Spring Cloud的ElasticSearch的进阶学习
目录
数据聚合
Bucket示例
Metric示例
RestAPI实现聚合
自动补全
使用拼音分词
自定义分词器
实现自动补全
RestAPI实现自动补全功能
数据同步
同步调用
异步通知
监听binlog
数据聚合
聚合可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量 (Metric)聚合:用以计算一些值,比如: 最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求成max、min、avg、sum等
- 管道(pipeline)聚合:其他聚合的结果为基础做聚合
需要注意的是,聚合的数据不能被分词。
Bucket示例
根据品牌名称做聚合
#聚合功能
GET /hotel/_search
{"size": 0,// 展示的文档个数"aggs": {// 聚合"brandAgg": { //聚合名称"terms": { //聚合方式"field": "brand", "order": {"_count": "desc"},"size": 10 //结果展示}}}
}
默认情况加Bucket聚合是对所有文档进行聚合,这样对内存消耗较大,因此我们可以通过query指定聚合范围
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 200}}}, "size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 10}}}
}
Metric示例
对每个品牌的评分进行聚合。
GET /hotel/_search
{"size": 0,"aggs": {"brandAggs": {"terms": {"field": "brand","size": 10},"aggs": {"score_stats": {"stats": {"field": "score"}}}}}
}
如果需要对评分做一个排序,实际上是对桶聚合排序
GET /hotel/_search
{"size": 0,"aggs": {"brandAggs": {"terms": {"field": "brand","size": 10,"order": {"score_stats.avg": "desc"}},"aggs": {"score_stats": {"stats": {"field": "score"}}}}}
}
RestAPI实现聚合
@Testpublic void testAggregation() throws Exception {SearchRequest request = new SearchRequest("hotel");//不需要接收文档request.source().size(0);request.source().aggregation(//聚合名称AggregationBuilders.terms("brandAgg")//聚合字段.field("brand")//取值.size(10));SearchResponse response = client.search(request, RequestOptions.DEFAULT);//结果解析Aggregations aggregations = response.getAggregations();Terms brand_agg = aggregations.get("brandAgg");List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();for (Terms.Bucket bucket : buckets) {String brand = bucket.getKeyAsString();System.out.println(brand);}}解析结果根据ES的返回内容依次获取就好

自动补全
所谓自动补全,是指输入部分内容会展示对应的相关内容

使用拼音分词
如果要实现根据字母补全内容,那么就需要对文档进行拼音分词。下载对应版本的拼音分词插件
GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
并放入es的插件目录下
GET /_analyze
{"text": ["我正在学分布式搜索"],"analyzer": "pinyin"
}
默认的拼音分词器只会单个汉字的拼音与整句的拼音首字母分词。并不能满足我们的业务需求。因此我们需要自定义分词器。
自定义分词器
elasticsearch中分词器的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条 (term)。例如keyword,就是不分词;还有ik_smart。
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等

自定义的分词器只能在创建索引库的时候指定
PUT /test
{"settings": {"analysis":{"analyzer": { // 自定义分词器"my_analyzer": {// 分词器名称"tokenizer":"ik_max_word","filter":"py"}},"filter": { // 自定义tokenizer filter"py":{ // 过滤器名称"type":"pinyin",// 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term" : true,"none_chinese_pinyin_tokenize":false}}}}
}拼音分词器只能创建倒排索引的时候使用而不适合在搜索的时候使用。

因此在创建索引库的时候,可以指定搜索分词器
PUT /test
{"settings": {"analysis":{"analyzer": { // 自定义分词器"my_analyzer": {// 分词器名称"tokenizer":"ik_max_word","filter":"py"}},"filter": { // 自定义tokenizer filter"py":{ // 过滤器名称//.....}}}},"mappings":{"properties": {"name" :{"type": "text","analyzer":"my_analyzer","search_analyzer": "ik_smart"}}}
}实现自动补全
ES提供completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了补全查询效率,对文档中字段有一定约束
- 参与补全的必须是completion类型
- 字段的内容一般是用来补全的多个词条形成的数组
PUT /test
{"mappings":{"properties":{"title":{"type":"completion"}}}
}POST /test/_doc
{"title":["Sony","WH-1000XM3"]
}POST /test/_doc
{"title":["SK-II","PITERA"]
}POST /test/_doc
{"title":["Niotendo","switch"]
}# 自动补全查询
GET /test/_search
{"suggest": {"title_suggest":{"text":"s", "completion":{"field":"title","skip_duplicates": true,"size": 10}}}
}
RestAPI实现自动补全功能

@Testpublic void testSuggest() throws Exception {SearchRequest request = new SearchRequest("hotel");request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",//自定义,后面解析响应的时候也输入这个值就好SuggestBuilders.completionSuggestion("suggestion").prefix("bj").skipDuplicates(true).size(10)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);CompletionSuggestion suggestions = response.getSuggest().getSuggestion("suggestions");for (CompletionSuggestion.Entry.Option option : suggestions.getOptions()) {String test = option.getText().string();System.out.println(test);}}数据同步
ES一般和数据库联合使用,ES的数据来源于数据库,但是数据库的内容并不是一成不变的,因此ES与数据库就存在了数据同步问题。
同步调用
当客户端发起请求后,首先数据库进行修改,修改完成后去调用搜索服务的更新ES接口,等ES更新完成后返回结果给保存数据库的服务,再返回给客户端

优点:实现简单
缺点:
- 代码耦合,在更新完数据库后需要添加调用ES更新接口的代码
- 耗时增加,性能下降
异步通知

优点:耦合度低,实现难度一般
缺点:依赖MQ的可靠性
监听binlog
数据库可以开启binlog功能。当数据库发生CURD时,binlog会发生改变,由canal通知ES服务修改ES数据。
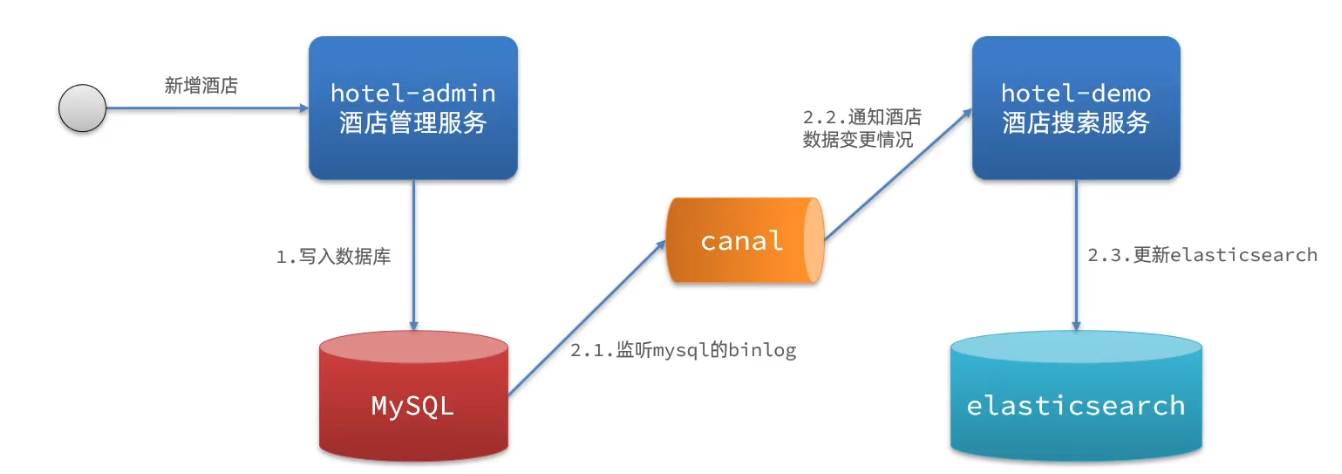
优点:完全解耦
缺点:开启binlog增加数据库负担。实现复杂度高
相关文章:
Spring Cloud的ElasticSearch的进阶学习
目录 数据聚合 Bucket示例 Metric示例 RestAPI实现聚合 自动补全 使用拼音分词 自定义分词器 实现自动补全 RestAPI实现自动补全功能 数据同步 同步调用 异步通知 监听binlog 数据聚合 聚合可以实现对文档数据的统计、分析、运算。聚合常见的有三类: …...

WordPress恢复时候遇到的几个问题
1,一键安装 LAMP 最好是选择 CentOS 这种成熟的系统,最开始用 Alibaba Linux 报了好几个错,懒得折腾,最后重置镜像了。 https://lnmp.org/ wget https://soft.lnmp.com/lnmp/lnmp2.0.tar.gz -O lnmp2.0.tar.gz && tar z…...

设备码解释
一、名词解释 Device ID:设备ID。 IMEI:(International Mobile Equipment Identity)国际移动设备标识的缩写。是由15位数字组成的“电子串号”,它与每台手机一一对应,每个IMEI在世界上都是唯一的。 MEID…...
基于Docker-consul容器服务更新与发现
目录 一、什么是服务注册与发现: 二、Docker-consul介绍: 三、consul的关键特性: 四、consul部署: 1.部署规划: 2.consul服务器部署: 2.1 建立consul服务: 启动consul后默认会监听5个端口&a…...
firefox浏览器添加自定义搜索引擎方法
firefox浏览器添加自定义搜索引擎方法 1.在地址栏添加搜索引擎2.Mycroft Project 搜索引擎附加组件3.通过扩展插件添加自定义搜索引擎 Firefox这货居然不支持直接网址%s的搜索引擎定义方式,以下是添加方法。 firefox国际版119.0 1.在地址栏添加搜索引擎 ÿ…...
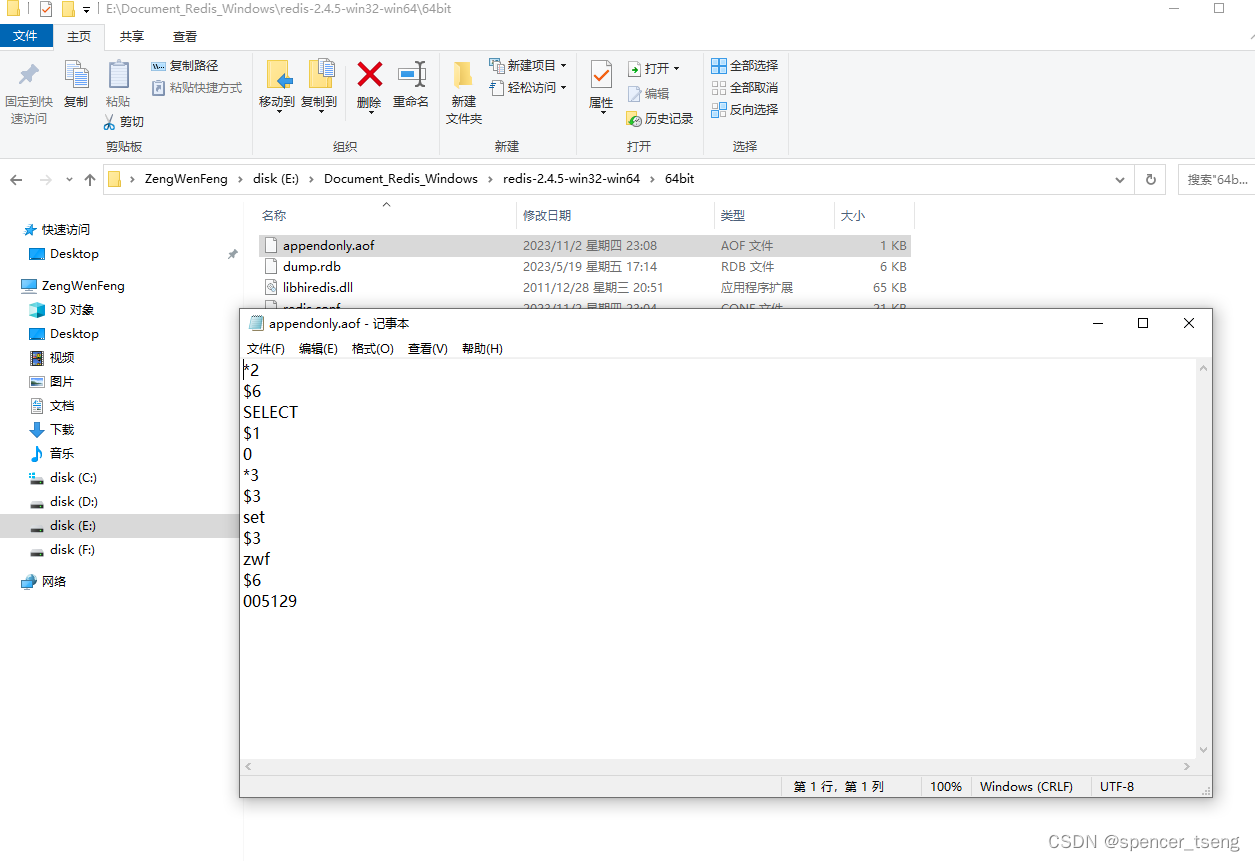
redis rdb aof
appendonly yes # appendfsync always appendfsync everysec # appendfsync no E:\Document_Redis_Windows\redis-2.4.5-win32-win64\64bit appendonly.aof...
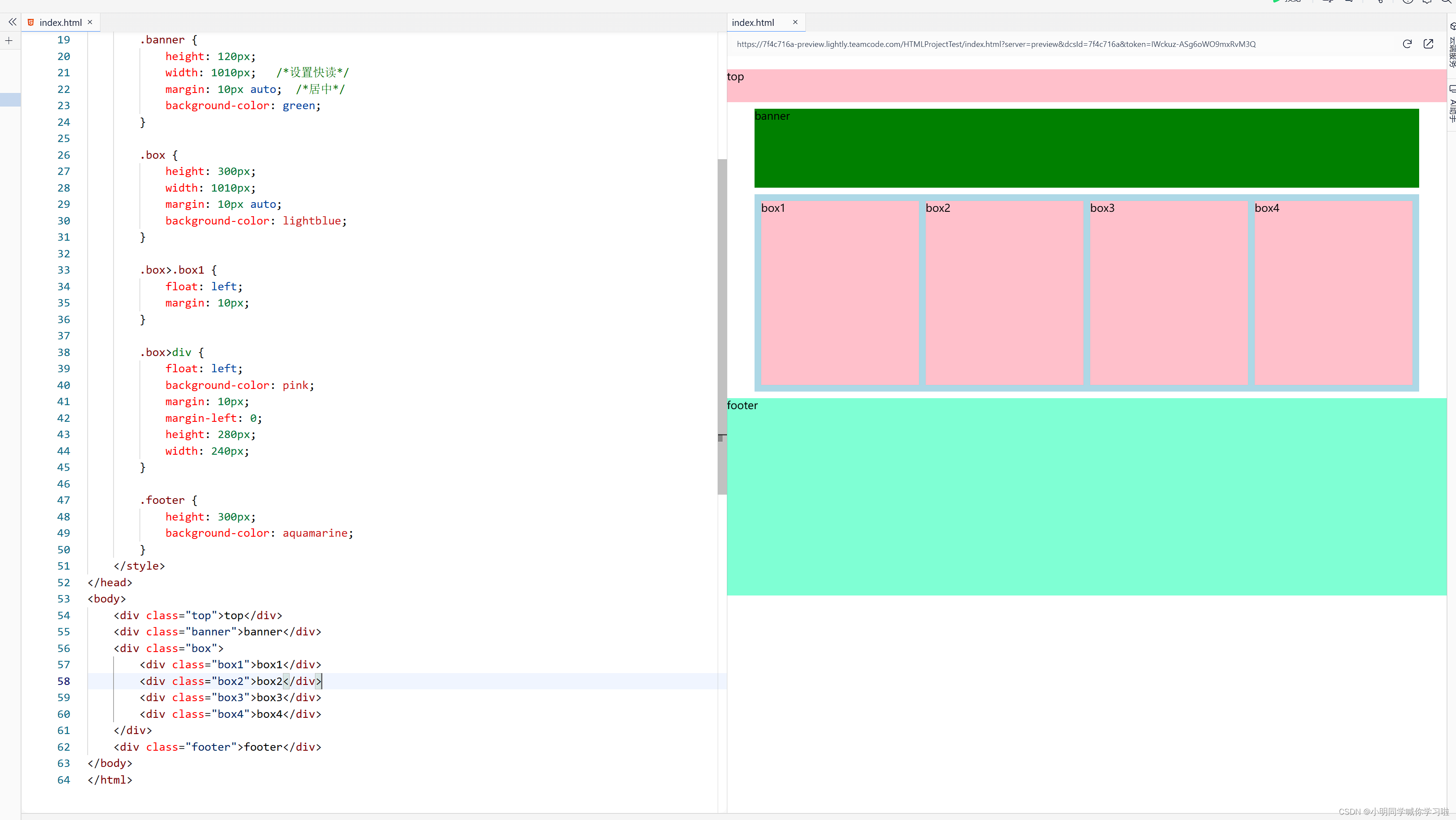
浮动模块布局
基本思路 若宽度和浏览器一样宽,则不需要设置width 一般父盒子使用标准流,然后标准流内使用浮动 一般父盒子需要居中显示,使用 margin: 0 auto; 注意浮动盒子之间的margin值 与 父盒子width、height值之间的相等关系,一定要计算…...

信号、进程、线程、I/O介绍
文章目录 信号进程进程通信线程可/不可重入函数线程同步互斥锁条件变量自旋锁读写锁 I/O操作阻塞/非阻塞I/OI/O多路复用存储映射I/O 信号 信号是事件发生时对进程的通知机制,可以看做软件中断。信号与硬件中断的相似之处在于其能够打断程序当前执行的正常流程。大多…...

【css3】涟漪动画
效果展示 dom代码 <div class"mapSelfTitle66"><div></div> </div> 样式代码 .mapSelfTitle66{width:120px;height:60px;position: relative;&>div{width:100%;height:100%;background: url("~/assets/images/video_show/err…...

基础课17——智能客服系统
客户服务是一种以客户为中心的服务模式,旨在提高客户满意度和忠诚度,促进企业业务增长和可持续发展。在客户服务中,企业需要了解客户需求,提供优质、高效、个性化的服务,解决客户问题,满足客户需求…...

vue3 ts 导出PDF jsPDF
jsPDF 是一个基于 HTML5 的客户端解决方案,用于生成各种用途的 PDF 文档。 1、安装:npm install jspdf npm install --save html2canvas 2、引入:import jsPDF from "jspdf" import html2canvas from html2canvas 3、使用 <…...

Agent 应用于提示工程
如果Agent模仿了人类在现实世界中的操作方式,那么,能否应用于提示工程即Prompt Engingeering 呢? 从LLM到Prompt Engineering 大型语言模型(LLM)是一种基于Transformer的模型,已经在一个巨大的语料库或文本数据集上进行了训练&…...

云原生安全日志审计
记得添加,把配置文件挂载进去 - mountPath: /etc/kubernetes/auditname: audit-policyreadOnly: true.....- hostPath:path: /etc/kubernetes/audit/type: DirectoryOrCreatename: audit-policy/etc/kubernetes/manifests/kube-apiserver.yaml 具体配置文件如下 a…...
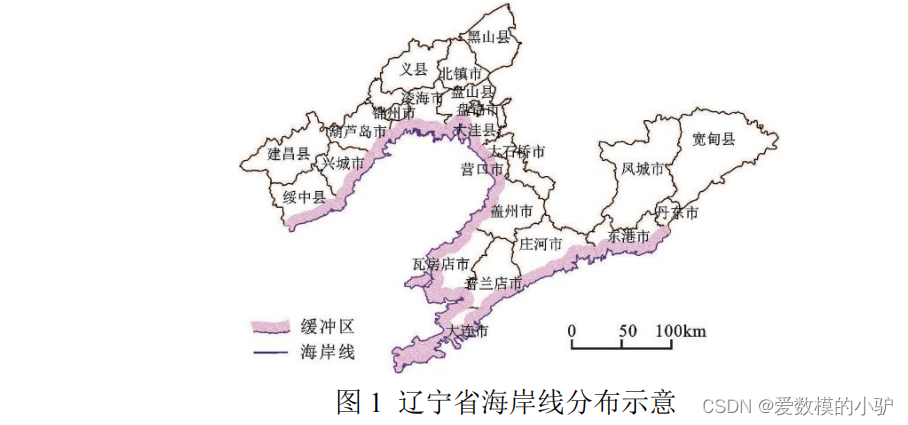
2023 辽宁省大学数学建模 B 题 数据驱动的水下导航适配区分类预测
“海洋强国”战略部署已成为推动中国现代化建设的重要组成部分,国家对 此提出“发展海洋经济,保护海洋生态环境,加快建设海洋强国”的明确要求。 《辽宁省“十四五”海洋经济发展规划》明确未来全省海洋经济的发展战略、 发展目标、重大任…...
ES 8.x新特性一览(完整版)
一、看点 在 2022 年 2 月 11 日,Elasticsearch(ES)正式发布了 8.0 版本,而截止到 2023 年 10 月,历经一年半时间,ES官方已经连续发布了多个版本,最新版本为 8.10.4。这一系列的更新引入了众多引…...

生产实战shell,给安全部门提供日志
生产实战shell,给安全部门提供日志 #!/bin/bashbackup_dir"/data/rw_copy" log_dir"/data/weblogic_log/test/yingyong" nginx_log_dir"/data/nginx_log" apache_log_dir"/data/apache_log" weblogic_log_dir"/data/weblogic_lo…...
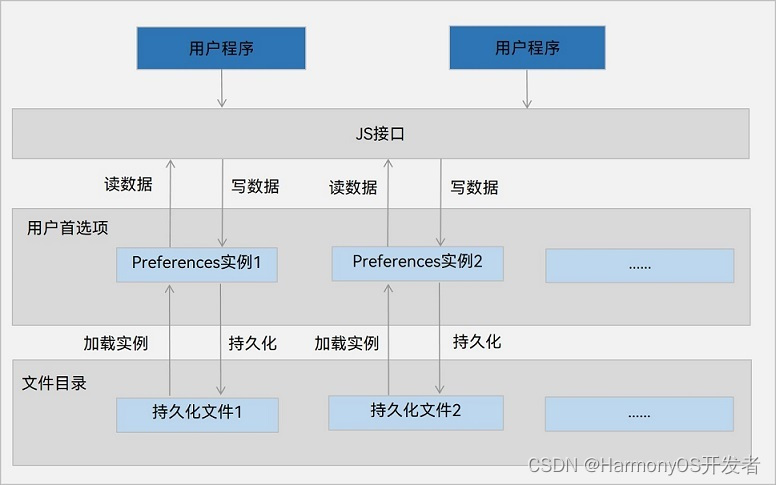
HarmonyOS数据管理与应用数据持久化(一)
一. 数据管理概述 功能介绍 数据管理为开发者提供数据存储、数据管理能力,比如联系人应用数据可以保存到数据库中,提供数据库的安全、可靠等管理机制。 数据存储:提供通用数据持久化能力,根据数据特点,分为用户首选项、…...

小型气象站在智慧农业高标准农田建设中的作用
了解“小型气象站在智慧农业高标准农田建设中的作用”,我们需要了解什么是小型气象站?什么是高标准农田? 所谓小型气象站是一种气象观测设备,根据应用领域不同可分为农业气象站,校园气象站,森林气象站&…...
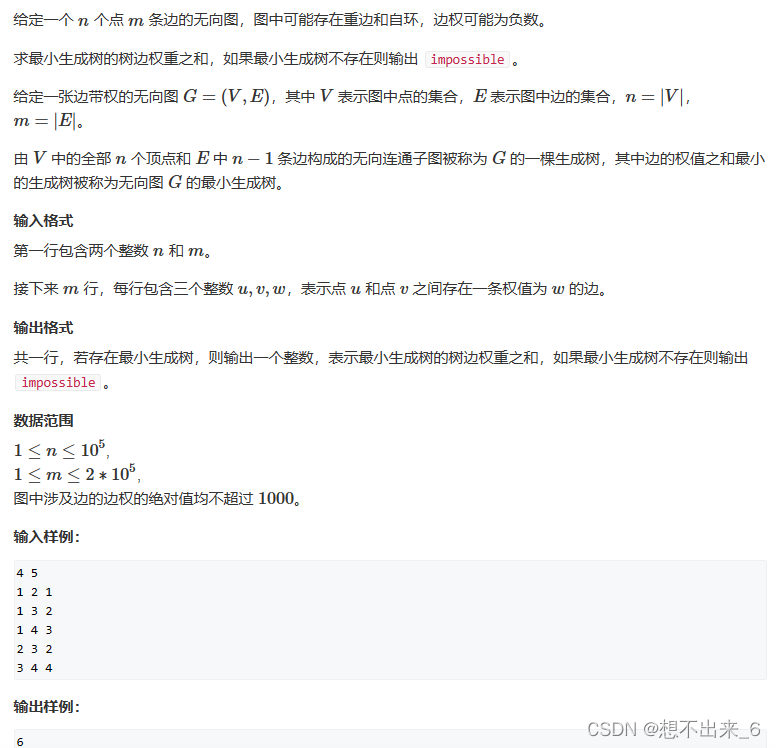
kruskal求最小生成树
算法思路: 将所有边按照权值的大小进行升序排序,然后从小到大一一判断。 如果这个边与之前选择的所有边不会组成回路,就选择这条边分;反之,舍去。 直到具有 n 个顶点的连通网筛选出来 n-1 条边为止。 筛选出来的边…...

876. 链表的中间结点
876. 链表的中间结点 算法 快慢指针 & 题目特征 需要对链表中的节点进行遍历,并且需要根据节点之间的相对位置或者距离进行操作 题目链接:https://leetcode.cn/problems/middle-of-the-linked-list/ 算法 快慢指针 & 题目特征 需要对链表中…...

UMA Unity角色系统深度解析:运行时人体编译器架构与跨平台实践
1. 为什么UMA不是“装上就能用”的Avatar系统——从三个典型失败案例说起我第一次在项目里引入Unity Multipurpose Avatar(UMA)时,信心满满地拖进Package Manager,点完Import,打开Demo场景,结果角色模型直接…...

智赋能源 安筑未来|济南昊安光电亮相 2026 第六届中国贵州国际能源产业博览交易会
2026 年 5 月 18 日 —5月 20日,2026 第六届中国贵州国际能源产业博览交易会(简称 “贵州能源博览会”)在贵阳国际会议展览中心盛大启幕。本届展会聚焦能源产业数字化转型、绿色低碳发展与安全高效生产,汇聚能源领域全产业链优质企…...

GHelper:华硕笔记本性能调优的轻量级革命
GHelper:华硕笔记本性能调优的轻量级革命 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertbook, RO…...

IPBan:企业级服务器安全防护解决方案的架构设计与实现
IPBan:企业级服务器安全防护解决方案的架构设计与实现 【免费下载链接】IPBan Since 2011, IPBan is the worlds most trusted, free security software to block hackers and botnets. With both Windows and Linux support, IPBan has your dedicated or cloud se…...

如何高效配置跨架构模拟器:Box64专业用户的终极实践指南
如何高效配置跨架构模拟器:Box64专业用户的终极实践指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 Box64是…...

PSLab Desktop性能优化:提升仪器响应速度与数据精度的终极指南
PSLab Desktop性能优化:提升仪器响应速度与数据精度的终极指南 【免费下载链接】pslab-desktop PSLab Desktop Application https://pslab.io 项目地址: https://gitcode.com/gh_mirrors/ps/pslab-desktop PSLab Desktop是一款强大的开源硬件实验平台应用程序…...

利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型 对于AIGC应用开发者而言,文本生成模型的选择直接影响着…...

为什么92.7%的用户生成不出真正包豪斯风格?——3大认知陷阱与48小时速成调参路径
更多请点击: https://kaifayun.com 第一章:包豪斯设计哲学的数字转译本质 包豪斯所倡导的“形式追随功能”“少即是多”“艺术与技术的新统一”,在当代前端工程、UI系统设计与可访问性实践中,已不再仅是美学信条,而成…...

Honey Select 2中文汉化补丁终极指南:一键安装完整中文体验
Honey Select 2中文汉化补丁终极指南:一键安装完整中文体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日语界面而烦恼吗…...
)
如何用1条提示生成可商用超现实IP?:Midjourney商业级输出的6道合规校验流程(含版权链存证路径)
更多请点击: https://codechina.net 第一章:超现实IP的商业价值与Midjourney生成范式跃迁 超现实IP正从边缘创意实验走向主流商业基础设施——其核心驱动力并非单纯视觉奇观,而是对用户心智注意力的结构性重构。当品牌不再依赖写实叙事建立信…...