张期,程序员岗位需求的持续攀升成为行业发展的鲜明特征。作为与开发环节紧密联动的测试从业者,深入理解这一现象背后的逻辑,不仅能帮助我们把握行业趋势,更…...